













Introduzione
Questo articolo riguarda uno dei migliori GAN oggi disponibili, StyleGAN, tratta dal paper Una Architettura Generatrice Basata sullo Stile per Reti Adversariali Generative, realizzeremo un’implementazione pulita, semplice e leggibile utilizzando PyTorch, cercando di replicare il più possibile il paper originale, quindi se avete letto il paper, l’implementazione dovrebbe essere praticamente identica.
Il dataset che utilizzeremo in questo blog è questo dataset da Kaggle che contiene 16240 capi d’abbigliamento superiori per donne con risoluzione 256*192.
Prerequisiti
Prima di immergervi nel lavoro con StyleGAN utilizzando PyTorch, assicuratevi di avere i seguenti prerequisiti:
-
Conoscenze di Base sull’Apprendimento Profondo
Comprensione delle reti neurali convoluzionali (CNN).
Familiarità con le Reti Adversariali Generative (GAN), inclusi concetti come il generatore, il discriminatore e la perdita avversaria. -
Requisiti Hardware
Una GPU potente (raccomandata NVIDIA) per una formazione e un’inferenza più rapide.
CUDA toolkit installato per l’accelerazione GPU (cudaecudnn). -
Familiarità con StyleGAN
È utile aver letto i documenti originali di StyleGAN o StyleGAN2 per comprendere i miglioramenti dell’architettura e i concetti chiave.
Caricare tutte le dipendenze di cui abbiamo bisogno
Prima importeremo torch dato che utilizzeremo PyTorch, e da lì importeremo nn. Questo ci aiuterà a creare e addestrare le reti, e ci permetterà anche di importare optim, un pacchetto che implements vari algoritmi di ottimizzazione (ad esempio sgd, adam,…). Da torchvision importeremo datasets e transforms per preparare i dati e applicare alcune trasformazioni.
Importeremo functional come F da torch.nn per upsample le immagini utilizzando interpolate, DataLoader da torch.utils.data per creare dimensioni di mini-lotti, save_image da torchvision.utils per salvare alcuni campioni falsi, e log2 da math perché abbiamo bisogno della rappresentazione inversa della potenza di 2 per implementare la dimensione di mini-lotto adattiva a seconda della risoluzione di output, NumPy per algebra lineare, os per l’interazione con il sistema operativo, tqdm per mostrare le barre di avanzamento, e infine matplotlib.pyplot per mostrare i risultati e confrontarli con quelli reali.
Iperparametri
- Inizializziamo il DATASET con il percorso delle immagini reali.
- Specificiamo l’inizio del train alle dimensioni di immagine 8×8.
- Inizializziamo il device con Cuda se disponibile e CPU altrimenti, e il tasso di apprendimento a 0.001.
- La dimensione del batch sarà diversa a seconda della risoluzione delle immagini che vogliamo generare, quindi inizializziamo BATCH_SIZES con una lista di numeri, puoi cambiarli a seconda della tua VRAM.
- Inizializziamo image_size a 128 e CHANNELS_IMG a 3 perché genereremo immagini RGB di 128 per 128.
- Nel paper originale, inizializzano Z_DIM, W_DIM e IN_CHANNELS a 512, ma io li inizializzo a 256 invece per un minor utilizzo della VRAM e per accelerare l’addestramento. Potremmo forse ottenere risultati migliori se li raddoppiassimo.
- Per StyleGAN possiamo utilizzare qualsiasi funzione di perdita GAN che vogliamo, quindi utilizzo WGAN-GP dal paper Improved Training of Wasserstein GANs. Questa perdita contiene un parametro chiamato λ e è comune impostare λ = 10.
- Inizializzare PROGRESSIVE_EPOCHS a 30 per ogni dimensione di immagine.
Ottieni il data loader
Ora creiamo una funzione get_loader per:
- Applicare alcune trasformazioni alle immagini (ridimensionare le immagini alla risoluzione che vogliamo, convertire in tensori, poi applicare alcune augmentazioni e infine normalizzare i pixel per essere tutti compresi tra -1 e 1).
- Identificare la dimensione corrente del batch utilizzando la lista BATCH_SIZES, e prendere come indice il numero intero della rappresentazione inversa della potenza di 2 della dimensione dell’immagine/4. Ed è esattamente così che implementiamo la dimensione del minibatch adattiva in base alla risoluzione di output.
- Preparare il dataset utilizzando ImageFolder perché è già strutturato in modo gradevole.
- Creare dimensioni di mini-lotti utilizzando DataLoader che prendono il dataset e la dimensione del lotto con la mescolatura dei dati.
- Infine, restituire il carico e il dataset.
Implementazione dei modelli
Adesso implementiamo il generatore e il discriminatore StyleGAN1 (ProGAN e StyleGAN1 hanno la stessa architettura del discriminatore) con le attribuzioni chiave del paper. Cercheremo di rendere l’implementazione compatta ma anche leggibile e comprensibile. In particolare, i punti chiave:
- Rete di Mappatura del Rumore
- Normalizzazione Adattiva dell’istanza (AdaIN)
- Crescita progressiva
In questo tutorial, genereremo solo immagini con StyleGAN1, senza implementare il mixing dello stile e la variazione stocastica, ma non dovrebbe essere difficile farlo.
Definiamo una variabile con il nome factors che contiene i numeri che moltiplicheranno IN_CHANNELS per ottenere il numero di canali che vogliamo in ogni risoluzione di immagine.
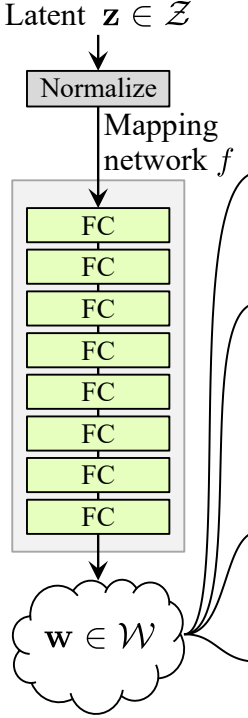
Rete di Mappatura del Rumore
La rete di mappatura del rumore prende Z e lo passa attraverso otto strati completamente connessi separati dasome attivazione. E non dimenticare di equalizzare il tasso di apprendimento come fanno gli autori in ProGAN (ProGAN e StyleGan scritti dagli stessi ricercatori).
Lasciamo innanzitutto costruire una classe con il nome WSLinear (weighted scaled Linear) che verrà ereditata da nn.Module.
- Nella parte init inviamo in_features e out_channels. Creiamo un livello lineare, poi definiamo una scala che sarà uguale alla radice quadrata di 2 diviso in_features, copiamo il bias della colonna corrente in una variabile perché non vogliamo che il bias del livello lineare sia scalato, poi lo rimuoviamo, infine inizializziamo il livello lineare.
- Nella parte forward, inviamo x e tutto ciò che faremo è moltiplicare x per scale e aggiungere il bias dopo averlo ridefinito.
Ora creiamo la classe MappingNetwork.
- Nella parte init inviamo z_dim e w_din, e definiamo la rete di mappatura che prima normalizza z_dim, seguita da otto WSLInear e ReLU come funzioni di attivazione.
- Nella parte forward, restituiamo la mappatura della rete.
Adaptive Instance Normalization (AdaIN)
Ora creiamo la classe AdaIN
- Nella parte init inviamo canali, w_dim e inizializziamo instance_norm che sarà la parte di normalizzazione dell’istanza, e inizializziamo style_scale e style_bias che saranno le parti adattive con WSLinear che mappa il Noise Mapping Network W nei canali.
- Nella parte forward inviamo x, applichiamo la normalizzazione dell’istanza e restituiamo style_sclate * x + style_bias.
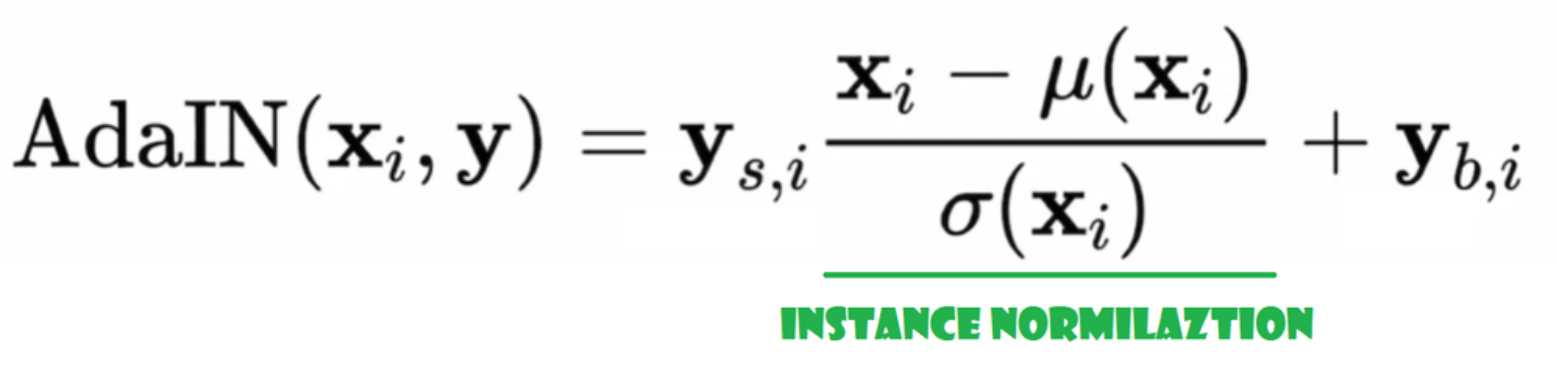
Inject Noise
Ora creiamo la classe InjectNoise per iniettare il rumore nel generatore
- Nella parte init abbiamo inviato canali e inizializziamo il peso da una distribuzione normale casuale e utilizziamo nn.Parameter in modo che questi pesi possano essere ottimizzati
- Nella parte forward inviamo un’immagine x e la restituiamo con rumore casuale aggiunto
classi utili
Gli autori costruiscono StyleGAN sull’implementazione ufficiale di ProGAN di Karras et al, utilizzano la stessa architettura del discriminatore, dimensione adattiva del minibatch, iperparametri, ecc. Quindi ci sono molte classi che rimangono le stesse dall’implementazione di ProGAN.
In questa sezione, creeremo le classi che non cambiano dall’architettura ProGAN.
Nel seguente frammento di codice puoi trovare la classe WSConv2d (strato convoluzionale con pesi scalati) per Equalized Learning Rate per gli strati convoluzionali.
Nel seguente frammento di codice puoi trovare la classe PixelNorm per normalizzare Z prima della Rete di Mappatura del Rumore.
Nel seguente frammento di codice puoi trovare la classe ConvBlock che ci aiuterà a creare il discriminante.
Nel seguente frammento di codice puoi trovare la classe Discriminatowhich è la stessa di quella in ProGAN.
Generatore
Nell’architettura del generatore, abbiamo alcuni schemi che si ripetono, quindi creiamo innanzitutto una classe per rendere il nostro codice il più pulito possibile; chiamiamo la classe GenBlock che sarà ereditata da nn.Module.
- Nella parte init inviamo in_channels, out_channels e w_dim, poi inizializziamo conv1 da WSConv2d che mappa in_channels in out_channels, conv2 da WSConv2d che mappa out_channels in out_channels, leaky da Leaky ReLU con una pendenza di 0.2 come usano nel paper, e poi la classe GenBlock.2 come nel documento, inject_noise1, inject_noise2 da InjectNoise, adain1 e adain2 da AdaIN
- Nella parte forward, inviamo x, lo passiamo a conv1 e poi a inject_noise1 con leaky, quindi lo normalizziamo con adain1, e di nuovo lo passiamo a conv2 e poi a inject_noise2 con leaky e lo normalizziamo con adain2. Infine, restituiamo x.
Ora abbiamo tutto ciò che ci serve per creare il generatore.
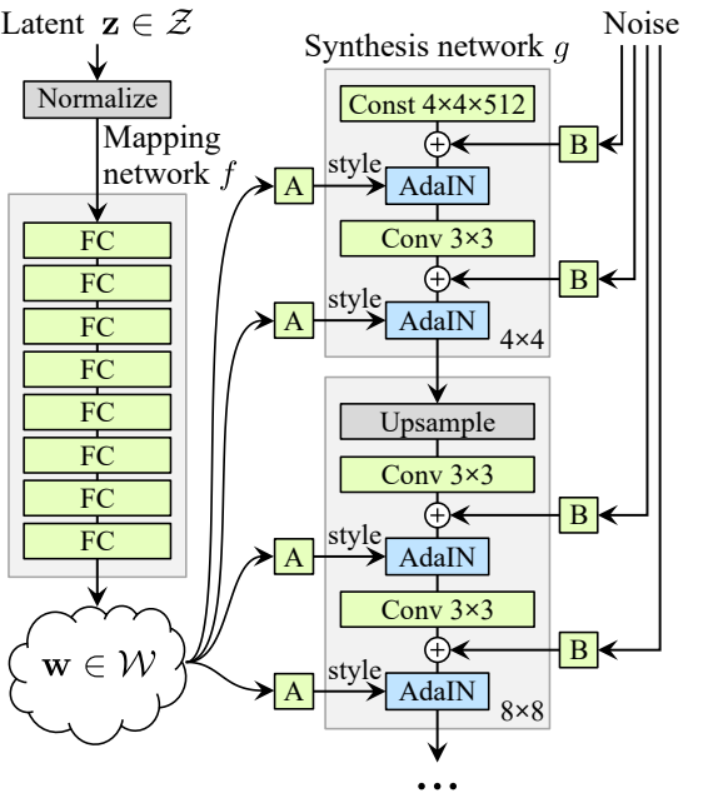
- nella parte init iniziamo ‘starting_constant’ con un tensore costante 4 x 4 (x 512 canali per il paper originale, e 256 nel nostro caso) che viene mandato attraverso un’iterazione del generatore, mappato da ‘MappingNetwork’, initial_adain1, initial_adain2 da AdaIN, initial_noise1, initial_noise2 da InjectNoise, initial_conv da un livello convoluzionale che mappa in_channels a se stesso, leaky da Leaky ReLU con una pendenza di 0.2, initial_rgb da WSConv2d che mappa in_channels a img_channels che è 3 per RGB, prog_blocks da ModuleList() che conterrà tutti i blocchi progressivi (indicando i canali di input/output della convoluzione moltiplicando in_channels che è 512 nel paper e 256 nel nostro caso per i fattori), e rgb_blocks da ModuleList() che conterrà tutti i blocchi RGB.
- Per sfumare nuovi livelli (un componente originale di ProGAN), aggiungiamo la parte fade_in, alla quale mandiamo alpha, scaled e generated, e restituiamo [tanh(alpha∗generated+(1−alpha)∗upscale)], La ragione per cui usiamo tanh è che sarà l’output (l’immagine generata) e vogliamo che i pixel siano nel range tra 1 e -1.
- Nella parte in avanti, inviamo il rumore (Z_dim), il valore alpha che si dissolverà gradualmente durante l’addestramento (alpha è compreso tra 0 e 1), e steps che è il numero della risoluzione corrente con cui stiamo lavorando, passiamo x nella mappa per ottenere il vettore di rumore intermedio W, passiamo starting_constant a initial_noise1, applichiamo both e per W initial_adain1, poi lo passiamo in initial_conv, e di nuovo aggiungiamo initial_noise2 per esso con leaky come funzione di attivazione, e applichiamo both e W initial_adain2. Poi controlliamo se steps = 0, se lo è, tutto quello che vogliamo fare è farlo scorrere attraverso l’initial RGB e abbiamo finito, altrimenti, iteriamo sul numero di passaggi, e in ogni ciclo eseguiamo l’upscaling(upscaled) e lo facciamo scorrere attraverso il blocco progressivo che corrisponde a quella risoluzione(out). Alla fine, restituiamo fade_in che prende alpha, final_out, e final_upscaled dopo averlo mappato a RGB.
Utils
Nella seguente porzione di codice puoi trovare la funzione generate_examples che accetta il generatore gen, il numero di passaggi per identificare la risoluzione corrente e un numero n=100. L’obiettivo di questa funzione è generare n immagini fake e salvarle come risultato.
Nella seguente porzione di codice puoi trovare la funzione gradient_penalty per la perdita WGAN-GP.
Funzione di addestramento
Per la funzione di addestramento, inviamo il critico (che è il discriminatore), gen (il generatore), il loader, il dataset, il passo, alpha e l’ottimizzatore per il generatore e per il critico.
Iniziamo ciclando su tutte le dimensioni dei mini-lotti che creiamo con il DataLoader, e prendiamo solo le immagini perché non ci serve un’etichetta.
Poi impostiamo l’addestramento per il discriminatore\Critico quando vogliamo massimizzare E(critico(reale)) – E(critico(falso)). Questa equazione significa quanto il critico riesce a distinguere tra immagini reali e fake.
Dopo đó, impostiamo l’addestramento per il generatore quando vogliamo massimizzare E(critic(fake)).
Infine, aggiorniamo il ciclo e il valore alpha per fade_in e ci assicuriamo che sia compreso tra 0 e 1, e lo restituiamo.
Addestramento
Ora che abbiamo tutto, mettiamo tutto insieme per addestrare il nostro StyleGAN.
Iniziamo initializing il generatore, il discriminatore/critico e gli ottimizzatori, poi convertiamo il generatore e il critico in modalità addestramento, quindi iteriamo su PROGRESSIVE_EPOCHS e in ogni ciclo chiamiamo la funzione di addestramento un numero di volte uguale alle epoche, poi generiamo alcune immagini false e le salviamo, come risultato, utilizzando la funzione generate_examples, e infine passiamo alla risoluzione dell’immagine successiva.
Risultato
Spero che tu possa seguire tutti i passaggi e ottenere una buona comprensione di come implementare StyleGAN nel modo corretto. Ora vediamo i risultati che otteniamo dopo aver addestrato questo modello su questo dataset con risoluzione 128*x 128.

Conclusione
In questo articolo, abbiamo realizzato un’implementazione pulita, semplice e leggibile da zero di StyleGAN1 utilizzando PyTorch. Abbiamo replicato il paper originale il più possibile, quindi se leggi il paper l’implementazione dovrebbe essere praticamente identica.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch