













ポリシーグラディエントメソッドの利点
ポリシーグラディエントメソッドの主な利点の1つは、伝統的な価値ベースのアプローチが苦戦する複雑なアクションスペースを扱える能力です。
高次元のアクションスペースの取り扱い
価値ベースの手法、例えばQ学習は、すべての可能な行動に対する価値関数を推定することによって機能します。環境の行動空間が連続的または離散的であっても大きい場合、これは困難になります。
ポリシー勾配法はポリシーをパラメータ化し、ポリシーのパラメータに対する累積報酬の勾配を推定します。この勾配を使用して、パラメータを更新することによってポリシーを直接最適化します。したがって、彼らは高次元または連続的な行動空間を効率的に扱うことができます。ポリシー勾配は、人間のフィードバックを利用した強化学習(RLHF)手法の基礎でもあります。
ポリシーをパラメータ化し、勾配に基づいてそのパラメータを調整することによって、ポリシー勾配は連続的かつ高次元の行動を効率的に扱うことができます。この直接的なアプローチは、より良い一般化と柔軟な探索を可能にし、ロボット制御やその他の複雑な環境のようなタスクに適しています。
確率的ポリシーの学習
観察のセットが与えられた場合:
- 確定的ポリシーは、エージェントが取る行動を指定します。
- 確率的ポリシーは、エージェントが各行動を選択する確率を示す一連の行動を与えます。
確率的ポリシーに従うと、同じ観測でも異なる反復で異なる行動を選択することができます。これにより、行動空間の探索が促進され、ポリシーが局所最適解に固執するのを防ぎます。そのため、探索が最大のリターンへと導く経路を発見するのに不可欠な環境では、確率的ポリシーが有用です。
ポリシーベースの手法では、ポリシーの出力が確率分布に変換され、各可能な行動に確率が割り当てられます。エージェントはこの分布をサンプリングして行動を選択し、確率的ポリシーを実装することが可能です。したがって、ポリシーグラディエント法は探索と活用を組み合わせ、複雑な報酬構造を持つ環境で有用です。
ポリシーグラディエント定理の導出
導出に入る前に、証明全体で使用される数学的表記と主要な概念を確立することが重要です。
数学的表記と準備
以前のセクションで述べたように、ポリシーグラディエント定理は、期待収益の導関数が収益とポリシーの対数の導関数の積の期待値であると述べています。
ポリシーグラディエント定理を導出する前に、以下の表記を導入します:
- E[X]は確率変数Xの確率期待値を表します。
- 数学的には、方針は異なる観測に基づいて異なる行動を選択する確率を与える確率行列として表されます。方針は通常、パラメータ化された関数としてモデル化され、パラメータはθで表されます。
- π θ は、θでパラメータ化されたポリシーを指します。実際には、これらのパラメータはポリシーをモデル化するニューラルネットワークの重みです。
- 軌道、τは、通常、ランダムな初期状態から始まり、現在の時間ステップまたは終端状態までの状態のシーケンスを指します。
- ∇θfは、fのパラメータに関する関数の勾配を示します。
- J(πθ)は、エージェントが方針πθに従って達成する期待リターンを指します。これは、勾配上昇の目的関数でもあります。
- 環境は、エージェントの行動に応じて各タイムステップで報酬を与えます。リターンは、初期状態から現在のタイムステップまでの累積報酬を指します。
- R(τ)は、τ軌道上で生成されたリターンを指します。
導出ステップ
私たちは、目的関数の展開から始め、対数微分トリックを使用して、ポリシー勾配定理をどのように導出し証明するかを示します。
目的関数(式1)
ポリシー勾配法における目的関数はリターンです。
Jは、π に基づいた軌跡をたどることで蓄積されます。このポリシーはパラメータθで表現されます。この目的関数は次のように与えられます:
![]()
上記の式で:
- 左辺(LHS)はポリシーπθに従って達成される期待リターンです。
- 右辺(RHS)は、ポリシー πθに従って生成される軌跡 τ の期待値です。各ステップで生成される収益の期待値は、軌跡 τ にわたって生成される収益 R(τ)です。
目的関数の微分(式2)
上記の式の両側を(θに関して)微分すると、次のようになります:
![]()
期待値の勾配(式3)
期待値(右辺)は、以下の積分として表現できます:
- 軌道をたどる確率τ
- 軌道上で生成されたリターン
したがって、式2の右辺は次のように再記述されます:
![]()
積分の勾配は勾配の積分に等しい。したがって、上記の式では、勾配 ∇θを積分記号の下に持ってくることができる。したがって、右辺は次のようになる:
![]()
したがって、式2は次のように書き直すことができます:
![]()
軌跡の確率(式4)
今、P(τ|θ)、エージェントが軌跡 τ に従う確率を調べます。ポリシーパラメータθを考慮した場合の確率です(したがってポリシーπθ)。軌跡は一連のステップで構成されます。したがって:
- 軌道を取得する確率は、以下の積です:
- すべての個々のステップに従う確率。
![]()
- 時間ステップtにおいて、エージェントは状態sから状態st+1に行動atを取る確率は以下の積で与えられます:
- そのポリシーが状態 st で行動 at を予測する確率
- 行動st+1を取った場合の、状態atと状態st
したがって、初期状態s0から始めて、エージェントがポリシーτに基づいて軌跡をたどる確率は、ポリシーπθによって与えられます:
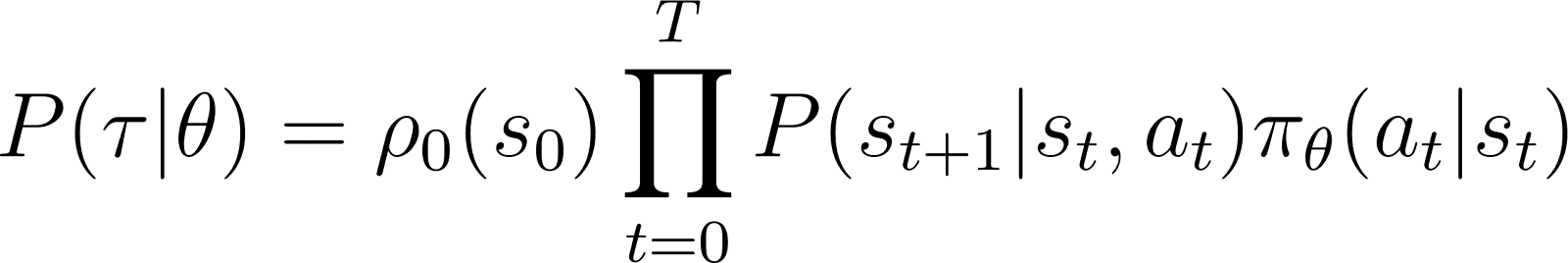
物事を単純化するために、上記のRHSの積を和で表現したいと思います。したがって、上記の方程式の両側に対数を取ります:
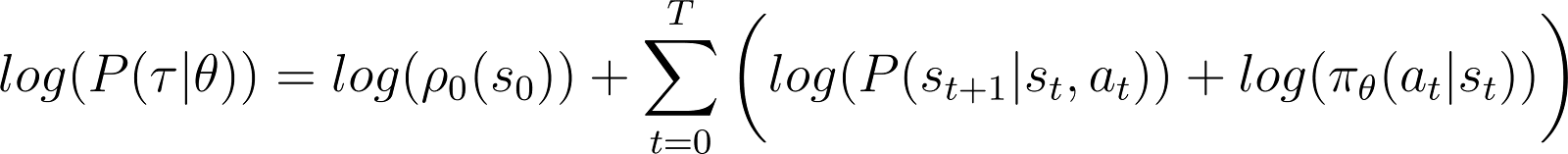
対数確率の導関数(方程式5)
今、上記の方程式の対数確率の導関数(θに関して)を取ります。
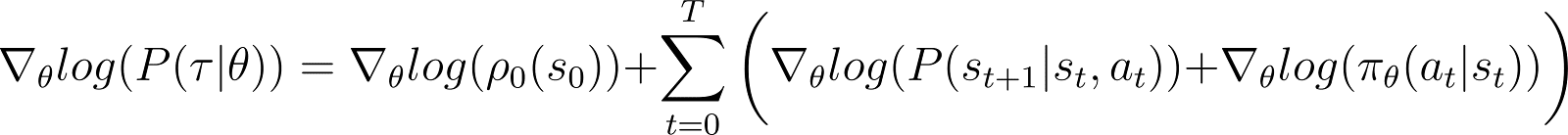
上記の方程式のRHSでは:
- 最初の項 log ρ0(s0) は θに関して定数です。したがって、その導関数は0です。
- Σ内の最初の項P(st+1|st, at) は、θ およびθ についても独立であり、その導関数も0である。
上記のゼロ項を方程式から取り除くと、以下のようになります(方程式5):
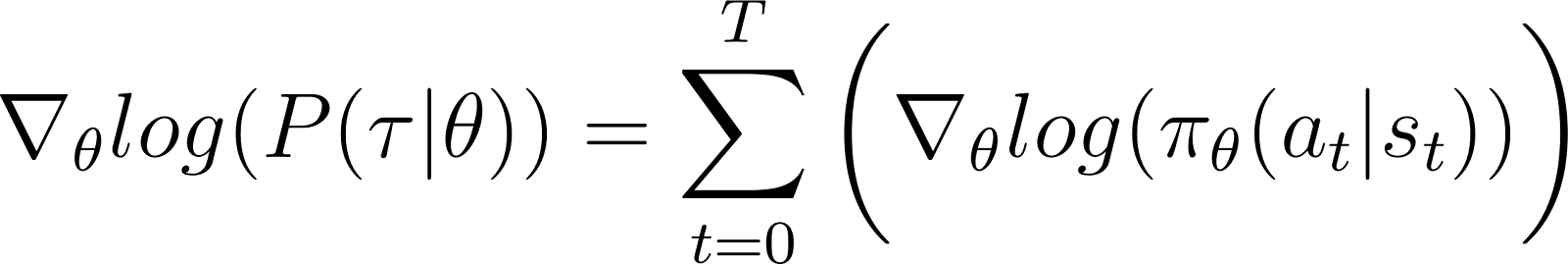
方程式2から思い出してください:
![]()
方程式5は、方程式2のRHSの最初の部分の対数を評価します。項の導関数とその対数との関係を示す必要があります。これは連鎖律と対数導関数のトリックを使用して行います。
対数導関数のトリック
私たちは一旦外れ道にそれて微積分のルールを使用して結果を導出し、前の方程式を単純化し、計算方法に適した形に変えます。
微積分では、対数の導関数は次のように表現されます:
![]()
したがって、上記の方程式を再配置することにより、xの導関数は、xの対数の導関数を用いて表現できます:
![]()
これは時々対数導関数トリックと呼ばれます。
連鎖律
チェーンルールによると、z(y) を関数として、y として、y がそれ自体が関数 θ の関数である場合、y(θ) の導関数は、z を θ に関して以下のように与えられます:
![]()
この場合、y(θ)はP(θ)を表し、z(y)はlog(y)を表します。したがって、
![]()
連鎖律の適用
微積分からわかることは、d(log(y)) / dy = 1/yです。これを上記の右辺の最初の式に使用します。
![]()
yを左辺に移動し、記法を使用します:
![]()
y は P(θ) です。したがって、上記の方程式は次のように等価です:
![]()
対数微分トリックを適用する
上記の結果は、以下に示す方程式2のRHSの最初の式を与えます。
方程式2のRHSの結果を使用すると、次のようになります:
![]()
以下のように、RHS積分の項を再配置します:
![]()
最終結果を導出
上記の式には期待値の積分展開が含まれていることに注意してください: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
したがって、上記のRHSは期待値として表現できます。
![]()
期待報酬の式に確率の対数の導関数を代入します。
![]()
上記の式において、∇logP(θ)の値を式5から代入してください:
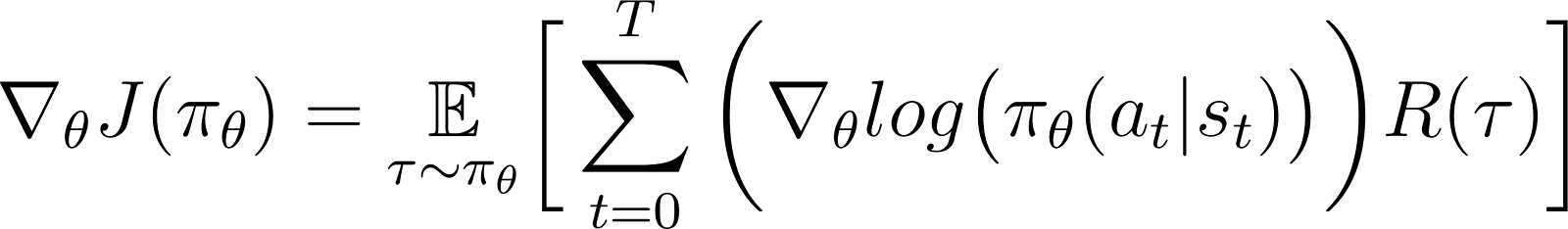
これはポリシー勾配定理に基づく報酬関数の勾配の表現です。
ポリシー勾配の直感
ポリシー勾配法は、ポリシーの出力を確率分布に変換します。エージェントはこの分布からサンプリングしてアクションを選択します。ポリシー勾配法はポリシーのパラメータを調整します。これにより、各イテレーションでこの確率分布が更新されます。更新された確率分布は、高い報酬につながるアクションを選ぶ可能性が高くなります。
ポリシー勾配アルゴリズムは、ポリシーのパラメータに関する期待リターンの勾配を計算します。この勾配の方向にポリシーのパラメータを移動させることにより、エージェントはトレーニング中に高い報酬をもたらすアクションを選択する確率を高めます。
基本的に、より良い結果をもたらしたアクションは将来選択される可能性が高くなり、ポリシーを徐々に改善して長期的な報酬を最大化します。
Source:
https://www.datacamp.com/tutorial/policy-gradient-theorem