













הקדמה
מאמר זה עוסק באחד מהרשתות GAN הטובות ביותר כיום, StyleGAN, מתוך המאמר ארכיטקטורת יוצר מושכת מבוססת סגנון עבור רשתות יוצר-יריב, נעשה המימוש הנקי, הגולמי והקריא שלו באמצעות PyTorch, וננסה לשחזר את המאמר המקורי ככל האפשר, אז אם קראתם את המאמר, היישום צריך להיות כמעט זהה.
אוסף הנתונים שנשתמש בו בבלוג זה הוא אוסף הנתונים מ-Kaggle שמכיל 16,240 בגדי עליונים לנשים ברזולוציה של 256*192.
דרישות מוקדמות
לפני שתתחילו לעבוד עם StyleGAN באמצעות PyTorch, ודאו שיש לכם את הדרישות הבאות:
-
ידע בסיסי בלמידה עמוקה
הבנה של רשתות נוירונים קונבולוציוניות (CNNs).
אינטימיות עם רשתות יוצר-יריב (GANs), כולל תפיסות כמו היוצר, התוקף ואובדן היריב. -
דרישות חומרה
GPU חזק (מומלץ NVIDIA) לאימון מהיר יותר ולהפעלה.
התקנת ערכת הכלים CUDA להאצת GPU (cudaו-cudnn). -
ידיעה של StyleGAN
זה יכול לעזור לקרוא את המאמרים המקוריים של StyleGAN או StyleGAN2 כדי להבין שיפורים בארכיטקטורה ומושגים מרכזיים.
טעינת כל התלויות הנחוצות לנו
ראשית נכניס את torch מכיוון שנשתמש ב PyTorch, ומשם נכניס nn. זה יעזור לנו ליצור ולאמן את הרשתות, וגם יאפשר לנו לכניס את optim, חבילה שמיישם אלגוריתמים שונים של אופטימיזציה (למשל sgd, adam,…). מ-torchvision נכניס datasets ו-transforms כדי להכין את הנתונים ולהחיל כמה שינויים.
נכניס functional כ-F מתוך torch.nn כדי להגדיל את התמונות באמצעות interpolate, DataLoader מתוך torch.utils.data כדי ליצור גודל חלקים קטנים, save_image מתוך torchvision.utils כדי לשמור כמה דוגמאות מזויפות, ו-log2 מתוך math כי אנחנו צריכים את הייצוג ההפוך של כח ה-2 כדי ליישם גודל חלקים אדפטיבי תלוי ברזולוציה של התוצאה, NumPy לאלגברה לינארית, os לאינטראקציה עם המערכת האופרטיבית, tqdm כדי להראות חזרות קדימה, ולבסוף matplotlib.pyplot כדי להראות את התוצאות ולהשוות אותם לאמיתיים.
מקדמים היפר
- להתחיל את ה-DATASET על ידי הנתיב של התמונות האמיתיות.
- לציין את ההתחלה של האימון בגודל תמונה 8×8.
- להתחיל את המכשיר על ידי Cuda אם זה זמין ואם לא CPU, ואת שיעור הלמידה ב-0.001.
- גודל החלק היה שונה בהתאם לרזולוציה של התמונות שאנחנו רוצים ליצור, אז אנחנו מתחילים את BATCH_SIZES על ידי רשימה של מספרים, אתה יכול לשנות אותם בהתאם ל-VRAM שלך.
- להתחיל את image_size ב-128 ו-CHANNELS_IMG ב-3 כי אנחנו ניצור תמונות RGB בגודל 128 על 128.
- במאמר המקורי, הם מתאימים את Z_DIM, W_DIM ו-IN_CHANNELS ל-512, אבל אני מתאים אותם ל-256 במקום, כדי להקטין את שימוש ב-VRAM ולהאיץ את האימון. ייתכן שאפילו נוכל להשיג תוצאות טובות יותר אם נכפיל אותם.
- ל-StyleGAN אנחנו יכולים להשתמש בכל פונקציית אובדן של GAN שנרצה, אז אני משתמש ב-WGAN-GP מהמאמר Improved Training of Wasserstein GANs. פונקציית האובדן הזו מכילה פרמטר בשם λ וזה נפוץ להגדיר λ = 10.
- תאים את PROGRESSIVE_EPOCHS ל-30 עבור כל גודל של תמונה.
השג טוען מידע
עכשיו בואו ניצור פונקציה get_loader כדי:
- להחיל שינויים על התמונות (לשנות את גודל התמונות לרזולוציה שאנחנו רוצים, להמיר אותן לטנסורים, לאפיין עליהן שינויים, ולבסוף לנורמל אותן כך שכל הפיקסלים ינועו בין -1 ל-1).
- לזהות את גודל המערך הנוכחי באמצעות הרשימה BATCH_SIZES, ולקחת כאינדקס את המספר השלם של הייצוג ההפוך של כוח 2 של image_size/4. וזו למעשה הדרך שבה אנחנו מיישמים את גודל המיניבאטץ' האדפטיבי התלוי ברזולוציית היצוא.
- להכין את המערכת באמצעות ImageFolder כי היא כבר מאורגנת בדרך נחמדה.
- יצור גודל מיני-לוחית באמצעות DataLoader שלוקח את המערכת וגודל הלוחית עם ערבוב הנתונים.
- לבסוף, חזיר את הטעינה והמערכת.
ישום מודלים
עכשיו באומץ ליישם את היוצר והמבחן של StyleGAN1 (לProGAN ולStyleGAN1 יש אותו חיזוק של המבחן) עם התכונות המרכזיות מהמאמר. ננסה לעשות את היישום קומפקטי אבל גם לשמור על קריאות והבנה. במיוחד, הנקודות המרכזיות:
- רשת מיפוי רעש
- נורמליזציה מותאמת למשתנים (AdaIN)
- גידול הדרגתי
במדריך זה, נוכל ליצור תמונות עם StyleGAN1, ולא ליישם עירבוב סגנון ושינוי סטוכסטי, אבל זה לא יהיה קשה לעשות זאת.
בוא נגדיר משתנה עם השם factors שיכיל את המספרים שיכפילו את IN_CHANNELS כדי לקבל את מספר הערוצים שנרצה בכל רזולוציה של התמונה.
רשת מיפוי רעש
הרשת המיפוי של הרעש לוקחת את Z ושמה אותו דרך שמונה שכבות מחוברות לחלוטין, שמופרדות על ידי פעילות כלשהי. ולא לשכוח להשוות את שיעור הלמידה כמו שעושים המחברים ב-ProGAN (ProGAN ו-StyleGan שנכתבו על ידי אותם חוקרים).
בואו קודם כל נבנה כיתה בשם WSLinear (רמת קווית משוקללת ומופחתת) שתורשה מ- nn.Module.
- בחלק init אנחנו שולחים in_features ו-out_channels. יוצרים שכבת קווית, אז אנחנו מגדירים קנה מידה שיהיה שווה לשורש ריבועי של 2 חלקי in_features, אנחנו מעתיקים את הביאס של העמודה הנוכחית למשתנה מכיוון שאנחנו לא רוצים שהביאס של השכבה הקווית יהיה מופחת, אז אנחנו מסירים אותו, ולבסוף אנחנו מאתחלים את שכבת הקווית.
- בחלק forward, אנחנו שולחים x וכל מה שאנחנו הולכים לעשות זה להכפיל את x עם קנה המידה ולהוסיף את הביאס לאחר הצורה משונה.
עכשיו בואו ניצור את כיתת MappingNetwork.
- בחלק init אנחנו שולחים z_dim ו-w_din, ואנחנו מגדירים את רשת המיפוי שראשית נורמלית את z_dim, ואז בואר שמונה WSLInear ו- ReLU כפעילויות.
- בחלק forward, אנחנו מחזירים את רשת המיפוי.
נורמליזציה מותאמת מקרה (AdaIN)
עכשיו בואו ניצור את כיתת AdaIN
- בחלק הinit אנחנו שולחים ערוצים, w_dim, ואנחנו מאתחלים את instance_norm שיהיה חלק הנורמליזציה למשתנה, ואנחנו מאתחלים את style_scale ו-style_bias שיהיו החלקים המתאימים עם WSLinear שממפה את רשת Noise Mapping Network W לערוצים.
