













Скорость развития искусственного интеллекта (AI) привела к мощному синергическому эффекту между крупными языковыми моделями (КЯМ) и агентами AI. Эта динамическая взаимосвязь похожа на сказание о Давиде и Голиафе (без битвы), где ловкие агенты AI усиливают и расширяют возможности гигантских КЯМ.
Это руководство исследует, как агенты AI – подобно Давиду – усиливают КЯМ – наши современные Голиафы – для помощи в революционизации различных отраслей и научных областей.
Содержание
Появление AI-агентов в языковых моделях
AI-агенты являются автономными системами, предназначенными для восприятия своей среды, принятия решений и осуществления действий для достижения конкретных целей. Когда они интегрируются с LLM, эти агенты могут выполнять сложные задачи, рассуждать о информации и генерировать инновационные решения.
Эта комбинация привела к существенным успехам во многих секторах, от разработки программного обеспечения до научных исследований.
Трансформирующий влияние на отрасли
Интеграция AI-агентов с LLM оказала глубокое влияние на различные отрасли:
-
Софтware разработка: AI-powered кодирование помощников, таких как GitHub Copilot, продемонстрировали способность создавать до 40% кода, приводя к заметному увеличению скорости разработки на 55%.
-
Образование: AI-powered учебные помощники показали перспективу в уменьшении среднего времени завершения курса на 27%, теоретически могущая революционизировать образовательную сферу.
-
Транспорт: Прогнозы предполагают, что 10% автомобилей будут беспилотными к 2030 году, и автономные ИИ-агенты в само guidoing автомобилях готовы трансформировать транспортную отрасль.
Продвижение научных открытий
Одним из самых захватывающих применений ИИ-агентов и БПСЛМ является их использование в научных исследованиях:
-
Обнаружение лекарств: ИИ-агенты ускоряют процесс обнаружения лекарств путем анализа огромных наборов данных и предсказания потенциальных кандидатов в лекарственные средства, значительно сокращая время и затраты, связанные с традиционными методами.
-
Физика частиц: В Large Hadron Collider CERN используются агенты AI для анализа данных о столкновениях частиц, используя детекцию аномалий для идентификации перспективных направлений, которые могут указать на существование не открытых частиц.
-
Общее научное исследование: Агенты AI повышают скорость и объем научных открытий, анализируя прошлые исследования, идентифицируя неожиданные связи и предлагая новые эксперименты.
Сочетание интеллектуальных агентов AI и крупных языковых моделей (LLMs) позволяет технологии искусственного интеллекта перейти на новую эру непредвиденных возможностей. Этот комплексный справочник исследует динамическое взаимодействие этих двух технологий, раскрывая их совместный потенциал революционизировать отрасли и решать сложные проблемы.
Мы проследим за эволюцией AI от его истоков до появления автономных агентов и подъема сложных LLMs. Мы также исследуем этические соображения, которые являются фундаментом ответственного развития AI. Это поможет нам убедиться, что эти технологии соответствуют нашим человеческим ценностям и благосостоянию общества.
Когда мы приходим к заключению этого справочника, у вас будет глубокое понимание синергетической силы AI-агентов и LLMs, а также знания и инструменты, чтобы использовать эту передовую технологию.
Раздел 1: Введение в Интеллектуальные Агенты AI и Языковые Модели
Что такие Интеллектуальные Агенты AI и Большие Языковые Модели?
быстрое развитие искусственного интеллекта (AI) привело к появлению трансформационного синергического взаимодействия между большими языковыми моделями (LLMs) и AI-агентами.
АИ-агенты являются автономными системами, предназначенными для восприятия их среды, принимания решений и выполнения действий для достижения определенных целей. Они проявляют такие качества, как автономия, восприятие, реактивность, умственные способности, принятие решений, обучение, коммуникация и ориентация на цели.
С другой стороны, СКИ являются сложными АИ-системами, использующими технику глубокого обучения и огромные наборы данных для понимания, генерации и предсказания похожего на человеческий текста.
Эти модели, такие как GPT-4, Mistral, LLama, продемонстрировали выдающиеся способности в задачах природного языкового процесса, включая генерацию текста, языковое перевода и диалогические агенты.
Ключевые характеристики АИ-агентов
У АИ-агентов есть ряд определяющих особенностей, которые отличают их от традиционного программного обеспечения:
-
Автономия: Они могут работать независимо от постоянного вмешательства человека.
-
Восприятие: Агенты могут воспринимать и интерпретировать свою среду с помощью различных входов.
-
Реактивность: Они динамично реагируют на изменения в своей среде.
-
Рассуждение и принятие решений: Агенты могут анализировать данные и принимать информированные решения.
-
Обучение: Они улучшают свои показатели с time through experience.
-
Коммуникация: Агенты могут взаимодействовать с другими агентами или людьми с помощью различных методов.
-
Ориентация на цели: Они предназначены для достижения определенных целей.
Capabilities of Large Language Models
LLMs have demonstrated a wide range of capabilities, including:
-
Текстовая генерация: LLMs can produce coherent and contextually relevant text based on prompts.
-
Перевод языка: They can translate text between different languages with high accuracy.
-
Резюме
: LLM могут сжать длинные тексты в краткие резюме, сохраняя ключевую информацию.
- Ответ на вопрос: Они могут提供更 точных ответов на вопросы на основе своей обширной базы знаний.
- Анализ эмоций: LLM могут анализировать и определять эмоции, выраженные в данном тексте.
- Генерация кода: Они могут генерировать фрагменты кода или целые функции на основе自然ного языкового описания.
Уровни агентов AIАгенты AI могут быть классифицированы по уровням в зависимости от их способностей и сложности.
- Уровень 1 (L1): Агенты AI в качестве научных помощников, где ученые устанавливают гипотезы и определяют задачи для достижения целей.
-
Уровень 2 (L2): Агенты AI, которые могут автономно выполнять конкретные задачи в определенных рамках, такие как анализ данных или простые решения.
- Уровень 3 (L3): Агенты AI, способные учиться на опыте и адаптироваться к новым ситуациям, улучшая процессы своего решения.
-
Уровень 4 (L4): Агенты AI с avanced reasonнing and problem-solving abilities, capable of handling complex, multi-step tasks.
- Уровень 5 (L5): Полностью автономные агенты AI, которые могут работать независимо в динамической среде, принимая решения и предпринимая действия без вмешательства человека.
Ограничения крупных моделей языка
Стоимость обучения и ограничения ресурсов
Крупные модели языка (LLMs), такие как GPT-3 и PaLM, революционизировали применение естественного языка (NLP) за счет использования техник глубокого обучения и огромных наборов данных.
Но эти усовершенствования приходят за значительный счет. Тренировка БПС требуетsubstantial computational resources, зачастую涉及thousands of GPUs и обширного потребления энергии.
По словам Сама Альтмана, генерального директора OpenAI, стоимость тренировки GPT-4 превысила $100 million. Это соответствует сообщаемому масштабу и сложности модели, с оценками, указывающими на примерно 1 триллион параметров. However,其他source提供不同的数字:
-
泄露的报告表明,GPT-4的训练成本约为$63 million, 考虑到计算能力和训练时间。
-
截至2023年年中,一些估计表明训练一个类似于GPT-4的模型可能需要大约$20 million,并需要大约55天,反映出效率的提升。
Эти высокие затраты на обучение и поддержку LLM ограничивают их широкое распространение и масштабируемость.
Ограничения данных и предрассудки
Эффективность LLM сильно зависит от качества и разнообразия обучающих данных. Несмотря на то, что модели обучены на огромных наборах данных, они могут все еще проявлять предубеждения, присутствующие в данных, что приводит к искаженным или неподходящим выводам. Эти предрассудки могут проявляться в различных формах, включая гендерные, расовые и культурные предрассудки, которые могут укреплять стереотипы и дезинформацию.
Кроме того, статичность обучающих данных означает, что LLM могут не быть обновлены до последней информации, что ограничивает их эффективность в динамической среде.
Специализация и сложность
Хотя LLM отлично справляются с общими задачами, они часто испытывают трудности с специализированными задачами, которые требуют знаний в специальной области и высокого уровня сложности.
Например, задачи в областях, таких как медицина, право и научные исследования, требуют глубокого понимания специальной терминологии и изощренного рассуждения, которые LLM могут не обладать изначально. Это ограничение требует интеграции дополнительных слоев экспертизы и точной настройки, чтобы сделать LLM эффективными в специализированных приложениях.
Ограничения ввода и чувствительности
Компьютерные программы, основанные на нейронных сетях, в основном обрабатывают текстовые входы, что ограничивает их способность взаимодействовать с миром в многокомпонентном порядке. хотя они могут генерировать и понимать текст, у них нет возможности обрабатывать прямо визуальные, слуховые или sensor inputs.
это ограничение препятствует их применению в областях, требующих всестороннего сенсорного объединения, таких как робототехника и автономные системы. например, компьютерные программы не могут объяснять визуальные данные с камеры или аудиосensor данные с микрофона без дополнительных процессорныхслоев.
ограничения в коммуникации и взаимодействии
текущие коммуникационные возможности компьютерных программ основаны на тексте, что ограничивает их способность участвовать в более глубоком и интерактивном общении.
например, хотя компьютерные программы могут генерировать текстовые ответы, они не могут производить видео содержание или голографические представления, которые все более важны в приложениях Virtua reality and Augmented reality (читать больше здесь). Это ограничение снижает эффективность компьютерных программ в средах, требующих обильного, многокомпонентного взаимодействия.
как преодолеть ограничения с помощью Агентов AI
агенты AI предлагают перспективные решения многих ограничений, с которыми сталкиваются компьютерные программы. эти агенты проектируются для работы автономно, воспринимать свое окружение, принимать решения и выполнять действия для достижения конкретных целей. при интеграции агентов AI с компьютерными программами можно улучшить их возможности и адресовать их внутренние ограничения.
- Улучшенный контекст и память: Агенты искусственного интеллекта могут сохранять контекст на протяжении множества взаимодействий, что позволяет обеспечивать более последовательные и контекстуально значимые ответы. Эта способность особенно полезна в приложениях, требующих долгосрочной памяти и непрерывности, таких как обслуживание клиентов и личные помощники.
-
Мультимодальная интеграция: Агенты искусственного интеллекта могут включать восприятие сенсорных входов из различных источников, таких как камеры, микрофоны и сенсоры, позволяя LLM обрабатывать и реагировать на визуальные, акустические и сенсорные данные. Эта интеграция критична для приложений в области робототехники и автономных систем.
-
Специальные знания и экспертность: AI agents can be fine-tuned with domain-specific knowledge, enhancing the ability of LLMs to perform specialized tasks. This approach allows for the creation of expert systems that can handle complex queries in fields such as medicine, law, and scientific research.
-
Interactive and Immersive Communication: AI agents can facilitate more immersive forms of communication by generating video content, controlling holographic displays, and interacting with virtual and augmented reality environments. This capability expands the application of LLMs in fields that require rich, multimodal interactions.
Несмотря на впечатляющие способности больших языковых моделей в обработке естественного языка, у них есть свои ограничения. Высокие затраты на обучение, смещения в данных, проблемы специализации, ограничения чувств и ограничения связи представляют собой значительные препятствия.
Но интеграция AI-агентов предлагает жизнеспособный путь для преодоления этих ограничений. Использование сильных сторон AI-агентов может улучшить функциональность, адаптируемость и приложимость LLM, тем самым проложив путь для более продвинутых и универсальных систем AI.
Глава 2: История искусственного интеллекта и AI-агентов
Зарождение искусственного интеллекта
Концепция искусственного интеллекта (AI) уходит своими корнями гораздо дальше современного цифрового века. Идея создания машин, способных к человеческому рассуждению, может быть прослежена до древних мифов и философских споров. Но формальное зарождение AI как научной дисциплины произошло в середине 20-го века.
Конференция в Дартмуте 1956 года, организованная Джоном McCarthy, Марвином Мински, НATHANIEL Rochester и Клодом Шэном, широко считается местом рождения AI как области исследований. Этот великийEvent brought together leading researchers to explore the potential of creating machines that could simulate human intelligence.
раннее восхищение и зима AI
ранние годы исследований AI были характеризованы неограниченным оптимизмом. Researchers made significant strides in developing programs capable of solving mathematical problems, playing games, and even engaging in rudimentary natural language processing.
но этот исходный энтузиазм был ослаблен признанием того, что создание настоящих интеллектуальных машин было намного сложнее, чем сначала предполагалось.
1970-е и 1980-е годы ознаменовали период сокращения финансирования и интереса к исследованиям AI, известный как “зима AI”. Этот спад был principalmente du à la faillite des systèmes AI de satisfaire aux attentes exagérées des premiers pionniers.
от систем на основе правил к Machine Learning
эра экспертных систем
1980-е годы стали свидетелями второго roaring interest in AI, primarily driven by the development of expert systems. These rule-based programs were designed to emulate the decision-making processes of human experts in specific domains.
Экспертные системы нашли применения в различных областях, включая медицину, финансы и инженерию. Однако их ограничивала неспособность приобретать знания из опыта или адаптироваться к новым ситуациям вне программируемых ими правил.
Развитие машинного обучения
Ограничения систем на основе правил открыли путь к смене Paradigm для машинного обучения. Этот подход, который стал превалировать в 1990-х и 2000-х годах, сфокусирован на разработке алгоритмов, которые могут leaned от данных и делать предсказания или решения.
Техники машинного обучения, такие как нейронные сети и машины поддержки vektorov, показали значительный успех в задачах, таких как распознавание моделей и классификация данных. Появление big data и увеличение вычислительной мощи еще больше ускорило развитие и применение алгоритмов машинного обучения.
Появление автономных агентов AI
от Narrow AI к General AI
По мере того, как технологии AI продолжали развиваться, исследователи начали исследовать возможность создания более versa и автономных систем. Этот shift marker ознаменовал переход от узких AI, предназначенных для конкретных задач, к стремлению создать искусственную общую интеллектуальность (AGI).
Цель AGI состоит в развитии систем, способных выполнять любую интеллектуальную задачу, которую может выполнять человек. Хотя истинная AGI остается далекой целью, были достигнуты значительные успехи в создании более гибких и адаптивных систем AI.
Роль глубокого обучения и нейронных сетей
Появление глубокого обучения, подмножества машинного обучения, основанного на искусственных нейронных сетях, стало ключевым моментом в развитии области AI.
Алгоритмы глубокого обучения, вдохновленные структурой и функцией человеческого мозга, продемонстрировали необыкновенные способности в таких областях, как распознавание изображений и голоса, обработка природных языков и игровая деятельность. Эти успехи положили основы для развития более сложных автономных агентов AI.
Характеристики и типы агентов AI
Агенты AI являются автономными системами, способными воспринимать свое окружение, принимать решения и выполнять действия для достижения конкретных целей. У них есть характеристики, такие как автономия, восприятие, реактивность, мышление, принятие решений, обучение, коммуникация и ориентация на цели.
Есть несколько типов агентов AI, each with unique capabilities:
-
Простые рефлективные агенты: реагируют на специфические стимулы на основе предdefinite rules.
-
Агенты на основе модели рефлексии: Поддерживают внутреннюю модель окружения для принятия решений.
-
Целевые агенты: Выполняют действия для достижения конкретных целей.
-
Агенты на основе полезности: Рассматривают потенциальные результаты и выбирают действия, максимизирующие ожидаемую полезность.
-
Обучающиеся агенты: Улучшают процесс принятия решений со временем с помощью техник машинного обучения.
Проблемы и этические соображения
По мере того, как системы искусственного интеллекта становятся всё более продвинутыми и автономными, они представляют важные соображения для обеспечения того, чтобы их использование оставалось в пределах социально приемлемых границ.
Крупные языковые модели (КЯМ), в частности, действуют как турбонаддувы производительности. Но это поднимает важный вопрос: Что будут эти системы турбонаддувать — доброе или злое намерение? Когда намерение за использованием ИИ является злонамеренным, становится необходимым для этих систем обнаруживать такое злоупотребление с помощью различных техник NLP или других инструментов, которые у нас есть.
Инженеры LLM имеют доступ к целому ряду инструментов и методологий для решения этих проблем:
-
Анализ настроения: Использовав анализ настроения, LLMs могут оценить эмоциональный тон текста, чтобы обнаружить вредное или агрессивное языкое поведение, помогая идентифицировать потенциальное неверно использование в коммуникационных платформах.
-
Фильтрация контента: Инструменты, такие как фильтрация ключевых слов и сопоставление моделей, могут быть использованы для предотвращения генерации или распространения вредного контента, такого как враждебные высказывания, дезинформация или откровенный материал.
-
Инструменты обнаружения предвзятости: Внедрение фреймворков для обнаружения предвзятости, таких как AI Fairness 360 (IBM) или Indicators of Fairness (Google), может помочь идентифицировать и смягчить предвзятость в языковых моделях, обеспечивая справедливое и равноправное функционирование систем AI.
-
Объясняемость техник
: Использование инструментов объясняемости, таких как LIME (Локально интерпретируемые модели-независимые объяснения) или SHAP (Согласно Шапли), позволяет инженерам понимать и объяснять процессы принятия решений в КПИ, что упрощает обнаружение и коррекцию незамыслованных поведений.
-
Тесты против атак: Simulating malicious attacks or harmful inputs, engineers can stress-test LLMs using tools like TextAttack or Adversarial Robustness Toolbox, identifying vulnerabilities that could be exploited for malicious purposes.
-
Этические руководящие принципы и схемы для AI: Принятие этических руководящих принципов разработки AI, таких как те, что предоставляют IEEE или Partnership on AI, может направлять создание ответственных систем AI, которые ставят приоритетом благо общества.
Помимо этих инструментов, вот почему нам нужна специальная Красная команда для ИИ — команды, которые тестируют LLM до предела, чтобы выявить лакуны в их защите. Красные команды моделируют адversarialные сценарии и обнаруживают уязвимости, которые могли бы остаться незамеченными.
Но важно осознать, что люди за продуктом имеют наибольшее влияние на него. Многие из атак и вызовов, с которыми мы сталкиваемся сегодня, существовали ещё до разработки LLM, что подчёркивает, что человеческий фактор остаётся центральным для обеспечения этичного и ответственного использования ИИ.
Интеграция этих инструментов и методов в процесс разработки, наряду с деятельностью внимательной Красной команды, важна для обеспечения того, чтобы LLM использовались для повышения позитивных итогов, а также для обнаружения и предотвращения их злоупотребления.
Глава 3: Где ИИ-агенты светят ярче всего
Уникальные сильные стороны ИИ-агентов
ИИ-агенты отличаются способностью автономно воспринимать окружающую среду, принимать решения и осуществлять действия для достижения конкретных целей. Эта автономия, в сочетании с передовыми возможностями машинного обучения, позволяет ИИ-агентам выполнять задачи, которые либо слишком сложны, либо слишком повторяющиеся для людей.
Следующие ключевые преимущества делают агентов искусственного интеллекта блестящими:
-
Автономность и Эффективность: Агенты искусственного интеллекта могут работать независимо без постоянного вмешательства человека. Эта автономия позволяет им выполнять задачи круглосуточно, значительно повышая эффективность и производительность. Например, чат-боты с искусственным интеллектом могут обработать до 80% рутинных запросов клиентов, снижая операционные расходы и улучшая время ответа.
-
Расширенное Решение Проблем: Агенты искусственного интеллекта могут анализировать огромные объемы данных для принятия информированных решений. Эта способность особенно ценна в таких областях, как финансы, где торговые боты с искусственным интеллектом могут существенно повысить эффективность торговли.
-
Ученье и адаптивность: Агенты AI могут учиться на опыте и адаптироваться к новым ситуациям. Этот процесс постоянного усовершенствования позволяет им улучшать свои показатели с течением времени. Например, AI-ассистенты здравоохранения могут помочь уменьшить ошибки в диагностике, улучшая результаты лечения.
-
Персонализация: Агенты AI могут предоставлять персонализированные опыты, анализируя поведение пользователей и их предпочтения. Модель рекомендаций Amazon, которая приводит к 35% его продаж, является хорошим примером того, как агенты AI могут улучшать опыт пользователей и повышать доходы.
为什么AI代理是解决方案
AI-агенты решают многие проблемы, с которыми сталкиваются традиционные программные системы и системы, управляемые человеком. Вот почему они являются preferable choice:
-
Скалярность: AI-агенты могут масштабировать операции без пропорционального увеличения затрат. Это масштабность является критическим для бизнесов, которые хотят вырасти без значительного увеличения своего рабочего персонала или операционных расходов.
-
Согласованность и надежность: Unlike humans, AI-агенты не страдают от усталости или непоследовательности. Они могут выполнять повторяющиеся задачи с высокой точностью и надежностью, обеспечивая устойчивое поведение.
-
Data-Driven Insights: AI-агенты могут обрабатывать и анализировать большие наборы данных, чтобы обнаружить модели и INSIGHTS, которые могли бы быть пропущены человеком. This capability is invaluable for decision-making in areas such as finance, healthcare, and marketing.
-
Сокращение затрат: Благодаря автоматизации повседневных задач, агенты AI могут уменьшить потребность в рабочей силе, что приводит к значительному сокращению затрат. Например, системы распознавания мошенничества, основанные на AI, могут экономлять миллиарды долларов США в год, снижая раскраinedные действия.
Условия, необходимые для хорошего выполнения агентов AI
Для обеспечения успешного развертывания и хорошего выполнения агентов AI необходимо соблюсти certain conditions:
-
Clear Objectives and Use Cases: Defining specific goals and use cases is crucial for the effective deployment of AI agents. This clarity helps in setting expectations and measuring success. For instance, setting a goal to reduce customer service response times by 50% can guide the deployment of AI chatbots.
-
Качественные данные: Агенты AI создаются и работают на основе высококачественных данных. Убедиться, что данные являются точными, реlevantными и актуальными, необходимо для того, чтобы агенты могли принимать высококачественные решения и работать эффективно.
-
Integration with Existing Systems: Seamless integration with existing systems and workflows is necessary for AI agents to function optimally. This integration ensures that AI agents can access the necessary data and interact with other systems to perform their tasks.
-
Continuous Monitoring and Optimization: Regular monitoring and optimization of AI agents are crucial to maintain their performance. This involves tracking key performance indicators (KPIs) and making necessary adjustments based on feedback and performance data.
-
Этические соображения и смягчение предрассудков: рассмотрение этических аспектов и ослабление предрассудков у САИ важно для обеспечения справедливости и всеобъемлющих возможностей. Внедрение мероприятий для обнаружения и предотвращения предрассудков поможет в строительстве доверия и обеспечении ответственного развертывания.
Лучшие практики для развертывания САИ
При развертывании САИ соблюдение лучших практик может обеспечить их успех и эффективность:
-
Определить цели и сценарии использования: ясно определить цели и сценарии использования САИ. Это помогает установить ожидания и измерять успех.
-
Выберите правильную платформу искусственного интеллекта: Выберите платформу искусственного интеллекта, соответствующую вашим целям, сценариям использования и существующей инфраструктуре. Учитывайте такие факторы, как возможности интеграции, масштабируемость и стоимость.
-
Разработайте комплексную базу знаний: Создайте хорошо структурированную и точную базу знаний, чтобы позволить агентам искусственного интеллекта предоставлять актуальные и надежные ответы.
-
Обеспечьте беспроблемную интеграцию: Интегрируйте агентов искусственного интеллекта с существующими системами, такими как CRM и технологии колл-центра, чтобы обеспечить единое клиентское взаимодействие.
-
Обучайте и оптимизируйте агентов искусственного интеллекта: Непрерывно обучайте и оптимизируйте агентов искусственного интеллекта с использованием данных из взаимодействий. Оценивайте производительность, выявляйте области для улучшения и соответствующим образом обновляйте модели.
-
Внедрите адекватные процедуры эскалации
: Установите протоколы для передачи сложных или эмоциональных вызовов человеческим агентам, обеспечивая гладкий переход и эффективное разрешение.
