













Warum Policy-Gradient-Methoden verwenden?
Ein wesentlicher Vorteil von Policy-Gradient-Methoden ist ihre Fähigkeit, komplexe Aktionsräume zu handhaben, in denen traditionelle wertbasierte Ansätze Schwierigkeiten haben.
Umgang mit hochdimensionalen Aktionsräumen
Wertbasierte Methoden wie Q-Learning arbeiten, indem sie die Wertefunktion für alle möglichen Aktionen schätzen. Dies wird schwierig, wenn der Aktionsraum der Umgebung entweder kontinuierlich oder diskret, aber groß ist.
Policy-Gradienten-Methoden parametrisieren die Richtlinie und schätzen den Gradienten der kumulativen Belohnungen in Bezug auf die Richtlinienparameter ab. Sie verwenden diesen Gradienten, um die Richtlinie direkt zu optimieren, indem sie ihre Parameter aktualisieren. Daher können sie effizient mit hochdimensionalen oder kontinuierlichen Aktionsräumen umgehen. Policy-Gradienten bilden auch die Grundlage für Methoden des Verstärkungslernens mit menschlichem Feedback (RLHF).
Indem die Richtlinie parametrisiert und ihre Parameter basierend auf Gradienten angepasst werden, können Policy-Gradienten kontinuierliche und hochdimensionale Aktionen effizient handhaben. Dieser direkte Ansatz ermöglicht eine bessere Generalisierung und flexiblere Exploration, was sie für Aufgaben wie die robotergestützte Steuerung und andere komplexe Umgebungen gut geeignet macht.
Das Lernen von stochastischen Richtlinien
Angenommen, es liegt eine Menge von Beobachtungen vor:
- Eine deterministische Richtlinie legt fest, welche Aktion der Agent ausführt.
- Eine stochastische Richtlinie gibt eine Reihe von Aktionen und die Wahrscheinlichkeit an, mit der der Agent jede Aktion wählt.
Bei der Befolgung einer stochastischen Richtlinie kann dieselbe Beobachtung in verschiedenen Iterationen zu verschiedenen Aktionen führen. Dies fördert die Exploration des Aktionsraums und verhindert, dass die Richtlinie in lokalen Optima stecken bleibt. Aus diesem Grund sind stochastische Richtlinien nützlich in Umgebungen, in denen die Exploration entscheidend ist, um den Weg zu maximalen Erträgen zu entdecken.
In Policy-basierten Methoden wird die Richtlinienausgabe in eine Wahrscheinlichkeitsverteilung umgewandelt, wobei jeder möglichen Aktion eine Wahrscheinlichkeit zugewiesen wird. Der Agent wählt eine Aktion, indem er diese Verteilung abtastet, was die Implementierung einer stochastischen Richtlinie ermöglicht. Somit kombinieren Policy-Gradienten-Methoden Exploration mit Ausbeutung, was in Umgebungen mit komplexen Belohnungsstrukturen nützlich ist.
Herleitung des Policy-Gradienten-Theorems
Vor dem Eintauchen in die Ableitung ist es wichtig, die mathematische Notation und die Schlüsselkonzepte festzulegen, die im gesamten Beweis verwendet werden.
Mathematische Notation und Grundlagen
Wie bereits in einem vorherigen Abschnitt erwähnt, besagt der Policy-Gradientensatz, dass die Ableitung des erwarteten Rückgabewerts die Erwartung des Produkts aus der Rückgabe und der Ableitung des Logarithmus des Policies ist.
Bevor wir den Policy-Gradientensatz herleiten, führen wir die Notation ein:
- E[X] bezieht sich auf die probabilistische Erwartung einer Zufallsvariablen X.
- Mathematisch wird die Richtlinie als Wahrscheinlichkeitsmatrix ausgedrückt, die die Wahrscheinlichkeit der Auswahl verschiedener Aktionen basierend auf verschiedenen Beobachtungen angibt. Eine Richtlinie wird typischerweise als parametrisierte Funktion modelliert, wobei die Parameter als θ dargestellt werden.
- πθ bezieht sich auf eine Richtlinie, die durch θ parametrisiert ist. In der Praxis handelt es sich bei diesen Parametern um die Gewichte des neuronalen Netzwerks, das die Richtlinie modelliert.
- Die Trajektorie, τ, bezieht sich auf eine Sequenz von Zuständen, die in der Regel von einem zufälligen Anfangszustand bis zum aktuellen Zeitschritt oder zum Endzustand verläuft.
- ∇θf bezieht sich auf den Gradienten einer Funktion f bezüglich des Parameters θ.
- J(πθ) bezieht sich auf die erwartete Rendite, die der Agent gemäß der Richtlinie πθ erzielt. Dies ist auch die Zielgröße für den Gradientenaufstieg.
- Die Umgebung belohnt zu jedem Zeitschritt, abhängig von der Aktion des Agenten. Die Rückkehr bezieht sich auf die kumulativen Belohnungen vom Anfangszustand bis zum aktuellen Zeitschritt.
- R(τ) bezieht sich auf die Rendite, die über die Trajektorie τ generiert wird.
Derivationsschritte
Wir zeigen, wie man den Richtliniengradientensatz aus den ersten Prinzipien ableiten und beweisen kann, indem man mit der Expansion der Ziel-Funktion beginnt und den Logarithmus-Derivat-Trick verwendet.
Die Ziel-Funktion (Gleichung 1)
Die Ziel-Funktion in der Richtliniengradientenmethode ist die Rendite.
Ich habe mich angesammelt, indem ich der Trajektorie gemäß der Richtlinie π gefolgt bin, die in Bezug auf Parameter θ ausgedrückt wird. Diese Ziel- oder Zweckfunktion ist gegeben als:
![]()
In der obigen Gleichung:
- Die linke Seite (LHS) ist die erwartete Rendite, die durch die Befolgung der Richtlinie πθ erreicht wird.
- Die rechte Seite (RHS) ist die Erwartung (über die Trajektorie τ , die durch das Befolgen der Richtlinie πθ in jedem Schritt generiert wird) der Rückkehr R(τ) generiert über die Trajektorie τ.
Die Ableitung der Zielfunktion (Gleichung 2)
Durch Differentiation (in Bezug auf θ) beider Seiten der obigen Gleichung ergibt:
![]()
Der Gradient der Erwartung (Gleichung 3)
Die Erwartung (auf der rechten Seite) kann als Integral über das Produkt von ausgedrückt werden:
- Die Wahrscheinlichkeit, einer Trajektorie τ zu folgen
- Die Renditen, die über die Trajektorie τ
Daher wird die rechte Seite von Gleichung 2 wie folgt neu formuliert:
![]()
Der Gradient eines Integrals ist gleich dem Integral des Gradienten. Daher können wir in obigem Ausdruck den Gradienten ∇θ unter das Integralzeichen bringen. Also wird die rechte Seite zu:
![]()
Daher kann Gleichung 2 umgeschrieben werden als:
![]()
Die Wahrscheinlichkeit der Trajektorie (Gleichung 4)
Wir werfen nun einen genaueren Blick auf P(τ|θ), die Wahrscheinlichkeit, dass der Agent der Trajektorie τ gemäß den Policy-Parametern θ (und damit der Policy πθ). Eine Trajektorie besteht aus einer Reihe von Schritten. Daher:
- Die Wahrscheinlichkeit, die Trajektorie τ zu erhalten, ist das Produkt von:
- Die Wahrscheinlichkeit, alle einzelnen Schritte zu befolgen.
![]()
- Im Zeitschritt t wechselt der Agent vom Zustand s zum Zustand st+1 durch die Ausführung der Aktion at. Die Wahrscheinlichkeit dafür ergibt sich aus dem Produkt von:
- Die Wahrscheinlichkeit, dass die Richtlinie die Aktion vorhersagt at im Zustand st
- Die Wahrscheinlichkeit, in Zustand st+1 zu gelangen, gegeben die Aktion at und Zustand st ist.
So ergibt sich, ausgehend von einem Anfangszustand s0 die Wahrscheinlichkeit, dass der Agent die Trajektorie τ basierend auf der Richtlinie πθ gegeben ist als:
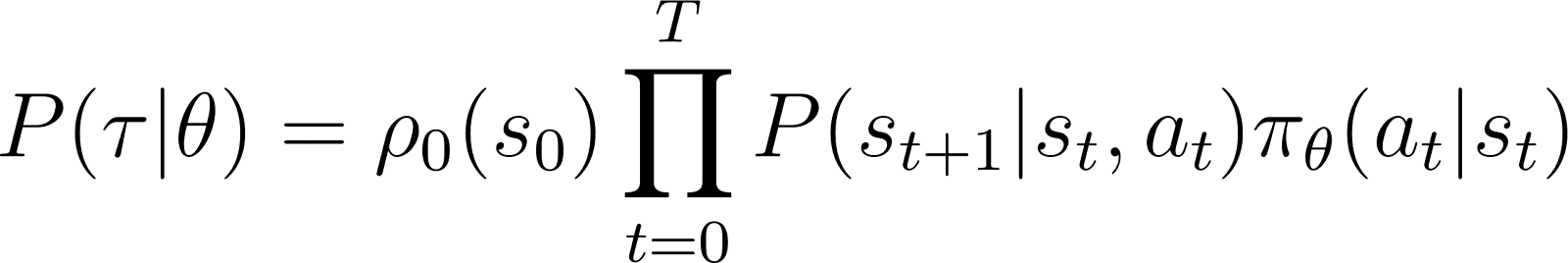
Um es einfacher zu machen, möchten wir das Produkt in der RHS oben als Summe ausdrücken. Also nehmen wir den Logarithmus auf beiden Seiten der obigen Gleichung:
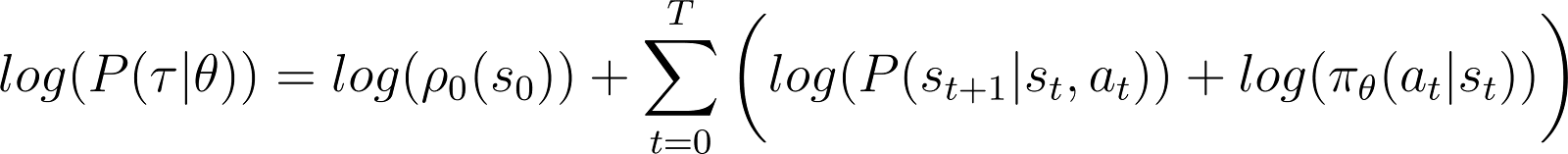
Die Ableitung der Log-Wahrscheinlichkeit (Gleichung 5)
Wir nehmen nun die Ableitung (in Bezug auf θ) der Log-Wahrscheinlichkeit in der obigen Gleichung.
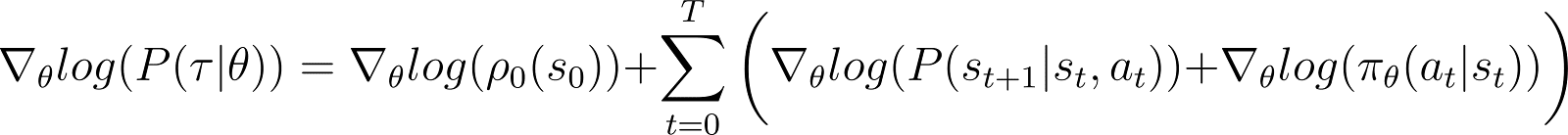
Auf der RHS der obigen Gleichung:
- Der erste Term log ρ0(s0) ist konstant in Bezug auf θ. Daher ist seine Ableitung 0.
- Der erste Term innerhalb der Summe P(st+1|st, at) ist auch unabhängig von θ und seine Ableitung nach θ ist ebenfalls 0.
Entfernen wir die obigen Nullterme aus der Gleichung, bleiben wir mit (Gleichung 5):
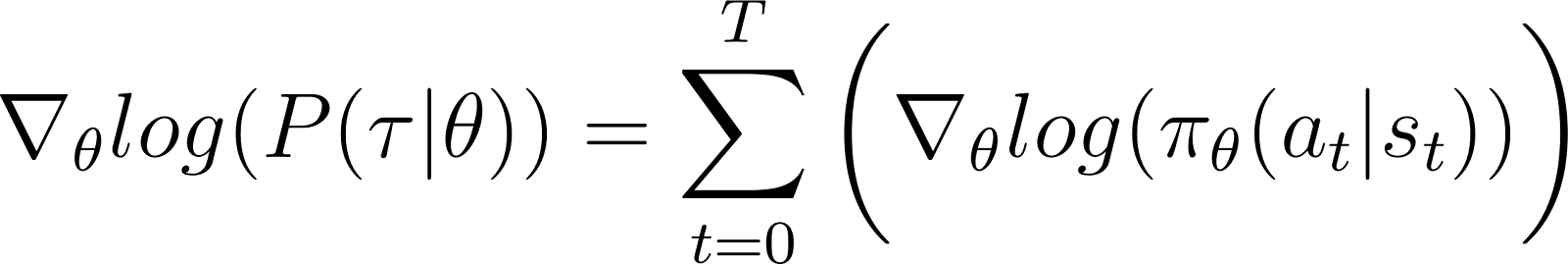
Erinnern wir uns an Gleichung 2:
![]()
Gleichung 5 bewertet den Logarithmus des ersten Teils der RHS von Gleichung 2. Wir müssen die Ableitung eines Terms mit seinem Logarithmus in Beziehung setzen. Dies tun wir unter Verwendung der Kettenregel und des Logarithmus-Ableitungstricks.
Der Logarithmus-Ableitungstrick
Wir machen einen Umweg und verwenden die Regeln der Analysis, um ein Ergebnis abzuleiten, das wir verwenden werden, um die vorherige Gleichung zu vereinfachen und für rechnergestützte Methoden geeignet zu machen.
In der Analysis kann die Ableitung eines Logarithmus wie folgt ausgedrückt werden:
![]()
Auf diese Weise kann durch Umstellen der obigen Gleichung die Ableitung von x in Bezug auf die Ableitung des Logarithmus von x ausgedrückt werden:
![]()
Dies wird manchmal als der Logarithmus-Ableitungstrick bezeichnet.
Die Kettenregel
Gemäß der Kettenregel ist die Ableitung von z(y) nach y, wobei y selbst eine Funktion von θ ist, als:
![]()
In diesem Fall, y(θ) steht für P(θ) und z(y) steht für log(y). Somit,
![]()
Anwendung der Kettenregel
Wir wissen aus der Analysis, dass d(log(y)) / dy = 1/y. Verwenden Sie dies im ersten Ausdruck auf der rechten Seite oben.
![]()
Bewegen Sie y auf die linke Seite und verwenden Sie die Notation:
![]()
y steht für P(θ). Also ist die obige Gleichung äquivalent zu:
![]()
Durch Anwendung des Logarithmus-Differentiations-Tricks
Das obige Ergebnis liefert den ersten Ausdruck auf der rechten Seite von Gleichung 2 (unten gezeigt).
Unter Verwendung des Ergebnisses auf der rechten Seite von Gleichung 2 erhalten wir:
![]()
Wir ordnen die Terme unter dem Integral auf der rechten Seite wie folgt um:
![]()
Das endgültige Ergebnis ableiten
Beachten Sie, dass der obige Ausdruck die Integralentwicklung einer Erwartung enthält: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
Somit kann die obige RHS als Erwartung ausgedrückt werden:
![]()
Wir substituieren die Ableitung der Log-Wahrscheinlichkeit in der Ausdruck der erwarteten Belohnung:
![]()
In der obigen Gleichung den Wert von ∇logP(θ) aus Gleichung 5 einsetzen, um zu erhalten:
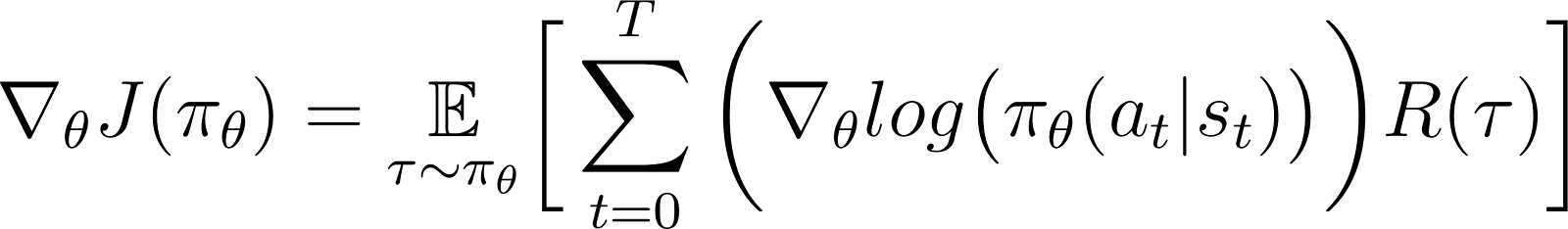
Dies ist der Ausdruck für den Gradienten der Belohnungsfunktion gemäß dem Policy-Gradienten-Theorem.
Die Intuition hinter dem Policy-Gradient
Policy-Gradient-Methoden wandeln die Ausgabe der Policy in eine Wahrscheinlichkeitsverteilung um. Der Agent zieht eine Stichprobe aus dieser Verteilung, um eine Aktion auszuwählen. Policy-Gradient-Methoden passen die Parameter der Policy an. Dies führt dazu, dass diese Wahrscheinlichkeitsverteilung in jeder Iteration aktualisiert wird. Die aktualisierte Wahrscheinlichkeitsverteilung hat eine höhere Wahrscheinlichkeit, Aktionen auszuwählen, die zu höheren Belohnungen führen.
Der Policy-Gradient-Algorithmus berechnet den Gradienten des erwarteten Ertrags bezüglich der Policy-Parameter. Indem die Policy-Parameter in Richtung dieses Gradienten bewegt werden, erhöht der Agent die Wahrscheinlichkeit, Aktionen auszuwählen, die während des Trainings zu höheren Belohnungen führen.
Im Wesentlichen werden Aktionen, die zu besseren Ergebnissen führten, in Zukunft wahrscheinlicher gewählt, was die Policy schrittweise verbessert, um langfristige Belohnungen zu maximieren.
Source:
https://www.datacamp.com/tutorial/policy-gradient-theorem