













L’évolution rapide de l’intelligence artificielle (IA) a permis l’apparition d’une puissante synergie entre les grands modèles de langue (LLM) et les agents intelligents. Cette dynamique interplay est telle que les agiles agents intelligents renforcent et amplifient les capacités des colossales LLM.
Ce manuel explore comment les agents intelligents, semblables à David, superchargent les LLM – nos modernes Goliaths – pour aider à révolutionner diverses industries et domaines scientifiques.
Table des matières
-
L’émergence des agents intelligents dans les modèles de langue
-
Chapitre 1 : Introduction aux agents intelligents et aux modèles de langue
-
Chapitre 2 : L’histoire de l’intelligence artificielle et des agents intelligents
-
Chapitre 4 : La base philosophique des systèmes intelligents
-
Chapitre 6 : Conception architecturale pour l’intégration des agents IA avec les LLM
-
Chapitre 8 : Les agents intelligents dans les domaines de mission critique
L’émergence des agents intelligents dans les modèles de langue
Les agents intelligents sont des systèmes autonomes conçus pour percevoir leur environnement, prendre des décisions et exécuter des actions pour atteindre des objectifs spécifiques. Lorsqu’ils sont intégrés à des GdL, ces agents peuvent effectuer des tâches complexes, réfléchir à l’information et générer des solutions innovantes.
Cette combinaison a permis d’obtenir des avancées significatives dans de multiples secteurs, du développement logiciel à la recherche scientifique.
Impact transformateur sur les industries
L’intégration des agents intelligents avec les GdL a eu un impact profond sur diverses industries :
-
Développement de logiciels : Les assistants de codage dotés d’IA, tels que GitHub Copilot, ont montré la capacité à générer jusqu’à 40 % du code, ce qui a permis une augmentation remarquable de 55 % de la vitesse de développement.
-
Éducation : Les assistants d’apprentissage dotés d’IA ont montré de prometteuses performances en réduisant le temps moyen de terminaison des cours de 27 %, ce qui pourrait révolutionner le paysage éducatif.
-
Transportation: Des projections suggèrent que 10% des véhicules seront autonomes d’ici 2030, ce qui amènerait les agents AI autonomes dans les voitures sans conducteur à transformer l’industrie des transports.
Avancer les découvertes scientifiques
Une des applications les plus passionnantes des agents AI et des GMT est dans la recherche scientifique :
-
Découverte de médicaments : Les agents AI accélèrent le processus de découverte de médicaments en analysant des jeux de données importants et en prédisant les candidats potentiels de médicaments, réduisant significativement le temps et le coût associés aux méthodes traditionnelles.
-
Physique des Particules : Au Grand collisionneur hadronique de CERN, des agents IA sont utilisés pour analyser les données de collisions de particules, utilisant la détection d’anomalies pour identifier des pistes prometteuses indiquant peut-être l’existence de particules non découvertes.>
-
Recherche Scientifique Générale : Des agents IA sont améliorant le rythme et la portée de découvertes scientifiques en analysant des études passées, en identifiant des liens imprévus et en proposant de nouvelles expériences.
La convergence d’agents intelligents et de grands modèles de langue (GML) propulse l’intelligence artificielle dans une nouvelle ère de capacités sans précédent. Ce manuel complet examine l’interaction dynamique entre ces deux technologies, dévoilant leur potentiel combiné pour révolutionner les industries et résoudre les problèmes complexes.
Nous retracerons l’évolution de l’IA de ses origines à l’avènement d’agents autonomes et du développement de GML sophistiqués. Nous explorerons également les considérations éthiques, qui sont fondamentales au développement responsable de l’IA. Cela nous aidera à nous assurer que ces technologies alignent nos valeurs humaines et le bien-être de la société.
A la fin de ce manuel, vous aurez une compréhension profonde du pouvoir synergique des agents intelligents et des GML, ainsi que les connaissances et outils pour exploiter cette technologie de pointe.
Chapitre 1 : Introduction aux Agents Intelligents et aux Modèles de Langue
Qu’est-ce que des Agents Intelligents et des Grandes Modèles de Langue ?
L’évolution rapide de l’intelligence artificielle (IA) a mis en évidence une synergie transformative entre les grands modèles de langue (GML) et les agents intelligents.
Les agents intelligents sont des systèmes autonomes conçus pour percevoir leur environnement, prendre des décisions et exécuter des actions pour atteindre des objectifs spécifiques. Ils présentent des caractéristiques telles que l’autonomie, la perception, la réactivité, la raisonnement, la prise de décision, l’apprentissage, la communication et l’orientation vers les objectifs.
D’autre part, les LLM (Large Language Models) sont des systèmes intelligents complexes qui utilisent des techniques d’apprentissage profondes et de vastes jeux de données pour comprendre, générer et prédire du texte semblable à celui des humains.
Ces modèles, tels que GPT-4, Mistral, LLama, ont démontré des capacités remarquables dans les tâches de traitement du langage naturel, y compris la génération de texte, la traduction de langue et les agents de conversation.
Caractéristiques clés des agents intelligents
Les agents intelligents possèdent plusieurs caractéristiques distinctives qui les différencient des logiciels traditionnels :
-
Autonomie: Ils peuvent fonctionner indépendamment de l’intervention constante de l’humain.
-
Perception: Les agents peuvent ressentir et interpréter leur environnement à travers diverses entrées.
-
Réactivité: Ils réagissent dynamiquement aux changements dans leur environnement.
-
Raisons et Prise de décision : Les agents peuvent analyser des données et prendre des choix informés.
-
Apprentissage : Ils améliorent leurs performances au fil du temps par l’expérience.
-
Communication : Les agents peuvent interagir avec d’autres agents ou avec des humains à l’aide de diverses méthodes.
-
Orientation vers des objectifs : Ils sont conçus pour atteindre des objectifs spécifiques.
Capacités des grands modèles de langue
Les gros modèles de langue ont montré une large gamme de capacités, y compris :
-
Génération de texte : Les MMT peuvent produire du texte cohérent et pertinent selon les prompts.
-
Traduction de langue : Ils peuvent traduire du texte entre différentes langues avec une grande précision.
-
Résumé
: Les GLLM peuvent condenser de longs textes en sommaires courts tout en conservant les informations clés.
- Recherche de réponses : Ils peuvent fournir des réponses précises aux questions basées sur leur base de connaissances vaste.
- Analyse des sentiments : Les GLLM peuvent analyser et déterminer le sentiment exprimé dans un texte donné.
- Génération de code : Ils peuvent générer des extraits de code ou des fonctions entières sur la base de descriptions en langue naturelle.
Niveaux des agents intelligents
Les agents intelligents peuvent être classés dans différents niveaux en fonction de leurs capacités et de leur complexité. Selon un papier sur arXiv, les agents intelligents sont catégorisés en cinq niveaux :
- Niveau 1 (L1) : Les agents intelligents en tant que assistants de recherche, où les scientifiques définissent des hypothèses et spécifient des tâches pour atteindre des objectifs.
-
Niveau 2 (N2) : Des agents intelligents autonomes pouvant exécuter des tâches spécifiques dans un certain domaine défini, telles que l’analyse des données ou des processus de décision simples.
-
Niveau 3 (N3) : Des agents intelligents capables d’apprendre à partir de l’expérience et d’adapter leur comportement aux nouvelles situations, améliorant ainsi leurs processus de décision.
-
Niveau 4 (N4) : Des agents intelligents dotés de capacités de raisonnement avancées et de résolution de problèmes, pouvant gérer des tâches complexes à plusieurs étapes.
-
Niveau 5 (N5) : Des agents intelligents autonomes complètement indépendants pouvant fonctionner de manière autonome dans des environnements dynamiques, prenant des décisions et agissant sans intervention humaine.
Limitations des Grands Modèles de Langue
Coûts de formation et contraintes de ressources
Les grands modèles de langue tels que GPT-3 et PaLM ont révolutionné le traitement du langage naturel (TLN) en exploitant des techniques de deep learning et de vastes jeux de données.
Cependant, ces avancées reviennent à un coût significatif. L’entraînement de GGUs nécessite de substantiels ressources calculatoires, souvent impliquant des milliers de GPU et une consommation énergétique importante.
Selon Sam Altman, PDG d’OpenAI, les coûts d’entraînement pour GPT-4 ont dépassé 100 millions de dollars. Cela correspond au volume et à la complexité du modèle annoncés, avec des estimations suggérant qu’il possède environ 1 trillion de paramètres. Cependant, d’autres sources offrent des chiffres différents :
-
Un rapport divulgué indiquait que les coûts d’entraînement de GPT-4 étaient d’environ 63 millions de dollars, en tenant compte de la puissance calculatoire et de la durée de l’entraînement.
-
Au milieu de 2023, certaines estimations suggéraient que l’entraînement d’un modèle similaire à GPT-4 pourrait coûter environ 20 millions de dollars et prendre environ 55 jours, reflétant les progrès en matière d’efficacité.
Ces coûts élevés d’entraînement et de maintenance des GMT limitent leur adoption large et leur scalabilité.
Limitations des données et biais
La performance des GMT est fortement tributaire de la qualité et de la diversité des données d’entraînement. Malgré l’entraînement sur de vastes ensembles de données, les GMT peuvent encore présenter les biais présents dans les données, conduisant à des sorties décalées ou inappropriées. Ces biais peuvent se manifester sous diverses formes, y compris des biais selon le sexe, la race et la culture, qui peuvent perpétuer les stéréotypes et les informations erronées.
De plus, la nature statique des données d’entraînement signifie que les GMT peuvent ne pas être à jour avec les informations les plus récentes, limitant ainsi leur efficacité dans des environnements dynamiques.
Spécialisation et complexité
Bien que les GMT soient excellents dans les tâches générales, elles font souvent face à des défis dans les tâches spécialisées exigeant des connaissances spécifiques au domaine et une complexité élevée.
Par exemple, les tâches dans les domaines tels que la médecine, le droit et la recherche scientifique exigent une compréhension profonde du vocabulaire spécialisé et de la logique nuancée, que les GMT ne possèdent pas nécessairement intrinsèquement. Cette limitation exige l’intégration de couches supplémentaires d’expertise et l’entraînement fine pour rendre les GMT efficaces dans les applications spécialisées.
Limitations des entrées et des sens.
Les GIE primaire traitent des entrées basées sur le texte, ce qui limite leur capacité à interagir avec le monde de manière multimodale. Bien qu’ils puissent générer et comprendre du texte, ils ne sont pas capables de traiter directement les entrées visuelles, auditives ou sensorielle.
Cette limitation entrave leur application dans des domaines exigeant une intégration sensorielle complète, tels que la robotique et les systèmes autonomes. Par exemple, un GIE ne peut pas interpréter les données visuelles d’une caméra ou les données auditives d’un microphone sans des couches de traitement supplémentaires.
Contraintes de communication et d’interaction
Les capacités de communication actuelles des GIE sont principalement basées sur le texte, ce qui limite leur capacité à s’engager dans des formes de communication plus immersives et interactives.
Par exemple, si bien que des GIE peuvent générer des réponses textuelles, ils ne peuvent pas produire de contenu vidéo ou des représentations holographiques, qui sont de plus en plus importants dans les applications de réalité virtuelle et augmentée (lire plus ici). Cette contrainte réduit l’efficacité des GIE dans des environnements exigeant des interactions riches et multimodales.
Comment surmonter les limites avec les agents intelligents
Les agents intelligents offrent une solution prometteuse à bon nombre des limites rencontrées par les GIE. Ces agents sont conçus pour fonctionner de manière autonome, percevoir leur environnement, prendre des décisions et exécuter des actions pour atteindre des objectifs spécifiques. En intégrant des agents intelligents aux GIE, il est possible d’améliorer leurs capacités et de lever leurs limitations inhérentes.
-
Amélioration du contexte et de la mémoire : Les agents intelligents peuvent conserver le contexte sur plusieurs interactions, permettant de donner des réponses plus cohérentes et pertinentes dans le contexte. Cette capacité est particulièrement utile dans les applications qui requièrent de la mémoire à long terme et une continuité, telles que le service client et les assistants personnels.
-
Intégration multimodale : Les agents intelligents peuvent intégrer des entrées sensorielle provenant de diverses sources, telles que les caméras, les microphones et les capteurs, permettant aux GLL de traiter et de répondre aux données visuelles, auditives et sensorielle. Cette intégration est essentielle pour les applications dans les systèmes robots et autonomes.
-
Connaissance et expertise spécialisées : Les agents AI peuvent être affinés avec des connaissances spécifiques au domaine, ce qui améliore la capacité des LLM à exécuter des tâches spécialisées. Cette méthode permet de créer des systèmes experts capables de traiter des demandes complexes dans des domaines tels que la médecine, le droit et la recherche scientifique.
-
Communication interactive et immersive : Les agents AI peuvent faciliter des formes plus immersives de communication en générant du contenu vidéo, contrôlant des affichages holographiques et interagissant avec des environnements de réalité virtuelle et augmentée. Cette capacité élargit l’application des LLM dans des domaines nécessitant des interactions multimodales riches.
Bien que les grands modèles de langue naturelle aient montré des capacités remarquables dans le traitement du langage naturel, ils présentent des limites. Les coûts de formation élevés, les biais de données, les défis de spécialisation, les limitations sensorielle et les contraintes de communication posent des obstacles importants.
Cependant, l’intégration d’agents intelligents offre un chemin viable pour surmonter ces limites. En exploitant les forces des agents intelligents, il est possible d’améliorer les fonctionnalités, l’adaptabilité et l’applicabilité des GMT, ouvrant la voie vers des systèmes d’IA plus avancés et polyvalents.
Chapitre 2 : L’histoire de l’intelligence artificielle et des agents d’IA
Le début de l’intelligence artificielle
La notion d’intelligence artificielle (IA) a des racines beaucoup plus anciennes que l’ère numérique moderne. L’idée de créer des machines capables de raisonner comme l’homme peut être retracée jusqu’à des mythes antiques et des débats philosophiques. Mais la naissance formelle de l’IA en tant que discipline scientifique a eu lieu dans la deuxième moitié du 20e siècle.
La conférence de Dartmouth de 1956, organisée par John McCarthy, Marvin Minsky, Nathaniel Rochester et Claude Shannon, est largement considérée comme le berceau de l’IA en tant que domaine d’étude. Cet événement seminal a rassemblé les principaux chercheurs pour explorer le potentiel de la création de machines capable de simuler l’intelligence humaine.
L’Optimisme des débuts et l’hiver de l’IA
Les premières années de recherche en IA étaient caractérisées par un optimisme sans entraves. Les chercheurs ont fait des progrès importants dans la création de programmes capables de résoudre des problèmes mathématiques, de jouer aux jeux et même de procéder à une communication naturelle de base.
Cependant, cet enthousiasme initial a été tempéré par la réalité que créer des machines véritablement intelligentes était beaucoup plus complexe que prévu initialement.
Les années 1970 et 1980 ont vu une période de financement réduit et d’intérêt moindre pour les recherches en IA, couramment appelée la « hiver de l’IA« . Cette baisse était principalement due à l’échec des systèmes IA à atteindre les espérances élevées des pionniers早期.
De la logique des règles à l’apprentissage automatique
L’ère des systèmes experts
Les années 1980 ont été témoins d’un regain d’intérêt en IA, principalement impulsé par le développement des systèmes experts. Ces programmes basés sur des règles étaient conçus pour émuler les processus de décision des experts humains dans des domaines spécifiques.
Les systèmes experts trouvent des applications dans divers domaines, y compris la médecine, les finances et l’ingénierie. Cependant, ils étaient limités par leur incapacité d’apprendre à partir de l’expérience ou d’adapter à de nouvelles situations en dehors de leurs règles programmées.
L’émergence de l’apprentissage automatique
Les limites des systèmes basés sur des règles ont ouvert la voie pour un changement de paradigme vers l’apprentissage automatique. Cette approche, qui a pris de l’importance dans les années 1990 et 2000, se concentre sur la développement d’algorithmes qui peuvent apprendre à partir de données et faire des prédictions ou des décisions.
Les techniques d’apprentissage automatique, telles que les réseaux de neurones et les machines à support vectoriel, ont montré un succès remarquable dans des tâches telles que la reconnaissance de modèles et la classification des données. L’avènement du big data et l’accroissement de la puissance de calcul ont encore accéléré le développement et l’application des algorithmes d’apprentissage automatique.
L’émergence d’agents intelligents autonomes
De l’IA restreinte à l’IA générale
Avec l’évolution continue des technologies IA, les chercheurs ont commencé à explorer la possibilité de créer des systèmes plus polyvalents et autonomes. Ce changement a marqué la transition de l’IA restreinte, conçue pour des tâches spécifiques, vers la poursuite de l’intelligence artificielle générale (AGI).
L’IA générique vise à développer des systèmes capables de réaliser toute tâche intellectuelle que peut effectuer un humain. Si l’IA générique reste un objectif éloigné, des progrès importants ont été réalisés dans la création de systèmes IA plus flexibles et adaptables.
Le rôle de l’apprentissage profond et des réseaux de neurones
L’apparition de l’apprentissage profond, un sous-domaine de l’apprentissage automatique basé sur les réseaux de neurones artificiels, a été essentiel pour avancer dans le domaine de l’IA.
Les algorithmes d’apprentissage profond, inspirés par la structure et la fonction du cerveau humain, ont démontré des capacités remarquables dans des domaines tels que la reconnaissance d’images et de la parole, le traitement du langage naturel et le jeu. Ces avancées ont jeté les fondations pour le développement d’agents autonomes IA plus sophistiqués.
Caractéristiques et types d’agents IA
Les agents IA sont des systèmes autonomes capable de percevoir leur environnement, de prendre des décisions et d’effectuer des actions pour atteindre des objectifs spécifiques. Ils possèdent des caractéristiques telles que l’autonomie, la perception, la réactivité, la raisonnement, la prise de décision, l’apprentissage, la communication et l’orientation vers les objectifs.
Il existe plusieurs types d’agents IA, chacun avec des capacités uniques :
-
Agents de réflexe simples : répondent à des stimuli spécifiques en fonction de règles prédéfinies.
-
Agents Reflexifs Basés sur un Modèle : Maintiennent un modèle interne de l’environnement pour la prise de décisions.
-
Agents Orientés vers des Objectifs : Exécutent des actions pour atteindre des objectifs spécifiques.
-
Agents Basés sur l’Utilité : Considerent les résultats potentiels et choisissent des actions maximisant l’utilité attendue.
-
Agents Apprenants : Améliorent la prise de décision au fil du temps grâce à des techniques d’apprentissage automatique.
Defis et Considérations Ethiques
Les systèmes d’IA de plus en plus avancés et autonomes soulèvent des considérations critiques pour assurer que leur utilisation reste dans les limites acceptées socialement.
Les Grands Modèles de Langue (GML), en particulier, agissent comme des surdouateurs de productivité. Mais cela soulève une question cruciale : Que vont ces systèmes surdonder — de bonnes intentions ou de mauvaises intentions ? Lorsque l’intention derrière l’utilisation de l’IA est malveillante, il devient impératif pour ces systèmes de détecter ce détournement à l’aide de diverses techniques de PLN ou d’autres outils à notre disposition.
Les ingénieurs en génie logiciel disposent d’un ensemble de outils et de méthodologies pour s’attaquer à ces défis :
-
Analyse dessentiments : En utilisant l’analyse dessentiments, les LLM peuvent évaluer le ton émotionnel du texte pour détecter un langage harmful ou agressif, aidant à identifier une potentielle utilisation abusive sur les plateformes de communication.
-
Filtre de contenu : Des outils tels que le filtrage par mot-clé et le matching de modèles peuvent être utilisés pour empêcher la génération ou la propagation de contenu harmful, comme le discours haineux, les informations fausses ou les matériaux explicites.
-
Outils de détection de biais : L’implémentation de cadres de détection de biais, tels que AI Fairness 360 (IBM) ou Indicateurs de Fairness (Google), peut aider à identifier et à atténuyer le biais dans les modèles de langue, visant à assurer une impartialité et une équité équitables dans les systèmes d’IA.
-
Techniques d’explicabilité
: En utilisant des outils d’explicabilité tels que LIME (Local Interpretable Model-agnostic Explanations) ou SHAP (SHapley Additive exPlanations), les ingénieurs peuvent comprendre et expliquer les processus de prise de décision des LLM (Large Language Models), ce qui facilite la détection et la correction de comportements non intentionnels.
-
Testage adversaire : En simulant des attaques malveillantes ou des entrées nocives, les ingénieurs peuvent mettre à l’épreuve les LLM en utilisant des outils tels que TextAttack ou Adversarial Robustness Toolbox, identifiant ainsi des vulnérabilités qui pourraient être exploitées à des fins malveillantes.
-
Guidelines et cadres éthiques pour l’IA : En adoptant des directives d’élaboration éthique de l’IA, telles que celles fournies par le IEEE ou le Partnership on AI, les ingénieurs peuvent guider la création de systèmes d’IA responsables qui privilégient le bien-être de la société.
En plus de ces outils, c’est pourquoi nous avons besoin d’une équipe Red Team spécialisée pour l’IA — des équipes spécialisées qui poussent les LLM à leurs limites pour détecter les lacunes dans leurs défenses. Les équipes rouges simulent des scénarios adversaires et découvrent les vulnérabilités qui pourraient sinon rester non remarquées.
Mais il est important de reconnaître que les personnes derrière le produit ont d’énormes effets sur celui-ci. Beaucoup des attaques et défis que nous confrontons aujourd’hui ont existé même avant que les LLM soient développées, soulignant que l’élément humain demeure central pour s’assurer que l’IA est utilisée de manière éthique et responsable.
L’intégration de ces outils et techniques dans la chaîne de développement, accompagnée d’une vigilante Red Team, est essentielle pour s’assurer que les LLM sont utilisées pour multiplier les résultats positifs tout en détectant et prévenant leur utilisation abusée.
Chapitre 3 : Les Points forts des Agents IA
Les forces uniques des agents IA
Les agents IA se démarquent grâce à leur capacité d’autonomes à percevoir leur environnement, prendre des décisions et exécuter des actions pour atteindre des objectifs spécifiques. Cette autonomie, combinée aux capacités avancées d’apprentissage automatique, permet aux agents IA de réaliser des tâches qui sont soit trop complexes ou trop répétitifs pour les humains.
Voici les principaux points forts qui font briller les agents intelligents :
-
Autonomie et Efficacité : Les agents intelligents peuvent fonctionner indépendamment sans intervention constante des humains. Cette autonomie leur permet de traiter des tâches 24 heures sur 24, ce qui améliore significativement l’efficacité et la productivité. Par exemple, les bots de chat dotés d’intelligence artificielle peuvent gérer jusqu’à 80% des demandes clients courantes, réduisant les coûts opérationnels et améliorant les délais de réponse.
-
Propriétés de décision avancées : Les agents intelligents peuvent analyser des quantités considérables de données pour prendre des décisions informées. Cette capacité est particulièrement précieuse dans les domaines tels que les finances, où les bots de trading dotés d’intelligence artificielle peuvent beaucoup accroître l’efficacité des transactions.
-
Apprentissage et adaptabilité : Les agents intelligents peuvent apprendre à partir de l’expérience et s’adapter à de nouvelles situations. Cette amélioration continue leur permet de renforcer leurs performances au fil du temps. Par exemple, les assistants médicaux intelligents peuvent aider à réduire les erreurs de diagnostic, améliorant ainsi les résultats des soins de santé.
- Personnalisation : Les agents intelligents peuvent offrir des expériences personnalisées en analysant le comportement et les préférences des utilisateurs. Le moteur de recommandations d’Amazon, qui représente 35 % de ses ventes, est un excellent exemple de la manière dont les agents intelligents peuvent améliorer l’expérience utilisateur et augmenter les revenus.
Pourquoi les agents intelligents sont la solution
Les agents intelligents offrent des solutions à de nombreux défis auxquels font face les logiciels traditionnels et les systèmes opérés par des humains. Voici pourquoi ils sont le choix préféré :
-
Évolutivité : Les agents intelligents peuvent élargir leurs opérations sans augmentation proportionnelle des coûts. Cette évolutivité est cruciale pour les entreprises souhaitant croître sans augmenter significativement leur effectif ou leurs dépenses opérationnelles.
-
Consistance et fiabilité : Contrairement aux humains, les agents intelligents ne sont pas affectés par la fatigue ou l’incohérence. Ils peuvent exécuter des tâches répétitives avec une haute précision et une fiabilité élevées, assurant ainsi un rendement cohérent.
-
Actions basées sur les données : Les agents intelligents peuvent traiter et analyser de grandes quantités de données pour découvrir des modèles et des informations que les humains pourraient manquer. Cette capacité est précieuse pour la prise de décisions dans des domaines tels que les finances, la santé et la marketing.
-
Économies de coûts : En automatisant les tâches routinières, les agents intelligents peuvent réduire la nécessité d’employés humains, aboutissant à des économies importantes. Par exemple, des systèmes de détection de fraude dotés d’IA peuvent économiser des milliards de dollars par année en réduisant les activités frauduleuses.
Conditions Requises pour le Bon Fonctionnement des Agents Intelligents
Pour assurer le déploiement réussi et le bon fonctionnement des agents intelligents, certaines conditions doivent être remplies :
-
Objectifs et Cas D’utilisation Clairs : Définir des objectifs et des cas d’utilisation spécifiques est crucial pour le déploiement efficace des agents intelligents. Cette clarté aide à établir des attentes et à mesurer le succès. Par exemple, fixer l’objectif de réduire le temps de réponse du service client de 50% peut guider le déploiement de robots d’assistance intelligents.
-
Données de qualité : Les agents intelligents ont besoin de données de haute qualité pour l’entraînement et le fonctionnement. Assurer que les données sont exactes, pertinentes et à jour est essentiel pour que les agents puissent prendre des décisions informées et fonctionner efficacement.
-
Intégration avec les systèmes existants : Une intégration sans faille avec les systèmes existants et les flux de travail est nécessaire pour que les agents intelligents fonctionnent de manière optimale. Cette intégration garantit que les agents intelligents peuvent accéder aux données nécessaires et interagir avec d’autres systèmes pour exécuter leurs tâches.
-
Surveillance et optimisation continues : La surveillance et l’optimisation régulières des agents intelligents sont cruciales pour maintenir leurs performances. Cela implique le suivi des indicateurs clés de performance (KPIs) et la mise à jour des données de rendement pour apporter les ajustements nécessaires.
-
Considérations éthiques et atténuation des biais : Traiter les considérations éthiques et atténuer les biais chez les agents IA est essentiel pour assurer l’équité et l’inclusivité. Mettre en œuvre des mesures pour détecter et prévenir les biais peut aider à construire la confiance et à assurer un déploiement responsable.
Meilleures pratiques pour le déploiement d’agents IA
Lors du déploiement d’agents IA, suivre les meilleures pratiques peut assurer leur succès et leur efficacité :
-
Définir les objectifs et les cas d’utilisation : Identifier clairement les objectifs et les cas d’utilisation pour le déploiement d’agents IA. Cela aide à établir les attentes et à mesurer le succès.
-
Choisir la plateforme AI correcte : Sélectionnez une plateforme AI qui est alignée avec vos objectifs, les cas d’utilisation et l’infrastructure existante. Pensez aux facteurs tels que les capacités d’intégration, la scalabilité et le coût.
-
Développer une base de connaissance complète : Construisez une base de connaissance bien structurée et précise pour permettre aux agents AI de fournir des réponses pertinentes et fiables.
-
S’assurer de l’intégration en une seule foulée : Intégrez les agents AI avec les systèmes existants tels que le CRM et les technologies de centres d’appels pour fournir une expérience client unifiée.
-
Former et optimiser les agents AI : Formez et optimisez constamment les agents AI à l’aide de données provenant des interactions. Surveillez le rendement, identifiez les domaines à améliorer, et mettez à jour les modèles correspondant.
-
Mettre en œuvre des procédures d’escalade adéquates : Définir des protocoles pour transférer les appels complexes ou émotionnels à des agents humains, en assurant une transition fluide et une résolution efficace.
-
Surveiller et analyser la performance : Suivre les indicateurs clés de performance (KPIs) tels que les taux de résolution des appels, le temps de traitement moyen et les scores de satisfaction client. Utilisez des outils d’analyse pour obtenir des insights basés sur les données et prendre des décisions.
-
Assurer la confidentialité et la sécurité des données : Des mesures de sécurité robustes sont essentielles, telles que rendre les données anonymes, assurer une surveillance humaine, définir des politiques pour la conservation des données et mettre en œuvre des mesures d’encodage fortes pour protéger les données clientales et maintenir la confidentialité.
AGENTS AI + GLLM : UN NOUVEAU SIÈCLE DE LOGICIELS INTELLIGENTS
Imaginez un logiciel capable not seulement de comprendre vos demandes mais également de les exécuter. C’est la promesse de la combinaison d’agents intelligents avec des Grands Modèles de Langue (GML). Cette association puissante crée une nouvelle génération d’applications plus intuitives, capables et impactantes que jamais auparavant.
Les Agents Intelligents : Au-delà de l’Exécution de Tâches Simples
Bien que souvent comparés aux assistants numériques, les agents intelligents sont bien plus que des suiveurs de script devenus arrondis. Ils englobent une gamme de technologies sophistiquées et opèrent dans un cadre qui permet le processus décisionnel dynamique et l’exécution d’actions.
-
Architecture : Un agent intelligent typique est composé de plusieurs composants clés :
-
Capteurs : Ces derniers permettent à l’agent de percevoir son environnement, en collectant des données provenant de diverses sources telles que des capteurs, des API ou de l’entrée utilisateur.
-
État des Croyances : Il représente la compréhension de l’agent du monde en fonction des données collectées. Il est constamment mis à jour à mesure que de nouvelles informations sont disponibles.
-
Moteur de Raisons : Il s’agit du cœur du processus de décision de l’agent. Il utilise des algorithmes, souvent basés sur l’apprentissage par renforcement ou sur des techniques de planification, pour déterminer la meilleure action en fonction de ses croyances et de ses objectifs actuels.
-
Actionneurs : Ils sont les outils de l’agent pour interagir avec le monde. Ils peuvent aller从envoyer des appels API à contrôler des robots physiques.
-
-
Challenges : Les agents intelligents traditionnels, quoique habiles à traiter des tâches bien définies, font souvent face à :
-
Comprendre le Langage Naturel : Interpréter le langage humain nuancé, gérer l’ambiguïté et extraire du sens du contexte demeure un défi significatif.
-
Réasonner avec le Sens Commun : Les agents intelligents actuels souffrent souvent d’un manque de connaissances de base et de capacités de raisonnement que les humains tiennent pour acquis.
-
Généralisation : L’entraînement d’agents pour s’exécuter bien sur des tâches non vues ou pour s’adapter à de nouveaux environnements demeure une zone clé de recherche.
-
LLM : Déverrouiller la compréhension et la génération du langage
Les LLM, avec leur connaissance imense encodée dans des milliards de paramètres, apportent des capacités linguistiques sans précédent à la table :
-
Architecture Transformer : La base de la plupart des LLM modernes est l’architecture transformer, une conception de réseau de neurones qui excelle dans le traitement de données séquentielles comme le texte. Cela permet aux LLM de capturer les dépendances à long terme dans le langage, les rendant capables de comprendre le contexte et de générer du texte cohérent et pertinent du point de vue contextuel.
-
Capacités : Les LLM se démarquent dans une large gamme de tâches basées sur le langage :
-
Génération de texte : Des écrits de fiction créative à la génération de code dans plusieurs langages de programmation, les LLM font preuve d’une remarquable aisance et de créativité.
-
Réponse à des questions : Ils peuvent fournir des réponses concises et exactes à des questions, même lorsque l’information est dispersée dans des documents longs.
-
Résumé : Les LLM peuvent résumer des volumes importants de texte en extraissant les informations clés et en éliminant les détails inutiles.
-
-
Limitations : Malgré leurs capacités impressionnantes, les GLL présentent des limitations :
-
Manque de base dans le monde réel : Les GLL opèrent principalement dans le domaine du texte et n’ont pas la capacité d’interagir directement avec le monde physique.
-
Potentiel de biais et d’illusion : Entraînés sur des jeux de données massifs et non ciblés, les GLL peuvent hériter des biais présents dans les données et parfois générer des informations factuellement incorrecte ou absurde.
-
La synergie : Faire le lien entre le langage et l’action
La combinaison d’agents intelligents et de GLLM permet de surmonter les limitations de chacun, créant des systèmes qui sont à la fois intelligents et capables :
-
Les GLLM en tant qu’interprètes et planificateurs : Les GLLM peuvent traduire les instructions naturelles en un format que les agents peuvent comprendre, permettant une interaction humain-ordinateur plus intuitive. Elles peuvent également utiliser leurs connaissances pour aider les agents à planifier des tâches complexes en les décomposant en plus petits et plus aisés.
- Les agents intelligents en tant qu’exécutants et apprenants : Les agents intelligents offrent aux LLM la capacité d’interagir avec le monde réel, de rassembler des informations et de recevoir des retours sur leurs actions. Cette immersion dans le monde réel peut aider les LLM à apprendre par expérience et à améliorer leurs performances au fil du temps.
Cette synergie puissante est à l’origine du développement d’une nouvelle génération d’applications plus intuitives, adaptables et capables que jamais. Avec l’avancement des technologies tant des agents intelligents que des LLM, nous pouvons attendre la naissance de plus d’innovations et d’applications impactantes, repensant ainsi le paysage de l’édition de logiciels et de l’interaction homme-ordinateur.
Exemples réels : transformation des industries
Cette combinaison puissante est déjà en train de secouer divers secteurs :
-
Service client : résoudre des problèmes avec une prise en compte contextuelle
- Exemple : Envisagez un client qui contacte un détaillant en ligne à propos d’une expédition retardée. Un agent AI alimenté par une MM peut comprendre la frustration du client, accéder à leur historique d’ commandes, suivre le colis en temps réel et proposer proactivement des solutions telles que l’expédition accélérée ou une remise sur leur prochaine commande.
-
Création de contenu : génération de contenu de haute qualité à l’échelle
- Exemple : Une équipe de marketing peut utiliser un système d’agent AI + MM pour générer des publications ciblées sur les réseaux sociaux, écrire des descriptions de produits ou même créer des scripts de vidéo. L’MM garantit que le contenu est engageant et informatif, tandis que l’agent AI gère le processus de publication et de distribution.
-
Développement de logiciels : Accélération du codage et du débogage
- Exemple : Un développeur peut décrire une fonctionnalité de logiciel qu’il souhaite créer en utilisant le langage naturel. L’IA large peut alors générer des extraits de code, identifier les erreurs potentielles et proposer des améliorations, accélérant considérablement le processus de développement.
-
Santé : Personnaliser le traitement et améliorer les soins aux patients
- Exemple : Un agent intelligent doté d’un LLM et ayant accès à l’historique médical d’un patient peut répondre à leurs questions sur la santé, leur fournir des rappels personnalisés de médicaments et même proposer des diagnostics préliminaires en fonction de leurs symptômes.
-
Droit : rationaliser la recherche juridique et la rédaction de documents
- Exemple : Un avocat doit rédiger un contrat avec des clauses spécifiques et des précédents juridiques. Un agent IA alimenté par une MMJ peut analyser les instructions de l’avocat, parcourir de vastes bases de données juridiques, identifier les clauses et précédents pertinents, et même rédiger des parties du contrat, réduisant显著ement le temps et les efforts requis.
-
Création de vidéos : générer des vidéos engageantes avec facilité
- Exemple : Une équipe de marketing souhaite créer une courte vidéo expliquant les caractéristiques de leur produit. Ils peuvent fournir un système d’IA + MMJ avec un schéma de script et des préférences pour le style visuel. L’MMJ peut alors générer un script détaillé, suggérer de la musique et des images appropriées, et même éditer la vidéo, automatisant une grande partie du processus de création de vidéos.
-
Architecture : concevoir des bâtiments avec des insights rapides par intelligence artificielle
- Exemple : Un architecte conçoit un nouveau bâtiment de bureaux. Il peut utiliser un agent IA + un système LLM pour saisir ses objectifs de conception, tels que maximiser la lumière naturelle et optimiser l’utilisation de l’espace. L’LLM peut alors analyser ces objectifs, générer différentes options de conception, et même simuler comment le bâtiment fonctionnerait sous différentes conditions environnementales.
-
Construction : Améliorer la sécurité et l’efficacité sur les sites de construction
- Exemple : Un agent AI équipé de caméras et de capteurs peut surveiller un site de construction à la recherche de dangers pour la sécurité. Si un ouvrier n’est pas habillé avec l’équipement de sécurité adéquat ou si un appareil est laissé dans une position dangereuse, le MGAA peut analyser la situation, alerter le superviseur du site et même arrêter automatiquement les opérations si nécessaire.
L’avenir est ici : Une nouvelle ère de développement de logiciels
La convergence d’agents AI et de MGAA marque une avancée significative dans le domaine du développement de logiciels. Comme ces technologies continuent à évoluer, nous pouvons attendre davantage d’applications innovantes qui transformeront les industries, rationaliseront les flux de travail et créeront complètement de nouvelles possibilités pour l’interaction homme-ordinateur.
Les agents AI brillent le plus dans les domaines qui exigent le traitement de grandes quantités de données, l’automatisation de tâches répétitives, la prise de décisions complexes et la fourniture d’expériences personnalisées. En répondant aux conditions nécessaires et en suivant les meilleures pratiques, les organisations peuvent exploiter pleinement le potentiel des agents AI pour stimuler l’innovation, l’efficacité et la croissance.
Chapitre 4 : La base philosophique des systèmes intelligents
Le développement de systèmes intelligents, en particulier dans le domaine de l’intelligence artificielle (IA), nécessite une compréhension approfondie des principes philosophiques. Ce chapitre explore les idées philosophiques fondamentales qui ont influencé la conception, le développement et l’utilisation de l’IA. Il met en avant l’importance de aligner le progrès technologique sur les valeurs éthiques.
La base philosophique des systèmes intelligents n’est pas uniquement une exercise théorique – c’est un cadre vital qui assure que les technologies de l’IA profitent à l’humanité. En promouvant la justice, l’inclusivité et l’amélioration de la qualité de vie, ces principes orientent l’IA pour servir nos meilleurs intérêts.
Considérations éthiques dans le développement de l’IA
Avec l’intégration croissante des systèmes d’IA dans tous les aspects de la vie humaine, depuis la santé et l’éducation jusqu’à la finance et la gouvernance, nous devons examiner rigoureusement et mettre en œuvre les impératifs éthiques guidant leur conception et leur déploiement.
La question éthique fondamentale se pose sur la manière dont l’IA peut être conçue pour répondre et défendre les valeurs humaines et les principes moraux. Cette question est centrale à la manière dont l’IA formera le futur de sociétés à travers le monde.
Au cœur de ce débat éthique se trouve le principe de la bénédiction, un pilier de la philosophie morale qui prévoit que les actions devraient viser à faire le bien et à accroître le bien-être des individus et de la société dans son ensemble (Floridi & Cowls, 2019).
Dans le contexte de l’IA, la bienveillance se traduit par la conception de systèmes qui contribuent activement au prospérité humaine – des systèmes qui améliorent les résultats de la santé, augmentent les opportunités éducatives et facilitent la croissance économique équitable.
Cependant, l’application de la bienveillance en IA est loin d’être simple. Elle exige une approche nuancée qui balance prudemment les avantages potentiels de l’IA avec les risques et les dommages possibles.
L’une des principales difficultés à l’application du principe de bienveillance à la phase de développement de l’IA est la nécessité d’un équilibre délicat entre l’innovation et la sécurité.
L’IA a le potentiel de révolutionner des domaines tels que la médecine, où des algorithmes préditifs peuvent diagnostiquer des maladies plus tôt et avec plus d’exactitude que les médecins humains. Cependant, sans un contrôle éthique rigoureux, ces mêmes technologies pourraient exacerber les inégalités existantes.
Cela pourrait par exemple se produire si elles sont principalement déployées dans les régions riches tandis que les communautés sous-servies continuent de manquer d’accès aux soins de santé de base.
En raison de cela, le développement éthique de l’IA nécessite non seulement une concentration sur la maximisation des avantages mais aussi une approche proactive de la réduction des risques. Cela implique l’implémentation de safeguards robustes pour prévenir l’utilisation abusive de l’IA et assurer que ces technologies n’ont pas de conséquences indésirables.
Le cadre éthique pour l’IA doit également être intrinsèquement inclusif, garantissant que les avantages de l’IA sont distribués équitablement à tous les groupes sociaux, y compris ceux qui sont traditionnellement marginalisés. Cela exige un engagement à la justice et à l’équité, en assurant que l’IA ne renforce pas simplement le statu quo mais agit activement pour démanteler les inégalités systématiques.
Par exemple, l’automatisation du travail assistée par l’IA peut potentiellement augmenter la productivité et la croissance économique. Cependant, elle pourrait également entraîner un déplacement significatif des emplois, affectant particulièrement les travailleurs à faible revenu.
Comme vous pouvez le voir, un cadre éthique pour l’IA doit inclure des stratégies pour un partage équitable des avantages et la fourniture de systèmes de soutien pour ceux touchés négativement par les avancées de l’IA.
Le développement éthique de l’IA nécessite un engagement constant avec des parties prenantes diverses, y compris des éthiciens, des technologues, des décideurs politiques et les communautés qui seront les plus touchées par ces technologies. Cette collaboration interdisciplinaire s’assure que les systèmes d’IA ne sont pas développés dans un vide, mais sont plutôt façonnés par un large éventail de perspectives et d’expériences.
C’est à travers ce effort collectif que nous pouvons créer des systèmes d’IA qui reflètent et soutiennent les valeurs qui définissent notre humanité – la compassion, l’équité, le respect de l’autonomie et un engagement en faveur du bien commun.
Les considérations éthiques dans le développement de l’IA ne sont pas seulement des directives, mais des éléments essentiels qui détermineront si l’IA sert de force positive dans le monde. En ancrant l’IA dans les principes de la bonté, de la justice et de l’inclusivité, et en adoptant une approche vigilante en matière d’équilibre entre l’innovation et le risque, nous pouvons assurer que le développement de l’IA ne progresse pas seulement dans la technologie, mais également améliore la qualité de vie pour tous les membres de la société.
Au fur et à mesure que nous explorons les capacités de l’IA, il est impératif que ces considérations éthiques restent à l’avant de nos efforts, guidant notre chemin vers un futur où l’IA véritablement profite à l’humanité.
L’imperative du design de l’IA centrée sur l’humain
Le design de l’IA centrée sur l’humain va au-delà de simples considérations techniques. Il est ancré dans des principes philosophiques profonds qui privilégient la dignité, l’autonomie et l’agentivité humaines.
Cette approche de l’évolution de l’IA est fondamentalement ancrée dans le cadre éthique kantien, qui affirme que les humains doivent être considérés en tant que des fins en eux-mêmes, pas uniquement comme des instruments pour atteindre d’autres objectifs (Kant, 1785).
Les implications de ce principe pour le design de l’IA sont profondes, exigeant que les systèmes IA soient développés avec un focus inébranlable sur le service des intérêts humains, la préservation de l’autonomie humaine et le respect de l’autonomie individuelle.
Implémentation technique des principes centrés sur l’humain
Améliorer l’autonomie humaine par l’IA : Le concept d’autonomie dans les systèmes IA est crucial, en particulier pour s’assurer que ces technologies empower les utilisateurs plutôt que de les contrôler ou d’exercer une influence indue sur eux.
En termes techniques, cela implique de concevoir des systèmes IA qui prioritaires de l’autonomie utilisateur en leur fournissant les outils et l’information nécessaires pour prendre des décisions informées. Cela exige que les modèles IA soient contextuellement conscients, ce qui signifie qu’ils doivent comprendre le contexte particulier dans lequel une décision est prise et adapter leurs recommandations en conséquence.
Du point de vue de la conception des systèmes, cela implique l’intégration d’une intelligence contextuelle dans les modèles IA, ce qui permet à ces systèmes de s’adapter dynamiquement à l’environnement de l’utilisateur, aux préférences et aux besoins.
Par exemple, dans le domaine de la santé, un système IA qui assiste les médecins dans la diagnose des pathologies doit prendre en considération l’histoire médicale unique de chaque patient, les symptômes actuels, et même l’état psychologique pour offrir des recommandations qui soutiennent l’expertise du médecin plutôt que de la remplacer.
Cette adaptation contextuelle assure que l’IA reste un outil de soutien qui améliore, plutôt que de diminuer, l’autonomie humaine.
Assurer des Processus de Décision Transparents : La transparence des systèmes IA est une exigence fondamentale pour assurer que les utilisateurs peuvent faire confiance et comprendre les décisions prises par ces technologies. Techniquement, cela se traduit par la nécessité d’avoir un IA explicable (XAI), qui implique la développement d’algorithmes capable d’articuler clairement la logique derrière leurs décisions.
Cela est particulièrement crucial dans les domaines tels que la finance, la santé et la justice pénale, où des processus de décision opaques peuvent conduire à la méfiance et aux problèmes éthiques.
La explicabilité peut être réalisée par plusieurs approches techniques. Une méthode commune est l’interprétabilité post-hoc, où le modèle IA génère une explication après que la décision ait été prise. Cela peut impliquer décomposer la décision en ses facteurs constitutifs et montrer comment chacun d’eux a contribué à l’issue finale.
Une autre approche consiste en modèles intrinsèquement interprétables, où l’architecture du modèle est conçue de telle manière que ses décisions sont transparentes par défaut. Par exemple, des modèles tels que les arbres de décision et les modèles linéaires sont naturellement interprétables parce que leur processus de prise de décision est facile à suivre et à comprendre.
Le défi de l’introduction de l’IA explicable consiste à établir un équilibre entre la transparence et la performance. souvent, les modèles plus complexes, tels que les réseaux de neurones profonds, sont moins interprétables mais plus précis. Par conséquent, la conception de l’IA axée sur l’humain doit considérer le compromis entre l’interprétabilité du modèle et sa capacité prédictive, en assurant que les utilisateurs peuvent avoir confiance et compréhension dans les décisions de l’IA sans sacrifier la précision.
Permettre un Contrôle Humain Signifiant : Le contrôle humain significatif est crucial pour s’assurer que les systèmes d’IA fonctionnent dans les limites éthiques et opérationnelles. Ce contrôle implique la conception de systèmes d’IA avec des systèmes d’arrêt d’urgence et des mécanismes d’annulation qui permettent aux opérateurs humains d’intervenir lorsque nécessaire.
La mise en œuvre technique du contrôle humain peut se faire de plusieurs manières.
Une approche consiste à intégrer des systèmes avec l’homme dans le circuit, où les processus de prise de décision de l’IA sont constamment supervisés et évalués par des opérateurs humains. Ces systèmes sont conçus pour permettre une intervention humaine à des points cruciaux, en assurant que l’IA n’agisse pas autonomiquement dans des situations où des jugements éthiques sont requis.
Par exemple, dans le cas des systèmes d’armes autonomes, une surveillance humaine est essentielle pour éviter que l’IA n’effectue des décisions de vie ou de mort sans l’intervention de l’homme. Cela pourrait impliquer la définition de frontières opérationnelles strictes que l’IA ne peut pas franchir sans autorisation humaine, en embarquant ainsi des garanties éthiques dans le système.
Une autre considération technique est le développement de traînes d’audit, qui sont des enregistrements de toutes les décisions et actions prises par le système IA. Ces traînes fournissent une histoire transparente qui peut être revue par les opérateurs humains pour s’assurer de la conformité avec les normes éthiques.
Les traînes d’audit sont particulièrement importantes dans des secteurs tels que la finance et le droit, où les décisions doivent être documentées et justifiables pour maintenir la confiance du public et satisfaire aux exigences réglementaires.
Balancer l’Autonomie et le Contrôle : Un des principaux défis techniques dans l’IA centrée sur l’homme est de trouver le bon équilibre entre l’autonomie et le contrôle. Alors que les systèmes IA sont conçus pour fonctionner autonomement dans de nombreux scénarios, il est crucial que cet autonomie ne mine pas le contrôle ou la surveillance humaine.
Cet équilibre peut être atteint par l’implémentation de niveaux d’autonomie, qui dictent le degré d’indépendance que l’IA a dans la prise de décisions.
Par exemple, dans les systèmes semi-autonomes tels que les voitures autonomes, les niveaux d’autonomie varient从基本辅助驾驶(其中人类驾驶员保留完全控制权)到完全自动化(其中AI负责所有驾驶任务)。
Le design de ces systèmes doit s’assurer que, à tout niveau d’autonomie donné, l’opérateur humain conserve la capacité d’intervenir et d’annuler l’IA si nécessaire. Cela nécessite des interfaces de contrôle sophistiquées et des systèmes de soutien à la décision qui permettent aux humains d’intervenir rapidement et efficacement lorsque c’est nécessaire.
De plus, l’élaboration de cadres éthiques pour l’IA est essentielle pour guider les actions autonomes des systèmes IA. Ces cadres sont des jeux de règles et de directives intégrés dans l’IA qui dictent comment elle devrait se comporter dans des situations éthiquement complexes.
Par exemple, dans le domaine de la santé, un cadre éthique pour l’IA pourrait inclure des règles sur le consentement du patient, la confidentialité et la priorité des traitements en fonction des besoins médicaux plutôt que des considérations financières.
En incorporant directement ces principes éthiques dans les processus de décision de l’IA, les développeurs peuvent s’assurer que l’autonomie du système est exercée de manière compatible avec les valeurs humaines.
L’intégration de principes humanCentriques dans le design de l’IA n’est pas seulement une idée philosophique mais une nécessité technique. En améliorant l’autonomie humaine, en assurant la transparence, en permettant un contrôle significatif et en équilibrant l’autonomie avec le contrôle, les systèmes IA peuvent être développés de manière à réellement servir l’humanité.
Ces considérations techniques sont essentielles pour créer une IA qui non seulement augmente les capacités humaines mais également respecte et défend les valeurs qui sont fondamentales à notre société.
Au fil de l’évolution de l’IA, l’engagement envers un design humanCentrique sera crucial pour s’assurer que ces puissantes technologies sont utilisées éthiquement et de manière responsable.
Comment assurer que l’IA profite à l’humanité : améliorer la qualité de vie
Lorsque vous participez à l’élaboration de systèmes d’IA, il est essentiel de vous fondre dans le cadre éthique du utilitarisme – une philosophie qui met l’accent sur l’amélioration du bonheur et du bien-être global.
Dans ce contexte, l’IA peut résoudre des défis sociaux cruciaux, en particulier dans des domaines tels que la santé, l’éducation et la durabilité environnementale.
Le but est de créer des technologies qui améliorent significativement la qualité de vie pour tous. Mais cette quête est accompagnée de complexités. Le utilitarisme offre un motif convaincant pour déployer l’IA de manière large, mais il met également à l’avant des questions éthiques importantes sur qui profite et qui pourrait être laissé derrière, en particulier dans les populations vulnérables.
Pour naviguer à travers ces défis, nous avons besoin d’une approche sophistiquée et informée techniquement – une balance entre la quête large du bien de la société et la nécessité de justice et d’équité.
Lorsque vous appliquez les principes du utilitarisme à l’IA, votre attention devrait se concentrer sur l’optimisation des résultats dans des domaines spécifiques. Dans le domaine de la santé, par exemple, les outils de diagnostic automatisés par IA peuvent améliorer significativement les résultats des patients en permettant des diagnostics plus précoces et plus précis. Ces systèmes peuvent analyser de vastes jeux de données pour détecter des patrons qui pourraient échapper aux praticiens humains, ce qui élargit ainsi l’accès à des soins de qualité, en particulier dans les environnements sous-ressource.
Cependant, le déploiement de ces technologies nécessite une réflexion minutieuse afin d’éviter de renforcer les inégalités existantes. Les données utilisées pour entraîner les modèles d’IA peuvent varier considérablement d’une région à l’autre, ce qui affecte l’exactitude et la fiabilité de ces systèmes.
Cette disparité souligne l’importance d’établir des cadres solides de gouvernance des données qui garantissent que vos solutions de santé basées sur l’IA sont à la fois représentatives et équitables.
Dans le domaine de l’éducation, la capacité de l’IA à personnaliser l’apprentissage est prometteuse. Les systèmes d’IA peuvent adapter le contenu éducatif aux besoins spécifiques de chaque élève, améliorant ainsi les résultats d’apprentissage. En analysant les données sur les performances et le comportement des élèves, l’IA peut identifier les difficultés rencontrées par un élève et fournir un soutien ciblé.
Mais en travaillant pour obtenir ces avantages, il est crucial de prendre conscience des risques, tels que le potentiel de renforcer les biais ou de marginaliser les élèves qui ne correspondent pas aux schémas d’apprentissage typiques.
Pour atténuer ces risques, il est nécessaire d’intégrer des mécanismes d’équité dans les modèles d’IA, afin de garantir qu’ils ne favorisent pas involontairement certains groupes. Et le rôle des éducateurs est essentiel. Leur jugement et leur expérience sont indispensables pour rendre les outils d’IA véritablement efficaces et favorables.
En termes de durabilité environnementale, le potentiel de l’IA est considérable. Les systèmes d’IA peuvent optimiser l’utilisation des ressources, surveiller les changements environnementaux et prédire les impacts du changement climatique avec une précision sans précédent.
Voici la traduction en français :
Pourquoi l’IA peut analyser d’immenses quantités de données environnementales pour prévoir les schémas météorologiques, optimiser la consommation énergétique et minimiser les déchets — des actions qui contribuent au bien-être des générations présentes et futures.
Mais cette avancée technologique présente ses propres défis, en particulier concernant l’impact environnemental des systèmes d’IA eux-mêmes.
La consommation d’énergie nécessaire pour faire fonctionner des systèmes d’IA à grande échelle peut annuler les avantages environnementaux qu’ils cherchent à atteindre. Il est donc crucial de développer des systèmes d’IA économes en énergie pour garantir que leur impact positif sur la durabilité ne soit pas compromise.
Lorsque vous développez des systèmes d’IA avec des objectifs utilitaires, il est important de considérer également les implications pour la justice sociale. L’utilitarisme se concentre sur le maximisation du bien-être général mais ne traite pas nécessairement la distribution des avantages et des dommages à travers différents groupes sociaux.
Cela soulève la possibilité que les systèmes d’IA profitent de manière disproportionnée à ceux qui sont déjà privilégiés, tandis que les groupes marginalisés pourraient voir peu ou pas de miglioramento dans leurs conditions.
Pour contrer cela, votre processus de développement d’IA devrait intégrer des principes axés sur l’équité, en assurant que les avantages sont distribués de manière juste et que les éventuels dommages sont corrigés. Cela pourrait impliquer de concevoir des algorithmes qui visent spécifiquement à réduire les biais et d’inclure une gamme diversifiée de perspectives dans le processus de développement.
Lorsque vous travaillez à développer des systèmes dotés d’IA destinés à améliorer la qualité de vie, il est essentiel de maintenir un équilibre entre l’objectif utilitaire de maximiser le bien-être et le besoin de justice et d’équité. Cela nécessite une approche nuancée, basée sur des connaissances techniques, qui tient compte des implications plus larges du déploiement d’IA.
En concevant délibérément des systèmes d’IA qui soient à la fois efficaces et équitables, vous pouvez contribuer à un avenir où les avancées technologiques servent véritablement les besoins diversifiés de la société.
Mettez en œuvre des mesures de protection contre les risques potentiels
Lors du développement de technologies dotées d’IA, vous devez reconnaître la potentialité d’origine du préjudice et établir activement des mesures de protection solides pour atténuer ces risques. Cette responsabilité est profondément enracinée dans les éthiques déontologiques. Cette branche de l’éthique met l’accent sur le devoir moral de respecter des règles établies et des normes éthiques, garantissant que la technologie que vous créez est alignée sur des principes moraux fondamentaux.
La mise en œuvre de protocoles de sécurité stricts n’est pas seulement une précautions, c’est une obligation éthique. Ces protocoles devraient englober des tests de biais complets, la transparence dans les processus algorithmiques et des mécanismes clairs de responsabilité.
De telles mesures de protection sont essentielles pour éviter que les systèmes d’IA ne provoquent des préjudices non intentionnels, que ce soit par des processus de décision biaisés, des processus opaques ou par manque de surveillance.
En pratique, la mise en œuvre de ces mesures de protection nécessite une bonne compréhension des dimensions techniques et éthiques de l’IA.
Le test de biais, par exemple, ne se limite pas à identifier et corriger les biais dans les données et les algorithmes, mais aussi à comprendre les implications sociales plus larges de ces biais. Vous devez vous assurer que vos modèles d’IA sont entraînés sur des jeux de données diversifiés et représentatifs, et qu’ils sont évalués régulièrement pour détecter et corriger tout biais qui pourrait apparaître au fil du temps.
De l’autre côté, la transparence exige que les systèmes d’IA soient conçus de manière à ce que leurs processus de décision puissent être facilement compris et examinés par les utilisateurs et les parties prenantes. Cela implique de développer des modèles d’IA explicables qui fournissent des sorties claires et interprétables, permettant aux utilisateurs de voir comment les décisions sont prises et faisant en sorte que ces décisions soient justifiables et équitables.
De plus, les mécanismes d’accountabilité sont cruciaux pour maintenir la confiance et assurer que les systèmes d’IA sont utilisés de manière responsable. Ces mécanismes devraient inclure des directives claires sur qui est responsable des résultats des décisions de l’IA, ainsi que des processus pour traiter et corriger tout préjudice qui pourrait survenir.
Vous devez établir un cadre où les considérations éthiques sont intégrées à toutes les étapes du développement de l’IA, de la conception initiale à la mise en œuvre et au-delà. Cela inclut non seulement le respect de directives éthiques mais aussi la surveillance continue et l’ajustement des systèmes d’IA au fur et à mesure qu’ils interagissent avec le monde réel.
En implémentant ces garanties dans la structure même du développement de l’IA, vous pouvez aider à assurer que le progrès technique sert le bien commun sans aboutir à des conséquences négatives non intentionnelles.
Le rôle de la surveillance humaine et des boucles de rétroaction.
La surveillance humaine dans les systèmes d’IA est un composant critique pour assurer un déploiement éthique de l’IA. Le principe de responsabilité sous-tend la nécessité d’une participation humaine continue dans l’opération des systèmes d’IA, particulièrement dans des environnements à hauts risques tels que la santé et la justice pénale.
Les boucles de rétroaction, où l’input humain est utilisé pour affiner et améliorer les systèmes d’IA, sont essentielles pour maintenir une responsabilité et une adaptabilité (Raji et al., 2020). Ces boucles permettent la correction d’erreurs et l’intégration de nouvelles considérations éthiques au fil de l’évolution des valeurs sociales.
En incorporant la surveillance humaine dans les systèmes d’IA, les développeurs peuvent créer des technologies qui sont non seulement efficaces mais également alignées sur les normes éthiques et les attentes humaines.
Coding Ethics: Translating Philosophical Principles into AI Systems
La traduction des principes philosophiques dans les systèmes d’IA est une tâche complexe mais nécessaire. Ce processus implique l’incorporation de considérations éthiques dans le code même qui anime les algorithmes d’IA.
Concepts tels que l’équité, la justice et l’autonomie doivent être codifiés dans les systèmes d’IA pour s’assurer qu’ils fonctionnent de manières qui reflètent les valeurs sociétales. Cela nécessite une approche multidisciplinaire, où des éthiciens, des ingénieurs et des scientifiques sociaux collaborent pour définir et mettre en œuvre des directives éthiques dans le processus de codage.
Le but est de créer des systèmes d’IA qui sont non seulement techniques de premier ordre mais également éthiquement solides, capables de prendre des décisions respectant la dignité humaine et promouvant le bien social (Mittelstadt et al., 2016).
Promouvoir l’inclusivité et l’accès équitable au développement et au déploiement de l’IA.
L’inclusivité et l’accès équitable sont fondamentaux au développement éthique de l’IA. Le concept de justice comme équité de Rawls offre une base philosophique pour assurer que les systèmes IA sont conçus et déployés de manière à profiter à tous les membres de la société, en particulier les plus vulnérables (Rawls, 1971).
Cela implique des efforts actifs pour inclure des perspectives diverses dans le processus de développement, en particulier des groupes sous- représentés et du Sud global.
En intégrant ces points de vue divers, les développeurs IA peuvent créer des systèmes plus équitables et plus réceptifs aux besoins d’un plus large éventail d’utilisateurs. De plus, assurer l’accès équitable aux technologies IA est crucial pour prévenir l’exacerbation des inégalités sociales existantes.
Traiter la Biais Algorithme et la justice
Le biais algorithme est une préoccupation éthique significative dans le développement de l’IA, car les algorithmes biaisés peuvent perpétuer et même exacerbuer les inégalités sociales. Traiter ce problème exige un engagement en faveur de la justice procédurale, en assurant que les systèmes IA sont développés par des processus équitables qui considèrent l’impact sur toutes les parties prenantes (Nissenbaum, 2001).
Cela implique l’identification et la réduction des biais dans les données d’entraînement, le développement d’algorithmes transparents et explicables, et l’application de vérifications de justice tout au long du cycle de vie de l’IA.
En traitant le biais algorithme, les développeurs peuvent créer des systèmes IA qui contribuent à une société plus juste et plus équitable, plutôt que de renforcer les disparités existantes.
Inclure des Perspectives Diverses dans le Développement de l’IA
Intégrer des perspectives diverses dans le développement de l’IA est essentiel pour créer des systèmes qui soient inclusifs et équitables. La participation de voix provenant de groupes sous-représentés assure que les technologies de l’IA ne reflètent pas simplement les valeurs et les priorités d’un petit segment de la société.
Cette approche est alignée sur le principe philosophique de la démocratie délibérative, qui met l’accent sur l’importance de processus de décision qui soient inclusifs et participatifs (Habermas, 1996).
En favorisant une participation diverse au développement de l’IA, nous pouvons assurer que ces technologies sont conçues pour servir les intérêts de l’humanité entière, plutôt que de quelques privilégiés.
Strategies for Bridging the AI Divide
La division de l’IA, caractérisée par un accès inégal aux technologies de l’IA et à leurs avantages, pose un défi significatif à l’équité mondiale. Pontonner cette division nécessite un engagement en faveur de la justice distributive, en assurant que les avantages de l’IA sont partagés largement entre différents groupes socioéconomiques et régions (Sen, 2009).
Nous pouvons le faire par l’initiative qui promeut l’accès à l’éducation de l’IA et aux ressources dans les communautés sous-servies, ainsi que par les politiques qui appuient la distribution équitable des gains économiques liés à l’IA. En traitant de la division de l’IA, nous pouvons assurer que l’IA contribue au développement mondial de manière inclusive et équitable.
Balance Innovation with Ethical Constraints
Balancer la poursuite de l’innovation avec les contraintes éthiques est crucial pour un développement responsable de l’IA. Le principe de précaution, qui milite en faveur de la prudence en présence de l’incertitude, est particulièrement pertinent dans le contexte du développement de l’IA (Sandin, 1999).
Tandis que l’innovation propulse le progrès, elle doit être tempérée par des considérations éthiques protégeant contre les潜在es dommages. Cela nécessite une évaluation prudente des risques et des avantages des nouvelles technologies AI, ainsi que l’implémentation de cadres réglementaires garantissant le respect de normes éthiques.
En équilibrant l’innovation avec les contraintes éthiques, nous pouvons favoriser le développement des technologies AI qui sont à la fois à la pointe et alignées sur les objectifs plus larges du bien-être sociétal.
Comme vous pouvez le voir, la base philosophique des systèmes intelligents fournit un cadre critique pour assurer que les technologies AI sont développées et déployées de manières éthiques, inclusives et bénéfiques pour toute l’humanité.
En fondant le développement de l’IA sur ces principes philosophiques, nous pouvons créer des systèmes intelligents qui non seulement avancent les capacités technologiques mais également améliorent la qualité de vie, promeuvent la justice et assurent que les avantages de l’IA sont partagés équitablement dans la société.
Chapitre 5 : Les agents AI comme améliorateurs des GAL
La fusion des agents AI avec les Grands Modèles de Langue (GML) représente un changement fondamental dans l’intelligence artificielle, traitant des limitations critiques des GML qui les ont limitées dans leur large appliquabilité.
Cette intégration permet aux machines de transcender leurs rôles traditionnels, passant d’agents de génération de texte passifs à des systèmes autonomes capables de raisonnement dynamique et de prise de décisions.
Comme les systèmes d’IA de plus en plus assurent des processus critiques dans divers domaines, comprendre comment les agents AI comblent les lacunes dans les capacités des GML est essentiel pour réaliser leur potentiel complet.
Fonctionnaliser les capacités des GLL
Les GLL, quoique puissantes, sont intrinsèquement limitées par les données sur lesquelles elles ont été entraînées et par la nature statique de leur architecture. Ces modèles fonctionnent dans un ensemble fixe de paramètres, généralement défini par le corpus de texte utilisé pendant leur phase d’entraînement.
Cette limitation signifie que les GLL ne peuvent pas rechercher automatiquement de nouvelles informations ou mettre à jour leur base de connaissances après l’entraînement. Par conséquent, les GLL sont souvent périmées et manquent de la capacité de fournir des réponses pertinentes dans le contexte qui exige des données ou des aperçus en temps réel en dehors de leurs données d’entraînement initiales.
Les agents IA brident ces lacunes en intégrant dynamiquement des sources externes de données, ce qui peut élargir l’horizon fonctionnel des GLL.
Par exemple, une GLL entraînée sur les données financières jusqu’en 2022 pourrait fournir des analyses historiques précises mais pourrait struggle à générer des prévisions de marché à jour. Un agent IA peut amplifier cette GLL en tirant à partir de données en direct des marchés financiers, en appliquant ces entrées pour générer des analyses plus pertinentes et actuelles.
Cette intégration dynamique garantit que les sorties ne sont pas seulement historiquement exactes mais sont également pertinentes dans le contexte actuel.
Améliorer l’autonomie des processus de décision
Une autre limitation significative des GLL est leur manque de capacités de prise de décision automatique. Les GLL sont excellents à la production d’outputs basés sur le langage mais manquent dans les tâches qui exigent une prise de décision complexe, en particulier dans des environnements caractérisés par l’incertitude et le changement.
Cette insuffisance est principalement due à la dépendance du modèle à des données préexistantes et l’absence de mécanismes pour la réasonnance adaptative ou l’apprentissage à partir de nouvelles expériences après le déploiement.
Les agents intelligents parcourent ce défi en fournissant l’infrastructure nécessaire pour la prise de décision autonome. Ils peuvent transformer les sorties statiques d’un GMT en utilisant des schémas de raisonnement avancés tels que des systèmes basés sur des règles, des heuristiques ou des modèles d’apprentissage par réinforcement.
Par exemple, dans un contexte de santé, un GMT pourrait générer une liste de diagnostics potentiels en fonction des symptômes et de l’historique médical d’un patient. Cependant, sans un agent intelligent, le GMT ne peut pas évaluer ces options ou recommander une action.
Un agent intelligent peut alors intervenir pour évaluer ces diagnostics en fonction de la littérature médicale actuelle, des données du patient et des facteurs contextuels, aboutissant finalement à une décision plus informée et suggérant des prochaines étapes pratiques. Cette synergie transforme les sorties du GMT de simples suggestions en décisions exécutables et sensibles au contexte.
Traiter la Complétude et la cohérence
La complétude et la cohérence sont des facteurs cruciaux pour assurer la fiabilité des sorties des GMT, en particulier dans les tâches de raisonnement complexe. En raison de leur nature paramétrisée, les GMT générent souvent des réponses qui sont soit incomplètes, soit manquantes de cohérence logique, surtout lorsqu’il s’agit de processus multi-étapes ou d’une compréhension complète de domaines divers.
Ces problèmes découlent de l’environnement isolé dans lequel les GMT opèrent, où ils sont incapables de cross-référencer ou de valider leurs sorties à des normes externes ou à des informations supplémentaires.
Les agents intelligents jouent un rôle crucial dans la réduction de ces problèmes en introduisant des mécanismes de rétroaction itératifs et des couches de validation.
Par exemple, dans le domaine juridique, une MMG pourrait élaborer une première version d’un mémoire juridique sur la base de ses données d’entraînement. Cependant, ce projet pourrait ignorer certains précédents ou ne pas structurer l’argumentation de manière logique.
Un agent intelligent peut examiner ce projet, veillant à ce qu’il réponde aux normes requises de complétude en faisant des références croisées avec des bases de données juridiques externes, en vérifiant la cohérence logique et en demandant des informations supplémentaires ou des éclaircissements où nécessaire.
Ce processus itératif permet la production d’un document plus robuste et fiable qui répond aux exigences rigoureuses de la pratique juridique.
Surmonter l’isolement par l’intégration
L’une des limitations les plus profondes des GMT est leur isolement inhérent par rapport à d’autres systèmes et sources de connaissance.
Les GMT, tel que conçus, sont des systèmes fermés qui ne communiquent pas nativement avec l’environnement externe ou les bases de données. Cet isolement limite significativement leur capacité d’adapter à de nouvelles informations ou à des opérations en temps réel, les rendant moins efficaces dans des applications nécessitant une interaction dynamique ou des décisions en temps réel.
Les agents intelligents surmontent cet isolement en agissant comme des plateformes d’intégration qui connectent les GMT à un écosystème plus large de sources de données et d’outils de calcul. A travers les API et d’autres cadres d’intégration, les agents intelligents peuvent accéder aux données en temps réel, collaborer avec d’autres systèmes intelligents et même interagir avec des appareils physiques.
Par exemple, dans les applications de service client, un GIE pourrait générer des réponses standardisées à partir de scripts pré-entraînés. Cependant, ces réponses peuvent être statiques et manquer de personnalisation requise pour un engagement client efficace.
Un agent IA peut enrichir ces interactions en intégrant des données en temps réel à partir de profils clients, des interactions précédentes et d’outils d’analyse des sentiments, ce qui aide à générer des réponses non seulement contextuellement pertinentes mais également adaptées aux besoins spécifiques du client.
Cette intégration transforme l’expérience client de une série d’interactions scriptées en une conversation dynamique et personnalisée.
Améliorer la Créativité et la Résolution des Problèmes
Bien que les GIE soient des outils puissants pour la génération de contenu, leur capacité créative et de résolution de problèmes est inhérentement limitée par les données sur lesquelles ils ont été entraînés. Ces modèles sont souvent incapables d’appliquer des concepts théoriques à de nouveaux défis ou imprévus, car leurs capacités de résolution de problèmes sont limitées par leur savoir existant et les paramètres de formation.
Les agents IA amplifient la créativité et le potentiel de résolution de problèmes des GIE en exploitant des techniques de raisonnement avancées et une plus large gamme d’outils analytiques. Cette capacité permet aux agents IA de dépasser les limitations des GIE, en appliquant des cadres théoriques à des problèmes pratiques de manière innovante.
Par exemple, considérez le problème de lutte contre les informations erronées sur les plateformes sociales. Un GIE pourrait identifier des modèles d’information erronée à l’aide d’analyse textuelle, mais il pourrait stagner à développer une stratégie complète pour atténuer la propagation de l’information fausse.
Un agent IA peut utiliser ces aperçus, appliquer des théories interdisciplinaires issues de domaines tels que la sociologie, la psychologie et la théorie des réseaux, et développer une approche robuste, multifacettes qui inclut le suivi en temps réel, l’éducation des utilisateurs et des techniques de modération automatisées.
Cette capacité de synthèse de cadres théoriques divers et de leur application aux défis mondiaux illustre les capacités de résolution de problèmes améliorées que les agents IA apportent à la table.
Exemples Plus Précis
Les agents IA, avec leur capacité d’interagir avec divers systèmes, d’accéder aux données en temps réel et d’exécuter des actions, traitent directement ces limitations, transformant les GMT de puissantes mais passives modèles de langue en solveurs dynamiques de problèmes mondiaux. Voyons quelques exemples :
1. De données statiques aux insights dynamiques : tenir les GMT à jour
-
Le problème : Imaginez-vous demandant à un GMT de formation sur des recherches médicales antérieures à 2023, « Quels sont les derniers progrès dans le traitement du cancer? » Sa connaissance serait périmée.
-
La solution de l’agent IA : Un agent IA peut connecter le GMT aux revues médicales, bases de données de recherche et flux de nouvelles. Maintenant, le GMT peut fournir des informations à jour sur les derniers essais cliniques, les options de traitement et les conclusions de recherche les plus récentes.
2. De l’analyse à l’action : Automatiser les tâches basées sur les aperçus de l’LLM
-
Le problème : Un LLM qui surveille les médias sociaux pour une marque pourrait identifier une forte poussée de sentiment négatif mais ne peut rien faire pour y remédier.
-
La solution agents intelligents : Un agent intelligent connecté aux comptes sociaux des médias de la marque et équipé de réponses préapprouvées peut automatiquement s’attaquer aux préoccupations, répondre à des questions et même faire remonter les problèmes complexes à des représentants humains.
3. De la première version au produit fini : Assurer la qualité et l’exactitude
-
Le problème : Un LLM chargé de traduire un manuel technique pourrait produire des traductions grammaticalement correctes mais techniques inexactes en raison de son manque de connaissances spécialisées dans le domaine.
-
La solution de l’agent IA : Un agent IA peut intégrer l’LLM à des dictionnaires spécialisés, à des glosaires et même le connecter à des experts domaine pour un feedback en temps réel, assurant ainsi que la traduction finale soit à la fois accurate linguistiquement et solide techniquelement.
4. Brisant les barrières : Connecter les LLM au monde réel
-
Le problème : Un LLM conçu pour la commande intelligente du domicile pourrait éprouver des difficultés à s’adapter aux routines et aux préférences changeantes de l’utilisateur.
-
La solution de l’agent IA : Un agent IA peut connecter l’LLM à des capteurs, des appareils intelligents et aux calendriers des utilisateurs. En analysant les comportements d’utilisation des utilisateurs, l’LLM peut apprendre à anticiper les besoins, à ajuster automatiquement les réglages d’éclairage et de température et même à suggérer des playlists personnalisés de musique en fonction de l’heure de la journée et de l’activité de l’utilisateur.
5. De l’imitation à l’innovation : élargir la créativité de la LLM
-
Le problème : Une LLM chargée de composer de la musique pourrait créer des œuvres qui ressemblent à des copies ou qui manquent de profondeur émotionnelle, car elle se fie principalement aux patrons trouvés dans ses données d’entraînement.
-
La solution代理人IA : Un agent IA peut connecter la LLM à des capteurs de biofeedback mesurant les réactions émotionnelles d’un compositeur à différents éléments musicaux. En intégrant ce feedback en temps réel, la LLM peut créer de la musique non seulement technique mais également émouvante et originale.
L’intégration d’agents IA comme améliorateurs de GLL n’est pas simplement une amélioration progressive ; elle représente une extension fondamentale de ce que l’intelligence artificielle peut accomplir. En traitant les limitations inhérentes aux GLL traditionnelles, telles que leur base de connaissances statique, leur autonomie de décision limitée et leur environnement d’opérations isolé, les agents IA permettent à ces modèles de fonctionner à leur plein potentiel.
Avec l’évolution continue de la technologie IA, le rôle des agents IA dans l’amélioration des GLL sera de plus en plus critique, non seulement dans l’expansion des capacités de ces modèles mais aussi dans la rédefinition des frontières de l’intelligence artificielle elle-même. Cette fusion ouvre la voie vers la prochaine génération de systèmes IA, capables de raisonnement autonome, d’adaptation en temps réel et de résolution de problèmes innovants dans un monde en perpétuel changement.
Chapitre 6 : Conception architecturale pour l’intégration d’agents IA avec des GLL
L’intégration d’agents IA avec des GLL dépend de la conception architecturale, qui est cruciale pour l’amélioration de la décision, de l’adaptabilité et de la scalabilité. L’architecture doit être soigneusement conçue pour permettre une interaction fluide entre les agents IA et les GLL, en veillant à ce que chaque composant fonctionne de manière optimale.
Une architecture modulaire, où l’agent IA agit en tant qu’orchestrateur, dirigeant les capacités de la GLL, est une approche qui appuie la gestion dynamique des tâches. Ce design exploite les forces de la GLL dans le traitement du langage naturel tout en permettant aux agents IA de gérer des tâches plus complexes, telles que la réasonnance à plusieurs étapes ou la prise de décisions contextuelles en environnements de temps réel.
De manière alternative, un modèle hybride, qui combine des LLM avec des modèles spécialisés et finement réglés, offre une flexibilité en permettant à l’agent IA de déléguer des tâches au modèle le plus approprié. Cette approche optimise les performances et améliore l’efficacité sur un large éventail d’applications, ce qui la rend particulièrement efficace dans des contextes opérationnels divers et variables (Liang et al., 2021).

Méthodologies de formation et meilleures pratiques
La formation d’agents IA intégrés avec des LLM nécessite une approche méthodique qui balance la généralisation avec l’optimisation spécifique aux tâches.
Le transfert de apprentissage est une technique clé ici, qui permet à une LLM pré-entraînée sur un corpus large et divers de être réglée sur des données spécialisées dans le domaine relevant des tâches de l’agent IA. Cette méthode conserve la base de connaissances large de l’LLM tout en permettant de se spécialiser dans des applications particulières, améliorant ainsi l’efficacité globale du système.
De plus, le apprentissage par renforcement (RL) joue un rôle crucial, en particulier dans les scénarios où l’agent IA doit s’adapter à des environnements en évolution. Par l’interaction avec son environnement, l’agent IA peut améliorer constamment ses processus de décision, devenant ainsi mieux adapté à relever des défis nouveaux.
Pour assurer une performance fiable dans différents scénarios, des critères d’évaluation rigoureux sont essentiels. Ces derniers devraient inclure à la fois des benchmarks standards et des critères spécifiques aux tâches, garantissant que l’entraînement du système soit robuste et complet (Silver et al., 2016).
Introduction aux concepts de réglage de une Grande Machine à Écrire (LLM) et à l’apprentissage par renforcement
Ce code montre diverses techniques impliquant l’apprentissage automatique et le traitement du langage naturel (NLP), axées sur la finition précise de grands modèles de langue (LLM) pour des tâches spécifiques et l’implémentation d’agents d’apprentissage par renforcement (RL). Le code couvre plusieurs domaines clés :
-
Fine-tuning un LLM : Utilisation de modèles pré-entraînés tels que BERT pour des tâches telles que l’analyse de sentiment, en utilisant la bibliothèque Hugging Face
transformers. Cela implique la tokenisation des jeux de données et l’utilisation d’arguments d’entraînement pour guider le processus de finition. -
Apprentissage par renforcement (RL) : Introduction des bases de l’apprentissage par renforcement avec un agent de Q-apprentissage simple, où un agent apprend par expériences et erreurs en interagissant avec un environnement et en mettant à jour ses connaissances via des tables Q.
-
Modélisation de récompense avec l’API d’OpenAI : Une méthode conceptuelle pour utiliser l’API d’OpenAI pour fournir dynamiquement des signaux de récompense à un agent d’apprentissage par renforcement, permettant à un modèle de langue d’évaluer des actions.
-
Évaluation et enregistrement de modèles : Utilisation de bibliothèques telles que
scikit-learnpour évaluer le rendement des modèles à travers la précision et les scores F1, etSummaryWriterde PyTorch pour visualiser les progrès de l’entraînement. -
Concepts avancés en RL : Mise en œuvre de concepts plus avancés tels que les réseaux de gradient de politique, l’apprentissage par cours de traitement et l’arrêt prématuré pour améliorer l’efficacité de l’entraînement du modèle.
Cette approche globale couvre à la fois l’apprentissage supervisé, avec la personnalisation de l’analyse de sentiment, et l’apprentissage par rétroaction, offrant des aperçus sur la manière dont les systèmes d’IA modernes sont construits, évalués et optimisés.
Exemple de code
Étape 1 : Importation des bibliothèques nécessaires.
Avant de plonger dans la finition de modèles et l’implémentation d’agents, il est essentiel de configurer les bibliothèques et les modules nécessaires. Ce code inclut des importations de bibliothèques populaires telles que les transformers de Hugging Face et PyTorch pour gérer les réseaux neuronaux, scikit-learn pour évaluer la performance du modèle, et quelques modules généraux tels que random et pickle.
-
Bibliothèques Hugging Face : Elles vous permettent d’utiliser et de finir l’entraînement de modèles et de tokenisateurs prédéfinis depuis le Hub des Modèles.
-
PyTorch : Il s’agit de la plateforme de base pour l’apprentissage profond de l’opération, y compris les couches de réseaux neuronaux et les optimiseurs.
-
scikit-learn : Fournit des métriques telles que l’accurité et la marge F1 pour évaluer la performance du modèle.
-
API OpenAI : Accès aux modèles de langue d’OpenAI pour diverses tâches telles que le modèle de récompense.
-
TensorBoard : Utilisé pour visualiser le progrès de l’entraînement.
Voici le code d’importation des bibliothèques nécessaires :
# Importez le module random pour la génération de nombres aléatoires.
import random
# Importez les modules nécessaires de la bibliothèque transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importez load_dataset pour charger les jeux de données.
from datasets import load_dataset
# Importez les métriques pour évaluer les performances du modèle.
from sklearn.metrics import accuracy_score, f1_score
# Importez SummaryWriter pour enregistrer les progrès de l'entraînement.
from torch.utils.tensorboard import SummaryWriter
# Importez pickle pour sauver et charger les modèles entraînés.
import pickle
# Importez openai pour utiliser l'API d'OpenAI (nécessite une clé API).
import openai
# Importez PyTorch pour les opérations d'apprentissage profond.
import torch
# Importez le module réseau neuronale de PyTorch.
import torch.nn as nn
# Importez le module d'optimiseur de PyTorch (non utilisé directement dans cet exemple).
import torch.optim as optim
Chacune de ces importations joue un rôle crucial dans différentes parties du code, allant de l’entraînement et de l’évaluation du modèle à l’enregistrement des résultats et à l’interaction avec les API externes.
Étape 2 : Fine-tuning d’un Modèle de Langue pour l’Analyse des Sentiments
Fine-tuning d’un modèle prêté pour une tâche spécifique telle que l’analyse des sentiments implique de charger un modèle prêté, de l’ajuster pour le nombre de labels de sortie (positif/négatif dans ce cas), et d’utiliser un jeu de données approprié.
Dans cet exemple, nous utilisons la classe AutoModelForSequenceClassification de la bibliothèque transformers, avec le jeu de données IMDB. Ce modèle pré-entraîné peut être finement réglé sur une petite partie du jeu de données pour économiser du temps de calcul. Le modèle est ensuite entraîné à l’aide d’un jeu personnalisé d’arguments d’entraînement, qui inclut le nombre d’epochs et la taille des lots.
Voici le code pour charger et régler le modèle :
# Spécifier le nom du modèle pré-entraîné de l'Hub des Modèles Hugging Face.
model_name = "bert-base-uncased"
# Charger le modèle pré-entraîné avec le nombre d'classes de sortie spécifié.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Charger un tokenisateur pour le modèle.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Charger le jeu de données IMDB de Hugging Face Datasets, en utilisant seulement 10% pour l'entraînement.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokeniser le jeu de données
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Associer le jeu de données aux entrées tokenisées
tokenized_dataset = dataset.map(tokenize_function, batched=True)
Dans cet exemple, le modèle est chargé en utilisant une architecture basée sur BERT et le jeu de données est préparé pour l’entraînement. Ensuite, nous définissons les arguments d’entraînement et initialisons l’Entraîneur.
# Définir les arguments d'entraînement.
training_args = TrainingArguments(
output_dir="./results", # Spécifier le répertoire de sortie pour enregistrer le modèle.
num_train_epochs=3, # Définir le nombre d'epochs d'entraînement.
per_device_train_batch_size=8, # Définir la taille du lot par appareil.
logging_dir='./logs', # Répertoire pour enregistrer les journaux.
logging_steps=10 # Enregistrer un journal tous les 10 pas.
)
# Initialiser l'Entraîneur avec le modèle, les arguments d'entraînement et les données.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Démarrer le processus d'entraînement.
trainer.train()
# Enregistrer le modèle finement ajusté.
model.save_pretrained("./fine_tuned_sentiment_model")

Étape 3 : Mise en œuvre d’un simple agent d’apprentissage par Q
L’apprentissage par Q est une technique d’apprentissage par rétroaction où un agent apprend à prendre des actions de manière à maximiser le gain cumulatif.
Dans cet exemple, nous définissons un agent de Q-apprentissage de base qui stocke les paires état-action dans une table Q. L’agent peut explorer aléatoirement ou exploiter l’action la plus connue basée sur la table Q. La table Q est mise à jour après chaque action à l’aide d’une fréquence d’apprentissage et d’un facteur de réduction pour pondérer les récompenses futures.
Voici le code qui implémente cet agent d’apprentissage par Q :
# Définir la classe d'agent de Q-learning.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Initialiser la table Q.
self.q_table = {}
# Enregistrer les actions possibles.
self.actions = actions
# Définir le taux d'exploration.
self.epsilon = epsilon
# Définir le taux d'apprentissage.
self.alpha = alpha
# Définir le facteur de réduction.
self.gamma = gamma
# Définir la méthode get_action pour sélectionner une action en fonction de l'état actuel.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# Explorer aléatoirement.
return random.choice(self.actions)
else:
# Exploiter l'action la plus optimale.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
L’agent sélectionne des actions en fonction de l’exploration ou de l’exploitation et met à jour les valeurs Q après chaque étape.
# Définir la méthode update_q_table pour mettre à jour la table Q.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
Étape 4 : Utiliser l’API d’OpenAI pour le modèle de récompense
Dans certains scénarios, au lieu de définir une fonction de récompense manuelle, nous pouvons utiliser un puissant modèle de langage comme GPT d’OpenAI pour évaluer la qualité des actions prises par l’agent.
Dans cet exemple, la fonction get_reward envoie un état, une action et l’état suivant à l’API d’OpenAI pour recevoir une note de récompense, nous permettant de capitaliser sur les grands modèles de langage pour comprendre des structures de récompense complexes.
# Définir la fonction get_reward pour obtenir un signal de récompense de l'API d'OpenAI.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # Remplacer par votre clé d'API OpenAI réelle.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
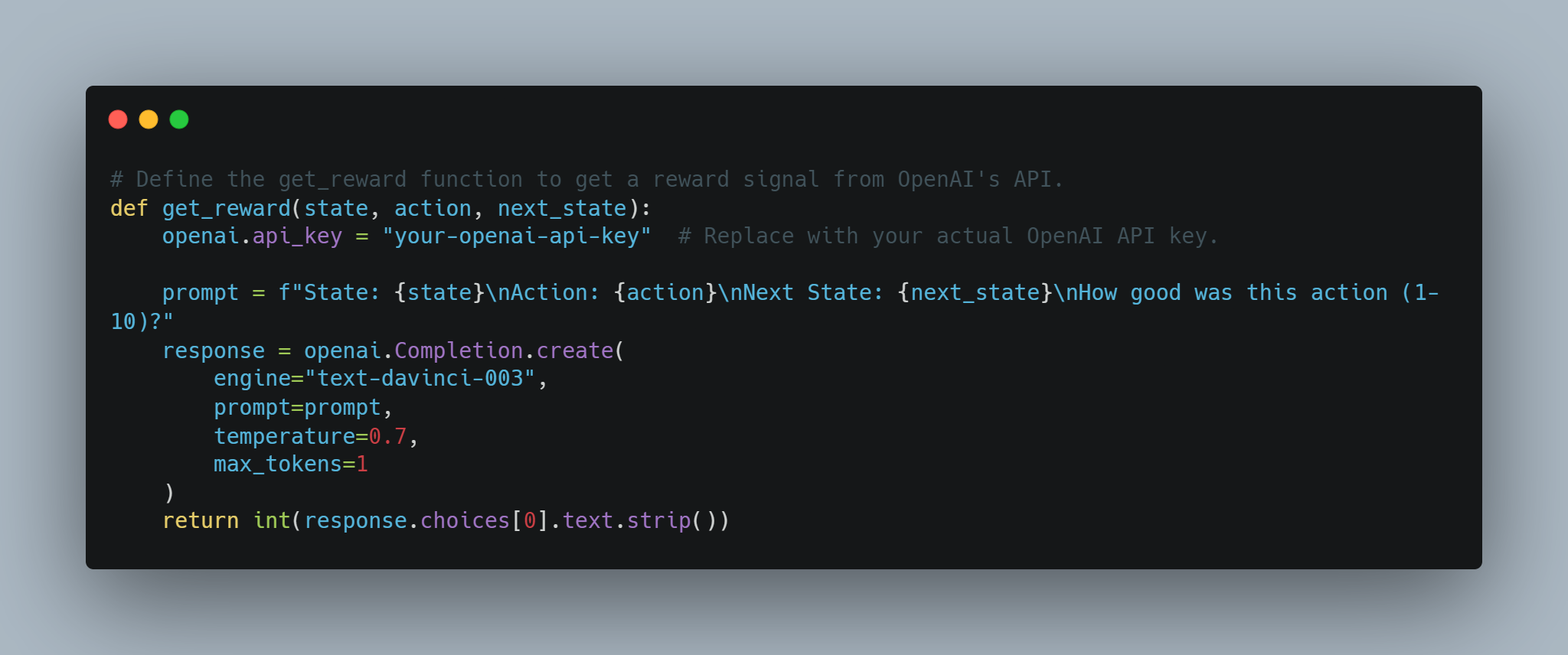
Cela permet une approche conceptuelle où le système de récompense est déterminé dynamiquement en utilisant l’API d’OpenAI, ce qui pourrait être utile pour des tâches complexes où les récompenses sont difficiles à définir.
Étape 5 : Évaluation du Performance du Modèle
Une fois qu’un modèle d’apprentissage automatique est entraîné, il est essentiel d’évaluer son performance en utilisant des métriques standard comme la précision et l’ordonnée F1.
Cette section calcule les deux en utilisant les étiquettes vraies et prédites. La précision fournit une mesure globale de la correctitude, tandis que l’ordonnée F1 équilibre la précision et la récupération, ce qui est particulièrement utile dans des jeux de données imbalancés.
Voici le code pour évaluer la performance du modèle :
# Définir les étiquettes vraies pour l'évaluation.
true_labels = [0, 1, 1, 0, 1]
# Définir les étiquettes prédites pour l'évaluation.
predicted_labels = [0, 0, 1, 0, 1]
# Calculer le score de précision.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calculer l'ordonnée F1.
f1 = f1_score(true_labels, predicted_labels)
# Afficher le score de précision.
print(f"Accuracy: {accuracy:.2f}")
# Afficher l'ordonnée F1.
print(f"F1-Score: {f1:.2f}")
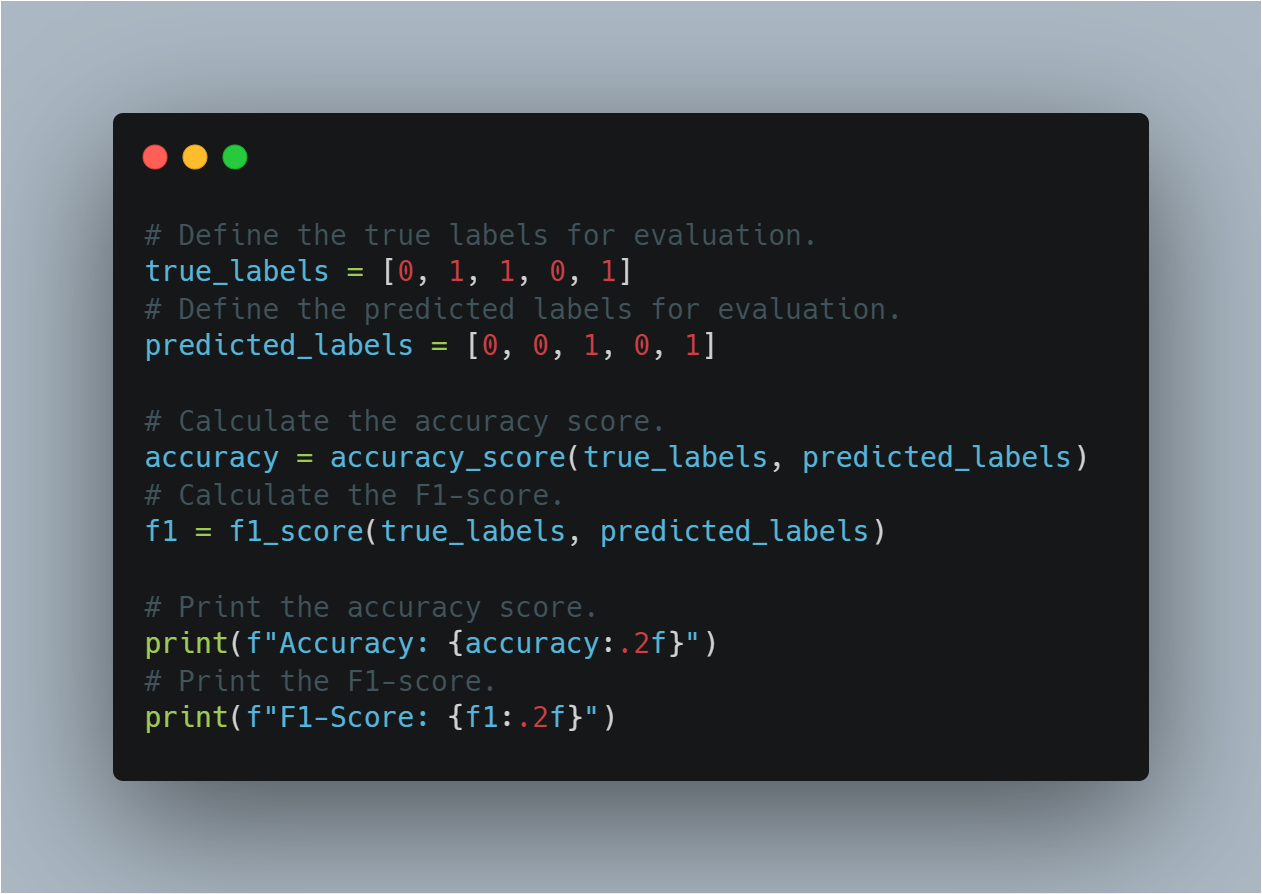
Cette section aide à évaluer comment bien le modèle a généralisé aux données non vues en utilisant des métriques d’évaluation bien établies.
Étape 6 : Agent de Gradient de Politique de Base (En Utilisant PyTorch)
Les méthodes de gradient de politique dans l’apprentissage par renforcement optimisent directement la politique en maximisant la récompense attendue.
Cette section démonstre une simple implémentation d’une plateforme de politique utilisant PyTorch, qui peut être utilisée pour la prise de décision dans les RL (Réinforcement par apprentissage). La plateforme de politique utilise une couche linéaire pour sortir des probabilités pour différentes actions, et on applique la fonction softmax pour s’assurer que ces sorties forment une distribution de probabilités valable.
Voici le code conceptuel pour définir un agent de gradient de politique de base :
# Définir la classe de réseau de politique.
class PolicyNetwork(nn.Module):
# Initialiser le réseau de politique.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# Définir une couche linéaire.
self.linear = nn.Linear(input_size, output_size)
# Définir le passage avant du réseau.
def forward(self, x):
# Appliquer la fonction softmax à la sortie de la couche linéaire.
return torch.softmax(self.linear(x), dim=1)
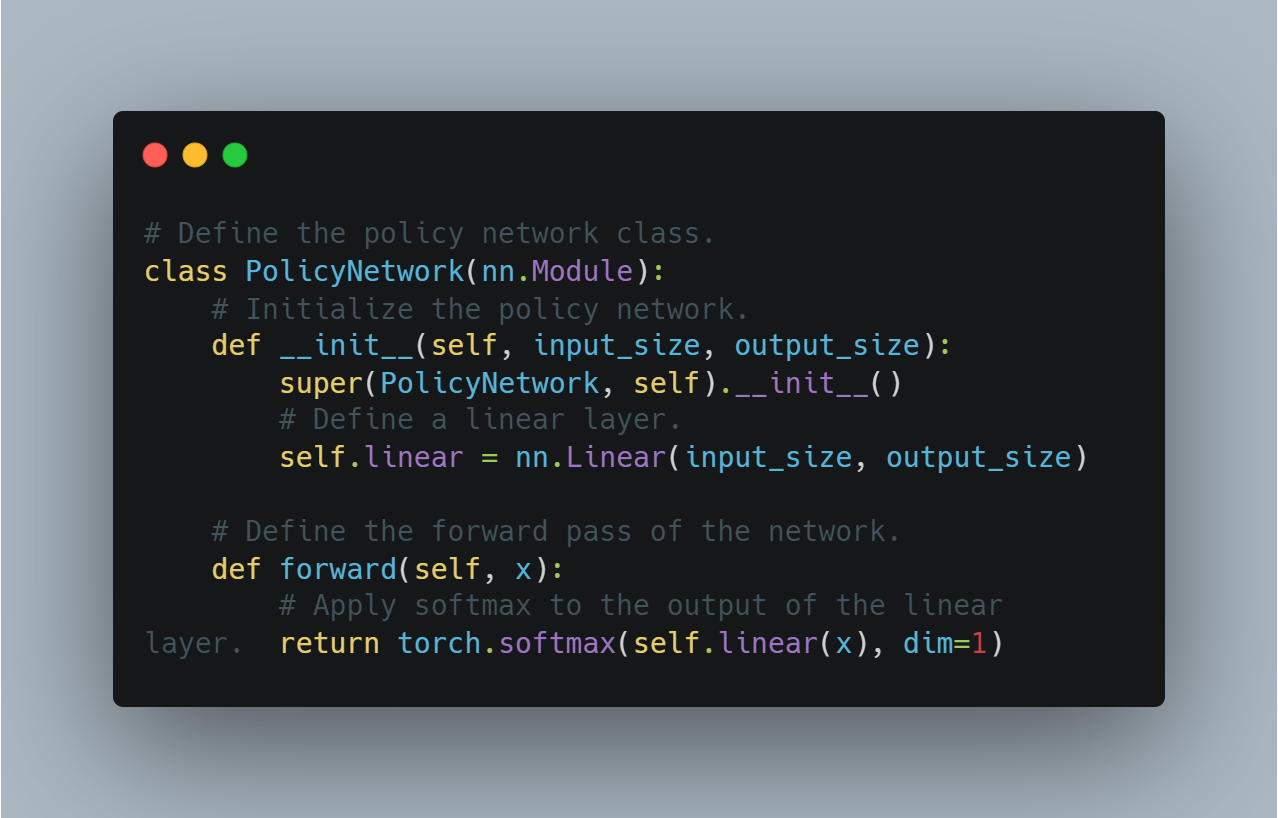
Cela sert de pas fondamental pour implémenter des algorithmes d’apprentissage par réinforcement plus avancés qui utilisent l’optimisation de politique.
Étape 7 : Visualiser le progrès d’entraînement avec TensorBoard
Visualiser les métriques d’entraînement, telles que la perte et la précision, est essentiel pour comprendre comment la performance du modèle évolue au fil du temps. TensorBoard, un outil populaire pour cela, peut être utilisé pour enregistrer les métriques et les visualiser en temps réel.
Dans cette section, nous créons une instance de SummaryWriter et enregistrons des valeurs aléatoires pour simuler le processus de suivi de la perte et de la précision pendant l’entraînement.
Voici comment vous pouvez enregistrer et visualiser le progrès d’entraînement en utilisant TensorBoard :
# Créer une instance de SummaryWriter.
writer = SummaryWriter()
# Exemple de boucle d'entraînement pour la visualisation avec TensorBoard :
num_epochs = 10 # Définir le nombre d'époques.
for epoch in range(num_epochs):
# Simuler des valeurs aléatoires de perte et de précision.
loss = random.random()
accuracy = random.random()
# Enregistrer la perte et la précision dans TensorBoard.
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# Fermer l'instance de SummaryWriter.
writer.close()
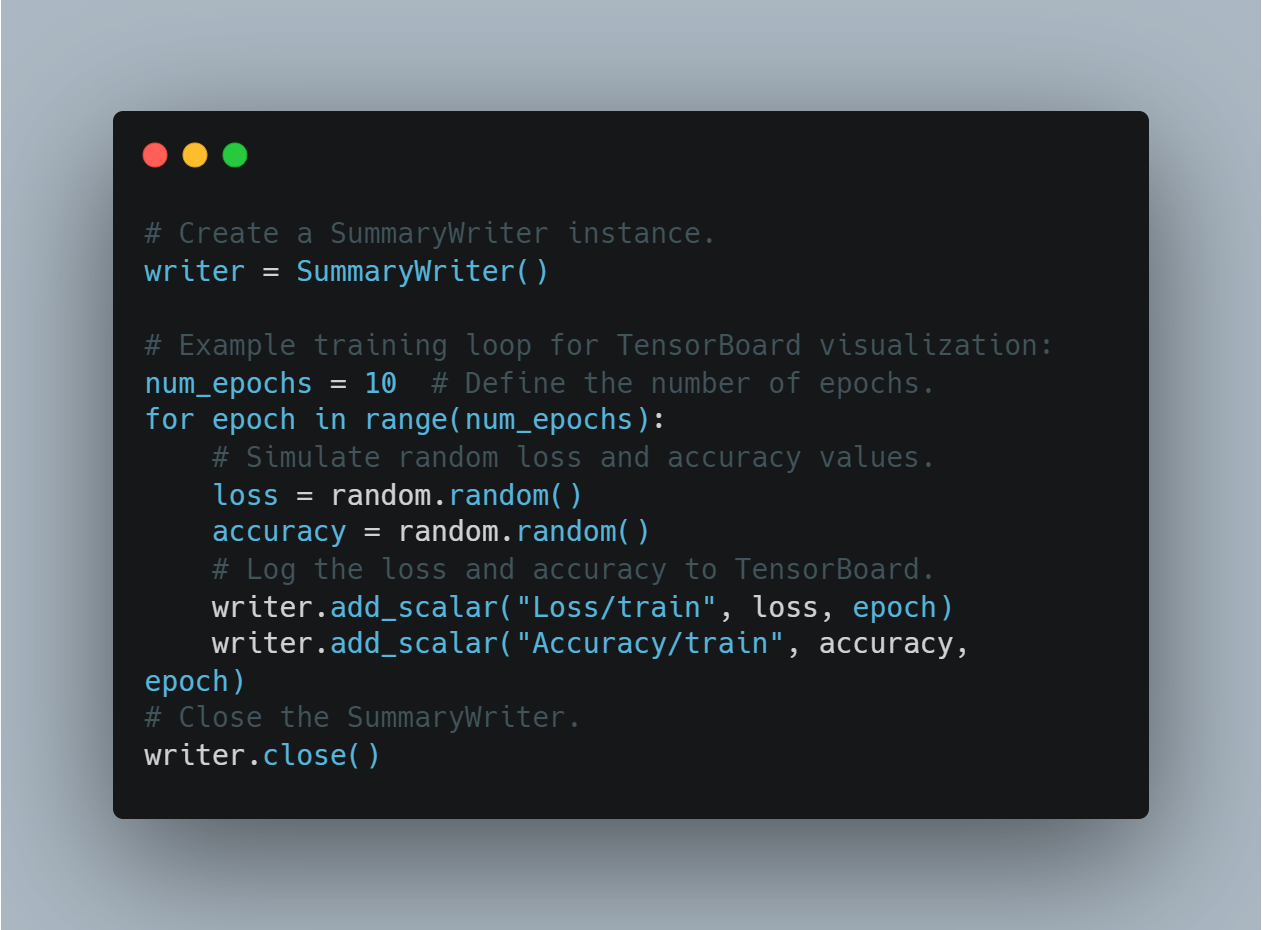
Cela permet aux utilisateurs de surveiller l’entraînement du modèle et d’apporter des ajustements en temps réel en fonction de la feedback visuel.
Étape 8 : Enregistrement et Chargement des Checkpoints d’Agents Entraînés
Après l’entraînement d’un agent, il est crucial d’enregistrer son état appris (par exemple, les valeurs Q ou les poids du modèle) afin de pouvoir les réutiliser ou les évaluer ultérieurement.
Cette section montre comment enregistrer un agent entraîné à l’aide du module pickle de Python et comment le recharger depuis le disque.
Voici le code pour enregistrer et charger un agent Q-learning entraîné :
# Créer une instance de l'agent Q-learning.
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# Entraîner l'agent (non affiché ici).
# Enregistrement de l'agent.
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# Chargement de l'agent.
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
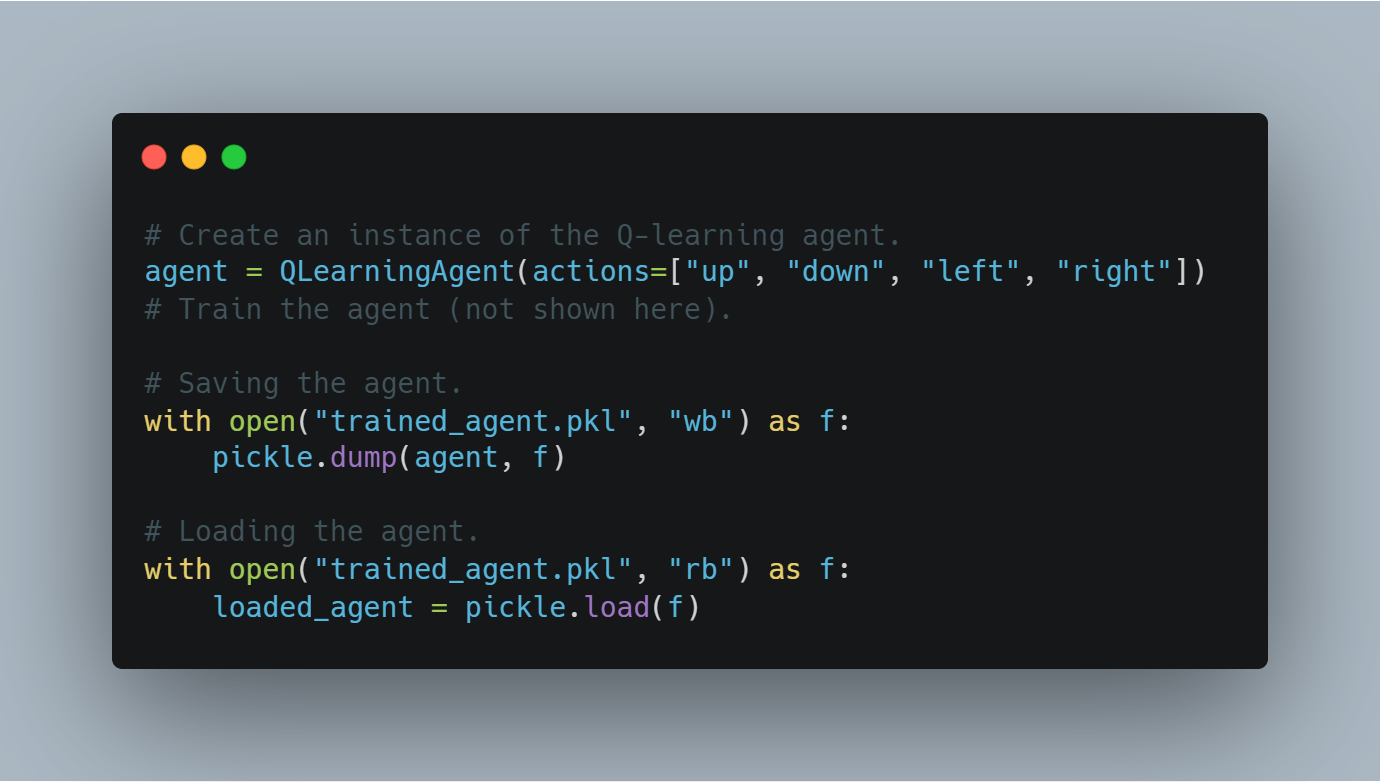
Ce processus de checkpointing garantit que les progrès de l’entraînement ne sont pas perdus et que les modèles peuvent être réutilisés dans des expériences futures.
Étape 9 : Apprentissage par Curriculum
L’apprentissage par cours de formation implique de progressiverment augmenter la difficulté des tâches présentées au modèle, en commençant par les exemples les plus faciles et en s’orientant vers les plus difficiles. Cela peut aider à améliorer les performances et la stabilité du modèle pendant l’entraînement.
Voici un exemple d’utilisation de l’apprentissage par cours de formation dans un boucle d’entraînement :
# Définir la difficulté de tâche initiale.
initial_task_difficulty = 0.1
# Exemple de boucle d'entraînement avec apprentissage par cours de formation :
for epoch in range(num_epochs):
# Augmenter progressivement la difficulté de la tâche.
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# Générer des données d'entraînement avec une difficulté ajustée.
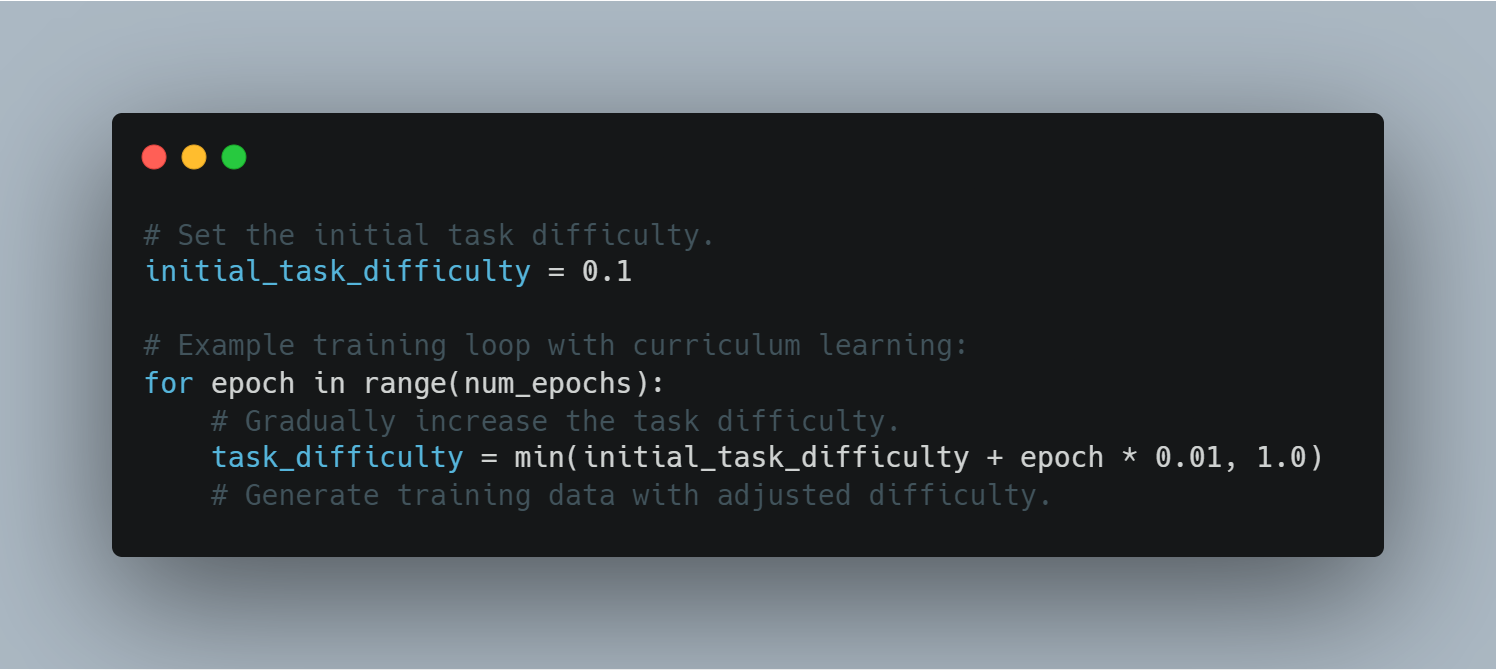
En contrôlant la difficulté de la tâche, l’agent peut progressivement gérer des défis plus complexes, améliorant ainsi l’efficacité de l’apprentissage.
Étape 10 : Mise en œuvre de l’arrêt prématuré
L’arrêt prématuré est une technique permettant d’éviter l’overfitting pendant l’entraînement en arrêtant le processus si la perte de validation ne s’améliore pas après un certain nombre d’epochs (patience).
Cette section montre comment mettre en œuvre l’arrêt prématuré dans une boucle d’entraînement, utilisant la perte de validation comme indicateur clé.
Voici le code pour mettre en œuvre l’arrêt prématuré :
# Initialiser la meilleure perte de validation à l'infini.
best_validation_loss = float("inf")
# Définir la valeur de patience (nombre d'epochs sans amélioration).
patience = 5
# Initialiser le compteur d'epochs sans amélioration.
epochs_without_improvement = 0
# Exemple de boucle d'entraînement avec l'arrêt prématuré:
for epoch in range(num_epochs):
# Simuler une perte de validation aléatoire.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

L’arrêt prématuré améliore la généralisation du modèle en évitant l’entraînement inutile une fois que le modèle commence à surévaluer.
Étape 11 : Utiliser un MMN pré-entraîné pour le transfert de tâche zéro-shot
Dans le transfert de tâche zéro-shot, un modèle pré-entraîné est appliqué à une tâche pour laquelle il n’a pas été spécifiquement réglé.
En utilisant la pipeline de Hugging Face, cette section montre comment appliquer un modèle BART pré-entraîné à la résumé sans entraînement supplémentaire, illustrant le concept d’apprentissage de transfert.
Voici le code pour utiliser un MMN pré-entraîné pour le résumé :
# Charger une pipeline de résumé pré-entraînée.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Définir le texte à résumer.
text = "This is an example text about AI agents and LLMs."
# Générer le résumé.
summary = summarizer(text)[0]["summary_text"]
# Afficher le résumé.
print(f"Summary: {summary}")
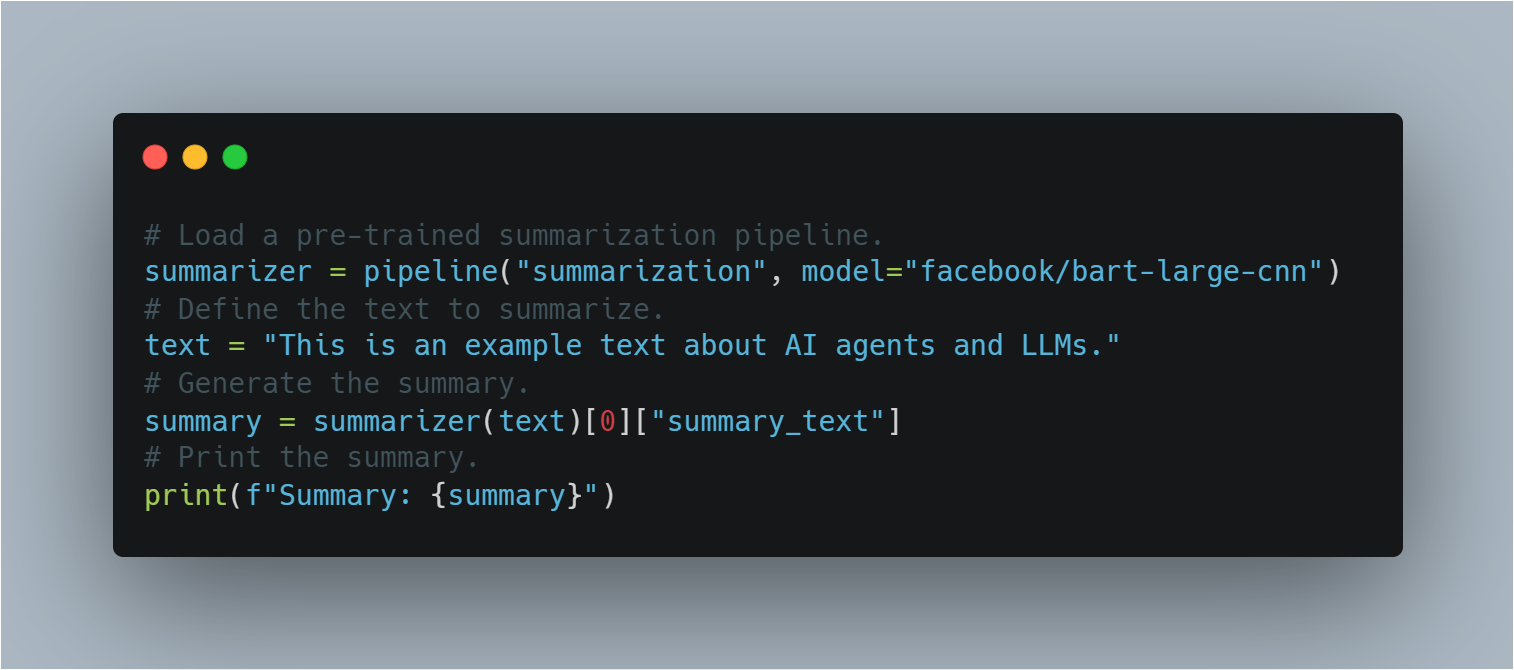
Cela illustre la flexibilité des MMN dans l’exécution de tâches diverses sans besoin d’entraînement supplémentaire, en utilisant leur connaissance préexistante.
Exemple complet de code.
# Importer le module random pour la génération de nombres aléatoires.
import random
# Importer les modules nécessaires de la bibliothèque transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importer load_dataset pour charger des ensembles de données.
from datasets import load_dataset
# Importer metrics pour évaluer la performance du modèle.
from sklearn.metrics import accuracy_score, f1_score
# Importer SummaryWriter pour enregistrer les progrès de l'entraînement.
from torch.utils.tensorboard import SummaryWriter
# Importer pickle pour sauvegarder et charger des modèles entraînés.
import pickle
# Importer openai pour utiliser l'API d'OpenAI (nécessite une clé API).
import openai
# Importer PyTorch pour les opérations d'apprentissage profond.
import torch
# Importer le module de réseau de neurones de PyTorch.
import torch.nn as nn
# Importer le module d'optimiseur de PyTorch (non utilisé directement dans cet exemple).
import torch.optim as optim
# --------------------------------------------------
# 1. Ajustement fin d'un LLM pour l'analyse de sentiment
# --------------------------------------------------
# Spécifier le nom du modèle pré-entraîné depuis Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Charger le modèle pré-entraîné avec le nombre spécifié de classes de sortie.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Charger un tokenizer pour le modèle.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Charger l'ensemble de données IMDB depuis Hugging Face Datasets, en utilisant seulement 10 % pour l'entraînement.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokeniser l'ensemble de données
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Mapper l'ensemble de données aux entrées tokenisées
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Définir les arguments d'entraînement.
training_args = TrainingArguments(
output_dir="./results", # Spécifier le répertoire de sortie pour sauvegarder le modèle.
num_train_epochs=3, # Définir le nombre d'époques d'entraînement.
per_device_train_batch_size=8, # Définir la taille de lot par appareil.
logging_dir='./logs', # Répertoire pour stocker les journaux.
logging_steps=10 # Journaliser tous les 10 pas.
)
# Initialiser le Trainer avec le modèle, les arguments d'entraînement et l'ensemble de données.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Démarrer le processus d'entraînement.
trainer.train()
# Sauvegarder le modèle ajusté.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. Mise en œuvre d'un agent Q-learning simple
# --------------------------------------------------
# Définir la classe de l'agent Q-learning.
class QLearningAgent:
# Initialiser l'agent avec des actions, epsilon (taux d'exploration), alpha (taux d'apprentissage) et gamma (facteur d'actualisation).
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Initialiser la table Q.
self.q_table = {}
# Stocker les actions possibles.
self.actions = actions
# Définir le taux d'exploration.
self.epsilon = epsilon
# Définir le taux d'apprentissage.
self.alpha = alpha
# Définir le facteur d'actualisation.
self.gamma = gamma
# Définir la méthode get_action pour sélectionner une action en fonction de l'état actuel.
def get_action(self, state):
# Explorer aléatoirement avec une probabilité epsilon.
if random.uniform(0, 1) < self.epsilon:
# Retourner une action aléatoire.
return random.choice(self.actions)
else:
# Exploiter la meilleure action basée sur la table Q.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# Définir la méthode update_q_table pour mettre à jour la table Q après avoir effectué une action.
def update_q_table(self, state, action, reward, next_state):
# Si l'état n'est pas dans la table Q, l'ajouter.
if state not in self.q_table:
# Initialiser les valeurs Q pour le nouvel état.
self.q_table[state] = {a: 0.0 for a in self.actions}
# Si le prochain état n'est pas dans la table Q, l'ajouter.
if next_state not in self.q_table:
# Initialiser les valeurs Q pour le nouvel état suivant.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# Obtenir l'ancienne valeur Q pour la paire état-action.
old_value = self.q_table[state][action]
# Obtenir la valeur Q maximale pour le prochain état.
next_max = max(self.q_table[next_state].values())
# Calculer la valeur Q mise à jour.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# Mettre à jour la table Q avec la nouvelle valeur Q.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. Utilisation de l'API d'OpenAI pour le modélisation des récompenses (conceptuel)
# --------------------------------------------------
# Définir la fonction get_reward pour obtenir un signal de récompense depuis l'API d'OpenAI.
def get_reward(state, action, next_state):
# S'assurer que la clé API d'OpenAI est correctement définie.
openai.api_key = "your-openai-api-key" # Remplacer par votre clé API OpenAI réelle.
# Construire le prompt pour l'appel API.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# Faire l'appel API au point de terminaison de Complétion d'OpenAI.
response = openai.Completion.create(
engine="text-davinci-003", # Spécifier le moteur à utiliser.
prompt=prompt, # Passer le prompt construit.
temperature=0.7, # Définir le paramètre de température.
max_tokens=1 # Définir le nombre maximum de tokens à générer.
)
# Extraire et retourner la valeur de récompense de la réponse de l'API.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. Évaluer la performance du modèle
# --------------------------------------------------
# Définir les vraies étiquettes pour l'évaluation.
true_labels = [0, 1, 1, 0, 1]
# Définir les étiquettes prédites pour l'évaluation.
predicted_labels = [0, 0, 1, 0, 1]
# Calculer le score de précision.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calculer le score F1.
f1 = f1_score(true_labels, predicted_labels)
# Afficher le score de précision.
print(f"Accuracy: {accuracy:.2f}")
# Afficher le score F1.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. Agent de gradient de politique de base (utilisant PyTorch) - Conceptuel
# --------------------------------------------------
# Définir la classe de réseau de politique.
class PolicyNetwork(nn.Module):
# Initialiser le réseau de politique.
def __init__(self, input_size, output_size):
# Initialiser la classe parente.
super(PolicyNetwork, self).__init__()
# Définir une couche linéaire.
self.linear = nn.Linear(input_size, output_size)
# Définir le passage avant du réseau.
def forward(self, x):
# Appliquer softmax à la sortie de la couche linéaire.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. Visualiser les progrès de l'entraînement avec TensorBoard
# --------------------------------------------------
# Créer une instance de SummaryWriter.
writer = SummaryWriter()
# Exemple de boucle d'entraînement pour la visualisation TensorBoard :
# num_epochs = 10 # Définir le nombre d'époques.
# for epoch in range(num_epochs):
# # ... (Votre boucle d'entraînement ici)
# loss = random.random() # Exemple : valeur de perte aléatoire.
# accuracy = random.random() # Exemple : valeur de précision aléatoire.
# # Journaliser la perte dans TensorBoard.
# writer.add_scalar("Loss/train", loss, epoch)
# # Journaliser la précision dans TensorBoard.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (Journaliser d'autres métriques)
# # Fermer le SummaryWriter.
# writer.close()
# --------------------------------------------------
# 7. Sauvegarder et charger des points de contrôle d'agent entraîné
# --------------------------------------------------
# Exemple :
# Créer une instance de l'agent Q-learning.
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (Entraîner votre agent)
# # Sauvegarder l'agent
# # Ouvrir un fichier en mode écriture binaire.
# with open("trained_agent.pkl", "wb") as f:
# # Sauvegarder l'agent dans le fichier.
# pickle.dump(agent, f)
# # Charger l'agent
# # Ouvrir le fichier en mode lecture binaire.
# with open("trained_agent.pkl", "rb") as f:
# # Charger l'agent depuis le fichier.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. Apprentissage par curriculum
# --------------------------------------------------
# Définir la difficulté initiale de la tâche.
initial_task_difficulty = 0.1
# Exemple de boucle d'entraînement avec apprentissage par curriculum :
# for epoch in range(num_epochs):
# # Augmenter progressivement la difficulté de la tâche.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (Générer des données d'entraînement avec une difficulté ajustée)
# --------------------------------------------------
# 9. Mise en œuvre de l'arrêt précoce
# --------------------------------------------------
# Initialiser la meilleure perte de validation à l'infini.
best_validation_loss = float("inf")
# Définir la valeur de patience (nombre d'époques sans amélioration).
patience = 5
# Initialiser le compteur pour les époques sans amélioration.
epochs_without_improvement = 0
# Exemple de boucle d'entraînement avec arrêt précoce :
# for epoch in range(num_epochs):
# # ... (Étapes d'entraînement et de validation)
# # Calculer la perte de validation.
# validation_loss = random.random() # Exemple : perte de validation aléatoire.
# # Si la perte de validation s'améliore.
# if validation_loss < best_validation_loss:
# # Mettre à jour la meilleure perte de validation.
# best_validation_loss = validation_loss
# # Réinitialiser le compteur.
# epochs_without_improvement = 0
# else:
# # Incrémenter le compteur.
# epochs_without_improvement += 1
# # Si aucune amélioration pendant 'patience' époques.
# if epochs_without_improvement >= patience:
# # Afficher un message.
# print("Arrêt précoce déclenché !")
# # Arrêter l'entraînement.
# break
# --------------------------------------------------
# 10. Utilisation d'un LLM pré-entraîné pour le transfert de tâche sans entraînement
# --------------------------------------------------
# Charger un pipeline de résumé pré-entraîné.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Définir le texte à résumer.
text = "This is an example text about AI agents and LLMs."
# Générer le résumé.
summary = summarizer(text)[0]["summary_text"]
# Afficher le résumé.
print(f"Summary: {summary}")

Difficultés de déploiement et d’échelle
Le déploiement et l’échelle d’agents intelligents intégrés avec des LLM posent des défis techniques et opérationnels significatifs. L’une des principales difficultés est le coût computationnel, en particulier à mesure que les LLM deviennent plus importants et plus complexes.
Traiter ce problème implique de stratégies économes en ressources telles que le nettoyage de modèles, la quantification et le calcul distribué. Cela peut aider à réduire la charge computationnelle sans sacrifier la performance.
Le maintien de la fiabilité et de la robustesse dans les applications réelles est également crucial, nécessitant un suivi permanent, des mises à jour régulières et la mise au point de mécanismes de secours pour gérer les entrées imprévues ou les défaillances du système.
Lorsque ces systèmes sont déployés dans diverses industries, l’observation de normes éthiques – y compris l’équité, la transparence et la responsabilité – devient de plus en plus importante. Ces considérations sont centrales à l’acceptation et au succès à long terme du système, impactant la confiance du public et les implications éthiques des décisions drivées par l’IA dans des contextes sociaux divers (Bender et al., 2021).
La mise en œuvre technique d’agents intelligents intégrés avec des LLM implique une conception architecturale prudente, des méthodologies de formation rigoureuses et un examen attentif des défis de déploiement.
L’efficacité et la fiabilité de ces systèmes dans les environnements réels dépendent de l’addressage à la fois des problèmes techniques et éthiques, garantissant que les technologies de l’IA fonctionnent smoothly et responsablement dans diverses applications.
Chapitre 7 : L’avenir des agents intelligents et des LLM
La convergence des LLM avec l’apprentissage par renforcement
Lorsque vous explorez le futur des agents intelligents par ordinateur et des grands modèles de langue naturelle (MLN), la convergence des MLN avec l’apprentissage par réinforcement se révèle une évolution particulièrement transformatrice. Cette intégration dépasse les frontières de l’IA traditionnelle en permettant aux systèmes non seulement de générer et de comprendre la langue, mais également d’apprendre en temps réel grâce à leurs interactions.
Par l’apprentissage par réinforcement, les agents intelligents peuvent adapter leurs stratégies en fonction de la rétroaction reçue de leur environnement, ce qui entraîne une refonte continue de leurs processus de décision. Cela signifie que, contrairement aux modèles statiques, les systèmes d’IA dotés de l’apprentissage par réinforcement peuvent gérer des tâches de plus en plus complexes et dynamiques avec une supervision humaine minimale.
Les conséquences de tels systèmes sont profondes : dans des applications allant de la robotique autonome à l’éducation personnalisée, les agents intelligents pourraient améliorer leur performance indépendamment au fil du temps, ce qui les rendrait plus efficaces et réceptifs aux demandes évolutives de leur contexte opérationnel.
Exemple : Jeu de Texte
Envisagez un agent intelligent jouant à un jeu de type aventure textuelle.
-
Environnement : Le jeu en lui-même (règles, descriptions de l’état, etc.)
-
MLN : Traite le texte du jeu, comprend la situation actuelle et génére des actions possibles (par exemple, « allez au nord », « prenez l’épée »).
-
Récompense :octroyée par le jeu en fonction de l’issue de l’action (par exemple, une récompense positive pour trouver le trésor, une récompense négative pour perdre la vie).
Exemple de code (conceptuel en Python et avec l’API d’OpenAI) :
import openai
import random
# ... (Logique de l'environnement de jeu - non affichée ici) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (Boucle de formation de l'apprentissage par reinforcement - simplifiée) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (Mise à jour de l'agent par reinforcement en fonction de la récompense - non affichée) ...
state = next_state
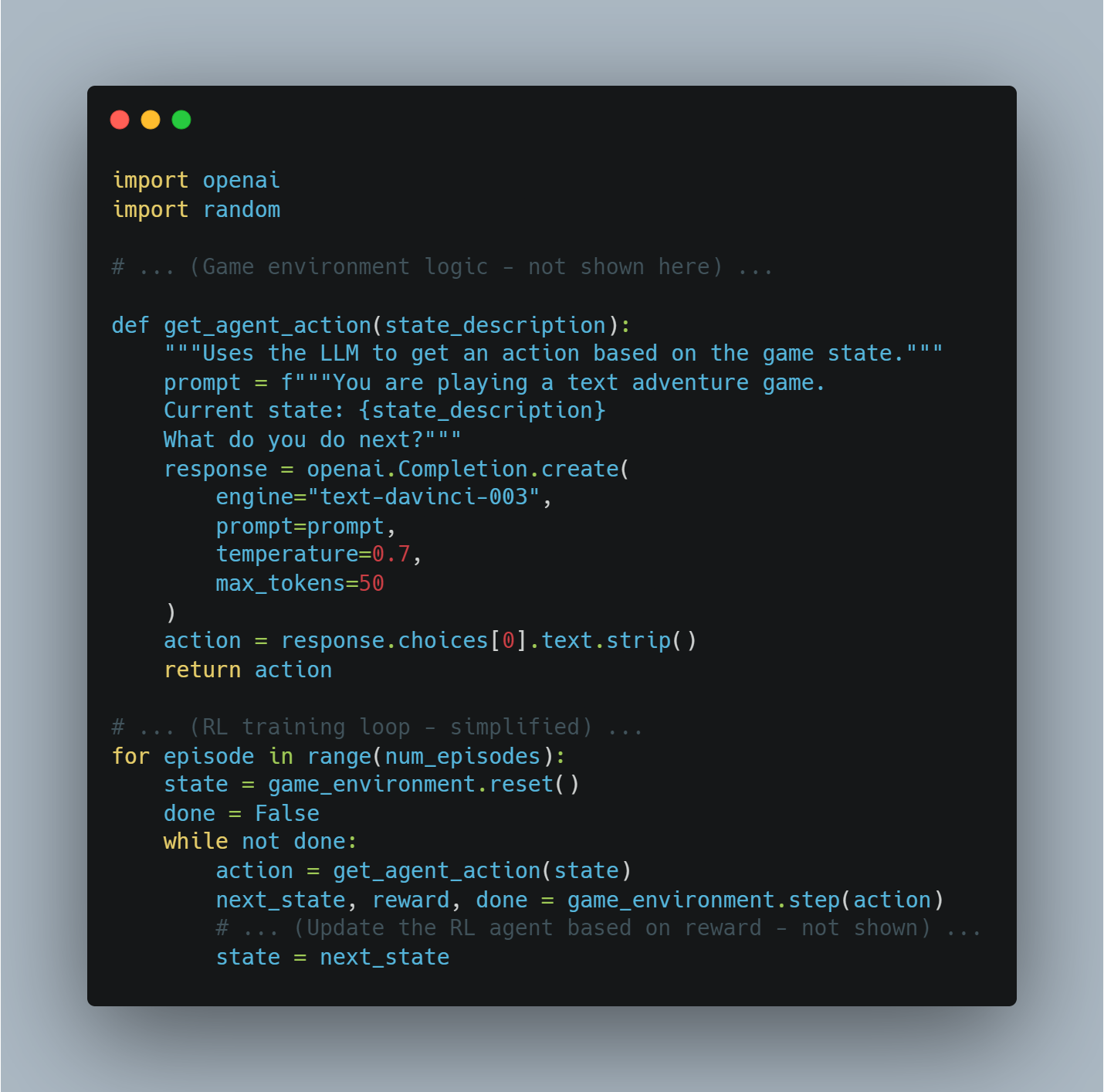
Intégration de l’IA multimodale
L’intégration de l’IA multimodale est une autre tendance critique qui façonne l’avenir des agents intelligents. En permettant aux systèmes de traiter et de combiner des données provenant de diverses sources, telles que le texte, les images, l’audio et les entrées sensorielle, l’IA multimodale offre une meilleure compréhension des environnements dans lesquels ces systèmes opèrent.
Par exemple, dans les véhicules autonomes, la capacité de synthèse des données visuelles depuis les caméras, des données contextuelles depuis les cartes et des mises à jour temporelles du trafic permet à l’IA de prendre des décisions de conduite plus informées et donc plus sûres.
Cette capacité s’étend à d’autres domaines tels que la santé où un agent IA pourrait intégrer les données des patients provenant de dossiers médicaux, d’imagerie diagnostique et d’informations génomiques pour fournir des recommandations de traitement plus précises et personnalisées.
Le défi ici se situe dans l’intégration en cascade et le traitement en temps réel de divers flux de données, ce qui exige des avancées dans l’architecture des modèles et les techniques de fusion de données.
Réussir à surmonter ces défis sera crucial pour déployer des systèmes IA véritablement intelligents et capables de fonctionner dans des environnements complexes et réels.
Exemple d’IA multimodale 1 : La génération de description d’images pour la réponse à des questions visuelles
-
Objectif : Un agent IA capable de répondre à des questions sur des images.
-
Modalités : Image, Texte
-
Processus :
-
Extraction de caractéristiques de l’image : Utilisez une CNN (Convolutional Neural Network) pré-entraînée pour extraire des caractéristiques de l’image.
-
Génération de la description : Utilisez un LLM (like une transformation du modèle) pour générer une description de l’image en fonction des caractéristiques extraites.
-
Réponse à la question : Utilisez un autre LLM pour traiter à la fois la question et la description générée pour fournir une réponse.
-
Exemple de code (conceptuel en Python et Hugging Face Transformers) :
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# Charger les modèles prénuits
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# Fonction pour générer une légende d'image
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# Fonction pour répondre à des questions sur l'image
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# Exemple d'utilisation
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
Exemple 2 de multimodal AI : Analyse de sentiment à partir de texte et d’audio
-
Objectif : Un agent IA qui analyse le sentiment à partir de textes et de tons dans un message.
-
Modalités : Texte, Audio
-
Processus :
-
Sentiment du Texte : Utiliser un modèle pré-entraîné d’analyse de sentiment sur le texte.
-
Sentiment de l’Audio : Utiliser un modèle de traitement audio pour extraire des caractéristiques telles que le ton et la hauteur, puis utiliser ces caractéristiques pour prédire le sentiment.
-
Fusion : Combiner les scores de sentiment du texte et de l’audio (par exemple, moyenne pondérée) pour obtenir le sentiment global.
-
Exemple de Code (Conceptuel en Python) :
from transformers import pipeline # Pour l'analyse de sentiment des textes
# ... (Importation de bibliothèques de traitement audio et d'analyse de sentiment - non affichée) ...
# Chargement des modèles pré-entraînés
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# Analyse de sentiment du texte
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# Analyse de sentiment de l'audio
# ... (Traitement de l'audio, extraction de caractéristiques, prédiction de sentiment - non affichée) ...
audio_sentiment = # ... (Résultat du modèle de sentiment de l'audio)
audio_confidence = # ... (Score de confiance du modèle audio)
# Fusion des sentiments (exemple : moyenne pondérée)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# Exemple d'utilisation
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
Défis et considérations :
-
Alignement des données : Assurer que les données de différentes modalités sont synchronisées et alignées est essentiel.
-
Complexité du modèle : Les modèles multimodaux peuvent être complexes à entraîner et exiger de grandes jeux de données diversifiés.
-
Techniques de fusion : Choisir la méthode correcte pour combiner l’information provenant de différentes modalités est important et spécifique au problème.
L’IA multicible est un domaine évoluant rapidement qui a le potentiel de révolutionner la manière dont les agents intelligents interagissent et perçoivent le monde.
Systèmes d’IA distribués et calcul en bordure
En examinant l’évolution des infrastructures d’IA, le passage vers des systèmes d’IA distribués, soutenus par le calcul en bordure, représente une avancée significative.
Les systèmes d’IA distribués décentralisent les tâches de calcul en traitant les données plus près de leur source — comme les appareils IoT ou les serveurs locaux — plutôt que de comptabiliser sur les ressources cloud centralisées. Cette approche non seulement réduit la latence, qui est cruciale pour les applications sensibles au temps telles que les drones autonomes ou l’automatisation industrielle, mais aussi améliore la protection de la privacy et de la sécurité des données en conservant l’information sensible locale.
De plus, les systèmes d’IA distribués améliorent la scalabilité, permettant le déploiement de l’IA sur de vastes réseaux, comme les villes intelligentes, sans surcharger les centres de données centraux.
Les défis techniques associés aux systèmes d’IA distribués incluent le maintien de la cohérence et de la coordination across des nœuds distribués, ainsi que l’optimisation de l’allocation des ressources pour maintenir des performances dans des environnements divers et potentiellement contraignants.
En développant et en déployant des systèmes d’IA, l’adoption de architectures distribuées sera cruciale pour créer des solutions d’IA résilientes, efficientes et scalables qui répondent aux exigences des applications futures.
Systèmes d’IA distribués et calcul à la périphérie exemple 1 : Apprentissage fédéré pour le training de modèles protégeant la confidentialité
-
Objectif : Former un modèle commun sur plusieurs appareils (par exemple, smartphones) sans partager directement les données sensibles des utilisateurs.
-
Approche :
-
Formation locale : Chaque appareil forme un modèle local sur ses propres données.
-
Aggregation des paramètres : Les appareils envoyent les mises à jour du modèle (gradients ou paramètres) à un serveur central.
-
Mise à jour du modèle global : Le serveur aggrege les mises à jour, améliore le modèle global et envoie le modèle mis à jour aux appareils.
-
Exemple de code (Conceptuel en Python et PyTorch) :
import torch
import torch.nn as nn
import torch.optim as optim
# ... (Code pour la communication entre appareils et serveur - non affiché) ...
class SimpleModel(nn.Module):
# ... (Définir votre architecture de modèle ici) ...
# Fonction d'entraînement côté appareil
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # Commencer avec le modèle global
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (Entraîner local_model sur device_data) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# Fonction d'agrégation côté serveur
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (Boucle de apprentissage fédéré simplifiée) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

Exemple 2 : Détection d’objets en temps réel sur les appareils Edge
-
Objectif : Déployer un modèle de détection d’objets sur un appareil à ressources limitées (par exemple, une Raspberry Pi) pour une inférence en temps réel.
-
Approche :
-
Optimisation du Modèle : Utilisez des techniques telles que la quantification ou la taille du modèle pour réduire la taille du modèle et les exigences de calcul.
-
Déploiement sur le Edge : Déployez le modèle optimisé sur l’appareil edge.
-
Inférence Locale : L’appareil effectue la détection d’objets localement, réduisant la latence et la dépendance à la communication cloud.
-
Exemple de Code (Conceptuel utilisant Python et TensorFlow Lite) :
import tensorflow as tf
# Charger le modèle pré-entraîné (en supposant qu'il soit déjà optimisé pour TensorFlow Lite)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# Obtenir les détails des entrées et des sorties
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (Capture d'image depuis la caméra ou chargement depuis un fichier - non montré) ...
# Prétraiter l'image
input_data = ... # Redimensionner, normaliser, etc.
interpreter.set_tensor(input_details[0]['index'], input_data)
# Exécuter l'inférence
interpreter.invoke()
# Obtenir les sorties
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (Traiter output_data pour obtenir des boîtes englobantes, des classes, etc.) ...
Défis et considérations :
-
Surcharges de communication : La coordination et la communication efficaces entre les nœuds distribués sont cruciales.
-
Gestion des ressources : L’optimisation de l’allocation des ressources (CPU, mémoire, bande passante) sur les appareils est importante.
-
Sécurité : La sécurité des systèmes distribués et la protection de la confidentialité des données sont des préoccupations primordiales.
L’IA distribuée et le calcul en bordure sont essentiels pour construire des systèmes d’IA évolutifs, efficaces et respectueux de la confidentialité, en particulier à l’approche d’un futur où des milliards d’appareils interconnectés sont envisagés.
Les progrès dans le traitement du langage naturel
Le traitement du langage naturel (TLN) demeure à l’avant-garde des progrès de l’IA, permettant d’améliorer significativement la façon dont les machines comprennent, génèrent et interagissent avec le langage humain.
Les dernières avancées dans le TLN, telles que l’évolution des transformateurs et des mécanismes d’attention, ont considérablement amélioré la capacité de l’IA à traiter des structures linguistiques complexes, rendant les interactions plus naturelles et plus conscientes du contexte.
Ces progrès ont permis aux systèmes d’IA de comprendre les nuances, les sentiments et même les références culturelles dans le texte, menant à des communications plus exactes et significatives.
Par exemple, dans le service client, les modèles avancés de TLN peuvent non seulement traiter les requêtes avec précision mais également détecter les codes émotionnels des clients, permettant des réponses plus empathetic et efficaces.
A l’avenir, l’intégration de capacités multilingues et d’une compréhension sémantique plus profonde dans les modèles de TLN élargira leur application, permettant une communication fluide across différentes langues et dialectes, et même permettant à des systèmes d’IA de servir de traducteurs en temps réel dans des contextes mondiaux divers.
Le traitement du langage naturel (TLN) évolue rapidement, avec des progrès dans des domaines comme les modèles transformateurs et les mécanismes d’attention. Voici quelques exemples et extraits de code pour illustrer ces avancées :
Exemple de TAL 1 : Analyse de sentiment avec des transformateurs affinés
-
Objectif: Analyser le sentiment d’un texte avec une grande précision, en capturant les nuances et le contexte.
-
Approche: Affiner un modèle de transformateur pré-entraîné (comme BERT) sur un ensemble de données d’analyse de sentiment.
Exemple de code (utilisant Python et Hugging Face Transformers):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Charger le modèle pré-entraîné et l'ensemble de données
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3 étiquettes : Positif, Négatif, Neutre
dataset = load_dataset("imdb", split="train[:10%]")
# Définir les arguments d'entraînement
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# Affiner le modèle
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# Sauvegarder le modèle affiné
model.save_pretrained("./fine_tuned_sentiment_model")
# Charger le modèle affiné pour l'inférence
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# Exemple d'utilisation
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
Exemple de TAL 2 : Traduction automatique multilingue avec un seul modèle
-
Objectif: Traduire entre plusieurs langues en utilisant un seul modèle, en exploitant des représentations linguistiques partagées.
- Approche : Utiliser un modèle transformeur multilingue grand et performant (comme mBART ou XLM-R) qui a été entraîné sur un ensemble de données massif de textes parallèles dans plusieurs langues.
Exemple de code (en utilisant Python et Hugging Face Transformers) :
from transformers import pipeline
# Charger une pipeline de traduction multilingue pré-entraînée
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# Utilisation exemple : de l'anglais vers le français
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# Utilisation exemple : du français vers l'espagnol
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
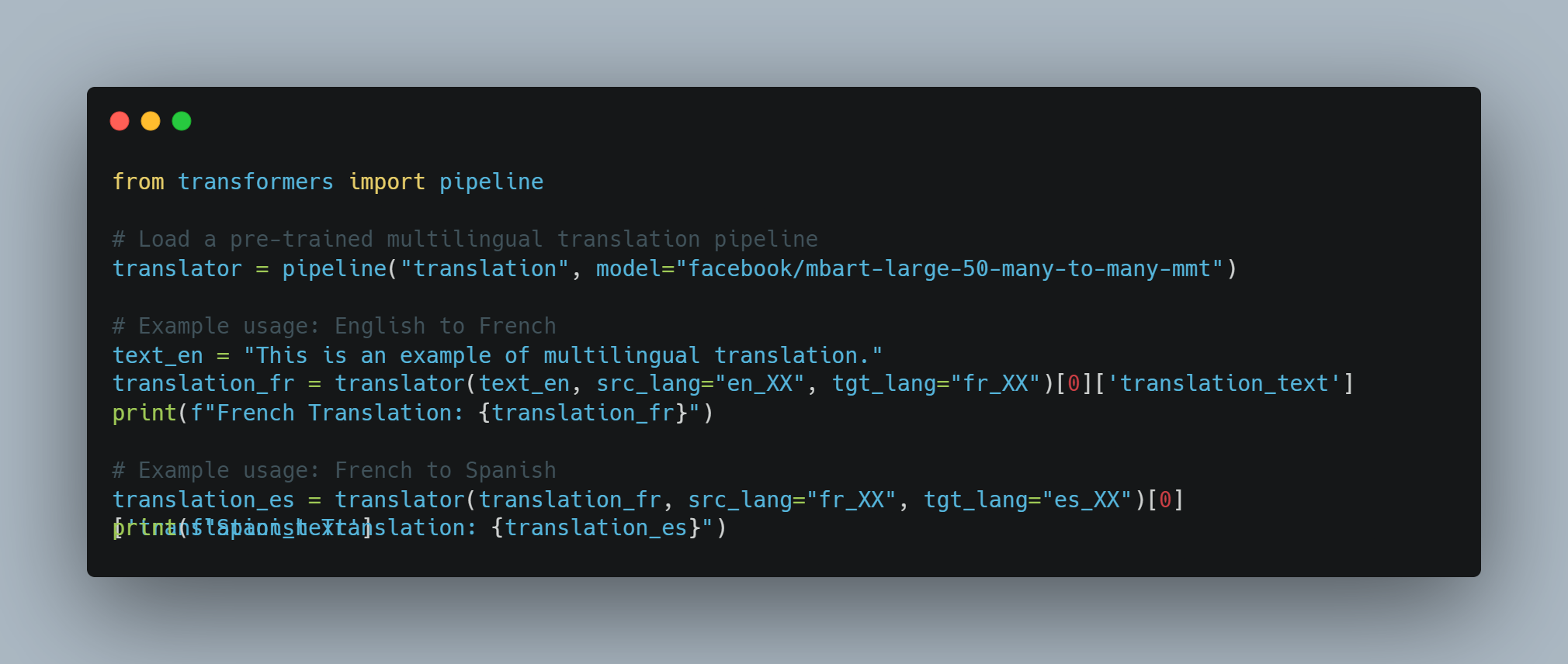
Exemple NLP 3 : Embeddings de mots contextuels pour la similarité sémantique
-
Objectif : Déterminer la similarité entre des mots ou des phrases, en tenant compte du contexte.
-
Approche : Utiliser un modèle transformeur (comme BERT) pour générer des embeddings de mots contextuels, qui capturent le sens des mots dans une phrase spécifique.
Exemple de code (en utilisant Python et Hugging Face Transformers) :
from transformers import AutoModel, AutoTokenizer
import torch
# Charger le modèle pré-entraîné et le tokenizer
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Fonction pour obtenir les embeddings des phrases
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# Utiliser l'embedding du token [CLS] comme embedding de phrase
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# Exemple d'utilisation
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# Calculer la similarité cosinus
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
Défis et Directions Futures :
-
Biais et Équité : Les modèles NLP peuvent hériter de biais de leurs données d’entraînement, ce qui peut entraîner des résultats injustes ou discriminatoires. Traiter le biais est essentiel.
-
Raisonnement Sens Commun : Les LLM font encore face à des difficultés dans le raisonnement sens commun et la compréhension d’information implicite.
-
Interprétabilité : Le processus de prise de décision des modèles NLP complexes peut être opaque, ce qui rend difficile de comprendre pourquoi ils génèrent certaines sorties.
Malgré ces défis, la NLP avance rapidement. L’intégration de l’information multimodale, l’amélioration de la raisonnement communautaire et l’accroissement de l’explicabilité sont des domaines clés de recherche en cours qui revolutionneront davantage la manière dont l’IA interagit avec le langage humain.
Assistants IA personnalisés
Le futur des assistants IA personnalisés est sur le point de devenir de plus en plus sophistiqué, allant au-delà de la gestion de tâches de base pour offrir un soutien intuitif et proactive réellement adapté aux besoins individuels.
Ces assistants utiliseront des algorithmes avancés d’apprentissage machine pour apprendre en continu à partir de vos comportements, préférences et routines, offrant des recommandations de plus en plus personnalisées et automatisant des tâches plus complexes.
Par exemple, un assistant IA personnalisé pourrait gérer non seulement votre emploi du temps, mais également anticiper vos besoins en suggérant des ressources pertinentes ou en ajustant votre environnement en fonction de votre humeur ou de vos préférences passées.
À mesure que les assistants IA deviennent plus intégrés dans la vie quotidienne, leur capacité à s’adapter aux contextes changeants et à fournir un support fluide et multiplateforme deviendra un facteur clé de différenciation. Le défi consiste à équilibrer la personnalisation avec la confidentialité, nécessitant des mécanismes robustes de protection des données pour s’assurer que l’information sensible est gérée de manière sécurisée tout en offrant une expérience fortement personnalisée.
Exemple 1 d’assistants IA : Suggestion de tâches adaptées au contexte
-
Objectif : Un assistant qui suggère des tâches en fonction du contexte actuel de l’utilisateur (emplacement, heure, comportement antérieur).
- Approche : Combiner les données de l’utilisateur, les signaux contextuels et un modèle de recommandation de tâches.
Exemple de code (conceptuel en Python) :
# ... (Code pour la gestion des données de l'utilisateur, détection du contexte - non affiché) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# Exemple : Suggestions basées sur le temps
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# Exemple : Suggestions basées sur l'emplacement
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (Ajouter d'autres règles ou utiliser un modèle d'apprentissage automatique pour les suggestions) ...
# Classement et filtrage des suggestions
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- Exemple d'utilisation ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... autres préférences ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... autres données de contexte ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
Exemple 2 d’assistants intelligents : distribution proactive d’information
-
Objectif : Un assistant qui fournit proactivement des informations pertinentes en fonction du calendrier de l’utilisateur et de ses préférences.
- Approche : Intégrer les données de calendrier, les intérêts de l’utilisateur et un système de recherche de contenu.
Exemple de code (Conceptuel en Python) :
# ... (Code pour l'accès au calendrier, le profil d'intérêts de l'utilisateur - non affiché) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (Récupérer les informations de la société, les profils des participants, etc.) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (Récupérer l'état du vol, les informations de destination, etc.) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- Exemple d'utilisation ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... d'autres préférences ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

Exemple 3 d’assistant IA : Recommandation de contenu personnalisée
-
Objectif : Un assistant qui recommande du contenu (articles, vidéos, musique) adapté aux préférences de l’utilisateur.
-
Approche : Utiliser le filtrage collaboratif ou les systèmes de recommandation basés sur le contenu.
Exemple de code (Conceptuel en Python et une bibliothèque comme Surprise) :
from surprise import Dataset, Reader, SVD
# ... (Code de gestion des évaluations des utilisateurs, base de données de contenu - non affiché) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (Obtenir des prédictions pour tous les articles, les classer, et retourner les N premiers) ...
# --- Exemple d'utilisation ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... plus d'évaluations ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
Defis et Considérations Éthiques :
-
Vie Privée des Données : Gérer les données utilisateur de manière responsable et transparente est crucial.
-
Partialité et Équité : La personnalisation ne doit pas amplifier les biais existants.
-
Contrôle des Utilisateurs : Les utilisateurs devraient avoir le contrôle sur leurs données et les paramètres de personnalisation.
La construction d’assistants intelligents personnalisés nécessite une considération prudente à la fois des aspects techniques qu’éthiques pour créer des systèmes utiles, dignes de confiance et respectueux de la vie privée des utilisateurs.
IA dans les Industries Créatives
L’IA pénètre significativement les industries créatives, transformant la manière dont l’art, la musique, le film et la littérature sont produits et consommés. Avec les progrès dans les modèles générateurs, tels que les Réseaux Générateurs Adversaires (GANs) et les modèles basés sur les transformateurs, l’IA peut maintenant générer du contenu qui rivalise avec la créativité humaine.
Par exemple, l’IA peut composer de la musique reflétant des genres spécifiques ou des humeurs, créer de l’art numérique imitant le style de peintres célèbres, ou même élaborer des scénarios narratifs pour films et romans.
Dans l’industrie de la publicité, l’IA est utilisée pour générer du contenu personnalisé qui résonne avec les consommateurs individuels, augmentant l’engagement et l’efficacité.
La montée de l’IA dans les domaines créatifs soulève cependant des questions sur l’auteur, l’originalité et le rôle de la créativité humaine. Lorsque vous interagissez avec l’IA dans ces domaines, il sera crucial de explorer comment l’IA peut compléter la créativité humaine plutôt que de la remplacer, en favorisant la collaboration entre les humains et les machines pour produire du contenu innovant et impactant.
Voici un exemple de comment GPT-4 peut être intégré à un projet Python pour des tâches créatives, spécifiquement dans le domaine de l’écriture. Ce code montre comment exploiter les capacités de GPT-4 pour générer des formats de texte créatif, tels que la poésie.
import openai
# Mettez votre clé API OpenAI
openai.api_key = "YOUR_API_KEY"
# Définissez une fonction pour générer de la poésie
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# Exemple d'utilisation
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
Voyons ce qui se passe ici :
-
Importer la bibliothèque OpenAI : Le code importe d’abord la bibliothèque
openaipour accéder à l’API OpenAI. -
Définir une clé API : Remplacez
"YOUR_API_KEY"avec votre clé API OpenAI réelle. -
Définir la fonction
generate_poetry: Cette fonction prend letopicet lestyledu poème en entrée et utilise l’API ChatCompletion d’OpenAI pour générer le poème. -
Construire le prompt : Le prompt combine le
topicet lestyleen une instruction claire pour GPT-4. -
Envoyer le prompt à GPT-4 : Le code utilise
openai.ChatCompletion.createpour envoyer le prompt à GPT-4 et reçoit le poème généré en tant que réponse. -
Retourner le poème : Le poème généré est ensuite extrait de la réponse et retourné par la fonction.
-
Utilisation de l’exemple :
Le code montre comment appeler la fonction
generate_poetryavec un sujet et un style spécifiques. Le poème résultant est ensuite affiché dans la console.
Mondes virtuels alimentés par l’IA
Le développement de mondes virtuels alimentés par l’IA représente un bond significatif dans l’expérience immersive, où les agents IA peuvent créer, gérer et faire évoluer des environnements virtuels interactifs et réactifs à l’entrée utilisateur.
Ces mondes virtuels, propulsés par l’IA, peuvent simuler des écosystèmes complexes, des interactions sociales et des narrations dynamiques, offrant aux utilisateurs une expérience profondément engageante et personnalisée.
Par exemple, dans l’industrie du jeu vidéo, l’IA peut être utilisée pour créer des personnages non joueurs (PNJ) qui apprennent du comportement du joueur, adaptant leurs actions et stratégies pour fournir une expérience plus difficile et réaliste.
Au-delà du jeu vidéo, les mondes virtuels alimentés par l’IA ont des applications potentielles dans l’éducation, où les salles de classe virtuelles peuvent être adaptées aux styles d’apprentissage et au progrès des élèves, ou dans la formation des entreprises, où des simulations réalistes peuvent préparer les employés à divers scénarios.
Le futur de ces environnements virtuels dépendra des progrès de l’IA dans la génération et la gestion de vastes écosystèmes numériques complexes en temps réel, ainsi que des considérations éthiques entourant les données utilisateur et les impacts psychologiques des expériences fortement immersives.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# Initialisation des agents
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# Attribuer une position aléatoire dans l'environnement
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# Créer et ajouter l'agent
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# Déplacer les agents (mouvement simplifié pour la démonstration)
for agent in self.agents:
agent.move(self.environment)
# TODO : Implémenter une logique plus complexe pour les interactions, les changements de l'environnement, etc.
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# Déterminer la direction de déplacement (aléatoire pour cet exemple)
direction = random.choice(['N', 'S', 'E', 'W'])
# Appliquer le déplacement en fonction de la direction
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# Mettre à jour l'environnement pour refléter la nouvelle position de l'agent
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# Exemple d'utilisation
if __name__ == "__main__":
# Définir les paramètres du monde
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# Créer le monde virtuel
world = VirtualWorld(environment_size, agent_types, agent_properties)
# Simuler le monde pendant plusieurs étapes
for _ in range(10):
world.update()
world.display()
print() # Ajouter une ligne vide pour une meilleure lisibilité
Voici ce qui se passe dans ce code :
-
Classe VirtualWorld :
-
Définit le cœur du monde virtuel.
-
Contient le quadrillage de l’environnement, une liste d’agents et les informations liées aux agents.
-
__init__(): Initialise le monde avec une taille, des types d’agents et leurs propriétés. -
add_agent(): Ajoute un nouvel agent d’un type spécifié au monde. -
update(): Effectue une mise à jour d’une seule étape du monde.- Elle ne fait actuellement que déplacer les agents, mais vous pouvez ajouter une logique complexe pour les interactions des agents, les changements de l’environnement, etc.
-
display(): Affiche une représentation basique de l’environnement.
-
-
Classe Agent :
-
Représente un agent individuel dans le monde.
-
__init__(): Initialise l’agent avec son type, sa position et ses propriétés. -
move(): Gère le déplacement de l’agent, mettant à jour sa position dans l’environnement. Cette méthode fournit actuellement un déplacement aléatoire simple, mais peut être élargie pour inclure des comportements AI complexes.
-
-
Exemple d’utilisation :
-
Configure les paramètres du monde tels que la taille, les types d’agents et leurs propriétés.
-
Créé un objet VirtualWorld.
-
Exécute la méthode
update()multiple fois pour simuler l’évolution du monde. -
Appelle
display()après chaque mise à jour pour visualiser les modifications.
-
Améliorations :
-
Plus d’IA complexe pour les agents : Implémente une IA plus sophistiquée pour le comportement des agents. Vous pouvez utiliser :
-
Algorithmes de pathfinding : Aide les agents à naviguer efficacement dans l’environnement.
-
Arbres de décision/Apprentissage automatique : Permet aux agents de prendre des décisions plus intelligentes en fonction de leur environnement et de leurs objectifs.
-
Apprentissage par réinforcement : Enseigne aux agents à apprendre et à adapter leur comportement au fil du temps.
-
-
Interaction avec l’environnement : Ajoutez des éléments dynamiques à l’environnement, comme des obstacles, des ressources ou des points d’intérêt.
-
Interaction entre agents : Implémentez des interactions entre les agents, telles que la communication, le combat ou la coopération.
-
Représentation visuelle : Utilisez des bibliothèques telles que Pygame ou Tkinter pour créer une représentation visuelle du monde virtuel.
Cet exemple constitue une base simple pour créer un monde virtuel alimenté par l’IA. Le niveau de complexité et de sophistication peut être ultérieurement étendu pour correspondre à vos besoins spécifiques et à vos objectifs créatifs.
Informatique neuromorphique et IA
L’informatique neuromorphique, inspirée de la structure et du fonctionnement du cerveau humain, est en train de révolutionner l’IA en offrant de nouvelles façons de traiter l’information efficacement et en parallèle.
Contrairement aux architectures de calcul traditionnelles, les systèmes neuromorphes sont conçus pour imiter les réseaux neuronaux du cerveau, ce qui permet à l’IA de réaliser des tâches telles que la reconnaissance de modèles, le traitement des sensations et la prise de décisions avec une plus grande vitesse et une efficacité énergétique.
Cette technologie promet une immense promesse pour développer des systèmes IA plus adaptatifs, capables d’apprendre à partir de données minimales et efficaces dans des environnements en temps réel.
Par exemple, dans la robotique, les puces neuromorphes pourraient permettre aux robots de traiter les entrées sensorielle et de prendre des décisions avec un niveau d’efficacité et de vitesse que les architectures actuelles ne peuvent pas atteindre.
Le défi à venir sera de scaler l’informatique neuromorphique pour gérer la complexité des applications AI à grande échelle, en l’intégrant avec les cadres d’IA existants pour tirer pleinement parti de son potentiel.
Les agents IA dans l’exploration spatiale.
Les agents intelligents sont de plus en plus impliqués dans l’exploration spatiale, où ils sont chargés de naviguer dans des environnements difficiles, de prendre des décisions en temps réel et d’effectuer des expériences scientifiques autonomes.
Avec les missions qui s’aventurent de plus en plus loin dans l’espace, la nécessité d’implémenter des systèmes d’IA indépendants de la supervision terrestre est de plus en plus forte. Les futurs agents intelligents seront conçus pour s’adapter à l’imprévisibilité de l’espace, comme les obstacles imprévus, les modifications des paramètres de mission ou même la nécessité d’auto-réparation.
Par exemple, l’IA pourrait être utilisée pour guider les rovers sur Mars pour explorer autonomement des terrains, identifier des sites scientifiquement précieux et même percer des échantillons avec un minimum d’intervention de la part du contrôle de mission. Ces agents intelligents pourraient également gérer les systèmes de vie supportant les missions de longue durée, optimiser l’utilisation de l’énergie et s’adapter aux besoins psychologiques des astronautes en leur offrant de la compagnie et un stimulant mental.
L’intégration de l’IA dans l’exploration spatiale non seulement améliore les capacités des missions mais ouvre également de nouvelles possibilités pour l’exploration humaine du cosmos, où l’IA sera un partenaire indispensable dans la quête de compréhension de notre univers.
Chapitre 8 : Agents intelligents dans des domaines critique pour la mission
Santé
Dans le domaine de la santé, les agents intelligents ne jouent pas uniquement un rôle de soutien mais sont devenus une composante intégrale de tout le processus de soins aux patients. Leurs effets sont les plus évidents dans la télésanté, où les systèmes d’IA ont redéfini la méthode de prestation de soins de santé à distance.
En utilisant des processus avancés de traitement du langage naturel (TLN) et d’apprentissage automatique, ces systèmes réalisent des tâches complexes telles que le tri des symptômes et la collecte préliminaire de données avec une hauteur de précision. Ils analysent les symptômes signalés par les patients et les antécédents médicaux en temps réel, en croisant cette information contre des bases de données médicales extensives pour identifier des conditions potentielles ou des avertissements.
Cela permet aux fournisseurs de soins de santé de prendre des décisions informées plus rapidement, en réduisant le temps jusqu’au traitement et potentiellement en sauvant des vies. De plus, les outils de diagnostic assistés par l’IA dans l’imagerie médicale sont transformant la radiologie en détectant des patrons et anomalies dans les radiographies, IRM et scanner qui pourraient être imperceptibles à l’œil humain.
Ces systèmes sont entraînés sur des jeux de données vastes composés de millions d’images annotées, ce qui leur permet non seulement de répliquer mais souvent de dépasser les capacités diagnostiques humaines.
L’intégration de l’IA dans les soins de santé s’étend également aux tâches administratives, où l’automatisation de la programmation des rendez-vous, des rappels de médicaments et des suivis patients réduit considérablement le fardeau opérationnel des employés de santé, leur permettant de se concentrer sur les aspects pluscritiques du traitement des patients.
Finance
Dans le secteur financier, les agents intelligents ont révolutionné les opérations en introduisant des niveaux d’efficience et de précision sans précédent.
Le trading algorithmique, qui repose fortement sur l’IA, a transformé la façon dont les transactions sont exécutées sur les marchés financiers.
Ces systèmes sont capables d’analyser des jeux de données massifs en millisecondes, à identifier les tendances du marché et à effectuer des transactions au moment optimal pour maximiser les profits et minimiser les risques. Ils exploitent des algorithmes complexes qui intègrent des techniques d’apprentissage automatique, d’apprentissage profond et d’apprentissage par renforcement pour s’adapter aux conditions du marché changeantes, prenant des décisions en millisecondes que les négociateurs humains ne pourraient jamais atteindre.
Au-delà du trading, l’IA joue un rôle crucial dans la gestion du risque en évaluant les risques de crédit et en détectant les activités frauduleuses avec une précision remarquable. Les modèles d’IA utilisent l’analyse prédictive pour évaluer la probabilité de défaut du prêteur en analysant les modèles dans les historiques de crédit, les comportements de transactions et d’autres facteurs pertinents.
De plus, dans le domaine de la conformité réglementaire, l’IA automatise le suivi des transactions pour détecter et signaler des activités suspectes, assurant que les institutions financières respectent des exigences réglementaires strictes. Cette automatisation non seulement atténue le risque d’erreur humaine, mais aussi streamline les processus de conformité, réduisant les coûts et améliorant l’efficacité.
Gestion des urgences
Le rôle de l’IA dans la gestion des urgences est de transformation, modifiant fondamentalement la façon dont les crises sont prédites, gérées et atténuées.
Dans les opérations de secours, les agents IA traite des quantités immenses de données provenant de multiples sources – allant des images satellite à les flux des réseaux sociaux – pour fournir une vue d’ensemble de la situation en temps réel. Des algorithmes d’apprentissage automatique analysent ces données pour identifier des modèles et prédire la progression des événements, permettant aux intervenants de réponse d’urgence deffectuer des ressources plus efficacement et de prendre des décisions informées sous pression.
Par exemple, lorsqu’une catastrophe naturelle telle que l’ouragan, les systèmes d’IA peuvent prédire la trajectoire et l’intensité de la tempête, permettant aux autorités de déclencher des ordres d’évacuation à temps et de déployer des ressources dans les régions les plus vulnérables.
Dans l’analyse prédictive, les modèles d’IA sont utilisés pour prédire les événements d’urgence potentiels en analysant les données historiques ainsi que les entrées en temps réel, permettant des mesures proactives qui peuvent prévenir les catastrophes ou atténuer leur impact.
Les systèmes de communication publique dotés d’IA jouent également un rôle crucial pour s’assurer que l’information exacte et à temps atteint les populations touchées. Ces systèmes peuvent générer et diffuser des alertes d’urgence sur plusieurs plateformes, personnalisant le message selon différentes démographies pour assurer la compréhension et le respect.
Et l’IA améliore la préparation des干预istes d’urgence en créant des simulations de formation hautement réalistes à l’aide de modèles génératifs. Ces simulations répliquent les complexités des urgences mondiales réelles, permettant aux干预istes de raffiner leurs compétences et d’améliorer leur préparer pour les événements réels.
Transports
Les systèmes d’IA sont devenus indispensables dans le secteur des transports, où ils améliorent la sécurité, l’efficacité et la fiabilité dans divers domaines, y compris la gestion du trafic aérien, les véhicules autonomes et les transports publics.
Dans la gestion du trafic aérien, les agents d’IA sont cruciaux pour optimiser les trajectoires de vol, prédire les conflits potentiels et gérer les opérations des aéroports. Ces systèmes utilisent l’analyse prédictive pour prévoir les embouts de trafic aérien potentiels, réaffectant en temps réel les vols pour assurer la sécurité et l’efficacité.
Dans le domaine des véhicules autonomes, l’IA est au cœur de la capacité des véhicules à traiter les données des capteurs et à prendre des décisions à la seconde précédente dans des environnements complexes. Ces systèmes utilisent des modèles d’apprentissage profond permis par des jeux de données volumineux pour interpréter les données visuelles, auditives et spatiales, permettant une navigation sécurisée dans des conditions dynamiques et imprévisibles.
Les systèmes de transport public bénéficient également de l’IA par l’optimisation des itinéraires, l’entretien prédictif des véhicules et la gestion du flux passagers. En Analyse des données historiques et en temps réel, les systèmes IA peuvent ajuster les horaires de transports, prévoir et prévenir les défaillances des véhicules et gérer la circulation pendant les heures de pointe, améliorant ainsi l’efficacité et la fiabilité des réseaux de transport.
Le secteur de l’énergie
L’IA joue un rôle crucial dans le secteur de l’énergie, notamment dans la gestion du réseau électrique, l’optimisation des énergies renouvelables et la détection des anomalies.
Dans la gestion du réseau électrique, des agents IA surveillent et contrôlent les réseaux électriques en analysant les données en temps réel provenant de capteurs répartis dans le réseau. Ces systèmes utilisent l’analyse prédictive pour optimiser la distribution de l’énergie, assurant que la demande est satisfaite tout en minimisant la perte d’énergie. Des modèles IA prédisent également les potentiels défaillances dans le réseau, permettant un entretien préventif et réduisant le risque d’interruptions.
Dans le domaine des énergies renouvelables, les systèmes IA sont utilisés pour prédire les patrons météorologiques, ce qui est crucial pour optimiser la production d’énergie solaire et éolienne. Ces modèles analysent les données météorologiques pour prédire l’intensité du soleil et la vitesse du vent, permettant de faire des prédictions plus précises de la production d’énergie et une meilleure intégration des sources renouvelables dans le réseau.
La détection des défauts est une autre domaine où l’IA fait d’importantes contributions. Les systèmes IA analysent les données de capteurs provenant d’équipements tels que les transformateurs, les turbines et les générateurs pour identifier les signes d’usure et de défaillance potentielles avant qu’elles ne provoquent des pannes. Cette approche de maintenance prédictive non seulement prolonge la durée de vie de l’équipement mais assure également une distribution continue et fiable d’énergie.
Cybersécurité
Dans le domaine de la cybersécurité, les agents IA sont essentiels pour maintenir l’intégrité et la sécurité des infrastructures numériques. Ces systèmes sont conçus pour surveiller en continu le trafic réseau, en utilisant des algorithmes d’apprentissage automatique pour détecter les anomalies qui pourraient indiquer une violation de la sécurité.
En analysant des quantités vastes de données en temps réel, les agents IA peuvent identifier les patrons de comportement malveillant, tels que des tentatives d’accès de login inhabituels, des activités d’exfiltration de données ou la présence de malware. Une fois une menace potentielle détectée, les systèmes IA peuvent automatiquement initier des mesures correctives, telles que l’isolation des systèmes compromise et la déploiement de correctifs, pour prévenir un dommage ultérieur.
L’évaluation des vulnérabilités est une autre application critique de l’IA dans la cybersécurité. Les outils dotés d’IA analysent le code et les configurations systèmes pour identifier les faiblesses de sécurité potentielles avant qu’elles ne puissent être exploitées par des attaquants. Ces outils utilisent des techniques d’analyse statique et dynamique pour évaluer la posture de sécurité des composants logiciels et matériels, fournissant des informations pratiques aux équipes de cybersécurité.
L’automatisation de ces processus non seulement améliore la vitesse et l’exactitude de la détection et de la réponse aux menaces, mais réduit également la charge de travail des analystes humains, leur permettant de se concentrer sur des défis de sécurité plus complexes.
Fabrication
Dans la fabrication, l’IA est à l’origine de progrès importants dans la qualité du contrôle, l’entretien prédictif et l’optimisation de la chaîne d’approvisionnement. Les systèmes de vision par ordinateur dotés d’IA sont désormais capables d’inspecter les produits pour les défauts à une vitesse et une précision qui dépassent nettement les capacités humaines. Ces systèmes utilisent des algorithmes d’apprentissage profond é entraînés sur des milliers d’images pour détecter les plus petites imperfections des produits, assurant ainsi une qualité uniforme dans un environnement de production à haute volume.
L’entretien prédictif est un autre domaine dans lequel l’IA a un impact profond. En analysant les données provenant de capteurs intégrés dans la machinerie, les modèles IA peuvent prédire quand un équipement est susceptible de failler, permettant la planification de l’entretien avant l’occurrence d’un arrêt. Cette approche non seulement réduit le temps d’arrêt mais also prolonge la durée de vie de la machinerie, entraînant des économies importantes.
Dans la gestion de la chaîne d’approvisionnement, les agents IA optimisent les niveaux d’inventaire et les logistiques en analysant les données de toute la chaîne d’approvisionnement, y compris les prévisions de demande, les calendriers de production et les itinéraires de transport. En effectuant des ajustements en temps réel aux plans d’inventaire et de logistique, l’IA assure que les processus de production se déroulent sans encombre, minimalisant les retards et réduisant les coûts.
Ces applications démontrent le rôle crucial de l’IA dans l’amélioration de l’efficacité opérationnelle et de la fiabilité dans la fabrication, en faisant d’elle un outil indispensable pour les entreprises souhaitant rester concurrentielles dans une industrie évoluant rapidement.
Conclusion
L’intégration d’agents IA avec de grands modèles de langue (LLM) marque une étape significative dans l’évolution de l’intelligence artificielle, débloquant des capacités sans précédent dans diverses industries et domaines scientifiques. Cette synergie améliore la fonctionnalité, l’adaptabilité et l’applicabilité des systèmes IA, traitant les limitations inhérentes aux LLM et permettant des processus de décision plus dynamiques, contextuels et autonomes.
De révolutionner la santé et les finances à transformer les transports et la gestion des urgences, les agents IA sont les drivers de l’innovation et de l’efficacité, ouvrant la voie vers un futur où les technologies IA sont profondément imbriquées dans notre vie quotidienne.
Au fur et à mesure que nous explorons le potentiel des agents IA et des LLM, il est crucial de fonder leur développement sur des principes éthiques qui mettent le bien-être humain, l’égalité et l’inclusivité en priorité. En assurant que ces technologies sont conçues et déployées de manière responsable, nous pouvons exploiter leur potentiel pour améliorer la qualité de vie, promouvoir la justice sociale et relever les défis mondiaux.
L’avenir de l’IA se trouve dans l’intégration sans bords des agents IA avancés avec des LLM sophistiqués, créant des systèmes intelligents qui non seulement augmentent les capacités humaines mais également défendent les valeurs qui définissent notre humanité.
La convergence des agents IA et des LLM représente un nouvel paradigme dans l’IA, où la collaboration entre l’agile et le puissant débloque un univers de possibilités sans frontières. En exploitant cette synergie, nous pouvons stimuler l’innovation, faire avancer les découvertes scientifiques et créer un avenir plus équitable et prospère pour tous.
A propos de l’auteur
Voici Vahe Aslanyan, au carrefour de la science informatique, des sciences des données et de l’IA. Visitez vaheaslanyan.com pour voir un portfolio témoignant de précision et de progrès. Mon expérience relie le développement full-stack et l’optimisation de produits IA, motivé par la résolution de problèmes de nouvelles manières.
Avec un dossier qui comprend le lancement d’un bootcamp de data science de premier plan et de collaboration avec les meilleurs spécialistes de l’industrie, mon attention reste concentrée sur l’élévation de l’éducation technique aux normes universelles.
Comment pouvez-vous plonger plus profondément ?
Après l’étude de ce guide, si vous souhaitez plonger encore plus profondément et que le style d’apprentissage structuré vous convient, envisagez de vous joindre à nous à LunarTech, nous offrons des cours individuels et un Bootcamp en Science des Données, Apprentissage Automatique et Intelligence Artificielle.
Nous proposons un programme complet offrant une compréhension approfondie de la théorie, une mise en œuvre pratique, un matériel de pratique extensif et une préparation personnalisée aux entretiens pour vous préparer au succès à votre propre étape.
Vous pouvez vous inscrire à notre Bootcamp Data Science ultime et profiter d’un essai gratuit pour vous familiariser avec le contenu. Il a été reconnu comme l’un des Meilleurs Bootcamps de Data Science de 2023 et a été présenté dans des publications renommées telles que Forbes, Yahoo, Entrepreneur et d’autres. C’est votre chance de devenir membre d’une communauté qui prospère sur l’innovation et le savoir. Voici le message de bienvenue !
Connectez-vous avec moi

Suivez-moi sur LinkedIn pour avoir plein de Ressources Gratuites en SI, ML et IA
-
Abonnez-vous à mon Newsletter de la Science des Données et de l’IA
Si vous voulez en savoir plus sur une carrière dans les Sciences des Données, l’Apprentissage Automatique et l’Intelligence Artificielle, et apprendre comment obtenir un emploi dans les Sciences des Données, vous pouvez télécharger ce guide gratuit Handbook de Carrière en Science des Données et en Intelligence Artificielle.
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/