













為什麼使用政策梯度法?
政策梯度方法的一個關鍵優勢是它們能夠處理複雜的動作空間,傳統的基於價值的方法難以應對。
處理高維度的動作空間
基於價值的方法,如Q-learning,通過估計所有可能動作的價值函數來工作。當環境的動作空間是連續的或是離散但很大時,這變得困難。
策略梯度方法對策略進行參數化,並估計相對於該策略參數的累積獎勵的梯度。它們使用這個梯度直接優化策略,通過更新其參數。因此,它們可以有效處理高維度或連續的動作空間。策略梯度也是強化學習使用人類反饋(RLHF)方法的基礧。 使用人類反饋進行強化學習(RLHF)方法。
通過對策略進行參數化並根據梯度調整其參數,策略梯度可以有效處理連續和高維度動作。這種直接方法能夠更好地泛化和更靈活地探索,使其非常適合於機器人控制和其他複雜環境的任務。
學習隨機策略
給定一組觀察:
- 確定性策略指定了代理人採取的行動。
- 隨機策略提供一組行動以及代理人選擇每個行動的概率。
遵循隨機策略時,同一觀察結果可能導致在不同迭代中選擇不同的行動。這促進了對行動空間的探索,防止策略陷入局部最優解。因此,在探索尋找導致最大回報路徑至關重要的環境中,隨機策略非常有用。
在基於策略的方法中,將策略輸出轉換為概率分佈,每個可能的行動被分配一個概率。代理人通過對該分佈進行抽樣來選擇行動,從而實現了隨機策略。因此,策略梯度方法結合了探索和利用,在具有複雜獎勵結構的環境中非常有用。
政策梯度定理的推導
在深入推导之前,建立数学符号和证明过程中使用的关键概念非常重要。
数学符号和基础知识
正如前面的部分所述,策略梯度定理指出预期回报的导数是回报和策略对数的导数乘积的期望。
在推导策略梯度定理之前,我们引入以下符号:
- E[X]表示随机变量X的概率期望。
- 從數學上來說,政策被表達為一個概率矩陣,根據不同的觀察給出選擇不同行動的概率。政策通常被建模為一個帶有參數的函數,其中參數表示為θ。
- πθ 指的是由θ参数化的政策。在实践中,这些参数是模拟政策的神经网络的权重。
- 軌跡τ指的是一系列狀態,通常從隨機初始狀態開始,直到當前時間步或終端狀態。
- ∇θf 指的是對於參數 f 的梯度θ。
- J(πθ) 指的是代理根据策略 πθ 所实现的预期回报。这也是梯度上升的目标函数。
- 環境在每個時間步驟根據代理的動作給予獎勵。回報是從初始狀態到當前時間步驟的累積獎勵。
- R(τ) 指的是在轨迹τ上生成的回报。
導出步驟
我們展示如何從第一原理開始推導並證明政策梯度定理,從擴展的目標函數出發,並使用對數導數技巧。
目標函數(方程式1)
政策梯度方法中的目標函數是回報
J根據政策π 的軌跡進行累積,並以參數θ表示。這個目標函數如下:
![]()
在上述方程中:
- 左侧(LHS)是按照政策πθ实现的预期回报。
- 右手邊(RHS)是根據沿著政策τ 生成的軌跡期望的期望(在每個步驟上)πθ的回報R(τ)是在軌跡τ上生成的。
目標函數的微分(方程2)
對上述方程的兩側進行微分(關於θ)得:
![]()
期望的梯度(方程3)
右側的期望可以表示為乘積的積分:
- 遵循軌跡 τ
- 在軌跡上生成的回報τ
因此,方程式2的右手邊被重新表述為:
![]()
積分的梯度等於梯度的積分。因此,在上述表達式中,我們可以將梯度∇θ放在積分符號下。因此,右邊變為:
![]()
因此,方程式2可以被重寫為:
![]()
軌跡的機率(方程式4)
現在我們更仔細地觀察 P(τ|θ),代理人按照軌跡 τ 給定策略參數 θ (因此策略 πθ)。一個軌跡由一組步驟組成。因此:
- 獲得軌跡 τ 的機率是以下各項的乘積:
- 遵循所有個別步驟的機率。
![]()
- 在時間步驟 t,代理人從狀態 s 轉移到狀態 st+1,採取動作 at 的機率是以下乘積給出的:
- 該策略預測在狀態at中採取行動的機率
- 在给定动作at和状态st的情况下,最终处于状态st+1的概率
因此,從初始狀態s0開始,代理根據策略τ的軌跡機率如下所示:
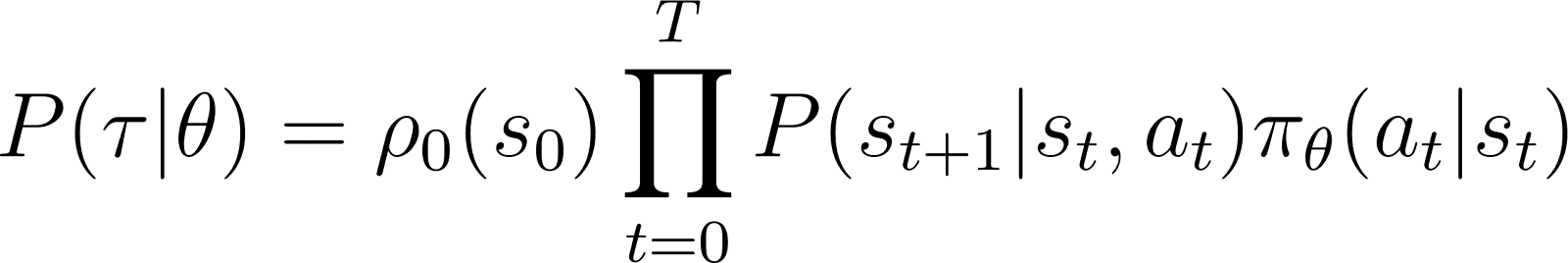
為了讓事情變得更簡單,我們希望將上面的 RHS 產品表示為一個和。因此,我們對上面的方程式兩邊取對數:
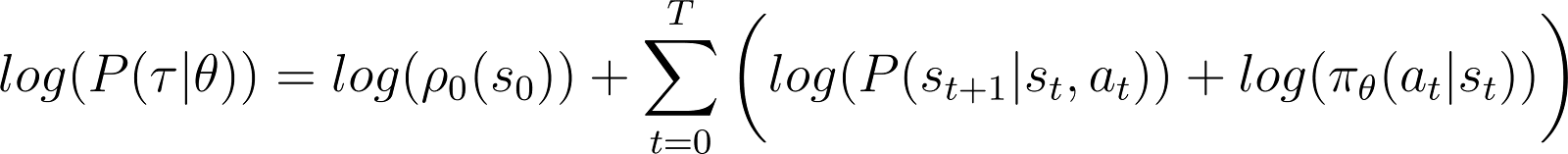
對數概率的導數(方程式 5)
現在我們對上述方程式中的對數概率進行導數(關於 θ)。
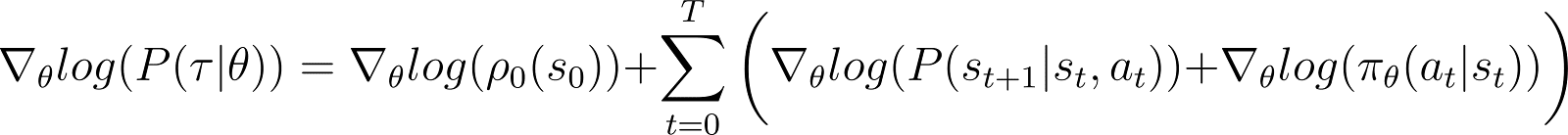
在上述方程式的 RHS:
- 第一个术语log ρ0(s0)对于θ是常数。因此其导数为0。
- 求和符號內的第一項P(st+1|st, at) 也與 θ 及其對於 θ 的導數也為0。
從方程式中刪除上述的零項,我們得到(方程式5):
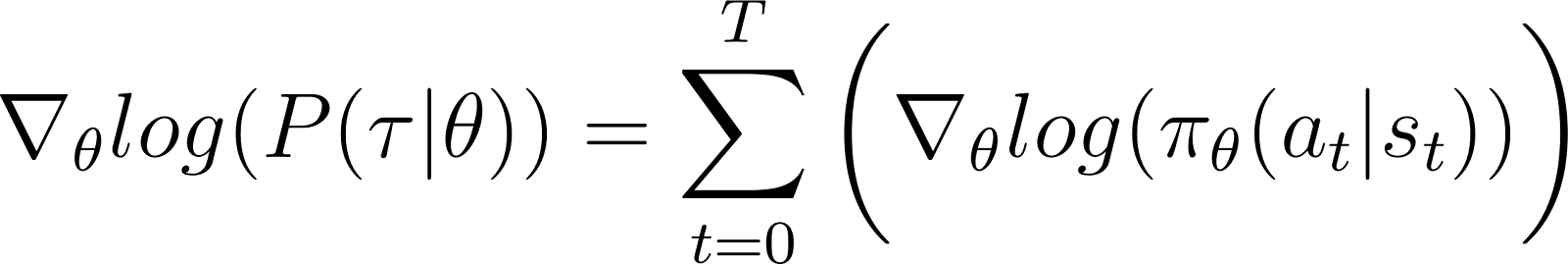
回想一下方程式2:
![]()
方程式5評估了方程式2右手邊第一部分的對數。我們需要將一個項的導數與其對數關聯起來。我們使用鏈式法則和對數導數技巧來完成這一步。
對數導數技巧
我們暫時採用微積分規則來推導出一個結果,我們將使用這個結果來簡化先前的方程式,使之適合於計算方法。
在微積分中,對數的導數可以表示為:
![]()
因此,重新排列以上方程式,x的導數可以用對數的導數表示:
![]()
這有時被稱為對數導數技巧。
链规则
根據鏈式法則,給定 z(y) 作為 y 的函數,其中 y 本身是 θ 的函數, y(θ),對於 z 關於 θ 的導數如下所示:
![]()
在這種情況下,y(θ)代表P(θ)並且z(y)代表log(y)。因此,
![]()
應用鏈規則
我們從微積分知道,d(log(y)) / dy = 1/y。將此應用在上述右手邊的第一個表達式中。
![]()
將 y 移至左手邊並使用 標記:
![]()
y代表P(θ)。因此,上述方程等同於:
![]()
應用對數導數技巧
上述結果給出了方程2 RHS 的第一個表達式(如下所示)。
使用方程2 RHS 中的結果,我們得到:
![]()
我們將 RHS 積分下的項重新排列如下:
![]()
推導最終結果
觀察上述表達式中包含期望值的積分展開: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
因此,上述的RHS可以被表达为期望值:
![]()
我们在期望回报的表达式中替换对数概率的导数:
![]()
在上述方程中,將∇的值代入從方程5中得到的logP(θ),得到:
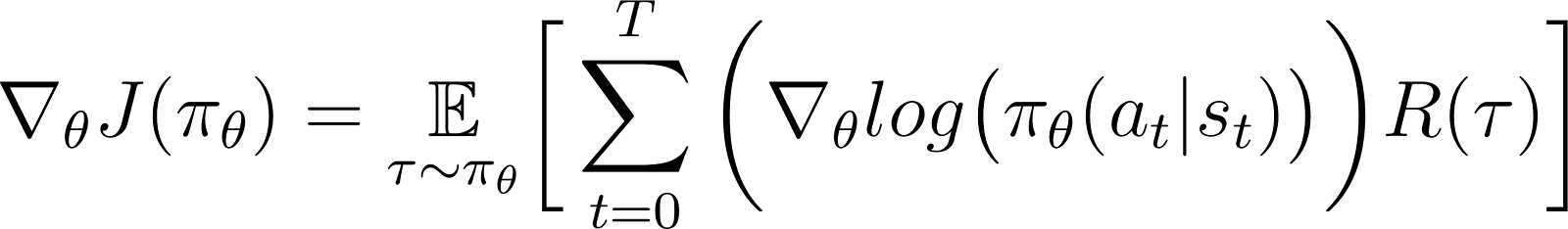
這是根據策略梯度定理的獎勵函數的梯度表達式。
策略梯度的直覺
策略梯度方法將策略的輸出轉換為概率分佈。代理從這個分佈中進行抽樣以選擇行動。策略梯度方法會調整策略參數。這導致在每次迭代中更新這個概率分佈。更新後的概率分佈在選擇導致更高獎勵的行動時具有更高的可能性。
策略梯度算法計算期望回報對策略參數的梯度。通過朝著這個梯度的方向移動策略參數,代理在訓練過程中增加選擇導致更高獎勵的行動的概率。
本質上,導致更好結果的行動在未來變得更有可能被選擇,逐步改善策略以最大化長期獎勵。
Source:
https://www.datacamp.com/tutorial/policy-gradient-theorem