













مقدمة
يتناول هذا المقال أحد أفضل نماذج الشبكات المنافسة في الأنماط (GANs) في الوقت الحالي، StyleGAN من الورقة البحثية بنية مولدة تعتمد على الأسلوب للشبكات المنافقة المولدة، سنقوم بإنشاء تنفيذ نظيف وبسيط وقابل للقراءة له باستخدام PyTorch، و سنحاول ت reproduction الورقة الأصلية بقدر الإمكان، لذا إذا قرأت الورقة، يجب أن يكون التنفيذ مشابهًا تقريبًا.
ال一套 بيانات الذي سنستخدمه في هذا الموقع هو هذا مجموعة بيانات من Kaggle والذي يحتوي على 16240 قطعة من الملابس العلوية للنساء بdziel 256*192.
المتطلبات المسبقة
قبل أن تغوص في العمل مع StyleGAN باستخدام PyTorch، تأكد من أنك ت满足 المتطلبات التالية:
-
المعرفة الأساسية للتعلم العميق
فهم للشبكات العصبية المت 卷积ية (CNNs).
ألف مع الشبكات المنافقة المولدة (GANs)، بما في ذلك المفاهيم مثل المولد، المميز، و الخسارة المنافقة. -
متطلبات الأجهزة
وحدة معالجة رسومية قوية (مستحسن NVIDIA) للتدريب والاستدلال بشكل أسرع.
تثبيت أداة CUDA ل تسريع وحدة المعالجة الرسومية (cudaوcudnn). -
الإلمام بـ StyleGAN
من المفيد أن تكون قد قرأت الأوراق الأصلية لـ StyleGAN أو StyleGAN2 لفهم تحسينات البنية والمفاهيم الرئيسية.
تحميل جميع التبعيات التي نحتاجها
سنقوم أولاً باستيراد مكتبة torch لأننا سنستخدم PyTorch، ومن هناك سنستورد nn. سي帮助我们创建和训练 الشبكات، وسي permit нам استيراد optim، حزمة تنفذ العديد من خوارزميات التحسين (مثل sgd، adam،…). من torchvision سنستورد datasets وtransforms لتحضير البيانات وتطبيق بعض التحولات.
سنستورد functional كـ F من torch.nn لزيادة دقة الصور باستخدام interpolate، DataLoader من torch.utils.data لإنشاء أحجام مجموعات صغيرة، save_image من torchvision.utils ل保存 بعض العينات المزيفة، وlog2 من math لأننا نحتاج تمثيل عكسي لقوة 2 لتنفيذ حجم المجموعة الصغيرة التكيفي بناءً على دقة المخرجات، NumPy للرياضيات الخطية، os للتفاعل مع نظام التشغيل، tqdm لعرض شريط التقدم، وأخيرًا matplotlib.pyplot لعرض النتائج ومقارنتها بالONES الحقيقية.
المعلمات الفائقة
- تهيئة DATASET بمسار الصور الحقيقية.
- تحديد بدء التدريب بحجم صورة 8×8.
- تهيئة الجهاز باستخدام Cuda إذا كان متاحًا وCPU要不然،率和 التعلم بـ 0.001.
- حجم المجموعة سيكون مختلفًا بناءً على دقة الصور التي نريد إنشائها، لذا ن initialize BATCH_SIZES بحجم قائمة الأعداد، يمكنك تغييرها بناءً على VRAM الخاص بك.
- تهيئة image_size بـ 128 وCHANNELS_IMG بـ 3 لأننا سن generate صور RGB بحجم 128 × 128.
- في الورقة الأصلية، قاموا بتهيئة Z_DIM، W_DIM، وIN_CHANNELS بـ 512، ولكنني أهيئها بـ 256 بدلاً من ذلك لاستخدام أقل VRAM وتقليل وقت التدريب. قد نحصل على نتائج أفضل حتى لو ضاعفناها.
- للمodel StyleGAN يمكننا استخدام أي من وظائف الخسارة الخاصة بـ GAN التي نريدها، لذا استخدمت WGAN-GP من الورقة Improved Training of Wasserstein GANs. تحتوي هذه الخسارة على معلمة تسمى λ ومن الشائع إعداد λ = 10.
- تهيئة PROGRESSIVE_EPOCHS بـ 30 لكل حجم صورة.
الحصول على محمل البيانات
الآن دعونا ننشئ دالة get_loader ل:
- تطبيق بعض التحويلات على الصور (تغيير حجم الصور إلى الدقة التي نريدها، تحويلها إلى مصفوفات، ثم تطبيق بعض التعزيزات، وأخيرًا ت规范化ها بحيث تكون جميع البكسلات بين -1 و1).
- تحديد حجم المجموعة الحالية باستخدام القائمة BATCH_SIZES، وتحديد المؤشر كعدد صحيح تمثيل العكس لأس جبري 2 لحجم الصورة/4. وهذا بالفعل كيفية تنفيذ حجم المجموعة الصغيرة التكيفي بناءً على دقة المخرجات.
- تحضير مجموعة البيانات باستخدام ImageFolder لأنها منظمة بشكل جيد بالفعل.
- يتم إنشاء_sizes المini-批次 باستخدام DataLoader والذي يأخذ المجموعة البيانية وال尺寸 الم batching مع تحريك البيانات.
- في النهاية، يتم إرجاع المLoader والمجموعة البيانية.
تطبيق النماذج
الآن دعونا نطبق نموذج StyleGAN1 للمنشئ والمدمر (ProGAN و StyleGAN1 لهما نفس بنية المدمر) مع الصفات الرئيسية من الورقة البحثية. سنحاول جعل التطبيق مختصراً ولكن في نفس الوقت يمكن فهمه وتفسيره. تحديداً النقاط الرئيسية:
- شبكة تعيين الضوضاء
- الت normalize التكيفي للنموذج الفردي (AdaIN)
- النمو التدريجي
في هذا الدليل، سنقوم بإنشاء صور باستخدام StyleGAN1، و لن نقوم بتحقيق خلط الأنماط والتنوع العشوائي، ولكن لا يجب أن يكون من الصعب القيام بذلك.
دعونا نحدد متغيراً باسم factors يحتوي على الأرقام التي ستضرب في IN_CHANNELS للحصول على عدد القنوات الذي نريده في كل دقة صورة.
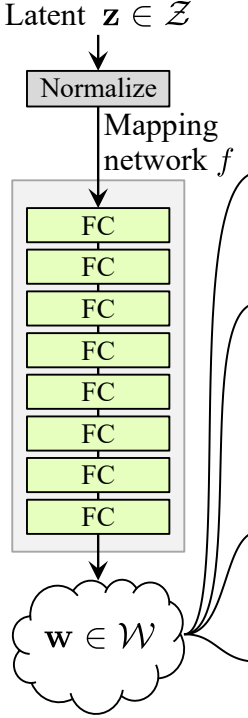
شبكة تعيين الضوضاء
شبكة تعيين الضوضاء تأخذ Z وتمرره عبر ثمانية طبقات متصلة بالكامل مفصولة ببعض التنشيط. ولا تنسى تساوي معدل التعلم كما يفعلون في ProGAN (ProGAN وStyleGan من تأليف نفس الباحثين).
دعونا أولاً نبني فئة باسم WSLinear (الخطي المقياس الموزن) التي ستعتمد من nn.Module.
- في جزء init نرسل in_features وout_channels. ننشئ طبقة خطية، ثم نحدد المقياس الذي سيكون مساوياً لجذر 2 مقسوماً على in_features، ننسخ تحيز الطبقة الحالية إلى متغير لأننا لا نريد أن يتم تقييس تحيز الطبقة الخطية، ثم نزيله، وأخيراً نقوم بتهيئة الطبقة الخطية.
- في الجزء forward، نرسل x وكل ما سنفعله هو ضرب x في المقياس وإضافة التحيز بعد إعادة تشكيله.
الآن دعونا ننشئ فئة MappingNetwork.
- في الجزء init نرسل z_dim وw_din، ونحدد شبكة التمثيل التي تبدأ بتنعيم z_dim، تليها ثماني طبقات من WSLInear وReLU كوظائف تنشيط.
- في الجزء forward، نعيد شبكة التمثيل.
التنعيم التكيفي للطبقة (AdaIN)
الآن دعونا ننشئ فئة AdaIN
- في الجزء init نرسل القنوات، w_dim، ون�始化 instance_norm الذي سيكون الجزء الخاص بتنعيم الحالة، ون�始化 style_scale وstyle_bias التي ستكون الأجزاء التكيفية مع WSLinear التي ترسم شبكة карт_noise W إلى القنوات.
- في عملية forward، نرسل x، نطبق تنعيم الحالة عليه، ونرجع style_sclate * x + style_bias.
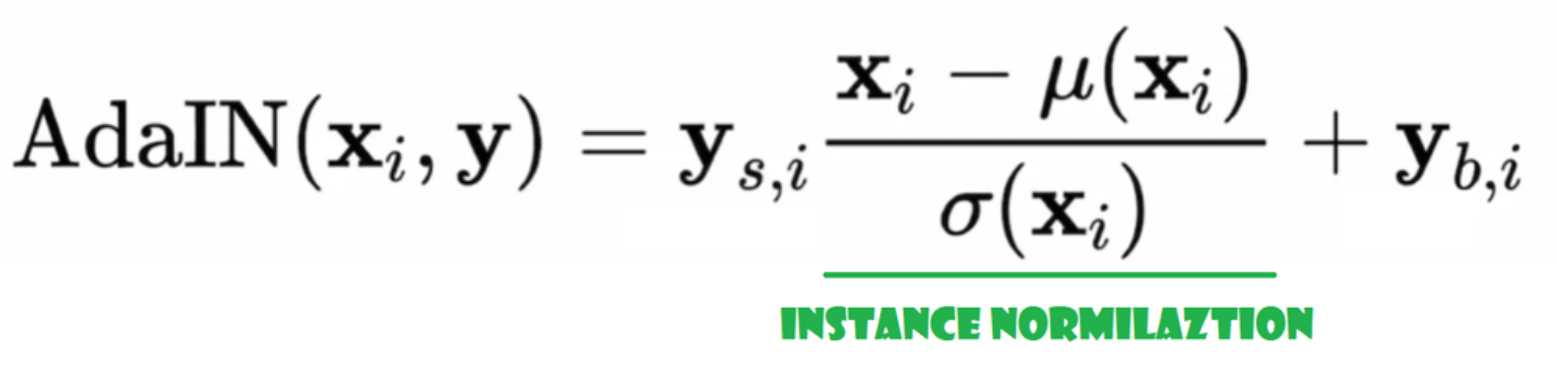
حقن الضوضاء
الآن دعونا ننشئ فئة InjectNoise لحقن الضوضاء في المولد
- في الجزء init نرسل القنوات ون�始化 الوزن من توزيع طبيعي عشوائي ونستخدم nn.Parameter حتى يمكن تحسين هذه الأوزان
- في الجزء forward، نرسل صورة x ونرجعها مع إضافة ضوضاء عشوائية
فئات مفيدة
قام المؤلفون ببناء StyleGAN على تنفيذ ProGAN الرسمي من قبل Karras وآخرين، يستخدمون نفس بنية الم discriminator، حجم المجموعات الصغيرة التكيفي، المعلمات، إلخ. لذا هناك الكثير من الفئات التي تظل نفسها من تنفيذ ProGAN.
في هذا القسم، سننشئ الفئات التي لا تتغير من بنية ProGAN.
في المقطع البرمجي أدناه يمكنك العثور على فئة WSConv2d (طبقة التجميع الموزونة المقياس) لتحقيق المعدل المتساوٍ للتعلم في طبقات التجميع.
في المقطع البرمجي أدناه يمكنك العثور على فئة PixelNorm لتنعيم Z قبل شبكة 매핑 الضوضاء.
في المقطع البرمجي أدناه يمكنك العثور على فئة ConvBlock التي ستساعدنا في إنشاء المميز.
في المقطع البرمجي أدناه يمكنك العثور على فئة Discriminatowich وهي نفسها كما في ProGAN.
مولد
في架构 المولد، لدينا بعض الأنماط التي تكرر، لذا دعونا أولاً إنشاء فئة لها لجعل كودنا نظيفاً قدر الإمكان، دعونا نسمي الفئة GenBlock التي سترث من nn.Module.
- في جزء init نرسل in_channels، out_channels، و w_dim، ثم ن�始化 conv1 بـ WSConv2d التي تحول in_channels إلى out_channels، وconv2 بـ WSConv2d التي تحول out_channels إلى out_channels، وleaky بـ Leaky ReLU مع انحدار 0.2 كما هو المستخدم في الورقة، وinject_noise1، وinject_noise2 بـ InjectNoise، وadain1، وadain2 بـ AdaIN
- في الجزء forward، نرسل x، ونمرره من خلال conv1 ثم إلى inject_noise1 مع leaky، ثم ن normalizeه مع adain1، ومرة أخرى نمرره من خلال conv2 ثم إلى inject_noise2 مع leaky ون normalizeه مع adain2. وأخيراً، نعيد x.
الآن لدينا كل ما نحتاجه لإنشاء المولد.
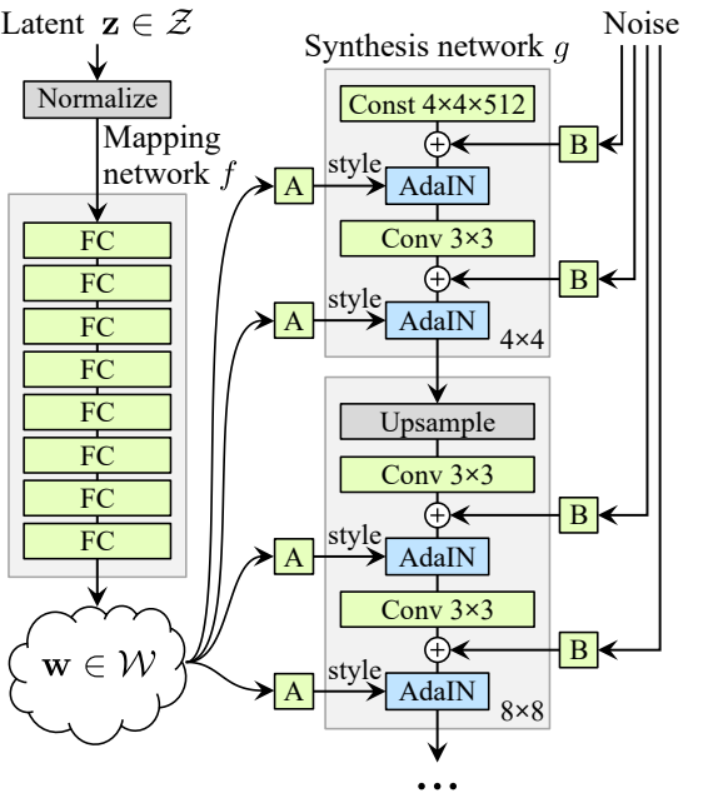
- في الجزء init دعونا ن�始化 ‘starting_constant’ بTensor ثابت 4×4 (x 512 قناة في الورقة الأصلية، و 256 في حالتنا) والذي يمر بiteración من الجينيراتور، ويتم تعيينه بواسطة ‘MappingNetwork’, initial_adain1، initial_adain2 بواسطة AdaIN، initial_noise1، initial_noise2 بواسطة InjectNoise، initial_conv بواسطة طبقة التراكم التي تربط في_channels مع نفسه، leaky بواسطة Leaky ReLU مع انحدار 0.2، initial_rgb بواسطة WSConv2d التي تربط في_channels مع img_channels والتي تكون 3 للRGB، prog_blocks بواسطة ModuleList() والذي س يحتوي على جميع الكتل التقدمية (ن indicate مدخل/مخرج القنوات التراكمية عن طريق ضرب في_channels والذي هو 512 في الورقة و 256 في حالتنا في عوامل)، و rgb_blocks بواسطة ModuleList() والذي س يحتوي على جميع الكتل RGB.
- لإدخال طبقات جديدة (جزء أصل ProGAN)، نضيف الجزء fade_in، والذي نرسل إليه alpha، scaled، و generated، ونقوم بإرجاع [tanh(alpha∗generated+(1−alpha)∗upscale)]، السبب في استخدامنا tanh هو أن سيكون الناتج (الصورة المحتلة) ونريد أن تكون القيم بين 1 و -1.
- في الجزء الأمامي، نرسل الضجيج (Z_dim)، والقيمة ألفا التي ستظهر تدريجياً أثناء التدريب (ألفا بين 0 و1)، وخطوات وهي عدد الدقة الحالية التي نعمل معها، نمرر x في الخريطة ل��取 المتجه الضجيج الوسيط W، نمرر starting_constant إلى initial_noise1، ونطبقه عليها و على W initial_adain1، ثم نمرره في initial_conv، مرة أخرى نضيف initial_noise2 له مع وظيفة نشاط leaky، ونطبقه عليها و على W initial_adain2. ثم نتحقق مما إذا كانت الخطوات تساوي 0، إذا كانت كذلك، فكل ما نريد القيام به هو تشغيلها عبر RGB الأولي ونكون انتهينا، وإلا، نكرر عدد الخطوات، وفي كل حلقة ن放大 (upscaled) ونمرر عبر الكتلة التدريجية التي correspond إلى تلك الدقة (out). في النهاية، نعيد fade_in التي تأخذ ألفا، final_out، وfinal_upscaled بعد نقلهما إلى RGB.
أدوات
في المقطع الكودي أدناه يمكنك العثور على دالة generate_examples التي تأخذ المولد gen، عدد الخطوات لتحديد الحلزون الحالي، وعدد n=100. هدفت هذه الدالة هي توليد n صور وهمية وتخزينها كناتج.
في المقطع الكودي أدناه يمكنك العثور على دالة gradient_penalty لخسارة WGAN-GP.
دالة التدريب
لدالة التدريب، نرسل النقد (التمييز)، المولد gen، الموزع loader، المجموعة البيانية dataset، الخطوة step، والمعامل alpha، ومحسن المولد والنقد.
نبدأ بتحويل جميع أحجام المجموعات الصغيرة التي ننشئها باستخدام DataLoader، ونأخذ فقط الصور لأننا لا نحتاج إلى علامة.
ثم نعداد التدريب للتمييز\Critic عندما نريد تحقيق E(critic(real)) – E(critic(fake)). تعني هذه المعادلة إلى أي مدى يمكن للنقد التمييز بين الصور الحقيقية والوهمية.
بعد ذلك، ن configure التدريب للمعالج عند الرغبة في تعظيم E(المحكم(المزيف)).
في النهاية، نقوم بتحديث الحلقة وقيمة ألفا لـ fade_in ون确保 أنها بين 0 و1، ثم نعيد إرجاعها.
التدريب
الآن بما أن لدينا كل شيء، دعونا ندمجها معًا لتدريب StyleGAN الخاص بنا.
نبدأ بتهيئة المعالج، المحكم/المحكم، والمحسنات، ثم نحول المعالج والمحكم إلى وضع التدريب، ثم ن loop عبر PROGRESSIVE_EPOCHS، وفي كل حلقة، نستدعي دالة التدريب عدد مرات العصر، ثم نولد بعض الصور المزيفة ونحفظها كنتيجة، باستخدام دالة generate_examples، وأخيرًا، ننتقل إلى دقة الصورة التالية.
النتيجة
نأمل أن تكون قادرًا على متابعة جميع الخطوات وفهم كيفية تطبيق StyleGAN بالطريقة الصحيحة. دعنا الآن نتحقق من النتائج التي نحصل عليها بعد تدريب هذا النموذج على هذا مجموع البيانات بدقة 128×128.

الخاتمة
في هذا المقال، قمنا بإنشاء تنفيذ نظيف وبسيط وقابل للقراءة من الصفر لـ StyleGAN1 باستخدام PyTorch. قمنا بتقليد الورقة الأصلية بقدر الإمكان، لذا إذا قرأت الورقة، يجب أن يكون التنفيذ مشابهًا جدًا لها تقريبًا.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch