













Inleiding
Dit artikel gaat over één van de beste GANs van tegenwoordig, StyleGAN van het paper Een Style-Based Generator Architecture for Generative Adversarial Networks, we zullen een schone, eenvoudige en leesbare implementatie ervan maken met PyTorch, en proberen de originele paper zoveel mogelijk na te bootsen, dus als je het paper leest, zou de implementatie vrijwel identiek moeten zijn.
De dataset die we in deze blog gebruiken is deze dataset van Kaggle die 16240 bovenkleding voor vrouwen bevat met een resolutie van 256*192.
Voorkennis
Voordat je aan de slag gaat met StyleGAN met PyTorch, zorg ervoor dat je de volgende voorkennis hebt:
-
Basiskennis van Diepe Lering
Begrip van convolutionele neurale netwerken (CNNs).
Vertrouwdheid met Generative Adversarial Networks (GANs), inclusief concepten zoals de generator, discriminator en adversarische verlies. -
Hardware vereisten
Een krachtige GPU (NVIDIA aanbevolen) voor snellere training en inferentie.
CUDA toolkit geïnstalleerd voor GPU-versnelling (cudaencudnn). -
Vertrouwdheid met StyleGAN
Het is nuttig om de originele StyleGAN of StyleGAN2 papers te hebben gelezen om de architectuurverbeteringen en belangrijkste concepten te begrijpen.
Laad alle afhankelijkheden die we nodig hebben
We gaan eerst torch importeren omdat we PyTorch gaan gebruiken, en daarna importeren we nn. Dat helpt ons om netwerken te maken en te trainen, en ook om optim te importeren, een pakket dat verschillende optimalisatiealgoritmen implementeert (bijv. sgd, adam, …). Van torchvision importeren we datasets en transforms om de data voor te bereiden en enkele transformaties toe te passen.
We importeren functional als F van torch.nn om de afbeeldingen op te schalen met interpolate, DataLoader van torch.utils.data om mini-batchgroottes te maken, save_image van torchvision.utils om enkele valse voorbeelden op te slaan, en log2 van math omdat we de inverse representatie van de macht van 2 nodig hebben om de aanpasbare minibatchgrootte afhankelijk van de uitvoerresolutie te implementeren, NumPy voor lineaire algebra, os voor interactie met het besturingssysteem, tqdm om voortgangsbalken te tonen, en uiteindelijk matplotlib.pyplot om de resultaten te tonen en te vergelijken met de echte.
Hyperparameters
- Initialiseer de DATASET met het pad van de echte afbeeldingen.
- Specificeer de start van de training bij een afbeeldingsgrootte van 8×8.
- Initialiseer het apparaat met Cuda als het beschikbaar is en CPU anders, en de leergraad op 0.001.
- De batchgrootte zal verschillen afhankelijk van de resolutie van de afbeeldingen die we willen genereren, dus we initialiseren BATCH_SIZES met een lijst van getallen, je kunt ze aanpassen afhankelijk van je VRAM.
- Initialiseer image_size op 128 en CHANNELS_IMG op 3 omdat we 128×128 RGB-afbeeldingen gaan genereren.
- In het oorspronkelijke paper initialiseren ze Z_DIM, W_DIM en IN_CHANNELS met 512, maar ik initialiseer ze met 256 in plaats daarvan voor minder VRAM-gebruik en versnelde training. We zouden zelfs betere resultaten kunnen krijgen als we ze verdubbelden.
- Voor StyleGAN kunnen we elke GANs-verliesfunctie gebruiken die we willen, dus ik gebruik WGAN-GP uit het paper Improved Training of Wasserstein GANs. Deze verlies bevat een parameter genaamd λ en het is gebruikelijk om λ = 10 in te stellen.
- Initialiseer PROGRESSIVE_EPOCHS met 30 voor elke afbeeldingsgrootte.
Verkrijg data loader
Laten we nu een functie get_loader maken om:
- Enkele transformaties toe te passen op de afbeeldingen (afbeeldingen resizing naar de gewenste resolutie, ze om te zetten naar tensors, dan enkele augmentaties toe te passen en uiteindelijk te normaliseren zodat alle pixels variëren van -1 tot 1).
- De huidige batchgrootte te identificeren met behulp van de lijst BATCH_SIZES, en als index te nemen het integere getal van de inverse vertegenwoordiging van de macht van 2 van image_size/4. En dit is eigenlijk hoe we de adaptieve minibatchgrootte implementeren afhankelijk van de uitvoerresolutie.
- De dataset voor te bereiden door ImageFolder te gebruiken omdat het al op een nette manier is gestructureerd.
- Maak mini-batchgroottes met DataLoader die de dataset en batchgrootte gebruiken met het shuffelen van de gegevens.
- Daarnaast retourneren we de loader en dataset.
Implementatie van modellen
Laten we nu de StyleGAN1 generator en discriminator implementeren (ProGAN en StyleGAN1 hebben dezelfde discriminatorarchitectuur) met de belangrijkste attributen uit het paper. We zullen proberen de implementatie compact te maken, maar ook leesbaar en begrijpelijk te houden. Specifiek de belangrijkste punten:
- Noise Mapping Network
- Adaptive Instance Normalization (AdaIN)
- Progressieve groei
In deze tutorial zullen we alleen afbeeldingen genereren met StyleGAN1, en geen style mixing en stochastische variatie implementeren, maar dat zou niet moeilijk moeten zijn.
Laten we een variabele definiëren met de naam factors die de getallen bevatten die vermenigvuldigd moeten worden met IN_CHANNELS om het aantal kanalen te verkrijgen dat we in elke afbeeldingsresolutie willen.
Noise Mapping Network
Het geluidsmappingnetwerk neemt Z en voert het door acht volledig verbonden lagen, gescheiden door een activatie, en vergeet niet het leerrendement te egaliseren zoals de auteurs dat doen in ProGAN (ProGAN en StyleGan, geschreven door dezelfde onderzoekers).
Laten we eerst een klasse bouwen met de naam WSLinear (gewogen geschaalde Lineair) die wordt afgeleid van nn.Module.
- In het init-gedeelte sturen we in_features en out_channels door. We maken een lineaire laag, definiëren vervolgens een schaal die gelijk is aan de vierkantswortel van 2 gedeeld door in_features, kopiëren de bias van de huidige kolomlaag naar een variabele omdat we de bias van de lineaire laag niet willen schalen, verwijderen we deze vervolgens en initialiseren we de lineaire laag.
- In het forward-gedeelte sturen we x door en alles wat we gaan doen is x vermenigvuldigen met scale en de bias toevoegen nadat deze is herschikt.
Laten we nu de MappingNetwork-klasse maken.
- In het init-gedeelte sturen we z_dim en w_din door, en we definiëren het netwerk mapping dat eerst z_dim normaliseert, gevolgd door acht WSLInear en ReLU als activatiefuncties.
- In het forward-gedeelte retourneren we het netwerk mapping.
Adaptieve Instance Normalisatie (AdaIN)
Laten we nu de AdaIN-klasse maken.
- In de init-deel sturen we kanalen, w_dim, en we initialiseren instance_norm die het deel voor instance normalisatie zal zijn, en we initialiseren style_scale en style_bias die de adaptieve delen zullen zijn met WSLinear die de Noise Mapping Network W naar kanalen mapt.
- In de forward-doorvoer sturen we x, passen we instance normalization toe ervoor, en retourneren we style_sclate * x + style_bias.
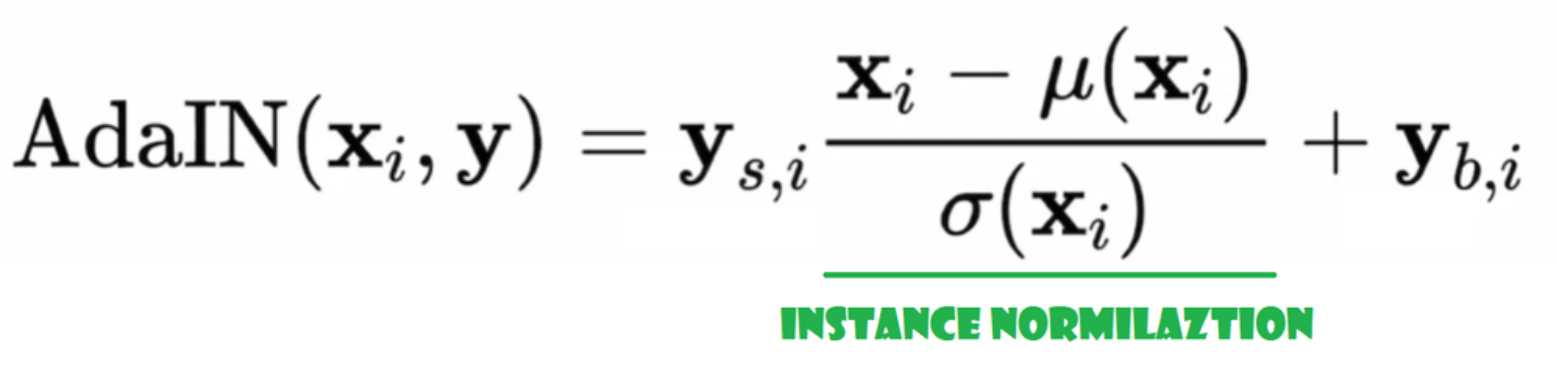
Inject Noise
Laten we nu de klasse InjectNoise maken om ruis in de generator in te voegen
- In het init-deel stuurden we kanalen en we initialiseren het gewicht uit een willekeurige normale verdeling en we gebruiken nn.Parameter zodat deze gewichten geoptimaliseerd kunnen worden
- In de forward-deel sturen we een afbeelding x en we retourneren het met toegevoegde willekeurige ruis
helpful classes
De auteurs bouwen StyleGAN op de officiële implementatie van ProGAN door Karras et al, ze gebruiken dezelfde discriminatorarchitectuur, adaptieve minibatch-grootte, hyperparameters, etc. Dus er zijn veel klassen die hetzelfde blijven van de ProGAN-implementatie.
In dit gedeelte zullen we de klassen maken die niet veranderen van de ProGAN-architectuur.
In de onderstaande codefragment kunt u de klasse WSConv2d (gegewogen geschaalde convolutielaag) vinden voor Equalized Learning Rate voor de conv lagen.
In de onderstaande codefragment kunt u de klasse PixelNorm vinden om Z te normaliseren voor de Noise Mapping Network.
In de onderstaande codefragment kunt u de klasse ConvBock vinden die ons zal helpen de discriminator te maken.
In de onderstaande codefragment kunt u de klasse Discriminatowich vinden die hetzelfde is als in ProGAN.
Generator
In de generatorarchitectuur hebben we enkele patronen die zich herhalen, dus laten we eerst een klasse maken voor het zo proper mogelijke code, laten we de klasse GenBlock noemen die wordt afgeleid van nn.Module.
- In het init-gedeelte sturen we in_channels, out_channels en w_dim door, dan initialiseren we conv1 met WSConv2d die in_channels naar out_channels mapt, conv2 met WSConv2d die out_channels naar out_channels mapt, leaky met Leaky ReLU met een helling van 0.2 zoals ze dat in het paper gebruiken, inject_noise1 en inject_noise2 met InjectNoise, adain1 en adain2 met AdaIN.
- In het forward-gedeelte sturen we x door en we passen het toe op conv1 dan op inject_noise1 met leaky, dan normaliseren we het met adain1, en weer passen we dat toe op conv2 dan op inject_noise2 met leaky en we normaliseren het met adain2. En tenslotte geven we x terug.
Nu hebben we alles wat we nodig hebben om de generator te maken.
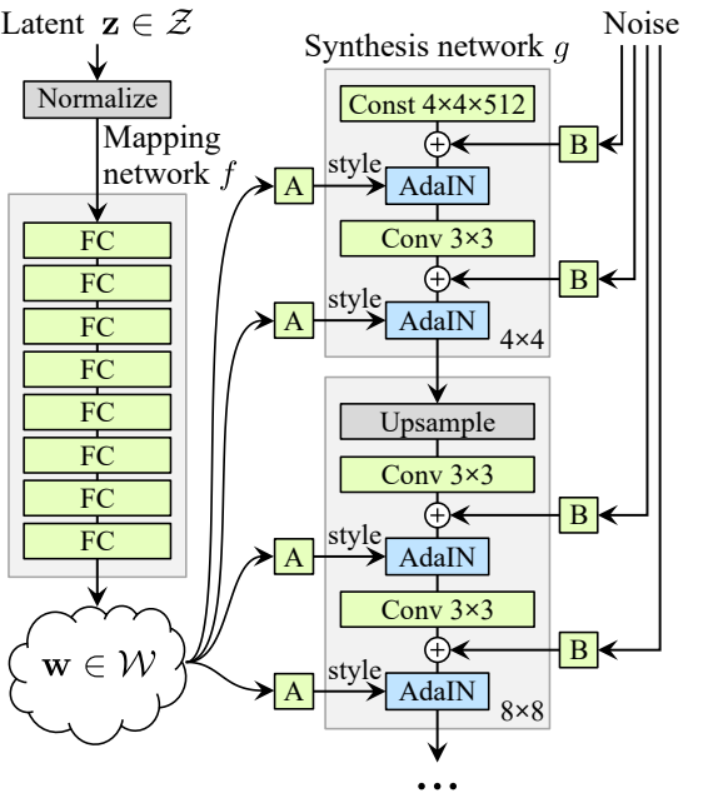
- in het init gedeelte initialiseren we ‘starting_constant’ door een constante 4 x 4 (x 512 kanalen voor het originele paper, en 256 in ons geval) tensor die door een iteratie van de generator wordt gestuurd, gemapt door ‘MappingNetwork’, initial_adain1, initial_adain2 door AdaIN, initial_noise1, initial_noise2 door InjectNoise, initial_conv door een conv laag die in_channels naar zichzelf mapt, leaky door Leaky ReLU met een helling van 0.2, initial_rgb door WSConv2d die in_channels naar img_channels mapt wat 3 is voor RGB, prog_blocks door ModuleList() die alle progressieve blokken zal bevatten (we geven convolutie invoer/uitvoer kanalen aan door in_channels te vermenigvuldigen wat 512 is in het paper en 256 in ons geval met factoren), en rgb_blocks door ModuleList() die alle RGB blokken zal bevatten.
- Om nieuwe lagen in te faden (een oorspronkelijke component van ProGAN), voegen we het fade_in gedeelte toe, waarin we alpha, scaled, en gegenereerd sturen, en we retourneren [tanh(alpha∗gegenereerd+(1−alpha)∗opschaal)], De reden dat we tanh gebruiken is dat dit de uitvoer (het gegenereerde beeld) zal zijn en we willen dat de pixels in het bereik tussen 1 en -1 liggen.
- In de voorwaartse deel, sturen we het geluid (Z_dim), de alpha-waarde die langzaam fade-in zal gaan tijdens de training (alpha ligt tussen 0 en 1), en stappen die het nummer van de huidige resolutie is waar we mee werken, we voeren x door de kaart om de tussenliggende ruisvector W te krijgen, we voeren starting_constant door initial_noise1, passen het toe en voor W initial_adain1, vervolgens voeren we het door initial_conv, en weer voegen we initial_noise2 toe voor het met leaky als activatiefunctie, en passen het toe en W initial_adain2. Dan controleren we of stappen = 0, als dat zo is, dan willen we alleen maar door de initial RGB laten lopen en dat is het, anders, we lopen over het aantal stappen, en in elke lus schalen we op (upscaled) en we lopen door het progressieve blok dat overeenkomt met die resolutie (out). Aan het einde, retourneren we fade_in dat alpha, final_out, en final_upscaled neemt na het mappen naar RGB.
Utils
In de onderstaande code snippet kun je de functie generate_examples vinden die de generator gen, het aantal stappen om de huidige resolutie te identificeren, en een getal n=100 accepteert. Het doel van deze functie is om n nepafbeeldingen te genereren en deze op te slaan als resultaat.
In de onderstaande code snippet kun je de gradient_penalty functie voor WGAN-GP verlies vinden.
Train functie
Voor de train functie sturen we de critic (wat de discriminator is), gen(generator), loader, dataset, stap, alpha, en optimizer voor de generator en voor de critic.
We beginnen met het doorlopen van alle mini-batch groottes die we maken met de DataLoader, en we nemen alleen de afbeeldingen omdat we geen label nodig hebben.
Daarna stellen we de training voor de discriminator\Critic in when we want to maximize E(critic(real)) – E(critic(fake)). Deze vergelijking betekent hoeveel de critic kan onderscheiden tussen echte en nepafbeeldingen.
Daarna stellen we de training in voor de generator wanneer we E(critic(fake)).
uiteindelijk de lus bijwerken en de alpha-waarde voor fade_in bijstellen en ervoor zorgen dat deze tussen 0 en 1 ligt, en deze retourneren.
Training
Nu we alles hebben, laten we het samenstellen om onze StyleGAN te trainen.
We beginnen met het initialiseren van de generator, de discriminator/critic en de optimizers, zetten de generator en de critic in train-modus, en lopen vervolgens over PROGRESSIVE_EPOCHS, en in elke lus roepen we het trainingsfunctie het aantal keren dat het aantal epochs is, vervolgens genereren we wat nepafbeeldingen en slaan deze op als resultaat met behulp van de generate_examples-functie, en tenslotte gaan we naar de volgende afbeeldingsresolutie.
Resultaat
Hopelijk kun je alle stappen volgen en een goed begrip krijgen van hoe je StyleGAN op de juiste manier kunt implementeren. Laten we nu de resultaten bekijken die we verkrijgen na het trainen van dit model in deze dataset met een resolutie van 128*x 128.

Conclusie
In dit artikel maken we een schone, eenvoudige en leesbare implementatie van StyleGAN1 vanaf nul met behulp van PyTorch. We repliceren het originele paper zo dicht mogelijk, dus als je het paper leest, zou de implementatie vrijwel identiek moeten zijn.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch