













تطور مفاجئ للذكاء المصنوعي (الإنترنت الذكي) أدى إلى تأليف توازن قوي بين نماذج اللغة الكبيرة (النماذج اللغوية الكبيرة) والأجهزة الذكاء المصنوعية. هذا التعامل الحيوي والمتناوب مثل قصة داوود وجالوت (بدون القتال), حيث تمكن الأجهزة الذكاء المصنوعة الناعمة من تعزيز وتكبير قدرات النماذج اللغوية الكبيرة.
سيكون هذا الدليل يبحث عن كيفية تعزيز أجهزة الذكاء المصنوعة – التي تشبه داوود – لنماذج اللغوية الكبيرة – أعظم معظمنا اليوم – لمساعدة في ثورة مختلفة من الصناعات والمجالات العلمية.
جدول محتويات
ظهور المميزات الذكية في نماذج اللغة
تمكن المميزات الذكية التي تتكون منها الأنظمة المستقلة من الاستشعار بيئتها، والقرار-مaking، والقيام بالأفعال لتحقيق أهداف معينة. عندما يتم دمجها مع نماذج اللغة الكبيرة، يمكن لهذه المميزات القيام بالمهام المعقدة، والتفكير حول المعلومات، وتوليد حلول مبتكرة.
هذا التركيب أدى إلى تقدمات كبيرة في قطاعات متعددة، من تطوير البرمجيات إلى البحث العلمي.
التأثير التحولي في كل الصناعات
تأثير دمج المميزات الذكية مع نماذج اللغة الكبيرة كان كبيراً في كل صناعات المجالات:
-
تطوير البرمجيات: واجهات المساعدة البرمجية القائمة على التعلم التلقائي، مثل GitHub Copilot، أظهرت قدرتها على توليد الى 40% من البرمجيات، مما أدى إلى زيادة باهرة في السرعة المتسعة بنسبة 55%.
-
التعليم: أظهرت مساعدات التعلم القائمة على التعلم التلقائي توقعات في خفض معدل إنجاز المقررات بنسبة 27%، مما يمكن أن يحدث ثورة في مناظر التعليم.
-
النقل: مع التنبؤات التي ت sugests أن 10% من المركبات ستكون بدون سيارين بحلول عام 2030، فإن وكلاء الأنظمة الذكية القائمين على السيارات الذاتية القيادة على وشك تحويل الصناعة النقلية.
تقدم الاكتشاف العلمي
إحدى أكثر التطبيقات المثيرة لوكلاء الأنظمة الذكية والوظائف الكبيرة هي في البحث العلمي:
-
اكتشاف الدواء: وكلاء الأنظمة الذكية يسرع عملية اكتشاف الدواء بتحليل البيانات الكبيرة وتنبؤ بمركبات الدواء المحتملة، تخفيض بشكل كبير وقت وتكاليف الطرق التقليدية.
- علم الجسيمات: في مصادم الجسيمات الكبير لCERN، تستخدم وكالات التعقيدات لتحليل بيانات مصادمات الجسيمات، وتستخدم كشف الانواع للتعرف على القنادس المشاهدة التي قد تشير إلى وجود جسيمات غير مكتشفة بعد.
- البحث العلمي العام: وكالات التعقيدات تحسين المعدل والنطاق الذي تمت به عملية اكتشافات العلمية بتحليل الدراسات السابقة وتحديد الروابط الغير متوقعة وتقدم تجارب جديدة.
تركيز الأجهزة الذكية البشرية والنماذج الكبيرة لللغة (النماذج الكبيرة اللغوية) يقود الذكاء المصنوعي إلى عصر جديد من قدرات unprecedented. يبحث هذا المعجز الشامل في التفاعل الحيوي بين هذين التكنولوجياتين، ويكشف قدراتهم المجموعة لتحقيق ثورة في الصناعات وحل المشاكل المعقدة.
سنتتبع تطور المصنوعي الذكي من أصله إلى ظهور الموكلين المتمتعين بالautonomy وارتفاع النماذج اللغوية المتطورة. سنبحث أيضًا عن الأحكام الأخلاقية، والتي هي أساسية لتطوير المصنوعي الذكي المسؤول. ستساعدنا هذا على ضمان توافق هذه التكنولوجيات مع قيمنا البشرية والخير للمجتمع.
وفي نهاية هذا المعجز، سيكون لديك فهم عميق لقوة التوافق بين المجهزات الذكية البشرية والنماذج الكبيرة اللغوية، وسيكون لديك المعرفة والأدوات لتسخير هذه التكنولوجيا الأقدم.
الفصل 1: معرفة المجهزات الذكية البشرية والنماذج اللغوية
ما هي المجهزات الذكية البشرية والنماذج الكبيرة اللغوية؟
تطور المصنوعي الذكي (الآلة البشرية) بسرعة كبيرة أوضح تحالف معين بين النماذج الكبيرة اللغوية (النماذج الكبيرة) والمجهزات الذكية البشرية.
والوكلاء الذكية هي أنظمة ذاتية مصممة للإدراك بيئتهم الخارجية، والتحكم في القرارات، وتنفيذ الإجراءات لتحقيق الأهداف الخاصة بهم. يظهرون ماهيات كالتنقل الذاتي، والإدراك، والإستجابة، والتفكير، والقرار، والتعلم، والتواصل، والاتجاه نحو الهدف.
من ناحية أخرى، LLMs هي أنظمة ذكية متطورة تستخدم تقنيات التعلم العميق وبيانات عظيمة لفهم، وتوليد، وتوقع النصوص البشرية.
هذه النماذج، مثل GPT-4، Mistral، LLama، قدمت مقدرات مذهلة في مهام معالجة اللغة الطبيعية، بما في ذلك توليد النص، وترجمة اللغة، ووكلاء الحوار.
الصفات الرئيسية لوكلاء الذكاء الاصطناعي
يمتلكون العديد من الصفات التعريفية التي تمزقهم عن البرمجيات التقليدية:
- التنقل الذاتي: يمكنهم التشغيل بشكل مستقل بدون تدخل بشري دائم.
- الإدراك: يمكن للوكلاء أن يحس ويفسر بيئتهم الخارجية من خلال إدخالات مختلفة.
- الإستجابة: يستجيبون بشكل ديناميكي للتغيرات في بيئتهم الخارجية.
-
التفكير واتخاذ القرارات: يستطيع العملاء تحليل البيانات واتخاذ خيارات مستنيرة.
-
التعلم: يحسنون أدائهم مع مرور الوقت من خلال التجربة.
-
التواصل: يستطيع العملاء التفاعل مع العملاء الآخرين أو البشر باستخدام طرق مختلفة.
-
توجيه الأهداف: تم تصميمهم لتحقيق أهداف محددة.
قدرات النماذج اللغوية الكبيرة
لقد أظهرت النماذج اللغوية الكبيرة مجموعة واسعة من القدرات، بما في ذلك:
-
إنتاج النصوص: يمكن للنماذج اللغوية الكبيرة إنتاج نصوص مترابطة وذات صلة بالسياق بناءً على الاستفسارات.
-
ترجمة اللغات: يمكنها ترجمة النصوص بين لغات مختلفة بدقة عالية.
-
تلخيص: يمكن للنماذج اللغوية اللهاثة تلخيص النصوص الطويلة إلى ملخصات موجزة مع الاحتفاظ بالمعلومات الرئيسية.
-
الإجابة عن الأسئلة: يمكنها تقديم إجابات دقيقة على الاستفسارات بناءً على قاعدة معرفتها الواسعة.
-
تحليل المشاعر: يمكن للنماذج اللغوية اللهاثة تحليل وتحديد المشاعر المعبر عنها في نص معين.
-
توليد الشيفرات: يمكنها توليد مقاطع شيفرة أو وظائف كاملة بناءً على وصف باللغة الطبيعية.
مستويات وكلاء الذكاء الاصطناعي
يمكن تصنيف وكلاء الذكاء الاصطناعي إلى مستويات مختلفة بناءً على قدراتهم وتعقيدهم. وفقًا لورقة بحثية على arXiv، تصنف وكلاء الذكاء الاصطناعي إلى خمسة مستويات:
-
المستوى 1 (L1): وكلاء الذكاء الاصطناعي كمساعدين بحثيين، حيث يحدد العلماء الفرضيات ويحددون المهام لتحقيق الأهداف.
-
المستوى 2 (L2): وكلاء الذكاء الاصطناعي القادرين على أداء مهام محددة بشكل مستقل ضمن نطاق محدد، مثل تحليل البيانات أو اتخاذ القرارات البسيطة.
-
المستوى 3 (L3): وكلاء الذكاء الاصطناعي القادرين على التعلم من التجربة والتكيف مع الوضعيات الجديدة، مما يعزز عمليات اتخاذ القرارات لديهم.
-
المستوى 4 (L4): وكلاء الذكاء الاصطناعي ذوي القدرات المتقدمة في التفكير وحل المشاكل، قادرين على التعامل مع مهام معقدة متعددة الخطوات.
-
المستوى 5 (L5): وكلاء الذكاء الاصطناعي المستقلين تمامًا القادرين على العمل بشكل مستقل في بيئات ديناميكية، واتخاذ القرارات واتخاذ الإجراءات دون تدخل بشري.
قيود النماذج اللغوية الكبيرة
تكاليف التدريب وقيود الموارد
النماذج اللغوية الكبيرة (LLMs) مثل GPT-3 و PaLM قد غيّرت عمليات معالجة اللغات الطبيعية (NLP) من خلال استغلال تقنيات التعلم العميق وقواعد بيانات ضخمة.
لكن هذه التطورات تأتي بتكلفة كبيرة. تدريب نماذج LLMs يتطلب موارد حاسوبية كبيرة، وغالبا ما يتضمن الآلاف من الأجهزة الرقمية الخاصة بالتصور (GPU) وإستهلاك طاقة واسع.
وفقاً لسام ألتمان، الرئيس التنفيذي لشركة OpenAI، تكلفة تدريب GPT-4 تفوق 100 مليون دولار. هذا يتماشى مع الحجم المب報 للنموذج وتعقيده، ومعدلات تفرض أن لديه حوالي تريليون باراميتر. ومع ذلك، تقدم مصادر أخرى أرقام مختلفة:
-
تم الحصول على تقرير سريّ يشير إلى أن تكلفة تدريب GPT-4 تبلغ حوالي $63 مليون، وذلك بعد تحديد القوة الحاسوبية ومدة التدريب.
-
وفي منتصف 2023، تشير بعض التقديرات إلى أن تكلفة تدريب نموذج مشابه لـ GPT-4 قد تكون تقريباً $20 مليون وتستغرق حوالي 55 يومًا، مرجعاً للتحسينات في الكفاءة.
تكلفة التدريب والصيانة العالية للLLM تحدد توسع اتخاذها وتوسعها.
قصورات البيانات والتحيز
أداء الLLM يعتمد بشكل كبير على جودة وتنوع بيانات التدريب. بغض النظر عن تدريبها على مجموعات بيانات هائلة، يمكن للLLM أن يعرض تحيزات توجد في البيانات، مما يؤدي إلى إخراجات مشوشة أو غير مناسبة. يمكن لهذه التحيزات أن تظهر في أشكال متعددة، بما في ذلك التحيزات الجنسية والعرقية والثقافية، والتي يمكن أن تعزز الستيريوتيبس والمعلومات الخاطئة.
بالإضافة إلى ذلك، فإن طبيعة البيانات التدريبية الثابتة تعني أن الLLM قد لا تكون في إطلاعها بأحدث المعلومات، مما يحد من فعاليتها في البيئات الديناميكية.
التخصص والتعقيد
بينما يتميز الLLM في المهام العامة، يواجهون عادة مشاكل في المهام المتخصصة التي تتطلب معرفة محددة للمجال وتعقيدات عالية.
على سبيل المثال، تتطلب المهام في مجالات كالطب والقانون والبحث العلمي فهم عميق للترميزات المتخصصة والحكمة الدقيقة، والتي قد لا تكون لدى الLLM بشكل طبيعي. تحدد هذه القصورات الحاجة إلى دمج طبقات إضافية من الخبرة وتنقيح دقيق لجعل الLLM فعالين في التطبيقات المتخصصة.
القصور في الإدخال والحواس
ar
LLMs تعالج أساساً الإدخالات القائمة على النص، وهذا يحد من قدرتها على التفاعل مع العالم بطريقة متعددة الوسائط. بينما يمكنها توليد وفهم النص، فإنها تفتقد إلى القدرة على معالجة البيانات البصرية أو السمعية أو الحسية مباشرة.
هذه القصورة تحد من تطبيقها في الحقول التي تتطلب تكامل شامل للأحاسيس، مثل الروبوتات والأنظمة الآلية. على سبيل المثال، لا يمكن لـLLM تفسير البيانات البصرية من الكاميرا أو البيانات السمعية من الميكروفون دون طبقات معالجة إضافية.
القيود على التواصل والتفاعل
إمكانيات التواصل الحالية لـLLMs تعتمد أساساً على النص، وهذا يحد من قدرتها على المشاركة في أشكال أكثر تواجداً وتفاعلية من التواصل.
على سبيل المثال، بينما يمكن لـLLMs توليد ردود نصية، فلا يمكنها إنتاج محتوى فيديو أو تمثيلات هولوجرافية، وهي تزداد أهمية في التطبيقات الإفتراضية والمدمجة (اقرأ المزيد هنا). وهذه القيود تقلل من فعالية LLMs في البيئات التي تتطلب تفاعلات متعددة الوسائط والغنية.
كيفية التغلب على قصور الوكلاء الذكاء الاصطناعي
وكلاء الذكاء الاصطناعي يوفرون حلًا مشمولًا لمعظم القصور التي تواجهها LLMs. يتم تصميم هؤلاء الوكلاء ليعملوا بأوتونومية، يدركون بيئتهم، يتخذون قرارات، وينفذون إجراءات لتحقيق أهداف محددة. من خلال تكامل الوكلاء الذكاء الاصطناعي مع LLMs، يمكن تعزيز قدراتهم وتعالج القصور التي لها بشكل طبيعي.
-
تحسين السياق والذاكرة: يمكن لعبات التعلم ال artificial إبقاء السياق مع التفاعلات المتعددة، مما يسمح للردود المتناظرة والمتعلقة بالسياق. وهذه القدرة مفيدة بشكل خاص في التطبيقات التي تتطلب الذاكرة الطويلة الأمد والت连续ة، مثل الخدمة الممولة للزبائن والمساعدين الشخصيين.
-
التكامل المتعدد الحيوي: يمكن لعبات التعلم ال artificial استعمال الإدخالات الحسية من مصادر مختلفة، مثل الكاميرات والميكرفونيات والمستشعرات، مما يمكن للنصوص اللامنظمة أن تمارس وتستجيب للبيانات البصرية والصوتية والحسية. هذا التكامل يعمل بشكل أساسي للتطبيقات في الروبوتات والأنظمة الautonomous.
- المعرفة التخصصية والخبرة: يمكن تنقيط معين لعبات التعلم الآلي بالمعرفة الخاصة بالمجالات، مما يحسن قدرة النظم اللفظية الكبيرة على إنجاز مهام تخصصية. هذا النهج يسمح للبناء لنظم الخبراء التي يمكنها معالجة أسئلة معقدة في مجالات مثل الطب، القانون، والبحث العلمي.
- التواصل التفاعلي والمكافح: يمكن لعبات التعلم الآلي تسهيل أشكال التواصل الأكثر تأمينًا عن طريق توليد المحتويات الفيديوية، والسيطرة على العروض الهولوغرافية، والتفاعل مع بيئات الواقع المعدل والإفتراضية. توفير هذه القدرة يوسع تطبيق النظم اللفظية الكبيرة في مجالات التي تتطلب التفاعلات المتعددة الحوسية.<
بينما أظهرت نماذج اللغة الكبيرة قدرات بارزة في معالجة اللغة الطبيعية، فإنها غير بلا محدوديات. التكاليف العالية للتدريب، التحيزات في البيانات، التحديات التخصصية، قيود الحوسية، وقيود التواصل تعكس معدلات كبيرة.
لكن تركيبة الكائنات التصنيعية توفر مسار جيد لتخطي هذه المحدوديات. من خلال تسخير قواء الكائنات التصنيعية، يمكنك تعزيز الوظائف، القابلية للتكيف، وقيود النماذج اللغوية الكبيرة، وتوسيع طريقة الوصول إلى نظم التصنيع الأكثر تقدماً والتي تتوافر في القدرات.
الفصل 2: تاريخ الذكاء الإصطناعي والكائنات التصنيعية
البدء بالذكاء الإصطناعي
فكرة الذكاء الإصطناعي (التعاليم) تمتد إلى ما يفوق العصر الرقمي الحديث. فكرة إنشاء آلات قادرة على التفكير البشري قد تم تتبعها إلى الأساطير القديمة والمناظر الفلسفية. لكن بدأ تعين الذكاء الإصطناعي كعلم علمي في القرن العشرين الوسط.
المؤتمر دارموث 1956، الذي أنشأه جون ماكارثي، مارفين مينزكي، ناثانيل روكسيلين، و كلاود شانوني، يعتبر بشكل واسع من منازل الذكاء الاصطناعي كمكان ولادة تخص المجالات الدراسية. تلك الحدث الأصلي جلبت معظم الباحثين الرئيسيين للبحث في إمكانية إنشاء آلات تمامًا تمثل الذكاء البشري.
التفاؤل المبكر والحريق الثاني
كانت السنوات الأولى للبحث في الذكاء الاصطناعي معروفة بالتفاؤل اللاحق. و قدم الباحثون خطوات كبيرة في تطوير البرامج القادرة على حل المسائل الرياضية و اللعب بالألعاب و حتى التفاعل باللغة الطبيعية البسيطة.
لكن هذا التحمس البدائي تخفيف بوعي الواقع أن إنشاء آلات حقًا ذكية كان أكثر تعقيدًا من المتوقع البدائي.
رأينا في السبعينات والثمانينات فترة من التنقلات و الاهتمام الأقل في بحث الذكاء الاصطناعي و التي يطلق عليها الـ “الحريق الثاني للذكاء“. و كان هذا الإنخفاض يعود بالفعل إلى فشل الأنظمة الذكاءية في إيجاد التوقعات المرتفعة التي أنشأها الباحثون البدائيون.
من أنظمة قائمة على القوانين إلى التعلم الآلي
عصر الأنظمة الخبرية
نشأت العلم الاصطناعي الجديدة في الثمانينات بواسطة تطوير الأنظمة الخبرية. كانت هذه البرامج القائمة على القوانين تستهدف تقليد عمليات قراءة الخبراء في مجالات معينة.
الأنظمة الخبراء وجدت تطبيقات في مجالات مختلفة ، بما في ذلك الطب والمالية والهندسة. ولكنها تعاقبت بعيدًا بعدمها القدرة على التعلم من الخبرة أو التكيف مع أوضاع جديدة خارج قواعدها البرمجية.
النهوض بالتعلم الآلي
قصور الأنظمة القائمة على القواعد أبعد الطريق للتحول إلى التعلم الآلي. هذا المقاربة التي أكدت أولاً في التسعينات والعشرينات من القرن الماضي، تركز على تطوير الخوارزميات القادرة على التعلم من البيانات والتنبؤ أو القرارات بناءً على البيانات.
تقنيات التعلم الآلي مثل الشبكات العصبية والمحركات المدعومة، أظهرت نجاحًا يبدو باستثنائي في المهام التي تشمل التعرف على الأنماط والتصنيف البيانات. ظهور البيانات الكبيرة والقوة المحاسبية الزائدة تعجل أيضًا بتطوير وتطبيق الخوارزميات التعلمية.
ظهور العوامل الذين يعملون بشكل مستقل
من التعلم المحدود إلى التعلم العام
وأثناء تطور تقنيات التعلم الآلي ما تستمرت، بدأ الباحثون بالبحث في إمكانية إنشاء أنظمة أكثر قابلية ومستقلة. هذا التحول يعني تحول من التعلم المحدود المتخصص للمهام الواحدة إلى مطاردة الذكاء الإصطناعي العام (AGI).
AGI تهدف إلى تطوير أنظمة قادرة على أداء أي مهمة فكرية يمكن أن يقوم بها الإنسان. بينما يبقى الAGI الحقيقي هدفًا بعيدًا فإن تحقيقات كبيرة تم بالفعل في إنشاء أنظمة الخوارزميات الذكية الأكثر مرونة والقابلة للتأقلم.
دور التعلم العميق والشبكات العصبية
بدأ تطور التعلم العميق، وهو مجموعة فرعية للتعلم الآلي والمبنية على الشبكات العصبية الصناعية، بدأ يكون في الوسيلة الرئيسية لتقدم مجال التعلم الآلي.
الخوارزميات التعلمية العميقة، التي تلهمها بنية ووظيفة الدماغ البشري، أظهرت قدرات لا تُصدق في مجالات مثل تعرف الصور والتعرف على الكلام الطبيعي ولعب الألعاب. تلك التقدمات أسست أساسًا لتطوير المجموعات التلقائية الأكثر تعقيدًا للتعلم الآلي.
المامورات وأنواع المجموعات التلقائية الذكية
تعتبر المجموعات التلقائية الذكية أنظمة مستقلة التنفس تتمكن من إدراك بيئتها، وتخذ قرارات وتقوم بأفعال لتحقيق أهداف معينة. يمتلكون خصائص مثل التنفس، الإدراك، التفاعلية، المنطق، القرار التحكمي، التعلم، التواصل وتوجيه الأهداف.
وهناك أنواع مختلفة من المجموعات التلقائية الذكية، كل منها لها قدرات فريدة:
- المجموعات التلقائية البسيطة المستجيبة: تستجيب للمحركات المحددة بواسط
-
وكلاء تفاعليين مبنيين على نموذج: يحتفظون بنموذج داخلي للبيئة للاتخاذ القرارات.
-
وكلاء مبنيين على الأهداف: يؤديون إجراءات لتحقيق أهداف محددة.
-
وكلاء مبنيين على الاستفادة: يأخذون النتائج الحتمية ويختارون الإجراءات التي تكبر الاستفادة المتوقعة.
-
وكلاء التعلم: يحسنون قراراتهم مع مرور الوقت من خلال تقنيات تعلم الآلة.
التحديات والاعتبارات الأخلاقية
وبما أن الأنظمة الذكية تصبح أكثر تقدما وتتمتع بالتلكتومية، تحمل معها ملاحظات حرجة لضمان استخدامها في معتمد على الحدود الموجودة في المجتمع.
وفي الأخص، نماذج اللغات الكبيرة (LLM) تعمل كمضخم للإنتاجية. ولكن هذا يثير سؤالا حرجا: ما الذي سيُشغّل هذه الأنظمة — النية الجيدة أم السيئة؟ عندما تكون النية خلف استخدام الذكاء الاصطناعي سيئة، يصبح ضروريا على هذه الأنظمة أن تكتشف تلك الاستخدامات الخاطئة باستخدام تقنيات NLP متعدد
توفر مهندسو المعدات الالكترونية على مجموعة واسعة من الأدوات والمethodologies للتعامل مع هذه التحديات:
-
تحليل المزاج: من خلال استخدام تحليل المزاج، يمكن للنظم اللغوية الكبيرة تقييم اللحاظ العاطفي للنصوص لكشف عن اللغة السلبية أو العنيفة، مما يساعد في تحديد استخدام قدرة في أنظمة التواصل.
- تصفية المحتويات: يمكن استخدام أدوات مثل تصفية الكلمات الرئيسية وموافقة الأنماط لمنع إنتاج أو توزيع المحتويات السلبية، مثل الحرب العنصرية، المعلومات الخاطئة أو المواد البارعة.
- أدوات تحديد التحيز: من خلال تطبيق هياكل تحديد التحيز، مثل AI Fairness 360 (IBM) أو مؤشرات المساواة (Google),يمكن تحديد وتخفيض التحيز في نماذج اللغة، وتأكد من عمل الأنظمة التي تقوم بالتعامل الآلي بشكل عادل ومتساوي.
-
تقنيات الوصف
: باستخدام أدوات وصف النماذج مثل (LIME) (وصفات مواجهة لا متعلقة بالنماذج المحلية) أو (SHAP) (وصفات متأخرة للشابلي), يمكن للمهندسين فهم ووصف عملية اتخاذ القرار للنظم الكبيرة التعلمية، مما يسهل إكتشاف وتعامل مع أي تصرفات غير مقصودة.
- إختبار المعادي: من خلال تمويل هجمات خبيثة أو معلومات سيئة، يمكن للمهندسين تجارب توسعة للنظم التعلمية الكبيرة باستخدام أدوات مثل (TextAttack) أو (Adversarial Robustness Toolbox),وتحديد الأخطاء التي قد تُستخدم لأغراض خبيثة.
- إجمالي المبادئ الأخلاقية والإطارات للتعلم التكنولوجي الأخلاقي: عندما يتم اتخاذ إجمالي المبادئ الأخلاقية لتطوير التعلم التكنولوجي الأخلاقي، مثل التوجه
بالإضافة إلى تلك الأدوات، لهذا السبب نحن بحاجة إلى فريق أحمر خاص للتعلم التلقائي — فرق متخصصة تحاول تحطيم حدود التعلم التلقائي اللامنظمة لكي تكتشف الثغرات في دفاعها. تمثل الفرق الحمراء المحاكاة لأوضاع معتدية وتكشف عن الأخطار التي قد تستبدل بدون اكتشاف.
لكن من المهم أن ندرك بأن الأشخاص وراء المنتج له تأثيره أقوى بما فيه الكثير. معظم هجمات وتحدياتنا اليوم كانت موجودة حتى قبل تطوير التعلم التلقائي، ما يبرز أن العنصر البشري لا يزال مركزيا لضمان استخدام التعلم التلقائي بأخلاقية ومسؤولية.
التكامل من هذه الأدوات والتقنيات في قناة تطويرنا بجانب فريق أحمر من الراديكالية هو أساسي لضمان أن تستخدم التعلم التلقائي اللامنظمة لتعزيز نتائج إيجابية كبيرة بينما تكشف عن استخدامها بشكل خاطئ.
الفصل 3: أفضل مناظر للوكيل التلقائي
قوات التعلم التلقائي الفريدة
تميز أجهزة التعلم التلقائي بسبب قدراتها على التمييز الautonomously في بيئتها
القوى الرئيسية التي تجعل عوامل الذكاء الاصطناعي يبراقون:
-
التخليع والكفاءة: يمكن لعوامل الذكاء الاصطناعي التشغيل بشكل مستقل دون تدخل إنساني مستمر. هذه الخصائص التخليعية تسمح لهم بتنفيذ المهام 24/7، مما يحسن الكفاءة وإنتاجية بشكل ملحوظ. على سبيل المثال، يمكن لربوتات الدردشة الممولة بالذكاء الاصطناعي تعالج 80% من الاستفسارات الرئيسية العادية للزبائن، مما يقلل من تكاليف العمليات ويحسن وقت الرد.
-
القرارات المتقدمة: يمكن لعوامل الذكاء الاصطناعي تحليل كميات هائلة من البيانات لاتخاذ قرارات مستنيرة. تتميز هذه القدرة بالقيمة بشكل خاص في مجالات كالتمويل، حيث يمكن لروبوتات التداول الممولة بالذكاء الاصطناعي زيادة كفاءة التداول بشكل كبير.
-
التعلم والقدرة على التكيف: يمكن لوكلاء الذكاء الاصطناعي أن يتعلموا من الخبرة ويتكيفوا مع الحالات الجديدة. يمكن لهذه التحسينات المستمرة أن تمكنهم من تحسين أدائهم مع مرور الوقت. على سبيل المثال، يمكن لمساعدي الصحة الذكية أن يساعدوا في تقليل أخطاء التشخيص، مما يحسن نتائج الرعاية الصحية.
-
التخصيص: يمكن لوكلاء الذكاء الاصطناعي توفير تجارب شخصية من خلال تحليل سلوك المستخدمين وتفضيلاتهم. محرك توصيات أمازون، الذي يعزز 35% من مبيعاتها، هو مثال بارز على كيفية استخدام وكلاء الذكاء الاصطناعي لتعزيز تجربة المستخدم وزيادة الإيرادات.
لماذا تعتبر وكلاء الذكاء الاصطناعي الحلول.
تقدم وكلاء الذكاء الاصطناعي حلولاً للعديد من التحديات التي تواجه البرمجيات التقليدية والأنظمة التي تعمل بواسطة البشر. إليك لماذا يعتبرون الخيار المفضل:
-
التوسعة: يمكن لوكلاء الذكاء الاصطناعي توسيع العمليات دون زيادة تناسبية في التكلفة. هذه التوسعة ضرورية بالنسبة للشركات التي تسعى للنمو دون زيادة كبيرة في قوت العمل أو نفقات التشغيل.
-
الاستقرار والموثوقية: على عكس البشر، لا تعاني وكلاء الذكاء الاصطناعي من التعب أو عدم الاتساق. يمكنهم أداء المهام المتكررة بدقة وموثوقية عالية، مما يضمن أداءً متسقًا.
-
البيانات المستندة إلى البيانات: يمكن لوكلاء الذكاء الاصطناعي معالجة وتحليل مجموعات بيانات كبيرة لاكتشاف الأنماط والمعلومات التي قد يغفلها البشر. هذه القدرة لا تقدر بثمن في اتخاذ القرارات في مجالات مثل التمويل والرعاية الصحية والتسويق.
-
توفير التكاليف: بواسطة تطوير المهام الروتينية ، يمكن لوكلاء الذكاء الاصطناعي تقليل حاجة الموارد البشرية ، مما يؤدي إلى توفير تكاليف كبيرة. على سبيل المثال ، يمكن لنظم الكشف عن الاحتيال التي تعمل بالذكاء الاصطناعي أن توفر مليارات الدولارات سنويًا من خلال تقليل الأنشطة الاحتيالية.
الشروط المطلوبة لأداء وكلاء الذكاء الاصطناعي بشكل جيد
لضمان نجاح نشر وأداء وكلاء الذكاء الاصطناعي ، يجب توفر بعض الشروط:
-
أهداف وحالات استخدام واضحة: تحديد أهداف محددة وحالات استخدام مهمة لنجاح نشر وكلاء الذكاء الاصطناعي. تساعد هذه الوضوح في تحديد التوقعات وقياس النجاح. على سبيل المثال ، يمكن لتعيين هدف لتقليل أوقات الاستجابة لخدمة العملاء بنسبة 50٪ توجيه نشر روبوتات المحادثة بالذكاء الاصطناعي.
-
البيانات ذات الجودة: يعتمد وكلاء الذكاء الاصطناعي على بيانات عالية الجودة للتدريب والعمل. إن ضمان دقة وصلة وتحديث البيانات ضروري لأن يتمكن الوكلاء من اتخاذ قرارات مستنيرة وأداء بشكل فعال.
-
التكامل مع الأنظمة القائمة: التكامل السلس مع الأنظمة وسير العمل القائمة ضروري لأن يعمل وكلاء الذكاء الاصطناعي بصورة مثلى. يضمن هذا التكامل أن يتمكن وكلاء الذكاء الاصطناعي من الوصول إلى البيانات اللازمة والتفاعل مع الأنظمة الأخرى لأداء مهامهم.
-
المراقبة المستمرة والتحسين: يعد المراقبة والتحسين المنتظمين لوكلاء الذكاء الاصطناعي أمرًا حاسمًا للحفاظ على أدائهم. ويشمل ذلك تتبع مؤشرات الأداء الرئيسية وإجراء التعديلات اللازمة استنادًا إلى التعليقات وبيانات الأداء.
- احترام المبادئ الأخلاقية وخفض التحيز: تلبية الاعتبارات الأخلاقية وخفض التحيز في وكلاء الأعمال الآلية ضرورية لضمان العدالة والمشاركة. تنفيذ تدابير لكشف التحيز ومنعه يمكن أن يساعد في بناء الثقة وضمان توزيع المسؤولية مسؤولًا.
أفضل ممارسات لتنفيذ الوكلاء الآليين
عندما تنفيذ الوكلاء الآليين، يمكنك أن تتبع أفضل ممارسات لتأكد من نجاحهم وفعاليتهم:
- تحديد الأهداف والحالات الاستخدمة: تحديد بوضوح الأهداف والحالات التي يتم تطبيق الوكلاء الآليين لها. هذا يساعد في تعيين التوقعات وقياس النجاح.
-
اختر المنصة الذكاء الاصطناعي المناسبة: اختر منصة ذكاء اصطناعي تتوافق مع أهدافك وحالات الاستخدام والبنية التحتية الموجودة. انظر إلى العوامل مثل قدرات التكامل والقابلية للتوسعة والتكلفة.
-
طور قاعدة معرفية شاملة: قم ببناء قاعدة معرفية منظمة ودقيقة لتمكين وكلاء الذكاء الاصطناعي من تقديم إجابات ذات صلة وموثوقة.
-
ضمن التكامل السلس: قم بدمج وكلاء الذكاء الاصطناعي مع الأنظمة الموجودة مثل أنظمة إدارة علاقات العملاء وتكنولوجيا مراكز الاتصال لتوفير تجربة عملاء موحدة.
-
قم بتدريب وتحسين وكلاء الذكاء الاصطناعي: قم بتدريب وتحسين وكلاء الذكاء الاصطناعي باستمرار باستخدام البيانات من التفاعلات. راقب الأداء وتعرف على المجالات التي يمكن تحسينها وقم بتحديث النماذج وفقًا لذلك.
-
إنشاء إجراءات التصعيد المناسبة
: أقام قواعد لتحويل الاتصالات المعقدة أو العاطفية إلى عمال متخصصين، مؤكدا التنقل السلس والحلول الكفيلة.
- راقب وحلل الأداء: تتبع مؤشرات الأداء الرئيسية (KPIs) مثل معدلات حل الاتصالات، والوقت المتوسط للتعامل، ونقاط معيار الرضا الزبائن. إستخدم أدوات التحليل للحصول على تفسيرات وقرارات مبنية على البيانات.
- تأكد من خصوصية البيانات وأمنها: القواعد الأمنية القوية هي الأساس، مثل تجعل البيانات مجهولة، وتأكد من المراقبة البشرية، وإقامة سياسات لتخزين البيانات، وضع تدابير التشفير القوية لحماية بيانات الزبائن وإبقاء الخصوصية.
وكلاء الـ AI + LLMs: عهد جديد للبرمجيات الذكية
تخيل البرمجيات التي لا تفهم فقط الطلبات الخاصة بك ولكن يمكنها أيضًا إنجازها. هذه هي الوعدة التي تتمثل في تجميع عوامل الذكاء الاصطناعي مع نماذج اللغات الكبيرة (LLM). هذا التزامن القوي يخلق جيل جديد من التطبيقات التي تمتلك إنعاشًا وقدرات وتأثير أكثر من أي وقت مضى.
عوامل الذكاء الاصطناعي: فوق تنفيذ المهام البسيطة
بينما يُقارنون عادة بالمساعدين الرقميين، فإن عوامل الذكاء الاصطناعي تتعدى الأشخاص الذين يتبعون النصوص المزيفة. يشملون مجموعة من التقنيات المتطورة ويعملون على إطار يسمح بالقرارات الديناميكية والتأثير على الواقع.
-
الهيكلية: يتألف عامل الذكاء الاصطناعي العادي من عدة مكونات رئيسية:
-
المستشعرات: تسمح للعامل بإدراك محيطه، وتجميع البيانات من مصادر مختلفة كالمستشعرات أو واجهات البرمجة الوظيفية أو إدخالات المستخدم.
-
حالة الاعتقاد: تمثل فهم العامل للعالم بناءً على البيانات التي جُمعت. تتم تحديثها باستمرار كلما يصبح متاحا معلومات جديدة.
-
محرك التّعقل: هذا هو قلب عملية قرارات العامل. يستخدم خوارزميات، وغالبًا ما يستند على تقنيات التعلم الإيجابي أو التخطيط، لتحديد أفضل مسار العمل بناءً على اعتقاداته الحالية وأهدافه.
-
الآليات التّفكيرية: تُعد هذه أدوات العامل للتفاعل مع العالم. يمكن أن تتراوح من إرسال إلى واجهات برمجة التطبيق إلى تحكم الروبوتات الفيزيائية.
-
-
التحديات: على الرغم من أن الوكلاء الذكاء الاصطناعي التقليديين، على الرغم من كفاءتهم في التعامل مع المهام المحددة بشكل جيد، إلا أنهم غالبًا ما يواجهون صعوبات في:
-
فهم اللغة الطبيعية: تفسير اللغة البشرية المعقدة، والتعامل مع الغموض، واستخلاص المعنى من السياق تبقى تحديات كبيرة.
-
الاستدلال بالمنطق الشائع: غالبًا ما يفتقر الوكلاء الذكاء الاصطناعي الحاليون إلى معرفة الحس الشائع وقدرات الاستدلال التي يأخذها البشر كشيء مسلم به.
-
التعميم: تدريب الوكلاء للأداء بشكل جيد في المهام غير المرئية أو التكيف مع بيئات جديدة يبقى مجالًا رئيسيًا للأبحاث.
-
المترجمات اللغوية المتناولة: فتح الفهم والتوليد اللغوي
المترجمات اللغوية الكبيرة المعرفة، والتي يتم تخزينها ضمن مليارات من المادات، تحمل قدرات اللغة بشكل غير مسبوق:
- الهيكل التحويلي: أساس معظم المترجمات اللغوية الحديثة هو الهيكل التحويلي، تصميم لعبة عصبية تهدف إلى معالجة البيانات التسلسلية مثل النصوص. هذا يسمح للمترجمات اللغوية بالتقاط الاتباع البعيد في اللغة، مما يسمح لها بفهم السياق وتوليد النصوص المنظمة والمتناسقة مع السياق.
-
القدرات: تعظم المترجمات اللغوية في مجموعة واسعة من المهام القائمة على اللغة:
توليد النص: من كتابة الأداء الإبداعي إلى توليد البرمجيات في أشكال عديدة من اللغات البرمجية، تظهر المترجمات اللغوية بتواضع وإبداع لا مس
- قيود: وعلى الرغم من قدراتها المذهلة ، للنظم الكبيرة للمعلومات قيود:</diy19
التحالف: بناء الجسم بين اللغة والعمل
تتحقق الصفقة بين الوكلاء الآليين والمجموعات العقلية المتعددة مع تعزيز قيود كل منهم، من شأنه أن يؤدي إلى أنظمة هوية وقادرة على التفكير:
- تعريف وخطة للمجموعات العقلية المتعددة: يمكن للمجموعات
-
وكلاء الذكاء الاصطناعي كمنفذين ومتعلمين: يمنح وكلاء الذكاء الاصطناعي الأقواس القدرة على التفاعل مع العالم، وجمع المعلومات، وتلقي ردود الفعل على أفعالها. يمكن أن يساعد هذا الأساس الحقيقي في تعلم الأقواس من الخبرة وتحسين أدائها مع مرور الوقت.
تدفع هذه الترابط الفعالة تطوير جيل جديد من التطبيقات أكثر بديهية وقابلة للتكيف وقادرة من أي وقت مضى. مع استمرار تقدم تقنيتي الوكيل الذكاء الاصطناعي والأقواس، يمكننا توقع ظهور المزيد من التطبيقات الابتكارية والمؤثرة التي ستعيد تشكيل مشهد تطوير البرامج والتفاعل بين الإنسان والكمبيوتر.
أمثلة حقيقية: تحويل الصناعات
هذا التركيب القوي يحدث تأثيرًا في مختلف القطاعات بالفعل:
-
خدمة العملاء: حل المشاكل بوعي التكوين الحالي
- مثال: تخيل عميل يتصل بمتجر إلكتروني بشأن شحنة متأخرة. يمكن لوكيل الرياضي الآلي الممول بمعرفة التكوينات العظيمة أن يفهم الإحباط لدى العميل، ويحصل على تاريخ طلبه، ويتتبع الشحنة في الوقت الحقيقي، ويقدم بشكل تفاعلي حلول مثل الشحن المسرع أو خصم على شراءهم القادم.
-
إنشاء المحتوى: توليد محتوى عالي الجودة بحجم كبير
- مثال: يمكن لفريق ال市场营销 أن يستخدم نظام وكيل الرياضي الآلي + معرفة التكوينات العظيمة لتوليد منشورات للشبكات التواصل الاجتماعي المستهدفة، كتابة وصفات المنتجات، أو حتى خلق نصوص الفيديو. يضمن معرفة التكوينات العظيمة أن يكون المحتوى مشوقا ومعانيا، بينما يتعامل الوكيل الآلي بعملية النشر والتوزيع.
-
تعزيز التطوير البرمجي: تسريع الكود والتصحيح
- مثال: يمكن للمطور أن يوصف ميزة البرمجيات التي يريد بناءها باستخدام اللغة الطبيعية. يمكن للعبة اللاقطة العالمية إنتاج قطع البرمجيات، تحديد الأخطاء المحتملة، وتوصية تحسينات، مما يسرع بشكل كبير العملية التطويرية.
-
الرعاية الصحية: تخصيص العلاج وتحسين الرعاية المريضية
- مثال: يمكن لعبة الأعمال التي تمتلك عناية طبية للمريض ومع تطوير العبة اللاقطة العالمية إجابة أسئلتهم بشأن الصحة، وتوافير تذكيرات شفاء شخصية، وتقديم تشخيصات جديدة بناءً على أعراضهم.
-
القانون: تسريع البحث القانوني وتصميم الوثائق
- مثال: يحتاج محامي إلى تصميم عقد مع أحكام محددة ومنهج محكم. يمكن لوكيل الذكاء الاصطناعي المُشَغَّل بواسطة LLM أن يتحليل تعاليم المحامي، يبحث في قواعد بيانات قانونية واسعة، يحدد الأحكام والمنهج الصحيحة، وحتى يصمم جزء من العقد، مما يخفض بشكل كبير الوقت والجهد المطلوب.
-
إنشاء الفيديو: إنتاج الفيديوهات المشتغلة بسهولة
- مثال: تريد فريق تسويقي أن يصنع فيديو قصير يشرح خصائص منتجهم. يمكن أن يوفر الفريق لوكيل الذكاء الاصطناعي + نظام LLM خطة النص وتفضيلات الأسلوب البصري. يمكن للLLM بعد ذلك توليد نص مفصل، واقتراح الموسيقى والصور المناسبة، وحتى تحرير الفيديو، مؤتمر جزء كبير من عملية إنشاء الفيديو.
-
الهندسة: تصميم المباني بالبصمات القوية التي تمتد من التعلم التجريدي
-
مثال: يتم تصميم مبنى مكاتب جديد. يمكن للمهندس المعماري استخدام عامل تعلم الألة + نظام LLM لإدخال أهدافهم للتصميم، مثل تحسين ضوء الطبيعة وتحسين إستخدام المساحة. يمكن للLLM معالجة هذه الأهداف، إنشاء خيارات تصميم مختلفة، وحتى تخيل كيف سيؤدي المبنى إلى ما يتمتع بالظروف البيئية المختلفة.
-
البناء: تحسين الأمان والكفاءة في مواقع البناء
- مثال: وكائن تتخصص بالتعلم المتقابل مع الكاميرات والمجسات يمكنه الرقابة على موقع البناء للخطرات الأمنية. إذا كان عاملًا لم يرتدي معدات الأمان المناسبة أو كان جهازًا ما بموقف خطر، يمكن للوظيفة العامة التعلمية التحليل من الموقف، إنذار المراقب الرئيسي للموقع وحتى إيقاف تلقائيًا الأعمال إذا كان ذلك ضروريًا.
المستقبل هنا: عصر جديد للتطوير البرمجي
تحويل وكلاء البرمجيات التعلمية والوظائف التعلمية يعني قفزة هامة أمام التطوير البرمجي. وأثناء تطور هذه التكنولوجيات ما يستمر، نتوقع رؤية تطورات ابتكارية أكثر تتمكن منها، تحول الصناعات، تسريع الأدوات، وتوليد إمكانيات جديدة للتفاعل الإنساني-الكمبيوتري.
يبرز الوكلاء التعلمي
الفصل 4: الأسس الفلسفية للأنظمة الذكية
تطوير الأنظمة الذكية، وخاصة في مجال الذكاء الصناعي (التعلم المصنوعي), يتطلب فهم شديد للمبادئ الفلسفية. يتمرر هذا الفصل في الأفكار الفلسفية الجوهرية التي تشكل تصميم التعلم المصنوعي. يبرز أهمية موافقة التقدم التكنولوجي مع القيم الأخلاقية.
أسس الأنظمة الذكية الفلسفية لا تختلف عن ممارسة تئيدية فقط إنها هي هي إطار حيوي يضمن تفعيل تكنولوجيات التعلم المصنوعي للإنسانية. من خلال تعزيز العدالة والتضمين وتحسين جودة الحياة، تساعد هذه المبادئ على توجيه التعلم المصنوعي لخدمة أهم مصالحنا.
الاعتبارات الأخلاقية في تطوير التعلم المصنوعي
وأثناء تكوين أنظمة التعلم المصنوعي بشكل متزايد في كل جانب من الحياة البشرية، من الرعاية الصحية والتعليم إلى المالية والحكومة، نحتاج إلى بحث دقيق وتطبيق اللوائح الأخلاقية التي توجيه تصميمها وتطبيقها.
السؤال الأخلاقي الأساسي يدور حول كيفية تشييد التعلم المصنوعي لتتبع القيم البشرية ومبادئ الأخلاق. هذا السؤال مركزي لطريقة تشكيل التعلم المصنوعي للمستقبل الاجتماعي العالمي.
في قلب هذه المناظرة الأخلاقية يوجد المبدأ المتعلق بال المصداقية، وهو جانب رئيسي من الفلسفة الأخلاقية الذي يقول أن الأفعال يجب أن تسير بهدف القيام بالخير وتحسين جودة حياة الأفراد والم
في سياق تقنية الإنترنت، تترجم الإنماء إلى تصميم نظم تساهم في الواقع في تعزيز الإزدهار البشري—نظم تحسين النتائج الصحية، وتعزيز فرص التعليم، وتسهيل النمو الاقتصادي المتكافئ.
ولكن تطبيق الإنماء في تقنية الآلية الذكية ليس ببساطة. يتطلب منه تأقلم متنوع يقوم بتوزيع الفوائد المحتملة لتقنية الآلية الذكية على وجه الأخطار والضرر الممكن.
أحد التحديات الرئيسية في تطبيق مبدأ الإنماء في تطوير تقنية الآلية الذكية هو الحاجة إلى توازن دقيق بين الابتكار والأمان.
تقنية الآلية الذكية تملك الإمكانية للتغيير الثوري في مجالات كالطب، حيث يمكن للخوارزميات التنبؤية أن تشكل تشخيص الأمراض مبكرا ومع دقة أكبر من الأطباء البشر. ولكن بدون إشراف أخلاقي قاسي، قد تتسبب هذه التقنيات نفسها في تفجيع الانعدام الموجود.
هذا قد يحدث على سبيل المثال، إذا تم توجيهها على الأساس في المناطق الغنية بينما المجتمعات الغير مخدومة تظل تفتقر إلى الوصول الأساسي للرعاية الصحية.
ولهذا السبب، تطوير تقنية الآلية الذكية الأخلاقي يتطلب ليس فقط التركيز على زيادة الفوائد بل مقاربة إجتثاث الخطر. وهذا يتضمن تنفيذ حواجز مرنة لمنع إساءة استخدام تقنية الآلية الذكية وضمان أن هذه التقنيات لا تسبب تلقائيا الضرر.
يتطلب إطار أخلاقي تقنية الآلية الذكية أيضا أن يكون منفتحاً تماماً، مكناً من توزيع فوائد تقنية الآلية الذكية بمساواة عبر جميع المجموعات الاجتماعية، بما فيهم الذين يعانون من التمييز التقديمي. هذا يتطلب الالتزام بالعدالة والإنصاف، مضمناً أن تقنية الآلية الذكية لا تعزز فقط الوضع الحالي بل تعمل تحريضاً لتحليل الانعدامات النظامية.
لديك الإمكانية لتعزيز الإنتاجية والنمو الاقتصادي من خلال تشغيل الوظائف بواسطة الذكاء الإصطناعي. ولكنه يمكن أيضًا أن يؤدي إلى تغيير كبير في الوظائف، يؤثر بصورة غير متناسبة على العاملين ذوي الدخل المنخفض.
وكما ترون، يجب أن يتضمن إطار الذكاء الإصطناعي الأخلاقي المناسب توجيهات لتقاسم الفوائد بشكل عادل وإيفاية الأنظمة الدعمية لأولئك الذين سيتأذى من تطورات الذكاء الإصطناعي.
التطور الأخلاقي للذكاء الإصطناعي يتطلب الإشراك المستمر مع مختلف الأطراف، بما في ذلك الأخلاقيين، والتقنيين، ومشرفي السياسة، والمجتمعات التي ستتأثر بشكل كبير بتلك التقنيات. هذا التعاون المتعدد الأعضاء يؤكد أن نظم الذكاء الإصطناعي لا تُطوّر في فراغ، بل يتم تشكيلها بواسطة مجموعة واسعة من النظريات والتجارب.
ومن خلال هذه الجهود الجماعية يمكننا خلق نظم الذكاء الإصطناعي التي لا تعكس فقط القيم التي تحدد الإنسانية — التعاطف، العدالة، إحترام الاستقلال، والالتزام بالمصلحة العامة.
الاعتبارات الأخلاقية في تطوير الذكاء الإصطناعي ليست مجرد مبادئ، بل هي عناصر أساسية ستحدد ما إذا كان الذكاء الإصطناعي يخدم كقوة للخير في العالم. بواسطة إرتكاز الذكاء الإصطناعي على مبادئ الخير، والعدالة، والشمولية، وبوجهة الرصد الجاد للتوازن بين الإبتكار والمخاطر، يمكننا التأكد من أن تطوير الذكاء الإصطناعي لا يقترح فقط تقدماً تقنياً، بل يعزز كذلك جودة حياة جميع أعضاء المجتمع.
فيما نواصل دراستة قدرات الذكاء الإصطناعي، من المهم أن تظل الاعتبارات الأخلاقية في قمة مسعفاتنا، توجيهنا نحو مستقبل حيث يعمل الذكاء الإصطناعي لصالح البشرية بصورة حقيقية.
الشروط الأساسية لتصميم الأي.أي. ذات المركز البشري
تعتمد تصميم الأي.أي. الذي يعتمد على المبادئ الفلسفية العميقة التي تفوّق على الكرامة البشرية والautonomy والسياسة الشخصية.
هذا المقاربة للتطوير التي تنبني على الإيكونديري الأخلاقي لكانت تؤكد أن البشر يجب أن يرادوا بحق النهاية وليس مجرد أدوات لتحقيق أهداف أخرى (كانت, 1785).
تأثير هذه المبدأ على تصميم الأي.أي. هو كبير يتطلب أن تتم تطوير الأنظمة الإلكترونية مع تركيز ثابت على خدمة المصالح البشرية وحفظ السياسة البشرية وتحترم الautonomy الشخصي.
تنفيذ مبادئ التركيب البشري للتكنولوجيا
تعزيز الautonomy البشري من خلال الأي.أي.: مفهوم الautonomy في نظم الأي.أي. هو مهم بشكل كبير معظم التكنولوجيات لضمان أن تتمكن هذه التكنولوجيات من تمكين المستخدمين بدلاً من سيطرةهم أو تأثيرهم بشكل غير مستعمل.
وفي المصطلحات التكنولوجية ، يتطلب هذا تصميم نظم الأي.أي. التي تأخذ في الاعتبار التوجه المستقل للمستخدمين من خلال تقديم الأدوات والمعلومات التي يحتاجونها للقيام بالقرارات المعلومة. وهذا يتطلب أن تكون نماذج الأي.أي. تعرف السياق وهذا يعني أنها يجب أن تفهم السياق التي يتم فيه إتخاذ القرار وتغير توجيهاتها وفقاً لذلك.
من المنظورة التكنولوجية للنظم ، يتطلب هذا التكنولوجيا
على سبيل المثال، في مجال الرعاية الصحية، يتوجب على نظام التعلم ال artificial intelligence التي تساعد الأطباء في التشخيص تأمين التاريخ الطبي الفريد للمريض، والأعراض الحالية، وحتى الوضع النفسي الحالي لتقدم توصيات تدعم المهارات الطبية الخاصة بالأطباء بدلاً من تحريكهم.
هذه التكيفة السياسية تضمن أن التعلم ال artificial intelligence يبقى أداة دعمية تحسين ما بدلاً من خفض الautonomy البشرية.
ضمان عمليات القرار-حكم الشفافية: والشفافية في الأنظمة ال artificial intelligence تعتبر من الrequirement الأساسي لضمان أن المستخدمين يمكن أن يثقوا بها ويفهموا القرارات التي يتم إتخاذها بواسطة هذه التكنولوجيات. من التقني ، هذا يترجم إلى حاجة إلى التعلم المفهومي البيني (XAI)، والذي يتضمن تطوير الخوارزميات التي قادرة على توحيد بشكل واضح سببيات خروجها بالقرارات.
هذا مهم بشكل خاص في مجالات مثل المالية والرعاية الصحية والعدالة الجنائية، حيث قد تؤدي إلى تواطؤ ومسائل أخلاقية تتسبب بعدم الثقة وفي القرارات الغامرة.
يمكن حصول التفسير التقني عن طريق عدة طرق. وهناك طريقة شائعة تدعى post-hoc interpretability، حيث يولد النموذج ال AI التفسير بعد القرار المحدد. قد يتضمن ذلك تفريق القرار إلى عناصره المكونة وإظهار كيف أن كل واحد منهم ساهم في نتيجة الخروج.
وهناك مقاربة أخرى بالنظام البرمجي تلقاء نفسه قابل للتفسير ، حيث يتم تصميم هيكل النموذج بطريقة تجعل قراراته شفافة بشكل افتراضي. على سبيل المثال ، تعتبر النماذج المتفاعلة مثل الأشجار القائمة بالقرارات والنماذج الخطية قابلة للتفسير بشكل طبيعي لأن عملية قرارها سهلة التتبع والفهم.
التحدي في تنفيذ التعلم الذاتي القابل للتفسير يكمن في توازن الشفافية مع الأداء. عادةً ، النماذج الأكثر تعقيدًا ، مثل شبكات الخواند العميقة ، أقل قابلية للتفسير ولكن أدق في التنبؤ. وبذلك يتوجب على تصميم التعلم الآلي التحضري التوجه إلى معاملة المقايضة بين قابلية التفسير للنموذج وقوته في التنبؤ ، متأكدًا من أن المستخدمون يمكن أن يثقوا بوجه دفع القرارات التي تتخذ بدون تضييع الدقة.
تمكين المراقبة الإنسانية المعنية: تمكين المراقبة الإنسانية المعنية هو أهمية كبيرة في ضمان أن تعمل أنظمة التعلم الآلي في مجالات الأخلاقيات والحدود التامة. تتضمن هذا المراقبة تصميم الأنظمة التي تحتوي على أجهزة نقاط الفشل والآليات التي تسمح للمشغلين الإنسانيين بالتدخل في الأحيان المعينة.
يمكن تنفيذ تلك المراقبة التقنية بطرق عديدة.
إحدى هذه الطرق هي تضمين نظم الإنسان في الدورة حيث يتم مراقبة وتقييم عملية القرارات التي تقوم بها الأنظمة التعلم الآلي بو
مثلاً في حالة أنظمة الأسلحة الautonomous، يتمحور من الضروري إدارة البشر لمنع التقنية الذهنية من أخذ قرارات بين الحياة والموت بدون تسجيل بشري. قد تتضمن وضع حدود تشغيلية قاسية لا يمكن تخطئها بدون تصريح بشري، مما يدفع لتضمين أخلاقي في النظام.
ويتم إعتبار أخر معايير تقنية، وهي سجلات جميع القرارات والأفعال التي يتخذها نظام التقنية الذهنية. توفر هذه السجلات تاريخ شفاف يمكن مراجعته من قبل مُدِراء بشريين لضمان الاتفاق بمعايير الأخلاقيات.
وتلك السجلات مهمة بشكل خاص في قطاعات مثل المال والقانون، حيث يتوجب توثيق القرارات وتوجيهها للحفاظ بثقة العام والإنجاز بالأحكام التنظيمية.
توازن الautonomy وال Control: تتمحور أحد التحديات التقنية الرئيسية في التقنيات التي تحوي إنسان المركز على إيجاد التوازن الصحيح بين الautonomy وال Control. بينما تصمم الأنظمة التقنية الذهنية لتعمل بautonomy في مجموعة كبيرة من الحالات، يتمنى أن تتأسس هذا الautonomy بدون تتهيب السيطرة البشرية أو المراقبة.
يمكن إنجاز هذا التوازن من خلال تنفيذ المستويات التقنية للautonomy، والتي تدفع لمدى تحركات التقنية الذهنية بالإستقلال.
على سبيل المثال، في أنظمة نصف-autonomous مثل السيارات الذاتية القيادة، تتراوح مستويات الautonomy من دعم القيادة الأبسط (حيث يبقى السائق البشري في سيطرة كاملة) إلى التو
يجب أن تتأكد الهياكل التي تم تصميمها من أن العامل البشري يحتفظ بالقدرة على التدخل وتجاوز الذكاء الاصطناعي عند الاحتجاج. هذا يتطلب واجهات تحكم متطورة وأنظمة دعم القرار التي تسمح للبشر بالتحكم بسرعة وفعالية في حين الاحتجاج.
بالإضافة إلى ذلك، يتعين تطوير إطارات الذكاء الاصطناعي الأخلاقية لتوجيه الأفعال الأوتونومية لأنظمة الذكاء الاصطناعي. تتكون هذه الإطارات من مجموعات من القواعد والإرشادات المدمجة داخل الذكاء الاصطناعي التي تحدد كيفية تصرفه في الوضعيات الأخلاقية المعقدة.
على سبيل المثال، في الرعاية الصحية، قد تتضمن إطار الذكاء الاصطناعي الأخلاقي قواعد حول إذن المريض، الخصوصية، وتسلسل العلاجات بحسب الحاجة الطبية بدلاً من الاعتبارات المالية.
بإدماج هذه المبادئ الأخلاقية مباشرة في عمليات اتخاذ القرار للذكاء الاصطناعي، يمكن للمطورين أن يتأكدوا من أن سلطة النظام الأوتونومية تم تمريرها بطريقة تتوافق مع قيمنا البشرية.
تكامل مبادئ التمركز على البشر في تصميم الذكاء الاصطناعي ليس مجرد مثال فلسفي بل إنها حاجة تقنية. من خلال تعزيز سلطة البشر، وضمان الشفافية، وتمكين الراقبة الفعالة، وتحقيق التوازن بين الأوتونومية والتحكم، يمكن تطوير أنظمة الذكاء الاصطناعي بطريقة تخدم بشكل حقيقي البشرية.
هذه الإعتبارات التقنية الضرورية لخلق الذكاء الاصطناعي الذي ليس فقط يعزز القدرات البشرية ولكن يحترم ويحمي القيم التي هي أساسية لمجتمعنا.
فيما يتابع تطور الذكاء الاصطناعي، يكون الالتزام بتصميم التمركز على البشر مهم جداً لضمان أن تستخدم تكنولوجيات الذكاء القوية بصورة أخلاقية ومسؤولة.
كيف تتأكد من أن الأعمال التي يقوم بها المجتمع الإصطناعية تساهم في الإنسان: تحسين جودة الحياة
فيما يتعلق بمشاركتك في تطوير أنظمة المجتمع الإصطناعية، فإنه من الأساسي أن تقوم بجهودك بإطار إطار أخلاقي يشمل الإستفادة من المصلحة الجماعية — فلسفة تولّي أهمية تعزيز السعادة والخيرة الكلية.
ضمن هذا السياق، يمكن للمجتمع الإصطناعي أن يوفر قدرات لمعالجة التحديات الاجتماعية الحادة، وخاصة في مجالات مثل الرعاية الصحية، التعليم، والاستدامة البيئية.
وهدفنا هو إنشاء تكنولوجيات تحسن جودة الحياة للجميع بشكل كبير. ولكن هذا التطلع يأتي مع تعقيدات. يقدم المصلحة الجماعية سبب ملهم لإنشاء المجتمع الإصطناعي بشكل واسع، ولكنه يجلب أيضًا أسئلة أخلاقية مهمة حول من يستفيد ومن قد يتم إغفاله بالأقل، خاصة في الأوجه المعروفة للأوجه الضعيفة.
لتحرك من خلال تلك التعقيدات، نحن بحاجة إلى طريقة متطورة ومستنيرة تقنيًا — وهي توازن بين مطالعة واسعة للخير الجماعي وحاجة العدالة والمساواة.
حين تطبق مبادئ المصلحة الجماعية على المجتمع الإصطناعي، ينبغي عليك التركيز على تحسين النتائج في مجالات معينة. فعلى سبيل المثال في الرعاية الصحية، يمكن أن تكون أدوات التشخيص المولدة بواسطة المجتمع الإصطناعي تحسن مؤشرًا كبيرًا في نتائج المرضى م
ولكن تنمية هذه التكنولوجيات تتطلب اعتبار دقيق لتجنب تعزيز تباينات موجودة بالفعل. قد تختلف تعداد البيانات التي يتم استخدامها لتمرين النماذج التي تشتمل على التعلم الذاتي بشكل كبير في المناطق المختلفة، وهو ما يؤثر على دقة وثبات هذه الأنظمة.
هذا التباين يوضح أهمية تأسيس frameworks للإدارة القوية للبيانات التي تضمن أن حلولك الصحية التي تتدفق من خلال التعلم الآلي تكون تمثلة ومناسبة.
في ميدان التعليم، تمثل قدرات التعلم الشخصي التي يمتلكها التعلم الآلي أمل كبير. يمكن للأنظمة التي تتكيف مع محتوى التعليم التي توفر على ما يحتاجه الطلاب المعينين، مما يزيد من نتائج التعلم. من خلال تحليل البيانات عن أداء وسلوك الطلاب، يمكن للتعلم الآلي إيجاد ما يمكن أن يصاب به الطالب وتقدم دعم متمركز.
لكن في ما يتعلق بالمضي قدماً نحو هذه المزايا، من المهم جداً أن تكون واعيًا بخطرات —مثل قدرة التعزيز للتعصبات أو تعزيز الطلاب الذين لا يناسبون أنماط التعلم المعتادة.
تجنب هذه الخطرات يتطلب تدمير آلياً للأنظمة التي تتمكن من تفويض المجموعات المعينة بشكل لا محذوف. ويكون من المهم جدًا إبقاء دور المعلمين مستقرًا. تعتبر تحكمهم وخبرتهم ضرورية لجعل أدوات التعلم الآلية فعالة وداعمة حقًا.
وفي مجال الاستدامة البيئية، يمثل قدرات
على سبيل المثال، يمكن للتكنولوجيا الذكية تحليل أعداد كبيرة من البيانات البيئية لتنبؤ بأنماط الطقس، و تنظيم استهلاك الطاقة، و تخفيض نفايات المصرف — أعمال تساهم في رفاهية الأجيال الحالية و المستقبلية.
و لكن هذا التقدم التكنولوجي يأتي معه تحدياته الخاصة، و بالأخص حول تأثير الأنظمة التي يتم تطويرها العلم المتقدم على البيئة.
يتم استهلاك الطاقة المطلوب للعملية الكبيرة للأنظمة التي تحاول تحقيق المزايا البيئية التي تحاول تحقيقها. لذا يمكن أن تكون تطوير الأنظمة التي تستخدم الطاقة بالكفاءة مهماً لضمان أن تأثيرها الإيجابي في الاستدامة لا يتم تحطيمه.
و أثناء تطوير الأنظمة التي تحقيق أهدافها التجاربية، من المهم أيضًا أن تنظر إلى آثارها على العدالة الاجتماعية. يركز التعمد العام على زيادة السعادة الكلية و لكنه لا يتناول بشكل برمته توزيع المزايا و الآثار السلبية عبر المجموعات الاجتماعية المختلفة.
هذا يقود إلى قدرة الأنظمة التي تحاول تحقيقها التكافؤ بما يزيد من الممتلكات الموجودة بالفوائد و قبالة الأقليات المحرومة من التحسين بشكل مناسب.
و لكي تمكن من معالجة هذا، ينبغي على عملية تطوير الأنظمة التي تحتوي مبادئ توزيع المساواة، مما يضمن توزيع المزايا بالعدالة و تعاليم الأخطاء الممكنة. قد يتطلب هذا التصميم لألغو أي ت
بينما تقوم بتطوير أنظمة الذكاء الإصطناعي تهدف إلى تحسين جودة الحياة، من المهم تحقيق التوازن بين الهدف الاستبدادي لزيادة الرفاهية بحاجة إلى العدالة والإنصاف. هذا يتطلب منهجية تدريجية، منحى تقني مترمز لاحتواء التأثيرات الأوسع لتطبيق الذكاء الإصطناعي.
بواسطة تصميم أنظمة الذكاء الإصطناعي التي تكون كلاها فعالة وعادلة، يمكنك المساهمة في مستقبل حيث تحقق التقنيات التطورية خدمة الاحتياجات المتنوعة للمجتمع.
تنفيذ حواجز منع الضرر الإحتمالي
في تطوير تقنيات الذكاء الإصطناعي، يجب أن تتعرف على الإمكانية الفطرية للضرر وتقوم بإنشاء حواجز جيدة لتخفيف هذه الأخطار. هذه المسؤولية متجذرة في أخلاقيات التوجيهية. تؤكد هذه الفرعية من الأخلاق أن الواجب الأخلاقي على الموالاة بالقواعد والمعايير الأخلاقية الموجودة، مما يضمن أن التكنولوجيا التي تصنعها تتماشى مع المبادئ الأخلاقية الأساسية.
تنفيذ برامج حماية جيدة ليس فقط تدابير احتياطية ولكن واجب أخلاقي. يجب أن تشمل هذه البرامج تجارب تحيز شاملة، وشفافية في عملية الخوارزميات، وآليات واضحة للمساءلة.
تلك الحواجز الضرورية لمنع أنظمة الذكاء الإصطناعي من سبب الضرر غير المقصود، سواء من خلال التصرفات التحيزية أو العمليات الغير الشفافة أو نقص الإشراف.
في الواقع، تنفيذ هذه الحواجز يتطلب فهم عميق للبعد التقني والبعد الأخلاقي للذكاء الإصطناعي.
تجربة التحيز، على سبيل المثال، تتضمن ليس فقط إكتشاف وتصحيح التحيزات في البيانات والخوارزميات ولكن أيضًا فهم التأثيرات الاجتماعية الشاملة لتلك التحيزات. يجب عليك أن تتأكد بأن نماذج الذكاء الاصطناعي التي تدرب عليها تتم بواسطة مجموعات بيانات متنوعة وممثلة وتتم إقراضيتها بانتظام للكشف وتصحيح أي تحيزات قد تظهر مع مرور الوقت.
الشفافية، من ناحية أخرى، تتطلب أن تصمم نظم الذكاء الاصطناعي بطريقة تسمح بمفهوم سهل لعمليات اتخاذ القرار ومراقبتها من قبل المستخدمين والأطراف. هذا يتضمن تطوير نماذج الذكاء الشفافة التي توفر خرجات واضحة وقابلة للتفسير، مما يسمح للمستخدمين برؤية كيفية اتخاذ القرارات وتأكد من تبرير وعدالة تلك القرارات.
ومؤشرات المساءلة أيضًا أساسية لإبقاء الثقة وضمان استخدام نظم الذكاء الاصطناعي بمسؤولية. يجب أن تتضمن هذه الآليات توجيهات واضحة لمن يكون مسؤولاً عن نتائج قرارات الذكاء الاصطناعي، بالإضافة إلى العمليات المعالجة وتصحيح أي إيذاء قد يحدث.
يجب علىك إقامة إطار حيث تتم دمج الاعتبارات الأخلاقية في كل مرحلة من تطوير الذكاء الاصطناعي، من التصميم الأولي إلى التطبيق وما بعده. هذا يتضمن ليس فقط اتباع المواصفات الأخلاقية ولكن أيضًا مراقبة المستمرة وتعديل نظم الذكاء الاصطناعي وهي تتفاعل مع العالم الحقيقي.
من خلال إدماج هذه الحمايات في النسيج الأساسي لتطوير الذكاء الاصطناعي، يمكنك مساعدة في ضمان أن التقدم التكنولوجي يخدم الخير العام بدون تسبب لتأثيرات سلبية غير مقصودة.
دور المراقبة البشرية والحلقات التغذية.
إشراف البشر في أنظمة الذكاء الاصطناعي هو عنصر حاسم في التأكد من إطلاق الذكاء الاصطناعي الأخلاقي. المبدأ الذي يحمل الإantwortabilité يؤكد الحاجة إلى مشاركة البشر المستمرة في عملية تشغيل الذكاء الاصطناعي، خاصة في بيئات معدلات الخطر العالية مثل الرعاية الصحية والعدالة الجنائية.
الحلقات التغذية، التي تستخدم إشراف البشر لتحسين وتحسين أنظمة الذكاء الاصطناعي، ضرورية للحفاظ على المساءلة والقابلية للتكيف (راجي وآخرون، 2020). تسمح هذه الحلقات بتصحيح الأخطاء وادمج الاعتبارات الأخلاقية الجديدة بما يتماشى مع تطور قيم المجتمع.
بإشراف البشر في أنظمة الذكاء الاصطناعي، يمكن للمطورين إنشاء تقنيات ليست فقط فعالة لكن أيضًا متماسكة مع القواعد الأخلاقية وتوقعات البشر.
ترجمة الأخلاقيات: ترجمة المبادئ الفلسفية إلى أنظمة الذكاء الاصطناعي
ترجمة المبادئ الفلسفية إلى أنظمة الذكاء الاصطناعي هي مهمة معقدة ولكنها ضرورية. يتمثل هذا العمل في تضمين الاعتبارات الأخلاقية في نفس شفرة التي تحرك خوارزميات الذكاء الاصطناعي.
مفاهيم مثل العدالة، والكرامة، والتحررية يجب أن تُشفر داخل أنظمة الذكاء الاصطناعي لضمان أنها تعمل بطرق تعكس قيم المجتمع. هذا يتطلب منهج متعدد التخصصي، حيث تتشارك مفكرون أخلاقيون، ومهندسون، وعلماء الاجتماع يحددون ويطبقون المبادئ الأخلاقية في عملية التشفير.
الهدف هو إنشاء أنظمة الذكاء الاصطناعي ليس فقط مهارية تقنيًا لكن أيضًا صوتًا أخلاقيًا، قادرة على إتخاذ قرارات تحترم كرامة البشر وتعزز الخير الاجتماعي (ميتلستاد وآخرون، 2016).
تعزيز الشمولية والوصول المتساوٍ في تطوير وإطلاق الذ
الشمولية والحصول على الوصول المتساوٍ هي أساسين لتطوير الذكاء الاصطناعي بمعنى إيثيكي. مفهوم العدالة كالمساواة في الصفة الراولزية يوفر إعتماد فلسفي لضمان أن نظم الذكاء الاصطناعي تصمم وتُطبق بطرق تعمم الفوائد لجميع أعضاء المجتمع، وخاصةً الأكثر ضعفًا (روالز، 1971).
هذا يتضمن جهود تناوبية لتضمين وجهات النظر المتنوعة في عملية التطوير، خاصةً من الفئات غير الممثلة والجنوب العالمي.
من خلال إدماج هذه الآراء المتنوعة، يمكن لمطوري الذكاء الاصطناعي إنشاء أنظمة تعمل بمعدل أكثر تساواة وإستجابة لاحتياجات نطاق واسع من المستخدمين. وكذلك، ضمان الوصول المتساوٍ إلى تقنيات الذكاء الاصطناعي حاسم لمنع تفجير الفجوات الاجتماعية القائمة.
تحديد التحيز الخوارزمي والعدالة
التحيز الخوارزمي هو قضية إيثيكية كبيرة في تطوير الذكاء الاصطناعي، لأن الخوارزميات التي تحمل تحيزًا يمكن أن تستمر وحتى تعزيز الفجوات الاجتماعية. والتصدي لهذه القضية تتطلب التزام بالعدالة الإجرائية، مما يضمن أن نظم الذكاء الاصطناعي تطوير من خلال عمليات عادلة تأخذ في عين الاعتبار التأثير على جميع الأطراف (نيسنباوم، 2001).
هذا يتضمن تحديد وتخفيف الأحكام السلبية في بيانات التدريب، وتطوير خوارزميات واضحة وقابلة للشرح، وتنفيذ التحققات العدالة عبر حياة نظام الذكاء الاصطناعي.
من خلال التعامل مع التحيز الخوارزمي، يمكن للمطورين إنشاء نظم الذكاء الاصطناعي التي تساهم في إيجاد مجتمع أكثر عدالة وتساواة، بدلاً من تعزيز الفجوات القائمة.
إدماج وجهات النظر المتنوعة في تطوير الذكاء الاصطناعي
إندماج وجهات النظر المتنوعة في تطوير الذكاء الاصطناعي أمر ضروري لخلق نظم تضمن الشمولية والإنصاف. تضمين صوتات الفئات غير الممثلة يؤكد أن تقنيات الذكاء الاصطناعي لا تعكس فقط قيم وأولويات قشرة من المجتمع فقط.
هذه النهجة تتماشى مع المبدأ الفلسفي للديمقراطية التشريعية، الذي يبرز أهمية الانخراط الشامل والمشارك في عمليات اتخاذ القرار (هابرماس، 1996).
بتعزيز المشاركة المتنوعة في تطوير الذكاء الاصطناعي، يمكننا التأكد من أن تلك التقنيات مصممة لخدمة مصالح البشرية بأكملها، بدلاً من القليل من الممنوحين بالميزة.
استراتيجيات لعبر الفجوة الذكاء الاصطناعي
تعتبر الفجوة الذكاء الاصطناعي، التي تميزها عدم تساوي الوصول إلى تقنيات الذكاء الاصطناعي وفوائدها، تحدي كبير للإنصاف العالمي. يتطلب العبر منها التزام بالعدالة التوزيعية، مما يؤكد أن فوائد الذكاء الاصطناعي تتم إشتراكها واسعاً عبر الفئات الاجتماعية والاقتصادية المختلفة والمناطق (سين، 2009).
يمكننا فعل ذلك من خلال مبادرات تروج للوصول إلى تعليم الذكاء الاصطناعي والموارد في المجتمعات غير المخدومة، وبالإضافة إلى السياسات التي تدعم توزيع الأرباح الاقتصادية المدفوعة بالذكاء الاصطناعي بشكل عادل. بمعالجة فجوة الذكاء الاصطناعي، يمكننا التأكد من أن الذكاء الاصطناعي يسهم في التنمية العالمية بطريقة شاملة وعادلة.
التوازن بين الإبتكار والقيود الأخلاقية
التوازن بين السعي بالإبتكار والقيود الأخلاقية حاسم للتقدم المسؤول في مجال الذكاء الاصطناعي. المبدأ الوقائي، الذي يؤكد على الحذر في وجه الشكوك، مستبعد في السياق التطويري للذكاء الاصطناعي (ساندين، 1999).
ar
بينما يقود الإبتكار التقدم، يتوجب أن يُشكل بمساعدة التفكير الأخلاقي لحماية المجتمع من الضرر الإحتمالي. هذا يتطلب تقييم دقيق للمخاطر والفوائد التي تتنقل بواسطة تقنيات الذكاء الإصطناعي الجديدة، بالإضافة إلى تطبيق إطارات التنظيم التي تضمن تحفظ المعايير الأخلاقية.
بالتوازن بين الإبتكار والقيود الأخلاقية، يمكننا تعزيز تطوير تقنيات الذكاء الإصطناعي التي هي على جبهة الإبتكار ومتوافقة مع الأهداف العامة للحداثة الإجتماعية.
كما ترون، الأساس الفلسفي للأنظمة الذكية يوفر إطارًا حاسمًا لضمان تطوير تقنيات الذكاء الإصطناعي وتطبيقها بطرقٍ أخلاقية، وفيما يؤدى إلى جميع أفراد البشرية بصورة مشمولة ومفيدة.
بواسطة ركيزة تطوير الذكاء الإصطناعي على هذه المبادئ الفلسفية، يمكننا إنشاء أنظمة ذكية تقوم ليس فقط بتقدم قدرات التكنولوجيا ولكن أيضًا بتحسين جودة الحياة، وتعزيز العدالة، وضمان تساوي التفرقة في ممارسة فوائد الذكاء الإصطناعي عبر المجتمع.
الفصل 5: عوامل الذكاء الإصطناعي كمعالجين للمجموعات الكبيرة لللغات
دمج عوامل الذكاء الإصطناعي مع مجموعات اللغة الكبيرة (LLMs) يمثل تحولاً جوهرياً في الذكاء الإصطناعي، يعالج القصور الحرج الذي تعاني منه مجموعات اللغة الكبيرة والذي يحد من تطبيقها على نطاق واسع.
هذه الدمج تمكن الآلات من التخطى عن الأدوار التقليدية، التقدم من مولدات نصوص passives إلى أنظمة ذاتية قادرة على التفكير الديناميكي واتخاذ القرارات.
فيما يزداد استخدام الأنظمة الذكية في قيادة العمليات الحرجة في مختلف المجالات، يصبح فهم كيفية تعالج عوامل الذكاء الإصطناعي لثغرات قدرات LLMs أمراً حاسم
plaintext
تحقيق الفراغات في قدرات LLM
في حين أن LLM قوية، فهي تتمحور بشكل طبيعي على البيانات التي تم تدريبها عليها وطبيعة البنية الثابتة. هذه النماذج تعمل في مجموعة منتظمة من الزوايا، وهي تعرف عادةً بالمجموعة النصية التي تستخدم أثناء مرحلة تدريبها.
هذه القصورة تعني أن LLM لا يمكنها تنفيذًا تلقائيًا البحث عن معلومات جديدة أو تحديث قاعدة المعرفة بعد التدريب. ونتيجة لذلك، يفتقرون LLM عادةً إلى الحدث ويفتقرون إلى قدرة الإجابة التي تتطلب بيانات حية أو معارف تتخطى بداية بياناتها التدريبية.
ويعبر الوكلاء الآلية عن هذه الفجوات بتكامل ديناميكي لمصادر البيانات الخارجية، والذي يمكنه توسيع الأفق الوظيفي لـLLM.
مثلاً، قد يُدرب LLM على بيانات مالية حتى عام 2022 وقد يقدم تحليلات تاريخية دقيقةً لكن سيصب بصعوبة في إنشاء توقعات سوقية حديثة. يمكن لوكيل الآلية أن يعزز هذا الLLM بسحب بيانات السوق المالي الحية، وتطبيق هذه الإدخالات لتوليد تحاليل أكثر وجهة النظر ومواكبة للوقت.
ويؤكد هذا التكامل الديناميكي أن النتائج ليست فقط دقيقةً تاريخياً بل أيضًا تلائم الظروف الحالية.
تعزيز سلطة القرار التلقائية
واحدة من القصورات الرئيسية التي يعاني منها LLM هي قلة قدراتها على إتخاذ القرارات التلقائية. ويتميز LLM بإنتاجات لغوية قوية ولكن يفتقر في المهام التي تتطلب إتخاذ قرارات معقدة، خاصةً في بيئات معروفة بالشكوك والتغيير.
هذا العجز الرئيسي يعود بشكل كبير إلى الإعتماد الذي تضعه النموذج على البيانات القائمة مسبقًا وعدم وجود ميكانيزمات للتعقل التكيفي أو التعلم من التجارب الجديدة بعد النشر.
ويعالجون هذه العجز الوكلاء الذكاء الاصطناعي بتوفير البنية التحتية الضرورية للقرارات الاستقلالية. يمكنهم أن يأخذوا النتائج الثابتة للمؤشرات الطويلة الأجل ويمرروها من خلال إطارات التعقل المتقدمة كالأنظمة القائمة على القواعد، أو التلائميات، أو نماذج التعلم الإيجابي.
على سبيل المثال، في البيئة الصحية، قد يولد مؤشر الطويلة الأجل قائمة بالتشخيصات الحتمية بناءً على أعراض المريض وتاريخه الطبي. ولكن بدون وكيل الذكاء الاصطناعي، لن يستطيع مؤشر الطويلة الأجل تقييم هذه الخيارات أو توصية بمسار عمل.
يمكن لوكيل الذكاء الاصطناعي التدخل لتقييم هذه التشخيصات مقابل المنشورات الطبية الحالية، وبيانات المريض، والعوامل التكونية، وبالنهاية يتخذ قراراً أكثر عقلانية ويقترح خطوات عملية قابلة للتنفيذ. هذا التوافق يحوّل نتائج مؤشر الطويلة الأجل من الاقتراحات إلى قرارات معروفة للمحيط.
التعامل مع الكمالية والتماسك
الكمالية والتماسك هما عوامل حاسمين في ضمان معدل النتائج المؤشرات الطويلة الأجل، خاصة في المهام التعقلية المعقدة. بسبب طبيعتهم البارامترية، يولد المؤشرات الطويلة الأجل نتائجًا إما غير كاملة أو تفتقر إلى التماسك اللوجيكي، خاصة عند التعامل مع عمليات متعددة الخطوات أو الحاجة إلى فهم شامل في مجالات متعددة.
هذه القضايا تنبع من البيئة المعزولة التي يعمل بها مؤشر الطويلة الأجل، حيث لا يمكنهم التشاور أو التحقق من النتائج ضد معايير خارجية أو معلومات إضافية.
تلعب وكلاء الأجهزة التيلكوماتية دورًا رئيسيًا في تخفيض هذه المشاكل بتقديم أجهزة تعامل تعامل تكرارية وطبقات تحقيق.
على سبيل المثال، في مجال القانون، قد تكتب وكلاء الأجهزة التيلكوماتية نسخة 初步 من وثيقة قضائية وفقاً لبياناتها التدريبية. ولكن هذه النسخة الأولية قد تتجاهل بعض المراجعات السابقة أو تفشل في تشكيل الحجة بشكل منطقي.
يمكن لوكلاء الأجهزة التيلكوماتية التقييم من هذه النسخة الأولية، ما يتمكن من تأكد أنها تتوافق بمعايير الإكمال المطلوبة بالتنقل مع bases القانونية الخارجية، مراجعة للتوافق المنطقي، وطلب المزيد من المعلومات أو التوضيح حيث يتوجب التوافق.
هذه العملية التكرارية تمكن من إنتاج وثيقة أكثر قوة وموثوقية وتوافق بالمتطلبات الشديدة للممارسة القانونية.
تغلب العزلة من خلال التكامل
أحد القيود الأكثر عمق على وكلاء الأجهزة التيلكوماتية هو عزلتهم من الأنظمة الأخرى ومصادر المعرفة.
وكلاء الأجهزة التيلكوماتية ، كما تم تصميمهم، هي أنظمة مغلولة تتعامل بشكل لا يطلق النظر مع البيئات الخارجية أو قاعدات البيانات. هذه العزلة تحدد بشكل كبير قدراتهم على التأقلم مع المعلومات الجديدة أو التعامل في الوقت الحقيقي، مما يجعلهم أقل فاعلية في التطبيقات التي تتطلب التفاعل الحالي أو القرارات الحالية.
يتم
تشكيل الردود القياسية في تطبيقات خدمة العملاء، قد تولد الأنظمة النطقية العظيمة الإجابات القياسية بناءً على السكربتات المُعَدَّةَ مسبقاً. ومع ذلك، قد تكون هذه الإجابات ساكنة وتفتقر إلى الشخصية المطلوبة للتواصل الفعال مع العملاء.
يمكن للوكيل الذكي الإشراك في تواصلات المستخدمين بالبيانات الحية من الحسابات الشخصية للعملاء، التفاعلات السابقة، وأدوات تحليل المشاعر، مما يساعد على إنتاج إجابات ليست فقط متماثلة بالسياق بل أيضًا مصممة لاحتياجات العميل بالتحديد.
تحويل التجربة للعميل من سلسلة من التفاعلات الموجودة في السكربت إلى حوار ديناميكي ومخصص.
توسيع الإبداع وحل المشاكل
بينما تُعد الأنظمة النطقية العظيمة أدوات قوية لتوليد المحتوى، إن إبداعها وقدرات حل المشاكل محدودة بما فيه الكفاية بالبيانات التي تم تدريبها عليها. وغالبًا ما يفشل هذه النماذج في تطبيق مفاهيم النظرية على التحديات الجديدة أو غير المتوقعة، لأن قدراتها على حل المشاكل محدودة بمعرفتها الموجودة مسبقاً ومعامل التدريب.
يعزز الوكلاء الذكيون إمكانيات الإبداع وحل المشاكل للأنظمة النطقية العظيمة بإستخدام تقنيات التفكير المتقدمة ومجموعة أوسع من الأدوات التحليلية. هذه القدرة تسمح للوكيل الذكي بتخطي الحدود التي يوجد لها الأنظمة النطقية العظيمة، وتطبيق إطارات النظرية على المشاكل العملية بطرقٍ إبداعية.
على سبيل المثال، تأمل المشكلة التي تواجهها منع تعميم المعلومات الخاطئة على منصات وسائل الإعلام الاجتماعية. قد يعيد النظام النطقي العظيم التعريف النمطي للمعلومات الخاطئة بناءً على التحليل النصوي، ولكن قد يصبح عجزاً في تطوير استراتيجية شاملة لتخفيف
تأخذ الوكيل الآلي هذه النظرات، يطبق نظريات متعددة التخصصات من مجالات كالاجتماعية، والنفسية، ونظرية الشبكات، ويطور مقاربة متعددة الوجهات التي تتضمن مراقبة زمنية، تعليم المستخدمين، وتقنيات التنظيم التلقائي.
هذه القدرة على تركيب إطارات نظرية متنوعة وتطبيقها على التحديات الواقعية تمثل القدرات المُحسنة على حل المشاكل التي تحملها وكلبوا الآلية.
أمثلة أكثر تحديداً
وكلبوا الآلية، بقدرتها على التفاعل مع نظم مختلفة، والوصول إلى البيانات الزمنية، وتنفيذ الإجراءات، تعالج هذه القصور مباشرة، محولة نماذج اللغة العميقة من نماذج لغوية قوية لكن سلبية إلى محللات مشاكل واقعية دينامية. دعونا ننظر إلى بعض الأمثلة:
1. من البيانات الثابتة إلى معرفة الحالة الدينامية: إبقاء نماذج اللغة العميقة في الحلقة
-
المشكلة: تخيل السؤال من نموذج اللغة العميقة المتدرب على بحوث طبية قبل 2023، “ما هي الإنجازات الأخيرة في علاج السرطان؟” سيكون معرفته تقديمية.
-
حل وكيل الآلية: يمكن لوكيل الآلية الاتصال بنموذج اللغة العميقة بمجلات طبية، قواعد بيانات البحث، وتغذية الأخبار. الآن، يستطيع نموذج اللغة العميقة توفير معلومات حديثة عن التجارب الكلينيكية، وخيارات العلاج، ونتائج البحث.
2. من التحليل إلى العمل: توطين المهام بناءً على تحليلات LLM
-
المشكلة: قد يحدد LLM الذي يراقب وسائل الإعلام الاجتماعية لعلامة تجارية ارتفاعاً في الشعور السلبي ولكن لا يستطيع القيام بأي شيء لمعالجته.
-
حل الوكيل الذكي: يمكن لوكيل الذكاء الإصطناعي الذي يتصل بحسابات وسائل الإعلام الاجتماعية للعلامة ومجهز بالردود الموافقة مسبقًا أن يتمكن من التصدي للقلقيات، والإجابة على الأسئلة، وحتى ترفع القضايا المعقدة إلى الممثلين البشريين.
3. من المسودة الأولى إلى المنتج النهائي: ضمان الجودة والدقة
-
المشكلة: قد يقدم LLM المعين بترجمة الدليل التقني ترجمات صحيحة جرامريا ولكن غير دقيقة تقنيًا بسبب عجزه عن المعرفة المحددة للمجال.
- الحل من خلال العميل التكنولوجي الأولي: يمكن للعميل التكنولوجي الأولي أن يدمج ال LLM مع القواميس التخصصية والقواميس المفاصلة وحتى يربطه بالخبراء في المواضيع للملاحظات الحالية والتي تضمن أن يكون الترجمة النهائية دقيقة لغوياً ومؤكدة تقنياً.
4. تحطيم العقبات: ربط ال LLMs بالعالم الحقيقي
- المشكلة: قد يصاب محرك كلمات مصمم للتحكم في المنازل الأذكياء بالتحديد بالتأقلم مع مناورات المستخدم وتفضيلاته.
- الحل من خلال العميل التكنولوجي الأولي: يمكن للعميل التكنولوجي الأولي أن يربط ال LLM بالمستشعرات والأجهز
5. من المحاكاة إلى الإبتكار: توسيع خلاقية المحادثة الطويلة الأموال
-
المشكلة: قد يصنع عميل الذكاء الاصطناعي المكلف بتأليف الموسيقى قطعًا تبدو مشتقة أو تفتقر إلى عمقٍ عاطفي، لأنه يعتمد بشكل أساسي على الأنماط التي وجدت في بيانات تدريبه.
-
الحل الذي يقدمه عميل الذكاء الاصطناعي: يمكن لعميل الذكاء الاصطناعي أن يربط المحادثة الطويلة الأموال بمجسات تقييم التغذية البيولوجية التي تقيس استجابات المؤلف العاطفية للعناصر الموسيقية المختلفة. من خلال إدماج هذه الاستجابة في الوقت الحقيقي، يمكن للمحادثة الطويلة أن تصنع موسيقى ليس فقط تقنياً موهوبة ولكن أيضًا تحفز العاطفة ومبدعة.
ar
تكامل أوكيز الذكاء الاصطناعي كمحفزات للمجموعات الكبيرة من الكلمات هو ليس تحسين تدريجي فقط — إنه توسيع جوهري لما يمكن أن تحققه الذكاء الاصطناعي. بتعالج القصور الخفي في المجموعات الكبيرة من الكلمات التقليدية، مثل قاعدة المعرفة الثابتة، والحرية القصيرة في الاتخاذ القراري، والبيئة التشغيلية المعزولة، تمكن الوكيز الذكاء الاصطناعي من تشغيل هذه النماذج بكامل قدراتها.
فيما يتم تطور تقنية الذكاء الاصطناعي، ستصبح دور الوكيز الذكاء الاصطناعي في تعزيز المجموعات الكبيرة من الكلمات أكثر أهمية، ليس فقط في توسيع قدرات هذه النماذج ولكن أيضًا في إعادة تعريف حدود الذكاء الاصطناعي نفسه. هذه الإنصهارة تحدد طريق الجيل القادم من الأنظمة الذكاء الاصطناعي، القادرة على التَّحكم الذاتي، التَّكيفة في الوقت الحقيقي، وحلول الأمور الإبتكارية في عالم يتغير دائمًا.
الفصل 6: تصميم الهيكلية لتكامل الوكيز الذكاء الاصطناعي مع المجموعات الكبيرة من الكلمات
تكامل الوكيز الذكاء الاصطناعي مع المجموعات الكبيرة من الكلمات يعتمد على تصميم الهيكلية، الذي هو حاسم لتعزيز الاتخاذ القراري، والتكيفية، والقابلية للتحجيم. يجب تصميم الهيكلية بعناية لتمكين التفاعل السلس بين الوكيز الذكاء الاصطناعي والمجموعات الكبيرة من الكلمات، مؤكداً أن كل عنصر يعمل بأفضل ما يستطيع.
هيكلية وحداتية، حيث يؤدي الوكيز الذكاء الاصطناعي دور المؤقت، يوجه قدرات المجموعة الكبيرة من الكلمات، هو إتجاه واحد يدعم إدارة المهام الديناميكية. يستفيد هذا التصميم من قوة المجموعة الكبيرة من الكلمات في معالجة اللغة الطبيعية بينما يتيح للوكيز الذكاء الاصطناعي إدارة المهام الأكثر تعقيدًا، مثل التَّ
بما في الخيارات الاخرى، نموذج مزيد من المناظرة المزدوجة، الذي يتكامل مع نماذج متخصصة ومتمددة بعناية كبيرة، يقدم مرونة بما يمكن للجهد الآلي التيكوني أن يتعين عليه تعيين المهام في النموذج الأكثر مناسبة. هذه الطريقة تOptimize الأداء وتحسين الفاعلية عبر مجموعة واسعة من التطبيقات، مما يجعلها فعالة بشكل خاص في contextos تنمو وتتغير كثير (Liang et al., 2021).

مناهج التدريب وأفضل ممارسات
تتوجب على المتواجدين في المجال تدريب الجهود التي تتمكن من توازن بين التعميم والتفكير في المهام الخاصة.
تلقيح التحاليل هو تقنية رئيسية هنا ، تسمح للنموذج الكبير لللغة الذي قد تم تجهيزه مسبقاً على مجموعة كبيرة ومتنوعة من المجموعات بتنقيح بعناية على بيانات خاصة بالمجال تتمتع بالمهام الخاصة بالجهود التي تساعد في تحسين الفاعلية الكلية للنظام.
أيضًا، تلعب التعلم التجاوزي دوراً رئيسيًا بالنسبة لأي مشاهد يتوجب التأقلم مع بيئات تتغير.
لضمان أداء موثوق عبر أماكن مختلفة ، معايير تقييم دقيقة هي ضرورية. ينبغي أن تشمل كلا من المعايير القياسية والخاصة بالمهام لتتأكد من أن التدريب على النظام قوي وشامل (Silver et al., 2016).
مقدمة للتدريب على نموذج كبير لللغة ومفاهيم التعلم التجاوزي
هذا البرمجيات يظهر تنوع في التقنيات التي تتضمنها التعلم الآلي والتحليل اللغوي الطبيعي (NLP) والتركيز على تنقيح النماذج الكبيرة للنظم اللغوية (LLMs) للمهام المعينة وتنفيذ الأجينت التعلمي التعاملي (RL). يمتد البرمجيات على عدة مناطق رئيسية:
-
تنقيح النموذج الكبير: تسخير النماذج المسبق التدريب مثل BERT للمهام المثل تحليل المزاج واستخدام مكتبة
transformersمن Hugging Face. هذا يتضمن توكنيزات البيانات واستخدام المعارف التعليمية لتوجيه عملية التنقيح. -
التعلم التحاوري التعاملي (RL): تقديم أساسيات مبادئ الRL مع عجينة تعلمية بسيطة من التعلم القائم على التجارب والتخليق بما فيه التعامل مع البيئة وتحديث معلوماته عبر جداول الـ Q.
- النموذج الاعانات مع OpenAI API: طريقة conceptual لاستخدام خدمات OpenAI الرئيسية لتوفير إشارات المكافأة
- التقييم والتسجيل: من خلال استخدام مجموعات مثل
scikit-learnلتقييم أداء النماذج من خلال نسبة الدقة والنسبة F1، وSummaryWriterمن PyTorch لتشكيل تقدم التدريب. - مبادئ إفتراضية فائقة للتدريب التجاوزي: تنفيذ مبادئ أكثر إفتراضية مثل شبكات التعميم السياسي، والتعلم الدوري الترتيبي، والتوقف المبكر لتحسين فاعلية تدريب النماذج.
هذا المقاربة الكاملة تغطي كلاً من التعلم الموازين، مع تعديل تحليل المزاج والتدريب التجاوزي، وتوفير نظرة عن كيفية بناء واختبار وتحسين الأنظمة التقنية الحديثة الآلية.
مثال للشيفرة
خطوة 1: استيراد المكتبات المطلوبة.
قبل الانغماس في ضبط النموذج وتنفيذ الوكيل، من الضروري إعداد المكتبات والوحدات اللازمة. يتضمن هذا الكود استيرادات من المكتبات الشهيرة مثل transformers لـ Hugging Face و PyTorch لمعالجة الشبكات العصبونية، scikit-learn لتقييم أداء النموذج، وبعض الوحدات متعددة الاستخدامات مثل random و pickle.
-
مكتبات Hugging Face: تتيح لك استخدام وضبط النماذج المدربة مسبقًا ومحللات الرموز من Model Hub.
-
PyTorch: هذه هي الإطار الأساسي للتعلم العميق المستخدم للعمليات، بما في ذلك طبقات الشبكات العصبونية ومحسنات الأداء.
-
scikit-learn: يوفر مقاييس مثل الدقة ونسبة F1 لتقييم أداء النموذج.
-
واجهة برمجة تطبيقات OpenAI: الوصول إلى نماذج لغوية من OpenAI لمهام مختلفة مثل نمذجة المكافأة.
-
TensorBoard: يستخدم لتصور تقدم التدريب.
هذا هو الشيء الذي سيساعدك على ترجمة البرامج التقنية الى اللغة العربية:
# تحميل وحدة التصاعد العشوائي لتوليد أرقام عشوائية.
import random
# تحميل وحدات من المكتبة المحتوية على التحويلات للاستخدام.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# تحميل ما يتم باسم load_dataset لتحميل المجموعات البيانية.
from datasets import load_dataset
# تحميل المعايير لتقييم أداء النموذج.
from sklearn.metrics import accuracy_score, f1_score
# تحميل SummaryWriter للدخول للمساعدة في سجل التقدم التدريبي.
from torch.utils.tensorboard import SummaryWriter
# تحميل pickle للحفظ وجلب النماذج المentrenadas.
import pickle
# تحميل openai لاستخدام تعاملات الـ API لـ OpenAI (يتطلب مفاتيح API خاصة).
import openai
# تحميل PyTorch للأعمال العميقة التعاملية.
import torch
# تحميل وحدة الشبكة العصبية من PyTorch.
import torch.nn as nn
# تحميل وحدة الموكل من PyTorch (غير مستخدم بوابة في هذا المثال).
import torch.optim as optim
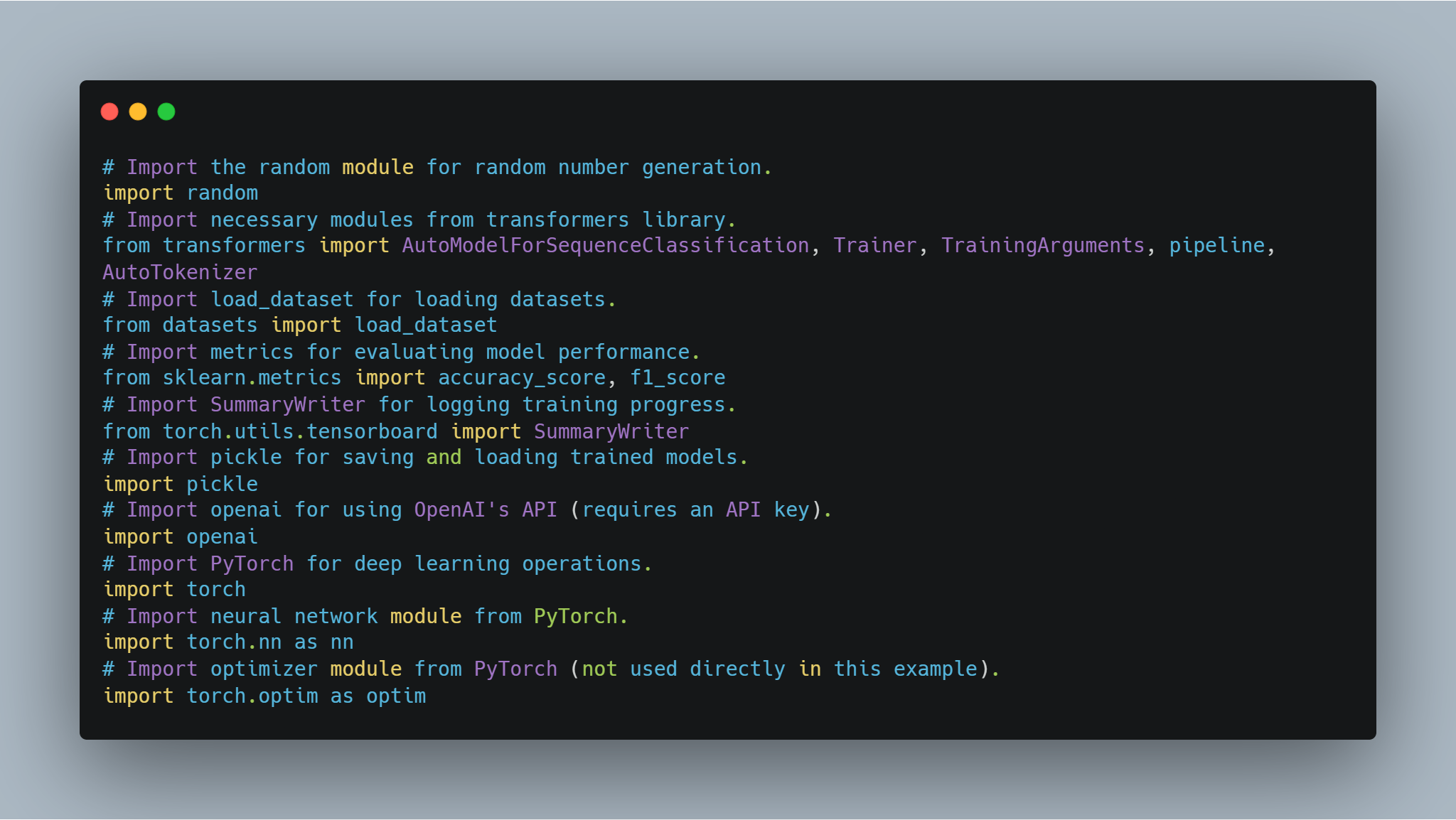
كل واحد من هذه الترجمات يلعب دور مهم في أجزاء البرمجيات المختلفة من التدريب والتقييم للنماذج إلى السجل والتفاعل مع الAPI الخارجي.
الخطوة 2: تنقيح نموذج اللغة لتحديد المزاج
تنقيح نموذج مسبق التrenado لمهمة معينة مثل تحديد المزاج يتطلب تحميل نموذج مسبق التrenado، وتغييره لعدد التسميات الخارجي (إيجابي/سلبي في هذه الحالة)، واستخدام قاعدة بيانات مناسبة.
ar
في هذا العимер, نستخدم AutoModelForSequenceClassification من مكتبة transformers، مع قاعدة بيانات IMDB. يمكن تحسين هذا النموذج المُعَدَّ بشكل ما على جزء أصغر من القاعدة البياناتية لتوفير وقت الحوسبة. ومن ثم يتم تدريب النموذج باستخدام مجموعة مخصصة من الأحداث التدريبية، والتي تتضمن عدد الأعوام وحجم الدفعة。
أدناه الكود لتحميل وتحسين النموذج:
# أحدد اسم النموذج المُعَدَّ مسبقاً من مركز Hugging Face Model Hub.
model_name = "bert-base-uncased"
# تحميل النموذج المُعَدَّ مع عدد الفئات الخارجية المحدد.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# تحميل مُعالج العبارات للنموذج.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# تحميل قاعدة بيانات IMDB من مركز Hugging Face Datasets، باستخدام فقط 10% للتدريب.
dataset = load_dataset("imdb", split="train[:10%]")
# توكينيزة القاعدة البياناتية
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# تعيين القاعدة البياناتية إلى إدخالات التوكين
tokenized_dataset = dataset.map(tokenize_function, batched=True)
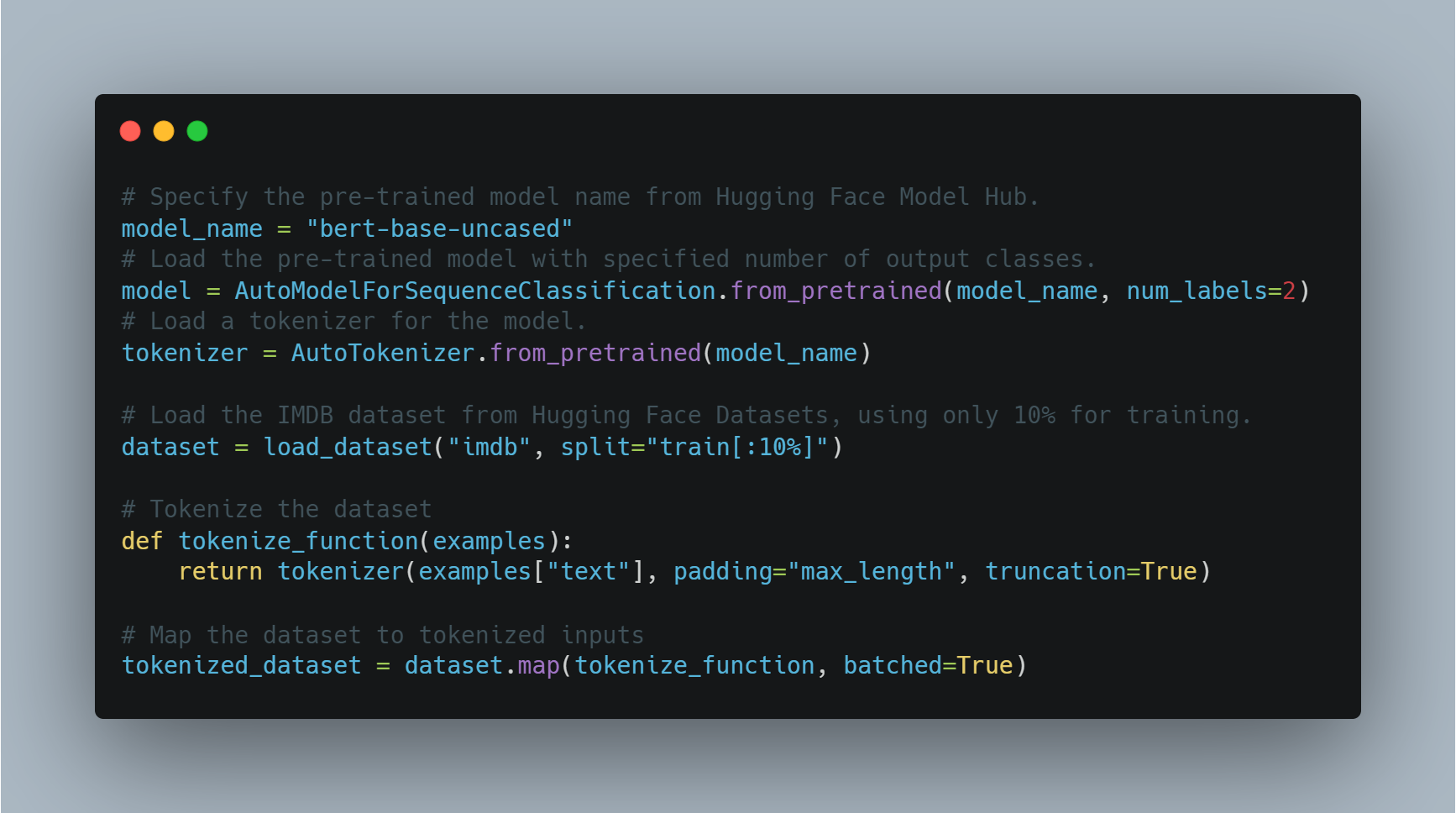
هنا، يتم تحميل النموذج باستخدام البنية التحتية المبنية على BERT ويجهز القاعدة البياناتية للتدريب. ومن ثم، نعرف الحدثات التدريبية ونبدأ المدرب.
# تعريف المعارف التعليمية.
training_args = TrainingArguments(
output_dir="./results", # تحديد مجلد الخروج لحفظ النموذج.
num_train_epochs=3, # تعيين عدد المرات التدريبية.
per_device_train_batch_size=8, # تعيين حجم المجموعة الرئيسية لكل جهاز.
logging_dir='./logs', # مجلد لتخزين السجلات.
logging_steps=10 # سجل كل 10 خطوات.
)
# تكوين المدرب مع النموذج والمعارف التعليمية والبيانات.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# بدء عملية التدريب.
trainer.train()
# حفظ النموذج المدرب بشكل جيد.
model.save_pretrained("./fine_tuned_sentiment_model")

خطوة 3: تطوير عميل تعلم Q بسيط
تعلم Q هو تقنية للتعلم التعاملي حيث يتعلم العميل تأخذ الإجراءات التي تحسن المكافأة التجمعية.
في هذا المثال، نحن نعرف عميل Q-learning بسيط يقوم بتخزين أجراء-وضع أساسي في جدول Q. يمكن للعميل أن يكتشف بشكل عشوائي أو يستخدم الإجراء الأفضل المعروف بالجدول Q. يتم تحديث جدول Q بعد كل إجراءة بواسطة معدل التعلم وعامل التخفيف لتوزين المكافأات المستقبلية.
أسفل هنا هي البرمجيات التي تنفيذ هذا العميل Q-learning:
# تعريف فئة العميل المتعلم بالـ Q.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# تم تسجيل الجدول الـ Q.
self.q_table = {}
# تخزين الأفعال الممكنة.
self.actions = actions
# تحديد معدل الاستكشاف.
self.epsilon = epsilon
# تحديد معدل التعلم.
self.alpha = alpha
# تحديد عامل التخفيض.
self.gamma = gamma
# تعريف طريقة اختيار العمل وفقاً للحالة الحالية.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# البحث عن طريق العشوائية.
return random.choice(self.actions)
else:
# استخدام أفضل العمليات.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
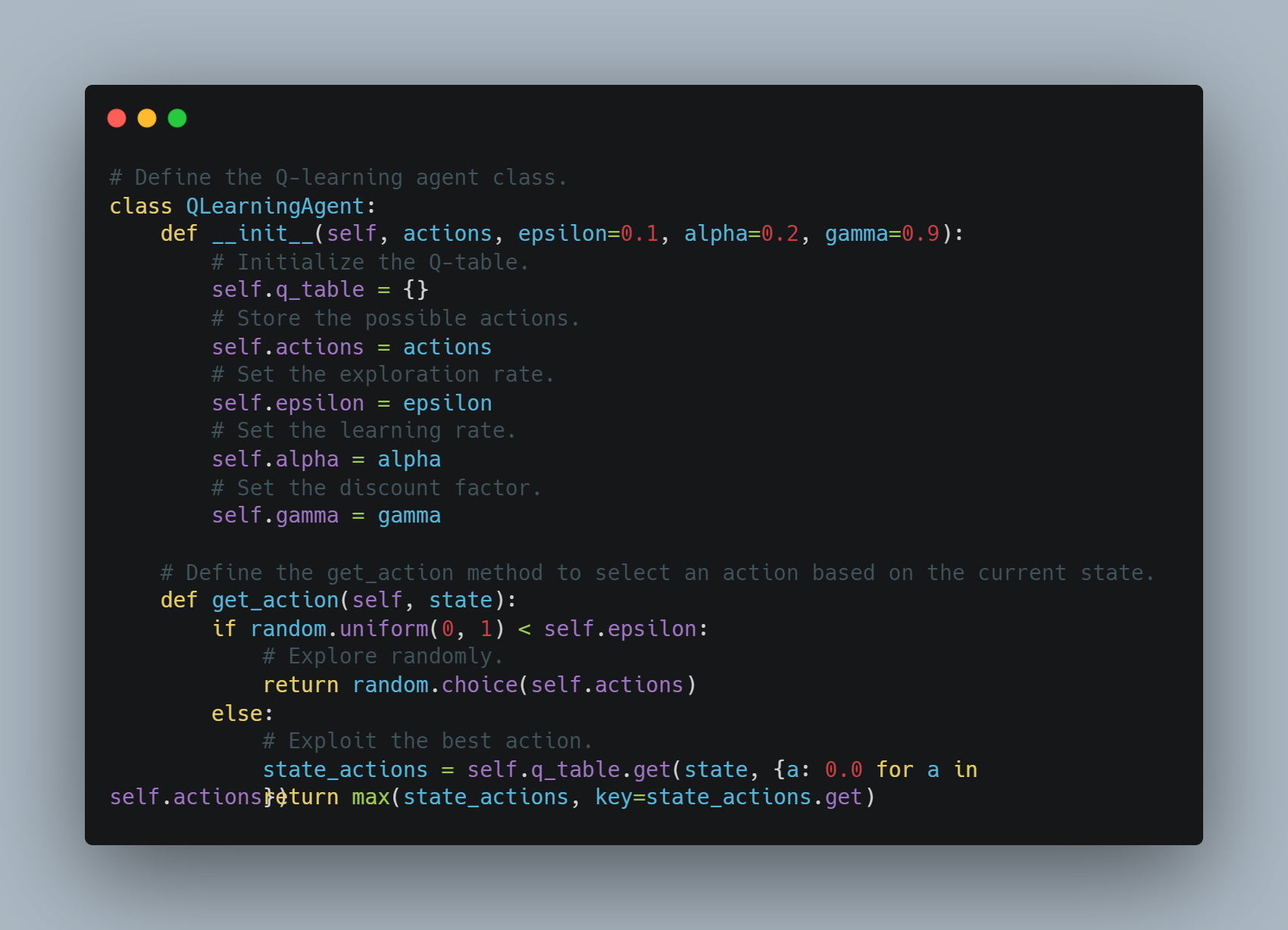
يتم إختيار العمليات بناءاً على الاستكشاف أو الاستغلال وتحديث قيم الـ Q بعد كل خطوة.
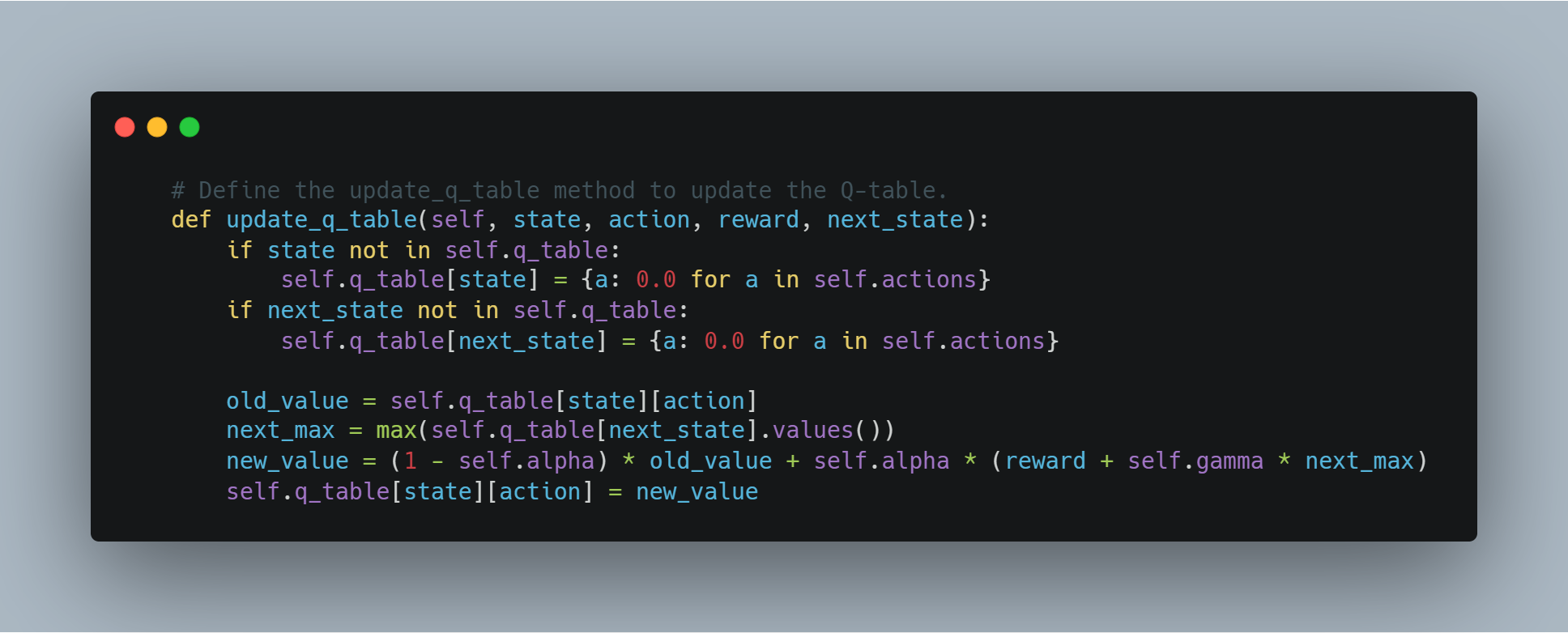
# تعريف طريقة تحديث الجدول الـ Q لتحديث الجدول الـ Q.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
الخطوة 4: استخدام تعامل الـ OpenAI لتشكيل المكافأة
في بعض الحالات، بدلاً عن تعريف وظيفة المكافأة اليدوية، يمكننا استخدام نموذج قوي من اللغة مثل نموذج GPT لـ OpenAI لتقييم جودة الأعمال التي يقوم بها العميل.
في هذا المثال، تتم بواسطة وظيفة get_reward إرسال الحالة والعملية والحالة القادمة إلى تعامل الـ OpenAI لتحصل على نسبة المكافأة، مما يسمح لنا باستخدام نماذج كبيرة من اللغة لفهم التركيبات المكافأة المعقدة.
# تعريف وظيفة get_reward للحصول على إشارة المكافأة من تعامل الـ OpenAI.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # بدل مفاتيح تعامل الـ OpenAI الحقيقية.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
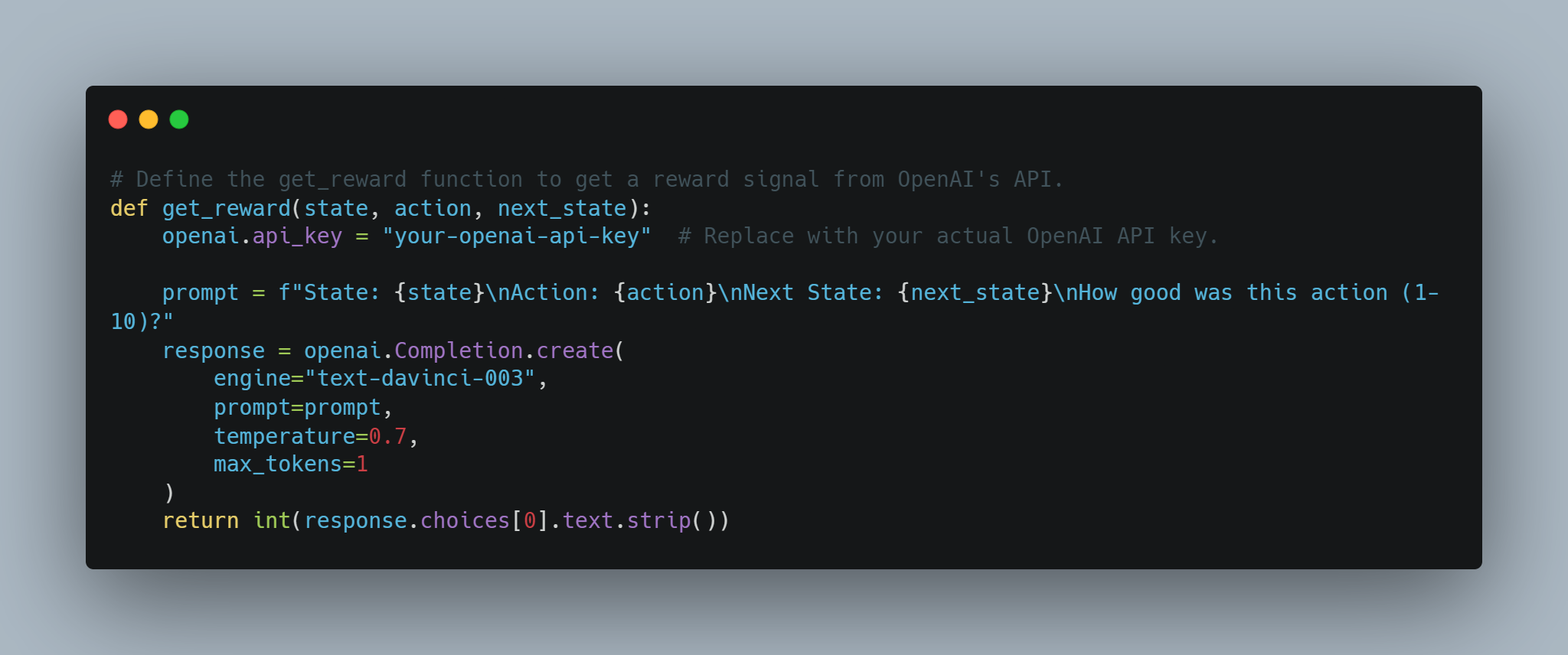
يمكن هذا التفكير المفاهيمي حيث يتم تعرف النظام الجائزي بشكل ديناميكي باستخدام API OpenAI، وهو قد يكون مفيدا للمهام المعقدة التي يصعب تعريف المكافأة.
خطوة 5: تقييم أداء النموذج
حينما يتم تدريب نموذج للتعلم الآلي، يتوجب علينا تقييم أداءه بواسطة معايير قياس واحدة كالدقة ونسبة F1.
هذا المقطع يحسب كلاهما باستخدام تسميات المعلومات الصحيحة والمتوقعة. توفير الدقة توفير معيار عام للدقة، بينما توفير النسبة F1 توفر توازنًا بين الدقة والاستعمال المتزايد، وهذا مفيد بالنسبة لتوازن البيانات الغير متجانسة.
هذه هي البرمجيات لتقييم أداء النموذج:
# تعريف التسميات الصحيحة للاقتطاع.
true_labels = [0, 1, 1, 0, 1]
# تعريف التسميات المتوقعة للاقتطاع.
predicted_labels = [0, 0, 1, 0, 1]
# حساب نسبة الدقة.
accuracy = accuracy_score(true_labels, predicted_labels)
# حساب نسبة F1.
f1 = f1_score(true_labels, predicted_labels)
# طباعة نسبة الدقة.
print(f"Accuracy: {accuracy:.2f}")
# طباعة نسبة F1.
print(f"F1-Score: {f1:.2f}")
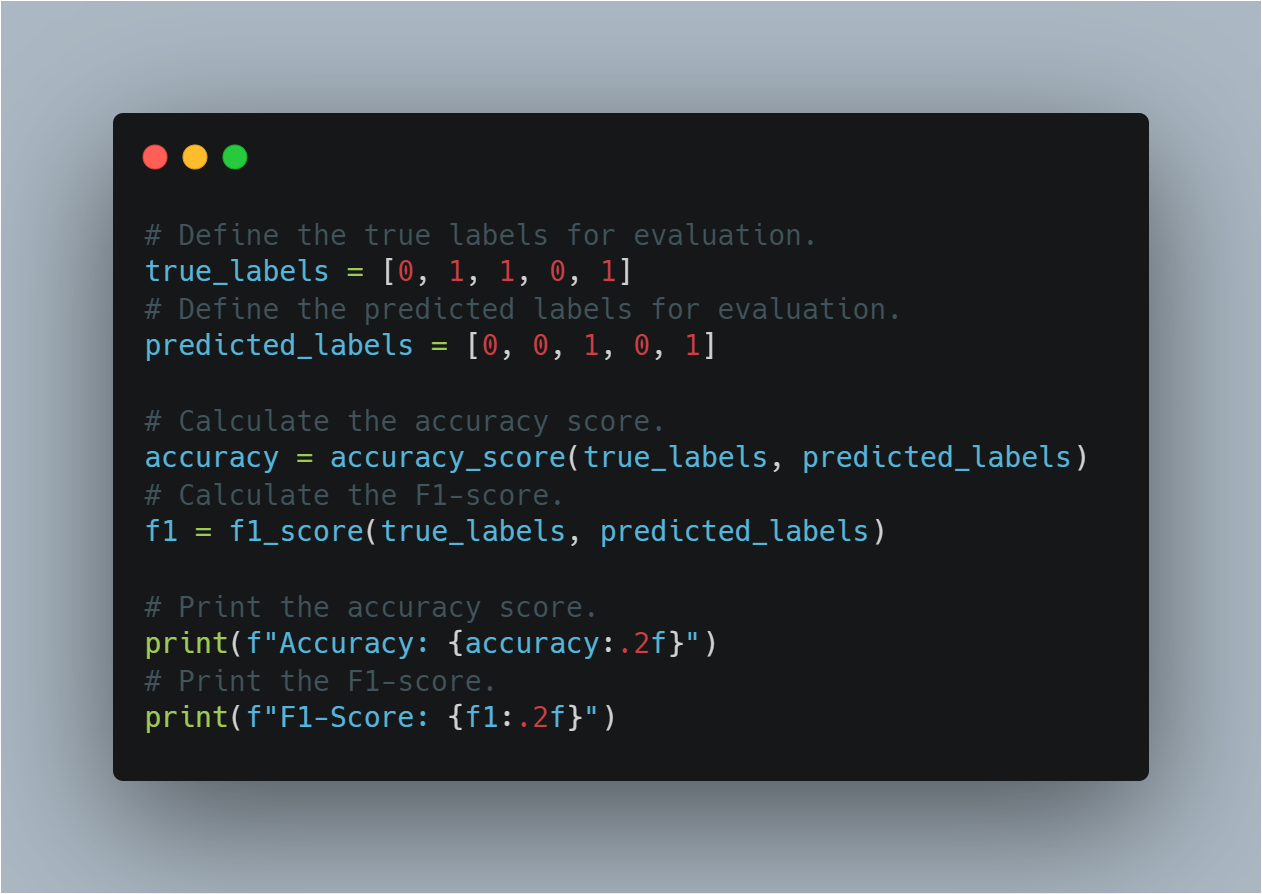
هذا المقطع يساعد في تقييم كيف أن النموذج قد عمِّر على البيانات اللامعروفة باستخدام معايير التقييم الموحدة بشكل مؤكد.
خطوة 6: عميل سياسة التدرجة الأساسي (باستخدام PyTorch)
أساليب تدريجة السياسة في التعلم التجاوزي المتعدد الجهود تتمكن من تحسين السياسة بتحسين المكافأة المتوقعة.
هذا المقطع يوضح تطبيق بسيط لشبكة السياسات باستخدام بيتورش، والذي يمكن استخدامه للخيارات التي تتم في التعلم التجازي. تستخدم الشبكة السياسية طبقة خط سلبي لتخرج بعمليات الاحتمالات للأفعال المختلفة، ويتم تطبيق الsoftmax لضمان أن هذه الخروجات تشكل توزيع الاحتمالات المستنامي.
هذه هي الشيء التخيلي لتعريف العميل السياسي البسيط:
# تعريف فئة شبكة السياسات.
class PolicyNetwork(nn.Module):
# تأسيس الشبكة السياسية.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# تعريف طبقة خط سلبي.
self.linear = nn.Linear(input_size, output_size)
# تعريف المرور الأمامي للشبكة.
def forward(self, x):
# تطبيق الsoftmax على خروج طبقة الخط السلبي.
return torch.softmax(self.linear(x), dim=1)
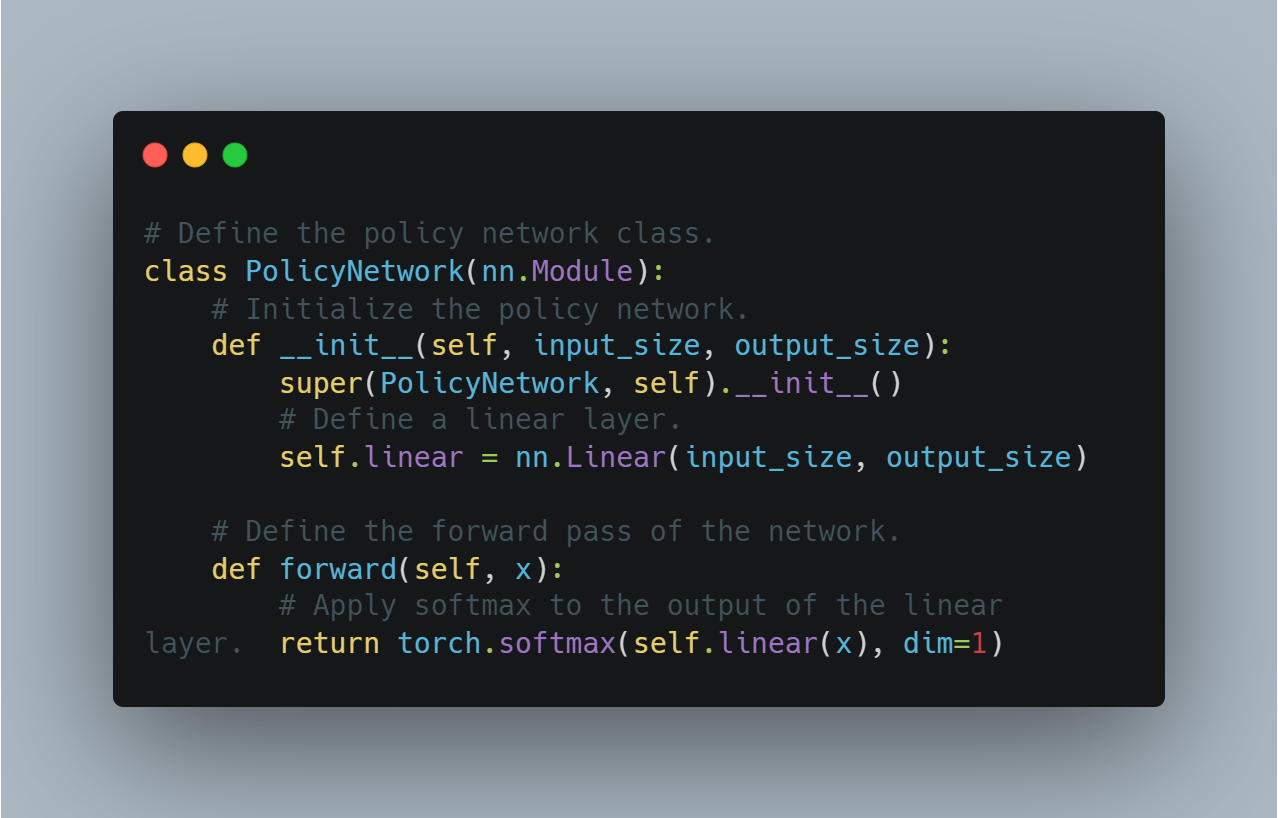
هذا يشكل خطوة أساسية لتطبيق الخوارزميات التعلم التجازي المتقدمة التي تستخدم التحسين السياسي.
الخطوة 7: تصور التقدم التعليمي بواسطة TensorBoard
تصور المعاملات التعليمية، مثل الخسارة والدقة، هو أساسي لفهم كيف تتطور أداء النموذج عبر الوقت. TensorBoard، الأداة المتسلسلة لهذا الغرض، يمكن استخدامه لتسجيل المعاملات وتصويرها في الوقت الحالي.
في هذه القسم، نحن نخلق مثالية للمُستند التقدمي ونسجل قيم عشوائية لمحاكاة عملية تتبعة الخسارة والدقة أثناء التعلم.
