













Почему использовать методы градиента политики?
Одно из ключевых преимуществ методов градиента политики заключается в их способности обрабатывать сложные пространства действий, где традиционные подходы на основе ценностей испытывают трудности.
Обработка пространств действий с высоким размером
Методы на основе оценки ценности, такие как Q-обучение, работают путем оценки функции ценности для всех возможных действий. Это становится сложным, когда пространство действий среды является непрерывным или дискретным, но большим.
Методы градиента политики параметризуют политику и оценивают градиент кумулятивных наград по отношению к параметрам политики. Они используют этот градиент для прямой оптимизации политики путем обновления ее параметров. Поэтому они могут эффективно обрабатывать пространства действий высокой размерности или непрерывные. Градиенты политики также являются основой методов Обучения с подкреплением с использованием обратной связи человека (RLHF).
Путем параметризации политики и корректировки ее параметров на основе градиентов градиенты политики могут эффективно обрабатывать непрерывные и высокоразмерные действия. Этот прямой подход обеспечивает лучшую обобщенность и более гибкое исследование, что делает его подходящим для задач, таких как управление роботами и другие сложные среды.
Обучение стохастических политик
Учитывая набор наблюдений:
- Детерминированная стратегия определяет, какое действие совершает агент.
- Стохастическая стратегия предоставляет набор действий и вероятность того, что агент выберет каждое действие.
При использовании стохастической стратегии одно и то же наблюдение может привести к выбору разных действий в разных итерациях. Это способствует исследованию пространства действий и предотвращает застревание стратегии в локальных оптимумах. Именно поэтому стохастические стратегии полезны в средах, где исследование является ключевым для обнаружения пути, ведущего к максимальным вознаграждениям.
В методах на основе стратегий вывод стратегии преобразуется в вероятностное распределение, при этом каждому возможному действию присваивается вероятность. Агент выбирает действие, выбирая образец из этого распределения, что позволяет реализовать стохастическую стратегию. Таким образом, методы градиента стратегии объединяют исследование с эксплуатацией, что полезно в средах с комплексными структурами вознаграждения.
Выведение Теоремы о Градиенте Стратегии
Перед тем как приступить к выводу, важно установить математическую нотацию и ключевые концепции, используемые во время доказательства.
Математическая нотация и предварительные сведения
Как упоминалось в предыдущем разделе, теорема о градиенте политики утверждает, что производная ожидаемого возврата является ожиданием произведения возврата и производной логарифма политики.
Прежде чем получить теорему о градиенте политики, мы вводим нотацию:
- E[X] обозначает вероятностное ожидание случайной величины X.
- С математической точки зрения, политика выражается в виде матрицы вероятностей, которая показывает вероятность выбора различных действий на основе различных наблюдений. Политика обычно моделируется как параметризованная функция, параметры которой представлены как θ.
- πθ относится к политике, параметризованной θ. На практике эти параметры представляют собой веса нейронной сети, моделирующей политику.
- Траектория, τ, обозначает последовательность состояний, обычно начиная с случайного начального состояния до текущего временного шага или конечного состояния.
- ∇θf относится к градиенту функции f относительно параметра(ов) θ.
- J(πθ) относится к ожидаемому доходу, достигаемому агентом, следуя политике πθ. Это также целевая функция для градиентного восхождения.
- Среда дает вознаграждение на каждом временном шаге в зависимости от действия агента. Возврат относится к накопленным вознаграждениям от начального состояния до текущего временного шага.
- R(τ) относится к доходности, генерируемой по траектории τ.
Шаги вывода
Мы покажем, как получить и доказать теорему о градиенте политики с первых принципов, начиная с разложения целевой функции и используя трюк с логарифмической производной.
Целевая функция (Уравнение 1)
Целевая функция в методе градиента политики – это возврат.
J накопленный в результате следования траектории, основанной на политике π , выраженной через параметры θ. Эта целевая функция задается как:
![]()
В приведенном уравнении:
- Левая сторона (LHS) представляет собой ожидаемую доходность, достигнутую при следовании политике πθ.
- Правая сторона (RHS) является ожиданием (по траектории τ , генерируемой следованием политики πθ на каждом шаге) возвратов R(τ), генерируемых по траектории τ.
Дифференциал целевой функции (Уравнение 2)
Дифференцируя (по отношению к θ) обе стороны указанного уравнения, получаем:
![]()
Градиент ожидания (Уравнение 3)
Ожидание (на ППП) можно выразить как интеграл от произведения:
- Вероятность следования траектории τ
- Возвраты, генерируемые на траектории τ
Таким образом, правая часть уравнения 2 переформулирована как:
![]()
Градиент интеграла равен интегралу градиента. Таким образом, в выражении выше мы можем перенести градиент ∇θ под знаком интеграла. Таким образом, ППП становится:
![]()
Таким образом, уравнение 2 можно переписать как:
![]()
Вероятность траектории (уравнение 4)
Мы теперь внимательно рассмотрим P(τ|θ), вероятность агента следовать траектории τ при заданных параметрах политики θ (и, следовательно, политика πθ). Траектория состоит из набора шагов. Таким образом:
- Вероятность получения траектории τ является произведением:
- Вероятность выполнения всех отдельных шагов.
![]()
- На временном шаге t, агент переходит из состояния s в состояние st+1 , следуя действию at. Вероятность этого события равна произведению:
- Вероятность того, что политика предсказывает действие at в состоянии st
- Вероятность оказаться в состоянии st+1 при выполнении действия at и состоянии st
Таким образом, начиная с начального состояния s0, вероятность того, что агент будет следовать траектории τ на основе политики πθ задается как:
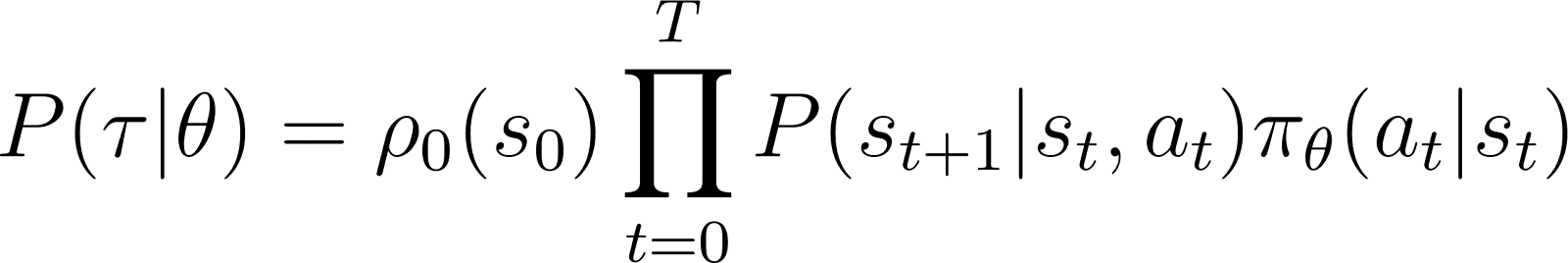
Чтобы упростить задачу, мы хотим выразить произведение в правой части уравнения выше в виде суммы. Поэтому мы берем логарифм с обеих сторон вышеуказанного уравнения:
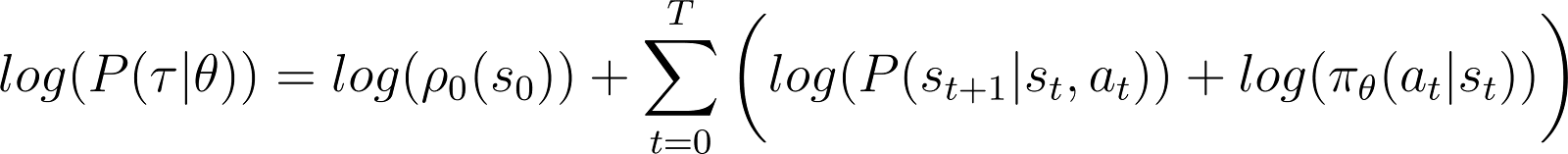
Производная логарифмической вероятности (Уравнение 5)
Теперь мы берем производную (по θ) логарифмической вероятности в вышеприведенном уравнении.
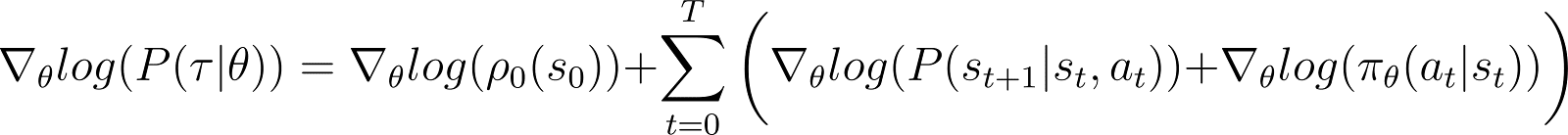
С правой стороны вышеуказанного уравнения:
- Первый член log ρ0(s0) является постоянной по отношению к θ. Поэтому его производная равна 0.
- Первый термин внутри суммы P(st+1|st, at) также не зависит от θ и его производной по отношению к θ также равна 0.
Удаление нулевых членов из уравнения приводит к (Уравнение 5):
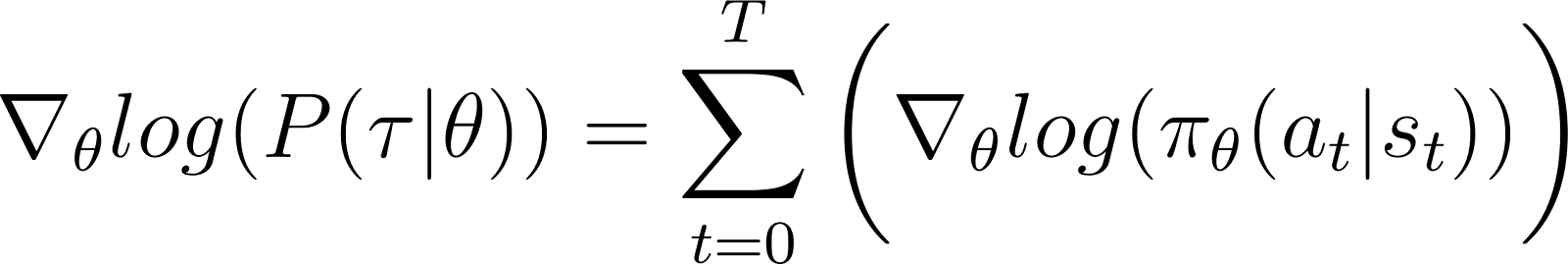
Помним из Уравнения 2, что:
![]()
Уравнение 5 оценивает логарифм первой части правой части Уравнения 2. Нам нужно связать производную члена с его логарифмом. Мы делаем это, используя правило цепочки и трюк с логарифмической производной.
Трюк с логарифмической производной
Мы делаем обход и используем правила исчисления для вывода результата, который мы будем использовать для упрощения предыдущего уравнения и приведения его в удобную для вычислений форму.
В исчислении производная логарифма может быть выражена как:
![]()
Таким образом, переставив вышеуказанное уравнение, производная x может быть выражена через производную логарифма x:
![]()
Это иногда называется логарифмическим трюком производной.
Правило цепочки
Согласно правилу цепочки, учитывая z(y) как функцию y, где y сам по себе является функцией θ, y(θ), производная z по отношению к θ задаётся следующим образом:
![]()
В этом случае, y(θ) обозначает P(θ) и z(y) обозначает log(y). Таким образом,
![]()
Применение правила цепочки
Мы знаем из математического анализа, что d(log(y)) / dy = 1/y. Используйте это в первом выражении в RHS выше.
![]()
Перенесите y в LHS и используйте обозначение:
![]()
y обозначает P(θ). Таким образом, вышеуказанное уравнение эквивалентно:
![]()
Применение трюка с логарифмической производной
Вышеприведенный результат дает первое выражение в правой части уравнения 2 (показанное ниже).
Используя результат в правой части уравнения 2, мы получаем:
![]()
Мы перегруппируем члены под интегралом в правой части уравнения:
![]()
Получение окончательного результата
Обратите внимание, что вышеупомянутое выражение содержит интегральное разложение ожидания: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
Таким образом, правая часть выше может быть выражена как ожидание:
![]()
Мы подставляем производную логарифмической вероятности в выражение ожидаемой награды:
![]()
В указанном уравнении подставьте значение ∇logP(θ) из Уравнения 5, чтобы получить:
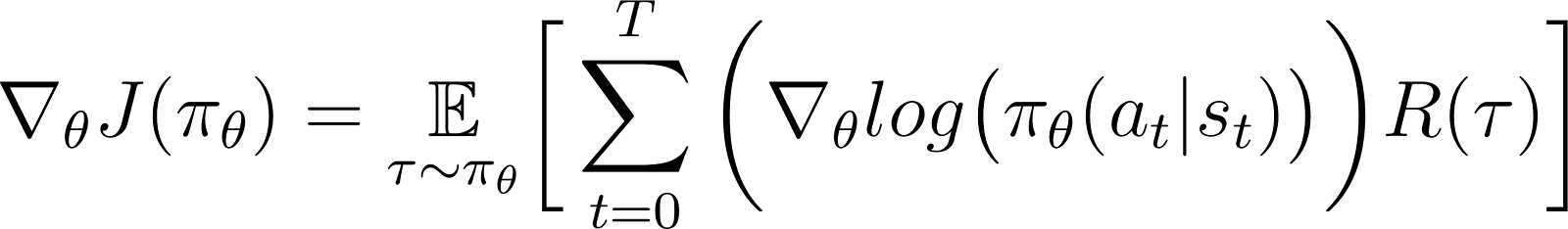
Это выражение для градиента функции вознаграждения в соответствии с теоремой градиента политики.
Интуиция за градиентом политики
Методы градиента политики преобразуют выходные данные политики в распределение вероятностей. Агент выбирает действие, основываясь на этой выборке. Методы градиента политики настраивают параметры политики. Это приводит к обновлению этого распределения вероятностей на каждой итерации. Обновленное распределение вероятностей имеет более высокую вероятность выбора действий, которые приводят к более высоким вознаграждениям.
Алгоритм градиента политики вычисляет градиент ожидаемого дохода относительно параметров политики. Перемещая параметры политики в направлении этого градиента, агент увеличивает вероятность выбора действий, которые приводят к более высоким вознаграждениям в процессе обучения.
По сути, действия, которые привели к лучшим результатам, становятся более вероятными для выбора в будущем, постепенно улучшая политику для максимизации долгосрочных вознаграждений.
Source:
https://www.datacamp.com/tutorial/policy-gradient-theorem