













为什么使用策略梯度方法?
策略梯度方法的一个关键优势是其能够处理复杂的动作空间,传统价值方法难以应对。
处理高维度的动作空间
基于价值的方法,例如Q学习,通过估计所有可能行动的价值函数来工作。当环境的行动空间是连续的或离散但又很大时,这变得困难。
策略梯度方法对策略进行参数化,并估计与策略参数相关的累积奖励的梯度。它们使用这个梯度直接优化策略,通过更新其参数。因此,它们能够有效处理高维或连续的行动空间。策略梯度也是使用人类反馈的强化学习(RLHF)方法的基础。
通过对策略进行参数化并根据梯度调整其参数,策略梯度能够有效处理连续和高维的行动。这种直接的方法使得更好的泛化和更灵活的探索成为可能,特别适合于机器人控制和其他复杂环境等任务。
学习随机策略
给定一组观察:
- 确定性策略指定了代理程序采取的行动。
- 随机策略给出一组行动以及代理程序选择每个行动的概率。
遵循随机策略时,相同的观察结果可能导致在不同迭代中选择不同的行动。这有助于探索行动空间,并防止策略陷入局部最优解。因此,随机策略在需要探索以发现通往最大回报路径的环境中很有用。
在基于策略的方法中,策略输出被转换为概率分布,每个可能的行动被分配一个概率。代理程序通过对该分布进行抽样来选择行动,从而实现了随机策略。因此,策略梯度方法将探索与利用结合起来,适用于具有复杂奖励结构的环境。
策略梯度定理的推导
在深入推导之前,建立数学符号和整个证明过程中使用的关键概念是非常重要的。
数学符号和预备知识
正如前面的部分所述,策略梯度定理指出预期回报的导数是回报与策略对数的导数的乘积的期望值。
在推导策略梯度定理之前,我们引入以下符号:
- E[X]表示随机变量X的概率期望。
- 在数学上,策略被表示为一个概率矩阵,基于不同的观察结果给出选择不同动作的概率。策略通常被建模为一个参数化函数,其中参数表示为θ。
- πθ 指的是由θ参数化的策略。在实践中,这些参数是模拟策略的神经网络的权重。
- 轨迹,τ,指的是一系列状态,通常从随机的初始状态开始,直到当前时间步或终止状态。
- ∇θf 指的是函数 f 相对于参数 θ 的梯度。
- J(πθ) 指的是代理根据策略 πθ 所实现的预期回报。这也是梯度上升的目标函数。
- 环境根据代理的行动在每个时间步提供奖励。回报是指从初始状态到当前时间步的累积奖励。
- R(τ)指的是在轨迹τ上产生的回报。
推导步骤
我们展示如何从第一原理推导和证明策略梯度定理,从目标函数的展开开始,使用对数导数技巧。
目标函数(方程1)
策略梯度方法中的目标函数是回报
J根据基于政策π 表达的参数θ的轨迹累积。该目标函数如下:
![]()
在上述方程中:
- 左侧(LHS)是通过遵循策略πθ实现的预期回报。
- 右侧 (RHS) 是在每一步遵循策略 πθ 生成的轨迹 τ 上的回报 R(τ) 的期望τ。
目标函数的微分(方程2)
对上述方程两边分别进行微分(相对于θ)得到:
![]()
期望的梯度(方程3)
右侧的期望可以表示为乘积的积分:
- 遵循轨迹的概率 τ
- 在轨迹上产生的回报 τ
因此,方程2的右侧可以重新表述为:
![]()
积分的梯度等于梯度的积分。因此,在上述表达式中,我们可以将梯度 ∇θ 移至积分符号下方。因此,右侧变为:
![]()
因此,方程2可以改写为:
![]()
轨迹的概率(方程4)
我们现在更仔细地看一下 P(τ|θ),即代理根据轨迹 τ 遵循策略参数 θ (因此遵循策略 πθ)。一个轨迹包括一系列步骤。因此:
- 获得轨迹τ 的概率是以下因子的乘积:
- 遵循所有个别步骤的概率。
![]()
- 在时间步t中,代理从状态s转移到状态st+1,遵循动作at的概率是以下乘积:
- 该政策预测在状态at中采取行动的概率 st
- 在给定动作at和状态st的情况下,最终处于状态st+1
因此,从初始状态 s0开始,智能体遵循基于策略 πθτ的轨迹的概率为:
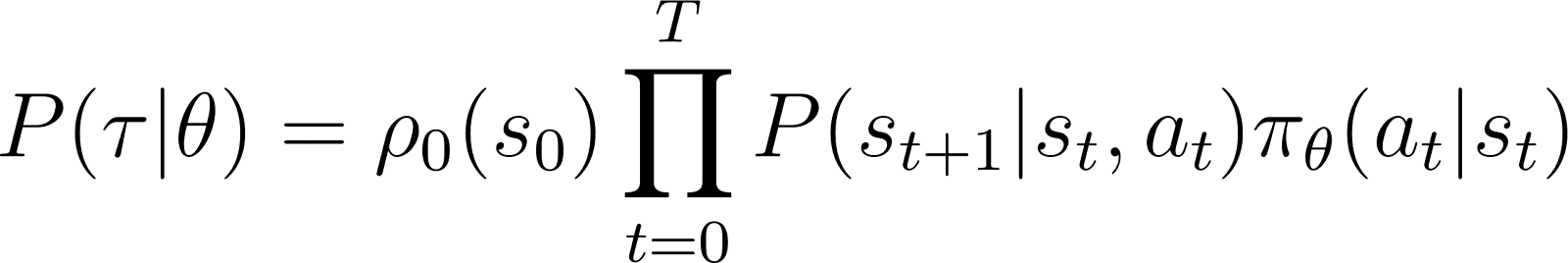
为了简化问题,我们希望将上面的RHS产品表示为一个和。因此,我们对上述方程两边取对数:
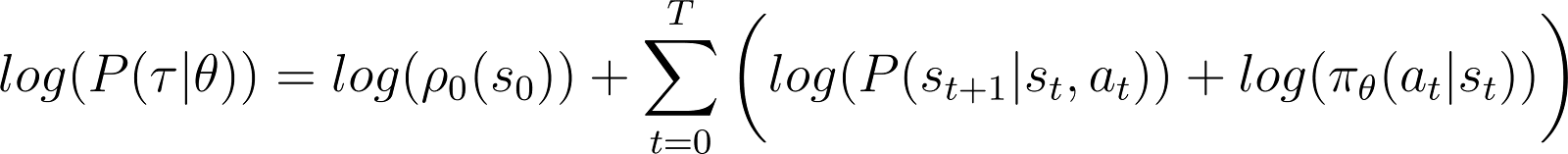
对数概率的导数(方程5)
现在我们对上述方程中的对数概率进行导数(相对于θ)。
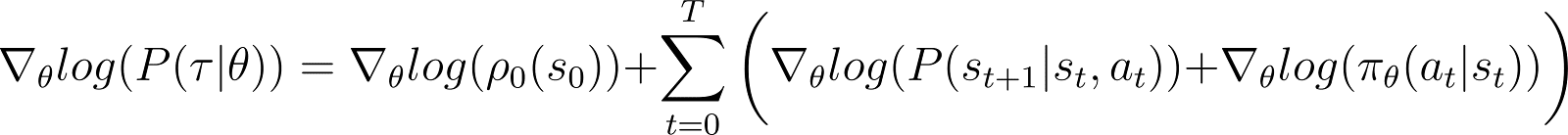
在上述方程的RHS:
- 第一项 log ρ0(s0) 是关于 θ 的常数。因此它的导数为 0。
- 求和中的第一个项 P(st+1|st, at) 也与 θ 无关,关于 θ 的导数也是 0。
去掉方程中的零项后,我们得到(方程5):
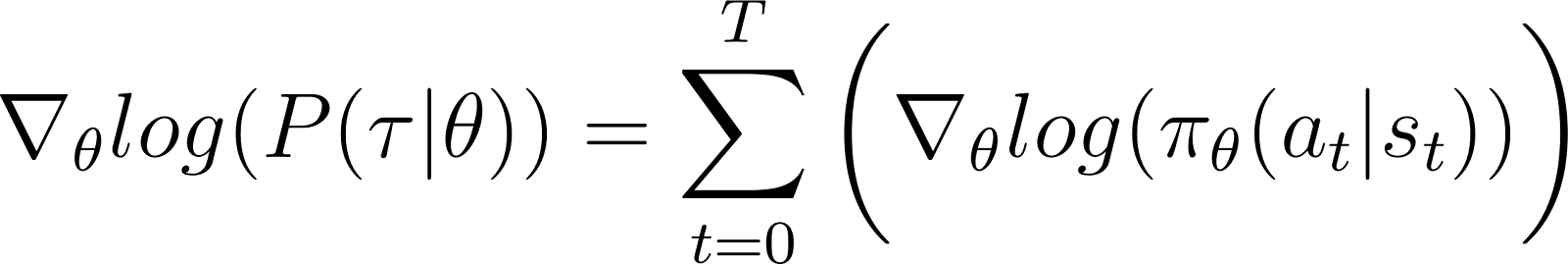
回忆方程2:
![]()
方程5计算了方程2右侧第一部分的对数。我们需要将一个项的导数与其对数相关联。我们将使用链式法则和对数导数技巧来实现这一点。
对数导数技巧
我们绕道而行,使用微积分的规则推导一个结果,这将用于简化前面的方程,并使其适合计算方法。
在微积分中,对数的导数可以表示为:
![]()
因此,通过重新排列上述方程,x 的导数可以用 x 的对数导数表示:
![]()
这有时被称为对数导数技巧。
链式法则
根据链式法则,给定z(y)作为的函数y,其中y本身是θ的函数,y(θ),则z关于θ的导数为:
![]()
在这种情况下,y(θ) 代表 P(θ) 而 z(y) 代表 log(y)。因此,
![]()
应用链式法则
我们从微积分中知道d(log(y)) / dy = 1/y。将这个结论用在上述右手边的第一个表达式中。
![]()
将 y 移到左手边,并使用 符号:
![]()
y 代表 P(θ)。因此,上述方程等价于:
![]()
应用对数导数技巧
上述结果给出了方程2(如下所示)右侧的第一个表达式。
利用方程2右侧的结果,我们得到:
![]()
我们将右侧积分下的项重新排列如下:
![]()
推导最终结果
请注意,上述表达式包含期望的积分展开: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
因此,上述的RHS可以表示为期望:
![]()
我们将对数概率的导数代入到期望奖励的表达式中:
![]()
在上述方程中,将∇的值代入logP(θ)的方程5中得到:
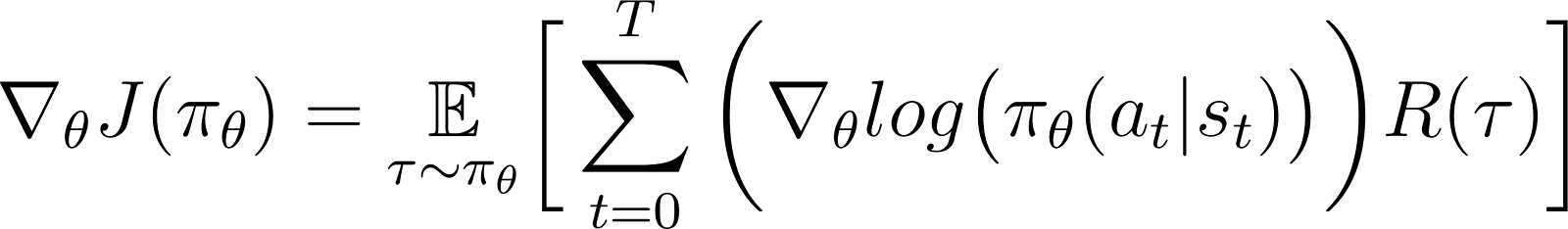
这是根据策略梯度定理得到的奖励函数梯度的表达式。
策略梯度背后的直觉
策略梯度方法将策略的输出转换为概率分布。代理从这个分布中抽样以选择一个动作。策略梯度方法调整策略参数。这导致在每次迭代中更新这个概率分布。更新后的概率分布更有可能选择导致更高奖励的动作。
策略梯度算法计算期望回报相对于策略参数的梯度。通过沿着这个梯度的方向移动策略参数,代理在训练过程中增加选择导致更高奖励的动作的概率。
本质上,导致更好结果的动作在未来被选择的可能性增加,从而逐步改善策略以最大化长期奖励。
Source:
https://www.datacamp.com/tutorial/policy-gradient-theorem