













人工知能(AI)の迅速な進化により、大規模言語モデル(LLM)とAIエージェント之间に強力な協力が生まれています。このようなダイナミックな交流は、小さなAIエージェントが巨大なLLMの能力を強化し、放大了するもので、デイビッドとゴリアテとの物語(争いを除く)に似ています。
このハンドブックは、AIエージェントが、デイビッドのように、我々の现代のゴリアテとしてのLLMを超電気化し、様々な産業や科学分野を革新するためにどのようにして機能しているかを探ることにします。
目次
-
第3章:AIエージェントが最も輝く場所
言語モデルにおけるAIエージェントの興起
AIエージェントは、自らの環境を認識し、決定をし、特定の目標を達成するために行動を実行することができる自律システムである。LLMと統合されると、これらのエージェントは複雑な任务を行い、情報について推理し、革新的な解決策を生成することができる。
この組み合わせは、ソフトウェア開発から科学研究までの多くの分野で、重要な進歩をもたらしている。
各産業に及ぶ変革的な影響
AIエージェントとLLMの統合は、各産業に深い影響を与えています:
-
ソフトウェア開発: GitHub CopilotなどのAI搭載コーディングアシスタントは、コードの最大40%を生成する能力を示し、開発速度を55%向上させることを実証しています。
-
教育: AI搭載学習アシスタントは、平均コース完了時間を27%短縮する可能性を示し、教育の景色を革命的に変える可能性があります。
-
交通:2030年までに車両の10%が無人運転になると予測されており、自動運転車の中での自律AIエージェントは交通業界を変革する準備が整っています。
科学的な発見の進歩
AIエージェントとLLMの最もエキサイティングな応用の1つは科学研究にあります:
-
薬剤探索:AIエージェントは広範なデータセットの分析と潜在的な薬剤候補の予測により、従来の方法に比べて時間とコストを大幅に削減し、薬剤探索プロセスを加速しています。
-
素粒子物理学: CERNの大型ハドロン衝突型加速器では、AIエージェントが素粒子衝突データを分析しており、異常検出を使用して、未発見の素粒子が存在する可能性を指し示す候補を特定しています。
-
一般科学研究: AIエージェントは、過去の研究を分析し、予期しない関連を识別し、新しい実験を提案しています。これにより、科学の発見の速度と範囲を拡大しています。
AIエージェントと大規模言語モデル(LLM)の融合は、人工知能を前例のない能力を持つ新時代に導いています。この完全なハンドブックは、この2つの技術間の動的な相互影響を見ていくことで、彼らの組み合わさる可能性を解明し、産業を革新し、複雑な問題を解決することができることを示しています。
私たちはAIの起源から自律型エージェントの出现までに変遷し、洗練されたLLMの興りを追いかけます。また、倫理の考慮についても探索します。これらの技術が人間の価値観と社会の福祉に合致することを保証するのを助けることになります。
このハンドブックを終えると、AIエージェントとLLMの協力の力を深く理解できるでしょう。また、この先端技術を活用する知識とツールも入手できます。
第1章:AIエージェントと言語モデルについての導入
AIエージェントと大規模言語モデルは何ですか?
人工知能(AI)の急速な進化は、大規模言語モデル(LLM)とAIエージェントの変革的な協力を生み出しました。
AIエージェントは自律的なシステムで、環境を認識し、決断を行い、特定の目標を達成するための行動を実行するよう設計されています。彼らは自律性、認識、反応性、推論、決策、学習、通信、目標指向性などの特徴を持っています。
一方、LLMは深層学習技術と巨大なデータセットを利用して、人間的なテキストを理解、生成、予測する高度なAIシステムです。
これらのモデル、たとえばGPT-4、Mistral、LLamaは、驚くべき能力を発揮しています、自然言語処理のタスクにおいて、テキスト生成、言語翻訳、会話型エージェントなど。
AIエージェントの主要特徴
AIエージェントは、従来のソフトウェアとは異なるいくつかの定義的特徴を持っています:
-
自律性:常に人間の介入を必要とせずに独立して動作することができます。
-
認識:エージェントは様々な入力を通じて環境を感知し解釈することができます。
-
反応性:彼らは環境の変化に動的に反応します。
-
推理と決定: エージェントはデータを分析して情報を基に選択をしていく。
-
学習: 彼らは経験を通じて時間とともに性能を向上させる。
-
コミュニケーション: エージェントは他のエージェントや人間とさまざまな方法で交流できる。
-
目標指向性: 彼らは特定の目標を達成するために設計されている。
大規模言語モデルの能力
LLMは、以下のような幅広い能力を示しています。
-
テキスト生成: LLMはプロンプトに基づいて一貫性のあるコンテキストに関連したテキストを生成する。
-
言語翻訳: 彼らは高精度で異なる言語間でテキストを翻訳することができる。
-
要約: LLMは長い文章を簡潔な要約にまとめ、重要な情報を保持することができる。
-
質問回答: 彼らは幅広い知識ベースを基に、質問に正確な回答を提供することができる。
-
感情分析: LLMは与えられた文章における感情表現を分析し、感情を決定することができる。
-
コード生成: 彼らは自然言語の描述に基づいて、コードの片段や整个の関数を生成することができる。
AIエージェントのレベル
AIエージェントは、能力と复杂性に基づいて異なるレベルに分けられる。arXiv上の論文によるところで、AIエージェントは5つのレベルに分かれている:
-
レベル1 (L1): AIエージェントは研究者の助手として機能し、科学者が仮説を設定し、目的を達成するための任务を指定する。
-
第2レベル(L2)
:データ分析や簡単な決定メーキングなど、定義されたスコープの中で自律的に特定のタスクを行うことができるAIエージェント。
-
第3レベル(L3):経験から学び、新しい状況に適応することができ、決定過程を改善することができるAIエージェント。
-
第4レベル(L4):高度な推理と問題解決能力を持ったAIエージェント、複雑で多段階のタスクを処理することができます。
-
第5レベル(L5):動的環境で独立して操作でき、人間の介入無しに決定と行動を取ることができる完全自律的なAIエージェント。
大規模言語モデルの限界
訓練コストとリソース制約
GPT-3やPaLMなどの大規模言語モデル(LLM)は、深層学習技術と大規模なデータセットを活用して、自然言語処理(NLP)を革新しました。
しかし、これらの進歩には大きなコストがあります。LLMのトレーニングには、通常何千ものGPUを使用し、広範囲なエネルギー消費を伴う計算資源が必要です。
OpenAIのCEO、Sam Altmanによると、GPT-4のトレーニングコストは1億ドルを超えています。これはモデルの報告された规模と複雑さに合致し、約1兆のパラメータを持つことが予想される。しかし、他の源による数字は異なる:
-
漏洩された報告によると、GPT-4のトレーニングコストは6300万ドル程度で、計算能力とトレーニング期間を考慮しています。
-
2023年中ごろのいくつかの見積もりによれば、GPT-4に似たモデルのトレーニングは約2000万ドルに及ぶか、約55日かかるという进歩の影响を反映しています。
このような高いトレーニングおよび維持费は、LLMの普及とスケーラビリティを制限しています。
データの限定と偏見
LLMの性能は、トレーニングデータの品質と多様性に強く依存しています。大規模なデータセットでトレーニングされているにも関わらず、LLMはデータに存在する偏見を示して、歪んだまたは不適切な出力を示すことがあります。これらの偏見は様々な形で現れることがあり、例えば性、人種、文化的な偏見があり、これらはステレオタイプや誤った情報を永続化することがあります。
また、トレーニングデータの静的な性質は、LLMが最新の情報にアップデートされていないため、動的な環境での効果を制限します。
特殊化と複雑さ
LLMは一般の課題に対して優れていますが、 Doman-specific knowledgeや高レベルの複雑さが必要な专业化課題には苦しみます。
例えば、医学、法律、科学研究などの分野の課題は、専門的な用語の深い理解と細かい推理が必要で、これらはLLMには固有のものではないため、追加の専門知識を統合することと、細かい調整を行うことで、专业化のアプリケーションにLLMを有効にする必要があります。
入力と感覚の限定
LLMは主にテキストベースの入力を処理するため、マルチモーダルな方法で世界とのやりとりを制限しています。LLMはテキストを生成和理解できますが、直接視覚的、聴覚的、感覚的な入力を処理する機能がありません。
この制限は、ロボットィクスや自律システムなど、包括的な感覚統合が必要な分野でのLLMの応用を妨げています。たとえば、LLMは、追加の処理層無しにカメラからの視覚データやマイクからの聴覚データを解釈することはできません。
通信とやりとりの制約
現在のLLMの通信能力は主にテキストベースであり、より身近感がありやりとりができる通信形式には限界があります。
たとえば、LLMはテキストレスポンスを生成できますが、動画コンテンツやホログラフィック表現を生成することはできず、これらはヴァーチャルリアリティや拡張現実のアプリケーションにおいてますます重要になっています(詳細はこちらを読んでください)。この制約は、豊富なマルチモーダルやりとりを要求する環境でのLLMの効果を低下させます。
AIエージェントでのLLMの制約を克服する方法
AIエージェントは、LLMが直面する多くの制約に対する有望な解決策を提供します。これらのエージェントは自主的に動作し、環境を認識し、決定をし、特定の目標を達成するための行動を実行します。AIエージェントをLLMと統合することで、その機能を強化し、内在の制約を解決することが可能です。
-
改善されたコンテキストとメモリ: AIエージェントは複数のインタラクションを通じてコンテキストを維持することができ、より一貫性のある、コンテキストに合わせた反応が可能になります。この機能は、長期的な記憶と連贯性を必要とするアプリケーションに特に有用です。例えば、顧客サービスや個人アシスタントなどです。
-
マルチモーダル統合: AIエージェントはカメラ、マイクロフォン、センサーなどの様々な源からの感觉的な入力を統合することができ、LLMがビジュアル、听覚、感觉的なデータを処理し、反応することができます。この統合は、ロボットと自律型システムのアプリケーションに非常に重要です。
-
専門知識と専門技術: AIエージェントは、分野固有の知識による细かい調整を受けることができ、LLMが専門的な業務を行う能力を高める。この手法により、医学、法律、科学研究などの分野で複雑な質問に対応できる専門システムを作成することができます。
-
インタラクティブ・アンド・インマージブル・コミュニケーション: AIエージェントは、ビデオコンテントを生成し、ホログラフィックディスプレイを制御し、仮想現実や拡張現実環境とインタラクトすることで、よりインマージブルなコミュニケーションを促進することができます。この機能は、豊富で多モーダルな対話を必要とする分野でLLMの応用を拡大することができます。
大规模な言語モデルは、自然言語処理において显著な能力を示していますが、それには限りがあります。トレーニングの高コスト、データの偏見、スペシャルイЗアレンスの困難、感覚の限界、およびコミュニケーションの制約が大きな壁を作り出しています。
しかし、AIエージェントの統合は、これらの限りを乗り越える有効なパスを提供します。AIエージェントの強みを活用することで、LLMの機能性、適応性、および適用性を強化することができ、より高度で多様なAIシステムにつながる道を辟いています。
第2章:人工知能とAIエージェントの歴史
人工知能の起源
人工知能(AI)の概念は、現代デジタル時代よりも遥かに遡る根拠を持っています。人間のような推理能力を持った機械を作ることの考えは、古代の神話や哲学者の debatteに溯源できます。しかし、AIを科学分野としての正式な設立は、20世紀の中頃で行われました。
1956年のダートマス会議は、ジョン・マッカサリー、マービン・ミンスキー、ネサニエル・ロchester、クロード・シャノンによって主催され、AIという研究分野の誕生地として広く知られています。この画期的なイベントは、研究の先頭にいる研究者を集め、人間の知能を模倣する機械を創造する可能性を探索しました。
初期の楽観主義とAIの冬
AI研究の初期は、自由奔放な楽観主義に特徴づけられていました。研究者たちは、数学的問題を解くプログラムの開発、ゲームのプレイ、そして初期の自然言語処理においてかなりの進歩を遂げました。
しかし、この初期の熱意は、本当に知能のある機械を作り出すことが最初に想定されたよりもはるかに複雑だという認識によって冷静化されました。
1970年代と1980年代は、AI研究への資金と関心が減少した時代であり、一般的に”AIの冬“と呼ばれています。この不況は、AIシステムが初期の先駆者によって設定された過大な期待を果たすことができずに起きたものです。
ルールベースのシステムから機械学習へ
専門家システムの時代
1980年代は、専門家システムの開発によってAIに対する関心が再び高まった時代でした。これらのルールベースのプログラムは、特定の分野での人間の専門家の決策過程を模倣するよう設計されていました。
エキスパートシステムは、医療、金融、工学分野など幅広い领域に応用されていました。しかし、経験から学びることができず、プログラムされたルール以外の新しい状況に適応できないため、限界がありました。
機械学習の兴起
ルールベースシステムの限界によって、機械学習への Paradigm Shiftが生まれました。この取り組みは、1990年代と2000年代に主流となり、データから学び、予測や決定を行うことができるアルゴリズムの開発に焦点を置いていました。
神経망やサポートベクターマシンなどの機械学習技術は、パターン認識やデータ分類などの任务で優れた成果を示しました。大規模データの到来と計算能力の向上により、機械学習アルゴリズムの開発や適用がさらに加速しました。
自律的なAIエージェントの出現
Narrow AIからGeneral AIへ
AI技術がさらに進化していくにつれて、研究者たちはより多様性を持ち、自律的なシステムを作る可能性を探求しました。これは、特定の任务に設計されたNarrow AIから、人工的普通的一般能力(AGI)を追求するへの移行を表します。
AGIは、人間が行えるあらゆる知的任务を行うことができるシステムの開発を目指しています。真のAGIはまだ遠いゴールですが、より柔軟で适応性のあるAIシステムの開発には重要な進展がありました。
深層学習と Neural Networksの役割
人工 neural networksに基づく機械学習のスubsethat は深層学習と呼ばれ、AI域の進展に大変重要な役割を果たしています。
深層学習アルゴリズムは、人間の脳の構造と機能に inspireされ、画像と音声認識、自然言語処理、ゲームプレイなどの分野で素晴らしい能力を示してきました。これらの進歩は、より洗練された自律型AIエージェントの開発に基盤を提供しました。
AIエージェントの特徴と種類
AIエージェントは、環境を感知し、特定のゴールを実現するために決定をし、行動を行うことができる自律的なシステムです。彼らは自律性、感知、反応性、推理、決定作成、学習、コミュニケーション、ゴール志向性などの特徴を持っています。
AIエージェントには独自の能力を持つ数々の種類があります。
-
Simple Reflex Agents: 事前定義されたルールに基づいて特定の刺激に対する反応を行います。
-
モデルベースのリフレクショナルエージェント: 環境に内部モデルを保持して決策を行う。
-
ゴールベースのエージェント: 特定のゴールを達成するための行動を実行する。
-
效用ベースのエージェント: 潜在の結果を考慮し、期待される効用を最大限にする行動を選ぶ。
-
学習エージェント: 機械学習技術を通じて時間と共に決定作成能力を向上させる。
挑戦と倫理上の考慮
AIシステムがより高度で自律的になるにつれて、彼らの使用が社会的に受け入れられる範囲内に保証される Critical considerationsを持ってくる。
特に大規模言語モデル(LLM)は生産性を飞跃的に高める。しかし、これは重要な問題を引き起こす:これらのシステムがどのような意图を超chargingするのか? AIを使用する意図が悪意的になる場合、これらのシステムがそのような不正使用を Detectionする必要があることが明确になります。 various NLP techniquesや他のツールを利用して。
LLMの技術者たちは、これらの課題を解決するために幅広いツールと方法論をアクセスしています。
-
感情分析:感情分析を應用して、LLMはテキストの感情色素を評価し、有害的かあるいは攻撃的な言葉を検出することができ、コミュニケーションプラットフォームでの潜在的な不当使用を特定するのを助けます。
-
コンテントフィルタリング:キーワードフィルタリングやパターンマッチングなどのツールを使用して、ヘイトスピーチ、誤った情報、または露出的な内容などの有害なコンテンツの生成や流布を防止することができます。
-
偏見検出ツール:AI Fairness 360 (IBM)やFairness Indicators (Google)のような偏見検出フレームワークを実装して、言語モデルの偏見を識別して軽減することができます。これにより、AIシステムが公平にとって equitableに機能するようにすることができます。
-
説明可能な技術
: LIME (Local Interpretable Model-agnostic Explanations)やSHAP (SHapley Additive exPlanations)などの説明可能なツールを使用して、工程師はLLMの決定プロセスを理解し、説明することができ、意図せぬ行動の検出と対処を容易にする。
-
アドバージャリアルテスティング: 悪意のある攻撃や有害な入力をシミュレートすることで、工程師はTextAttackやAdversarial Robustness Toolboxなどを使用してLLMをストレステストすることができ、悪意的な目的に利用することができる脆弱性を特定する。
-
倫理的なAIガイドラインとフレームワーク: IEEEやPartnership on AIから提供されるような倫理的なAI開発ガイドラインを採用することで、社会的福祉を最優先にした責任あるAIシステムの作成を指導することができます。
これらのツールに加えて、私たちはAI用に専門的なレッドチームを必要としています。これはLLMを限界まで試すことで、彼らの防衛に隙間を見つける specialize teams です。レッドチームは敵対的な状況をシミュレートし、それまでに気付かなかった脆弱性を発見します。
しかし、製品の背後にいる人々がそれに比べて最も強い影響を与えていることを認識することが重要です。私たちが今直面している攻撃や挑戦の多くは、LLMの開発以前に存在していたことを示しており、これは人間の要素がAIを倫理的にも責任あるものとして使用するために中心的であることを指しています。
これらのツールと技術を開発パイプラインに統合し、警覺的なレッドチームと一緒に使用することは、LLMをポジティブな結果を加速し、その不当な使用を検出し防ぐために基本です。
第3章: AIエージェントが最も輝く場所
AIエージェントのユニークな強み
AIエージェントは、自己制御的に環境を認識し、決断を下し、特定の目標を達成するために行動を実行する能力で眉目を立てます。この自己制御性と高度な機械学習能力の組み合わせにより、AIエージェントは、人間がするより複雑かつやや重複しすぎるタスクを実行することができます。
AIエージェントが輝いている主要な強みは以下の通りです。
-
自律性と効率性: AIエージェントは常に人間の介入を必要としないで独立して作動することができます。この自律性により、24時間7日間にわたって業務を处理することができ、効率と生産性を大幅に向上させることができます。たとえば、AI駆動のチャットボットは80%までの通常の顧客質問に対応でき、運営コストを削減し、対応時間を短縮することができます。
-
高度な決断力: AIエージェントは大量のデータを分析して適切な決断を下すことができます。この能力は金融などの分野で特に有益です。AIトレーディングボットはトレーディングの効率を大幅に向上させることができます。
-
学習と适应性: AIエージェントは経験から学び、新しい状況に適応することができます。この持続的な改善により、随時のパフォーマンス向上が可能です。たとえば、AIヘルスアシスタントは診断ミスを減らすことで、ヘルスケアの成果を改善することができます。
-
個人化: AIエージェントはユーザーの行動や好みを分析して、個人化された体験を提供することができます。アマゾンの推奨エンジンは、売上の35%を驱动しているのが最も良い例であり、AIエージェントが用户体験を向上させ、売上を増やすことが可能です。
AIエージェントは解決策である理由
AIエージェントは、従来のソフトウェアや人間操縦のシステムに直面していた多くの課題に解決策を提供しています。なぜ、これらは最も好まれる選択肢であるかという理由があります。
-
スケール性:AIエージェントは、 proportional cost increases なしに操作をスケールすることができます。このスケール性は、人件費や運営费を大きく増やすことなく成長したいビジネスには欠かせません。
-
一貫性と信頼性:人間とは異なり、AIエージェントは疲労や不具合に苦しません。高精度と信頼性でリピートされるタスクを行い、一定のパフォーマンスを保証します。
-
データ駆動の洞見:AIエージェントは、人間が見落としがちなパターンや洞察を発見するために大規模なデータセットを処理し分析します。この能力は、金融、医療、マーケティングなどの分野の決定には非常に価値があります。
-
コスト削減: 日常的な業務を自動化することで、AIエージェントは人材の需要を reduced し、显著なコスト削減につながります。たとえば、AI駆動のフード検出システムは、不正行為を reduced することで年間数十億ドルの節約ができます。
AIエージェントが良く機能するための条件
AIエージェントの成功のためにデプロイを Ensure するために、特定の条件は満たされなければなりません。
-
明確な目標と用途: AIエージェントの効果的なデプロイを Ensure するために、特定のゴールと用途を定義することは重要です。この明確さは期待値を設定し、成功を測定するのを助けます。たとえば、顧客サービスの応答時間を50%削減するゴールを設定することは、AIチャットボットのデプロイを指導することができます。
-
品質データ: AIエージェントは、トレーニングと運用のために高品質のデータに依存します。データが正確で、関連性があり、最新であることを保証することは、エージェントが情報を基に決定を下し、効果的に機能することが基本的です。
-
既存システムの統合: AIエージェントが最適な機能を果たすために、既存のシステムやワークフローと无缝な統合が必要です。この統合は、AIエージェントが必要なデータにアクセスできるようにし、そのようなタスクを行うために他のシステムと交流できるようにする。
-
継続的なモニタリングと最適化: AIエージェントのパフォーマンスを維持するために、定期的なモニタリングと最適化が重要です。これにより、主要なパフォーマンス指標(KPI)を追跡し、フィードバックとパフォーマンスデータに基づいて必要な調整を行います。
-
倫理上的考慮と偏見軽減: AIエージェントに偏見を軽減するための措置を講じ、公平性と包括的性を確保することは、信頼を築くことと、責任ある導入を Ensureすることが重要です。
AIエージェントの導入のベストプラクティス
-
AIエージェントを導入する際、ベストプラクティスに従い、彼らの成功と効果を確保することができます。
目的と用途の定義: AIエージェントを導入する目的と用途を明確に识别します。これは、期待を設定し、成功を測定する役割を果たします。
-
適切なAIプラットフォームを選択: 目標、使用案例、既存のインフラに合わせてAIプラットフォームを選択してください。統合能力、スケーラビリティ、コストなどの要因を考慮してください。
-
詳細な知識ベースを開発: AIエージェントが関連性のある正確な応答を提供するために、よく構築された構造の知识的ベースを作成してください。
-
无缝な統合を Ensure: CRMやコールセンター技術などの既存システムにAIエージェントを統合して、一貫した顧客体験を提供してください。
-
AIエージェントを訓練および最適化する: 対話からのデータを使用してAIエージェントを不间断に訓練および最適化してください。パフォーマンスをモニターし、改善のための領域を特定し、モデルを更新していくでしょう。
-
適切な Escalation 手順の実装: 複雑なものや感情的なコールを人間のエージェントに移譲するためのプロトコルを作成し、 smooth transition と効率的な解決を保証する。
-
パフォーマンスの監視と分析: コール解決率、平均処理時間、顧客満足度などの主要なパフォーマンス指標(KPI)を追跡します。データ駆動の洞察と決定のために分析ツールを使用してください。
-
データのプライバシーとセキュリティを保証する: 強力なセキュリティ措置が重要です。データを匿名化し、人間の監視を確保し、データ保持のポリシーを設定し、顧客データを保護してプライバシーを维持するために強力な暗号化措置を取ります。
AIエージェント + LLM: 知能ソフトの新時代
AIエージェントと大規模言語モデルの組み合わせることで、あなたの要求を理解し、その要求を果たすことができるソフトウェアを考えてみてください。これらの強力なパアは、よりインテリジェントで、有効な新しい種類のアプリケーションを創り出しています。
AIエージェント:単純なタスク実行を超える
デジタルアシスタントと比較されることが多いが、AIエージェントはスクリプトの追従者だけではなく、高度な技術を包括しています。これらの技術は、動的な決定と行動の取り決めを可能にするフレームワークを持っています。
-
アーキテクチャ:典型的なAIエージェントはいくつかの关键的なコンポーネントで構成されています。
-
センサー:エージェントが環境を感知するための手段で、センサーやAPI、またはユーザーの入力からデータを集めることができます。
-
信念状態:これは、集めたデータに基づいてエージェントが世界を理解するものです。新たな情報が入手可能になるたびに更新されます。
-
推理エンジン:これはエージェントの決定プロセスの核であり、現在の信念と目標に基づいて最善の行動を決定するために、強制学習や計画技術に基づくアルゴリズムを使用します。
-
アクチュアー:これらはエージェントが世界とInteractするツールであり、API呼び出しを送信したり、物理的ロボットの制御を行うことができます。
-
-
課題:
従来の人工知能エージェントは、明确规定された任务をうまく処理することができますが、しばしば以下の点に直面します。
-
自然言語理解: 细かい人間の言葉を解釈し、曖昧さを処理し、文脈から意味を抽出することは、依然として重要な課題です。
-
共感推理: 現在のAIエージェントは、人間が当然と考える共感知識と推理能力を多く所持していません。
-
一般化: AIエージェントを未知の任务に适したり、新しい環境に適応させるためのトレーニングは、研究上の重要な分野です。
-
LLM: 言語理解と生成の解鎖
LLMは数十億のパラメータによって記録された广大的な知識を持っており、前例のない言語能力を提供します:
-
トランスフォーマーアーキテクチャー: 现代の多くのLLMの基盤となっているトランスフォーマーアーキテクチャーは、テキストのような序列的データを処理するのに最適な神経ネットワーク設計であり、これによりLLMは言語内の長距離依存を捕捉することができ、コンテキストを理解し、一貫性とコンテキストに合わせた文脈的なテキストを生成することができます。
-
能力: LLMは幅広い言語基盤のタスクで優れています:
-
テキスト生成: クリエイティブな小説を書いたり、複数のプログラミング言語のコードを生成したり、LLMは驚くほどの流暢性と創造性を見せます。
-
質問回答: それは長い文書に散らかれている情報に基づいて、簡潔で正確な答えを提供することができます。
-
要提高: LLMは大きな量のテキストを簡潔な要提高にまとめ、重要な情報を抽出し、関連性のない詳細を捨てることができます。
-
-
限界:それらの素晴らしい能力にも限界があります:
-
現実世界との接地の欠如:LLMは主にテキストの領域で动作し、物的な世界と直接やりとりする能力を持っていません。
-
偏見と幻覚の可能性:大量的で整理されていないデータセットで学習したため、LLMはデータに存在する偏見を引き継ぎ、時には事実上不正確なまたは不合理な情報を生成することがあります。
-
言語と行動の間の沟を架ける協力:
AIエージェントとLLMの組み合わせは、それぞれの制約を解決し、知的で能力のあるシステムを作成します。
-
LLMを解釈者と計画者として:LLMは自然言語の命令をAIエージェントが理解できる形式に翻訳することができ、より直观的な人間とコンピュータの交流を可能にします。また、彼らの知識を活用して、エージェントが複雑な作業を小さい、管理可能な段階に分解して計画することを助けることもできます。
-
AIエージェントの実行と学習役割: AI エージェントは LLM に世界との交流、情報の集め、行動に対するフィードバックを提供することができます。この実際の世界の根拠は、LLM が経験から学び、時間とともに性能を向上させることを助けることができます。
この強力な协力が新たな世代のアプリケーションの開発を推し進めています。これらはより直观的で、適応性があり、それまで以上の能力を持っています。AI エージェントと LLM の技術がどのようにも進化すれば、さらに革新的で影響力のあるアプリケーションが生まれ出し、ソフトウェア開発や人間とコンピュータの交流の scenery を変えることを期待することができます。
実際の例:産業の変革
この強力な組み合わせは、すでにさまざまな分野で波を起こしています:
-
顧客サービス:コンテキスト認識を持って問題解決
- 例:在庫切れのために発送が遅れたことについて、オンラインの零售商に連絡を取る顧客を考えてください。LLMを搭載したAIエージェントは、顧客の不満を理解し、彼の発注履歴にアクセスし、実時間でパッケージの追跡を行い、急便の発送や次回購入時のディスカウントなどの解決策を積極的に提供することができます。
-
コンテント创作:スケール上で高品質なコンテンツを生成
- 例:マーケティングチームは、AIエージェントとLLMシステムを使用して、目标的なソーシャルメディア投稿を生成し、商品の説明を書いたり、またはビデオスクリプトを作成したりすることができます。LLMはコンテンツが魅力的で情報的なものであることを保証し、AIエージェントは発表と配布プロセスを处理します。
-
ソフトウェア開発:コードとデバッグの加速
- 例:開発者は自然言語を使用して、作成したいソフトウェア機能を描述することができ。LLMは、その後、コードのスニペットを生成し、潜在的なエラーを识別し、改善の提案を提供し、開発プロセスを大幅に加速する。
-
医疗:治療の個人性化と患者のケアの改善
- 例: LLMを搭載した、患者の医療歴にアクセスできるAIエージェントは、彼らの健康に関する質問に答えること、個人的なメディケアの提醒を提供すること、そして症状に基づいて予防的な診断を提供することができる。
-
法律:法的研究所と文書草稿のストreamlining
- 例:法律家は、特定の条項と法的的先例に基づいて契约を草稿しなければならない。LLMを搭載したAIエージェントは、法律家の指示を分析し、広大な法律データベースを搜索し、関連のある条項と先例を识別し、契约の一部を書き立てることができ、必要な時間と努力を大幅に減少させる。
-
ビデオ制作:簡単に魅力的なビデオを生成する
- 例:マーケティングチームは、彼らの製品の特徴を説明する短いビデオを作成したい。彼らは、AIエージェント + LLMシステムにスクリプトの概要とビジュアルスタイルの偏好を提供することができる。LLMはそれに基づいて詳細なスクリプトを生成し、適切なミュージックとビジュアルを提案し、ビデオを編集することができ、ビデオ制作プロセスの多くを自動化する。
-
アーキテクチャ:AIパワーの洞察をもつ建筑设计
- 例:建築家は新しいオフィスビルを設計しています。彼らは、AIエージェントとLLMシステムを使用し、設計の目標を入力できます。例えば、最大限の自然光を取り入れることと、空间の活用を最適化することです。LLMは、これらの目標を分析し、異なる設計オプションを生成し、建物が異なる環境条件下でどのように機能するかをシミュレートすることができます。
-
建設:建設现场の安全性と効率を向上させる
- 例:カメラとセンサーを装備したAIエージェントは、建設现场の安全Σ隐患を監視することができます。作业者が適切な安全装備を着用していないか、 equipmentが危険な位置に残っている場合、LLMは状況を分析し、現場監督に警告し、必要であれば操作を自動的に中止することができます。
未来は現在である:ソフトウェア開発の新時代
AIエージェントとLLMの融合は、ソフトウェア開発における重要な飛躍を表します。これらの技術がさらに進化するにつれて、もっと革新的な応用が生まれることを期待することができます。これらは産業を変身させ、 workflowを流暢にする、人とコンピュータの交流に新しい可能性を生み出すに至るでしょう。
AIエージェントは、大量のデータを処理し、repetitive tasksをautomating、複雑な決定を作成し、個人化された体験を提供する必要がある域で最も輝きます。必要な条件を満たし、ベストプracticesに従って、組織はAIエージェントの全ての可能性を引き出し、イノベーション、効率、および成長を促進することができます。
第4章:知的システムの哲学的基盤
知的システムの開発,特に人工知能(AI)の分野において,哲学的原則に深く理解する必要があります。この章は,AIの設計,開発および使用に影響を与える核心的な哲学的アイデアについて探ることにします。技術の進歩と倫理的価値に合わせる重要性を強調します。
知的システムの哲学的基盤は,理論的な練習のみではなく,AI技術が人間の利益に贡献するための重要な基盤を保証するのに必要です。公平性,包括性,生活の質の向上を促進することで,これらの原則は,AIが私たちの最佳の利益を服务するよう指導します。
AI開発における倫理的な考慮
AIシステムが人間生活のすべての側面に徐々に取り込まれるにつれて、設計や導入における倫理的な要求を厳密に检討し実施する必要があります。
基本的な倫理的な質問は、AIが人間の価値や道徳の原則を体現し支持するように作られるかどうかに関することです。この質問は、AIが世界のあらゆる社会に将来的にどのように形づくられるかに関する中央的な要素です。
この倫理的な議論の中心にあるのは、慈善の原則であり、道徳哲学の Cornerstone であり、行動は、個人および社会全体の福祉を増やすことを目的とするべきであると決めることです(Floridi & Cowls, 2019)。
AIの場合、善政は人間の豊かさに積極的に貢献するシステムを設計することになります。これには、医療の成果を改善し、教育の機会を増やし、公平な経済成長を促進するシステムです。
しかし、AIにおける善政の適用は簡単ではありません。AIの可能な利点と潜在的なリスクや損害とを慎重に衡量しながら応用する必要があります。
善政の原則をAI開発に適用する際の主要な課題の1つは、イノベーションと安全との微細なバランスを保つ必要があります。
AIは、予測的アルゴリズムが人間の医師よりもより早く正確に病気を診断することができる医学を革新するかもしれません。しかし、厳格な倫理のオーバーサイプなしに、同じ技術は既存の不平等を悪化させるかもしれません。
例えば、これらの技術が主要に豊かな地域に導入され、基本的な医療アクセスが乏しい未開のコミュニティーが引き続き続けることがあります。
このため、倫理的なAI開発は、益を最大化するだけでなく、リスク軽減の積極的な取り組みも必要です。これには、AIの不正使用を防ぐための強い保護が必要で、これらの技術が意図せぬ損害を引き起こすことがないようにすることです。
AIの倫理フレームワークは、固有の内容を持たなくてはならず、AIの利点が社会のすべての集団、特に伝統的に边鄙地帯に均等に分配されるようにする必要があります。これには、正義と公平さを約束する必要があります。AIは、现状を強まるだけでなく、系统性の不平等を解消するために積極的に働く必要があります。
たとえば、AI駆動の仕事自動化は、生産性と経済成長を向上させる可能性がある。しかし、これは、低所得者層に特に影響を与える、大きな仕事変更をもたらすかもしれない。
ご覧のように、倫理的に立得住脚のAI框組みには、均等な利益共有の策略と、AIの進展によって悪影響を受ける人々に対するサポートシステムの提供が含まれなければならない。
AIの倫理的な発展には、倫理家、技術者、政策立案者、およびこれら技術に最も影響を受けるコミュニティを含む多様な利害関係者との一貫した関与が必要である。この多門科学の協力は、AIシステムが真空で開発されるのではなく、広範囲の視点や経験に基づいて形づくられることを保証します。
この集団的努力により、私たちは、慈悲、公正、自己決定への尊重、そして公共の利益への Commitmentを反映し、持ち続けるAIシステムを作ることができます。
AI開発における倫理的な考慮は、单纯的なガイドラインではなく、AIが世界に良影響を及ぼす力を決定する重要な要素である。利恵、正義、および包括性の原則に基づいてAIを根拠づけ、イノベーションとリスクのバランスに対する警戒的な取り組みを维持することで、AI開発はただ技術を進化させるだけでなく、社会の全員の生活の質を向上させることができます。
私たちがAIの能力をさらに探求するにしたがって、これらの倫理的な考慮が私たちの取り組みの最前面に留まらないことが重要であり、私たちが人間のための未来を実現するに向かう道を導くことが必要です。
人間中心のAI設計の必要性
人間中心のAI設計は、単なる技術的な考慮を超え、人間の尊厳、自律性、そして行為の主动性を優先する深い哲学的な原則に根ざしています。
このAI開発の取り組みは、根本的に、康德の倫理観念に基づいています。康德(1785)は、人間が他の目的を達成するための手段であるだけでなく、自分自身としての終わりを持っていると断言しました。
この原則は、AI設計にとって深い意味を持ち、AIシステムの開発は、人間の利益に対する一貫したサービス提供、人間の自律性の保ち、そして個人の自律性の尊重に集中する必要があることを求めます。
人間中心の原則の技術的実装
AIを通じた人間の自律性の向上: AIシステムにおける自律性の概念は、特に、これらの技術がユーザーを支配または不当に影響するのではなく、それらをユーザーに力を与えることが重要です。
技術的な用語では、これは、AIシステムを設計して、ユーザーの自律性を優先して、彼らが情報を得て決定をしたりする手段を提供する必要があります。これには、AIモデルが決断を下す具体的な環境を理解し、それに応じて推奨を調整することが必要です。
システム設計の観点から見ると、これにはAIモデルにコンテクストual intelligenceを統合する必要があります。これにより、システムは動的に、ユーザーの環境、好み、需要に対応できます。
例えば、医療分野では、 AIシステムが医者を助けて症候を診断する際には、患者の独自の既往歴、現在の症狀、そして심리的な状態を考慮する必要があり、医者の専門知識をサポートしていく推奨を提供しなければならない。
このコンテキストの適応は、 AIが人的の自主权を缩小するのではなく、強化するサポートツールとして持続していることを保証します。
透明な決定過程を確保する: AIシステムの透明性は、用户がこの技術による決定を信頼し、理解することを保証する基本要件です。技術的には、説明可能なAI (XAI) を開発する必要があります。これには、決定の根拠について明确に説明できる算法の開発が含まれます。
これは、金融、医療、そして司法等领域で、決定プロセスの不透明性によって信頼を失うことと倫理的な懸念が生じるので、特に重要です。
説明可能性はいくつかの技術的な方法で实现できます。一般的な手法の一つは、決定後の説明性をもたらすpost-hoc interpretabilityです。これは、決定をその構成要因に分割し、それぞれが最終的な結果にどのように貢献したかを示すことで実現します。
もう一つの取り組み方は、本来が解釈可能なモデルに基づいています。このようなモデルのアーキテクチャは、データの決定を透明にするように設計されています。たとえば、決定木や線形モデルなどは、決定プロセスが簡単に追跡でき、理解できるため、自然に解釈可能です。
解釈可能なAIの実装上の課題は、透明性とパフォーマンスのバランスを保証することです。より複雑なモデル、例えば深層のニューラルネットワークなどは、解釈性が低くながら、精度が高いため、人間中心型のAIの設計は、モデルの解釈性と予測能力のトレードオフを考慮する必要があります。これにより、精度を弃てずに、人間がAIの決定を信頼し、理解できるようにすることができます。
意味のある人間のオーバーサイドを可能にする:意味のある人間のオーバーサイドは、AIシステムが倫理的・運用の範囲内で作動していることを保証するために非常に重要です。このオーバーサイドには、AIシステムにフェイル・セーフやオーバーライド・メカニズムを設計することが含まれます。これにより、必要であれば人間のオペレータが介入できます。
人間のオーバーサイドの技術的な実装はいくつかの方法で行えます。
一つの方法は、人間がループ内でAIの決定プロセスを連続的に監視・評価する人間インレップションシステムを取り入れることです。これらのシステムは、倫理的な判断が必要な状況でAIが自律的に行動するのを防止するため、人間の介入を許可しています。
たとえば、自律型武器システムの場合、人間が AI が人間の指示無しに生死を決めることを防止するために、人間の监制が欠かせない。これは、AI が人間の承認無しに越えられない厳格な運用上の境界を設定することで、倫理上的な保護をシステムに組み込む。
もう一つの技術的な考慮は、AI システムが行ったすべての決定と行動の記録である監査トレールの開発である。これらのトレールは、人間の操作者による伦理的な基準に従っているかどうかを確認するために、透明な過去の歴史を提供する。
監査トレールは、決定を記録し、大众の信頼を保ち、 regulatory requirements を満たすために、文書化し、正当化する必要がある金融と法律などの分野で特に重要である。
自律と控制在籍: 人間中心の AI における主要な技術的な課題は、自律と控制在籍を適切にバランスすることである。 AI システムは多くの状況で自律的に操作することが設計されているが、この自律は人間の控制在籍やオーバーサイドを損なわないことが重要である。
このバランスは、AI が決定を下すのにどの程度の独立性を持つかを決定する自律レベルの実装で Achieve できる。
たとえば、自律的な運転車などの半自律的なシステムでは、自律レベルは、人間の運転手が完全なコントロールを持ち続ける基本の運転支援までに跨る完全な自動化までに範囲を持つ。
これらのシステムの設計は、任意の自律性レベルで、人間の操作者が必要であれば介入してAIをオーバーライドすることができるように保証する必要があります。これには、人間が必要であれば迅速にとって効果的に制御を取ることができる高度なコントロールインターフェースと決定サポートシステムが必要です。
また、倫理的なAIフレームワークの開発は、AIシステムの自律的な行動を指導するために重要です。これらのフレームワークは、AIに組み込まれた規則とガイドラインのセットで、AIが倫理的に複雑な状況でどのように行動すべきかを決定することを指示します。
たとえば、医療では、倫理的なAIフレームワークは、患者の同意、プライバシー、財務の考量に基づくではなく、医療需要に基づく治療の優先順位の規則などを含む可能性があります。
これらの倫理的な原則を直接AIの決定過程に埋め込むことで、開発者はシステムの自律性が人間の価値に沿った方法で行使されることを保証することができます。
AI設計に人間中心 principleを取り入れることは、哲学的な理想的に過ぎず、技術的な必要性です。人間の自律性を向上させること、透明性を確保すること、有意义な上了司を可能にすること、自律性と制御を慎重にバランスを保ちます。これらの手段で、AIシステムは本当に人間に為してあることを開発することができます。
これらの技術的な考慮は、AIが人間の能力を増強するだけでなく、私たちの社会が根本的な価値を尊重し支持することも必要です。
AIが持続的に進化していくにつれて、人間中心の設計への取り組みは、これらの強力な技術が倫理的にも責任感があるように使用されることを保証する重要な条件になるでしょう。
plaintext
AIが人類に利益をもたらすための方法:生活の質を向上させる
AIシステムの開発に取り組む際には、功利主義という倫理的な枠組みに基づいて努力することが必須です。この哲学は、全体の幸福と福祉の向上を強調するものです。
この文脈では、AIは、特に健康管理、教育、環境の持続性などの分野で、社会の重要な課題に取り組む可能性を持っています。
目標は、全員の生活の質を大幅に改善する技術を創ることです。しかし、この追求は複雑性を伴います。功利主義はAIを広く展開する強い理由を提供しますが、同時に、誰が利益を受け、特に脆弱な人口が落ちこぼれるかという重要な倫理的問題も持ち出します。
これらの挑戦を乗り越えるためには、洗練された、技術的に知識豊富なアプローチが必要です。これは、社会の善の広範な追求と、正義と公平の需要をバランスを保ちながら捉えます。
功利主義の原則をAIに適用する際には、特定の分野での結果を最適化することに集中するべきです。たとえば、健康管理において、AI駆動の診断ツールは、より早期かつ正確な診断を可能にすることで、患者の結果を大幅に改善することができます。これらのシステムは、人間の専門家には見逃されがちな大規模なデータセットを分析し、質の高いケアへのアクセスを拡大することができます。特に資源不足な設定でこれが truer です。
しかし、これらの技術の導入には、既存の不平等を強めないよう慎重に考える必要があります。AIモデルに使用されるデータは、地域ごとに大きく異なり、これらのシステムの精度と信頼性に影響を与えます。
このギャップは、強力なデータ治理フレームワークを設立する重要性を強調しています。これにより、AI駆動のヘルスケアソリューションが代表性があり、公平であることを保証できます。
教育域では、AIの学習个性化の能力は有望です。AIシステムは、教育コンテンツを個別の学生の特定の需要に适応させることで、学習の結果を向上させることができます。学生の学習や行動のデータを分析することで、AIは学生が困難があることを認識し、対象指向のサポートを提供できます。
しかし、これらの利点に取り組むためには、潜在的な偏見を強める可能性や、典型的な学習パターンに不符する学生を边緣化させる可能性など、リスクを認識することが重要です。
これらのリスクを軽減するためには、AIモデルに公平性機構を組み込む必要があります。これにより、モデルが意図せぬところで特定のグループを好ましくすることが防がれます。また、教育者の役割を維持することが非常に重要です。彼らの判断と経験は、AIツールを本当に効果的でサポート的なものにするのに不可欠です。
環境持続可能性のためにも、AIの可能性は大きいです。AIシステムはリソースの使用を最適化し、環境変化を監視し、前例のない精度で気候変動の影響を予測することができます。
例えば、AIは大規模な環境データを分析し、天候パターンを予測し、エネルギー消費を最適化し、廃棄物を最小限にすることができ、これらの行動は現在と未来の世代の福祉に貢献する。
しかし、この技術の進歩には自分たちの課題も伴い、特にAIシステム自体の環境影響について。
大規模なAIシステムの運転に必要なエネルギー消費は、彼らが実現しようとする環境に対する利点を相殺することができる。したがって、エネルギー効率の高いAIシステムの開発は、彼らの環境に対するポジティブな影響が破壊されるのを防ぐために重要である。
utilitarianismが最も重视するのは、総体的な幸福を最大化することであるが、それ自体は利点や害の分配を異なる社会的なグループに対して取り扱うものではないことに注意しなくてはならない。
これは、AIシステムが既に优位にある人々にとって disproportional benefit を与えられ、社会的な边陲部族が状況の改善にはほとんど影響を及ぼさないことを可能性にあげる。
これを対策として、あなたのAI開発プロセスはequity-focused principlesを取り入れるべきであり、利点が公平に分配されることを保証し、潜在的な害がaddressされることを求める。これは、特に偏見をreduceする算法を設計することや、開発プロセスにわたり divers range of perspectives を取り入れることで可能である。
生活の質を改善するAIシステムの開発に取り組む際、Utilitarianismの目標である幸福を最大化することと、正義と公平性の需要を両立することは基本です。これには、AIの導入の更なる影響を考慮した细やかで技術的に根ざした取り組みが必要です。
AIシステムを効果的で equity-focused に設計することで、多様な社会的需要を本当にサポートする技術の進歩の未来を作ることができます。
潜在的な危害に対する保護措置の実装
AI技術の開発の際、潜在的な危害を認識し、これらのリスクを軽減するために強力な保護措置を活性化することは、デーントロロジカル・エストティックスに根ざしています。この倫理の分野は、既存の規則と倫理基準に従い、技術として作られたものが基本の道徳的な原則と一致することを強調します。
厳格な安全性ポリシーの実装は、予防的な措置であるだけでなく、倫理的義務でもあります。これらのポリシーは、包括的な偏見テスト、アルゴリズムのプロセスの透明性、責任の明確なメカニズムを含むべきです。
これらの保護措置は、偏見のある決定作成、アルゴリズムの透明性のなさ、またはオーバーサイドの欠如による意図しない危害を防ぐために基本です。
実践上、これらの保護措置の実装は、AIの技術的な側面と倫理的な側面を深く理解する必要があります。
偏見のテストは、データとアルゴリズムに偏見を識別し、修復するだけでなく、それらの偏見の更广泛的な社会的影响を理解するものです。AIモデルは、多様的な代表的なデータセットで訓練され、時間の経過によって発生する可能性のある偏見を検出し、修正するために定期的に評価されなければならないことを保証する必要があります。
その一方、透明性は、AIシステムが用户や関連者によって簡単に理解でき、監視されるように設計されなければならないことを求めます。これには、説明可能なAIモデルの開発が含まれ、明瞭で解釈可能な出力を提供し、用户が決定がどのように行われたかを見ることができ、決定が正当か否かを保証することが重要です。
また、責任の機構は、信頼を维持し、AIシステムが責任ある方法で使用されることを保証するために非常に重要です。これらの機構には、AI決定の結果に対して責任がある者の明確なガイドラインが含まれ、発生する可能性のある損傷に対する対応と修復プロセスが含まれます。
あなたは、倫理的な考慮がAI開発のすべての段階、最初の設計からデプロイメント以降に含まれるフレームワークを設立する必要があります。これには、倫理のガイドラインに従っているだけでなく、AIシステムが実際の世界とやりとりしている間にも継続的に監視し、調整する必要があります。
これらの保護装置をAI開発の根本的な構成要素として取り込んだ場合、技術の進歩が意図せぬネガティブな結果に导くことを防ぐことができます。
人的な監督とフィードバックループの役割
人工知能(AI)システムにおける人間の监视は、倫理的なAIの導入を保証する非常に重要なコンポーネントです。責任の原則は、人工知能の操作において、特に医療や犯罪司法などの高ストレス環境では常に人間の関与を必要としています。
フィードバックループは、人工知能システムを细め改良するために人間のinputsを使う必要があり、社会的価値が変化していくにつれて誤差の修正や新しい倫理的な考慮の取り入れを可能にします(Raji et al., 2020)。これらのループは、エラーの修正や新しい伦理的な考慮の取り入れを可能にします。
人工知能システムに人間の監視を組み込むことで、開発者は、効果的で、倫理的な Norms と人間の期待に合わせた技術を開発することができます。
伦理的なコーディング:哲学的な原則を人工知能システムに翻訳する
哲学的な原則を人工知能システムに翻訳することは、複雑で必要な作业です。このプロセスは、人工知能アルゴリズムを動かすコードに倫理的な考慮を組み込むことで行われます。
公平性、正義、そして自主性などの概念は、AIシステムの中にコード化されなければならないでしょう。これは、社会的価値を反映してAIが動くことを保証します。これには、伦理学者、エンジニア、社会的科学者が協力して定義し、コーディングプロセスに実装する倫理のガイドラインを作る多跨域アプローチが必要です。
ゴールは、技術的に優れただけでなく、道徳的にも健全なAIシステムを作ることです。これらのシステムは、人間の尊厳を尊重し、社会の福祉を促進するような決定をし得ます(Mittelstadt et al., 2016)。
AIの開発と導入において包容性と equitable accessを促進する
正义と公平さとは、人工知能(AI)の倫理的発展に欠かせない基本的な要素である。ジョン・ロールズ(John Rawls)のロールズの公平さとは正义という概念は、AIシステムが社会の全メンバーにとって有益であるよう設計・導入されることを保証する PHL 哲学的な基盤を提供しています(Rawls, 1971)。
これは、特に最も脆弱な人々(Rawls, 1971)からの多様な視点を含める積極的な努力を含む。
これらの多様な見方を取り入れることで、AI開発者はより公平で、幅広いユーザーニーズに対応するシステムを開発することができます。また、AI技術に equitable access(均等なアクセス)を保証することは、既存の社会的な不平等を悪化させないことが重要である。
アルゴリズムの偏見と公平性について
AI開発におけるアルゴリズムの偏見は、偏見のあるアルゴリズムが社会の不平等を持続し、甚或悪化させることが懸念されています。この問題を解決するためには、プロセスの正義に対する commit(誓約)が必要で、AIシステムがすべての関与者に影響を与える公平なプロセスを通じて開発されることを保証する必要があります(Nissenbaum, 2001)。
これは、トレーニングデータの偏見を识別し、軽減すること、透明で説明可能なアルゴリズムの開発、AIライフサイクル全体で公平性の確認を実施することを含む。
アルゴリズムの偏見に取り組むことで、開発者は、既存の不平等を強化するのではなく、より公正で均等な社会を貢献するAIシステムを作り出すことができます。
AI開発に多様な視点を取り入れる
多様な視点をAIの開発に組み入れることは、それが包括的で平等なシステムを創り出すことに不可欠です。代表性の低いグループの声を含めることで、AI技術は単に社会の狭い範囲の価値観と優先順位を反映するだけではなく、より包括的で平等なものになります。
この取り組みは、参与到民衆主義の哲学的原理に沿っています。これは、包括的で参与型の決定過程の重要性を強調します(Habermas, 1996)。
AI開発に多様な参加を促すことによって、これらの技術が特权の少数によるためだけでなく、全人類の利益をサポートするように設計されることを保証することができます。
AIのギャップを bridge する戦略
AIのギャップは、AI技術とその利益に対する不平等なアクセスを特徴付ける。このギャップを橋渡るためには、分配的正義に着手する必要があります。これにより、さまざまな社会的経済のグループや地域にAIの恩恵が広く分配されます(Sen, 2009)。
これは、未開の地域にAI教育とリソースを提供するイニシアティブや、AI駆動の経済的利益の均等な分配をサポートするポリシーを取りまとめることで実現できます。AIのギャップを取り組むことで、AIが包括的で平等なように、全球開発に貢献することを保証できます。
イノベーションと倫理の制約のバランス
イノベーションを追求することと倫理の制約をバランスすることは、責任あるAIの進展には重要です。不確実性面前に慎重な态度を推進する稳健主義の原則は、AI開発の背景に最も関連性があります(Sandin, 1999)。
革新は進歩を促進する一方で、潜在的な害を防ぐために倫理的な考慮によって抑えられなければならない。新しいAI技術のリスクと利点を慎重に評価し、倫理の標準を守るための規則の実施が必要である。
革新と倫理的な制約をバランスを保って持ち込むことで、AI技術の開発を促进し、社会的福祉の较广いゴールに沿っているようにすることができる。
如你所見、知能システムの哲学的な基盤は、AI技術が开発され、導入される方法が倫理的で、包括的で、人類全体の利益にとって有益であることを保証する Critical Framework を提供する。
これらの哲学的な原則に基づいてAIの開発を行い、知能システムを作成することで、技術的な能力を向上させるだけでなく、生活の質を高める、正義を促進する、AIの利点が社会的にEquitably shared されるようにすることができる。
第5章:AIエージェントはLLM Enhancers
AIエージェントと大規模な言語モデル(LLM)の融合は、人工知能における根本的な変革を表しており、LLMにおける critical limitations が较广い適用を制限してきた。
この統合は、機械が自らの伝統的な役割を超え、被动的なテキスト生成器から、独自の推理と決定能力を持つ自律的なシステムに進化させる。
AIシステムがさらに多くの分野で重要なプロセスを動かしていくにつれて、AIエージェントがLLMの能力のギャップを埋めた方法を理解することは、彼らの完全な可能性を実現するために重要である。
LLMの機能の欠如を补完する
LLMは強力ですが、それらは本能的に、学習されたデータとそのアーキテクチャの静的な性質によって制約されています。これらのモデルは固定されたパラメーターのセットで操作します。通常、学習段階で使用されたテキストのコープスに基づいて定義されます。
この制約のために、LLMは新しい情報を自給的に探すことも、学習後に知識ベースを更新することもできません。したがって、LLMは常に过时しており、最初の学習データを超えたリアルタイムデータや洞察を必要とする、文脈的に関連性のある応答を提供することができません。
AIエージェントは、これらのギャップを動的に外部のデータ源と統合します。これはLLMの機能の範囲を拡大することができます。
例えば、2022年までの金融データで訓練されたLLMは、正確な歴史分析を提供することができますが、リアルタイムの市場予測を生成するのには苦労します。AIエージェントは、このLLMを拡張するために、金融市場からのリアルタイムデータを引き込み、これらの入力を適用して、より関連性のある現在の分析を生成することができます。
この動的統合は、出力がただ歴史的に正確でなく、現在の状況に合わせて文脈的に適切なものです。
決定の自主性を向上させる
LLMのもう一つの重要な制約は、自主的な決定能力の欠如です。LLMは言語ベースの出力を生成することが長所でありますが、不确定性和变化性の高い環境での複雑な決定を要求する課題には適応しません。
この欠如は主にモデルが既存のデータに依存しており、デプロイ後新たな経験から適応的思考や学習の機構の缺乏によるものです。
AIエージェントは、自律的な決定作成に必要なインフラを提供してこの問題を解決します。LLMの静的な出力を取り出し、規則基のシステム、ヒューリスティック、または強化学習モデルなどの高度な推理フレームワークを通して処理することができます。
たとえば、医疗環境では、LLMは患者の症状や医学歴から潜在的な診断を生成することができます。しかし、AIエージェントなしでは、LLMはこれらの選択肢を重み付けたり、行動のコースを推奨したりすることができません。
AIエージェントは、これらの診断に現在の医学文献、患者データ、および状況的な要因に対して評価を行い、最終的により情報量の多い決定を下し、実行可能な次の行動のステップを提示します。これらの協力は、LLMの出力を单纯な提案に留まらず、実行可能で状況意識のある決定に変換します。
完了性と一致性の取り扱い
完了性と一致性は、LLMの出力の信頼性を保証するために重要な要素です特别是在複雑な推理タスクにおいて。パラメータ化された性质のために、LLMは多段階プロセスや異なる領域の幅広い理解を要求する場合に、不完全な response や論理的な一貫性がない response を生成することがあります。
これらの問題は、LLMが操作している孤立した環境に由来しており、外部の標準や追加情報に基づいて cross-reference や validation を行わず、出力を確認することができません。
AIエージェントは、Iterative feedback mechanisms and validation layersを取り引入いて、これらの問題を軽減するために重要な役割を果たしています。
たとえば、法的分野では、LLMは学習データに基づいて法的很短文の最初のバージョンを草稿します。しかし、この草稿は特定の先例を見落としたり、論理的な構造を取れなかったりします。
AIエージェントはこの草稿をレビューし、必要な完璧さを保証するために、外部の法的データベースと比較し、論理的な一貫性を確認し、必要であれば追加情報や説明を求めます。
この迭代プロセスは、法的実践に厳格な要件を満たすようなより強固で信頼性のある文書の生成を可能にします。
孤立している状態を克服するための統合
LLMの最も深刻な制約の1つは、他のシステムや知識の源との固有の隔離です。
LLMは、設計されたとおり、外部の環境やデータベースとのやりとりを行わない、封鎖されたシステムです。この隔離は、新しい情報に适应する能力、または実時間での操作を制限し、動的な交流や実時間の決定を必要とする应用において、有効な働きを果たすことを大きく制限します。
AIエージェントは、LLMをより广いデータ源や計算ツールの生態系に接続する統合プラットフォームとして、この孤立している状態を克服します。APIsや他の統合フレームワークを通じて、AIエージェントは実時間のデータにアクセスし、他のAIシステムと協力し、物的装置ともやりとりすることができます。
例えば、顧客サービスのアプリケーションにおいて、LLMは事前にトレーニングされたスクリプトに基づいて標準的な応答を生成することができます。しかし、これらの応答は静的で、効果的な顧客との取り組みに求められる个性的さを欠くことがあります。
AIエージェントは、顧客プロファイル、過去の取り組み、感情分析ツールからのリアルタイムデータを統合することで、これらの取り組みを豊かにすることができます。これにより、文脈に合わせた応答だけでなく、顧客の特定の需要に合わせた応答を生成することができます。
この統合は、スクリプト化された取り組みのシリーズから、動的で个性的な会話への変換をもたらします。
創造性と問題解決の拡大
LLMはコンテント生成において強力なツールであるが、彼らの創造性と問題解決能力は訓練されたデータに固有の制約を持っています。これらのモデルは、新しいまたは予期しない挑戦に対して理論的な概念を適用することが困難であり、彼らの問題解決能力は既存の知識とトレーニングパラメーターに制約されています。
AIエージェントは、先端の推理技術とより幅広い分析ツールを活用して、LLMの創造性と問題解決能力を向上させます。この能力により、AIエージェントはLLMの制約を超え、理論的な框架を実践的な問題に新しい方法で適用することができます。
たとえば、ソーシャルメディア平台上での不正確な情報の取り除く問題を考えます。LLMは、テキスト分析に基づいて不正確な情報のパターンを识別することができますが、虚偽な情報の広がりを抑制する全面的な戦略を開発することには困難があるかもしれません。
AIエージェントは、これらの洞察を取り入れ、社会学、心理学、およびネットワーク理論などの分野からの多くの学術理論を適用し、リアルタイム監視、ユーザー教育、および自動化的なモデレーション技術を含む健全で多様な取り組み方法を開発することができます。
このような多様な理論框架を合成し、実際の挑戦に適用する能力は、AIエージェントが提供する強化された問題解決能力を示しています。
より具体的な例
AIエージェントは、多様なシステムと交わり、リアルタイムデータにアクセスし、アクションを実行する能力を持っており、これらの限界を直面して解決することで、 LLMを Dynamic, real-world problem solvers に変換します。いくつかの例を見てみましょう。
1. From Static Data to Dynamic Insights: Keeping LLMs in the Loop
-
The Problem: 2023年以前の医学研究に基づいて訓練されたLLMを引用符で「最新的なガン治療の進展は何ですか?」と尋ねると、その知識は古いと思われます。
-
The AI Agent Solution: AIエージェントは、LLMを医学誌、研究データベース、およびニュースフィードに接続することができます。それにより、LLMは最新の臨床試験、治療選択肢、および研究結果の情報を提供できます。
2. 分析から行動へ:LLMの洞察に基づいたタスク自動化
-
問題:品牌のソーシャルメディアをモニターしているLLMは、否定的な感情が急増したことを認識しますが、それに対応することができません。
-
人工知能エージェントソリューション:品牌のソーシャルメディアアカウントに接続され、事前に承認された回答を装備したAIエージェントは、 automaticaly 懸念をaddress、質問に答えることができ、 complex issues を人間の代表にescalate することができます。
3. 初稿から完成の作品へ:品質と正確性を確保する
-
問題:技術的手冊を翻訳するLLMは、領域特定の知識の缺乏により、文法的に正しいが技術的に不正確な翻訳を生成することがあります。
-
AI エージェントの解決策:AI エージェントは、LLM を専門的な辞書、専門用語集に統合し、また、実時間のフィードバックを得るためにそれを主題の専門家に接続することができます。これにより、最終的な翻訳は言語的に正確で、技術的にも健全なものとなります。
4. 壁を打破する:LLM を実際の世界に接続する
-
問題:スマートホームコントロール用に設計された LLM は、用户の変わるルーティンアルと好みに適応することが難しいかもしれません。
-
AI エージェントの解決策:AI エージェントは、LLM をセンサー、スマートデバイス、ユーザーのカレンダーに接続することができます。ユーザーの行動パターンを分析することで、LLM はニーズを予測し、ライトと温度設定を自動的に調整し、時間とユーザーの活動に基づいて個人化されたミュージックプレイリストを提案することができます。
5. 模倣から革新へ:LLMの創造性を拡大する
-
問題: LLMが音楽を作曲しようとしたとき、それは主要に学習データ内で見つかるパターンに依って、似ている曲や感情深さを欠く曲を作り出すことがあります。
-
AIエージェントソリューション: AIエージェントは、作曲家の異なる音楽要素に対する感情反応を測定する生物フィードバックセンサーにLLMを接続することができます。このリアルタイムのフィードバックを取り込むことで、LLMは技術的に熟练し、感情的に訴えかけて、独创的な音楽を作り出すことができます。
AIエージェントをLLMの拡張機能として取り込むことは、渐々の改善ではなく、人工知能が達成できるものの根本的な拡大を意味します。传统のLLMに固有の限界を踏まえると、静的な知識ベース、制御の自律性の制限、及び孤立的な操作環境など、AIエージェントはこれらのモデルがその全ての可能性を発揮することを可能にします。
AI技術がどのようにも進化していくにつれて、AIエージェントがLLMを強化する役割は、これらのモデルの能力の拡大だけでなく、人工知能そのものの境界を再定義することにおいてもより重要になるでしょう。この融合は、人工知能システムの次世代、自給自足な推理能力、実時間の適応能力、そして持続的に変化する世界で新しい問題解決能力を持ったものに道を開くでしょう。
第6章:AIエージェントをLLMに統合するアーキテクチャの設計
AIエージェントをLLMに統合するのには、アーキテクチャの設計が关键です。これは、決定 Makings、適応性、およびスケール性を高めるために重要です。アーキテクチャは慎重に設計され、AIエージェントとLLMの間に流的な交流を可能にし、各コンポーネントが最適に機能するようにする必要があります。
AIエージェントがオーケストラーとして機能し、LLMの能力を指挥するモジュール化されたアーキテクチャは、動的なタスク管理をサポートする一つの方法です。この設計は、LLMの自然言語処理の強みを利用しつつ、AIエージェントがより複雑なタスクを管理し、たとえば実時間環境でのマルチステップ推理やコンテクストUAL決定を可能にするようにする。
ハイブリッドモデル、 LLMと特殊化され、细かく調整されたモデルの結合を、AIエージェントが最適なモデルにタスクを委譲することで、柔軟性を提供する。この手法は、性能を最適化し、幅広いアプリケーションにおいて効率を向上させます。また、多様性と変動性のある運用コンテキストにおいて、特に効果的です(Liang et al., 2021)。

トレーニング方法とベストプラクティス
LLMと統合されたAIエージェントのトレーニングは、一般化とタスク特定の最適化をバランスする方法论を必要とします。
転移学習はここで重要な技術で、大規模で多様なコープスに PretrainedされたLLMを、AIエージェントのタスクに関連した領域の特定のデータにfine-tuneすることができます。この方法はLLMの广範囲の知識ベースを保持しつつ、特定の应用に专业化することで、システムの全体的な効果を向上させます。
また、強制学习(RL)は特に、AIエージェントが変化する環境に適応する必要があるシーンで、重要な役割を果たします。環境との相互作用を通じて、AIエージェントは決断プロセスを持続的に改善することができ、新しい挑戦に対応する能力を向上させます。
異なるシーンで信頼性のあるパフォーマンスを保証するためには、厳密な評価基準が必要です。これには標準的なベンチマークとタスク特定の基準が含まれ、システムのトレーニングが強くなり、包括的であることを保証します(Silver et al., 2016)。
大規模言語モデル(LLM)の细かい調整と強制学習概念の紹介
このコードは、機械学習と自然言語処理(NLP)に関する様々な技術を示しています。それは、大規模な言語モデル(LLM)を特定のタスクによく適応させることと、強化学習(RL)エージェントを実装することを焦点にしています。このコードは、いくつかのキー分野をカバーしています。
-
LLMの细調: BERTなどの预训练されたモデルを利用し、感情分析などのタスクに适応させる。これには、Hugging Faceの
transformersライブラリを使用し、データセットのトークン化や、細調プロセスを指导和するトレーニング引数の使用が含まれます。 -
強化学習(RL): 簡単なQ学習エージェントを用いたRLの基本を介绍します。エージェントは、環境とのやり取りを通じて試行錯誤を行い、Qテーブルを通じて知識を更新することで学びます。
-
OpenAI APIを使用した報酬モデル링: OpenAIのAPIを使用して、RLエージェントに対して動的に報酬信号を提供する概念的な方法。これにより、言語モデルがアクションを評価することができます。
-
モデル評価とログ記録:
scikit-learnなどのライブラリを使用して、精度とF1スコアを通じてモデルの性能を評価し、PyTorchのSummaryWriterを使用してトレーニングの進行を可視化する。 -
高度なRL概念: ポリシー勾配ネットワーク、カリキュラム学習、早期停止などのより高度な概念を実装し、モデルトレーニングの効率を向上させる。
この全体的な方法は、サポート学習、感情分析を通じた最適化を含む、報酬学習の両方をカバーしており、現在のAIシステムがどのように構築、評価、最適化されるかを説明する。
コード例
ステップ1:必要なライブラリを導入する。
モデルの微調整とエージェントの実装に入る前に、必要なライブラリとモジュールをセットアップすることが重要です。このコードには、Hugging FaceのtransformersやPyTorchなど、人気のあるライブラリからのインポートが含まれています。ニューラルネットワークの処理にはPyTorchを使用し、モデルのパフォーマンス評価にはscikit-learnを使用します。また、randomやpickleなどの汎用モジュールも含まれています。
-
Hugging Faceライブラリ: モデルハブから事前学習済みモデルやトークナイザーを使用し、微調整するためのものです。
-
PyTorch: ニューラルネットワークの層や最適化手法など、操作に使用されるディープラーニングのコアフレームワークです。
-
scikit-learn: 精度やF1スコアなどのメトリクスを提供し、モデルのパフォーマンスを評価します。
-
OpenAI API: 報酬モデリングなどのさまざまなタスクに対してOpenAIの言語モデルにアクセスするためのものです。
-
TensorBoard: トレーニングの進捗状況を可視化するために使用されます。
以下は、必要なライブラリーをインポートするコードです。
# 乱数生成のためのrandomモジュールをインポートする。
import random
# transformersライブラリーの必要なモジュールをインポートする。
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# load_datasetをインポートしてデータセットを読み込む。
from datasets import load_dataset
# モデルのパフォーマンスを評価するためのmetricsをインポートする。
from sklearn.metrics import accuracy_score, f1_score
# トレーニング進行を記録するためのSummaryWriterをインポートする。
from torch.utils.tensorboard import SummaryWriter
# トレーニングされたモデルを保存したり読み込むためのpickleをインポートする。
import pickle
# OpenAIのAPIを使用するためのopenaiをインポートする(APIキーが必要)。
import openai
# deep learning操作のためのPyTorchをインポートする。
import torch
# PyTorchのNeural Networkモジュールをインポートする。
import torch.nn as nn
# PyTorchの最適化器モジュールをインポートする(この例で直接使用しない)。
import torch.optim as optim
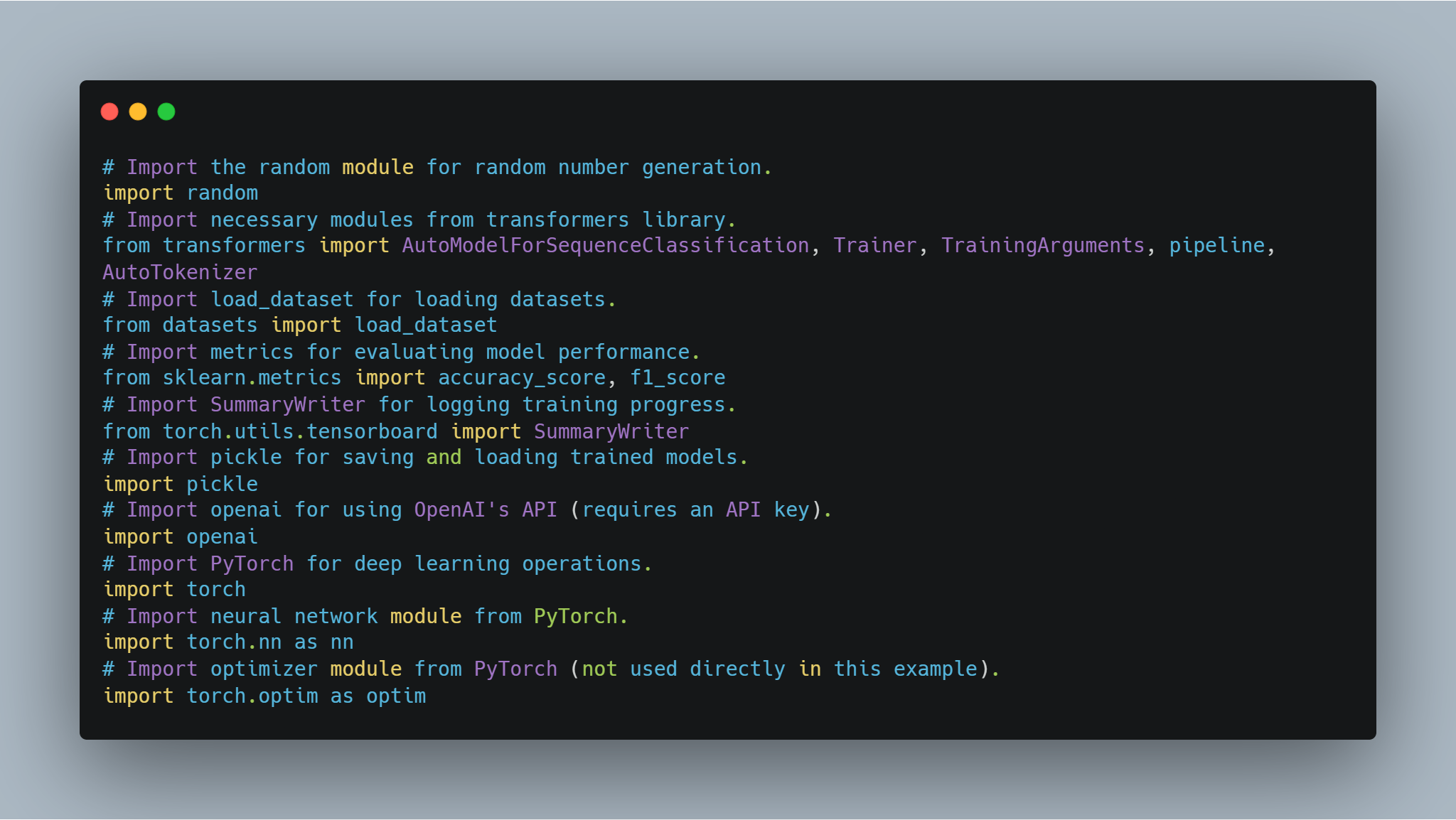
これらのインポートは、モデルのトレーニングと評価から結果の記録や外部APIとのやりとりにおいて重要な役割を果たしています。
ステップ2: 感情分析用のLanguage ModelのFine-tuning
感情分析のような特定のタスクに適用するために、既にトレーニングされたモデルを読み込んだ後、出力ラベルの数(この場合はポジティブ/ネガティブ)に合わせて調整し、適切なデータセットを使用することが必要です。
この例では、transformersライブラリのAutoModelForSequenceClassificationを使用し、IMDBデータセットを使用します。この事前トレーニングされたモデルは、計算時間を節約するために、データセットの小さな一部にfine-tuningすることができます。その後、学習が行われ、学習するための訓練引数を自定制します。それには、エポック数とバッチサイズが含まれます。
以下は、モデルの読み込みとfine-tuningのためのコードです:
# Hugging Face Model Hubから事前トレーニングされたモデルの名前を指定します。
model_name = "bert-base-uncased"
# 指定された出力クラス数で事前トレーニングされたモデルを読み込みます。
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# モデルのためのトークンizerを読み込みます。
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Hugging Face DatasetsからIMDBデータセットを読み込みます。学習には10%のみ使用します。
dataset = load_dataset("imdb", split="train[:10%]")
# データセットをトークン化します。
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# データセットをトークン化された入力にマッピングします。
tokenized_dataset = dataset.map(tokenize_function, batched=True)
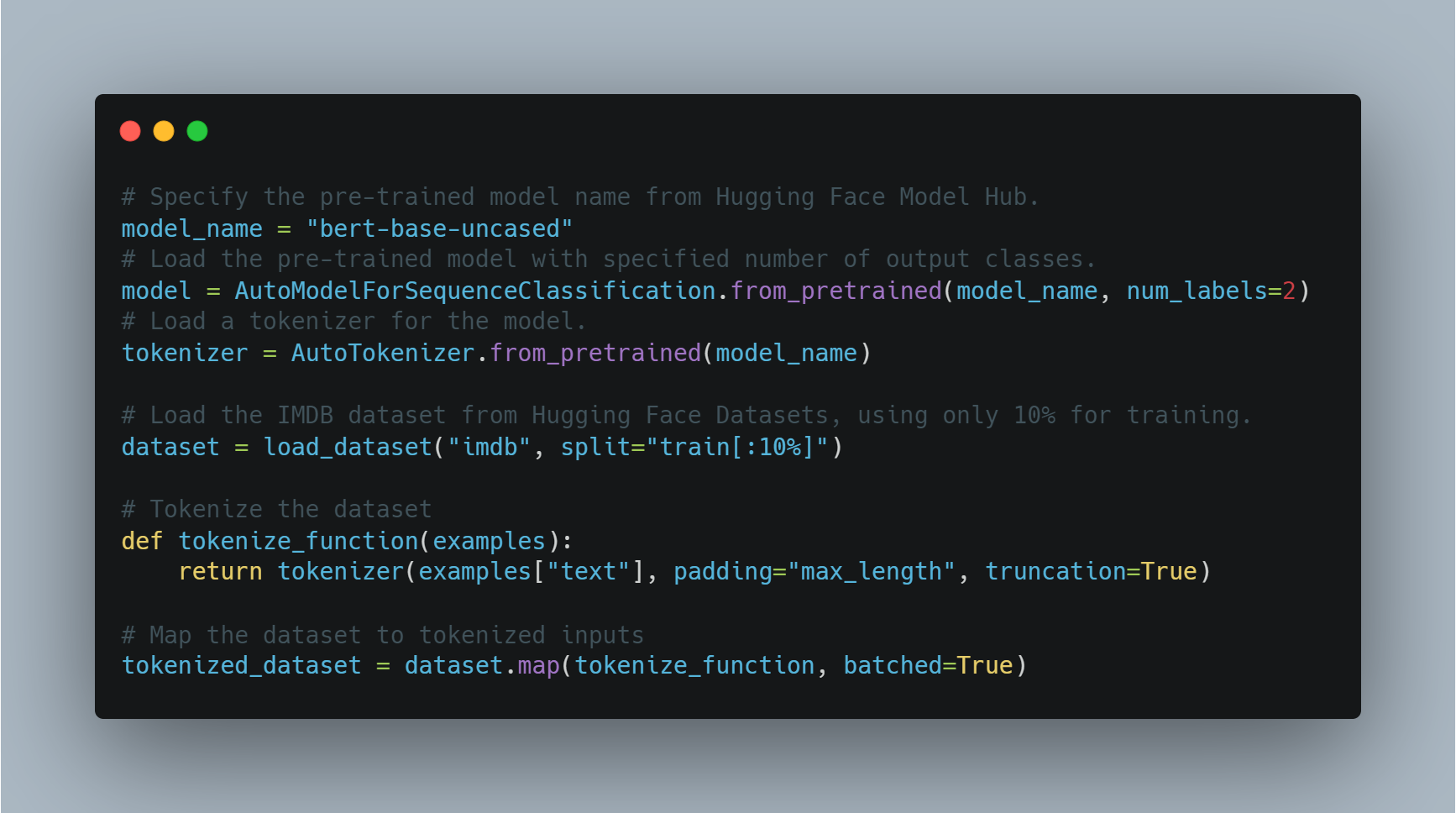
ここで、BERTベースのアーキテクチャを使用してモデルを読み込み、学習のためにデータセットを準備します。次に、学習引数を定義し、Trainerを初期化します。
# トレーニング引数を定義します。
training_args = TrainingArguments(
output_dir="./results", # モデルを保存する出力ディレクトリを指定します。
num_train_epochs=3, # トレーニングエポック数を設定します。
per_device_train_batch_size=8, # 装置ごとのバッチサイズを設定します。
logging_dir='./logs', # ログを保存するディレクトリです。
logging_steps=10 # 10ステップごとにログを記録します。
)
# モデル、トレーニング引数、およびデータセットでTrainerを初期化します。
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# トレーニングプロセスを開始します。
trainer.train()
# 調整されたモデルを保存します。
model.save_pretrained("./fine_tuned_sentiment_model")

手順3: シンプルなQ学習エージェントの実装
Q学習は、エージェントが累计報酬を最大化する动作を学ぶ手段を提供する強制学習技術です。
この例では、Qテーブルに状態行動のペアを記憶した基本的なQ学習エージェントを定義します。エージェントは、乱数で探索するか、Qテーブルに基づいて最も知られている行動を利用することができます。Qテーブルは、学習率とディスカウント因子を使用して、未来の報酬の重み付けによって各行動後に更新されます。
以下は、このQ学習エージェントを実装するコードです。
# Q学習エージェントクラスを定義します。
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Qテーブルを初期化します。
self.q_table = {}
# 可能な行動を存储します。
self.actions = actions
# 探索率を設定します。
self.epsilon = epsilon
# 学習率を設定します。
self.alpha = alpha
# 割引因子を設定します。
self.gamma = gamma
# get_actionメソッドを定義して、現在の状態に基づいて行動を選択することをできます。
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# ランダムに探索します。
return random.choice(self.actions)
else:
# 最良の行動を利用します。
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
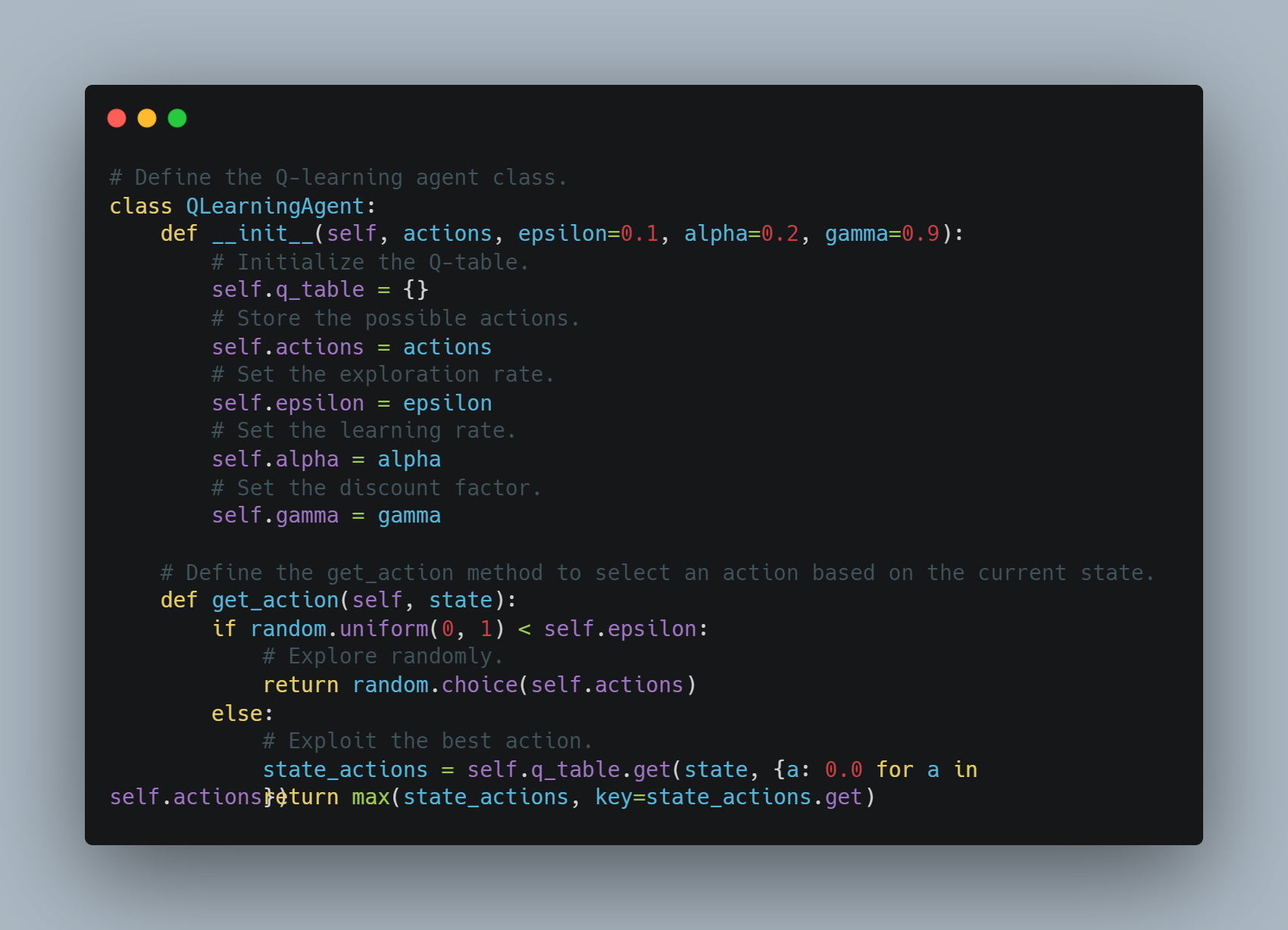
エージェントは、探索または利用に基づいて行動を選択し、各ステップ後にQ値を更新します。
# Qテーブルを更新するupdate_q_tableメソッドを定義します。
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
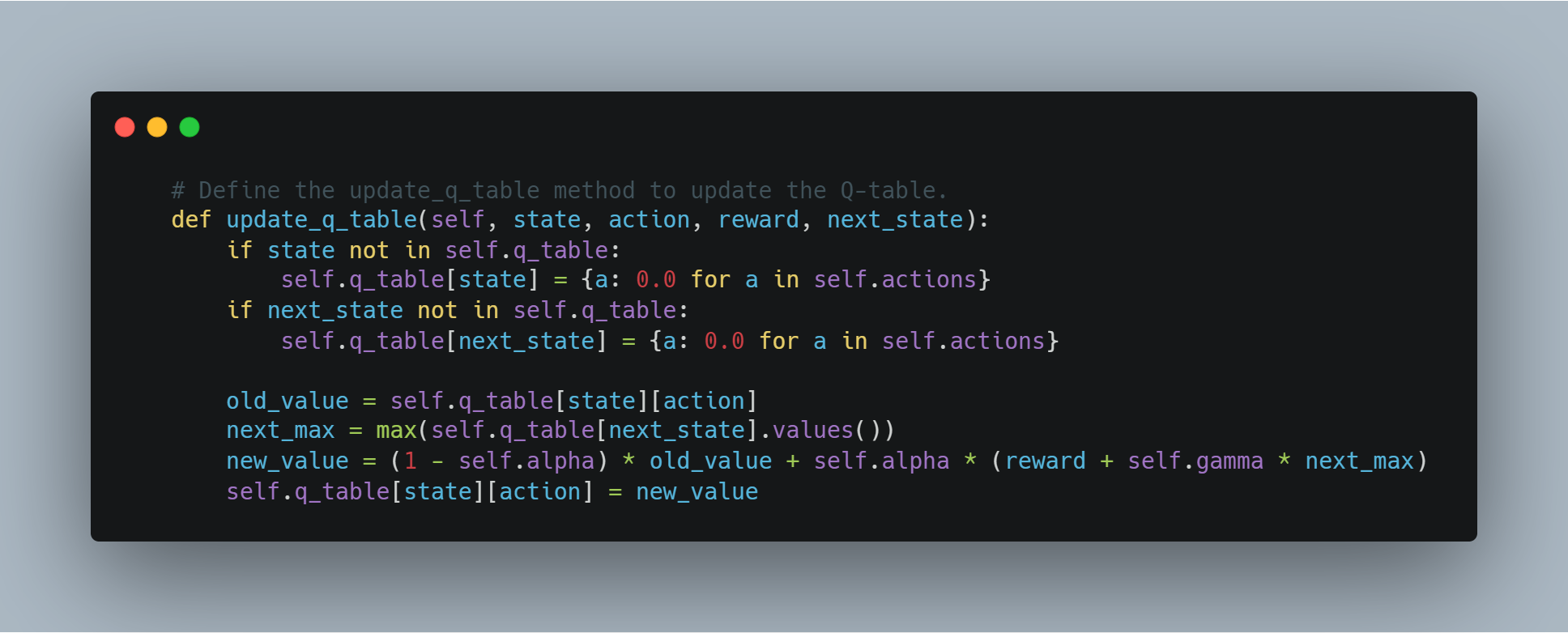
ステップ4: OpenAI APIを使用して報酬モデルを作成する
手動で定義する代わりに、エージェントが行った行動の質を評価するには、OpenAIのGPTなどの強力な言語モデルを使用することができます。
この例では、get_reward関数は状態、行動、次の状態をOpenAI APIに送信し、報酬スコアを受信します。これにより、大きな言語モデルを利用して複雑な報酬構造を理解することができます。
# OpenAI APIから報酬信号を取得するget_reward関数を定義します。
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # 実際のOpenAI APIキーで置き換えてください。
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
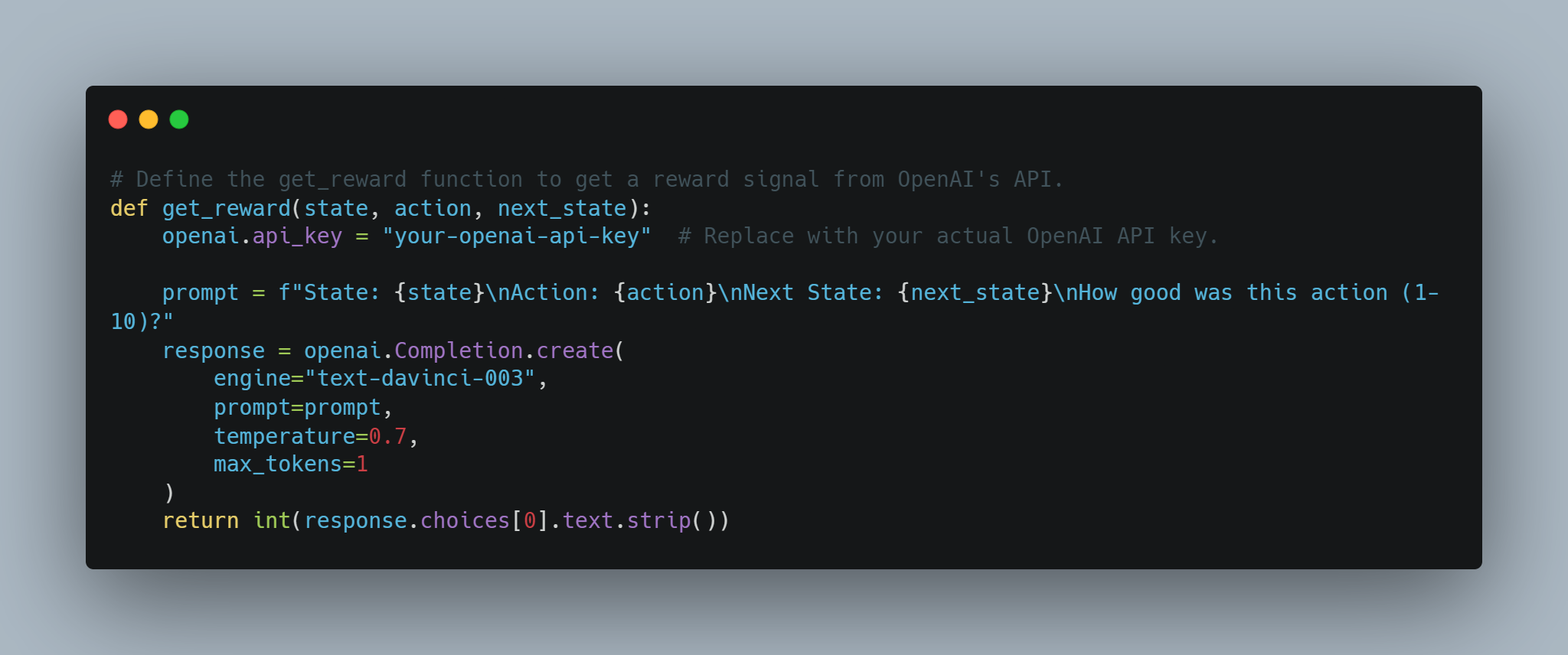
これにより、報酬システムを動的に決定する概念的な方法が可能になり、報酬の定義が難しい複雑なタスクに有用かもしれない。
ステップ5: モデルパフォーマンスの評価
機械学習モデルが訓練された後、その性能を accuracyとF1スコアなどの標準的な指標で評価することが重要です。
この節では、真のラベルと予測されたラベルを使用して両方を計算します。精度は正しい割合を提供し、F1スコアは精度と召回率をバランス付けて使用し、特に不平衡なデータセットで有益です。
ここには、モデルの性能を評価するコードがあります。
# 評価用の真のラベルを定義します。
true_labels = [0, 1, 1, 0, 1]
# 評価用の予測されたラベルを定義します。
predicted_labels = [0, 0, 1, 0, 1]
# 精度スコアを計算します。
accuracy = accuracy_score(true_labels, predicted_labels)
# F1スコアを計算します。
f1 = f1_score(true_labels, predicted_labels)
# 精度スコアを表示します。
print(f"Accuracy: {accuracy:.2f}")
# F1スコアを表示します。
print(f"F1-Score: {f1:.2f}")
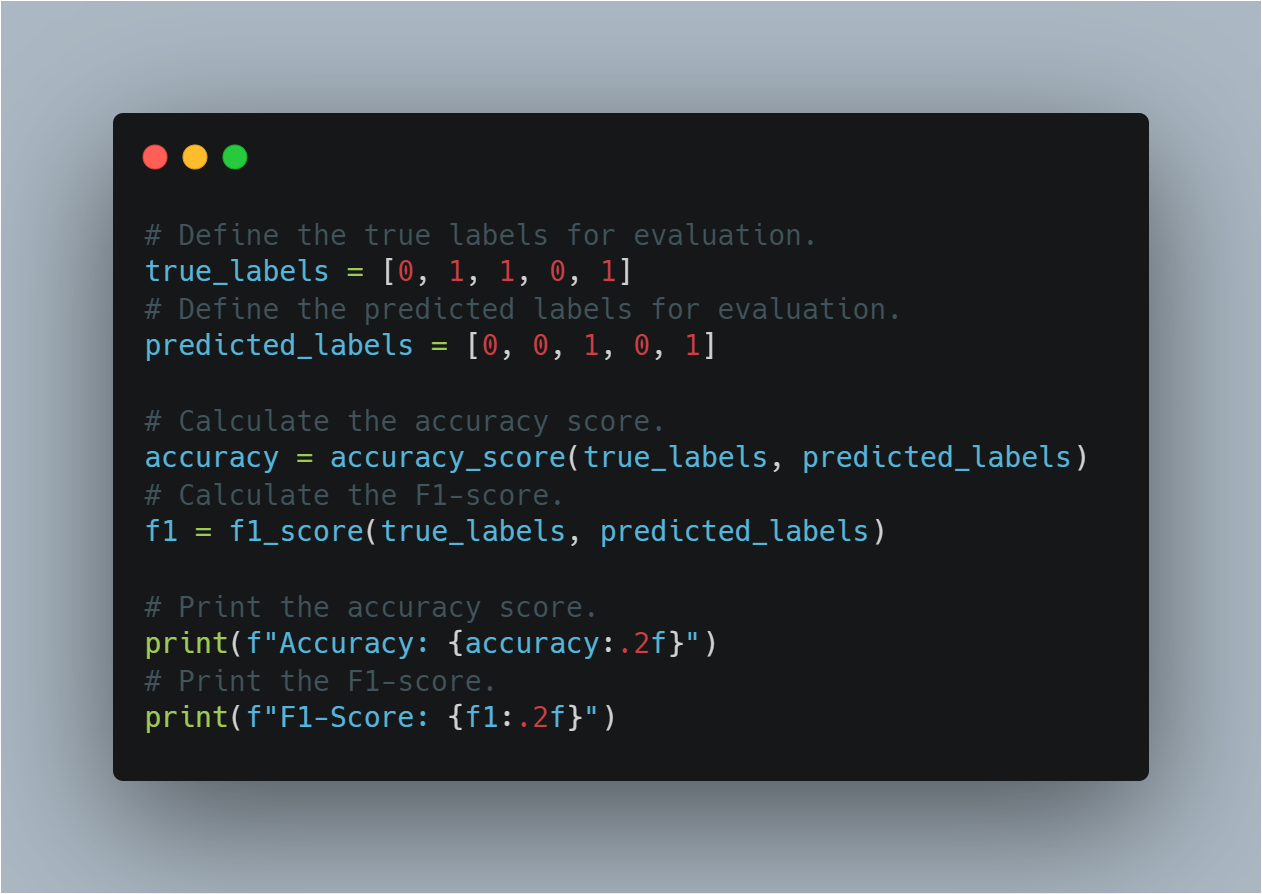
この節は、よくある評価指標を使用して、モデルが見たことのないデータに一般化しているかどうかを評価するために使用します。
ステップ6: 基本的なポリシー勾配エージェント(PyTorchを使用)
強制学习のポリシー勾配方法は、予測報酬を最大化することで直接ポリシーを最適化します。
このセクションでは、PyTorchを使用したポリシーネットワークの簡単な実装を示しています。このポリシーネットワークは、異なる行動に対する確率を出力する線形層を使用し、ソフトマックス関数を適用して、これらの出力が有効な確率分布を形成するようにします。
以下は、基本的なポリシー勾配エージェントを定義する概念的なコードです。
# ポリシーネットワーククラスを定義します。
class PolicyNetwork(nn.Module):
# ポリシーネットワークを初期化します。
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# 線形層を定義します。
self.linear = nn.Linear(input_size, output_size)
# ネットワークの前向きパスを定義します。
def forward(self, x):
# 線形層の出力にソフトマックス関数を適用します。
return torch.softmax(self.linear(x), dim=1)
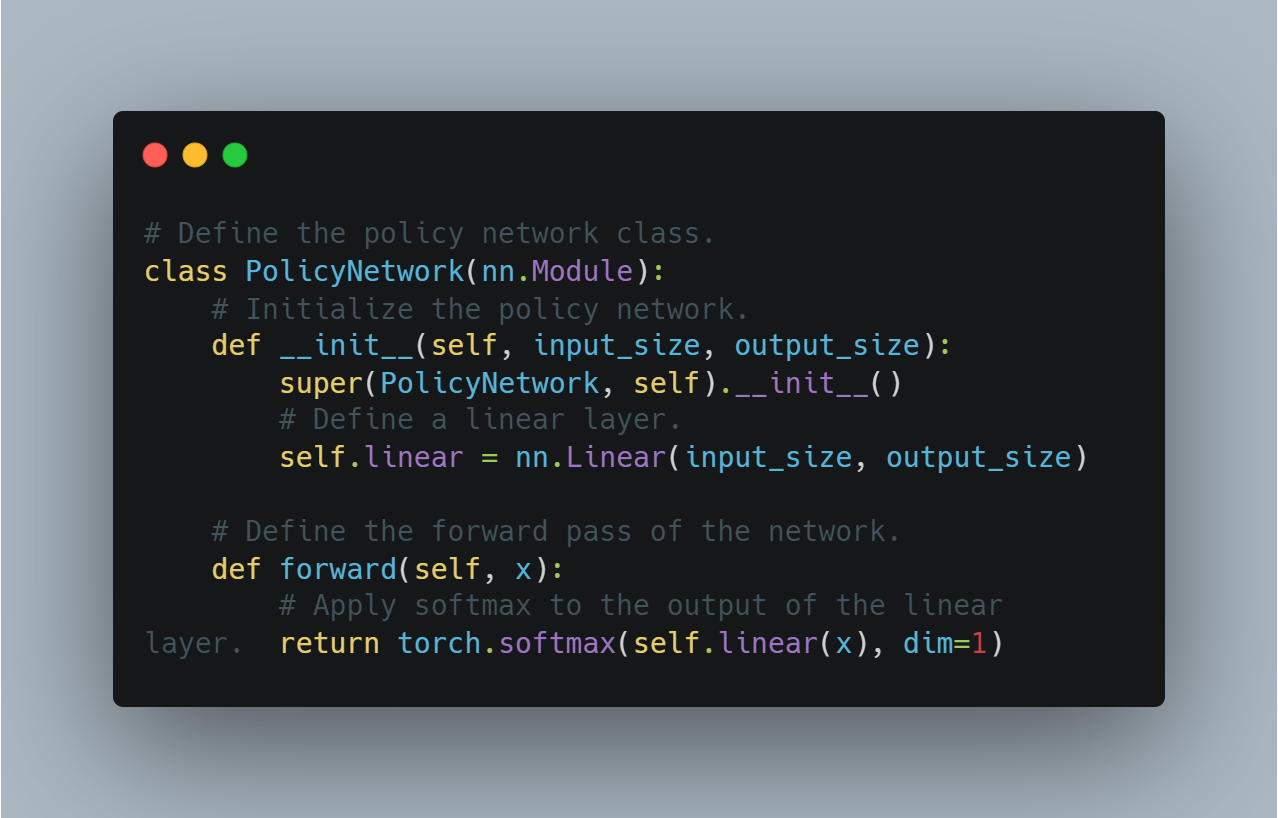
これは、ポリシー最適化を使用するより高度な強化学習アルゴリズムの実装の基础を提供します。
ステップ 7: TensorBoardを使用して学習進行を可視化
学習指標の可視化は、モデルのパフォーマンスが時間とともにどのように変化するか理解するために重要です。これには、テンソルボードという人気のあるツールが使われています。これは、指標を記録して、学習中の損失と精度をリアルタイムで可視化することができます。
このセクションでは、SummaryWriter インスタンスを作成し、学習中の損失と精度を追跡する過程を擬似的にするために乱数値を記録することで、
TensorBoardを使用して学習進行を記録し、可視化する方法は以下の通りです。
# サマリライターのインスタンスを作成する。
writer = SummaryWriter()
# TensorBoardの可視化のための例のトレーニングループ:
num_epochs = 10 # エポック数を定義する。
for epoch in range(num_epochs):
# ランダムな損失と精度の値をシミュレートする。
loss = random.random()
accuracy = random.random()
# 損失と精度をTensorBoardに記録する。
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# サマリライターを閉じる。
writer.close()
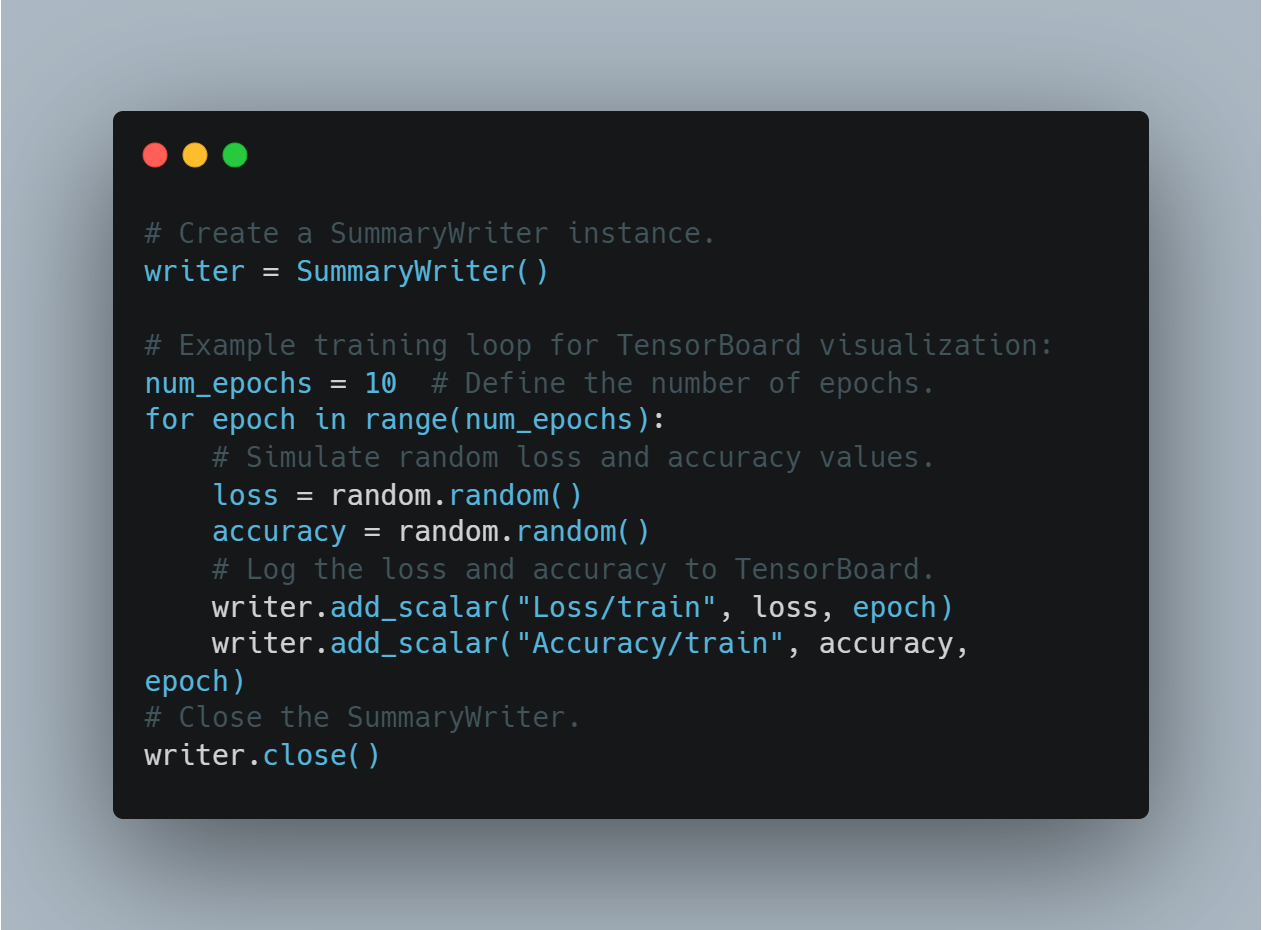
これにより、使用者はモデルの学習をモニターし、視覚的なフィードバックに基づいてリアルタイムの調整を行うことができます。
ステップ8: 学習されたエージェントのチェックポイントの保存と読み込み
エージェントを学習した後、学習された状態(たとえばQ値やモデルの重み)を保存することは、後で再利用または評価することができるように重要です。
この節では、Pythonのpickleモジュールを使用して学習されたエージェントを保存し、ディスクから再読み込む方法を示します。
学習されたQ学習エージェントを保存したり読み込んだりするコードは以下の通りです:
# Q学習エージェントのインスタンスを作成する。
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# エージェントをトレーニングする(ここでは示されていません)。
# エージェントを保存する。
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# エージェントを読み込む。
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
このチェックポイントンのプロセスは、学習の進捗が失われないようにし、将来の実験で再利用できるモデルを提供します。
ステップ9: カリキュラム学習
课程学習は、モデルに与えられる課題の难度を徐々に増やすことで、簡単な例から難しいものに向かって進めます。これは、学習段階のモデルの性能と安定性の改善を助けることができます。
以下は、学習루프で课程学習を使用する例です。
# 初期の課題难度を設定します。
initial_task_difficulty = 0.1
# 課程学習を含む学習루PEを示す例:
for epoch in range(num_epochs):
# 徐々に課題の难度を増やします。
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# 調整された难度でトレーニングデータを生成します。
課題难度を制御することで、エージェントは徐々に複雑な課題に対応する能力を持ちます。これにより学習の効率が改善されます。
ステップ10: 早期停止の実装
早期停止は、トレーニング過程で過学習を防ぐ技術です。一定のepoch数(patience)でvalidation lossが改善されない場合、学習を中断します。
この節は、学習璐PEで早期停止を実装する方法を示します。
以下は、早期停止を実装するコードです。
# 最良の確認損失を無限大に初期化します。
best_validation_loss = float("inf")
# 忍耐値(改善無しのエポック数)を設定します。
patience = 5
# 改善無しのエポックカウンタを初期化します。
epochs_without_improvement = 0
# 早期停止を含む学習ループの例:
for epoch in range(num_epochs):
# ランダムな確認損失をシミュレートします。
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

早期停止は、モデルが過学習し始めたときに不要な学習を防ぐことで、モデルの一般化能力を改善します。
ステップ11: 既に学習されたLLMをゼロショットタスク転移に使用する
ゼロショットタスク転移では、特に最適化されていないモデルをそれに特化されていない任务に適用します。
Hugging Faceのパイプラインを使用して、この節では追加の学習せずに事前に学習されたBARTモデルを要約に適用する方法を示し、転移学習の概念を説明します。
以下は、要約に事前学習されたLLMを使用するコードです。
# 事前学習された要約パイプラインを読み込みます。
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# 要約するテキストを定義します。
text = "This is an example text about AI agents and LLMs."
# 要約を生成します。
summary = summarizer(text)[0]["summary_text"]
# 要約を印刷します。
print(f"Summary: {summary}")
これは、LLMが追加の学習不要で多様な任务を実行する柔軟性を示しています。
完全なコードの例
# 乱数生成のためにrandomモジュールをインポートします。
import random
# transformersライブラリから必要なモジュールをインポートします。
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# データセットをロードするためにload_datasetをインポートします。
from datasets import load_dataset
# モデルの性能を評価するためのmetricsをインポートします。
from sklearn.metrics import accuracy_score, f1_score
# トレーニングの進捗を記録するためにSummaryWriterをインポートします。
from torch.utils.tensorboard import SummaryWriter
# 訓練済みモデルの保存とロードのためにpickleをインポートします。
import pickle
# OpenAIのAPIを使用するためにopenaiをインポートします(APIキーが必要です)。
import openai
# 深層学習の操作のためにPyTorchをインポートします。
import torch
# PyTorchからニューラルネットワークモジュールをインポートします。
import torch.nn as nn
# PyTorchからオプティマイザモジュールをインポートします(この例では直接使用されません)。
import torch.optim as optim
# --------------------------------------------------
# 1. LLMの感情分析用ファインチューニング
# --------------------------------------------------
# Hugging Face Model Hubから事前学習済みモデル名を指定します。
model_name = "bert-base-uncased"
# 指定した出力クラス数で事前学習済みモデルをロードします。
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# モデル用のトークナイザーをロードします。
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Hugging Face DatasetsからIMDBデータセットをロードし、トレーニングに10%のみ使用します。
dataset = load_dataset("imdb", split="train[:10%]")
# データセットをトークン化します。
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# トークン化された入力にデータセットをマップします。
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# トレーニング引数を定義します。
training_args = TrainingArguments(
output_dir="./results", # モデルを保存するための出力ディレクトリを指定します。
num_train_epochs=3, # トレーニングエポック数を設定します。
per_device_train_batch_size=8, # デバイスごとのバッチサイズを設定します。
logging_dir='./logs', # ログを保存するディレクトリ。
logging_steps=10 # 10ステップごとにログを記録します。
)
# モデル、トレーニング引数、データセットでTrainerを初期化します。
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# トレーニングプロセスを開始します。
trainer.train()
# ファインチューニングされたモデルを保存します。
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. シンプルなQラーニングエージェントの実装
# --------------------------------------------------
# Qラーニングエージェントクラスを定義します。
class QLearningAgent:
# アクション、イプシロン(探索率)、アルファ(学習率)、ガンマ(割引率)でエージェントを初期化します。
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Qテーブルを初期化します。
self.q_table = {}
# 可能なアクションを保存します。
self.actions = actions
# 探索率を設定します。
self.epsilon = epsilon
# 学習率を設定します。
self.alpha = alpha
# 割引率を設定します。
self.gamma = gamma
# 現在の状態に基づいてアクションを選択するget_actionメソッドを定義します。
def get_action(self, state):
# イプシロンの確率でランダムに探索します。
if random.uniform(0, 1) < self.epsilon:
# ランダムなアクションを返します。
return random.choice(self.actions)
else:
# Qテーブルに基づいて最適なアクションを選択します。
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# アクションを取った後にQテーブルを更新するupdate_q_tableメソッドを定義します。
def update_q_table(self, state, action, reward, next_state):
# 状態がQテーブルにない場合は追加します。
if state not in self.q_table:
# 新しい状態のQ値を初期化します。
self.q_table[state] = {a: 0.0 for a in self.actions}
# 次の状態がQテーブルにない場合は追加します。
if next_state not in self.q_table:
# 新しい次の状態のQ値を初期化します。
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# 状態-アクションペアの古いQ値を取得します。
old_value = self.q_table[state][action]
# 次の状態の最大Q値を取得します。
next_max = max(self.q_table[next_state].values())
# 更新されたQ値を計算します。
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# 新しいQ値でQテーブルを更新します。
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. OpenAIのAPIを使用した報酬モデリング(概念的)
# --------------------------------------------------
# OpenAIのAPIから報酬信号を取得するためのget_reward関数を定義します。
def get_reward(state, action, next_state):
# OpenAI APIキーが正しく設定されていることを確認します。
openai.api_key = "your-openai-api-key" # 実際のOpenAI APIキーに置き換えます。
# API呼び出しのプロンプトを構築します。
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# OpenAIのCompletionエンドポイントにAPI呼び出しを行います。
response = openai.Completion.create(
engine="text-davinci-003", # 使用するエンジンを指定します。
prompt=prompt, # 構築したプロンプトを渡します。
temperature=0.7, # 温度パラメータを設定します。
max_tokens=1 # 生成するトークンの最大数を設定します。
)
# API応答から報酬値を抽出して返します。
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. モデルの性能評価
# --------------------------------------------------
# 評価のための真のラベルを定義します。
true_labels = [0, 1, 1, 0, 1]
# 評価のための予測されたラベルを定義します。
predicted_labels = [0, 0, 1, 0, 1]
# 正確度スコアを計算します。
accuracy = accuracy_score(true_labels, predicted_labels)
# F1スコアを計算します。
f1 = f1_score(true_labels, predicted_labels)
# 正確度スコアをプリントします。
print(f"Accuracy: {accuracy:.2f}")
# F1スコアをプリントします。
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. 基本的なポリシーグラデーションエージェント(PyTorchを使用) - 概念的
# --------------------------------------------------
# ポリシーネットワーククラスを定義します。
class PolicyNetwork(nn.Module):
# ポリシーネットワークを初期化します。
def __init__(self, input_size, output_size):
# 親クラスを初期化します。
super(PolicyNetwork, self).__init__()
# 線形層を定義します。
self.linear = nn.Linear(input_size, output_size)
# ネットワークのフォワードパスを定義します。
def forward(self, x):
# 線形層の出力にソフトマックスを適用します。
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. TensorBoardでのトレーニング進捗の可視化
# --------------------------------------------------
# SummaryWriterインスタンスを作成します。
writer = SummaryWriter()
# TensorBoard可視化のためのトレーニングループの例:
# num_epochs = 10 # エポック数を定義します。
# for epoch in range(num_epochs):
# # ... (トレーニングループをここに記述します)
# loss = random.random() # 例:ランダムな損失値。
# accuracy = random.random() # 例:ランダムな正確度値。
# # TensorBoardに損失を記録します。
# writer.add_scalar("Loss/train", loss, epoch)
# # TensorBoardに正確度を記録します。
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (他の指標を記録します)
# # SummaryWriterを閉じます。
# writer.close()
# --------------------------------------------------
# 7. 訓練済みエージェントのチェックポイントの保存と読み込み
# --------------------------------------------------
# 例:
# Qラーニングエージェントのインスタンスを作成します。
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (エージェントをトレーニングします)
# # エージェントの保存
# # ファイルをバイナリ書き込みモードで開きます。
# with open("trained_agent.pkl", "wb") as f:
# # ファイルにエージェントを保存します。
# pickle.dump(agent, f)
# # エージェントの読み込み
# # ファイルをバイナリ読み取りモードで開きます。
# with open("trained_agent.pkl", "rb") as f:
# # ファイルからエージェントを読み込みます。
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. カリキュラムラーニング
# --------------------------------------------------
# 初期のタスク難易度を設定します。
initial_task_difficulty = 0.1
# カリキュラムラーニングを使用したトレーニングループの例:
# for epoch in range(num_epochs):
# # タスク難易度を徐々に上げます。
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (調整された難易度でトレーニングデータを生成します)
# --------------------------------------------------
# 9. アーリーストッピングの実装
# --------------------------------------------------
# 最良の検証損失を無限大に初期化します。
best_validation_loss = float("inf")
# 忍耐値(改善のないエポック数)を設定します。
patience = 5
# 改善のないエポック数のカウンタを初期化します。
epochs_without_improvement = 0
# アーリーストッピングを使用したトレーニングループの例:
# for epoch in range(num_epochs):
# # ... (トレーニングと検証ステップ)
# # 検証損失を計算します。
# validation_loss = random.random() # 例:ランダムな検証損失。
# # 検証損失が改善された場合。
# if validation_loss < best_validation_loss:
# # 最良の検証損失を更新します。
# best_validation_loss = validation_loss
# # カウンタをリセットします。
# epochs_without_improvement = 0
# else:
# # カウンタを増やします。
# epochs_without_improvement += 1
# # '忍耐' エポックの間改善がない場合。
# if epochs_without_improvement >= patience:
# # メッセージを表示します。
# print("アーリーストッピングがトリガーされました!")
# # トレーニングを停止します。
# break
# --------------------------------------------------
# 10. 事前学習済みLLMを使用したゼロショットタスク転送
# --------------------------------------------------
# 事前学習済みの要約パイプラインをロードします。
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# 要約するテキストを定義します。
text = "This is an example text about AI agents and LLMs."
# 要約を生成します。
summary = summarizer(text)[0]["summary_text"]
# 要約を表示します。
print(f"Summary: {summary}")

部署とスケーリングにおける課題
LLMを搭載した統合されたAIエージェントの部署とスケーリングには、技術的とOperationalの重要な課題があります。最も主要な課題の1つは、計算コストであり、特にLLMがサイズや複雑性を増やすに伴っています。
この問題を解決するためには、モデルのプリング、量化和分散計算などのリソース効率の高い戦略が必要で、パフォーマンスを損なわないように計算の負担を軽減することができます。
また、実際の应用での信頼性と robustnessの维持も重要で、予期しない入力やシステムの失敗を管理するために常時監視、定期的な更新、およびファイルセーフメカニズムの開発が必要です。
これらのシステムがさまざまな産業で展開されるにつれて、倫理の標準に従っており、公平性、透明性、そして責任を含むことが重要になります。これらの考慮は、システムの受け入れと長期的な成功に関連し、社会的なコンテキストでAIによる決断の倫理的な影響や公共の信頼に影響します(Bender et al., 2021)。
LLMを搭載したAIエージェントの技術的な実装は、慎重なアーキテクチャ設計、厳密なトレーニング方法论、および部署の課題について深思した考慮を含みます。
実際の環境でのこれらのシステムの効果と信頼性は、技術的と倫理的な問題を解決することに依存しており、AI技術がさまざまなアプリケーションでスムーズにとっており、責任感に耐えることが必要です。
第7章:AIエージェントとLLMの未来
LLMと強化学習の統合
将来的に、人工知能エージェントや大規模言語モデル(LLM)の未来について探索すると、LLMとリンforcement学習の統合が特に transformativeな開発となって注目されます。この統合は、 traditionaI AIの边界を押し出し、システムが言語を生成して理解するだけでなく、リアルタイムで彼らとの交流から学びます。
リンforcement学習を通じて、人工知能エージェントは環境からのフィードバックに基づいて自适应的に戦略を変更することができ、決定プロセスを持続的に精练させます。これは、静的なモデルとは異なり、リンforcement学習を強化された人工知能システムは、最少の人間の監督でより複雑で動的な課題に対応できます。
このようなシステムの影響は深いです。自己制御ロボット技術から个别的教習までに及ぶアプリケーションで、AIエージェントは時間とともに自律的に性能を改善し、それぞれの運用コンテキストにおいて、効率を向上させ、変化する要件に対応できるようにすることができます。
例:テキストベースのゲームプレイ
AIエージェントがテキストベースの冒険ゲームをプレイしているところを考えてください。
-
環境:ゲームそのもの(ルール、状態の説明など)
-
LLM:ゲームのテキストを処理し、現在の状況を理解し、可能な行動を生成する(例えば、「北へ行く」、「剣を取る」など)。
-
報酬:ゲームによって行動の結果に基づいて与えられる(例えば、宝を見つけた場合はプラスの報酬、体力を失った場合はマイナスの報酬)。
コードの例(PythonとOpenAIのAPIを使用した概念的なもの):
import openai
import random
# ...(ゲーム環境のロジック - ここには表示されていません)...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ...(RLトレーニングループ - 簡略化されたもの)...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ...(報酬に基づいてRLエージェントを更新する - 表示されていません)...
state = next_state
マルチモーダルAIの統合
マルチモーダルAIの統合は、AIエージェントの将来を形作るもう一つの重要なトレンドです。テキスト、画像、音声、感覚入力など、さまざまなソースからのデータを処理・結合することで、マルチモーダルAIはこれらのシステムが操作する環境をより包括的に理解することができます。
たとえば、自動運転車では、カメラからの視覚データ、地図からのコンテキストデータ、リアルタイムの交通情報を統合することで、AIはより的確かつ安全な運転の判断をすることができます。
この機能は、ヘルスケアなどの他の分野にも拡張される。AIエージェントは、診断画像や遺伝子情報に加えて、病歴からの患者データを統合し、より正確かつ個别的な治療推奨を提供することができます。
ここでの課題は、様々なデータストreamを一貫したものとして統合し、実時間で処理することであり、これにはモデルアーキテクチャとデータ融合技術の進歩が必要です。
これらの課題を成功に乗り越えることで、本当に知的で、複雑な実際の環境で機能することが可能なAIシステムをデプロイすることが关键的になる。
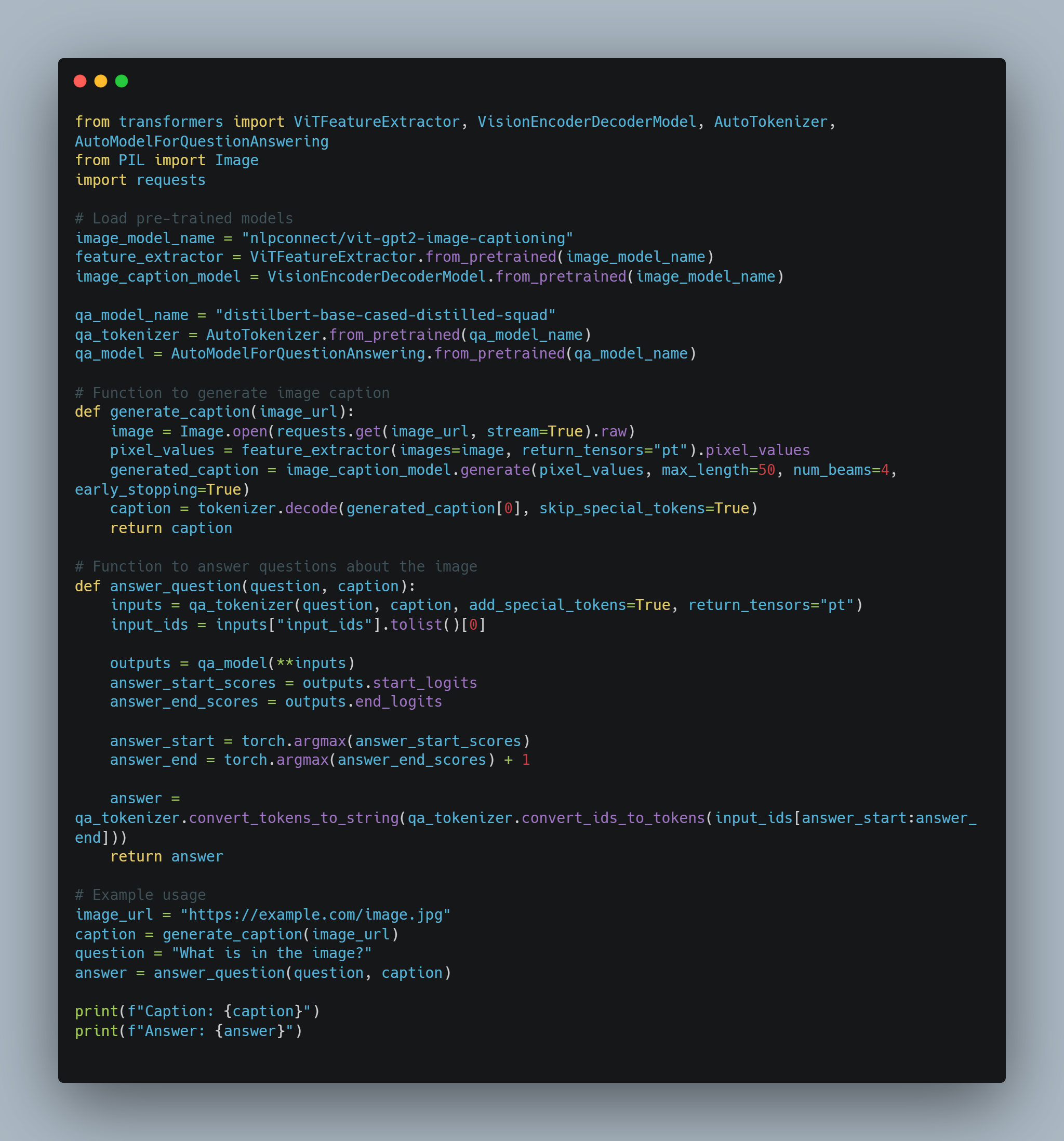
マルチモーダルAIの例1: ビジュアル質問回答のための画像のキャプション
-
目標: 画像について質問を答えるAIエージェント。
-
モーダルITY: 画像, テキスト
-
プロセス:
-
画像特徴抽出: 事前トレーニングされた畳み込み Neural Network (CNN)を使用して画像の特徴を抽出する。
-
キャプション生成: 抽出された特徴に基づいて、画像を説明するキャプションを生成するために、TransformerモデルのようなLLMを使用する。
-
質問回答: 質問と生成されたキャプションを処理して、答えを提供するために別のLLMを使用する。
-
コード例(概念的なPythonとHugging Face Transformersの使用):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# 事前トレーニングされたモデルを読み込む
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# 画像キャプション生成の関数
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# 画像に関する質問を回答する関数
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# 例の使用
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
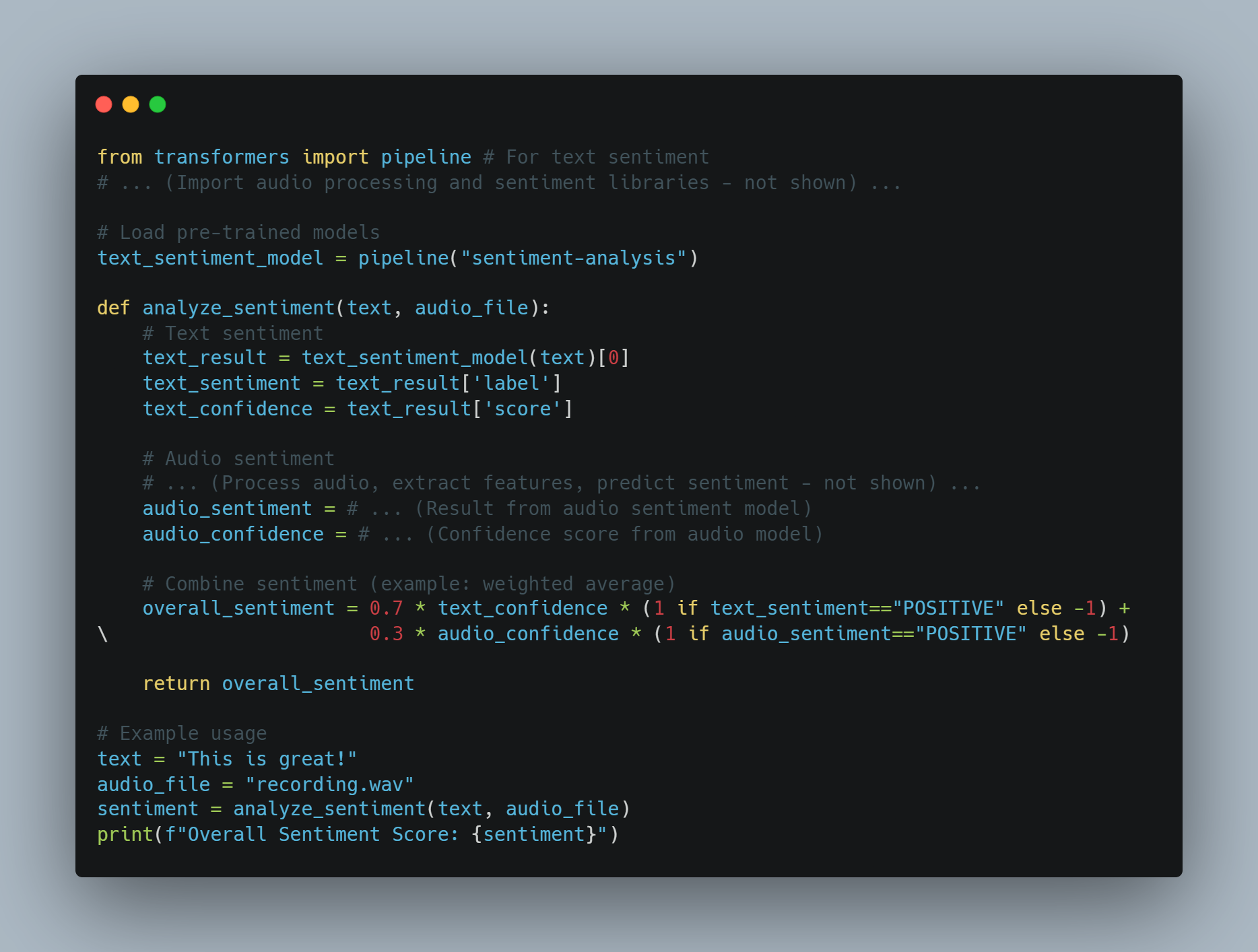
マルチモーダルAIの例2: テキストと音声から感情分析
-
目標: メッセージのテキストと音声から感情を分析するAIエージェント。
-
手法: テキスト、音声
-
プロセス:
-
テキスト感情: テキストに対して事前トレーニングされた感情分析モデルを使用します。
-
音声感情: 音声処理モデルを使用して、音高や調子などの特徴を抽出し、それらを使用して感情を予測します。
-
融合: テキストと音声の感情スコアを(例えば加重平均)結合して、全体の感情を得ます。
-
コード例(Pythonを使用した概念的な例):
from transformers import pipeline # テキストの感情
# ... (音声処理と感情ライブラリーの読み込み - 表示されない) ...
# 事前トレーニングされたモデルの読み込み
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# テキストの感情
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# 音声の感情
# ... (音声の処理、特徴量の抽出、感情の予測 - 表示されない) ...
audio_sentiment = # ... (音声感情モデルの結果)
audio_confidence = # ... (音声モデルの信頼度スコア)
# 感情を合成する (例: 重み付け平均)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# 使用例
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
挑戦と考慮事項:
-
データアラインメント:異なるモーダリティのデータが同期され、合わせられていることを保証することは重要です。
-
モデルの複雑性:マルチモーダルモデルはトレーニングするのに复杂で、大規模で多様なデータセットが必要です。
-
Fusion Techniques:異なるモーダリティの情報を合成する適切な方法を選ぶことは重要で、問題に固有の方法です。
マルチモーダルAIは、AIエージェントが世界を認識し、対話する方法を革命する可能性のある、急速に進化している分野です。
分散型AIシステムと端末コンピューティング
AIインフラの進化を見ていくと、分散型AIシステムに移行する動向は、端末コンピューティングを支えて、重要な進歩を表しています。
分散型AIシステムは、IoTデバイスやローカルサーバーなどの源に近くでデータ処理を行い、集中型クラウドリソースに依存しないように計算タスクを分散させます。このアプローチは、自給自律の无人機や工業自動化などの時間敏感なアプリケーションにおいて重要なlatencyを短縮し、敏感な情報をローカルに保持することでデータのプライバシーと安全性を向上させます。
また、分散型AIシステムはスケーラビリティを向上させ、スマートシティなどの広大なネットワークにAIを展開することができ、集中型データセンターを押し溃しないようにします。
分散型AIに関連する技術的な課題には、分散されたノード間の一貫性と調整、および多様で可能に限られた環境での性能維持のためのリソース割り当ての最適化が含まれます。
AIシステムを開発して部署する際には、分散型アーキテクチャーを取り入れることが、将来のアプリケーションの要望に応じて強固で、効率の高い、スケーラブルなAI解決策を作成する关键になります。
分散型AIシステムと端末処理の例1:プライバシー保護のためのモデルトレーニングの連携学習
-
目標:デバイス間で共有するモデルを訓練する(例えば、スマートフォン)しながら、直接的に敏感なユーザーデータを共有しない。
-
手法:
-
ローカルトレーニング:各デバイスは自分のデータでローカルなモデルをトレーニングする。
-
パラメータ聚合:デバイスはモデルの更新(勾配やパラメータ)を中央のサーバーに送信する。
-
グローバルモデルアップデート:サーバーは更新を聚合し、グローバルなモデルを改善し、改善されたモデルをデバイスに送信する。
-
PythonとPyTorchを使用した概念的なコードの例:
import torch
import torch.nn as nn
import torch.optim as optim
# ... (デバイスとサーバー間の通信コード - 表示されていません) ...
class SimpleModel(nn.Module):
# ... (ここにあなたのモデルのアーキテクチャを定義してください) ...
# デバイス側の学習関数
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # 世界的なモデルから始める
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (device_data上でlocal_modelを学習するコード) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# サーバー側の集約関数
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (主要なフェデレート学習のループ - 簡略化されています) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

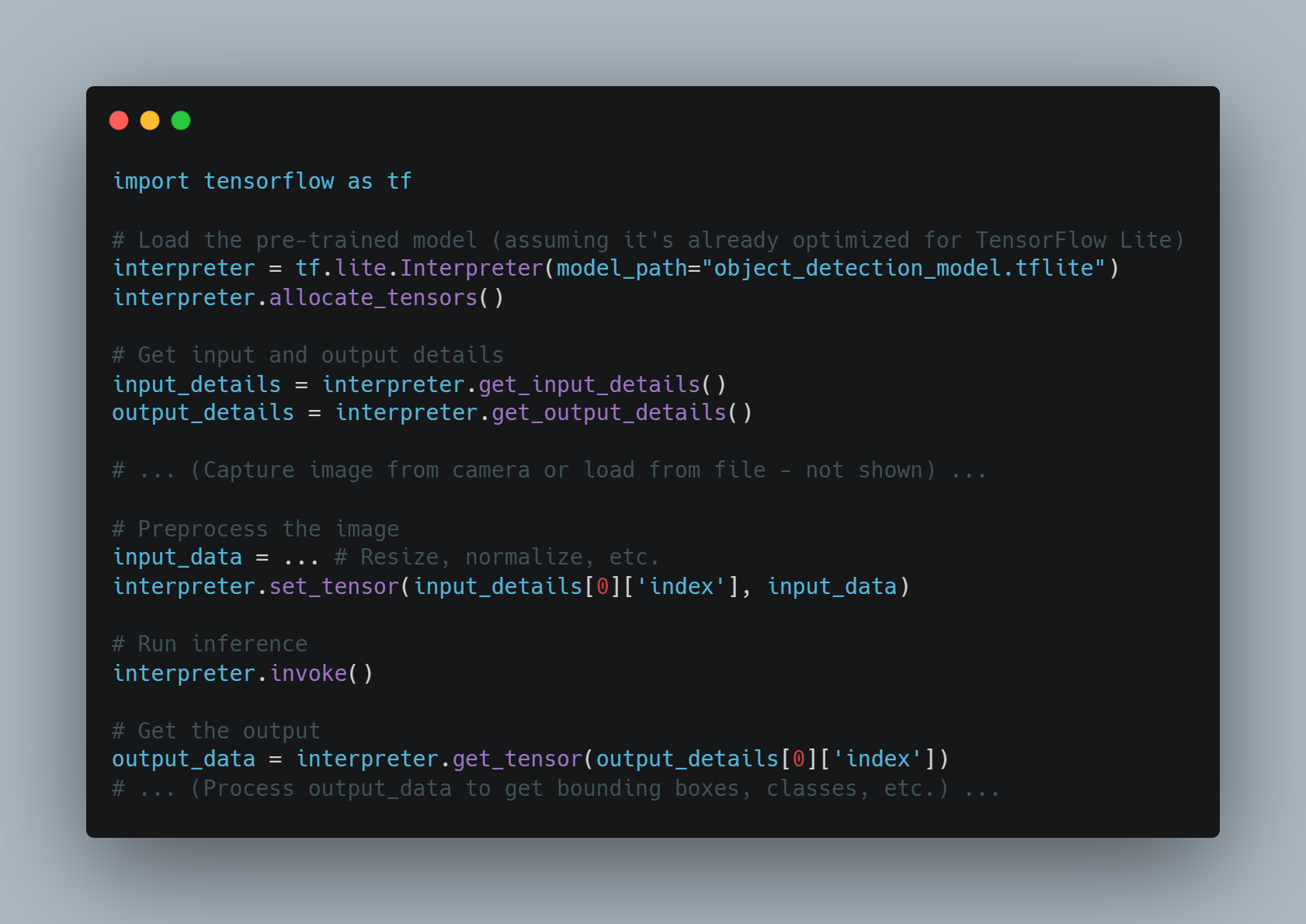
例2: 端末装置上の実时光学物体認識
-
目標: リソース制約されたデバイス (たとえば、Raspberry Pi) 上で物体認識モデルを実時間推論にデプロイします。
-
アプローチ:
-
モデル最適化: モデル量子化や剪定などの技術を使用して、モデルのサイズを縮小し、計算要件を低減します。
-
エッジデプロイメント: 最適化されたモデルをエッジデバイスにデプロイします。
-
ローカル推論: デバイスはローカルに物体検出を行い、レイテンシを短縮し、クラウド通信への依存を減らします。
-
コード例(概念的なPythonとTensorFlow Liteを使用):
import tensorflow as tf
# 事前トレーニングされたモデルを読み込む(TensorFlow Liteに最適化されていると仮定します)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# 入力と出力の詳細を取得する
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (カメラから画像を捕らえたり、ファイルから読み込んだり - 表示されていません... ...) ...
# 画像の前処理を行う
input_data = ... # リサイズ、正規化などを行う
interpreter.set_tensor(input_details[0]['index'], input_data)
# 推論を行う
interpreter.invoke()
# 出力を取得する
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (出力_dataを処理して境界領域、クラスなどを取得する... ...) ...
挑戦と考慮事項:
-
通信オーバーヘッド: 分散したノード間で効率的な調整と通信を行うことは重要です。
-
リソース管理: 装置間でリソースの分配(CPU、メモリ、带宽)を最適化することが重要です。
-
セキュリティ: 分散システムを守ることとデータプライバシーを保護することは最優先の关心です。
分散型人工知能と端末計算は、数十億のインターコネクトされたデバイスの未来に向かっていくにつれて、スケール性、効率、そしてプライバシーに注意を払う人工知能システムを構築するために不可欠です。
自然言語処理の進歩
自然言語処理(NLP)は、人工知能の進歩の先端をいくつか持っています。これは、機械が人間の言語を理解し、生成し、対話する方法に大きな改善をもたらしています。
NLPの最近の発展により、トランスフォーマーとアトテンション機構の進化など、AIが複雑な言語構造を処理する能力が大きく向上しました。これにより、対話がより自然でコンテキストに意識したものになりました。
この進歩により、AIシステムはテキスト内の细微信号、感情、そして甚至於文化参照を理解することができるようになり、より正確で意味深いコミュニケーションを可能にしました。
例えば、顧客サービスでは、先进のNLPモデルは精度よくクエリを処理するだけでなく、顧客の感情的なクールを認識することができ、共感を深め、効果的な対応を行うことができます。
将来的には、NLPモデルにマルチ言語能力とより深い意味理解を統合することにより、彼らの適用性をさらに拡大することができます。これにより、異なる言語や方言を跨えた一貫したコミュニケーションが可能になり、多様な世界的なコンテキストで人工知能システムが実時間の翻訳者として機能することができます。
自然言語処理(NLP)は急速に進化しており、トランスフォーマーモデルやアトテンション機構などの分野でのブレイクスルーがあります。これらの進歩を説明するために、いくつかの例とコードスニペットがあります。
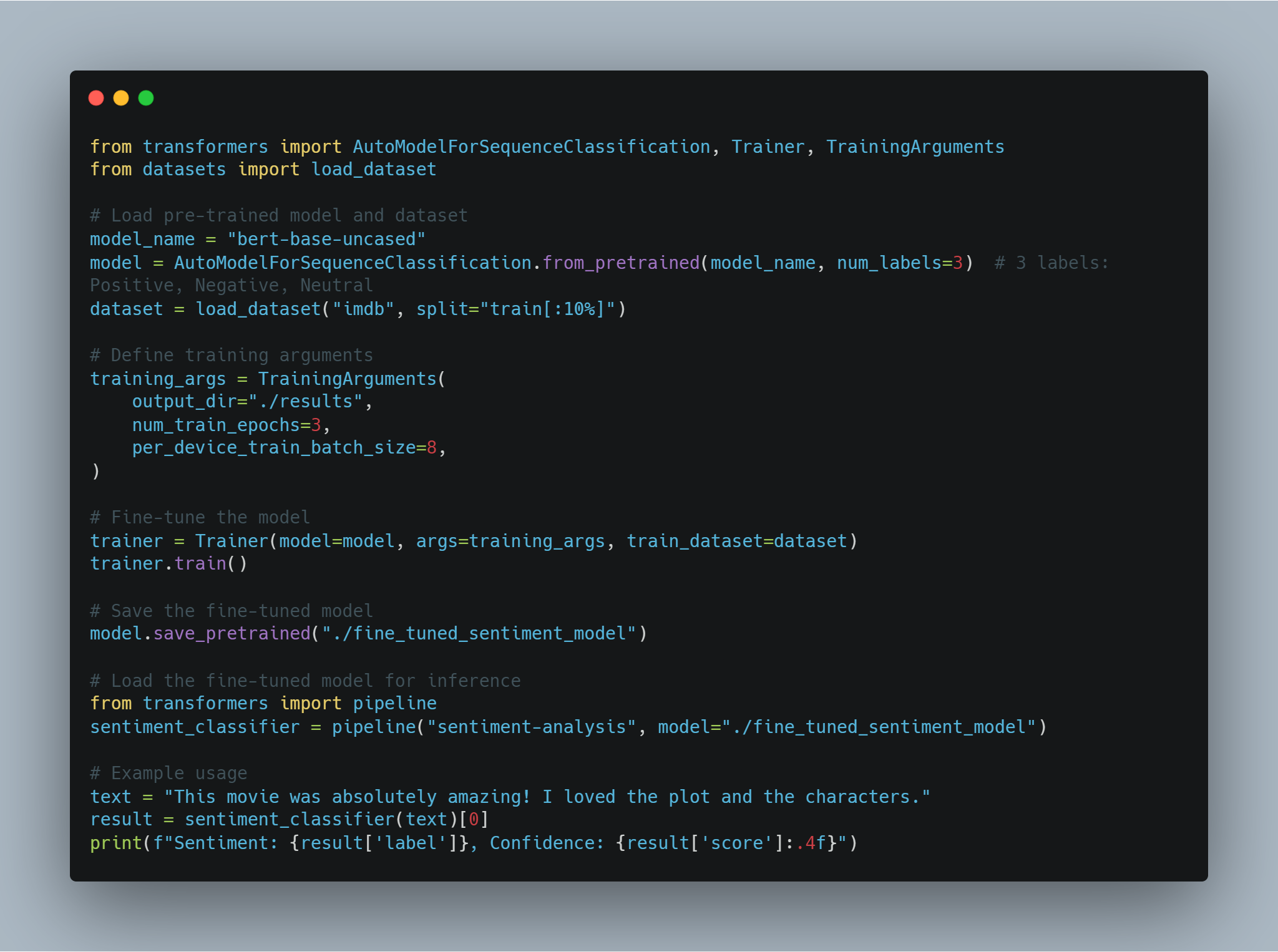
NLPの例1: より正確に感情分析を行うためにfine-tuned Transformersを使用する
-
目標: テキストの感情を分析し、细かいことや上下文を捉えること。
-
方法: 学習済みのtransformersモデル(BERTのような)を感情分析用のデータセットでfine-tuningする。
PythonおよびHugging Face Transformersを使用したコードの例:
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# 学習済みモデルとデータセットを読み込む
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3つのラベル: ポジティブ、ネガティブ、ニュートラル
dataset = load_dataset("imdb", split="train[:10%]")
# トレーニング引数を定義する
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# モデルをfine-tuningする
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# fine-tunedモデルを保存する
model.save_pretrained("./fine_tuned_sentiment_model")
# inference用にfine-tunedモデルを読み込む
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# 例の使用
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
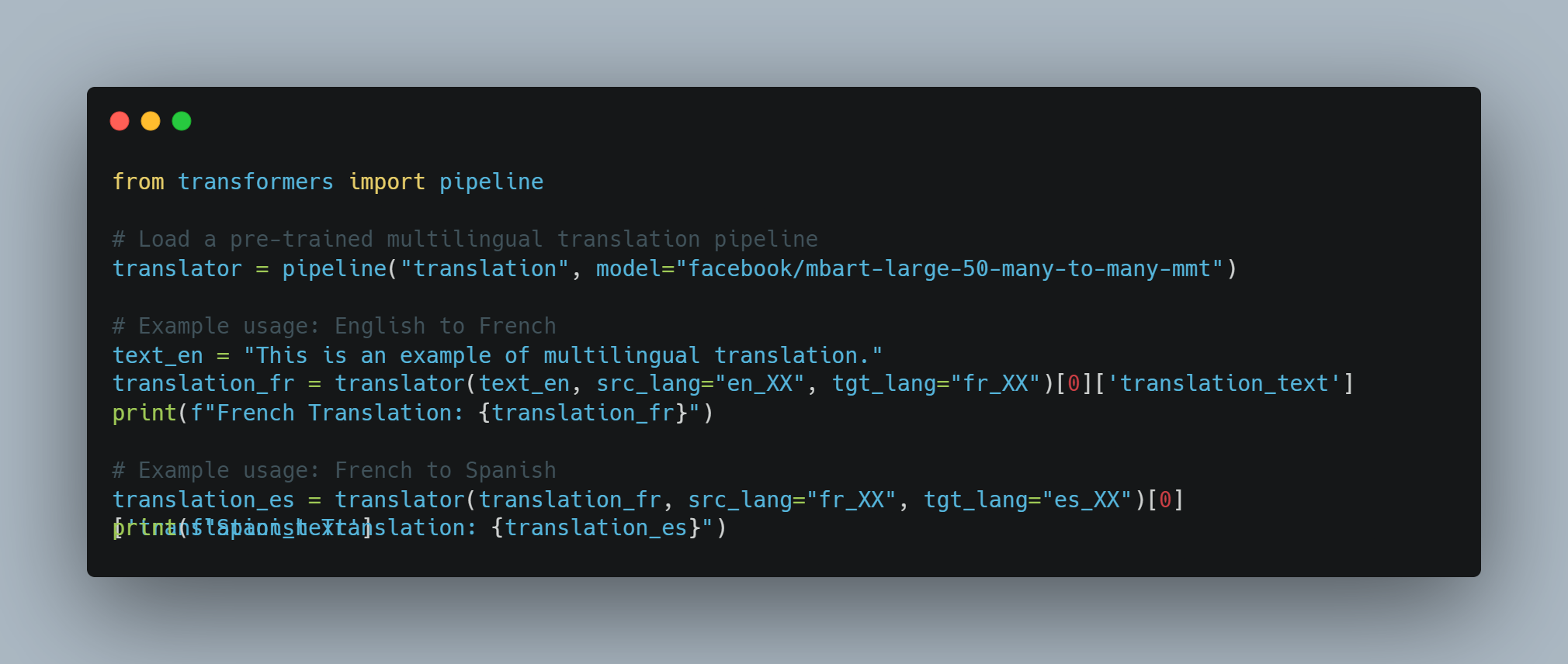
NLPの例2: 1つのモデルでマルチlingual Machine Translation
-
目標: 1つのモデルを使用して複数の言語間で翻訳すること、共有した言語学的な表現を利用する。
-
手法: マルチlingualな大型トランスフォーマーモデル(mBARTやXLM-Rのような)を使用して、複数の言語の大規模の平行テキストデータセットで学習します。
PythonとHugging Face Transformersを使用したコード例:
from transformers import pipeline
# 学習済みのマルチlingual翻訳パイプラインを読み込み
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# 例:英語からフランス語への使用
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# 例:フランス語からスペイン語への使用
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
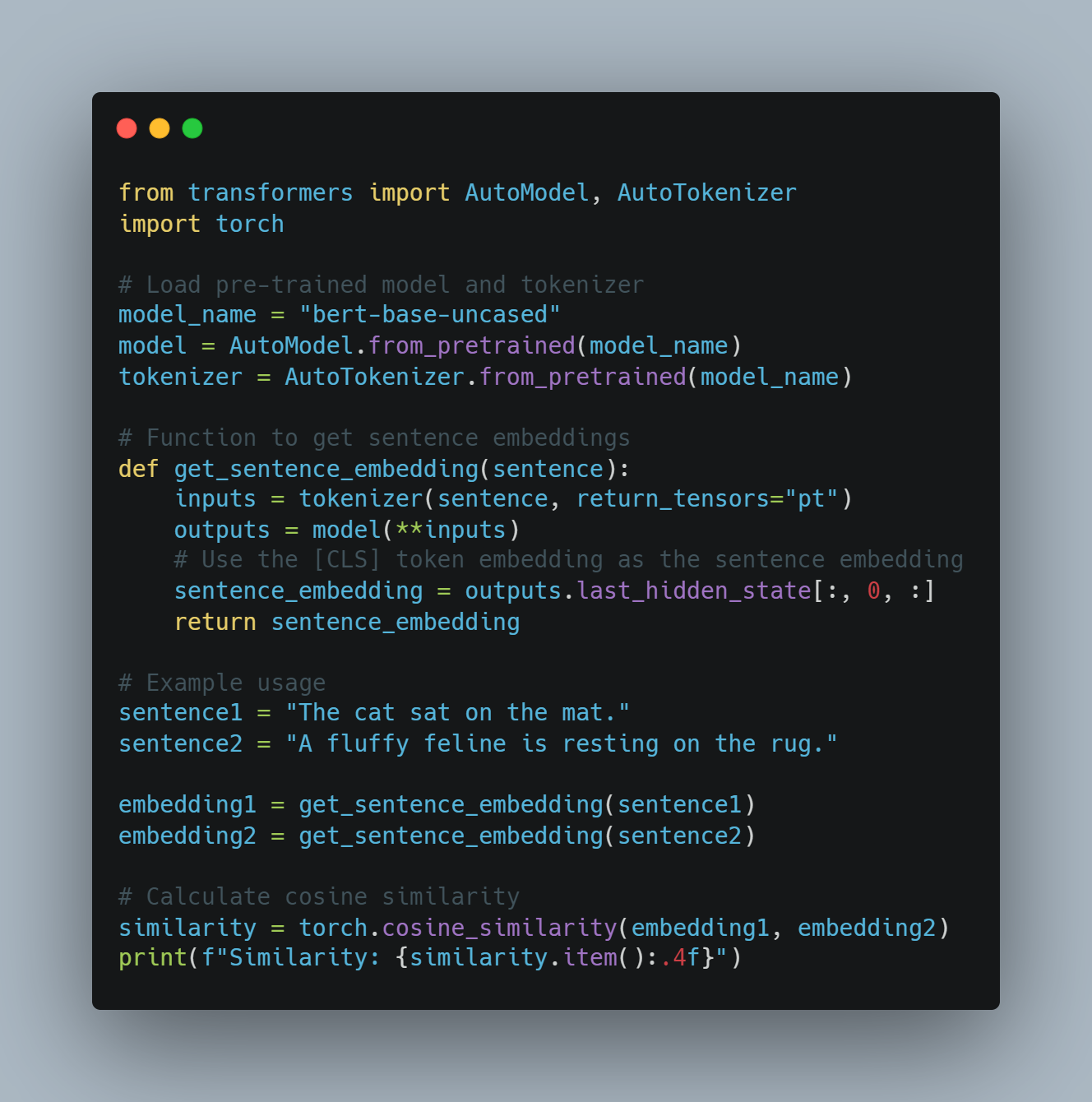
NLP例3: 意味の類似性を捉えるコンテキストUALな単語エンブeddings
-
目標: コンテキストを考慮して単語や文の類似性を決定します。
-
手法: BERTのようなトランスフォーマーモデルを使用して、文の中で単語の意味を捉えるコンテキストUALな単語エンブeddingsを生成します。
PythonとHugging Face Transformersを使用したコード例:
from transformers import AutoModel, AutoTokenizer
import torch
# 学習済みモデルとトークナイザーを読み込む
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 文章嵌入を取得する関数
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# [CLS]トークン嵌入を文章嵌入として使用する
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# 例の使用
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# コサイン類似度を計算する
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
挑戦と将来の方向性:
-
偏見と公正性: NLPモデルは学習データから偏見を引き継ぎ、不公平または差別的な結果につながることがあります。偏見を取り除くことは重要です。
-
共感の理解: LLMは共感の理解においてもまだ困難を期しており、暗黙の情報を理解するために苦労しています。
-
説明可能性: 複雑なNLPモデルの決定プロセスは不透明であり、特定の出力を生成する理由を理解するのが困難です。
これらの挑戦にも関わらず、NLPは急速に進化しています。マルチモーダル情報の統合、共通の知恵の推理の改善、説明性の向上が、AIが人間の言語とのやり取りを革新するに至る鍵となる研究領域で、進行中です。
個人化されたAIアシスタント
個人化されたAIアシスタントの将来は、基本的なタスク管理を超えて、個人的な需要に合わせた真正の直观的なプロアクティブなサポートにまで進展するであろうです。
これらのアシスタントは、高度な機械学習アルゴリズムを利用して、行動、好み、ルーティンあるいは习惯から学び続け、个性化的な推奨を提供し、より複雑なタスクを自動化するようになります。
たとえば、個人化されたAIアシスタントは、スケジュール管理だけでなく、過去の偏好や気分に基づいて環境を調整したり、関連リソースを提案したりすることで、ユーザーの需要を予測することができます。
AIアシスタントが日常的により整合し、プラットフォーム間でスムーズなサポートを提供する能力が主要な区別要素となります。この課題は、プライバシーと個人化のバランスを保証するために、機能的なデータ保護機構を必要とします。これにより、機密情報が安全に管理されながら、深い個人化された体験を提供できます。
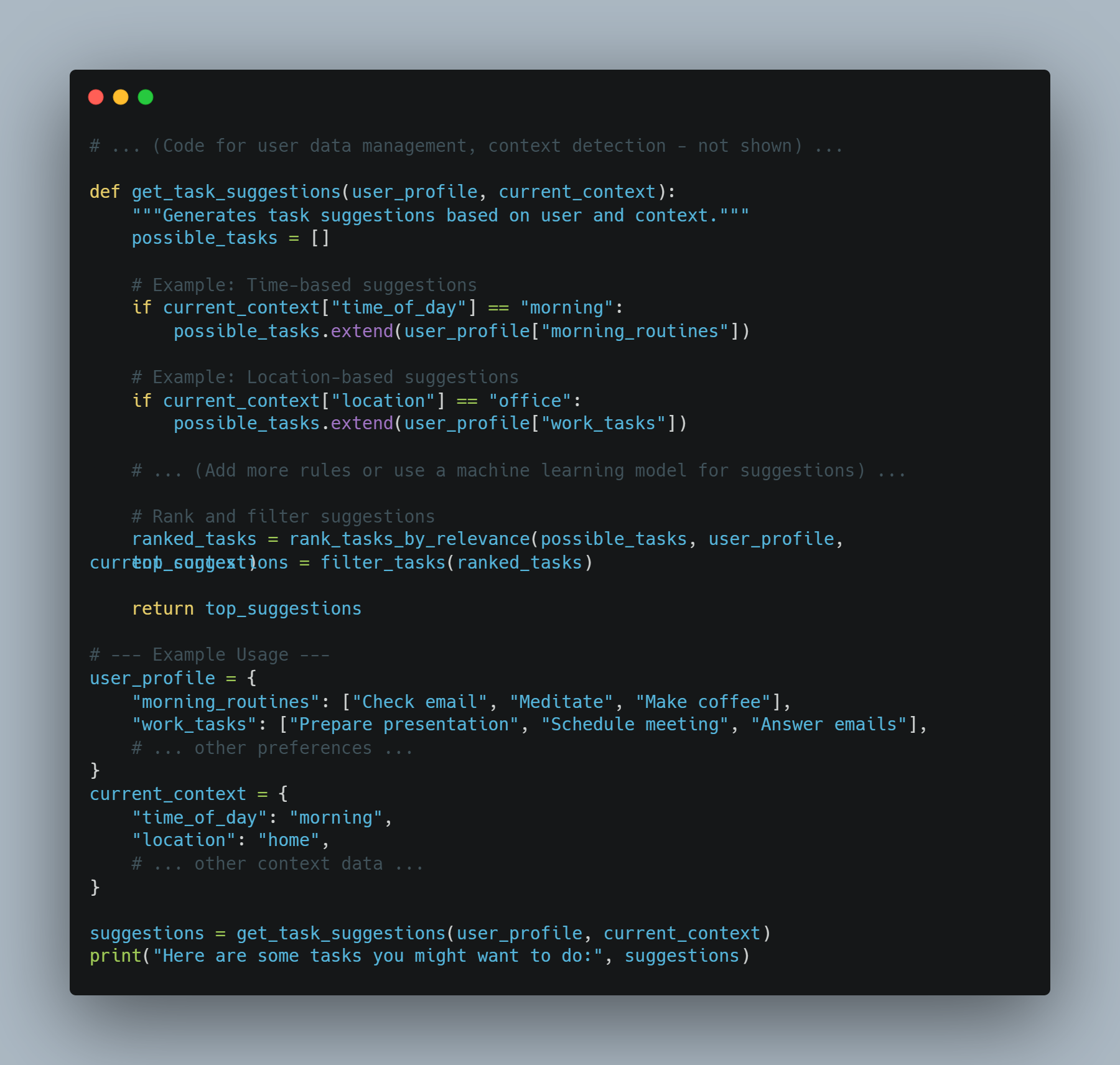
AIアシスタントの例1: コンテキスト感知のタスク推奨
-
ゴール: 現在のコンテキスト(場所、時間、過去の行動)に基づいてユーザーにタスクを推奨するアシスタント。
-
アプローチ: ユーザーデータ、コンテキスト的な信号、および作業推奨モデルを結合する。
コード例(Pythonを使用した概念的な例):
# ... (ユーザーデータ管理、コンテキスト検出のコード - 表示されない) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# 例:時間に基づいた提案
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# 例:位置に基づいた提案
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (提案にたいする追加のルールまたは機械学習モデルを使用する) ...
# 提案の順位付けと絞り込み
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- 使用例 ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... その他の好み ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... その他のコンテキストデータ ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
AIアシスタントの例2: プロアクティブな情報提供
-
ゴール: ユーザーのスケジュールと好みに基づいて適切な情報をプロアクティブに提供するアシスタント。
-
アプローチ: カレンダーデータ、ユーザーの趣味、およびコンテンツ取得システムを統合する。
Pythonを使用した概念的なコード例:
# ... (カレンダーアクセス、ユーザーの興味のプロファイル - 表示されない) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (会社情報、参加者プロファイルなどを取得) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (フライトステータス、目的地情報などを取得) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- 使用例 ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... その他の好み ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

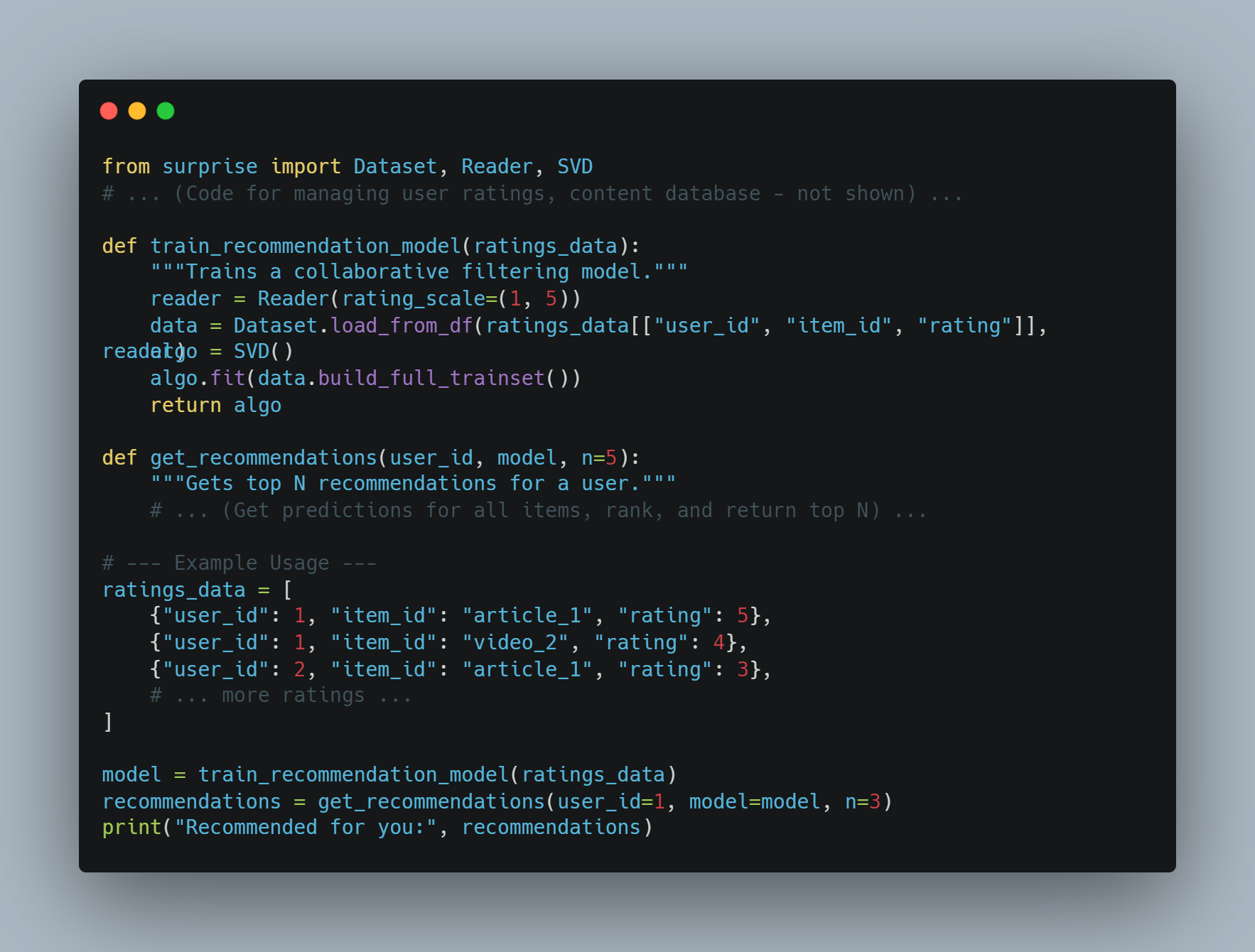
AIアシスタントの例3:個人化コンテント推奨
-
目標: ユーザーの好みに合わせてコンテント(記事、動画、音楽)を推奨するアシスタント。
-
アプローチ: コラボフィルタリングやコンテントベースの推奨システムを使用する。
PythonとSurpriseのようなライブラリを使用した概念的なコード例:
from surprise import Dataset, Reader, SVD
# ... (ユーザーの評価、コンテンツデータベースを管理するコード - 表示しない) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (すべてのアイテムの予測、ランクを取得し、N以内の最も上位のものを返す) ...
# --- 例の使用法 ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... もっと評価 ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
課題と倫理上の考慮:
-
データプライバシー: ユーザーのデータを責任ある所存で处理し、透明にすることは非常に重要です。
-
偏見と公正性: 個人化は既存の偏見を拡大するべきではありません。
-
ユーザーコントロール: ユーザーは自分のデータと個人化設定を控制するべきです。
个性的なAIアシスタントを開発するためには、技術的な面も倫理的な面も慎重に考慮する必要があります。助けのある、信頼性のある、ユーザーのプライバシーを尊重するシステムを作るために。
創造的産業におけるAI
AIは創造的産業に大きな影響を与えており、芸術、音楽、映画、文学の生成と消費の方法を変えています。生成型モデルの進歩により、GANsやトランスフォーマーベースのモデルなどが人間の創造力を凌駕するコンテンツを生成することができました。
例えば、AIは特定のジャンルやムードを反映した音楽を作曲すること、有名の絵画家のスタイルを模倣するデジタルアートを创作すること、そして映画や小説の物語の构成を草稿することもできます。
広告産業では、AIを使用して個人的なコンテンツを生成し、個人的な消费者と共感させることで、関心を深め、効果を高めています。
しかし、創造的な分野でのAIの成長は、著者性、独创性、そして人の創造性の役割についての疑問を引き起こします。あなたがこれらの分野でAIと取り組む際には、AIが人の創造性を取代する代わりに、それを补強することで、人と機械の协作を促進し、革新的で影響力のあるコンテンツを生み出すことが非常に重要です。
以下は、GPT-4をPythonプロジェクトに创造的なタスクに統合する方法の一例です。特に、詩のような創造的なテキスト形式の生成に適用しています。
import openai
# OpenAI API キーを設定する
openai.api_key = "YOUR_API_KEY"
# 詩を生成する関数を定義する
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# 例の使用
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
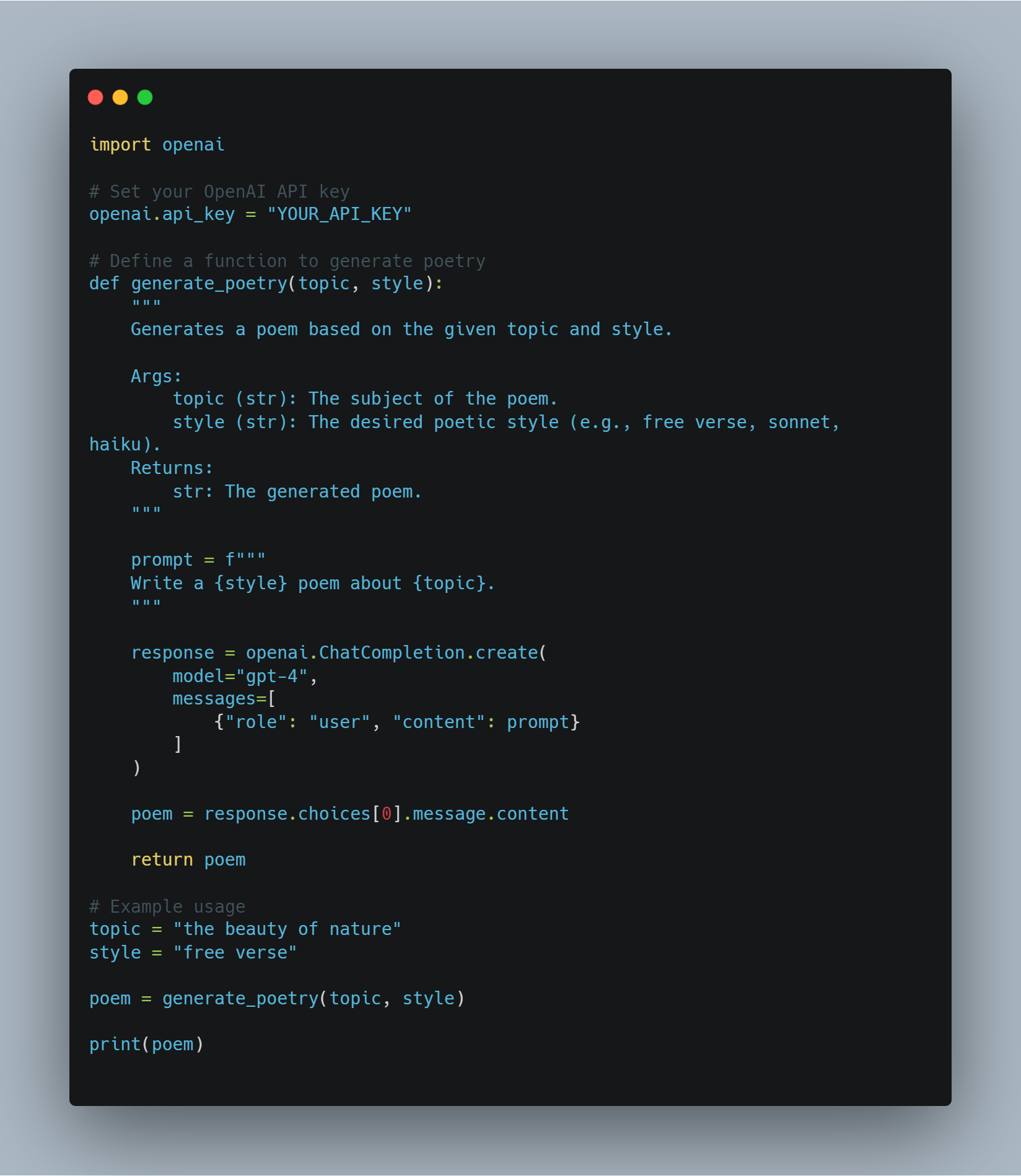
どうやってここまで来たのかを見てみましょう。
- OpenAI ライブラリを導入: このコードでは、OpenAI APIにアクセスするために最初に
openaiライブラリを導入します。 - API キーを設定:
"YOUR_API_KEY"をあなたの実際のOpenAI API キーに置き換えてください。 - 関数 `generate_poetry` を定義する: この関数は詩の `topic` と `style` を入力として、OpenAIのChatCompletion APIを使用して詩を生成します。
- プロンプトを構築する: プロンプトは `topic` と `style` をGPT-4に対する明確な指示として結合します。
- GPT-4にプロンプトを送信する: コードは `openai.ChatCompletion.create` を使用してプロンプトをGPT-4に送信し、生成された詩を返信として受け取ります。
- 詩を返却する: 生成された詩は返信から抽出され、関数から返却されます。
-
使用例: このコードは、
generate_poetry関数を特定の主题とスタイルで呼び出す方法を示しています。その結果の詩は、その後コンソールに出力されます。
AI駆動の仮想世界
AI駆動の仮想世界は、インマersion体験における重要な飛躍を表しています。AIエージェントは、インタラクティブでユーザーの入力に反応することができる仮想環境を作成、管理、および進化させることができます。
AIを驱使したこれらの仮想世界は、複雑な生態系、社会的な交流、および動的な物語をシミュレートすることができ、ユーザーには深い関与と个性化的な経験を提供します。
たとえば、ゲーム産業では、AIを使用して、プレイヤーの行動から学び、行動や戦略を適切に変更する非プレイヤーキャラクター(NPC)を作成することができます。これにより、より困難な体験や現実的な経験を提供することができます。
ゲームを超えて、AI駆動の仮想世界は教育においても応用できます。虚拟的な教室は、个别の学生の学習スタイルと進みに応じて調整できます。また、企業トレーニングにおいても、現実的なシミュレーションが従業員にさまざまな状況に対応する準備をすることができます。
これらの仮想環境の未来は、AIが実時間で大規模で複雑なデジタル生態系を生成および管理する能力の向上に依存しており、ユーザーデータについての倫理的な考慮や高いインマersion体験の心理学的影响についての考慮に基づいています。
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
エージェントを初期化する
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
環境内の随机の位置に配置する
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
エージェントを作成して追加する
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
エージェントの移動(デモ用の簡略化された移動)
for agent in self.agents:
agent.move(self.environment)
TODO: エージェント間の交流、環境の変更などにはより複雑なロジックを実装する
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
移動方向を決定する(この例では随机)
direction = random.choice(['N', 'S', 'E', 'W'])
方向に基づいて移動を適用する
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
エージェントの新しい位置を反映して環境を更新する
environment[self.position[1]][self.position[0]] = self.agent_type[0]
使用例
if __name__ == "__main__":
世界のパラメーターを定義する
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
虚拟的な世界を作成する
world = VirtualWorld(environment_size, agent_types, agent_properties)
数ステップごとに世界をシミュレートする
for _ in range(10):
world.update()
world.display()
print() より良い可読性を위해空行を追加する
このコードで何が行われているかというと、以下のようになります。
-
仮想世界クラス:
-
仮想世界の核心を定義します。
-
環境格子、エージェントのリスト、およびエージェント関連情報を含みます。
-
__init__(): サイズ、エージェントの種類、および特性を初期化します。 -
add_agent(): 指定した種類の新しいエージェントを世界に追加します。 -
update(): 世界の一つの時間ステップの更新を行います。- 現在、エージェントの移動しか行われていませんが、エージェント間の相互作用、環境の変更などの複雑なロジックを追加することができます。
-
display(): 環境の基本的な表現を出力します。
-
-
エージェントクラス:
-
世界内の個体エージェントを表します。
-
__init__(): エージェントをそのタイプ、位置、属性として初期化します。 -
move(): エージェントの移動を处理し、環境内の位置を更新します。このメソッドは現在、単純な乱数移動を提供していますが、複雑なAI行動を含めることができます。
-
-
使用例:
-
世界のパラメーターを設定します。大きさ、エージェントの種類、そしてその属性などです。
-
VirtualWorld オブジェクトを作成します。
-
update()メソッドを何度も呼び出して、世界の進化をシミュレートします。 -
更新後に
display()を呼び出して、変化を可視化します。
-
改善:
-
より複雑なエージェント AI:エージェントの行動により複雑なAIを実装します。以下を使用できます:
-
パスファイングアルゴリズム:エージェントが環境を効果的に移動するための手助け。
-
決定木/機械学習:エージェントが周りの状況とゴールに基づいてより贤明な決定をすることを可能にします。
-
強制学習:エージェントが時間とともに行動を学び、適応することを教えます。
-
-
環境の相互作用:環境に動的要素を追加します。例えば障害物、リソース、または興味深い場所など。
-
エージェント同士の相互作用:エージェント間のやり取り、コミュニケーション、戦闘、または協力などの相互作用を実装します。
-
視覚表現:PygameやTkinterなどのライブラリを使用して、仮想世界の視覚表現を作成します。
この例は、AI駆動の仮想世界を作成する基本的な基盤です。複雑さと洗練度は、具体的な需要と創造的なゴールに合わせてさらに拡大することができます。
神経学的コンピューティングとAI
人間の脳の構造と機能に啟発された神経学的コンピューティングは、情報の効率的な並列処理を提供する新しい方法を提供して、AIに革命的な変革をもたらすものです。
伝統的なコンピュータ構造とは異なり、神経学的システムは人間の脳の神経网路を模倣する設計に基づいています。これにより、AIは、現在のアーキテクチャーでは行えないような、パターン認識、感覚処理、決定作成などのタスクをより速く、エネルギー効率に優れた方法で行えます。
この技術は、より適応性のあるAIシステムの開発に大変有用で、少ないデータから学習することができ、実時間環境で効果的なものになると期待されます。
例えば、ロボット技術において、神経学的チップは、現在のアーキテクチャーに比べて、ロボットが感覚的な入力を処理し、決定を下すための効率的で速い方法を提供するかもしれません。
今後の課題は、大規模なAIアプリケーションの複雑さに対応するために、神経学的コンピューティングをスケールアップすることです。既存のAIフレームワークと整合して、その潜在的な能力を最大限に利用するために。
宇宙探査中のAIエージェント
AIエージェントは、連邦航空局のスペース探索活動において、より多くの役割を果たしています。彼らは、厳しい環境をナビゲートすること、実際の時間で決定を下すこと、自律的に科学実験を行うことを課題にしています。
ミッションが深い宇宙に向かって進むにつれ、地球基盤からのコントロールを離れて独自に作動できるAIシステムが必要になるほどになります。将来のAIエージェントは、宇宙の不可 Predictabilityを処理すること、予期しない障害、ミッションパラメータの変更、または自己修復の必要などを処理することができるように設計されます。
たとえば、AIは火星のローバーを自律的に地形を探索し、科学的に有効な場所を特定し、甚至に采样本钻孔を行い、ミッションコントロールからの最小限の入力で可能にするかもしれません。これらのAIエージェントは、長期間のミッション上の生命維持システムを管理し、エネルギーの使用を最適化し、アストロノートの心理的な需要に応じて companionとして、メンタルストリームを提供することもできます。
スペース探索におけるAIの統合は、ミッションの能力を高めるだけでなく、人間が宇宙を探查する新たな可能性を開くし、我々の宇宙を理解するために不可或缺なパートナーとなることです。
第8章:ミッションクリティカル领域におけるAIエージェント
医療
医療において、AIエージェントはサポート役だけでなく、患者ケアの整个に密接に取り組むようになっています。彼らの影響は、テレメディクスにおいて、远隔医疗の取り組み方を再定義したAIシステムにより明らかになっています。
高度な自然言語処理(NLP)と機械学習アルゴリズムを活用して、これらのシステムは Complex tasks such as symptom triage and preliminary data collection を高精度で行います。患者からの症状報告と医学歴を实时に分析し、この情報を广い医学データベースに基づいて可能な障害や危険信号を识別します。
これにより、医療提供者はより迅速に知情的な決定を下すことができ、治療にかかる時間を短縮し、命の救いを可能にします。また、医学画像のAI駆動の診断ツールは、X線やMRI、CTスキャンに表示されるパターンや異常を人間の目には見えない程度に認識しています。
これらのシステムは数百万の記述された画像から学習しており、彼らは不但 Replicate しただけでなく、人間の診断能力をしばしば上回る能力を持っています。
AIを医療に統合することは、administrative tasks にも及ぶことにまで扩展しています。アポンでのスケジュール設定、medication reminders、患者のFollow-up など、これらの自動化は、医療スタッフにとってOperational burden を大幅に軽減し、患者护理のより重要な側面に集中することができます。
Finance
在金融部門では、AIエージェントは、前例のない効率と精度をもたらすように操作を革新しました。
算法取引は、AIに依存しており、金融市場で取引が行われる方法を変えました。
これらのシステムは、市场监管における動向を瞬時に分析し、利益を最大化し、リスクを最小化するために最適な时机で取引を行うことができます。これらは、マシン学習、深層学習、及び強化学習技術を含んだ複雑なアルゴリズムを利用して、市場情勢の変化に適応しています。人間の取引者が追い付かない、亚秒単位の決断をしています。
取引のためだけでなく、AIはリスク管理において重要な役割を果たしています。credi风险を評価し、素晴らしい精度で詐欺活動を発見しています。AIモデルは、信贷歴、取引行動、その他の関連因子を分析して、 defaultの可能性を評価する予測分析を利用しています。
また、規制遵守の分野では、AIは取引のモニタリングを自動化して、疑わしい活動を発見し、報告しています。これにより、金融機関は厳格な規制要求に従うことができます。この自動化は、人間のミスを軽減し、合规プロセスを流暢にすることで、コストを削減し、効率を向上させます。
非常時管理
AIは非常時管理において、危機の予測、管理、及び軽減策における変革的な役割を果たしています。
災害対応において、AIエージェントは、衛星画像から社交媒体フィードまでの多くの源からのデータを処理し、现场の状況を実時間で Comprehensive overviewを提供しています。機械学習アルゴリズムは、これらのデータを分析してパターンを识別し、事件の進行を予測しています。これにより、緊急対応者はリソースをより効果的に分配し、プレッシャー下で情報に基づいた決定をします。
たとえば、ハリケーンなどの自然災害の間、AIシステムは嵐の経路と強さを予測することができ、当局は及时の避難令報を発令し、最も脆弱な地域にリソースを配置することができます。
予測的アナリティクスにおいて、AIモデルは過去のデータを分析し、実時間の入力と一緒に潜在的な紧急状態を予測するために利用されます。これにより、災害を防ぐまたはその影響を軽減するための先行措置が可能です。
AI駆動の公共コミュニケーションシステムは、影響を受ける人々に正確で及时な情報が届けられることを保証する重要な役割を果たします。これらのシステムは、多くのプラットフォームで緊急警報を生成し、広く配信し、異なるdemographicsに合わせてメッセージを調整して、理解と従ってもらうことを保証します。
また、AIは、生成型モデルを使用して非常に現実的なトレーニングシミュレーションを作成し、緊急対応者の準備を強化します。これらのシミュレーションは、実際の世界の災害の複雑さを再現し、対応者は彼らのスキルを锻炼し、実際の事件のための準備を改善することができます。
交通
交通分野では、AIシステムは安全性、効率、そして信頼性を高めるために不可欠になりつつあります。これ包括air traffic control、自律型車両、そして公共交通機などの様々な分野で使用されています。
空港業務では、AIエージェントはフライトパスの最適化、潜在的な衝突の予測、そして空港業務の管理を行います。このシステムは予測的アナリティクスを使用して、空交通の瓶颈を予測し、実時間でフライトを再路由し、安全性と効率を保証します。
自走車分野では、AIが車両が複雑な環境で感測器データを処理し、瞬時の決断を下すことを可能にしている。これらのシステムは、広大なデータセットに基づいて学習された深層学習モデルを使用して、視覚、聴覚、およびスペクトルデータを解釈し、動的で予想不可能な状況を安全に通過することができます。
公共交通機関も、AIを利用して最適なルート計画、車両の予測性メンテナンス、および乗客の流れの管理を行うことで恩恵を受けています。過去のデータと实时データを分析して、AIシステムは交通機材の時間表を調整し、車両の故障を予測し防ぐことができ、ピーク時間に人々を制御することができるため、交通網の全体的な効率と信頼性を向上させます。
エネルギー部門でも、AIは电网管理、再生可能エネルギーの最適化、およびフault Detectionで重要な役割を果たしています。
电网管理では、AIエージェントは、网络上に分散された感測器からの实时データを分析して、電力網を監視しコントロールします。これらのシステムは、予測分析を使用して、電力の分配を最適化し、供給が需給に合わせ、エネルギーの無駄使いを最小限にするようにします。AIモデルはまた、电网の潜在的な失敗を予測することができ、予防的なメンテナンスを行い、停電の危険性を最小限にすることができます。
再生可能エネルギーの分野では、AIシステムは、気候パターンの予測を行いますが、それは、太陽光と風力のエネルギー生成を最適化することが重要です。これらのモデルは、気象データを分析して、太陽光の強さと風速を予測することができます。これにより、エネルギー生成をより正確に予測することができ、再生可能な源を电网により良く統合することができます。
AIは、障害検知もまた大変重要な分野で、重要な貢献をしています。AIシステムは、変压器、風力タービン、発電機などの装置からのセンサーデータを分析し、耐久性や潜在的な異常動作の兆候を予測することで、それらが失敗の原因となる前に detection system
サイバーセキュリティ
サイバーセキュリティ域では、AIエージェントはデジタルインフラの完整性和安全性を维持するために欠かせません。これらのシステムは、マシン学習アルゴリズムを使用して、ネットワークトラフィックを継続的に監視して、サイバー攻撃の可能性を示す異常性を検出することができます。
リアルタイムで大量のデータを分析することで、AIエージェントは、異常なログイン試行、データ外部化活動、またはウィルコムの存在などの悪意のある行動パターンを特定することができます。潜在的な脅威が検出されると、AIシステムは自動的に対策を発動し、例えばコンプライアンスの破壊を防ぐためには、妥协したシステムを隔離し、パッチの展開を行います。
脆弱性评価は、サイバーセキュリティ域でAIの別の重要な適用です。AIパワードトールは、コードとシステム設定を分析して、攻撃者によって利用される前に潜在的なセキュリティ脆弱性を特定することができます。これらのツールは、静的解析と動的解析技術を使用して、ソフトウェアとハードウェアコンポーネントの安全性の状態を評価し、サイバーセキュリティチームに対する行動可能な洞察を提供します。
これらのプロセスの自動化は、脅威のdetectionおよびresponseの速度と精度を高め、人間のアナリストの負荷を軽減し、彼らがより複雑なセキュリティーの挑戦に集中することができます。
製造
在製造业において、AIは品質管理、予測 maintenance、およびサプライチェーン最適化において大きな飛躍的な進歩を引き起こしています。AI駆動のコンピュータビジョンシステムは、人間の能力を遥かに上回る速さと精度で製品の欠陥を検出することができます。これらのシステムは、数천の画像に基づいて学習された深層学習アルゴリズムを使用して、製品の最も小さな不整地を検出します。これにより、高密度の生産環境で的一貫性のある品質を保証します。
予測 maintenanceは、AIが大きな影響を与えているもう一つの分野です。機械に埋め込まれたセンサーからのデータを分析して、AIモデルは装备が失敗する可能性を予測することができます。これにより、失敗が起こる前にmaintenanceを予定することができます。この方法は、ダウンタイムを減らし、機械の寿命を延長し、 substancial cost savingsを实现します。
サプライチェーン管理において、AIエージェントは、需要在予測、生産スケジュール、輸送ルートなど、サプライチェーン全体からのデータを分析して、在庫レベルと物流を最適化します。これにより、在庫と物流計画を実時間で調整することによって、生産プロセスを流れるようにし、遅延を最小限にし、コストを减少します。
これらの適用例は、AIが製造业の操作効率と信頼性の改善に重要な役割を果たし、急速に変化する産業で競争力を持ち続けることを求める会社の不可欠なツールです。
結論
人工知能エージェントと大規模言語モデル(LLM)の統合は、人工知能の進化における重要なマイルストーンであり、さまざまな産業および科学分野において今までにない能力を解放しています。この協力は、AIシステムの機能性、適応性、および適用性を高め、LLMの固有の限界を克服し、よりダイナミックでコンテキストに敏感な決定づくりプロセスを実現させます。
ヘルスケアや金融を革新し、交通や非常時管理を変革すると共に、AIエージェントはイノベーションと効率向上を促進し、AI技術が私たちの日常生活に深く埋め込まれる未来への道を開いています。
AIエージェントとLLMの可能性をさらに探求するには、彼らの開発を人の福祉、公平性、および包括性を重視する倫理原則に根ざすことが重要です。これらの技術を責任ある設計および導入に基づいて開発し続けることで、生活の質を向上させ、社会的正義を促進し、世界的な課題に取り組むことができます。
AIの未来は、高度なAIエージェントと複雑なLLMを統合することであり、人間の能力を增幅するだけでなく、人間性を支える価値を持ち続ける知的システムを作り出すことです。
AIエージェントとLLMの合流は、人工知能における新たなパラダイムを表しています。敏捷さと強力さのコラボレーションは、限りない可能性の領域を unlocks します。この协力の力を活用することで、イノベーションを促進し、科学の発見を進展させ、 Equity および豊かさを持った未来をすべての人に提供することができます。
作者について
私はヴァーヘ・アスラニャンです。コンピュータ科学、データ科学、AIの交差点にいます。私のポートフォリオは、精密さと進歩の証であるvaheaslanyan.comに訪れてください。私の経験は、フルスタック開発とAI製品最適化の間を結びつけ、新しい方法で問題解決に取り組むことによって動いています。
历吏には、主要なデータ科学ブートキャンプを立ち上げ、業界トップの専門家と共事した経験も含まれます。私の注力は、テクノロジー教育を普遍的な標準に合わせることに焦点を置いています。
どうやって深めることができるのでしょう?
このガイドを学んだ後、もっと深くなることに興味を持ち、構造化された学習があなたのスタイルだと思う場合、LunarTechに加入してみてください。私たちは、データ科学、機械学習、AIについての個別コースとブートキャンプを提供しています。
私たちは、理論に深い理解を提供し、実際の実装のための手法を提供し、充実した練習資料と、あなたの段階に合わせたインタビューの準備を提供しています。これらを通じて、成功のための準備をしています。
以下のテキストを日本語に翻訳します。最強データサイエンスブートキャンプをチェックし、無料トライアルに参加してコンテンツを直接体験してください。これは2023年の
私と連絡を取りましょう

LinkedInで私をフォローして、CS、ML、AIに関する多くの無料リソースを入手しましょう
データサイエンス、機械学習、AIの分野においてキャリアを探求している場合、データサイエンスの仕事を獲得する方法を学ぶために、この無料のデータサイエンスとAIキャリアハンドブックをダウンロードすることができます。
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/