













טרנדים בשוק המניות חיזוי הם אתגר משמעותי למשקיעים ולמדעני נתונים בשל גיאותיות ומורכבות של השוק. עם הופעת למידת מכונה (ML), נהייתה אפשרות לפתח מודלים חיזוניים הנועדים לנתח מידע היסטורי ולהעניק תובנות על תנועות פוטנציאליות בעתיד. במדריך המקיף הזה, נחקור איך ניתן להשתמש בפייתון ולמידת מכונה לחזות בצורה יעילה את מחירי המניות וטרנדים השוקיים.
1. סקירת הבעיה
השוק המניות הושפע על ידי גורמים מרבים, כולל:
-
אינדיקטורים כלכליים גדולים (כמו התדרדרות, גדולת התוצרה הלאומית, שכירות)
-
יסודות החברה (רווחים, הכנסות, רשת רווחים)
-
רגשות השוק (מאמרי חדשות, פעילות במדיה חברתית)
-
גורמים טכניים (פעולת מחיר, ממוצעים נעים, מגמות נפח)
גילוי של התוצאות המועדפות לא יכול להיות מוצג על ידי מודל בגלל הבלתי ידוע ברמה גבוהה של השוק המני. עם זאת, על ידי ניתוח נתוני מחיר היסטוריים וסימני טכניים, אנחנו יכולים להפיק דפוסים שעוזרים לחזות מגמות מחיר עתידיות, כמו לדעת האם מניות יעלו או ירדו בערך בתקופה קצרה או ארוכה.
2. אספת נתוני שוק המני
השלב הראשון בבניית מודל חזותי למניות הוא לאסוף נתוני מניות היסטוריים. נתונים אלו זמינים בקלות מספקי נתונים פיננסיים כמו:
-
Yahoo Finance (באמצעות חבילת
yfinanceבפייתון) -
Quandl
-
Alpha Vantage
בשימוש ב-yfinance, אתה יכול להוריד נתוני מניות היסטוריים. בואו נשלוף נתונים עבור Apple (AAPL) במהלך 10 השנים האחרונות.
pip install yfinance
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
הנתונים כולל עמודות מהותיים כמו:
-
Open: מחיר הפתיחה ליום
-
High: המחיר הגבוה ביום
-
Low: המחיר הנמוך ביום
-
סגירה
: מחיר הסגירה ליום
- סיטים: מספר המניות המונעות ביום
- סגירה מתודלקת: מחיר הסגירה המתודלקת, בהשקעת דיבידים ופלוטות
3. הנדסת תכונות
הנדסת תכונות היא חיונית בממשק לarning מכונה. היא מתרחשת בעזרת תכונות קיימות על מנת להעלית את כח החיזוי של המודל. כשמגיעה לחיזוי המניות, חלק מהתכונות המשמשות באופן נפוץ הם סימנים טכניים.
סימנים טכניים מקובלים:
-
ממוצע הלך פשוט (SMA): ממוצע הלך שנוצר על-ידי חישוב הממוצע של סך המחירים במספר תקופות מסויימות.
-
ממוצע הלך מושפע (EMA): ממוצע הלך משקלים שמעדיף מידע המחירים האחרונים.
- התאמה מעבר ממוצע נייד (MACD): מדד עוקב אחר המגמה שמראה את היחסים בין שתי ממוצעות ניידות של מחיר המניות.
- מחוץ המעגלים בולינגר (Bollinger Bands): מדד חלל הרעילות שמורכב מסבך ביניין (SMA) ושני סביבות חיצוניים (רמת הסטנדרט).
אז כך אתה יכול לחשב חלק מהמדדים הטכניים האלה בעזרת הערך הפינקציונלי של Python:
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values
data = data.dropna()
הרבה מהמדדים הטכניים האלה יגבירו את ערך המידע שלך עבור האימון של מודלים ללמידה מכונה. אך ורק ודא שהמדדים המובחנים מובילים למטרה התחזית שלך.
4. הכנת המאגר עבור למידת המכונה
עכשיו שיצרת את המדדים הטכניים שלך, עליך להכין את המאגר על ידי חלוף את המידע לתכונות (X) ומטרה (y). המטרה היא המשתנה שאתה רוצה לחזות (ל
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (dropping unnecessary columns)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Drop rows with missing values
X = X.dropna()
y = y[X.index] # Ensure target variable aligns with features
מחלקת את המידע למערכות האימון ולמערכות הבדיקה כדי לבחון את הביצועים של המודל:
from sklearn.model_selection import train_test_split
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. בחירת ועידן מכנה למדע מכונה
יש מספר אלגוריתמים להשערות בשוק המניות, כוללים:
-
התערבות לינארית: מודל פשוט לחיזוי בהתבסס על יחסים בין משתנים.
-
יער אקראי: מודל גדול סגול שמסוגל לטפל ביחסים לא לינאריים ובהתרבות בעיקר.
-
מכונה תומכת מערך (SVM): שימושי למשימות קלטיות והגדרה.
-
זיכרון קצר-טוול (LSTM): סוג מסויים של רשת מוח שמתאים בעיקר למידע ציר זמן.
לפעמים פשוטה, בואו נתחיל עם יער אקראי מדד להגעת, אלגוריתם קבוצתי בעל כוח גדול:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")

6. בדיקת
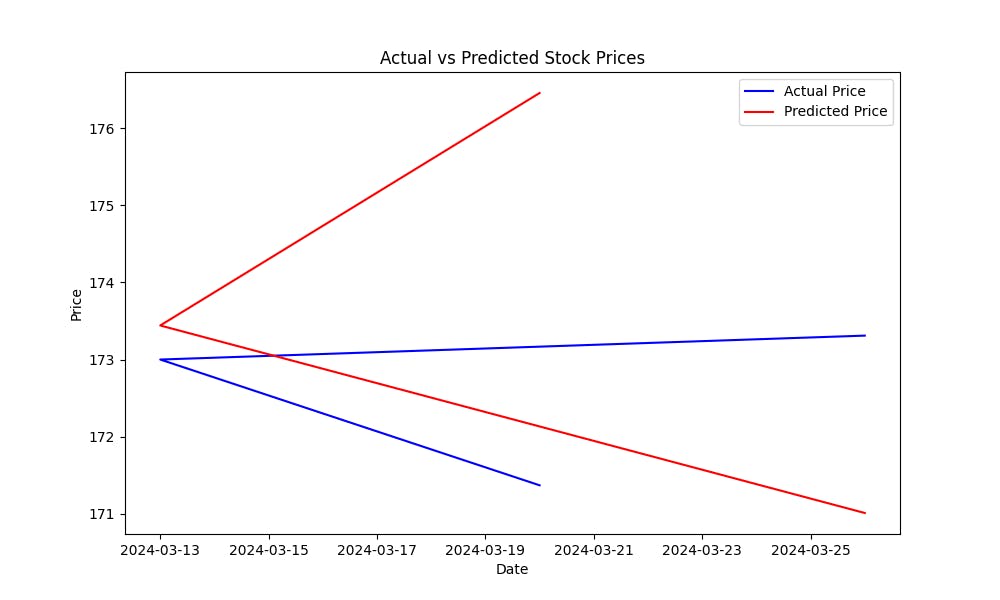
מה שעוזר למדידה של טעות ההערכה של המודל. המאובטח יותר הMSE, היטב יותר ההערכות של המודל. כדי להסתכל כיצד המודל מציע הערכות למחירי המניות, צור טבלה בין המחירים הממוצעים למחירים הניתנים:
import matplotlib.pyplot as plt
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
טבלה זו תעזור לך באופן ויזואלי להעריך את הביצועים של המודל, מראה כמה קרובה הערכות הניתנים למחירי המניות האמיתיים.
קוד מלא:
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import yfinance as yf
# Fetch data for Apple (AAPL) from Yahoo Finance
data = yf.download('AAPL', start='2024-01-01', end='2024-04-01')
print(data.head()) # View the first few rows of the dataset
# Calculate Simple Moving Averages (SMA)
data['SMA_20'] = data['Close'].rolling(window=20).mean()
data['SMA_50'] = data['Close'].rolling(window=50).mean()
# Calculate Exponential Moving Averages (EMA)
data['EMA_20'] = data['Close'].ewm(span=20, adjust=False).mean()
# Calculate Relative Strength Index (RSI)
delta = data['Close'].diff(1)
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
avg_gain = gain.rolling(window=14).mean()
avg_loss = loss.rolling(window=14).mean()
rs = avg_gain / avg_loss
data['RSI'] = 100 - (100 / (1 + rs))
# Drop rows with NaN values (due to moving averages and RSI)
data = data.dropna()
# Define the target variable as the next day's closing price
data['Target'] = data['Close'].shift(-1)
# Drop the last row, which has NaN in the 'Target' column
data = data.dropna(subset=['Target'])
# Feature set (SMA, EMA, RSI)
X = data[['SMA_20', 'SMA_50', 'EMA_20', 'RSI']]
y = data['Target']
# Split into training and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
# Initialize and train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot actual vs predicted prices
plt.figure(figsize=(10, 6))
plt.plot(y_test.index, y_test, label='Actual Price', color='blue')
plt.plot(y_test.index, y_pred, label='Predicted Price', color='red')
plt.title('Actual vs Predicted Stock Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
7. התאמה אותה למודל
עכשיו שבנית את המודל הבסיסי, יש דרכים מספרות לשיפור הדיוק שלו:
- השתמש בתכונות נוספות: כולל יותר סימנים טכניים, מידע על רגשות מחשבה מחדשות ומדיה חברתית, או אפילו משקלים כלכלים רחבים.
- מודלים מדעיים מתקדמים: ניסו אלגוריתמים מתקדמים יותר כמו XGBoost, מכונות גבולת תדמית (GBM), או מודלים ללמידה עמוקה כמו LSTM עבור ביצועים טובים יותר על מידע ציר זמן.
-
כוונון פרמטרים: אופטימיזציה של פרמטרי המודל באמצעות טכניקות כמו GridSearchCV או RandomSearchCV כדי למצוא את התצורה הטובה ביותר של המודל.
-
בחירת מאפיינים: שימוש בטכניקות כמו Recursive Feature Elimination (RFE) כדי לזהות את המאפיינים החשובים ביותר שתורמים לניבויים.
Conclusion
על ידי כיוונון מתמשך של המודל שלך, שילוב יותר נתונים וניסויים באלגוריתמים שונים, תוכל לשפר את כוח הניבוי של המודל לחיזוי מגמות בשוק המניות.
השלבים הבאים
-
ניסוי עם אינדיקטורים טכניים נוספים ומקורות נתונים נוספים.
-
נסה אלגוריתמים שונים של למידת מכונה (למשל, LSTMs ללמידה עמוקה).
-
בצע בדיקות אחורה למודל שלך על ידי סימולציה של עסקאות באמצעות נתונים היסטוריים.
-
המשך לכוונן ולבצע אופטימיזציה למודל שלך בהתבסס על משוב מהביצועים בעולם האמיתי.
Source:
https://blog.bytescrum.com/how-to-predict-stock-market-trends-with-python-and-machine-learning