













简介
本文介绍的是目前最好的生成对抗网络之一,StyleGAN,源自论文《基于风格的生成对抗网络生成器架构》。我们将使用PyTorch对其进行清晰、简单且易于理解的实现,并尽可能接近原文的实现,所以如果你阅读了论文,那么这个实现应该与论文非常相似。
本文将使用的数据集是来自Kaggle的数据集,其中包含16240件分辨率为256*192的女性上装。
预备知识
在开始使用PyTorch进行StyleGAN的工作之前,请确保你具备以下基础知识:
-
深度学习基础知识
了解卷积神经网络(CNN)。
熟悉生成对抗网络(GANs),包括生成器、判别器和对抗损失等概念。 -
硬件要求
推荐使用强大的GPU(NVIDIA显卡)以加快训练和推理速度。
已安装CUDA工具包以实现GPU加速(cuda和cudnn)。
加载我们需要的所有依赖项
我们首先会导入torch,因为我们将会使用PyTorch,并从中导入nn。这将帮助我们创建和训练网络,同时也能让我们导入optim,这是一个实现了各种优化算法(例如sgd、adam等)的包。从torchvision我们导入datasets和transforms来准备数据和应用一些转换。
我们将从torch.nn导入functional作为F来使用interpolate上采样图像,从torch.utils.data导入DataLoader来创建小批量大小,从torchvision.utils导入save_image来保存一些假样本,从math导入log2,因为我们需要2的幂的逆表示来实现根据输出分辨率调整自适应小批量大小,导入NumPy进行线性代数计算,导入os与操作系统交互,导入tqdm显示进度条,最后导入matplotlib.pyplot来显示结果并与真实结果进行比较。
超参数
- 通过真实图片的路径初始化数据集DATASET。
- 指定起始训练的图像大小为8×8。
- 根据Cuda是否可用初始化设备,否则使用CPU,并将学习率初始化为0.001。
- 批量大小将根据我们想要生成的图像分辨率而有所不同,因此我们通过一个数字列表初始化BATCH_SIZES,你可以根据你的VRAM更改它们。
- 将image_size初始化为128,CHANNELS_IMG初始化为3,因为我们将会生成128×128的RGB图像。
- 在原始论文中,他们使用512初始化Z_DIM、W_DIM和IN_CHANNELS,但我为了减少VRAM的使用并加速训练,将它们初始化为256。如果我们加倍这些值,也许还能得到更好的结果。
- 对于StyleGAN,我们可以使用任何我们想要的GAN损失函数,所以我使用了论文中的WGAN-GP Improved Training of Wasserstein GANs。这个损失函数包含一个名为λ的参数,通常设置λ=10。
- 将PROGRESSIVE_EPOCHS初始化为每个图像大小的30。
获取数据加载器
现在我们来创建一个函数get_loader来:
- 对图像应用一些转换(将图像调整为我们想要的分辨率,将它们转换为张量,然后应用一些增强,最后将它们归一化,使所有像素值在-1到1之间)。
- 使用列表BATCH_SIZES识别当前批处理大小,并取图像大小除以4的2的幂的反向表示的整数值作为索引。这实际上就是我们如何实现根据输出分辨率自适应最小批处理大小的。
- 通过使用ImageFolder准备数据集,因为它已经以很好的方式结构化了。
- 使用DataLoader创建mini-batch大小,它接收数据集和批量大小,并对数据进行打乱。
- 最后,返回加载器和数据集。
模型实现
现在让我们实现StyleGAN1生成器和判别器(ProGAN和StyleGAN1具有相同的判别器架构),并从论文中提取关键属性。我们将尝试使实现简洁,同时保持可读性和可理解性。具体的关键点:
- 噪声映射网络
- 自适应实例归一化(AdaIN)
- 逐步增长
在本教程中,我们将只使用StyleGAN1生成图像,而不实现风格混合和随机变化,但这样做应该并不困难。
让我们定义一个名为factors的变量,它包含将乘以IN_CHANNELS的数字,以便在每个图像分辨率中拥有我们想要的通道数。
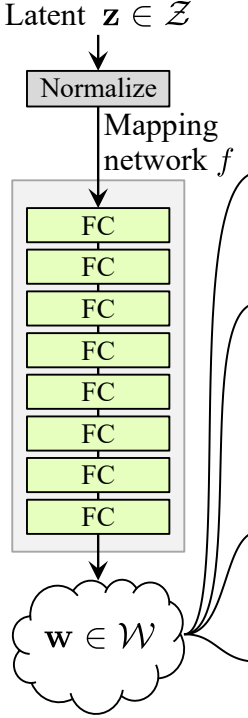
噪声映射网络
噪声映射网络将Z输入并通过八个全连接层,每层之间有一些激活函数。别忘了像ProGAN(由同一研究人员创作的ProGAN和StyleGan)的作者那样平衡学习率。
让我们首先构建一个名为WSLinear(加权缩放线性)的类,它将从nn.Module继承。
- 在初始化部分,我们传入in_features和out_channels。创建一个线性层,然后我们定义一个等于2的平方根除以in_features的缩放比例,我们将当前列层的偏置复制到一个变量中,因为我们不希望线性层的偏置被缩放,然后我们移除它,最后初始化线性层。
- 在正向传播部分,我们传入x,我们要做的就是将x乘以缩放比例,并在重塑后加上偏置。
现在让我们创建MappingNetwork类。
- 在初始化部分,我们传入z_dim和w_din,我们定义了网络映射,首先正规化z_dim,然后是八个WSLinear和ReLU作为激活函数。
- 在正向传播部分,我们返回网络映射。
自适应实例归一化(AdaIN)
现在让我们创建AdaIN类
- 在初始化部分,我们发送通道,w_dim,并且初始化instance_norm,它将是实例归一化部分,我们还初始化style_scale和style_bias,它们将是与WSLinear映射噪声映射网络W到通道的自适应部分。
- 在前向传播过程中,我们发送x,对它应用实例归一化,并返回style_sclate * x + style_bias。
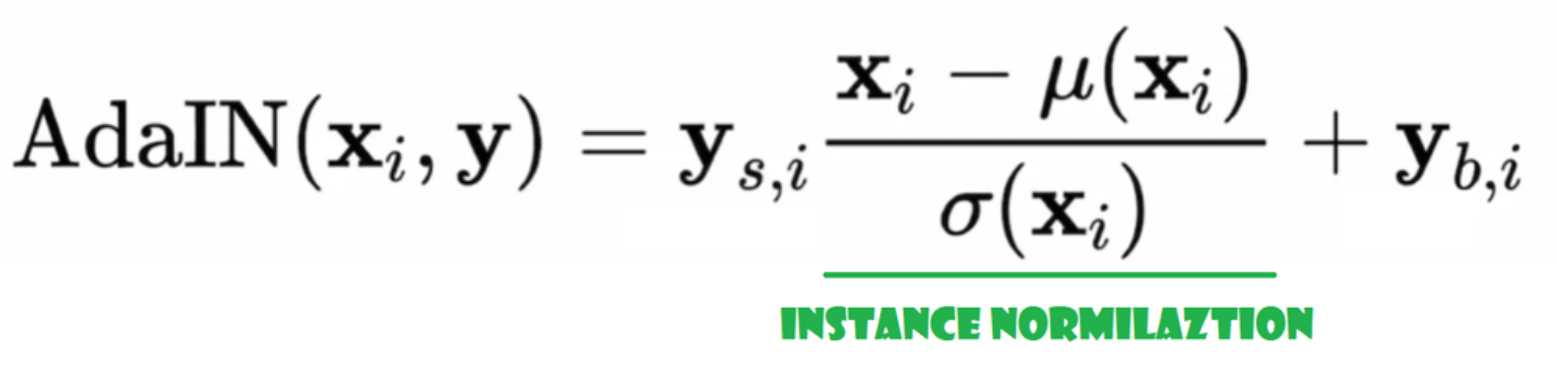
注入噪声
现在让我们创建一个InjectNoise类来向生成器中注入噪声
- 在初始化部分,我们发送通道,并且从一个随机正态分布中初始化权重,我们使用nn.Parameter以便这些权重可以被优化
- 在前向传播部分,我们发送一个图像x,并且返回添加了随机噪声的它
有用的类
作者在ProGAN的官方实现基础上构建了StyleGAN,他们使用了相同的判别器架构、自适应小批量大小、超参数等。因此,从ProGAN实现中有很多类保持不变。
在本节中,我们将创建与ProGAN架构不变的类。
在下面的代码片段中,你可以找到类 WSConv2d(加权缩放卷积层)用于卷积层的等化学习率。
在下面的代码片段中,你可以找到类 PixelNorm 用于在噪声映射网络之前标准化 Z。
在下面的代码片段中,你可以找到类 ConvBlock,它将帮助我们创建判别器。
在下面的代码片段中,你可以找到类 Discriminatowich,它与 ProGAN 中的相同。
生成器
在生成器架构中,我们有一些模式会重复,所以让我们首先为它创建一个类,以使我们的代码尽可能整洁,我们将这个类命名为GenBlock,它将从nn.Module继承。
- 在初始化部分,我们传入in_channels、out_channels和w_dim,然后我们通过WSConv2d初始化conv1,它将in_channels映射到out_channels,通过WSConv2d初始化conv2,它将out_channels映射到out_channels,leaky通过Leaky ReLU,其斜率为0.2,正如论文中使用的那样,inject_noise1和inject_noise2通过InjectNoise,adain1和adain2通过AdaIN。
- 在前向传播部分,我们传入x,然后将其传递给conv1,接着传递给inject_noise1和leaky,然后我们用adain1进行归一化,再次将结果传递给conv2,然后传递给inject_noise2和leaky,并用adain2进行归一化。最后,我们返回x。
现在我们已经有了创建生成器所需的所有东西。
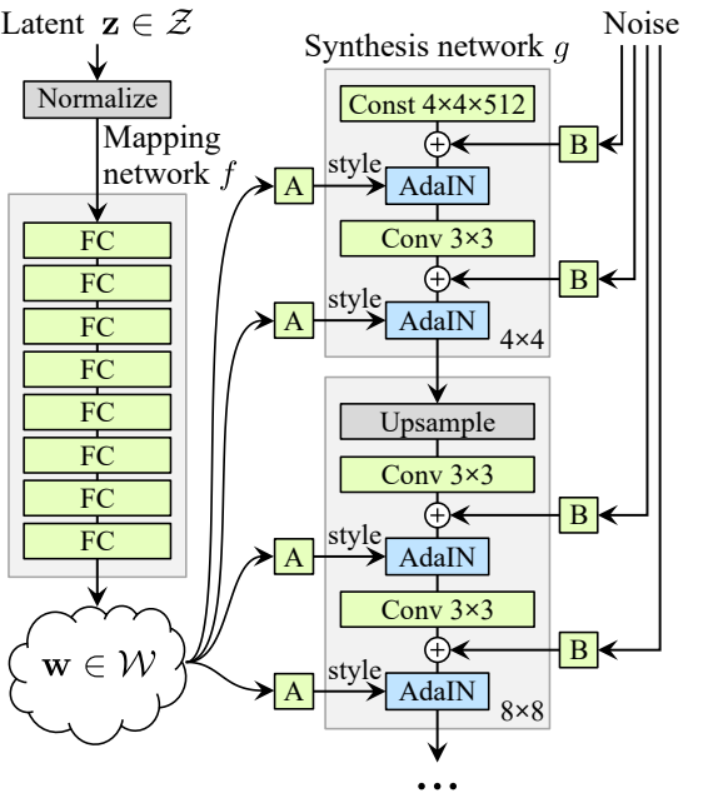
- 在初始化部分,让我们通过一个生成器的迭代来初始化‘starting_constant’,这是一个4×4(原始论文中为512通道,我们这里为256通道)的常量张量,通过‘MappingNetwork’映射,由AdaIN初始化initial_adain1和initial_adain2,通过InjectNoise初始化initial_noise1和initial_noise2,通过一个卷积层初始化initial_conv,该卷积层将输入通道映射到自身,leaky为斜率为0.2的Leaky ReLU,通过WSConv2d初始化initial_rgb,该层将输入通道映射到img_channels,RGB中为3,prog_blocks通过ModuleList()初始化,将包含所有渐进块(我们通过乘以因素来指示卷积输入/输出通道,原始论文中为512,我们这里为256),rgb_blocks通过ModuleList()初始化,将包含所有RGB块。
- 为了渐显新的层(ProGAN的原始组件),我们添加了渐显部分,我们发送alpha、scaled和generated,然后返回[tanh(alpha∗generated+(1−alpha)∗upscale)],我们使用tanh的原因是输出(生成的图像)的像素值应该在-1到1之间。
- 在前向部分,我们发送噪声(Z_dim),在训练过程中逐渐淡入的alpha值(alpha介于0和1之间),以及steps,它是我们正在处理的当前分辨率的编号,我们将x传入map以获得中间噪声向量W,将starting_constant传递给initial_noise1,应用它以及W的initial_adain1,然后将其传入initial_conv,再次为它添加initial_noise2,并使用泄漏作为激活函数,应用它以及W的initial_adain2。然后我们检查steps是否等于0,如果是,那么我们只需将其通过初始RGB即可完成,否则,我们遍历步数,在每个循环中我们进行升级(upscaled)并运行对应于该分辨率的渐进块(out)。最后,我们返回淡入,它接收alpha、final_out和final_upscaled,在映射到RGB之后。
工具
在下面的代码片段中,你可以找到generate_examples函数,它接收生成器 gen,用于确定当前分辨率的步数,以及n=100的数字。这个函数的目的是生成n个假图像并将它们保存为结果。
在下面的代码片段中,你可以找到用于WGAN-GP损失的gradient_penalty函数。
训练函数
对于训练函数,我们发送评判者(即判别器)、gen(生成器)、loader、数据集、步数、alpha以及生成器和评判者的优化器。
我们首先遍历所有由DataLoader创建的迷你批次大小,并且只取图像,因为我们不需要标签。
然后我们为判别器\Critic设置训练,当我们想要最大化E(评判者(真实)) – E(评判者(伪造))。这个方程意味着评判者能够在多大程度上区分真实和伪造的图像。
之后,当我们想要最大化E(评判者(伪造)).
最后,我们更新循环和fade_in的alpha值,确保它在0和1之间,然后返回它。
训练
现在我们已经有了所有东西,让我们将它们结合起来训练我们的StyleGAN。
我们首先初始化生成器、判别器/评判者和优化器,然后将生成器和评判者转换为训练模式,然后在PROGRESSIVE_EPOCHS上循环,每次循环中,我们调用train函数进行epoch次数的训练,然后我们生成一些伪造图像并保存它们,作为结果,使用generate_examples函数,最后我们进展到下一个图像分辨率。
结果
希望您能够遵循所有步骤并很好地理解如何以正确的方式实现StyleGAN。现在让我们看看在数据集中以128*128分辨率训练这个模型后得到的结果。

结论
在本文中,我们使用PyTorch从头开始实现了一个干净、简单且易于理解的StyleGAN1。我们尽可能地复制原始论文,所以如果您阅读了论文,实现应该与论文非常相似。
Source:
https://www.digitalocean.com/community/tutorials/implementation-stylegan-from-scratch