













Börsentrends voraussage stellt sowohl Investoren als auch Datenwissenschaftlern aufgrund der Volatilität und Komplexität des Marktes eine erhebliche Herausforderung dar. Allerdings hat mit der Entwicklung von Maschinelles Lernen (ML) die Möglichkeit zu den Entwicklung von vorhersagenden Modellen, die historische Daten analysieren und Rückschlüsse auf potenzielle zukünftige Bewegungen ziehen, eingeführt worden. In diesem umfassenden Leitfaden werden wir erkunden, wie Sie Python und maschinelles Lernen verwenden können, um Börsenpreise und Markt trends effektiv vorherzusagen.
1. Problemübersicht
Der Börsenmarkt wird von mehreren Faktoren beeinflusst, einschließlich:
-
Großwirtschaftlichen Indikatoren (wie Inflation, BIP, Arbeitslosenquote)
-
Unternehmensgrundlagen (Gewinne, Umsätze, BPS)
-
Marktstimmung (Artikel in den Medien, Aktivität auf sozialen Medien)
-
Technische Faktoren (Preisentwicklung, beweglichen Durchschnittspreise, Volumestrends)
Angesichts der hohen Unsicherheit des Börsenmarktes kann kein Modell perfekte Vorhersagen anbieten. Allerdings können wir durch die Analyse historischer Preisdaten und technischer Indikatoren Muster extrahieren, die helfen, zukünftige Preisentwicklungen vorherzusagen, wie z.B. ob ein Aktie in kurz- oder langfristiger Sicht an Wert steigen oder sinken wird.
2. Sammeln von Börsendaten
Der erste Schritt bei der Erstellung eines vorhersagenden Aktienmodells besteht darin, historische Aktendaten zu sammeln. Diese Daten sind aus Financial Data Providers wie folgendermaßen erhältlich:
-
Yahoo Finance (über das
yfinancePython-Paket) -
Quandl
-
Alpha Vantage
Mit yfinance können Sie historische Aktendaten herunterladen. Lass uns Daten für Apple (AAPL) aus den letzten zehn Jahren holen.
pip install yfinance
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
Die Daten enthalten wichtige Spalten wie z.B.:
-
Open: Eröffnungspreis für den Tag
-
High: Höchstpreis am Tag
-
Low: Tiefstpreis am Tag
-
Schlusskurs
: Der Schlusskurs für den Tag
-
Volumen: Anzahl der Handelstexte während des Tages
-
Korrigierter Schlusskurs: Korrigerter Schlusskurs, der Dividendenzahlungen und Aktiensplits berücksichtigt
3. Merkmalsengineering
Merkmalsengineering ist entscheidend für maschinelles Lernen. Es umfasst die Erstellung neuer Merkmale aus bestehenden Daten, um die Vorhersagekraft des Modells zu verbessern. Bei der Aktienprognose sind einige der am häufigsten verwendeten Merkmale technische Indikatoren.
Gängige technische Indikatoren:
-
Einfaches moving Average (SMA): Ein bewegliches Durchschnittsverfahren, das durch die arithmetische Mittelung eines gegebenen Preissets über einer bestimmten Anzahl von Perioden berechnet wird.
-
Exponentielles moving Average (EMA): Ein gewichtetes Durchschnittsverfahren, das den jüngsten Preisdaten mehr Gewicht gibt.
-
Relativer Stärkeindex (RSI)
: Ein Impulsoszillograph, der die Geschwindigkeit und den Verlauf von Preisbewegungen misst.
-
Moving Average Convergence Divergence (MACD): Ein Trendfolgemechanismus, der die Beziehung zwischen zwei beweglichen Durchschnittspreisen eines Aktienpreises anzeigt.
-
Bollinger Bänder: Ein Volatilitätsindikator, bestehend aus einer mittleren Band (SMA) und zwei äußeren Bändern (Standardabweichung).
Hier ist, wie Sie einige dieser technischen Indikatoren in Python berechnen können:
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values
data = data.dropna()
Je mehr technische Indikatoren Sie enthalten, desto reicher wird Ihr Datensatz für die Ausbildung von maschinellen Lernmodellen. Allerdings stellen Sie sicher, dass die Indikatoren, die Sie wählen, relevant für Ihre Vorhersageaufgaben sind.
4. Datenbank Vorbereitung für die maschinelle Lernung
Nachdem Sie Ihre technischen Indikatoren erstellt haben, müssen Sie die Datenbank vorbereiten, indem Sie sie in Merkmale (X) und Ziel (y) aufteilen. Das Ziel ist die Variable, die Sie vorhersagen möchten (z.B. der nächste Tag Schließpreis). Hier ist, wie Sie dies einrichten können:
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (dropping unnecessary columns)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Drop rows with missing values
X = X.dropna()
y = y[X.index] # Ensure target variable aligns with features
Nächstes, splitten Sie die Daten in Trainings- und Testdaten集, um die Leistung des Modells zu beurteilen:
from sklearn.model_selection import train_test_split
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. Wählen und Trainieren eines Maschinelles Lernmodells
Für die Prognose der Aktienmärkte können verschiedene maschinelle Lernalgorithmen verwendet werden, darunter:
-
Lineare Regression: Ein einfaches Modell für die Prognose auf der Basis der Beziehung zwischen Variablen.
-
Random Forest: Ein vielseitiges Modell, das gut mit nichtlinearen Beziehungen und Überfitting umgeht.
-
Support Vector Machine (SVM): Nützlich für sowohl Klassifizierungs- als auch Regressionsaufgaben.
-
Long Short-Term Memory (LSTM): Ein Typ von neuronalem Netz, das besonders für zeit序列daten geeignet ist.
Um die Simplizität zu wahren, beginnen wir mit einem Random Forest Regressor, einem kraftvollen Ensemble-Lernalgorithmus:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")

6. Modellbewertung
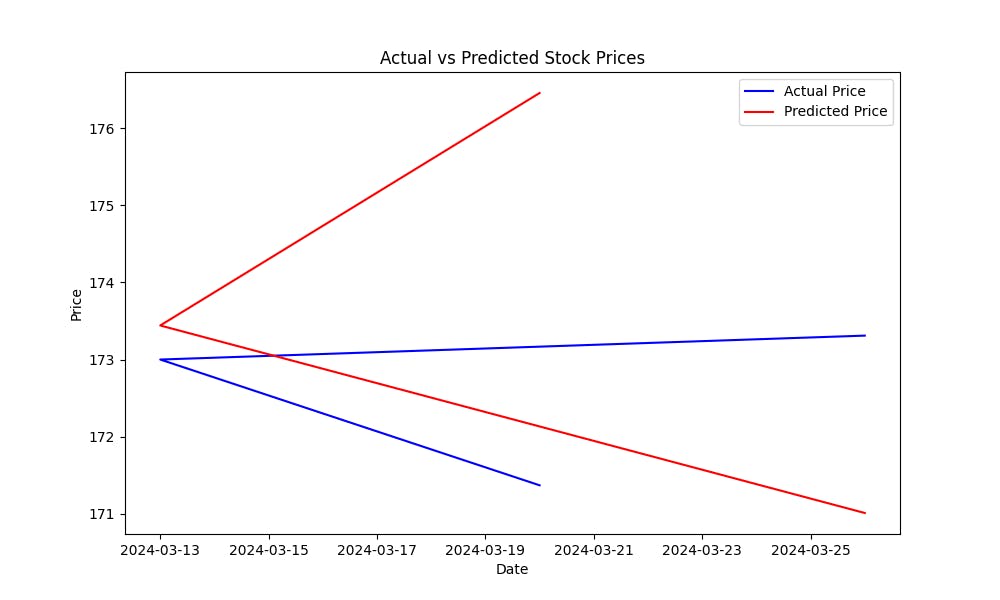
Der Mean Squared Error (MSE) hilft, die Vorhersagefehler des Modells zu messen. Je niedriger der MSE, desto besser sind die Vorhersagen des Modells. Um zu可视化, wie gut das Modell Aktienpreise vorhersagt, plotte den tatsächlichen gegen die vorhergesagten Preise:
import matplotlib.pyplot as plt
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
Dieser Plot wird Ihnen helfen, das Leistungsmoment des Modells visuell einzuschätzen und zu zeigen, wie nahe die vorhergesagten Werte den tatsächlichen Aktienpreisen sind.
Code vollständig:
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values (due to moving averages and RSI)
data = data.dropna()
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (SMA, EMA, RSI)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
7. Verbesserung des Modells
Nun, da Sie ein grundlegendes Modell aufgebaut haben, gibt es mehrere Möglichkeiten, um seine Genauigkeit zu verbessern:
-
Verwenden Sie zusätzliche Merkmale: Fügen Sie weitere technische Indikatoren, Daten von Nachrichten und Social Media für Sentimentanalyse oder sogar makroökonomische Variablen hinzu.
-
fortschrittliche Maschinenlernmodelle: Probieren Sie komplexere Algorithmen wie XGBoost, Gradient Boosting Machines (GBM)oder Deep Learning-Modelle wie LSTM für bessere Leistung auf zeitreihenbasierten Daten.
-
Hyperparameter Optimierung
: Verwende Techniken wie GridSearchCV oder RandomSearchCV zur Optimierung von Modellparametern, um die beste Modelkonfiguration zu finden.
-
Feature Selection: Verwende Techniken wie Rekursive Feature Elimination (RFE), um die wichtigsten Merkmale zu identifizieren, die zu Prognosen beitragen.
Conclusion
Durch die kontinuierliche Verfeinerung Ihres Modells, das Hinzufügen weiterer Daten und die Experimentation mit verschiedenen Algorithmen, können Sie die prädiktive Kraft Ihres Modells für die Marktentwicklungsvorschau verbessern.
Nächste Schritte
-
Experimentiere mit weiteren technischen Indikatoren und Datenquellen.
-
Probiere verschiedene maschinelle Lernalgorithmen aus (z.B., LSTM für Deep Learning).
-
Teste dein Modell durch Backtesting, indem du mit historischen Daten Simulationshandelsoperationen durchführst.
-
Verfeinere und optimiere dein Modell ständig auf der Basis der Rückmeldungen aus der reellen Welt.
Source:
https://blog.bytescrum.com/how-to-predict-stock-market-trends-with-python-and-machine-learning