













Beursmarktgevoeligheid voorspellen is een grote uitdaging voor beleggers en data wetenschappers vanwege de marktvolatiliteit en complexiteit. Echter, met de opkomst van machine learning (ML), is het mogelijk geworden om voorspellende modellen te ontwikkelen die historische gegevens analyseren en inzichten bieden over potentiële toekomstige bewegingen. In deze complete gids zullen we zien hoe u Python en machine learning kunt gebruiken om aandelenprijzen en marktgevoeligheid effectief kan voorspellen.
1. Overzicht van het probleem
De beursmarkt wordt beïnvloed door meerdere factoren, inclusief:
-
Macro-economische indicatoren (zoals inflatie, BNP, arbeidsloonpercentage)
-
Bedrijfsfundamenten (resultaten, omzet, P/E-ratio)
-
Marktgevoeligheid (nieuwsartikelen, sociale mediaactiviteit)
-
Technische factoren (prijsbewegingen, bewegingen gemiddelden, volume trends)
Given de beursmarkt’s hoge mate van onzekerheid, kan geen model perfecte voorspellingen bieden. Wel kunnen we, door historische beurskoersgegevens en technische indicatoren te analyseren, patronen extraheren die helpen bij het voorschatten van toekomstige koerstrends, zoals of een aandeel zal stijgen of dalen in waarde over een korte- of lange-termijnperiode.
2. Collecteren van Beursmarktgegevens
Het eerste stappetje in het bouwen van een voorspellende beursmodel is het verzamelen van historische beursgegevens. Deze gegevens zijn gemakkelijk beschikbaar vanuit financiële gegevensproviders zoals:
-
Yahoo Finance (via de
yfinancePython-pakket) -
Quandl
-
Alpha Vantage
Met yfinance kunt u historische beursgegevens downloaden. Laat ons gegevens voor Apple (AAPL) ophalen over de afgelopen tien jaar.
pip install yfinance
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
De gegevens bevatten essentiële kolommen zoals:
-
Open: openingsprijs voor de dag
-
Hoog: hoogste prijs tijdens de dag
-
Laag: laagste prijs tijdens de dag
-
Sluitingsprijs
: Sluitingsprijs van de dag
-
Volume: Aantal aandelen verhandeld tijdens de dag
-
Aangepaste Sluitingsprijs: Aangepaste sluitingsprijs, in rekening brengen van dividend en splitsing
3. Feature Engineering
Feature engineering is crucial in machine learning. It involves creating new features from existing data to enhance the predictive power of the model. When it comes to stock prediction, some of the most commonly used features are technical indicators.
Common Technical Indicators:
-
Simple Moving Average (SMA): Een bewegende gemiddelde dat wordt berekend door de aritmetische gemiddelde van een gegeven set van prijzen over een specifiek aantal periodes te nemen.
-
Exponential Moving Average (EMA): Een gewogen bewegende gemiddelde dat recente prijsgegevens meer belang geeft.
-
Relatieve Strength Index (RSI)
: Een momentumoscillator die de snelheid en verandering van prijsbewegingen meet.
-
Gevolgde gemiddelde verschillen (MACD): Een tendensvolgende momentumindicator dat de relatie tussen twee bewegende gemiddelden van een aandelenprijs weergeeft.
-
Bollinger banen: Een variantieindicator dat bestaat uit een middenband (SMA) en twee buitenbanen (standaardafwijking).
Hieronder zie je hoe u enkele van deze technische indicatoren in Python kan berekenen:
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values
data = data.dropna()
Hoe meer technische indicatoren u opnemen, hoe rijker uw dataset wordt voor het trainen van machine learningmodellen. Maak er echter zeker van dat de indicatoren die u kiest relevant zijn voor uw voorspelings taak.
4. Het voorbereiden van het dataset voor Machine Learning
Nu u uw technische indicatoren heeft gemaakt, moet u het dataset voorbereiden door het te splitsen in kenmerken (X) en doel (y). Het doel is de variabele die u wilt voorspellen (bijvoorbeeld de slotprijs van de volgende dag). Zie hieronder hoe u dit kunt instellen:
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (dropping unnecessary columns)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Drop rows with missing values
X = X.dropna()
y = y[X.index] # Ensure target variable aligns with features
Vervolgens splits u de gegevens in training- en testsets om de prestaties van het model te evalueren:
from sklearn.model_selection import train_test_split
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. Kiezen en trainen van een machine learning model
Verschillende machine learning-algoritmen kunnen gebruikt worden voor beursmarktvoorspellingen, inclusief:
-
Lineaire Regressie: Een eenvoudig model voor voorspellingen gebaseerd op de relatie tussen variabelen.
-
Willekeurige Bos: Een alledaags model dat goed werkt met niet-lineaire relaties en overfitting.
-
Steunvektor machine (SVM): Handige voor zowel classificatie als regressie taken.
-
Long Short-Term Memory (LSTM): Een soort neural network die speciaal geschikt is voor tijdreeksdata.
Voor de simpelheid aan de hand van een Willekeurige Bos Regressor, een krachtige verzameling leer algoritmen:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")

6. Model evaluatie
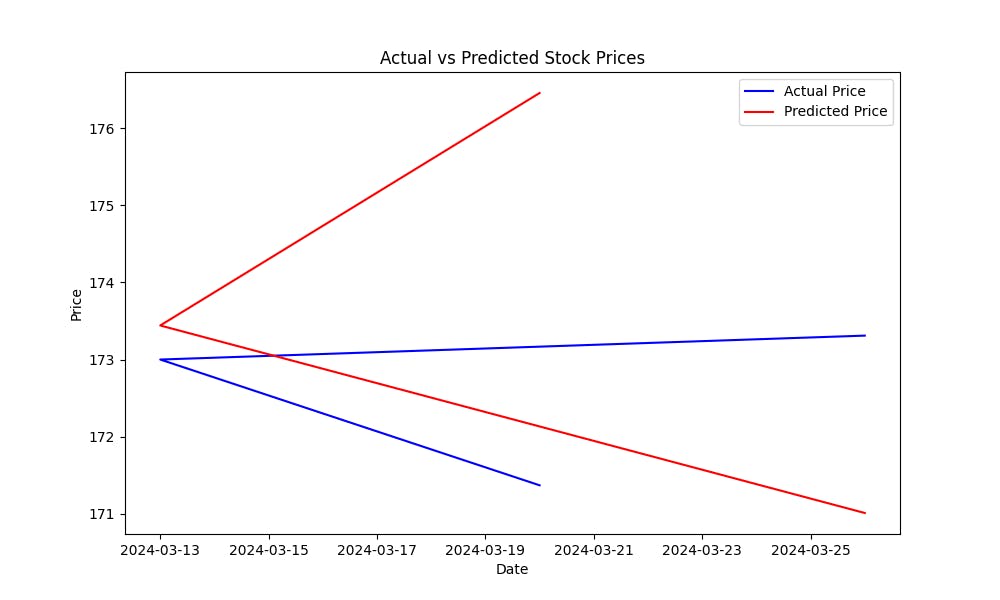
De Mean Squared Error (MSE) helpt de foutmarge van de modelverwachtingen te meten. Hoe lager de MSE hoe beter de verwachtingen van het model. Om te zien hoe goed het model aandelenprijzen voorschiet, plot de actuele tegenover de voorspelde prijzen:
import matplotlib.pyplot as plt
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
Deze plot helpt u visueel de prestaties van het model te evalueren, tonend hoe dicht de voorspelde waarden bij de actuele aandelenprijzen zijn.
Volledig code:
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values (due to moving averages and RSI)
data = data.dropna()
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (SMA, EMA, RSI)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
7. Verbetering van het Model
Nu u een basismodel heeft gebouwd, zijn er verschillende manieren om zijn nauwkeurigheid te verbeteren:
-
Gebruik Extrakenmerken: Neem meer technische indicatoren, sentimentgegevens uit nieuws en sociale media, of zelfs macro-economische varianten mee in het model.
-
Geavanceerde Machine Learning Modellen: Probeer meer geavanceerde algoritmen zoals XGBoost, Gradient Boosting Machines (GBM), of Deeplarning modellen zoals LSTM voor betere prestaties op timeseries data.
-
Hyperparameter aanpassing
: Modelparameters optimaliseren met technieken zoals GridSearchCV of RandomSearchCV om de beste modelconfiguratie te vinden.
-
Feature Selectie: Gebruik technieken zoals Recursive Feature Elimination (RFE) om de meest belangrijke kenmerken te identificeren die bijdragen aan voorspellingen.
Conclusion
door uw model steeds te verfijnen, meer data toe te voegen en verschillende algoritmen uit te proberen, kunt u de voorspellende kracht van uw model voor de beursmarkt trendvoorspelling verbeteren.
Volgende stappen
-
Experimenteer met aanvullende technische indicatoren en databronnen.
-
Probeer verschillende machine learning algoritmen uit (bijv. LSTMs voor diep leren).
-
Backtest uw model door handelssimulaties uit te voeren met behulp van historische data.
-
Blijf uw model verfijnen en optimaliseren op basis van feedback uit de reële wereld prestaties.
Source:
https://blog.bytescrum.com/how-to-predict-stock-market-trends-with-python-and-machine-learning