













La previsione delle trend del mercato azionario è un grande挑战 per sia gli investitori che i datascientisti a causa della volatilità e della complessità del mercato. Tuttavia, con l’avvento dell’apprendimento automatico (ML), è diventato possibile sviluppare modelli predittivi che analizzano i dati storici e forniscono insights sulle potenziali future mosse. In questo guida completa, esploreremo come utilizzare Python e l’apprendimento automatico per prevedere i prezzi delle azioni e le tendenze del mercato in modo efficiente.
1. Panoramica del problema
Il mercato azionario è influenzato da molti fattori, inclusi:
-
Indicatori macroeconomici (come l’inflazione, il PIL, il tasso di disoccupazione)
-
I fattori fondamentali delle aziende (utili, entrate, rapporto P/E)
-
Il sentimento del mercato (articoli di notizie, attività sui social media)
-
Fattori tecnici (azioni del prezzo, media mobile, trend del volume)
Data la elevata incertezza del mercato azionario, nessun modello può fornire previsioni perfette. Tuttavia, analizzando i dati storici dei prezzi e gli indicatori tecnici, è possibile estrarre schemi che aiutano a prevedere le tendenze di prezzo futura, come il fatto che un’azione incrementerà o decreterà di valore in un periodo di breve o lungo termine.
2. Raccolta dati del mercato azionario
Il primo passo nella costruzione di un modello stocastico per le azioni è raccogliere i dati storici delle azioni. Questi dati sono disponibili facilmente da fornitori di dati finanziari come:
-
Yahoo Finance (tramite il pacchetto Python
yfinance) -
Quandl
-
Alpha Vantage
Usando yfinance, è possibile scaricare i dati storici delle azioni. Scriviamo per estrarre i dati per Apple (AAPL) negli ultimi dieci anni.
pip install yfinance
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
I dati contengono colonne essentiali come:
-
Apertura: Prezzo di apertura dell’ giorno
-
Alta: Prezzo massimo raggiunto durante il giorno
-
Bassa: Prezzo minimo raggiunto durante il giorno
-
Chiusura
: Prezzo di chiusura dell’ giorno
-
Volume: Numero di azioni scambiate durante il giorno
-
Chiusura Aggiornata: Prezzo di chiusura aggiornato, considerando le quote di dividende e i tagli
3. Engineeratura delle Caratteristiche
L’engineering delle caratteristiche è fondamentale nella machine learning. Si tratta di creare nuove caratteristiche da dati esistenti per migliorare il potere predittivo del modello. Quando si tratta di previsioni di quote azionarie, alcune delle caratteristiche più comunemente utilizzate sono indicatori tecnici.
Indicatori Tecnici Comuni:
-
Moving Average Semplice (SMA): Una media mobile calcolata prendendo la media aritmetica di un dato insieme di prezzi su un numero specifico di periodi.
-
Moving Average Eccentrica (EMA): Una media mobile pesata che dà maggiore importanza ai dati di prezzo recenti.
- Convergenza Divergenza Media Mobile (MACD): Un indicatore di tendenza e momento che mostra la relazione tra due medie mobili del prezzo di un’azione.
- Bandiere Bollinger: Un indicatore di volatilità costituito da una fascia media (SMA) e due fasce esterne (deviazione standard).
Ecco come puoi calcolare alcuni di questi indicatori tecnici in Python:
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values
data = data.dropna()
Più indicatori tecnici includeresti, più ricca diventerà la tua base dati per l’addestramento di modelli di apprendimento automatico. Tuttavia, assicurati che gli indicatori scelti siano relevanti alla tua task di predizione.
4. Preparazione del Set di Dati per l’Apprendimento Automatico
Ora che hai creato i tuoi indicatori tecnici, devi preparare il set di dati dividendolo in feature (X) e target (y). La target è la variabile che vuoi predire (ad esempio, il prezzo di chiusura del giorno successivo). Ecco come puoi impostare questo setup:
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (dropping unnecessary columns)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Drop rows with missing values
X = X.dropna()
y = y[X.index] # Ensure target variable aligns with features
Successivamente, dividere i dati in set di addestramento e test per valutare il rendimento del modello:
from sklearn.model_selection import train_test_split
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. Scelta e addestramento di un modello di apprendimento automatico
Sono disponibili diversi algoritmi di apprendimento automatico per le previsioni del mercato azionario, tra cui:
-
Regressione lineare: Un modello semplice per la previsione basato sulla relazione tra variabili.
-
Forestiera casuale: Un modello versatile che gestisce bene relazioni non lineari e sovraaddestramento.
-
Macchina da支持向量机 (SVM): Utilizzabile sia per compiti di classificazione che di regressione.
-
Ricordo a lungo termine (LSTM): Un tipo di rete neurale particolarmente adatto per i dati a serie tempo.
Per semplicità, cominceremo con un Forestiera casuale Regressore, un potente algoritmo di apprendimento collettivo:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")

6. Valutazione del modello
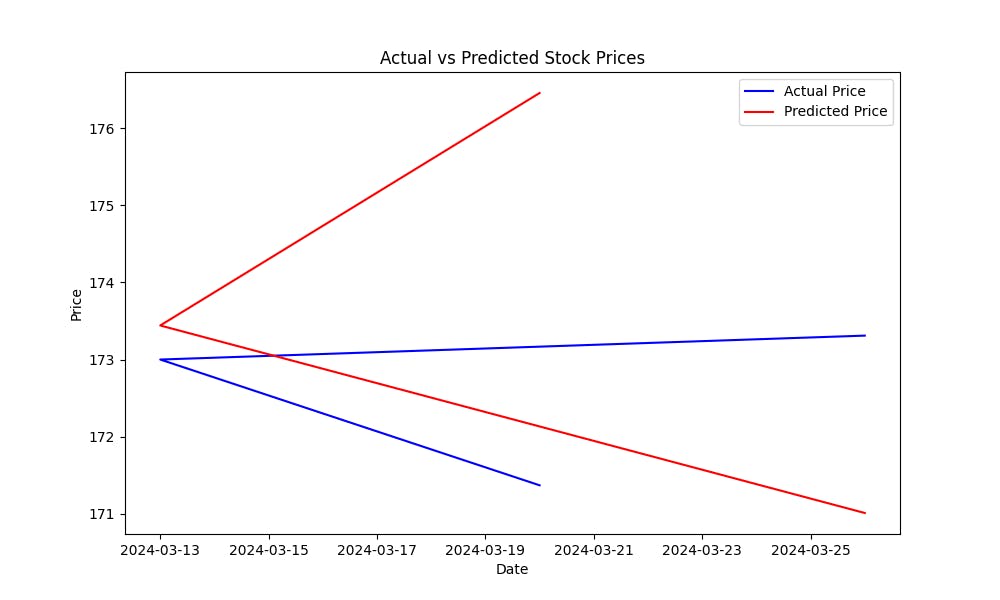
L’Errore Quadratico Medio (MSE) aiuta a misurare l’errore di previsione del modello. Più basso è l’MSE, migliore sono le previsioni del modello. Per visualizzare quanto bene il modello predica i prezzi delle azioni, tracciate i prezzi reali contro i prezzi predetti:
import matplotlib.pyplot as plt
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
questo grafico vi aiuterà a valutare visivamente il rendimento del modello, mostrando quanto sono vicini i valori predetti ai prezzi reali delle azioni.
Codice completo:
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values (due to moving averages and RSI)
data = data.dropna()
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (SMA, EMA, RSI)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
7. Miglioramento del Modello
Ora che hai costruito un modello di base, esistono diversi modi per aumentare la sua accuratezza:
-
Usa Caratteristiche Aggiuntive: Includi più indicatori tecnici, dati di analisi del sentimento dalla notizie e dai social media, o persino variabili macroeconomiche.
-
Modelli di Machine Learning Avanzati: Prova algoritmi più sofisticati come XGBoost, Macchine a Incremento (GBM), o Modelli diapprendimento profondo come LSTM per un migliore rendimento sui dati a serie tempo.
-
Ottimizzazione degli Iperparametri: Ottimizza i parametri del modello utilizzando tecniche come GridSearchCV o RandomSearchCV per trovare la migliore configurazione del modello.
-
Selezione delle Caratteristiche: Usa tecniche come Recursive Feature Elimination (RFE) per identificare le caratteristiche più importanti che contribuiscono alle previsioni.
Conclusion
Continuando a perfezionare il tuo modello, incorporando più dati ed esperimentando con diversi algoritmi, puoi migliorare il potere predittivo del modello di previsione delle tendenze di mercato azionario.
Prossimi Passi
-
Sperimenta con ulteriori indicatori tecnici e fonti di dati.
-
Prova diversi algoritmi di apprendimento automatico (ad es., LSTM per il deep learning).
-
Testa retroattivamente il tuo modello simulando operazioni utilizzando dati storici.
-
Continua a perfezionare e ottimizzare il tuo modello in base al feedback delle prestazioni nel mondo reale.
Source:
https://blog.bytescrum.com/how-to-predict-stock-market-trends-with-python-and-machine-learning