













Introducción
Este artículo trata sobre una de las mejores GAN hoy en día, StyleGAN del artículo Una Arquitectura Generadora Basada en Estilo para Redes Adversariales Generativas, haremos una implementación limpia, sencilla y legible de la misma utilizando PyTorch, y trataremos de replicar el artículo original lo más posible, así que si lees el artículo, la implementación debería ser prácticamente idéntica.
El conjunto de datos que utilizaremos en este blog es este conjunto de datos de Kaggle que contiene 16240 prendas de ropa superior para mujeres con resolución 256*192.
Prerrequisitos
Antes de sumergirte en trabajar con StyleGAN utilizando PyTorch, asegúrate de cumplir con los siguientes prerrequisitos:
-
Conocimientos Básicos de Aprendizaje Profundo
Entendimiento de redes neuronales convolucionales (CNNs).
Familiaridad con Redes Adversariales Generativas (GANs), incluyendo conceptos como el generador, el discriminador y la pérdida adversaria. -
Requisitos de Hardware
Una GPU potente (se recomienda NVIDIA) para un entrenamiento e inferencia más rápidos.
Kit de herramientas CUDA instalado para la aceleración por GPU (cudaycudnn). -
Familiaridad con StyleGAN
Es útil haber leído los papers originales de StyleGAN o StyleGAN2 para entender las mejoras en la arquitectura y conceptos clave.
Cargar todas las dependencias que necesitamos
Primero importaremos torch ya que utilizaremos PyTorch, y desde allí importamos nn. Eso nos ayudará a crear y entrenar las redes, y también nos permitirá importar optim, un paquete que implementa varios algoritmos de optimización (por ejemplo, sgd, adam,…). Desde torchvision importamos datasets y transforms para preparar los datos y aplicar algunas transformaciones.
Importaremos functional como F desde torch.nn para upsampler las imágenes utilizando interpolate, DataLoader desde torch.utils.data para crear tamaños de mini-lotes, save_image desde torchvision.utils para guardar algunos ejemplos falsos, y log2 desde math porque necesitamos la representación inversa de la potencia de 2 para implementar el tamaño de mini-lote adaptable dependiendo de la resolución de salida, NumPy para algebra lineal, os para interactuar con el sistema operativo, tqdm para mostrar barras de progreso, y finalmente matplotlib.pyplot para mostrar los resultados y compararlos con los reales.
Hipерпarámetros
- Inicializamos el DATASET con la ruta de las imágenes reales.
- Especificamos el inicio del entrenamiento en tamaño de imagen 8×8.
- Inicializamos el dispositivo con Cuda si está disponible y CPU de lo contrario, y la tasa de aprendizaje en 0.001.
- El tamaño del lote será diferente dependiendo de la resolución de las imágenes que queramos generar, por lo que inicializamos BATCH_SIZES con una lista de números, puedes cambiarlas dependiendo de tu VRAM.
- Inicializamos image_size en 128 y CHANNELS_IMG en 3 porque generaremos imágenes RGB de 128 por 128.
- En el documento original, inicializan Z_DIM, W_DIM, y IN_CHANNELS en 512, pero yo los inicializo en 256 para reducir el uso de VRAM y acelerar el entrenamiento. Podríamos quizás obtener mejores resultados si los duplicáramos.
- Para StyleGAN podemos usar cualquiera de las funciones de pérdida de GAN que queramos, así que uso WGAN-GP del paper Improved Training of Wasserstein GANs. Esta pérdida contiene un parámetro llamado λ y es común establecer λ = 10.
- Inicializar PROGRESSIVE_EPOCHS en 30 para cada tamaño de imagen.
Obtener el cargador de datos
Ahora creemos una función get_loader para:
- Aplicar algunas transformaciones a las imágenes (redimensionar las imágenes a la resolución que queremos, convertirlas a tensores, luego aplicar algunas aumentaciones, y finalmente normalizarlas para que todos los píxeles varíen de -1 a 1).
- Identificar el tamaño actual del lote utilizando la lista BATCH_SIZES, y tomar como índice el número entero de la representación inversa de la potencia de 2 del tamaño de imagen/4. Y esto es en realidad cómo implementamos el tamaño de minibatch adaptativo dependiendo de la resolución de salida.
- Preparar el conjunto de datos usando ImageFolder porque ya está estructurado de una manera adecuada.
- Crear tamaños de mini-lotes utilizando DataLoader que tomen el conjunto de datos y el tamaño de lote con mezcla de datos.
- Finalmente, devuelve el cargador y el conjunto de datos.
Implementación de modelos
Now let’s Implement the StyleGAN1 generator and discriminator(ProGAN and StyleGAN1 have the same discriminator architecture) with the key attributions from the paper. We will try to make the implementation compact but also keep it readable and understandable. Specifically, the key points:
- Red de Mapeo de Ruido
- Normalización Adaptativa de Instancia (AdaIN)
- Crecimiento Progresivo
En este tutorial, solo generaremos imágenes con StyleGAN1, y no implementaremos la mezcla de estilos y la variación estocástica, pero no debería ser difícil hacerlo.
Definamos una variable con el nombre factors que contenga los números que se multiplicarán con IN_CHANNELS para tener el número de canales que queremos en cada resolución de imagen.
Red de Mapeo de Ruido
La red de mapeo de ruido toma Z y lo hace pasar por ocho capas completamente conectadas separadas por alguna activación. Y no olvides igualar la tasa de aprendizaje como hacen los autores en ProGAN (ProGAN y StyleGan escrito por los mismos investigadores).
Vamos a construir primero una clase con el nombre WSLinear (Lineal Escalado Ponderado) que se heredará de nn.Module.
- En la parte init enviamos in_features y out_channels. Creamos una capa lineal, luego definimos una escala que será igual a la raíz cuadrada de 2 dividida por in_features, copiamos el sesgo de la capa actual en una variable porque no queremos que el sesgo de la capa lineal sea escalado, luego lo quitamos, finalmente, inicializamos la capa lineal.
- En la parte forward, enviamos x y todo lo que vamos a hacer es multiplicar x con la escala y agregar el sesgo después de deformarlo.
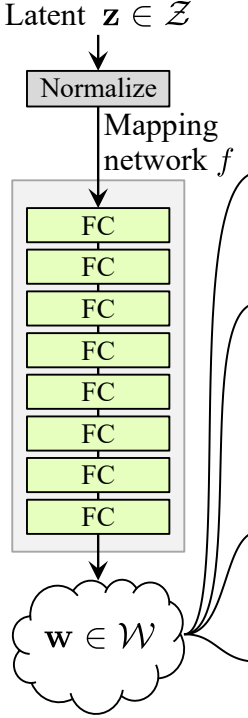
Ahora creemos la clase MappingNetwork.
- En la parte init enviamos z_dim y w_din, y definimos la red de mapeo que primero normaliza z_dim, seguido de ocho WSLInear y ReLU como funciones de activación.
- En la parte forward, devolvemos la red de mapeo.
Normalización Adaptativa de Instancia (AdaIN)
Ahora creemos la clase AdaIN
- En la parte init enviamos canales, w_dim, y inicializamos instance_norm que será la parte de normalización de instancia, y también inicializamos style_scale y style_bias que serán las partes adaptables con WSLinear que mapea la Red de Mapeo de Ruido W en canales.
- En la pasada forward, enviamos x, aplicamos la normalización de instancia para él, y devolvemos style_sclate * x + style_bias.
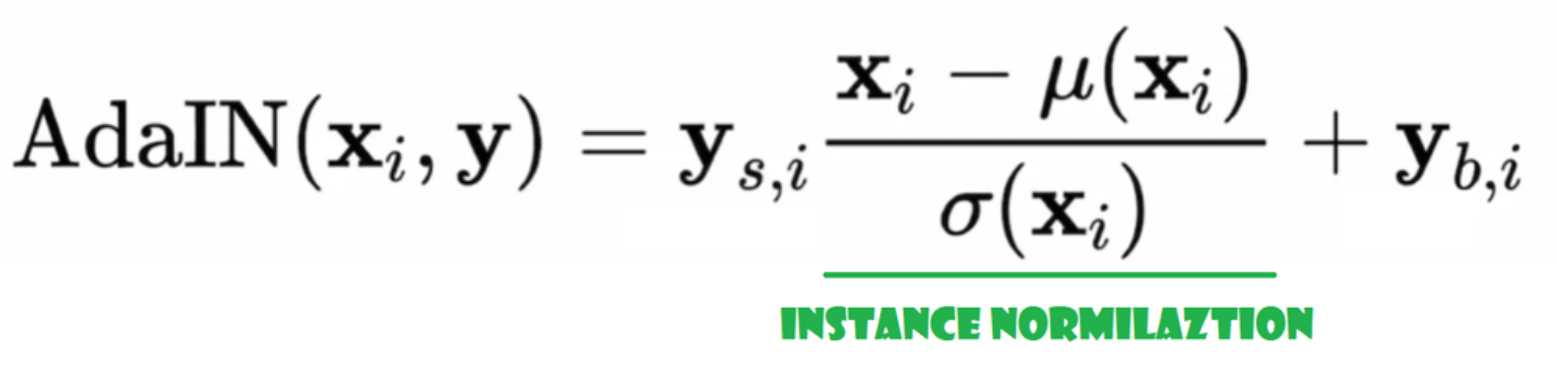
Inyectar Ruido
Ahora creemos la clase InjectNoise para inyectar el ruido en el generador
- En la parte init enviamos canales y inicializamos el peso desde una distribución normal aleatoria y usamos nn.Parameter para que estos pesos puedan ser optimizados
- En la parte forward, enviamos una imagen x y la devolvemos con ruido aleatorio agregado
clases útiles
Los autores construyen StyleGAN sobre la implementación oficial de ProGAN de Karras et al, usan la misma arquitectura de discriminador, tamaño de minibatch adaptativo, hiperparámetros, etc. Así que hay muchas clases que se mantienen igual en la implementación de ProGAN.
En esta sección, crearemos las clases que no cambian de la arquitectura de ProGAN.
En el fragmento de código a continuación puedes encontrar la clase WSConv2d (capa de convolución ponderada y escalada) para Equalized Learning Rate para las capas de convolución.
En el fragmento de código a continuación puedes encontrar la clase PixelNorm para normalizar Z antes de la Red de Mapeo de Ruido.
En el fragmento de código a continuación puedes encontrar la clase ConvBock que nos ayudará a crear el discriminador.
En el fragmento de código a continuación puedes encontrar la clase Discriminatowich que es la misma que en ProGAN.
Generador
En la arquitectura del generador, tenemos algunos patrones que se repiten, así que primero creemos una clase para ellos y hagamos que nuestro código sea lo más limpio posible, llamemos a la clase GenBlock que se heredará de nn.Module.
- En la parte de init enviamos in_channels, out_channels y w_dim, luego inicializamos conv1 con WSConv2d que mapea in_channels a out_channels, conv2 con WSConv2d que mapea out_channels a out_channels, leaky con Leaky ReLU con una pendiente de 0.2 como lo usan en el paper, inject_noise1, inject_noise2 con InjectNoise, adain1 y adain2 con AdaIN
- En la parte de forward, enviamos x, y lo pasamos a conv1 luego a inject_noise1 con leaky, luego lo normalizamos con adain1, y de nuevo pasamos eso a conv2 luego a inject_noise2 con leaky y lo normalizamos con adain2. Y finalmente, devolvemos x.
Ahora tenemos todo lo que necesitamos para crear el generador.
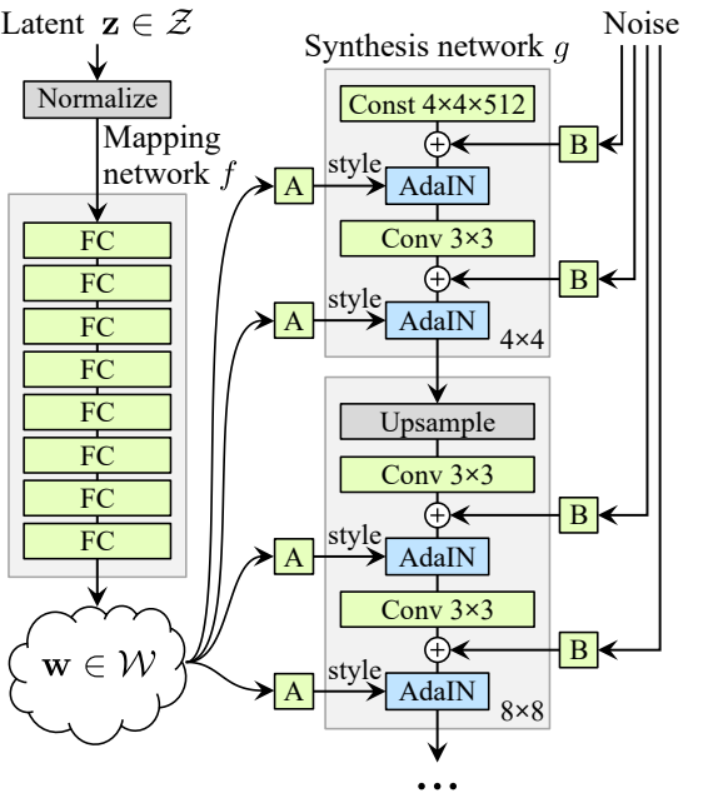
- en la parte init inicialicemos ‘starting_constant’ con un tensor de 4 x 4 (x 512 canales para el paper original, y 256 en nuestro caso) que se somete a una iteración del generador, mapeado por ‘MappingNetwork’, initial_adain1, initial_adain2 por AdaIN, initial_noise1, initial_noise2 por InjectNoise, initial_conv por una capa convolucional que mapea in_channels a sí misma, leaky por Leaky ReLU con una pendiente de 0.2, initial_rgb por WSConv2d que mapea in_channels a img_channels que es 3 para RGB, prog_blocks por ModuleList() que contendrá todos los bloques progresivos (indicamos los canales de entrada/salida de la convolución multiplicando in_channels que es 512 en el paper y 256 en nuestro caso con factores), y rgb_blocks por ModuleList() que contendrá todos los bloques RGB.
- Para fundir nuevas capas (un componente original de ProGAN), añadimos la parte fade_in, a la que enviamos alpha, scaled y generated, y retornamos [tanh(alpha∗generated+(1−alpha)∗upscale)], La razón por la que usamos tanh es que será la salida (la imagen generada) y queremos que los píxeles estén en un rango entre 1 y -1.
- En la parte adelante, enviamos el ruido (Z_dim), el valor de alpha que se va a desvanecer lentamente durante el entrenamiento (alpha está entre 0 y 1), y los pasos que es el número de la resolución actual con la que estamos trabajando, pasamos x al mapa para obtener el vector de ruido intermedio W, pasamos starting_constant a initial_noise1, aplicamos para él y para W initial_adain1, luego lo pasamos a initial_conv, y de nuevo añadimos initial_noise2 para él con leaky como función de activación, y aplicamos para él y W initial_adain2. Luego verificamos si steps = 0, si es así, entonces todo lo que queremos hacer es ejecutarlo a través del initial RGB y ya está, de lo contrario, recorremos el número de pasos, y en cada bucle escalamos (upscaled) y pasamos a través del bloque progresivo que corresponde a esa resolución(out). Al final, devolvemos fade_in que toma alpha, final_out, y final_upscaled después de mapearlo a RGB.
Utils
En el siguiente fragmento de código puedes encontrar la función generate_examples que toma el generador gen, el número de pasos para identificar la resolución actual, y un número n=100. El objetivo de esta función es generar n imágenes falsas y guardarlas como resultado.
En el siguiente fragmento de código puedes encontrar la función gradient_penalty para la pérdida WGAN-GP.
Función de entrenamiento
Para la función de entrenamiento, enviamos el crítico (que es el discriminador), gen (el generador), el cargador, el conjunto de datos, el paso, alfa, y el optimizador para el generador y para el crítico.
Comenzamos ciclando sobre todos los tamaños de mini-lotes que creamos con el DataLoader, y solo tomamos las imágenes porque no necesitamos una etiqueta.
Luego configuramos el entrenamiento para el discriminador\Critico cuando queremos maximizar E(critic(real)) – E(critic(fake)). Esta ecuación significa cuánto puede distinguir el crítico entre imágenes reales y falsas.
Después de eso, configuramos el entrenamiento para el generador cuando queremos maximizar E(critic(fake)).
Finalmente, actualizamos el bucle y el valor de alpha para fade_in y nos aseguramos de que esté entre 0 y 1, y lo devolvemos.
Entrenamiento
Ahora que tenemos todo, vamos a unirlo todo para entrenar nuestro StyleGAN.
Comenzamos inicializando el generador, el discriminador/critic y los optimizadores, luego convertimos el generador y el critic al modo de entrenamiento, luego iteramos sobre PROGRESSIVE_EPOCHS, y en cada bucle, llamamos a la función de entrenamiento el número de épocas veces, luego generamos algunas imágenes falsas y las guardamos como resultado, utilizando la función generate_examples, y finalmente, avanzamos a la siguiente resolución de imagen.
Resultado
Espero que puedas seguir todos los pasos y obtener una buena comprensión de cómo implementar StyleGAN de la manera correcta. Ahora vamos a revisar los resultados que obtenemos después de entrenar este modelo en este conjunto de datos con resolución 128*x 128.

Conclusión
En este artículo, realizamos una implementación limpia, simple y legible desde cero de StyleGAN1 utilizando PyTorch. replicamos el paper original lo más cerca posible, por lo que si lees el paper, la implementación debería ser prácticamente idéntica.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch