













소개
이篇文章는 현재 최고의 GAN 중 하나인 StyleGAN에 대해 설명합니다. 논문 Style-Based Generator Architecture for Generative Adversarial Networks에서 제안된 StyleGAN을 사용하여, PyTorch를 통해 깨끗하고 간결하며 이해하기 쉬운 구현을 만들어보고, 원래 논문을 가능한 한 똑같이 재현해보려 합니다. 논문을 읽는다면, 구현은 거의 동일할 것입니다.
이 블로그에서 사용할 데이터셋은 Kaggle에서 제공하는 데이터셋으로, 256*192 해상도의 여성 상의 16240개가 포함되어 있습니다.
사전 요구사항
PyTorch를 사용하여 StyleGAN을 다루기 전에 다음과 같은 사전 요구사항을 확인해야 합니다:
-
딥러닝의 기본 지식
.convolutional neural networks (CNNs)에 대한 이해.
Generative Adversarial Networks (GANs)에 대한 익숙함, 생성자, 식별자, 그리고 대립 손실과 같은 개념 포함. -
하드웨어 요구 사항
더 빠른 훈련과 추론을 위한 강력한 GPU(NVIDIA 권장).
GPU 가속을 위해 CUDA 툴킷이 설치되어 있어야 합니다(cuda및cudnn). -
스타일간에 익숙해지기
아키텍처 개선 사항과 주요 개념을 이해하려면 원본 StyleGAN 또는 StyleGAN2 문서를 읽어두면 도움이 됩니다.
필요한 모든 의존성 로드
우선 PyTorch를 사용하기 위해 torch를导입하겠습니다. 그리고 거기서 nn을导입하여 네트워크를 생성하고 훈련하는 데 도움을 주며, 또한 optim을导입하여 여러 최적화 알고리즘(예: sgd, adam, …)을 구현하는 패키지를 가져올 수 있습니다. torchvision에서 datasets와 transforms를 데이터 준비와 일부 변환을 적용하기 위해导입합니다.
torch.nn에서 F로 functional을导입하여 이미지를 interpolate를 사용하여 upsample하고, torch.utils.data에서 DataLoader를 사용하여 미니 배치 크기를 생성하고, torchvision.utils에서 save_image를 사용하여 몇 가지 가짜 샘플을 저장하며, math에서 log2를 사용하여 2의 거듭제곱의 역 표현을 구현하기 위해 필요한 출력 해상도에 따른 적응형 미니 배치 크기를 구현합니다. 선형 대수학을 위한 NumPy, 운영 체제와 상호작용을 위한 os, 진행 바를 표시하기 위한 tqdm, 그리고 결과를 표시하고 실제 것과 비교하기 위한 matplotlib.pyplot를导입합니다.
Hyperparameters
- 실제 이미지의 경로로 DATASET을 초기화합니다.
- 이미지 크기 8×8에서 훈련을 시작하도록 지정합니다.
- Cuda가 가능하면 Cuda로, 그렇지 않으면 CPU로 장치를 초기화하고, 학습률을 0.001로 설정합니다.
- 생성할 이미지의 해상도에 따라 배치 크기가 달라지므로, BATCH_SIZES를 수치 목록으로 초기화하고, VRAM에 따라 변경할 수 있습니다.
- 이미지 크기를 128으로 설정하고, CHANNELS_IMG을 3으로 설정하여 128×128 RGB 이미지를 생성합니다.
- 원본 논문에서는 Z_DIM, W_DIM, IN_CHANNELS를 512로 초기화하지만, 저는 VRAM 사용량을 줄이고 학습 속도를 높이기 위해 256으로 초기화합니다. 이를 두배로 늘리면 더 나은 결과를 얻을 수도 있을 것입니다.
- StyleGAN의 경우 원하는GAN 손실 함수 중任何一个를 사용할 수 있기 때문에, 저는 논문 Improved Training of Wasserstein GANs에서 제안한 WGAN-GP를 사용합니다. 이 손실 함수에는 λ이라는 매개변수가 포함되어 있으며, 일반적으로 λ = 10으로 설정합니다.
- 각 이미지 크기에 대해 PROGRESSIVE_EPOCHS를 30으로 초기화합니다.
데이터 로더 가져오기
이제 get_loader 함수를 만들어 보겠습니다:
- 이미지에 어떤 변환을 적용합니다 (이미지를 원하는 해상도로 조정하고, 텐서로 변환한 후 일부 확장을 적용하고, 마지막으로 모든 픽셀을 -1에서 1 사이로 정규화합니다).
- 현재 배치 사이즈를 BATCH_SIZES 목록을 사용하여 식별하고, 이미지 크기의 4배수의 역수의 2의 거스름수의 정수 값을 인덱스로 사용하여 적응형 미니 배치 사이즈를 구현합니다.
- ImageFolder를 사용하여 데이터셋을 준비합니다. 이미지 폴더는 이미 구조적으로 정리되어 있기 때문입니다.
- 데이터셋과 배치 크기를 사용하여 데이터를 섞어 mini-batch sizes를 만들기 위해 DataLoader를 생성합니다.
- 마지막으로, 로더와 데이터셋을 반환합니다.
모델 구현
이제 스타일GAN1 생성기와 식별자(ProGAN과 스타일GAN1은 같은 식별자 아키텍처를 가짐)를 논문의 주요 속성을 사용하여 구현해 보겠습니다. 구현을 간결하게 만들되, 동시에 읽기 쉽고 이해하기 쉽게 만들겠습니다. 구체적으로 다음의 주요 포인트:
- Noise Mapping Network
- Adaptive Instance Normalization (AdaIN)
- Progressive growing
이 튜토리얼에서는 스타일GAN1로 이미지만 생성하고, 스타일 혼합과 확률적 변이는 구현하지 않지만, 그렇게 하기는 어렵지 않습니다.
이제 IN_CHANNELS와 곱할 수 있는 숫자를 포함하는 변수 factors를 정의하여 각 이미지 해상도에서 원하는 채널 수를 얻습니다.
Noise Mapping Network
소음 매핑 네트워크는 Z를 취하여 8개의 완전 연결 레이어를 통해 통과시키고 각 레이어 사이에 활성화 함수를 적용합니다. 그리고 ProGAN(ProGAN과 StyleGan은 같은 연구자에 의해 작성됨)의 저자들이 하는 것처럼 학습률을 동일하게 조정하지 마 заб�.
우선 WSLinear(가중치 스케일된 선형)이라는 이름의 클래스를 nn.Module을 상속받아 만들어 보겠습니다.
- init 부분에서 in_features와 out_channels를 받아들입니다. 선형 레이어를 생성한 후, 스케일을 in_features의 제곱근을 2로 나눈 값으로 정의합니다. 현재 컬럼 레이어의偏이值를 변수에 복사합니다. 왜냐하면 선형 레이어의偏이值를 스케일링하고 싶지 않기 때문입니다. 그런 다음偏이를 제거하고, 마지막으로 선형 레이어를 초기화합니다.
- forward 부분에서 x를 받아들이고, x를 스케일과 곱한 후, 변형된偏이를 더하는 것만 합니다.
이제 MappingNetwork 클래스를 생성해 보겠습니다.
- init 부분에서 z_dim과 w_din을 받아들이고, z_dim을 정규화한 후 8개의 WSLinear과 ReLU를 활성화 함수로 사용하는 네트워크 매핑을 정의합니다.
- forward 부분에서 네트워크 매핑을 반환합니다.
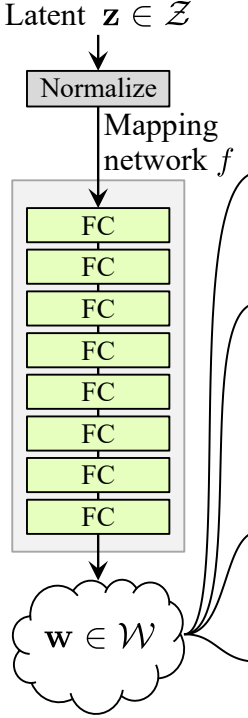
어답티브 인스턴스 정규화(AdaIN)
이제 AdaIN 클래스를 생성해 보겠습니다.
- 초기화 부분에서 채널, w_dim을 보내고, 인스턴스 정규화 부분이 될 instance_norm을 초기화하며, 스타일 스케일과 스타일 바이어스를 초기화하여 노이즈 맵핑 네트워크 W를 채널로 매핑하는 WSLinear의 적응 부분으로 사용합니다.
- 순전방 전달 단계에서 x를 보내고, 그에 대해 인스턴스 정규화를 적용한 후 style_scale * x + style_bias를 반환합니다.
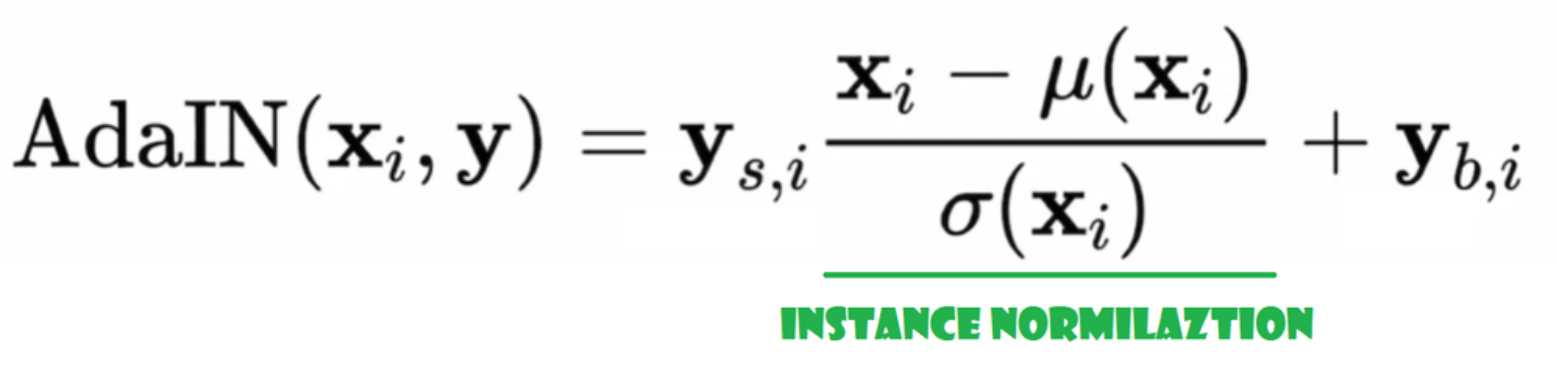
노이즈 주입
이제 노이즈를 생성기에 주입하기 위한 InjectNoise 클래스를 만들겠습니다.
- 초기화 부분에서 채널을 보내고, 무작위 정규 분포에서 중량을 초기화하며, 이 중량을 최적화할 수 있도록 nn.Parameter를 사용합니다.
- 순전방 전달 단계에서 이미지 x를 보내고, 무작위 노이즈를 추가하여 반환합니다.
유용한 클래스들
저자들은 StyleGAN을 Karras 등의 공식적인 ProGAN 구현을 기반으로 구축하였으며, 동일한 구분자 아키텍처, 적응형 최소 배치 크기, 하이퍼파라미터 등을 사용합니다. 따라서 ProGAN 구현에서 많은 클래스가 동일하게 유지됩니다.
이 절에서는 ProGAN 아키텍처에서 변경되지 않는 클래스를 만들겠습니다.
아래 코드 스니佩트에서 클래스 WSConv2d(가중치 스케일드 컨볼루션 레이어)를 등화 학습률(Equalized Learning Rate)을 위해 컨볼루션 레이어에 사용할 수 있습니다.
아래 코드 스니佩트에서 클래스 PixelNorm를 찾아 Z를 노이즈 맵핑 네트워크 전에 정규화할 수 있습니다.
아래 코드 스니佩트에서 클래스 ConvBlock를 찾아 디스크리미네이터를 생성하는 데 도움을 줄 수 있습니다.
아래 코드 스니佩트에서 클래스 Discriminator를 찾아 ProGAN과 동일한 것입니다.
ジェネレーター
ジェネレーター構造では、いくつかのパターンが繰り返されるので、まずそれらのクラスを作成してコードをできるだけクリーンにするために、nn.Moduleから継承されるGenBlockというクラスを作成しましょう。
- init部分では、in_channels、out_channels、w_dimを受け取り、WSConv2dを使用してin_channelsをout_channelsにマッピングするconv1を初期化し、WSConv2dを使用してout_channelsをout_channelsにマッピングするconv2を初期化し、論文で使用されている0.2のスロープを持つLeaky ReLUのleaky、InjectNoiseを使用してinject_noise1、inject_noise2を初期化し、AdaINを使用してadain1、adain2を初期化します。
- forward部分では、xを受け取り、まずconv1にパスし、inject_noise1でleakyを適用し、adain1で正規化します。その後、conv2にパスし、inject_noise2でleakyを適用し、adain2で正規化します。最後に、xを返します。
これで、ジェネレーターを作成するために必要なすべてのものが揃いました。
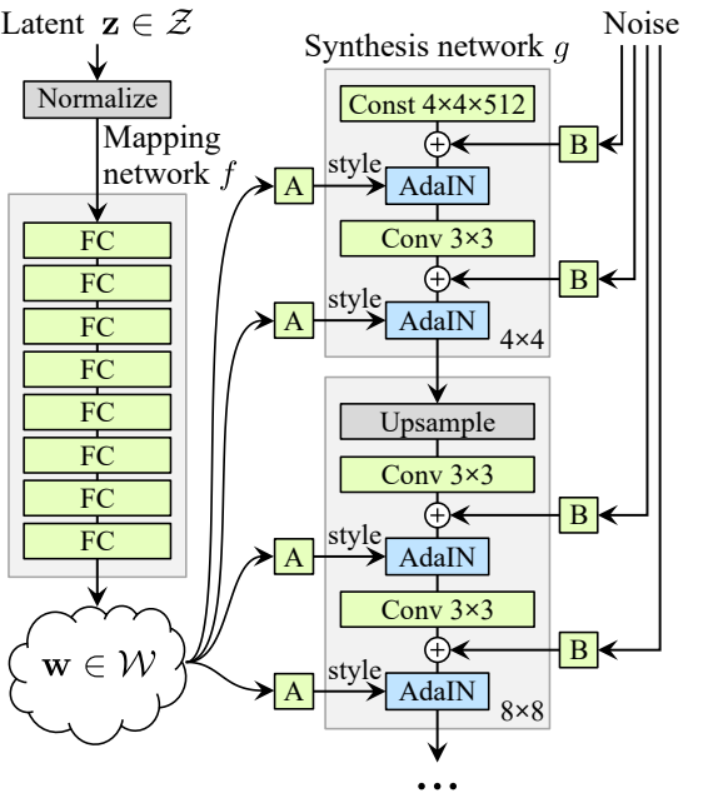
- 시작 초기화 부분에서 ‘starting_constant’을 원본 논문에서는 4 x 4 (512 채널) 텐서로 초기화하고, 우리의 경우에는 256 채널로 초기화하겠습니다. 이 텐서는 생성기의 반복을 거칩니다. ‘MappingNetwork’을 통해 매핑하고, initial_adain1, initial_adain2는 AdaIN을 통해 초기화하며, initial_noise1, initial_noise2는 InjectNoise를 통해 초기화합니다. initial_conv는 in_channels를 자신으로 매핑하는 卷积層(Leaky ReLU의 기울기가 0.2인 leaky), initial_rgb는 in_channels를 img_channels로 매핑하는 WSConv2d로, RGB의 경우 img_channels는 3입니다. prog_blocks는 모든 진화 블록을 포함할 ModuleList()로, 논문에서는 in_channels가 512인 반면 우리의 경우는 256으로 곱한 요소들로 초기화하며, rgb_blocks는 모든 RGB 블록을 포함할 ModuleList()입니다.
- 새 레이어를 부드럽게 추가하기 위해 (ProGAN의 원본 구성 요소인 fade-in), fade_in 부분을 추가합니다. 여기서 alpha, scaled, generated를 전달하고, [tanh(alpha∗generated+(1−alpha)∗upscale)]를 반환합니다. tanh를 사용하는 이유는 출력(생성된 이미지)이 되기 때문에 픽셀 값이 -1에서 1 사이의 범위를 가지기를 원하기 때문입니다.
- forward 부분에서, 우리는 노이즈(Z_dim), 훈련 중 서서히 페이드 인되는 알파 값(알파는 0과 1 사이에 있음)과 현재 우리가 작업하고 있는 해상도의 번호인 steps를 보냅니다. x를 맵에 통과시켜 중간 노이즈 벡터 W를 얻고, starting_constant를 initial_noise1에 적용하고, W에 대해서는 initial_adain1을 적용한 후 initial_conv에 통과시키고, 다시 initial_noise2를 추가하고 리어키를 활성화 함수로 사용하여 initial_adain2에 적용합니다. 그런 다음 steps가 0인지 확인합니다. 그렇다면 초기 RGB를 통해 실행하고 끝냅니다. 그렇지 않으면, 스텝 수에 대해 루프를 돌고, 각 루프에서 업스케일링(upscaled)을 수행하고 해당 해상도에 해당하는 progressive block(out)을 통해 실행합니다. 마지막으로, 우리는 fade_in를 반환합니다. 이는 알파, final_out, 그리고 RGB로 맵핑된 final_upscaled를 받습니다.
Utils
아래 코드 스니佩트에서는 generate_examples 함수를 찾을 수 있습니다. 이 함수는 제너레이터 gen, 현재 해상도를 식별하는 데 필요한 스텝 수, 그리고 n=100을 받습니다. 이 함수의 목표는 n 개의 가짜 이미지를 생성하고 그 결과를 저장하는 것입니다.
아래 코드 스니佩트에서는 WGAN-GP 손실을 위한 gradient_penalty 함수를 찾을 수 있습니다.
학습 함수
학습 함수의 경우, 크리틱(디스크리미네이터), 제너레이터 gen, 로더, 데이터셋, 스텝, 알파, 그리고 제너레이터와 크리틱에 대한 최적화기를 보냅니다.
우리는 DataLoader를 사용하여 생성한 모든 미니 배치 크기에 대해 루프를 돌고, 레이블이 필요하지 않기 때문에 이미지만을 가져옵니다.
그런 다음, 디스크리미네이터\Critic의 학습을 설정합니다. 디스크리미네이터\Critic이 E(critic(real)) – E(critic(fake))를 최대화하려고 할 때입니다. 이 방정식은 크리틱이 실제와 가짜 이미지를 구분할 수 있는 정도를 의미합니다.
그 후, 우리는 E(criic(fake)).
를 최대화하려고 할 때 생성기의 훈련을 설정합니다. 마지막으로, 우리는 루프를 업데이트하고 fade_in의 alpha 값을 업데이트하며 0과 1 사이를 유지하고 반환합니다.
훈련
이제 모든 것이 준비되었으므로, StyleGAN을 훈련하기 위해 이를 모두 통합해 보겠습니다.
먼저 생성기, 식별자/평가자, 최적화기를 초기화한 후, 생성기와 평가자를 훈련 모드로 전환하고, PROGRESSIVE_EPOCHS를 반복하면서 각 루프에서 훈련 함수를 에포크 수 만큼 호출하고, 가짜 이미지를 생성하여 저장하는 generate_examples 함수를 사용하여 결과로 저장하고, 마지막으로 다음 이미지 해상도로 진행합니다.
결과
모든 단계를 따라가면서 올바른 방식으로 StyleGAN을 구현하는 방법을 잘 이해할 수 있기를 바랍니다. 이제 128*x 128 해상도의 데이터 세트에서 이 모델을 훈련한 후 얻은 결과를 확인해 보겠습니다.

결론
이 글에서는 PyTorch를 사용하여 StyleGAN1을 처음부터 깔끔하고 간단하며 읽기 쉽게 구현했습니다. 최대한 원본 논문을 복제했기 때문에 논문을 읽으면 구현이 거의 동일하게 될 것입니다.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch