













La predicción de tendencias en los mercados de valores es un desafío significativo tanto para los inversionistas como para los científicos de datos debido a la volatilidad y complejidad del mercado. Sin embargo, con el advenimiento de la aprendizaje automático (ML), ha sido posible desarrollar modelos predictivos que analizan los datos históricos y ofrecen insights sobre posibles movimientos futuros. En este guía comprensivo, exploraremos cómo puede utilizar Python y la aprendizaje automático para predecir efectivamente las tendencias de precios de acciones y mercados.
1. Resumen del Problema
Los mercados de valores están influenciados por múltiples factores, incluyendo:
-
Indicadores macroeconómicos (como la inflación, el PIB, la tasa de desempleo)
-
Fundamentos de la compañía (ganancias, ingresos, ratio P/E)
-
Sentimiento del mercado (artículos de noticias, actividad en medios sociales)
-
Factores técnicos (acciones de precio, medias móviles, tendencias de volumen)
Dada la alta incertidumbre del mercado de valores, ningún modelo puede ofrecer predicciones perfectas. Sin embargo, analizando los datos de precios históricos y los indicadores técnicos, podemos extraer patrones que ayudan a predecir tendencias de precios futuras, como si una acción aumentará o disminuirá en valor en un periodo corto o largo.
2. Recolección de datos del mercado de valores
El primer paso en la construcción de un modelo predictivo de acciones es recolectar datos históricos de acciones. Estos datos están disponibles fácilmente de proveedores de datos financieros como:
-
Yahoo Finance (a través del paquete de Python
yfinance) -
Quandl
-
Alpha Vantage
Usando yfinance, se puede descargar datos históricos de acciones. Vamos a obtener datos para Apple (AAPL) en los últimos diez años.
pip install yfinance
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
Los datos contienen columnas esenciales como:
-
Apertura: Precio de apertura del día
-
Alto: Precio máximo del día
-
Bajo: Precio mínimo del día
-
Cierre
: Precio de cierre del día
-
Volumen: Número de acciones negociadas durante el día
-
Cierre Ajustado: Precio de cierre ajustado, teniendo en cuenta los dividendos y las divisiones
3. Ingeniería de Características
La ingeniería de características es crucial en machine learning. Incluye la creación de nuevas características a partir de datos existentes para mejorar el poder predictivo del modelo. Cuando se trata de predicciones de acciones, algunas de las características más comúnmente utilizadas son indicadores técnicos.
Indicadores Técnicos Comunes:
-
Media Móvil Simple (SMA): Una media móvil calculada tomando la media aritmética de un conjunto dado de precios over un número específico de períodos.
-
Media Móvil Exponencial (EMA): Una media móvil ponderada que da más importancia a los datos de precio reciente.
-
Índice de Fuerza Relativa (RSI): Un oscilador de momentum que mide la velocidad y el cambio en los movimientos del precio.
-
Convergencia-Divergencia de Media Móvil (MACD): Un indicador de momentum que sigue la tendencia y muestra la relación entre dos medias móviles del precio de una acción.
-
Bandas de Bollinger: Un indicador de volatilidad que consta de una banda central (SMA) y dos bandas exteriores (desviación estándar).
Aquí está cómo puedes calcular algunos de estos indicadores técnicos en Python:
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values
data = data.dropna()
Los más indicadores técnicos que incluyas, más rico se vuelve tu conjunto de datos para el entrenamiento de modelos de aprendizaje automático. Sin embargo, asegúrate de que los indicadores que elijas sean relevantes para tu tarea de predicción.
4. Preparación del Conjunto de Datos para Aprendizaje Automático
Ahora que has creado tus indicadores técnicos, debes preparar el conjunto de datos dividiéndolo en características (X) y objetivo (y). El objetivo es la variable que quieres predecir (por ejemplo, el precio de cierre del siguiente día). Así es cómo puedes configurar esto:
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (dropping unnecessary columns)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Drop rows with missing values
X = X.dropna()
y = y[X.index] # Ensure target variable aligns with features
A continuación, dividirá los datos en conjuntos de entrenamiento y prueba para evaluar el rendimiento del modelo:
from sklearn.model_selection import train_test_split
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. Elección y Entrenamiento de un Modelo de Aprendizaje Automático
Se pueden utilizar varios algoritmos de aprendizaje automático para predicciones del mercado de valores, incluyendo:
-
Regressión Lineal: Un modelo simple para la predicción basada en la relación entre variables.
-
Bosque Aleatorio: Un modelo versátil que maneja bien relaciones no lineales y sobreajuste.
-
Máquina de Soporte Vectorial (SVM): Útil para tareas de clasificación y regresión.
-
Memoria de largo plazo corto (LSTM): Un tipo de red neural particularmente adecuado para datos de series temporales.
Para simplificar, empezaré con un Regressor de Bosque Aleatorio, un poderoso algoritmo de aprendizaje por ensamble:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")

6. Evaluación del Modelo
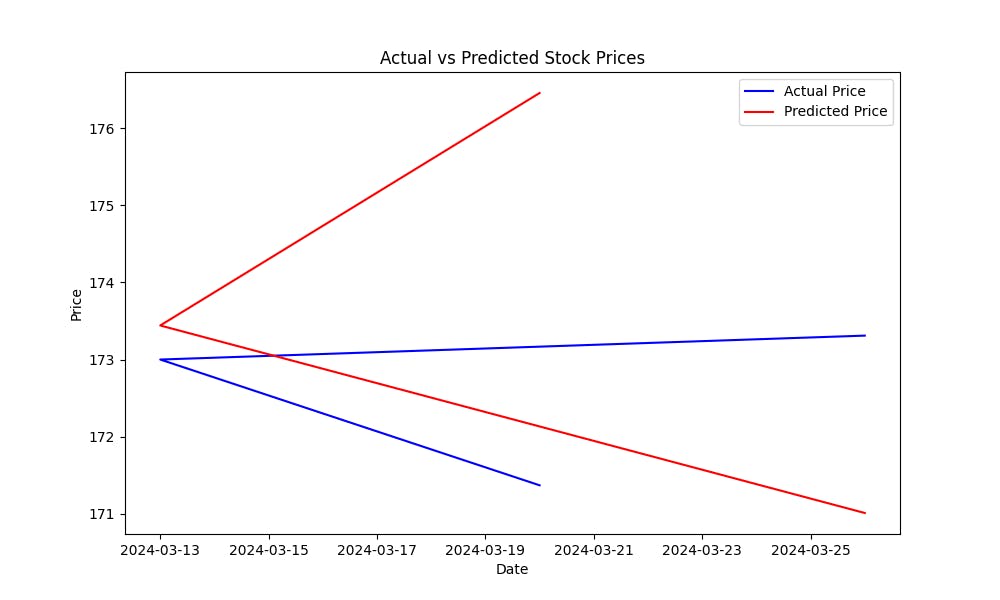
La Error Cuadrático Medio (MSE) ayuda a medir la error de predicción del modelo. Cuanto menor es la MSE, mejores son las predicciones del modelo. Para visualizar cuán bien el modelo predice los precios de las acciones, graficar los precios reales contra los precios predichos:
import matplotlib.pyplot as plt
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
Este gráfico le ayudará a evaluar visualmente el rendimiento del modelo, mostrando cuán cerca están los valores predichos de los precios reales de las acciones.
Código completo:
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values (due to moving averages and RSI)
data = data.dropna()
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (SMA, EMA, RSI)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
7. Mejorar el Modelo
Ahora que ha construido un modelo básico, hay varias maneras de mejorar su precisión:
-
Usar Características Adicionales: Include más indicadores técnicos, datos de análisis de sentimiento de noticias y medios sociales, o incluso variables macroeconómicas.
-
Modelos de Aprendizaje Automático Avanzados: Pruebe algoritmos más sofisticados como XGBoost, Máquinas de Aprendizaje por Boosting de Gradiente (GBM), o modelos de Aprendizaje Automático Profundo como LSTM para un mejor desempeño en datos de series de tiempo.
-
Ajuste de Hiperparámetros: Optimiza los parámetros del modelo utilizando técnicas como GridSearchCV o RandomSearchCV para encontrar la mejor configuración del modelo.
-
Selección de Características: Utiliza técnicas como Eliminación Recursiva de Características (RFE) para identificar las características más importantes que contribuyen a las predicciones.
Conclusion
Al refinar continuamente tu modelo, incorporando más datos y experimentando con diferentes algoritmos, puedes mejorar el poder predictivo de tu modelo de predicción de tendencias del mercado de valores.
Próximos Pasos
-
Experimenta con indicadores técnicos adicionales y fuentes de datos.
-
Prueba diferentes algoritmos de aprendizaje automático (por ejemplo, LSTMs para aprendizaje profundo).
-
Realiza backtesting de tu modelo simulando operaciones utilizando datos históricos.
-
Sigue refinando y optimizando tu modelo basado en el rendimiento del mundo real.
Source:
https://blog.bytescrum.com/how-to-predict-stock-market-trends-with-python-and-machine-learning