- בשלב הforward אנחנו שולחים x, מיישם נורמליזציה למשתנה עבורו, ומחזירים style_sclate * x + style_bias.
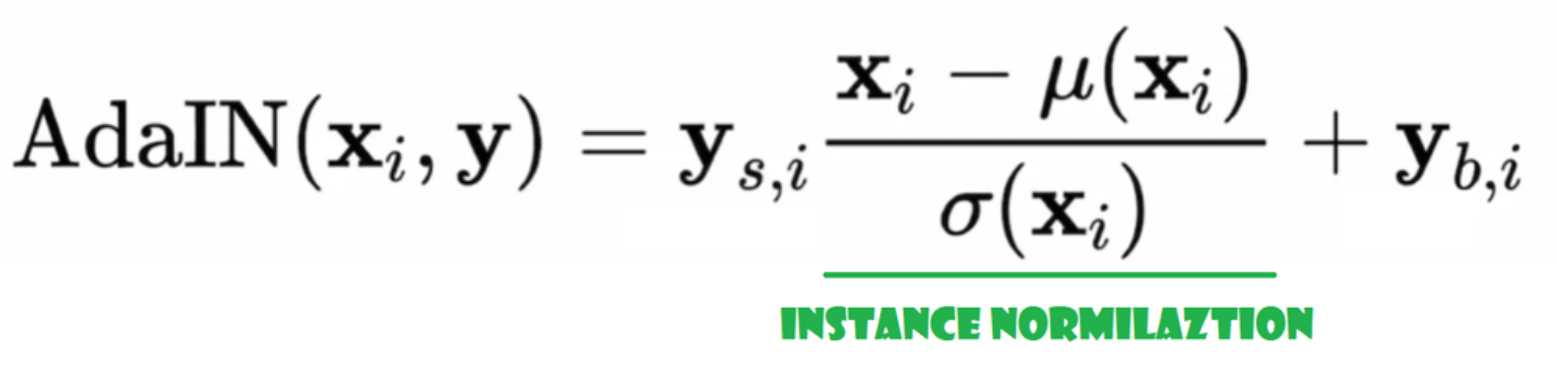
הזרקת רעש
עכשיו בוא ניצור את הכיתה InjectNoise להזרקת הרעש ליצרן
- בחלק הinit שלחנו ערוצים ואנחנו מאתחלים משקל מתוך התפלגות נורמל רנדומית ואנחנו משתמשים ב-nn.Parameter כדי שהמשקלים הללו יוכלו להיות מופיעים
- בשלב הforward אנחנו שולחים תמונה x ואנחנו מחזירים אותה עם רעש רנדומי מוסף
כיתות יעילות
המחברים בנו את StyleGAN על בסיס היישום הרשמי של ProGAN על ידי Karras ואחרים, הם משתמשים באותה ארכיטקטורת מפלט כמו ב-ProGAN, גודל מיניבאטץ' אדפטיבי, מקדמים וכו'. כך שיש הרבה כיתות שנשארות אותו דבר כמו ביישום ProGAN.
בחלק הזה, ניצור את הכיתות שלא משתנות מהארכיטקטורה של ProGAN.
בקטע הקוד למטה ניתן למצוא את הכיתה WSConv2d (שכבת קונבולוציה מוכנסת משקלים) לשוויון של קצב למידה לשכבות הקונבולוציה.
בקטע הקוד למטה ניתן למצוא את הכיתה PixelNorm לנורמליזציה של Z לפני רשת מיפוי הרעש.
בקטע הקוד למטה ניתן למצוא את הכיתה ConvBlock שתעזור לנו ליצור את המפריד.
בקטע הקוד למטה ניתן למצוא את הכיתה Discriminator שהיא זהה לזו ב-ProGAN.
גנרטור
בארכיטקטורת הגנרטור, יש לנו כמה תבניות שחוזרות, אז בואו קודם כל ניצור כיתה עבורם כדי להפוך את הקוד שלנו לנקי ככל האפשר, בואו נקרא לכיתה GenBlock שתורשה מ nn.Module.
- בחלק init אנחנו שולחים in_channels, out_channels, ו- w_dim, אז אנחנו מאתחלים את conv1 באמצעות WSConv2d שממפה in_channels ל out_channels, conv2 באמצעות WSConv2d שממפה out_channels ל out_channels, leaky באמצעות Leaky ReLU עם שיפוע של 0.2 כפי שמשתמשים בו במאמר, inject_noise1, inject_noise2 באמצעות InjectNoise, adain1, ו- adain2 באמצעות AdaIN
- בחלק forward, אנחנו שולחים x, ואנחנו עוברים אותו דרך conv1 אז ל inject_noise1 עם leaky, אז אנחנו נורמלים אותו עם adain1, ושוב אנחנו עוברים אותו דרך conv2 אז ל inject_noise2 עם leaky ואנחנו נורמלים אותו עם adain2. ולבסוף, אנחנו מחזירים x.
עכשיו יש לנו את כל מה שצריך ליצור את הגנרטור.
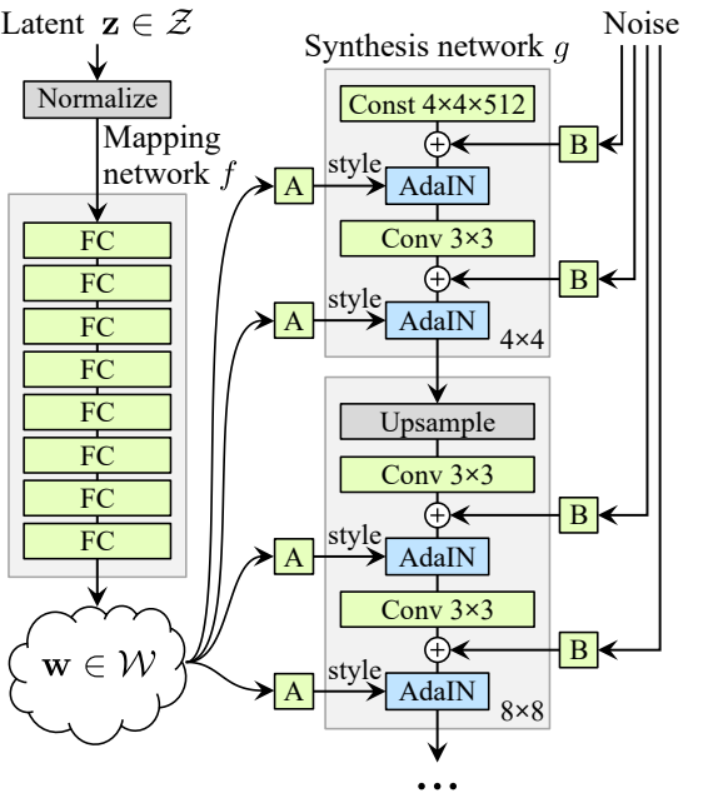
- בחלק הinit הבה נאתחל את ‘starting_constant’ על ידי טנזור קבוע של 4 x 4 (x 512 ערוצים לפי המאמר המקורי, ו-256 במקרה שלנו) שעובר סבב של המחולל, ממופה על ידי ‘MappingNetwork’, initial_adain1, initial_adain2 על ידי AdaIN, initial_noise1, initial_noise2 על ידי InjectNoise, initial_conv על ידי שכבת קונבולוציה שממפה in_channels לעצמה, leaky על ידי Leaky ReLU עם שיפוע של 0.2, initial_rgb על ידי WSConv2d שממפה in_channels ל img_channels שהוא 3 ל-RGB, prog_blocks על ידי ModuleList() שיכיל את כל הבלוקים הפרוגרסיביים (אנו מציינים את ערוצי הקלט/פלט של הקונבולוציה על ידי כפל in_channels שהוא 512 במאמר ו-256 במקרה שלנו עם גורמים), ו-rgb_blocks על ידי ModuleList() שיכיל את כל בלוקי ה-RGB.
- כדי להדהד שכבות חדשות (רכיב מקורי של ProGAN), אנו מוסיפים את חלק הfade_in, אותו אנו שולחים alpha, scaled, ו-generated, ואנו מחזירים [tanh(alpha∗generated+(1−alpha)∗upscale)], הסיבה לשימוש ב-tanh היא שזה יהיה הפלט (התמונה המיוצרת) ואנו רוצים שהפיקסלים יהיו בטווח בין 1 ל–1.
- בחלק הקדימי, אנחנו שולחים את הרעש (Z_dim), את הערך alpha שעומד להתבהר בהדרגה במהלך האימון (alpha הוא בין 0 ל1), ושלבים שהוא מספר הרזולוציה הנוכחי שאנחנו עובדים איתו, אנחנו מעבירים x למפה כדי לקבל את הוקטור הרעש הבינאמצעי W, אנחנו מעבירים starting_constant לinitial_noise1, מיישם אותו ולW initial_adain1, אז אנחנו מעבירים אותו לinitial_conv, ושוב אנחנו מוסיפים initial_noise2 לו עם leaky כתפוקת, ומיישם אותו ולW initial_adain2. אז בודקים אם steps = 0, אם כן, כל מה שאנחנו רוצים לעשות זה לרוץ אותו דרך initial RGB וסיימנו, אחרת, אנחנו חוזרים על מספר השלבים, ובכל לולאה אנחנו מגדילים (upscaled) ומריצים דרך הבלוק הפרוגרסיבי שמתאים לרזולוציה הזו (out). בסוף, אנחנו מחזירים fade_in שלוקח alpha, final_out, וfinal_upscaled אחרי שמפים אותו לRGB.
אולך
בקטע הקוד שלהלן אתה יכול למצוא את הפונקציה generate_examples שמקבלת את הגנרטור gen, מספר הצעדים לזהות את הרזולוציה הנוכחית, ומספר n=100. מטרת הפונקציה היא ליצור n תמונות מזויפות ולשמור אותן כתוצאה.
בקטע הקוד שלהלן אתה יכול למצוא את פונקציית gradient_penalty להפסד WGAN-GP.
פונקציית אימון
לפונקציית האימון, אנחנו שולחים את המבקר (שהוא האותנטיקטור), gen (הגנרטור), loader, dataset, step, alpha, ומפעלן עבור הגנרטור ועבור המבקר.
אנחנו מתחילים בללול מעל כל אוגרי המיני-לוחות שאנחנו יוצרים עם DataLoader, ואנחנו לוקחים רק את התמונות מכיוון שאנחנו לא צריכים תווית.
אז אנחנו מתקינים את האימון עבור האותנטיקטור\מבקר כאשר אנחנו רוצים למקסם E(מבקר(אמיתי)) – E(מבקר(מזויף)). המשוואה הזו אומרת כמה המבקר יכול להבחין בין תמונות אמיתיות ומזויפות.
לאחר מכן, אנחנו מגדירים את האימון עבור הגנרטור כשאנחנו רוצים למקסם E(קריטיק(מזויף)).
לבסוף, אנחנו מעדכנים את הלולאה ואת ערך האלפא עבור fade_in ומבטיחים שהוא בין 0 ל-1, ואז אנחנו מחזירים אותו.
אימון
עכשיו, בגלל שיש לנו הכל, בואו נשיל אותם יחד כדי לאמן את StyleGAN שלנו.
אנחנו מתחילים על ידי איתוח הגנרטור, המפריד/המבקר והאופטימיזרים, אז מכניסים את הגנרטור והמבקר למצב אימון, אז חוזרים על PROGRESSIVE_EPOCHS ובכל לולאה, אנחנו קוראים לפונקציית האימון מספר פעמים של האפוך, אז אנחנו מייצרים כמה תמונות מזויפות ושומרים אותן, כתוצאה, בעזרת פונקציית generate_examples, ולבסוף, אנחנו מתקדמים לרזולוציית התמונה הבאה.
תוצאה
בתקו� תוכל לעקוב אחר כל השלבים ולהבין היטב כיצד ליישם את StyleGAN בדרך הנכונה. עכשיו בואו נבדוק את התוצאות שאנחנו מקבלים אחרי אימון המודל הזה על המערכת ברזולוציה של 128*x 128.

מסקנה
במאמר הזה, אנחנו יוצרים יישום נקי, פשוט וקריא של StyleGAN1 מלמטה למעלה באמצעות PyTorch. אנחנו משכפלים את המאמר המקורי ככל שניתן, כך שאם תקרא את המאמר, היישום יהיה כמעט זהה.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch