













導入
この記事では、現在最も優れたGANの一つであるStyleGANについて説明します。論文「A Style-Based Generator Architecture for Generative Adversarial Networks」に基づいて、PyTorchを使用してクリーンでシンプルで読みやすい実装を行い、元の論文を可能な限り再現します。したがって、論文を読んだ場合、この実装は非常に似ているはずです。
このブログで使用するデータセットは、Kaggleから取得したデータセットで、256*192の解像度を持つ女性の上着16240点が含まれています。
前提知識
PyTorchを使用してStyleGANを扱う前に、以下の前提知識を確認してください:
-
ディープラーニングの基本知識
コンボリューショナルニューラルネットワーク(CNN)の理解。
生成対向ネットワーク(GANs)の熟悉、生成器、判別器、対向損失などの概念。 -
ハードウェア要件
高速なトレーニングと推論のための強力なGPU(NVIDIA推奨)。
GPU加速のためのCUDAツールキットがインストールされていること(cudaおよびcudnn)。 -
StyleGANに精通していること
アーキテクチャの改善と主要な概念を理解するために、オリジナルのStyleGANまたはStyleGAN2の論文を読んでおくと役立つ。
必要なすべての依存関係を読み込む
まず、PyTorchを使用するためtorchをインポートし、nnをインポートします。これにより、ネットワークの作成と訓練が可能になり、最適化アルゴリズム(例:SGD、Adamなど)を実装するためのoptimパッケージをインポートできます。torchvisionからは、データの準備と変換を適用するためのdatasetsとtransformsをインポートします。
torch.nnからfunctionalをFとしてインポートし、画像をインターポレートしてアップサンプリングするため、DataLoaderをtorch.utils.dataからインポートし、いくつかのfakeサンプルを保存するためのsave_imageをtorchvision.utilsからインポートし、2のべき乗の逆表現を implementするためにmathのlog2をインポートし、線形代数のためのNumPyをインポートし、オペレーティングシステムとのインタラクションのためのosをインポートし、プログレスバーを表示するためのtqdmをインポートし、最後に結果を表示し、実際のものと比較するためのmatplotlib.pyplotをインポートします。
ハイパーパラメータ
- 実際の画像のパスでDATASETを初期化します。
- 画像サイズ8×8でトレーニングを開始指定します。
- Cudaが利用可能な場合はデバイスを初期化し、CPUの場合はそれに従い、学習率を0.001に設定します。
- 生成したい画像の解像度に応じてバッチサイズが異なるため、BATCH_SIZESを数値のリストで初期化し、VRAMに応じて変更できます。
- 画像サイズを128に初期化し、CHANNELS_IMGを3に初期化します。なぜなら、128×128のRGB画像を生成するからです。
- 元の論文では、Z_DIM、W_DIM、IN_CHANNELSを512として初期化していますが、私はVRAMの使用量を減らし、トレーニングを高速化するために256として初期化します。それを倍にすると、より良い結果が得られるかもしれません。
- StyleGANでは、私たちが望むGANの損失関数を使用することができますので、私は論文Improved Training of Wasserstein GANsのWGAN-GPを使用しています。この損失にはλという名前のパラメータがあり、λ = 10に設定することが一般的です。
- 各画像サイズごとにPROGRESSIVE_EPOCHSを30として初期化します。
データローダーを取得する
では、get_loaderという関数を作成して:
- 画像にいくつかの変換を適用します(画像を希望する解像度にリサイズし、テンソルに変換し、いくつかの増加を適用し、最後にすべてのピクセルを-1から1の範囲に正規化します)。
- 現在のバッチサイズをリストBATCH_SIZESを使って特定し、画像サイズ/4の2の逆数の整数指数をインデックスとして取り、これが実際にアダプティブミニバッチサイズを出力解像度に基づいて実装する方法です。
- ImageFolderを使ってデータセットを準備します。なぜなら、それはすでにきれいに構造化されているからです。
- データローダーを使用してミニバッチサイズを作成し、データセットとバッチサイズを指定し、データをシャッフルします。
- 最後に、ローダーとデータセットを返します。
モデルの実装
さて、StyleGAN1のジェネレータとディスクリミネータ(ProGANとStyleGAN1はディスクリミネータのアーキテクチャが同じです)を実装し、論文の主要な特性を取り入れてみましょう。実装をコンパクトにし、同時に読みやすく理解しやすいようにします。特に以下のポイント:
- ノイズマッピングネットワーク
- アダプティブインスタンス正規化(AdaIN)
- 段階的な成長
このチュートリアルでは、StyleGAN1を使用して画像を生成するだけで、スタイルミックスやスト Dichャスティック変動を実装はしませんが、それほど難しいことはありません。
各画像解像度におけるチャネル数を得るためにIN_CHANNELSに乗算する数を含む変数factorsを定義しましょう。
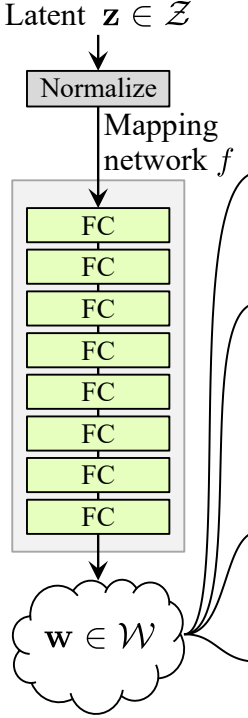
ノイズマッピングネットワーク
ノイズマッピングネットワークはZを取り入れ、8つの完全接続レイヤーに分けてアクティベーションを挟みます。そして、ProGAN(同じ研究者によって記述されたProGANとStyleGan)の作者が行うように、学習率を等価にしてください。
まず、WSLinear(加重スケールリニア)という名前のクラスをnn.Moduleから継承して構築しましょう。
- init部分ではin_featuresとout_channelsを受け取り、リニアレイヤーを作成します。その後、スケールを定義し、それは2の平方根をin_featuresで割った値になります。現在のコラムレイヤーのバイアスを変数にコピーし、リニアレイヤーのバイアスをスケールしないためにその後バイアスを削除し、最後にリニアレイヤーを初期化します。
- forward部分ではxを受け取り、行うこと全心がxにスケールを掛け、リシェイプしたバイアスを加えることです。
次にMappingNetworkクラスを作成しましょう。
- init部分ではz_dimとw_dinを受け取り、ネットワークマッピングを定義します。まずz_dimを正規化し、その後WSLinearとReLUをアクティベーション関数として8回繰り返します。
- forward部分ではネットワークマッピングを返します。
アダプティブインスタンス正規化(AdaIN)
さて、AdaINクラスを作成しましょう。
- initの部分では、チャンネル、w_dimを送信し、インスタンス正規化の部分となるinstance_normを初期化し、スタイルスケールとスタイルバイアスをWSLinearでノイズマッピングネットワークWをチャンネルにマッピングするアダプティブな部分として初期化します。
- forwardパスでは、xを送信し、インスタンス正規化を適用し、style_sclate * x + style_biasを返します。
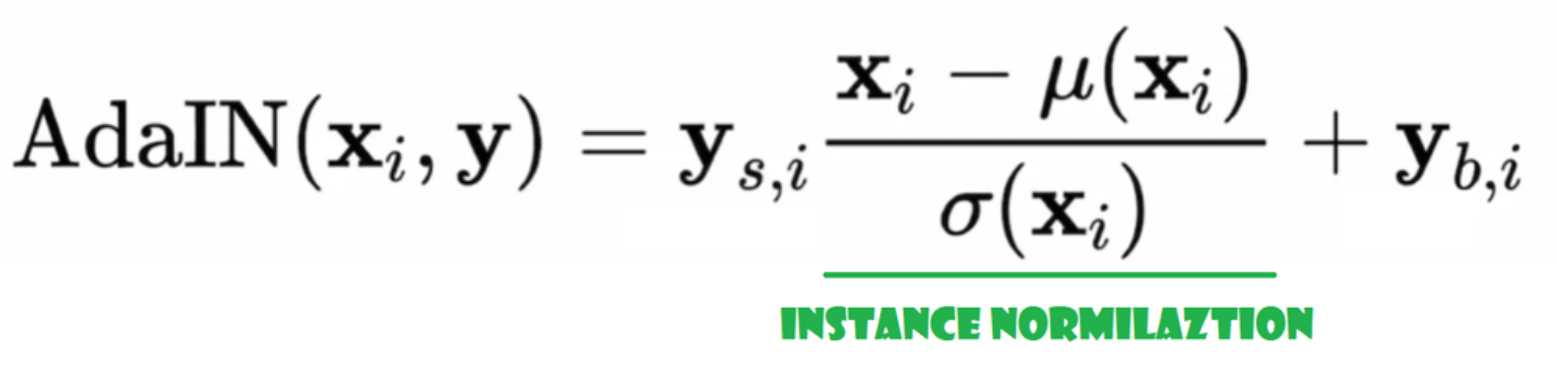
ノイズ注入
さて、ノイズをジェネレーターに注入するためのクラスInjectNoiseを作成しましょう。
- initの部分では、チャンネルを送信し、ランダムな正規分布からの重みを初期化し、nn.Parameterを使用してこれらの重みを最適化できるようにします。
- forwardの部分では、画像xを送信し、ランダムなノイズを追加して返します。
役立つクラス
著者はStyleGANをKarras et alのProGANの公式実装之上に構築し、同じディスクリミネーターのアーキテクチャ、アダプティブミニバッチサイズ、ハイパーパラメータなどを使用しています。したがって、ProGANの実装から変更されていないクラスが多くあります。
この節では、ProGANのアーキテクチャから変更されていないクラスを作成します。
コードスニペット below に、クラス WSConv2d(加重スケーリングコンボリューションレイヤー)を Equalized Learning Rate ための conv レイヤー見つけることができます。
コードスニペット below に、ノイズマッピングネットワークの前に Z を正規化するためのクラス PixelNorm を見つけることができます。
コードスニペット below に、ディスクリミネーターの作成を助けるクラス ConvBock を見つけることができます。
コードスニペット below に、ProGAN と同じディスクリミネータークラス Discriminatowich を見つけることができます。
ジェネレータ
ジェネレータアーキテクチャでは、いくつかのパターンが繰り返されるため、まずそれらのクラスを作成してコードをできるだけクリーンにします。クラス名をGenBlockとし、nn.Moduleから継承します。
- init 部分では、in_channels、out_channels、w_dimを引数として受け取り、WSConv2dを使用してin_channelsをout_channelsにマッピングするconv1を初期化し、WSConv2dを使用してout_channelsをout_channelsにマッピングするconv2を初期化し、論文で使用されている0.2のスロープを持つLeaky ReLUをleakyとして初期化し、InjectNoiseを使用してinject_noise1、inject_noise2を初期化し、AdaINを使用してadain1、adain2を初期化します。
- forward 部分では、xを引数として受け取り、conv1に渡してからinject_noise1とleakyに渡し、adain1で正規化し、その後conv2に渡してからinject_noise2とleakyに渡し、adain2で正規化します。最後に、xを返します。
これで、ジェネレータを作成するために必要なすべてのものが揃いました。
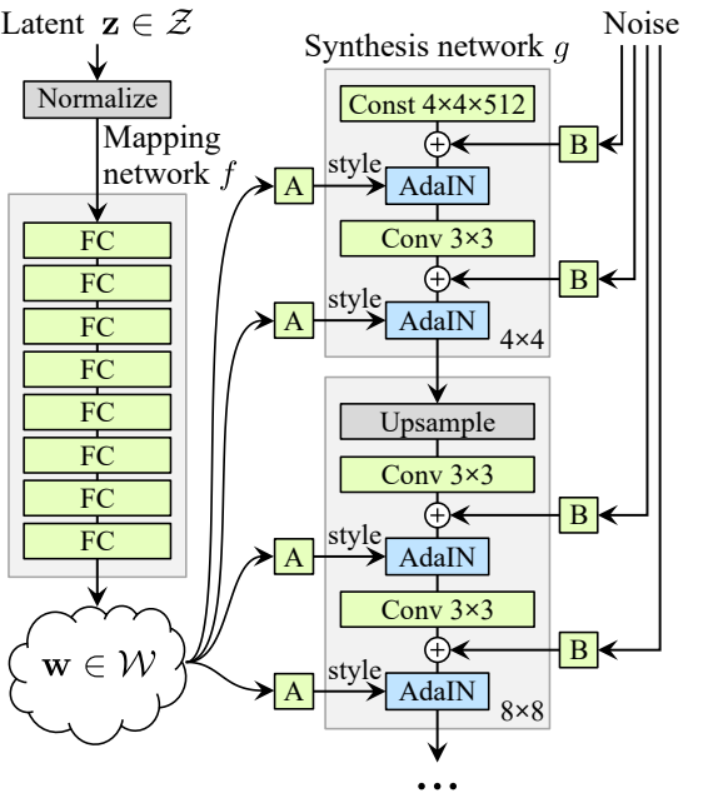
في الجزء init دعونا ن�始化 ‘starting_constant’ باستخدام متجه ثابت 4×4 (x 512 قناة في ورقة الأصل، و 256 في حالتنا) والذي يمر بiteración من الجينيراتور، يُرسم بواسطة ‘MappingNetwork’, initial_adain1، initial_adain2 بواسطة AdaIN، initial_noise1، initial_noise2 بواسطة InjectNoise، initial_conv بواسطة طبقة التحويل التي ترسم في_channels إلى نفسها، leaky بواسطة Leaky ReLU مع انحدار 0.2، initial_rgb بواسطة WSConv2d التي ترسم في_channels إلى img_channels والتي تكون 3 للRGB، prog_blocks بواسطة ModuleList() والذي سيحتوي على جميع الكتل التدرجية (نindicate مدخل/مخرج القنوات التيرجولية بضرب في_channels وهو 512 في الورقة و 256 في حالتنا في العوامل)، و rgb_blocks بواسطة ModuleList() والذي سيحتوي على جميع الكتل RGB.- لإدراج طبقات جديدة (جزء الأصل في ProGAN)، نضيف الجزء fade_in، الذي نرسل إليه alpha، scaled، و generated، ونقوم بإرجاع [tanh(alpha∗generated+(1−alpha)∗upscale)]، السبب في استخدامنا لتانх هو أن سيكون هو المخرج (الصورة المولدة) ونريد أن تكون البكسلات في نطاق بين 1 و -1.
- 前方の部分では、ノイズ(Z_dim)、トレーニング中にゆっくりとフェードインするアルファ値(アルファは0から1の間)、現在取り扱っている解像度のステップ数を送信し、xをマップにパスして中間ノイズベクトルWを取得し、starting_constantをinitial_noise1に適用し、Wにinitial_adain1を適用します。次にinitial_convにパスし、再びleakyアクティベーション関数を使用してinitial_noise2を追加し、それとWにinitial_adain2を適用します。ステップが0かどうかを確認し、0の場合は初期RGBを通過させて終了します。それ以外の場合は、ステップ数をループし、各ループでアップスケーリング(upscaled)を行い、対応する解像度のプログレッシブブロック(out)を通過させます。最後に、フェードイン関数を返します。この関数はアルファ、final_out、RGBにマッピングしたfinal_upscaledを受け取ります。
Utils
以下のコードスニペットに、ジェネレータ gen、現在の解像度を特定するためのステップ数、および n=100 の数字を取る generate_examples 関数が含まれています。この関数の目的は、n個の偽画像を生成し、結果として保存することです。
以下のコードスニペットに、WGAN-GP損失のための gradient_penalty 関数が含まれています。
トレーニング関数
トレーニング関数では、クリティック(ディスクリミネータ)、ジェネレータ gen、ローダー、データセット、ステップ、アルファ、およびジェネレータとクリティックのためのオプティマイザを送信します。
まず、DataLoaderで作成したすべてのミニバッチサイズをループし、画像だけを取り出します。なぜなら、ラベルは必要ないからです。
その後、ディスクリミネータ/Cリティックのトレーニングを設定し、E(critic(real)) – E(critic(fake))を最大化したいときに使用します。この方程式は、クリティックが実際の画像と偽画像をどれだけ区別できるかを意味します。
その後、生成器のトレーニングを設定し、E(critic(fake))。
最終的に、ループを更新し、fade_inのアルファ値を0から1の間に保ち、それを返します。
トレーニング
今、すべてが揃っているので、それらを合わせてStyleGANをトレーニングしましょう。
まず、生成器、ディスクリミネーター/クリティック、オプティマイザを初期化し、生成器とクリティックをトレーニングモードにします。その後、PROGRESSIVE_EPOCHSをループし、各ループでトレーニング関数をエポック数回呼び出し、いくつかのフェイク画像を生成し保存し、generate_examples関数を使って結果として保存し、最終的に次の画像解像度に進みます。
結果
be
hopes that you can follow all the steps and gain a good understanding of how to correctly implement StyleGAN. Let’s now look at the results we get after training this model on this dataset with a resolution of 128×128.

Conclusion
In this article, we have created a clean, simple, and readable implementation of StyleGAN1 from scratch using PyTorch. We have replicated the original paper as closely as possible, so if you read the paper, the implementation should be almost identical.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch