













介紹
本文將介紹目前最佳的生成對抗網絡之一,來自論文《A Style-Based Generator Architecture for Generative Adversarial Networks》的StyleGAN。我們將使用PyTorch進行乾淨、簡單且易於閱讀的實現,並盡可能地模擬原論文的內容,所以如果您讀過這篇論文,這個實現應該與之幾乎完全相同。
我們在這篇部落格中將使用的數據集是來自Kaggle的數據集,其中包含了16240張解析度為256*192的女性上衣圖片。
先備知識
在您開始使用PyTorch進行StyleGAN的工作之前,請確保您具備以下先備知識:
-
深度學習的基本知識
理解卷積神經網絡(CNNs)。
熟悉生成對抗網絡(GANs),包括生成器、判別器和對抗損失等概念。 -
硬件要求
一個強大的GPU(推薦NVIDIA)以加快訓練和推理速度。
安裝CUDA工具包以支持GPU加速(cuda和cudnn)。
加載我們所需的所有依賴
我們首先會導入torch,因為我們將使用PyTorch,然後從中導入nn。這將幫助我們創建和訓練網絡,並讓我們導入optim,一個實現各種優化算法(例如sgd、adam…)的包。從torchvision我們導入datasets和transforms來準備數據和應用一些轉換。
我們將從torch.nn導入functional作為F來使用interpolate上掇圖像,從torch.utils.data導入DataLoader來創建小批量大小,從torchvision.utils導入save_image來保存一些假樣本,從math導入log2因為我們需要2的冪的逆表示來實現根據輸出解析度自適應的批量大小,導入NumPy來進行線性代數計算,導入os來與操作系統交互,導入tqdm來顯示進度條,最後導入matplotlib.pyplot來顯示結果和與真實的進行比較。
超參數
- 通過真實圖像的路徑初始化DATASET。
- 指定從8×8圖像大小開始訓練。
- 通過Cuda(如果可用)或CPU初始化設備,並將學習率設為0.001。
- 批量大小將根據我們想要生成的圖像解析度而有所不同,因此我們通過一個數字列表初始化BATCH_SIZES,你可以根據你的VRAM更改它們。
- 將image_size初始化為128,將CHANNELS_IMG初始化為3,因為我們將生成128×128的RGB圖像。
- 在原始論文中,他們將Z_DIM、W_DIM和IN_CHANNELS初始化為512,但我則將它們初始化為256,以減少VRAM的使用並加速訓練。我們甚至可以通過將它們翻倍來獲得更好的結果。
- 對於StyleGAN,我們可以使用任何我們想要的GAN損失函數,所以我選擇了論文中的WGAN-GPImproved Training of Wasserstein GANs。這個損失函數包含一個名為λ的參數,通常設置λ = 10。
- 將PROGRESSIVE_EPOCHS初始化為每個圖像大小30。
獲取數據加載器
現在讓我們創建一個函數get_loader來:
- 對圖像應用一些轉換(將圖像調整到我們想要的解析度,將它們轉換為張量,然後應用一些增強,最後將它們正規化以使所有像素範圍在-1到1之間)。
- 使用列表BATCH_SIZES識別當前批量大小,並將圖像大小除以4的2的冪的逆表示的整數數字作為索引。這就是我們如何實現依賴於輸出解析度的自適應最小批量大小的方法。
- 使用ImageFolder準備數據集,因為它已經以一種很好的方式結構化。
- 創建使用DataLoader的迷你批次大小,該DataLoader接受數據集和批次大小,並對數據進行洗牌。
- 最後,返回加載器和數據集。
模型實現
現在讓我們實現StyleGAN1的生成器和判別器(ProGAN和StyleGAN1具有相同的判別器架構),並從論文中提取關鍵屬性。我們將努力使實現簡潔,同時保持可讀性和可理解性。具體來說,關鍵點:
- 噪聲映射網絡
- 自適應實例歸一化(AdaIN)
- 逐步增長
在本教程中,我們將僅使用StyleGAN1生成圖像,而不實現風格混合和隨機變化,但這應該不難做到。
讓我們定義一個名為factors的變量,其中包含將與IN_CHANNELS相乘的數字,以在我們想要的每個圖像解析度中獲得通道數。
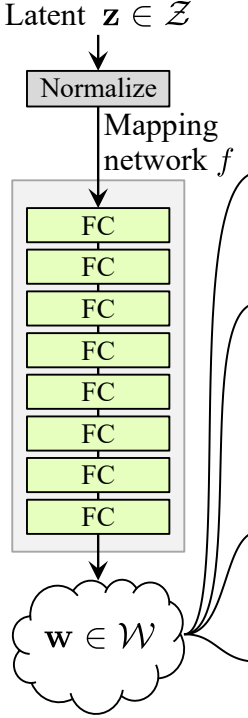
噪聲映射網絡
噪音映射網絡將 Z 輸入並通過八個全連接層,層與層之間有一些激活函數。並不要忘了像 ProGAN(由同一組研究者創作的 ProGAN 和 StyleGan)的作者那樣平衡學習率。
我們首先建立一個名為 WSLinear(加權縮放線性)的類,它將繼承自 nn.Module。
- 在 init 部分我們傳入 in_features 和 out_channels。創建一個線性層,然後我們定義一個 scale,它將等於 2 的平方根除以 in_features,我們將當前列層的偏置複製到一個變量中,因為我們不希望線性層的偏置被縮放,然後我們移除它,最後初始化線性層。
- 在 forward 部分中,我們傳入 x,而我們要做的只是將 x 與 scale 相乘,並在重塑後加上偏置。
現在我們來創建 MappingNetwork 類。
- 在 init 部分我們傳入 z_dim 和 w_din,並定義網絡映射,首先對 z_dim 進行標準化,然後接八個 WSLInear 和 ReLU 作為激活函數。
- 在 forward 部分中,我們返回網絡映射。
自適應實例歸一化(AdaIN)
現在我們來創建 AdaIN 類
- 在初始化部分,我們傳送通道、w_dim,並初始化instance_norm,這將是實例歸一化的部分;我們還初始化style_scale和style_bias,這將是與WSLinear映射Noise Mapping Network W到通道的自適應部分。
- 在前向傳播過程中,我們傳送x,對其應用實例歸一化,並返回style_sclate * x + style_bias。
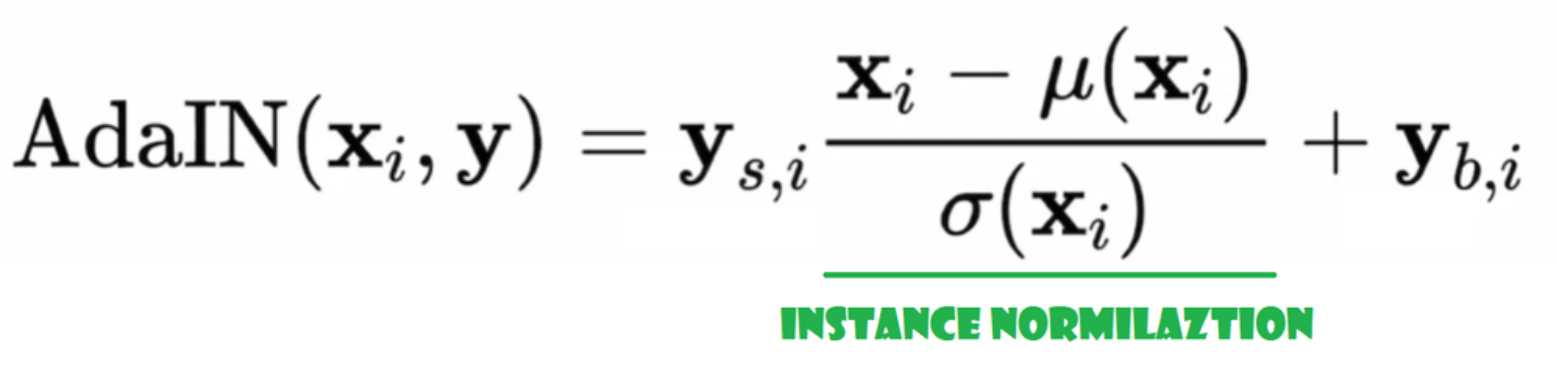
注入噪音
現在讓我們創建類InjectNoise以將噪音注入生成器
- 在初始化部分,我們傳送通道,並從隨機正態分佈中初始化權重,我們使用nn.Parameter以便這些權重可以被優化
- 在前向傳播部分,我們傳送一幅圖像x,並返回添加了隨機噪音的圖像
有助的類別
作者在StyleGAN的基礎上建立了ProGAN的官方實現,由Karras等人提出,他們使用相同的判別器結構、自適應小批量大小、超參數等。因此,從ProGAN實現中保留了很多類別。
在這一部分,我們將創建從ProGAN架構中不變的類別。
在以下代碼片段中,您可以找到類別 WSConv2d(加權縮放卷積層)以實現卷積層的等化學習率。
在以下代碼片段中,您可以找到類別 PixelNorm 用於在噪聲映射網絡之前對 Z 進行歸一化。
在以下代碼片段中,您可以找到類別 ConvBock,它將幫助我們創建判別器。
在以下代碼片段中,您可以找到類別 Discriminatowich,它與 ProGAN 中的相同。
生成器
在生成器架构中,我们有一些模式会重复,所以让我们首先为它创建一个类,以使我们的代码尽可能清晰,我们将这个类命名为GenBlock,它将从nn.Module继承。
- 在初始化部分,我们传入in_channels、out_channels和w_dim,然后我们通过WSConv2d初始化conv1,它将in_channels映射到out_channels,通过WSConv2d初始化conv2,它将out_channels映射到out_channels,leaky通过Leaky ReLU,其斜率为0.2,正如论文中使用的那样,inject_noise1和inject_noise2通过InjectNoise,adain1和adain2通过AdaIN。
- 在前向传播部分,我们传入x,然后将其传递给conv1,再传递给inject_noise1和leaky,然后我们用adain1对其进行归一化,接着我们再次将结果传递给conv2,再传递给inject_noise2和leaky,并用adain2进行归一化。最后,我们返回x。
现在我们已经拥有创建生成器所需的所有内容。
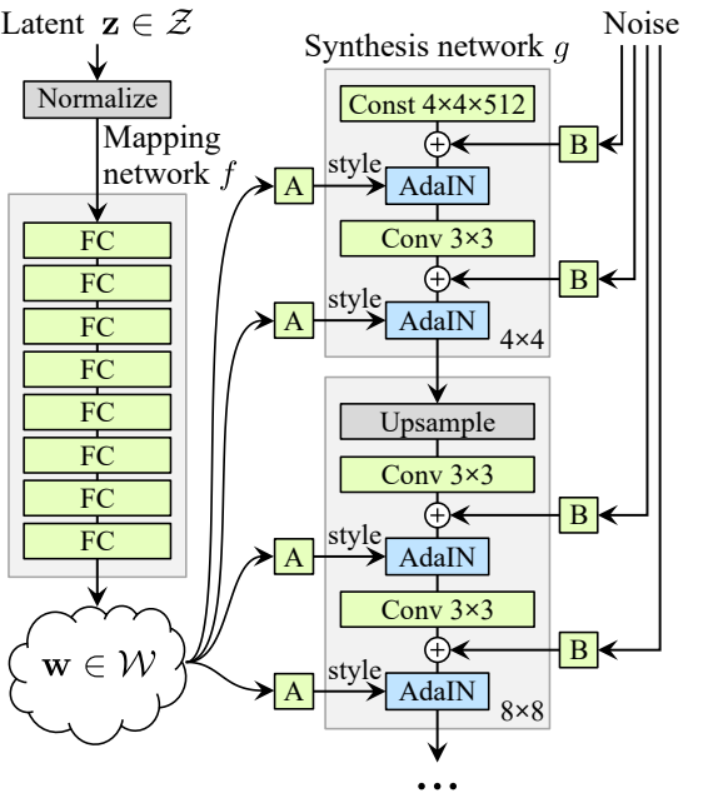
- 在初始化部分,讓我們通過生成器的一次迭代來初始化 ‘starting_constant’,這個常數是一個 4 x 4(原始論文中為 512 個通道,我們的案例中為 256 個通道)的張量。通過 ‘MappingNetwork’ 映射,使用 AdaIN 初始化 initial_adain1 和 initial_adain2,使用 InjectNoise 初始化 initial_noise1 和 initial_noise2,使用卷積層初始化 initial_conv 將輸入通道映射到自身,leaky 是具有 0.2 倾斜度的 Leaky ReLU,使用 WSConv2d 初始化 initial_rgb 將輸入通道映射到 RGB 的 img_channels,即 3。prog_blocks 是 ModuleList(),將包含所有的進展性區塊(我們用乘積表示卷積的輸入/輸出通道,論文中為 512,我們的案例中為 256,並乘以係數)。rgb_blocks 是 ModuleList(),將包含所有的 RGB 區塊。
- 為了逐漸引入新層(ProGAN 的原始组件),我們添加了淡入部分,我們傳送 alpha、scaled 和 generated,並返回 [tanh(alpha∗generated+(1−alpha)∗upscale)]。我們使用 tanh 的原因是這將是輸出(生成的圖像),我們希望像素值在 -1 到 1 之間。
- 在前向部分,我們傳送噪音(Z_dim),在訓練過程中會逐漸淡入的alpha值(alpha介於0和1之間),以及steps,這是我們正在处理的當前解析度的數字,我們將x傳入map以獲得中間噪音向量W,我們將starting_constant傳給initial_noise1,對其進行應用,並對W進行initial_adain1的應用,然後我們將其傳入initial_conv,再次為其添加initial_noise2並使用leaky作為激活函數,並對其和W進行initial_adain2的應用。然後我們檢查steps是否等於0,如果是,那麼我們所要做的就是讓它通過initial RGB,然後就完成了,否則,我們會循環步數,並在每次循環中進行升采样(upscaled),並通過與該解析度相對應的進步塊(out)。最後,我們返回淡入,它將alpha、final_out和經過RGB映射的final_upscaled作為參數。
工具
在下面的代碼片段中,您可以找到 generate_examples 函數,它接受 生成器 gen、用於識別當前解析度的 步數,以及 n=100 的數字。這個函數的目標是生成 n 個假圖像並將它們作為結果保存。
在下面的代碼片段中,您可以找到用於 WGAN-GP 損失的 gradient_penalty 函數。
訓練函數
對於訓練函數,我們傳遞評論家(即判別器)、生成器 gen、數據加載器 loader、數據集 dataset、步數 step、alpha,以及生成器和評論家的優化器。
我們首先遍歷我們使用 DataLoader 創建的所有的最小批量大小,並且只取圖像,因為我們不需要標籤。
然後我們設置判別器\評論家的訓練,當我們想要最大化 E(評論家(真)) – E(評論家(假)) 時。這個方程意味著評論家區分真實和假圖像的能力。
之後,當我們想要最大化E(評論者(假圖))
時,我們為生成器設置訓練。
訓練
現在既然我們已經有了所有東西,讓我們把它們組合起來來訓練我們的StyleGAN。
我們從初始化生成器、判別器/評論者以及優化器開始,然後將生成器和評論者轉換為訓練模式,接著循環遍歷PROGRESSIVE_EPOCHS,在每次循環中,我們調用train函數指定次數的epoch,然後生成一些假圖像並將它們保存起來,因此,使用generate_examples函數,最後我們進展到下一個圖像解析度。
結果
希望您能遵循所有步骤,並充分理解如何以正確的方式實現StyleGAN。現在我們來查看在這個數據集中以128*x 128解析度訓練此模型後我們得到的结果。

結論
在本文中,我們從頭開始使用PyTorch進行了一個乾淨、簡單且易於閱讀的StyleGAN1的實現。我們盡可能接近原論文的內容,所以如果您閱讀了論文,那麼這個實現應該與之非常相似。
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch