













لماذا استخدام أساليب ميل السياسة؟
إحدى المزايا الرئيسية لأساليب ميل السياسة هي قدرتها على التعامل مع مساحات أفعال معقدة، حيث تواجه النهج التقليدي المعتمد على القيم صعوبات.
التعامل مع مساحات أفعال عالية الأبعاد
تعمل الطرق القائمة على القيم، مثل تعلم الفهم (Q-learning)، من خلال تقدير وظيفة القيمة لجميع الإجراءات الممكنة. يصبح ذلك صعبًا عندما يكون مساحة الإجراءات في البيئة إما مستمرة أو متقطعة ولكن كبيرة.
تقوم طرق تدرج السياسة بتعميم السياسة وتقدير تدرج المكافآت التراكمية بالنسبة للمعلمات السياسية. يستخدمون هذا التدرج لتحسين السياسة مباشرة من خلال تحديث معلماتها. وبالتالي، يمكنهم التعامل بكفاءة مع مساحات الإجراءات عالية الأبعاد أو المستمرة. تعتبر تدرجات السياسة أساسًا أيضًا لطرق تعلم التعزيز باستخدام تغذية راجعة من البشر (RLHF).
من خلال تعميم السياسة وضبط معلماتها بناءً على التدرجات، يمكن لتدرجات السياسة التعامل بكفاءة مع الإجراءات المستمرة وذات الأبعاد العالية. يتيح هذا النهج المباشر التعميم الأفضل والاستكشاف المرن أكثر، مما يجعله مناسبًا تمامًا للمهام مثل التحكم في الروبوتات وبيئات أخرى معقدة.
تعلم السياسات العشوائية
بناءً على مجموعة من الملاحظات:
- تحدد السياسة التحديدية الإجراء الذي يتخذه الوكيل.
- تعطي السياسة الاحتمالية مجموعة من الإجراءات واحتمالية اختيار الوكيل لكل إجراء.
عند اتباع سياسة احتمالية، يمكن أن تؤدي نفس الملاحظة إلى اختيار إجراءات مختلفة في تكرارات مختلفة. يعزز ذلك استكشاف مساحة الإجراءات ويمنع السياسة من العلق في النقاط المحلية الأمثل. وبسبب ذلك، تكون السياسات الاحتمالية مفيدة في البيئات حيث يكون الاستكشاف ضروريًا لاكتشاف المسار الذي يؤدي إلى أقصى عوائد.
في الطرق القائمة على السياسة، يتم تحويل إخراج السياسة إلى توزيع احتمالي، مع تخصيص احتمالية لكل إجراء ممكن. يختار الوكيل إجراءً عن طريق أخذ عينة من هذا التوزيع، مما يجعل من الممكن تنفيذ سياسة احتمالية. وبالتالي، تجمع طرق التدرج في السياسة بين الاستكشاف والاستغلال، مما يكون مفيدًا في البيئات ذات الهياكل المعقدة للمكافآت.
اشتقاق نظرية تدرج السياسة
قبل الانغماس في الاشتقاق، من المهم تحديد العلامات الرياضية والمفاهيم الرئيسية المستخدمة طوال البرهان.
العلامات الرياضية والمقدمات
كما ذُكر في القسم السابق، تقول نظرية تدرج السياسة أن مشتقة العائد المتوقع هي توقع حاصل ضرب العائد ومشتقة اللوغاريتم للسياسة.
قبل استنباط نظرية تدرج السياسة، نقدم العلامات التالية:
- E[X] تشير إلى التوقع الاحتمالي لمتغير عشوائي X.
- رياضيًا، تُعبّر السياسة عن مصفوفة احتمالات تُعطي احتمال اختيار أفعال مختلفة استنادًا إلى ملاحظات مختلفة. تُنمذج السياسة عادةً كدالة معلمة، حيث تُمثل المعلمات بشكل θ.
- πθ يشير إلى سياسة معلمة بواسطة θ. في الممارسة، هذه المعلمات هي أوزان الشبكة العصبية التي تقوم بنمذجة السياسة.
- المسار، τ، يشير إلى تسلسل من الحالات، عادة ما يبدأ من حالة أولية عشوائية حتى الخطوة الزمنية الحالية أو الحالة النهائية.
- ∇θf يشير إلى التدرج لوظيفة f بالنسبة للمعلمة(المعلمات) θ.
- J(πθ)يشير إلى العائد المتوقع الذي يحققه الوكيل باتباع السياسة πθ. وهذه أيضًا الدالة الهدف لصعود التدرج.
- تقدم البيئة مكافأة في كل فترة زمنية، اعتمادًا على إجراء العميل. يشير العائد إلى المكافآت التراكمية من الحالة الابتدائية إلى الفترة الزمنية الحالية.
- R(τ) يشير إلى العائد الذي تم تحقيقه على مدار τ.
خطوات الاشتقاق
نوضح كيفية استقرار وإثبات نظرية تدرج السياسات من المبادئ الأولية، بدءًا من توسيع الدالة الهدف واستخدام خدعة الاشتقاق اللوغاريتمي.
الدالة الهدف (المعادلة 1)
الدالة الهدف في طريقة تدرج السياسة هي العائد
لقد تم تراكم من خلال اتباع المسار بناءً على السياسة π المعبرة بمصطلحات المعلمات θ. تُعطى هذه الوظيفة الهدف على النحو التالي:
![]()
في المعادلة أعلاه:
- الجانب الأيسر (LHS) هو العائد المتوقع الذي يتم تحقيقه باتباع السياسة πθ.
- الجانب الأيمن (RHS) هو التوقع (على مدار τ المُولد باتباع السياسة πθ في كل خطوة) للعوائد R(τ) المولدة على مدار τ.
التفاضل لدالة الهدف (المعادلة 2)
تفضيلا (بالنسبة إلى θ) كلتي الجانبين للمعادلة أعلاه يعطي:
![]()
الميل للتوقع (المعادلة 3)
يمكن تعبير التوقع (على الجانب الأيمن) عن طريق التكامل على حاصل ضرب:
- احتمال اتباع مسار τ
- تمت إعادة توليد العوائد التي تم تحقيقها على مدار τ
بالتالي، يتم إعادة صياغة الجزء الأيمن من المعادلة 2 على النحو التالي:
![]()
ميل التكامل يساوي التكامل من الميل. لذلك، في التعبير أعلاه، يمكننا جلب الميل ∇θ تحت علامة التكامل. لذلك، تصبح الجهة اليمنى:
![]()
وبالتالي، يمكن إعادة صياغة المعادلة 2 على النحو التالي:
![]()
احتمالية المسار (المعادلة 4)
نلقي الآن نظرة أقرب على P(τ|θ)، احتمالية أن يتبع العامل المسار τ معلمات السياسة θ (وبالتالي السياسة πθ). يتكون المسار من مجموعة من الخطوات. وبالتالي:
- احتمال الحصول على مسار τ هو ناتج ضرب:
- احتمال اتباع جميع الخطوات الفردية.
![]()
- في الخطوة الزمنية t, ينتقل الوكيل من الحالة s إلى الحالة st+1 عن طريق اتباع الإجراء at. إحتمال حدوث هذا الأمر يعطى حاصل ضرب:
- احتمالية أن يتنبأ السياسة بالإجراء أل في الحالة ست
- إحتمال الوصول إلى الحالة st+1 بعد اتخاذ الإجراء at وفي الحالة st
وبالتالي، ابتداءً من الحالة الابتدائية s0، يتم تحديد احتمالية تبع الوكيل لمسار τ بناءً على السياسة πθ على النحو التالي:
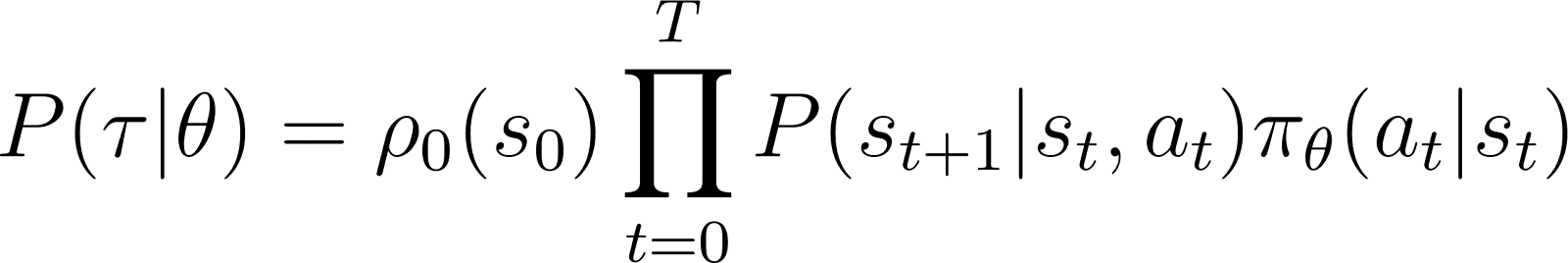
لتبسيط الأمور، نود تعبير المنتج في الجانب الأيمن من الفرقة السابقة على شكل مجموعة. لذلك، نأخذ اللوغاريتم على كلا الجانبين من المعادلة أعلاه:
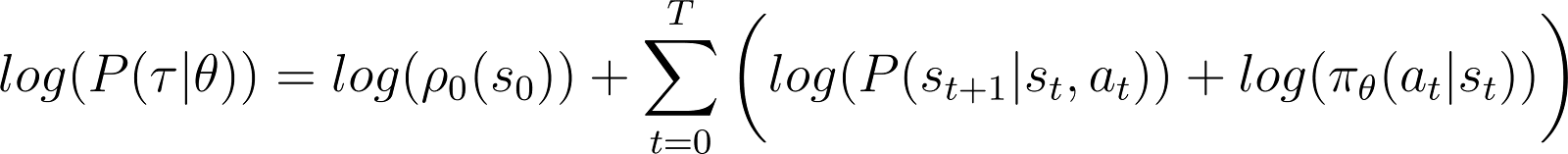
المشتقة للإحتمالية باللوغاريتم (المعادلة 5)
نأخذ الآن المشتقة (بالنسبة إلى θ) للإحتمالية باللوغاريتم في المعادلة أعلاه.
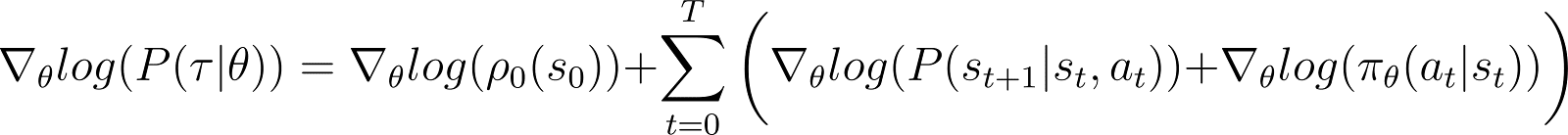
على الجانب الأيمن من المعادلة أعلاه:
- المصطلح الأول log ρ0(s0) هو ثابت بالنسبة إلى θ. لذا مشتقته هي 0.
- المصطلح الأول داخل الجمع P(st+1|st, at) مستقل أيضًا من θ ومشتقته بالنسبة لـ θ هي أيضًا 0.
بعد إزالة المصطلحات الصفرية أعلاه من المعادلة، نبقى مع (المعادلة 5):
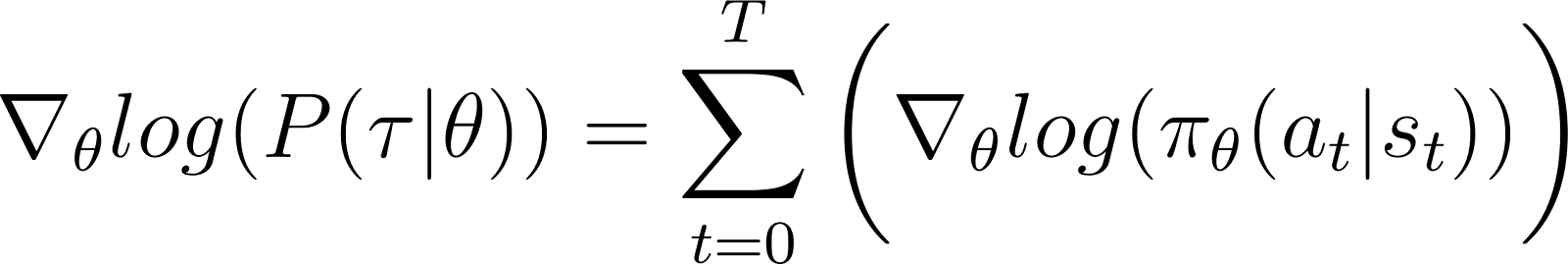
تذكر من المعادلة 2 أن:
![]()
المعادلة 5 تقوم بحساب اللوغاريتم للجزء الأول من RHS للمعادلة 2. نحتاج إلى ربط مشتقة المصطلح بلوغاريتمه. نقوم بذلك باستخدام قاعدة السلسلة وخدعة اللوغاريتم للمشتقة.
خدعة اللوغاريتم للمشتقة
نأخذ مسارًا آخر ونستخدم قواعد الحساب لاستنتاج نتيجة، سنستخدمها لتبسيط المعادلة السابقة وجعلها مناسبة للأساليب الحسابية.
في الحساب، يمكن التعبير عن مشتقة اللوغاريتم على النحو التالي:
![]()
وبالتالي، من خلال إعادة ترتيب المعادلة أعلاه، يمكن تعبير المشتقةx بالنسبة لمشتق اللوغاريتم من x:
![]()
ويُطلق عليها أحيانًا خدعة المشتق المتعامد.
قاعدة السلسلة
وفقًا لقاعدة السلسلة، مع توفير z(y) كدالة لـ y، حيث y هو دالة لـ θ، y(θ)، يتم توفير مشتق z بالنسبة إلى θ على النحو التالي:
![]()
في هذه الحالة، y(θ) تعني P(θ) و z(y) تعني log(y). وبالتالي،
![]()
تطبيق قاعدة السلسلة
نحن نعرف من الحساب التفاضلي أن d(log(y)) / dy = 1/y. استخدم هذا في التعبير الأول للجانب الأيمن أعلاه.
![]()
انقل y إلى الجانب الأيسر واستخدم علامة الـ :
![]()
y تمثل P(θ). لذلك، المعادلة أعلاه مكافئة ل:
![]()
تطبيق خدعة المشتقة اللوغاريتمية
النتيجة أعلاه تعطي التعبير الأول لجانب الحقل من المعادلة 2 (الموضحة أدناه).
باستخدام النتيجة في الجانب الأيمن من المعادلة 2، نحصل على:
![]()
نعيد ترتيب الحدود تحت التكامل في الجانب الأيمن كما هو موضح أدناه:
![]()
استنتاج النتيجة النهائية
لاحظ أن التعبير أعلاه يحتوي على توسيع متكامل للتوقع: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
وبالتالي، يمكن تعبير RHS أعلاه على أنه التوقع:
![]()
نقوم بتبديل المشتقة من سجل الاحتمال في تعبير المكافأة المتوقعة:
![]()
في المعادلة أعلاه، قم بتعويض قيمة ∇logP(θ) من المعادلة 5 للحصول على:
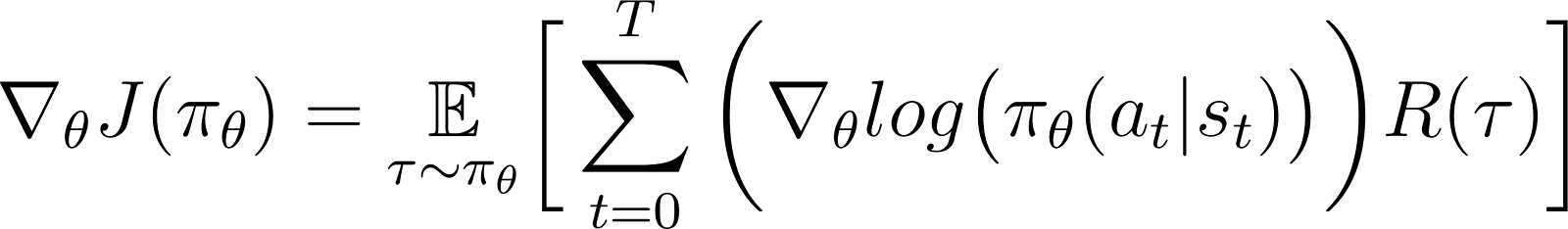
هذا هو التعبير عن التدرج لدالة الأجر وفقا لنظرية تدرج السياسة.
الحدس وراء تدرج السياسة
تحويل طرق تدرج السياسة إلى توزيع احتمالي. يقوم العامل بعينات من هذا التوزيع لاختيار إجراء. تقوم طرق تدرج السياسة بضبط معلمات السياسة. يؤدي ذلك إلى تحديث هذا التوزيع الاحتمالي في كل تكرار. يزيد التوزيع الاحتمالي المحدث من احتمالية اختيار الإجراءات التي تؤدي إلى مكافآت أعلى.
يحسب خوارزمية تدرج السياسة تدرج العائد المتوقع بالنسبة لمعلمات السياسة. من خلال نقل معلمات السياسة في اتجاه هذا التدرج، يزيد العامل من احتمالية اختيار إجراءات تؤدي إلى مكافآت أعلى خلال التدريب.
بشكل أساسي، تصبح الإجراءات التي أدت إلى نتائج أفضل أكثر احتمالية لتكون مختارة في المستقبل، مما يحسن تدريجيًا السياسة لتعظيم المكافآت على المدى الطويل.
Source:
https://www.datacamp.com/tutorial/policy-gradient-theorem