- Мониторинг и анализ производительности: Следите за ключевыми показателями производительности (КПИ), такими как ставки решения вызовов, среднее время обработки и оценки удовлетворения клиентов. Используйте инструменты аналитики для получения данных-ориентированных выводов и принятия решений.
- Обеспечение конфиденциальности и безопасности данных: важным являются жесткие меры безопасности, такие как анонимизация данных, обеспечение человеческого контроля, установление политики хранения данных и внедрение сильных методов шифрования для защиты данных клиентов и сохранения конфиденциальности.
AI-агенты + LLM: Новая эра умного программного обеспечения
Представьте программное обеспечение, которое не только понимает ваши запросы, но и может также выполнять их. Это обещание является результатом комбинации агентов искусственного интеллекта с большими языковыми моделями (БЯМ). Эта мощная пара создает новое поколение приложений, которые стали более интуитивными, способными и влиятельными, чем когда-либо раньше.
Агенты искусственного интеллекта: Выполнение не только простых задач
Часто сравниваемые с цифровыми помощниками, агенты искусственного интеллекта намного больше, чем просто доработанные следователи сценариев. Они включают в себя ряд изощренных технологий и работают на основе-framework, который позволяет динамическое принятие решений и действия.
-
Архитектура: Типичный агент искусственного интеллекта состоит из нескольких ключевых компонентов:
-
Сенсоры: Они позволяют агенту воспринимать свою среду, собирая данные из различных источников, таких как датчики, API или ввод пользователя.
-
Состояние убеждения: Это представляет понимание агентом мира на основе собранной информации. Оно постоянно обновляется по мере поступления новых данных.
-
Система рассуждений: Это ядро процесса принятия решений агентом. Она использует алгоритмы, часто основанные на методах укрепления обучения или планирования, для определения наилучшего курса действий на основе текущих убеждений и целей.
-
Актуаторы: Это инструменты агента для взаимодействия с миром. Они могут варьироваться от отправки API-запросов до управления физическими роботами.
-
-
Преимущества:
Традиционные искусственные интеллектуальные агенты, хотя и славятся эффективностью в обработке хорошо определенных задач, часто испытывают трудности следующим:
-
Обработка природного языка: Interpreting nuanced human language, handling ambiguity, and extracting meaning from context remain significant challenges.
-
Рассуждения с common sense: Current AI agents often lack the common sense knowledge and reasoning abilities that humans take for granted.
-
Общей трансформацией: Train agents to perform well on unseen tasks or adapt to new environments remains a key area of research.
-
LLM: Разблокирование понимания и генерации языка
LLM, обладающие огромными знаниями, закодированными в миллиардах параметров, приносят безпрецедентные языковые способности:
-
Архитектура Transformer: Основа большинства современных LLM является архитектурой Transformer, дизайн нейронной сети, который превосходно обрабатывает последовательные данные, такие как текст. Это позволяет LLM улавливать длинные зависимости в языке, что позволяет им понимать контекст и генерировать связный и контекстуально релевантный текст.
-
Возможности: LLM отлично справляются с широким спектром языковых задач:
-
Генерация текста: От написания креативной фантастики до генерации кода на многих языках программирования, LLM проявляют удивительную гибкость и креативность.
-
Ответы на вопросы: Они могут давать краткие и точные ответы на вопросы, даже когда информация разбросана по длинным документам.
-
Резюмирование: LLM могут сводить большие объемы текста в краткие резюме, извлекая ключевую информацию и отбрасывая незначимые детали.
-
-
Ограничения: несмотря на их впечатляющие способности, СМЯМ имеют ограничения:
-
Отсутствие привязки к реальному миру: СМЯМ в основном работают в области текста и неспособны взаимодействовать напрямую с физическим миром.
-
Потенциаль для предвзятости и иллюзорности: TRAINED на огромных, необученных данных, СМЯМ могут наследовать предвзятости, присутствующие в данных, и иногда генерировать фактически неверную или нелогичную информацию.
-
Сочетание: Bridging the Gap Between Language and Action
Комбинация AI агентов и СВП адресует ограничения каждого, создавая системы, которые являются и интеллектуальными и способными:
-
СВП в качестве трансляторов и планировщиков: СВП могут транслировать приказы自然ного языка в формат, который понимает AI агент, что позволяет более интуитивную взаимодействию между человеком и компьютером. Они также могут использовать свои знания, чтобы помочь агентам в планировании сложных задач, разбивая их на более маленькие, управляемые шаги.
- AI агенты как исполнители и учителя: AI агенты обеспечивают LLM возможность взаимодействия с миром, сбора информации и получения обратной связи о своих действиях. Этот реальный привязанность может помочь LLM научиться на опыте и улучшить свои показатели с течением времени.
Эта сильная связь идет впереди развития нового поколения приложений, которые sont plus intuitifs, adaptables et capables que jamais. Avec la poursuite du progrès des technologies à la fois des agents AI et LLM, nous pouvons attendre la mise en évidence de plus des applications innovantes et impactives, remodelant ainsi le paysage de l’édition logicielle et de l’interaction homme-ordinateur.
Exemples réels: Transformation des industries
Cette combinaison puissante est déjà provoquant des ondes à travers divers secteurs:
-
Клиентская служба: решение проблем с учетом контекста
- Пример: Представьте, что клиент связывается с онлайн-розничным продавцом по поводу задержанного поставочного заказа. Агент AI, работающий с помощью системы LLM, может понять обида клиента, получить доступ к истории заказов, отслеживать пакет в реальном времени и активно предлагать решения, такие как ускоренная доставка или скидка на следующий заказ.
-
Создание контента: генерация массового качественного контента
- Пример: команда маркетинга может использовать систему AI-агент + LLM для генерации целевых социальных медиа-постов, написания описаний продуктов или даже создания сценариев для видеороликов. Система LLM保证了内容的吸引力和信息性,同时 AI-агент обеспечивает процесс публикации и распределения.
-
Разработка программного обеспечения: Ускорение кодирования и отладки
- Пример: Разработчик может описать желаемую функцию программного обеспечения с использованием естественного языка. LLM может затем генерировать фрагменты кода, идентифицировать потенциальные ошибки и предлагать улучшения, значительно ускоряя процесс разработки.
-
Здравоохранение: Персонализация лечения и улучшение ухода за пациентами
- Пример: AI-агент с доступом к медицинской истории пациента и оборудованный LLM может отвечать на их вопросы, связанные со здоровьем, предоставлять персонализированные напоминания о приёме лекарств и даже предлагать предварительные диагнозы на основе их симптомов.
-
Закон: Стандартизация правового исследования и подготовки документов
- Пример: Адвокату нужно составить контракт с конкретными положениями и правовыми прецедентами. AI-агент, оснащенный LLM, может анализировать указания адвоката, искать в обширных правовых базах данных, идентифицировать соответствующие положения и прецеденты, и даже подготовить части контракта, значительно сокращая трудозатраты.
-
Создание видео: Легкое создание захватывающих видеороликов
- Пример: Маркетинговой команде нужно создать короткое видео, объясняющее особенности их продукта. Они могут предоставить AI-агенту + системе LLM концепцию сценария и предпочтения визуального стиля. LLM может затем сгенерировать детальный сценарий, предложить соответствующую музыку и визуальные элементы, и даже отредактировать видео, автоматизировав значительную часть процесса создания видео.
-
Архитектура: проектирование зданий с помощью AI-обеспеченных знаний
- Пример: Архитектор проектирует новый офисный здание. Он может использовать систему AI-агента + LLM, чтобы ввести свои цели дизайна, такие как максимизация естественного света и оптимизация использования пространства. LLM может затем проанализировать эти цели, сгенерировать различные варианты дизайна и даже симулировать, как здание будет функционировать под различными экологическими условиями.
-
Строительство: улучшение безопасности и эффективности на строительных объектах
- Пример: Агент AI, оборудованный камерой и датчиками, может контролировать строительный объект в поисках опасностей безопасности. Если работник не носит соответствующего снаряжения или оборудование оставлено в опасном положении, LLM может анализировать ситуацию, оповещать руководителя стройки и даже автоматически останавливать работы, если это необходимо.
Будущее здесь: новый эпоха разработки программного обеспечения
Сочетание агентов AI и LLM ознаменовало значительный шаг вперед в разработке программного обеспечения. Будучи продолжающими развиваться, эти технологии могут ожидать еще более инновационных применений, трансформируя отрасли, уStreamlining процессов, и создавая целые новые возможности для взаимодействия человек-компьютер.
AI агенты наиболее яркими в областях, требующих обработки огромных объемов данных, автоматизации повторяющихся задач, принимания сложных решений и обеспечения индивидуальных ощущений. При соблюдении необходимых условий и соблюдении лучших практик организации могут использовать полный потенциал AI агентов, чтобы двигать инновации, эффективность и рост.
Глава 4: Философская основа умных систем
Развитие умных систем, особенно в области искусственного интеллекта (AI), требует глубокого понимания философских принципов. В этой главе рассматриваются коренные философские идеи, которые формируют дизайн, разработку и использование AI. Внимание уделено важности согласования прогресса технологии с этическими ценностями.
Философская основа умных систем не является только теоретическим упражнением – это жизненно важная структура, которая гарантирует, что технологии AI приносят пользу человечеству. Продвигая справедливость, инклюзивность и улучшая качество жизни, эти принципы помогают направлять AI на служение нашим лучшим интересам.
Этические соображения в разработке AI
По мере того, как системы AI становятся все более интегрированными в каждую сферу человеческой жизни, от здравоохранения и образования до финансов и управления, нам надо строго исследовать и внедрить этические принципы, направляющие их дизайн и развертывание.
Основная этическая вопрос касается того, как AI могут быть созданы для того, чтобы воплощать и поддерживать человеческие ценности и моральные принципы. Этот вопрос играет центральную роль в том, как AI будет формировать будущее обществ по всему миру.
В центре этой этической дискуссии находится принцип благожелательности, который является краеугольным камнем моральной философии и учитывает, что действия должны направляться на совершение добра и улучшение блага индивидов и общества в целом (Floridi & Cowls, 2019).
В контексте ИТ, благожелательность означает проектирование систем, которые активно способствуют процветанию человека — системы, которые улучшают результаты здравоохранения, увеличивают возможности образования и содействуют экономическому росту справедливости.
Но применение благожелательности в ИТ далеко от простого. Оно требует сложного подхода, который тщательно сопоставит потенциальные преимущества ИТ с возможными рисками и вредами.
Одним из основных проблем при применении принципа благожелательности к развитию ИТ является необходимость сбалансировать инновации и безопасность.
ИТ обладает потенциалом революционизировать области, такие как медицина, где прогнозирующие алгоритмы могут диагностировать болезни раньше и с большей точностью, чем врачи-люди. Но без жесткого этического надзора эти технологии могли бы усугубить существующие неравенства.
Это, например, может произойти, если технологии будут в основном размещены в богатых регионах, в то время как обслуженные общины по-прежнему останутся без доступа к базовому здравоохранению.
В связи с этим этическое развитие ИТ требует не только focus на максимизации преимуществ, но и активного подхода к уменьшению рисков. Это означает внедрение надежных защитных мероприятий, чтобы предотвратить неправильное использование ИТ и обеспечить, чтобы эти технологии не случайно причиняли вред.
Этическая основа ИТ также должна быть имманентно инклюзивной, обеспечивая равномерное распределение благ ИТ среди всех слоев общества, включая те, которые традиционно являются маргинализированными. Это требует приверженности принципам справедливости и справедливости, чтобы ИТ не просто укрепляла статус-кво, но активно работала на разрушение системных неравенств.
К примеру, автоматизация профессиональных задач с использованием AI может значительно увеличить производительность и экономический рост. Однако она также может привести к значительному изменению рабочих мест, особенно сказываясь на низкоквалифицированных рабочих.
Как вы можете видеть, этически устойчивая основа AI должна включать стратегии для равномерного распределения выгод и обеспечения поддержки для тех, кто негативно сказывается от усовершенствований AI.
Этическое развитие AI требует непрерывного взаимодействия с различными заинтересованными сторонами, включая этических ученых, технологических специалистов, политических деятелей и общин, которые будут наиболее затронуты этими технологиями. Эта междисциплинарная кооперация гарантирует, что AI-системы не разрабатываются в условиях изоляции, а instead are instead shaped by a broad spectrum of perspectives and experiences.
Именно благодаря этому коллективному усилию мы можем создавать AI-системы, которые не только отражают, но и поддерживают ценности, определяющие нашу человечность – сострадание, справедливость, уважение автономии и приверженность общему благу.
Этические соображения в развитии AI не являются просто руководствами, но являются необходимыми элементами, которые определяют, будет ли AI служить силой добра в мире. Утверждая, что AI основано на принципах благожелательности, справедливости и инклюзивности и поддерживая осторожный подход to the balance of innovation and risk, мы можем убедиться, что развитие AI не просто ускоряет технологии, но также повышает качество жизни всех членов общества.
По мере того, как мы продолжаем исследовать возможности AI, чтобы эти этические соображения оставались в центре нашего стремления, направляя нас к будущему, где AI настоящим образом будет служить человечеству.
Императив дизайна искусственного интеллекта, ориентированного на человека
Дизайн искусственного интеллекта, ориентированный на человека, превосходит простые технические соображения. Он основан на глубоких философских принципах, которые придают приоритет человеческому достоинству, автономии и агентству.
Этот подход к разработке искусственного интеллекта фундаментально укоренен в кантовской этической системе, которая утверждает, что людей следует рассматривать как конечные цели, а не просто как средства для достижения других целей (Кант, 1785 год).
Импликации этого принципа для дизайна искусственного интеллекта глубоки, требуя, чтобы системы искусственного интеллекта разрабатывались с неизменным фокусом на служение интересам человека, сохранение человеческого агентства и уважение индивидуальной автономии.
Техническая реализация принципов, ориентированных на человека
Повышение человеческой автономии через искусственный интеллект: Понятие автономии в системах искусственного интеллекта критично, особенно в обеспечении того, чтобы эти технологии давали пользователю полномочия, а не контролировали или несправедливо влияли на них.
С технической точки зрения это включает в себя разработку систем искусственного интеллекта, придающих приоритет автономии пользователя, предоставляя им необходимые инструменты и информацию для принятия обоснованных решений. Для этого модели искусственного интеллекта должны быть осведомлены о контексте, что означает, что они должны понимать конкретный контекст, в котором принимается решение, и соответственно корректировать свои рекомендации.
С точки зрения проектирования систем это включает в себя интеграцию контекстуального интеллекта в модели искусственного интеллекта, что позволяет этим системам динамически адаптироваться к окружению пользователя, его предпочтениям и потребностям.
К примеру, в медицине, система, основанная на AI, которая помогает врачам диагностиковать состояния здоровья, должна учитывать уникальную медицинскую историю пациента, текущие симптомы, и даже психологическое состояние, чтобы предложить рекомендации, которые поддерживают экспертизу врача, а не заменили бы ее.
Этот контекстуальный адаптационный процесс помогает AI оставаться инструментом поддержки, улучшающим, а не умаляющим, автономию человека.
Гарантирование прозрачности процессов принятия решений: Прозрачность в AI-системах является фундаментальным требованием для обеспечения того, что пользователи могут верить и понимать решения, принимаемые этими технологиями. technically, это транслируется как необходимость разъясняемой AI (XAI), которая заключается в разработке алгоритмов, которые могут ясно представить причину за их решения.
Это особенно важно в областях, таких как финансы, медицина и уголовное право, где непрозрачные процессы принятия решений могут привести к недоверию и этическим проблемам.
Согласно нескольким техническим подходам можно достичь объяснительности. Один из наиболее распространенных методов – это постфукситивная интерпретируемость, когда модель AI-генерирует объяснение после принятия решения. Это может涉及 разбиение решения на его компонентных факторов и показать, как каждый из них внес свой вклад в итоговое результат.
Другая стратегия состоит в применении по умолчанию прозрачных моделей, в которых архитектура модели направлена на то, чтобы ее решения были прозрачными. Например, модели, такие как решение деревьев и линейные модели, являются естественно прозрачными, поскольку их процесс принятия решений легко следовать и понять.
Однако основная проблема в реализации объясняемого AI заключается в нахождении баланса между прозрачностью и поperformацией. Оften, более сложные модели, такие, как глубокие нейронные сети, менее прозрачны, но более точны. Таким образом, разработка AI центрированного на человеке должна учитывать торговый оператор между прозрачностью модели и ее предсказательной силой, обеспечивая то, что пользователи могут верить и понять решения AI без потери точности.
Разрешение значимого руководства Homo sapiens: значимое руководство Homo sapiens очень важно для обеспечения работы AI систем в этических и операционных рамках. Это руководство включает создание AI систем с safety и оверIDE системами, которые позволяют операторам вмешаться, когда это необходимо.
Техническое реализация руководства Homo sapiens может быть принята several ways.
Одним из подходов является включение систем с Homo sapiens в цикл, где процессы принятия решений AI постоянно наблюдаются и оцениваются операторами Homo sapiens. Эти системы проектировались для того, чтобы позволить вмешательство Homo sapiens на критических перекрёстках, обеспечивая, что AI не действует автономно в ситуациях, требующих этических заключений.
В случае систем автономного оружия, контроль человека является необходимым для предотвращения того, что AI делает решения, связанные с жизнью и смертью, без вклада человека. Это может включать установление строгих операционных границ, которые AI не может пересекать без человеческого разрешения, тем самым внедряя этические предохранители в систему.
Другим техническим моментом является разработка аудитных трейлов, которые являются записями всех решений и действий, совершенных системой AI. Эти трейлы обеспечивают прозрачную историю, которую человеческие операторы могут проверять для обеспечения соблюдения этических стандартов.
Аудитные трейлы особенно важны в таких секторах, как финансы и право, где решения должны быть документально подтверждены и обоснованы для поддержания общественного доверия и соответствия регулятивным требованиям.
Сочетание автономии и контроля: Ключевой технический вызов в человекоцентрическом AI заключается в нахождении правильного баланса между автономией и контролем. Хотя системы AI разрабатываются для автономной работы во многих сценариях, важно, чтобы эта автономия не подрывала человеческий контроль или наблюдение.
Этот баланс может быть достигнут через внедрение уровней автономии, которые определяют степень независимости AI в принятии решений.
Например, в полуавтономных системах, таких как самоуправляемые автомобили, уровни автономии варьируются от базовой помощи водителю (где человек остается под полным контролем) до полной автоматизации (где AI отвечает за все функции управления автомобилем).
Дизайн этих систем должен обеспечить, чтобы при любом уровне автономии человеческий оператор сохранял возможность вмешаться и переопределить AI, если это необходимо. Это требует изысканных контрольных интерфейсов и систем поддержки решений, которые позволяют людям быстро и эффективно взять управление, когда это необходимо.
Кроме того, разработка этических рамок AI является необходима для направления самостоятельных действий систем AI. Эти рамки – это наборы правил и направлений, встроенных в AI и указывающих, каким образом оно должно вести себя в этически сложных ситуациях.
Например, в здравоохранении, этическая рамка AI может включать правила о соглашении пациента, конфиденциальности и определении приоритетов лечения на основе медицинских потребностей, а не финансовых соображений.
При встроении этих этических принципов непосредственно в процессы принятия решений AI, разработчики могут уверенно заявить, что автономия системы осуществляется способом, согласным человеческим ценностям.
Интеграция человекоцентричных принципов в дизайн AI является не только философской идеей, но и технической необходимостью. Улучшая автономию человека, обеспечивая прозрачность, позволяя значительному надзору и精巧но балансируя автономию с контролем, системы AI могут быть разработаны таким образом, что соответствуют истинному служению человечеству.
Эти технические соображения обеспечивают создание AI, которая не только усиливает человеческие возможности, но и уважает и поддерживает ценности, которые являются фундаментом нашего общества.
По мере продолжения развития AI, приверженность дизайну, центрированному на человеке, будет ключевой для обеспечения того, чтобы эти могущественные технологии были использованы этическим и ответственным образом.
Как обеспечить, чтобы ИИ выгодно влиял на человечество: улучшение качества жизни
Когда вы продвигаетесь в разработке систем ИИ, важно опора ваших усилий на этическую основу utilitarianism — философию, которая акцентирует улучшение общего счастья и благополучия.
В этом контексте ИИ обладает потенциалом решать важные общественные проблемы, особенно в таких областях как здравоохранение, образование и устойчивость окружающей среды.
Цель состоит в создании технологий, которые значительно улучшают качество жизни для всех. Но преследование этого амбициозного целевого охраняемое комплексностью. Utilitarianism предлагает убедительные причины для широкого применения ИИ, но также выносит на передний план важные этические вопросы о том, кто извлекает выгоду и кто может оказаться за бортом, особенно среди уязвимых групп населения.
Чтобы обойти эти проблемы, нам нужна сложная, технически проинформированная стратегия — одна, которая балансирует широкий поиск общественного блага с необходимостью справедливости и справедливости.
При применении принципов utilitarianism к ИИ ваше внимание должно быть сфокусировано на оптимизации результатов в конкретных областях. В здравоохранении, например, диагностические средства, driven by AI, имеют потенциал значительного улучшения исходов лечения за счет позволяющего более раннее и точное диагнозирование системы. Эти системы могут анализировать обширные данные, чтобы обнаружить модели, которые могут упустить человеческие практики, тем самым расширяя доступ к качественному обслуживанию, особенно в недостаточно ресурсированных условиях.
Но внедрение these технологий требует осторожного рассмотрения, чтобы избегать усиления существующих неравенств. Данные, используемые для обучения моделей AI, сильно варьируются по регионам, влияя на точность и надежность этих систем.
Этот разрыв подчеркивает важность установления прочных структур управления данными, которые обеспечивают, чтобы ваши AI-основанные решения в здравоохранении были как репрезентативными, так и справедливыми.
В области образования AI способность personalize learning является обещающей. Системы AI могут адаптировать учебный контент для соответствия особым потребностям отдельных студентов, тем самым enhancing learning outcomes. Analyzing данные о показателях успеваемости и поведения студентов, AI может идентифицировать места, где студент может быть в difficulty и предоставить целевую поддержку.
But while you work towards these benefits, it’s crucial to be aware of the risks — such as the potential to reinforce biases or marginalize students who don’t fit typical learning patterns.
Mitigating these risks requires the integration of fairness mechanisms into AI models, ensuring they do not inadvertently favor certain groups. And maintaining the role of educators is critical. Their judgment and experience are indispensable in making AI tools truly effective and supportive.
In terms of environmental sustainability, AI’s potential is considerable. AI systems can optimize resource use, monitor environmental changes, and predict the impacts of climate change with unprecedented precision.
Например, ИИ может анализировать огромные объемы экологических данных, чтобы предсказывать погодные условия, оптимизировать потребление энергии и минимизировать отходы – действия, способствующие благосостоянию текущих и будущих поколений.
Но это технологическое развитие приносит и свои собственные проблемы, особенно в связи с экологическим воздействием самих ИИ-систем.
Потребление энергии, необходимое для работы масштабных ИИ-систем, может компенсировать экологические преимущества, которые они намерены достичь. Таким образом, разработка энергоэффективных ИИ-систем является ключевой для обеспечения того, что их положительное влияние на устойчивость не будет поставлено под угрозу.
Когда вы разрабатываете ИИ-системы с утилитарными целями, важно также учитывать последствия для социальной справедливости.Utilitarianism фокусируется на максимизации общей счастливости, но не исходя из этого активизирует распределение выгод и негативных последствий среди различных социальных групп.
Это поднимает возможность того, что ИИ-системы неравномерно выгодят тех, кто уже обладает привилегиями, в то время как маргинализированные группы могут лишь слабо улучшить свое положение.
Чтобы этому противостоять, ваш процесс разработки ИИ должен включать принципы, сфокусированные на равенстве, убеждаясь, что выгоды распределяются Fairly и что любые возможные вредам обращаются внимание. Это может涉及 создание алгоритмов, направленных на уменьшение предрассудков, и включение в процесс разработки различных точек зрения.
Во время разработки систем АИ, направленных на повышение качества жизни, важно найти баланс между утилитарной целью максимизации блага и необходимостью справедливости и Fairness. Это требует изящного, технически обоснованного подхода, который рассматривает более широкие последствия развертывания систем AI.
Продуктивно создавая AI системы, которые являются как эффективными, так и равноправными, вы можете способствовать будущему, где технологические усовершенствования истинно обслуживают различные потребности общества.
Внедрь защитные меры против возможного вреда
При разработке технологий AI, вы должны признать внутреннюю возможность для вреда и активно устанавливать устойчивые защитные меры, чтобы смягчить эти риски. Эта ответственность глубоко укоренена в деONTOLOGICAL этической. Эта ветка этики акцентирует внимание на моральную обязанность соблюдать установленные правила и стандарты этической политики, обеспечивая сходство созданных вами технологий с основными моральными принципами.
Внедрение жестких протоколов безопасности не является только предохранительным, но и моральным обязательством. Эти протоколы должны включать всесторонние тесты для определения предвзятости, прозрачность в алгоритmic процессах и ясные механизмы для управления ответственностью.
Такие защитные меры крайне важны для предотвращения непреднамеренного вреда, который AI системы могут причинить, either through biased decision-making, opaque processes, or lack of oversight.
На практике внедрение этих мер требует глубокого понимания как технических так и этических аспектов AI.
Тестирование на предвзятость, например, включает не только идентификацию и коррекцию предвзятостей в данных и алгоритмах, но и понимание более широких социальных последствий этих предвзятостей. Вы должны убедиться, что ваши модели AI тренировались на различных, представительных наборах данных и регулярно оценивались для обнаружения и исправления любых предвзятостей, которые могут возникнуть с течением времени.
С другой стороны, требования прозрачности требуют, чтобы системы AI были разработаны так, что их процессы принятия решений легко понимались и проверялись пользователями и заинтересованными сторонами. Это включает разработку понятных моделей AI, которые предоставляют ясные, интерпретируемые выходы, позволяя пользователям видеть, как принимаются решения, и обеспечивая, чтобы эти решения были обоснованны и справедливы.
Кроме того, механизмы ответственности очень важны для поддержания доверия и обеспечения ответственного использования систем AI. Эти механизмы должны включать четкие руководства о том, кто ответственен за результаты решений AI, а также процессы для обработки и исправления любых ущербов, которые могут произойти.
Вы должны установить рамку, где этические соображения интегрированы во все стадии разработки AI, от исходного дизайна до развертывания и далее. Это включает не только следование этическим руководствам, но и постоянное мониторинг и настройку систем AI, когда они взаимодействуют с реальным миром.
При внедрении этих гарантий в самую основу разработки AI вы можете помочь обеспечить, что технологический прогресс служит большему благу без приводствия незапланированных негативных последствий.
Роль человеческого надзора и циклов обратной связи
Человеческий надзор в СИ является критическим компонентом для обеспечения этической практики развертывания AI. Принцип ответственности подкрепляет необходимость непрерывного участия людей в работе AI, особенно в серьезных средах, таких как здравоохранение и уголовное правосудие.
Циклы обратной связи, в которых используется ввод человека для усовершенствования и улучшения систем AI, являются необходимыми для поддержания ответственности и адаптивности (Raji et al., 2020). Эти циклы позволяют исправлять ошибки и интегрировать новые этические соображения в связи с эволюцией общественных ценностей.
При внедрении человеческого надзора в системы AI разработчики могут создавать технологии, которые не только эффективны, но и соответствуют этическим нормам и ожиданиям людей.
Кодирование этики: перевод философских принципов в AI системы
Перевод философских принципов в AI системы является сложной, но необходимой задачей. Этот процесс включает внедрение этических соображений в собственно код, управляющий алгоритмами AI.
Понятия, такие как справедливость, справедливость и самоуправление, должны быть кодифицированы в AI системах, чтобы убедиться, что их действия отражают общественные ценности. Это требует многодисциплинарного подхода, в котором этические ученые, инженеры и социологи сотрудничают, чтобы определить и реализовать этические руководства в процессе кодирования.
Цель состоит в создании AI систем, которые не только технически компетентны, но и морально устойчивы, способные принимать решения, уважающие достоинство человека и способствующие общественному благу (Mittelstadt et al., 2016).
Продвижение инклюзивности и равного доступа в разработку и развертывание AI
Включение и равноправный доступ являются фундаментальными для этического развития ИИ. Концепция справедливости как справедливости Джона Роулза (Rawlsian) обеспечивает философскую основу для обеспечения того, чтобы системы ИИ были разработаны и внедрены таким образом, чтобы поощрять блага всех членов общества, особенно самых уязвимых (Роулз, 1971).
Это требует проактивных усилий включить различные точки зрения в процесс разработки, особенно из не представленных групп и Южного полушария.
Проинтегрировав эти различные точки зрения, разработчики ИИ могут создавать системы, которые более эквивалентны и реагируют на потребности ширшего спектра пользователей. Кроме того, обеспечение эквивалентного доступа к технологиям ИИ важно для предотвращения усиления существующих социальных неравенств.
Решайте вопросы алгоритмической несправедливости и справедливости
Алгоритмическая несправедливость является значительным этическим проблемой в развитии ИИ, поскольку нейтральные алгоритмы могут поддерживать и даже усиливать социальные неравенства. решая эту проблему требуется стремление к процедурной справедливости, обеспечивая, чтобы системы ИИ были разработаны через справедливые процессы, учитывающие влияние на все заинтересованные стороны (Ниссенауб, 2001).
Это заключается в идентификации и смягчении предвзятых взглядов в тренировочных данных, разработке ясных и объясняемых алгоритмов и внедрении проверок справедливости на различных стадиях жизненного цикла ИИ.
При решении вопросов алгоритмической несправедливости разработчики могут создавать системы ИИ, которые способствуют более справедливому и эквивалентному обществу, а не усилению существующих различий.
Включите различные точки зрения в разработку ИИ
Включение различных точек зрения в разработку искусственного интеллекта необходимо для создания систем, которые будут инклюзивными и справедливыми. Участие голосов представителей малопредставленных групп гарантирует, что технологии искусственного интеллекта не будут просто отражать ценности и приоритеты узкого сегмента общества.
Этот подход соответствует философскому принципу делиберативной демократии, который подчеркивает важность инклюзивных и участвующих процессов принятия решений (Хабермас, 1996).
Содействуя разнообразному участию в разработке искусственного интеллекта, мы можем гарантировать, что эти технологии разрабатываются для обслуживания интересов всего человечества, а не только немногих привилегированных.
Стратегии преодоления разрыва в области искусственного интеллекта
Разрыв в области искусственного интеллекта, характеризующийся неравным доступом к технологиям искусственного интеллекта и их преимуществами, представляет собой значительное вызов для глобальной справедливости. Преодоление этого разрыва требует обязательства перед распределительной справедливостью, гарантируя, что преимущества искусственного интеллекта распространяются широко по различным социоэкономическим группам и регионам (Сен, 2009).
Мы можем добиться этого через инициативы, способствующие доступу к образованию в области искусственного интеллекта и ресурсам в недооцененных общинах, а также через политики, поддерживающие справедливое распределение экономических выгод, приносимых искусственным интеллектом. Решая проблему разрыва в области искусственного интеллекта, мы можем гарантировать, что искусственный интеллект вносит свой вклад в глобальное развитие способом, который является инклюзивным и справедливым.
Находите баланс между инновациями и этическими ограничениями
Нахождение баланса между стремлением к инновациям и этическими ограничениями является ключевым аспектом ответственного продвижения в области искусственного интеллекта. Принцип предосторожности, который призывает к осторожности в условиях неопределенности, особенно актуален в контексте разработки искусственного интеллекта (Сандин, 1999).
Новаторство, driving progress, должно быть смягчено przez этические соображения, защищающие от возможных вредных последствий. Это требует тщательного анализа рисков и выгод новых технологий AI, а также внедрения регламентных рамок, обеспечивающих соблюдение этических стандартов.
Проведя баланс между инновацией и этическими ограничениями, мы можем содействовать развитию технологий AI, которые являются одновременно передовыми и соответствующими общественному благосостоянию.
Как вы можете видеть, философская основа умных систем обеспечивает критическую структуру для обеспечения того, что технологии AI разрабатываются и внедряются в этических, включающих и полезных для всего человечества способах.
При опоре на эти философские принципы развитие AI, мы можем создавать умные системы, которые не только усовершенствуют технологические возможности, но и улучшают качество жизни, способствуют справедливости и обеспечивают равномерное распределение благ AI по всему обществу.
Глава 5: AI-агенты как улучшители LLM
Слияние AI-агентов с крупными моделями языка (LLM) представляет собой фундаментальный сдвиг в искусственном интеллекте, решая критические ограничения LLM, которые limit their broader applicability.
Эта интеграция позволяет машинам преодолеть свои традиционные роли, перейдя от пассивных текстовых генераторов к автономным системам, способным к динамическому ratioch и принятию решений.
Так как системы AI все более управляют критическими процессами в различных областях, понимание того, как AI-агенты заполняют пробелы в возможностях LLM, является необходимым для реализации их полного потенциала.
Преодоление пробелов в возможностях LLM
LLM, несмотря на свою мощь, имеют врожденные ограничения, связанные с данными, на которых они обучались, и статичной природой их архитектуры. Эти модели работают в рамках фиксированного набора параметров, обычно определенных корпусом текста, использованного во время их обучения.
Это ограничение означает, что LLM не могут автономно искать новую информацию или обновлять свою базу знаний после обучения. В результате LLM часто устаревают и не могут предоставлять контекстно-релевантные ответы, требующие реальных данных или понимания, выходящего за пределы их исходных данных обучения.
AI-агенты преодолевают эти пробелы, динамически интегрируя внешние источники данных, что позволяет расширить функциональные возможности LLM.
Например, LLM, обученная на финансовых данных до 2022 года, может предоставлять точные исторические анализы, но будет испытывать трудности при генерации актуальных прогнозов рынка. AI-агент может дополнить эту LLM, получая актуальные данные с финансовых рынков и применяя их для генерации более соответствующих и текущих анализов.
Такая динамическая интеграция гарантирует, что результаты не только исторически точны, но и контекстно соответствуют текущим условиям.
Повышение автономии принятия решений
Еще одним значительным ограничением LLM является их отсутствие автономных возможностей принятия решений. LLM отлично справляются с генерацией языковых выводов, но не могут справиться с задачами, требующими сложного принятия решений, особенно в средах, характеризующихся неопределенностью и изменениями.
СHORTAGE ОF FUNCTIONALITY PRIMARILY ОCCURS DUE TО THE MODEL’S DEPENDENCE ОN EXISTING DATA AND THE LACK ОF MECHANISMS FOR ADAPTIVE REASONING OR LEARNING FROM NEW EXPERIENCES AFTER DEPLOYMENT.
АGЕNTЫ ИИ РЕШАЮТ ЭТО, ОПРЕДЕЛЯЯ НЕОБХОДИМУЮ ИНФРАСТРУКТУРУ ДЛЯ АВТОНОМНОГО ПРИНЯТИЯ РЕШЕНИЙ. ОНИ МОГУТ ВЗЯТЬ СТАТИЧЕСКИЕ ВЫВОДЫ ЛПМ И ОБРАБОТАТЬ ИХ С ПОМОЩЬЮ ПРОГРАММНЫХ ФРАМЕВОК ДЛЯ ПРОВЕРКИ ЗНАНИЙ, ОСНОВАННЫХ НА ПРАВИЛАХ, ЭВРИСТИКИ ИЛИ МОДЕЛЕЙ УСИЛЕНИЯ ОБУЧЕНИЯ.
Например, в медицинской сфере ЛПМ может создать список потенциальных диагнозов на основе симптомов и медицинской истории пациента. Но без агента ИИ ЛПМ не может оценить эти варианты или рекомендовать курс действий.
Агент ИИ может взять на себя роль оценки этих диагнозов в соответствии с текущей медицинской литературой, данными о пациенте и контекстуальными факторами, в конечном итоге принимая более обоснованное решение и предлагая выполнимые следующие шаги. Эта синергия преобразует выводы ЛПМ из простых предложений в выполнимые, основанные на контексте решения.
РЕШЕНИЕ ПРОБЛЕМЫ ПОЛНОТЫ И СООТВЕТСТВИЯ
Полнота и последовательность являются критическими факторами для обеспечения надежности выводов ЛПМ, особенно в сложных задачах рассуждения. Из-за своей параметризованной природы ЛПМ часто генерируют ответы, которые либо неполны, либо лишены логической связности, особенно при работе с многошаговыми процессами или требующими всестороннего понимания различных областей.
Эти проблемы происходят из изолированной среды, в которой работают ЛПМ, где они не могут сравнивать или проверять свои выводы с внешними стандартами или дополнительной информацией.
Агенты AI играют решающую роль в смягчении этих проблем, внедряя итеративные механизмы обратной связи и слои валидации.
например, в сфере права, LLM может написать первоначальную версию законодательного заявления на основе своих тренировочных данных. Но этот проект может пропустить certain precedents или не организовать аргумент логически.
Агент AI может проверить этот проект, обеспечивая соответствие требуемым стандартам полноты путем сравнения с внешними базами юридической информации, проверки логической последовательности и запроса дополнительной информации или разъяснения, где требуется.
Этот итеративный процесс позволяет произвести более устойчивый и надеждной документ, соответствующий строгим требованиям практики права.
Overcoming Isolation Through Integration
Одна из самых глубоких ограничений LLM заключается в их внутренней изоляции от других систем и источников знаний.
LLM, как они были спроектированы, являются закрытыми системами, которые неродственно взаимодействие с внешним окружением или базами данных. Эта изоляция значительно ограничивает их способность адаптироваться к новой информации или работать в реальном времени, делая их менее эффективными в приложениях, требующих динамического взаимодействия или реального времени принятия решений.
AI агенты преодолевают эту изоляцию, действуя как интеграционные платформы, соединяющие LLM с более широкой экосистемой данных и вычислительных средств. Through APIs и других интеграционных средств, AI агенты могут получить доступ к реальному времени данные, сотрудничать с другими системами AI и даже взаимодействовать с физическими устройствами.
Например, в приложениях для обслуживания клиентов, LLM может генерировать стандартные ответы на основе предварительно обученных скриптов. Однако эти ответы могут быть статичными и не содержать необходимой для эффективного взаимодействия с клиентами персонализации.
Агент AI может улучшить эти взаимодействия, интегрируя реаль-time данные из профилей клиентов, предыдущих взаимодействий и инструментов анализа эмоционального состояния, что помогает генерировать ответы, которые являются не только контекстуально значимыми, но и направлены на определение особых потребностей клиента.
Эта интеграция превращает经验ние клиента от ряда сценаризированных взаимодействий в динамичную, персонализированную беседу.
Расширение творческого потенциала и способности решать проблемы
尽管LLM是非常强大的生成内容的工具,但是他们的创造力和解决问题的能力本质上是受限于他们在训练时使用的数据。这些模型通常无法将理论概念应用于新的或未曾预见到的挑战,因为它们的问题解决能力受限于它们既有的知识和训练参数。
AI代理通过运用先进的推理技术和更广泛的分析工具,增强了LLM的创造力和解决问题的潜力。这种能力使得AI代理能够突破LLM的限制,以创新的方式将理论框架应用于实际问题。
例如,考虑社交媒体平台上的误导信息问题。LLM可能会基于文本分析识别误导信息的模式,但它可能难以开发出全面遏制虚假信息传播的策略。
Агент-AI может использовать这些洞见, применить теории междисциплинарных наук, таких как социология, психология и сетевая теория, и развить устойчивую, многостороннюю стратегию, которая включает реальное время мониторинг, образование пользователей и автоматизированные способы модерации.
Эта способность синтезировать различные теоретические рамки и применять их к реальным мирным проблемам является примером улучшенных производственных способностей, которые AI агенты приносят на стол.
более конкретные примеры
AI агенты, обладая способностью взаимодействовать с различными системами, получать реальные данные и выполнять действия, решают эти ограничения прямо, трансформируя LLM из мощного, но пассивного языкового модель в динамичных, мирных проblem solvers.みなさんはいくつかの例を見てみょう:
1. от статичных данных до динамических взглядов: LLM в круге
-
Проблема: представьте себе, что вы спросите LLM, обученного до 2023 г. медицинским исследованиям, “Какие самые последние инновации в лечении рака?” Его знания уже устарело.
-
Решение AI агента: AI агент может подключить LLM к медицинским журналам, исследовательским базам данных и новостным потокам. сейчас LLM может предоставлять информацию о последних клинических исследованиях, лечебных возможностях и найденных исследованиях.
2. от анализа к действию: автоматизация задач на основе взглядов LLM
-
Проблема: LLM, наблюдающий за социальными медиа для бренда, может идентифицировать резкое увеличение негативных эмоций, но не может ничего сделать для их решения.
-
Решение AI-агента: AI-агент, подключенный к социальным аккаунтам бренда и оснащенный предварительно одобренными ответами, может автоматически решать проблемы, отвечать на вопросы и даже передавать сложные вопросы человеческим представителям.
3. от первого черновика до отполированного продукта: обеспечение качества и точности
-
Проблема: LLM, назначенный на перевод технического руководства, может произвести грамматически правильные, но технически неточные переводы из-за отсутствия специальных знаний.
- Решение AI-агента: AI-агент может интегрировать LLM с специальными словарями, справочниками и даже подключить его к экспертам по теме для получения реального времени обратной связи, что обеспечит конечный перевод, являющийся как грамматически правильным, так и технически correct.
4. Обход барьеров: Подключение LLMs к реальному миру
- Проблема: LLM, спроектированный для управления смарт-дом, может испытывать трудности при адаптации к изменяющимся распорядкам и предпочтениям пользователя.
- Решение AI-агента: AI-агент может подключить LLM к сенсорам, смарт-устройствам и календарям пользователей. Analyzing поведение пользователя, LLM может научиться предсказывать потребности, автоматически настраивать настройки освещения и температуры и предлагать персонализированные плейлисты музыки в соответствии с временем дня и деятельностью пользователя.
5. От имитации к инновации: расширение креативности LLM
-
Проблема: LLM, ответственный за создание музыки, может создавать произведения, звучащие заимствованными или лишенные эмоциональной глубины, так как в первую очередь опирается на модели, обнаруженные в его тренировочных данных.
-
Решение с использованием AI-агента: AI-агент может подключить LLM к биофидбэк-датчикам, измеряющим эмоциональные реакции композитора на различные музыкальные элементы. Использовав эту реальную временную отдачу, LLM может создавать музыку, которая не только технически грамотна, но и эмоционально вызывает воспоминания и оригинальна.
Комбинация AI-агентов как усилителей LLM представляет не просто ступенчатое улучшение, а фундаментальное расширение возможностей искусственного интеллекта. За счет решения ограничений, присущих традиционным LLM, таких как статичная база знаний, ограниченная автономия принятия решений и изолированная операционная среда, AI-агенты позволяют этим моделям работать на полную мощность.
По мере развития технологии искусственного интеллекта, роль AI-агентов в усилении LLM будет становиться все более важной, не только расширяя возможности этих моделей, но и переопределяя границы искусственного интеллекта самого по себе. Эта синтезия проложит путь для следующего поколения AI-систем, способных к самостоятельному рассуждению, реальному времени адаптации и инновационному решению проблем в постоянно меняющемся мире.
Глава 6: Архитектурное проектирование для интеграции AI-агентов с LLM
Интеграция AI-агентов с LLM зависит от архитектурного проектирования, которое является ключевым для улучшения принятия решений, адаптируемости и масштабируемости. Архитектура должна быть тщательно спроектирована для обеспечения бесшовного взаимодействия между AI-агентами и LLM, гарантируя оптимальную работу каждого компонента.
Модульная архитектура, в которой AI-агент выполняет роль дирижёра, направляя способности LLM, является одним из подходов, который поддерживает динамическое управление задачами. Этот дизайн использует сильные стороны LLM в обработке естественного языка, позволяя AI-агенту управлять более сложными задачами, такими как многоступенчатое рассуждение или контекстуальное принятие решений в реальном времени.
альтернативно, гибридная модель, сочетающая LLM с специализированными, подобранными моделями, обеспечивает гибкость, позволяя агенту AI делегировать задачи наиболее подходящим моделям. Этот подход оптимизирует производительность и улучшает эффективность по широкому кругу приложений, делая его особенно эффективным в различных и изменчивых операционных контекстах (Liang et al., 2021).

Методологии и лучшие практики тренировки
Тренировка AI-агентов, интегрированных с LLM, требует методичного подхода, который балансирует общее обобщение с оптимизацией для конкретных задач.
Перенос обучения является ключевой техникой в данном случае, позволяя LLM, предварительно тренированному на большом разнообразном корпусе, быть подобраным на домен-специфических данных, связанных с задачами AI-агента. Этот метод сохраняет широкий значительный базис знаний LLM, позволяя ему специализироваться в определенных приложениях, улучшая общую эффективность системы.
Также в этом качестве играет критическая роль рефолс-обучение (RL), особенно в сценариях, когда AI-агент должен адаптироваться к изменяющимся средам. Благодаря взаимодействию с его средой AI-агент может непрерывно улучшать процессы принятия решений, становясь умелым в обработке новых проблем.
Чтобы обеспечить надежную работу в различных сценариях, необходимы тщательно разработанные метрики оценки. Эти метрики должны включать и стандартные оси по сравнению и критерии для конкретных задач, чтобы обеспечить, чтобы система была гибкой и всесторонне обучена (Silver et al., 2016).
Введение в подобрание большой модели языка (LLM) и концепции рефолс-обучения
Этот код демонстрирует различные техники, включающие машинное обучение и природное языковое процессование (NLP), сфокусируясь на微调 крупных языковых моделей (LLMs) для специфических задач и реализации агентов рефолдования leaning (RL). Код охватывает несколько ключевых областей:
-
Micro-tuning LLM: Использование предварительно обученных моделей, таких как BERT, для таких задач, как анализ сентимента, используя библиотеку Hugging Face
transformers. Это включает токенизацию набора данных и использование тренировочных аргументов для направления процесса микро-тренинга. -
Рефолдование Learning (RL): Введение в основы рефолдования с помощью простого Q-learning агента, где агент учится через опыт и ошибки, взаимодействуя с средой и обновляя свои знания через Q-таблицы.
-
Моделирование награды с помощью API OpenAI: концептуальный метод использования API OpenAI для динамического обеспечения сигналов награды рефолдованию агенту, позволяя языковой модели оценивать действия.
-
Оценка модели и логирование: Использование библиотек, таких как
scikit-learn, для оценки Performances модели по accuracy и F1-оценкам, а также PyTorchSummaryWriterдля визуализации процесса обучения. -
Продвинутые концепции RL: Имплементация более продвинутых концепций, таких как сети политик градиентного шага, курса обучения и остановка рано, для повышения эффективности обучения модели.
Этот гибридный подход охватывает как supervised learning, с fine-tuning анализа настроения, так и реинформационное обучение, предлагая Insights о том, как современные системы AI строятся, оцениваются и оптимизируются.
Пример кода
Шаг 1: Импорт необходимых библиотек
plaintext
Перед тем, как заняться тонкой настройкой моделей и реализацией агента, важно настроить необходимые библиотеки и модули. Этот код включает импорты из популярных библиотек, таких как Hugging Face’s transformers и PyTorch для работы с нейронными сетями, scikit-learn для оценки производительности модели, а также некоторые модули общего назначения, как random и pickle.
-
Библиотеки Hugging Face: Они позволяют использовать и тонко настраивать предобученные модели и токенизаторы из Model Hub.
-
PyTorch: Это ядро глубокого обучения, используемое для операций, включая слои нейронных сетей и оптимизаторы.
-
scikit-learn: Предоставляет метрики, такие как точность и F1-скор, для оценки производительности модели.
-
API OpenAI: Доступ к языковым моделям OpenAI для различных задач, таких как моделирование наград.
