













Waarom beleidsgradentools gebruiken?
Een belangrijk voordeel van beleidsgradentools is hun vermogen om met complexe actieruimtes om te gaan, waar traditionele op waarde gebaseerde benaderingen moeite mee hebben.
Omgaan met hoog-dimensionale actieruimtes
Waarde-gebaseerde methoden, zoals Q-learning, werken door de waarde functie voor alle mogelijke acties te schatten. Dit wordt moeilijk wanneer de actie ruimte van de omgeving continu of discreet maar groot is.
Beleidsgraad methoden parametriseren het beleid en schatten de gradient van de cumulatieve beloningen ten opzichte van de beleidsparameters. Ze gebruiken deze gradient om het beleid rechtstreeks te optimaliseren door de parameters bij te werken. Daarom kunnen ze efficiënt omgaan met hoge-dimensionale of continue actie ruimtes. Beleidsgradiënten zijn ook de basis van Versterkend Leren met Menselijke Feedback (RLHF) methoden.
Door het beleid te parameteriseren en de parameters aan te passen op basis van gradiënten, kunnen beleidsgradiënten efficiënt omgaan met continue en hoge-dimensionale acties. Deze directe aanpak maakt betere generalisatie en flexibelere verkenning mogelijk, waardoor het goed geschikt is voor taken zoals robotcontrole en andere complexe omgevingen.
Leven van stochastische beleids
Gegeven een set observaties:
- Een deterministisch beleid specificeert welke actie de agent onderneemt.
- Een stochastisch beleid geeft een set acties en de waarschijnlijkheid dat de agent elke actie kiest.
Bij het volgen van een stochastisch beleid kan dezelfde observatie leiden tot het kiezen van verschillende acties in verschillende iteraties. Dit bevordert de verkenning van de actieruimte en voorkomt dat het beleid vastloopt in lokale optima. Om deze reden zijn stochastische beleidsvormen nuttig in omgevingen waar verkenning essentieel is om het pad te ontdekken dat leidt tot de maximale opbrengsten.
In beleid-gebaseerde methoden wordt de beleidsoutput omgezet in een waarschijnlijkheidsverdeling, waarbij elke mogelijke actie een waarschijnlijkheid toegewezen krijgt. De agent kiest een actie door deze verdeling te bemonsteren, waardoor het mogelijk wordt om een stochastisch beleid te implementeren. Zo combineren beleidgradiëntmethoden verkenning met exploitatie, wat nuttig is in omgevingen met complexe beloningsstructuren.
Afleiding van de Beleidsgradiëntstelling
Voordat we in de afleiding duiken, is het belangrijk om de wiskundige notatie en de belangrijkste concepten die in het bewijs worden gebruikt, vast te stellen.
Wiskundige notatie en preliminaires
Zoals vermeld in een vorige sectie, stelt de beleidsgraadstelling dat de afgeleide van de verwachte opbrengst de verwachting is van het product van de opbrengst en de afgeleide van de logaritme van het beleid.
Voordat we de beleidsgraadstelling afleiden, introduceren we de notatie:
- E[X] verwijst naar de probabilistische verwachting van een random variabele X.
- Wiskundig wordt het beleid uitgedrukt als een waarschijnlijkheidsmatrix die de kans geeft om verschillende acties te kiezen op basis van verschillende waarnemingen. Een beleid wordt meestal gemodelleerd als een geparametriseerde functie, waarbij de parameters worden weergegeven als θ.
- πθ verwijst naar een beleid dat is geparametriseerd door θ. In de praktijk zijn deze parameters de gewichten van het neurale netwerk dat het beleid modelleert.
- De trajectorie, τ, verwijst naar een reeks van staten, meestal beginnend vanuit een willekeurige initiële staat tot aan ofwel de huidige tijdstap of de terminale staat.
- ∇θf verwijst naar de gradient van een functie f ten opzichte van parameter(s) θ.
- J(πθ) verwijst naar het verwachte rendement dat door de agent wordt behaald volgens het beleid πθ. Dit is ook de doelstelling voor gradient ascent.
- De omgeving geeft een beloning bij elke tijdstap, afhankelijk van de actie van de agent. De return verwijst naar de cumulatieve beloningen van de oorspronkelijke staat tot de huidige tijdstap.
- R(τ) verwijst naar het rendement gegenereerd over de trajectorie τ.
Ableidingstappen
We laten zien hoe we de beleidsgradiëntstelling kunnen afleiden en bewijzen vanuit eerste beginselen, beginnend met de uitbreiding van de doelfunctie en gebruikmakend van de log-afgeleide truc.
De doelfunctie (Vergelijking 1)
De doelfunctie in de beleidsgradiëntmethode is de return.
Ik ben samengesteld door de trajecten te volgen op basis van het beleid π uitgedrukt in termen van parameters θ. Deze objectieve functie is als volgt:
![]()
In de bovenstaande vergelijking:
- De linkerkant (LHS) is het verwachte rendement dat wordt behaald door het volgen van het beleid πθ.
- De rechterkant (RHS) is de verwachting (over de traject τ gegenereerd door het volgen van het beleid πθ in elke stap) van de opbrengsten R(τ) gegenereerd over het traject τ.
De differentiaal van de doelfunctie (Vergelijking 2)
Differentieren (met betrekking tot θ) beide zijden van de bovenstaande vergelijking geeft:
![]()
De gradient van de verwachting (Vergelijking 3)
De verwachting (aan de RHS) kan worden uitgedrukt als een integraal over het product van:
- De kans om een traject τ te volgen
- De rendementen gegenereerd over de trajectorie τ
Dus, de RHS van Vergelijking 2 wordt als volgt herhaald:
![]()
De gradiënt van een integraal is gelijk aan de integraal van de gradiënt. Dus, in de bovenstaande uitdrukking, kunnen we de gradiënt ∇θ onder het integraalteken brengen. Dus, de RHS wordt:
![]()
Dus kan Vergelijking 2 worden herschreven als:
![]()
De kans op de trajectorie (Vergelijking 4)
We bekijken nu P(τ|θ), de kans dat de agent de traject volgt τ gegeven beleidsparameters θ (en dus beleid πθ). Een traject bestaat uit een set stappen. Dus:
- De kans om traject τ is het product van:
- De kans om alle individuele stappen te volgen.
![]()
- In de tijdstap t, gaat de agent van de staat s naar de staat st+1 door de actie at te volgen. De waarschijnlijkheid van dit gebeuren is het product van:
- De kans dat het beleid actie at in toestand st
- De waarschijnlijkheid om in staat te eindigen te zijnst+1gegeven actieat en staatst
Dus, uitgaande van een initiële toestand s0, wordt de waarschijnlijkheid dat de agent traject τ volgt op basis van beleid πθ als volgt gegeven:
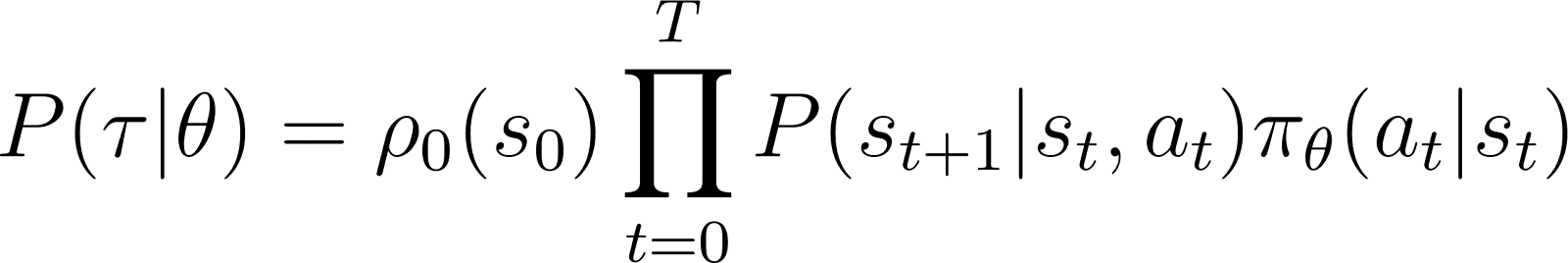
Om dingen eenvoudiger te maken, willen we het product aan de rechterkant hierboven uitdrukken als een som. Dus nemen we de logaritme aan beide zijden van de bovenstaande vergelijking:
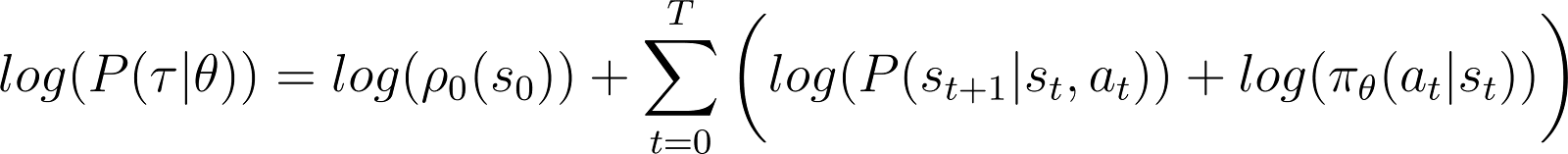
De afgeleide van de log-kans (Vergelijking 5)
We nemen nu de afgeleide (ten opzichte van θ) van de log-kans in de bovenstaande vergelijking.
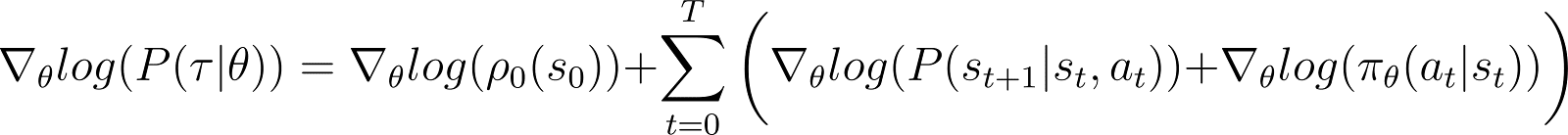
Aan de rechterkant van de bovenstaande vergelijking:
- De eerste term log ρ0(s0) is constant ten opzichte van θ. Dus is de afgeleide 0.
- De eerste term binnen de som P(st+1|st, at) is ook onafhankelijk van θ en de afgeleide ervan ten opzichte van θ is ook 0.
Door de bovengenoemde nultermen uit de vergelijking te verwijderen, blijven we over met (Vergelijking 5):
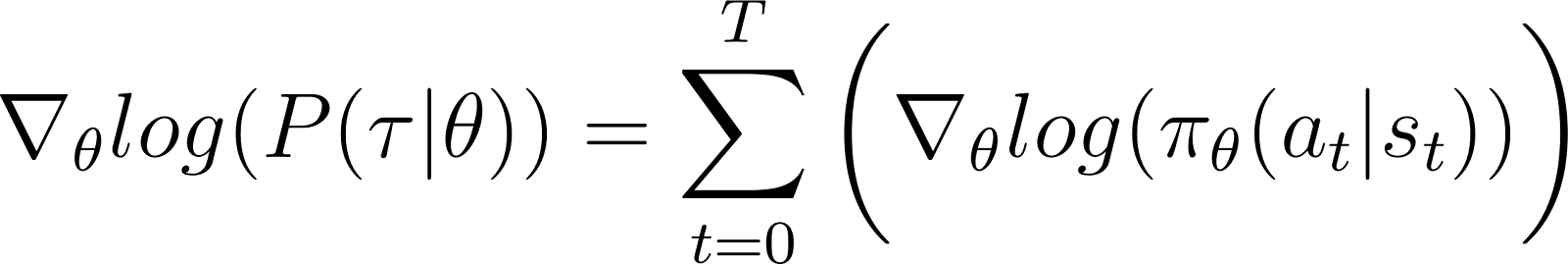
Vergeet niet uit Vergelijking 2 dat:
![]()
Vergelijking 5 evalueert de log van het eerste deel van de RHS van Vergelijking 2. We moeten de afgeleide van een term relateren aan zijn logaritme. Dit doen we met behulp van de kettingregel en de log-afgeleide truc.
De log-afgeleide truc
We nemen een omweg en gebruiken de regels van de calculus om een resultaat af te leiden, dat we zullen gebruiken om de vorige vergelijking te vereenvoudigen en geschikt te maken voor computermethoden.
In de calculus kan de afgeleide van een logaritme worden uitgedrukt als:
![]()
Door dus de bovenstaande vergelijking te herschikken, kan de afgeleide van x worden uitgedrukt in termen van de afgeleide van de logaritme van x:
![]()
Dit wordt soms de log-afgeleide truc genoemd.
De kettingregel
Volgens de kettingregel, gegeven z(y) als een functie van y, waar y zelf een functie is van θ, y(θ), de afgeleide van z met betrekking tot θ is gegeven als:
![]()
In dit geval, y(θ) staat voor P(θ) en z(y) staat voor log(y). Zo,
![]()
Toepassen van de kettingregel
We weten uit de calculus dat d(log(y)) / dy = 1/y. Gebruik dit in de eerste uitdrukking van de RHS hierboven.
![]()
Verplaats y naar de LHS en gebruik de notatie:
![]()
y staat voor P(θ). Dus de bovenstaande vergelijking is equivalent aan:
![]()
Toepassen van de logafgeleide truc
Het bovenstaande resultaat geeft de eerste uitdrukking van de RHS van Vergelijking 2 (hieronder weergegeven).
Door het resultaat in de RHS van Vergelijking 2 te gebruiken, krijgen we:
![]()
We herschikken de termen onder de RHS integraal als hieronder:
![]()
Afleiden van het eindresultaat
Merk op dat de bovenstaande uitdrukking de integrale uitbreiding van een verwachting bevat: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
Dus kan de RHS hierboven worden uitgedrukt als de verwachting:
![]()
We vervangen de afgeleide van de logwaarschijnlijkheid in de uitdrukking van de verwachte beloning:
![]()
In de bovenstaande vergelijking, vervang de waarde van ∇logP(θ) uit Vergelijking 5 om te krijgen:
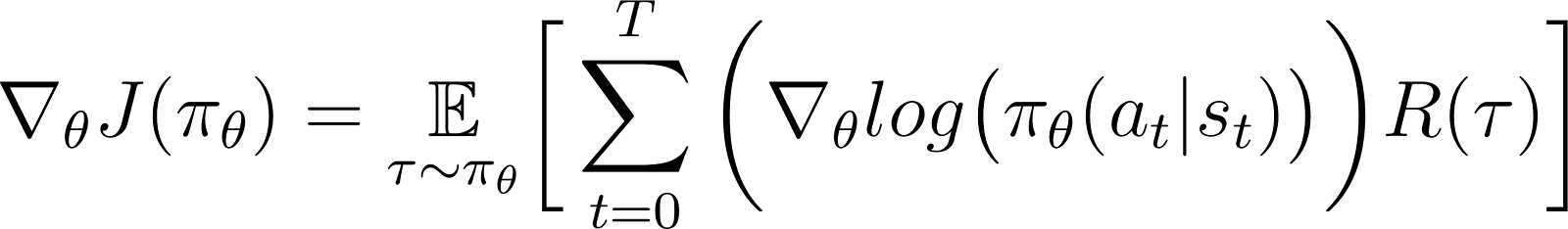
Dit is de uitdrukking voor de gradiënt van de beloningsfunctie volgens de beleidsgradiëntstelling.
De intuïtie achter de beleidsgradiënt
Beleidsgradiëntmethoden zetten de uitvoer van het beleid om in een waarschijnlijkheidsverdeling. De agent monster deze verdeling om een actie te kiezen. Beleidsgradiëntmethoden passen de beleidsparameters aan. Dit leidt tot het bijwerken van deze waarschijnlijkheidsverdeling in elke iteratie. De bijgewerkte waarschijnlijkheidsverdeling heeft een grotere kans om acties te kiezen die leiden tot hogere beloningen.
Het beleidsgradiëntalgoritme berekent de gradiënt van het verwachte rendement ten opzichte van de beleidsparameters. Door de beleidsparameters in de richting van deze gradiënt te verplaatsen, vergroot de agent de kans om acties te kiezen die tijdens de training tot hogere beloningen leiden.
Wezenlijk worden acties die tot betere resultaten hebben geleid, geleidelijk waarschijnlijker gekozen in de toekomst, waarbij het beleid geleidelijk wordt verbeterd om langetermijnbeloningen te maximaliseren.
Source:
https://www.datacamp.com/tutorial/policy-gradient-theorem