













Perché utilizzare i metodi di gradiente della politica?
Un vantaggio chiave dei metodi di gradiente della politica è la loro capacità di gestire spazi azionari complessi, dove gli approcci tradizionali basati sul valore fanno fatica.
Gestire spazi azionari ad alta dimensione
I metodi basati sul valore, come il Q-learning, funzionano stimando la funzione valore per tutte le azioni possibili. Questo diventa difficile quando lo spazio delle azioni dell’ambiente è continuo o discreto ma grande.
I metodi di gradiente della politica parametrizzano la politica e stimano il gradiente delle ricompense cumulative rispetto ai parametri della politica. Usano questo gradiente per ottimizzare direttamente la politica aggiornando i suoi parametri. Pertanto, possono gestire in modo efficiente spazi di azione ad alta dimensione o continui. I gradienti della politica sono anche alla base dei metodi di Apprendimento per Rinforzo con Feedback Umano (RLHF).
Parametrizzando la politica e regolando i suoi parametri in base ai gradienti, i gradienti della politica possono gestire in modo efficiente azioni continue e ad alta dimensione. Questo approccio diretto consente una migliore generalizzazione e un’esplorazione più flessibile, rendendolo adatto per compiti come il controllo robotico e altri ambienti complessi.
Apprendimento di politiche stocastiche
Data una serie di osservazioni:
- Una politica deterministica specifica quale azione l’agente intraprende.
- Una politica stocastica fornisce un insieme di azioni e la probabilità che l’agente scelga ciascuna azione.
Seguendo una politica stocastica, la stessa osservazione può portare a scegliere azioni diverse in iterazioni diverse. Questo favorisce l’esplorazione dello spazio delle azioni e impedisce alla politica di rimanere bloccata in ottimi locali. Per questo motivo, le politiche stocastiche sono utili in ambienti in cui l’esplorazione è essenziale per scoprire il percorso che porta ai massimi ritorni.
Nei metodi basati sulla politica, l’output della politica viene convertito in una distribuzione di probabilità, con ogni azione possibile assegnata a una probabilità. L’agente sceglie un’azione campionando questa distribuzione, rendendo possibile implementare una politica stocastica. Pertanto, i metodi di gradiente della politica combinano esplorazione ed sfruttamento, utili in ambienti con strutture di ricompensa complesse.
Derivazione del Teorema del Gradiente della Politica
Prima di immergersi nella derivazione, è importante stabilire la notazione matematica e i concetti chiave utilizzati nel corso della dimostrazione.
Notazione matematica e preliminari
Come accennato in una sezione precedente, il teorema del gradiente della politica afferma che la derivata del rendimento atteso è l’aspettativa del prodotto del rendimento e della derivata del logaritmo della politica.
Prima di derivare il teorema del gradiente della politica, introduciamo la notazione:
- E[X] si riferisce all’aspettativa probabilistica di una variabile casuale X.
- Matematicamente, la politica è espressa come una matrice di probabilità che fornisce la probabilità di scegliere diverse azioni in base a diverse osservazioni. Una politica è tipicamente modellata come una funzione parametrizzata, con i parametri rappresentati come θ.
- πθ si riferisce a una politica parametrizzata da θ. In pratica, questi parametri sono i pesi della rete neurale che modella la politica.
- La traiettoria, τ, si riferisce a una sequenza di stati, in genere a partire da uno stato iniziale casuale fino al tempo corrente o allo stato terminale.
- ∇θf si riferisce al gradiente di una funzione f rispetto al parametro(i) θ.
- J(πθ) si riferisce al rendimento atteso ottenuto dall’agente seguendo la politica πθ. Questa è anche la funzione obiettivo per la salita del gradiente.
- L’ambiente fornisce una ricompensa ad ogni passo temporale, a seconda dell’azione dell’agente. Il ritorno si riferisce alle ricompense cumulative dallo stato iniziale al passo temporale corrente.
- R(τ) si riferisce al rendimento generato lungo il percorso τ.
Passaggi di derivazione
Mostriamo come derivare e dimostrare il teorema del gradiente della politica a partire dai principi fondamentali, iniziando con l’espansione della funzione obiettivo e utilizzando il trucco della derivata logaritmica.
La funzione obiettivo (Equazione 1)
La funzione obiettivo nel metodo del gradiente della politica è il ritorno
Jaccumulato seguendo la traiettoria basata sulla politica π espressa in termini di parametri θ. Questa funzione obiettivo è data da:
![]()
Nell’equazione sopra:
- Il lato sinistro (LHS) è il rendimento atteso ottenuto seguendo la politica πθ.
- Il lato destro (RHS) è l’aspettativa (sulla traiettoria τ generata seguendo la politica πθ in ogni passo) dei ritorni R(τ) generati sulla traiettoria τ.
Il differenziale della funzione obiettivo (Equazione 2)
Differenziando (rispetto a θ) entrambi i lati dell’equazione precedente si ottiene:
![]()
Il gradiente dell’aspettazione (Equazione 3)
L’aspettazione (nel lato destro) può essere espressa come un integrale sul prodotto di:
- La probabilità di seguire una traiettoria τ
- I rendimenti generati lungo la traiettoria τ
Quindi, il lato destro dell’Equazione 2 viene riformulato come:
![]()
Il gradiente di un integrale è uguale all’integrale del gradiente. Quindi, nell’espressione sopra, possiamo portare il gradiente ∇θ sotto il segno dell’integrale. Quindi, il lato destro diventa:
![]()
Quindi, l’Equazione 2 può essere riscritta come:
![]()
La probabilità della traiettoria (Equazione 4)
Ora diamo un’occhiata più da vicino a P(τ|θ), la probabilità che l’agente segua la traiettoria τ date le condizioni del policy θ (e quindi la policy πθ). Una traiettoria consiste in un insieme di passi. Quindi:
- La probabilità di ottenere la traiettoria τ è il prodotto di:
- La probabilità di seguire tutti i singoli passaggi.
![]()
- Nel passo di tempo t, l’agente passa dallo stato s allo stato st+1 seguendo l’azione at. La probabilità che ciò accada è data dal prodotto di:
- La probabilità della politica che predice l’azione at nello stato st
- La probabilità di finire nello stato st+1 dato l’azione at e lo stato st
Quindi, partendo da uno stato iniziale s0, la probabilità che l’agente segua la traiettoria τ basata sulla politica πθ è data da:
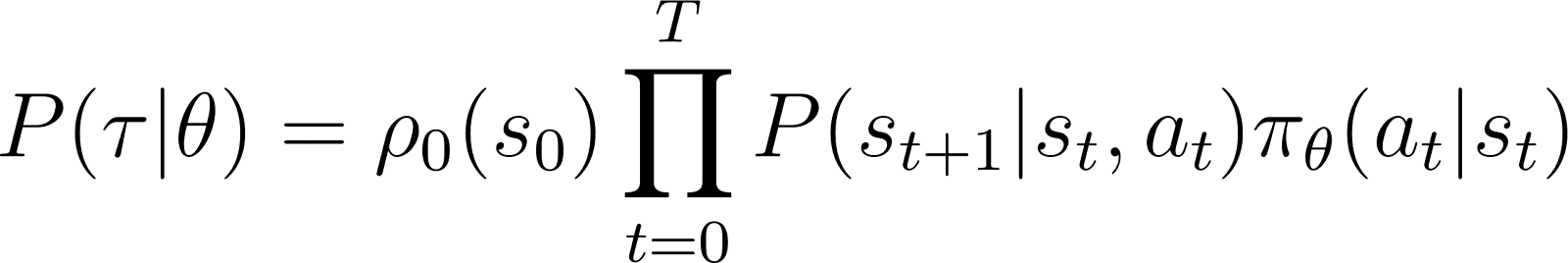
Per semplificare le cose, vogliamo esprimere il prodotto nel RHS sopra come una somma. Quindi, prendiamo il logaritmo di entrambi i lati dell’equazione sopra:
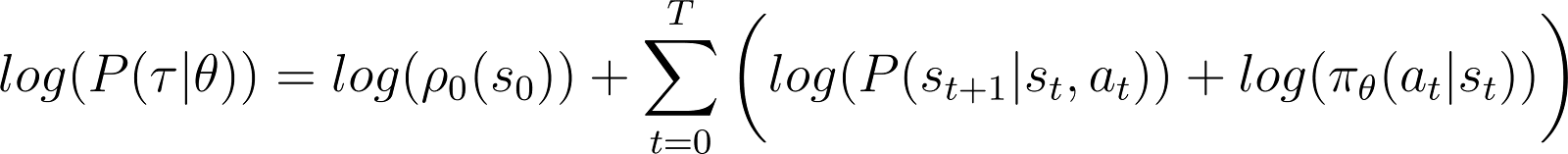
La derivata della log-probabilità (Equazione 5)
Ora prendiamo la derivata (rispetto a θ) della log-probabilità nell’equazione sopra.
