













주식 시장 trenD 예측은 투자자들과 데이터 과학자들에게 시장의 불확실성과 複雑성에 의한 중요한 도전입니다. 그러나 머신 leaning (ML)의 도입으로 이전 데이터를 분석하여 미래의 기회를 예측하는 예측 모델을 개발하는 것이 가능하게 되었습니다. 이 전문적인 가이드에서는 Python과 머신 leaning을 사용하여 주식 가격과 시장 trenD를 효과적으로 예측하는 방법을 탐구하고자 합니다.
1. 문제 개요
주식 시장은 다양한 요인에 의해 영향을 받습니다. 예를 들어:
-
대형 경제 지표 (인flation, GDP, 실업률 등)
-
기업 FUNDAMENTALS (수익, revENUE, P/E 비율 등)
-
시장 감정 (뉴스 기사, 사회 미디어 활동 등)
-
기술적 요인 (가격 행동, 이동 평균, volUME 추이 등)
주식 시장의 고정하지 않은 수준에서, 완벽한 예측을 제공할 수 있는 모델이 없습니다. 그러나 이전 가격 데이터和技术 지표를 분석하여 주식의 가격 추이를 예측하는 등의 모델을 생성할 수 있습니다. 예를 들어 한 주 또는 장기 기간 안에 주식의 가격이 상승하거나 하락할지 여부 등의 패턴을 추출할 수 있습니다.
2. 주식 시장 데이터 수집
예측적인 주식 모델을 구성하는 첫 단계는 이전 주식 데이터 수집입니다. 이러한 데이터는 finanical data providers like:
-
Yahoo Finance (
yfinancePython 패키지 사용) -
Quandl
-
Alpha Vantage
yfinance를 사용하면 이전 주식 데이터를 다운로드할 수 있습니다. 지난 十年간 애플(AAPL)의 데이터를 가져봅시다.
pip install yfinance
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
데이터는 다음과 같은 기본 열을 포함합니다:
-
Open: 하루 시작时的 가격
-
High: 하루 중간에 가장 높은 가격
-
Low: 하루 중간에 가장 낮은 가격
-
종료: 하루의 마감 가격
-
거래량: 하루 동안 거래된 주식 수
-
조정 종료: ividend과 split을 고려한 조정 마감 가격
3. 特徴 엔지니어링
特徴 엔지니어링은 機械学習에서 중요한 부분であり、기존 데이터에서 새로운 특징을 생성하여 모델의 예측 능력을 향상시키는 것이 포함되며, 주식 예측에 대해서는 기술 지표로 사용되는 가장 일반적인 특징 중 하나입니다. 기술 지표이라고 합니다.
일반 기술 지표:
-
単純 이동 평균(SMA): 주어진 가격 集合의 지정 기간의 算术 평균을 이용하여 이동 평균을 computes.
-
Exponential Moving Average (EMA): 가중치를 가지고 있는 이동 평균으로 최근 가격 데이터를 더 중요시 합니다.
-
상대 강도 지수 (RSI)
: 가격 이동의 速率和 변화를 측정하는 动力 지수.
-
이동 평균 합 분岐 지수 (MACD): 주식 가격의 두 이동 평균 사이의 관계를 나타내는 tren 遵循 动力 지수.
-
볼리nger 밴드: 가격의 变异性를 나타내는 지수로 중앙 밴드 (SMA)와 두 outsider 밴드 (표준 편차)로 구성되어 있습니다.
이러한 기술적 지수들의 일부를 펀텀 로 Python에서 계산할 수 있습니다.
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values
data = data.dropna()
기술적 지수를 더 많이 포함하면 기계 leaning 모델 트레이닝을 위한 데이터셋이 richer 해지ます. 그러나 你所하는 예측 任务에 관련이 있는지 확인하십시오.
4. 기계 leaning 모델 준비
이제 기술적 지수를 생성했으면, 이를 특성 (X)와 목표 (y)로 분할하여 데이터셋을 준비해야 합니다. 목표는 다음날의 마감 가격을 예측하고자 하는 변수입니다. 다음과 같이 이 셋을 구성할 수 있습니다:
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (dropping unnecessary columns)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Drop rows with missing values
X = X.dropna()
y = y[X.index] # Ensure target variable aligns with features
다음으로 데이터를 훈련 세트와 테스트 세트로 분할하여 모델의 성능을 평가합니다:
from sklearn.model_selection import train_test_split
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. 기계 학습 모델 선택과 훈련
주식 시장 예측에는 다음과 같은 기계 학습 알고리즘을 사용할 수 있습니다:
-
선형 회귀: 변수间的 관계를 기반으로 하는 간단한 예측 모델입니다.
-
랜덤 포레스트: 비선형 관계와 과적합을 잘 다루는 유용한 모델입니다.
-
지지 벡터 머신 (SVM): 분류와 회귀 작업 모두에 유용합니다.
-
장단기 기억 신경망 (LSTM): 시계열 데이터에 특히 적합한 신경망 유형입니다.
간단성을 위해 우리는 강력한 합성 학습 알고리즘인 랜덤 포레스트 회귀 분석기로 시작합시다:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")

6. 모델 평가
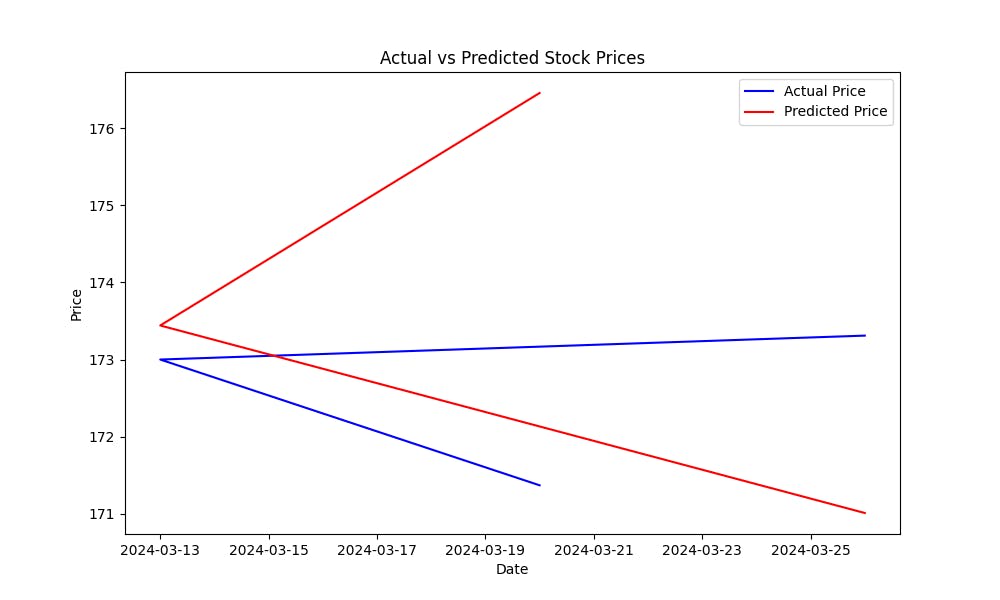
Mean Squared Error (MSE)는 모델의 예측 오차를 측정하는 도구입니다. MSE가 낮으면 모델의 예측이 좋은 것입니다. 모델이 주식 가격을 어떻게 예측하는지 시각적으로 표시하고자 하면 실제 가격과 예측 가격을 플롯 시키면 도움이 됩니다.:
import matplotlib.pyplot as plt
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
이 플롯은 모델의 パフォーマンス를 시각적으로 평가하는 것을 도울 것입니다. 예측 값이 실제 주식 가격에 얼마나 가까웠는지 보여줍니다.
전체 코드:
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values (due to moving averages and RSI)
data = data.dropna()
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (SMA, EMA, RSI)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
7. 모델 강화
기본적인 모델을 built 했습니다. 정확도를 높여야 합니다.
-
extra Features: 더 많은 기술적인 지표, 언론과 社交媒体의 감정 분석 데이터, 심리 omics 변수를 포함합니다.
- Avanced Machine Learning Models: XGBoost, Gradient Boosting Machines (GBM), 或者 Deep Learning models like LSTM 这样的更高级的算法来更好地处理时间序列数据。
-
超参数调优 : GridSearchCV나 RandomSearchCV과 같은 기술을 사용하여 모델 パラ미터를 최적화하여 가장 좋은 모델 구성을 찾습니다.
-
特徴选择 : 递归特征消除(RFE)과 같은 기술을 사용하여 예측에 기여하는 가장 重要な 특성을 식별합니다.
Conclusion
您的模型を 계속적으로 精炼하고, 더 많은 데이터를 取り込んだり, 다양한 算法을 실험하여 株市場 趋勢 예측 모델의 예측력을 높일 수 있습니다.
次のステップ
-
추가적인 技術的 지표와 데이터 소스를 실험하십시오.
-
다양한 機械学習 算法 (예 : 深層学习의 LSTMs)을 시도하십시오.
-
이전 데이터를 사용하여 모델을 バックテス트하십시오.
-
실제 세계적 パフォーマン스로부터 피드백을 기반으로 모델을 계속해서 精炼하고 최적화하십시오.
Source:
https://blog.bytescrum.com/how-to-predict-stock-market-trends-with-python-and-machine-learning