













Тренды на рынке акций предсказание представляют собой значительную проблему как для инвесторов, так и для ученых данных из-за нестабильности и сложности рынка. Тем не менее, с появлением машинного обучения (МО), стало возможным разработать прогнозные модели, которые анализируют исторические данные и предлагают взгляды на возможные будущие движения. В этой комплексной справочной статье мы рассмотрим, как можно использовать Python и машинное обучение для эффективного предсказания цен на акции и тенденций на рынке.
1. Общее описание проблемы
Рынок акций влияет на многие факторы, включая:
-
Макроэкономические показатели (такие как инфляция, ВВП, уровень безработицы)
-
Основные показатели компании (доходы, revenue, P/E ratio)
-
Социальные настроения (новости, активность социальных сетей)
-
Технические факторы (действие цен, скользящие средние, тренды объема)
В связи с высокой неопределенностью рынка акций, никакая модель не может предсказать события безупречно. Тем не менее, анализ исторических данных о ценах и технических индикаторах позволяет выявить модели, помогающие предсказать будущие тенденции, такие, как взлет или падение цены акций в краткосрочной или долгосрочной перспективе.
2. Сбор данных о рынке акций
Первым шагом в создании прогнозной модели рынка акций является сбор исторических данных о ценах. Эти данные легко получить от поставщиков финансовых данных, например:
-
Yahoo Finance (через Python-пакет
yfinance) -
Quandl
-
Alpha Vantage
Используя yfinance, вы можете скачать исторические данные о ценах. Посмотрим, как можно получить данные для Apple (AAPL) за последние десять лет.
pip install yfinance
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
Данные включают необходимые столбцы, такие как:
-
Open: Открывающая цена за день
-
High: Самая высокая цена за день
-
Low: Самая низкая цена за день
-
закрытие
: закрытие цены за день
-
объем: количество акций, торгованных за день
-
откорректированное закрытие: откорректированная цена закрытия, учитывающая дивиденды и сplit
3. Feature Engineering
Feature engineering is crucial in machine learning. It involves creating new features from existing data to enhance the predictive power of the model. When it comes to stock prediction, some of the most commonly used features are technical indicators.
Common Technical Indicators:
-
Simple Moving Average (SMA): A moving average calculated by taking the arithmetic mean of a given set of prices over a specified number of periods.
-
Exponential Moving Average (EMA): A weighted moving average that gives more importance to recent price data.
-
Относительная сила индекс (RSI): Oscillator моментума, измеряющий скорость и изменения движений цен.
-
Соединение скользящих средних (MACD): индикатор тенденции, следующий моментуму, показывающий взаимоотношения между двумя скользящими средними цены актива.
-
Пара скользящих средних Bollinger: индикатор волатильности, состоящий из средней полосы (SMA) и двух внешних полос (система стандартных отклонений).
Также можно вычислить несколько этих технических индикаторов в Python:
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values
data = data.dropna()
Если вы включите больше технических индикаторов, ваше dataset станет более обширным для обучения моделей машинного обучения. Однако убедитесь, что выбранные индикаторы являются соответствующими для вашей задачи предсказания.
4. Подготовка dataset для машинного обучения
Теперь, когда вы создали свои технические индикаторы, вам нужно подготовить dataset, разделив его на признаки (X) и целевую переменную (y). Целевая переменная – это переменная, которую вы хотите предсказать (например, цену закрытия на следующий день). Вот как вы можете установить это:
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (dropping unnecessary columns)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Drop rows with missing values
X = X.dropna()
y = y[X.index] # Ensure target variable aligns with features
from sklearn.model_selection import train_test_split
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. Выбор и обучение модели машинного обучения
Для прогнозирования рыночных курсов акций можно использовать несколько алгоритмов машинного обучения, в том числе:
-
Линейная регрессия: Простая модель для прогнозирования, основанная на взаимосвязи переменных.
-
Случайный лес: Универсальная модель, которая хорошо обрабатывает нелинейные отношения и переобучение.
-
Машина поддерживающих векторов (SVM): Полезна для классификации и задач регрессии.
-
Долгосрочная и краткосрочная память (LSTM): Тип нейронной сети, особенно подходящий для временных рядов данных.
Для простоты начнем с Случайного леса регрессора, мощного алгоритма энsemble learning:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")

6. Оценка модели
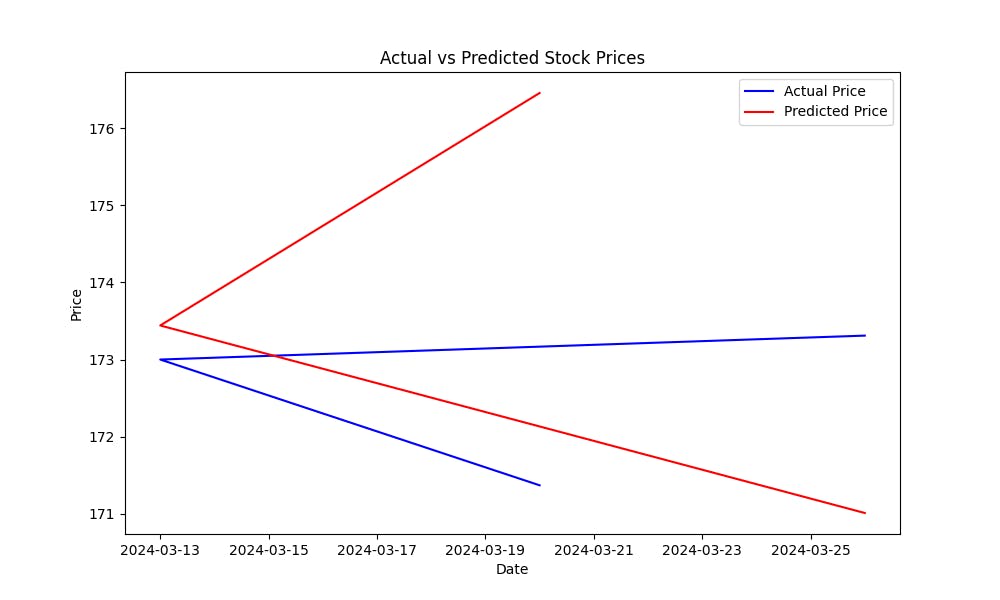
Среднеквадратическое отклонение (MSE) помогает измерять ошибку предсказаний модели. Чем меньше MSE, тем лучше предсказания модели. Чтобы visualization того, насколько хорошо модель предсказывает цены на акции, нарисуйте график фактических versus предсказанных цен:
import matplotlib.pyplot as plt
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
Этот график поможет вам visually оценить performаnce модели, показывая, насколько близки предсказанные значения к фактическим ценным бумагам.
Полный код:
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values (due to moving averages and RSI)
data = data.dropna()
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (SMA, EMA, RSI)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
7. Улучшение модели
Теперь, когда вы создали базовую модель, есть несколько способов улучшить ее точность:
- Использование дополнительных характеристик: Включите дополнительные технические индикаторы, данные анализа отношенияльности из СМИ и социальных сетей или даже макроэкономические переменные.
- Продвинутые модели машинного обучения: попробуйте более сложные алгоритмы, такие как XGBoost, машины градиентного усиления (GBM) или деepное обучение модели, например, LSTM, для лучшего desiplay на данных time-series.
-
Параметр-гиперпараметр настройки
: Оптимизировать параметры модели с помощью таких техник, как GridSearchCV или RandomSearchCV, чтобы найти лучшую конфигурацию модели.
-
ВыборFeature Selection: Использовать технику, как Recursive Feature Elimination (RFE), чтобы идентифицировать наиболее важные признаки, вкладывающиеся в предсказания.
Conclusion
Процесс постоянного совершенствования вашей модели, внедрения большего количества данных и экспериментирования с различными алгоритмами может улучшить предсказательную силу вашей модели прогнозирования тенденций на рынке акций.
Следующие шаги
-
Экспериментируйте с дополнительными техническими индикаторами и источниками данных.
-
Пробуждайте различные алгоритмы машинного обучения (например, LSTM для глубокого обучения).
-
Восстановите вашу модель, имитируя торговые операции с использованием исторических данных.
-
Продолжайте совершенствование и оптимизацию вашей модели на основе отзывов от реальной работы.
Source:
https://blog.bytescrum.com/how-to-predict-stock-market-trends-with-python-and-machine-learning