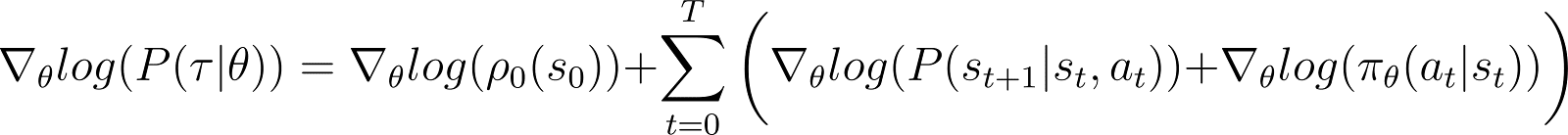
Nel RHS dell’equazione sopra:
- Il primo termine log ρ0(s0) è costante rispetto a θ. Quindi la sua derivata è 0.
- Il primo termine all’interno della sommatoria P(st+1|st, at) è anch’esso indipendente da θ e la sua derivata rispetto a θ è anch’essa 0.
Rimuovendo i termini zero sopra citati dall’equazione, rimaniamo con (Equazione 5):
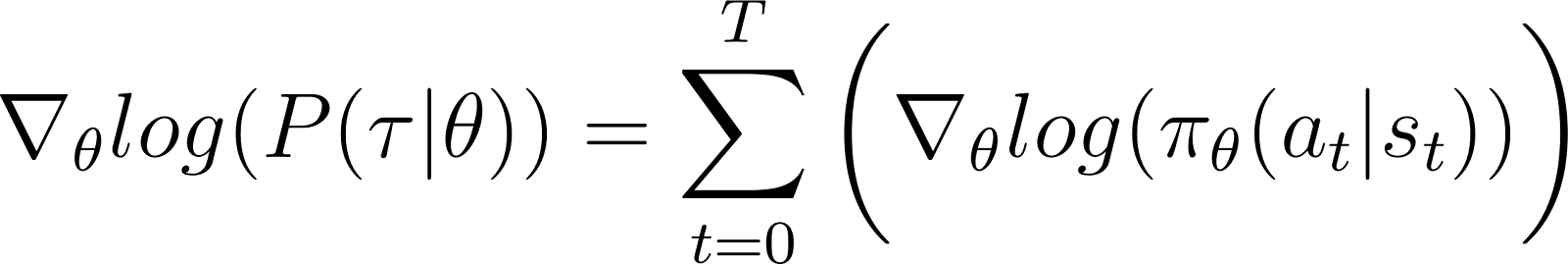
Ricordiamo dall’Equazione 2 che:
![]()
L’Equazione 5 valuta il logaritmo della prima parte del lato destro dell’Equazione 2. Dobbiamo collegare la derivata di un termine con il suo logaritmo. Facciamo ciò utilizzando la regola della catena e il trucco della derivata del logaritmo.
Il trucco della derivata del logaritmo
Facciamo una deviazione e utilizziamo le regole del calcolo per derivare un risultato, che useremo per semplificare l’equazione precedente e renderla adatta ai metodi computazionali.
Nel calcolo, la derivata di un logaritmo può essere espressa come:
![]()
Così, riarrangiando l’equazione sopra, la derivata di x può essere espressa in termini della derivata del logaritmo di x:
![]()
Questo è a volte chiamato il trucco della log-derivata.
La regola della catena
Secondo la regola della catena, dato z(y) come funzione di y, dove y è a sua volta una funzione di θ, y(θ), la derivata di z rispetto a θ è data da:
![]()
In questo caso, y(θ) sta per P(θ) e z(y) sta per log(y). Quindi,
![]()
Applicando la regola della catena
Sappiamo dalla matematica che d(log(y)) / dy = 1/y. Usa questo nella prima espressione del lato destro sopra.
![]()
Sposta y a sinistra e usa la notazione:
![]()
y sta per P(θ). Quindi l’equazione sopra è equivalente a:
![]()
Applicando il trucco del logaritmo-derivato
Il risultato sopra riportato fornisce la prima espressione del lato destro dell’Equazione 2 (mostrata di seguito).
Utilizzando il risultato nel lato destro dell’Equazione 2, otteniamo:
![]()
Riorganizziamo i termini sotto l’integrale del lato destro come segue:
![]()
Derivando il risultato finale
Osserva che l’espressione sopra contiene lo sviluppo integrale di un’aspettativa: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
Quindi, il lato destro dell’equazione sopra può essere espresso come l’aspettativa:
![]()
Sostituiamo la derivata della probabilità logaritmica nell’espressione del premio atteso:
![]()
Nell’equazione sopra, sostituisci il valore di ∇logP(θ) dall’Equazione 5 per ottenere:
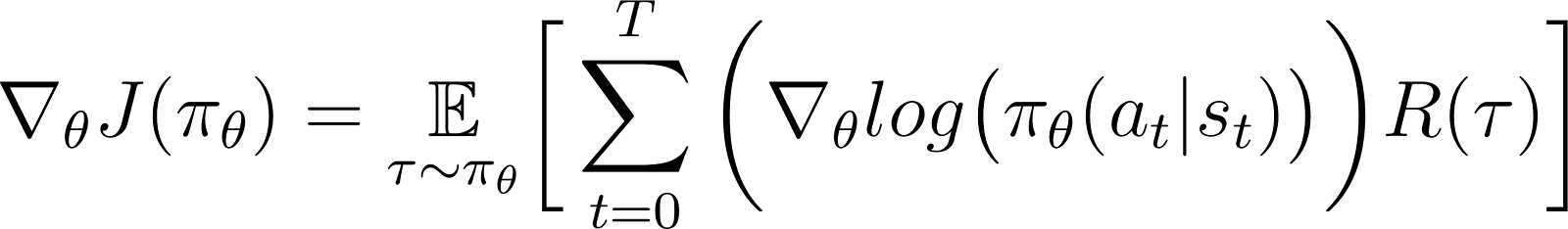
Questa è l’espressione per il gradiente della funzione di ricompensa secondo il teorema del gradiente della politica.
L’intuizione dietro il gradiente della politica
I metodi del gradiente della politica convertono l’output della politica in una distribuzione di probabilità. L’agente campiona questa distribuzione per scegliere un’azione. I metodi del gradiente della politica regolano i parametri della politica. Questo porta ad aggiornare questa distribuzione di probabilità in ogni iterazione. La distribuzione di probabilità aggiornata ha una maggiore probabilità di scegliere azioni che portano a ricompense più elevate.
L’algoritmo del gradiente della politica calcola il gradiente del ritorno atteso rispetto ai parametri della politica. Spostando i parametri della politica nella direzione di questo gradiente, l’agente aumenta la probabilità di scegliere azioni che portano a ricompense più elevate durante l’addestramento.
Fondamentalmente, le azioni che hanno portato a risultati migliori diventano più probabili da scegliere in futuro, migliorando gradualmente la politica per massimizzare le ricompense a lungo termine.
Source:
https://www.datacamp.com/tutorial/policy-gradient-theorem