













למה להשתמש בשיטות גרדיאנט מדיניות?
אחת מיתרונות המרכזיים של שיטות גרדיאנט מדיניות היא היכולת שלהן להתמודד עם מרחבי פעולה מורכבים, שבהם גישות מבוססות ערך מסורבלות.
טיפול במרחבי פעולה במימדים גבוהים
שיטות מבוססות ערך, כמו Q-learning, פועלות על ידי הערכת פונקציית הערך עבור כל הפעולות האפשריות. זה הופך לקשה כאשר מרחב הפעולות של הסביבה הוא או רציף או דיסקרטי אך גדול.
שיטות גרדיאנט מדיניות מפרמטרות את המדיניות ומעריכות את הגרדיאנט של הפרסים המצטברים ביחס לפרמטרי המדיניות. הם משתמשים בגרדיאנט הזה כדי למקסם ישירות את המדיניות על ידי עדכון הפרמטרים שלה. לכן, הם יכולים להתמודד ביעילות עם מרחבי פעולה גבוהי מימד או רציפים. גרדיאנטים של מדיניות הם גם הבסיס ל-למידת חיזוק באמצעות משוב אנושי (RLHF) שיטות.
על ידי פרמטריזציה של המדיניות והתאמת הפרמטרים שלה על סמך גרדיאנטים, גרדיאנטים של מדיניות יכולים להתמודד ביעילות עם פעולות רציפות וגבוהות מימד. גישה ישירה זו מאפשרת הכללה טובה יותר וחקר גמיש יותר, מה שהופך אותה למתאימה היטב למשימות כמו שליטה רובוטית וסביבות מורכבות אחרות.
למידת מדיניות סטוכסטית
בהינתן קבוצת תצפיות:
- מדיניות דטרמיניסטית מציינת איזו פעולה הסוכן בוחר.
- מדיניות סטוכסטית מציעה סט של פעולות וההסתברות שהסוכן יבחר בכל פעולה.
בעקבות מדיניות סטוכסטית, אותה תצפיה עשויה להוביל לבחירת פעולות שונות באיטרציות שונות. זה מעודד חקירת המרחב של הפעולה ומונע מהמדיניות להיצמד לאופטימום מקומי. עקב כך, מדיניות סטוכסטית שימושית בסביבות שבהן חקירה היא אופציה חיונית לגילוי הנתיב שמביא להחזרים מקסימליים.
בשיטות המבוססות על מדיניות, פלט המדיניות מומר להפצת ההסתברות, כאשר לכל פעולה אפשרית מוקצתת הסתברות. הסוכן בוחר פעולה על ידי דגימת ההפצה הזו, מה שהופך אפשרי ליישם מדיניות סטוכסטית. כך, שיטות הגרדיינט של מדיניות משלבות חקירה עם פיתוח, שימושיות בסביבות עם מבנים פרסום מורכבים.
הפקת משפט גרדיינט המדיניות
לפני שנצלול לגזירת התיאוריה, חשוב לקבוע את הסימון המתמטי והמושגים המרכזיים המשמשים לאורך ההוכחה.
סימון מתמטי ומבואות
כפי שצוין במקטע קודם, תיאורית גרדיאנט המדיניות קובעת כי הנגזרת של התשואה הצפויה היא הציפייה של מכפלת התשואה והנגזרת של הלוגריתם של המדיניות.
לפני שנגזור את תיאורית גרדיאנט המדיניות, אנו מציגים את הסימון:
- E[X] מתייחס לציפייה הסתברותית של משתנה אקראי X.
- מבחינה מתמטית, המדיניות מבוטאת כמטריצת הסתברויות שמעניקה את ההסתברות לבחירת פעולות שונות בהתבסס על תצפיות שונות. מדיניות בדרך כלל מודלגת כפונקציה פרמטרית, כאשר הפרמטרים מיוצגים כ-θ.
- πθ מתייחס למדיניות המוגדרת על ידי θ. בפועל, הפרמטרים הללו הם המשקלים של הרשת העצבית שמדמה את המדיניות.
- המסלול, τ, מתייחס לרצף של מצבים, בדרך כלל מתחיל ממצב ראשוני אקראי עד או עד לזמן הנוכחי או למצב הסופי.
- ∇θf מתייחס לגרדיאנט של פונקציה f ביחס לפרמטר(ים) θ.
- J(πθ) מתייחס לתשואה הצפויה שהושגה על ידי הסוכן בעקבות המדיניות πθ. זה גם הפונקציה המטרה עבור עלייה גרדיאנטית.
- הסביבה נותנת פרס בכל שלב זמן, תלוי בפעולת הסוכן. ההחזר הוא התמרת הפרסים הצפויה מהמצב ההתחלתי עד לשלב הנוכחי.
- R(τ) מתייחס להחזר הנוצר מעל המסלול τ.
שלבי ההפקה
אנו מראים כיצד להפיק ולהוכיח את משפט הגרדיאנט מהמדיניות מהעקרונות הראשוניים, התחלה עם הרחבת פונקציית המטרה ושימוש בטריק הלוג-נגזרת.
פונקציית המטרה (משוואה 1)
פונקציית המטרה בשיטת גרדיאנט המדיניות היא ההחזרה
השקפתי כתוצאה מהמסלול שנבחר על פי המדיניות π הביטוי באמצעות הפרמטרים θ. פונקציית המטרה היא:
![]()
במשוואה לעיל:
- הצד שמאל (LHS) מייצג את ההחזר הצפוי שניתן להשיג על ידי עקיפת המדיניות πθ.
- צד ימין (RHS) הוא הציפייה (על פני המסלול τ שנוצר על ידי מעקב אחרי המדיניות πθ בכל שלב) של התשואות R(τ) שנוצרו על פני המסלול τ.
ההבדל של פונקציית המטרה (משוואה 2)
בניפול (נגד θ) שני הצדדים של המשוואה מעלה:
![]()
הגרדיינט של הציפיות (משוואה 3)
הציפיות (בצד ימין) ניתן להבעה כאינטגרל על כפל של:
- הסיכוי לעקוב אחר טרקטוריה τ
- ההחזרים שנוצרו במהלך המסלול τ
כך, צד ימין של משוואה 2 מנוסח מחדש כ:
![]()
הגרדיינט של אינטגרל הוא שווה לאינטגרל של הגרדיינט. לכן, בביטוי לעיל, אנו יכולים להעביר את הגרדיינט ∇θ תחת סימן האינטגרל. לכן, הצד הימני מתהפך להיות:
![]()
לכן, משוואה 2 יכולה להיות כתובה מחדש כך:
![]()
הסיכוי של המסלול (משוואה 4)
אנו מסתכלים כעת בקרבה על P(τ|θ), הסיכוי של הסוכן לעקוב אחר טרטוריה τ נתונים פרמטרי מדיניות θ (ובכך גם מדיניות πθ). טרטוריה כוללת סט של שלבים. לכן:
- הסתברות לקבלת טרקטוריה ט היא כפל של:
- ההסתברות של עקבות את כל השלבים האישיים.
![]()
- בשלב הזמן t, הסוכן עובר מהמצב s למצב st+1 על ידי ביצוע הפעולה at. ההסתברות לקריאה זו מתקבלת כמכפלת של:
- הסתברות המדיניות חוזה הזיווג פעולה at במצב st
- הסיכוי לסיים במצב st+1 נתון פעולה at ומצב st
כך, החל ממצב ראשוני s0, הסיכוי של הסוכן לעקוב אחרי מסלול τ בהתבסס על מדיניות πθ ניתנת כ:
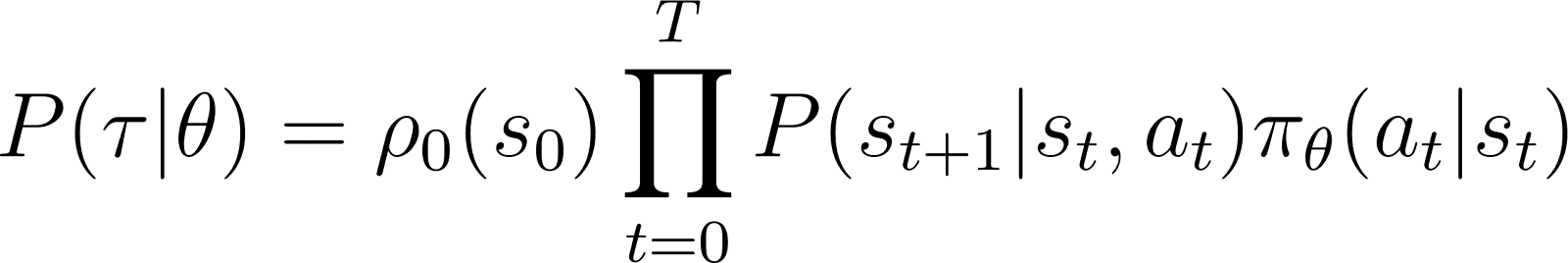
כדי לפשט דברים, אנו רוצים לבטא את המוצר בצד ימין של המשוואה למעלה כסכום. לכן, ניקח את הלוגריתם משני הצדדים של המשוואה הנ"ל:
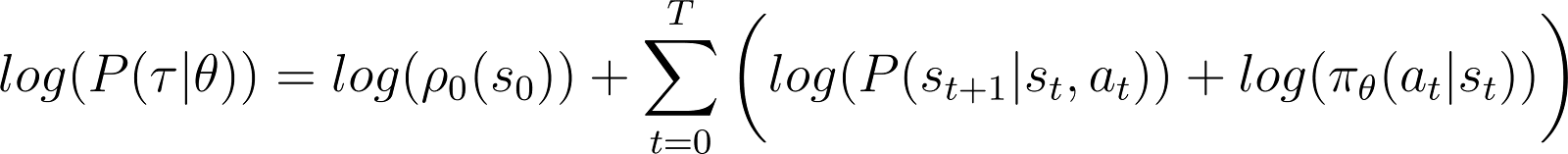
נגזרת הלוגריתם-סיכוי (משוואה 5)
עכשיו ניקח את הנגזרת (לגבי θ) של הלוגריתם סיכוי במשוואה למעלה.
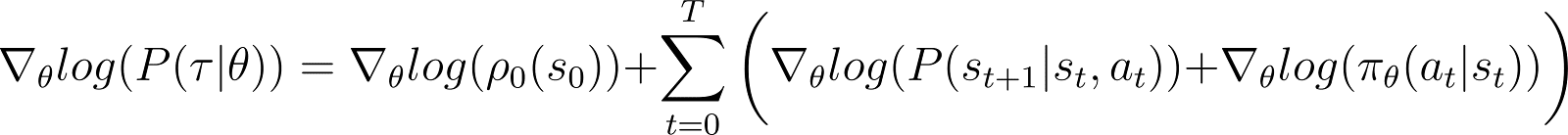
בצד ימין של המשוואה למעלה:
- המונח הראשון לוג ρ0(s0) הוא קבוע ביחס ל־θ. לכן הנגזרת שלו היא 0.
- המונח הראשון בסכימה P(st+1|st, at) גם תלוי תלתות ב- θ והנגזרת שלו לגבי θ היא גם 0.
בהסרת את המונחים מעל לאפס מהמשוואה, נותר לנו (משוואה 5):
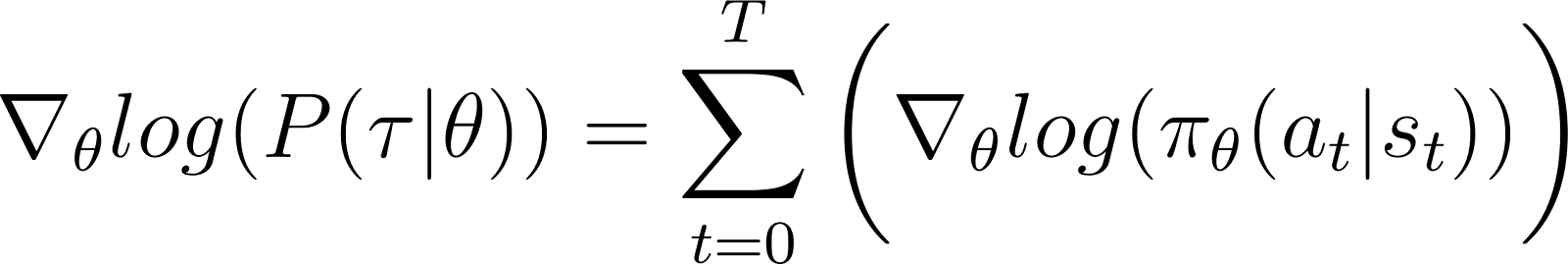
זכרו ממשוואה 2 ש:
![]()
משוואה 5 מעריכה את הלוגריתם של החלק הראשון של ה-RHS של משוואה 2. אנו צריכים לקשר בין הנגזרת של מונח לבין הלוגריתם שלו. אנו עושים זאת באמצעות כלל השרשרת וטכניקת הלוגריתם-נגזרת.
טכניקת הלוגריתם-נגזרת
אנו עושים עיקוף ומשתמשים בחוקי החשבון הדיפרנציאלי כדי להפיק תוצאה, שתשמש אותנו לפשט את המשוואה הקודמת ולהתאימה לשיטות חישוביות.
בחשבון דיפרנציאלי, הנגזרת של לוגריתם יכולה להיות מבוטאת כך:
![]()
לכן, על ידי שינוי סידור המשוואה שלמעלה, הנגזרת של x ניתן לבטא בצורה של הנגזרת של הלוגריתם של x:
![]()
מינה היא לפעמים נקראת הטריק של ההפקדה בלוגריתם.
חוק השרשרת
לפי כלל השרשור, בהנתן z(y) כפונקציה של y, כאשר y עצמו הוא פונקציה של θ, y(θ), הנגזרת של z לגבי θ ניתנת כך:
![]()
במקרה הזה, y(θ) מתייחס לP(θ) וz(y) מתייחס לlog(y). לכן,
![]()
החילול השרשרתי
אנו יודעים מחשבון שהמפתח של d(log(y)) / dy הוא 1/y. נשתמש בזה בביטוי הראשון של RHS למעלה.
![]()
נעביר y ל-LHS ונשתמש ב סימון הבא:
![]()
y עומד על P(θ). לכן המשוואה לעיל שקולה ל:
![]()
החילוק בשיטת הנגזרת הלוגרתם
התוצאה לעיל נותנת את הביטוי הראשון של צד ימין של משוואה 2 (המוצגת למטה).
באמצעות התוצאה בצד ימין של משוואה 2, נקבל:
![]()
אנו מאחדים את המונים תחת האינטגרל בצד ימין כך:
![]()
מפענחים את התוצאה הסופית
שימו לב כי הביטוי הנ"ל מכיל את ההרחבה האינטגרלית של ציפייה: ∫P(θ)∇logP(θ) = E[∇logP(θ)]
לכן, ניתן להביע את ה-RHS לעיל כהון:
![]()
אנו מחליף את הנגזרת של ההסתברות הלוגרית בביטוי של התגמול המצופה:
![]()
במשוואה לעיל, החלף את הערך של ∇logP(θ) ממשוואה 5 כדי לקבל:
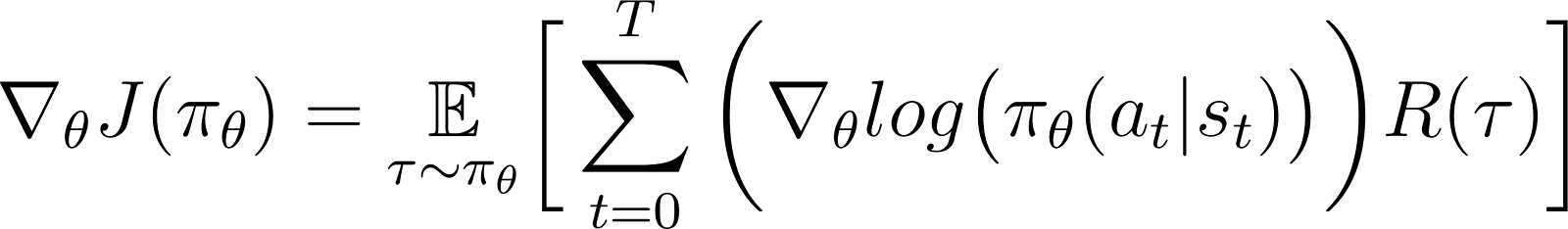
זוהי ההבעה עבור הגרדיאנט של פונקציית התגמול בהתאם לתיאוריית גרדיאנט המדיניות.
האינטואיציה מאחורי גרדיאנט המדיניות
שיטות גרדיאנט המדיניות ממירות את הפלט של המדיניות להפצת הסתברויות. הסוכן מדגם הפצה זו כדי לבחור פעולה. שיטות גרדיאנט המדיניות מתאימות את פרמטרי המדיניות. זה מביא לעדכון הפצת ההסתברויות בכל איטרציה. הפצת ההסתברויות המעודכנת יש סבירות גבוהה יותר לבחור פעולות שמובילות לתגמולים גבוהים יותר.
אלגוריתם גרדיאנט המדיניות מחשב את הגרדיאנט של התשואה הצפויה ביחס לפרמטרי המדיניות. על ידי הזזת פרמטרי המדיניות בכיוון של גרדיאנט זה, הסוכן מגדיל את הסבירות לבחור פעולות שמניבות תגמולים גבוהים יותר במהלך האימון.
בעצם, פעולות שהובילו לתוצאות טובות יותר הופכות ליותר סבירות להיבחר בעתיד, ובכך משפרות בהדרגה את המדיניות למקסום תגמולים לטווח ארוך.
Source:
https://www.datacamp.com/tutorial/policy-gradient-theorem