













A rápida evolução da inteligência artificial (IA) resultou em uma poderosa sinergia entre os grandes modelos de linguagem (MMLs) e os agentes da IA. Essa interação dinâmica é como se fosse a história de David e Goliato (sem a luta), onde os agêntes de IA ágeis melhoram e ampliam as capacidades dos colossais MMLs.
Este manual explorará como os agentes de IA, semelhantes a David, estão supercarregando os MMLs – nossos Goliatos modernos – para ajudar a revolucionar várias indústrias e domínios científicos.
Sumário
-
Capítulo 1: Introdução aos Agentes da IA e Modelos de Linguagem
-
Capítulo 2: A História da Inteligência Artificial e Agentes da IA
-
Capítulo 6: Projeto de Arquitetura para a Integração de Agentes AI com LLMs
A Emergência de Agentes AI em Modelos de Linguagem
Agentes AI são sistemas autônomos projetados para perceber o seu ambiente, tomar decisões e executar ações para alcançar objetivos específicos. Quando integrados com LLMs, esses agentes podem executar tarefas complexas, raciocinar sobre informações e gerar soluções inovadoras.
Essa combinação levou a avanços significativos em vários setores,从软件开发到科学研究。
Impacto Transformador em Várias Indústrias
A integração de agentes AI com LLMs teve um profundo impacto nas indústrias:
-
Desenvolvimento de Software: assistentes de programação baseados em IA, como o GitHub Copilot, têm demonstrado a capacidade de gerar até 40% do código, resultando em uma aumento impressionante de 55% na velocidade de desenvolvimento.
-
Educação: assistentes de aprendizagem baseados em IA têm mostrado potencial em reduzir o tempo médio de conclusão do curso em 27%, potencialmente revolucionando o panorama educacional.
-
Transporte: Com projeções que sugerem que 10% dos veículos serão sem condutor até 2030, agentes artificiais autônomos em carros autônomos estão prontos para transformar a indústria de transporte.
Próximo Ciclo de Descoberta Científica
Uma das aplicações mais entusiasmantes de agentes AI e LLM é na pesquisa científica:
-
Descoberta de Fármacos: Agentes AI estão acelerando o processo de descoberta de fármacos ao analisar grandes conjuntos de dados e prever candidatos de fármacos potenciais, reduzindo significativamente o tempo e o custo associados aos métodos tradicionais.
-
Física de Partículas: No Grande Colisionador de Hadrões (LHC) do CERN, agentes AI são usados para análise de dados de colisões de partículas, usando detecção de anomalias para identificar pistas promissoras que podem indicar a existência de partículas não descobertas.
-
Pesquisa Científica Geral: Os agentes AI estão aumentando o ritmo e a amplitude da descoberta científica ao analisar estudos passados, identificando ligações inesperadas e propondo experimentos novos.
A convergência de agentes de AI e de modelos de linguagem grande (LLMs) está impulsionando a inteligência artificial para uma nova era de capacidades sem precedentes. Este manual abrangente examina a interação dinâmica entre estas duas tecnologias, revelando seu potencial combinado para revolucionar as indústrias e solucionar problemas complexos.
Nós vamos rastrear a evolução da AI de suas origens até o advento de agentes autônomos e o surgimento de sofisticadas LLMs. Também exploraremos considerações éticas, que são fundamentais para o desenvolvimento responsável de AI. Isso nos ajudará a garantir que essas tecnologias estão alinhadas com nossos valores humanos e o bem-estar da sociedade.
Ao final deste manual, você terá um profundo entendimento do poder sinergético dos agentes de AI e LLMs, bem como o conhecimento e ferramentas para aproveitar esta tecnologia de ponta.
Capítulo 1: Introdução aos Agentes de AI e a Modelos de Linguagem
O que são Agentes de AI e Modelos de Linguagem Grande?
A rápida evolução da inteligência artificial (AI) trazendo uma síntese transformadora entre modelos de linguagem grandes (LLMs) e agentes de AI.
Os agentes AI são sistemas autônomos projetados para perceber seu ambiente, tomar decisões e executar ações para alcançar objetivos específicos. Eles apresentam características tais como autonomia, percepção, reatividade, raciocínio, tomada de decisões, aprendizagem e comunicação, além de orientação a objetivos.
Por outro lado, os LLMs são sistemas AI sofisticados que usam técnicas de aprendizagem profunda e conjuntos de dados extensivos para entender, gerar e prever texto humano-like.
Modelos como estes, como GPT-4, Mistral, LLama, têm exibido capacidades notáveis em tarefas de processamento de linguagem natural, incluindo geração de texto, tradução de linguagem e agentes conversacionais.
Características Chave dos Agentes AI
Os agentes AI têm várias características definitivas que os distinguem de softwares tradicionais:
-
Autonomia: Podem operar independentemente sem intervenção humana constante.
-
Percepção: Os agentes podem sentir e interpretar seu ambiente através de várias entradas.
-
Reatividade: Eles respondem dinamicamente a mudanças em seu ambiente.
-
Pensamento e Tomada de Decisão: Agentes podem analisar dados e tomar escolhas informadas.
-
Aprendizado: Eles melhoram sua performance ao longo do tempo através da experiência.
-
Comunicação: Agentes podem interagir com outros agentes ou humanos usando diferentes métodos.
-
Orientação a Objetivos: Eles são projetados para alcançar objetivos específicos.
Capacidades dos Modelos de Linguagem Grande
Modelos de Linguagem Grande (LLMs) têm demonstrado uma ampla variedade de capacidades, incluindo:
-
Geração de Texto: LLMs podem produzir texto coerente e relevante contextualmente com base em prompts.
-
Tradução de Linguagem: Eles podem traduzir texto entre diferentes linguagens com alta precisão.
-
Resumo
: LLMs podem condensar textos longos em resumos concisos enquanto retêm informações chave.
- Perguntas e Respostas: Eles podem fornecer respostas precisas a perguntas com base em seu vasto banco de conhecimento.
- Análise de Sentimento: LLMs podem analisar e determinar o sentimento expresso em um texto dado.
- Geração de Código: Eles podem gerar trechos de código ou funções inteiras com base nas descrições em linguagem natural.
Níveis de Agentes AI
Agentes AI podem ser classificados em diferentes níveis com base em suas capacidades e complexidade. De acordo com um artigo no arXiv, os agentes AI são categorizados em cinco níveis:
- Nível 1 (L1): Agentes AI como assistentes de pesquisa, onde cientistas definem hipóteses e especificam tarefas para alcançar objetivos.
-
Nível 2 (L2): Agentes AI que podem realizar tarefas específicas de forma autônoma dentro de um escopo definido, como análise de dados ou tomada de decisões simples.
-
Nível 3 (L3): Agentes AI capazes de aprender com a experiência e adaptar-se a novas situações, melhorando seus processos de tomada de decisão.
-
Nível 4 (L4): Agentes AI com capacidades de raciocínio avançado e resolução de problemas, capazes de lidar com tarefas complexas, multi-passos.
-
Nível 5 (L5): Agentes AI totalmente autônomos que podem operar independentemente em ambientes dinâmicos, tomando decisões e tomando ações sem intervenção humana.
Limitações dos Modelos de Linguagem de Grande Escala
Custos de Treinamento e Constraints de Recursos
Modelos de linguagem de grande escala (LLMs), como GPT-3 e PaLM, revolucionaram o processamento de linguagem natural (NLP) através da utilização de técnicas de aprendizagem profunda e de vastos conjuntos de dados.
Mas essas melhorias chegam com um custo significativo. O treinamento de LLMs requer recursos computacionais substanciais, muitas vezes envolvendo milhares de GPUs e consumo de energia extensivo.
De acordo com Sam Altman, CEO da OpenAI, o custo de treinamento para GPT-4 ultrapassou 100 milhões de dólares. Isto corresponde com o tamanho e complexidade do modelo relatados, com estimativas sugerindo que ele tem cerca de 1 trilhão de parâmetros. No entanto, outras fontes oferecem números diferentes:
-
Um relatório divulgado indicou que o custo de treinamento de GPT-4 era de aproximadamente 63 milhões de dólares, considerando a potência computacional e a duração do treinamento.
-
Ao meio de 2023, algumas estimativas sugeriram que treinar um modelo semelhante a GPT-4 poderia custar cerca de 20 milhões de dólares e levar cerca de 55 dias, refletindo avanços na eficiência.
Esse alto custo de treinamento e manutenção de LLMs limita sua adoção generalizada e escalabilidade.
Limitações de Dados e Viés
O desempenho de LLMs depende fortemente da qualidade e diversidade dos dados de treinamento. Apesar de serem treinados em conjuntos de dados massivos, LLMs ainda podem apresentar viéses presentes nos dados, levando a saídas distorcidas ou inadequadas. Esses viéses podem manifestar-se em várias formas, incluindo viéses de gênero, racial e cultural, que podem perpetuar estereótipos e desinformação.
Além disso, a natureza estática dos dados de treinamento significa que LLMs podem não estar atualizados com as informações mais recentes, limitando sua efetividade em ambientes dinâmicos.
Especialização e Complexidade
Embora LLMs sejam excelentes em tarefas gerais, eles muitas vezes têm dificuldade com tarefas especializadas que requerem conhecimento específico de domínio e alta complexidade.
Por exemplo, tarefas em campos como medicina, direito e pesquisa científica demandam um entendimento profundo de terminologia especializada e raciocínio sutil, o que LLMs podem não possuir inherentemente. Essa limitação necessita da integração de camadas adicionais de expertise e ajustes finos para tornar LLMs efetivos em aplicações especializadas.
Limitações de Entrada e Sensoriais
Processadores de linguagem natural (PLN)primariamente processam entradas textuais, o que limita sua capacidade de interagir com o mundo de modo multimodal. Embora possam gerar e entender texto, eles não têm a capacidade de processar entradas visuais, auditivas ou sensoriais diretamente.
Essa limitação impede sua aplicação em campos que exigem integração sensorial abrangente, como robótica e sistemas autônomos. Por exemplo, um PLN não pode interpretar dados visuais de uma câmera ou dados auditivos the de um microfone sem camadas de processamento adicionais.
Constraints de Comunicação e Interação
As capacidades de comunicação atuais de PLN são predominantemente baseadas em texto, o que limita sua capacidade de se envolver em formas de comunicação mais imersivas e interativas.
Por exemplo, embora PLN possam gerar respostas textuais, eles não podem produzir conteúdo de vídeo ou representações holográficas, que são cada vez mais importantes em aplicações de realidade virtual e aumentada (leia mais aqui). essa limitação reduce a eficácia de PLN em ambientes que exigem interações multimodais rica.
Como superar Limitações com Agentes AI
Agentes AI oferecem soluções promissoras para muitas das limitações enfrentadas por PLN. Esses agentes são projetados para operar de forma autônoma, perceber seu ambiente, tomar decisões e executar ações para alcançar objetivos específicos. Integrando agentes AI com PLN é possível melhorar suas capacidades e abordar suas limitações inatas.
-
Enhanced Context and Memory: Os agentes AI podem manter o contexto em várias interações, permitindo respostas mais coherentes e relevantes no contexto. Esta capacidade é particularmente útil em aplicações que requerem memória de longo prazo e contínua, como atendimento ao cliente e assistentes pessoais.
-
Integração Multimodal: Os agentes AI podem incorporar entradas sensoriais de várias fontes, como câmeras, microfones e sensores, permitindo que LLMs processem e respondam a dados visuais, auditivos e sensoriais. Esta integração é crucial para aplicações em robôs e sistemas autônomos.
-
Conhecimento Especializado e Competência: Os agentes AI podem ser finamente ajustados com conhecimento específico do domínio, melhorando a capacidade dos MLs de realizar tarefas especializadas. Este método permite a criação de sistemas de peritos que podem lidar com consultas complexas em campos como medicina, direito e pesquisa científica.
-
Comunicação Interativa e Imersiva: Os agentes AI podem facilitar formas mais imersivas de comunicação gerando conteúdo de vídeo, controlando exibições holográficas e interagindo com ambientes virtuais e de realidade aumentada. Esta capacidade expande a aplicação dos MLs em campos que exigem interações rica e multimodais.
Embora modelos de linguagem grandes tenham demonstrado capacidades notáveis em processamento de linguagem natural, eles não estão sem limitações. Os altos custos de treinamento, biases de dados, desafios de especialização, limitações sensoriais e constrangimentos de comunicação representam grandes obstáculos.
Mas a integração de agentes artificiais inteligentes oferece um caminho viável para superar essas limitações. Ao aproveitar as vantagens dos agentes artificiais inteligentes, é possível melhorar a funcionalidade, adaptabilidade e aplicabilidade de LLMs, abrindo caminho para sistemas AI mais avançados e versáteis.
Capítulo 2: A História da Inteligência Artificial e Agentes AI
O surgimento da Inteligência Artificial
O conceito de inteligência artificial (IA) tem raízes que se estendem muito além da idade digital moderna. A ideia de criar máquinas capazes de raciocínio semelhante a humanos pode ser rastreada até mitos antigos e debates filosóficos. Mas a formalização da IA como uma disciplina científica ocorreu no meio do século XX.
A Conferência de Dartmouth de 1956, organizada por John McCarthy, Marvin Minsky, Nathaniel Rochester e Claude Shannon, é amplamente considerada o berço da inteligência artificial (IA) como um campo de estudo. Este evento seminal reuniu investigadores líderes para explorar o potencial de criar máquinas que pudessem simular a inteligência humana.
Otimismo Inicial e o Inverno da IA
Os primeiros anos da pesquisa em IA foram caracterizados por optimismo sem restrições. Investigadores fizeram progressos significativos na develop programs capable of solving mathematical problems, playing games, and even engaging in rudimentary natural language processing.
Mas este entusiasmo inicial foi abafado pela compreensão de que criar verdadeiramente inteligentes era muito mais complexo do que inicialmente antecipado.
A década de 1970 e 1980 assistiram a um período de financiamento reduzido e interesse na pesquisa de IA, comumente referido como o “Inverno da IA“. Essa decadência principalmente decorreu do fracasso dos sistemas da IA para atingir as expectativas altas estabelecidas pelos pioneiros iniciais.
De Sistemas Baseados em Regras para Aprendizagem Automática
A Era dos Sistemas Expertos
Os anos 1980 testemunharam um ressurgimento de interesse em AI, principalmente driven by the development of expert systems. These rule-based programs were designed to emulate the decision-making processes of human experts in specific domains.
Sistemas expertos encontraram aplicações em vários campos, incluindo medicina, finanças e engenharia. Mas eles foram limitados pela sua incapacidade de aprender a partir da experiência ou adaptar-se a situações novas fora das regras programadas.
O surgimento do Aprendizado de Máquina
As limitações dos sistemas baseados em regras abriram caminho para uma mudança de paradigma para o aprendizado de máquina. Este método, que ganhou relevância nos anos 90 e 2000, se concentra na desenvolvimento de algoritmos que podem aprender a partir de dados e fazer previsões ou decisões baseadas em dados.
Técnicas de aprendizado de máquina, como redes neurais e máquinas de suporte vetorial, mostraram um sucesso notável em tarefas como reconhecimento de padrões e classificação de dados. O advento de big data e a potência computacional aumentada进一步加速了开发和应用机器学习算法。
A Emergência deAgentes AI Autônomas
Do AI Especializado para AI Geral
Ao evoluir as tecnologias de AI, os investigadores começaram a explorar a possibilidade de criar sistemas mais versáteis e autônomos. Este movimento marcou a transição do AI especializado, projetado para tarefas específicas, para a busca de inteligência artificial generalizada (AGI).
AGI tem como objetivo desenvolver sistemas capazes de realizar qualquer tarefa intelectual que um humano puder fazer. Enquanto o AGI verdadeiro permanece um objetivo distante, progressos significativos foram feitos na criação de sistemas AI mais flexíveis e adaptáveis.
O papel de aprendizagem profunda e redes neurais
O surgimento de aprendizagem profunda, um subconjunto de aprendizagem automática baseado em redes neurais artificiais, tem sido instrumental na avançada do campo de AI.
Algoritmos de aprendizagem profunda, inspirados na estrutura e função do cérebro humano, têm demonstrado capacidades notáveis em áreas como reconhecimento de imagem e fala, processamento de linguagem natural, e jogos. Esses avanços têm sido o ponto de partida para o desenvolvimento de agentes AI autônomos mais sofisticados.
Características e tipos de agentes AI
Agentes AI são sistemas autônomos que conseguem perceber seu ambiente, tomar decisões e executar ações para alcançar objetivos específicos. Possuem características tais como autonomia, percepção, reatividade, raciocínio, decisão, aprendizagem, comunicação e orientação a objetivos.
Existem vários tipos de agentes AI, cada um com capacidades únicas:
-
Agentes de Reflexo Simples: respondem a estímulos específicos com base em regras predefinidas.
-
Agentes Reflexivos Baseados em Modelo: Manterão um modelo interno do ambiente para toma de decisões.
-
Agentes Baseados em Meta-objetivos: Executarão ações para alcançar meta-objetivos específicos.
-
Agentes Baseados em Utilidade: Considerarão resultados potenciais e escolherão ações que maximizam a utilidade esperada.
-
Agentes Aprendiz: Melhorarão a toma de decisões ao longo do tempo através de técnicas de aprendizagem automática.
Desafios e Considerações Éticas
Como os sistemas AI tornam-se cada vez mais avançados e autônomos, trazem considerações críticas para garantir que seu uso permaneça dentro dos limites aceitáveis pela sociedade.
Modelos de Linguagem Grande (LLMs), particularmente, atuam como super-aceleradores de produtividade. Mas isso levanta uma questão crucial: O que esses sistemas super-acelerarão – intenção boa ou má? Quando a intenção para o uso de AI é malévola, torna-se imprescindível que esses sistemas detectem tais abusos usando diferentes técnicas de PRL ou outras ferramentas disponíveis.
Engenheiros de LLM têm acesso a uma variedade de ferramentas e abordagens para abordar estes desafios:
-
Análise de Sentimento: Ao aplicar análise de sentimento, LLMs podem avaliar o tom emocional do texto para detectar linguagem prejudicial ou agressiva, ajudando a identificar potencial uso indevido em plataformas de comunicação.
-
Filtragem de Conteúdo: Ferramentas como filtragem por palavra-chave e correspondência de padrões podem ser usadas para evitar a geração ou divulgação de conteúdo prejudicial, como discurso de ódio, desinformação ou material explícito.
-
Ferramentas de Detecção de Bias: Ao implementar frameworks de detecção de viés, como AI Fairness 360 (IBM) ou Indicadores de Equidade (Google), pode ajudar a identificar e mitigar o viés em modelos de linguagem, garantindo que os sistemas AI operam de forma justa e equitativa.
-
Técnicas de Explicabilidade
: Usando ferramentas de explicabilidade como LIME (Local Interpretable Model-agnostic Explanations) ou SHAP (SHapley Additive exPlanations), engenheiros podem entender e explicar os processos de tomada de decisão de LLMs, tornando mais fácil detetar e corrigir comportamentos não intencionais.
-
Testes Adversários: Simulando ataques maliciosos ou entradas prejudiciais, engenheiros podem testar a resistência dos LLMs usando ferramentas como TextAttack ou Adversarial Robustness Toolbox, identificando vulnerabilidades que podem ser exploradas para fins maliciosos.
-
Guidelines e Frameworks Éticos de AI: Adotando guias de desenvolvimento ético de AI, como as fornecidas pela IEEE ou a Partnership on AI, os engenheiros podem orientar a criação de sistemas AI responsáveis que priorizam o bem-estar da sociedade.
Além destas ferramentas, é por isso que precisamos de uma Equipe Vermelha dedicada para AI — times especializados que impulsionam LLMs às suas limitações para detectar falhas em suas defesas. Equipes Vermelhas simulam cenários adversários e descobrem vulnerabilidades que poderiam passar despercebidas.
Mas é importante reconhecer que as pessoas por trás do produto têm o maior efeito sobre ele. Muitos dos ataques e desafios que enfrentamos hoje existiam mesmo antes de LLMs serem desenvolvidos, destacando que o elemento humano permanece central para garantir que AI é usado ética e responsavelmente.
A integração destas ferramentas e técnicas na pipeline de desenvolvimento, juntamente com uma vigilante Equipe Vermelha, é fundamental para garantir que LLMs são usadas para supercarregar resultados positivos enquanto detecta e previne seu abuso.
Capítulo 3: Onde os Agentes AI Brilham mais Forte
As Forças únicas dos Agentes AI
Agentes AI se destacam por sua capacidade de perceber autonomamente o seu ambiente, tomar decisões e executar ações para alcançar objetivos específicos. Esta autonomia, combinada com capacidades avançadas de aprendizado de máquina, permite que agentes AI realizem tarefas que são ou demasiado complexas ou demasiado reprodutivas para serem executadas por humanos.
Aqui estão as principais vantagens que fazem os agentes AI brilharem:
-
Autonomia e Eficiência: Os agentes AI podem operar independentemente sem intervenção humana constante. Esta autonomia permite que eles gerem tarefas 24/7, melhorando significativamente a eficiência e a produtividade. Por exemplo, bots de chat com inteligência artificial podem atender até 80% das consultas de clientes rotineiras, reduzindo custos operacionais e melhorando o tempo de resposta.
-
Tomada de Decisões Avançadas: Os agentes AI podem analisar vastos quantos dados para tomar decisões informadas. Essa capacidade é particularmente valiosa em campos como a finança, onde bots de negociação AI podem aumentar a eficiência de negociações muito.
-
Aprendizagem e Adaptação: Agentes de AI podem aprender com a experiência e adaptar-se a novas situações. Essa melhoria contínua permite que eles melhorem seu desempenho ao longo do tempo. Por exemplo, assistentes de saúde AI podem ajudar a reduzir erros de diagnóstico, melhorando os resultados de cuidados de saúde.
-
Personalização: Agentes de AI podem fornecer experiências personalizadas analisando o comportamento e preferências dos usuários. O motor de recomendação da Amazon, que move 35% de suas vendas, é um exemplo primário de como agentes de AI podem melhorar a experiência do usuário e aumentar os rendimentos.
Por que os Agentes de AI são a Solução
Os agentes de inteligência artificial oferecem soluções para muitos dos desafios enfrentados por software tradicional e sistemas operados por humanos. Aqui está por que eles são a escolha preferida:
-
Escalabilidade: Agentes de inteligência artificial podem escalar operações sem aumentos proporcionais em custos. Esta escalabilidade é crucial para empresas que procuram crescer sem aumentar significativamente sua força de trabalho ou despesas operacionais.
-
Consistência e Confiabilidade: Diferentemente de humanos, agentes de inteligência artificial não sofrem de fatiga ou inconsistência. Eles podem executar tarefas repetitivas com alta precisão e confiabilidade, garantindo desempenho consistente.
-
Informações Driven por Dados: Agentes de inteligência artificial podem processar e analisar grandes conjuntos de dados para descobrir padrões e insights que podem ser perdidos por humanos. Essa capacidade é valiosa para tomar decisões em áreas como finanças, saúde e marketing.
-
Poupança em Custos: Autorizando tarefas rotineiras, os agentes AI podem reduzir a necessidade de recursos humanos, levando a poupanças consideráveis em custos. Por exemplo, sistemas de detecção de fraude funcionando com AI podem poupar milhares de milhões de dólares por ano, reduzindo as atividades fraudulentas.
Condições Necessárias para que os Agentes AI Exijam Bem
Para garantir o bom desempenho e a implantação bem-sucedida dos agentes AI, devem ser atendidas certas condições:
-
Objetivos e Casos de Uso Claros: A definição de objetivos específicos e casos de uso é crucial para o deploy bem-sucedido de agentes AI. Esta clareza ajuda a definir expectativas e medir o sucesso. Por exemplo, estabelecer um objetivo de reduzir o tempo de resposta do atendimento ao cliente em 50% pode guiar a implantação de chatbots de AI.
-
Qualidade dos Dados: Os agentes AI dependem de dados de alta qualidade para treinamento e operação. Assegurar que os dados são precisos, relevantes e atualizados é essencial para os agentes tomar decisões informadas e executarem de forma eficaz.
-
Integração com Sistemas Existentes: Uma integração sem problemas com sistemas existentes e fluxos de trabalho é necessária para que os agentes AI funcionem de forma ótima. Esta integração garante que os agentes AI possam acessar os dados necessários e interagir com outros sistemas para executar suas tarefas.
-
Monitoramento Contínuo e Otimização: O monitoramento contínuo e a otimização dos agentes AI são cruciais para manter sua performance. Isto envolve acompanhar indicadores de desempenho chave (KPIs) e fazer ajustes necessários com base em feedback e dados de desempenho.
-
Considerações Éticas e Mitigação de Viés: Abordar considerações éticas e mitigar vieses em agentes de IA é essencial para garantir equidade e inclusão. Implementar medidas para detectar e prevenir viés pode ajudar a construir confiança e garantir uma implementação responsável.
Melhores Práticas para Implantar Agentes de IA
Ao implantar agentes de IA, seguir melhores práticas pode garantir seu sucesso e eficácia:
-
Definir Objetivos e Casos de Uso: Identificar claramente os objetivos e casos de uso para implantar agentes de IA. Isso ajuda a definir expectativas e medir o sucesso.
-
Selecione a Plataforma de IA Correta: Escolha uma plataforma de IA que esteja alinhada com seus objetivos, casos de uso e infraestrutura existente. Considere fatores como capacidades de integração, escalabilidade e custo.
-
Desenvolva uma Base de Conhecimento Abrangente: Construa uma base de conhecimento bem estruturada e precisa para permitir que os agentes de IA forneçam respostas relevantes e confiáveis.
-
Garanta Integração Sem Interrupções: Integre agentes de IA com sistemas existentes como CRM e tecnologias de call center para fornecer uma experiência unificada ao cliente.
-
Treine e Otimize os Agentes de IA: Treine e otimize continuamente os agentes de IA usando dados das interações. Monitore o desempenho, identifique áreas de melhoria e atualize os modelos conforme necessário.
-
Implementar Procedimentos de Escaleamento Apropriado: Estabelecer protocolos para transferir chamadas complexas ou emocionais para agentes humanos, garantindo uma transição smooth e uma resolução eficiente.
-
Monitorar e Análizar Desempenho: Rastrear indicadores de desempenho chave (KPIs) como taxas de resolução de chamadas, tempo médio de atendimento e pontuações de satiedade do cliente. Usar ferramentas de análise para insights de decisão baseados em dados.
-
Garantir Privacidade e Segurança de Dados: medidas de segurança robustas são chaves, como tornar os dados anônimos, garantir supervisão humana, estabelecer políticas para retenção de dados e implementar medidas de criptografia fortes para proteger dados do cliente e manter a privacidade.
Agentes AI + LLMs: Um Novo Século de Software Inteligente
Imagine um software que não só entende suas solicitações como também as executa. Essa é a promessa de combinar agentes AI com Modelos de Linguagem Grande (LLMs). Essa poderosa parceria está criando uma nova geração de aplicações que é mais intuitiva, capaz e impactante do que nunca antes.
Agentes AI: Mais Além da Execução de Tarefas Simples
Enquanto frequentemente comparados a assistentes digitais, os agentes AI são muito mais do que seguidores de scripts glorificados. Eles abrangem uma gama de tecnologias sofisticadas e operam em um quadro que permite tomar decisões dinâmicas e tomar ações.
-
Arquitetura: Um agente AI típico compõe vários componentes chave:
-
Sensores: Estes permitem que o agente perceba seu ambiente, coletando dados de várias fontes, como sensores, APIs ou entrada do usuário.
-
Estado de Crença: Isso representa o entendimento do agente do mundo com base nos dados coletados. Ele é atualizado constantemente conforme novas informações ficam disponíveis.
-
Motor de Racionalização: Este é o coração do processo de decisão do agente. Ele usa algoritmos, frequentemente baseados em aprendizado por reforço ou técnicas de planejamento, para determinar a melhor ação com base em suas crenças atuais e objetivos.
-
Atuadores: Essas são as ferramentas do agente para interagir com o mundo. Elas podem variar de enviar chamadas API a controlar robôs físicos.
-
-
Desafios: Os agentes de IA tradicionais, embora proficientes em tarefas bem definidas, muitas vezes lutam com:
-
Compreensão de Linguagem Natural: A interpretação de linguagem humana nuanceda, a manutenção de ambiguidades e a extração de significado do contexto permanecem desafios significativos.
-
Razão com Sentido Comum: Os atuais agentes de IA frequentemente carecem do conhecimento comum e das capacidades de raciocínio que os seres humanos têm por padrão.
-
Generalização: Treinar agentes para funcionar bem em tarefas desconhecidas ou adaptarem-se a novos ambientes permanece um ponto chave de pesquisa.
-
LLMs: Desbloqueando Compreensão e Geração de Linguagem
LLMs, com seu vasto conhecimento codificado em milhões de parâmetros, trazem capacidades de linguagem sem precedentes à mesa:
-
Arquitetura de Transformer: A base de quase todos os LLMs modernos é a arquitetura de transformer, um design de rede neural que se destaca na processação de dados sequenciais, como texto. Isto permite que LLMs captuem dependências de longa distância na linguagem, permitindo que eles entendam o contexto e gerem texto coeso e relevante no contexto.
-
Capacidades: LLMs são excelentes em uma ampla gama de tarefas baseadas em linguagem:
-
Geração de Texto: Desde escrever ficção criativa até gerar código em vários linguagens de programação, LLMs mostram uma fluência e criatividade notáveis.
-
Respostas a Perguntas: Eles podem fornecer respostas concisas e precisas a perguntas, mesmo quando a informação está espalhada através de documentos longos.
-
Resumo: LLMs podem condensar grandes volumes de texto em resumos concisos, extraindo informações chave e descartando detalhes irrelevantes.
-
-
Limitações: Apesar de suas habilidades impressionantes, LLMs têm limitações:
-
Falta de Referência ao Mundo Real: LLMs operam principalmente no campo do texto e não possuem a capacidade de interagir diretamente com o mundo físico.
-
Potencial para Bias e Ilusão: Treinados the base de dados massivos, não curados, LLMs podem herdar padrões presentes em dados e às vezes gerar informação factualmente incorreta ou sem sentido.
-
A Sinergia: Atravessando o Gap entre Linguagem e Ação
A combinação de agentes AI e LLM aborda as limitações de cada um, criando sistemas que são tanto inteligentes quanto capazes:
-
LLMs como Interpretes e Planejadores: Os LLM podem traduzir instruções em linguagem natural em um formato que os agentes AI possam entender, permitindo uma interação humano-computador mais intuitiva. Eles também podem aproveitar seu conhecimento para assistir os agentes em planejar tarefas complexas, dividindo-as em passos menores e gerenciáveis.
-
Agentes AI como Executores e Aprendizes: Agentes AI fornecem a LLMs a capacidade de interagir com o mundo, coletar informações e obter feedback sobre suas ações. Esta integração com o mundo real pode ajudar LLMs a aprender das experiências e melhorar seu desempenho ao longo do tempo.
Esta poderosa sinergia está impulsionando o desenvolvimento de uma nova geração de aplicações que são mais intuitivas, adaptáveis e capazes do que nunca. Como as tecnologias tanto de agentes AI quanto de LLMs continuam a avançar, podemos esperar ver ainda mais aplicações inovadoras e impactantes surgindo, repensando o panorama de desenvolvimento de software e de interação humano-computador.
Exemplos da Realidade: Transformando as Indústrias
Esta poderosa combinação já está causando ondas em várias indústrias:
-
Atendimento ao Cliente: resolver problemas com consciência contextual
- Exemplo: Imagine um cliente contatando um retalhista online sobre um frete atrasado. Um agente de AI alimentado por uma AML pode entender a frustração do cliente, acessar seu histórico de pedidos, rastrear o pacote em tempo real e oferecer soluções proativas, como entrega加速ada ou desconto na próxima compra.
-
Criação de Conteúdo: gerando conteúdo de alta qualidade em escala
- Exemplo: Uma equipe de marketing pode usar um sistema de AI agente + AML para gerar posts de mídia social direcionados, escrever descrições de produto ou até mesmo criar roteiros de vídeo. A AML garante que o conteúdo é interessante e informativo, enquanto o agente de AI gerencia o processo de publicação e distribuição.
-
Desenvolvimento de Software: Acelerando o Código e o Debugging
- Exemplo: Um desenvolvedor pode descrever uma funcionalidade de software que ele quer construir usando linguagem natural. O LLM então pode gerar trechos de código, identificar erros potenciais e sugerir melhorias, acelerando significativamente o processo de desenvolvimento.
-
Cadeia de Saúde: Personalizar Tratamento e Melhorar Atendimento a Pacientes
- Exemplo: Um agente artificial com acesso à história clínica de um paciente e equipado com um LLM pode responder às suas perguntas relacionadas à saúde, fornecer lembretes de medicamentos personalizados e até oferecer diagnósticos preliminares baseados em seus sintomas.
-
Lei: simplificar pesquisa legal e redação de documentos
- Exemplo: Um advogado precisa redigir um contrato com cláusulas específicas e precedências legais. Um agente AI alimentado por uma AML pode analisar as instruções do advogado, pesquisar em bases de dados legais extensas, identificar cláusulas e precedências relevantes, e até mesmo redigir partes do contrato, reduzindo significativamente o tempo e esforço necessários.
-
Criação de Vídeo: Geração de Vídeos Engraçados com Facilidade
- Exemplo: Uma equipe de marketing quer criar um vídeo curto explicando as funcionalidades do seu produto. Eles podem fornecer a um agente AI + Sistema AML com um esboço de roteiro e preferências de estilo visual. A AML pode então gerar um roteiro detalhado, sugerir música e imagens apropriadas, e até mesmo editar o vídeo, automatizando muito do processo de criação de vídeo.
-
Arquitetura: Projetando edifícios com insights baseados em AI
- Exemplo: Um arquiteto está projetando um novo prédio de escritório. Eles podem usar um agente AI + um sistema LLM para inserir seus objetivos de projeto, como maximizar a luz natural e otimizar o uso de espaço. O LLM pode então analisar esses objetivos, gerar diferentes opções de projeto, e até simular como o edifício performaria sob diferentes condições ambientais.
-
Construção: Melhorar a Segurança e a Eficiência em Sites de Construção
- Exemplo: Um agente AI equipado com câmeras e sensores pode monitorar um site de construção para riscos de segurança. Se um funcionário não estiver usando o equipamento de segurança apropriado ou um equipamento for deixado em uma posição perigosa, o MLG pode analisar a situação, avisar o supervisor do site e até mesmo suspender automaticamente as operações se necessário.
O Futuro Está Aqui: Um Novo Era de Desenvolvimento de Software
A convergência de agentes AI e MLGs marca um avanço significativo no desenvolvimento de software. Enquanto essas tecnologias continuam a evoluir, podemos esperar ver ainda mais aplicações inovadoras emergindo, transformando indústrias, linearizando fluxos de trabalho e criando novas possibilidades inteiras para a interação humano-computador.
Agentes AI brilham mais quando é necessário processar grandes quantidades de dados, automatizar tarefas repetitivas, tomar decisões complexas e fornecer experiências personalizadas. Conforme atenderem as condições necessárias e seguirem as melhores práticas, as organizações podem aproveitar o potencial total de agentes AI para impulsionar inovação, eficiência e crescimento.
Capítulo 4: A Fundação Filosófica dos Sistemas Inteligentes
O desenvolvimento de sistemas inteligentes, especialmente no campo da inteligência artificial (IA), requer um entendimento profundo dos princípios filosóficos. Este capítulo explora as ideias filosóficas centrais que moldam o design, o desenvolvimento e o uso da IA. Ele destaca a importância de alinhar o progresso tecnológico com os valores éticos.
A fundação filosófica dos sistemas inteligentes não é apenas um exercício teórico – é um framework vital que garante que as tecnologias da IA beneficiam a humanidade. Promovendo ajustes, inclusividade e melhorando a qualidade de vida, esses princípios auxiliam a orientar a IA para servir os nossos melhores interesses.
Considerações Éticas no Desenvolvimento da AI
Como os sistemas AI se tornam cada vez mais integrados em todos os aspectos da vida humana, da saúde e educação à finanças e governança, precisamos examinar e aplicar rigorosamente as imperativos éticos que guiam seu design e implementação.
A questão étnica fundamental gira em torno de como a AI pode ser feita para abraçar e defender os valores humanos e os princípios morais. Essa questão é central ao modo como a AI moldará o futuro das sociedades em todo o mundo.
No cerne deste debate étnico está o princípio de beneficência, um pilar da filosofia moral que diz que as ações devem buscar fazer bem e melhorar o bem-estar dos indivíduos e da sociedade em geral (Floridi & Cowls, 2019).
No contexto da IA, a bondade traduz-se em projetar sistemas que contribuem ativamente para o florescimento humano — sistemas que melhoram os resultados de saúde, ampliam as oportunidades educacionais e facilitam o crescimento econômico equitativo.
Mas a aplicação da bondade na IA é longe de ser simples. Isso exige uma abordagem nuanciada que avalia cuidadosamente os benefícios potenciais da IA contra os riscos e danos possíveis.
Um dos principais desafios na aplicação do princípio da bondade à mudança de desenvolvimento da IA é a necessidade de equilíbrio delicado entre inovação e segurança.
A IA tem o potencial para revolucionar campos como a medicina, onde algoritmos preditivos podem diagnosticar doenças mais cedo e com maior exatidão do que os médicos humanos. Mas sem um controle ético estritamente supervisionado, essas mesmas tecnologias poderiam agravar as desigualdades existentes.
Isso poderia acontecer, por exemplo, se eles fossem principalmente implantados em regiões abastadas enquanto as comunidades subservidas continuam sem acesso básico à assistência médica.
Devido a isso, o desenvolvimento ético da AI exige não apenas foco na maximização dos benefícios, mas também uma abordagem proativa para mitigar riscos. Isto envolve a implementação de garantias robustas para prevenir o abuso da AI e garantir que essas tecnologias não causem danos acidentalmente.
O quadro ético para a AI também deve ser intrinsecamente inclusivo, garantindo que os benefícios da AI sejam distribuídos equitativamente entre todos os grupos da sociedade, incluindo aqueles que são tradicionalmente marginalizados. Isso chama de compromisso com a justiça e a equidade, garantindo que a AI não simplesmente reforça o status quo, mas trabalha ativamente para desmantelar as desigualdades sistémicas.
Por exemplo, a automatização de trabalhos impulsionada por IA tem o potencial para aumentar a produtividade e o crescimento econômico. Mas ela também poderia resultar em uma deslocalização de trabalhos significativa, afetando de forma desproporcionada trabalhadores de baixo rendimento.
Então, como podem ver, um framework ético para a IA deve incluir estratégias para o partilhamento equitativo de benefícios e a prestação de sistemas de apoio para aqueles afetados adversamente pelas avançadas tecnologias da IA.
O desenvolvimento ético da IA exige um envolvimento contínuo com diversos interessados, incluindo eticistas, tecnólogos, formuladores de políticas e comunidades que serão mais afetadas por essas tecnologias. essa colaboração interdisciplinar garante que os sistemas da IA não se desenvolvam em um vácuo, mas são moldados por uma ampla gama de perspectivas e experiências.
É através deste esforço coletivo que podemos criar sistemas da IA que refletem e mantêm os valores que definem a nossa humanidade – compaixão, justiça, respeito à autonomia e compromisso com o bem comum.
As considerações éticas no desenvolvimento da IA não são apenas guias, mas elementos essenciais que determinarão se a IA serve como uma força para o bem no mundo. Ao basear a IA nos princípios de bondade, justiça e inclusividade, e mantendo uma abordagem vigilante em relação ao equilíbrio da inovação e dos riscos, podemos garantir que o desenvolvimento da IA não avança apenas a tecnologia, mas também melhora a qualidade de vida de todos os membros da sociedade.
Ao continuarmos a explorar as capacidades da IA, é imprescindível que essas considerações éticas permaneçam no centro de nossos esforços, guiando-nos para um futuro onde a IA realmente beneficie a humanidade.
A Imperativa de Design de AI Centrado no Humano
O design de AI centrado no humano transcende considerações técnicas meras. Ele está arraigado em princípios filosóficos profundos que priorizam a dignidade humana, a autonomia e a agência.
Este approach para o desenvolvimento de AI é fundamentalmente ancorado no quadro ético kantiano, que afirma que os seres humanos devem ser considerados como fins em si mesmos, e não apenas como instrumentos para alcançar outros objetivos (Kant, 1785).
As implicações deste princípio para o design de AI são profundas, exigindo que sistemas de AI sejam desenvolvidos com foco inflexível em servir os interesses humanos, preservar a agência humana e respeitar a autonomia individual.
Implementação Técnica de Princípios Centrados no Humano
Melhorar Autonomia Humana através de AI: O conceito de autonomia em sistemas AI é crítico, particularmente em garantir que essas tecnologias empower usuários, em vez de controlar ou influenciar nelas de forma indevida.
Em termos técnicos, isso envolve o desenvolvimento de sistemas AI que priorizam a autonomia do usuário, fornecendo-lhes ferramentas e informações necessárias para tomar decisões informadas. Isso requer que modelos AI sejam contextuais, o que significa que eles devem entender o contexto específico em que uma decisão é feita e ajustar suas recomendações em conformidade.
Ao olhar para a perspectiva de projeto de sistemas, isso envolve a integração de inteligência contextual em modelos AI, o que permite que esses sistemas se adaptem dinamicamente ao ambiente, preferências e necessidades do usuário.
Por exemplo, no setor de saúde, um sistema de AI que assiste médicos na diagnose de condições deve considerar o histórico médico único do paciente, os sintomas atuais, e até mesmo o estado psicológico para oferecer recomendações que apoiem a expertise do médico, em vez de a substituir.
Essa adaptação contextual garante que o AI continue sendo uma ferramenta de apoio que melhora, em vez de diminuir, a autonomia humana.
Garantindo Processos de Decisão Transparentes: A transparência em sistemas de AI é um requisito fundamental para garantir que os usuários possam confiar e entender as decisões feitas por essas tecnologias. Tecnicamente, isso traduz-se na necessidade de explicabilidade de AI (XAI), que envolve o desenvolvimento de algoritmos que possam articular claramente a razão por trás das suas decisões.
Isso é particularmente crucial em domínios como finanças, saúde e justiça criminal, onde a tomada de decisões opacas pode levar a desconfiança e preocupações éticas.
A explicabilidade pode ser alcançada por várias abordagens técnicas. Uma das metodologias comuns é a interpretabilidade pós-hoc, onde o modelo de AI gera uma explicação após a decisão ter sido feita. Isso pode envolver a desagregação da decisão em seus fatores constituintes e mostrar como cada um deles contribuiu para o resultado final.
Outra abordagem é os modelos intrinsecamente interpretáveis, onde a arquitetura do modelo é projetada de modo a que suas decisões sejam transparentes por padrão. Por exemplo, modelos como árvores de decisão e modelos lineares são naturaismente interpretáveis porque seu processo de tomada de decisões é fácil de seguir e entender.
O desafio na implementação de IA explicável está em equilibrar a transparência com o desempenho. frequentemente, modelos mais complexos, como redes neurais profundas, são menos interpretáveis mas mais precisos. Portanto, o design de IA humano-centrada deve considerar o compromisso entre a interpretabilidade do modelo e sua capacidade preditiva, garantindo que usuários possam confiar e entender decisões de IA sem sacrificar precisão.
Permitindo Oversight Humano Significativo: O oversight humano significativo é fundamental para garantir que os sistemas AI operam dentro de limites ético e operacional. Este oversight envolve projetar sistemas AI com salvaguardas e mecanismos de sobreposição que permitam que operadores humanos intervendam quando necessário.
A implementação técnica de oversight humano pode ser abordada de várias maneiras.
Uma abordagem é incorporar sistemas human-in-the-loop, onde os processos de decisão da IA são monitorados e avaliados contínueismente por operadores humanos. Esses sistemas são projetados para permitir intervenção humana em pontos críticos, garantindo que a IA não actue de forma autônoma em situações onde juízes éticos são necessários.
Por exemplo, no caso de sistemas de armas autônomas, o supervisão humana é essencial para evitar que o AI faça decisões de vida ou morte sem entrada humana. Isso poderia envolver a definição de limites operacionais rígidos que o AI não pode transpor sem autorização humana, embutindo assim garantias éticas no sistema.
Outro considerado técnico é o desenvolvimento de trajetórias de auditoria, que são registros de todas as decisões e ações tomadas pelo sistema AI. Essas trajetórias fornecem uma história transparente que pode ser revisada por operadores humanos para garantir conformidade com padrões éticos.
Trajetórias de auditoria são particularmente importantes em setores como finanças e direito, onde decisões devem ser documentadas e justificáveis para manter a confiança pública e atender aos requisitos regulatórios.
Equilíbrio Entre Autonomia e Controle: Um desafio técnico chave em AI centrado no humano é encontrar o equilíbrio certo entre autonomia e controle. Embora os sistemas AI sejam projetados para operar autonomamente em muitos cenários, é crucial que essa autonomia não submeta o controle humano ou supervisão.
Esse equilíbrio pode ser alcançado através da implementação de níveis de autonomia, que determinam o grau de independência que o AI tem na tomada de decisões.
Por exemplo, em sistemas semi-autônomos como carros autônomos, os níveis de autonomia variam de assistência de condutor básica (onde o condutor humano permanece em controle total) à automação total (onde o AI é responsável por todas as tarefas de condução).
O design desses sistemas deve garantir que, em qualquer nível de autonomia, o operador humano mantenha a capacidade de intervir e anular o AI, se necessário. Isso requer interfaces de controle sofisticadas e sistemas de apoio à decisão que permitam que humanos assumam o controle rapidamente e eficazmente quando necessário.
Adicionalmente, o desenvolvimento de frameworks éticos de AI é fundamental para guiar as ações autônomas de sistemas de AI. Esses frameworks são conjuntos de regras e diretrizes embutidas no AI que ditam como ele deve se comportar em situações étnicamente complexas.
Por exemplo, em saúde, um framework ético de AI poderia incluir regras sobre consentimento do paciente, privacidade e priorização de tratamentos com base na necessidade médica, em vez de considerações financeiras.
Ao integrar esses princípios éticos diretamente nos processos de decisão do AI, os desenvolvedores podem garantir que a autonomia do sistema é exercida de modo que alinhe com os valores humanos.
A integração de princípios humanocêntricos no design de AI não é apenas um ideal filosófico, mas uma necessidade técnica. Ao melhorar a autonomia humana, garantindo transparência, permitindo controle significativo e equilibrando a autonomia com o controle, os sistemas de AI podem ser desenvolvidos de modo que realmente servem à humanidade.
essas considerações técnicas são essenciais para criar AI que não apenas amplia as capacidades humanas, mas também respeita e mantém os valores fundamentais à nossa sociedade.
Como o AI continua a evoluir, o compromisso com o design humanocêntrico será crucial para garantir que essas poderosas tecnologias sejam usadas ética e responsavelmente.
Como Garantir que a IA Beneficie a Humanidade: Melhorar a Qualidade de Vida
Enquanto se engaja na desenvolvimento de sistemas de IA, é essencial para você fixar seus esforços no quadro ético do utilitarismo – uma filosofia que dá importância para a melhoria da felicidade e bem-estar gerais.
No contexto deste, a IA tem o potencial para abordar desafios críticos da sociedade, particularmente em áreas como saúde, educação e sustentabilidade ambiental.
O objetivo é criar tecnologias que melhorem significativamente a qualidade de vida para todos. Mas essa busca apresenta complexidades. O utilitarismo oferece um motivo convincente para a ampla implantação da IA, mas também coloca questões éticas importantes sobre quem beneficia e quem pode ser deixado para trás, especialmente entre populações vulneráveis.
Para navegar nestes desafios, precisamos de um método sofisticado e informado técnicamente – um equilíbrio entre a busca ampla de bem-estar da sociedade e a necessidade de justiça e equidade.
Ao aplicar os princípios utilitários à IA, seu foco deve estar na otimização de resultados em domínios específicos. Na área de saúde, por exemplo, ferramentas de diagnóstico de IA têm o potencial para melhorar significativamente os resultados dos pacientes, permitindo diagnósticos mais rápidos e precisos. Estes sistemas podem analisar grandes bases de dados para detectar padrões que podem passar despercebidos por profissionais humanos, expandindo assim o acesso a cuidados de qualidade, particularmente em ambientes pouco recursos.
Mas, a implantação destas tecnologias exige uma consideração cuidadosa para evitar a reforçação de desigualdades existentes. Os dados usados para treinar modelos de AI podem variar significativamente entre regiões, afetando a precisão e a confiabilidade desses sistemas.
Essa disparidade destaca a importância de estabelecer frameworks robustos de governança de dados que garantam que suas soluções de saúde auxiliadas por AI sejam tanto representativas quanto equitativas.
Na esfera educacional, a capacidade de personalização do AI é promissora. Sistemas de AI podem adaptar o conteúdo educacional para atender às necessidades específicas de estudantes individuais, melhorando assim os resultados de aprendizagem. Analisando dados sobre o desempenho e o comportamento de estudantes, AI pode identificar onde um estudante pode estar tendo dificuldades e fornecer apoio direcionado.
Mas enquanto você trabalha em direção a esses benefícios, é crucial estar ciente dos riscos – como o potencial de reforçar estereótipos ou marginalizar estudantes que não se encaixam em padrões de aprendizagem típicos.
Mitigar esses riscos exige a integração de mecanismos de equidade em modelos de AI, garantindo que eles não favoreçam acidentalmente certos grupos. E manter o papel dos educadores é fundamental. Sua experiência e juízo são indispensáveis para tornar ferramentas de AI verdadeiramente eficazes e apoio.
Em termos de sustentabilidade ambiental, o potencial de AI é considerável. Sistemas de AI podem optimizar o uso de recursos, monitorar mudanças ambientais e prever os impactos do aquecimento global com precisão sem precedentes.
Por exemplo, a IA pode analisar grandes quantidades de dados ambientais para prever padrões meteorológicos, otimizar o consumo de energia e minimizar o desperdício — ações que contribuem para o bem-estar de gerações atuais e futuras.
Mas essa avançada tecnológica vem com um conjunto de desafios próprios, principalmente referente ao impacto ambiental dos próprios sistemas de IA.
O consumo de energia necessário para operar sistemas de IA em escala grande pode compensar os benefícios ambientais que eles buscam alcançar. Portanto, desenvolver sistemas de IA eficientes em energia é crucial para garantir que seu impacto positivo na sustentabilidade não é subvalorizado.
Enquanto você desenvolve sistemas de IA com objetivos utilitários, é importante considerar também as implicações para a justiça social. O utilitarismo se concentra na maximização da felicidade global, mas não aborda necessariamente a distribuição dos benefícios e danos entre diferentes grupos da sociedade.
Isto levanta o potencial de sistemas de IA beneficiar desproporcionalmente aqueles que já estão privilegiados, enquanto os grupos marginalizados pode ver pouca ou nenhuma melhoria nas suas circunstâncias.
Para contrabalançar isso, seu processo de desenvolvimento de AI deve incorporar princípios enfocados na equidade, garantindo que os benefícios são distribuídos justamente e que quaisquer potenciais danos são abordados. Isto poderia envolver o design de algoritmos que especificamente visam reduzir biases e envolver uma variedade de perspectivas diversas no processo de desenvolvimento.
Enquanto trabalhamos para desenvolver sistemas AI com o objetivo de melhorar a qualidade de vida, é essencial equilibrar o objetivo utilitarista de maximizar o bem-estar com a necessidade de justiça e equidade. Isso requer uma abordagem sofisticada, baseada em tecnologia, que considere as implicações mais amplas do deployamento de AI.
Ao projetar sistemas AI que sejam tanto eficazes quanto equitativos, você pode contribuir para um futuro onde as mudanças tecnológicas realmente atendam às diversas necessidades da sociedade.
ImplementarMedidas de Proteção contra Possíveis Danos
Ao desenvolver tecnologias AI, você deve reconhecer o potencial para danos e estabelecer ativamente medidas robustas para mitigar estes riscos. Esta responsabilidade está profundamente enraizada nas éticas deontológicas. Esta ramificação da ética dá importância à obrigação moral de seguir regras e padrões éticos estabelecidos, garantindo que a tecnologia criada se alinhe com princípios morais fundamentais.
A implementação de protocolos de segurança estritos não é apenas uma precaução, mas uma obrigação ética. Esses protocolos devem abranger testes de bias completos, transparência nos processos algoritmicos e mecanismos claros de responsabilidade.
Tais medidas de proteção são essenciais para prevenir que os sistemas AI causem dano não intencional, seja por decisões baseadas em preconceitos, processos opacos ou por falta de supervisão.
Na prática, a implementação dessas medidas de proteção requer um entendimento profundo das dimensões técnicas e éticas do AI.
Testes de propagação de erro, por exemplo, envolve não só a identificação e correção de propagações de erro em dados e algoritmos, mas também o entendimento das implicações sociais mais amplas dessas propagações de erro. Você deve garantir que seus modelos de AI estejam treinados em bases de dados diversas e representativas e sejam avaliados regularmente para detectar e corrigir quaisquer propagações de erro que possam surgir ao longo do tempo.
Por outro lado, a transparência exige que os sistemas de AI sejam projetados de modo a que seus processos de tomada de decisão sejam facilmente compreensíveis e questionáveis por usuários e stakeholders. Isso envolve o desenvolvimento de modelos de AI explicáveis que fornecem saídas claras e interpretáveis, permitindo que usuários vejam como as decisões são feitas e garantindo que essas decisões sejam justificáveis e equitativas.
Além disso, mecanismos de responsabilidade são cruciais para manter a confiança e garantir que os sistemas de AI são usados responsavelmente. Esses mecanismos devem incluir diretrizes claras sobre quem é responsável pelos resultados das decisões de AI, bem como processos para abordar e corrigir quaisquer danos que possam ocorrer.
Você deve estabelecer um framework onde as considerações éticas são integradas em cada estágio do desenvolvimento de AI, desde o design inicial até a implantação e além disso. Isso inclui não só seguir diretrizes éticas, mas também monitorar contínuamente e ajustar os sistemas de AI conforme interagem com o mundo real.
Ao integrar esses salvaguardas na própria estrutura do desenvolvimento de AI, você pode ajudar a garantir que o progresso tecnológico serve o bem maior sem levantar consequências negativas não intencionadas.
O papel de supervisão humana e ciclos de feedback
Supervisão humana em sistemas AI é um componente crítico para garantir oPLOYIMENTO ETICO DE AI. O princípio de responsabilidade apoia a necessidade de envolvimento humano contínuo na operação de AI, particularmente em ambientes de alto risco como saúde e justiça criminal.
Os laços de feedback, onde a entrada humana é usada para refinar e melhorar os sistemas AI, são essenciais para manter a responsabilidade e adaptabilidade (Raji et al., 2020). Esses laços permitem a correção de erros e a integração de novas considerações éticas à medida que os valores sociais evoluem.
Ao incorporar a supervisão humana em sistemas AI, os desenvolvedores podem criar tecnologias que não só são eficientes mas também alinhadas com normas éticas e expectativas humanas.
codificando Ética: Traduzindo Princípios Filosóficos em Sistemas AI
A tradução de princípios filosóficos em sistemas AI é uma tarefa complexa, mas necessária. Esse processo envolve a incorporação de considerações éticas no próprio código que guia os algoritmos de AI.
Conceitos como justiça, equidade e autonomia devem ser codificados em sistemas AI para garantir que operem de maneiras que refletem valores sociais. Isso requer uma abordagem multidisciplinar, onde eticistas, engenheiros e cientistas sociais colaboram para definir e implementar diretrizes éticas no processo de codificação.
O objetivo é criar sistemas AI que não só são tecnicamente proficientes mas também moralmente sólidos, capazes de tomar decisões que respeitam a dignidade humana e promovem o bem social (Mittelstadt et al., 2016).
Promoção de Inclusividade e Acesso Equitativo no Desenvolvimento ePLOYIMENTO DE AI
Inclusividade e acesso equitativo são fundamentais para o desenvolvimento ético de AI. O conceito Rawlsiano de justiça como equidade fornece uma fundação filosófica para garantir que os sistemas AI são projetados e implementados de modos que beneficiam de todos os membros da sociedade, particularmente aqueles que são os mais vulneráveis (Rawls, 1971).
Isso envolve esforços proativos para incluir perspectivas diversas no processo de desenvolvimento, especialmente de grupos subrepresentados e do Sul Global.
Ao incorporar essas perspectivas diversas, os desenvolvedores de AI podem criar sistemas que sejam mais equitativos e respondem melhor às necessidades de uma ampla gama de usuários. Além disso, garantir o acesso equitativo a tecnologias AI é crucial para prevenir a agravação de desigualdades sociais existentes.
Confrontar o Bias Algorítmico e a Justiça
O bias algorítmico é um problema ético significativo no desenvolvimento de AI, pois algoritmos com essa característica podem perpetuar e até agravar as desigualdades sociais. Para abordar esse assunto, é necessário um compromisso com a justiça procedural, garantindo que os sistemas AI são desenvolvidos através de processos justos que consideram o impacto em todos os interessados (Nissenbaum, 2001).
Isso envolve identificar e mitigar os biases nos dados de treinamento, desenvolver algoritmos que sejam transparentes e explicáveis e aplicar verificações de equidade ao longo do ciclo de vida do AI.
Ao abordar o bias algorítmico, os desenvolvedores podem criar sistemas AI que contribuam para uma sociedade mais justa e equitativa, em vez de reforçar as disparidades existentes.
Incorporar Perspectivas Diversas no Desenvolvimento de AI
Incorporar perspectivas diversas na pesquisa em inteligência artificial (IA) é fundamental para a criação de sistemas inclusivos e equitativos. A inclusão de vozes de grupos subrepresentados garante que as tecnologias da IA não refletem apenas os valores e prioridades de um pequeno segmento da sociedade.
Este enfoque está alinhado com o princípio filosófico da democracia deliberativa, que enfatiza a importância de processos decisórios inclusivos e participativos (Habermas, 1996).
Ao fomentar a participação diversa na pesquisa em IA, podemos garantir que essas tecnologias são desenhadas para servir os interesses de toda a humanidade, e não de apenas alguns privilegiados.
Estratégias para aompanhar a divisão da IA
A divisão da IA, caracterizada pela desigualdade de acesso às tecnologias e benefícios da IA, representa um desafio significativo para a equidade global. Contruir este caminho requer um compromisso com a justiça distributiva, garantindo que os benefícios da IA sejam divididos amplamente entre diferentes grupos sócioeconômicos e regiões (Sen, 2009).
Podemos fazer isso através de iniciativas que promovem o acesso à educação em IA e recursos em comunidades de serviço insuficiente, bem como políticas que apoiam a distribuição equitativa de ganhos econômicos driven por IA. Atendendo à divisão da IA, podemos garantir que a IA contribua ao desenvolvimento global de uma maneira inclusiva e equitativa.
Equilibrar a Inovação com as Constraints Éticas
Equilibrar a busca pela inovação com as restrições éticas é fundamental para o avanço responsável da IA. O princípio precautório, que defende a prudência na face da incerteza, é particularmente relevante no contexto do desenvolvimento da IA (Sandin, 1999).
Enquanto inovação drive progresso, deve ser equilibrada por considerações éticas que protegem contra potenciais danos. Isso requer uma avaliação cuidadosa dos riscos e benefícios das novas tecnologias de AI, bem como a implementação de frameworks regulatórios que garantam o cumprimento de padrões éticos.
Ao equilibrar inovação com restrições éticas, podemos fomentar o desenvolvimento de tecnologias de AI que sejam de ponta e alinhadas com os objetivos mais amplos de bem-estar da sociedade.
Como você pode ver, a fundamentação filosófica de sistemas inteligentes fornece um marco crítico para garantir que tecnologias de AI sejam desenvolvidas e implantadas de maneiras éticas, inclusivas e benéficas para toda a humanidade.
Ao basear o desenvolvimento de AI nestes princípios filosóficos, podemos criar sistemas inteligentes que não só avançam as capacidades tecnológicas, mas também melhoram a qualidade de vida, promovem a justiça e garantem que os benefícios de AI sejam partilhados equitativamente pela sociedade.
Capítulo 5: Agentes de AI como Enhancers de LLM
A fusão de agentes de AI com Modelos de Linguagem Grande (LLMs) representa um shift fundamental em inteligência artificial, abordando limitações críticas em LLMs que têm limitado sua aplicabilidade ampla.
Essa integração permite que as máquinas transcendam seus papéis tradicionais, avançando de geradores de texto passivos para sistemas autônomos capazes de raciocínio dinâmico e tomada de decisões.
Como sistemas AI cada vez mais dirigem processos críticos em diversos domínios, entender como os agentes de AI preenchem as lacunas nas capacidades de LLM é essencial para concretizar seu potencial total.
Ponteando asfalte em Capacidades de LLM
LLMs, embora poderosos, estão inherentemente limitados pelo conjunto de dados em que foram treinados e pela natureza estática de sua arquitetura. Esses modelos operam dentro de um conjunto fixo de parâmetros, normalmente definidos pelo corpus de texto usado durante sua fase de treinamento.
Essa limitação significa que LLMs não podem procurar informações novas de forma autônoma ou atualizar sua base de conhecimento após o treinamento. Consequentemente, LLMs são frequentemente desatualizados e carecem da capacidade de fornecer respostas relevantes de contexto que exijam dados ou insights além dos dados de treinamento iniciais.
Agentes de AI ponteiam essas lacunas ao integrar dinamicamente fontes de dados externos, o que pode extender o horizonte funcional de LLMs.
Por exemplo, um LLM treinado em dados financeiros até 2022 poderia fornecer análises históricas precisas, mas poderia ter dificuldade em gerar previsões de mercado atualizadas. Um agente de AI poderia complementar esse LLM, puxando dados reais em tempo real dos mercados financeiros e aplicando esses entradas para gerar análises mais relevantes e atuais.
Essa integração dinâmica garante que as saídas não são apenas precisas historicamente, mas também apropriadas contextualmente para condições atuais.
Melhoria na Autonomia na Tomada de Decisões
Outra limitação significativa de LLMs é sua falta de capacidades de tomada de decisão autônoma. LLMs excelentes em gerar saídas baseadas em linguagem, mas não conseguem realizar tarefas que requerem complexas decisões, especialmente em ambientes caracterizados por incerteza e mudança.
Essa deficiência principalmente é devido ao modelo dependendo de dados pré-existentes e a falta de mecanismos para raciocínio adaptativo ou aprendizagem a partir de novas experiências após a implantação.
Os agentes AI abordam isso fornecendo a infraestrutura necessária para decisões autônomas. Eles podem pegar as saídas estáticas de uma LLM e processá-las através de frameworks de raciocínio avançado, como sistemas baseados em regras, heurísticas ou modelos de aprendizagem por reforço.
Por exemplo, em um ambiente de saúde, uma LLM pode gerar uma lista de diagnósticos potenciais com base em sintomas de um paciente e histórico médico. Mas sem um agente AI, a LLM não consegue ponderar essas opções ou recomendar uma ação.
Um agente AI pode intervir para avaliar esses diagnósticos em relação à literatura médica atual, dados do paciente e fatores contextuais, fazendo assim decisões informadas e sugerindo próximas ações executáveis. Essa sinergia transforma as saídas da LLM de sugestões simples em decisões executáveis e contextuais.
Construindo Completude e Consistência
Completude e consistência são fatores críticos para garantir a confiabilidade dos resultados da LLM, particularmente em tarefas de raciocínio complexo. Devido à sua natureza parametrizada, LLMs frequentemente geram respostas incompletas ou logicamente incoerentes, especialmente quando lidam com processos de várias etapas ou exigem um entendimento abrangente em diversos domínios.
Esses problemas decorrem do ambiente isolado em que LLMs operam, onde eles não conseguem fazer referência cruzada ou validar suas saídas contra padrões externos ou informações adicionais.
Os agentes de inteligência artificial desempenham um papel crucial em mitigar estes problemas, ao introduzir mecanismos de feedback iterativo e camadas de validação.
Por exemplo, no domínio legal, uma MLG (Máquina de Lógica Generalista) pode elaborar uma versão inicial de um brief legal com base em seus dados de treinamento. Mas esse rascunho pode desconsiderar certos precedentes ou falhar em estruturar argumentos logicamente.
Um agente de inteligência artificial pode revisar esse rascunho, garantindo que ele atinja os padrões de completude requeridos, fazendo referência cruzada com bases de dados legais externas, verificando consistência lógica e solicitando informações adicionais ouclarificações onde necessário.
Este processo iterativo permite a produção de um documento mais robusto e confiável que atenda aos rigorosos requisitos da prática legal.
Superar a Isolamento por meio da Integração
Um dos maiores limitamentos das MLGs é sua inerente isolamento de outros sistemas e fontes de conhecimento.
MLGs, conforme projetadas, são sistemas fechados que não interagem naturalmente com ambientes externos ou bases de dados. Essa isolamento limita significativamente sua capacidade de adaptar a novas informações ou operar em tempo real, tornando-as menos efetivas em aplicações que requerem interação dinâmica ou decisões em tempo real.
Agentes de inteligência artificial superam este isolamento, atuando como plataformas integrativas que conectam MLGs a um ecosistema mais amplo de fontes de dados e ferramentas computacionais. Através de APIs e outras frameworks de integração, esses agentes podem acessar dados em tempo real, colaborar com outros sistemas de inteligência e até mesmo se interfaces com dispositivos físicos.
Por exemplo, em aplicações de serviço ao cliente, uma MLG (Máquina de Lógica de Geração) poderia gerar respostas padrão com base em scripts treinados prévios. Mas essas respostas podem ser estáticas e carecer da personalização necessária para o engajamento eficaz com o cliente.
Um agente de AI pode enriquecer essas interações integrando dados em tempo real de perfil do cliente, interações anteriores e ferramentas de análise de sentimento, o que ajuda a gerar respostas que não são apenas relevantes no contexto, mas também customizadas às necessidades específicas do cliente.
essa integração transforma a experiência do cliente de uma série de interações scriptadas em uma conversa dinâmica e personalizada.
Expandir Criatividade e Solução de Problemas
Enquanto as MLGs são ferramentas poderosas para a geração de conteúdo, sua criatividade e habilidades de resolução de problemas são intrinsecamente limitadas pelos dados em que foram treinadas. Esses modelos frequentemente não conseguem aplicar conceitos teóricos a novos desafios ou imprevistos, já que suas capacidades de resolução de problemas estão limitadas pelos conhecimentos prévios e parâmetros de treinamento.
Agentes de AI melhoram o potencial criativo e de resolução de problemas de MLGs, aproveitando técnicas de raciocínio avançadas e uma variedade maior de ferramentas de análise. Essa capacidade permite que agentes de AI ultrapassem as limitações das MLGs, aplicando frameworks teóricos a problemas práticos de forma inovadora.
Por exemplo, considere o problema de combater as informações falsas em plataformas de mídia social. Uma MLG poderia identificar padrões de informação falsa baseada em análises textuais, mas poderia ter dificuldade em desenvolver uma estratégia abrangente para mitigar a disseminação de informações falsas.
Um agente IA pode pegar nestes insights, aplicar teorias interdisciplinares de campos como sociologia, psicologia e teoria das redes, e desenvolver uma abordagem robusta, multifacetada que inclui monitoramento em tempo real, educação de usuários e técnicas de moderação automatizadas.
Esta capacidade de sintetizar frameworks teóricos diversos e aplicá-los a desafios do mundo real exemplifica as capacidades de resolução de problemas aprimoradas que os agentes IA trazem à mesa.
Exemplos Mais Específicos
Agentes IA, com sua capacidade de interagir com sistemas diversos, acessar dados em tempo real e executar ações, enfrentam essas limitações de frente, transformando LLMs de modelos de linguagem poderosos mas passivos em solucionadores de problemas dinâmicos e reais. Vamos olhar para alguns exemplos:
1. De Dados Estáticos para Insights Dinâmicos: Manter LLMs no Loop
-
O Problema: Imagine perguntar a um LLM treinado com pesquisa médica pré-2023, “Quais são as últimas mudanças no tratamento do cancro?” Sua informação estaria desatualizada.
- A Solução do Agente IA: Um agente IA pode conectar o LLM aos jornais médicos, bases de dados de pesquisa e fontes de notícias. Agora, o LLM pode fornecer informações atualizadas sobre os últimos ensaios clínicos, opções de tratamento e descobertas de pesquisa.
2. Da Análise à Ação: Automatizando Tarefas Baseadas em Insights do LLM
-
O Problema: Um LLM a monitorizar os media sociais para uma marca pode identificar uma explosão de sentimento negativo, mas não pode fazer nada para resolve-lo.
-
A Solução de Agente AI: Um agente AI conectado a contas de mídia social da marca e equipado com respostas pré-aprovadas pode automatizar a resolução de preocupações, responder a perguntas e até mesmo escalar questões complexas para representantes humanos.
3. Do Primeiro Rascunho ao Produto Polido: Garantindo Qualidade e Exatidão
-
O Problema: Um LLM encarregue de traduzir um manual técnico pode produzir traduções gramaticalmente corretas, mas técnicamente imprecisas devido à sua falta de conhecimento específico do domínio.
-
Solução do Agente IA: Um agente IA pode integrar o LLM com dicionários e glosários especializados, e até mesmo conectá-lo a expertos na matéria para retorno em tempo real, garantindo que a tradução final é tanto lingüísticamente correta quanto técnicamente confiável.
4. quebrando barreiras: conectando LLMs ao mundo real
-
O Problema: Um LLM projetado para controle de casa inteligente pode ter dificuldade em adaptar-se às rotinas e preferências mudando de um usuário.
-
Solução do Agente IA: Um agente IA pode conectar o LLM a sensores, dispositivos inteligentes e calendários do usuário. Analisando padrões de comportamento do usuário, o LLM pode aprender a antecipar necessidades, ajustar automaticamente configurações de iluminação e temperatura e até mesmo sugerir playlists de música personalizados baseados na hora do dia e na atividade do usuário.
5. Da Imitação à Inovação: Expandindo a Criatividade do LLM
-
O Problema: Um LLM incumbido com a composição de música pode criar peças que soam derivadas ou que carecem de profundidade emocional, já que ele primariamente depende de padrões encontrados em seus dados de treinamento.
-
A Solução de Agente AI: Um agente AI pode conectar o LLM a sensores de feedback biológico que medem as respostas emocionais de um compositor a elementos musicais diferentes. Incorporando essa feedback em tempo real, o LLM pode criar música que não é apenas tecnicamente competente mas também evoca emoções e é original.
A integração de agentes AI como melhoradores de LLM (Large Language Models) não é apenas uma melhoria incremental — ela representa uma expandição fundamental do que a inteligência artificial pode alcançar. Atendendo as limitações inerentes aos LLM tradicionais, como sua base de conhecimento estática, o limitado autocontrole de decisões e o ambiente operacional isolado, os agentes AI permitem que estes modelos funcionem ao seu potencial total.
Com a evolução da tecnologia AI, o papel de agentes AI no melhoramento de LLM se tornará cada vez mais crítico, não apenas em expandir as capacidades destes modelos mas também em redefinir os limites da própria inteligência artificial. Essa fusão está abrindo caminho para a próxima geração de sistemas AI, capazes de raciocínio autônomo, adaptação em tempo real e resolução de problemas inovadores em um mundo sempre em mudança.
Capítulo 6: Projeto de Arquitetura para a Integração de Agentes AI com LLM
A integração de agentes AI com LLM depende do projeto de arquitetura, que é crucial para o melhoramento da tomada de decisão, da adaptabilidade e da escalabilidade. A arquitetura deve ser cuidadosamente projetada para permitir uma interação fluida entre os agentes AI e LLM, garantindo que cada componente funcione de maneira ótima.
Uma arquitetura modular, onde o agente AI age como um orquestrador, direcionando as capacidades do LLM, é uma abordagem que apoia o gerenciamento dinâmico de tarefas. Este projeto aproveita as forças dos LLM em processamento de linguagem natural enquanto permite que o agente AI gerencie tarefas mais complexas, como raciocínio de vários passos ou decisões contextuais em ambientes em tempo real.
Alternativamente, um modelo híbrido, que combina LLMs com modelos especializados e finamente treinados, oferece flexibilidade, permitindo que o agente AI delegue tarefas ao modelo mais apropriado. Esta abordagem otimiza o desempenho e melhora a eficiência em uma ampla gama de aplicações, tornando-se particularmente eficaz em contextos operacionais diversos e variáveis (Liang et al., 2021).

Metodologias de Treinamento e Melhores Práticas
O treinamento de agentes AI integrados com LLMs require uma abordagem sistemática que equilibra a generalização com a otimização específica das tarefas.
O transfer learning é uma técnica chave aqui, permitindo que um LLM que foi pré-treinado the um grande e diverso conjunto de dados seja finamente treinado em dados específicos do domínio relevantes às tarefas do agente AI. Este método mantém a base de conhecimento ampla do LLM enquanto o permite especializar em aplicações particulares, aumentando a eficácia global do sistema.
Também, o aprendizado por reforço (RL) desempenha um papel crítico, especialmente em cenários onde o agente AI deve adaptar-se a ambientes em mudança. Através da interação com seu ambiente, o agente AI pode melhorar continuamente seus processos de decisão, tornando-se melhor capacitado para lidar com desafios novos.
Para garantir um desempenho confiável em diferentes cenários,metrics de avaliação rigorosos são essenciais. Estes devem incluir tanto marcadores padrão quanto critérios específicos das tarefas, garantindo que o treinamento do sistema seja robusto e abrangente (Silver et al., 2016).
Introdução ao Finetuning de um Modelo de Linguagem Larga (LLM) e Conceitos de Aprendizado por Reforço
Este código demonstra uma variedade de técnicas envolvendo aprendizagem de máquina e processamento de linguagem natural (NLP), com foco em fincaltar grandes modelos de linguagem (LLMs) para tarefas específicas e implementar agentes de aprendizagem por reforço (RL). O código abrange várias áreas chave:
-
Fine-tuning de um LLM: Aproveitando modelos pré-treinados como o BERT para tarefas como análise de sentimento, usando a biblioteca Hugging Face
transformers. Isso envolve tokenizar conjuntos de dados e usar argumentos de treinamento para guiar o processo de fine-tuning. -
Aprendizagem por Reforço (RL): Apresentando os fundamentos de RL the um simples agente de aprendizagem por Q, onde um agente aprende por tentativa e erro, interagindo com um ambiente e atualizando seu conhecimento via tabelas Q.
-
Modelagem de Recompensa com API da OpenAI: Um método conceitual para usar a API da OpenAI para fornecer sinais de recompensa dinamicamente a um agente de RL, permitindo que um modelo de linguagem avalie ações.
-
Avaliação de Modelo e Logging: Usando bibliotecas como
scikit-learnpara avaliar o desempenho do modelo através de acurácia e pontuações F1, e oSummaryWriterdo PyTorch para visualizar o progresso de treinamento. -
Conceitos Avançados em RL: Implementar conceitos avançados como redes de gradiente de política, aprendizado curricular e parada antecipada para aumentar a eficiência do treinamento do modelo.
Esta abordagem holística abrange tanto o aprendizado supervisionado, com o finetuning de análise de sentimento, quanto o aprendizado por reforço, oferecendo insights sobre como são construídos, avaliados e otimizados os sistemas de IA modernos.
Exemplo de Código
Passo 1: Importando as Bibliotecas Necessárias
Antes de mergulhar no ajuste fino do modelo e na implementação do agente, é essencial configurar as bibliotecas e módulos necessários. Este código inclui importações de bibliotecas populares como transformers da Hugging Face e PyTorch para lidar com redes neurais, scikit-learn para avaliar o desempenho do modelo, e alguns módulos de uso geral como random e pickle.
-
Bibliotecas Hugging Face: Permitem usar e ajustar modelos pré-treinados e tokenizadores do Model Hub.
-
PyTorch: É o principal framework de aprendizado profundo usado para operações, incluindo camadas de redes neurais e otimizadores.
-
scikit-learn: Fornece métricas como precisão e F1-score para avaliar o desempenho do modelo.
-
API OpenAI: Acesso aos modelos de linguagem da OpenAI para diversas tarefas, como modelagem de recompensas.
-
TensorBoard: Usado para visualizar o progresso do treinamento.
Aqui está o código para importar as bibliotecas necessárias:
# Importar o módulo random para geração de números aleatórios.
import random
# Importar os módulos necessários da biblioteca transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importar load_dataset para carregar conjuntos de dados.
from datasets import load_dataset
# Importar metrics para avaliar o desempenho do modelo.
from sklearn.metrics import accuracy_score, f1_score
# Importar SummaryWriter para registrar o progresso de treinamento.
from torch.utils.tensorboard import SummaryWriter
# Importar pickle para salvar e carregar modelos treinados.
import pickle
# Importar openai para usar a API do OpenAI (requer uma chave de API).
import openai
# Importar PyTorch para operações de aprendizado profundo.
import torch
# Importar o módulo de rede neural de PyTorch.
import torch.nn as nn
# Importar o módulo de otimizador de PyTorch (não usado diretamente neste exemplo).
import torch.optim as optim
Cada uma destas importações desempenha um papel crucial em diferentes partes do código, de treinamento e avaliação de modelos a registro de resultados e interação com APIs externas.
Passo 2: Ajustando um Modelo de Linguagem para Análise de Sentimento
Ajustar um modelo pré-treinado para uma tarefa específica, como análise de sentimento, envolve carregar um modelo pré-treinado, ajustá-lo para o número de rótulos de saída (positivo/negativo neste caso) e usar um conjunto de dados apropriado.
Neste exemplo, usamos a classe `AutoModelForSequenceClassification` da biblioteca `transformers`, com o dataset IMDB. Este modelo pré-treinado pode ser refinado em uma pequena porção do dataset para economizar tempo de computação. O modelo é então treinado usando um conjunto customizado de argumentos de treinamento, que inclui o número de épocas e o tamanho da batch.
Abaixo está o código para carregar e refinar o modelo:
# especifique o nome do modelo pré-treinado do Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Carregue o modelo pré-treinado com o número especificado de classes de saída.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Carregue um tokenizador para o modelo.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Carregue o dataset IMDB do Hugging Face Datasets, usando apenas 10% para treinamento.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokenize o dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Mapeie o dataset para entradas tokenizadas
tokenized_dataset = dataset.map(tokenize_function, batched=True)
Neste caso, o modelo é carregado usando uma arquitetura baseada em BERT e o dataset é preparado para treinamento. A seguir, definimos os argumentos de treinamento e inicializamos o Treinador.
# Define argumentos de treinamento.
training_args = TrainingArguments(
output_dir="./results", # Especificar o diretório de saída para salvar o modelo.
num_train_epochs=3, # Definir o número de épocas de treinamento.
per_device_train_batch_size=8, # Definir o tamanho da batch por dispositivo.
logging_dir='./logs', # Diretório para armazenamento de logs.
logging_steps=10 # Registrar a cada 10 passos.
)
# Inicializar o Treinador com o modelo, argumentos de treinamento e conjunto de dados.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Iniciar o processo de treinamento.
trainer.train()
# Salvar o modelo treinado com afinamento fino.
model.save_pretrained("./fine_tuned_sentiment_model")

Passo 3: Implementando um Agente de Aprendizagem por Reforço Simples
O aprendizagem por reforço é uma técnica de aprendizagem automática onde um agente aprende a tomar ações de forma que máxime a recompensa acumulada.
Neste exemplo, definimos um agente de aprendizagem por reforço básico que armazena pares de estado-ação em uma tabela Q. O agente pode explorar aleatoriamente ou explorar a melhor ação conhecida com base na tabela Q. A tabela Q é atualizada após cada ação usando uma taxa de aprendizagem e um fator de desconto para ponderar as recompensas futuras.
Abaixo está o código que implementa este agente de aprendizagem por reforço:
# Define a classe do agente Q-learning.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Inicialize a tabela Q.
self.q_table = {}
# Armazene as ações possíveis.
self.actions = actions
# Defina a taxa de exploração.
self.epsilon = epsilon
# Defina a taxa de aprendizado.
self.alpha = alpha
# Defina o fator de desconto.
self.gamma = gamma
# Defina o método get_action para selecionar uma ação com base no estado atual.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# Explorar aleatoriamente.
return random.choice(self.actions)
else:
# Explorar a melhor ação.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
O agente seleciona ações com base na exploração ou exploração e atualiza os valores Q após cada etapa.
# Define o método update_q_table para atualizar a tabela Q.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
Passo 4: Usando a API da OpenAI para Modelagem de Recompensa
Em alguns cenários, em vez de definir uma função de recompensa manual, podemos usar um modelo de linguagem poderoso como o GPT da OpenAI para avaliar a qualidade das ações tomadas pelo agente.
Neste exemplo, a função get_reward envia um estado, ação e próximo estado para a API da OpenAI para receber um score de recompensa, permitindo-nos aproveitar modelos de linguagem grandes para entender estruturas complexas de recompensa.
# Define a função get_reward para obter uma sinal de recompensa da API da OpenAI.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # Substitua com sua chave de API da OpenAI real.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
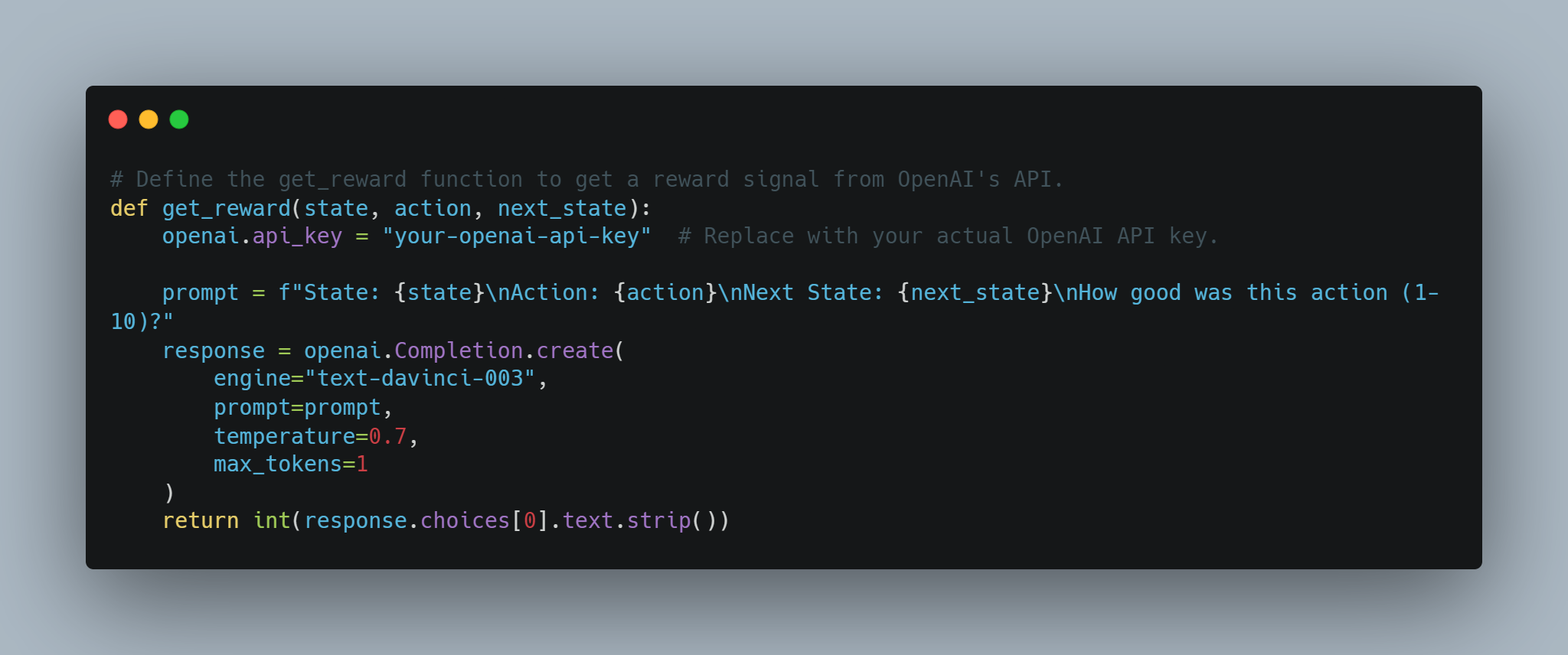
Isto permite uma abordagem conceitual onde o sistema de recompensas é determinado dinamicamente usando a API da OpenAI, o que pode ser útil para tarefas complexas onde as recompensas são difíceis de definir.
Passo 5: Avaliando o Desempenho do Modelo
Uma vez que um modelo de aprendizagem automática é treinado, é essencial avaliar seu desempenho usando métricas padrão como acurácia e métrica F1.
Esta seção calcula ambas usando rótulos verdadeiros e preditos. A acurácia fornece uma medida global de corretude, enquanto a métrica F1 equilibra a precisão e a recuperação, especialmente útil em conjuntos de dados desequilibrados.
Aqui está o código para avaliar o desempenho do modelo:
# Define os rótulos verdadeiros para avaliação.
true_labels = [0, 1, 1, 0, 1]
# Define os rótulos preditos para avaliação.
predicted_labels = [0, 0, 1, 0, 1]
# Calcula a pontuação de acurácia.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calcula a métrica F1.
f1 = f1_score(true_labels, predicted_labels)
# Imprime a pontuação de acurácia.
print(f"Accuracy: {accuracy:.2f}")
# Imprime a métrica F1.
print(f"F1-Score: {f1:.2f}")
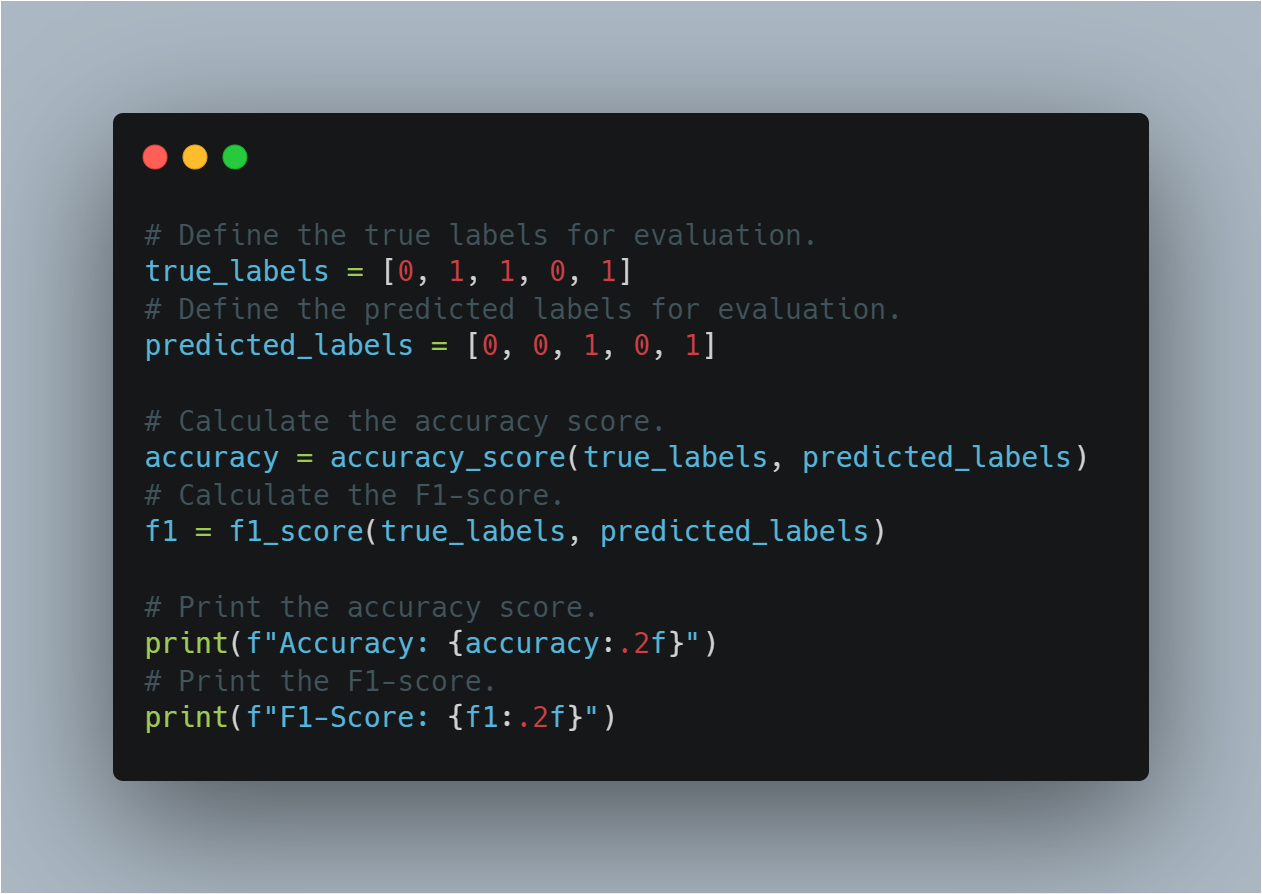
Esta seção ajuda a avaliar como bem o modelo generalizou para dados não vistos usando métricas de avaliação bem estabelecidas.
Passo 6: Agente de Gradiente de Política Básico (Usando PyTorch)
Métodos de gradiente de política em aprendizagem por reforço otimizam diretamente a política maximizando a recompensa esperada.
Esta seção demonstra uma implementação simples de uma rede de política usando PyTorch, que pode ser usada para tomada de decisões em RL. A rede de política usa uma camada linear para saídas de probabilidades para diferentes ações, e a softmax é aplicada para garantir que essas saídas formem uma distribuição de probabilidade válida.
Aqui está o código conceitual para definir um agente de gradiente de política básico:
# Define a classe da rede de política.
class PolicyNetwork(nn.Module):
# Inicializa a rede de política.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# Define uma camada linear.
self.linear = nn.Linear(input_size, output_size)
# Define a passagem frontal da rede.
def forward(self, x):
# Aplica a softmax na saída da camada linear.
return torch.softmax(self.linear(x), dim=1)
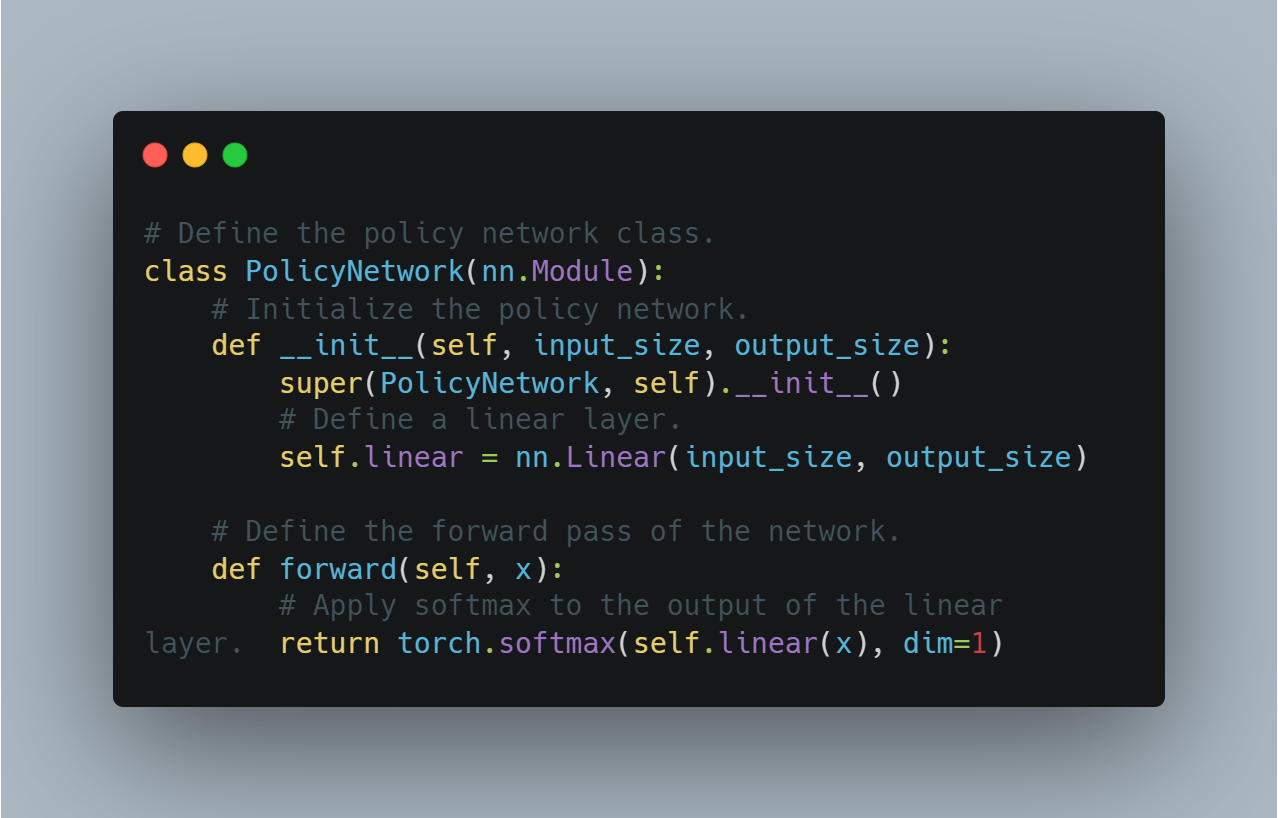
Isso serve como um passo fundamental para implementar algoritmos de aprendizagem por reforço avançados que usam otimização de política.
Passo 7: Visualizar o Progresso de Treinamento com TensorBoard
Visualizar os metrícos de treinamento, como perda e precisão, é fundamental para entender como o desempenho do modelo evolui ao longo do tempo. O TensorBoard, uma ferramenta popular para isso, pode ser usada para registrar metrícos e visualizá-las em tempo real.
Nesta seção, criamos uma instância de SummaryWriter e registramos valores aleatórios para simular o processo de rastreamento de perda e precisão durante o treinamento.
Aqui está como você pode registrar e visualizar o progresso de treinamento usando o TensorBoard:
# Criar uma instância do SummaryWriter.
writer = SummaryWriter()
# Exemplo de loop de treinamento para visualização no TensorBoard:
num_epochs = 10 # Defina o número de épocas.
for epoch in range(num_epochs):
# Simule valores aleatórios de perda e precisão.
loss = random.random()
accuracy = random.random()
# Logue a perda e a precisão no TensorBoard.
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# Feche o SummaryWriter.
writer.close()
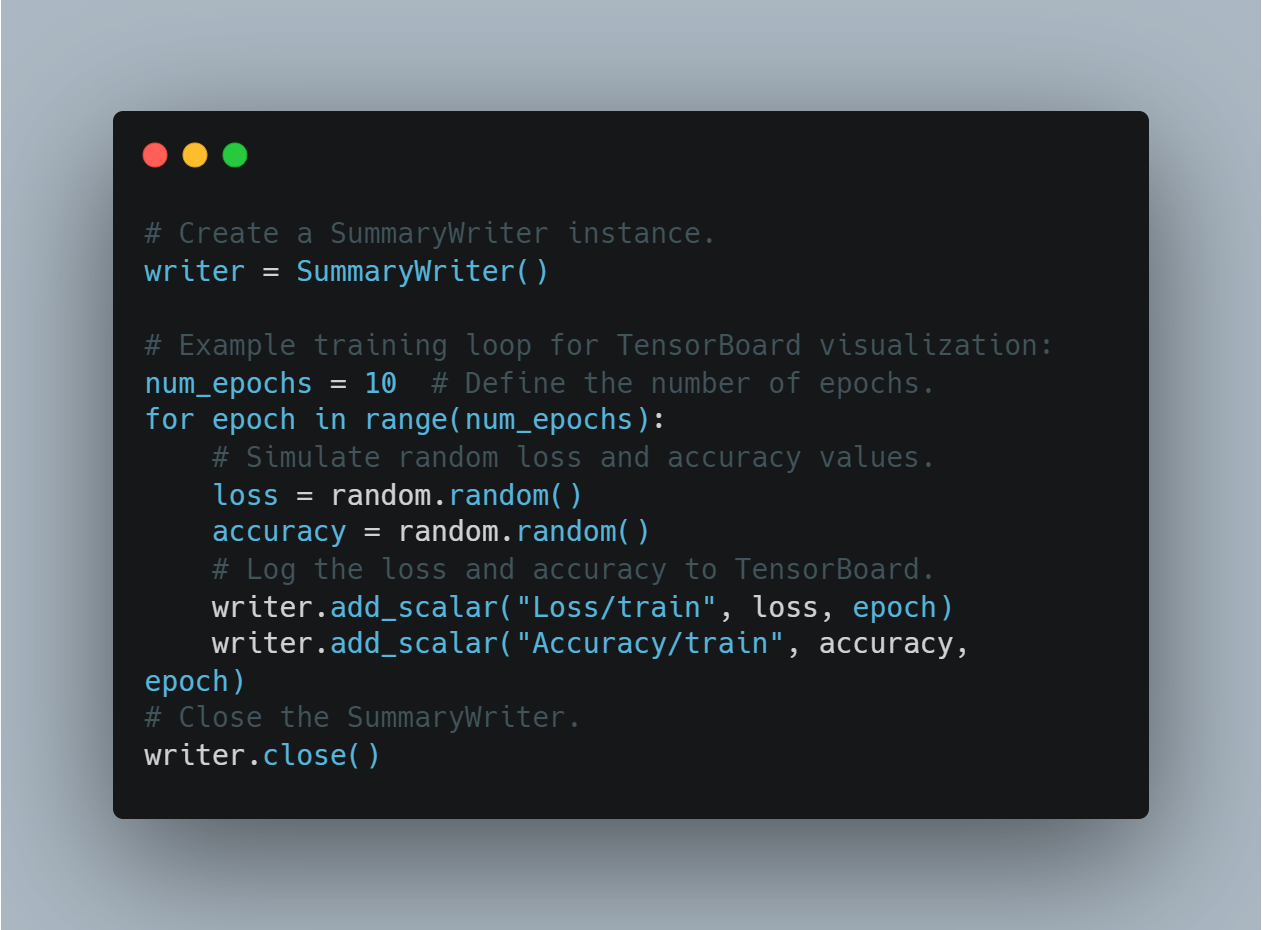
Isso permite que usuários monitorem o treinamento do modelo e façam ajustes em tempo real com base na feedback visual.
Passo 8: Salvando e Carregando Checkpoints de Agente Treinado
Após treinar um agente, é crucial salvar seu estado aprendido (por exemplo, valores Q ou pesos do modelo) para que possa ser reutilizado ou avaliado posteriormente.
Este capítulo mostra como salvar um agente treinado usando o módulo pickle do Python e como o carregar de disco.
Aqui está o código para salvar e carregar um agente de aprendizagem por Q treinado:
# Criar uma instância do agente de aprendizagem por Q.
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# Treinar o agente (não mostrado aqui).
# Salvar o agente.
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# Carregar o agente.
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
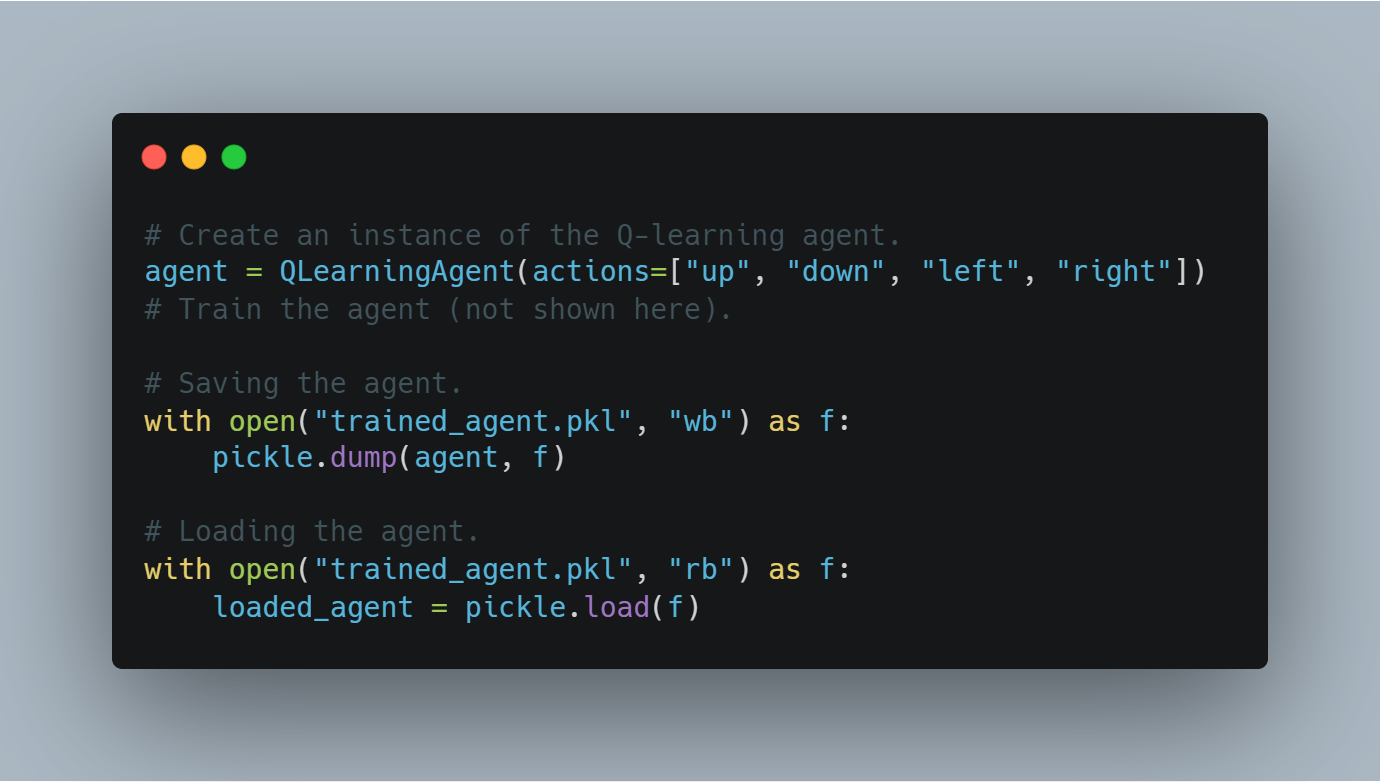
Este processo de marcador de ponto garante que o progresso de treinamento não é perdido e os modelos podem ser reutilizados em experimentos futuros.
Passo 9: Aprendizagem por Currículo
A aprendizagem por currículo envolve aumentar progressivamente a dificuldade das tarefas apresentadas ao modelo, começando com exemplos mais fáceis e seguindo para os mais difíceis. Isso pode ajudar a melhorar o desempenho e a estabilidade do modelo durante o treinamento.
Aqui está um exemplo de usar aprendizagem por currículo em um loop de treinamento:
# Defina a dificuldade inicial da tarefa.
initial_task_difficulty = 0.1
# Loop de treinamento com aprendizagem por currículo de exemplo:
for epoch in range(num_epochs):
# Aumente progressivamente a dificuldade da tarefa.
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# Gera dados de treinamento com dificuldade ajustada.
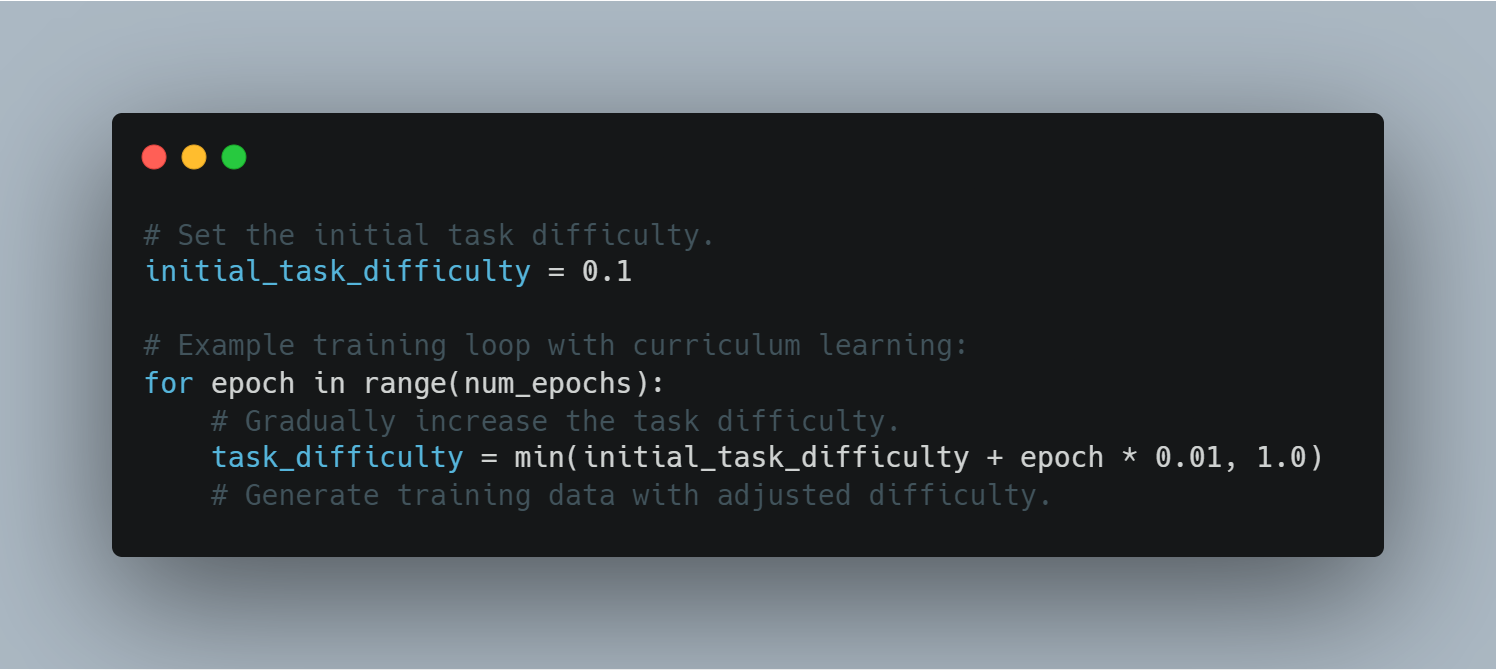
Controlando a dificuldade das tarefas, o agente pode lidar progressivamente com desafios mais complexos, resultando em melhor eficiência de aprendizagem.
Passo 10: Implementando Parada Early
A parada early é uma técnica para evitar o overfitting durante o treinamento, interrompendo o processo se a perda de validação não melhorar após um certo número de épocas (paciência).
Esta seção mostra como implementar a parada early em um loop de treinamento, usando a perda de validação como o indicador chave.
Aqui está o código para implementar a parada early:
# Inicializar a melhor perda de validação para infinito.
best_validation_loss = float("inf")
# Definir o valor de paciência (número de épocas sem melhoria).
patience = 5
# Inicializar o contador de épocas sem melhoria.
epochs_without_improvement = 0
# Exemplo de laço de treinamento com parada precoce:
for epoch in range(num_epochs):
# Simular perda de validação aleatória.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

A parada precoce melhora a generalização do modelo evitando treinamentos desnecessários após o modelo começar a overfit.
Passo 11: Usar um Modelo de LLM Pré-treinado para Transferência de Tarefa Sem-Preenchimento
Na transferência de tarefa sem-preenchimento, um modelo pré-treinado é aplicado a uma tarefa que ele não foi especificamente finamente ajustado para.
Usando a pipeline da Hugging Face, esta seção demonstra como aplicar um modelo BART pré-treinado para resumo sem treinamento adicional, ilustrando o conceito de aprendizado de transferência.
Aqui está o código para usar um LLM pré-treinado para resumo:
# Carregar uma pipeline de resumo pré-treinada.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Definir o texto para resumir.
text = "This is an example text about AI agents and LLMs."
# Gerar o resumo.
summary = summarizer(text)[0]["summary_text"]
# Imprimir o resumo.
print(f"Summary: {summary}")
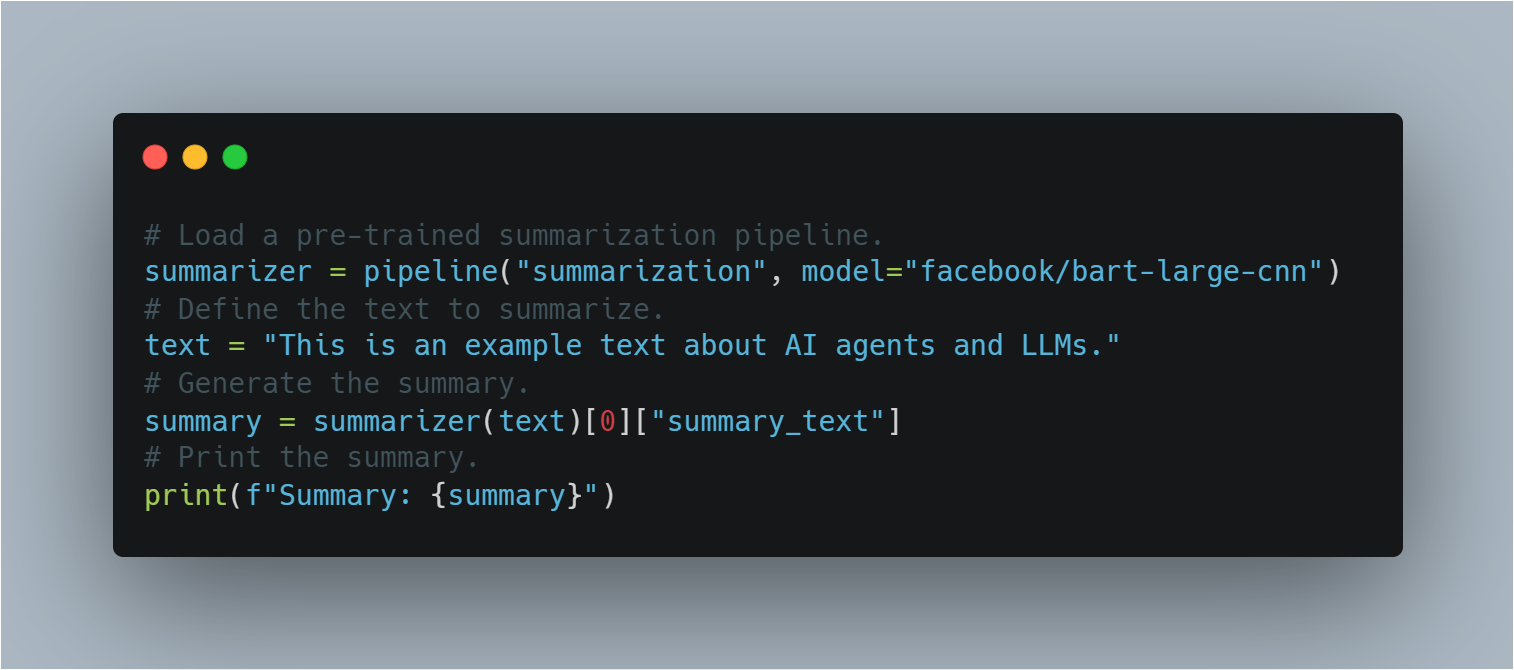
Isso ilustra a flexibilidade dos LLMs em executar tarefas diversas sem a necessidade de treinamento adicional, aproveitando seu conhecimento pré-existente.
O Exemplo de Código Completo
# Importar o módulo random para geração de números aleatórios.
import random
# Importar módulos necessários da biblioteca transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importar load_dataset para carregar conjuntos de dados.
from datasets import load_dataset
# Importar métricas para avaliar o desempenho do modelo.
from sklearn.metrics import accuracy_score, f1_score
# Importar SummaryWriter para registrar o progresso do treinamento.
from torch.utils.tensorboard import SummaryWriter
# Importar pickle para salvar e carregar modelos treinados.
import pickle
# Importar openai para usar a API da OpenAI (requer uma chave de API).
import openai
# Importar PyTorch para operações de aprendizado profundo.
import torch
# Importar módulo de rede neural do PyTorch.
import torch.nn as nn
# Importar módulo otimizador do PyTorch (não usado diretamente neste exemplo).
import torch.optim as optim
# --------------------------------------------------
# 1. Ajuste fino de um LLM para Análise de Sentimentos
# --------------------------------------------------
# Especificar o nome do modelo pré-treinado do Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Carregar o modelo pré-treinado com o número especificado de classes de saída.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Carregar um tokenizer para o modelo.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Carregar o conjunto de dados IMDB do Hugging Face Datasets, usando apenas 10% para treinamento.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokenizar o conjunto de dados
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Mapear o conjunto de dados para entradas tokenizadas
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Definir argumentos de treinamento.
training_args = TrainingArguments(
output_dir="./results", # Especificar o diretório de saída para salvar o modelo.
num_train_epochs=3, # Definir o número de épocas de treinamento.
per_device_train_batch_size=8, # Definir o tamanho do lote por dispositivo.
logging_dir='./logs', # Diretório para armazenar logs.
logging_steps=10 # Registrar a cada 10 passos.
)
# Inicializar o Trainer com o modelo, argumentos de treinamento e conjunto de dados.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Iniciar o processo de treinamento.
trainer.train()
# Salvar o modelo ajustado.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. Implementando um Agente Simples de Q-Learning
# --------------------------------------------------
# Definir a classe do agente de Q-learning.
class QLearningAgent:
# Inicializar o agente com ações, epsilon (taxa de exploração), alpha (taxa de aprendizado) e gamma (fator de desconto).
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Inicializar a tabela Q.
self.q_table = {}
# Armazenar as ações possíveis.
self.actions = actions
# Definir a taxa de exploração.
self.epsilon = epsilon
# Definir a taxa de aprendizado.
self.alpha = alpha
# Definir o fator de desconto.
self.gamma = gamma
# Definir o método get_action para selecionar uma ação com base no estado atual.
def get_action(self, state):
# Explorar aleatoriamente com probabilidade epsilon.
if random.uniform(0, 1) < self.epsilon:
# Retornar uma ação aleatória.
return random.choice(self.actions)
else:
# Explorar a melhor ação com base na tabela Q.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# Definir o método update_q_table para atualizar a tabela Q após tomar uma ação.
def update_q_table(self, state, action, reward, next_state):
# Se o estado não estiver na tabela Q, adicione-o.
if state not in self.q_table:
# Inicializar os valores Q para o novo estado.
self.q_table[state] = {a: 0.0 for a in self.actions}
# Se o próximo estado não estiver na tabela Q, adicione-o.
if next_state not in self.q_table:
# Inicializar os valores Q para o novo próximo estado.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# Obter o valor Q antigo para o par estado-ação.
old_value = self.q_table[state][action]
# Obter o valor Q máximo para o próximo estado.
next_max = max(self.q_table[next_state].values())
# Calcular o valor Q atualizado.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# Atualizar a tabela Q com o novo valor Q.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. Usando a API da OpenAI para Modelagem de Recompensa (Conceitual)
# --------------------------------------------------
# Definir a função get_reward para obter um sinal de recompensa da API da OpenAI.
def get_reward(state, action, next_state):
# Garantir que a chave da API da OpenAI esteja configurada corretamente.
openai.api_key = "your-openai-api-key" # Substitua pela sua chave real da API da OpenAI.
# Construir o prompt para a chamada da API.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# Fazer a chamada da API para o endpoint Completion da OpenAI.
response = openai.Completion.create(
engine="text-davinci-003", # Especificar o motor a ser utilizado.
prompt=prompt, # Passar o prompt construído.
temperature=0.7, # Definir o parâmetro de temperatura.
max_tokens=1 # Definir o número máximo de tokens a serem gerados.
)
# Extrair e retornar o valor de recompensa da resposta da API.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. Avaliando o Desempenho do Modelo
# --------------------------------------------------
# Definir os rótulos verdadeiros para avaliação.
true_labels = [0, 1, 1, 0, 1]
# Definir os rótulos previstos para avaliação.
predicted_labels = [0, 0, 1, 0, 1]
# Calcular a pontuação de acurácia.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calcular o F1-score.
f1 = f1_score(true_labels, predicted_labels)
# Imprimir a pontuação de acurácia.
print(f"Accuracy: {accuracy:.2f}")
# Imprimir o F1-score.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. Agente Básico de Gradiente de Política (usando PyTorch) - Conceitual
# --------------------------------------------------
# Definir a classe da rede de políticas.
class PolicyNetwork(nn.Module):
# Inicializar a rede de políticas.
def __init__(self, input_size, output_size):
# Inicializar a classe pai.
super(PolicyNetwork, self).__init__()
# Definir uma camada linear.
self.linear = nn.Linear(input_size, output_size)
# Definir o passo à frente da rede.
def forward(self, x):
# Aplicar softmax à saída da camada linear.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. Visualizando o Progresso do Treinamento com TensorBoard
# --------------------------------------------------
# Criar uma instância do SummaryWriter.
writer = SummaryWriter()
# Exemplo de loop de treinamento para visualização no TensorBoard:
# num_epochs = 10 # Definir o número de épocas.
# for epoch in range(num_epochs):
# # ... (Seu loop de treinamento aqui)
# loss = random.random() # Exemplo: Valor de perda aleatório.
# accuracy = random.random() # Exemplo: Valor de acurácia aleatório.
# # Registrar a perda no TensorBoard.
# writer.add_scalar("Loss/train", loss, epoch)
# # Registrar a acurácia no TensorBoard.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (Registrar outras métricas)
# # Fechar o SummaryWriter.
# writer.close()
# --------------------------------------------------
# 7. Salvando e Carregando Checkpoints de Agentes Treinados
# --------------------------------------------------
# Exemplo:
# Criar uma instância do agente de Q-learning.
# agent = QLearningAgent(actions=["cima", "baixo", "esquerda", "direita"])
# # ... (Treine seu agente)
# # Salvando o agente
# # Abrir um arquivo em modo de escrita binária.
# with open("trained_agent.pkl", "wb") as f:
# # Salvar o agente no arquivo.
# pickle.dump(agent, f)
# # Carregando o agente
# # Abrir o arquivo em modo de leitura binária.
# with open("trained_agent.pkl", "rb") as f:
# # Carregar o agente do arquivo.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. Aprendizado por Currículo
# --------------------------------------------------
# Definir a dificuldade inicial da tarefa.
initial_task_difficulty = 0.1
# Exemplo de loop de treinamento com aprendizado por currículo:
# for epoch in range(num_epochs):
# # Aumentar gradualmente a dificuldade da tarefa.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (Gerar dados de treinamento com dificuldade ajustada)
# --------------------------------------------------
# 9. Implementando Parada Antecipada
# --------------------------------------------------
# Inicializar a melhor perda de validação como infinito.
best_validation_loss = float("inf")
# Definir o valor de paciência (número de épocas sem melhoria).
patience = 5
# Inicializar o contador de épocas sem melhoria.
epochs_without_improvement = 0
# Exemplo de loop de treinamento com parada antecipada:
# for epoch in range(num_epochs):
# # ... (Passos de treinamento e validação)
# # Calcular a perda de validação.
# validation_loss = random.random() # Exemplo: Perda de validação aleatória.
# # Se a perda de validação melhorar.
# if validation_loss < best_validation_loss:
# # Atualizar a melhor perda de validação.
# best_validation_loss = validation_loss
# # Reiniciar o contador.
# epochs_without_improvement = 0
# else:
# # Incrementar o contador.
# epochs_without_improvement += 1
# # Se não houver melhoria por 'paciência' épocas.
# if epochs_without_improvement >= patience:
# # Imprimir uma mensagem.
# print("Parada antecipada ativada!")
# # Parar o treinamento.
# break
# --------------------------------------------------
# 10. Usando um LLM Pré-treinado para Transferência de Tarefa Zero-Shot
# --------------------------------------------------
# Carregar um pipeline de sumarização pré-treinado.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Definir o texto a ser resumido.
text = "This is an example text about AI agents and LLMs."
# Gerar o resumo.
summary = summarizer(text)[0]["summary_text"]
# Imprimir o resumo.
print(f"Summary: {summary}")

Desafios na implantação e escala
A implantação e a escala de agentes AI integrados com LMMs apresentam desafios técnicos e operacionais significativos. Um dos desafios primários é o custo computacional, particularmente conforme as LMMs crescem em tamanho e complexidade.
Ao lidar com este problema, envolve-se em estratégias eficientes em recursos, como o encolhimento de modelos, quantificação e computação distribuída. Estas podem ajudar a reduzir a carga computacional sem sacrificar desempenho.
Manter a confiabilidade e robustez em aplicações do mundo real também é crítico, exigindo monitoramento contínuo, atualizações regulares e o desenvolvimento de mecanismos de salvaguarda para gerenciar entradas inesperadas ou falhas do sistema.
Como esses sistemas são implantados em várias indústrias, a adesão a padrões éticos – incluindo equidade, transparência e responsabilidade – torna-se cada vez mais importante. Estas considerações são centrais para a aceitação do sistema e para o seu sucesso a longo prazo, impactando a confiança pública e as implicações éticas de decisões driven por AI em contextos sociais diversos (Bender et al., 2021).
A implementação técnica de agentes AI integrados com LMMs envolve um projeto arquitetônico cuidadoso, metodologias de treinamento rigorosas e uma consideração cuidadosa dos desafios de implantação.
O eficácia e a confiabilidade desses sistemas em ambientes do mundo real dependem de uma abordagem tanto técnica quanto ética, garantindo que as tecnologias AI funcionem suavemente e responsavelmente em várias aplicações.
Capítulo 7: O Futuro de Agentes AI e LMMs
Convergência de LMMs com Aprendizagem por Reforço
Enquanto você explora o futuro dos agentes de IA e de Modelos de Linguagem Grande (LLMs), a convergência dos LLMs com o aprendizado por reforço destaca-se como um desenvolvimento transformador em particular. Esta integração empurra as fronteiras da IA tradicional, permitindo que sistemas não só generem e entendam a linguagem, mas também aprendam das suas interações em tempo real.
Por meio do aprendizado por reforço, os agentes de IA podem modificar adaptativamente suas estratégias com base nas respostas de seu ambiente, resultando na refinamento contínuo de seus processos de decisão. Isso significa que, ao contrário dos modelos estáticos, os sistemas de IA avançados com aprendizado por reforço podem lidar com tarefas cada vez mais complexas e dinâmicas com mínimo de supervisão humana.
As implicações para tais sistemas são profundas: nas aplicações que vão de robótica autônoma a educação personalizada, os agentes de IA poderiam melhorar sua performance ao longo do tempo, tornando-os mais eficientes e adaptáveis às demandas evoluídas do seu contexto operacional.
Exemplo: Jogos de Texto
Imagine um agente de IA jogando em um jogo de aventura de texto.
-
Ambiente: O próprio jogo (regras, descrições de estado e assim por diante)
-
LLM: Processa o texto do jogo, entende a situação atual e gera ações possíveis (por exemplo, “ir para o norte”, “pegue a espada”).
-
Recompensa: Dada pelo jogo com base no resultado da ação (por exemplo, recompensa positiva por encontrar tesouro, negativa por perder saúde).
Exemplo de Código (Conceitual usando Python e a API da OpenAI):
import openai
import random
# ... (Lógica do ambiente do jogo - não mostrada aqui) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (Loop de treinamento de RL - simplificado) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (Atualizar o agente de RL com base na recompensa - não mostrado) ...
state = next_state
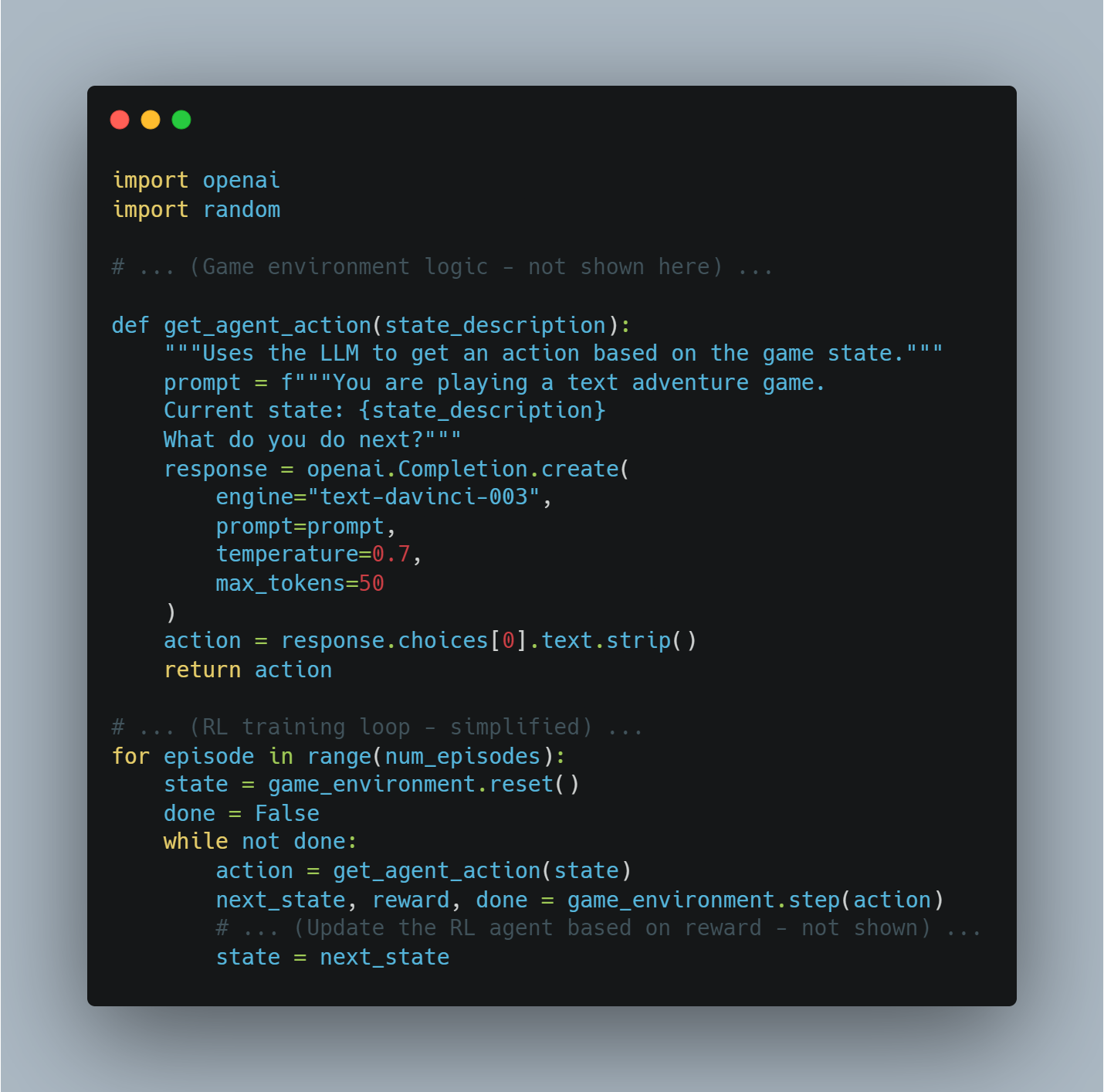
Integração de IA Multimodal
A integração de IA multimodal é outra tendência crítica que molda o futuro dos agentes de IA. Ao permitir que os sistemas processem e combinem dados de várias fontes—como texto, imagens, áudio e entradas sensoriais—a IA multimodal oferece uma compreensão mais abrangente dos ambientes em que esses sistemas operam.
Por exemplo, em veículos autônomos, a capacidade de sintetizar dados visuais de câmeras, dados contextuais de mapas e atualizações de tráfego em tempo real permite que a IA tome decisões de direção mais informadas e seguras.
Essa capacidade se estende a outros domínios, como a cadeia de saúde, onde um agente de AI pode integrar dados de pacientes de registros médicos, imagens de diagnóstico e informações genômicas para fornecer recomendações de tratamento mais precisas e personalizadas.
O desafio aqui está na integração fácil e processamento em tempo real de diferentes fontes de dados, o que requer avanços nas arquiteturas de modelos e técnicas de fundição de dados.
Com sucesso, superar esses desafios será fundamental para a implantação de sistemas AI que sejam realmente inteligentes e capazes de funcionar em ambientes complexos e reais do mundo.
Exemplo de AI multimodal 1: Tradução de imagens para respostas de pergunta visual
-
Meta: Um agente de AI que pode responder perguntas sobre imagens.
-
Módulos: Imagem, Texto
-
Processo:
-
Extração de recursos de imagem: Use uma Rede Neural Convolucional (CNN) treinada préviamente para extrair recursos da imagem.
-
Geração de legenda: Use um LLM (como um modelo de Transformer) para gerar uma legenda descrevendo a imagem com base nos recursos extraídos.
-
Resposta a pergunta: Use outro LLM para processar ambas a pergunta e a legenda gerada para fornecer uma resposta.
-
Exemplo de Código (Conceitual usando Python e Hugging Face Transformers):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# Carregar modelos pré-treinados
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# Função para gerar legenda de imagem
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# Função para responder perguntas sobre a imagem
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# Exemplo de uso
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
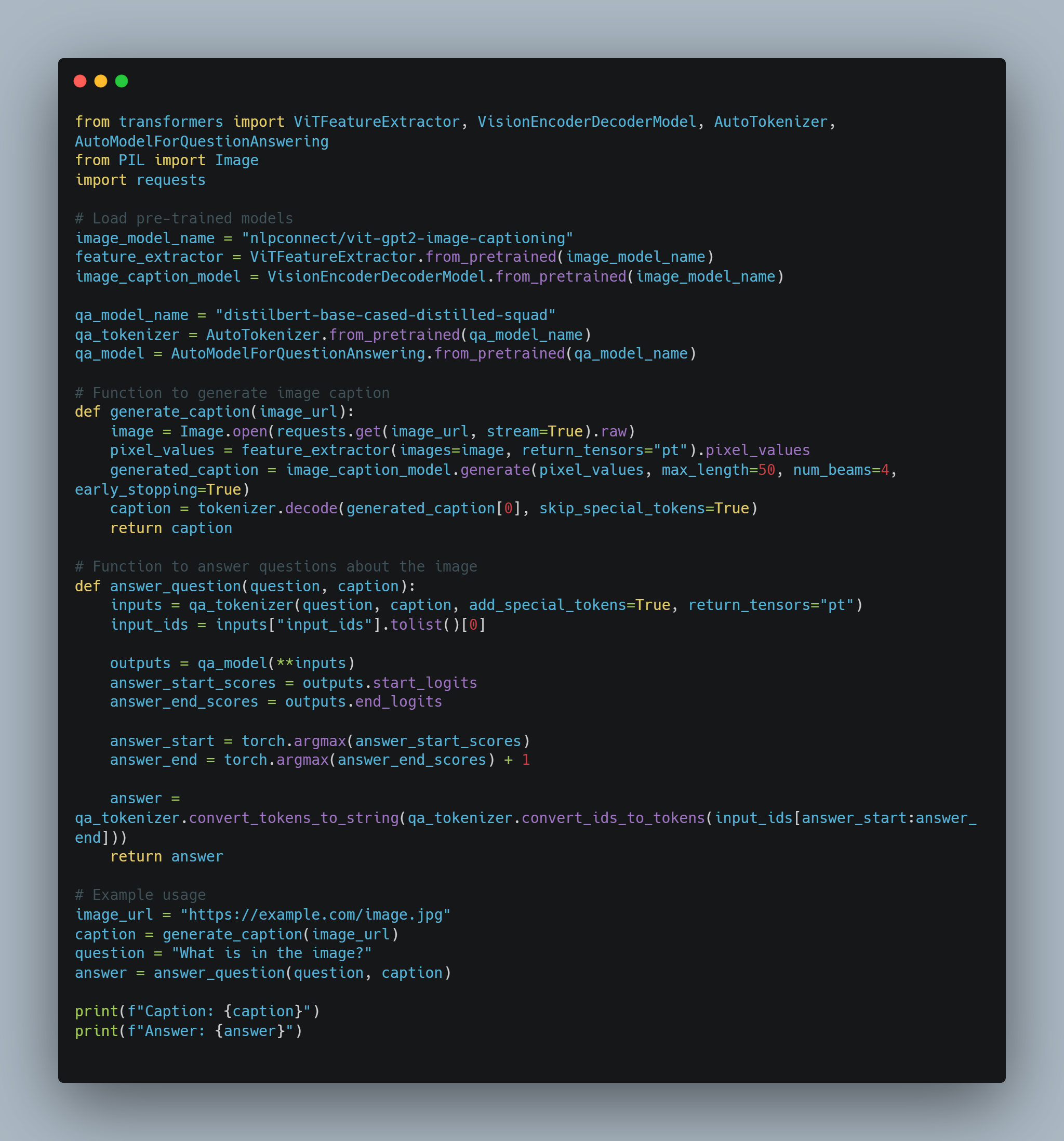
Exemplo 2 de AI Multimodal: Análise de Sentimento de Texto e Áudio
-
Objetivo: Um agente de AI que análise sentimento de ambos o texto e tom de uma mensagem.
-
Modalidades: Texto, Áudio
-
Processo:
-
Análise de Sentimento de Texto: Utilize um modelo de análise de sentimentos pré-treinado no texto.
-
Análise de Sentimento de Áudio: Utilize um modelo de processamento de áudio para extrair características como tom e pitch, e então utilize essas características para prever o sentimento.
-
Fusão: Combine as pontuações de sentimento de texto e áudio (por exemplo, média ponderada) para obter o sentimento geral.
-
Exemplo de Código ( Conceitual usando Python):
from transformers import pipeline # Para análise de sentimento de texto
# ... (Importar bibliotecas de processamento de áudio e análise de sentimento - não mostrado) ...
# Carregar modelos pré-treinados
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# Análise de sentimento de texto
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# Análise de sentimento de áudio
# ... (Processar áudio, extrair recursos, prever sentimento - não mostrado) ...
audio_sentiment = # ... (Resultado do modelo de sentimento de áudio)
audio_confidence = # ... (Pontuação de confiança do modelo de áudio)
# Combinar sentimento (exemplo: média ponderada)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# Exemplo de uso
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
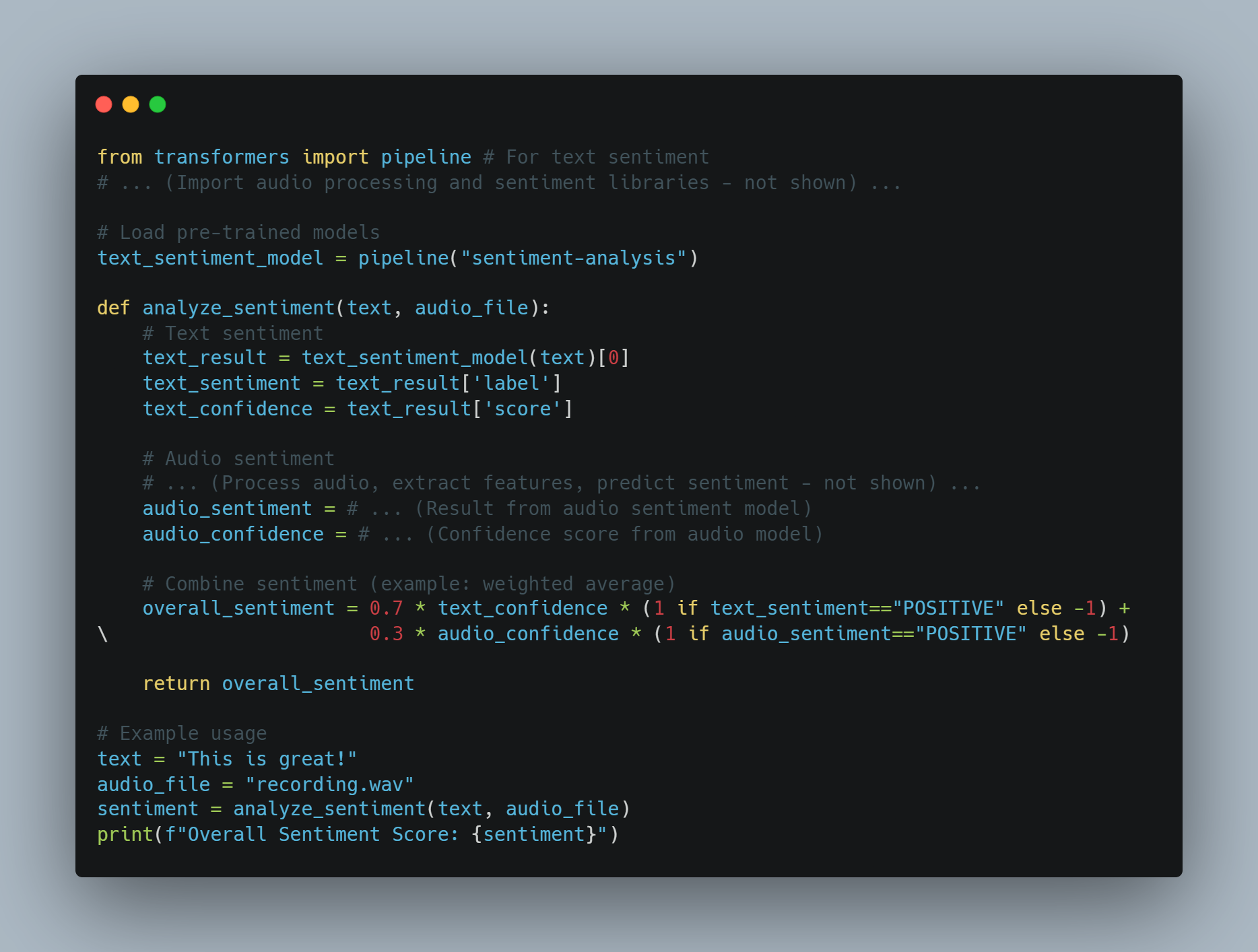
Desafios e Considerações:
-
Alinhamento de Dados: É crucial garantir que os dados de diferentes modalidades estejam sincronizados e alinhados.
-
Complexidade do Modelo: Modelos multimodais podem ser complexos para treinamento e requerem grandes conjuntos de dados diversos.
-
Técnicas de Fusão: Escolher a forma correta de combinar informações de diferentes modalidades é importante e específico do problema.
A IA multimodal é um campo em rápida evolução com o potencial para revolucionar a forma como os agentes AI percebem e interagem com o mundo.
Sistemas AI Distribuídos e Computação em Edges
O olhar para a evolução das infraestruturas de AI, a mudança para os sistemas AI distribuídos, apoiados pela computação em edges, representa uma avançada importante.
Sistemas AI distribuídos descentralizam tarefas computacionais processando dados mais perto da fonte – como dispositivos IoT ou servidores locais – em vez de confiar em recursos de nuvem centralizados. Esta abordagem não só reduce a latência, que é crucial para aplicações sensíveis ao tempo, como os drones autônomos ou a automatização industrial, mas também melhora a privacidade e a segurança dos dados mantendo informações sensíveis locais.
Além disso, os sistemas AI distribuídos melhoram a escalabilidade, permitindo a implantação de AI em vastas redes, como cidades inteligentes, sem sobrecarregar centros de dados centralizados.
Os desafios técnicos associados aos sistemas AI distribuídos incluem garantir consistência e coordenação entre os nós distribuídos, bem como otimizar a alocação de recursos para manter o desempenho em ambientes diversos e potencialmente constrangedores.
Enquanto você desenvolve e implementa sistemas AI, abraçar arquiteturas distribuídas será chave para criar soluções AI resistentes, eficientes e escaláveis que atendam às demandas de aplicações futuras.
Sistemas AI Distribuídos e Computação em Borda exemplo 1: Aprendizado Federação para Treinamento de Modelos com Proteção de Privacidade
-
Objetivo: Treinar um modelo compartilhado em vários dispositivos (por exemplo, smartphones) sem partilhar diretamente dados sensíveis de usuários.
-
Abordagem:
-
Treinamento Local: Cada dispositivo treina um modelo local em seus próprios dados.
-
Agregação de Parâmetros: Dispositivos envia atualizações de modelo (gradientes ou parâmetros) para um servidor central.
-
Atualização de Modelo Global: O servidor agrega as atualizações, melhora o modelo global e envia o modelo atualizado para os dispositivos.
-
Exemplo de Código (Conceitual usando Python e PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
# ... (Código para comunicação entre dispositivos e servidor - não mostrado) ...
class SimpleModel(nn.Module):
# ... (Defina sua arquitetura de modelo aqui) ...
# Função de treinamento do lado do dispositivo
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # Inicie com o modelo global
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (Treine local_model em device_data) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# Função de agregação do lado do servidor
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (Laço principal de Aprendizado Federação simplificado) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

Exemplo 2: Detecção de Objetos em Tempo Real em Dispositivos de Borda
-
Objetivo: Implementar um modelo de detecção de objetos em um dispositivo com recursos limitados (por exemplo, Raspberry Pi) para inferência em tempo real.
-
Enfoque:
-
Otimização de Modelo: Use técnicas como quantização de modelos ou redução de pesos para diminuir o tamanho do modelo e os requisitos de computação.
-
Implantação no Borda: Implante o modelo otimizado no dispositivo de borda.
-
Inferência Local: O dispositivo realiza detecção de objetos localmente, reduzindo o latência e a dependência da comunicação com o cloud.
-
Exemplo de Código (Conceitual usando Python e TensorFlow Lite):
import tensorflow as tf
# Carregar o modelo pré-treinado (sendo que já está otimizado para TensorFlow Lite)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# Obter detalhes de entrada e saída
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (Capturar imagem da câmera ou carregar de arquivo - não mostrado) ...
# Pré-processar a imagem
input_data = ... # Redimensionar, normalizar, etc.
interpreter.set_tensor(input_details[0]['index'], input_data)
# Executar a inferência
interpreter.invoke()
# Obter a saída
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (Processar output_data para obter boxes de bounding, classes, etc.) ...
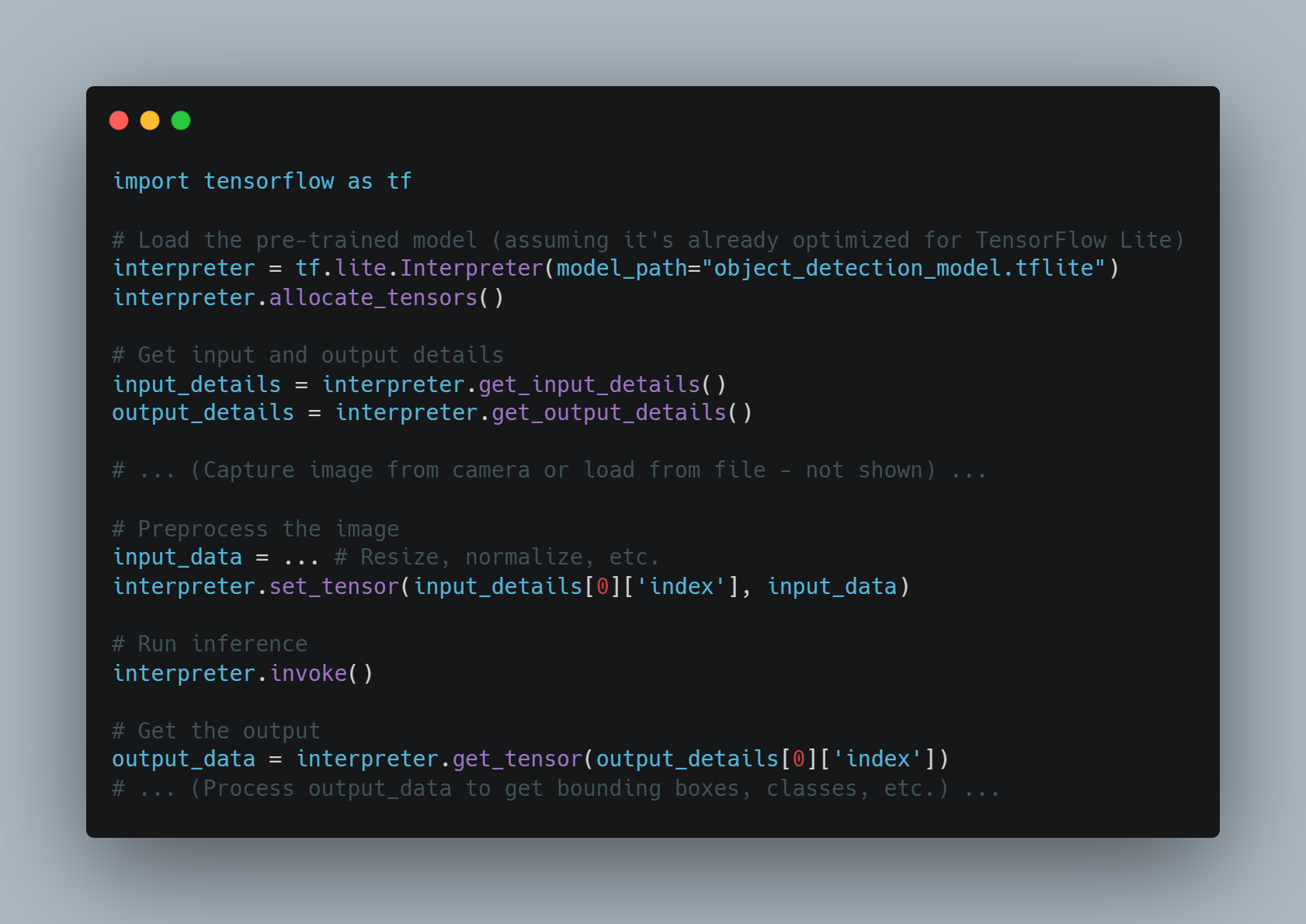
Desafios e Considerações:
-
Overhead de Comunicação: Coordenar e comunicar eficientemente entre nós distribuídos é crucial.
-
Gerenciamento de Recursos: Otimizar a alocação de recursos (CPU, memória, banda) em dispositivos é importante.
-
Segurança: Segurança de sistemas distribuídos e proteção de privacidade de dados são preocupações primordiais.
A IA distribuída e o computação em nuvem são fundamentais para construir sistemas de IA escaláveis, eficientes e alertas à privacidade, especialmente conforme nos movemos em direção a um futuro com milhares de milhões de dispositivos interconectados.
O Progresso na Processamento de Linguagem Natural
O Processamento de Linguagem Natural (PLN) continua a estar no centro dos avanços na IA, impulsionando melhorias significativas na forma como as máquinas entendem, geram e interagem com a linguagem humana.
Desenvolvimentos recentes no PLN, como a evolução dos transformadores e mecanismos de atenção, têm drasticamente aumentado a capacidade da IA de processar estruturas linguísticas complexas, tornando as interações mais naturais e contextuaismente conscientes.
Este progresso permitiu que os sistemas de IA entendam nuances, sentimentos e até referências culturais dentro do texto, levando a comunição mais precisa e significativa.
Por exemplo, no atendimento ao cliente, modelos avançados de PLN podem não só lidar com consultas com precisão mas também detetar pistas de emoção dos clientes, permitindo respostas mais empáticas e eficazes.
Olhando para o futuro, a integração de capacidades multilíngues e de entendimento semântico mais profundo em modelos de PLN expandirá sua aplicabilidade, permitindo comunição sem fricções em diferentes línguas e dialetos, e até mesmo permitindo que sistemas de IA funcionem como tradutores em tempo real em contextos globais diversos.
O Processamento de Linguagem Natural (PLN) está evoluindo rapidamente, com avanços em áreas como modelos de transformador e mecanismos de atenção. Aqui estão alguns exemplos e trechos de código para ilustrar esses avanços:
Exemplo de NLP 1: Análise de Sentimento com Transformers Ajustados
-
Objetivo: Analisar o sentimento de texto com alta precisão, capturando nuances e contexto.
-
Abordagem: Ajustar um modelo de transformer pré-treinado (como o BERT) em um conjunto de dados de análise de sentimento.
Exemplo de Código (usando Python e Transformers do Hugging Face):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Carregar modelo pré-treinado e conjunto de dados
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3 rótulos: Positivo, Negativo, Neutro
dataset = load_dataset("imdb", split="train[:10%]")
# Definir argumentos de treinamento
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# Ajustar o modelo
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# Salvar o modelo ajustado
model.save_pretrained("./fine_tuned_sentiment_model")
# Carregar o modelo ajustado para inferência
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# Exemplo de uso
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
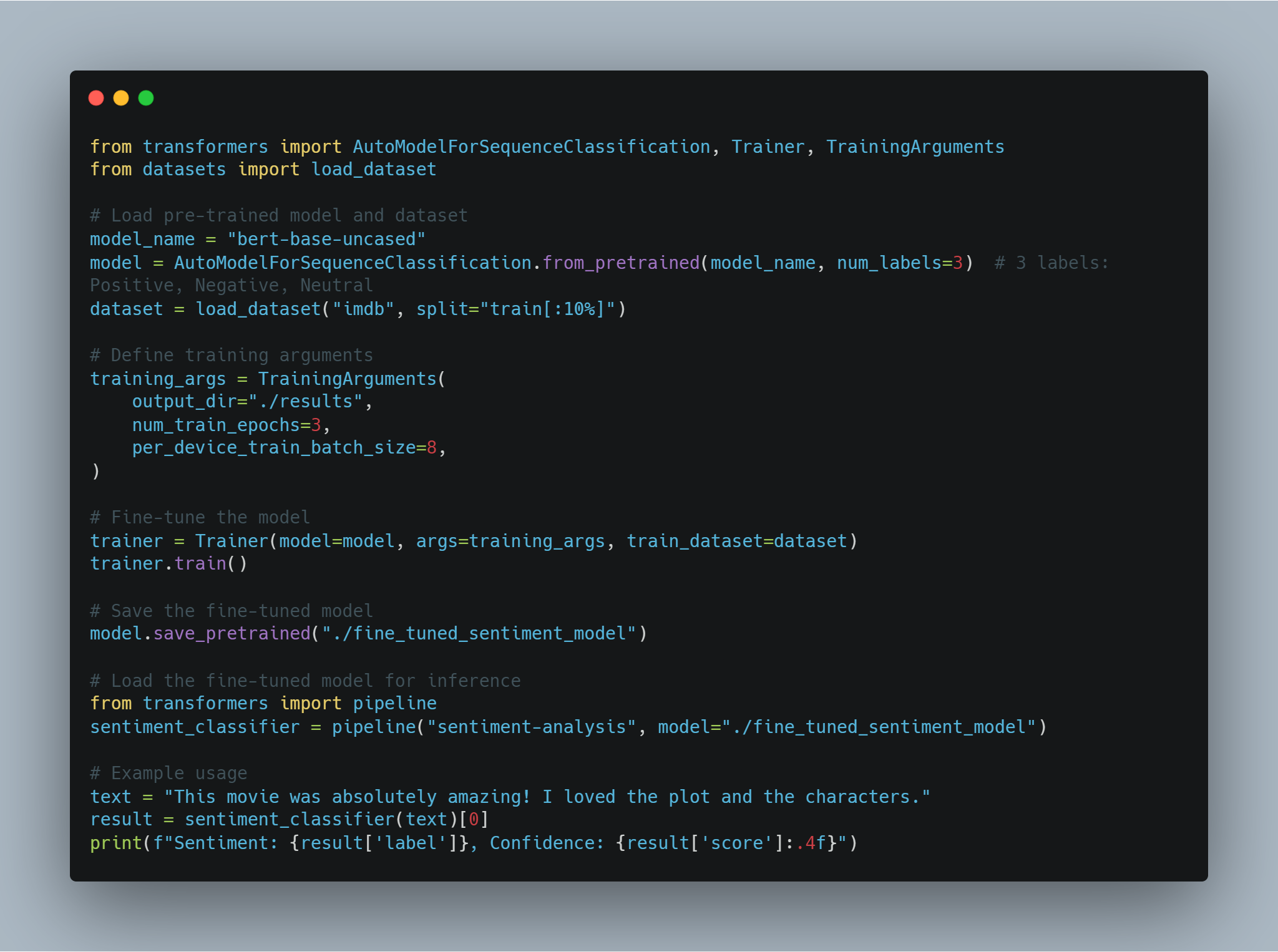
Exemplo de NLP 2: Tradução Multilíngue com um Único Modelo
-
Objetivo: Traduzir entre múltiplos idiomas usando um único modelo, aproveitando representações linguísticas compartilhadas.
-
Enfoque: Utilize un modelo de transformador grande e multilíngüe (como mBART ou XLM-R) que tenha sido treinado the um grande conjunto de dados de texto em paralelo em vários idiomas.
Exemplo de Código (usando Python e Hugging Face Transformers):
from transformers import pipeline
# Carregar uma pipeline de tradução multilíngue pré-treinada
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# Exemplo de uso: Inglês para Francês
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# Exemplo de uso: Francês para Espanhol
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
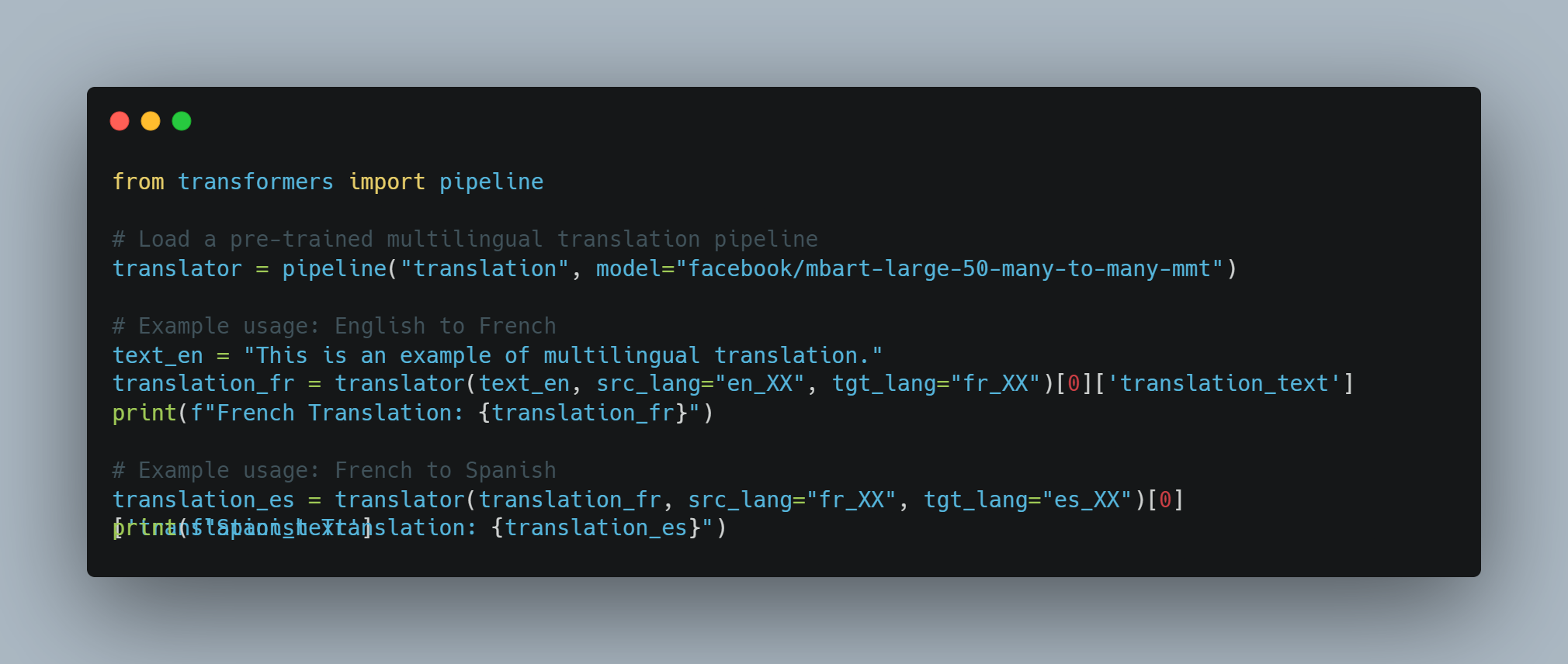
Exemplo de NLP 3: Embeddings de Palavras Contextuais para Semelhança Semântica
-
Objetivo: Determinar a semelhança entre palavras ou frases, levando em conta o contexto.
-
Enfoque: Use um modelo de transformador (como BERT) para gerar embeddings de palavras contextuais, que capturam o significado das palavras dentro de uma frase específica.
Exemplo de Código (usando Python e Hugging Face Transformers):
from transformers import AutoModel, AutoTokenizer
import torch
# Carregar modelo pré-treinado e tokenizador
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Função para obter embeddings de sentença
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# Usar o embeddings do token [CLS] como embeddings de sentença
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# Exemplo de uso
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# Calcular similaridade cosseniana
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
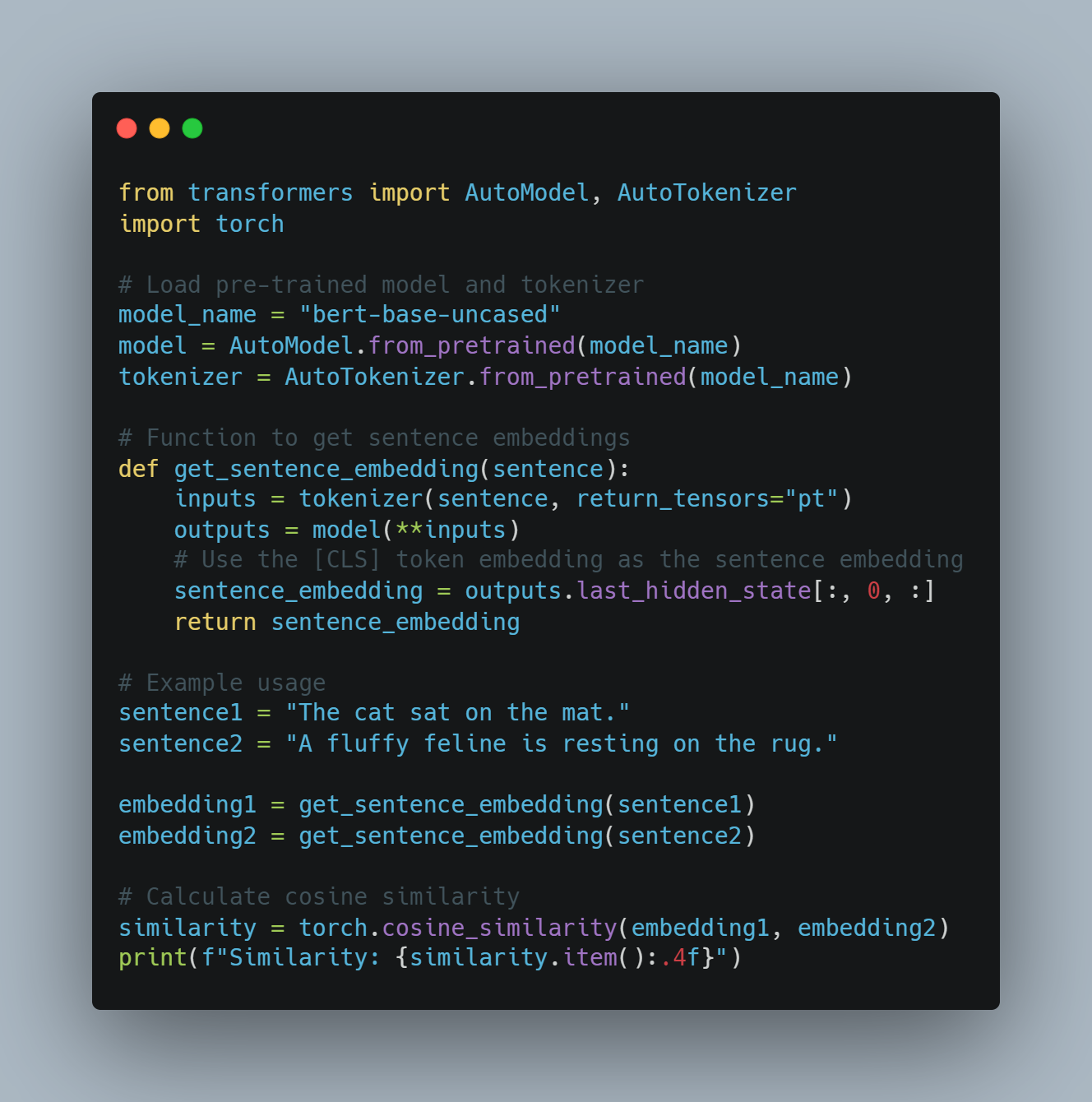
Desafios e Direções Futuras:
-
Bias e Justiça: Modelos de NLP podem herdar preconceitos de seus dados de treinamento, levando a resultados desiguais ou discriminatórios. A abordagem de preconceitos é fundamental.
- Pensamento Comum: Modelos de LLM ainda têm dificuldade com o raciocínio comum e com o entendimento de informações implícitas.
-
Explicabilidade: O processo de tomada de decisão de modelos de NLP complexos pode ser opaco, dificultando o entendimento de por que eles geram certas saídas.
Apesar destes desafios, a PNL está avançando rapidamente. A integração de informações multimodais, o raciocínio comum melhorado e a melhoria na explicabilidade são áreas chave de pesquisa em andamento que revolucionarão a interação da IA com o idioma humano.
Assistentes AI Personalizados
O futuro dos assistentes AI personalizados está prontificado a se tornar cada vez mais sofisticado, passando além da gerenciamento básico de tarefas para um apoio intuitivo, proativo e personalizado de acordo com as necessidades individuais.
Estes assistentes irão aproveitar algoritmos de aprendizagem automática avançados para continuamente aprender dos seus comportamentos, preferências e rotinas, oferecendo recomendações cada vez mais personalizadas e automatizando tarefas mais complexas.
Por exemplo, um assistente AI personalizado poderia gerenciar não só o seu cronograma, mas também prever suas necessidades, sugerindo recursos relevantes ou ajustando o ambiente baseado em seu humor ou preferências anteriores.
Com os assistentes AI se tornando mais integrados na vida diária, sua capacidade de adaptar a contextos em mudança e fornecer suporte fácil e cruzado entre plataformas tornar-se-á uma diferença chave. O desafio está em equilibrar a personalização com a privacidade, requerindo mecanismos robustos de proteção de dados para garantir que informações sensíveis são gerenciadas de forma segura enquanto fornecem uma experiência profundamente personalizada.
Exemplo de assistente AI 1: Sugestão de tarefa com consciência de contexto
-
Meta: Um assistente que sugere tarefas com base no contexto atual do usuário (localização, hora, comportamento passado).
-
Abordagem: Combine dados do usuário, sinais contextuais e um modelo de recomendação de tarefas.
Exemplo de Código (Conceitual usando Python):
# ... (Código para gerenciamento de dados do usuário, detecção de contexto - não mostrado) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# Exemplo: Sugestões baseadas na hora
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# Exemplo: Sugestões baseadas na localização
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (Adicione mais regras ou use um modelo de aprendizado de máquina para sugestões) ...
# Classifique e filtre as sugestões
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- Exemplo de Uso ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... outras preferências ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... outros dados de contexto ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
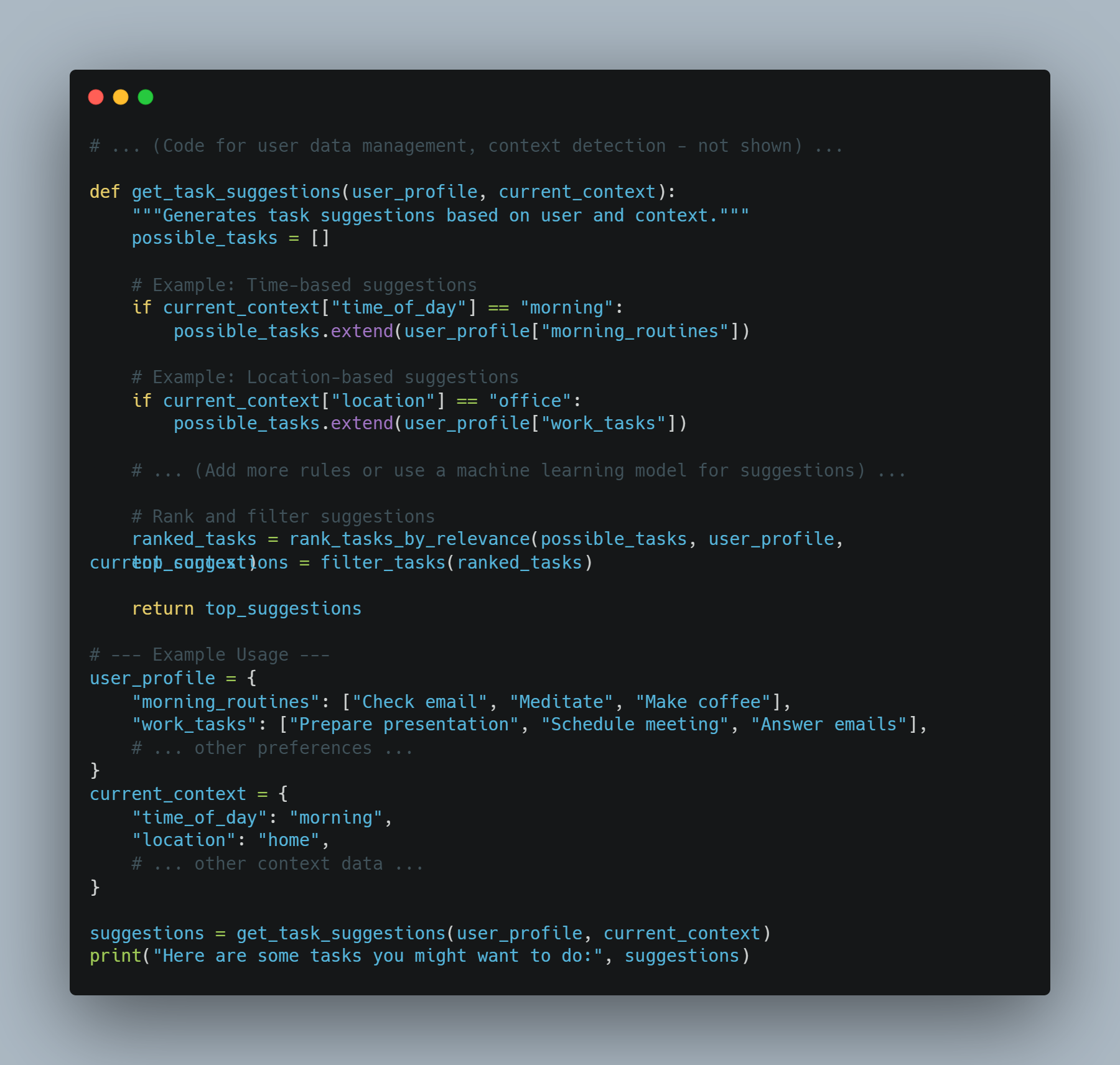
Exemplo 2 de Assistentes AI: Entrega Proativa de Informação
-
Meta: Um assistente que fornece informações relevantes de forma proativa com base no cronograma e preferências do usuário.
-
Abordagem: Integre dados de calendário, interesses do usuário e um sistema de recuperação de conteúdo.
Exemplo de Código (Conceitual usando Python):
# ... (Código para acesso ao calendário, perfil de interesses do usuário - não mostrado) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (Recuperar informações da empresa, perfil dos participantes, etc.) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (Recuperar status de vôo, informações de destino, etc.) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- Exemplo de Uso ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... outras preferências ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

Assistentes de IA exemplo 3: Recomendação de Conteúdo Personalizado
-
Objetivo: Um assistente que recomenda conteúdo (artigos, vídeos, música) adaptado às preferências do usuário.
-
Aproximação: Use filtragem colaborativa ou sistemas de recomendação baseada em conteúdo.
Exemplo de Código (Conceitual usando Python e uma biblioteca como Surprise):
from surprise import Dataset, Reader, SVD
# ... (Código para gerenciar classificações de usuários, banco de dados de conteúdo - não mostrado) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (Obter previsões para todos os itens, ranquear e retornar os top N) ...
# --- Exemplo de Uso ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... mais classificações ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
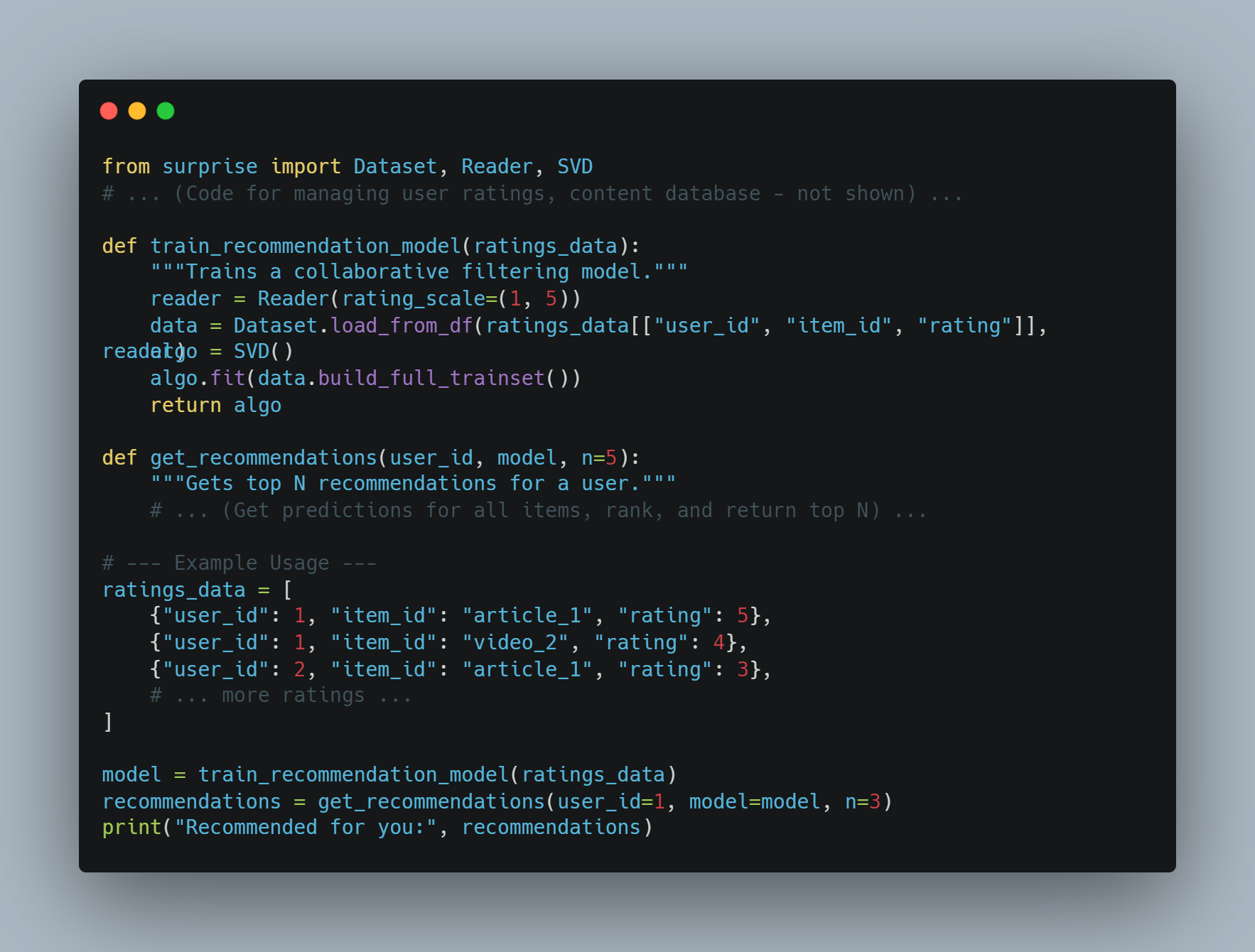
Desafios e Considerações Éticas:
-
Privacidade de Dados: Lidar com dados de usuários de forma responsável e transparente é crucial.
-
Viés e Equidade: A personalização não deve amplificar os viéses existentes.
-
Controle do Usuário: Os usuários devem ter controle sobre seus dados e configurações de personalização.
A construção de assistentes pessoalizados de AI requer uma consideração cuidadosa de aspectos técnicos e éticos para criar sistemas que são úteis, confiáveis e respeitam a privacidade do usuário.
AI nas Indústrias Criativas
A AI está fazendo avanços significativos nas indústrias criativas, transformando a forma como a arte, música, filmes e literatura são produzidos e consumidos. Com os avanços em modelos gerativos, como Redes Adversárias Gerativas (GANs) e modelos baseados em transformadores, a AI agora pode gerar conteúdo que rivaliza com a criatividade humana.
Por exemplo, o AI pode compor música que reflete gêneros musicais ou sentimentos específicos, criar arte digital que imita o estilo de pintores famosos, ou até mesmo draftar tramas narrativas para filmes e novelas.
Na indústria de publicidade, o AI está sendo usado para gerar conteúdo personalizado que ressoa com consumidores individuais, aumentando a engajamento e a eficácia.
Mas a ascensão do AI em campos criativos tambémlevanta questões sobre autoria, originalidade e o papel da criatividade humana. Enquanto se envolve com o AI nestes domínios, será crucial explorar como o AI pode complementar a criatividade humana, em vez de a substituir, fomentando a colaboração entre humanos e máquinas para produzir conteúdo inovador e impactante.
Aqui está um exemplo de como o GPT-4 pode ser integrado theum projeto Python para tarefas criativas, especificamente no campo da escrita. Este código demonstra como usar as capacidades de GPT-4 para gerar formatos de texto criativo, como poesia.
import openai
# Defina sua chave API OpenAI
openai.api_key = "YOUR_API_KEY"
# Defina uma função para gerar poesia
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# Exemplo de uso
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
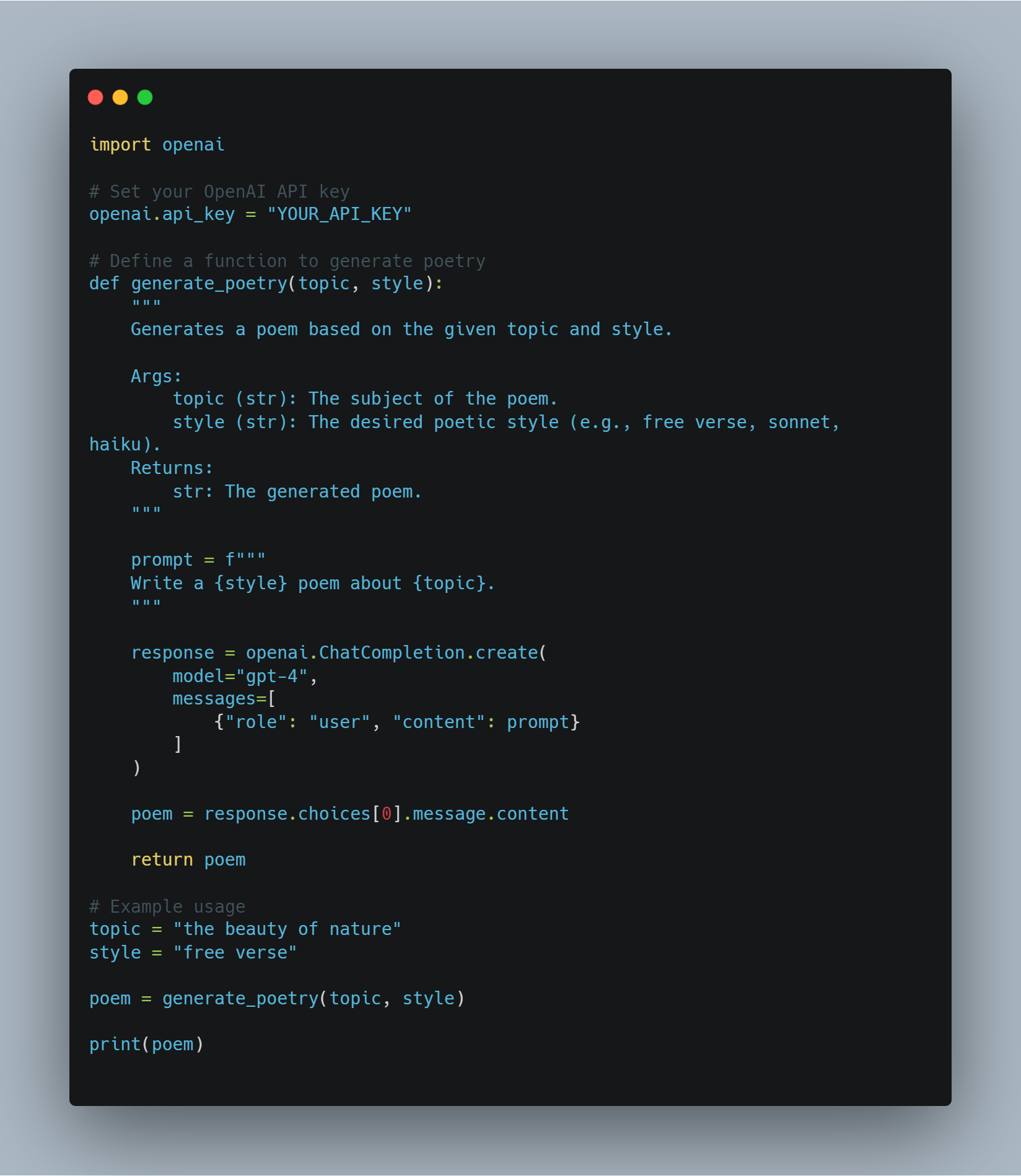
Vamos ver o que está acontecendo aqui:
-
Importar a biblioteca OpenAI: O código primeiro importa a biblioteca
openaipara acessar a API OpenAI. -
Definir chave API: Substitua
"YOUR_API_KEY"com sua chave API OpenAI real. -
Definir função
gerar_poesia: Esta função pega otemae oestiloda poesia como entradas e usa a API de ChatCompletion do OpenAI para gerar a poesia. -
Construir o prompt: O prompt combina o
temae oestiloem uma instrução clara para o GPT-4. -
Enviar prompt para o GPT-4: O código usa
openai.ChatCompletion.createpara enviar o prompt para o GPT-4 e receber a poesia gerada como resposta. -
Retornar a poesia: A poesia gerada é então extraída da resposta e retornada pela função.
-
Exemplo de uso: O código demonstra como chamar a função
generate_poetrycom um tópico e estilo específicos. O poema resultante é então impresso no console.
Mundos Virtuais impulsionados por IA
O desenvolvimento de mundos virtuais impulsionados por IA representa um salto significativo em experiências imersivas, onde agentes de IA podem criar, gerenciar e evoluir ambientes virtuais que são tanto interativos quanto responsivos ao input do usuário.
Esses mundos virtuais, movidos por IA, podem simular ecossistemas complexos, interações sociais e narrativas dinâmicas, oferecendo aos usuários uma experiência profundamente envolvente e personalizada.
Por exemplo, na indústria de jogos, a IA pode ser usada para criar personagens não jogáveis portamento do jogador, adaptando suas ações e estratégias para proporcionar uma experiência mais desafiadora e realista.
Além dos jogos, os mundos virtuais impulsionados por IA têm aplicações potenciais na educação, onde salas de aula virtuais podem ser adaptadas aos estilos de aprendizagem e progresso dos alunos individuais, ou no treinamento corporativo, onde simulações realistas podem preparar os funcionários para vários cenários.
O futuro desses ambientes virtuais dependerá dos avanços na capacidade da IA de gerar e gerenciar vastos e complexos ecossistemas digitais em tempo real, bem como das considerações éticas em torno dos dados dos usuários e dos impactos psicológicos das experiências altamente imersivas.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# Inicializar agentes
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# Atribuir posição aleatória dentro do ambiente
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# Criar e adicionar o agente
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# Mover agentes (movimento simplificado para demonstração)
for agent in self.agents:
agent.move(self.environment)
# TODO: Implementar lógica mais complexa para interações, mudanças no ambiente, etc.
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# Determinar direção de movimento (aleatória neste exemplo)
direction = random.choice(['N', 'S', 'E', 'W'])
# Aplicar movimento com base na direção
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# Atualizar o ambiente para refletir a nova posição do agente
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# Exemplo de Uso
if __name__ == "__main__":
# Definir parâmetros do mundo
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# Criar o mundo virtual
world = VirtualWorld(environment_size, agent_types, agent_properties)
# Simular o mundo por vários passos
for _ in range(10):
world.update()
world.display()
print() # Adicionar uma linha em branco para melhor leitura
O que está acontecendo neste código é o seguinte:
-
Classe VirtualWorld:
-
Define o cerne do mundo virtual.
-
Contém a grade de ambiente, uma lista de agentes e informações relacionadas aos agentes.
-
__init__(): Inicializa o mundo com tamanho, tipos de agentes e propriedades. -
add_agent(): Adiciona um novo agente de um tipo específico ao mundo. -
update(): Realiza uma atualização de passo de tempo único do mundo.- Atualmente, ela apenas move agentes, mas você pode adicionar lógica complexa para interações de agentes, mudanças no ambiente, etc.
-
display(): Exibe uma representação básica do ambiente.
-
-
Classe de Agente:
-
Representa um agente individual dentro do mundo.
-
__init__(): Inicializa o agente com seu tipo, posição e propriedades. -
move(): Gerencia o movimento do agente, atualizando sua posição no ambiente. Este método atualmente fornece um movimento aleatório simples, mas pode ser expandido para incluir comportamentos AI complexos.
-
-
Exemplo de Uso:
-
Define parâmetros do mundo, como tamanho, tipos de agentes e suas propriedades.
-
Cria um objeto VirtualWorld.
-
Executa o método
update()várias vezes para simular o desenvolvimento do mundo. -
Chama
display()após cada atualização para visualizar as mudanças.
-
Melhorias:
-
Inteligência Artificial de Agente Mais Complexa: Implemente IA mais sofisticada para o comportamento de agentes. Você pode usar:
-
Algoritmos de Caminhamento: Ajudam os agentes a navegar o ambiente eficientemente.
-
Árvores de Decisão/Aprendizado Automático: Permitem que os agentes façam decisões mais inteligentes com base em seu ambiente e objetivos.
-
Aprendizado por Reforço: Ensina os agentes a aprender e adaptar seu comportamento ao longo do tempo.
-
-
Interação com o Ambiente: Adicionar elementos dinâmicos ao ambiente, como obstáculos, recursos ou pontos de interesse.
-
Interação entre Agentes: Implementar interações entre agentes, como comunicação, combate ou cooperação.
-
Representação Visual: Usar bibliotecas como Pygame ou Tkinter para criar uma representação visual do mundo virtual.
Este exemplo serve de base básica para criar um mundo virtual com inteligência artificial. O nível de complexidade e sofisticação pode ser expandido ainda mais para atender às suas necessidades específicas e aos seus objetivos criativos.
Neuromorfismo e IA
O neuromorfismo, inspirado na estrutura e no funcionamento do cérebro humano, está prestes a revolucionar a IA ofrecendo novas formas de processar informação de forma eficiente e em paralelo.
Diferente das arquiteturas de computação tradicionais, os sistemas neuromórficos são projetados para imitar as redes neurais do cérebro, permitindo que as AI executem tarefas como reconhecimento de padrões, processamento de sensores e toma de decisões com maior velocidade e eficiência energética.
Esta tecnologia reserva um enorme potencial para o desenvolvimento de sistemas AI que sejam mais adaptáveis, capazes de aprender a partir de dados mínimos e eficazes em ambientes em tempo real.
Por exemplo, na robótica, os chips neuromórficos poderiam permitir que os robôs processem entradas sensoriais e tome decisões com uma eficiência e velocidade que as arquiteturas atuais não conseguem alcançar.
O desafio para o futuro será escalar o neuromorfismo para lidar com a complexidade de aplicações de IA em larga escala, integrando-o com frameworks de IA existentes para aproveitar totalmente seu potencial.
Agentes AI na Exploração Espacial
Os agentes de inteligência artificial estão cada vez mais desempenhando um papel crucial na exploração espacial, onde são responsáveis por navegar em ambientes adversos, tomar decisões em tempo real e realizar experimentos científicos de forma autônoma.
Com as missões avançando cada vez mais para o espaço profundo, a necessidade de sistemas de IA que possam operar independentemente do controle baseado na Terra torna-se mais pressente. Os agentes de IA futuros serão projetados para lidar com a imprevisibilidade do espaço, como obstáculos inesperados, mudanças em parâmetros de missão ou a necessidade de auto-reparo.
Por exemplo, a IA poderia ser usada para guiar as roveras em Marte para explorar automaticamente o terreno, identificar locais científicamente valiosos e até perfurar amostras com pouco input de controle de missão. Esses agentes de IA também poderiam gerenciar sistemas de suporte de vida em missões de longa duração, optimizar o uso de energia e adaptar-se às necessidades psicológicas dos astronautas fornecendo companhia e estímulo mental.
A integração da IA na exploração espacial não apenas melhora as capacidades das missões, mas também abre novas possibilidades para a exploração humana do cosmos, onde a IA será um parceiro indispensável na busca para entender o nosso universo.
Capítulo 8: Agentes de IA em Campos Críticos de Missão
Cadeia de Saúde
No setor de saúde, os agentes de inteligência artificial não são apenas papéis de apoio, mas estão se tornando integrais ao todo o ciclo de atendimento do paciente. Seu impacto é mais evidente em telemedicina, onde os sistemas de IA redefiniram o método de entrega de saúde remota.
Ao utilizar processamento de linguagem natural (NLP) avançado e algoritmos de aprendizagem de máquina, esses sistemas executam tarefas complexas como triagem de sintomas e coleta de dados preliminares com uma alta taxa de precisão. Eles analisam sintomas relatados pelos pacientes e histórias clínicas em tempo real, fazendo referências cruzadas nesta informação contra bases de dados médicas extensas para identificar condições potenciais ou sinais de alerta.
Isso permite que prestadores de cuidados de saúde façam decisões informadas mais rápido, reduzindo o tempo até o tratamento e potencialmente salvar vidas. Além disso, ferramentas de diagnóstico baseadas em AI em imagens médicas estão transformando a radiologia, detectando padrões e anomalias em radiografias, ressonâncias magnéticas e exames de computadorizado que podem ser imperceptíveis para o olho humano.
Estes sistemas são treinados the em grandes conjuntos de dados compostos por milhões de imagens anotadas, permitindo-lhes não apenas replicar, mas frequentemente ultrapassar as capacidades de diagnóstico humanas.
A integração de AI no setor de saúde também se estende a tarefas administrativas, onde a automação de agendamento de consultas, lembretes de medicamentos e acompanhamento de pacientes reduz significativamente o fardo operacional sobre o pessoal de saúde, permitindo-lhes se concentrar em aspectos mais críticos do cuidado ao paciente.
Finanças
No setor financeiro, os agentes AI revolucionaram as operações, introduzindo níveis de eficiência e precisão sem precedentes.
O trading algorítmico, que depende fortemente de AI, transformou a maneira como as operações são executadas em mercados financeiros.
Estes sistemas são capazes de analisar grandes conjuntos de dados em milissegundos, identificar tendências de mercado e executar negociações no momento ótimo para maximizar lucros e minimizar riscos. Eles aproveitam algoritmos complexos que Incorporam técnicas de aprendizagem automática, aprendizagem profunda e aprendizagem por reforço para adaptar-se a condições de mercado em mudança, fazendo decisões de milissegundos que os traders humanos nunca poderiam alcançar.
Além da negociação, o AI desempenha um papel crucial em gerenciamento de risco, avaliando riscos de crédito e detectando atividades fraudulentas com uma precisão notável. Modelos de AI utilizam análise preditiva para avaliar a probabilidade de default de um empréstimo por meio de análise de padrões em históricos de crédito, comportamentos de transação e outros fatores relevantes.
Também, no âmbito de conformidade regulatória, o AI automatiza o monitoramento de transações para detectar e relatar atividades suspeitas, garantindo que instituições financeiras cumpram rigorosos requisitos regulatórios. Esta automatização não só mitiga o risco de erro humano como também streamline os processos de conformidade, reduzindo custos e melhorando eficiência.
Gestão de Emergências
O papel do AI em Gestão de Emergências é transformador, alterando fundamentalmente a maneira como crises são previstas, gerenciadas e mitigadas.
Na resposta a desastres, agentes AI processam grandes quantidades de dados de várias fontes – variando de imagens de satélite a feeds de redes sociais – para fornecer uma visão geral de situação em tempo real. Algoritmos de aprendizagem automática analisam esses dados para identificar padrões e prever o progresso dos eventos, permitindo que respondentes de emergência aloqueiem recursos mais eficientemente e façam decisões informadas sob pressão.
Por exemplo, durante um desastre natural como um furacão, os sistemas de IA podem prever o caminho e a intensidade da tempestade, permitindo que as autoridades emitam ordens de evacuação a tempo e deploy recursos nas áreas mais vulneráveis.
Na análise preditiva, os modelos de IA são utilizados para prever emergências potenciais ao analisar dados históricos juntamente com entradas em tempo real, permitindo medidas proactivas que podem prevenir desastres ou mitigar seu impacto.
Sistemas de comunicação pública com IA também desempenham um papel crucial em garantir que informações precisas e em tempo hábil cheguem às populações afetadas. esses sistemas podem gerar e disseminar avisos de emergência por meio de várias plataformas, personalizando a mensagem para diferentes demográficas para garantir compreensão e cumprimento.
E a IA melhora a capacitação dos respondentes emergenciais criando simulações de treinamento altamente realistas usando modelos geradores. essas simulações replicam as complexidades dos emergências do mundo real, permitindo que os respondentes afinem suas habilidades e melhorem sua prontidão para eventos reais.
Transporte
Sistemas de IA estão se tornando indispensáveis no setor de transporte, onde melhoram a segurança, eficiência e confiabilidade em vários domínios, incluindo o controle de tráfego aéreo, veículos autônomos e transporte público.
No controle de tráfego aéreo, os agentes de IA são instrumentais em otimizar caminhos de voo, prever conflitos potenciais e gerir operações de aeroportos. Esses sistemas usam análise preditiva para prever potenciais engarrafamentos de tráfego aéreo, reencaminhando voos em tempo real para garantir segurança e eficiência.
No domínio dos veículos autônomos, o AI está no coração da funcionalidade que permite que os veículos processem dados de sensores e façam decisões rápidas em ambientes complexos. Estes sistemas usam modelos de aprendizagem profunda treinados em bases de dados extensivas para interpretar dados visuais, auditivos e espaciais, permitindo uma navegação segura através de condições dinâmicas e imprevisíveis.
Sistemas de transporte público também se beneficiam do AI através de planejamento de rotas otimizado, manutenção preventiva de veículos e gerenciamento do fluxo de passageiros. Analisando dados históricos e em tempo real, os sistemas de AI podem ajustar o cronograma de tráfego, prever e prevenir avarias de veículos e gerenciar o controle de multidões durante horários de pico, melhorando assim a eficiência e a confiabilidade das redes de transporte.
Setor Energético
O AI está desempenhando um papel crucial no setor energético, particularmente em gerenciamento de rede, otimização de energia renovável e detecção de falhas.
No gerenciamento de rede, agentes AI monitorizam e controlam as redes de energia através da análise de dados reais em tempo real provenientes de sensores distribuídos pela rede. Estes sistemas usam análise preditiva para otimizar a distribuição energética, garantindo que a oferta atinja a procura enquanto minimiza o desperdício de energia. Modelos de AI também preveem possíveis falhas na rede, permitindo manutenções preventivas e reduzindo o risco de interrupções.
No domínio de energia renovável, sistemas de AI são utilizados para prever padrões climáticos, o que é crítico para a otimização da produção de energia solar e eólica. Esses modelos analisam dados meteorológicos para prever a intensidade da luz solar e a velocidade do vento, permitindo previsões mais precisas de produção de energia e melhor integração de fontes renováveis à rede.
Detecção de falhas é outro setor onde a IA está fazendo contribuições significativas. Sistemas de IA analisam dados de sensores de equipamentos como transformadores, turbinas e geradores para identificar sinais de uso e desgaste ou potenciais avarias antes que elas levem a falhas. Esta abordagem de manutenção preventiva não só extende a vida útil do equipamento mas também garante uma energia contínua e confiável.
Cibersegurança
No campo da cibersegurança, agentes de AI são essenciais para manter a integridade e a segurança de infraestruturas digitais. Estes sistemas são projetados para monitorar continuamente o tráfego de rede, usando algoritmos de aprendizagem automática para detectar anomalias que podem indicar uma violação de segurança.
Analisando grandes quantidades de dados em tempo real, agentes de AI podem identificar padrões de comportamento malicioso, como tentativas de login anônimas, atividades de extração de dados ou a presença de malware. Uma vez que uma ameaça potencial for detectada, sistemas de AI podem自动地iniciar contramesuras, como isolar sistemas comprometidos e aplicar patchs, para prevenir danos adicionais.
Avaliação de vulnerabilidades é outra aplicação crítica de AI em cibersegurança. Ferramentas com Inteligência Artificial analisam código e configurações de sistema para identificar fraquezas de segurança potenciais antes que elas sejam exploradas por atacantes. Estas ferramentas usam técnicas de análise estática e dinâmica para avaliar a postura de segurança de componentes de software e hardware, fornecendo insights operacionais para equipes de cibersegurança.
A automatização destes processos não só melhora a velocidade e a precisão na detecção e resposta a ameaças, quanto também reduz a carga de trabalho dos分析师 humanos, permitindo-lhes se concentrar em desafios de segurança mais complexos.
Manufatura
Na manufatura, a IA está impulsionando avanços significativos em controle de qualidade, manutenção preventiva e otimização da cadeia de abastecimento. Sistemas de visão computacional alimentados pela IA agora são capazes de inspeções de produtos por defeitos a um nível de velocidade e precisão que supera as capacidades humanas. Estes sistemas usam algoritmos de aprendizagem profunda treinados em milhares de imagens para detectar as mais pequenas imperfeições em produtos, garantindo qualidade consistente em ambientes de produção de alta volume.
A manutenção preventiva é outro setor onde a IA está tendo impacto profundo. Analisando dados de sensores embutidos em máquinas, modelos de IA podem prever quando o equipamento está provável que falhe, permitindo a programação de manutenção antes do avaria ocorrer. Este método não só reduz o tempo de inatividade quanto também extende a vida útil de máquinas, resultando em economias significativas.
No gerenciamento de cadeia de abastecimento, agentes AI otimizam níveis de estoque e logística ao analisar dados de toda a cadeia de abastecimento, incluindo previsões de demanda, agendas de produção e rotas de transporte. Fazendo ajustes em tempo real aos planos de estoque e logística, a IA garante que os processos de produção sejam fluídos, minimizando atrasos e reduzindo custos.
Estas aplicações demonstram o papel crítico da IA na melhoria da eficiência operacional e da confiabilidade na manufatura, tornando-a uma ferramenta indispensável para empresas que procuram manter competitividade em uma indústria em rápida evolução.
Conclusão
A integração de agentes de inteligência artificial com modelos de linguagem grande (LLMs) marca um marco significativo na evolução da inteligência artificial, desbloqueando capacidades sem precedentes em diversas indústrias e domínios científicos. Esta sinergia melhora a funcionalidade, adaptabilidade e aplicabilidade dos sistemas de inteligência artificial, resolvendo as limitações inerentes aos LLMs e permitindo processos de decisão mais dinâmicos, contextuais e autônomos.
Da revolução na saúde e finanças à transformação do transporte e gerenciamento de emergências, os agentes de inteligência artificial estão impulsionando inovação e eficiência, abrindo caminho para um futuro onde as tecnologias de inteligência artificial estão profundamente integradas nas nossas vidas diárias.
Ao continuarmos a explorar o potencial de agentes de inteligência artificial e LLMs, é crucial para manter sua evolução baseada em princípios éticos que priorizam o bem-estar humano, a justiça e inclusividade. Ao garantir que essas tecnologias são projetadas e implementadas de forma responsável, podemos aproveitar seu potencial total para melhorar a qualidade de vida, promover a justiça social e abordar desafios globais.
O futuro da inteligência artificial está em uma integração fácil de agentes de inteligência avançados com modelos de linguagem sofisticados, criando sistemas inteligentes que não apenas ampliam as capacidades humanas mas também defendem os valores que definem a nossa humanidade.
A convergência de agentes de inteligência artificial e LLMs representa um novo paradigma na inteligência artificial, onde a colaboração entre o ágil e o poderoso desbloqueia um reino de possibilidades ilimitadas. Ao aproveitar este poder sinérgico, podemos impulsionar inovação, avançar descobertas científicas e criar um futuro mais equitativo e próspero para todos.
Sobre o Autor
Vahe Aslanyan aqui, no cruzamento entre ciência da computação, ciência dos dados e AI. Visite vaheaslanyan.com para ver um portfólio que é um testemunho à precisão e progresso. Minha experiência atua como ponte entre o desenvolvimento full-stack e a otimização de produtos AI, guiado pela resolução de problemas de novas maneiras.
Com um histórico que inclui a estreia de um liderado bootcamp de ciência dos dados e trabalhando com especialistas de topo da indústria, minha foco permanece em elevar a educação tecnológica a padrões universais.
Como Pode Voce Mergulhar mais Profundamente?
Após estudar este guia, se você quiser mergulhar ainda mais fundo e o estilo de aprendizagem estruturado é sua coisa, considere se juntar a nós em LunarTech, oferecemos cursos individuais e Bootcamp em Ciência de Dados, Aprendizagem Automática e AI.
Nós fornecemos um programa abrangente que oferece um entendimento profundo da teoria, implementação prática em mãos, material de prática extensivo e Preparação de Entrevista personalizada para colocar você no caminho do sucesso em sua própria fase.
Você pode aproveitar nossa Bootcamp de Ciência de Dados Ultimate e participar de um trial gratuito para testar o conteúdo de forma direta. Isto obteve reconhecimento como uma das Melhores Bootcamps de Ciência de Dados de 2023 e foi destacada em publicações respeitadas como Forbes, Yahoo, Entrepreneur e muitas outras. Esta é sua chance de fazer parte de uma comunidade que progride pela inovação e pelo conhecimento. Aqui está a mensagem de boas-vindas!
Conecte-se Conigo

Segue comigo no LinkedIn para acessar montes de Recursos Gratuitos em CI, ML e AI
-
Inscreva-se no meu Newsletter de Ciências de Dados e AI
Se você quiser saber mais sobre uma carreira em Ciências de Dados, Aprendizado de Máquina e AI, e aprender a conseguir um emprego de Ciências de Dados, você pode baixar este livro gratuito Guia de Carreira em Ciências de Dados e AI.
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/