-
TensorBoard: Используется для визуализации прогресса обучения.
В этом коде представлены настройки для импорта необходимых библиотек:
# Импортируем модуль random для генерации случайных чисел.
import random
# Импортируем необходимые модули из библиотеки transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Импортируем load_dataset для загрузки датасетов.
from datasets import load_dataset
# Импортируем метрики для оценки качества модели.
from sklearn.metrics import accuracy_score, f1_score
# Импортируем SummaryWriter для протоколирования процесса обучения.
from torch.utils.tensorboard import SummaryWriter
# Импортируем pickle для сохранения и загрузки обученных моделей.
import pickle
# Импортируем openai для использования API OpenAI (требуется API-ключ).
import openai
# Импортируем PyTorch для операций в области глубокого обучения.
import torch
# Импортируем модуль нейронной сети из PyTorch.
import torch.nn as nn
# Импортируем модуль оптимизатора из PyTorch (не используется непосредственно в этом примере).
import torch.optim as optim
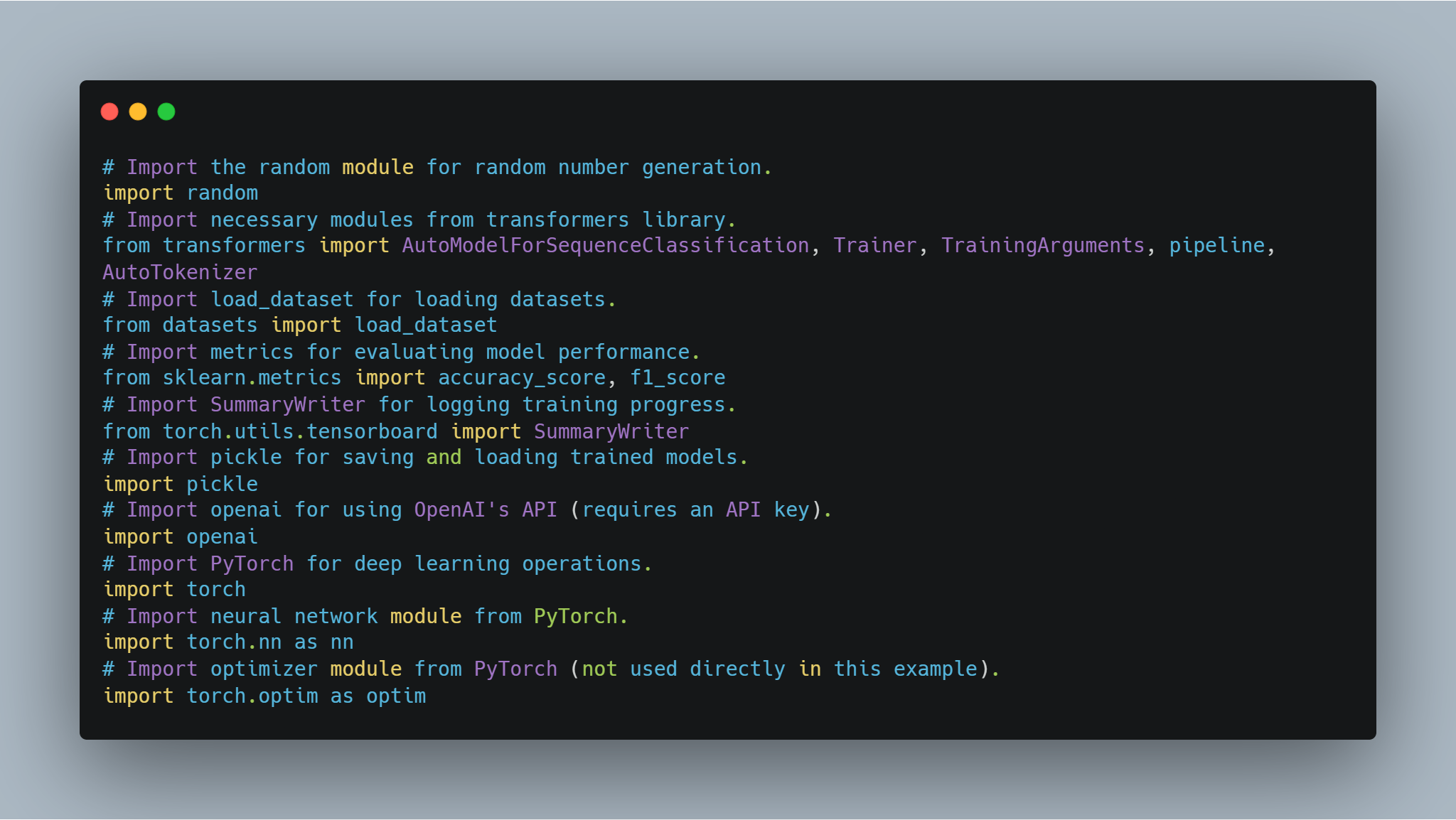
Каждый из этих импортов играет ключевую роль в различных частях кода, от обучения и оценки моделей до протоколирования результатов и взаимодействия с внешними API.
Шаг 2: Finetuning языковой модели для анализа эмоций
finetuning предварительно обученной модели для конкретной задачи, такой как анализ эмоций, включает загрузку предварительно обученной модели, настройку ее для количества выходных метк (положительных/негативных в данном случае) и использование соответствующего датасета.
В этом примере мы используем AutoModelForSequenceClassification из библиотеки transformers, с датасетом IMDB. Этот предварительно обученный модель может быть изменён на небольшой части датасета, чтобы сэкономить время вычислений. Затем модель обучается с помощью набора тренировочных аргументов, который включает количество эпох и размер batch-а.
Ниже приведено код для загрузки и custom fine-tuning модели:
# Указать имя предварительно обученной модели с Hub Model Hugging Face.
model_name = "bert-base-uncased"
# Загрузить предварительно обученную модель с указанным количеством классов выхода.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Загрузить токенизатор для модели.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Загрузить датасет IMDB с Hugging Face Datasets, используя только 10% для тренировки.
dataset = load_dataset("imdb", split="train[:10%]")
# Токенизировать датасет
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# mapped the dataset to tokenized inputs
tokenized_dataset = dataset.map(tokenize_function, batched=True)
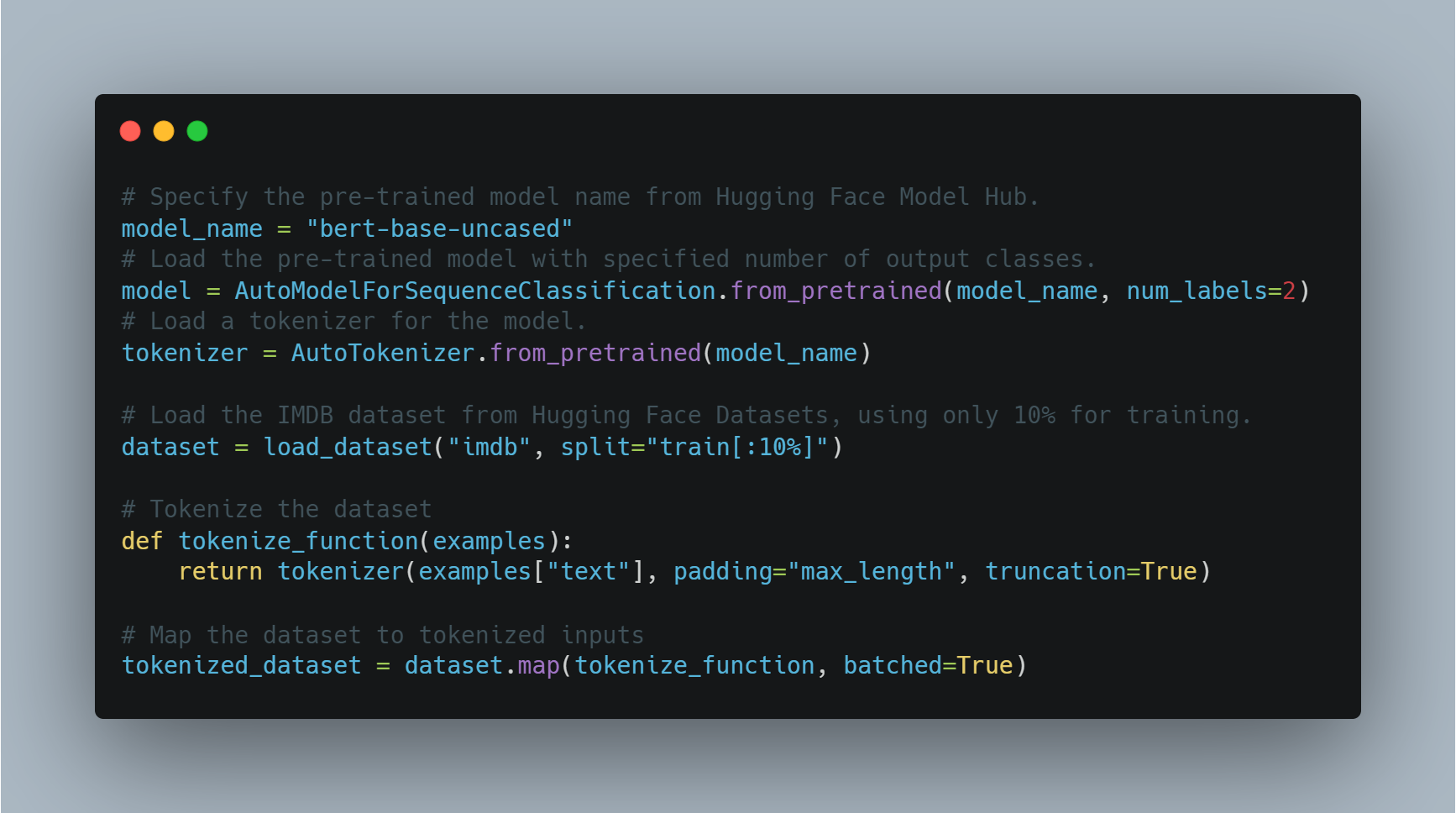
В этом случае модель загружена с использованием архитектуры на основе BERT и датасет подготовлен для тренировки. далее мы определяем тренировочные аргументы и инициализируем тренера.
# Определение параметров обучения.
training_args = TrainingArguments(
output_dir="./results", # Указание каталога для сохранения модели.
num_train_epochs=3, # Установка количества эпох обучения.
per_device_train_batch_size=8, # Установка размера пакета для каждого устройства.
logging_dir='./logs', # Каталог для сохранения журналов.
logging_steps=10 # Запись журнала каждые 10 шагов.
)
# Инициализация тренера с моделью, параметрами обучения и датасетом.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Запуск процесса обучения.
trainer.train()
# Сохранение отталкиваемой модели.
model.save_pretrained("./fine_tuned_sentiment_model")

Шаг 3: реализация простого агента Q-Learning
Q-Learning – это техника реинформационного обучения, в которой агент leaned to take actions in a way that maximizes the cumulative reward.
В этом примере мы определяем базового Q-Learning агента, который сохраняет пары состояние- действие в Q-таблице. Агент может исследовать случайно или использовать лучшее известное действие на основе Q-таблицы. Q-таблица обновляется после каждого действия с помощью учительского коэффициента и фактора снижения для придания веса будущим вознаграждениям.
Ниже представлен код, реализующий этого Q-Learning агента:
# Определение класса агента Q-обучения.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Инициализация таблицы Q.
self.q_table = {}
# Хранение возможных действий.
self.actions = actions
# Установка коэффициента исследования.
self.epsilon = epsilon
# Установка коэффициента обучения.
self.alpha = alpha
# Установка коэффициента дисконтирования.
self.gamma = gamma
# Определение метода get_action для выбора действия на основе текущего состояния.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# Случайное исследование.
return random.choice(self.actions)
else:
# Эксплуатация лучшего действия.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
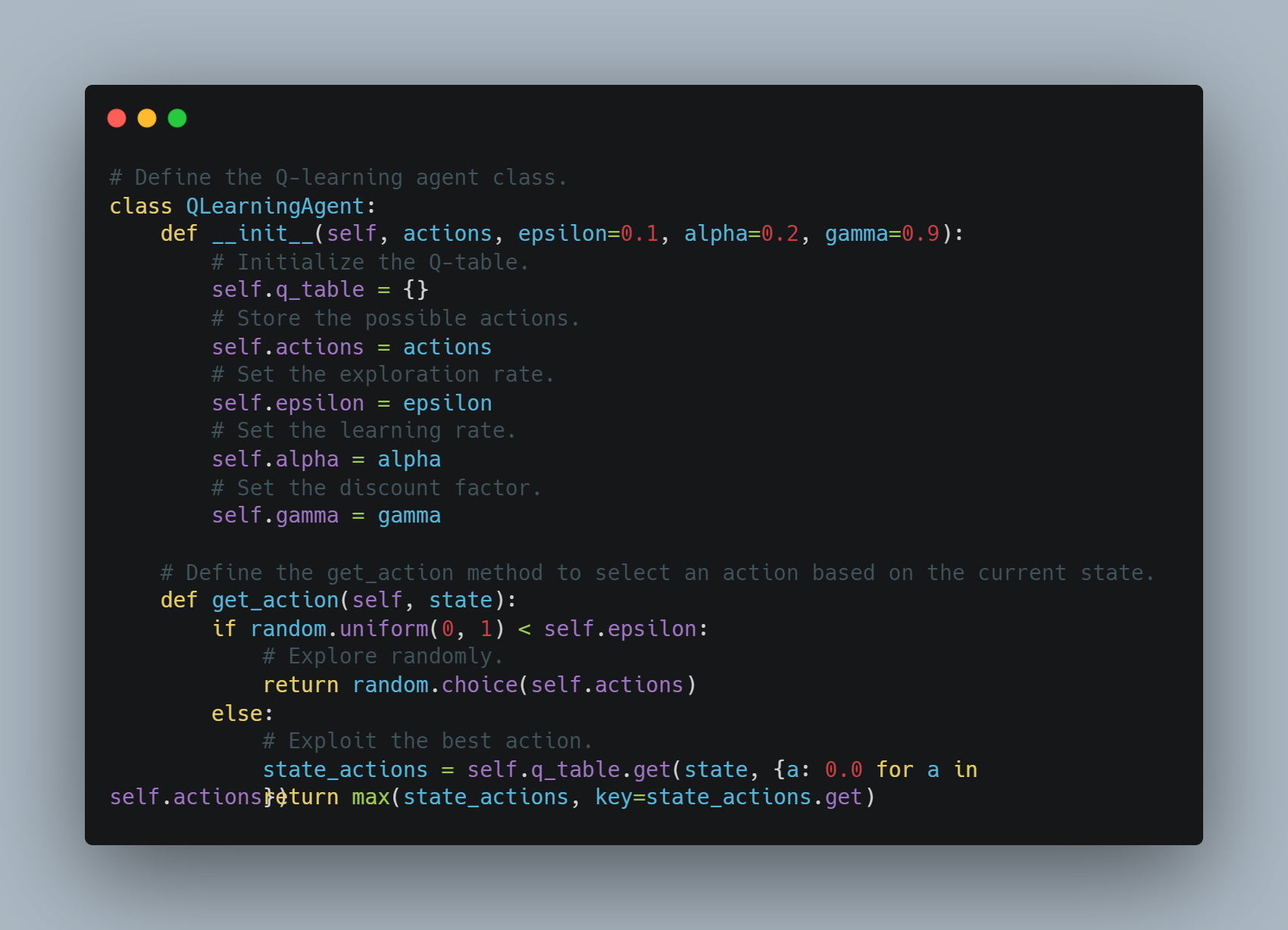
Агент выбирает действия на основе исследования или эксплуатации и обновляет значения Q после каждого шага.
# Определение метода update_q_table для обновления таблицы Q.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
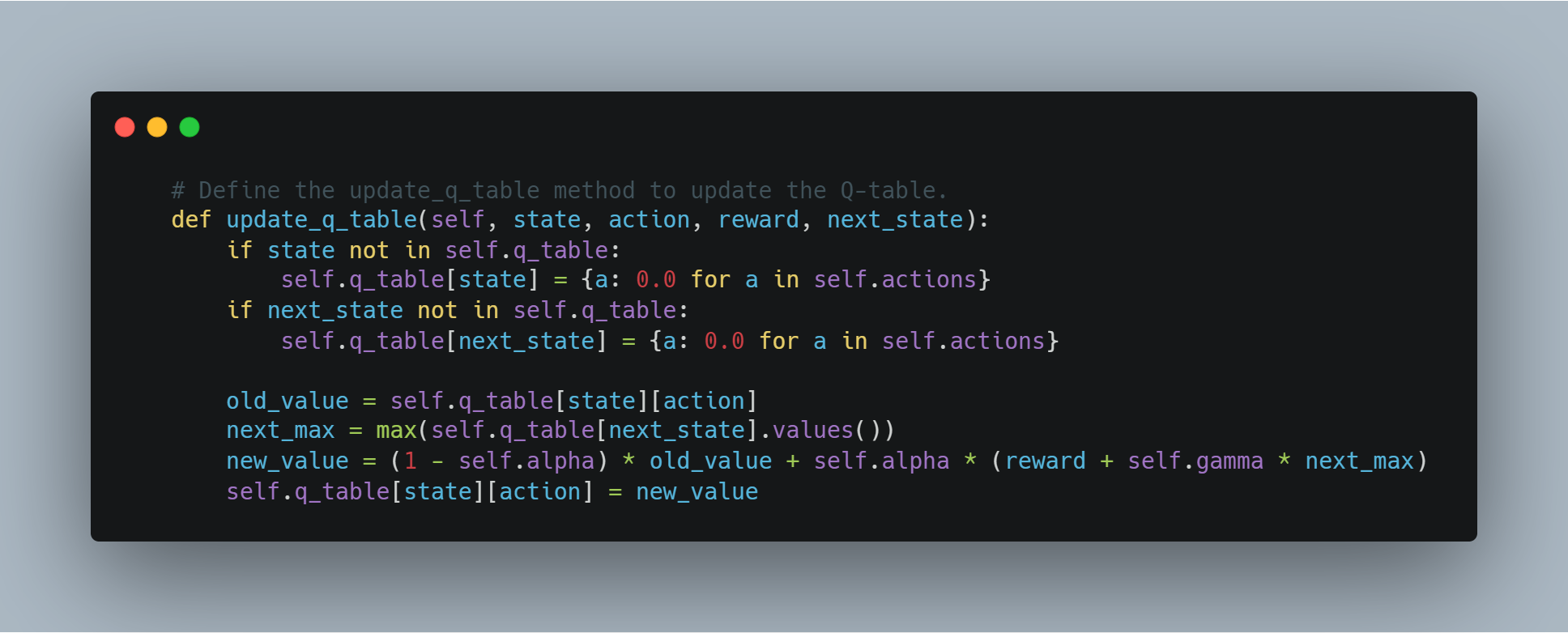
Шаг 4: Использование API OpenAI для моделирования вознаграждения
В некоторых сценариях, вместо определения ручной функции вознаграждения, мы можем использовать мощную языковую модель, такую как GPT от OpenAI, чтобы оценить качество действий, совершаемых агентом.
В этом примере функция get_reward отправляет состояние, действие и следующее состояние в API OpenAI для получения оценки вознаграждения, что позволяет использовать большие языковые модели для понимания сложных структур вознаграждения.
# Определение функции get_reward для получения сигнала вознаграждения от API OpenAI.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # Замените на ваш реальный ключ API OpenAI.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
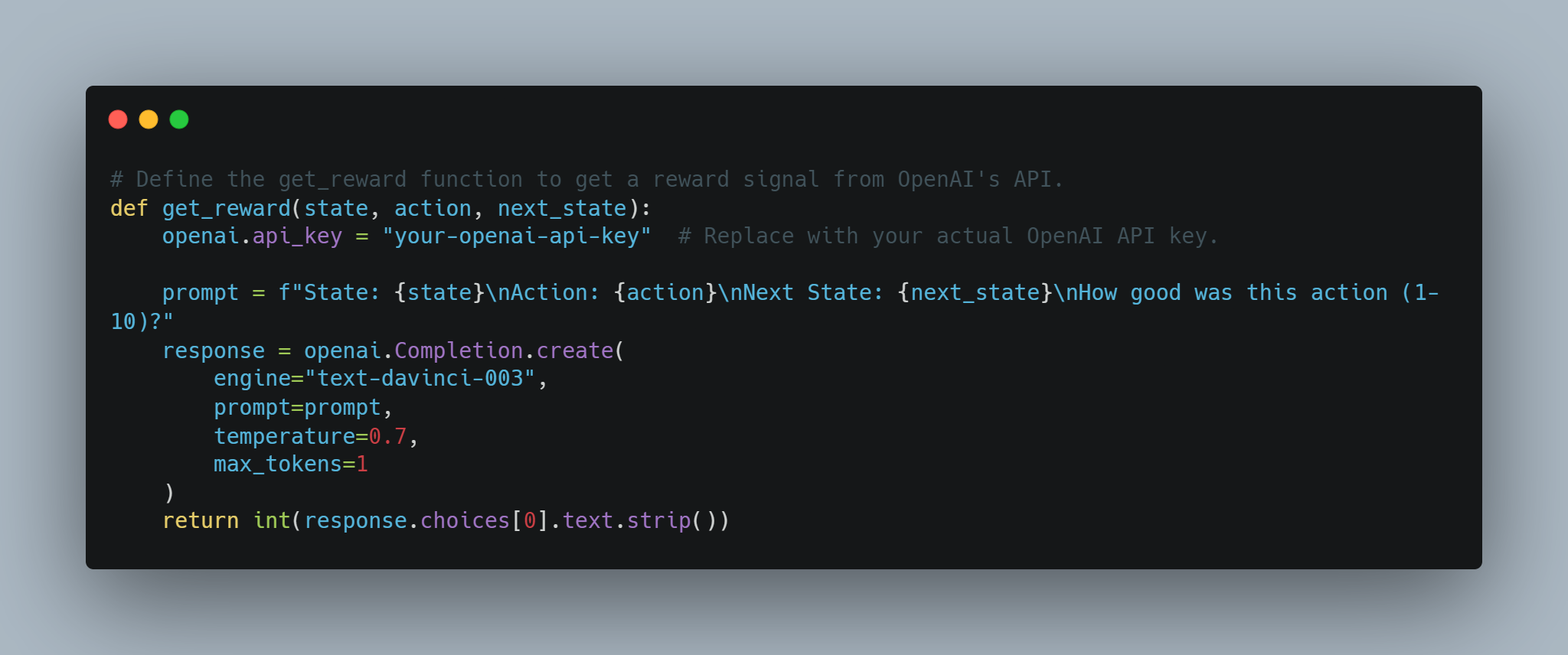
Это позволяет придерживаться концептуального подхода, где система наград определяется динамически с использованием API OpenAI, что может быть полезно для сложных задач, где определение наград трудно.
Шаг 5: оценка Performace модели
Когда модель машинного обучения обучена, необходимо оценить ее Performace с помощью стандартных метрик, таких как точность и оценка F1.
Эта секция вычисляет обе с true и predicte标签d labels. Точность обеспечивает общее衡量 correctness, в то время как оценка F1 балансирует precision и recall, особенно полезно в неравновесных dataset.
Здесь есть код для оценки Performace модели:
# Определить true labels для оценки.
true_labels = [0, 1, 1, 0, 1]
# Определить predicte标签d labels для оценки.
predicted_labels = [0, 0, 1, 0, 1]
# Вычислить точность score.
accuracy = accuracy_score(true_labels, predicted_labels)
# Вычислить оценку F1.
f1 = f1_score(true_labels, predicted_labels)
# Print точность score.
print(f"Accuracy: {accuracy:.2f}")
# Print оценку F1.
print(f"F1-Score: {f1:.2f}")
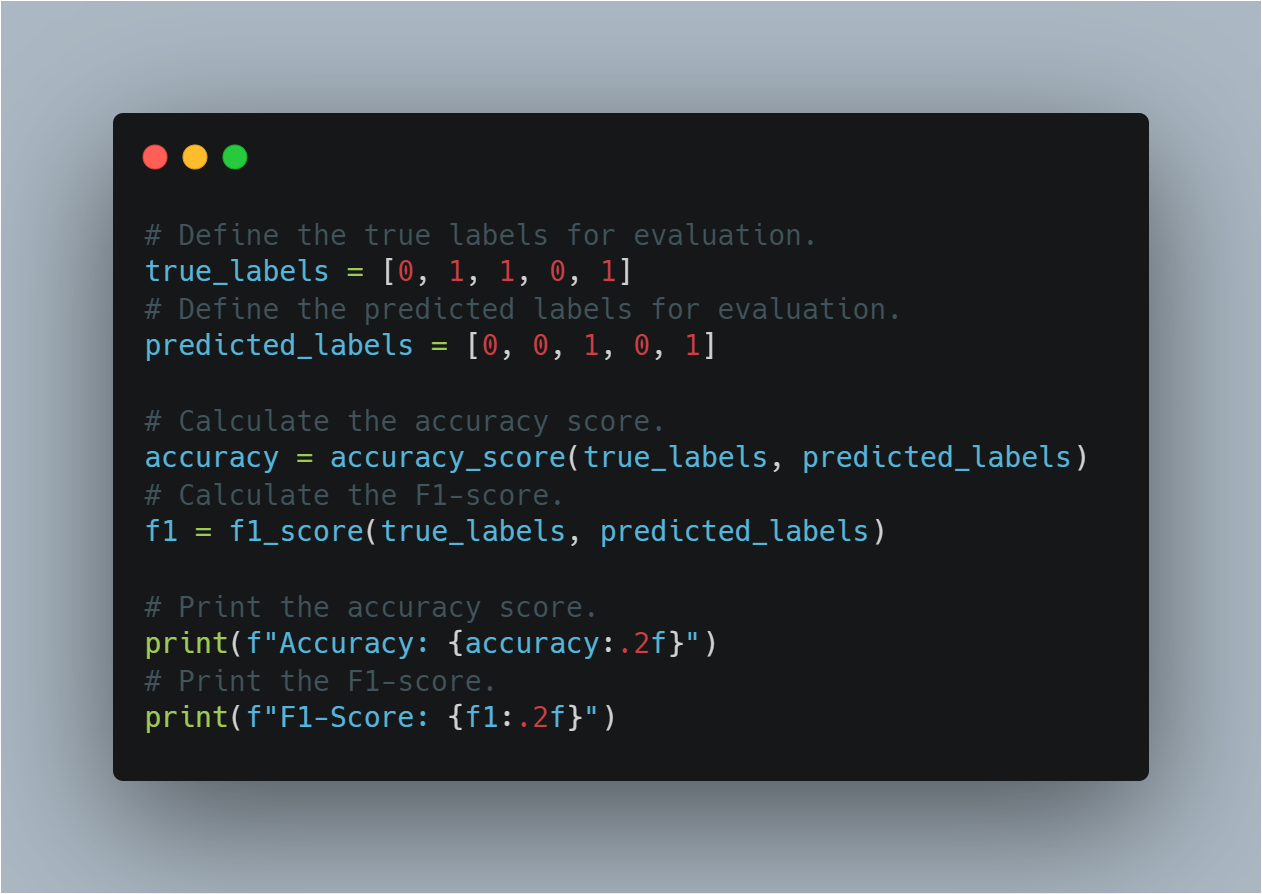
Эта секция помогает оценить, насколько хорошо модель generalize на невиденных данных с использованием хорошо установленных метрик оценки.
Шаг 6: базовая политика градиентного агента (使用 PyTorch)
Методы градиентного агента в обучении поощрения напрямую оптимизируют политику, максимизируя ожидаемую награду.
Эта часть демонстрирует простую реализацию сети политики с использованием PyTorch, которая может использоваться для принятия решений в_rl_. Сеть политики использует линейный слой для вывода вероятностей для различных действий, и softmax применяется для того, чтобы обеспечить, что эти выходы образуют допустимое распределение вероятности.
Вот концептуальный код для определения базового агента с градиентом политики:
# Определите класс сети политики.
class PolicyNetwork(nn.Module):
# Инициализируйте сеть политики.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# Определите линейный слой.
self.linear = nn.Linear(input_size, output_size)
# Определите прямой проход сети.
def forward(self, x):
# Примените softmax к выходу линейного слоя.
return torch.softmax(self.linear(x), dim=1)
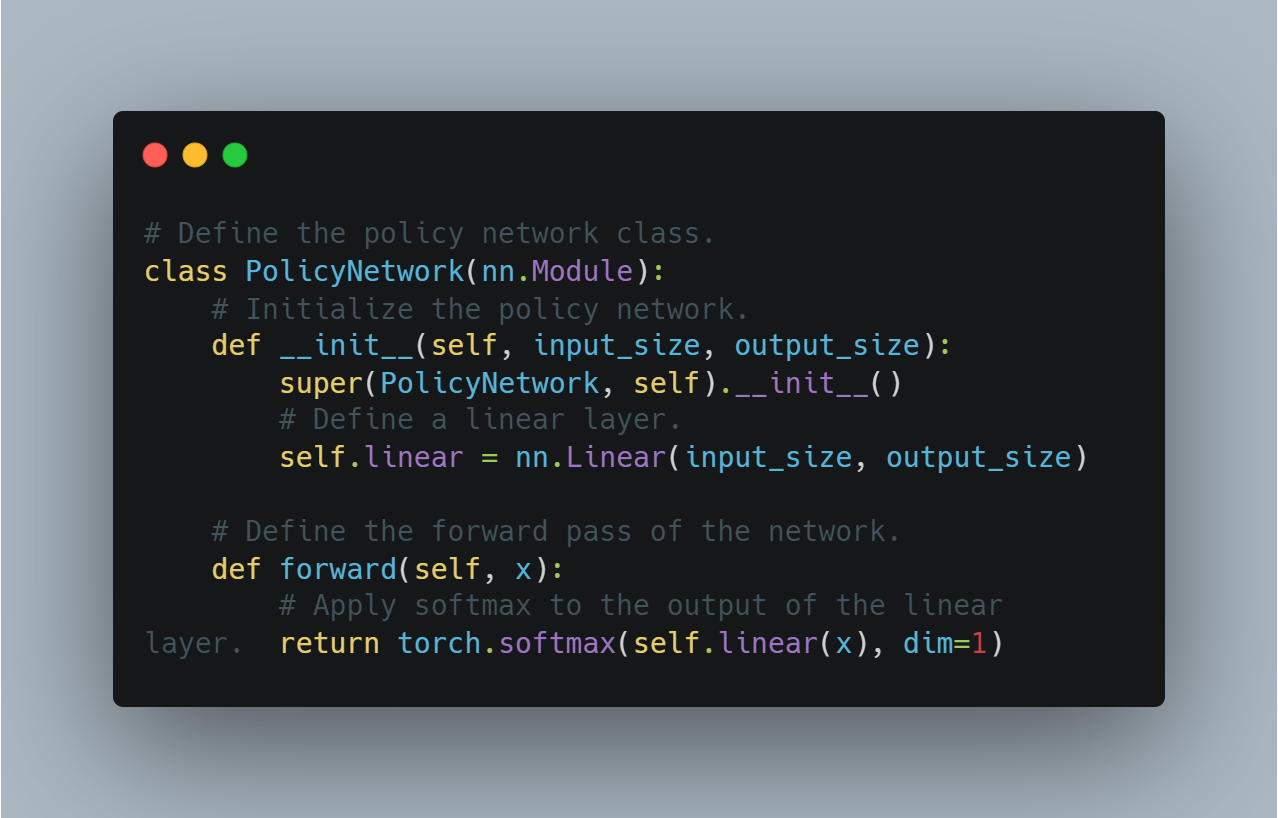
Это служит основным шагом для реализации более продвинутых алгоритмов усиления обучения, которые используют оптимизацию политики.
Шаг 7: Визуализация прогресса обучения с использованием TensorBoard
Визуализация метрик обучения, таких как потери и точность, крайне важна для понимания того, как изменяется производительность модели со временем. TensorBoard, популярный инструмент для этого, может использоваться для записи метрик и их визуализации в реальном времени.
В этом разделе мы создаем экземпляр SummaryWriter и записываем случайные значения, чтобы имитировать процесс отслеживания потерь и точности во время обучения.
Вот как вы можете записывать и визуализировать прогресс обучения с использованием TensorBoard:
Создайте экземпляр класса SummaryWriter.
writer = SummaryWriter()
Пример тренировочного цикла для визуализации с использованием TensorBoard:
num_epochs = 10 Определите количество эпох.
for epoch in range(num_epochs):
Симулируем случайные значения потерь и точности.
loss = random.random()
accuracy = random.random()
Записываем значения потерь и точности в TensorBoard.
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
Закройте SummaryWriter.
writer.close()
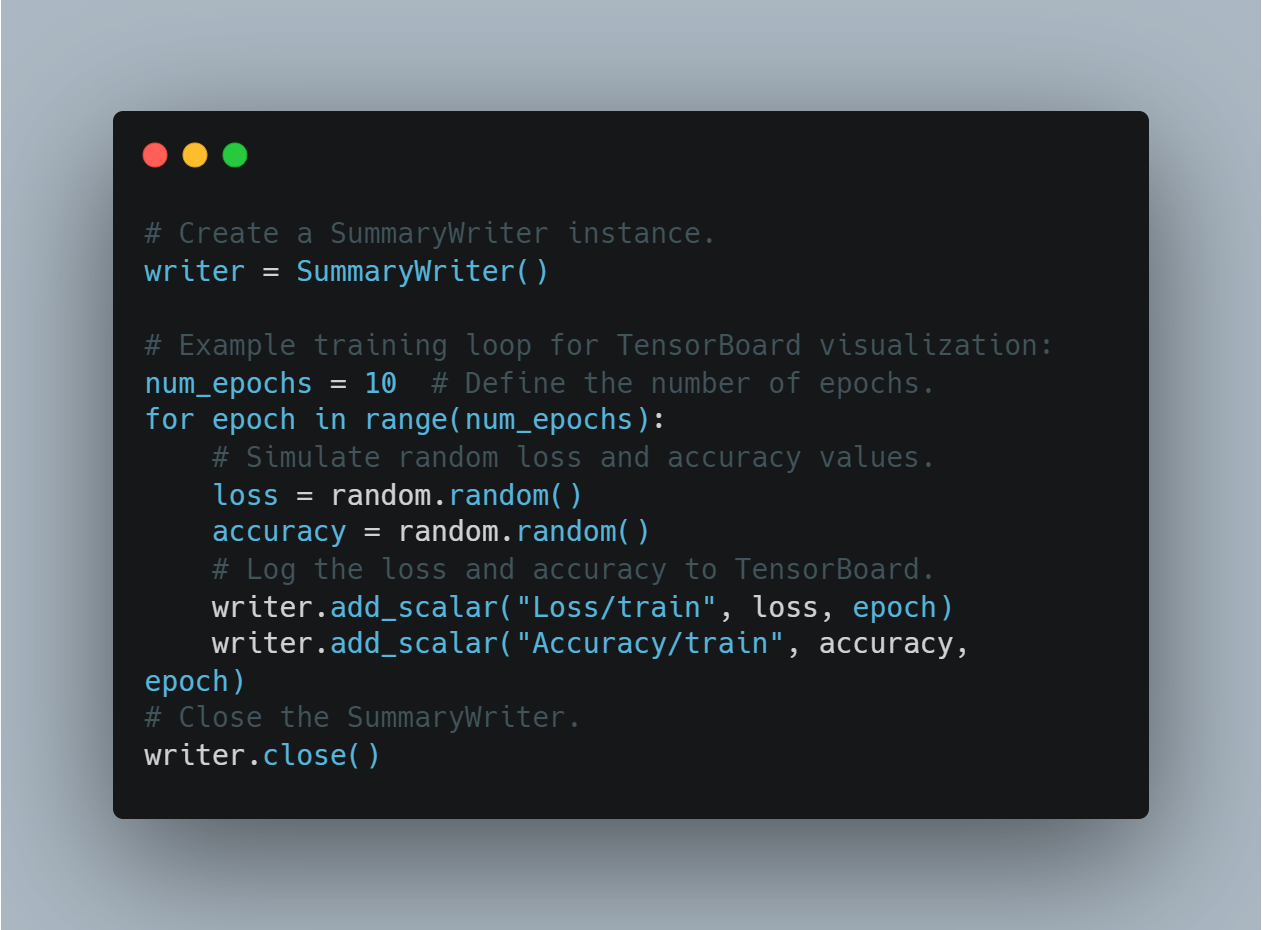
Это позволяет пользователям мониторить обучение модели и делать реально-временные корректировки на основе визуальной обратной связи.
Шаг 8: Сохранение и Загрузка Загруженных Чекпоинтов Агента
После обучения агента важно сохранить его изученное состояние (например, значения Q или веса модели), чтобы его можно было использовать повторно или оценить позднее.
В этом разделе показано, как сохранить обученного агента с использованием модуля Python pickle и как загрузить его с диска.
Вот код для сохранения и загрузки обученного агента Q-обучения:
Создайте экземпляр агента Q-обучения.
agent = QLearningAgent(actions=["up", "down", "left", "right"])
Обучите агента (не показано здесь).
Сохранение агента.
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
Загрузка агента.
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
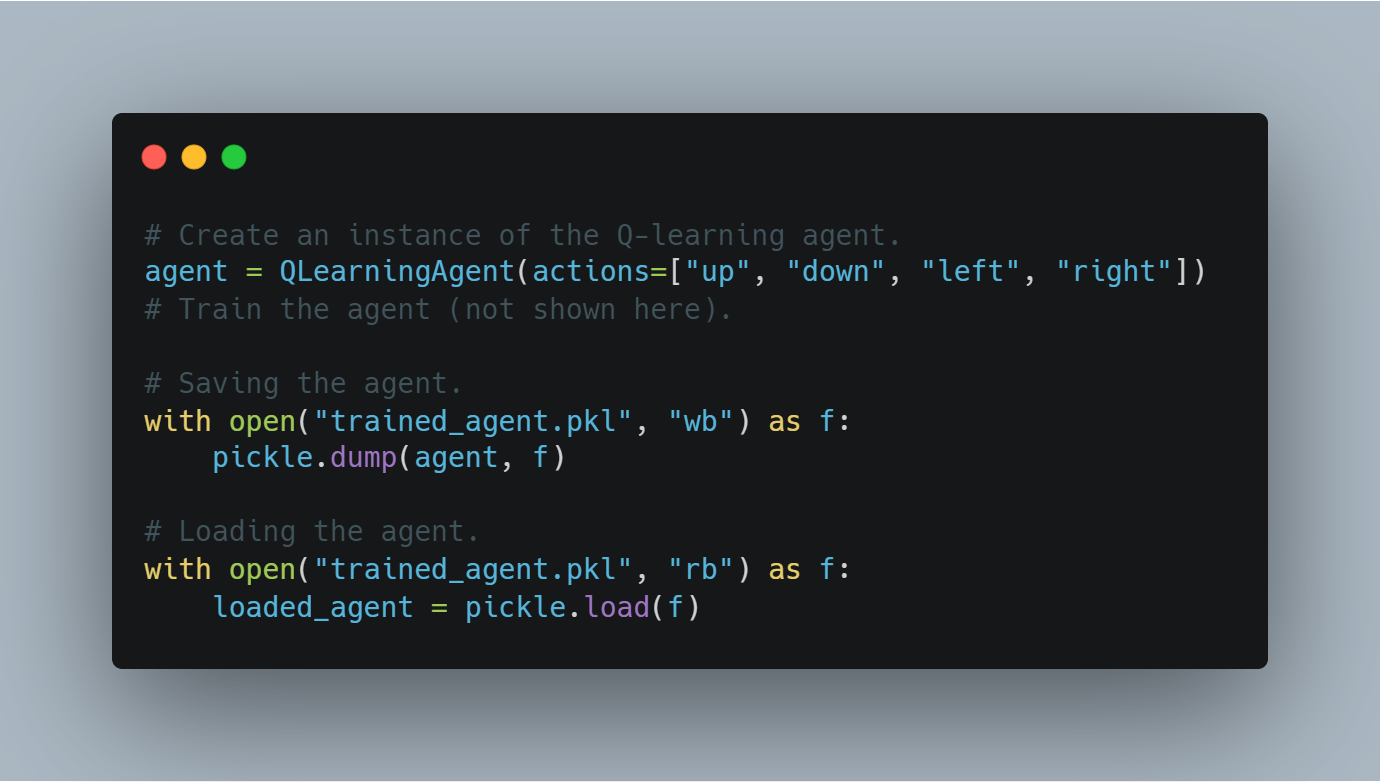
Этот процесс создания чекпоинтов обеспечивает сохранение прогресса обучения и возможность использования моделей в будущих экспериментах.
Шаг 9: Учебный курс (Curriculum Learning)
Процесс обучения по курсу заключается в постепенном увеличении сложности задач, которые выставляются модели, начиная с простых примеров и продвигаясь в направлении более сложных. Это может помочь улучшить показатели модели и ее устойчивость в процессе обучения.
Вот пример использования процесса обучения по курсу в цикле обучения:
# Установите начальную сложность задачи.
initial_task_difficulty = 0.1
# Пример цикла обучения с использованием процесса обучения по курсу:
for epoch in range(num_epochs):
# Постепенно увеличивайте сложность задачи.
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# Generate training data with adjusted difficulty.
При управлении сложностью задач агент может успешно решать всё более сложные проблемы, что приводит к повышению эффективности обучения.
Шаг 10: Внедрение раннего останова
Ранний остановка является техникой для предотвращения переобучения в процессе обучения, заключающаяся в прекращении процесса, если значение валидационной потерты не улучшается после определённого количества эпох (терпение).
В этом разделе показано, как внедрить ранний остановок в цикле обучения, используя валидационную потерту как ключевое показателе.
Вот код для реализации раннего останова:
# Инициализируйте лучшую потерю валидации как бесконечность.
best_validation_loss = float("inf")
# Установите значение терпения (число эпох без улучшения).
patience = 5
# Инициализируйте счетчик эпох без улучшения.
epochs_without_improvement = 0
# Пример цикла обучения с досрочным остановлением:
for epoch in range(num_epochs):
#Mock random validation loss.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

Early stopping improves model generalization by preventing unnecessary training once the model starts overfitting.
Step 11: Using a Pre-trained LLM for Zero-Shot Task Transfer
In zero-shot task transfer, a pre-trained model is applied to a task it wasn’t specifically fine-tuned for.
Using Hugging Face’s pipeline, this section demonstrates how to apply a pre-trained BART model for summarization without additional training, illustrating the concept of transfer learning.
Here’s the code for using a pre-trained LLM for summarization:
# Load a pre-trained summarization pipeline.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Define the text to summarize.
text = "This is an example text about AI agents and LLMs."
# Generate the summary.
summary = summarizer(text)[0]["summary_text"]
# Print the summary.
print(f"Summary: {summary}")
This illustrates the flexibility of LLMs in performing diverse tasks without the need for further training, leveraging their pre-existing knowledge.
The Full Code Example
# Импортируйте модуль random для генерации случайных чисел.
import random
# Импортируйте необходимые модули из библиотеки transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Импортируйте load_dataset для загрузки наборов данных.
from datasets import load_dataset
# Импортируйте metrics для оценки производительности модели.
from sklearn.metrics import accuracy_score, f1_score
# Импортируйте SummaryWriter для ведения журнала процесса обучения.
from torch.utils.tensorboard import SummaryWriter
# Импортируйте pickle для сохранения и загрузки обученных моделей.
import pickle
# Импортируйте openai для использования API OpenAI (требуется ключ API).
import openai
# Импортируйте PyTorch для операций глубокого обучения.
import torch
# Импортируйте модуль нейронной сети из PyTorch.
import torch.nn as nn
# Импортируйте модуль оптимизатора из PyTorch (не используется напрямую в этом примере).
import torch.optim as optim
# --------------------------------------------------
# 1. Тонкая настройка LLM для анализа настроений
# --------------------------------------------------
# Укажите имя предобученной модели из Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Загрузите предобученную модель с указанным количеством выходных классов.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Загрузите токенизатор для модели.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Загрузите набор данных IMDB из Hugging Face Datasets, используя только 10% для обучения.
dataset = load_dataset("imdb", split="train[:10%]")
# Токенизируйте набор данных
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Преобразуйте набор данных в токенизированные входные данные
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Определите аргументы обучения.
training_args = TrainingArguments(
output_dir="./results", # Укажите выходной каталог для сохранения модели.
num_train_epochs=3, # Установите количество эпох обучения.
per_device_train_batch_size=8, # Установите размер пакета для каждого устройства.
logging_dir='./logs', # Каталог для хранения журналов.
logging_steps=10 # Ведите журнал каждые 10 шагов.
)
# Инициализируйте Trainer с моделью, аргументами обучения и набором данных.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Начните процесс обучения.
trainer.train()
# Сохраните тонко настроенную модель.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. Реализация простого агента Q-обучения
# --------------------------------------------------
# Определите класс агента Q-обучения.
class QLearningAgent:
# Инициализируйте агента с действиями, эпсилон (коэффициент исследования), альфа (скорость обучения) и гамма (коэффициент дисконтирования).
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Инициализируйте Q-таблицу.
self.q_table = {}
# Храните возможные действия.
self.actions = actions
# Установите коэффициент исследования.
self.epsilon = epsilon
# Установите скорость обучения.
self.alpha = alpha
# Установите коэффициент дисконтирования.
self.gamma = gamma
# Определите метод get_action для выбора действия на основе текущего состояния.
def get_action(self, state):
# Исследуйте случайным образом с вероятностью эпсилон.
if random.uniform(0, 1) < self.epsilon:
# Верните случайное действие.
return random.choice(self.actions)
else:
# Используйте лучшее действие на основе Q-таблицы.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# Определите метод update_q_table для обновления Q-таблицы после выполнения действия.
def update_q_table(self, state, action, reward, next_state):
# Если состояние отсутствует в Q-таблице, добавьте его.
if state not in self.q_table:
# Инициализируйте Q-значения для нового состояния.
self.q_table[state] = {a: 0.0 for a in self.actions}
# Если следующее состояние отсутствует в Q-таблице, добавьте его.
if next_state not in self.q_table:
# Инициализируйте Q-значения для нового следующего состояния.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# Получите старое Q-значение для пары состояние-действие.
old_value = self.q_table[state][action]
# Получите максимальное Q-значение для следующего состояния.
next_max = max(self.q_table[next_state].values())
# Рассчитайте обновленное Q-значение.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# Обновите Q-таблицу с новым Q-значением.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. Использование API OpenAI для моделирования вознаграждений (концептуально)
# --------------------------------------------------
# Определите функцию get_reward для получения сигнала вознаграждения от API OpenAI.
def get_reward(state, action, next_state):
# Убедитесь, что ключ API OpenAI установлен правильно.
openai.api_key = "your-openai-api-key" # Замените на ваш фактический ключ API OpenAI.
# Сформируйте запрос для вызова API.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# Сделайте вызов API к конечной точке Completion OpenAI.
response = openai.Completion.create(
engine="text-davinci-003", # Укажите используемый движок.
prompt=prompt, # Передайте сформированный запрос.
temperature=0.7, # Установите параметр температуры.
max_tokens=1 # Установите максимальное количество токенов для генерации.
)
# Извлеките и верните значение вознаграждения из ответа API.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. Оценка производительности модели
# --------------------------------------------------
# Определите истинные метки для оценки.
true_labels = [0, 1, 1, 0, 1]
# Определите предсказанные метки для оценки.
predicted_labels = [0, 0, 1, 0, 1]
# Рассчитайте точность.
accuracy = accuracy_score(true_labels, predicted_labels)
# Рассчитайте F1-оценку.
f1 = f1_score(true_labels, predicted_labels)
# Выведите точность.
print(f"Accuracy: {accuracy:.2f}")
# Выведите F1-оценку.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. Основной агент градиента политики (с использованием PyTorch) - концептуально
# --------------------------------------------------
# Определите класс сети политики.
class PolicyNetwork(nn.Module):
# Инициализируйте сеть политики.
def __init__(self, input_size, output_size):
# Инициализируйте родительский класс.
super(PolicyNetwork, self).__init__()
# Определите линейный слой.
self.linear = nn.Linear(input_size, output_size)
# Определите прямой проход сети.
def forward(self, x):
# Примените softmax к выходу линейного слоя.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. Визуализация прогресса обучения с помощью TensorBoard
# --------------------------------------------------
# Создайте экземпляр SummaryWriter.
writer = SummaryWriter()
# Пример цикла обучения для визуализации в TensorBoard:
# num_epochs = 10 # Определите количество эпох.
# for epoch in range(num_epochs):
# # ... (Ваш цикл обучения здесь)
# loss = random.random() # Пример: случайное значение потерь.
# accuracy = random.random() # Пример: случайное значение точности.
# # Запишите потери в TensorBoard.
# writer.add_scalar("Loss/train", loss, epoch)
# # Запишите точность в TensorBoard.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (Запишите другие метрики)
# # Закройте SummaryWriter.
# writer.close()
# --------------------------------------------------
# 7. Сохранение и загрузка контрольных точек обученного агента
# --------------------------------------------------
# Пример:
# Создайте экземпляр агента Q-обучения.
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (Обучите вашего агента)
# # Сохранение агента
# # Откройте файл в двоичном режиме записи.
# with open("trained_agent.pkl", "wb") as f:
# # Сохраните агента в файл.
# pickle.dump(agent, f)
# # Загрузка агента
# # Откройте файл в двоичном режиме чтения.
# with open("trained_agent.pkl", "rb") as f:
# # Загрузите агента из файла.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. Обучение по программе
# --------------------------------------------------
# Установите начальную сложность задачи.
initial_task_difficulty = 0.1
# Пример цикла обучения с обучением по программе:
# for epoch in range(num_epochs):
# # Постепенно увеличивайте сложность задачи.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (Генерация обучающих данных с учетом сложности)
# --------------------------------------------------
# 9. Реализация ранней остановки
# --------------------------------------------------
# Инициализируйте наилучшие потери валидации как бесконечность.
best_validation_loss = float("inf")
# Установите значение терпимости (число эпох без улучшения).
patience = 5
# Инициализируйте счетчик эпох без улучшения.
epochs_without_improvement = 0
# Пример цикла обучения с ранней остановкой:
# for epoch in range(num_epochs):
# # ... (Шаги обучения и валидации)
# # Рассчитайте потери валидации.
# validation_loss = random.random() # Пример: случайные потери валидации.
# # Если потери валидации улучшаются.
# if validation_loss < best_validation_loss:
# # Обновите наилучшие потери валидации.
# best_validation_loss = validation_loss
# # Сбросьте счетчик.
# epochs_without_improvement = 0
# else:
# # Увеличьте счетчик.
# epochs_without_improvement += 1
# # Если нет улучшения в течение 'терпимости' эпох.
# if epochs_without_improvement >= patience:
# # Выведите сообщение.
# print("Сигнал ранней остановки!")
# # Остановите обучение.
# break
# --------------------------------------------------
# 10. Использование предобученного LLM для переноса задач без обучения
# --------------------------------------------------
# Загрузите предобученный конвейер для резюмирования.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Определите текст для резюмирования.
text = "This is an example text about AI agents and LLMs."
# Сгенерируйте резюме.
summary = summarizer(text)[0]["summary_text"]
# Выведите резюме.
print(f"Summary: {summary}")

Проблемы в установке и масштабировании
Для установки и масштабирования интегрированных агентов AI с LLM представлены значительные технические и операционные проблемы. Одна из основных проблем – это компьютерный объем, особенно по мере роста размера и сложности LLM.
Обращаясь с этим вопросом, используются стратегии эффективного использования ресурсов, такие как упрощение моделей, квантизация и распределенные вычисления. Эти средства могут помочь уменьшить нагрузку на вычисления без потерь в производительности.
Также важно сохранять надежность и устойчивость в реальных приложениях, для чего необходимо продолжающееся мониторинг, регулярные обновления и разработка механизмов для управления неожиданными входными данными или сбоями системы.
Когда эти системы внедряются в различные отрасли, важно соблюдать этические стандарты – включая справедливость, прозрачность и ответственность. Эти по Considerations are central to the system’s acceptance and long-term success, impacting public trust and the ethical implications of AI-driven decisions in diverse societal contexts (Bender et al., 2021).
Техническое реализование агентов AI, интегрированных с LLM, требует周全ного дизайна архитектуры, строгих методологий тренировки и размышлений о проблемах установки.
Эффективность и надежность этих систем в реальных средах зависит от решения технических и этических проблем, обеспечивая гладкое и ответственное функционирование AI технологий в различных приложениях.
Глава 7: Будущее агентов AI и LLM
Сочетание LLM с реинforcement Learning
Когда вы исследуете будущее искусственных интеллектуальных агентов и крупных языковых моделей (КЯМ), особенно выделяется их объединение с рефлексивным обучением. Эта интеграция выходит за рамки традиционного искусственного интеллекта, позволяя системам не только генерировать и понимать язык, но и учиться в реальном времени на своих взаимодействиях.
Через рефлексивное обучение, искусственные интеллектуальные агенты могут адаптивно изменять свои стратегии на основе обратной связи от своего окружения, приводя к непрерывной уточнению их процессов принятия решений. Это означает, что, в отличие от статических моделей, искусственные системы, улучшенные рефлексивным обучением, могут справиться с усложняющимися и динамическими задачами с минимальной вмешательством человека.
Implications for such systems are profound: in applications ranging from autonomous robotics to personalized education, AI agents could autonomously improve their performance over time, making them more efficient and responsive to the evolving demands of their operational contexts.
Пример: играя в текстовую игру
Представьте себе искусственного интеллектуального агента, играющего в текстовую приключенческую игру.
-
Окружение: сама игра (правила, описания состояний и т. д.)
-
КЯМ: обрабатывает текст игры, понимает текущее положение и генерирует возможные действия (например, ” идти на север “, ” взять меч “).
-
Награда: Устанавливается игрой на основе результата действия (например, положительная награда за нахождение сокровищ, отрицательная за потерю здоровья).
Пример кода (концептуально, используя Python и API OpenAI):
import openai
import random
# ... (логика игрового окружения - здесь не показано) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (цикл обучения RL - упрощен) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (обновление агента RL на основе награды - здесь не показано) ...
state = next_state
Интеграция мультимодальных AI
Інтеграція мультимодальних AI є ще одним ключовим трендом, що формує майбутність агентів AI. Permitting systems to process and combine data from various sources—such as text, images, audio, and sensory inputs—multimodal AI offers a more comprehensive understanding of the environments in which these systems operate.
Наприклад, у автономних автомобілях, здатність синтезувати візуальні дані від камер, контекстуальні дані від карт і реальні оновлення трафіку дозволяє AI робити більш інформовані і безпечні рішення при водінні.
Данная возможность расширяется на другие области, такие как здравоохранение, где агент AI может интегрировать данные о пациентах из медицинских записей, диагностической рентгенологии и генетической информации, чтобы обеспечить более точные и индивидуальные рекомендации по лечению.
Проблема здесь заключается в гладком интеграции и реального времени обработки различных потоков данных, что требует усовершенствований в архитектуре моделей и техник слияния данных.
Успешное решение этих проблем будет ключевым моментом в внедрении систем AI, которые действительно интеллектуальны и способны работать в сложных, реальных средах.
Пример мультиmodalного AI 1: Captioning изображений для ответа на вопросы о взгляде
-
Цель: Агент AI, способный отвечать на вопросы о изображениях.
-
Способы: Изображение, текст
-
Процесс:
-
Извлечение характеристик изображения: Использовать уже обученную коннективную нейронную сеть (CNN) для извлечения характеристик из изображения.
-
Генерация описания: Использовать LLM (такой как модель Transformera) для генерации описания изображения на основе извлеченных характеристик.
-
Ответ на вопрос: Использовать другой LLM для обработки вопроса и генерируемого описания, чтобы предоставить ответ.
-
Пример кода (концептуально, используя Python и Hugging Face Transformers):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# Загрузка уже обученных моделей
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# Функция для генерации заголовка изображения
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# Функция для ответа на вопросы о изображении
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# Пример использования
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
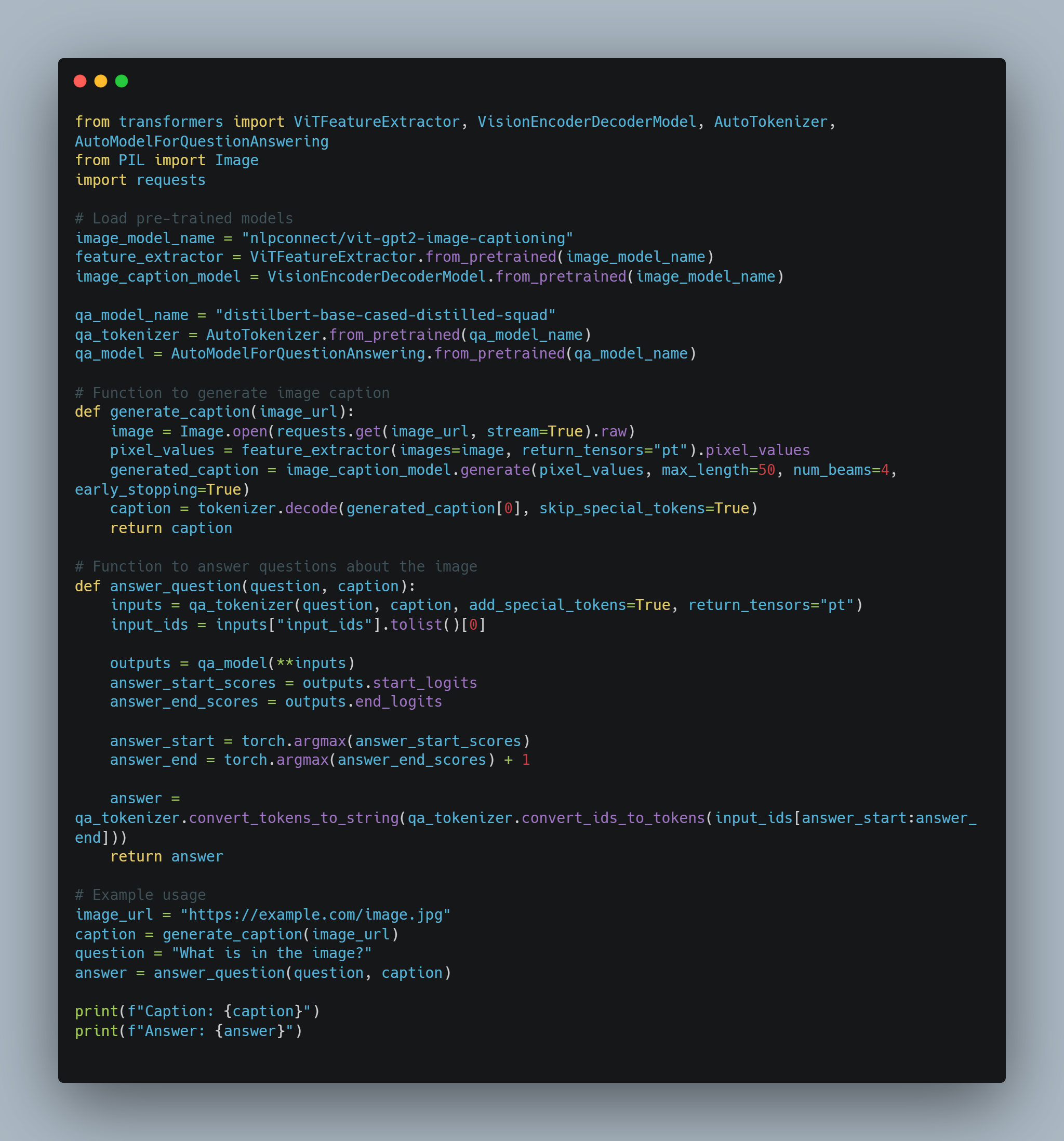
Мультимодальный пример 2: анализ эмоционального содержания из текста и аудио
- Цель: AI-агент, который анализирует эмоциональное содержание как текста, так и тона сообщения.
-
Методы:
Текст, Аудио
-
Процесс:
-
Оценка текста: Использовать предобученный модель анализа настроения на тексте.
-
Оценка аудио: Использовать модель обработки аудио для извлечения особенностей, таких как тон и высота, затем использовать эти особенности для предсказания настроения.
-
Сочетание: Корьбить оценку настроения текста и аудио (например, весеннее среднее) для получения общей оценки настроения.
-
Пример кода (концептуально, используя Python):
from transformers import pipeline # Для опредления текстового sentiment
# ... (Импортирование библиотек обработки звука и опредления sentiment - не показан) ...
# Загрузка предварительно обученных моделей
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# Текстовый sentiment
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# Звуковой sentiment
# ... (Обработка звука, извлечение featuers, предсказание sentiment - не показан) ...
audio_sentiment = # ... (Результат от модели звукового sentiment)
audio_confidence = # ... (Показатель доверия от звуковой модели)
# Суммирование sentiment (пример: ponderated среднее)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# Пример использования
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
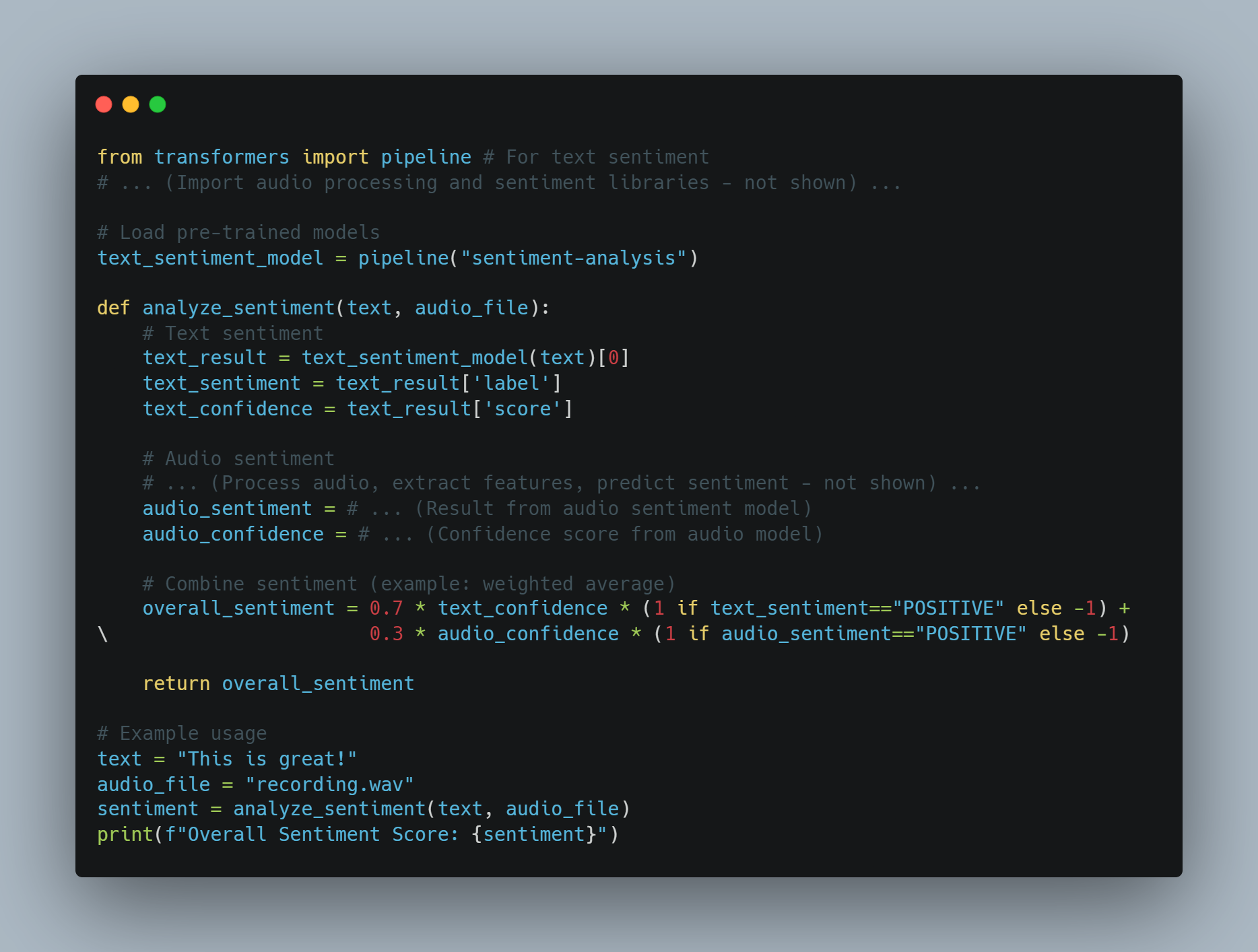
Проблемы и подумания:
-
Сопоставление данных: Важно обеспечить синхронизацию и выравнивание данных из различных модальностей.
-
Complexность модели: Многомодальные модели требуют сложной тренировки и требуют больших, разнообразных наборов данных.
-
Техники слияния: Выбор правильного метода для слияния информации из различных модальностей важен и зависит от проблемы.
Мультимодальные AI являются быстро развивающейся областью, обладающей потенциалом революционизировать способ, как AI-агентыPerceive and interact with the world.
Распределенные AI Системы и Бorder Computing
По направлению эволюции инфраструктур AI, переход к распределенным AI системам, поддерживаемым border computing, представляет собой значительный прогресс.
Распределенные AI системы децентрализуют вычислительные задачи путем обработки данных ближе к источнику,例如 IoT устройств или локальных серверов, а не на основе централизованных ресурсов облака. Этот подход не только уменьшаетLatency, который является crucial для time-sensitive applications,如autonomous drones или промышленная автоматизация, но также улучшает data privacy and security,保持sensitive information local.
Also, distributed AI systems improve scalability, allowing for the deployment of AI across vast networks, such as smart cities, without overwhelming centralized data centers.
Технические проблемы, связанные с distributed AI, включают обеспечение一致性和координации across distributed nodes, as well as optimizing resource allocation to maintain performance across diverse and potentially resource-constrained environments.
As you develop and deploy AI systems, embracing distributed architectures will be key to creating resilient, efficient, and scalable AI solutions that meet the demands of future applications.
Распределенные системы искусственного интеллекта и краевые вычисления пример 1: Федеративное обучение для сохранения конфиденциальности модели обучения
-
Цель: Обучить общую модель на多重ных устройствах (например, смартфонах) без прямого распространения чувствительных пользовательских данных.
-
Метод:
-
Локальное обучение: Каждое устройство обучает локальную модель на своих данных.
-
Агрегация параметров: Устройства посылают обновления модели (градиенты или параметры) на центральный сервер.
-
Обновление глобальной модели: Сервер агрегирует обновления, улучшая глобальную модель, и посылает обновленную модель обратно на устройства.
-
Пример кода (концептуально с использованием Python и PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
# ... (Код для связи между устройствами и сервером - не показан) ...
class SimpleModel(nn.Module):
# ... (Определите здесь свою модельную архитектуру) ...
# Функция обучения устройства
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # начать с глобальной моделью
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (Обучите local_model на device_data) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# Функция агрегации сервера
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (Основной цикл федеративного обучения - упрощен) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

Пример 2: реального времени обнаружение объектов на устройствах края
-
Цель: Деploy an object detection model on a resource-constrained device (for example, Raspberry Pi) for real-time inference.
-
Схема подхода:
-
Оптимизация модели: Использовать такие техники, как квантизация модели или усечение, для уменьшения размера модели и вычислительных требований.
-
Размещение на границе: Разместить оптимизированную модель на устройстве границы.
-
Локальный вference: Устройство выполняет локальное обнаружение объектов, уменьшая задержку и зависимость от связи с облаком.
-
Пример кода (концептуально, используя Python и TensorFlow Lite):
import tensorflow as tf
# Загрузить предварительно обученную модель (полагая, что она уже оптимизирована для TensorFlow Lite)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# Получить данные о входе и выходе
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (Получение изображения с камеры или загрузка из файла - не показано) ...
# Предобработать изображение
input_data = ... # Сжать, нормализовать и т.д.
interpreter.set_tensor(input_details[0]['index'], input_data)
# Выполнить инференс
interpreter.invoke()
# Получить выход
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (Обработать output_data, чтобы получить ограничивающие контуры, классы и т.п.) ...
Проблемы и аспекты, которые следует учитывать:
-
Перегрузка коммуникации: эффективное координации и коммуникации между распределенными узлами очень важно.
-
Управление ресурсами: важно оптимизировать распределение ресурсов (CPU, память, по bandwidth) по устройствам.
-
Безопасность: защита распределенных систем и защита данных являются главными проблемами.
Распределенный AI иEdge Computing являются необходимыми для создания масштабируемых, эффективных и сохраняющих приватность систем AI, особенно по мере того, как мы идем к будущему с миллиардами взаимосвязанных устройств.
Прогресс в области Natural Language Processing
自然语言处理 (NLP) по-прежнему остается впереди всех других достижений AI, приводя к значительному улучшению способностей машин понимать, генерировать и взаимодействовать с человеческим языком.
Последние разработки в области NLP, такие как эволюция трансформеров и механизмов внимания, значительно улучшили способность AI обрабатывать сложные языковые структуры, делая взаимодействия более естественными и контекстуальными.
Эти успехи позволили AI системам понимать нюансы, эмоции и даже культурные ссылки в тексте, что привело к более точной и значительной коммуникации.
Например, в сфере обслуживания клиентов avanced NLP модели могут не только правильно обрабатывать запросы, но и обнаруживать эмоциональные ключи у клиентов, позволяя обеспечить более empathetic и эффективные ответы.
Взятый вперёд, интеграция многоязычных возможностей и более глубокого понимания семантики в NLP модели будет еще более расширять их приложение, позволяя для глобальных контекстов для обеспечения глобальных контекстов.
自然语言处理 (NLP) быстро развивается, с прорывами в таких областях, как модели трансформеров и механизмы внимания. Вот несколько примеров и code snippets для иллюстрации этих усовершенствований:
Пример NLP 1: Анализ сентимента с тонкой настройки трансформеров
-
Цель: Анализировать сентимент текста с высокой точностью, учитывая нюансы и контекст.
-
Подход: Точно настроить модель трансформера (как BERT) на датасете анализа сентимента.
Пример кода (使用 Python 和 Hugging Face Transformers):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Загрузить модель и датасет с предобученными данными
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3 метки: Положительно, Отрицательно, Neutral
dataset = load_dataset("imdb", split="train[:10%]")
# Определить аргументы тренировки
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# Точно настроить модель
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# Сохранить точно настроенную модель
model.save_pretrained("./fine_tuned_sentiment_model")
# Загрузить точно настроенную модель для инференции
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# Пример использования
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
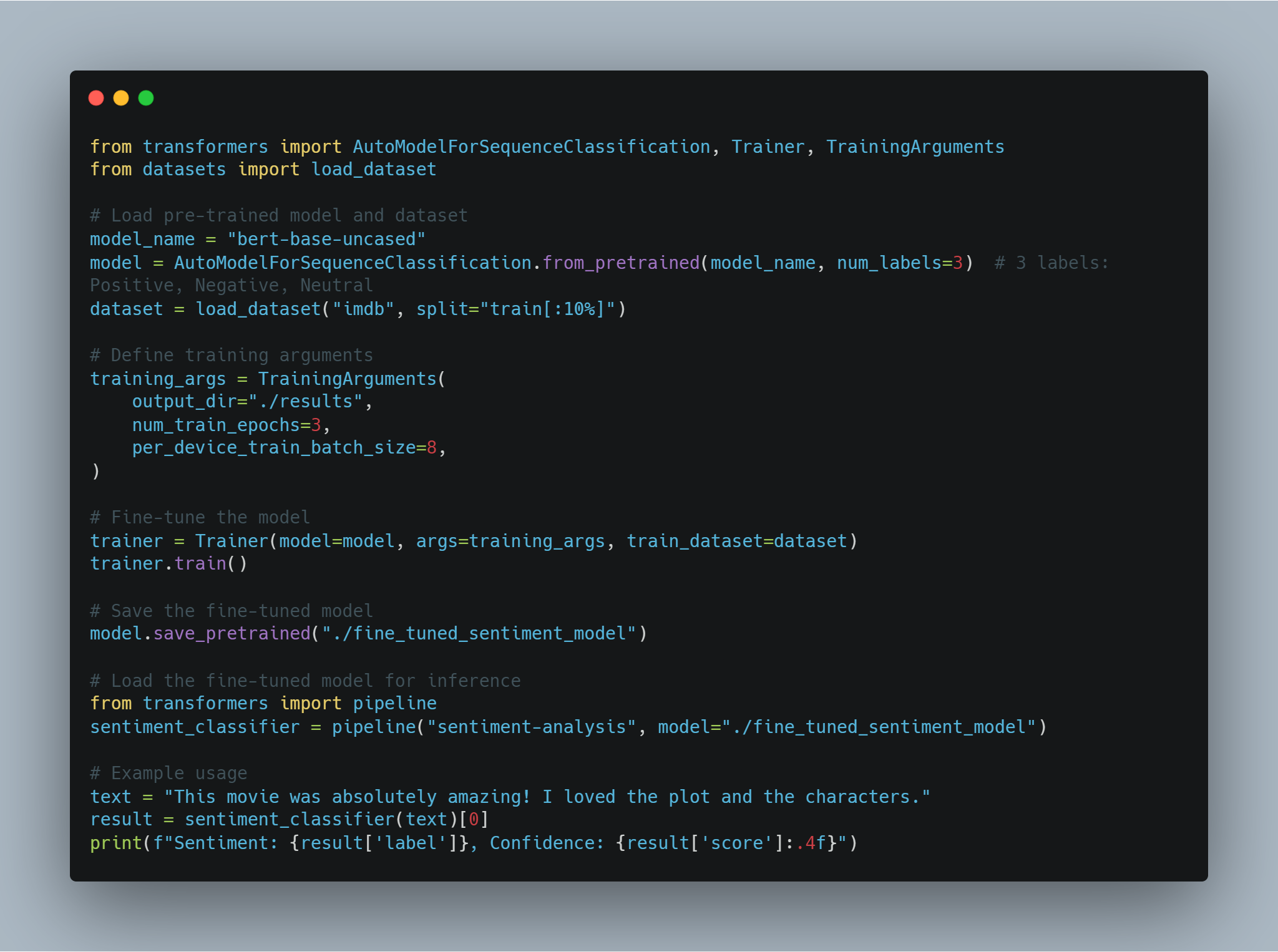
Пример NLP 2: Многоязычная машинный перевод с одной моделью
-
Цель: Переводить между множеством языков с использованием одной модели, используя общие языковые представления.
-
Схема: Использовать большой, многоязычный трансформерный модель (такие как mBART или XLM-R), обученный на огромном наборе данных параллельных текстов на нескольких языках.
Пример кода (使用Python和Hugging Face Transformers):
from transformers import pipeline
# Загрузить предварительно обученный многоязычный канал перевода
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# Пример использования: Английский на Французский
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# Пример использования: Французский на Испанский
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
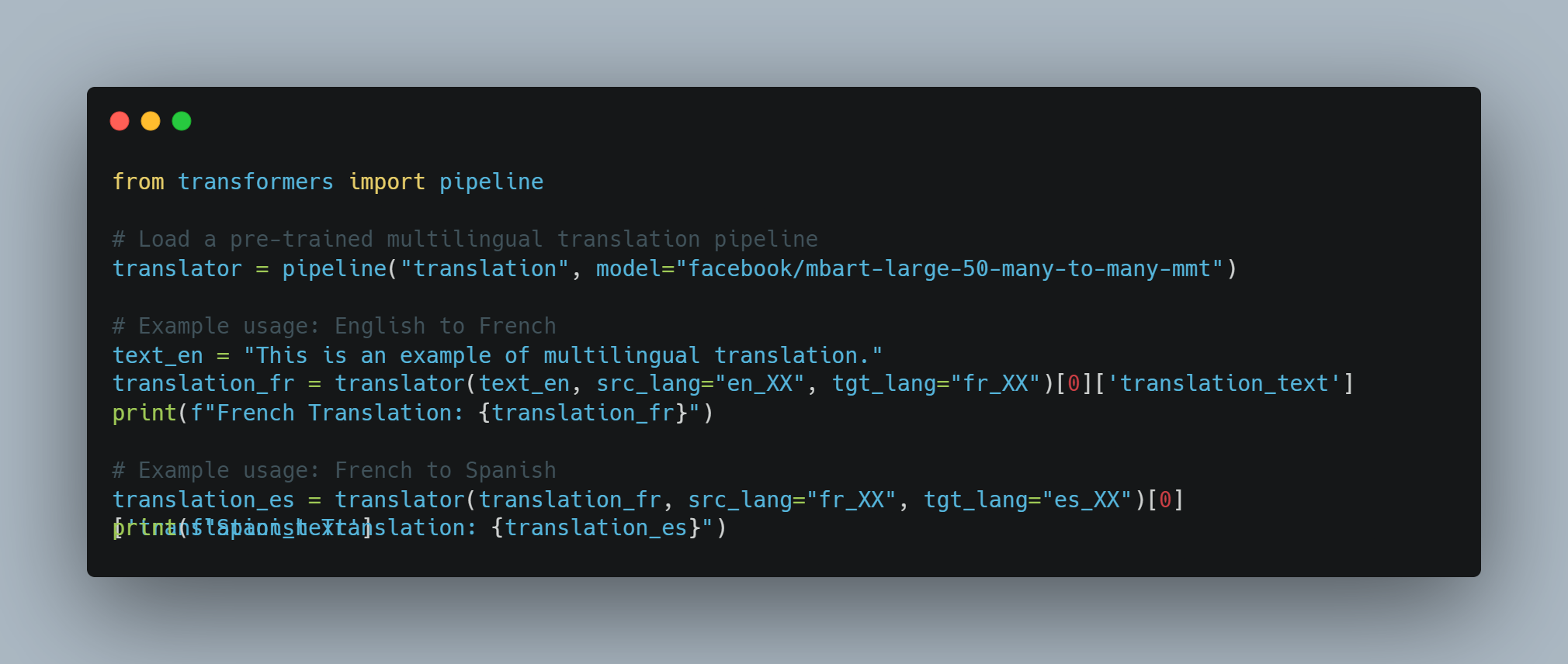
Пример NLP 3: Контекстуальные словарные векторы для семантической схожести
-
Цель: Определить схожесть между словами или предложениями, учитывая контекст.
-
Схема: Использовать трансформерную модель (также как BERT) для генерации контекстуальных словарных векторов, которые помечают значение слов в определенном предложении.
Пример кода (使用Python和Hugging Face Transformers):
from transformers import AutoModel, AutoTokenizer
import torch
# Загружаем предварительно обученную модель и токенизатор
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Функция для получения представлений предложений
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# Используется представление токена [CLS] в качестве представления предложения
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# Пример использования
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# Calculate cosine similarity
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
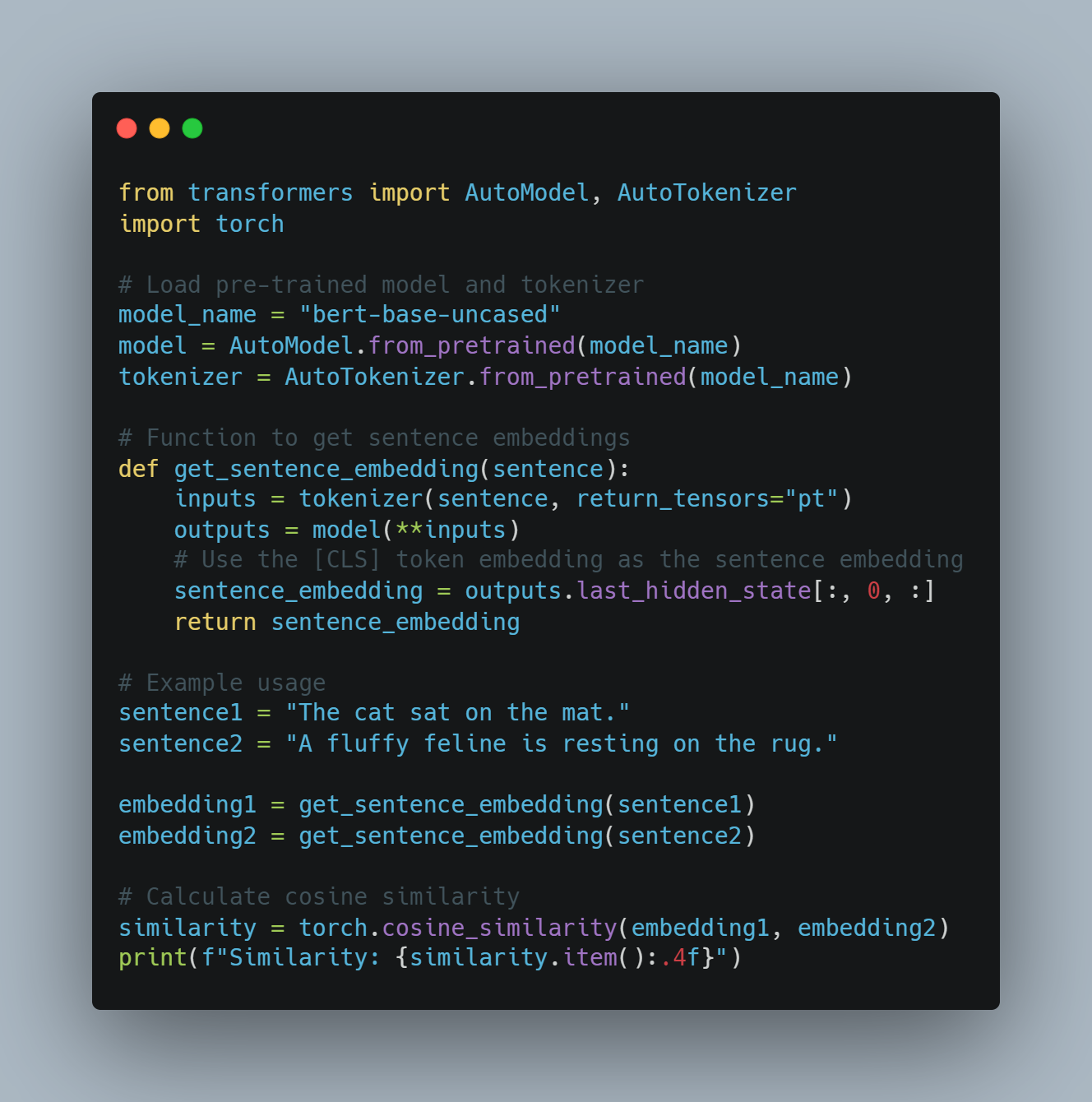
Предикты и будущие направления:
-
偏见的承继与公平性: NLP модели могут наследовать предрассудки от своей тренировочной выборки, что может привести к несправедливым или дискриминационным результатам. Обращаться с предрассудками важно.
-
Образование предрассудков: LLMs до сих пор испытывают трудности с образованием предрассудков и пониманием неявной информации.
-
Аналитичность:Decision-making process of complex NLP models can be opaque, making it difficult to understand why they generate certain outputs.
Несмотря на эти проблемы, NLP быстро продвигается вперёд. Интеграция мультимодальной информации, улучшение разумности повседневности и повышение объяснительности являются ключевыми направлениями текущих исследований, которые по-прежнему революционизируют способ, как AI взаимодействует с человеческим языком.
Персонализированные AI помощники
Будущее персонализированных AI помощников находится в позиции становиться все более сложными, переходя от базового управления задачами к истинному интуитивному, проактивному обслуживанию, разработанному на основе индивидуальных потребностей.
Эти помощники будут использовать передовые алгоритмы машинного обучения, чтобы непрерывно учиться на ваших поведениях, предпочтениях и повторяющихся действиях, предлагая все более и более персонализированные рекомендации и автоматизируя более сложные задачи.
Например, персонализированная AI помощница могла бы управлять не только вашей planner, но и предсказывать ваши потребности, предлагая соответствующие ресурсы или регулируя ваше окружение на основе вашего настроения или прошлых предпочтений.
Когда AI помощники станут более интегрированными в повседневную жизнь, их способность адаптироваться к изменяющимся контекстам и обеспечивать гладкое,跨платформенное обслуживание станет ключевым differentiator. Challenge lies in balancing personalization with privacy, requiring robust data protection mechanisms to ensure that sensitive information is managed securely while delivering a deeply personalized experience.
Пример AI помощников 1: Советы по задачам с учетом контекста
-
Goal: Помощник, предлагающий задачи на основе текущего контекста пользователя (местоположение, время, прошлое поведение).
-
Метод: Консолидировать данные пользователя, контекстуальные сигналы и модель рекомендации задач.
Пример кода (концептуально, используя Python):
# ... (Код по управлению данными пользователя, обнаружению контекста - не показан) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# Пример: Подсказки на основе времени
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# Пример: Подсказки на основе местоположения
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (Добавьте больше правил или используйте машинноearning модель для подсказок) ...
# Отсортировать и фильтровать подсказки
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- Пример использования ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... другие предпочтения ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... другие данные контекста ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
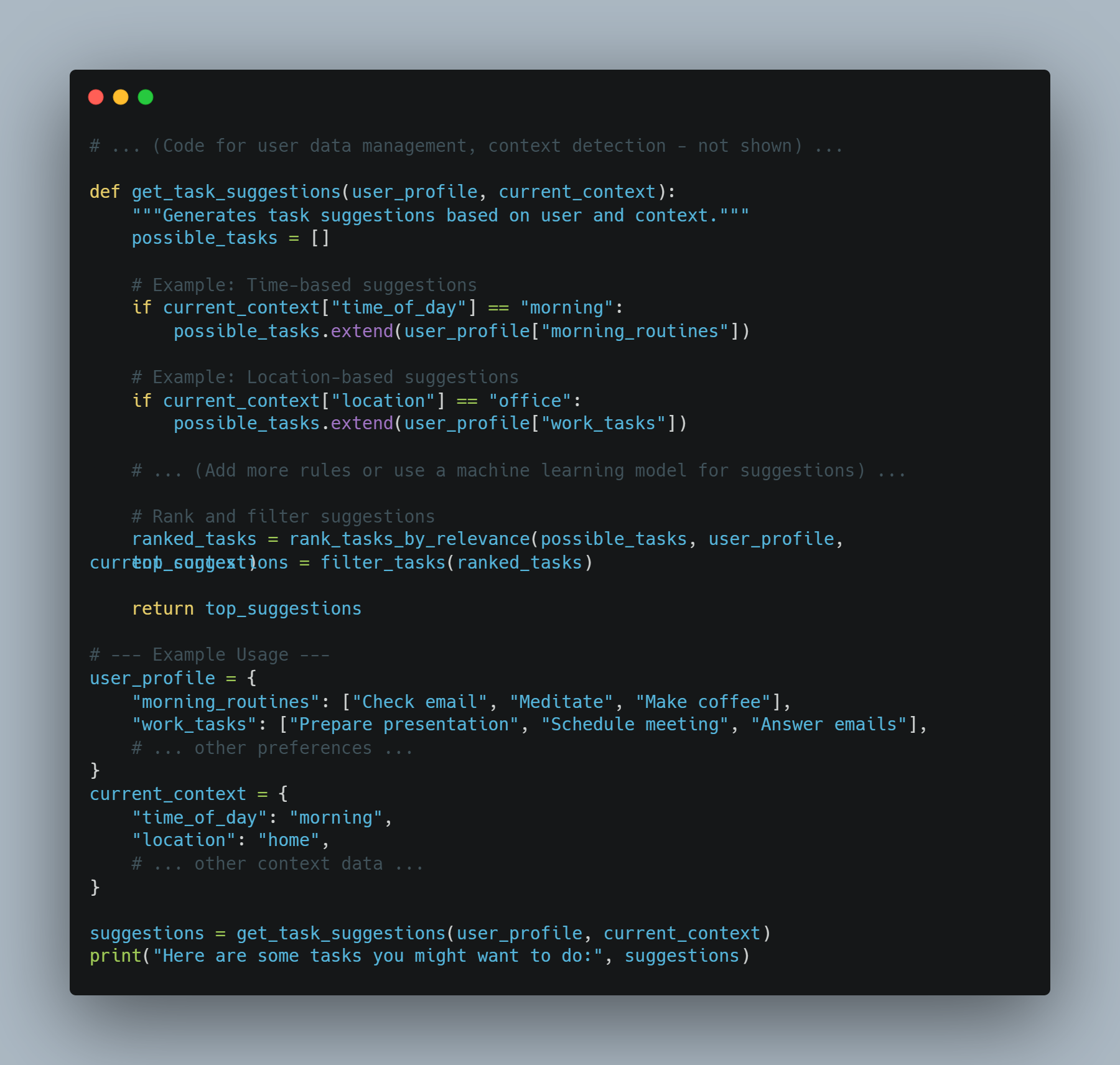
Пример ИИ-помощников 2: Proactive Information Delivery
-
Цель: Помощник, который активно обеспечивает соответствующую информацию на основе расписания пользователя и его предпочтений.
-
Метод: Интегрировать данные календаря, интересы пользователя и систему поиска содержимого.
Пример кода (концептуально, используя Python):
# ... (Код для доступа к календарю, профиль интересов пользователя - не показан) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (Получение информации о компании, профилей участников и т.п.) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (Получение статуса рейса, информации о месте назначения и т.п.) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- Пример использования ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... другие предпочтения ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

Пример 3: Система рекомендаций персонализированного содержимого
-
Цель: Система рекомендации содержимого (статей, видео, музыку) на основе пользовательских предпочтений.
-
Обход: Использовать совместный фильtering или системы рекомендаций на основе содержимого.
Пример кода (концептуально, используя Python и библиотеку, подобную Surprise):
from surprise import Dataset, Reader, SVD
# ... (Код для управления оценками пользователей, базой данных контента - не показан) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (Получение предсказаний для всех элементов, рейтинг и возврат N наиболее важных) ...
# --- Пример использования ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... дополнительные оценки ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
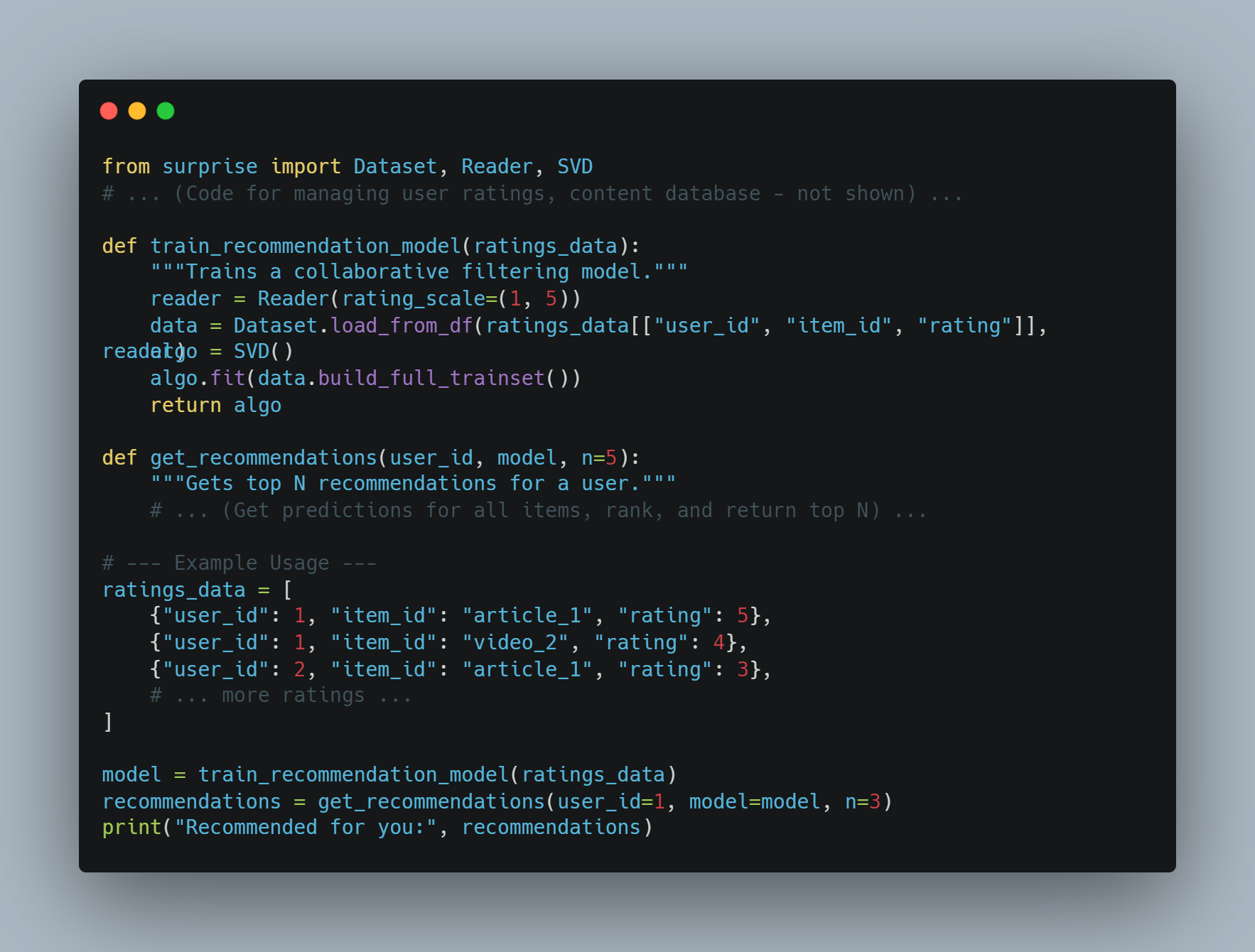
Проблемы и этические соображения:
-
Приватность данных: Соблюдение ответственности и прозрачности в обработке данных пользователей.
-
Ошибки и справедливость: Персонализация не должна усиливать существующих предрассудков.
-
Контроль пользователей: Пользователи должны контролировать свои данные и настройки персонализации.
Для создания персонализированных ИИ ассистентов требуется тщательное рассмотрение технических и этических аспектов, чтобы создать системы, которые являются полезными, надежными и уважают приватность пользователей.
ИИ в творческих отраслях
ИИ внедряется в творческие отрасли, изменяя способ, в котором производится и потребляется искусство, музыка, кино и литература. Благодаря достижениям в области генерирующих моделей, таких как генеративные антагонистические сети (GANs) и модели на основе трансформера, ИИ теперь может генерировать содержание, конкурирующее с творческой компетенцией человека.
Например, AI может сочинять музыку, отражающую определенные жанры или настроения, создаватьцифровую живопись, имитирующую стиль известных художников, или даже составлять сюжетные планы для фильмов и романов.
В рекламной индустрии AI используется для создания персонализированного содержания, которые соответствуют индивидуальным потребителям, усиливая вовлеченность и эффективность.
Однако появление AI в творческих областях вызывает вопросы о авторстве, оригинальности и роли человеческого творчества. Во время взаимодействия с AI в этих областях важно исследовать, как AI может улучшать, а не замещать человеческое творчество, содействуя сотрудничеству между людьми и машинами для производства инновационного и влиятельного содержания.
Вот пример, как GPT-4 может быть интегрирован в проект на Python для творческих задач, в частности в сфере писательства. Этот код демонстрирует, как можно использовать возможности GPT-4 для генерации творческих текстовых форматов, таких как поэзия.
import openai
# Set your OpenAI API key
openai.api_key = "YOUR_API_KEY"
# Define a function to generate poetry
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# Example usage
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
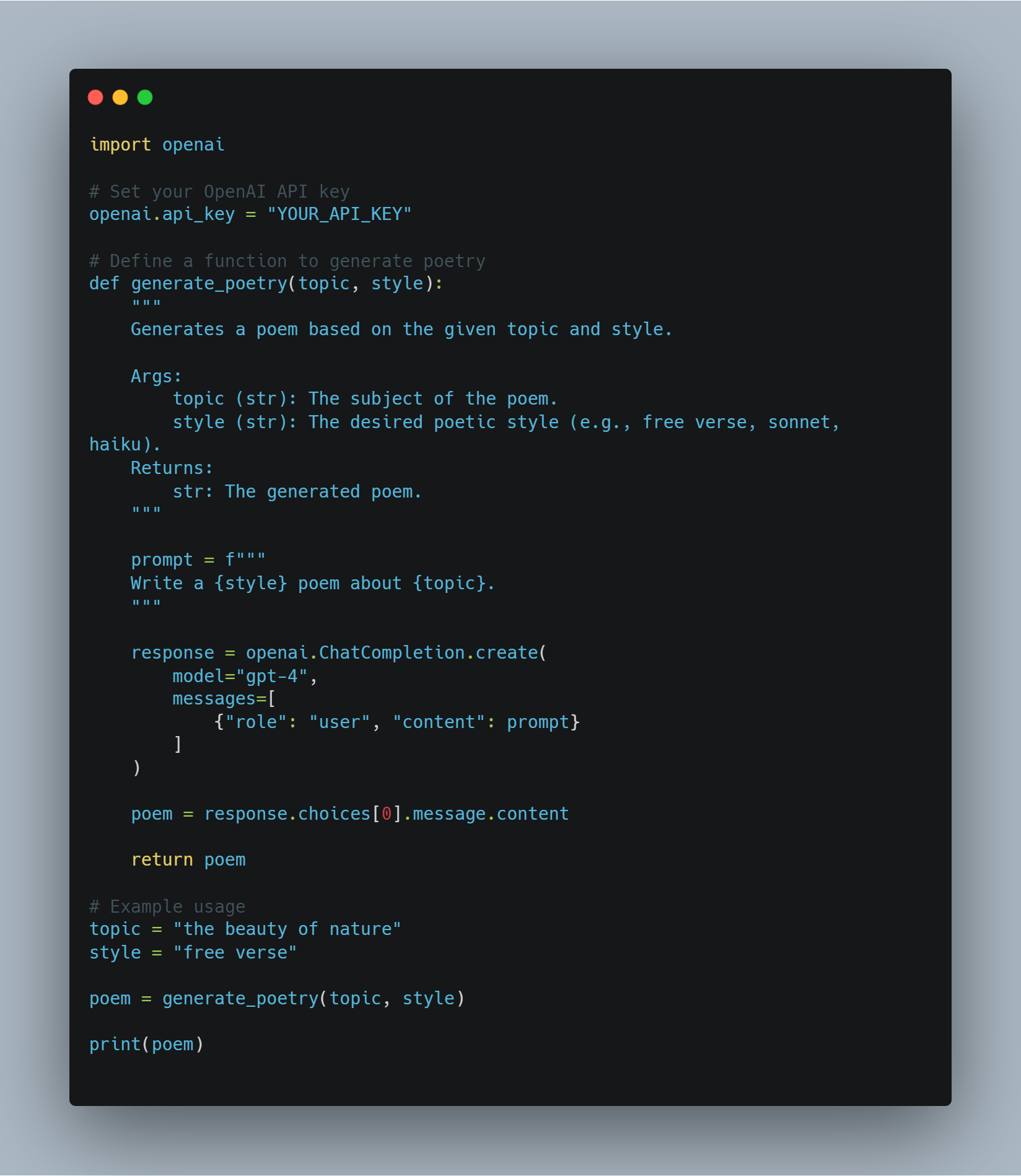
Let’s see what’s going on here:
-
Import OpenAI library: The code first imports the
openailibrary to access the OpenAI API. -
Set API key: Replace
"YOUR_API_KEY"with your actual OpenAI API key. -
Определите функцию
generate_poetry: Эта функция принимаеттемуистильпоэмы в качестве входных данных и использует API ChatCompletion OpenAI для генерации поэмы. -
Составите протол: Protoл объединяет
темуистильв ясное указание для GPT-4. -
Отправите протол GPT-4: Код использует
openai.ChatCompletion.createдля отправки протола GPT-4 и получения генерируемой поэмы в качестве ответа. -
Верните поэму: Генерируемая поэма затем извлекается из ответа и возвращается функцией.
-
Пример использования: Код демонстрирует, как вызывать функцию
generate_poetryс определенной темой и стилем. Полученный стих затем выводится на консоль.
АИ-управленные виртуальные миры
Развитие АИ-управленных виртуальных миров представляет собой значительный шаг в ускорение иммерсивных опытов, где агенты AI могут создавать, управлять и развивать виртуальные среды, которые являются интерактивными и реагируют на ввод пользователя.
Виртуальные миры, управляемые AI, могут имитировать сложные экосистемы, социальные взаимодействия и динамические сюжеты, предлагая пользователям глубоко привязанный опыт.
Например, в игровой отрасли AI может использоваться для создания неиграбельных персонажей (NPC), которые учитывают поведение игрока, адаптируя свои действия и стратегии для обеспечения более трудных и реалистичных опытов.
Beyond gaming, AI-powered virtual worlds have potential applications in education, where virtual classrooms can be tailored to the learning styles and progress of individual students, or in corporate training, where realistic simulations can prepare employees for various scenarios.
Будущее этих виртуальных средств будет зависеть от усовершенствований в способности AI генерировать и управлять огромными, сложными цифровыми экосистемами в реальном времени, а также от этических соображений относительно данных пользователя и психологического воздействия высокой иммерсии.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# Инициализируем агенты
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# назначаем случайные позиции внутри среды
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# Создаем и добавляем агента
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# перемещаем агентов (упрощенное движение для демонстрации)
for agent in self.agents:
agent.move(self.environment)
# TODO: реализовать более сложную логику взаимодействий, изменений среды и т.п.
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# Определяем направление движения ( случайное для примера)
direction = random.choice(['N', 'S', 'E', 'W'])
# Применяем движение на основе направления
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# Обновляем среду, чтобы отразить новую позицию агента
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# Пример использования
if __name__ == "__main__":
# Определите параметры мира
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# Создайте виртуальный мир
world = VirtualWorld(environment_size, agent_types, agent_properties)
# Simulate the world for several steps
for _ in range(10):
world.update()
world.display()
print() #Добавьте пустую строку для лучшего чтения
Что происходит в этом коде:
-
Класс VirtualWorld:
-
Определяет ядро виртуального мира.
-
Содержит сетку окружения, список агентов и информацию о соответствующих агентах.
-
__init__(): Инициализирует мир размером, типами агентов и их свойствами. -
add_agent(): Добавляет новый агент определенного типа в мир. -
update(): выполняет один проход обновления мира.- Текущим образом это просто перемещение агентов, но вы можете добавить сложные логику для взаимодействий агентов, изменения среды и т.п.
-
display(): выводит базовую representaцию среды.
-
-
Класс агента:
-
представляет отдельного агента в мире.
-
__init__(): инициализирует агента с его типом, позицией и свойствами. -
move(): обрабатывает перемещение агента, обновляя его позицию в среде. This method currently provides a simple random movement, но может быть расширен, чтобы включить сложные AI поведения.
-
-
Пример использования:
-
Устанавливает мировые параметры, такие как размер, типы агентов и их свойства.
-
Создает объект VirtualWorld.
-
Выполняет метод
update()multiple times для симуляции эволюции мира. -
Вызывает
display()после каждого обновления для visualization изменений.
-
Улучшения:
-
более сложные AI агентов: Разработать более сложную AI для поведения агентов. Можно использовать:
-
Паттернfinding алгоритмы: помочь агентам эффективно навигации в среде.
-
Дерева решений/машинное обучение: позволить агентам делать более умные решения на основе их окружения и целей.
-
Обучение с упражнением: научить агентов учиться и адаптировать свое поведение в течение времени.
-
-
Взаимодействие с окружением: добавить более динамические элементы в окружение, такие как препятствия, ресурсы или точки внимания.
-
Взаимодействие агентов между собой: реализовать взаимодействия между агентами, такие как коммуникация, бой или сотрудничество.
-
Визуальное представление: использовать библиотеки, такие как Pygame или Tkinter, для создания визуального представления виртуального мира.
Этот пример является базой для создания виртуального мира с помощью AI. Сложность и изящность могут быть дополнительно расширены для соответствия вашим специфическим потребностям и творческим целям.
Neuromorphic Computing и AI
Нeuromorphic computing, вдохновленный структурой и функционированием человеческого мозга, направлен на революцию в AI, предлагая новые способы эффективного и параллельного обработки информации.
В отличие от традиционных вычислительных архитектур, системы neuromorphic designed to mimic the neural networks of the brain, allowing AI to perform tasks such as pattern recognition, sensory processing, and decision-making with greater speed and energy efficiency.
Эта технология представляет огромный потенциал для развития систем AI, которые более адаптивны, способны учиться с минимальными данными и эффективны в реальных средах.
Например, в робототехнике, neuromorphic chips could enable robots to process sensory inputs and make decisions with a level of efficiency and speed that current architectures cannot match.
Однако основная проблема впереди заключается в масштабировании neuromorphic computing to handle the complexity of large-scale AI applications, integrating it with existing AI frameworks to fully leverage its potential.
Агенты AI в космической исследовании
Агенты AI все более играют ключевую роль в космической Exploration, где их задача – навигация в сложных средах, принимание реально-временных решений и самостоятельное проведение научных экспериментов.
По мере того как миссии идет вглубь космоса, потребность в AI системах, которые могут работать независимо от Земля-базированного контроля, становится более острой. будущие агенты AI будут проектироваться для обработки непредсказуемости космоса, таких как неожиданные препятствия, изменения параметров миссии или потребность саморемонта.
Например, AI может использоваться для направления rovers на Марсе для автономного исследования ландшафта, идентификации научно ценных объектов и даже бурения проб с минимальной информацией от миссионного контроля. Эти агенты AI также могут управлять системами поддержки жизни на долгосрочных миссиях, оптимизировать использование энергии и адаптироваться к психологическим потребностям астронавтов, предоставляя им компанию и умственное стимулирование.
Интеграция AI в космическое исследование не только усиливает способности миссии, но и открывает новые возможности для исследования космоса с помощью AI, который станет незаменимым напарником в поиске понимания нашего вселенной.
Каapter 8: AI Agents in Mission-Critical Fields
Здравоохранение
В здравоохранении AI агенты не являются только вспомогательными ролями, но становятся неотъемлемой частью всего континуума помощи пациентам. свое влияние наиболее очевидно в телемедицине, где системы AI обновили подход к удаленному оказанию медицинской помощи.
plaintext
Использование передовых технологий обработки естественного языка (NLP) и алгоритмов машинного обучения позволяет таким системам выполнять сложные задачи, такие как триаж симптомов и сбор предварительных данных, с высокой степенью точности. Они анализируют симптомы, сообщаемые пациентами, и медицинскую историю в реальном времени, сопоставляя эту информацию с обширными медицинскими базами данных для идентификации потенциальных состояний или предупреждающих знаков.
Это позволяет медицинским работникам делать информированные решения быстрее, сокращая время до лечения и потенциально спасая жизни. Кроме того, AI-ориентированные диагностические инструменты в медицинской визуализации трансформируют рентгенологию, обнаруживая шаблоны и аномалии в рентгенограммах, МРТ и КТ-сканах, которые могут быть незаметными для человеческого глаза.
Эти системы обучены на обширных наборах данных, включающих миллионы аннотированных изображений, что позволяет им не только воспроизводить, но и часто превосходить человеческие диагностические способности.
Интеграция AI в здравоохранение также распространяется на административные задачи, где автоматизация запланированных визитов, напоминаний о лекарствах и последующего контакта с пациентами значительно уменьшает операционную нагрузку на медицинский персонал, позволяя им сосредоточиться на более важных аспектах ухода за пациентами.
Финансы
В финансовом секторе AI-агенты революционировали операции, внедрив невиданные до этого уровни эффективности и точности.
Алгоритмическая торговля, в которой широко используется AI, изменила способ выполнения сделок на финансовых рынках.
Эти системы способны анализировать огромные наборы данных за миллисекунды, распознавать тенденции рынка и осуществлять сделки в оптимальный момент для максимизации доходов и минимизации рисков. Они используют сложные алгоритмы, включающие методы машинного обучения, глубокого обучения и усиления обучения, чтобы адаптироваться к изменяющимся рыночным условиям, делая мгновенные решения, которые не смогут соперничать человеческие трейдеры.
Помимо торговли, ИИ играет решающую роль в управлении рисками, оценивая кредитные риски и обнаруживая мошенническую деятельность с выдающейся точностью. Модели ИИ используют предиктивный анализ для оценки вероятности дефолта заемщика, анализируя модели поведения в кредитной истории, транзакциях и других соответствующих факторах.
Кроме того, в сфере регулятивного соблюдения, ИИ автоматизирует мониторинг транзакций для обнаружения и отчета о подозрительной деятельности, обеспечивая соблюдение финансовыми учреждениями строгих регулятивных требований. Эта автоматизация не только снижает риск человеческой ошибки, но и упрощает процессы соблюдения, сокращая затраты и повышая эффективность.
Управление чрезвычайными ситуациями
Роль ИИ в управлении чрезвычайными ситуациями трансформационна, фундаментально меняя способ предсказания, управления и смягчения кризисов.
В ответ на чрезвычайные ситуации, агенты ИИ обрабатывают огромные объемы данных из множества источников — от спутниковых снимков до лент новостей социальных медиа — для обеспечения всестороннего обзора ситуации в реальном времени. Алгоритмы машинного обучения анализируют эти данные для распознавания моделей и предсказания развития событий, что позволяет спасателям более эффективно распределять ресурсы и принимать информированные решения под давлением.
К примеру, во время природных катастроф, таких как ураган, системы AI могут предсказывать路径 и интенсивность бури, что позволяет властям выпускать своевременные приказы о эвакуации и направлять ресурсы в наиболее уязвимые области.
В предсказательной аналитике AI-модели используются для предсказания возможных кризисных ситуаций, анализируя исторические данные вместе с реаль-временными входными данными, что позволяет проводить профилактические мероприятия, которые могут предотвратить катастрофы или смягчить их влияние.
AI-способные системы массовой информации также играют crucial роль в обеспечении доставки точной и своевременной информации населению, пострадавшему. Эти системы могут генерировать и распространять сигналы экстренного оповещения по многим платформам, настраивая сообщения на различные демографические группы, чтобы обеспечить их понимание и соблюдение.
AI также улучшает готовность инженеров по emergencys by создавая реалистичные тренировочные simuluation с использованием generative моделей. Эти simuluation воспроизводят сложности реальных мировых экстренных ситуаций, позволяя инженерам тренироваться и совершенствовать свои навыки для реальных событий.
Транспорт
Системы AI становятся непременными в отрасли транспорта, где они улучшают безопасность, эффективность и надежность по всем областям, включая управление воздушным движением, автономные транспортные средства и общественный транспорт.
В управлении воздушным движением AI-агенты играют ключевую роль в оптимизации маршрутов полетов, предсказывании potention конфликтов и управлении операциями аэропортов. Эти системы используют предсказательную аналитику, чтобы предсказать potention ложбины в воздушном движении, перенаправляя полеты в реальном времени для обеспечения безопасности и эффективности.
В сфере автономных транспортных средств ИИ является главным инструментом, позволяющим транспортным средствам обрабатывать данные сенсоров и принимать Split-second решения в сложных средах. Эти системы используют глубокие leaneding модели, обученные на обширных наборах данных, для интерпретации визуальных, слуховых и пространственных данных, что позволяет безопасно навигаровать в динамичных и непредсказуемых условиях.
Public transit systems также выигрывают от ИИ через оптимизированное планирование маршрутов, прогнозируемое обслуживание транспортных средств и управление потоком пассажиров. Благодаря анализу исторических и реальных данных, системы ИИ могут регулировать расписания транспорта, прогнозировать и предотвращать выходы из строя транспортных средств, а также управлять толпой в часы пика, тем самым улучшая общую эффективность и надежность транспортных сетей.
Energy Sector
ИИ играет crucial роль в отрасли энергетики, особенно в управлении сетью, оптимизации возобновляемых источников энергии и обнаружении ошибок.
В управлении сетью ИИ-агенты наблюдают и управляют электросетями, анализируя реальные данные сенсоров, распределенных по сети. Эти системы используют предсказательные анализы для оптимизации распределения энергии, обеспечивая соответствие спроса и предложения и минимизируя мутьение энергии. ИИ-модели также предсказывают возможные отказы в сети, позволяя провести предупредительное обслуживание и снизить риск отключений.
В сфере возобновляемых источников энергии ИИ-системы используются для предсказания погодных условий, что важно для оптимизации производства солнечной и ветряной энергии. Эти модели анализируют метеорологические данные, предсказывая интенсивность солнечного света и скорость ветра, что позволяет делать более точные предсказания производства энергии и лучше интегрировать возобновляемые источники в сеть.
Системы обнаружения неисправностей являются еще одной областью, в которой AI вносит значительный вклад. Системы искусственного интеллекта анализируют данные сенсоров от оборудования, такого как трансформаторы, турбины и генераторы, для идентификации признаков износа или потенциальных неисправностей, прежде чем они приведут к сбоям. Этот подход к предсказательному обслуживанию не только увеличивает срок службы оборудования, но и обеспечивает непрерывное и надежное энергоснабжение.
Кибербезопасность
В области кибербезопасности агенты AI являются незаменимыми для поддержания целостности и безопасности цифровой инфраструктуры. Эти системы предназначены для постоянного мониторинга сетевого трафика, используя алгоритмы машинного обучения для обнаружения аномалий, которые могли бы указывать на нарушение безопасности.
Анализируя огромные объемы данных в реальном времени, агенты AI могут идентифицировать модели вредоносного поведения, такие как необычные попытки входа, активности экспулирования данных или наличие вредоносного программного обеспечения. Как только обнаружается потенциальная угроза, системы AI могут автоматически инициировать контрмеры, такие как изоляция поврежденных систем и развертывание патчей, чтобы предотвратить дальнейшие повреждения.
Оценка уязвимости является еще одним критическим применением AI в кибербезопасности. Инструменты с поддержкой AI анализируют код и конфигурации системы для идентификации потенциальных слабостей в безопасности, прежде чем они могут быть использованы атакующими. Эти инструменты используют статические и динамические методы анализа для оценки состояния безопасности программного и аппаратного обеспечения, предоставляя оперативные данные для команд кибербезопасности.
Автоматизация этих процессов не только ускоряет Velocity и точность обнаружения угроз и их реакции, но и снижает нагрузку на аналитиков, позволяя им сосредоточиться на более сложных проблемах безопасности.
Производство
В производстве AI водит значительные успехи в контроле качества, прогнозировании обслуживания и оптимизации цепочки поставок. AI-управляемые компьютерные системы видения сейчас способны контролировать продукцию за дефекты со скоростью и точностью, которые намного превышают человеческие возможности. Эти системы используют глубокое обучение алгоритмы, тренированные на тысячи изображений, чтобы обнаружить даже самые маленькие несоответствия в продукции, обеспечивая постоянное качество в высокоскоростных производственных сетях.
Еще одним ареаром, где AI оказывает существенное влияние, является прогнозирование обслуживания. Analyzing данные с датчиков, встроенных в машину, модели AI могут предсказать, когда оборудование, скорее всего, сломается, позволяя провести обслуживание до возникновения сбоя. Этот подход не только снижает downtime, но и extends срок службы машин, что ведет к значительным экономиям.
В управлении цепочкой поставок AI агенты оптимизируют уровни инвестиций и логистику, анализируя данные из всей цепочки поставок, включая прогнозы спроса, график производства и транспортные маршруты. Благодаря тому, что агенты AI делают реальные временные корректировки инвестиций и планов логистики, производственные процессы проходят гладко, минимизируя задержки и снижая затраты.
Эти приложения демонстрируют критическую роль AI в улучшении эффективности и надежности в производстве, делая его незаменимым инструментом для компаний, которые хотят оставаться конкурентными в быстро развивающейся индустрии.
Заключение
Интеграция агентов искусственного интеллекта с крупными языковыми моделями (КЯМ) является значимым этапом в эволюции искусственного интеллекта, открывая предыдуще неизвестные возможности во многих отраслях и научных областях. Эта синергия повышает функциональность, адаптируемость и приложимость систем искусственного интеллекта, компенсируя внутренние ограничения КЯМ и позволяя более динамичные, контекстно-зависимые и автономные процессы принятия решений.
От революции в здравоохранении и финансах до трансформации транспорта и управления чрезвычайными ситуациями, агенты искусственного интеллекта стимулируют инновации и эффективность, проложив путь к будущему, где технологии искусственного интеллекта глубоко проникнут в нашу повседневную жизнь.
По мере продолжения исследования потенциала агентов искусственного интеллекта и КЯМ, важно основывать их разработку на этических принципах, приоритетом которых являются благополучие человека, справедливость и инклюзивность. Обеспечивая ответственное проектирование и внедрение этих технологий, мы можем использовать их полный потенциал для улучшения качества жизни, продвижения социальной справедливости и решения глобальных проблем.
Будущее искусственного интеллекта заключается в гладкой интеграции продвинутых агентов искусственного интеллекта с изощрёнными КЯМ, создавая умные системы, которые не только усиливают человеческие способности, но и поддерживают ценности, определяющие нашу человечность.
Слияние агентов искусственного интеллекта и КЯМ представляет собой новую парадигму в искусственном интеллекте, где сотрудничество между гибкими и мощными системами открывает мир неограниченных возможностей. Использовав эту синергетическую силу, мы можем стимулировать инновации, продвигать научные открытия и создавать более справедливое и процветающее будущее для всех.
Об авторе
Здесь Vahe Aslanyan, на пересечении компьютерных наук, науки данных и ИИ. Посмотрите на vaheaslanyan.com, чтобы увидеть портфолио, которое является свидетельством точности и прогресса. Моя практика соединяет различные области разработки: от полностного стек разработки до оптимизации продуктов ИИ, и это продиктовано желанием решать проблемы в новых условиях.
Со свидетельством опыта, включающим запуск лидирующего бутка по науке данных и работу с ведущими специалистами в отрасли, моя focus остается на повышении стандартов технического образования до универсальных.
Как можно уйти еще глубже?
После изучения этого руководства, если вы хотите продолжить исследования и структурированное обучение — это ваш стиль, рассмотрите присоединиться к нам в LunarTech, где мы предлагаем индивидуальные курсы и бутcamp по науке данных, машинному обучению и ИИ.
Мы предоставляем комплексную программу, которая включает глубокое понимание теории, практическое применение, обширные упражнения и настраиваемое подготовку к интервью, чтобы подготовить вас к успеху в любом из этапов вашей карьеры.
Вы можете проверить наш Ultimate Data Science Bootcamp и присоединиться к бесплатному испытанию, чтобы опробовать содержимое на руках. Это принесло почетное звание Лучшего буткамапа по Data Science 2023 и было опубликовано в авторитетных изданиях, таких как Forbes, Yahoo, Entrepreneur и другие. Это ваша возможность стать частью сообщества, которое процветает на инновациях и знаниях. Вот приветственное сообщение!
Свяжитесь со мной

Следуйте за мной на LinkedIn и получите много бесплатных ресурсов по CS, ML и AI
-
Подпишитесь на мой Newsletter по Data Science и AI
Если вы хотите узнать больше о карьере в области Data Science, Machine Learning и AI, и узнать, как обеспечить себе работу Data Science, вы можете скачать бесплатно этот Руководство по карьере в Data Science и AI.
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/