













Introdução
Este artigo é sobre um dos melhores GANs hoje em dia, o StyleGAN, a partir do artigo <diy5 Uma Arquitetura de Gerador Baseada em Estilo para Redes Adversárias Gerativas, faremos uma implementação limpa, simples e legível usando PyTorch, e tentaremos replicar o artigo original o mais próximo possível, então, se você leu o artigo, a implementação deve ser praticamente idêntica.
O conjunto de dados que usaremos neste blog é este conjunto de dados do Kaggle, que contém 16.240 peças de roupas de cima para mulheres com resolução 256*192.
Pré-requisitos
Antes de mergulhar no trabalho com StyleGAN usando PyTorch, certifique-se de que você tem os seguintes pré-requisitos:
-
Conhecimento Básico de Aprendizado Profundo
Compreensão de redes neurais convolucionais (CNNs).
Familiaridade com Redes Adversárias Gerativas (GANs), incluindo conceitos como gerador, discriminador e perda adversária. -
Requisitos de Hardware
Uma GPU poderosa (NVIDIA recomendada) para treinamento e inferência mais rápidos.
Kit CUDA instalado para aceleração de GPU (cudaecudnn). -
Familiaridade com StyleGAN
É útil ter lido os papers originais do StyleGAN ou StyleGAN2 para entender melhorias na arquitetura e conceitos-chave.
Carregar todas as dependências que precisamos
Primeiro importaremos torch, pois utilizaremos PyTorch, e a partir disso importamos nn. Isso nos ajudará a criar e treinar as redes, e também nos permitirá importar optim, um pacote que implementa vários algoritmos de otimização (por exemplo, sgd, adam,…). Do torchvision importamos datasets e transforms para preparar os dados e aplicar algumas transformações.
Importaremos functional como F de torch.nn para upsampler as imagens usando interpolate, DataLoader de torch.utils.data para criar tamanhos de mini-lotes, save_image de torchvision.utils para salvar alguns exemplos falsos, e log2 de math, pois precisamos da representação inversa da potência de 2 para implementar o tamanho de mini-lote adaptativo dependendo da resolução de saída, NumPy para álgebra linear, os para interação com o sistema operacional, tqdm para exibir barras de progresso, e finalmente matplotlib.pyplot para mostrar os resultados e compará-los com os reais.
Hiperparâmetros
- Inicializaremos o DATASET pelo caminho das imagens reais.
- Especificaremos o início do treinamento no tamanho de imagem 8×8.
- Inicializaremos o dispositivo por Cuda, se disponível, ou CPU, caso contrário, e a taxa de aprendizado por 0.001.
- O tamanho do lote será diferente dependendo da resolução das imagens que queremos gerar, então inicializamos BATCH_SIZES com uma lista de números, você pode mudá-los dependendo da sua VRAM.
- Inicializamos image_size por 128 e CHANNELS_IMG por 3, pois geraremos imagens RGB de 128 por 128.
- No artigo original, eles inicializam Z_DIM, W_DIM e IN_CHANNELS com 512, mas eu os inicializo com 256 para menos uso de VRAM e aceleração do treinamento. Talvez até possamos obter melhores resultados se os dobrássemos.
- Para o StyleGAN podemos usar qualquer função de perda de GANs que quisermos, então uso WGAN-GP do artigo Improved Training of Wasserstein GANs. Esta perda contém um parâmetro chamado λ e é comum definir λ = 10.
- Inicialize PROGRESSIVE_EPOCHS com 30 para cada tamanho de imagem.
Obter carregador de dados
Agora vamos criar uma função get_loader para:
- Aplicar algumas transformações às imagens (redimensionar as imagens para a resolução que queremos, convertê-las em tensores, então aplicar algumas augmentações e, finalmente, normalizá-las para que todos os pixels variem de -1 a 1).
- Identificar o tamanho atual do lote usando a lista BATCH_SIZES, e tomar como índice o número inteiro da representação inversa da potência de 2 do image_size/4. E isso é realmente como implementamos o tamanho de minibatch adaptativo dependendo da resolução de saída.
- Preparar o conjunto de dados usando ImageFolder, pois já está estruturado de uma maneira agradável.
- Criar tamanhos de mini-lote usando DataLoader que tomam o conjunto de dados e o tamanho do lote com mesclagem dos dados.
- Finalmente, retornar o carregador e o conjunto de dados.
Implementação de Modelos
Agora vamos Implementar o gerador e discriminador StyleGAN1 (ProGAN e StyleGAN1 têm a mesma arquitetura de discriminador) com as atribuições-chave do artigo. Tentaremos tornar a implementação compacta, mas também legível e compreensível. Especificamente, os pontos-chave:
- Rede de Mapeamento de Ruído
- Normalização Adaptativa de Instância (AdaIN)
- Crescimento Progressivo
Neste tutorial,我们将 apenas gerar imagens com StyleGAN1, e não implementaremos mesclagem de estilos e variação estocástica, mas não deve ser difícil fazer isso.
Vamos definir uma variável com o nome factors que contém os números que serão multiplicados por IN_CHANNELS para ter o número de canais que queremos em cada resolução de imagem.
Rede de Mapeamento de Ruído
A rede de mapeamento de ruído pega Z e o passa por oito camadas completamente conectadas separadas por alguma ativação. E não esqueça de equalizar a taxa de aprendizado como os autores fazem no ProGAN (ProGAN e StyleGan são escritos pelos mesmos pesquisadores).
Vamos primeiramente construir uma classe com o nome WSLinear (Linear com Ponderação e Escala) que será herdada de nn.Module.
- No parte init nós mandamos in_features e out_channels. Criamos uma camada linear, então definimos uma escala que será igual à raiz quadrada de 2 dividida por in_features, copiamos o bias da camada atual na coluna para uma variável porque não queremos que o bias da camada linear seja escalado, então o removemos, finalmente inicializamos a camada linear.
- No parte forward, mandamos x e tudo o que vamos fazer é multiplicar x pela escala e adicionar o bias após变形.
Agora vamos criar a classe MappingNetwork.
- No parte init mandamos z_dim e w_din, e definimos a rede de mapeamento que primeiramente normaliza z_dim, seguido por oito WSLInear e ReLU como funções de ativação.
- No parte forward, retornamos o mapeamento da rede.
Normalização Adaptativa de Instância (AdaIN)
Agora vamos criar a classe AdaIN
- Na parte init enviamos canais, w_dim e inicializamos instance_norm, que será a parte de normalização de instância, e inicializamos style_scale e style_bias, que serão as partes adaptativas com WSLinear que mapeia a Rede de Mapeamento de Ruído W nos canais.
- Na passagem forward, enviamos x, aplicamos a normalização de instância para ele e retornamos style_scale * x + style_bias.
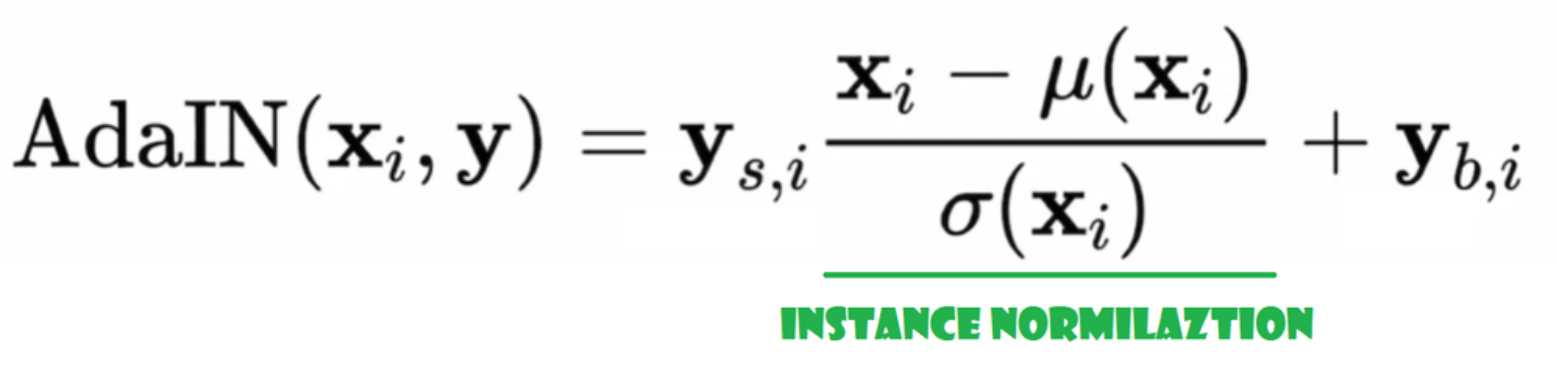
Injetar Ruído
Agora vamos criar a classe InjectNoise para injetar o ruído no gerador
- Na parte init enviamos canais e inicializamos o peso a partir de uma distribuição normal aleatória e usamos nn.Parameter para que esses pesos possam ser otimizados
- Na parte forward, enviamos uma imagem x e a retornamos com ruído aleatório adicionado
classes úteis
Os autores construíram StyleGAN com base na implementação oficial do ProGAN de Karras et al, eles usam a mesma arquitetura de discriminador, tamanho de minibatch adaptativo, hiperparâmetros, etc. Então há muitos classes que permanecem as mesmas da implementação do ProGAN.
Nesta seção, criaremos as classes que não mudam da arquitetura do ProGAN.
No trecho de código abaixo, você pode encontrar a classe WSConv2d (camada de convolução ponderada e escalonada) para Equalized Learning Rate para as camadas de convolução.
No trecho de código abaixo, você pode encontrar a classe PixelNorm para normalizar Z antes da Rede de Mapeamento de Ruído.
No trecho de código abaixo, você pode encontrar a classe ConvBlock que nos ajudará a criar o discriminador.
No trecho de código abaixo, você pode encontrar a classe Discriminatowich é a mesma que na ProGAN.
Gerador
Na arquitetura do gerador, temos alguns padrões que se repetem, então vamos primeiro criar uma classe para isso para tornar nosso código o mais limpo possível, vamos nomear a classe GenBlock que será herdada de nn.Module.
- No parte do init, enviamos in_channels, out_channels e w_dim, então inicializamos conv1 com WSConv2d que mapeia in_channels para out_channels, conv2 com WSConv2d que mapeia out_channels para out_channels, leaky com Leaky ReLU com uma inclinação de 0.2 como usam no artigo, inject_noise1 e inject_noise2 com InjectNoise, adain1 e adain2 com AdaIN
- No parte do forward, enviamos x, e o passamos por conv1, depois para inject_noise1 com leaky, então normalizamos com adain1, e novamente passamos isso para conv2, depois para inject_noise2 com leaky e normalizamos com adain2. E finalmente, retornamos x.
Agora temos tudo o que precisamos para criar o gerador.
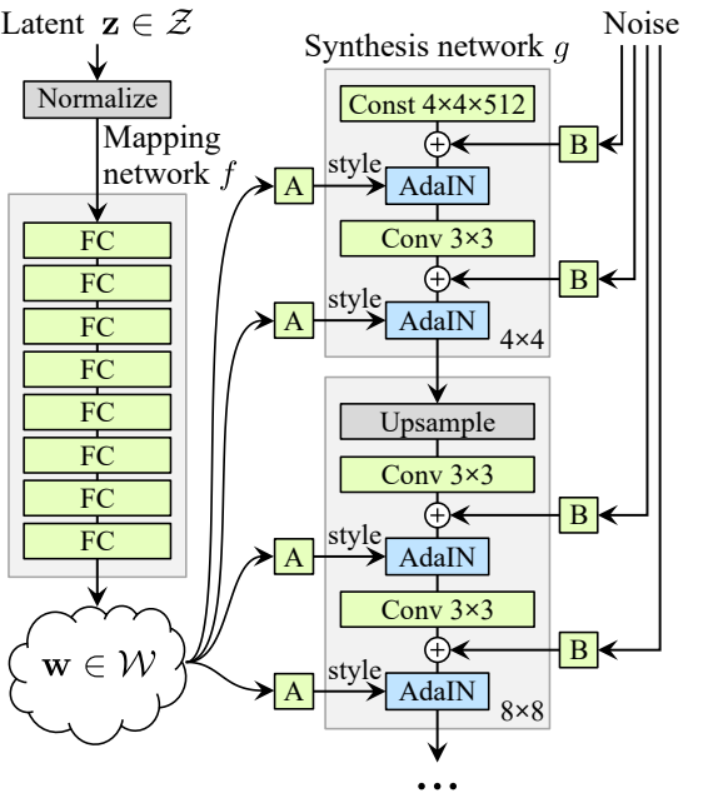
- na parte init vamos inicializar ‘starting_constant’ por um tensor 4 x 4 (x 512 canais para o artigo original, e 256 no nosso caso) que passa por uma iteração do gerador, mapeado pelo ‘MappingNetwork’, initial_adain1, initial_adain2 pelo AdaIN, initial_noise1, initial_noise2 pelo InjectNoise, initial_conv por uma camada convolucional que mapeia os in_channels para si mesmo, leaky pelo Leaky ReLU com uma inclinação de 0.2, initial_rgb pelo WSConv2d que mapeia os in_channels para img_channels que é 3 para RGB, prog_blocks por ModuleList() que contém todos os blocos progressivos (indicamos os canais de entrada/saída da convolução multiplicando in_channels, que é 512 no artigo e 256 no nosso caso, por fatores), e rgb_blocks por ModuleList() que contém todos os blocos RGB.
- Para fundir novas camadas (um componente original do ProGAN), adicionamos a parte fade_in, na qual enviamos alpha, scaled e generated, e retornamos [tanh(alpha∗generated+(1−alpha)∗upscale)], A razão pela qual usamos tanh é que será a saída (a imagem gerada) e queremos que os pixels estejam no intervalo entre 1 e -1.
- Na parte avançada, enviamos o ruído (Z_dim), o valor alpha que vai desvanecer gradualmente durante o treinamento (alpha está entre 0 e 1) e os passos que é o número da resolução atual com a qual estamos trabalhando, passamos x para o mapa para obter o vetor de ruído intermediário W, passamos starting_constant para initial_noise1, aplicamos para ele e para W initial_adain1, então passamos para initial_conv, e novamente adicionamos initial_noise2 para ele com leaky como função de ativação, e aplicamos para ele e W initial_adain2. Em seguida, verificamos se steps = 0, se for, então tudo o que queremos fazer é executá-lo através do initial RGB e estamos feitos, caso contrário, loopamos sobre o número de passos, e em cada loop faremos o upscaling (upscaled) e executamos através do bloco progressivo que corresponde àquela resolução (out). No final, retornamos fade_in que recebe alpha, final_out e final_upscaled após mapeá-lo para RGB.
Utils
No trecho de código abaixo, você pode encontrar a função generate_examples que recebe o gerador gen, o número de passos para identificar a resolução atual e um número n=100. O objetivo desta função é gerar n imagens falsas e salvá-las como resultado.
No trecho de código abaixo, você pode encontrar a função gradient_penalty para a perda WGAN-GP.
Função de treinamento
Para a função de treinamento, enviamos o crítico (que é o discriminador), gen (gerador), loader, conjunto de dados, passo, alpha e otimizador para o gerador e para o crítico.
Iniciamos fazendo um loop sobre todos os tamanhos de mini-lote que criamos com o DataLoader, e pegamos apenas as imagens, pois não precisamos de um rótulo.
Em seguida, configuramos o treinamento para o discriminador\Crítico quando queremos maximizar E(critic(real)) – E(critic(fake)). Esta equação significa quanto o crítico pode distinguir entre imagens reais e falsas.
Após isso, configuramos o treinamento do gerador quando queremos maximizar E(critic(fake)).
Finalmente, atualizamos o loop e o valor alpha para fade_in e garantimos que ele está entre 0 e 1, e o retornamos.
Treinamento
Agora que temos tudo, vamos juntar as peças para treinar nosso StyleGAN.
Iniciamos pelo descarregamento do gerador, do discriminador/crítico e dos otimizadores, depois convertemos o gerador e o crítico para o modo de treinamento, depois-loop sobre PROGRESSIVE_EPOCHS e em cada loop, chamamos a função de treinamento o número de vezes de epoch, então geramos algumas imagens falsas e as salvamos, como resultado, usando a função generate_examples, e finalmente, progredimos para a próxima resolução de imagem.
Resultado
Espero que você consiga seguir todos os passos e obtenha uma boa compreensão de como implementar o StyleGAN da maneira correta. Agora vamos verificar os resultados que obtemos após treinar este modelo neste conjunto de dados com resolução de 128*x 128.

Conclusão
Neste artigo, fizemos uma implementação limpa, simples e legível do StyleGAN1 do zero usando PyTorch. replicamos o artigo original o mais próximo possível, então, se você ler o artigo, a implementação deve ser praticamente idêntica.
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch