













Introduction
Cet article porte sur l’un des meilleurs GANs actuels, StyleGAN tiré de l’article A Style-Based Generator Architecture for Generative Adversarial Networks, nous allons en faire une implémentation propre, simple et lisible en utilisant PyTorch, et essayer de reproduire l’article original aussi fidèlement que possible, de sorte que si vous lisez l’article, l’implémentation devrait être à peu près identique.
Le jeu de données que nous allons utiliser dans ce blog est ce dataset de Kaggle qui contient 16240 vêtements supérieurs pour les femmes avec une résolution de 256*192.
Prérequis
Avant de vous plonger dans le travail avec StyleGAN en utilisant PyTorch, assurez-vous que vous avez les prérequis suivants:
- .
Connaissances de base en apprentissage profond
Compréhension des réseaux de neurones convolutifs (CNN).
Familiarité avec les réseaux adversaires génératifs (GAN), y compris des concepts tels que le générateur, le discriminateur et la perte adversaire. -
Exigences matérielles
Une GPU puissante (NVIDIA recommandée) pour un entraînement et une inférence plus rapides.
Kit CUDA installé pour l’accélération GPU (cudaetcudnn). -
Familiarité avec StyleGAN
Il est utile d’avoir lu les articles originaux StyleGAN ou StyleGAN2 pour comprendre les améliorations d’architecture et les concepts clés.
Charger toutes les dépendances dont nous avons besoin
Nous allons d’abord importer torch puisque nous utiliserons PyTorch, et à partir de là, nous importerons nn. Cela nous aidera à créer et à entraîner les réseaux, et nous permettra également d’importer optim, un package qui implémente divers algorithmes d’optimisation (par exemple, sgd, adam,…). De torchvision, nous importons datasets et transforms pour préparer les données et appliquer certaines transformations.
Nous allons importer functional comme F de torch.nn pour upsample les images en utilisant interpolate, DataLoader de torch.utils.data pour créer des tailles de mini-lots, save_image de torchvision.utils pour enregistrer quelques échantillons faux, et log2 de math car nous avons besoin de la représentation inverse de la puissance de 2 pour implémenter la taille de mini-lot adaptative en fonction de la résolution de sortie, NumPy pour l’algèbre linéaire, os pour l’interaction avec le système d’exploitation, tqdm pour afficher les barres de progression, et enfin matplotlib.pyplot pour montrer les résultats et les comparer avec les vrais.
Hyperparamètres
- Initialiser le DATASET par le chemin des images réelles.
- Spécifier le démarrage de l’entraînement à la taille d’image 8×8.
- Initialiser le périphérique par Cuda s’il est disponible et par CPU sinon, et le taux d’apprentissage par 0,001.
- La taille du lot sera différente en fonction de la résolution des images que nous voulons générer, donc nous initialisons BATCH_SIZES par une liste de nombres, vous pouvez les modifier en fonction de votre VRAM.
- Initialiser image_size par 128 et CHANNELS_IMG par 3 car nous allons générer des images RGB de 128 par 128.
- Dans l’article original, ils initialisent Z_DIM, W_DIM et IN_CHANNELS à 512, mais je les initialise à 256 plutôt pour utiliser moins de VRAM et accélérer l’entraînement. Nous pourrions peut-être même obtenir de meilleurs résultats si nous les doubillions.
- Pour StyleGAN, nous pouvons utiliser n’importe laquelle des fonctions de perte GAN que nous voulons, donc j’utilise WGAN-GP de l’article Improved Training of Wasserstein GANs. Cette perte contient un paramètre nommé λ et il est commun de régler λ = 10.
- Initialiser PROGRESSIVE_EPOCHS à 30 pour chaque taille d’image.
Obtenir le chargeur de données
Jetzt erstellen wir eine Funktion get_loader, um :
- Appliquer certaines transformations aux images (redimensionner les images à la résolution que nous voulons, les convertir en tenseurs, puis appliquer certaines augmentations, et enfin normaliser les pixels pour qu’ils varient de -1 à 1).
- Identifier la taille actuelle du lot en utilisant la liste BATCH_SIZES, et prendre comme index le nombre entier de la représentation inverse de la puissance de 2 de image_size/4. Et c’est ainsi que nous mettons en œuvre la taille de lot adaptative en fonction de la résolution de sortie.
- Préparer le jeu de données en utilisant ImageFolder car il est déjà structuré de manière agréable.
- Créer des tailles de mini-lots en utilisant DataLoader qui prennent le jeu de données et la taille du lot avec mélange des données.
- Finalement, retourner le chargeur et le jeu de données.
Implémentation des modèles
Jetzt implementieren wir den StyleGAN1 générateur et discriminateur (ProGAN et StyleGAN1 ont la même architecture de discriminateur) avec les attributions clés de l’article. Nous essayerons de rendre l’implémentation compacte mais aussi lisible et compréhensible. Plus précisément, les points clés :
- Réseau de cartographie du bruit
- Normalisation adaptative d’instance (AdaIN)
- Croissance progressive
Dans ce tutoriel, nous ne générerons que des images avec StyleGAN1, et ne mettrons pas en œuvre le mélange de styles et la variation stochastique, mais cela ne devrait pas être difficile à faire.
Reprenons une variable avec le nom factors qui contient les nombres qui multiplieront IN_CHANNELS pour avoir le nombre de canaux que nous voulons dans chaque résolution d’image.
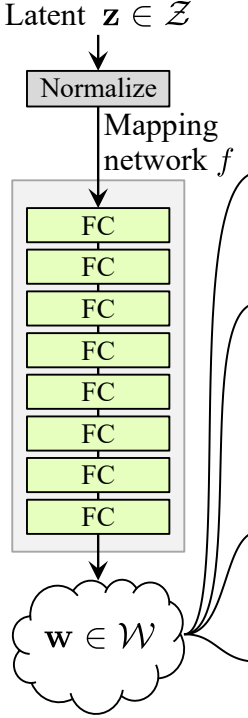
Réseau de cartographie du bruit
Le réseau de cartographie du bruit prend Z et le fait passer par huit couches entièrement connectées, séparées par une activation.
Et n’oubliez pas d’égaliser le taux d’apprentissage comme le font les auteurs dans ProGAN (ProGAN et StyleGan rédigés par les mêmes chercheurs).
- Commençons par construire une classe nommée WSLinear (weighted scaled Linear) qui héritera de nn.Module.Dans la partie init, nous envoyons in_features et out_channels. Créons une couche linéaire, puis nous définissons un scale qui sera égal à la racine carrée de 2 divisée par in_features, nous copions le biais de la couche colonne actuelle dans une variable car nous ne voulons pas que le biais de la couche linéaire soit scalaire, puis nous le retirons, enfin, nous initialisons la couche linéaire.
- Dans la partie forward, nous envoyons x et tout ce que nous allons faire, c’est multiplier x par scale et ajouter le biais après l’avoir redimensionné.
Jetzt erstellen wir die MappingNetwork-Klasse.
- Dans la partie init, nous envoyons z_dim et w_din, et nous définissons le réseau de cartographie qui commence par normaliser z_dim, suivi de huit WSLInear et ReLU en tant que fonctions d’activation.
- Dans la partie forward, nous renvoyons le réseau de cartographie.
Normalisation Adaptative Instance (AdaIN)
Jetzt erstellen wir die AdaIN-Klasse
- Dans la partie init, nous envoyons les canaux, w_dim, et nous initialisons instance_norm qui sera la partie de normalisation par instance, et nous initialisons style_scale et style_bias qui seront les parties adaptatives avec WSLinear qui mappe le réseau de cartographie du bruit W en canaux.
- Dans la passe forward, nous envoyons x, appliquons la normalisation par instance pour celui-ci, et retournons style_sclate * x + style_bias.
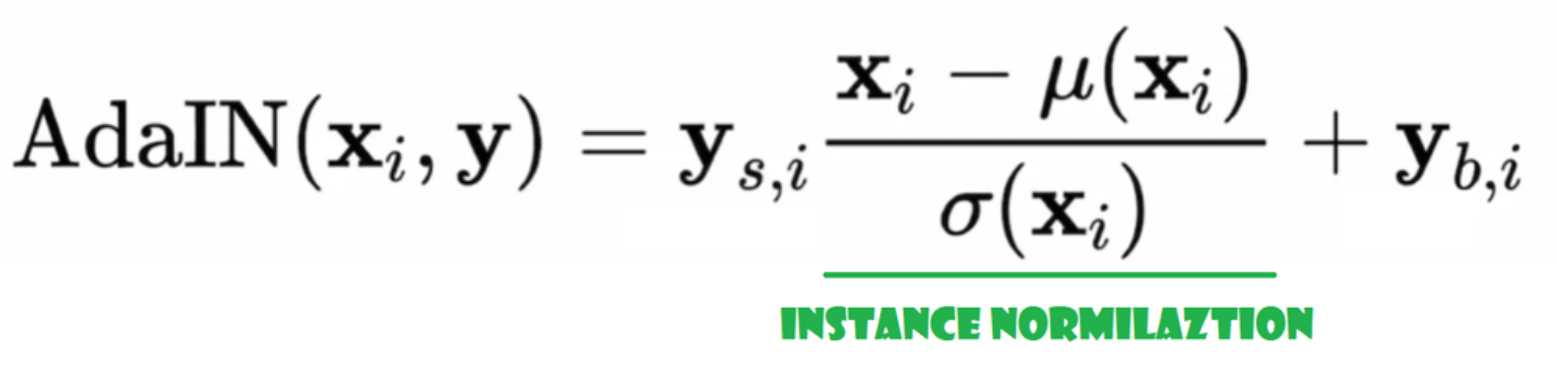
Inject Noise
Jetzt erstellen wir die Klasse InjectNoise, um den Generator mit Noise zu injizieren
- Dans la partie init, nous envoyons les canaux et nous initialisons le poids à partir d’une distribution normale aléatoire et nous utilisons nn.Parameter afin que ces poids puissent être optimisés
- Dans la partie forward, nous envoyons une image x et nous la retournons avec du bruit aléatoire ajouté
classes utiles
Les auteurs ont construit StyleGAN sur l’implémentation officielle de ProGAN par Karras et al., ils utilisent la même architecture de discriminateur, taille de mini-lot adaptative, hyperparamètres, etc. Il y a donc beaucoup de classes qui restent les mêmes que dans l’implémentation de ProGAN.
Dans cette section, nous allons créer les classes qui ne changent pas de l’architecture de ProGAN.
Dans l’extrait de code ci-dessous, vous pouvez trouver la classe WSConv2d (couche de convolution pondérée et échelonnée) pour Equalized Learning Rate pour les couches de convolution.
Dans l’extrait de code ci-dessous, vous pouvez trouver la classe PixelNorm pour normaliser Z avant le réseau de cartographie du bruit.
Dans l’extrait de code ci-dessous, vous pouvez trouver la classe ConvBlock qui nous aidera à créer le discriminant.
Dans l’extrait de code ci-dessous, vous pouvez trouver la classe Discriminatowich qui est la même que dans ProGAN.
Générateur
Dans l’architecture du générateur, nous avons des motifs qui se répètent, donc créons d’abord une classe pour cela afin de rendre notre code aussi propre que possible. Nommons cette classe GenBlock qui héritera de nn.Module.
- Dans la partie init, nous envoyons in_channels, out_channels et w_dim, puis nous initialisons conv1 avec WSConv2d qui mappe in_channels vers out_channels, conv2 avec WSConv2d qui mappe out_channels vers out_channels, leaky avec Leaky ReLU avec une pente de 0,2 comme ils l’utilisent dans le papier, inject_noise1 et inject_noise2 avec InjectNoise, adain1 et adain2 avec AdaIN.
- Dans la partie forward, nous envoyons x, et nous le faisons passer par conv1 puis par inject_noise1 avec leaky, puis nous le normalisons avec adain1, et à nouveau nous passons celui-ci dans conv2 puis par inject_noise2 avec leaky et nous le normalisons avec adain2. Et enfin, nous retournons x.
Jetzt haben wir alles, was wir brauchen, um den Generator zu erstellen.
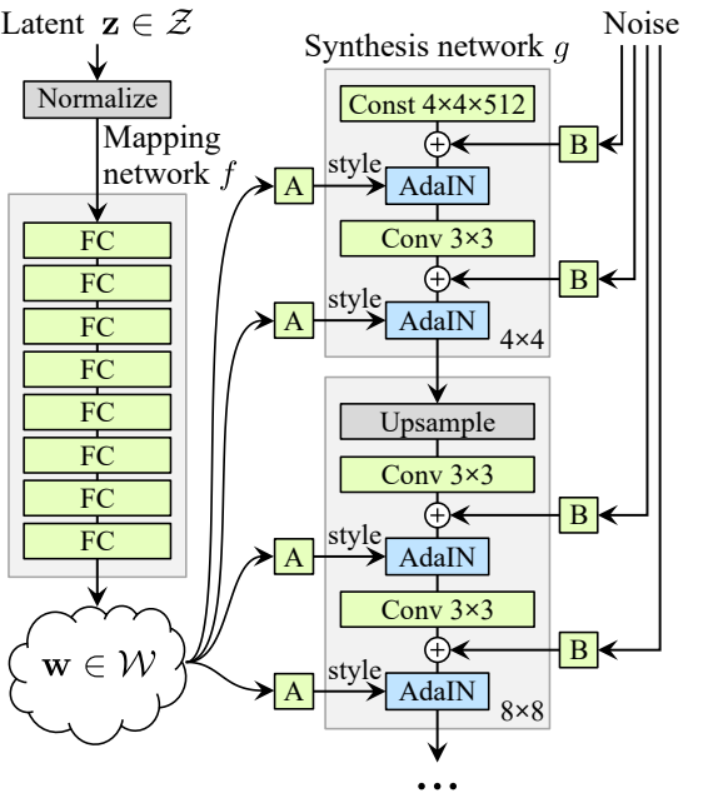
- dans la partie init, initialisons ‘starting_constant’ par un tenseur constant 4 x 4 (x 512 canaux pour l’article original, et 256 dans notre cas) qui est passé par une itération du générateur, mappé par ‘MappingNetwork’, initial_adain1, initial_adain2 par AdaIN, initial_noise1, initial_noise2 par InjectNoise, initial_conv par une couche de convolution qui mappe in_channels en lui-même, leaky par Leaky ReLU avec une pente de 0.2, initial_rgb par WSConv2d qui mappe in_channels en img_channels qui est 3 pour RGB, prog_blocks par ModuleList() qui contiendra tous les blocs progressifs (nous indiquons les canaux d’entrée/sortie de la convolution par multiplication de in_channels qui est 512 dans l’article et 256 dans notre cas par des facteurs), et rgb_blocks par ModuleList() qui contiendra tous les blocs RGB.
- Pour faire apparaître de nouvelles couches (un composant d’origine de ProGAN), nous ajoutons la partie fade_in, à laquelle nous envoyons alpha, scaled et generated, et nous retournons [tanh(alpha∗generated+(1−alpha)∗upscale)], La raison pour laquelle nous utilisons tanh est que cela sera la sortie (l’image générée) et nous voulons que les pixels soient dans une plage comprise entre 1 et -1.
- Dans la partie avancée, nous envoyons le bruit (Z_dim), la valeur alpha qui va s’estomper progressivement pendant l’entraînement (alpha est entre 0 et 1), et les étapes qui est le numéro de la résolution actuelle avec laquelle nous travaillons, nous passons x dans la carte pour obtenir le vecteur de bruit intermédiaire W, nous passons starting_constant à initial_noise1, l’appliquons et pour W initial_adain1, puis nous le passons dans initial_conv, et de nouveau nous ajoutons initial_noise2 pour lui avec leaky comme fonction d’activation, et l’appliquons pour lui et W initial_adain2. Ensuite, nous vérifions si steps = 0, si c’est le cas, alors tout ce que nous voulons faire, c’est le faire passer par le initial RGB et c’est tout, sinon, nous bouclons sur le nombre d’étapes, et à chaque boucle nous faisons de l’upscaling (upscaled) et nous passons par le bloc progressif qui correspond à cette résolution (out). À la fin, nous retournons fade_in qui prend alpha, final_out, et final_upscaled après l’avoir cartographié en RGB.
Utils
Dans l’extrait de code ci-dessous, vous pouvez trouver la fonction generate_examples qui prend le générateur gen, le nombre de étapes pour identifier la résolution actuelle, et un nombre n=100. Le but de cette fonction est de générer n images factices et de les enregistrer comme résultat.
Dans l’extrait de code ci-dessous, vous pouvez trouver la fonction gradient_penalty pour la perte WGAN-GP.
Fonction d’entraînement
Pour la fonction d’entraînement, nous envoyons le critique (qui est le discriminant), gen (générateur), le chargeur, le jeu de données, l’étape, alpha, et l’optimiseur pour le générateur et pour le critique.
Nous commençons par boucler sur toutes les tailles de mini-lots que nous créons avec le DataLoader, et nous prenons seulement les images car nous n’avons pas besoin d’un étiquetage.
Ensuite, nous mettons en place l’entraînement pour le discriminant/Critique lorsque nous voulons maximiser E(critique(réel)) – E(critique(factice)). Cette équation signifie combien le critique peut distinguer entre des images réelles et factices.
Après cela, nous configurons l’entraînement du générateur lorsque nous voulons maximiser E(critic(fake)).
Finalement, nous mettons à jour la boucle et la valeur alpha pour fade_in et nous nous assurons qu’elle est comprise entre 0 et 1, puis nous la retournons.
Entraînement
Jetzt da wir alles avons, mettons-le ensemble pour entraîner notre StyleGAN.
Nous commençons par initialiser le générateur, le discriminateur/critique et les optimiseurs, puis passons le générateur et le critique en mode entraînement, puis bouclons sur PROGRESSIVE_EPOCHS, et dans chaque boucle, nous appelons la fonction train un nombre d’époques, puis nous générons quelques images factices et les sauvegardons, en utilisant la fonction generate_examples, et enfin, nous passons à la résolution d’image suivante.
Résultat
En espérant que vous serez en mesure de suivre toutes les étapes et d’obtenir une bonne compréhension de la manière d’implémenter StyleGAN de la bonne façon. Maintenant, voyons les résultats que nous obtenons après avoir entraîné ce modèle sur ce jeu de données avec une résolution de 128*x 128.

Conclusion
Dans cet article, nous réalisons une implémentation propre, simple et lisible de StyleGAN1 à partir de zéro en utilisant PyTorch. nous replicons le papier original le plus fidèlement possible, donc si vous lisez le papier, l’implémentation devrait être presque identique.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch