













De snelle evolutie van de kunstmatige intelligentie (AI) heeft een krachtige synergie ontstaan tussen grote taalklassen (LLMs) en AI-agenten. Dit dynamische spel is eigenlijk wat als de sage van David en Goliath (zonder de strijd), waar agile AI-agenten de mogelijkheden van de colossale LLMs versterken en vergroten.
Dit handboek zal ontdekken hoe AI-agenten – vergelijkbaar met David – de LLMs – onze moderne Goliaths – superversterken om verschillende industrieën en wetenschappelijke domeinen te helpen revolutioneren.
Inhoudsopgave
-
Chapter 2: De geschiedenis van de kunstmatige intelligentie en AI-agenten
-
Hoofdstuk 4: De filosofische grondslag van intelligentie systemen
-
Hoofdstuk 6: Architectuur ontwerp voor de integratie van AI-agents met LLMs
De opkomst van AI-agenten in taalmodellen
AI-agenten zijn onafhankelijke systemen die zijn ontworpen om hun omgeving te waarnemen, beslissingen te nemen en acties uit te voeren om specifieke doelstellingen te behalen. Wanneer ze worden geïntegreerd met LLM’s, kunnen deze agenten complexe taken uitvoeren, informatie overleggen en nieuwe oplossingen genereren.
Deze combinatie heeft tot significante vooruitgang geleid in vele sectoren, van softwareontwikkeling tot wetenschappelijk onderzoek.
Transformerende impact over de industrie
De integratie van AI-agenten met LLM’s heeft een diepe impact gehad op verschillende industrieën:
-
Softwareontwikkeling: door AI-gebaseerde codeassistenten, zoals GitHub Copilot, die de mogelijkheid hebben ge demonstreerd maximaal 40% van het code te genereren, met name een opmerkelijke toename van 55% in de ontwikkelingssnelheid.
-
Onderwijs: door AI-gebaseerde leerassistenten, die beloftes hebben gemaakt in gemiddelde cursusafsluitingstijd met 27% te verkorten, en misschien de onderwijslandschap revolutionerend.
-
Vervoer: Met projecties die suggereren dat 10% van de voertuigen in 2030 zonder bestuurder zullen zijn, zijn autonome AI-agenten in zelfrijdende auto’s op het punt om de transportsector te transformeren.
Wetenschappelijke ontdekking
Een van de meest spannende toepassingen van AI-agenten en LLM’s is in de wetenschappelijke onderzoek:
-
Geneeskunde: AI-agenten zijn het voortouw nagelaten in het geneesproces door analyse van grote datasets en voorspellingen van potentiële geneesmiddelen, waardoor de tijd en kosten van traditionele methoden aanzienlijk worden verminderd.
-
Deeltjesfysica: Bij CERN’s LHC worden AI-agents ingezet om deeltjesbotsingdata te analyseren, gebruik makende van anomaliedetectie om gunstige leads te identificeren die kunnen wijzen op de bestaansmogelijkheid van onontdekte deeltjes.
-
Algemeen Wetenschappelijk Onderzoek: AI-agents verhogen de snelheid en de scope van wetenschappelijke ontdekkingen door het analyseren van voorgaande studies, de identificeren van onverwachte verbanden en het voorstellen van nieuwe experimenten.
De convergentie tussen AI-agents en grote taalkundige modellen (LLMs) drijft de kunstmatige intelligentie aan tot een nieuwe periode van ongeziene mogelijkheden. Dit compilatiewerk onderzoekt de dynamische interactie tussen deze twee technologieën, onthulende hun gecombineerde potentiële om industries te revolueren en complexe problemen op te lossen.
We zullen de evolutie van AI van zijn begin tot de opkomst van autonome agents en de ontwikkeling van geavanceerde LLMs volgen. We zullen ook ethische overwegingen verkennen, die fundamenteel zijn aan de verantwoorde ontwikkeling van AI. Dit zal helpen ons ervoor zorgen dat deze technologieën overeenstemmen met onze menselijke waarden en de welvaart van de maatschappij.
Na het afronden van dit handboek zult u een diepgaande begrip hebben van de synergistische kracht van AI-agents en LLMs, samen met de kennis en gereedschap om deze voorloperige technologie te benutten.
Hoofdstuk 1: Inleiding tot AI-agents en taalkundige modellen
Wat zijn AI-agents en grote taalkundige modellen?
De snelle evolutie van kunstmatige intelligentie (AI) heeft een vernieuwende synergie tussen grote taalkundige modellen (LLMs) en AI-agents opgeroepen.
AI-agenten zijn onafhankelijke systemen die ontworpen zijn om hun omgeving te beïnvloeden, beslissingen te nemen en acties uit te voeren om specifieke doelen te bereiken. Ze tonen kenmerken als autonomie, perceptie, reactiviteit, redenering, beslissen, leren, communicatie en doelgerichtheid.
Anders zijn LLM’s geavanceerde AI-systemen die diep leren technieken en grote datasets gebruiken om menselijkeachtige tekst te begrijpen, te genereren en te voorschrijven.
Deze modellen, zoals GPT-4, Mistral, LLama, hebben bijgewerkt aan verrassende mogelijkheden in natuurlijke taalverwerkingstaakken, inclusief tekstgeneratie, taalvertaling en conversatiesystemen.
Belangrijke kenmerken van AI-agenten
AI-agenten hebben enkele onderscheidende eigenschappen die hen van traditionele software onderscheiden:
- Autonomie: Ze kunnen zelfstandig operationeel zijn zonder constante menselijke干预.diy9>
-
Perceptie: Agenten kunnen hun omgeving door middel van diverse invoer detecteren en interpreteren.
-
Reactiviteit: Ze reageren dynamisch op veranderingen in hun omgeving.
-
Redeneren en besluitvorming: Agenten kunnen gegevens analyseren en geïnformeerde keuzes maken.
-
Leren: Ze verbeteren hun prestaties in de loop van de tijd door ervaring.
-
Communicatie: Agenten kunnen communiceren met andere agenten of mensen met behulp van verschillende methoden.
-
Doelgerichtheid: Ze zijn ontworpen om specifieke doelstellingen te bereiken.
Mogelijkheden van Grote Taalmodellen
Grote taalmodellen hebben een breed scala aan mogelijkheden aangetoond, waaronder:
-
Tekstgeneratie: Grote taalmodellen kunnen samenhangende en contextueel relevante tekst produceren op basis van aanwijzingen.
-
Taalvertaling: Ze kunnen tekst met hoge nauwkeurigheid vertalen tussen verschillende talen.
-
Samenvatting
: LLMs kunnen lange teksten samenvatten in korte samenvattingen terwijl belangrijke informatie behouden wordt.
-
Vraagbehandeling: Ze kunnen exacte antwoorden geven op vragen gebaseerd op hun uitgebreide kennisbank.
-
Sentiment Analyse: LLMs kunnen analyseren en bepalen van de gemoedsaard die uitgedragen wordt in een gegeven tekst.
-
Code Generatie: Ze kunnen code fragmenten of complete functies genereren op basis van natuurlijke taal beschrijvingen.
Niveaus van AI-agenten
AI-agenten kunnen op basis van hun mogelijkheden en complexiteit in verschillende niveaus worden onderverdeeld. Volgens een paper op arXiv, worden AI-agenten ingedeeld in vijf niveaus:
-
Niveau 1 (L1): AI-agenten als onderzoeksassistenten, waar wetenschappers hypoteses stellen en taken specificeren om doelstellingen te behalen.
-
Niveau 2 (L2): AI-agents die zelfstandig bepaalde specifieke taken kunnen uitvoeren binnen een vastgelegd scope, zoals data-analyse of eenvoudige besluitvorming.
-
Niveau 3 (L3): AI-agents die kunnen leren van ervaring en zich aanpassen aan nieuwe situaties, hun besluitvormingsprocessen verbeteringen aanreiking.
-
Niveau 4 (L4): AI-agents met geavanceerde redeneer- en problemoplossingsvaardigheden, in staat complexe, meerstaps taken te behandelen.
-
Niveau 5 (L5): Volledig zelfstandige AI-agents die onafhankelijk kunnen functioneren in dynamische omgevingen, beslissen en acties ondernemen zonder menselijke干预.
Beperkingen van Grote Taalmodellen
Trainingkosten en hulpbronnenbeperkingen
Grote taalmodellen (LLMs) zoals GPT-3 en PaLM hebben de natuurlijke taalverwerking (NLP) revolutioneerd door middel van diepe leertechnieken en uitgebreide datasets te benutten.
Maar deze vooruitgang komt met een significante kosten. Trainen van LLMs vereist omvangrijke computatieressourcen, vaak met behulp van duizenden GPU’s en uitgebreide energieverbruik.
Volgens Sam Altman, CEO van OpenAI, was de trainingskosten voor GPT-4 meer dan $100 miljoen. Dit is in lijn met de gemelde schaal en complexiteit van het model, met schattingen die suggereren dat het ongeveer 1 triljoen parameters heeft. Echter, andere bronnen geven andere getallen:
-
Een onthullende rapport uitgebracht dat de trainingskosten voor GPT-4 ongeveer $63 miljoen waren, rekening houdend met de rekenkracht en de trainingsduur.
-
Tot midden 2023 stelden sommige schattingen voor dat het trainen van een model gelijkend op GPT-4 ongeveer $20 miljoen kostte en ongeveer 55 dagen in beslag nam, reflecterend op vooruitgangen in efficiency.
De hoog kosten van het trainen en behouden van LLM’s beperken hun algemeen gebruik en schaalbaarheid.
Data beperkingen en vooroordelen
Het functioneren van LLM’s is erg afhankelijk van de kwaliteit en diversiteit van de trainingsgegevens. Ondanks dat LLM’s zijn getraind op massieve gegevenssets, kunnen ze nog steeds vooroordelen in de gegevens vertonen, wat leidt tot onjuist of ongepaste uitvoer.these vooroordelen kunnen zich in verschillende vormen manifesteren, inclusief gender, ras en culturele vooroordelen, die stereotypen en misinformatie kunnen doorsturen.
Ook de statische natuur van de trainingsgegevens betekend dat LLM’s misschien niet bijgewerkt zijn met de nieuwste informatie, wat hun effectiviteit in dynamische omgevingen beperkt.
Specialisatie en complexiteit
Alhoewel LLM’s goed zijn in algemene taken, struikelen ze vaak over bij specialiseerde taken die domeinspecifieke kennis en hoog niveau complexiteit vereisen.
Bijvoorbeeld taken in gebieden zoals geneeskunde, rechtspraak en wetenschappelijk onderzoek vereisen een diep begrip van specifieke termen en gecompliceerd redeneren, wat LLM’s mogelijk niet intrinsiek bezitten. Deze beperking maakt het noodzakelijk om extra lagen van expertise te integreren en de LLM’s te fijn afstemmen om effectief te zijn in specifieke toepassingen.
Invoer- en sensorische beperkingen
Krachten van LLM’s processen voornamelijk gebaseerd op tekstinput, wat hun vermogen beperkt om met de wereld op een multimodale manier te interacteren. Hoewel ze tekst kunnen genereren en begrijpen, ontberen ze de mogelijkheid om direct visuele, auditieve of sensorische input te verwerken.
Deze beperking hindert hun toepassing in gebieden die vereisen om een uitgebreide sensorische integratie, zoals robotica en autonome systemen. Bijvoorbeeld, een LLM kan geen visuele gegevens uit een camera of auditieve gegevens uit een microfoon interpreteren zonder aanvullende verwerkingseenheden.
Communicatie- en Interactiebeperkingen
De huidige communicatieve mogelijkheden van LLM’s zijn voornamelijk gebaseerd op tekst, wat hun vermogen beperkt om meer diepgravende en interactieve vormen van communicatie te ondernemen.
Bijvoorbeeld, terwijl LLM’s tekstreacties kunnen genereren, kunnen ze geen video- of hologrammen produceren, die steeds belangrijker worden in virtuele en geavanceerde realiteitstoepassingen (lees meer hier). Deze beperking vermindert de effectiviteit van LLM’s in omgevingen die rijke, multimodale interacties vereisen.
Hoe AI-agenten de beperkingen van LLM’s kunnen overbruggen
AI-agenten bieden eenpromisende oplossing aan veel van de beperkingen die LLM’s ondervinden. Deze agenten zijn ontworpen om autonoom te functioneren, hun omgeving perceptie te maken, beslissingen te nemen en acties uit te voeren om specifieke doelen te behalen. Door AI-agenten te integreren met LLM’s, is het mogelijk hun capaciteiten te verhogen en hun ingebouwde beperkingen aan te pakken.
-
Verbeterd Context en Geheugen: AI-agenten kunnen context handhaven over meerdere interacties, wat leidt tot meer coherente en contextueel relevante reacties. Deze mogelijkheid is bijzonder handig in toepassingen die langetermijneigenschappen en continuïteit vereisen, zoals klantenservice en persoonlijke assistenten.
-
Multimodale Integratie: AI-agenten kunnen sensorische invoer uit verschillende bronnen integreren, zoals camera’s, microfoons en sensoren, wat LLM’s in staat stelt om beeld- en geluidsgegevens te verwerken en te reageren. Deze integratie is crucial voor toepassingen in robotica en autonome systemen.
-
Gespecialiseerde kennis en expertise: AI-agenten kunnen gefine-tuned worden met domeinspecifieke kennis, die de capaciteit van LLM’s verbetert om geavanceerde taken uit te voeren. Dit aanpakken maakt het mogelijk om expert-systemen te ontwikkelen die complexe vragen kunnen behandelen in gebieden als geneeskunde, rechtspraak en wetenschappelijk onderzoek.
-
Interactive en immersieve communicatie: AI-agenten kunnen meer immersieve vormen van communicatie faciliteren door middel van het genereren van video-inhoud, het besturen van holografische voorstellingen en het interacteren met virtuele en geavanceerde realiteitsomgevingen. Deze mogelijkheid breidt de toepassingen van LLM’s uit in gebieden die vereisen om rijke, multimodale interacties te laten plaatsvinden.
Hoewel grote taalmodellen opmerkelijke capaciteiten hebben getoond in natuurlijke taalverwerking, zijn ze niet zonder beperkingen. De hoge trainingkosten, gegevensbiasssen, specialisatieproblemen, sensorische beperkingen en communicatiebeperkingen vormen aanzienlijke hindernissen.
Maar de integratie van AI-agenten biedt een haalbare manier om deze beperkingen te overwinnen. Door de sterke punten van AI-agenten te benutten, is het mogelijk om de functionaliteit, aanpasbaarheid en toepasbaarheid van LLM’s te verbeteren, waardoor de weg wordt vrijgemaakt voor meer geavanceerde en veelzijdige AI-systemen.
Hoofdstuk 2: De geschiedenis van kunstmatige intelligentie en AI-agenten
De oorsprong van kunstmatige intelligentie
Het concept van kunstmatige intelligentie (AI) heeft wortels die verder reiken dan de moderne digitale tijd. De gedachte van het creëren van machines die kunnen redeneren als mensen kan worden teruggevoerd naar oude mythen en filosofische debatten. Maar de formele introductie van AI als wetenschappelijke discipline vond plaats in de middeleeuwse twintigste eeuw.
De Dartmouth Conference van 1956, georganiseerd door John McCarthy, Marvin Minsky, Nathaniel Rochester en Claude Shannon, wordt algemeen beschouwd als de geboorteplaats van de AI als een vakgebied van onderzoek. Dit开创se gebeurtenis bracht vooraanstaande onderzoeksers samen om het potentieel van het creëren van machines die menselijke intelligentie konden imiteren te onderzoeken.
Vroege Optimisme en de AI Winter
De vroege jaren van AI-onderzoek waren gekenmerkt door ongeremde optimisme. Onderzoeksers maakten significante vooruitgang in het ontwikkelen van programma’s die in staat waren om wiskundige problemen op te lossen, spellen te spelen en zelfs eenvoudige natuurlijke taalverwerking uit te voeren.
Maar dit initiële enthousiasme werd gedempte door het inzien dat het creëren van echt intelligentie machines veel complexer was dan aanvankelijk verwacht werd.
De jaren 1970 en 1980 brachten een periode van verminderde financiën en interesse in AI-onderzoek, die vaak verwezen wordt als de “AI Winter“. Deze daling was vooral veroorzaakt door het mislukken van AI-systemen om de hoogte van de verwachtingen van de vroege pioniers te meeten.
Van rechtstreekse systemen naar machinelearning
De Eerste Klasse van Expert Systeem
De jaren 1980 werden getuige van een heroprichting van interesse in AI, voornamelijk geleid door de ontwikkeling van expert systemen. Deze rechtstreekse systemen waren ontworpen om de besluitvormingsprocessen van menselijke experts in specifieke domeinen na te bootsen.
Expertensystemen vonden toepassingen in verschillende gebieden, inclusief geneeskunde, financiën en techniek. Maar ze waren beperkt door hun onvermogen om uit ervaring te leren of zich aan te passen aan nieuwe situaties buiten hun geprogrammeerde regels.
Het opkomst van Machine Learning
De beperkingen van regelgebaseerde systemen maakten plaats voor eenparadigmenwisseling in de richting van machine learning. Deze benadering, die prominentie behaalde in de jaren 90 en 2000, concentreert op het ontwikkelen van algoritmen die kunnen leren van en voorspellingen of beslissingen kunnen maken op basis van gegevens.
Machine learning technieken, zoals neurale netwerken en steun vector machines, toonden uitzonderlijk succes in taken als patronen herkenning en gegevens classificering. Het verschijnen van big data en de toename van computationele kracht versnelde de ontwikkeling en toepassing van machine learning algoritmen nog meer.
De opkomst van Autonome AI-agenten
Van Nauw AI naar Algemeen AI
Terwijl AI-technologieën doorgingen met hun ontwikkeling, begonnen onderzoekers met het onderzoeken van de mogelijkheid om meer aanpasbare en autonome systemen te creëren. Deze transitie markeerde de overgang van nauw AI, ontworpen voor specifieke taken, naar het nastreven van kunstmatige algemeen intelligentie (AGI).
AGI heeft als doel systemen te ontwikkelen die in staat zijn elke intellectuele taak uit te voeren die een mens kan, terwijl de echte AGI nog steeds een verre doel is. Toch zijn er significante vooruitgangen gemaakt in het creëren van meer flexibele en aanpasbare AI-systemen.
De rol van diepe leren en neurale netwerken
Het ontstaan van diepe leren, een deelgebied van machineleren dat gebaseerd is op kunstmatige neurale netwerken, is een belangrijke factor geweest in het vooruitgang van het veld van AI.
Algoritmen voor diepe leren, geïnspireerd op de structuur en functie van het menselijke brein, hebben vertoond dat ze uitzonderlijke capaciteiten bezitten in gebieden zoals beeld- en spraakherkenning, natuurlijke taalverwerking en spellen spelen. Deze vooruitgangen hebben de grondslag gelegd voor het ontwikkelen van meer geavanceerde autonome AI-agents.
Kenmerken en typen van AI-agents
AI-agents zijn autonome systemen die in staat zijn hun omgeving perceptie te maken, beslissingen te nemen en acties uit te voeren om specifieke doelen te behalen. Ze bezitten kenmerken zoals autonomie, perceptie, reactiviteit, redeneren, beslissen, leren, communicatie en doelgerichtheid.
Er zijn verschillende typen AI-agents, elk met hun unieke capaciteiten:
-
Eenvoudige Reflexagents: Reageren op specifieke stimuli op basis van voorgedefinieerde regels.
-
Modelgebonden reflecterende agents: Behouden een interne model van het milieu voor besluitvorming.
-
Doelgerichte agents: Uitvoeren van acties om specifieke doelen te behalen.
-
Utiliteitsgerichte agents: Overwegen potentiële uitkomsten en kiezen acties die de verwachte utiliteit maximale.
-
Lerende agents: Verbetering van besluitvorming over tijd door middel van machinaal leren methodes.
Challenges and Ethical Considerations
Als AI-systemen steeds meer geavanceerd en autonoom worden, brengen ze kritische overwegingen met zich mee om te zorgen dat hun gebruik binnen de maatschappelijk aanvaardbare grenzen blijft.
Specifiek voor Grote Taalmodelen (LLMs) zijn ze een krachtbron voor productiviteit. Maar dit brengt een cruciale vraag met zich mee: WAT zal deze systemen supercharge—goede bedoelingen of slechte bedoelingen? Wanneer de bedoeling achter het gebruik van AI kwaad is, is het noodzakelijk dat deze systemen zoeken naar zulke misbruiken met behulp van diverse NLP-technieken of andere beschikbare hulpmiddelen.
Ingenieurs van LLM hebben toegang tot een reeks gereedschap en methodieken om deze uitdagingen aan te gaan:
-
Sentiment Analyse: Door middel van sentiment analyse kunnen LLM’s de emotionele toon van tekst beoordelen om gevaarlijke of agressieve taal te detecteren, waardoor potentiële misbruiken op communicatieplatforms kunnen worden geïdentificeerd.
-
Inhoud Filter: Gereedschappen zoals keywoordfiltering en patronenmatchen kunnen worden gebruikt om het genereren of verspreiden van gevaarlijke inhoud te voorkomen, zoals haatspreek, misinformatie of expliciete materialen.
-
Bias Detection Tools: Door middel van het implementeren van biaisframeworks, zoals AI Fairness 360 (IBM) of Fairness Indicators (Google), kunnen helpen identificeren en de biais in taalmodellen aan te pakken, waardoor AI-systemen fair en equitaatief operationeel zijn.
-
Verklaarbare technieken
: Door gebruik te maken van verklaarbare gereedschap zoals LIME (Local Interpretable Model-agnostic Explanations) of SHAP (SHapley Additive exPlanations) kunnen engineers de besluitvormingsprocessen van LLMs begrijpen en verklaren, waardoor het gemakkelijker wordt om ongerechtvaardigde gedragingen op te sporen en aan te pakken.
-
Adversairale testen: door middel van het simuleren van kwaadaardige aanvallen of schadelijke invoer, kunnen engineers LLMs met gereedschap zoals TextAttack of Adversarial Robustness Toolbox laten testen, identificerende kwetsbaarheden die misbruikt kunnen worden voor kwaadaardige doelen.
-
Ethische AI-richtlijnen en kaders: Door ethische AI-ontwikkelingsrichtlijnen aan te nemen, zoals die aangeboden worden door de IEEE of de Partnership on AI, kunnen engineers verantwoordelijke AI-systemen creëren die de welvaart van de maatschappij in prioriteit hebben.
Naast deze hulpmiddelen is dit waarom we een speciaal Red Team voor AI nodig hebben – gespecialiseerde teams die LLMs tot hun grenzen duwen om hun verdedigingen te testen. Red Teams simuleren vijandige scenario’s en ontdekken kwetsbaarheden die anders onopgemerkt zouden kunnen blijven.
Maar het is belangrijk te erkennen dat de mensen achter het product de grootste invloed op het hebben. Veel van de aanvallen en uitdagingen die we vandaag de dag tegenkomen bestonden al voordat LLMs ontwikkeld werden, wat aan het menselijke element herinnert dat centraal staat bij het waarborgen van de ethische en verantwoordelijke gebruik van AI.
De integratie van deze hulpmiddelen en technieken in de ontwikkelingspijplijn, samen met een vigilante Red Team, is essentieel voor het waarborgen dat LLMs gebruikt worden om positieve resultaten te versnellen terwijl detecteert en preventie van misbruik wordt opgemerkt.
Hoofdstuk 3: Waar AI-agenten het beste uitkomen
De unieke sterke punten van AI-agenten
AI-agenten onderscheiden zich door hun vermogen om autonoom hun omgeving waar te nemen, beslissingen te nemen en acties uit te voeren om specifieke doelstellingen te bereiken. Deze autonomie, in combinatie met geavanceerde machine learning-capabilities, maakt het mogelijk voor AI-agenten taken uit te voeren die te complex of te reproductief zijn voor mensen.
Dit zijn de kenmerkende sterktes die AI-agenten uitblinken:
-
Autonomie en Efficiëntie: AI-agenten kunnen zelfstandig werken zonder constante menselijke干预. Deze autonomie maakt het mogelijk voor hen taken 24/7 af te handelen, wat significant de efficiëntie en productiviteit verbeterd. Bijvoorbeeld, AI-gebaseerde chatbots kunnen tot 80% van de dagelijkse klantcontacten afhandelen, waardoor de operationele kosten worden verminderd en de responsestijden verbeterd.
-
Geavanceerd besluitvormingsvermogen: AI-agenten kunnen grote hoeveelheden gegevens analyseren om informatieve besluiten te nemen. Deze capaciteit is bijzonder waardevol in gebieden zoals financiën, waar AI-handelrobots de handelsefficiëntie aanzienlijk kunnen verhogen.
-
Leren en aanpassen
: AI-agenten kunnen uitervaring leren en zich aanpassen aan nieuwe situaties. Deze doorlopende verbeteringen maken het mogelijk voor hen hun prestaties over tijd te verbeteren. Bijvoorbeeld, AI-gezondheidsassistenten kunnen helpen bij het verminderen van diagnosefouten, waardoor de resultaten van de gezondheidszorg verbeterd kunnen worden.
- Personaliseren: AI-agenten kunnen persoonlijke ervaringen bieden door het analyseren van gebruikersgedrag en voorkeuren. Amazon’s aanbevelingsengine, die 35% van zijn omzet drijft, is een goed voorbeeld van hoe AI-agenten de gebruikerservaring kunnen verbeteren en inkomsten kunnen stijgen.
Waarom AI-agenten de oplossing zijn.
AI-agenten bieden oplossingen voor veel van de uitdagingen die traditionele software en menselijk bestuurde systemen aan komen. Dit zijn de redenen waarom ze de voorkeur krijgen:
-
Scalabiliteit: AI-agenten kunnen operaties scalen zonder gelijkenis in kosten. Deze scalabiliteit is crucial voor bedrijven die willen groeien zonder significante toename van hun werkkracht of operationele kosten.
-
Consistentie en Betrouwbaarheid: In tegenstelling tot mensen ondervinden AI-agenten geen moeilijkheden door vermoeidheid of inconsistentie. Ze kunnen reproductieve taken met hoge nauwkeurigheid en betrouwbaarheid uitvoeren, waardoor consistente prestaties zijn gegarandeerd.
-
Data-gebaseerde Inzichten: AI-agenten kunnen grote gegevenssets verwerken en analyseren om patronen en inzichten te onthullen die mensen misschien gemist zouden kunnen worden. Deze mogelijkheid is onbereikbaar voor besluitvorming in gebieden zoals financiën, gezondheidszorg en marketing.
-
Kostenbesparingen: door de automatisering van routine-taken kunnen AI-agenten de behoefte aan menselijke resources verminderen, wat tot significante kostenbesparingen leidt. Bijvoorbeeld, AI-gebaseerde fraudeenquêtes kunnen jaarlijks miljarden van dollars besparen door het verminderen van fraudeleveringen.
Vereisten voor AI-agenten om goed te presteren
Om de succesvolle implementatie en prestatie van AI-agenten te waarborgen, moeten certaingevonden worden:
-
Duidelijke doelstellingen en toepassingsgebieden: Het definiëren van specifieke doelstellingen en toepassingsgebieden is crucial voor de effectieve implementatie van AI-agenten. Deze duidelijkheid helpt bij het instellen van verwachtingen en het meten van succes. Bijvoorbeeld, het stellen van een doel om de reactietijd van de klantenservice door AI-chatbots te reduceren tot 50% kan de implementatie van AI-chatbots begeleiden.
-
Kwaliteit gegevens: AI-agenten zijn afhankelijk van goedkope gegevens voor training en operationeel gebruik. Zorgen dat de gegevens correct, relevant en up-to-date zijn, is essentieel voor de agenten om informerende beslissingen te nemen en effectief te functioneren.
-
Integreren met bestaande systemen: Vloeiende integratie met bestaande systemen en werkstromen is noodzakelijk voor het optimale functioneren van AI-agenten. Deze integratie zorgt ervoor dat AI-agenten toegang krijgen tot de noodzakelijke gegevens en kunnen interacteren met andere systemen om hun taken uit te voeren.
-
Continu monitor en optimaliseren: Regelmatig monitor en optimaliseren van AI-agenten is crucial voor het behoud van hun prestaties. Dit omvat het volgen van kritieke prestatieindicatoren (KPIs) en het op basis van feedback en prestatiedata nodige aanpassingen uitvoeren.
-
Ethische overwegingen en systematische vooroordelen: Het aanpakken van ethische overwegingen en systematische vooroordelen in AI-agents is essentieel voor het waarborgen van eerlijkheid en inclusiviteit. Het implementeren van maatregelen om vooroordelen te detecteren en te voorkomen helpt bij het opbouwen van vertrouwen en het verzekerden van een verantwoordelijke aanleg.
Best practices voor het implementeren van AI-agents
Bij het implementeren van AI-agents kunnen best practices ervoor zorgen dat hun succes en effectiviteit worden waarborgd:
-
Defineer doelstellingen en toepassingsgebieden: Duidelijk vaststellen van de doelstellingen en toepassingsgebieden voor het implementeren van AI-agents. Dit helpt bij het stellen van verwachtingen en het meten van succes.
-
Kies de juiste AI-platform
: Kies een AI-platform dat alignt met uw doelstellingen, gebruiksgevallen en bestaande infrastructuur. Overweeg factoren als integratiecapabilities, scalabiliteit en kosten.
- Ontwikkel een uitgebreide kennisbasis: Bouw een goed georganiseerde en accurate kennisbasis om AI-agenten in staat te stellen relevante en betrouwbare reacties te geven.
- Zorg ervoor dat de integratie vloeit: Integrate AI-agenten met bestaande systemen zoals CRM en callcenter technologieën om een geünificeerde klantervaring te bieden.
- Traineer en optimaliseer AI-agenten: Train AI-agenten continu met data uit interacties. Monitor de prestaties, identificeer areas voor verbetering en update de modellen daaropaf.
-
Implementeer correcte opwaarderingprocedures: Stel protocollen in voor het overdragen van complexe of emotionele oproepen aan menselijke agenten, om een vloeiende overgang en een effectieve oplossing te waarborgen.
-
Monitoreer en analyseer prestaties: Volg kritieke prestatiegenereringen (KPIs) zoals oproepoplossingspercentages, gemiddelde behandelingstijd en klanttevredenheidscijfers. Gebruik analytics tools voor data-gebaseerde inzichten en beslissingen.
-
Beveilig gegevens en bescherm privacy: sterke beveiligingsmaatregelen zijn crucial, zoals het anonimiseren van gegevens, erop toezien dat er menselijke toezicht is, het opstellen van beleidsregels voor gegevensbehandeling en het opzetten van sterke encryptiemaatregelen om klantgegevens te beschermen en privacy te handhaven.
AI-agenten + LLMs: Een nieuw tijdperk van slimme software.
Verbeeld software die niet alleen uw verzoeken begrijpt maar ook deze uitvoert. Dat is de belofte van het combineren van AI-agenten met Grote Taalmodellen (LLMs). Deze krachtige combinatie creëert een nieuwe generatie applicaties die intuitiever, krachtiger en meer impactvol zijn dan ooit eerder.
AI-agenten: Bijdrage aan geavanceerde takenuitvoering
Terwijl ze vaak vergeleken worden met digitaal assistenten, zijn AI-agenten veel meer dan verfraaide scriptvolgers. Ze omvatten een reeks geavanceerde technologieën en werken op een framework dat dynamische besluitvorming en actievoering mogelijk maakt.
-
Architectuur: Een typische AI-agent bestaat uit verschillende kernonderdelen:
-
Sensors: Deze stellen de agent in staat om zijn omgeving te waarnemen, gegevens verzameld van diverse bronnen zoals sensoren, APIs of gebruikersinvoer.
-
Belief State: Dit weergeeft de agenten begrip van de wereld op basis van de verzamelde gegevens. Het wordt constant bijgewerkt als nieuwe informatie beschikbaar komt.
-
Redeneeringsengine: Dit is het hart van het besluitvormingsproces van de agent. Het gebruikt algoritmen, vaak gebaseerd op reïnforcement learning of planningstechnieken, om de beste actie te bepalen op basis van zijn huidige overtuigingen en doelstellingen.
-
Actuatoren: Deze zijn de tools van de agent voor het interactie met de wereld. Ze kunnen variëren van het versturen van API-aanroepen tot het besturen van fysieke robots.
-
-
Challenges: traditionele AI-agenten, hoewel ze goed opgedane taken kunnen aanpakken, vechten vaak tegen:
-
Natuurlijke taal begrip: het interpreteren van subtiele menselijke taal, het handelen met ambiguïteit en het halen van betekenis uit context zijn nog steeds significante uitdagingen.
-
Redeneren met algemeen kennis: huidige AI-agenten hebben vaak het algemeen kennisgebruik en de redeneervaardigheden die mensen geneest, ontbroken.
-
Generalisatie: het trainen van agenten om goed te presteren op ongeziene taken of aan te passen aan nieuwe omgevingen, is nog steeds een belangrijk onderzoeksgebied.
-
LLM’s: Ontdekking van taalverstand en genereren
LLM’s brengen met hun uitgebreide kennis, ingecodeerd in miljarden parameters, een ongeziene taalkracht aan tafel:
-
Transformer-architectuur: De transformer-architectuur, de basis van de meeste moderne LLM’s, is een ontwerp voor een neural network dat uitstekend sequentieel gegevens als tekst verwerkt. Dit maakt het LLM’s mogelijk om in de taal lange-afstandsafhankelijkheden op te slaan, wat hen in staat stelt context te begrijpen en coherent en contextueel relevante tekst te genereren.
-
Capabilities: LLM’s zijn uitstekend in veel taal gebaseerde taken:
-
Tekstgeneratie: Van het schrijven van creatief fictie tot de generering van code in meerdere programmeertalen, tonen LLM’s ongekende vloeiendheid en creativiteit.
-
Vraagbehandeling: Ze kunnen korte en nauwkeurige antwoorden geven op vragen, zelfs als de informatie over lange documenten verspreid is.
-
Samenvatting: LLM’s kunnen grote hoeveelheden tekst samenvatten in korte samenvattingen, uit diepe informatie belangrijke informatie en onbelangrijke details wegwerkt.
-
-
Beperkingen: Ondanks hun indrukwekkende mogelijkheden hebben LLMs beperkingen:
-
Onrealistische Aanschakeling: LLMs werken voornamelijk in het domein van de tekst en hebben geen directe interactie met de fysieke wereld.
-
Mogelijke Bias en Verhalen: Geëxporteerd op grote, niet gecontroleerde datasets, kunnen LLMs de in de gegevens aanwezige vooroordelen erfden en soms feitelijk onjuist of onzinnig informatie genereren.
-
De Samenspraak: Het Kruisbestrating van Taal en Handeling
De combinatie van AI-agenten en LLM’s addressseert de beperkingen van elke, creatie van systemen die zowel intelligent als vermogen tot actie hebben:
-
LLM’s als Interpreten en Planners: LLM’s kunnen natuurlijke taalinstructies vertalen in een formaat dat AI-agenten kunnen begrijpen, waardoor de mens-computerinteractie intuitiever wordt. Ze kunnen ook hun kennis gebruiken om agenten te assisteren bij het plannen van complexe taken door ze op te delen in kleinere, door te kunnen komen stappen.
-
AI-agenten als uitvoerders en leerders: AI-agenten bieden LLM’s de mogelijkheid om met de wereld te interacteren, informatie te verzamelen en feedback op hun acties te ontvangen. Deze realistische basis kan LLM’s helpen leren van ervaring en hun prestaties langzaam te verbeteren.
Deze krachtige synergie drijft de ontwikkeling van een nieuwe generatie applicaties aan die intuïtiever, aanpasbaarder en krachtiger zijn dan ooit. Aan de hand van beide AI-agent- en LLM-technologieën die steeds verdergaan, kunnen we verwachten dat er nog meer innovatieve en impactvolle toepassingen zullen ontstaan, die het landschap van softwareontwikkeling en mens-computerinteractie veranderen.
Reële wereldvoorbeelden: transformerende bedrijfssectoren
Deze krachtige combinatie maakt al schommelingen in verschillende sectoren:
-
Klantenservice: Problemen oplossen met contextuele bewustheid
- Voorbeeld: Verlangen we een klant die een vertraagde levering van een online winkel aanroept. Een AI-agent die wordt aangedreven door een LLM kan de frustratie van de klant begrijpen, toegang krijgen tot hun bestelgeschiedenis, de pakketten in realtime volgen, en actief aanbiedingen doen zoals verhoogde levering of korting op de volgende aankoop.
-
Inhoud creëren: Grote hoeveelheden hoogwaardige inhoud produceren
- Voorbeeld: Een marketingteam kan een AI-agent + LLM-systeem gebruiken om doelgerichte sociale media-posts te genereren, productomschrijvingen te schrijven of zelfs video-scripts te maken. De LLM zorgt ervoor dat de inhoud Engelstalig en informatief is, terwijl de AI-agent de uitgeverij en distributieproces afhandelt.
-
Softwareontwikkeling: versnelling van codering en debugging
- Voorbeeld: Een ontwikkelaar kan een softwarefunctie beschrijven die ze willen bouwen door middel van natuurlijke taal. De LLM kan dan code fragmenten genereren, potentiele fouten identificeren en suggesties voor verbeteringen aanbieden, wat de ontwikkelingsproces significant versnelt.
-
Gezondheidszorg: personaliseren van behandeling en verbeteren van patientenzorg
- Voorbeeld: Een AI-agent met toegang tot een patiënts medische geschiedenis en uitgerust met een LLM kan antwoorden op hun gezondheidsgerelateerde vragen, personaliseerde medicijnenherinneringen aanbieden en zelfs voorlopige diagnose’s op basis van hun symptomen aanbieden.
-
Wetgeving: Efficiëntieverbetering in Juridisch Onderzoek en Documentenopstellen
- Voorbeeld: Een advocaat moet een contract opstellen met bepaalde clausules en juridische voorgangers. Een AI-agent aangedreven door een LLM kan de instructies van de advocaat analyseren, door grote juridische databases bladeren, relevante clausules en voorgangers identificeren, en zelfs delen van het contract opstellen, hetgeen het benodigde tijd en moeite aanzienlijk reduceert.
-
Video Creatie: Gemakkelijk Engagerende Video’s Genereren
- Voorbeeld: Een marketingteam wil een korte video maken die de functies van hun product uitlegt. Ze kunnen een AI-agent + LLM-systeem voorzien van een scriptuitlijning en voorkeuren voor visuele stijl. De LLM kan vervolgens een gedetailleerd script genereren, geschikte muziek en beelden voorstellen, en zelfs de video bewerken, waarbij een groot deel van het video-creatieproces geautomatiseerd wordt.
-
Architectuur: Ontwerpen van gebouwen met AI-gepowerde inzichten
- Voorbeeld: Een architect ontwerpt een nieuwe kantoorgebouw. Ze kunnen een AI-agent + LLM-systeem gebruiken om hun ontwerpgoals in te geven, zoals het maximale uitbruiken van natuurlijke licht en de optimalisering van ruimtegebruik. De LLM kan dan deze doelstellingen analyseren, verschillende ontwerpopties genereren, en zelfs simuleren hoe het gebouw zou presteren onder verschillende milieuomstandigheden.
-
Bouw: Veiligheid en Efficiëntie op Bouwlocaties Verbeteren
- Voorbeeld: Een AI-agent die uitgerust is met camera’s en sensoren kan een bouwlocatie monitoren op veiligheidsgevaarlijke situaties. Als een werknemer niet de juiste veiligheidsuitrusting draagt of een apparaat in een gevaarlijke positie wordt achtergelaten, kan de LLM de situatie analyseren, de sitebeheerder waarschuwen en zelfs automatisch de activiteiten onderbreken indien nodig.
Het Verleden is Verleden: Een Nieuwe Era van Softwareontwikkeling
De convergentie van AI-agenten en LLMs maakt een grote sprong vooruit in softwareontwikkeling. Terwijl deze technologieën doorgaan met evolueren, kunnen we verwachten dat er nog meer innovatieve toepassingen zullen ontstaan, die industries veranderen, werkstromen streamlineen en nieuwe mogelijkheden voor mens-computerinteractie creëren.
AI-agenten zijn het meest verlicht in gebieden die veel data verwerken, automatiseren van repeterende taken, maken van complexe beslissingen en bieden van persoonlijke ervaringen vereisen. Door de noodzakelijke voorwaarden te meeten en best practices te volgen, kunnen organisaties de volledige potentiële van AI-agenten benutten om innovatie, efficiency en groei aan te drijven.
Kapitel 4: De filosofische grondslag van intelligentie systemen
Het ontwikkelen van intelligentie systemen, vooral in het gebied van kunstmatige intelligentie (AI), vereist een diepgaande begrip van filosofische beginselen. In dit hoofdstuk wordt ingegaan op de kernfilosofische ideeën die de ontwerp, ontwikkeling en gebruik van AI bepalen. Het betonigt de noodzaak van aligneren van technologische vooruitgang met ethische waarden.
De filosofische grondslag van intelligentie systemen is geen theoretische oefening alleen – het is een essentieel raamwerk dat er voor zorgt dat AI-technologieën de mensheid behulpzaam zijn. Door de promotie van rechtvaardigheid, inclusiviteit en het verbeteren van de kwaliteit van leven, helpen deze beginselen AI terug te leiden naar onze beste belangen.
Ethisch overleg bij de ontwikkeling van AI
Als AI-systemen steeds meer geïntegreerd worden in elk aspect van de menselijke wereld, van gezondheidszorg en onderwijs tot financieren en bestuur, moeten we hun ontwerp en implementatie strikt ethisch beoordelen en toepassen.
Het algemeen ethische vraagstuk gaat over hoe AI kan worden geconstrueerd om de menselijke waarden en morele beginselen uit te voeren en te handhaven. Dit vraagstuk is centraal bij de manier waarop AI de toekomst van samenlevingen wereldwijd zal bepalen.
Het hart van dit ethische overleg is het beginsel van beneficie, een steunpunt van de morele filosofie dat voorschrijft dat handelingen moeten zijn gericht op het doen van goed en het verbeteren van de welzijn van individuen en de maatschappij in zijn geheel (Floridi & Cowls, 2019).
In het kader van AI betekent beschermende vruchtbaarheid het ontwerpen van systemen die actief bijdragen aan de bloei van de mensheid — systemen die de gezondheidsresultaten verbeteren, de educatieve mogelijkheden vergroten en de rechtvaardige economische groei faciliteren.
Maar de toepassing van beschermende vruchtbaarheid in AI is niet eenvoudig. Het vereist een gekleurde aanpak die voorzichtig de potentiële voordelen van AI weegt tegen de mogelijke risico’s en schades.
Eén van de belangrijkste uitdagingen bij het toepassen van het principe van beschermende vruchtbaarheid bij de ontwikkeling van AI is de nodige balanceren tussen innovatie en veiligheid.
AI heeft de mogelijkheid om velden als de geneeskunde revolutionair te maken, waar voorspellende algoritmen ziekten eerder en nauwkeuriger kunnen diagnoseren dan menselijke dokters. Maar zonder strikte ethische toezicht kunnen dezelfde technieken bestaande ongelijkheden versterken.
Dit zou bijvoorbeeld kunnen gebeuren als ze voornamelijk in rijke gebieden worden uitgevoerd terwijl minder ontwikkelde gemeenschappen nog steeds basisgezondheidszorg ontberen.
Omwille hiervan vereist ethische AI-ontwikkeling niet alleen een focus op het maximale uitbrengen van voordelen, maar ook een vooruitgangsgerichte aanpak voor risico-reductie. Dit betekent het invoering van solide bescherming om misbruik van AI te voorkomen en ervoor te zorgen dat deze technologieën per ongeluk geen schade toebrengen.
Het ethische kader voor AI moet ook inherent inclusief zijn, ervoor zorgende dat de voordelen van AI gelijkmatig worden verspreid over alle maatschappelijke groepen, inclusief die die traditioneel worden gediscrimineerd. Dit vraagt om een verbintenis aan recht en rechtvaardigheid, ervoor zorgende dat AI niet alleen de status quo bevestigt maar actief werkt systemische ongelijkheden neer te halen.
Bijvoorbeeld, automatisering van banen door middel van AI heeft potentiële bijdrages aan productiviteit en economische groei. Maar het kan ook leiden tot een significante vervanging van banen, die vooral arme werknemers ontelaat.
Zoals u kunt zien, moet een ethisch verantwoorde AI-raamwerk strategieën bevatten voor een rechtvaardig delen van de voordelen en de voorziening van ondersteuningssystemen voor diegene die negatief beïnvloed worden door de vooruitgang van AI.
Het ethische ontwikkelen van AI vereist continu deelname van diverse belanghebbenden, inclusief ethici, technologen, politieke beslissers en de gemeenschappen die het meest beïnvloed zullen worden door deze technologieën. Deze interdisciplinair samenwerking zorgt ervoor dat AI-systemen niet in een vacuüm ontwikkeld worden, maar in plaats daarvan gevormd worden door een breed scala van perspectieven en ervaringen.
Het is door deze collectieve inspanning dat we AI-systemen kunnen creëren die niet alleen de waarden weerspiegelen maar ook deze handhaven, die onze mensheid definiëren —compassie, eerlijkheid, respect voor autonomie en een verbintenis tot het algemeen belang.
De ethische overwegingen in de ontwikkeling van AI zijn niet alleen richtlijnen, maar essentiële elementen die bepalen of AI een goede kracht ter wereld is. door AI op de beginselen van deugd, rechtvaardigheid en inclusiviteit te gronden, en door een voorzichtige aanpak van de balans tussen innovatie en risico, kunnen we ervoor zorgen dat de ontwikkeling van AI niet alleen de technologie voordraagt, maar ook de kwaliteit van het leven voor alle leden van de maatschappij verbetert.
Als we doorgaan met het verkennen van de mogelijkheden van AI, is het noodzakelijk dat deze ethische overwegingen steeds aan het voorfront van onze pogingen blijven, ons geleidend naar een toekomst waarin AI echt de mensheid voordelen brengt.
De noodzaak van een mensgerichte AI-ontwikkeling
Mensgerichte AI-ontwikkeling gaat verder dan alleen maar technische overwegingen. Het is gevestigd in diepe filosofische beginselen die de menselijke waardigheid, autonomie en actieve beschiktheid voorstellen.
Deze aanpak van AI-ontwikkeling is fundamenteel geankerd in de kantiaanse ethische raamwerk, dat stelt dat mensen gezien moeten worden als doelen in zichzelf, niet alleen als instrumenten voor het behalen van andere doelen (Kant, 1785).
De implicaties van dit beginsel voor AI-ontwikkeling zijn diepgaand, die vereisen dat AI-systemen worden ontwikkeld met een onverzadigde focus op dienstbaarheid aan menselijke belangen, het behoud van menselijke agentie en de respectering van individuele autonomie.
Technische implementatie van de beginselen van mensgerichtheid
Autonomie van de mens vergroten door AI: Het concept van autonomie in AI-systemen is kritiek, vooral voor het behouden van de macht van gebruikers in plaats van het controleren of ongerechtvaardigd beïnvloeden van hen.
In technische termen betekent dit het ontwerpen van AI-systemen die de gebruikersautonomie prioriteren door hen de tool’s en informatie te bieden die nodig zijn om informeerde beslissingen te nemen. Dit vereist dat AI-modellen context-bewust zijn, wat betekent dat ze moeten begrijpen waarin de beslissing wordt genomen en hun aanbevelingen daarop aanpassen.
Vanuit het perspectief van systeemontwerp betekent dit de integratie van contextuele intelligentie in AI-modellen, die deze systemen in staat stellen dynamisch aan te passen aan de omgeving, voorkeuren en behoeften van de gebruiker.
Bijvoorbeeld in de gezondheidszorg, moet een AI-systeem dat artsen assisteert bij het diagnoseren van aandoeningen rekening houden met de unieke medische geschiedenis van de patient, de huidige symptomen, en zelfs de psychologische toestand om aanbevelingen uit te voeren die de expertise van de arts ondersteunen in plaats van haar te vervangen.
Dit contextuele aanpassen zorgt ervoor dat AI een ondersteunend instrument blijft dat versterkt, in plaats van verminderd, de menselijke autonomie.
Transparante besluitvormingsprocessen waarborgen: Transparantie in AI-systemen is een fundamentele vereiste voor het verzekeren dat gebruikers de beslissingen van deze technologieën kunnen vertrouwen en begrijpen. Technisch gezien betekent dit het nodige aan expliciete AI (XAI), dat betreft het ontwikkelen van algoritmen die hun beslissingsredenen duidelijk kunnen uitdrukken.
Dit is bijzonder belangrijk in domeinen als financiën, gezondheidszorg en gerechtelijke systemen, waar ondoorzichtige besluitvorming kan leiden tot wantrouwen en ethische bezwaren.
Explicietheid kan worden behaald door verschillende technische methodes. Eén van de algemene methodes is post-hoc interpretabiliteit, waarbij het AI-model een uitleg genereert nadat het besluit is genomen. Dit kan涉及 het opdelen van het besluit in zijn samenstellende factoren en tonen hoe elk ervan tot het uiteindelijke resultaat heeft bijgedragen.
Een andere aanpak is de door gebruikelijke interpretabele modellen, waar de architectuur van de modellen zo ontworpen is dat hun beslissingen vanzelf spraakzaam zijn. Bijvoorbeeld, modellen als beslissingbomen en lineaire modellen zijn natuurlijk interpretabel omdat hun beslissingsproces gemakkelijk gevolgd en begrepen kan worden.
Het probleem bij het implementeren van verklaarbaar AI ligt in het evenwicht houden tussen transparantie en prestatie. Veelal zijn meer complexe modellen, zoals diepe neurale netwerken, minder interpretabel maar nauwkeuriger. Daarom moet de ontwikkeling van mensgerichte AI de keuze tussen de interpretabiliteit van het model en zijn voorspelbare kracht in acht nemen, zodat gebruikers de AI-beslissingen kunnen vertrouwen en begrijpen zonder dat er nauwkeurigheid wordt opgeofferd.
In stand houden van Meerderheidshandhaving: Meerderheidshandhaving is crucial voor het zekerstellen dat AI-systemen operationeel binnen morele en operationele grenzen blijven. Deze handhaving omvat het ontwerpen van AI-systemen met failsafes en overschrijfmogelijkheden die menselijke operators de mogelijkheid geven te ingrijpen indien nodig.
De technische implementatie van de handhaving door mensen kan op verschillende manieren aanpakken.
Eén aanpak is het integreren van systemen met een mens in de loop, waarin de AI-beslissingsprocessen continu worden bewaakt en beoordeeld door menselijke operators. Deze systemen zijn ontworpen om menselijke ingrijpen mogelijk te maken bij cruciale momenten, waardoor AI niet autonoom handelt in situaties waar morele beslissingen nodig zijn.
Zoals bij autonome wapensystemen, is menselijke toezicht essentieel om te voorkomen dat de AI leven-of-doodbeslissingen neemt zonder menselijke invoer. Dit kan betekenen dat er strikte operationele grenzen worden ingesteld die de AI zonder menselijke autorisatie niet kan overschrijden, waardoor ethische veiligheidsmaatregelen in het systeem worden ingebed.
Een ander technisch aspect is het ontwikkelen van controlepaden, die een record zijn van alle beslissingen en acties die door het AI-systeem zijn genomen. Deze paden bieden een transparante geschiedenis die door menselijke operators kunnen worden bekeken om ervoor te zorgen dat de ethische normen worden nageleefd.
Controlepaden zijn vooral belangrijk in sectoren zoals financiën en recht, waar beslissingen gedocumenteerd moeten worden en verantwoordbaar zijn om het publieke vertrouwen te handhaven en aan de regelgeving te voldoen.
Balans tussen Autonomie en Controle: Een belangrijk technisch uitdaging in menscentrische AI is het vinden van de juiste balans tussen autonomie en controle. Hoewel AI-systemen zijn ontworpen om op veel scenario’s autonoom te functioneren, is het cruciaal dat deze autonomie het menselijke controle of toezicht niet ondermijnt.
Deze balans kan worden bereikt door de implementatie van autonomie-niveaus, die het mate van onafhankelijkheid aangeven die de AI heeft bij het maken van beslissingen.
Bijvoorbeeld, in semi-autonome systemen zoals zelfrijdende auto’s, variëren de autonomie-niveaus van basisrijhulp (waarbij de menselijke bestuurder volledig in controle blijft) tot volledige automatisering (waarbij de AI verantwoordelijk is voor alle rijtaken).
Het ontwerp van deze systemen moet ervoor zorgen dat, op elk gegeven niveau van autonomie, de menselijke operator de mogelijkheid behoudt om in te grijpen en de AI over te schemaan als nodig. Dit vereist geavanceerde controleinterface en beslissingsondersteuningssystemen die mensen de mogelijkheid geven snel en effectief de controle terug te krijgen als nodig.
Verder is de ontwikkeling van ethische AI-ramen noodzakelijk voor het bepalen van de autonome acties van AI-systemen. Deze richtlijnen zijn sets van regels en richtlijnen die ingebed zijn binnen de AI en bepalen hoe deze zich moet gedragen in ethisch complexe situaties.
Bijvoorbeeld, in de gezondheidszorg, zou een ethische AI-framebuffer mogelijke regels kunnen bevatten over patiëntenemandatum, privacy en de prioriteit van behandelingen op basis van medische behoeften in plaats van financiële overwegingen.
door deze ethische beginselen direct in het beslissingsproces van de AI in te brengen, kunnen ontwikkelaars ervoor zorgen dat de autonomie van het systeem wordt uitgeoefend in een manier die overeenkomt met menselijke waarden.
Het integreren van mens-centraal georiënteerde beginselen in de AI-ontwerp is niet alleen een filosofisch ideaal maar ook een technische noodzaak. door de menselijke autonomie te versterken, zorgen voor transparantie, mogelijke controle en voorzichtig balansen tussen autonomie en controle, kunnen AI-systemen worden ontwikkeld in een manier die echt de mensheid dienstdoet.
Deze technische overwegingen zijn essentieel voor het creëren van AI die niet alleen de menselijke mogelijkheden vergroot maar ook respect en handhaven van de waarden die fundamenteel zijn aan onze samenleving.
Met de voortdurende evolutie van de AI zal de verbinding met het mens-centraal ontwerpen belangrijk zijn om ervoor te zorgen dat deze krachtige technologieën ethisch en verantwoordelijk worden gebruikt.
Hoe uiteraard AI de mensheid een voordeel biedt: verbetering van de kwaliteit van leven
Als u zich bezighoudt met de ontwikkeling van AI-systemen, is het essentieel om uw pogingen op het morele kader van utilitarisme te gronden – een filosofie die de verbetering van de algemene geluk en welzijn benadrukt.
Binnen dit kader heeft AI de potentiële om op cruciale maatschappelijke uitdagingen te antwoorden, vooral in gebieden als gezondheidszorg, onderwijs en duurzame levensstijl.
Het doel is het creëren van technologieën die de kwaliteit van leven voor iedereen significant verbeteren. Maar deze jacht op vereist complexiteiten. Utilitarisme biedt een aantrekkelijke reden AI breed in te zetten, maar het brengt ook belangrijke morele vragen aan het licht over wie profiteert en wie misschien achterblijft, vooral onder kwetsbare bevolkingsgroepen.
Om deze uitdagingen aan te gaan, hebben we een geavanceerd, technisch ingestelde aanpak nodig – één die de breedte van de maatschappelijke goedheid in balans houdt met het nodige gerechtigheid en rechtvaardigheid.
Wanneer u utilitaire beginselen toegepast aan AI, moet u uw focus leggen op het optimaliseren van resultaten in specifieke domeinen. In de gezondheidszorg, bijvoorbeeld, hebben AI-gebaseerde diagnosegereedschappen de mogelijkheid om de resultaten voor patiënten drastisch te verbeteren door middel van eerder en nauwkeuriger diagnose. Deze systemen kunnen uitgebreide gegevenssets analyseren om patronen te detecteren die menselijke praktijken misschien overkijken, waardoor toegang tot kwalitatieve zorg wordt uitgebreid, vooral in onderresurserende omgevingen.
Maar het implementeren van deze technologieën vereist een voorzichtige aanpak om bestaande ongelijkheden niet te versterken. Het data gebruik voor het trainen van AI-modellen kan significant verschillen per regio, wat de nauwkeurigheid en betrouwbaarheid van deze systemen beïnvloedt.
Deze verschillen duiden op de noodzaak van het opzetten van sterke data governance-frameworks die ervoor zorgen dat uw AI-gebaseerde gezondheidsoplossingen zowel representatief als eerlijk zijn.
In het onderwijsveld biedt de AI de mogelijkheid persoonlijke leermethoden aan. AI-systemen kunnen lesmateriaal aanpassen aan de specifieke behoeften van individuele studenten, waardoor de leerresultaten verbeterd worden. door analyse van gegevens over studentenprestaties en gedrag, kunnen AI-systemen identificeren waar een student mogelijk last van heeft en specifieke steun bieden.
Maar als u zich richt op deze voordelen, is het belangrijk om van de risico’s op de hoogte te zijn – zoals het potentieel om biases te versterken of studenten die niet aan typische leerpatronen voldoen te marginaliseren.
Het verminderen van deze risico’s vereist de integratie van fairness-mechanismen in AI-modellen, ervan uitgaande dat zij niet per ongeluk bepaalde groepen voordelen. En het behouden van de rol van de educatieve professionalen is crucial. hun deskundigheid en ervaring zijn onvervangbaar bij het maken van AI-hulpmiddelen echt effectief en ondersteunend.
Inzake de duurzame ontwikkeling van het milieu biedt de AI een aanzienlijke potentie. AI-systemen kunnen resources optimaliseren, milieuveranderingen monitoren en de impacten van klimaatverandering met ongeëvenaard precision voorschijn laten treden.
Bijvoorbeeld, kan AI vastgesteldata uit het milieu analyseren om weerspatronen te voorspellen, de energieconsumptie te optimaliseren en afval te minimaliseren – acties die bijdragen aan het welzijn van de huidige en toekomstige generaties.
Maar deze technologische vooruitgang gaat gepaard met een reeks uitdagingen, in het bijzonder betreffende de milieueffecten van de AI-systemen zelf.
De energieconsumptie nodig om grote schaal AI-systemen te laten functioneren, kan de milieuvoordelen die ze nastreven, eveneens compenseren. Daarom is het ontwikkelen van energiebesparende AI-systemen crucial om er zeker van te zijn dat hun positieve impact op de duurzaamheid niet ondermijnd wordt.
Als u AI-systemen ontwikkelt met utilitaristische doelstellingen, is het belangrijk om ook de implicaties voor sociale rechtvaardigheid in acht te nemen. Utilitarisme richt zich op het maximum van het algemeen geluk maar adresseert niet per se de verdeling van voordelen en schorsingen over verschillende maatschappelijke groepen.
Dit opent de mogelijkheid dat AI-systemen ongeveer dezelfde voorrechtgenoten een ongeproportioneerd voordeel geven, terwijl de gemarginaliseerde groepen mogelijk geen verbetering in hun omstandigheden zien.
Om dit tegen te gaan, moet uw AI-ontwikkelingsproces de beginselen van gelijkheid bergen, zodat de voordelen fair worden verdeeld en dat eventuele schorsingen worden behandeld. Dit kan bijvoorbeeld door het ontwerpen van algoritmen die specifiek gericht zijn op het verminderen van biases en het betrekken van een diverse reeks van standpunten bij het ontwikkelingsproces.
Als u werkt aan het ontwikkelen van AI-systemen die de kwaliteit van het leven verbeteren, is het essentieel om de utilitaire doelstelling van het maximale welzijn te balancen met de nodige gerechtigheid en eerlijkheid. Dit vereist een geavanceerd, technisch gegrondsonderzoek dat de bredere implicaties van de AI-implementatie in acht neemt.
door AI-systemen te ontwerpen die zowel effectief als eerlijk zijn, kunt u bijdragen aan een toekomst waarin technologische vooruitgang echt de diverse behoeften van de samenleving dient.
Implementeer beschermingen tegen potentiële schade
Bij het ontwikkelen van AI-technologieën moet u erkennen dat de inherente potentiële schade wordt geactiveerd en actief maatregelen treffen om deze risico’s te verminderen. Deze verantwoordelijkheid is diep ingebed in deontologische ethiek. Dit deel van de ethiek legt de morele verplichting om aan vastgestelde regels en morele normen te voldoen, waardoor de technologie die u creëert overeenkomt met fundamentele morele beginselen.
Het implementeren van strikte veiligheidsprotocollen is niet alleen een voorzorg maar een morele verplichting. Deze protocollen moeten een alomvattende test voor vooroordelen, transparantie in de algoritmische processen en duidelijke mechanismen voor verantwoording bevatten.
Zo’n beschermingen zijn essentieel om te voorkomen dat AI-systemen onbedoeld schade veroorzaken, of door vooroordelen in besluitvorming, door ontransparante processen of door een tekort aan toezicht.
In de praktijk vereist het implementeren van deze beschermingen een diepgaande kennis van zowel de technische als de ethische dimensies van AI.
Bias testen omvat niet alleen het identificeren en corrigeren van vooroordelen in data en algoritmen, maar ook het begrijpen van de bredere maatschappelijke implicaties van die vooroordelen. U moet ervoor zorgen dat uw AI-modellen op diverse, representatieve datasets getraind worden en regelmatig worden geëvalueerd om vooroordelen op te sporen en te corrigeren die over tijd kunnen ontstaan.
Transparantie, aan de andere kant, vereist dat AI-systemen zo ontworpen zijn dat hun besluitvormingsprocessen gemakkelijk door gebruikers en belanghebbenden worden begrepen en gekeken kunnen worden. Dit omvat het ontwikkelen van verklaarbare AI-modellen die heldere, interpretabele uitvoer bieden, zodat gebruikers zien kunnen hoe beslissingen worden genomen en ervoor zorgen dat de beslissingen rechtvaardig en eerlijk zijn.
Ook zijn accountabiliteitsmechanismen cruciaal voor het behoud van vertrouwen en het verzekeren dat AI-systemen verantwoordelijk worden gebruikt. Deze mechanismen moeten een duidelijke richtlijn bevatten voor wie verantwoordelijk is voor de resultaten van AI-beslissingen, evenals processen voor het behandelen en herstellen van eventuele schade.
U moet een framework opzetten waarin ethische overwegingen zijn ingebed in elke fase van de AI-ontwikkeling, van het beginsel design tot de implementatie en daarna. Dit omvat niet alleen het volgen van ethische richtlijnen maar ook het continu monitoren en aanpassen van AI-systemen terwijl ze interacteren met de echte wereld.
door deze veiligheidtoepassingen in de borstel van de AI-ontwikkeling in te binden, kunt u helpen verzekeren dat de technologische vooruitgang dienstdoet aan het algemeen belang zonder onverwachte negatieve gevolgen te geven.
Het belang van menselijke toezicht en terugkoppelingslussen
Menselijke toezicht op AI-systemen is een kritisch onderdeel van het waarborgen van ethische AI-toepassingen. Het principe van verantwoordelijkheid ondersteunt de noodzaak van continue menselijke deelname aan de operationele AI, vooral in high-stakes-omgevingen zoals de gezondheidszorg en het crimelijk justitieel systeem.
Terugkoppelingen, waarin menselijke invoer wordt gebruikt om AI-systemen te verfijnen en te verbeteren, zijn essentieel voor het behoud van verantwoordelijkheid en aanpasbaarheid (Raji et al., 2020). Deze terugkoppelingen bieden de mogelijkheid fouten te corrigeren en nieuwe ethische overwegingen te integreren terwijl de waarden van de maatschappij evolueren.
Door menselijk toezicht in AI-systemen in te bouwen, kunnen ontwikkelaars technologieën creëren die niet alleen effectief zijn maar ook in lijn zijn met ethische normen en menselijke verwachtingen.
Ethiek coderen: Filosofische beginselen in AI-systemen omzetten
Het omzetten van filosofische beginselen in AI-systemen is een complex maar noodzakelijk taken. Dit proces omvat het vastleggen van ethische overwegingen in het code dat de AI-algoritmen drijft.
Concepten zoals rechtvaardigheid, gerechtigheid en autonomie moeten binnen AI-systemen worden vastgelegd om er voor te zorgen dat ze zich in overeenstemming met maatschappelijke waarden gedragen. Dit vereist een multidisciplinair aanpak, waarin ethici, ingenieurs en sociale wetenschappers samenwerken om ethische richtlijnen te defineren en toe te passen in het codering proces.
Het doel is om AI-systemen te creëren die niet alleen technisch getalenteerd zijn maar ook moreel verantwoord, in staat zijn beslissingen te nemen die de menselijke waardigheid respecteren en de maatschappelijke goedheid bevorderen (Mittelstadt et al., 2016).
Behoud inclusiviteit en gelijke toegang in de ontwikkeling en toepassing van AI
Inclusiviteit en gelijke toegang zijn fundamenteel voor de ethische ontwikkeling van AI. Het Rawlsiaanse concept van rechtvaardigheid als eerlijkheid biedt een filosofische grondslag voor het verzekeren dat AI-systemen zijn ontworpen en geïmplementeerd worden in manieren die voordelen hebben voor alle leden van de samenleving, in het bijzonder voor diegenen die het meest kwetsbaar zijn (Rawls, 1971).
Dit omvat vooruitgangsinitiatives om diverse perspectieven in het ontwikkelingsproces te betrekken, in het bijzonder vanuit de ondervertegenwoordigde groepen en het Global South.
Door deze diversen kanten op te nemen, kunnen AI-ontwikkelaars systemen creëren die meer eerlijk zijn en reageren op de behoeften van een bredere gebruikersgroep. Ook is het gewichtig voor het voorkomen van de verscherping van bestaande sociale ongelijkheden, de AI-technologieën evenwichtig toegankelijk te maken.
Addresseer Algoritmische Bias en Rechtvaardigheid
Algoritmische bias is een significante ethische zorg in de ontwikkeling van AI, aangezien biaiseerde algoritmen de bestaande maatschappelijke ongelijkheden kunnen voortzetten en zelfs versterken. Om deze kwestie aan te pakken vereist een verplichting tot procesrechtvaardigheid, ervoor zorgend dat AI-systemen zijn ontwikkeld door eerlijke processen die de impact op alle belanghebbenden in acht nemen (Nissenbaum, 2001).
Dit omvat het identificeren en verminderen van bias in trainingsgegevens, het ontwikkelen van algoritmen die transparant en verklaarbaar zijn, en het uitvoeren van rechtvaardigheidscontroles doorheen het levenscyclus van AI.
Door de algoritmische bias aan te pakken, kunnen ontwikkelaars AI-systemen creëren die bijdragen aan een eerlijker en meer rechtvaardige samenleving, in plaats van bestaande verschillen te versterken.
Integreer Diverse Perspectieven in de AI-Ontwikkeling
De integratie van diverse perspectieven in de ontwikkeling van AI is essentieel voor het creëren van systemen die inclusief en gerecht zijn. Het opnemen van stemmen uit onderrepresentede groepen zorgt ervoor dat AI-technologieën niet alleen de waarden en prioriteiten reflecteren van een smal segment van de samenleving.
Dit aanpak aligneert zich met de filosofische principes van dedeliberatieve democratie, die de import van inclusieve en deelnamegebaseerde besluitvormingsprocessen benadrukt (Habermas, 1996).
Door de diverse deelname aan de AI-ontwikkeling te bevorderen, kunnen we ervoor zorgen dat deze technologieën zijn ontworpen om de belangen van de gehele mensheid dienen, in plaats van enkel die van een voorgenomen kleine groep.
Strategieën voor het Overbruggen van de AI-Kloof
De AI-Kloof, gekenmerkt door ongelijke toegang tot AI-technologieën en hun voordelen, stelt een significante uitdaging voor wereldwijde gelijkheid. Om deze kloof over te bruggen, is een verbintenis tot deelname aan deelname nodig, ervoor zorgend dat de voordelen van AI breed worden verdeeld over verschillende socio-economische groepen en regio’s (Sen, 2009).
We kunnen dit door initiaties te bevorderen die toegang tot AI-onderwijs en -resources in onderserviced gemeenschappen bevorderen, evenals door beleid dat de rechtmatige verdeling van de economische winsten die door AI worden aangedreven, ondersteund. door het adresseren van de AI-Kloof, kunnen we ervoor zorgen dat AI bijdragen aan wereldwijde ontwikkeling in een manier die inclusief en gerecht is.
Balanceer Innovatie met Ethische Beperkingen
Het evenwicht tussen de jacht op innovatie en ethische beperkingen is crucial voor verantwoordelijke AI-voortgang. Het voorbehoedsprincipe, dat voorzichtigheid aanbevelend is bij onzekerheid, is bijzonder relevant in de context van AI-ontwikkeling (Sandin, 1999).
Terwijl innovatie de vooruitgang drijft, moet ze worden afgeremd door ethische overwegingen die bescherming bieden tegen potentiële schade. Dit vereist een voorzichtige evaluatie van de risico’s en de voordelen van nieuwe AI-technologieën, evenals de implementatie van regelingskaders die de handhaving van ethische standaarden waarborgen.
Door innovatie in evenwicht te brengen met ethische beperkingen, kunnen we de ontwikkeling van AI-technologieën die vooruitgangskrachtig zijn en overeenkomen met de bredere doelstellingen van de maatschappelijke welzijnsthema’s versterken.
Zoals u kunt zien levert de filosofische grondslag van intelligentiesystemen een cruciale raamwerk voor het waarborgen dat AI-technologieën op ethische, inclusieve en voor iedereen gunstige manieren worden ontwikkeld en geïmplementeerd.
door de AI-ontwikkeling op deze filosofische beginselen te gronden, kunnen we intelligentiesystemen creëren die niet alleen de technologische capaciteiten vooruit helpen maar ook de kwaliteit van het leven vergroten, de rechtvaardigheid bevorderen en ervoor zorgen dat de voordelen van AI gelijkmatig zijn verdeeld over de hele maatschappij.
Hoofdstuk 5: AI-agenten als LLM-versterkers
Het samenvoegen van AI-agenten met Grote Taal Modelen (LLM’s) stelt een fundamentele verandering in de kunstmatige intelligentie voor, die de kritieke beperkingen in LLM’s die hun bredere toepasbaarheid hebben beperkt, aanpakt.
Deze integratie maakt het voor machines mogelijk om hun traditionele rollen over te stijgen, van passieve tekstgeneratoren tot autonome systemen die in staat zijn tot dynamische redeneringen en besluitvorming.
Met name als AI-systemen steeds meer kritische processen over heel verschillende domeinen drijven, is het verstandig om te begrijpen hoe AI-agenten de schappen in de LLM-capaciteiten vullen en daarmee hun volledige potentieel realiseren.
Knopen in de mogelijkheden van LLM’s
LLM’s zijn, hoewel krachtig, inherent beperkt door de data waarop ze zijn getraind en de statische natuur van hun architectuur. Deze modellen werken binnen een vast geheel van parameters, meestal gedefinieerd door de tekstcorpus die werd gebruikt tijdens hun trainingsfase.
Deze beperking betekent dat LLM’s niet autonomie kunnen zoeken in nieuwe informatie of hun kennisbank bijwerken na hun trainingsfase. consequentie hiervan is dat LLM’s vaak verouderd zijn en de mogelijkheid ontberen om contextueel relevante reacties te leveren die realtime data of inzichten vereisen die buiten hun oorspronkelijke trainingsgegevens liggen.
AI-agenten overbruggen deze knoop door dynamisch geïntegreerde externe databronnen, die de functionele horizon van LLM’s kunnen uitbreiden.
Bijvoorbeeld, een LLM die tot 2022 op financiële gegevens is getraind, kan accurate historische analyses leveren maar zal moeite doen om actuele marktvoorspellingen te genereren. Een AI-agent kan deze LLM versterken door in realtime financiële marktdata aan te trekken en deze inpakten toe te passen om relevantere en actuele analyses te genereren.
Deze dynamische integratie zorgt ervoor dat de uitvoer niet alleen historisch correct is maar ook contextueel geschikt is voor de huidige omstandigheden.
Autonoom besluitvorming versterken
Een andere significante beperking van LLM’s is hun ontbrekende autonomie bij besluitvorming. LLM’s zijn goed in het genereren van taalgebonden uitvoer maar niet in taken die complexe besluitvorming vereisen, vooral in omgevingen die gekenmerkt zijn door onzekerheid en verandering.
Deze tekortkoming is voornamelijk het gevolg van de afhankelijkheid van bestaande data van het model en het ontbreken van mechanismen voor aanpassende redenering of leren van nieuwe ervaringen na implementatie.
AI-agenten beantwoorden hiertoe door de noodzakelijke infrastructure voor autonome beslissingen aan te bieden. Ze kunnen de statische uitvoer van een LLM nemen en deze verwerken via geavanceerde redenering framework zoals regelgebaseerde systemen, heuristieken of geÏnstalleerde leer modellen.
Bijvoorbeeld, in een gezondheidszorg omgeving, zou een LLM een lijst van mogelijke diagnose’s genereren op basis van de klachten en medische geschiedenis van een patient. Maar zonder een AI-agent kan de LLM deze opties niet wegen of een richtlijn voor actie aanbevelen.
Een AI-agent kan deze diagnose’s evalueren aan de hand van de huidige medische literatuur, patientgegevens en contextuele factoren, uiteindelijk een meer ingedeeld besluit nemen en suggesties voor actiebare volgende stappen aanbieden. Deze synergie verandert de LLM-uitvoer van enkel suggesties in uitvoerbare, context-gevoelige besluiten.
Aanvullend en consistentie behandelen
Volledigheid en consistentie zijn kritieke factoren voor het verzekeren van de betrouwbaarheid van LLM-uitvoer, vooral bij complexe redenering taken. Door hun parameteriseerde aard genereren LLM’s vaak antwoorden die of onvolledig zijn of geen logische coherente structuur bevatten, vooral bij het behandelen van meerstapsprocessen of vereiste voor een alomvattende verstandigheid over diverse domeinen.
Deze problemen zijn het gevolg van de afgesloten omgeving waarin LLM’s operationeel zijn, waar ze niet in staat zijn om hun uitvoer te vergelijken of te valideren tegen externe normen of aanvullende informatie.
AI-agenten spelen een cruciale rol in het verminderen van deze problemen door middel van iteratieve terugkoppelingmechanismen en validatierollen.
Bijvoorbeeld, in het rechtsgebied, zou een LLM misschien een eerste versie van een rechtsgrondslag op basis van zijn trainingsdata samenstellen. Maar dit voorstel kan bepaalde voorbeelden overschrijden of de argumenten niet logisch structuren.
Een AI-agent kan deze voorstel controleren, en zorgen dat het de vereiste standaard van compleetheid meet door te kruisen met externe rechtsdatabanken, controleren op logische consistentie, en extra informatie of duiding aanvragen indien nodig.
Dit iteratieve proces maakt het mogelijk om een robuuster en betrouwbaarder document te produceren dat aan de stringente vereisten van de rechtspraktijk voldoet.
Overwinnen van isolatie door integratie
Een van de diepste beperkingen van LLMs is hun ingebouwde isolatie van andere systemen en kennisbronnen.
LLMs, zoals ze zijn ontworpen, zijn gesloten systemen die niet van nature interactie bieden met externe omgevingen of databanken. Deze isolatie beperkt significant hun vermogen om zich aan nieuwe informatie aan te passen of in real-time operationeel te zijn, wat hen minder effectief maakt in toepassingen die dynamische interactie of real-time beslissingen vereisen.
AI-agenten overwinnen deze isolatie door als integratieve platforms te fungeren die LLMs verbinden met een breder systeem van gegevensbronnen en computatieleertools. Door middel van API’s en andere integratiekaders kunnen AI-agenten toegang krijgen tot real-time gegevens, samenwerken met andere AI-systemen, en zelfs communiceren met fysieke apparaten.
Bijvoorbeeld, in klantenserviceapplicaties kan een LLM standaardreacties genereren op basis van voorgeprogrammeerde scripts. Maar deze reacties kunnen statisch zijn en het benodigde personaliseren voor effectieve klantengagement ontbreken.
Een AI-agent kan deze interacties verrijken door realtime data van klantprofielen, vorige interacties en sentimentanalysegereedschappen te integreren, wat helpt om reacties te genereren die niet alleen contextueel relevant zijn, maar ook speciaal aangepast zijn aan de specifieke behoeften van de klant.
Deze integratie verandert de klantbeleving van een reeks van gescriptte interacties in een dynamische, persoonlijke conversatie.
Vervolgens vergroten Creativiteit en Probleemoplossing
Alhoewel LLMs krachtige tool zijn voor contentgeneratie, zijn hun creativiteit en probleemoplossingsvaardigheden inherent beperkt door de data waarop ze zijn getraind. Deze modellen kunnen vaak niet theoretische concepten toepassen op nieuwe of onverwachte uitdagingen, aangezien hun probleemoplossingscapabilities zijn beperkt tot hun bestaande kennis en trainingsparameters.
AI-agenten vergroten de creatieve en probleemoplossings potentie van LLMs door geavanceerde redeneertechnieken en een bredere reeks van analytische tools te gebruiken. Deze mogelijkheid laat AI-agenten de beperkingen van LLMs overschrijden, theoretische richtlijnen op praktische problemen toe te passen in innovatieve manieren.
Bijvoorbeeld, denk aan het probleem van het bestrijden van misinformatie op sociale mediasites. Een LLM kan patronen van misinformatie herkennen op basis van taalanalyses, maar het zou kunnen tegenhouden om een alomvattende strategie te ontwikkelen voor het verminderen van de verspreiding van onware informatie.
Een AI-agent kan deze inzichten nemen, interdisciplinair theorieën toepassen uit velden zoals sociologie, psychologie en networtheorie, en een robuust, veelzijdig aanpak ontwikkelen die rechtstreeks monitoren, gebruikersonderwijs en geautomatiseerde moderatie technieken omvat.
Deze mogelijkheid om diverse theorieën samen te vatten en hen toe te passen op praktische wereldproblemen illustreert de verbeterde problemenlossecapabilities die AI-agenten brengen aan tafel.
Meer specifieke Voorbeelden
AI-agenten, met hun vermogen om met diverse systemen te interacteren, realtime gegevens toe te kennen en acties uit te voeren, nemen deze beperkingen direct op, waardoor LLMs van machtige maar passieve taalmodellen worden tot dynamische, reële wereldprobleemoplossers. Laten we enkele voorbeelden bekijken:
1. Van statische gegevens naar dynamische inzichten: LLMs mee in de loop laten
-
Het probleem: Veronderstel dat u een LLM vraagt die is getraind op voor 2023 medische onderzoek, “Wat zijn de laatste doorbraken in de behandeling van kanker?” Zijn kennis zou verouderd zijn.
-
De AI-agent oplossing: Een AI-agent kan de LLM verbinden met medische tijdschriften, wetenschappelijke databases en nieuwssfeer. Nu kan de LLM up-to-date informatie verschaffen over de laatste klinische trials, behandelopties en wetenschappelijke vondsten.
2. Van Analyse naar Actie: Automatiseren van taken op basis van inzichten van de LLM
-
Het probleem: Een LLM die sociale media monitort voor een merk, zou een stijging in negatieve sentimenten kunnen identificeren maar kan er geen actie op ondernemen.
-
De AI-agent oplossing: Een AI-agent die verbonden is met de sociale mediaaccounts van het merk en uitgerust is met vooraf goedgekeurde reacties, kan automatisch problemen aanpakken, vragen beantwoorden en zelfs complexe kwesties aan menselijke vertegenwoordigers overdragen.
3. Van eerste schema tot gepolijst product: Zorgen voor kwaliteit en nauwkeurigheid
-
Het probleem: Een LLM die een technische handleiding moet vertalen, zou mogelijk correct grammaticaal zijn maar technisch niet correcte vertalingen kunnen produceren door een gebrek aan domeinspecifieke kennis.
-
De AI Agent Oplossing: Een AI-agent kan de LLM integreren met gespecialiseerde woordenboeken, glossaries en zelfs verbinding maken met vakdeskundigen voor real-time feedback, waardoor de uiteindelijke vertaling zowel linguïstisch accuraat als technisch verantwoord is.
4. Barrières verminderen: LLM’s verbinden met de echte wereld
-
Het Probleem: Een LLM ontworpen voor slimme thuisbesturing kan moeilijkheden hebben bij het aanpassen aan de veranderende routines en voorkeuren van een gebruiker.
-
De AI Agent Oplossing: Een AI-agent kan de LLM verbinden met sensoren, slimme apparaten en gebruikerskalenders. Door gebruikersgedrag te analyseren kan de LLM leren voorkeuren te anticiperen, automatisch licht- en temperatuurinstellingen aan te passen en zelfs gepersonaliseerde muziek afspeellijsten te suggereren op basis van de tijd van de dag en gebruikersactiviteit.
5. Van imitatie naar innovatie: LLM creativiteit uitbreiden
-
Het probleem: Een LLM die is toegewezen het componeren van muziek, zou misschien stukken maken die aanmatigend klinken of een gebrek aan emotionele diepte hebben, omdat het voornamelijk op patronen in zijn trainingsgegevens rust.
-
De AI-agentensolution: Een AI-agent kan de LLM verbinden met biofeedbacksensoren die meet hoe een componist emotionele reacties krijgt op verschillende muzikale elementen. door deze realtimefeedback toe te voegen, kan de LLM muziek maken die niet alleen technisch goed is maar ook emotioneel aantrekkelijk en origineel.
De integratie van AI-agenten als LLM-versterkers is geen gemakkelijke verbetering, maar vertegenwoordigt een fundamentele uitbreiding van wat de kunstmatige intelligentie kan bereiken. door de beperkingen van traditionele LLM’s aan te pakken, zoals hun statische kennisbron, beperkte autonomie in besluitvorming en een geïsoleerd operationeel milieu, kunnen AI-agenten deze modellen op hun volledige potentie laten functioneren.
Met de voortdurende evolutie van de AI-technologie wordt de rol van AI-agenten in de versterking van LLM’s steeds belangrijker, niet alleen in de uitbreiding van de mogelijkheden van deze modellen, maar ook in het herdefinemeisen van de grenzen van de kunstmatige intelligentie zelf. Deze samensmelting is de weg vrijmakend voor de volgende generatie van AI-systemen, die in staat zijn om autonoom te redeneren, in real-time aan te passen en innovatieve oplossingen te vinden in een altijd veranderende wereld.
Hoofdstuk 6: Architectuurontwerp voor de integratie van AI-agenten met LLM’s
De integratie van AI-agenten met LLM’s hangt af van het architectuurontwerp, dat crucial is voor de verbetering van besluitvorming, aanpassingsvermogen en schaalbaarheid. Het ontwerp moet zorgvuldig gecreëerd worden om een gemakkelijke interactie tussen de AI-agenten en LLM’s mogelijk te maken, ervoor zorgend dat elk component optimaal functioneert.
Een modulair architectuur, waarin de AI-agent een dirigent is, die de mogelijkheden van de LLM leidt, is een van de methodes die ondersteunt dynamisch takenbeheer. Dit ontwerp gebruikt de sterke punten van de LLM in natuurlijke taalverwerking, terwijl de AI-agent complexere taken beheert, zoals meerstapsredenering of contextuele besluitvorming in real-time-omgevingen.
Alternatief biedt een hybride model, dat LLM’s combineert met speciaal gekweekte, afgefinaleerde modellen, flexibiliteit door middel van het toewijzen van taken aan het meest geschikte model door de AI-agent. Deze aanpak optimaliseert de prestaties en verbetert de efficiëntie over een breed scala van toepassingen, waardoor ze bijzonder effectief is in diverse en variantieke operationele contexten (Liang et al., 2021).

Training Methodologieën en Best Practices
Training van AI-agenten die zijn geïntegreerd met LLM’s vereist een methodische aanpak die generalisatie balanceert met optimalisatie specifiek voor taken.
Overplaatsingsondersteuning is een belangrijke techniek hierbij, die een LLM toestaat die is voorge-trainen op een grote, diverse corpora, af te fineren op domeinspecifieke gegevens relevant voor taken van de AI-agent. Deze methode behoudt de breedte van de kennis van de LLM, terwijl het in staat wordt gebracht om zich te specialiseren in bepaalde toepassingen, hetgeen de algehele effectiviteit van het systeem verbetert.
Ook speelt reinforcement learning (RL) een cruciale rol, vooral in scenario’s waar de AI-agent moet aanpassen aan veranderende omgevingen. Door interactie met zijn omgeving, kan de AI-agent zijn besluitvormingsprocessen continu verbeteren, zodat hij beter wordt in het behandelen van nieuwe uitdagingen.
Om betrouwbare prestaties te waarborgen over verschillende scenario’s, zijn strikte evaluatiesmetriques noodzakelijk. Dit moet zowel standaard benchmarks als taken-specifieke criteria bevatten, waardoor de training van het systeem robust en comprehensief is (Silver et al., 2016).
Inleiding in het affinaleren van een Grote Taalmodel (LLM) en concepten van Reinforcement Learning
Dit code toont verschillende technieken die samenhangen met machine learning en natuurlijk taalverwerking (NLP), met name de fine-tuning van grote taalmodellen (LLMs) voor specifieke taken en het implementeren van reinforcement learning (RL) agents. Het code beslaat verschillende belangrijke gebieden:
-
Fine-tuning een LLM: Het gebruik van voorgeTrainde modellen zoals BERT voor taken zoals sentiment analyse, met behulp van de Hugging Face
transformersbibliotheek. Dit omvat tokenisering van datasets en het gebruik van trainingsargumenten om het fine-tuning proces te begeleiden. -
Reinforcement Learning (RL): Het introduceren van de basis van RL met een eenvoudige Q-learning agent, waar een agent door middel van proeven en fouten leert door met een omgeving te interactie en zijn kennis bij te werken via Q-tabellen.
-
Reward Modeling met OpenAI API: Een conceptuele methode voor het gebruik van de OpenAI API om dynamisch reward signaal te leveren aan een RL agent, waardoor een taalmodel acties kan evalueren.
-
Model Evaluatie en Logging: Gebruik maken van bibliotheken als
scikit-learnom modelprestaties te evalueren aan de hand van accurateit en F1-scores, en van PyTorch’sSummaryWritervoor het visualiseren van het trainingsproces. -
Geavanceerde RL Concepten: Implementeren van meer geavanceerde concepten zoals policy gradient netwerken, curriculum learning, en early stopping om de efficiëntie van modeltrainen te verbeteren.
Deze holistische aanpak beslaat zowel geleidetrainen, met sentiment analyse voor aanpassing, alsook reinforcerende leren, en biedt inzicht in hoe moderne AI-systemen worden gebouwd, getest, en geoptimaliseerd.
Code Voorbeeld
Stap 1: Importeren van noodzakelijke Bibliotheken
Voordat we ons verdiepen in het fijnafstemmen van het model en de implementatie van de agent, is het essentieel om de benodigde bibliotheken en modules in te stellen. Deze code bevat imports van populaire bibliotheken zoals Hugging Face’s transformers en PyTorch voor het verwerken van neurale netwerken, scikit-learn voor het evalueren van de prestaties van het model, en enkele algemene modules zoals random en pickle.
-
Hugging Face-bibliotheken: Hiermee kunt u voorgeleerde modellen en tokenizers uit de Model Hub gebruiken en verfijnen.
-
PyTorch: Dit is het kernframework voor diep leren dat wordt gebruikt voor operaties, waaronder neurale netwerklagen en optimalisatoren.
-
scikit-learn: Biedt metrieken zoals nauwkeurigheid en F1-score om de prestaties van het model te evalueren.
-
OpenAI API: Toegang tot de taalmodellen van OpenAI voor verschillende taken, zoals reward modelling.
-
TensorBoard: Gebruikt voor het visualiseren van de voortgang van de training.
Hier is het code voor het importeren van de nodige bibliotheken:
# Importeer het random module voor het genereren van willekeurige getallen.
import random
# Importeer noodzakelijke modules van de transformers bibliotheek.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importeer load_dataset voor het laden van datasets.
from datasets import load_dataset
# Importeer metrics voor het evalueren van model performantie.
from sklearn.metrics import accuracy_score, f1_score
# Importeer SummaryWriter voor het loggen van trainingsvoortgang.
from torch.utils.tensorboard import SummaryWriter
# Importeer pickle voor het opslaan en laden van getrainde modellen.
import pickle
# Importeer openai voor het gebruik van OpenAI's API (vereist een API-sleutel).
import openai
# Importeer PyTorch voor diepe leeroperaties.
import torch
# Importeer het module van de neural network van PyTorch.
import torch.nn as nn
# Importeer het module van de optimalisator van PyTorch (niet direct gebruikt in dit voorbeeld).
import torch.optim as optim
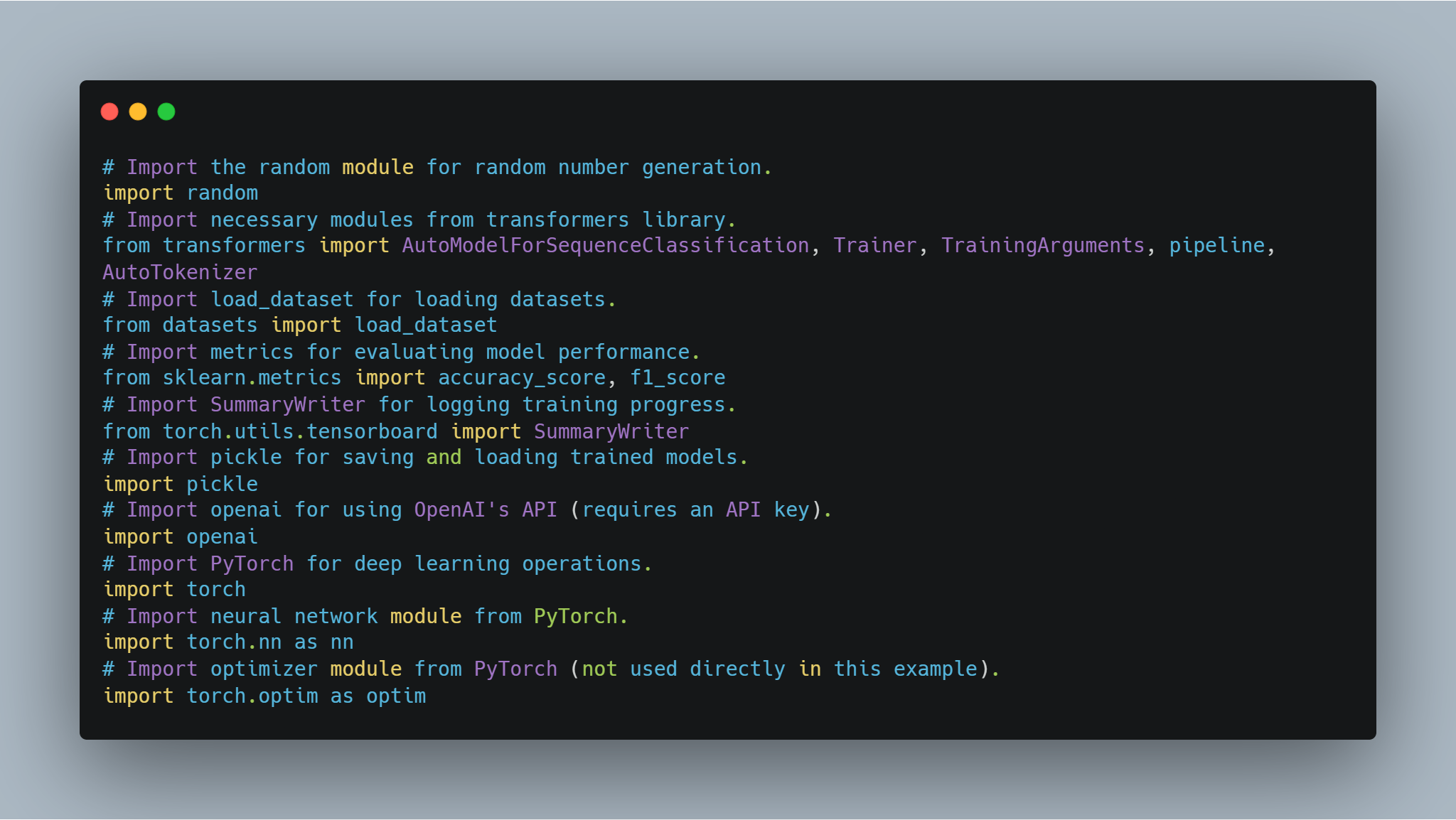
Elk van deze importeren speelt een cruciale rol in verschillende delen van het code, van model trainen en evalueren tot het loggen van resultaten en het interacteren met externe API’s.
Stap 2: Fijnafinemeren van een Taalklasseermodel voor Sentiment Analyse
Fijnafinemeren van een vooraf getrainde model voor een specifieke taak zoals sentiment analyse, betekend het laden van een vooraf getrainde model, het aanpassen ervan aan het aantal uitgaande labels (positief/negatief in dit geval) en het gebruiken van een geschikte dataset.
In dit voorbeeld gebruiken we de AutoModelForSequenceClassification van de transformers-bibliotheek, met de IMDB-dataset. Deze voorge Trainde model kan worden afgefinet op een kleinere deel van het dataset om computationele tijd te besparen. Het model wordt vervolgens getraind met een aangepaste set van trainingsargumenten, die de aantal epochs en batchgrootte bevat.
Hieronder is het code voor het laden en affinen van het model:
# Specificeer de naam van het voorge-trainde model van Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Laad het voorge-trainde model met een gespecificeerd aantal uitvoer klassen.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Laad een tokenizer voor het model.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Laad het IMDB-dataset van Hugging Face Datasets, en gebruik alleen 10% voor training.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokeizeer het dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Toon het dataset naar tokeizeerde invoer
tokenized_dataset = dataset.map(tokenize_function, batched=True)
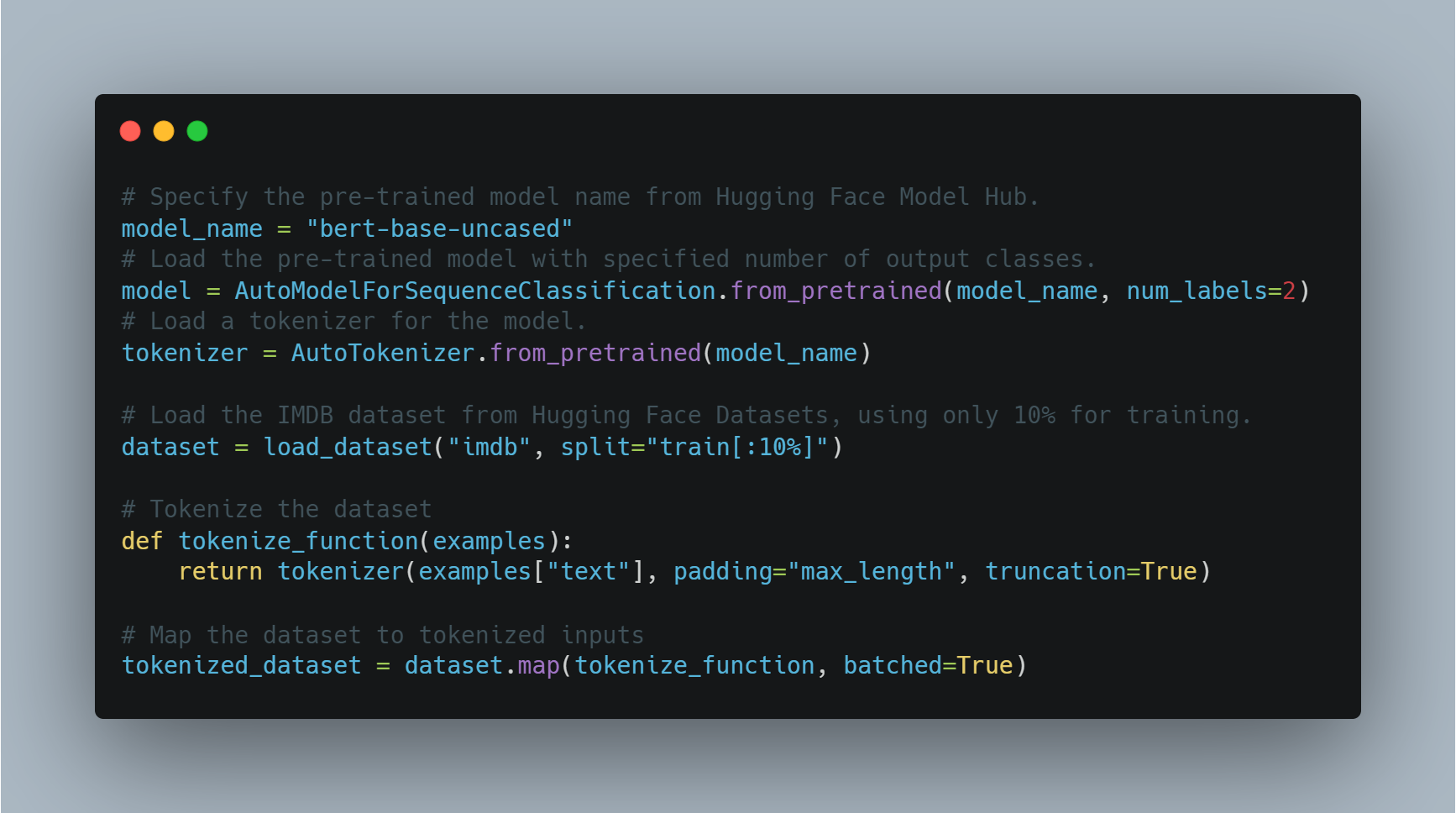
In dit geval wordt het model geladen met een BERT-gebaseerde architectuur en wordt het dataset voorbereid voor training. Vervolgens definiëren we de trainingsargumenten en initialiseren we de Trainer.
# Defineert trainingseigenschappen.
training_args = TrainingArguments(
output_dir="./results", # Specificheert de uitvoermap voor het opslaan van het model.
num_train_epochs=3, # Stel de aantal trainingsepochs in.
per_device_train_batch_size=8, # Stel de batchgrootte per apparaat in.
logging_dir='./logs', # Map voor het opslaan van logs.
logging_steps=10 # Log elke 10 stappen.
)
# Initialiseer de Trainer met het model, trainingseigenschappen en dataset.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Start het trainingsproces.
trainer.train()
# Sla de gefinaleerde model op.
model.save_pretrained("./fine_tuned_sentiment_model")

Stap 3: Implementeren van een eenvoudige Q-learning-agent
Q-learning is een techniek voor re-inforcement learning waarbij een agent leert handelen om de cumulatieve beloning tot maximum te brengen.
In dit voorbeeld definiëren we een basis Q-learning-agent die status-actieparen opslaat in een Q-tabel. Het agent kan ofwel aan de gang gaan door te verkennen ofwel de beste bekende actie gebruiken op basis van de Q-tabel. De Q-tabel wordt na elke actie bijgewerkt met behulp van een leeringsfactor en een afschaling factor om toekomstige beloningen te wegen.
Hieronder staat de code die dit Q-learning-agent implementeert:
# Definieer de Q-learning agentklasse.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Initialiseer de Q-tabel.
self.q_table = {}
# sla de mogelijke acties op.
self.actions = actions
# Stel de verkenningssnelheid in.
self.epsilon = epsilon
# Stel de leerfactor in.
self.alpha = alpha
# Stel de kortingfactor in.
self.gamma = gamma
# Definieer de get_action methode om een actie op basis van de huidige staat te selecteren.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# Verkennen op willekeurige wijze.
return random.choice(self.actions)
else:
# Exploiteren van de beste actie.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
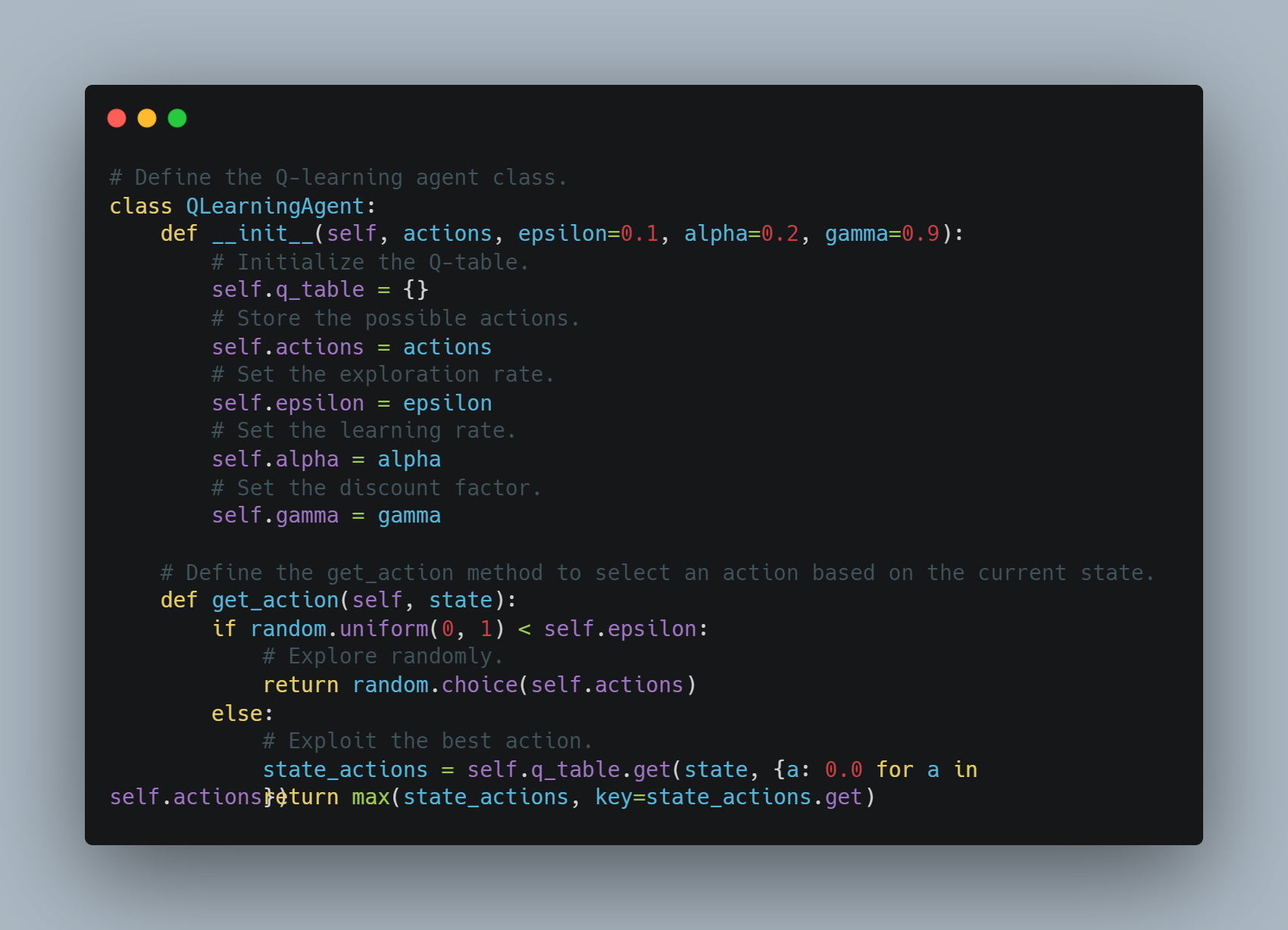
De agent selecteert acties op basis van verkenning of exploitatie en update de Q-waarden na elke stap.
# Definieer de update_q_table methode om de Q-tabel bij te werken.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
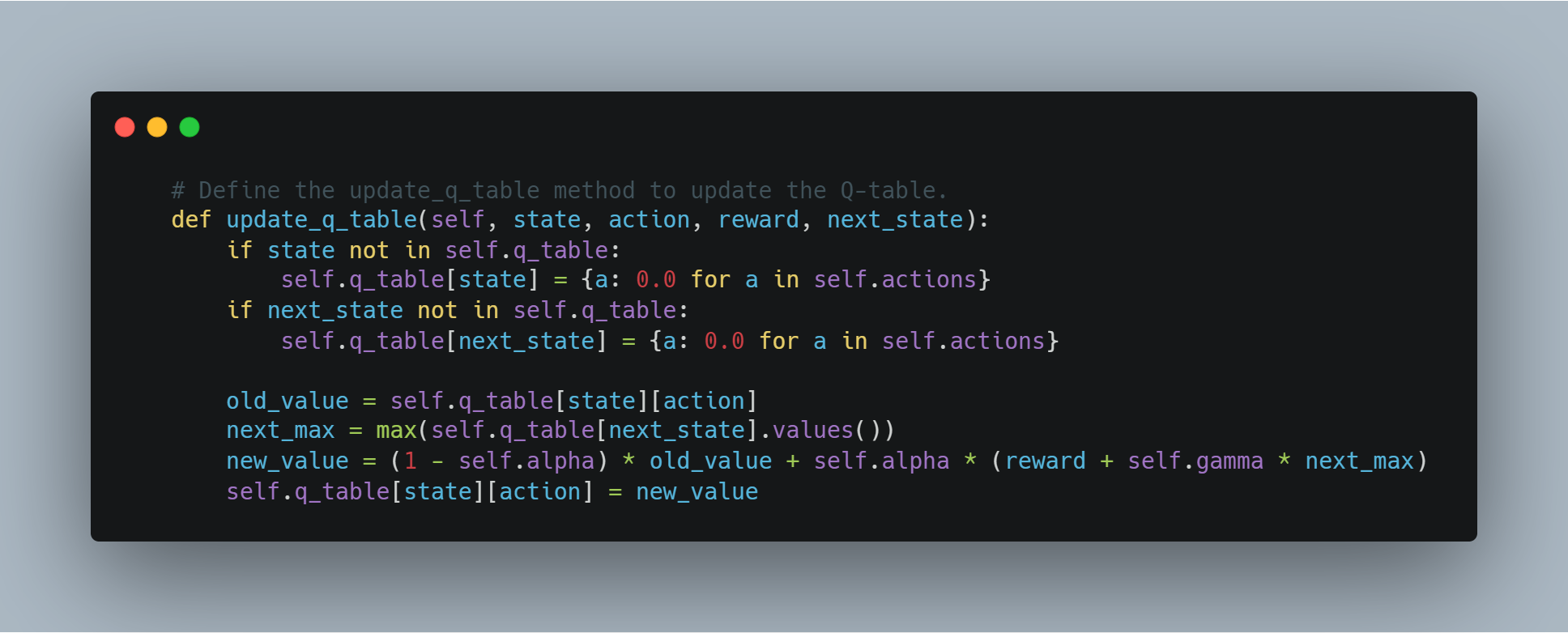
Stap 4: Gebruik van de OpenAI API voor Reward Modellering
In sommige scenario’s, in plaats van een handmatige beloningsfunctie te definiëren, kunnen we een krachtig taalmodel zoals OpenAI’s GPT gebruiken om de kwaliteit van de door de agent uitgevoerde acties te evalueren.
In dit voorbeeld stuurt de get_reward functie een staat, actie en volgende staat naar OpenAI’s API om een beloningscore te ontvangen, waardoor we grote taalmodellen kunnen gebruiken om complexe beloningsstructuur te begrijpen.
# Definieer de get_reward functie om een beloningssignaal vanuit OpenAI's API te krijgen.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # Vervang dit door je echte OpenAI API-sleutel.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
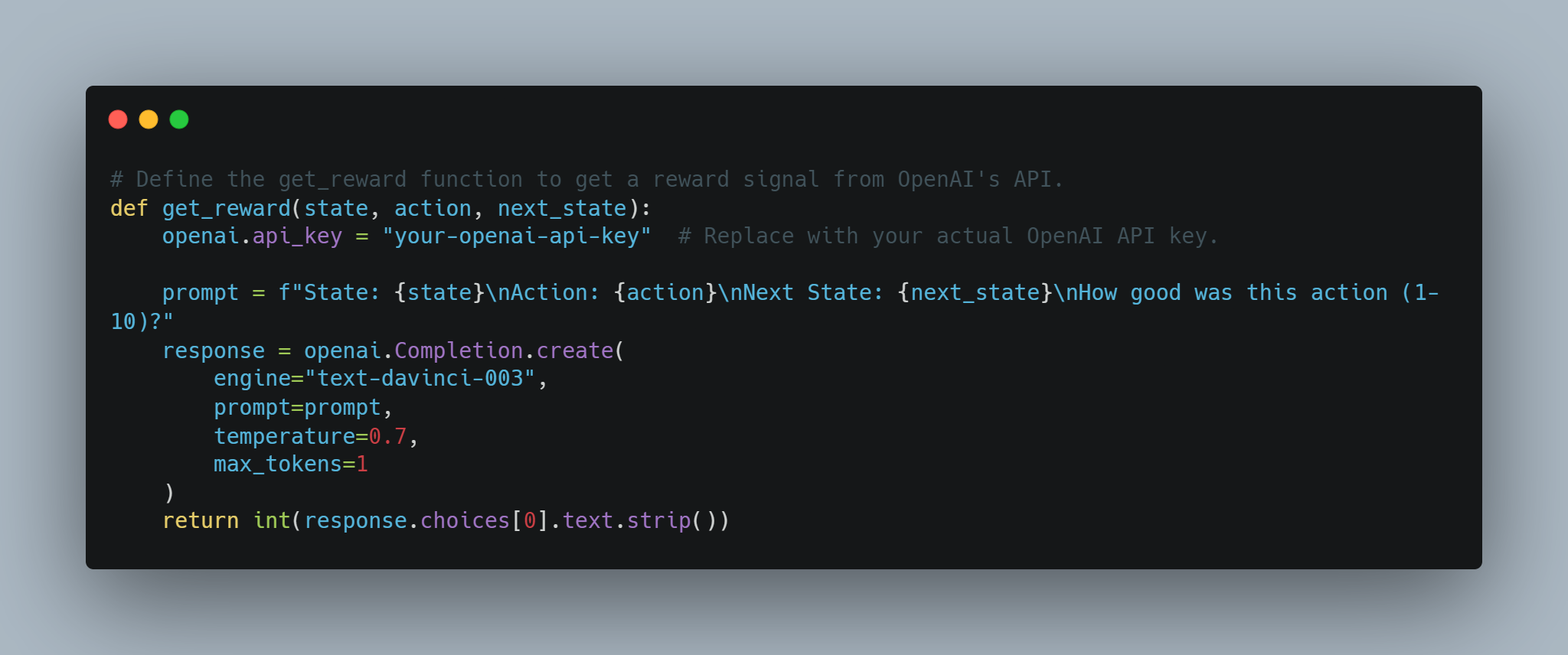
Dit maakt het mogelijk voor een conceptuele benadering waarin het beloningssysteem dynamisch wordt berekend met behulp van de API van OpenAI, wat nuttig kan zijn voor complexe taken waarvoor beloningen moeilijk te definiëren zijn.
Stap 5: Evaluatie van Modelprestaties
Eenmaal een machine learningmodel is getraind, is het essentieel om zijn prestaties te evalueren met behulp van standaardmetrieken zoals accurate en F1-score.
Deze sectie berekent beide, gebruik makend van ware en voorspelde labels. Accuracy biedt een alomvattende maat van correctheid, terwijl de F1-score de nauwkeurigheid en herkenbaarheid balanceert, vooral nuttig in onbalancierte gegevenssets.
Hier is de code voor de evaluatie van de modelprestaties:
# Definieer de ware labels voor evaluatie.
true_labels = [0, 1, 1, 0, 1]
# Definieer de voorspelde labels voor evaluatie.
predicted_labels = [0, 0, 1, 0, 1]
# Bereken de accurate score.
accuracy = accuracy_score(true_labels, predicted_labels)
# Bereken de F1-score.
f1 = f1_score(true_labels, predicted_labels)
# Toon de accurate score.
print(f"Accuracy: {accuracy:.2f}")
# Toon de F1-score.
print(f"F1-Score: {f1:.2f}")
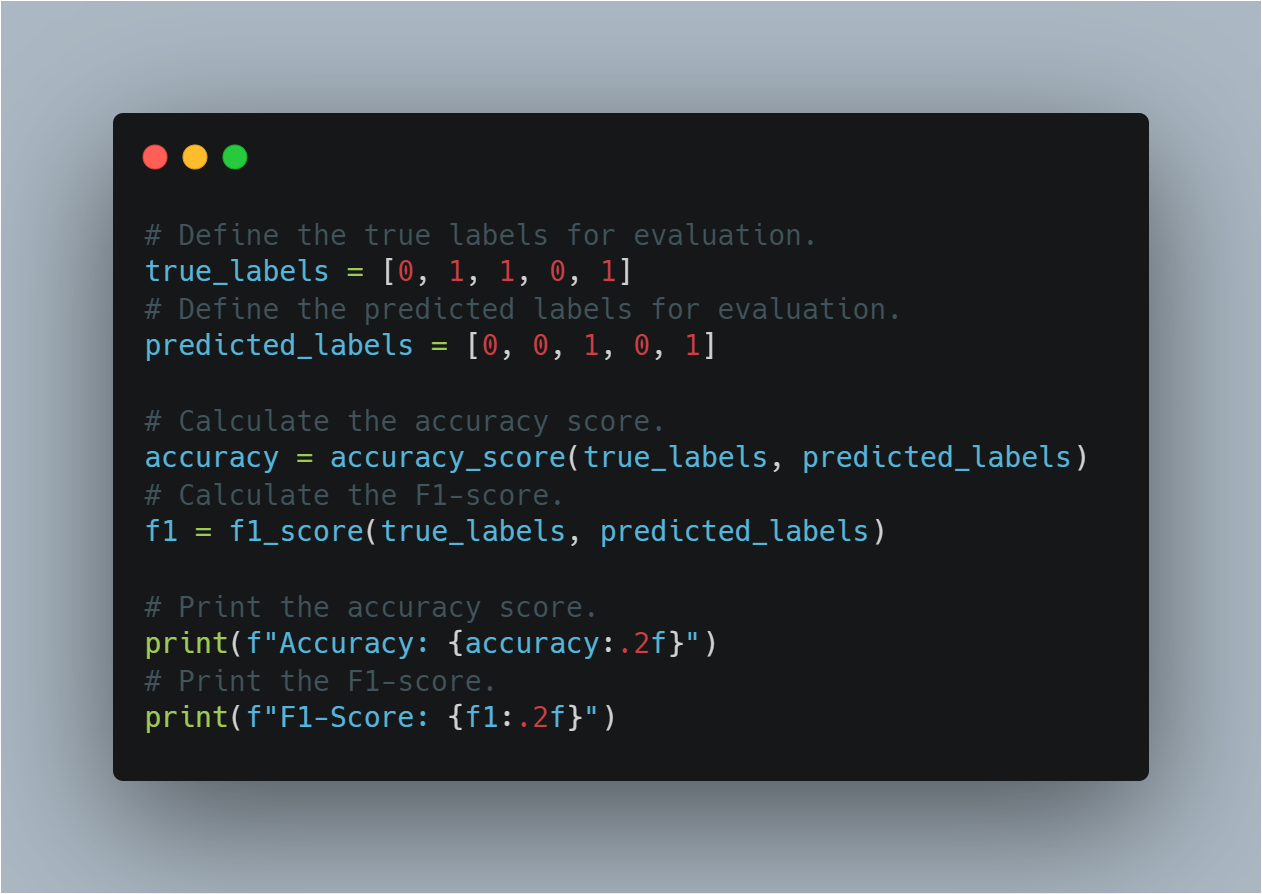
Deze sectie helpt bij het beoordelen van hoe goed het model is gegeneraliseerd naar ongeziene gegevens door gebruik te maken van gevestigde evaluatietoepassingen.
Stap 6: Basisbeleidsgradiëntagent (Met PyTorch)
Beleidsgradiëntmethodes in re-inforcement learning optimaliseren direct de beleid door de verwachte beloning te maximaliseren.
Dit gedeelte toont een eenvoudige implementatie van een beleidnetwerk met PyTorch, die kan worden gebruikt voor beslissingen in RL (Reinforcement Learning). Het beleidnetwerk gebruikt een lineaire laag om voor differenten acties probabilitaten uit te voeren, en softmax wordt toegepast om er zeker van te zijn dat deze uitvoer een geldige kansdistributie vormt.
Hier is de conceptuele code voor het definiëren van een basisbeleidsprijntingagent:
# Definieer de klasse van het beleidnetwerk.
class PolicyNetwork(nn.Module):
# Initialiseer het beleidnetwerk.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# Definieer een lineaire laag.
self.linear = nn.Linear(input_size, output_size)
# Definieer de voorwaartse pass van het netwerk.
def forward(self, x):
# Toepassing van softmax op de uitvoer van de lineaire laag.
return torch.softmax(self.linear(x), dim=1)
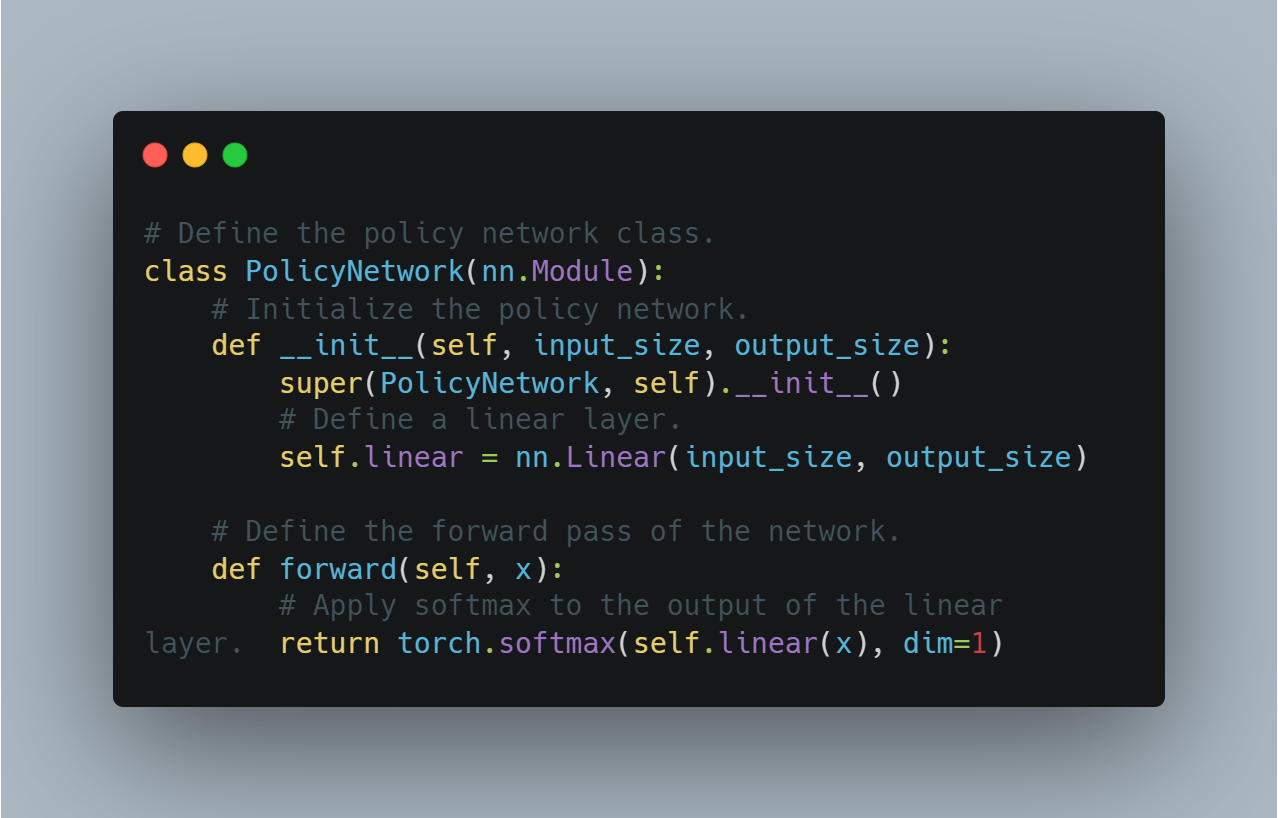
Dit vormt een grondslag voor het implementeren van meer geavanceerde reinforcement learning-algoritmen die gebruikmaken van beleidsondersteuning.
Stap 7: Visualisering van Trainingsvoortgang met TensorBoard
Visualiseren van trainingsmetrieken, zoals verlies en nauwkeurigheid, is crucial voor het begrijpen hoe de prestaties van een model zich over tijd ontwikkelen. TensorBoard, een populair gereedschap voor dit doel, kan worden gebruikt om metrieken vast te leggen en ze in real-time te visualiseren.
In dit gedeelte creëren we een SummaryWriter-instantie en loggen we willekeurige waarden om het proces van het bijhouden van verlies en nauwkeurigheid tijdens de training te simuleren.
Hier is hoe u trainingsvoortgang kunt loggen en visualiseren met behulp van TensorBoard:
# Maak een SummaryWriter-instantie.
writer = SummaryWriter()
# Voorbeeld trainingsslusiel voor TensorBoard-visualisatie:
num_epochs = 10 # Definieer het aantal epochen.
for epoch in range(num_epochs):
# Simuleer willekeurige verlies en nauwkeurigheidswaarden.
loss = random.random()
accuracy = random.random()
# Log het verlies en de nauwkeurigheid in TensorBoard.
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# Sluit de SummaryWriter.
writer.close()
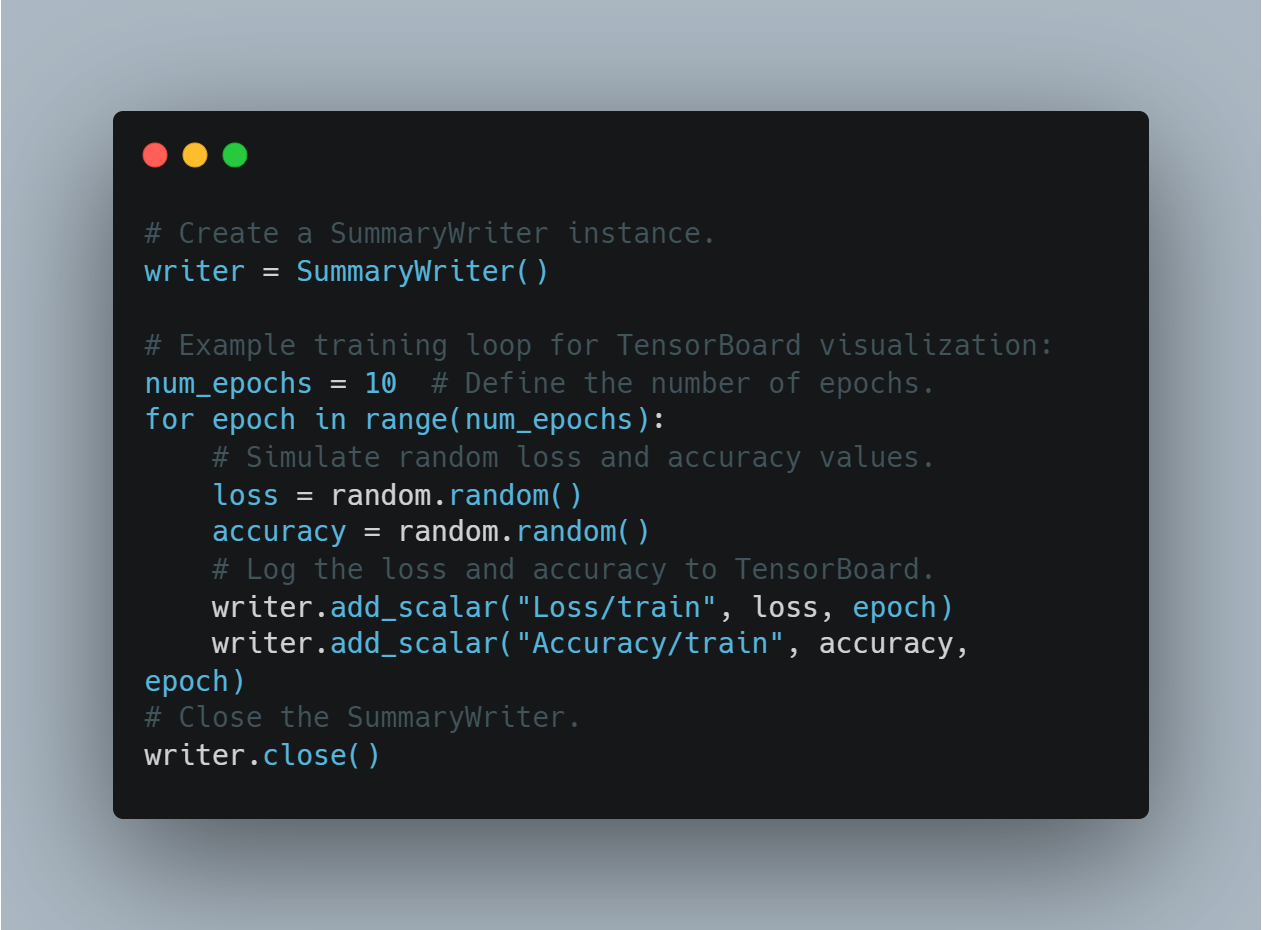
Dit stelt gebruikers in staat om het trainen van een model te monitoren en op basis van visuele feedback op tijd aanpassingen te maken.
Stap 8: Opslaan en Laden van Getrainde Agent Checkpoints
Nadat een agent is getraind, is het cruciaal om zijn geleerde toestand op te slaan (bijvoorbeeld Q-waarden of modelgewichten) zodat deze later kan worden hergebruikt of geëvalueerd.
In dit gedeelte wordt getoond hoe een getrainde agent kan worden opgeslagen met behulp van Python’s pickle-module en hoe deze vanaf schijf kan worden geladen.
Hier is de code voor het opslaan en laden van een getrainde Q-learning-agent:
# Maak een instantie van de Q-learning-agent.
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# Train de agent (niet hier getoond).
# Sla de agent op.
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# Laad de agent.
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
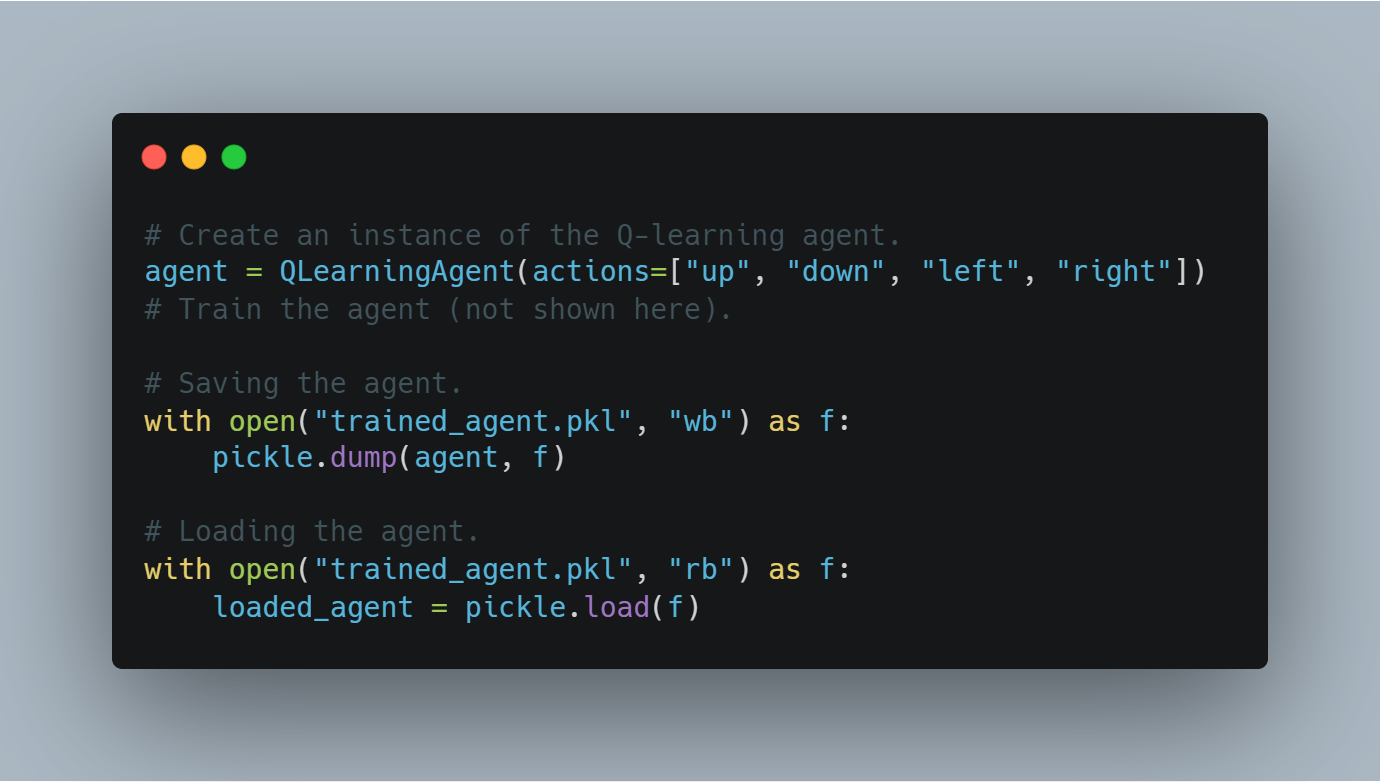
Deze process van checkpointen zorgt ervoor dat trainingsvoortgang niet verloren gaat en modellen kunnen worden hergebruikt in toekomstige experimenten.
Stap 9: Curriculum Learning
Leren via curriculum omvat het geleidelijk verhogen van de moeilijkheidsgraad van de taken die aan het model worden voorgelegd, van gemakkelijke voorbeelden naar moeilijkere taken. Dit kan helpen bij het verbeteren van de prestaties en de stabiliteit van het model tijdens de training.
Hier is een voorbeeld van het gebruik van curriculum leren in een training loop:
# Stel de beginmoeilijkheidsgraad van de taak in.
initial_task_difficulty = 0.1
# Voorbeeld training loop met curriculum leren:
for epoch in range(num_epochs):
# Verhoog de moeilijkheidsgraad van de taak geleidelijk.
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# Genereer trainingsdata met aangepaste moeilijkheidsgraad.
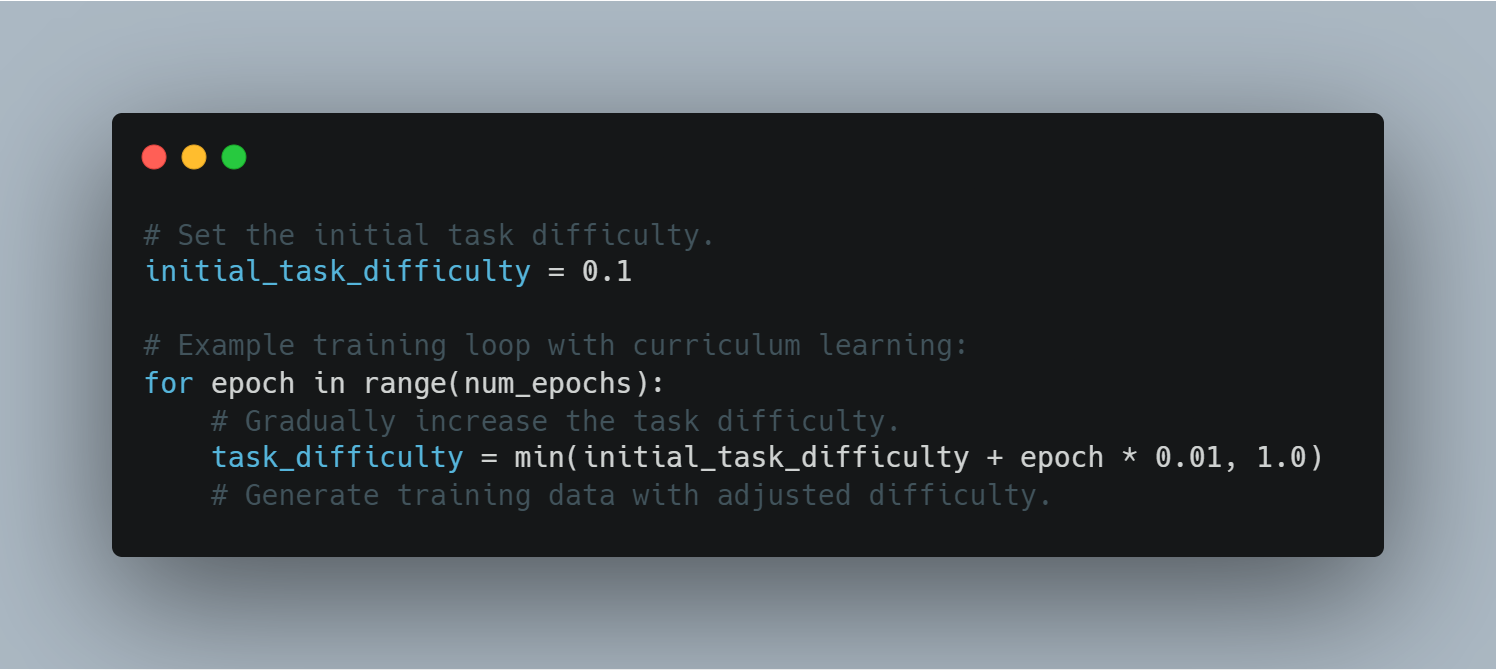
door de moeilijkheidsgraad van de taak te controleren, kan de agent geleidelijk complexere uitdagingen aan, wat tot verbetering van de leer efficiëntie leidt.
Stap 10: Implementeren van Early Stopping
Early stopping is een techniek om overfitting tijdens de training tegen te gaan door de training stop te zetten als de validatieloosheid na een bepaald aantal epochs (vertraging) niet meer verbeterd.
Deze sectie laat zien hoe early stopping kan worden geïmplementeerd in een training loop, met de validatieloosheid als de belangrijkste indicator.
Hier is de code voor het implementeren van early stopping:
# Initializeer de beste validatieverlies tot oneindig.
best_validation_loss = float("inf")
# Stel de patience-waarde in (aantal epochs zonder verbetering).
patience = 5
# Initializeer de teller voor epochs zonder verbetering.
epochs_without_improvement = 0
# Voorbeeld van training loop met early stopping:
for epoch in range(num_epochs):
# Simuleer willekeurig validatieverlies.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

Early stopping verbeterd de generalisatie van het model door te voorkomen dat er onnodig training plaatsvindt nadat het model overfitting heeft begonnen.
Stap 11: Gebruik een voorgebroken LLM voor Zero-Shot Taak Overdracht
In zero-shot taak overdracht wordt een voorgebroken model toegepast op een taak waarvoor het specifiek niet is gefine-tuned.
Met de pipeline van Hugging Face wordt in deze sectie gemonstrateerd hoe een voorgebroken BART-model voor samenstelling gebruikt kan worden zonder extra training, illustrerend het concept van overdracht van kennis.
Hier is de code voor het gebruik van een voorgebroken LLM voor samenstelling:
# Laad een voorgebroken samenstellingspipeline.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Definieer de te samenstellen tekst.
text = "This is an example text about AI agents and LLMs."
# Genereer de samenvatting.
summary = summarizer(text)[0]["summary_text"]
# Print de samenvatting.
print(f"Summary: {summary}")
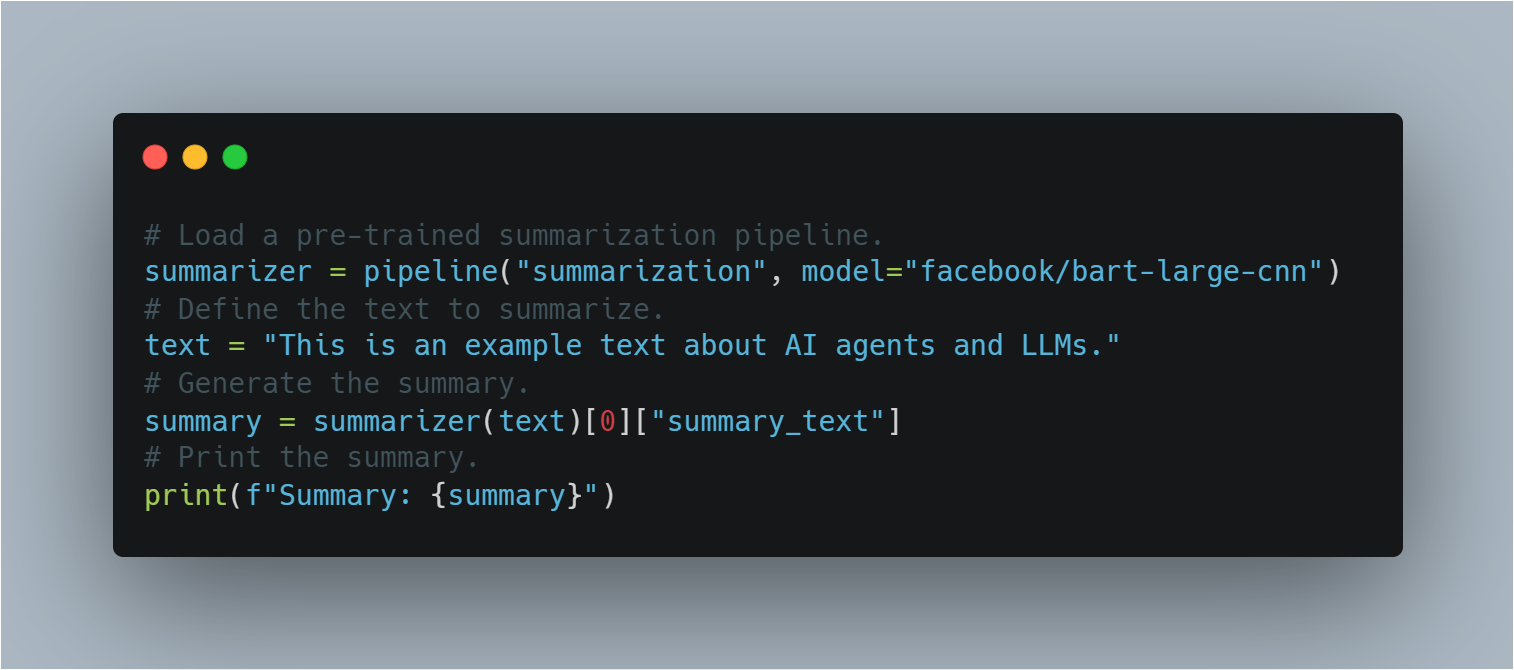
Dit illustreert de flexibiliteit van LLMs in het uitvoeren van diverse taken zonder verdere training, door hun bestaande kennis te benutten.
Het volledige codevoorbeeld.
# Import the random module for random number generation.
import random
# Import necessary modules from transformers library.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Import load_dataset for loading datasets.
from datasets import load_dataset
# Import metrics for evaluating model performance.
from sklearn.metrics import accuracy_score, f1_score
# Import SummaryWriter for logging training progress.
from torch.utils.tensorboard import SummaryWriter
# Import pickle for saving and loading trained models.
import pickle
# Import openai for using OpenAI's API (requires an API key).
import openai
# Import PyTorch for deep learning operations.
import torch
# Import neural network module from PyTorch.
import torch.nn as nn
# Import optimizer module from PyTorch (not used directly in this example).
import torch.optim as optim
# --------------------------------------------------
# 1. Fine-tuning an LLM for Sentiment Analysis
# --------------------------------------------------
# Specify the pre-trained model name from Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Load the pre-trained model with specified number of output classes.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Load a tokenizer for the model.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load the IMDB dataset from Hugging Face Datasets, using only 10% for training.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokenize the dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Map the dataset to tokenized inputs
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Define training arguments.
training_args = TrainingArguments(
output_dir="./results", # Specify the output directory for saving the model.
num_train_epochs=3, # Set the number of training epochs.
per_device_train_batch_size=8, # Set the batch size per device.
logging_dir='./logs', # Directory for storing logs.
logging_steps=10 # Log every 10 steps.
)
# Initialize the Trainer with the model, training arguments, and dataset.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Start the training process.
trainer.train()
# Save the fine-tuned model.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. Implementing a Simple Q-Learning Agent
# --------------------------------------------------
# Define the Q-learning agent class.
class QLearningAgent:
# Initialize the agent with actions, epsilon (exploration rate), alpha (learning rate), and gamma (discount factor).
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Initialize the Q-table.
self.q_table = {}
# Store the possible actions.
self.actions = actions
# Set the exploration rate.
self.epsilon = epsilon
# Set the learning rate.
self.alpha = alpha
# Set the discount factor.
self.gamma = gamma
# Define the get_action method to select an action based on the current state.
def get_action(self, state):
# Explore randomly with probability epsilon.
if random.uniform(0, 1) < self.epsilon:
# Return a random action.
return random.choice(self.actions)
else:
# Exploit the best action based on the Q-table.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# Define the update_q_table method to update the Q-table after taking an action.
def update_q_table(self, state, action, reward, next_state):
# If the state is not in the Q-table, add it.
if state not in self.q_table:
# Initialize the Q-values for the new state.
self.q_table[state] = {a: 0.0 for a in self.actions}
# If the next state is not in the Q-table, add it.
if next_state not in self.q_table:
# Initialize the Q-values for the new next state.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# Get the old Q-value for the state-action pair.
old_value = self.q_table[state][action]
# Get the maximum Q-value for the next state.
next_max = max(self.q_table[next_state].values())
# Calculate the updated Q-value.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# Update the Q-table with the new Q-value.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. Using OpenAI's API for Reward Modeling (Conceptual)
# --------------------------------------------------
# Define the get_reward function to get a reward signal from OpenAI's API.
def get_reward(state, action, next_state):
# Ensure OpenAI API key is set correctly.
openai.api_key = "your-openai-api-key" # Replace with your actual OpenAI API key.
# Construct the prompt for the API call.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# Make the API call to OpenAI's Completion endpoint.
response = openai.Completion.create(
engine="text-davinci-003", # Specify the engine to use.
prompt=prompt, # Pass the constructed prompt.
temperature=0.7, # Set the temperature parameter.
max_tokens=1 # Set the maximum number of tokens to generate.
)
# Extract and return the reward value from the API response.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. Evaluating Model Performance
# --------------------------------------------------
# Define the true labels for evaluation.
true_labels = [0, 1, 1, 0, 1]
# Define the predicted labels for evaluation.
predicted_labels = [0, 0, 1, 0, 1]
# Calculate the accuracy score.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calculate the F1-score.
f1 = f1_score(true_labels, predicted_labels)
# Print the accuracy score.
print(f"Accuracy: {accuracy:.2f}")
# Print the F1-score.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. Basic Policy Gradient Agent (using PyTorch) - Conceptual
# --------------------------------------------------
# Define the policy network class.
class PolicyNetwork(nn.Module):
# Initialize the policy network.
def __init__(self, input_size, output_size):
# Initialize the parent class.
super(PolicyNetwork, self).__init__()
# Define a linear layer.
self.linear = nn.Linear(input_size, output_size)
# Define the forward pass of the network.
def forward(self, x):
# Apply softmax to the output of the linear layer.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. Visualizing Training Progress with TensorBoard
# --------------------------------------------------
# Create a SummaryWriter instance.
writer = SummaryWriter()
# Example training loop for TensorBoard visualization:
# num_epochs = 10 # Define the number of epochs.
# for epoch in range(num_epochs):
# # ... (Your training loop here)
# loss = random.random() # Example: Random loss value.
# accuracy = random.random() # Example: Random accuracy value.
# # Log the loss to TensorBoard.
# writer.add_scalar("Loss/train", loss, epoch)
# # Log the accuracy to TensorBoard.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (Log other metrics)
# # Close the SummaryWriter.
# writer.close()
# --------------------------------------------------
# 7. Saving and Loading Trained Agent Checkpoints
# --------------------------------------------------
# Example:
# Create an instance of the Q-learning agent.
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (Train your agent)
# # Saving the agent
# # Open a file in binary write mode.
# with open("trained_agent.pkl", "wb") as f:
# # Save the agent to the file.
# pickle.dump(agent, f)
# # Loading the agent
# # Open the file in binary read mode.
# with open("trained_agent.pkl", "rb") as f:
# # Load the agent from the file.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. Curriculum Learning
# --------------------------------------------------
# Set the initial task difficulty.
initial_task_difficulty = 0.1
# Example training loop with curriculum learning:
# for epoch in range(num_epochs):
# # Gradually increase the task difficulty.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (Generate training data with adjusted difficulty)
# --------------------------------------------------
# 9. Implementing Early Stopping
# --------------------------------------------------
# Initialize the best validation loss to infinity.
best_validation_loss = float("inf")
# Set the patience value (number of epochs without improvement).
patience = 5
# Initialize the counter for epochs without improvement.
epochs_without_improvement = 0
# Example training loop with early stopping:
# for epoch in range(num_epochs):
# # ... (Training and validation steps)
# # Calculate the validation loss.
# validation_loss = random.random() # Example: Random validation loss.
# # If the validation loss improves.
# if validation_loss < best_validation_loss:
# # Update the best validation loss.
# best_validation_loss = validation_loss
# # Reset the counter.
# epochs_without_improvement = 0
# else:
# # Increment the counter.
# epochs_without_improvement += 1
# # If no improvement for 'patience' epochs.
# if epochs_without_improvement >= patience:
# # Print a message.
# print("Early stopping triggered!")
# # Stop the training.
# break
# --------------------------------------------------
# 10. Using a Pre-trained LLM for Zero-Shot Task Transfer
# --------------------------------------------------
# Load a pre-trained summarization pipeline.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Define the text to summarize.
text = "This is an example text about AI agents and LLMs."
# Generate the summary.
summary = summarizer(text)[0]["summary_text"]
# Print the summary.
print(f"Summary: {summary}")

Challenges bij implementatie en schaalbaarheid
Het implementeren en schalen van geïntegreerde AI-agents met lineaire lussen (LLMs) brengt significante technische en operationele uitdagingen met zich mee. Eén van de primaire uitdagingen is de computercost, vooral als LLMs in grootte en complexiteit toenemen.
Het aanpakken van dit probleem vereist strategieën voor resourcebewaring zoals modelpruning, quantificatie en gedistribueerd rekenen. Dit kan helpen de computercost te verminderen zonder de prestaties te schelen.
Het behoud van betrouwbaarheid en robustheid in real-world-toepassingen is ook erg belangrijk, wat het behoud van een aan de slag zijn, periodieke updates en de ontwikkeling van failsafe-mechanismen vereist om onverwachte invoer of systemefouten te behandelen.
Als deze systemen over verschillende industriën worden uitgevoerd, is het nageleven van ethische standaarden – inclusief rechtvaardigheid, transparantie en verantwoordelijkheid – steeds belangrijker. Deze overwegingen zijn centraal aan de acceptatie en langetermijnsucces van het systeem, die de publieke vertrouwens en de ethische implicaties van door AI geleide beslissingen in diverse maatschappelijke contexten beïnvloeden (Bender et al., 2021).
Het technische implementeren van AI-agents geïntegreerd met LLMs vereist goed geconstrueerde architectuur, rigoureuze trainingsmethodieken en nauwkeurige aanpak van implementatie uitdagingen.
De effectiviteit en betrouwbaarheid van deze systemen in real-world-omgevingen hangen af van het aanpakken van zowel technische als ethische zorgen, ervoor zorgend dat AI-technologieën vlot en verantwoordelijk functioneren over verschillende toepassingen.
Hoofdstuk 7: Het toekomstige van AI-agents en LLMs
Convergentie van LLMs met Reïnforcement Learning
Als u de toekomst van AI-agenten en Grote Taalmodellen (LLM’s) verkent, stelt zich de convergentie van LLM’s met reinforcement learning vooral voor als een bijzonder transformatief ontwikkeling. Deze integratie duwt de grenzen van traditionele AI verder uit door systemen in staat te stellen niet alleen taal te genereren en te begrijpen, maar ook vanuit hun interacties in real-time te leren.
Door behulp van reinforcement learning kunnen AI-agenten hun strategieën adaptief aanpassen op basis van feedback van hun omgeving, waardoor hun besluitvormingsprocessen continu worden gerefineerd. Dit betekent dat, in tegenstelling tot statische modellen, AI-systemen die worden versterkt met reinforcement learning in staat zijn complexere en dynamische taken te behandelen met minimaal menselijke toezicht.
De implicaties voor dergelijke systemen zijn diepgaand: in toepassingen vanaf autonome robotica tot persoonlijke opleiding kunnen AI-agenten over tijd autonomie ontwikkelen om hun prestatie te verbeteren, waardoor ze efficiënter en responsiever worden voor de evoluerende eisen van hun operationele context.
Voorbeeld: Tekstgebaseerd Spel Spelen
Imagineer een AI-agent die een tekstgebaseerd avonturenspel speelt.
-
Omgeving: Het spel zelf (regels, status beschrijvingen, enzovoort)
-
LLM: Verwerkt de tekst van het spel, begrijpt de huidige situatie, en genereert mogelijke acties (bijvoorbeeld, “ga noord”, “neem zwaard”).
-
Beloning: Gegeven door het spel op basis van het resultaat van de actie (bijvoorbeeld, een positieve beloning voor het vinden van schat, een negatieve voor het verliezen van gezondheid).
Codevoorbeeld (Conceptueel gebruikmakend van Python en OpenAI’s API):
import openai
import random
# ... (Spelomgeving logica - hier niet getoond) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (RL training lus - gereduceerd) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (Update RL agent op basis van beloning - hier niet getoond) ...
state = next_state
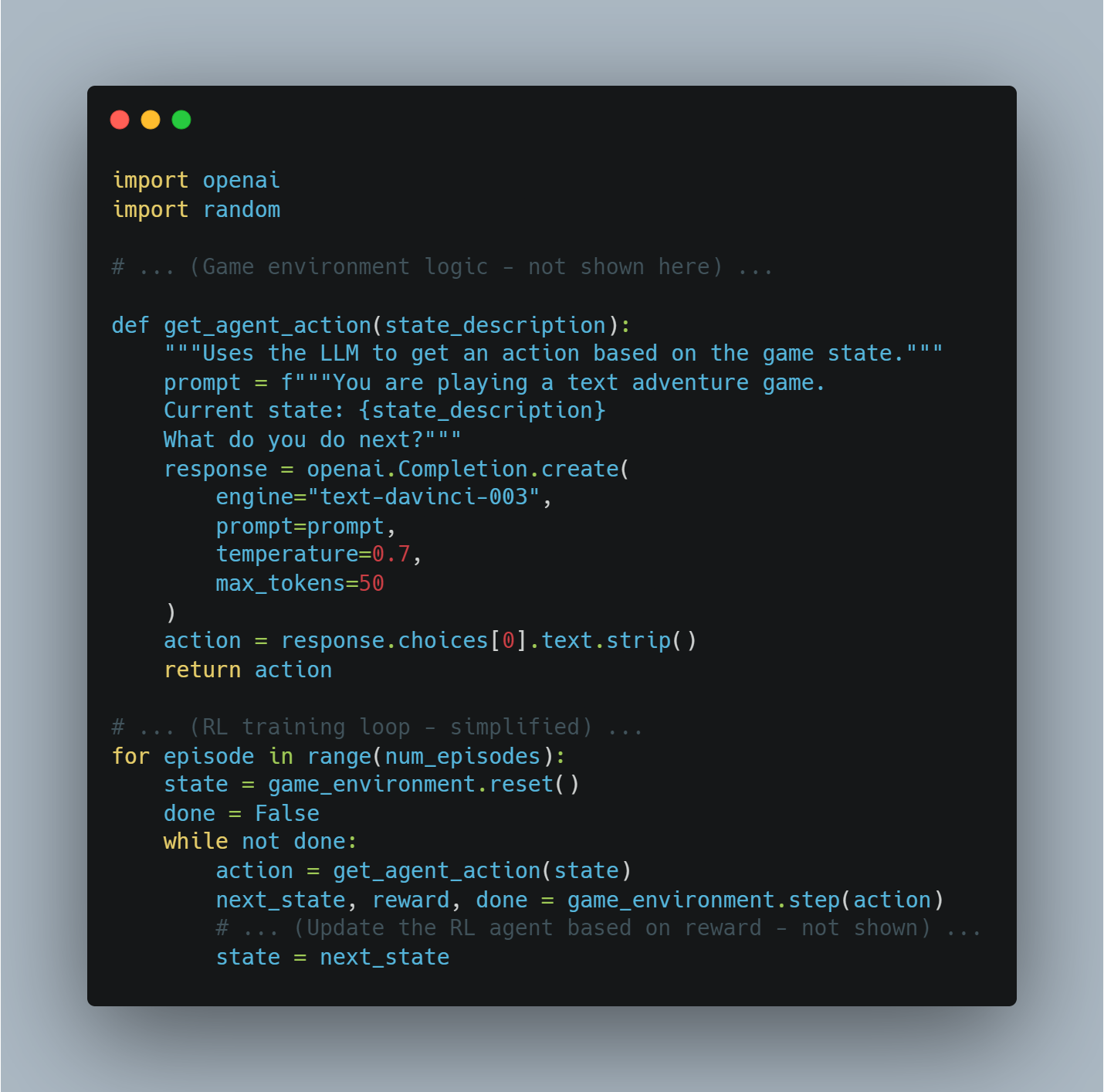
Multimodale AI-integratie
De integratie van multimodale AI is een andere kritieke trend die de toekomst van AI-agenten bepaalt. door middel van het toestaan van systemen om gegevens uit verschillende bronnen te verwerken en te combineren – zoals tekst, afbeeldingen, geluid en sensorische invoer – biedt multimodale AI een meer alomvattende verstand van de omgevingen waarin deze systemen operationeel zijn.
Bijvoorbeeld, voor autonome voertuigen, de mogelijkheid om visuele gegevens van camera’s, contextuele gegevens van kaarten en real-time verkeersupdates te synthetiseren laat de AI meer geïnformeerde en veiligere rij beslissingen maken.
Deze mogelijkheid wordt uitgebreid naar andere domeinen zoals de gezondheidszorg, waar een AI-agent gegevens over patiënten van medische records, diagnostische afbeeldingen en genomische informatie kunnen integreren om meer nauwkeurige en persoonlijke behandelingse aanbevelingen uit te voeren.
Hierin ligt het probleem in de doorlopende integratie en realtime verwerking van verschillende gegevensstromen, wat vooruitgang nodig heeft in model architectuur en data samenvoeging technieken.
Succesvol overwinnen van deze uitdagingen zal beslissend zijn bij het implementeren van AI-systemen die echt intelligent zijn en in complexe, echte wereld omgevingen kunnen functioneren.
Voorbeeld van multimodale AI 1: Afbeeldingsbeschrijving voor visuele vraagbehandeling
-
Doel: Een AI-agent dat antwoorden kan geven op vragen over afbeeldingen.
-
Modaliteiten: Afbeelding, Tekst
-
Proces:
-
Afbeeldingsfunctie Extractie: Gebruik een geïnstalleerde Convolutionele Neurale Netwerken (CNN) om functies uit de afbeelding te extraheren.
-
Beschrijvingsgeneratie: Gebruik een LLM (zoals een Transformeermodel) om een beschrijving van de afbeelding te genereren op basis van de geëxtraheerde functies.
-
Vraagbehandeling: Gebruik een andere LLM om zowel de vraag als de gegenereerde beschrijving te verwerken om een antwoord te geven.
-
Codevoorbeeld (conceptueel met Python en Hugging Face Transformers):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# Laad voorgeprogrammeerde modellen
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# Functie om afbeeldingstitel te genereren
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# Functie om vragen over de afbeelding te beantwoorden
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# Voorbeeld van gebruik
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
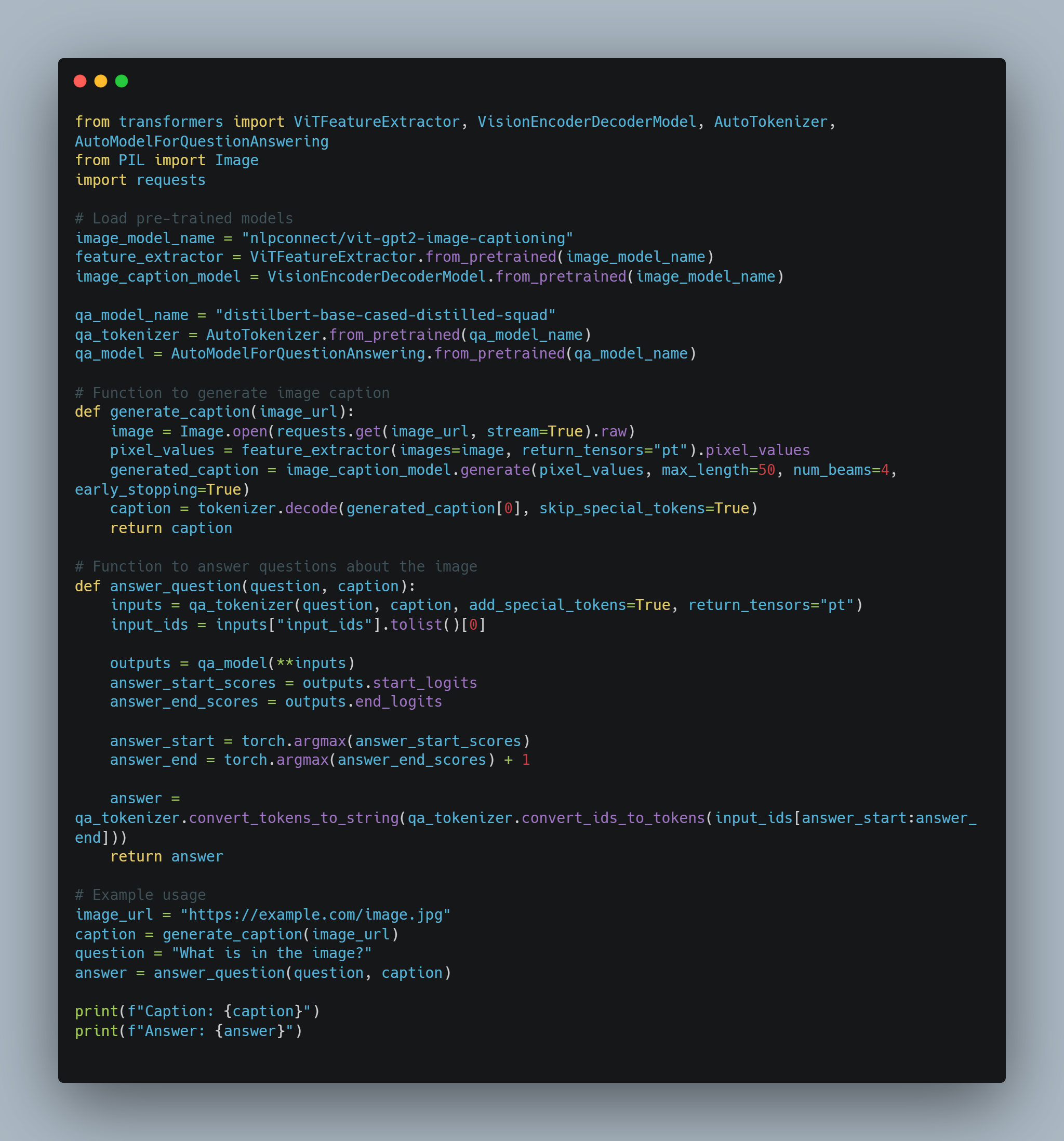
Multimodale AI-voorbeeld 2: Gevoelensanalyse uit Tekst en Audio
-
Doel: Een AI-agent die gevoelens analyseert uit zowel de tekst als het toon van een bericht.
-
Modaliteiten: Tekst, Audio
-
Proces:
-
Tekstgevoel: Gebruik een vooraf getraind sentimentanalysemodel op de tekst.
-
Audiogevoel: Gebruik een audioprocessingmodel om kenmerken zoals toon en pitch te extraheren, en gebruik deze kenmerken om het sentiment te voorspellen.
-
Fusie: Combineer de tekst- en audio-sentimentscores (bijvoorbeeld, gewogen gemiddelde) om het algemene sentiment te krijgen.
-
Voorbeeldcode (Conceptueel gebruikmakend van Python):
from transformers import pipeline # Voor tekst sentiment
# ... (Importeren van audio-bewerking en sentimentbibliotheken - niet getoond) ...
# Laad voorbereide modellen
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# Tekst sentiment
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# Geluids sentiment
# ... (Audio verwerken, functies uitvinden, sentiment voorspelen - niet getoond) ...
audio_sentiment = # ... (Resultaten van de geluids-sentimentmodel)
audio_confidence = # ... (Score van vertrouwen van het geluidmodel)
# Syncretize sentiment (example: weighted average)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# Example usage
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
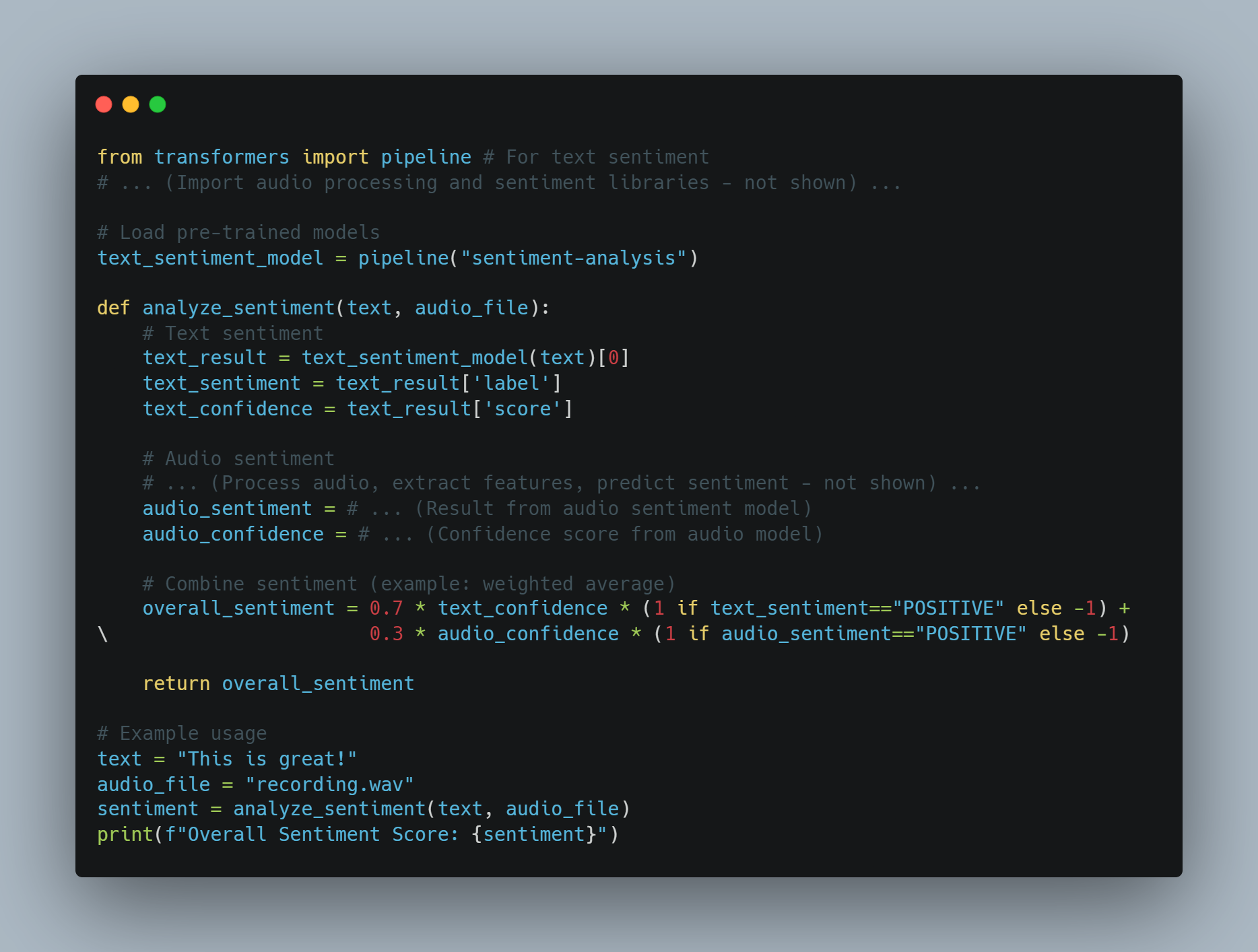
Challenges and Considerations:
-
Data Alignment: Het is crucial dat gegevens uit verschillende modaliteiten gecontroleerd en gealigneerd zijn.
-
Model Complexity: Multimodale modellen zijn moeilijk te trainen en vereisen grote, diverse gegevenssets.
-
Fusion Techniques: Het kiezen van de juiste methode om informatie uit verschillende modaliteiten samen te voegen is belangrijk en specifiek voor elk probleem.
Multimodale AI is een snel ontwikkelend veld dat de mogelijkheid biedt de manier waarop AI-agenten de wereld perken en interacteren te revolutioneren.
Gedistribueerde AI-systemen en Edge-computing
Bij het inzien van de ontwikkeling van AI-infrastructuren, vertegenwoordigt de overstap naar gedistribueerde AI-systemen, ondersteund door edge-computing, een significante vooruitgang.
Gedistribueerde AI-systemen dekent computaties taken uit door data dicht bij de bron te verwerken—zoals IoT-apparaten of lokale servers—in plaats van te vertrouwen op centraal gelegen cloudbronnen. Deze aanpak reduceert niet alleen de vertraging, die crucial is voor tijdsgevoelige toepassingen zoals onafhankelijke drones of industriële automatisering, maar verbetert ook de data privacy en veiligheid door gevoelige informatie lokaal te houden.
Hierbij wordt de schaalbaarheid ook verbeterd, waardoor AI over uitgebreide netwerken kan worden geïmplementeerd, zoals in slimme steden, zonder de centrale gegevenscentra te overbelasten.
De technische uitdagingen van gedistribueerde AI omvatten het waarborgen van consistentie en coördinatie over verspreide knooppunten, evenals het optimaliseren van resource-toewijzing om de prestaties te behouden over divers en potentiëel resource-beperkte omgevingen.
Bij het ontwikkelen en implementeren van AI-systemen, zal het omarmen van gedistribueerde architecturen de sleutel zijn tot het creëren van flexibele, efficiënte en schaalbare AI-oplossingen die aan de eisen van toekomstige toepassingen voldoen.
Gedistribueerde AI-systemen en edge computing voorbeeld 1: Federaal leren voor privacybeschermend modeltrainen
-
Doel: Een gedeeld model op meerdere apparaten (bijvoorbeeld, smartphones) trainen zonder direct gevoelige gebruikersdata te delen.
-
Approach:
-
Lokale training: Elk apparaat train een lokale model op zijn eigen gegevens.
-
Parametersamenstelling: Apparaten sturen modelupdates (gradienten of parameters) naar een centrale server.
-
Globale modelupdate: De server samenstelt de updates, verbeterd het globale model, en stuurt de bijgewerkte model terug naar de apparaten.
-
Codevoorbeeld (Conceptueel gebruikend Python en PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
# ... (Code voor de communicatie tussen apparaten en server - niet getoond) ...
class SimpleModel(nn.Module):
# ... ( Definieer uw modelarchitectuur hier) ...
# Apparaatkant trainingsfunctie
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # Begin met globale model
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (Traineer local_model op device_data) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# Serverkant aggregeerfunctie
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (Hoofd Federated Learning lus - ge simplifyd) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

Voorbeeld 2: Real-time Object Detection op Edge Apparaten
-
Doel: Implementeer een objectdetectiemodel op een resourcenaderig apparaat (bijvoorbeeld, Raspberry Pi) voor real-time inferentie.
-
Approach:
-
ModelOptimalisatie:gebruik technieken zoals model quantificatie of afknippen om de grootte van het model en de rekenvermogen te verminderen.
-
Edge-implementatie: Implementeer het geoptimaliseerde model op het edge-apparaat.
-
Lokale Inferentie: Het apparaat voert objectdetectie lokaal uit, waardoor de latency wordt verminderd en de afhankelijkheid van de cloudcommunicatie wordt verminderd.
-
Codevoorbeeld (Conceptueel gebruikmakende Python en TensorFlow Lite):
import tensorflow as tf
# Laad de geëvalueerde model (genomen dat het al geevalueerd is voor TensorFlow Lite)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# Verkrijg de details van de invoer en uitvoer
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (Afbeelding opnemen van camera of vanbestand - niet getoond) ...
# Behandel de afbeelding
input_data = ... # Vergrootte, normaliseer, enzovoort.
interpreter.set_tensor(input_details[0]['index'], input_data)
# Voer inferentie uit
interpreter.invoke()
# Verkrijg de uitvoer
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (Verwerkt uitvoergegevens tot kaders, klassen, enzovoort) ...
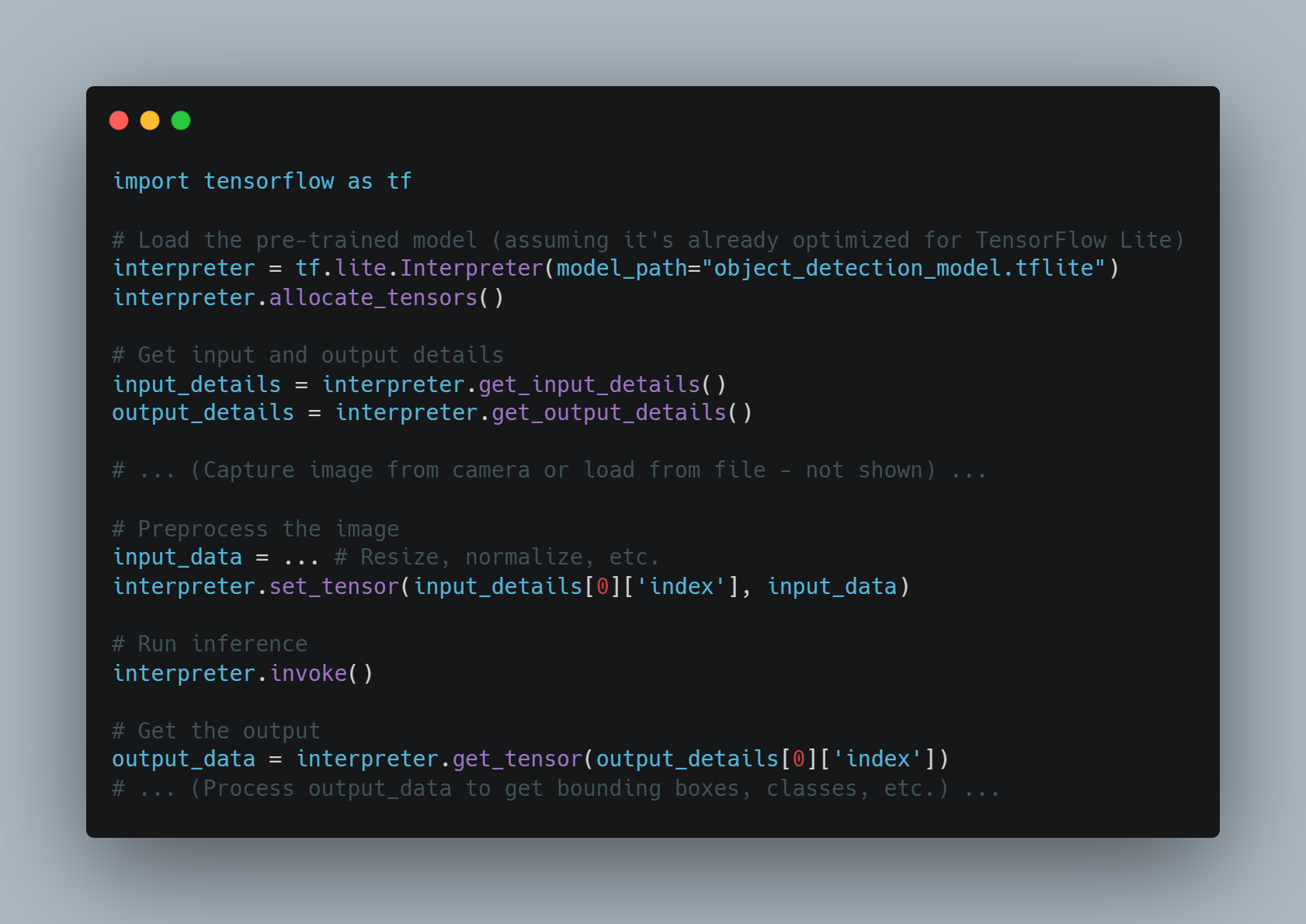
Challenges and Considerations:
-
Communication Overhead: Efficiently coordinating and communicating between distributed nodes is crucial.
-
Resource Management: Optimizing resource allocation (CPU, memory, bandwidth) across devices is important.
-
Security: Securing distributed systems and protecting data privacy are paramount concerns.
Gedistribueerde AI en edge computing zijn essentieel voor het bouwen van scalabele, efficiënte en privacybewuste AI-systemen, vooral als we naar een toekomst met miljarden van gesloten apparaten toegaan.
Vorderingen in de Natuurlijke Taalverwerking
Natuurlijke Taalverwerking (NLP) blijft een van de voorhoede zijn van de voortgang in AI, die significante verbeteringen brengt in hoe machines begrijpen, genereren en interacteren met menselijke taal.
Recente ontwikkelingen in NLP, zoals de evolutie van transformers en aandachtsmechanismen, hebben de vaardigheden van AI omvangrijk versterkt om complexe taalkundige structuren te verwerken, waardoor de interacties natuurlijker en contextueel bewuster worden.
Deze vooruitgang heeft ervoor gezorgd dat AI-systemen nu inzicht kunnen krijgen in subtielheden, sentimenten en zelfs culturele verwijzingen binnen tekst, leidend tot meer nauwkeurige en betekenislijke communicatie.
Bijvoorbeeld, in klantenservice, kunnen geavanceerde NLP-modellen niet alleen vragen met precision afhandelen, maar kunnen ook emotionele kenmerken van klanten detecteren, waardoor meer empatische en effectieve reacties mogelijk zijn.
Blijvend aan het oog, de integratie van meertalige kennis en een diepere semantische verstand van NLP-modellen zal hun toepasbaarheid verder uitbreiden, waardoor gemakkelijke communicatie mogelijk wordt over verschillende talen en dialecten, en zelfs mogelijk maakt dat AI-systemen als real-time vertalers dienen in diverse wereldwijde contexten.
Natuurlijke Taalverwerking (NLP) ontwikkelt zich snel, met doorbraken in gebieden als transformermodellen en aandachtsmechanismen. Hier zijn enkele voorbeelden en code-fragmenten om deze vooruitgang te illustreren:
NLP voorbeeld 1: Sentiment Analyse met gefine-tuned Transformers
-
Doel: Analyseer de sentimenten van tekst met hoge nauwkeurigheid, met inachtneming van subtiele details en context.
-
Approach: Fijn afstemmen van een voorbereid model van een transformer (zoals BERT) op een dataset voor sentiment analyse.
Code Voorbeeld (gebruik makend van Python en Hugging Face Transformers):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Laad voorbereid model en dataset
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3 labels: Positief, Negatief, Neutraal
dataset = load_dataset("imdb", split="train[:10%]")
# Definieer training argumenten
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# Fijn afstemmen van het model
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# Sla het gefine-tuned model op
model.save_pretrained("./fine_tuned_sentiment_model")
# Laad het gefine-tuned model voor inferentie
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# Voorbeeld van gebruik
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
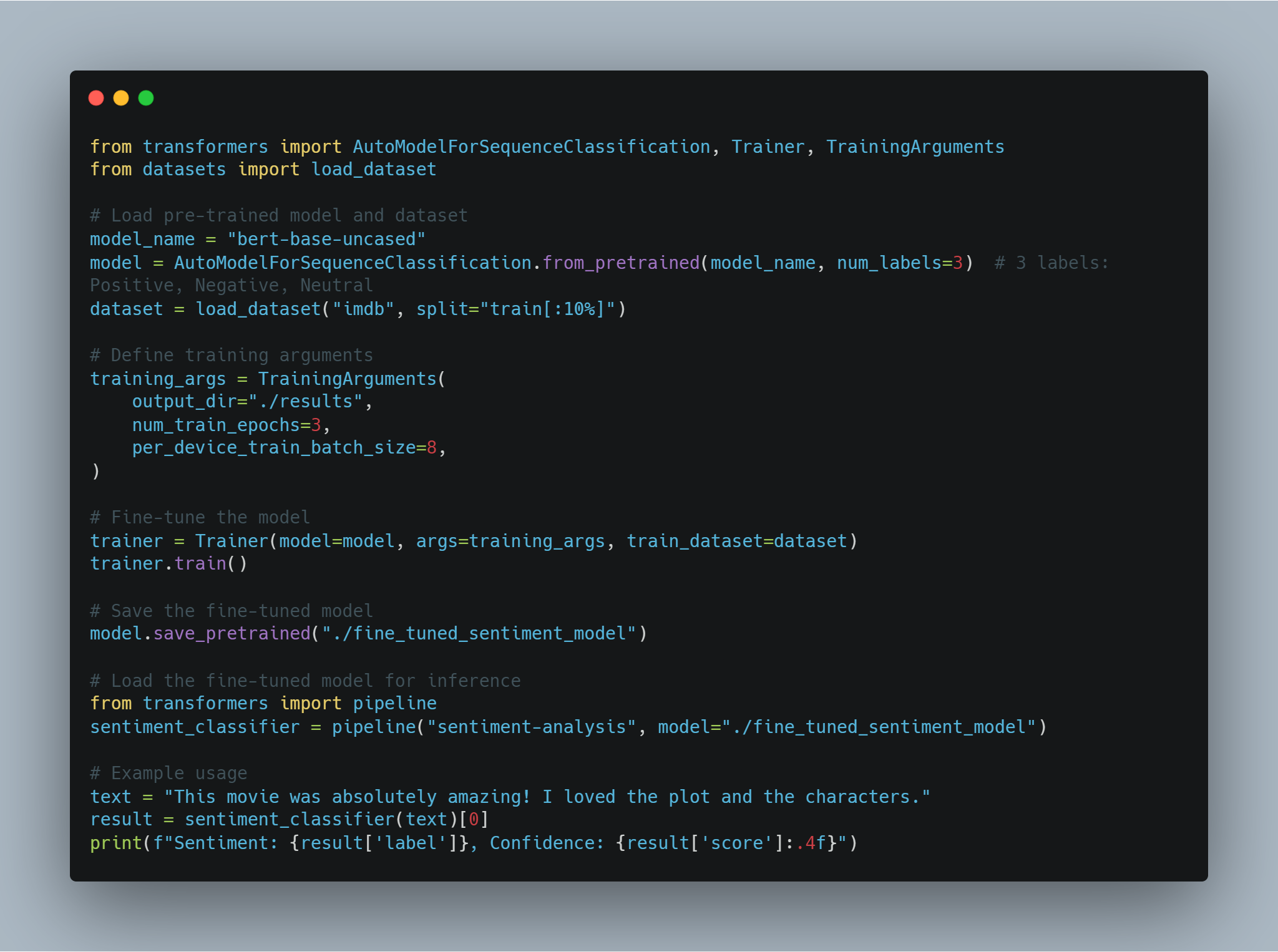
NLP voorbeeld 2: Multilinguale Machine Translation met een Enkel Model
-
Doel: Vertaal tussen meerdere talen met behulp van een enkel model, door middel van gedeelde linguistische representaties.
- Aanpak: Gebruik een groot, meertalig transformatiemodel (zoals mBART of XLM-R) dat is getraind op een enorme dataset van parallelle tekst in meerdere talen.
Codevoorbeeld (met behulp van Python en Hugging Face Transformers):
from transformers import pipeline
# Laad een voor-getraind meertalig vertalingspijplijn
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# Voorbeeldgebruik: Engels naar Frans
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# Voorbeeldgebruik: Frans naar Spaans
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
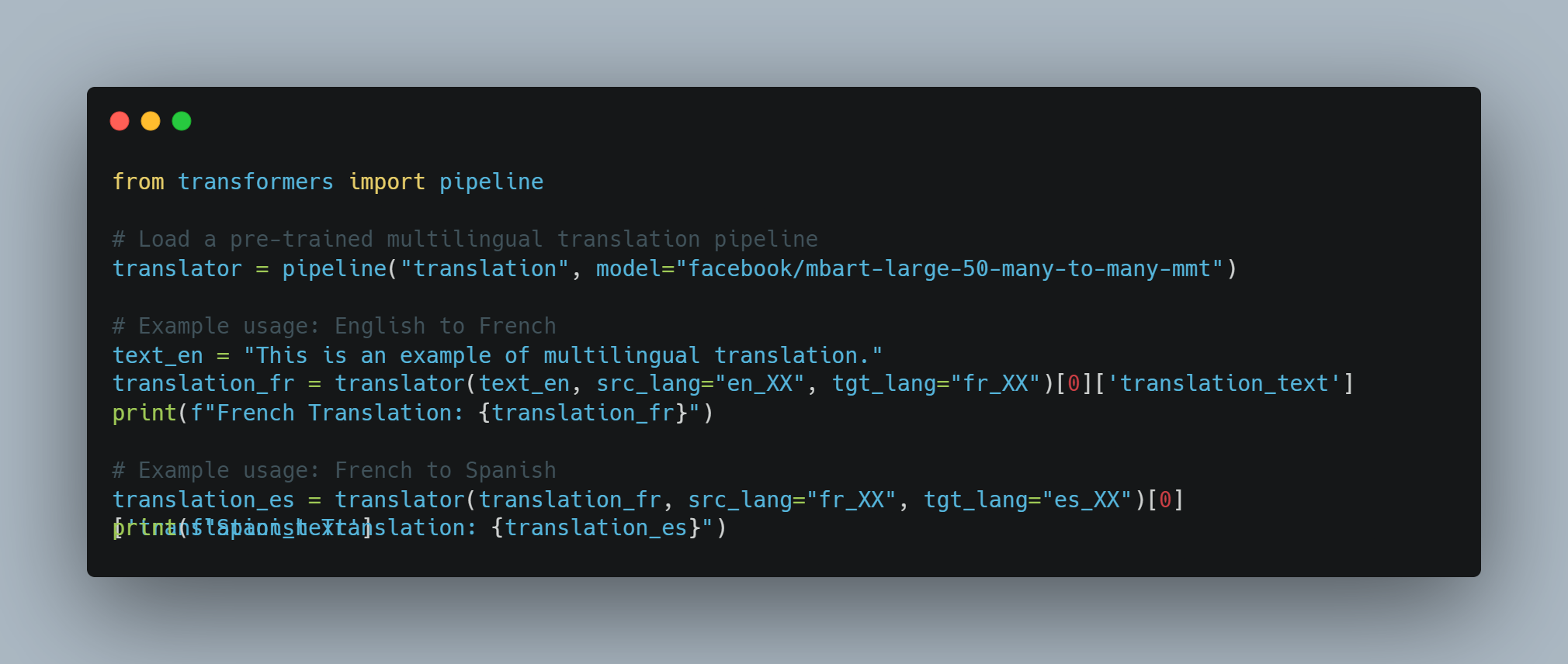
NLP Voorbeeld 3: Contextuele Woordembeddings voor Semantische Overeenkomst
-
Doel: Bepaal de overeenkomst tussen woorden of zinnen, rekening houdend met de context.
-
Aanpak: Gebruik een transformatiemodel (zoals BERT) om contextuele woordembeddings te genereren, die de betekenis van woorden binnen een bepaalde zin vastleggen.
Codevoorbeeld (met behulp van Python en Hugging Face Transformers):
from transformers import AutoModel, AutoTokenizer
import torch
# Laad het voorgeleerde model en tokenizer
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Functie om zin-embeddings te verkrijgen
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# Gebruik het [CLS]-token-embedding als de zin-embedding
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# Voorbeeldgebruik
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# Bereken cosinusgelijkenis
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
Uitdagingen en toekomstige richtingen:
-
Vooroordeel en rechtvaardigheid: NLP-modellen kunnen vooroordelen overnemen uit hun trainingsgegevens, wat kan leiden tot oneerlijke of discriminerende resultaten. Het aanpakken van vooroordelen is cruciaal.
-
Gemeenschappelijk zinvol redeneren: LLM’s hebben nog steeds moeite met het redeneren over gezond verstand en het begrijpen van impliciete informatie.
-
Uitlegbaarheid: Het besluitvormingsproces van complexe NLP-modellen kan ondoorzichtig zijn, waardoor het moeilijk is om te begrijpen waarom ze bepaalde resultaten genereren.
Onderweg door deze uitdagingen is NLP snel vooruitgang maakend. De integratie van multimodale informatie, verbeterde common sense redeneringen en verbetering van de verklaarbaarheid zijn kerngebieden van actuele onderzoek die de manier waarop AI interactie heeft met menselijke taal veranderen zullen.
Personaliseerbare AI assistenten
Het toekomstige van personaliseerbare AI assistenten zal steeds complexer en geavanceerder worden, waarbij ze zich ontwikkelen van basale takenbeheer tot intuïtief, vooruitstrevend en aan de persoonlijke behoeften aangepast ondersteuningsfunctionaliteit.
Deze assistenten zullen geavanceerde machine learning algoritmen gebruiken om continu van uw gedrag, voorkeuren en schema’s te leren, en uiteraard ook steeds persoonlijkere aanbevelingen aanbieden en complexere taken automatiseren.
Bijvoorbeeld: een personaliseerbare AI assistent kan niet alleen uw schema beheren, maar kan ook uw behoeften voorstellen door relevante bronnen te suggesteren of uw omgeving aan te passen aan uw humeur of eerdere voorkeuren.
Met de invoering van AI assistenten in de dagelijkse omgeving zal hun vermogen om zich aan te passen aan veranderende contexten en vloeiend, cross-platform ondersteuning aanbieden, een belangrijke differentiator worden. Het probleem bestaat erin het evenwicht te vinden tussen personalisering en privacy, wat sterke data beschermingsmechanismen nodig maakt om ervoor te zorgen dat gevoelige informatie veilig wordt behandeld terwijl een diep persoonlijke ervaring wordt geboden.
AI Assistenten voorbeeld 1: Contextgebonden Taakaanbeveling
-
Doel: Een assistent die taken aanbevelen op basis van de huidige context van de gebruiker (locatie, tijd, eerdere gedrag).
-
Aanpak: Combineer gebruikersgegevens, contextuele signalen en een model voor taakaanbevelingen.
Voorbeeldcode (conceptueel gebruik van Python):
# ... (Code voor beheer van gebruikersgegevens, detectie van context - niet getoond) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# Voorbeeld: Tijdsgebaseerde suggesties
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# Voorbeeld: Locatiegebaseerde suggesties
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (Voeg meer regels toe of gebruik een machine learning-model voor suggesties) ...
# Rangschik en filter suggesties
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- Voorbeeldgebruik ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... andere voorkeuren ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... andere contextgegevens ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
Voorbeeld 2 van AI-assistenten: Proactieve informatieverstrekking
-
Doel: Een assistent die proactief relevante informatie biedt op basis van de planning en voorkeuren van de gebruiker.
-
Aanpak: Integreer kalendergegevens, gebruikersinteresses en een inhoudsophaalsysteem.
Code Voorbeeld (Conceptueel met Python):
# ... (Code voor agenda toegang, gebruikers interesse profiel - niet getoond) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (Ophalen van bedrijfsinfo, deelnemers profielen, enz.) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (Ophalen van vliegtuig status, bestemming info, enz.) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- Voorbeeld van gebruik ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... andere voorkeuren ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

AI Assistents voorbeeld 3: Persoonlijke Inhoudaanbeveling
-
Doel: Een assistent dat inhoud aanbevelen die aangepast is aan gebruikersvoorkeuren (artikelen, video’s, muziek).
-
Approach: Gebruik colaboratieve filter of basis op basis van aanbevelingssystemen.
Code Voorbeeld (Conceptueel met Python en een bibliotheek zoals Surprise):
from surprise import Dataset, Reader, SVD
# ... (Code voor het beheer van gebruikersbeoordelingen, contentdatabase - niet getoond) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (Verkrijg voorspellingen voor alle items, rangschikking en geef de top N terug) ...
# --- Voorbeeldgebruik ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... meer beoordelingen ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
Challenges and Ethical Considerations:
-
Data Privacy: Het verantwoord en transparant behandelen van gebruikersgegevens is crucial.
-
Bias and Fairness: Personalisering moet bestaande vooroordelen niet versterken.
-
User Control: Gebruikers moeten controle hebben over hun gegevens en persoonlijke instellingen.
Bouwen van persoonlijke AI assistenten vereist een voorzichtig in acht nemen van zowel technische als ethische aspecten om systemen te creëren die helpprofiel, vertrouwd zijn en de privacy van de gebruiker respecteren.
AI in Creatieve industrieën
AI maakt significante inroads in de creatieve industrieën, waardoor de productie en consumptie van kunst, muziek, film en literatuur wordt veranderd. Met de vooruitgang van generatieve modellen, zoals Generative Adversarial Networks (GANs) en transformer-gebaseerde modellen, kan AI nu content genereren die de menselijke creativiteit kan benaderen.
Bijvoorbeeld, AI kan muziek componeren die specifieke genres of stemmingen reflecteert, digitale kunst creëren die de stijl van beroemde schilders imiteert, of zelfs verhaallussen voor films en romans ontwerpen.
In de reclamebranche wordt AI gebruikt om persoonlijke content te genereren die reageert op individuele consumenten, waardoor de Engagement en effectiviteit worden verhoogd.
Maar de opkomst van AI in creatieve vakgebieden brengt ook vragen over auteurschap, origineelheid en de rol van de menselijke creativiteit. Als u zich engageert met AI in deze domeinen, zal het belangrijk zijn om te ontdekken hoe AI de menselijke creativiteit kan aanvullen in plaats van te vervangen, door de samenwerking tussen mensen en machines te bevorderen om innovatieve en impactvolle inhoud te produceren.
Hier is een voorbeeld van hoe GPT-4 kan worden ingebouwd in een Python-project voor creatieve taken, specifiek in het domein van het schrijven. Deze code toont hoe GPT-4’s capaciteiten kunnen worden gebruikt om creatieve tekstformaten zoals poëzie te genereren.
import openai
# Stel uw OpenAI API-sleutel in
openai.api_key = "YOUR_API_KEY"
# Definieer een functie om poëzie te genereren
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# Voorbeeld van gebruik
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
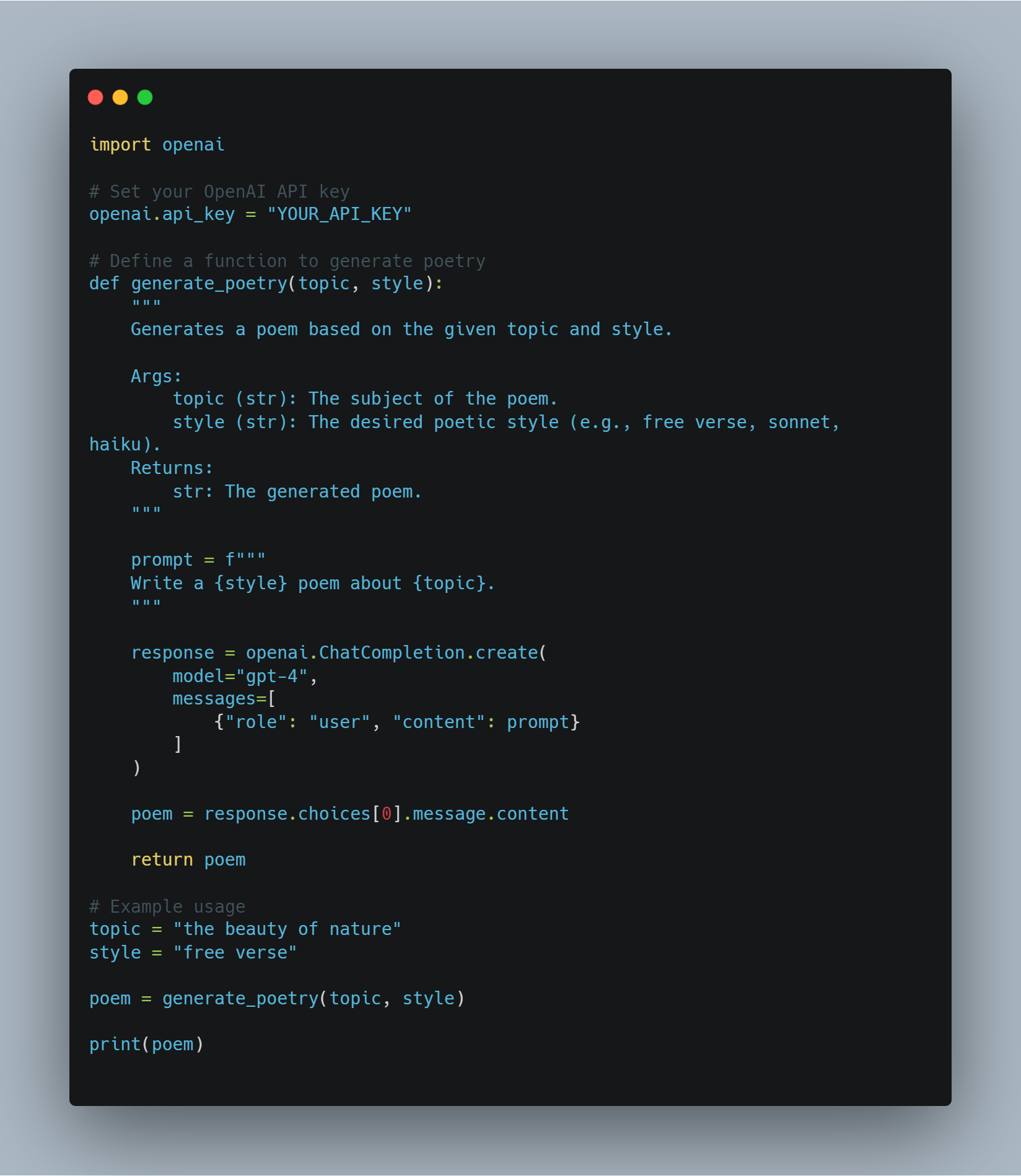
Laat’s zien wat hier gaat gebeuren:
-
Importeer de OpenAI-bibliotheek: Het code eerst de
openai-bibliotheek importeert om toegang te krijgen tot de OpenAI API. -
Stel API-sleutel in: Vervang
"YOUR_API_KEY"door uw actuele OpenAI API-sleutel. -
Defineer de functie
generate_poetry: Deze functie neemt hettopicenstylevan het gedicht in als invoer en gebruikt OpenAI’s ChatCompletion API om het gedicht te genereren. -
Bouw het voorwerp: Het voorwerp combineert het
topicenstylein een duidelijke instructie voor GPT-4. -
Stuur voorwerp naar GPT-4: Het code gebruikt
openai.ChatCompletion.createom het voorwerp naar GPT-4 te sturen en ontvangt het gegenereerde gedicht als reactie. -
Geef het gedicht terug: Het gegenereerde gedicht wordt dan uit de reactie gehaald en door de functie teruggegeven.
-
Voorbeeld van gebruik: Het code geeft een voorbeeld hoe de
generate_poetryfunctie kan worden aangeroepen met een specifiek thema en stijl. Het resulterende gedicht wordt vervolgens weergegeven op de console.
Gebruik van AI in virtuele werelden
De ontwikkeling van virtuele werelden aangedreven door AI is een belangrijke sprong voor de ervaring van immersie, waarin AI-agenten virtuele omgevingen kunnen creëren, beheren en evolueren die zowel interactief als reagerend zijn op gebruikersinput.
Deze virtuele werelden, aangedreven door AI, kunnen complexe ecosystemen, sociale interacties en dynamische verhalen simuleren, biedende gebruikers een diepgaande en persoonlijke ervaring.
Bijvoorbeeld, in de spelindustrie kan AI worden gebruikt om niet-spelbare personages (NPCs) te creëren die kunnen leren van spelersgedrag, hun acties en strategieën aanpassen om een uitdagingend en realistisch spelervaring te bieden.
Buiten de spellen heeft de AI-gebaseerde virtuele werelden potentiële toepassingen in de onderwijs, waar virtuele klassenrooms aangepast kunnen worden aan de leerstijlen en vooruitgang van individuele studenten, of in bedrijfsopleidingen, waar realistische simulaties voorbereiden kunnen worden op medewerkers voor diverse scenario’s.
Het toekomst van deze virtuele omgevingen zal afhangen van de vooruitgang in de AI-vaardigheden om in real-time uitgebreide, complexe digitale ecosystemen te genereren en te beheren, alsook van ethische overwegingen rondom gebruikersgegevens en de psychologische impacten van zeer immersieve ervaringen.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# Initializeer agents
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# Toewijzen van een random positie binnen het milieu
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# Maak en voeg de agent toe
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# Verplaats agents (ge simplifyde beweging voor demonstratie)
for agent in self.agents:
agent.move(self.environment)
# TODO: Implementeer meer complexe logica voor interacties, veranderingen in het milieu, enzovoort.
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# Bereken de bewegingrichting (willekeurig voor dit voorbeeld)
direction = random.choice(['N', 'S', 'E', 'W'])
# Toepassen van de beweging op basis van de richting
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# Bijwerken van het milieu om de nieuwe positie van de agent weer te geven
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# Voorbeeld van gebruik
if __name__ == "__main__":
# Definieer wereldparameters
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# Maak de virtuele wereld
world = VirtualWorld(environment_size, agent_types, agent_properties)
# Simuleer de wereld voor enkele stappen
for _ in range(10):
world.update()
world.display()
print() # Voeg een lege regel toe voor betere leesbaarheid
Hier is wat er gebeurt in dit code:
-
VirtualWorld Klasse:
-
Bepaalt het hart van het virtuele universum.
-
Bevat de omgevingsmatrix, een lijst van agents en informatie die bij agents hoort.
-
__init__(): Initializeert het universum met grootte, soorten agents en eigenschappen. -
add_agent(): Voegt een nieuw agent van een opgegeven type toe aan het universum. -
update(): voert een enkele tijdschiftupdate uit van het universum.- Het verplaatst momenteel agents, maar u kunt complexe logica toevoegen voor agentinteracties, veranderingen in het milieu, enzovoort.
-
display(): Toont een basisweergave van de omgeving.
-
-
Agent Klasse:
-
代表世界中的一个个体代理。
-
__init__(): Initializeert de agent met zijn type, positie en eigenschappen. -
move(): Handleert de beweging van de agent en updateert zijn positie binnen de omgeving. Deze methode biedt momenteel eenvoudige random beweging, maar kan worden uitgebreid om complexe AI gedrag in te sluiten.
-
-
Voorbeeldgebruik:
-
Stel wereldparameters in zoals grootte, soorten agents en hun eigenschappen.
-
Creëert een VirtualWorld-object.
-
Voer de
update()-methode meerdere malen uit om de evolutie van de wereld te simuleren. -
Roep
display()aan na elke update om de veranderingen te visualiseren.
-
Verbeteringen:
-
Meer complexe Agent AI: Implementeer een meer geavanceerde AI voor agentgedrag. U kunt gebruik maken van:
-
Pathfinding-algoritmen: help agents om effectief door hun omgeving te navigeren.
-
Besluitboom/Machineleren: Laat agents meer geïntegreerde besluiten nemen gebaseerd op hun omgeving en doelstellingen.
-
Reinforcement Learning: Laat agents leren en hun gedrag aanpassen over tijd.
-
-
Interactie met het milieu: Voeg meer dynamische elementen toe aan het milieu, zoals obstakels, resources of punten van interesse.
-
Interactie tussen agenten: Implementeer interacties tussen agenten, zoals communicatie, gevechten of samenwerking.
-
Visuele weergave: Gebruik bibliotheken zoals Pygame of Tkinter om een visuele weergave van het virtuele wereld te maken.
Dit voorbeeld vormt een basis voor het maken van een virtuele wereld op basis van AI. De complexiteit en de geavanceerde mate kunnen verder worden uitgebreid om aan uw specifieke behoeften en creatieve doelstellingen te voldoen.
Neuromorfe computing en AI
Neuromorfe computing, geïnspireerd door de structuur en functioneren van het menselijke brein, zal de AI revolutionair maken door nieuwe manieren aan te bieden informatie efficiënt en in parallel te verwerken.
In tegenstelling tot traditionele computearchitecturen zijn neuromorfe systemen ontworpen om de neurale netwerken van het brein te imiteren, waardoor AI taken zoals patronen herkenning, sensorische verwerking en besluitvorming met grotere snelheid en energieëfficiëntie uitvoert.
Deze technologie biedt immense beloften voor het ontwikkelen van AI-systemen die meer aanpasbaar zijn, in staat zijn om uit minder data te leren en effectief zijn in real-time-omgevingen.
Bijvoorbeeld, in robotica, kunnen neuromorfe chips robots latenprocessen sensorische inputen en beslissen met een niveau van efficiëntie en snelheid die de huidige architecturen niet kunnen bieden.
Het uitdagende deel van de toekomst zal zijn om neuromorfe computing op schaal te brengen om de complexiteit van grote schaal AI-toepassingen aan te kunnen bieden, het te integreren met bestaande AI-framesoorten om daadwerkelijk zijn potentiële volledig uit te kunnenassen.
AI-agenten in ruimteonderzoek
AI-agents spelen steeds meer een cruciale rol in ruimteonderzoek, waar ze zijn toegewezen aan het navigeren van harde omgevingen, realtime beslissingen te nemen en zelfstandig wetenschappelijke experimenten uit te voeren.
Met missies die verder de ruimte in trekken, wordt de behoefte aan AI-systemen die zelfstandig kunnen functioneren buiten de controle op Aarde steeds dringender. Toekomstige AI-agents zullen zijn ontworpen om de onvoorspelbaarheid van de ruimte te kunnen handelen, zoals onverwachte obstakels, veranderingen in missieparameters of de behoefte tot zelfherstel.
Bijvoorbeeld, AI kan worden gebruikt om rovers op Mars zelfstandig terrein te verkennen, wetenschappelijk waardevolle locaties te identificeren en zelfs monsters te boren met minimaal ingreep van de missiecontrole. Deze AI-agents kunnen ook levenssteuningsystemen op langdurige missies beheren, de energiebesteding optimaliseren en zich aanpassen aan de psychologische behoeften van astronauten door gezelschap en mentale stimulering te bieden.
De integratie van AI in ruimteonderzoek verbetert niet alleen de capaciteiten van missies, maar opent ook nieuwe mogelijkheden voor de menselijke ontdekking van het cosmos, waarin AI een onvervangbaar partner zal zijn in het streven naar het begrijpen van ons universum.
Hoofdstuk 8: AI-agents in missie-belangrijkevelden
Gezondheidszorg
In de gezondheidszorg zijn AI-agents niet enkel een ondersteunende rol, maar worden ze integraal aan het hele patientencare- continuum verbonden. Hun impact is het meest duidelijk in telemedicine, waar AI-systemen de aanpak van de afstandsgezondheidszorg hebben herbewerkt.
Door het gebruik van geavanceerde natuurlijk taalverwerking (NLP) en machine learning-algoritmen, kunnen deze systemen ingewikkeldheden als symptoomtriage en voorlopige gegevensverzameling uitvoeren met een hoog niveau van nauwkeurigheid. Ze analyseren patiënten gemelde symptomen en medische historieën in real-time, en vergelijken deze informatie tegenover uitgebreide medische databestanden om mogelijke aandoeningen of waarschuwingssignalen te identificeren.
Dit maakt het mogelijk voor gezondheidsproviders sneller informatiekeuzen te maken, de behandelingstijd te verkorten en wellicht levens te redden. Ook zijn diagnosegereedschap voor medische beelden, gesteund door AI, de radiologie transformerend door patronen en afwijkingen in röntgenfoto’s, MRI- en CT-scans te detecteren die voor de menselijke oog te onopgemerkt zijn.
Deze systemen zijn getraind op uitgebreide datasets die bestaan uit miljoenen gemarkeerde beelden, wat hen in staat stelt niet alleen te navolgen maar vaak ook de menselijke diagnosecapaciteiten te overschrijden.
De integratie van AI in de gezondheidszorg wordt ook uitgebreid naar administratieve taken, waarbij de automatisering van afspraak planning, medicijnenherinneringen en patiëntenvolgen de operationele last van gezondheidsmedewerkers aanzienlijk reduceert, waardoor ze zich kunnen richten op kritieke aspecten van de patiëntenzorg.
Financieel
In de financiële sector heeft AI-agenten de operationele efficiëntie en nauwkeurigheid tot een niveau verhoogd dat tot dan toe ongeziene hoogtes behaald heeft.
Algoritmisch handelen, dat voornamelijk op AI berust, heeft de manier waarop handelen op financiële markten wordt uitgevoerd veranderd.
Deze systemen zijn in staat om massieve datasets binnen milliseconden te analyseren, markt trends te identificeren en transacties op het optimale moment uit te voeren om winsten te maximaliseren en risico’s te minimaliseren. Ze leveren complexe algoritmen die machine learning, diep leren en herinnerings leren technieken incorporeren om aan veranderende markt omstandigheden te kunnen aanpassen, waardoor ze seconde- tot seconde beslissingen nemen die door menselijke handelaren nooit gehaald zouden kunnen worden.
Buiten de handel, speelt AI een cruciale rol in risicomanagement door creditrisico’s te beoordelen en fraude activiteiten met opmerkelijke nauwkeurigheid te detecteren. AI-modellen gebruiken predictive analytics om de defaultkans van een lenener te evalueren door patronen in creditgeschiedenissen, transactiegedrag en andere relevante factoren te analyseren.
Ook in het domein van de regelgeving, automatiseert AI het monitoren van transacties om fraude en andere verdachte activiteiten te detecteren en te rapporteren, waardoor financiële instellingen aan strikte regelgevingsvereisten kunnen voldoen. Deze automatisering beschermt niet alleen tegen de risico’s van menselijke fouten, maar streamline ook de compliantieproces, waardoor kosten worden verlaagd en efficiëntie verbeterd.
Crisisbeheersing
Het rol van AI in de crisisbeheersing is transformerend, het fundamenteel verandert hoe crisis’ worden voorspeld, behandeld en gemitigd.
Bij de hulpverlening bij rampen, verwerkt AI-agenten massieve hoeveelheden gegevens van verschillende bronnen – van satellietbeelden tot sociale media-uitlaten – om in real-time een compleet overzicht van de situatie te bieden. Machine learning-algoritmen analyseren deze gegevens om patronen te identificeren en de voortgang van gebeurtenissen te voorspellen, waardoor hulpverleners resources effectiever kunnen toewijzen en onder druk ingestelde beslissingen kunnen nemen.
Bijvoorbeeld, tijdens een natuurlijke ramp zoals een orkaan, kunnen AI-systemen de baan en intensiteit van de storm voorschrijven, wat de autoriteiten in staat stelt tijdige evakuatieorders uit te geven en resources naar de meest kwetsbare gebieden te sturen.
In predictive analytics worden AI-modellen gebruikt om potentiële noodlijdings situaties te voorschrijven door historische gegevens samen te voegen met realtime-invoer, wat proactive maatregelen mogelijk maakt die rampen kunnen voorkomen of hun impact kunnen verminderen.
AI-gebaseerde openbare communicatiesystemen spelen ook een cruciale rol in het verzekeren dat accurate en tijdige informatie aan de getroffen bevolking wordt getoond. Deze systemen kunnen noodalarmen genereren en verspreiden over verschillende platformen, de boodschaging aan verschillende demografieën aanpassend om zekerheid en gehoorzaamheid te waarborgen.
En AI verbetert de voorbereidheid van hulpverleners door zeer realistische trainingssimulaties te maken met generatieve modellen. Deze simulaties naderden de complexiteit van de echte wereld-noodsituaties, wat de hulpverleners in staat stelt hun vaardigheden te verfijnen en hun voorbereiding op echte gebeurtenissen te verbeteren.
Verkeer
AI-systemen zijn steeds onontbeerbaarder in het verkeerssector, waar ze veiligheid, efficiency en betrouwbaarheid verbeteren over verschillende domeinen, inclusief luchtverkeersleiding, autonome voertuigen en openbare vervoersystemen.
In luchtverkeersleiding zijn AI-agents nuttig voor het optimaliseren van vliegwegen, voorschrijven van potentiële conflicten en beheer van vliegveldoperaties. Deze systemen gebruiken predictive analytics om potentiële verkeersknopen in de lucht te voorschrijven, en herroute vluchten in realtime om veiligheid en efficiency te waarborgen.
In het domein van de zelfrijdende auto’s is AI het hart van de techniek die auto’s in staat stelt sensorgegevens te verwerken en in complexe omgevingen splitse seconden beslissingen te nemen. Deze systemen gebruiken diep leer modellen die op uitgebreide datasets zijn getraind om visuele, audiogene en ruimtelijke gegevens te interpreteren, wat veilige navigatie door dynamische en onvoorspelbare omstandigheden mogelijk maakt.
Ook openbare vervoerssystemen profiteren van AI door geoptimaliseerde route plannen, voorspelde onderhoud van voertuigen en de besturing van de passagiersstromen. Door historische en realtime data te analyseren, kunnen AI systemen transitie schema’s aanpassen, voorspellen en voorkomen dat voertuigen stuk gaan en de verkeerstoegang reguleren tijdens piek uren, waardoor de algehele efficiëntie en betrouwbaarheid van het vervoersnetwerk wordt verbeterd.
Energie Sector
AI speelt een cruciale rol in de energie sector, vooral in netwerkbeheer, optimering van duurzame energie en foutdetectie.
In netwerkbeheer controleert AI-agenten de energienetwerken door realtime gegevens van sensoren die over het netwerk zijn verspreid te analyseren. Deze systemen gebruiken predictive analytics om de energiedistributie te optimaliseren, ervoor zorgend dat de aanbod en vraag worden gekoppeld terwijl energieverspilling wordt verminderd. AI-modellen voorspellen ook potentiële fouten in het netwerk, wat preventief onderhoud mogelijk maakt en het risico van uitval vermindert.
Binnen de duurzame energiebranche gebruiken AI-systemen om weerspatronen te voorschrijven, wat crucial is voor de optimalisering van de productie van zonne- en windenergie. Deze modellen analyseren meteorologische data om de intensiteit van het zonlicht en de snelheid van de wind te voorschrijven, wat accurate voorspellingen van de energieproductie mogelijk maakt en een betere integratie van duurzame bronnen in het netwerk mogelijk maakt.
Foutdetectie is een ander gebied waar AI significant bijdraagt. AI-systemen analyzeren sensordata van apparaaten zoals transformatoren, turbines en generatoren om tekenen van slijtage of potentiële storingen te identificeren voordat ze leiden tot fouten. Deze preventieve onderhoudsbenadering verlengt niet alleen de levensduur van apparatuur, maar zorgt ook voor een doorlopende en betrouwbare energieverschaffing.
Cybersecurity
In het gebied van cybersecurity zijn AI-agenten essentieel voor het behoud van de integriteit en de veiligheid van digitale infrastructuren. Deze systemen zijn ontworpen om constant netwerkverkeer te monitoren, gebruikmakende van machine learning-algoritmen om afwijkingen te detecteren die kunnen wijzen op een security breach.
door het analyseren van grote hoeveelheden data in real-time, kunnen AI-agenten patronen van kwaadaardige gedrag herkennen, zoals ongebruikelijke loginpogingen, data exfiltratieactiviteiten of de aanwezigheid van malware. Zodra een potentiële bedreiging wordt gedetecteerd, kunnen AI-systemen automatisch contramiddelen activeren, zoals isolatie van ge compromiseerde systemen en het uitvoeren van patches, om verdere schade te voorkomen.
Vulnerabiliteitsonderzoek is een andere kritieke toepassing van AI in cybersecurity. AI-gestuurde tools analyseren code en systeemconfiguraties om potentiële veiligheidstoren te identificeren voordat ze kunnen worden aangevallen door aanvallers. Deze tools gebruiken statische en dynamische analyse technieken om de beveiligingsstatus van software- en hardwareonderdelen te evalueren, biedende actieverleidende inzichten aan cybersecurityteams.
De automatisering van deze processen verbetert niet alleen de snelheid en nauwkeurigheid van het detecteren en reageren op bedreigingen, maar helpt ook de arbeidsbelasting op menselijkeanalisten, waardoor zij zich kunnen richten op complexere veiligheidsuitdagingen.
Productie
In de productie, drijft AI significante vooruitgang aan in kwaliteitscontrole, voorspellende onderhoud en optimering van de supply chain. AI-gebaseerde computerbeeldingssystemen zijn nu in staat producten op fouten te inspecteren op een niveau van snelheid en nauwkeurigheid die de menselijke mogelijkheden overschrijdt. Deze systemen gebruiken diepgeleerde algoritmen die zijn getraind op duizenden afbeeldingen om zelfs de kleinste afwijkingen in producten te detecteren, waardoor er een consistente kwaliteit wordt gegarandeerd in high-volume productieomgevingen.
Voorspellende onderhoud is een ander gebied waar AI een diepgaande impact heeft. Door data van sensoren in machines te analyseren, kunnen AI-modellen voorspellen wanneer apparaat gevaarlijk kan zijn om te falen, waardoor onderhoud kan worden gepland vooral voordat een breakdown optreedt. Dit aanpak reduceert niet alleen downtime maar verlengd ook de levensduur van de machine, wat significante kostenbesparingen oplevert.
In het beheer van de supply chain, optimaliseren AI-agenten voorraden en logistiek door data van de gehele supply chain te analyseren, inclusief voorverwachtingen, productieschema’s en transportroutes. door in real-time aanpassingen te doen aan voorraden en logistiek plannen, zorgt AI ervoor dat de productieprocessen vlot verlopen, minimale vertragingen en reduceert kosten.
Deze toepassingen tonen het kritieke rol van AI bij het verbeteren van de operationele efficiëntie en betrouwbaarheid in de productie, waardoor het een onvervangbaar gereedschap is voor bedrijven die willen blijven concurreren in een snel evoluerende industrie.
Conclusie
De integratie van AI-agenten met grote taalmodellen (LLM’s) maakt een belangrijke milestone in de evolutie van de kunstmatige intelligentie onthuld, die ongeziene mogelijkheden vrijmaakt in verschillende industrieën en wetenschappelijke domeinen. Deze synergie verbetert de functionaliteit, aanpasbaarheid en toepasbaarheid van AI-systemen, die de inherente beperkingen van LLM’s aanpakt en meer dynamische, context-bewuste en autonome besluitvormingsprocessen mogelijk maakt.
Van revolutionerende gezondheidszorg en financiën tot het transformeren van vervoer en noodbeheersing, drijven AI-agenten de innovatie en de efficiëntie aan, wat de weg vrijmaakt voor een toekomst waarin AI-technologieën diep ingebed zijn in ons dagelijks leven.
Als we doorgaan met het verkennen van de potentie van AI-agenten en LLM’s, is het cruciaal dat hun ontwikkeling op ethische beginselen wordt gegrond, die de menselijke welzijn, rechtvaardigheid en inclusiviteit prioriteren. Door ervoor te zorgen dat deze technologieën zorgvuldig ontworpen en geïmplementeerd worden, kunnen we hun volledige potentie benutten om de kwaliteit van leven te verbeteren, de sociale rechtvaardigheid te bevorderen en wereldwijde uitdagingen aan te spreken.
De toekomst van de AI ligt in de vloeiende integratie van geavanceerde AI-agenten met geavanceerde LLM’s, die intelligent systemen niet alleen de menselijke mogelijkheden vergroten maar ook de waarden behouden die onze mensheid definiëren.
De convergentie van AI-agenten en LLM’s vertegenwoordigt een nieuw paradigma in de kunstmatige intelligentie, waar de samenwerking tussen de agile en de krachtige de deuren openen voor een wereld van onbegrensde mogelijkheden. door deze synergie te benutten, kunnen we innovatie aansteken, wetenschappelijke ontdekkingen vooruitdragen en een meer gelijke en voorspoedige toekomst creëren voor iedereen.
Over de auteur
Vahe Aslanyan, hier, op de snelweg tussen computerwetenschap, datascience en AI. Bezoek vaheaslanyan.com om een portfolio te zien dat getuigt van精确heid en vooruitgang. Mijn ervaring brugt de kloof tussen volledig programma-ontwikkeling en AI product optimalisatie, aangedreven door het oplossen van problemen op nieuwe manieren.
Met een solide record, inclusief het lanceren van een leidende datascience-opleiding en samenwerken met topspecialisten binnen de industrie, blijft mijn focus op het verhogen van de techonderwijsstandaarden tot universele normen.
Hoe kun je dieper duiken?
Nadat u deze gids hebt gelezen, als u nog dieper wilt duiken en structuurdelen is uw stijl, overweeg dan om bij ons aan te sluiten bij LunarTech, we bieden individuele cursussen en een Bootcamp in Datascience, Machine Learning en AI aan.
We bieden een alomvattende programma aan dat een diepgaande begrip van de theorie, praktische implementatie, uitgebreid praktijk materiaal en gepersonaliseerde interview voorbereiding biedt om u voor te bereiden op succes aan uw eigen fase.
U kunt onze Ultimate Data Science Bootcamp bekijken en deelname aan een gratis proefles om de inhoud zelf te testen. Dit heeft de erkenning gekregen om een van de Best Data Science Bootcamps van 2023 te zijn en is gepubliceerd in respectabele publicaties zoals Forbes, Yahoo, Entrepreneur en meer. Dit is uw kans om deel uit te maken van een community die groeit aan de hand van innovatie en kennis. Hier is het welkomstbericht!
Connecteer mee

Volg me op LinkedIn voor een heleboel Gratis Resources in CS, ML en AI
-
Schrijf je in voor mijn The Data Science and AI Newsletter
Als u meer wilt leren over een carrière in Data Science, Machine Learning en AI, en hoe u een Data Science baan kan verdienen, kunt u dit gratis Data Science and AI Carrière Handboek downloaden.
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/