













La prédiction des tendances boursières est un défi significatif pour les investisseurs et les scientifiques des données en raison de la volatilité et de la complexité du marché. Cependant, avec l’avènement de l’apprentissage automatique (ML), il est devenu possible de développer des modèles prédicteurs qui analysent les données historiques et offrent des informations sur les mouvements potentiels de l’avenir. Dans ce guide complet, nous explorerons comment vous pouvez utiliser Python et l’apprentissage automatique pour prédire les cours d’actions et les tendances boursières efficacement.
1. Aperçu du problème
Le marché des actions est influencé par plusieurs facteurs, y compris :
-
Des indicateurs macroéconomiques (tels que l’inflation, le PIB, le taux de chômage)
-
Les fondamentaux des entreprises (les bénéfices, le chiffre d’affaires, le ratio PE)
-
Le sentiment du marché (les articles de presse, l’activité sur les réseaux sociaux)
-
Des facteurs techniques (la dynamique des prix, les moyennes mobiles, les tendances du volume)
Compte tenu de l’aléa élevé du marché des actions, aucun modèle ne peut offrir de prédictions parfaites. Cependant, en analysant les données historiques des cours et les indicateurs techniques, nous pouvons extraire des modèles qui aident à prédire les tendances de cours futures, telles que l’augmentation ou la diminution de la valeur d’une action sur une période courte ou longue.
2. Collecter des données sur le marché des actions
La première étape dans la construction d’un modèle préditif pour les actions est de collecter des données historiques sur le marché des actions. Ces données sont disponibles facilement à travers des fournisseurs de données financières tels que :
-
Yahoo Finance (au moyen du package Python
yfinance) -
Quandl
-
Alpha Vantage
En utilisant yfinance, vous pouvez télécharger des données historiques sur le marché des actions. Allons-y chercher les données pour Apple (AAPL) sur une période de dix ans.
pip install yfinance
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
Les données contiennent les colonnes essentielles telles que :
-
Ouverture : Prix d’ouverture du jour
-
Cours maximum : Plus haut prix atteint pendant la journée
-
Cours minimum : Plus bas prix atteint pendant la journée
-
Fermer : Prix de clôture de la journée
-
Volume : Nombre d’actions échangées pendant la journée
-
Fermeture Ajustée : Prix de clôture ajusté, tenant compte de les distributions et des scissions
3. Ingénierie des Caractéristiques
L’ingénierie des caractéristiques est essentielle dans le domaine de l’apprentissage automatique. Elle consiste à créer de nouvelles caractéristiques à partir de données existantes pour améliorer la capacité prédictive du modèle. En ce qui concerne la prévision des actions, certaines des caractéristiques les plus couramment utilisées sont les indicateurs techniques.
Indicateurs Techniques Communs :
-
Moyenne Mobile Simple (MMS) : Une moyenne mobile calculée en prenant la moyenne arithmétique d’un ensemble donné de prix sur un nombre spécifié de périodes.
-
Moyenne Mobile Exponentielle (MME) : Une moyenne mobile pondérée qui accorde plus d’importance aux données de prix récentes.
-
Indice de force relative (RSI)
: Un oscillateur de mouvement mesurant la vitesse et la variation des mouvements de prix.
- Convergence-Divergence mobile (MACD) : Un indicateur de suivi de tendance basé sur la vitesse du mouvement qui montre la relation entre deux moyennes mobiles de prix d’une action.
- Bandes de Bollinger : Un indicateur de volatilité composé d’une bande moyenne (SMA) et de deux bandes externes (écart-type).
Voici comment vous pouvez calculer certains de ces indicateurs techniques en Python :
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values
data = data.dropna()
Plus vous incluez d’indicateurs techniques, plus votre jeu de données devient riche pour l’entraînement de modèles d’apprentissage automatique. Toutefois, veillez à ce que les indicateurs que vous choisissez soient pertinents pour votre tâche de prévision.
4. Préparation du jeu de données pour l’apprentissage automatique
Maintenant que vous avez créé vos indicateurs techniques, vous devez préparer le jeu de données en le divisant en features (X) et en cible (y). La cible est la variable que vous voulez prédire (par exemple, le prix de clôture du jour suivant). Voici comment vous pouvez mettre ça en place :
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (dropping unnecessary columns)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Drop rows with missing values
X = X.dropna()
y = y[X.index] # Ensure target variable aligns with features
Procédez ensuite à la division des données en ensembles d’entraînement et de test pour évaluer la performance du modèle :
from sklearn.model_selection import train_test_split
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. Choix et entraînement d’un modèle d’apprentissage automatique
Plusieurs algorithmes d’apprentissage automatique peuvent être utilisés pour les prédictions boursières, notamment :
-
Régression linéaire : Un modèle simple pour la prévision basé sur la relation entre les variables.
-
Forêt aléatoire : Un modèle polyvalent qui gère bien les relations non linéaires et l’overfitting.
-
Machine à vecteurs de support (SVM) : Utile pour les tâches de classification et de régression.
-
Mémoire à court et long terme (LSTM) : Un type de réseau de neurones particulièrement adapté aux données temporelles.
Par simplicité, commençons par un Random Forest Regressor, un puissant algorithme d’apprentissage en ensemble :
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")

6. Évaluation du modèle
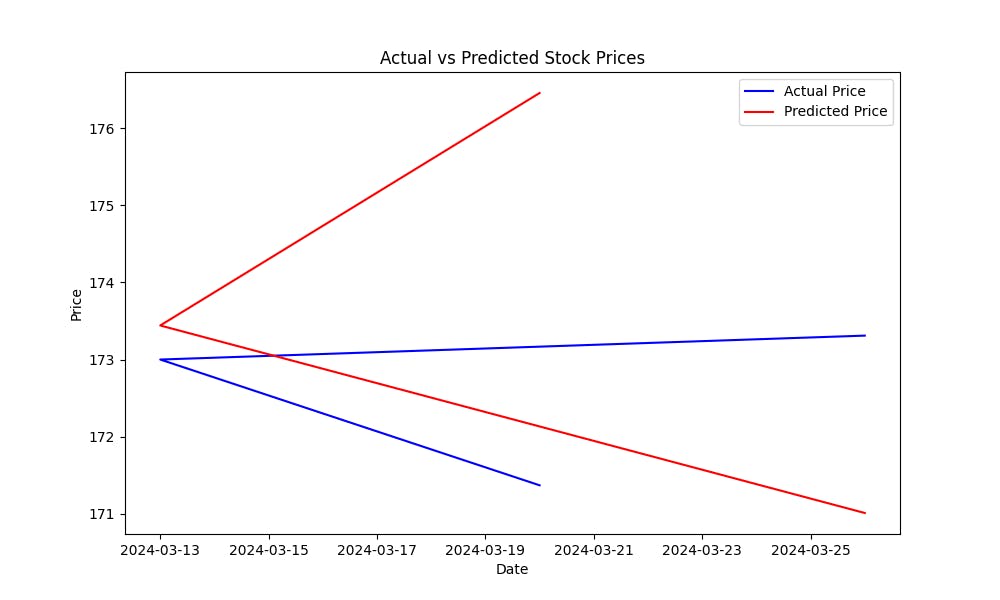
Le Erreur Carré Moyenne (MSE) permet de mesurer l’erreur de prédiction du modèle. Plus la MSE est basse, plus les prédictions du modèle sont bonnes. Pour visualiser comment bien le modèle prédit les cours d’actions, tracez les cours réels vs prédictifs :
import matplotlib.pyplot as plt
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
Ce graphique vous aidera à évaluer visuellement la performance du modèle, montrant à quelle distance les valeurs prédites se situent par rapport aux cours réels des actions.
Code complet :
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values (due to moving averages and RSI)
data = data.dropna()
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (SMA, EMA, RSI)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
7. Améliorer le Modèle
Maintenant que vous avez construit un modèle de base, il existe plusieurs moyens pour améliorer sa précision :
-
Utilisez des Caractéristiques supplémentaires : Incluez plus d’indicateurs techniques, des données d’analyse de sentiment provenant des nouvelles et des médias sociaux, ou même des variables macroéconomiques.
-
Modèles d’Apprentissage Automatique Avancés : Essayez des algorithmes plus sophistiqués tels que XGBoost, Machines d’Apprentissage Par Boosting (GBM), ou Modèles d’Apprentissage Profond tels que LSTM pour un meilleur rendement sur les données temporelles.
-
Tunage des hyperparamètres
: Optimisez les paramètres du modèle en utilisant des techniques telles que GridSearchCV ou RandomSearchCV pour trouver la meilleure configuration du modèle.
- Sélection des caractéristiques : Utilisez des techniques telles que Recursive Feature Elimination (RFE) pour identifier les caractéristiques les plus importantes contribuant aux prédictions.
Conclusion
En raffinant constamment votre modèle, en intégrant plus de données et en expérimentant différents algorithmes, vous pouvez améliorer la capacité de prévision de votre modèle de prediction des tendances du marché des actions.
Prochaines étapes
-
Experimentez avec d’autres indicateurs techniques et sources de données.
-
Essayez différents algorithmes de apprentissage automatique (par exemple, LSTMs pour l’apprentissage profond).
-
Faisiez des backtests de votre modèle en simulant des transactions à l’aide de données historiques.
-
Continuez à raffiner et à optimiser votre modèle en fonction de la rétroaction issue de la performance mondiale.
Source:
https://blog.bytescrum.com/how-to-predict-stock-market-trends-with-python-and-machine-learning