













Einführung
Dieser Artikel behandelt eine der besten GANs heute, StyleGAN aus dem Papier Une Style-Based Generator Architecture for Generative Adversarial Networks, wir werden eine saubere, einfache und lesbare Implementierung davon mit PyTorch erstellen und versuchen, das Originalpapier so nah wie möglich nachzubilden, sodass wenn Sie das Papier lesen, die Implementierung pretty much identical sein sollte.
Der Datensatz, den wir in diesem Blog verwenden werden, ist dieser Datensatz von Kaggle, der 16240 Oberteile für Frauen mit einer Auflösung von 256*192 enthält.
Voraussetzungen
Bevor Sie sich in die Arbeit mit StyleGAN unter Verwendung von PyTorch stürzen, stellen Sie sicher, dass Sie die folgenden Voraussetzungen erfüllen:
-
Grundkenntnisse im Deep Learning
Verständnis von konvolutionellen neuronalen Netzen (CNNs).
Vertrautheit mit Generative Adversarial Networks (GANs), einschließlich Konzepte wie Generator, Diskriminator und adversarische Verluste. -
Hardware-Anforderungen
Eine leistungsstarke GPU (NVIDIA empfohlen) für schnelleres Training und Inferenz.
Installiertes CUDA-Toolkit zur GPU-Beschleunigung (cudaundcudnn). -
Vertrautheit mit StyleGAN
Es ist hilfreich, die ursprünglichen StyleGAN oder StyleGAN2 Papiere gelesen zu haben, um die Architekturverbesserungen und Schlüsselkonzepte zu verstehen.
Laden Sie alle Abhängigkeiten, die wir brauchen
Wir werden zunächst torch importieren, da wir PyTorch verwenden werden, und davon nn importieren. Das wird uns helfen, Netzwerke zu erstellen und zu trainieren, und uns auch erlaubt, optim zu importieren, ein Paket, das verschiedene Optimierungs-Algorithmen implementiert (z.B. sgd, adam, …). Von torchvision importieren wir datasets und transforms, um die Daten vorzubereiten und einige Transformationen anzuwenden.
Wir werden functional als F von torch.nn importieren, um die Bilder mit interpolate hochzurechnen, DataLoader von torch.utils.data, um Mini-Batch-Größen zu erstellen, save_image von torchvision.utils, um einige Fake-Beispiele zu speichern, und log2 von math, weil wir die inverse Darstellung der Potenz von 2 benötigen, um die adaptive Mini-Batch-Größe abhängig der Ausgabelösung zu implementieren, NumPy für lineare Algebra, os für die Interaktion mit dem Betriebssystem, tqdm, um Fortschrittsbalken anzuzeigen, und schließlich matplotlib.pyplot, um die Ergebnisse anzuzeigen und sie mit den echten zu vergleichen.
Hyperparameter
- Initialisiere das DATASET durch den Pfad der echten Bilder.
- Gebe die Startgröße für das Training bei 8×8 Bildgröße an.
- Initialisiere das Gerät mit Cuda, falls verfügbar, andernfalls mit CPU, und den Lernrate auf 0.001.
- Die Batch-Größe wird je nach der Auflösung der zu generierenden Bilder unterschiedlich sein, daher initialisieren wir BATCH_SIZES mit einer Liste von Zahlen, die du abhängig von deinem VRAM ändern kannst.
- Initialisiere image_size auf 128 und CHANNELS_IMG auf 3, weil wir 128×128 RGB-Bilder generieren werden.
- In der ursprünglichen Arbeit initialisieren sie Z_DIM, W_DIM und IN_CHANNELS mit 512, aber ich initialisiere sie stattdessen mit 256, um weniger VRAM zu verwenden und das Training zu beschleunigen. Wir könnten vielleicht sogar bessere Ergebnisse erzielen, wenn wir sie verdoppeln.
- Für StyleGAN können wir jede der GAN-Verlustfunktionen verwenden, die wir wollen,also verwende ich WGAN-GP aus dem Papier Improved Training of Wasserstein GANs. Diese Verlustfunktion enthält einen Parameter namens λ und es ist üblich, λ = 10 zu setzen.
- Initialisiere PROGRESSIVE_EPOCHS mit 30 für jede Bildgröße.
Datenlader abrufen
Jetzt erstellen wir eine Funktion get_loader, um:
- Einige Transformationen auf die Bilder anzuwenden (die Bilder auf die gewünschte Auflösung verkleinern, sie in Tensoren umwandeln, dann einige Erweiterungen anwenden und schließlich normalisieren, sodass alle Pixel im Bereich von -1 bis 1 liegen).
- Die aktuelle Batchgröße zu identifizieren, indem die Liste BATCH_SIZES verwendet wird, und als Index die ganzzahlige Darstellung der inverse Potenz von 2 der Bildgröße/4 zu nehmen. Und das ist tatsächlich, wie wir die adaptive Minibatch-Größe abhängig der Ausgabelösung implementieren.
- Das Dataset vorzubereiten, indem ImageFolder verwendet wird, weil es bereits in einer schönen Weise strukturiert ist.
- Erstellen Sie Mini-Batch-Größen mit DataLoader, der den Datensatz und die Batch-Größe übernimmt und die Daten mischt.
- Schließlich geben Sie den Loader und den Datensatz zurück.
Modellimplementierung
Jetzt implementieren wir den StyleGAN1-Generator und -Diskriminator (ProGAN und StyleGAN1 haben die gleiche Diskriminatorarchitektur) mit den Schlüsselattributen aus dem Papier. Wir werden versuchen, die Implementierung kompakt zu gestalten, aber auch lesbar und verständlich zu halten. Insbesondere die folgenden Schlüsselpunkte:
- Rauschabbildungsnetzwerk
- Adaptive Instanznormalisierung (AdaIN)
- Progressives Wachsen
In diesem Tutorial werden wir nur Bilder mit StyleGAN1 generieren und nicht die Stil mieszene und stochastische Variation implementieren, aber das sollte nicht schwer sein.
Definieren wir eine Variable mit dem Namen factors, die die Zahlen enthält, die mit IN_CHANNELS multipliziert werden, um die gewünschte Anzahl von Kanälen in jeder Bildauflösung zu erhalten.
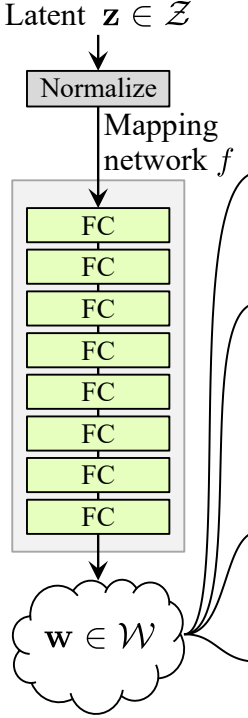
Rauschabbildungsnetzwerk
Das RauschORKartierungsnetzwerk nimmt Z und führt es durch acht vollständig verbundene Schichten, die durch einige Aktivierung getrennt sind. Und vergessen Sie nicht, die Lernrate zu equalisieren, wie die Autoren in ProGAN (ProGAN und StyleGan von denselben Forschern verfasst) tun.
Lassen Sie uns zunächst eine Klasse mit dem Namen WSLinear (gewichtete skalierte Lineare) erstellen, die von nn.Module erben wird.
- In der init-Teil geben wir in_features und out_channels weiter. Erstellen Sie eine lineare Ebene, dann definieren wir eine Skalierung, die gleich dem Quadratwurzel von 2 geteilt durch in_features ist, wir kopieren den Bias der aktuellen Spaltenschicht in eine Variable, weil wir den Bias der linearen Schicht nicht skalieren möchten, dann entfernen wir ihn, schließlich initialisieren wir die lineare Ebene.
- In der forward-Teil senden wir x und alles, was wir tun werden, ist x mit der Skalierung zu multiplizieren und den Bias nach dem Umformen hinzuzufügen.
Jetzt erstellen wir die MappingNetwork-Klasse.
- In der init-Teil senden wir z_dim und w_din, und wir definieren das Netzwerk-Mapping, das zuerst z_dim normalisiert, gefolgt von acht WSLInear und ReLU als Aktivierungsfunktionen.
- In der forward-Teil geben wir das Netzwerk-Mapping zurück.
Anpassende Instanznormalisierung (AdaIN)
Jetzt erstellen wir die AdaIN-Klasse
- In der INIT-Teil senden wir Kanäle, w_dim und initialisieren instance_norm, das der Instanznormalisierungsteil sein wird, und initialisieren style_scale und style_bias, die die adaptiven Teile mit WSLinear sein werden, die das Noise Mapping Network W in Kanäle abbilden.
- In der FORWARD-Pass senden wir x, wenden die Instanznormalisierung darauf an und geben style_scale * x + style_bias zurück.
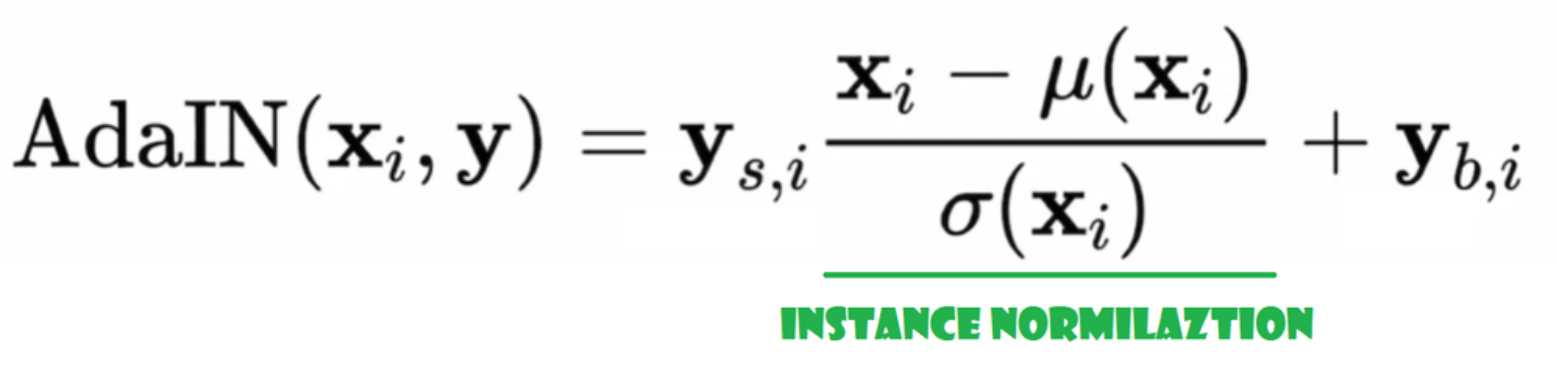
Geräusch injizieren
Jetzt erstellen wir die Klasse InjectNoise, um das Geräusch in den Generator zu injizieren
- In der INIT-Teil haben wir Kanäle gesendet und das Gewicht aus einer zufälligen Normalverteilung initialisiert und nn.Parameter verwendet, damit diese Gewichte optimiert werden können
- In der FORWARD-Teil senden wir ein Bild x und geben es mit zufälligem Geräusch hinzugefügt zurück
Hilfreiche Klassen
Die Autoren haben StyleGAN auf der offiziellen Implementierung von ProGAN von Karras et al aufgebaut, sie verwenden die gleiche Diskriminatorarchitektur, adaptive Minibatch-Größe, Hyperparameter usw. Daher gibt es viele Klassen, die von der ProGAN-Implementierung gleich bleiben.
In diesem Abschnitt werden wir die Klassen erstellen, die von der ProGAN-Architektur nicht geändert werden.
Im folgenden Code-Schnipptel finden Sie die Klasse WSConv2d (gewichtete skalierte Konvolutionslage) für die Equalized Learning Rate für die Konvolutionslagen.
Im folgenden Code-Schnipptel finden Sie die Klasse PixelNorm zur Normalisierung von Z vor dem Noise Mapping Network.
Im folgenden Code-Schnipptel finden Sie die Klasse ConvBlock, die uns dabei hilft, den Diskriminator zu erstellen.
Im folgenden Code-Schnipptel finden Sie die Klasse Discriminatowich, die derselben wie in ProGAN ist.
Generator
In der Generatorarchitektur haben wir einige Muster, die sich wiederholen, therefore erstellen wir zuerst eine Klasse dafür, um unseren Code so sauber wie möglich zu gestalten. Nennen wir die Klasse GenBlock, die von nn.Module erblickt.
- In der init-Methode übergeben wir in_channels, out_channels und w_dim, initialisieren dann conv1 mit WSConv2d, der in_channels auf out_channels abbildet, conv2 mit WSConv2d, der out_channels auf out_channels abbildet, leaky mit Leaky ReLU mit einer Neigung von 0.2, wie sie im Papier verwenden, inject_noise1 und inject_noise2 mit InjectNoise, adain1 und adain2 mit AdaIN.
- In der forward-Methode übergeben wir x und leiten es durch conv1, dann durch inject_noise1 mit leaky, normalisieren es mit adain1 und leiten es erneut durch conv2, dann durch inject_noise2 mit leaky und normalisieren es mit adain2. Und schließlich geben wir x zurück.
Jetzt haben wir alles, was wir brauchen, um den Generator zu erstellen.
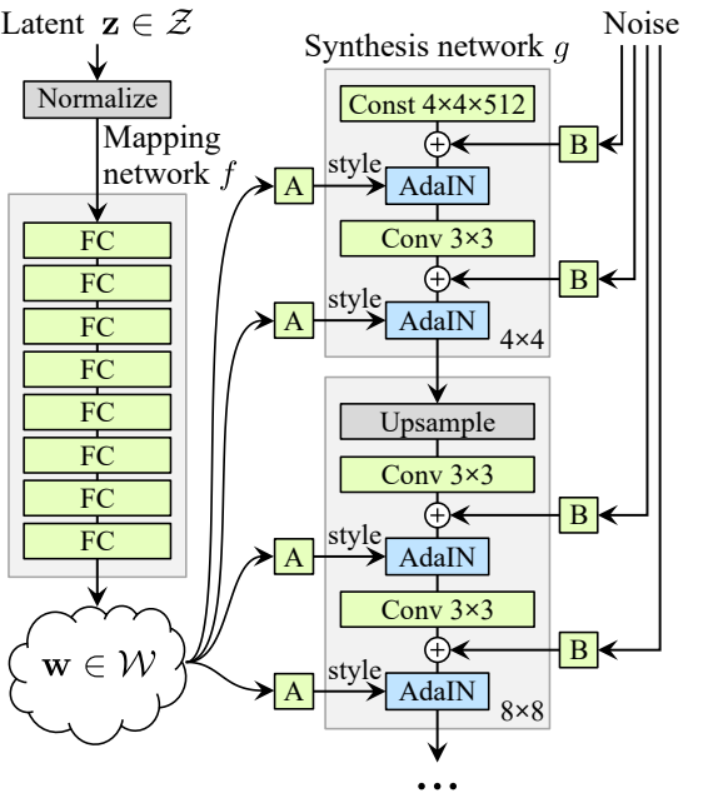
- Im init-Teil initialisieren wir die ‘starting_constant’ durch einen Tensor mit der Konstanten 4 x 4 (x 512 Kanälen für denOriginalartikel und 256 in unserem Fall), der durch eine Iteration des Generators,abbildung durch ‘MappingNetwork’, initial_adain1, initial_adain2 durch AdaIN, initial_noise1, initial_noise2 durch InjectNoise, initial_conv durch eine Konvolutionslage, die in_channels auf sich selbst abbildet, leaky durch Leaky ReLU mit einer Neigung von 0.2, initial_rgb durch WSConv2d, die in_channels auf img_channelsabbildet, was für RGB 3 ist, prog_blocks durch ModuleList(), die alle progressiven Blöcke enthalten wird (wir geben die Kanäle der Konvolutionseingabe/Ausgabe durch Multiplikation mit in_channels an, das im Artikel 512 und in unserem Fall 256 ist, mit Faktoren), und rgb_blocks durch ModuleList(), die alle RGB-Blöcke enthalten wird.
- Um neue Ebenen einblenden zu können (ein ursprüngliches Element von ProGAN), fügen wir den fade_in-Teil hinzu, dem wir alpha, scaled und generated übergeben, und wir geben [tanh(alpha∗generated+(1−alpha)∗upscale)] zurück. Der Grund, warum wir tanh verwenden, ist, dass dies die Ausgabe (das generierte Bild) sein wird und wir möchten, dass die Pixel im Bereich zwischen 1 und -1 liegen.
- In der vorward-Teil senden wir das Rauschen (Z_dim), den Alpha-Wert, der während des Trainings langsam einblendet (Alpha liegt zwischen 0 und 1), und die Schritte, die die aktuelle Auflösung sind, mit der wir arbeiten. Wir übergeben x in die Karte, um den intermediären Rauschenvektor W zu erhalten, übergeben starting_constant an initial_noise1, wenden es an und initial_adain1 für W an, dann geben wir es in initial_conv weiter, und wieder.addieren wir initial_noise2 für es mit leaky als Aktivierungsfunktion und wenden es und W initial_adain2 an. Dann überprüfen wir, ob steps = 0 ist, wenn ja, dann möchten wir es nur durch das initial RGB laufen lassen und wir sind fertig, andernfalls wiederholen wir die Anzahl der Schritte und in jeder Schleife skalieren wir hoch (upscaled) und laufen durch den progressiven Block, der dieser Auflösung entspricht (out). Am Ende geben wir fade_in zurück, das alpha, final_out und final_upscaled nach der Abbildung auf RGB nimmt.
Utils
In dem folgenden Code-Schnipsel finden Sie die Funktion generate_examples, die den Generator gen, die Anzahl der Schritte zur Identifizierung der aktuellen Auflösung und eine Zahl n=100 akzeptiert. Das Ziel dieser Funktion ist es, n gefälschte Bilder zu generieren und diese als Ergebnis zu speichern.
In dem folgenden Code-Schnipsel finden Sie die Funktion gradient_penalty für die WGAN-GP-Verlustfunktion.
Trainingsfunktion
Für die Trainingsfunktion übermitteln wir den Kritiker (der Diskriminator), den Generator gen, den Loader, den Datensatz, den Schritt, Alpha und den Optimierer für den Generator und den Kritiker.
Wir beginnen mit einer Schleife über alle Mini-Batch-Größen, die wir mit dem DataLoader erstellen, und nehmen nur die Bilder, da wir keine Label benötigen.
Dann richten wir das Training für den Diskriminator\Critic ein, wenn wir E(critic(real)) – E(critic(fake)) maximieren möchten. Diese Gleichung bedeutet, wie gut der Kritiker zwischen realen und gefälschten Bildern unterscheiden kann.
Nachdem wir das setup für den Generator durchgeführt haben, wenn wir E(critic(fake)).
maximieren möchten, aktualisieren wir die Schleife und den Alpha-Wert für fade_in und stellen sicher, dass er zwischen 0 und 1 liegt, und geben ihn zurück.
Training
Jetzt, da wir alles haben, lassen wir uns an die Arbeit machen und unseren StyleGAN trainieren.
Wir beginnen mit der Initialisierung des Generators, des Diskriminators/Kritikers und der Optimierer,然后将 Generator und Kritiker in den Trainingsmodus versetzen, dann iterieren wir über PROGRESSIVE_EPOCHS und rufen in jeder Schleife die Trainingsfunktion die Anzahl der Epochen auf, erstellen einige fake-Bilder und speichern sie mithilfe der generate_examples-Funktion und schreiten schließlich zur nächsten Bildauflösung vor.
Ergebnis
Hoffentlich können Sie alle Schritte folgen und eine gute Vorstellung davon bekommen, wie man StyleGAN auf die richtige Weise implementiert.Nun schauen wir uns die Ergebnisse an, die wir nach dem Training dieses Modells in diesem Datenbestand mit einer Auflösung von 128*x 128 erzielen.

Schlussfolgerung
In diesem Artikel haben wir eine saubere, einfache und lesbare Implementierung von StyleGAN1 von Grund auf mit PyTorch erstellt. Wir haben die Originalarbeit so nah wie möglich nachgeahmt, sodass die Implementierung, wenn Sie die Arbeit lesen, Pretty viel identisch sein sollte.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch