













Введение
Эта статья посвящена одному из лучших GAN на сегодняшний день, StyleGAN из статьи Style-Based Generator Architecture for Generative Adversarial Networks, мы создадим чистую, простую и читаемую реализацию на основе PyTorch и постараемся как можно ближе复制 исходную статью, чтобы если вы читали статью, реализация должна быть практически идентичной.
Массив данных, который мы будем использовать в этом блоге, это массив данных с Kaggle, который содержит 16240female upper clothes с разрешением 256*192.
Предпосылки
Прежде чем приступить к работе с StyleGAN на основе PyTorch, убедитесь, что у вас есть следующие предпосылки:
-
Основные знания в области深海学习
Понимание convolutions neural networks (CNN).
Знакомство с Generative Adversarial Networks (GAN), включая такие концепции, как генератор, дискриминатор и враждебная потеря. -
Требования к оборудованию
Мощная видеокарта (рекомендуется NVIDIA) для ускорения обучения и вывода.
Установленный toolkit CUDA для ускорения работы с GPU (cudaиcudnn). -
Знакомство со StyleGAN
Полезно будет прочитать оригинальные статьи StyleGAN или StyleGAN2, чтобы понять улучшения архитектуры и ключевые концепции.
Загрузить все необходимые зависимости
Мы сначала импортируем torch, так как мы будем использовать PyTorch, и из него импортируем nn. Это поможет нам создавать и обучать сети, а также позволит импортировать optim, пакет, реализующий различные оптимизационные алгоритмы (например, sgd, adam,…). Из torchvision мы импортируем datasets и transforms для подготовки данных и применения некоторых преобразований.
Мы импортируем functional как F из torch.nn для increase images usando interpolate, DataLoader из torch.utils.data для создания размеров mini-batch, save_image из torchvision.utils для сохранения некоторых подделанных примеров, log2 из math, так как нам нужно обратное представление степени 2 для реализации адаптивного размера mini-batch в зависимости от разрешающей способности вывода, NumPy для линейной алгебры, os для взаимодействия с операционной системой, tqdm для отображения индикаторов прогресса и, наконец, matplotlib.pyplot для отображения результатов и сравнения их с реальными.
Гиперпараметры
- Инициализируем DATASET по пути к реальным изображениям.
- Указываем размер изображения для начала обучения 8×8.
- Инициализируем устройство через Cuda, если оно доступно, и через CPU в противном случае, а такжеlearning rate в 0.001.
- Размер batch size будет различаться в зависимости от разрешения изображений, которые мы хотим генерировать, поэтому мы инициализируем BATCH_SIZES списком чисел, которые вы можете изменить в зависимости от вашей VRAM.
- Инициализируем image_size в 128 и CHANNELS_IMG в 3, так как мы будем генерировать изображения 128 на 128 в формате RGB.
- В оригинальной статье они инициализируют Z_DIM, W_DIM и IN_CHANNELS значением 512, но я инициализирую их значением 256 вместо этого для уменьшения использования VRAM и ускорения обучения. Возможно, мы могли бы получить даже лучшие результаты, если бы удвоили их.
- Для StyleGAN мы можем использовать любую функцию потерь GAN, которую хотим, поэтому я использую WGAN-GP из статьи Improved Training of Wasserstein GANs. Эта функция потерь содержит параметр с именем λ, и обычно устанавливают λ = 10.
- Инициализируйте PROGRESSIVE_EPOCHS значением 30 для каждого размера изображения.
Получите загрузчик данных
Теперь создадим функцию get_loader, чтобы:
- Применить некоторые преобразования к изображениям (изменить размер изображений до desired resolution, convert them to tensors, затем применить некоторые улучшения и, наконец, normalize их, чтобы все пиксели находились в диапазоне от -1 до 1).
- Определить текущий размер пакета, используя список BATCH_SIZES, и взять в качестве индекса целое число, обратное представлению степени 2 размера изображения/4. И именно так мы реализуем адаптивный размер минипакета в зависимости от разрешающей способности выхода.
- Подготовить набор данных, используя ImageFolder, так как он уже структурирован удобным образом.
- >Создайте размеры mini-batch с использованием DataLoader, который принимает набор данных и размер batch size с перемешиванием данных.
- Наконец, верните загрузчик и набор данных.
Реализация моделей
Теперь давайте реализуем генератор и дискриминатор StyleGAN1 (ProGAN и StyleGAN1 имеют одинаковую архитектуру дискриминатора) с основными атрибутами из статьи. Мы постараемся сделать реализацию компактной, но также читаемой и понятной. Specifically, the key points:
- Network Noise Mapping
- Adaptive Instance Normalization (AdaIN)
- Progressive growing
В этом руководстве мы будем просто генерировать изображения с помощью StyleGAN1, не реализуя стилирование и стохастическое разнообразие, но это shouldn’t быть太难.
Давайте определим переменную с названием factors, которая содержит числа, умножаемые на IN_CHANNELS для получения desired количества каналов в каждом разрешении изображения.
Network Noise Mapping
Шумовая картографическая сеть принимает Z и пропускает его через восемь teljes connected слоев, разделенных какой-то активацией. И не забудьте equalize темп обучения, как это делают авторы в ProGAN (ProGAN и StyleGan написаны теми же исследователями).
Давайте сперва создадим класс с названием WSLinear (weighted scaled Linear), который будет унаследован от nn.Module.
- В части init мы передаем in_features и out_channels. Создаем линейный слой, затем определяем scale, который будет равен квадратному корню из 2, деленному на in_features, мы копируем bias текущего столбцового слоя в переменную, потому что мы не хотим, чтобы bias линейного слоя был масштабирован, затем удаляем его, наконец, инициализируем линейный слой.
- В части forward мы передаем x и все, что мы будем делать, это умножить x на scale и добавить bias после его преобразования.
Теперь создадим класс MappingNetwork.
- В части init мы передаем z_dim и w_din, и определяем сеть картографирования, которая сначала normalize z_dim, затем следует восемь WSLInear и ReLU в качестве активационных функций.
- В части forward мы возвращаем сеть картографирования.
Адаптивная инстанс normalization (AdaIN)
Теперь создадим класс AdaIN
- В части init мы отправляем каналы, w_dim, и мы инициализируем instance_norm, который будет частью инстанс-нормализации, а также инициализируем style_scale и style_bias, которые будут адаптивными частями с WSLinear, который отображает Noise Mapping Network W в каналы.
- В процессе forward мы отправляем x, применяем для него инстанс-нормализацию и возвращаем style_sclate * x + style_bias.
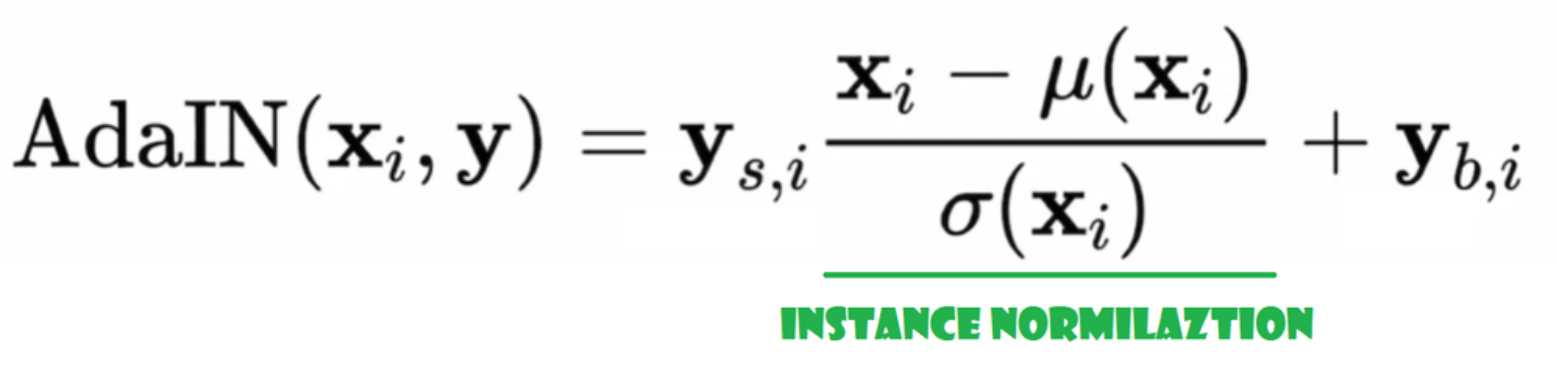
Введение шума
Теперь создадим класс InjectNoise для внедрения шума в генератор
- В части init мы отправляем каналы и инициализируем вес из случайного нормального распределения, используя nn.Parameter, чтобы эти веса можно было оптимизировать
- В части forward мы отправляем изображение x и возвращаем его с добавленным случайным шумом
полезные классы
Авторы создали StyleGAN на основе официальной реализации ProGAN от Karras и др., они используют ту же архитектуру дискриминатора, адаптивный размер minibatch, гиперпараметры и т.д. Поэтому есть множество классов, которые remained неизменными по сравнению с реализацией ProGAN.
В этом разделе мы создадим классы, которые не изменяются по сравнению с архитектурой ProGAN.
В фрагменте кода ниже вы можете найти класс WSConv2d (ciosл加权 масштабированный конволюционный слой) для Equalized Learning Rate для конволюционных слоев.
В фрагменте кода ниже вы можете найти класс PixelNorm для normalization Z передNoise Mapping Network.
В фрагменте кода ниже вы можете найти класс ConvBock, который поможет нам создать дискриминатор.
В фрагменте кода ниже вы можете найти класс Discriminatowich, который такой же, как и в ProGAN.
for Генератор
В архитектуре генератора у нас есть некоторые паттерны, которые повторяются, поэтому давайте сперва создадим класс для них, чтобы сделать наш код как можно чище, назовем класс GenBlock, который будет наследоваться от nn.Module.
- В части инициализации мы передаем in_channels, out_channels и w_dim, затем инициализируем conv1 через WSConv2d, который отображает in_channels на out_channels, conv2 через WSConv2d, который отображает out_channels на out_channels, leaky через Leaky ReLU с наклоном 0.2, как это используется в статье, inject_noise1 и inject_noise2 через InjectNoise, adain1 и adain2 через AdaIN.
- В части forward мы передаем x и пропускаем его через conv1, затем через inject_noise1 с leaky, затем normalize с adain1, и снова пропускаем его через conv2, затем через inject_noise2 с leaky и normalize с adain2. И finally, мы возвращаем x.
Теперь у нас есть все, что нам нужно для создания генератора.
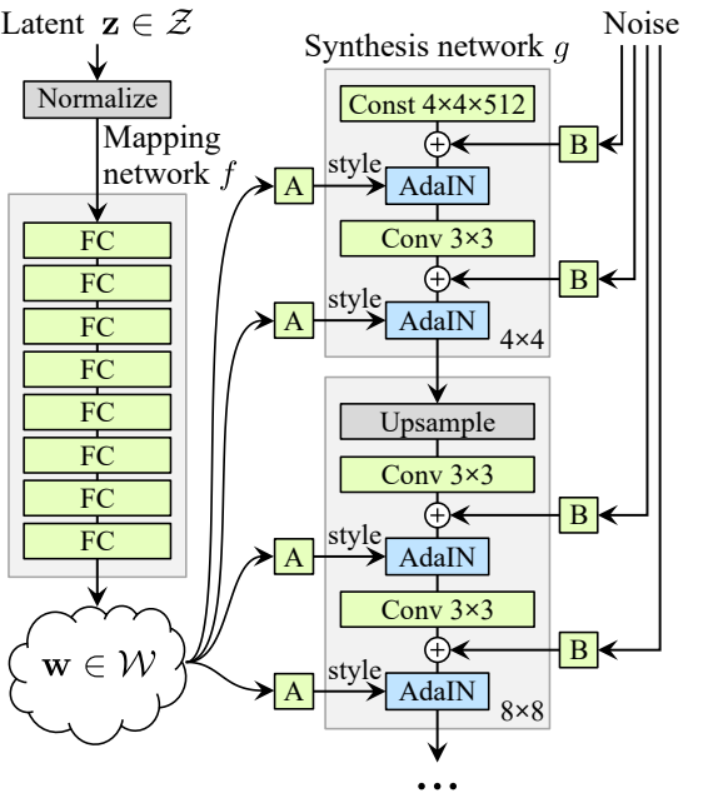
- В части init давайте инициируем ‘starting_constant’ константой 4 x 4 (x 512 каналов для оригинальной статьи, и 256 в нашем случае) тензора, который проходит итерацию генератора, map через ‘MappingNetwork’, initial_adain1, initial_adain2 через AdaIN, initial_noise1, initial_noise2 через InjectNoise, initial_conv через конволюционный слой, который отображает in_channels на самого себя, leaky через Leaky ReLU с наклоном 0.2, initial_rgb через WSConv2d, который отображает in_channels на img_channels, что equals 3 для RGB, prog_blocks через ModuleList(), который будет содержать все прогрессивные блоки (мы указываем входные/выходные каналы конволюции, умножая in_channels, что equals 512 в статье и 256 в нашем случае, на коэффициенты), и rgb_blocks через ModuleList(), который будет содержать все RGB блоки.
- Чтобы gradually добавлять новые слои (оригинальный компонент ProGAN), мы добавляем часть fade_in, в которую мы передаем alpha, scaled и generated, и мы возвращаем [tanh(alpha∗generated+(1−alpha)∗upscale)], Причина, по которой мы используем tanh, заключается в том, что это будет вывод (сгенерированное изображение), и мы хотим, чтобы пиксели находились в диапазоне между 1 и -1.
- В части вперёд, мы отправляем шум (Z_dim), значение alpha, которое будет медленно исчезать во время обучения (alpha находится между 0 и 1), и шаги, которые являются номером текущего разрешения, с которым мы работаем, передаём x в карту, чтобы получить промежуточный вектор шума W, передаём starting_constant в initial_noise1, применяем его и для W initial_adain1, затем передаём его в initial_conv, и снова добавляем initial_noise2 для него с leaky в качестве функции активации, и применяем его и W initial_adain2. Затем проверяем, равны ли шаги 0, если да, то всё, что мы хотим сделать, это пропустить его через initial RGB и мы закончили, в противном случае, мы循环 по количеству шагов, и в каждом цикле мы масштабируем (upscaled) и пропускаем через прогрессирующий блок, соответствующий этому разрешению (out). В конце, мы возвращаем fade_in, который принимает alpha, final_out и final_upscaled после его mapping к RGB.
Утилиты
В фрагменте кода ниже вы можете найти функцию generate_examples, которая принимает генератор gen, количество шагов для определения текущего разрешения и число n=100. Цель этой функции – сгенерировать n поддельных изображений и сохранить их в качестве результата.
В фрагменте кода ниже вы можете найти функцию gradient_penalty для WGAN-GP loss.
Функция обучения
Для функции обучения мы отправляем критик (который является дискриминатором), gen (генератор), лоадер, набор данных, шаг, альфу и оптимайзеры для генератора и критика.
Мы начинаем с цикла по всем размерам迷你- батчей, которые мы создаем с помощью DataLoader, и берем только изображения, так как нам не нужен ярлык.
Затем мы настраиваем обучение для дискриминатора\Критика, когда хотим максимизировать E(critic(real)) – E(critic(fake)). Это уравнение означает, насколько критик может различать реальные и поддельные изображения.
После этого мы настраиваем обучение генератора, когда хотим максимизировать E(critic(fake)).
Наконец, мы обновляем цикл и значение альфа для fade_in и обеспечиваем, чтобы оно было между 0 и 1, и возвращаем его.
Обучение
Теперь, когда у нас есть все, давайте объединим их, чтобы обучить наш StyleGAN.
Мы начинаем с инициализации генератора, дискриминатора/критика и оптимизаторов, затем переводим генератор и критик в режим обучения, затем循环 по PROGRESSIVE_EPOCHS и в каждом цикле вызываем функцию обучения количество итераций, затем генерируем некоторые поддельные изображения и сохраняем их, как результат, используя функцию generate_examples, и, наконец, переходим к следующему разрешению изображения.
Результат
Надеюсь, вам удастся следовать всем шагам и получить хорошее понимание того, как реализовать StyleGAN的正确ным образом. Теперь давайте рассмотрим результаты, которые мы получаем после обучения этой модели на этом наборе данных с разрешением 128×128.

Заключение
В этой статье мы создаем чистую, простую и читаемую реализацию с нуля StyleGAN1 с использованием PyTorch. Мы как можно ближе replicируем оригинальную статью, поэтому, если вы читали статью, реализация должна быть практически идентичной.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch