













تنبؤ بالمنحنى السوقي هو تحدي كبير للمستثمرين وعلماء البيانات بسبب تنوع وتعقيد السوق. ومع ظهور التعلم الآلي (المايكرو لرنينج), أصبح من الممكن تطوير نماذج تنبؤية تتحلل البيانات التاريخية وتوفر بيانات عن تحركات مستقبلية ممكنة. سنقوم في هذه المرشدة الشاملة بالبحث في كيفية استخدام بيانات بوتفوراً والتعلم الآلي لتنبؤ بأسعار الأسهم والمنحنى السوقي بشكل فعال.
1. إجمالي المشكل
يؤثر السوق الأسهم على عدة عوامل بما في ذلك:
-
مؤشرات الاقتصاد الكلي (مثل التضخم، الناتج القومي، معدل البطالة)
-
الأساسيات التجارية (الايرادات، المبيعات، نسبة المخزون)
-
المزاج السوقي (مثل المقالات، نشاط الشبكات الاجتماعية)
-
عوامل تقنية (تحرك الأسعار، المتوسطات المتنقلة، موجيات الحجم)
توفر سوق الأسهم مستوىً عالٍ من عدم اليقين، ولا يمكن لأي نموذج أن يوفر تنبؤات مثالية. ومع ذلك، من خلال تحليل بيانات الأسعار التاريخية والمؤشرات التقنية، يمكننا استخراج أنماط يساعدون في تنبؤ باتجاهات الأسعار المستقبلية، مثلما لو ستزداد أو تنخفض قيمة سهم في فترة قصيرة أو طويلة.
2. جمع بيانات سوق الأسهم
أول خطوة في بناء نموذج الأسهم التنبؤي هو جمع بيانات الأسهم التاريخية. تتوفر هذه البيانات من مزودي البيانات المالية مثل:
-
Yahoo Finance (بواسطة حزمة Python
yfinance) -
Quandl
-
Alpha Vantage
باستخدام yfinance، يمكنك تحميل بيانات الأسهم التاريخية. دعونا نجمع بيانات الشركة Apple (AAPL) على مدى العشر سنوات الماضية.
pip install yfinance
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
تحتوي البيانات على أعمدة أساسية مثل:
-
Open: سعر الافتتاح لليوم
-
High: أعلى سعر خلال اليوم
-
Low: أقل سعر خلال اليوم
-
الإغلاق: سعر الإغلاق لليوم
-
الحجم: عدد الأسهم المتداولة خلال اليوم
-
الإغلاق المعدل: سعر الإغلاق المعدل مع مراعاة الأرباح والتقسيمات
3. هندسة الميزات
هندسة الميزات ضرورية في تعلم الآلة. تتضمن إنشاء ميزات جديدة من البيانات الموجودة لتعزيز القوة التنبؤية للنموذج. عندما يتعلق الأمر بتوقع الأسهم، فإن بعض الميزات الأكثر استخدامًا هي المؤشرات الفنية.
المؤشرات الفنية الشائعة:
-
المتوسط المتحرك البسيط (SMA): متوسط متحرك يتم حسابه عن طريق أخذ المتوسط الحسابي لمجموعة معينة من الأسعار على عدد محدد من الفترات.
-
المتوسط المتحرك الأسي (EMA): متوسط متحرك مرجح يعطي أهمية أكبر للبيانات السعرية الحديثة.
-
معدل القوة النسبية (RSI): مُؤشر موجة النشاط الذي يقيس سرعة وتغيير حركات الأسعار.
-
معدل تجميع المتوسط التناولي (MACD): مُؤشر متبع للموجة الذي يظهر علاقة بين معدلين تحركين لسعر مواد التمويل.
-
الحزم البولينجري: مُؤشر تعريفي يتكون من حزمة وسطية (SMA) واثنتين خارجيتين (تحقيق الاستانداد).
هذه هي طريقة تحليل بعض هذه المؤشرات التقنية في برنامج Python:
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values
data = data.dropna()
كلما زادت معدلات التقنيات الأكثر, يصبح مجموعة البيانات أغنى لتمويل نماذج التعلم الآلي. ومع ذلك ، تأكد من أن معدلات التقنيات التي تختار مناسبة لمهمتك.
4. إعداد البيانات للتعلم الآلي
وبمجرد إنشاء مؤشراتك التقنية الخاصة، يجب عليك تحضير البيانات بتقسيمها إلى خصائص (X) وهدف (y). وهدف المتغير الذي تريد تنبؤ به (
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (dropping unnecessary columns)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Drop rows with missing values
X = X.dropna()
y = y[X.index] # Ensure target variable aligns with features
تقسيم البيانات التالية إلى مجموعات التدريب واختبار لتقييم أداء النموذج:
from sklearn.model_selection import train_test_split
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. إختيار وتدريب نموذج للتعلم الآلي
يمكن استخدام عدة خوارزميات التعلم الآلي لتوقعات سوق الأسهم، بما فيها:
-
التنموذج الخطي للتنبؤ: نموذج بسيط للتوقع على أساس العلاقة بين العوامل.
-
الغابة العشوائية: نموذج متعدد الاستخدامات يتعامل جيداً مع العلاقات غير الخطية والتفريط.
-
آلة الدعم الفاصلية (SVM): مناسبة للمهام الفردية والتنبؤية.
-
الذاكرة القصيرة والطويلة (LSTM): نوع من الشبكات العصبية ميزة للبيانات الزمنية.
للبساطة، دعونا نبدأ بـمتنبئ الغابة العشوائية، خوارزمية مؤثرة للتعلم التركيبي:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")

6. تقييم النموذج
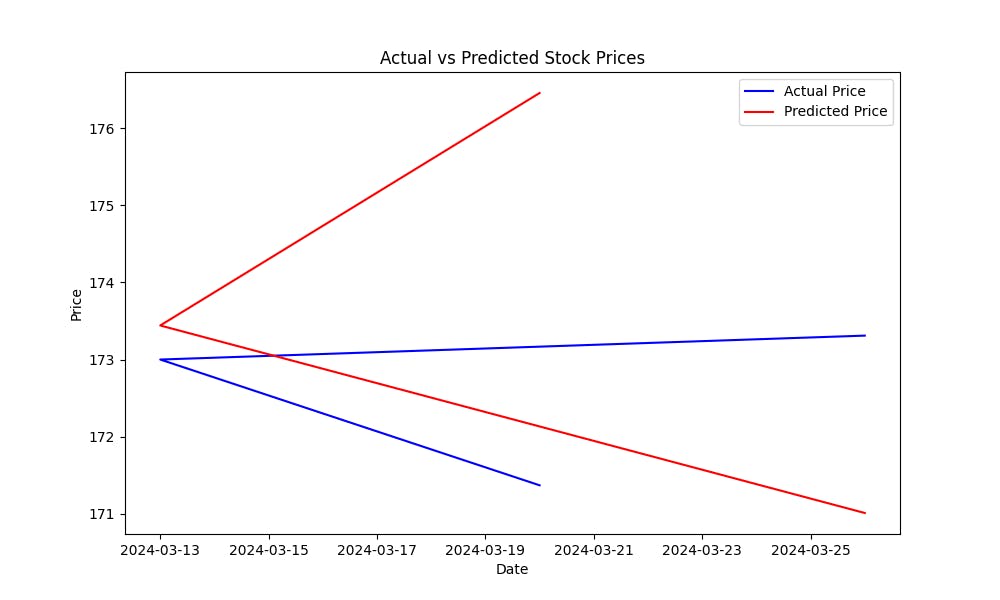
يساعد معدل الخطأ المترابط (MSE) في قياس خطأ التنبؤ للنموذج. كلما كان مستوى MSE أقل ، كلما كان نتائج التنبؤ التي ينتجها النموذج أفضل. لتبين كيف يتم التنبؤ بأسعار الأسهم بواسطة النموذج، قم برسم مخطط الحقيقة versus التنبؤ:
import matplotlib.pyplot as plt
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
سيساعد هذا المخطط على التقدير البصري لأداء النموذج، ويظهر كيف قريب هي القيم المتنبؤة عن الأسعار الحقيقية للأسهم.
توالي الكود:
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values (due to moving averages and RSI)
data = data.dropna()
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (SMA, EMA, RSI)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
7. تحسين النموذج
بعد أن قمت ببناء نموذج بسيط، فهناك طرق عديدة يمكن تحسين دقةه:
- استخدم ميزات إضافية: قم بشمول أكثر من مؤشرات تقنية أو بيانات تحليل المزاج من الأخبار والمواقع الاجتماعية أو حتى المتغيرات الاقتصادية الكليدية.
- نموذجات المachine Learning المتقدمة: تجربة نموذجات أكثر تعقيدًا مثل XGBoost, الماشينات المتقدمة بالتعزيز المتقارن (GBM) أو نموذجات الAprendizaje Profundo مثل LSTM لتحسين أداء البيانات الزمنية.
-
تضبيط المعاملات الفائقة: تحسين معلمات النموذج باستخدام تقنيات مثل GridSearchCV أو RandomSearchCV للعثور على أفضل تكوين للنموذج.
-
اختيار الميزات: استخدم تقنيات مثل إزالة الميزات التكرارية (RFE) لتحديد الميزات الأكثر أهمية التي تساهم في التنبؤات.
Conclusion
من خلال الاستمرار في تحسين النموذج الخاص بك، ودمج المزيد من البيانات، وتجربة خوارزميات مختلفة، يمكنك تحسين القدرة التنبؤية لنموذج توقع اتجاه السوق المالي.
الخطوات التالية
-
جرب مؤشرات فنية إضافية ومصادر بيانات.
-
جرب خوارزميات تعلم الآلة المختلفة (مثل LSTMs للتعلم العميق).
-
اختبر نموذجك بواسطة محاكاة التداولات باستخدام البيانات التاريخية.
-
استمر في تحسين وتضبيط النموذج الخاص بك بناءً على التغذية الراجعة من الأداء في العالم الحقيقي.
Source:
https://blog.bytescrum.com/how-to-predict-stock-market-trends-with-python-and-machine-learning