













Previsão de tendências do mercado de ações é um desafio significativo para investidores e cientistas de dados devido à volatilidade e complexidade do mercado. No entanto, com o advento do aprendizado de máquina (AM), tornou-se possível desenvolver modelos preditivos que analisam dados históricos e oferecem insights sobre movimentos potenciais futuros. Nesta guia abrangente, exploraremos como você pode usar o Python e o aprendizado de máquina para prever preços de ações e tendências de mercado eficazmente.
1. Visão Geral do Problema
O mercado de ações é influenciado por múltiplos fatores, incluindo:
-
Indicadores macroeconômicos (como inflação, PIB, taxa de desemprego)
-
Fundamentos das empresas (lucros, receita, taxa de preço/resultado)
-
Sentimento do mercado (artigos noticiosos, atividade de mídia social)
-
Fatores técnicos (ação de preço, médias móveis, tendências de volume)
Dada a alta incerteza do mercado de ações, nenhum modelo pode oferecer previsões perfeitas. No entanto,分析ado dados de preço histórico e indicadores técnicos, podemos extrair padrões que ajudam a prever tendências de preço futuras, como saber se uma ação irá aumentar ou diminuir em valor num período curto ou longo.
2. Coletando Dados de Mercado de Ações
O primeiro passo na construção de um modelo de ações preditivo é coletar dados de ações históricas. Estes dados estão disponíveis prontamente de fornecedores de dados financeiros como:
-
Yahoo Finance (através do pacote Python
yfinance) -
Quandl
-
Alpha Vantage
Usando yfinance, você pode baixar dados de ações históricos. Vamos buscar dados para a Apple (AAPL) ao longo dos últimos dez anos.
pip install yfinance
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
Os dados contêm colunas essenciais como:
-
Abertura: Preço de abertura do dia
-
Alta: Preço máximo durante o dia
-
Baixa: Preço mínimo durante o dia
-
Fechar: Preço de fechamento do dia
-
Volume: Número de ações negociadas durante o dia
-
Fechamento Ajustado: Preço de fechamento ajustado, considerando dividendos e divisões
3. Engenharia de Recursos
A engenharia de recursos é crucial em aprendizagem automática. Ela envolve criar novos recursos a partir de dados existentes para melhorar o poder preditivo do modelo. Quando se trata de previsão de ações, alguns dos recursos mais comumente usados são indicadores técnicos.
Indicadores Técnicos Comuns:
-
Média Móvel Simples (SMA): Uma média móvel calculada pela média aritmética de um conjunto dado de preços em um número especifico de períodos.
-
Média Móvel Exponencial (EMA): Uma média móvel ponderada que dá maior importância aos dados de preço recentes.
-
Índice de Força Relativa (RSI): Um oscilador de momento que mede a velocidade e a mudança dos movimentos de preço.
-
Convergência e Divergência de Médias Móveis (MACD): Um indicador de tendência que mostra a relação entre duas médias móveis do preço de uma ação.
-
Bandas de Bollinger: Um indicador de volatilidade que consiste em uma faixa central (SMA) e duas faixas exteriores (desvio padrão).
Aqui está como você pode calcular algumas destas indicadores técnicos em Python:
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values
data = data.dropna()
Quantos indicadores técnicos você incluir, mais rico seu conjunto de dados torna-se para treinar modelos de aprendizagem automática. No entanto, certifique-se de que os indicadores que você escolheu são relevantes para sua tarefa de previsão.
4. Preparando o conjunto de dados para o Aprendizado de Máquina
Agora que você criou seus indicadores técnicos, você deve preparar o conjunto de dados dividindo-o em features (X) e alvo (y). O alvo é a variável que você deseja prever (por exemplo, o preço de fechamento do dia seguinte). Aqui está como você pode configurar isso:
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (dropping unnecessary columns)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Drop rows with missing values
X = X.dropna()
y = y[X.index] # Ensure target variable aligns with features
Aqui, divirta os dados em conjuntos de treinamento e teste para avaliar o desempenho do modelo:
from sklearn.model_selection import train_test_split
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. Escolher e Treinar um Modelo de Aprendizagem Automática
Vários algoritmos de aprendizagem automática podem ser usados para previsões de mercado de ações, incluindo:
-
Regressão Linear: Um modelo simples para previsão baseado na relação entre variáveis.
-
Floresta Aleatória: Um modelo versátil que consegue lidar bem com relações não-lineares e com overfitting.
-
Máquina de Vetores de Suporte (SVM): Útil para tarefas de classificação e regressão.
-
Memória de Longa Duração (LSTM): Um tipo de rede neural particularmente adequado para dados de séries temporais.
Para simplificar, vamos começar com um Regressor de Floresta Aleatória, um poderoso algoritmo de aprendizagem por conjunto:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")

6. Avaliação do Modelo
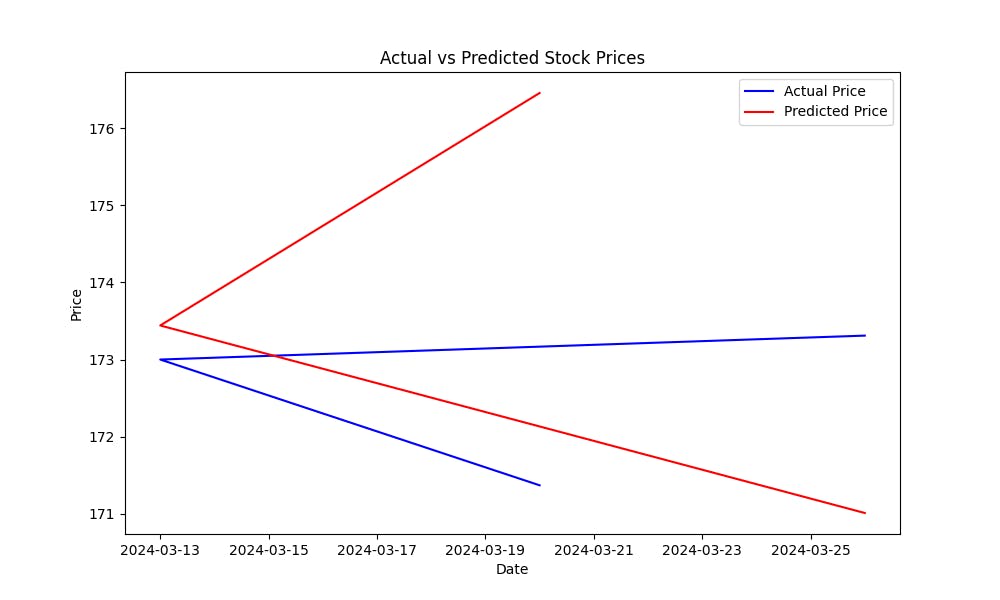
O Erro Quadrático Médio (MSE) ajuda a medir a taxa de erro de previsão do modelo. Quanto menor o MSE, melhores as previsões do modelo. Para visualizar como o modelo prevê preços de ações, plotar o preço real vs. previsão de preço:
import matplotlib.pyplot as plt
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
Este gráfico ajudará você a avaliar visualmente o desempenho do modelo, mostrando quão próximos os valores previstos estão dos preços reais das ações.
Código completo:
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values (due to moving averages and RSI)
data = data.dropna()
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (SMA, EMA, RSI)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
7. Melhorando o Modelo
Agora que você construiu um modelo básico, há várias maneiras de aumentar sua precisão:
-
Usar Recursos Adicionais: Incluir mais indicadores técnicos, dados de análise de sentimento de notícias e mídias sociais, ou até mesmo variáveis macroeconômicas.
- Modelos de Aprendizagem Automática Avançados: Experimentar algoritmos mais sofisticados, como XGBoost, Máquinas de Aprendizagem por Reforço (GBM), ou Modelos de Aprendizagem Profunda como LSTM para melhores desempenhos em dados de série temporal.
-
Ajuste de Hiperparâmetros: Optimize model parameters using techniques like GridSearchCV or RandomSearchCV to find the best model configuration.
-
Seleção de Atributos: Use techniques like Recursive Feature Elimination (RFE) to identify the most important features contributing to predictions.
Conclusion
By continuously refining your model, incorporating more data, and experimenting with different algorithms, you can improve the predictive power of your stock market trend prediction model.
Próximas etapas
-
Experimente com indicadores técnicos adicionais e fontes de dados.
-
Experimente com diferentes algoritmos de aprendizagem automática (por exemplo, LSTMs para aprendizagem profunda).
-
Backtest your model by simulating trades using historical data.
-
Keep refining and optimizing your model based on feedback from real-world performance.
Source:
https://blog.bytescrum.com/how-to-predict-stock-market-trends-with-python-and-machine-learning