هذه هي الطريقة التي يمكنك بها التسجيل وتصوير التقدم التعليمي باستخدام TensorBoard:
# إنشاء مثال للمُراسل المجموعي
writer = SummaryWriter()
# دائرة تدريبية مثالية لتخيل TensorBoard:
num_epochs = 10 # تعريف عدد المرات التدريبية.
for epoch in range(num_epochs):
# تمثيل خسائر عشوائية ومعدلات دقة.
loss = random.random()
accuracy = random.random()
# تسجيل خسائر البيانات ومعدلاتها في TensorBoard.
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# إغلاق المُراسل المجموعي.
writer.close()
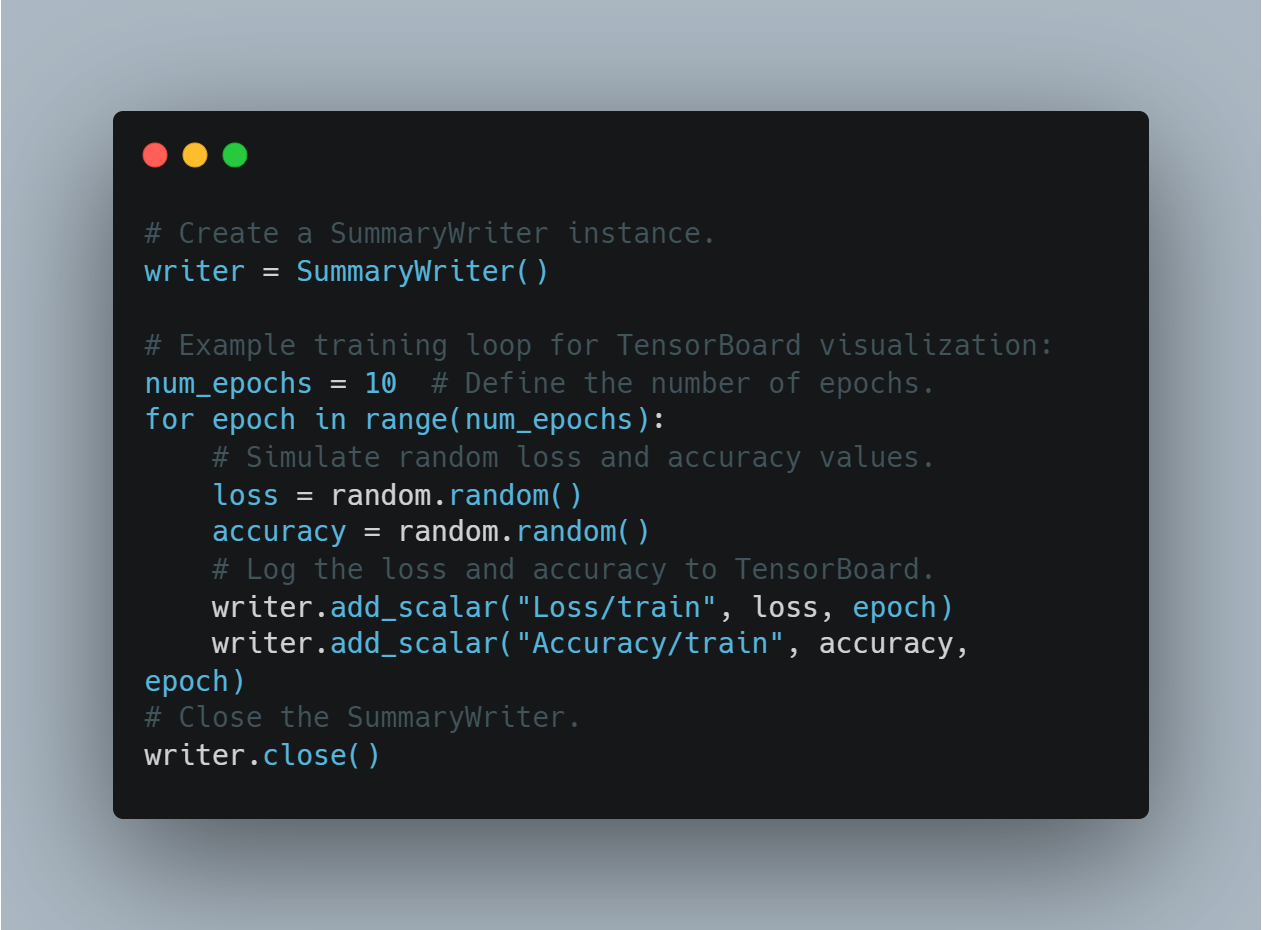
هذا يسمح للمستخدمين بالمراقبة على محاولة تدريب النماذج والتعديلات الفعالة وفقاً للمعلومات البصرية.
خطوة 8: حفظ وتحميل مراجعات مرشد العميل المدرب
بعد تدريب العميل، من المهم جداً أن تحفظ حالته التعلمية (على سبيل المثال، قيم القياس أو وزنات النموذج المدرب) حتى يمكن استخدامها مرة أخرى أو تقييمها في المستقبل.
هذا المقطع الأول يوضح كيفية حفظ عميل مدرب بواسطة وحدة Python `pickle` وكيفية تحميله من القرص.
هذا هو الشيء الذي سيحفظ ويحمل عميل مدرب بالتعلم القيمي:
# إنشاء مواد العميل المدرب.
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# تدريب العميل (لا يظهر هنا).
# حفظ العميل.
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# تحميل العميل.
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
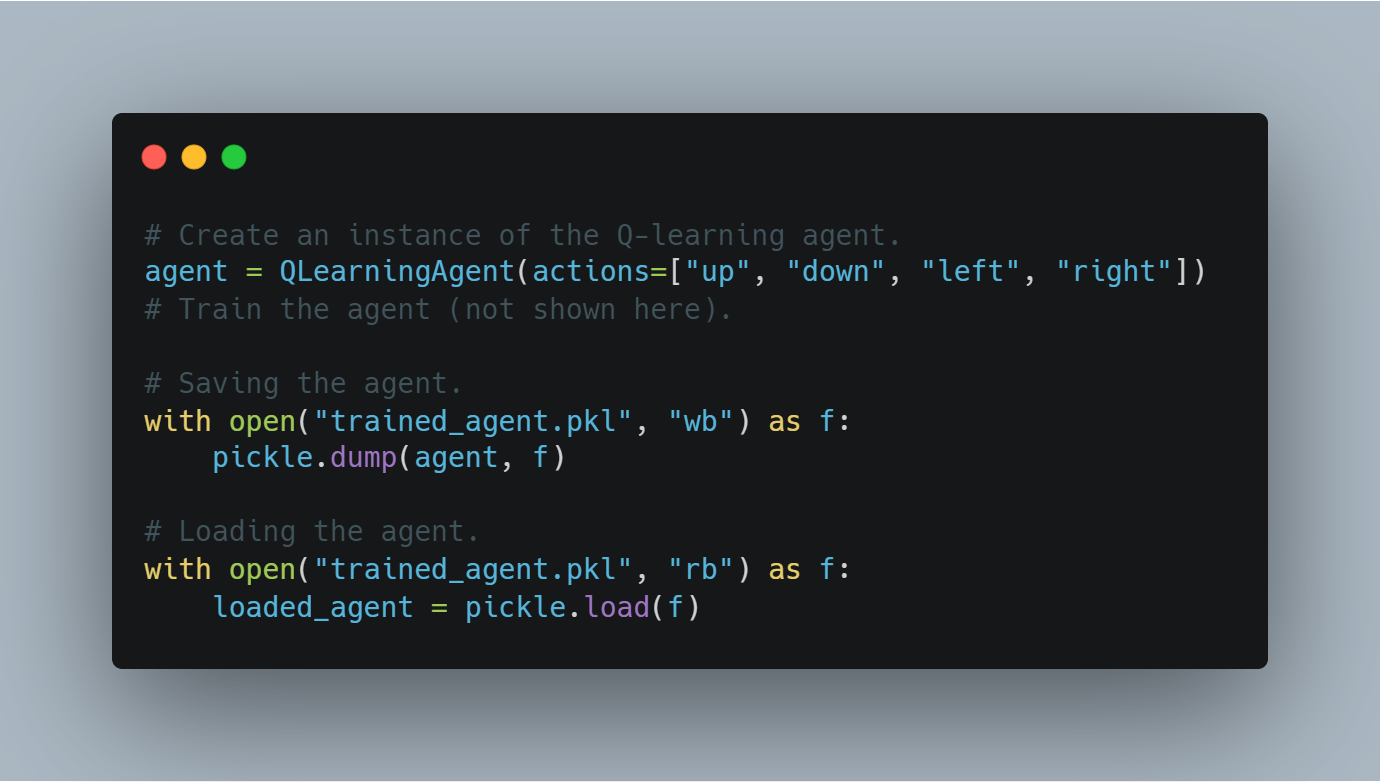
هذه التسجيلات التقريرية تؤكد أن التقدم في التدريب لم يخسر ويمكن استخدام النماذج في تجارب المستقبل.
خطوة 9: التعلم الترتيبي.
تعلم المنهاج يشمل تراكم التعديل على تعقيد المهام التي يتم تقديمها للنموذج، بدءًا من الأمثلة الأسهل وتحولًا إلى الأكثر تحديًا. قد يساعد هذا على تحسين أداء النموذج والاستقرار أثناء التدريب.
هذا مثال لاستخدام التعلم المنهاجي في دائرة التدريب:
# تعيين تعقيد المهمة البدئية.
initial_task_difficulty = 0.1
# دائرة التدريب مع التعلم المنهاجي:
for epoch in range(num_epochs):
# تراكم تعقيد المهمة بشكل متأخر.
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# توليد البيانات التدريبية بتعقيد معين.
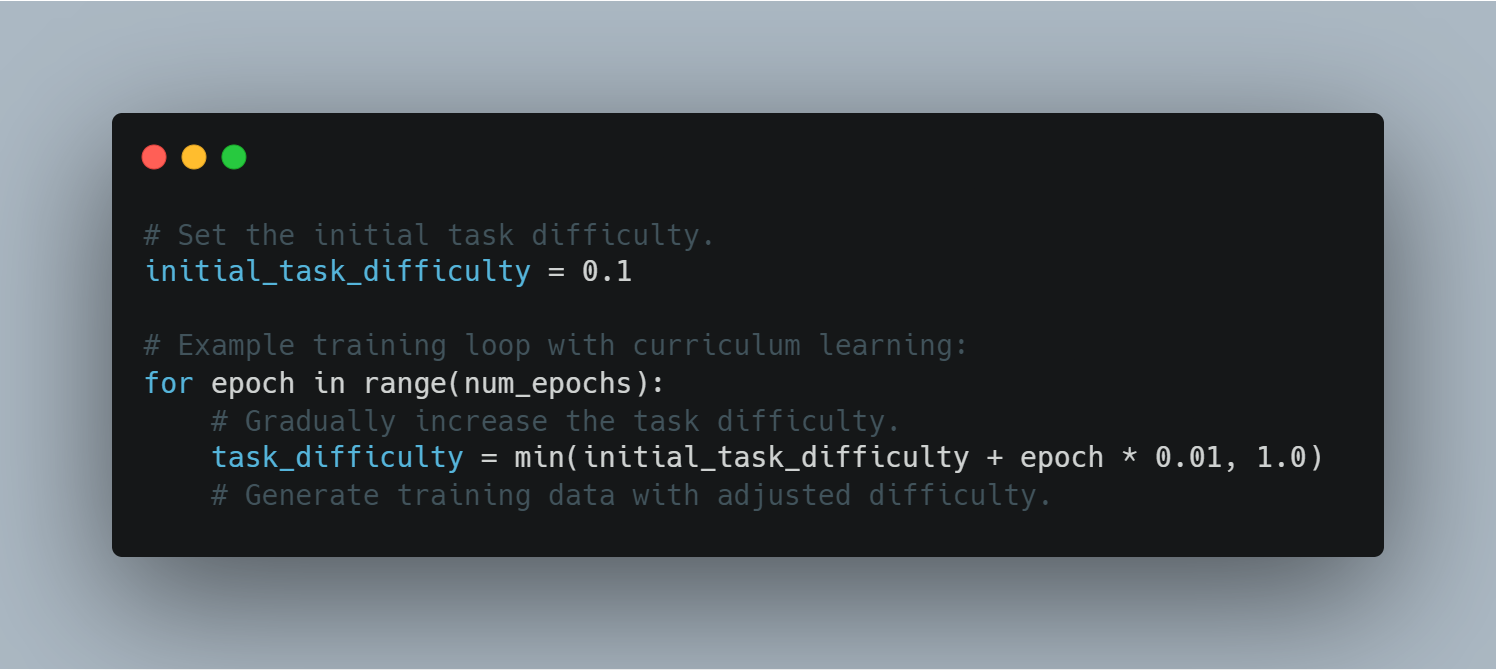
من خلال تحكم في تعقيد المهمة، يمكن للعميل تخطي التحديات الأكثر تعقيدًا بشكل متقدم، مما يؤدي إلى تحسين فعالية التعلم.
خطوة 10: تنفيذ التوقف المبكر
التوقف المبكر هو تقنية لمنع التعقيد أثناء التدريب بإيقاف العمل إذا لم يتحسن الخسران التجاري التخصيصي بعد عدد معين من المرات (صبر).
هذا المقطع يوضح كيفية تنفيذ التوقف المبكر في دائرة التدريب، مستخدمًا خسران التجاري التخصيصي كمؤشر رئيسي.
هذا هو البرمجيات لتنفيذ التوقف المبكر:
# تعيين أقل خسارة للتفاوض إلى مجهود.
best_validation_loss = float("inf")
# تعيين قيمة الصبر (عدد المرات بدون تحسن).
patience = 5
# تعيين عداد المرات بدون تحسن للمرات.
epochs_without_improvement = 0
# دورة التمرين مع التوقف المبكر:
for epoch in range(num_epochs):
# تخيل خسارة التفاوض العشوائية.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

توقف المبكر يحسن التعميم النموذجي للنموذج بمنع دورة التمرين بعد الذي يبدأ في التعجيز بعد التفاوض.
خطوة 11: استخدام نموذج مسبق التدريب لتحويل المهام البدون صفقة
في تحويل المهام البدون صفقة، يتم تطبيق نموذج مسبق التدريب على مهمة لم يتم تحسينها بشكل خاص.
باستخدام قناة Hugging Face، يظهر هذا القسم كيفية تطبيق نموذج BART مسبق التدريب للتوسيع بدون تدريب إضافي، معروفًا بمفهوم التعلم النقلي.
هذا هو الشيء التالي للتوسيع:
# تحميل قناة توحد التفاوض المسبق التدريب.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# تعريف النص الذي يجب توحده.
text = "This is an example text about AI agents and LLMs."
# توليد التوحد.
summary = summarizer(text)[0]["summary_text"]
# طباعة التوحد.
print(f"Summary: {summary}")
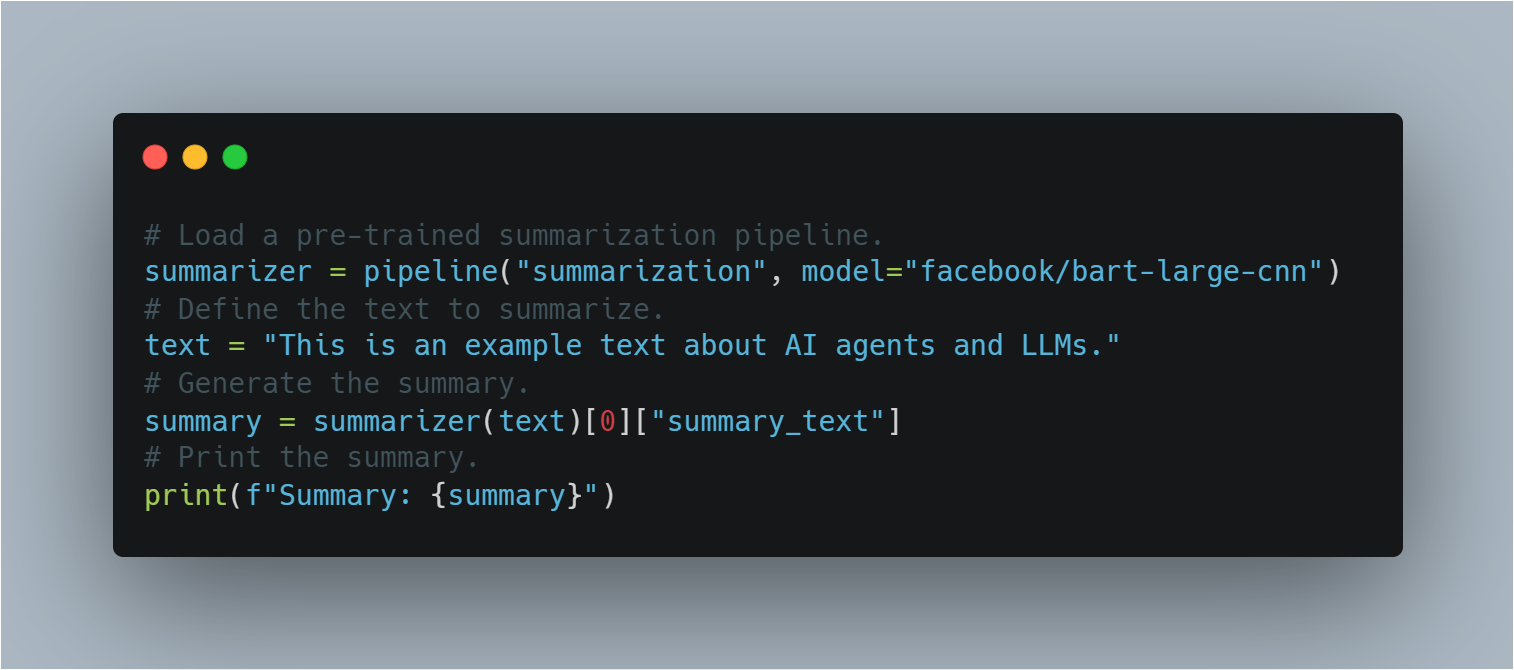
هذه توضح مرونة LLMs في أداء مهام متنوعة بدون حاجة إلى التدريب الإضافي، من خلال تسخير معرفتهم المسبقة.
المثال الكامل للبرنامج.
# استيراد وحدة random لتوليد الأرقام العشوائية.
import random
# استيراد الوحدات اللازمة من مكتبة transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# استيراد load_dataset لتحميل مجموعات البيانات.
from datasets import load_dataset
# استيراد metrics لتقييم أداء النموذج.
from sklearn.metrics import accuracy_score, f1_score
# استيراد SummaryWriter لتسجيل تقدم التدريب.
from torch.utils.tensorboard import SummaryWriter
# استيراد pickle لحفظ وتحميل النماذج المدربة.
import pickle
# استيراد openai لاستخدام واجهة برمجة تطبيقات OpenAI (يتطلب مفتاح API).
import openai
# استيراد PyTorch لعمليات التعلم العميق.
import torch
# استيراد وحدة الشبكة العصبية من PyTorch.
import torch.nn as nn
# استيراد وحدة optimizer من PyTorch (غير مستخدمة مباشرة في هذا المثال).
import torch.optim as optim
# --------------------------------------------------
# 1. تحسين نموذج LLM لتحليل المشاعر
# --------------------------------------------------
# تحديد اسم النموذج المدرب مسبقًا من Hugging Face Model Hub.
model_name = "bert-base-uncased"
# تحميل النموذج المدرب مسبقًا مع عدد محدد من فئات الإخراج.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# تحميل tokenizer للنموذج.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# تحميل مجموعة بيانات IMDB من Hugging Face Datasets، باستخدام 10% فقط للتدريب.
dataset = load_dataset("imdb", split="train[:10%]")
# تحويل مجموعة البيانات إلى رموز
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# ربط مجموعة البيانات بالمدخلات المرمزة
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# تعريف معلمات التدريب.
training_args = TrainingArguments(
output_dir="./results", # تحديد دليل الإخراج لحفظ النموذج.
num_train_epochs=3, # تحديد عدد دورات التدريب.
per_device_train_batch_size=8, # تحديد حجم الدفعة لكل جهاز.
logging_dir='./logs', # دليل لتخزين السجلات.
logging_steps=10 # تسجيل كل 10 خطوات.
)
# تهيئة المدرب مع النموذج ومعلمات التدريب ومجموعة البيانات.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# بدء عملية التدريب.
trainer.train()
# حفظ النموذج المحسن.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. تنفيذ وكيل Q-Learning بسيط
# --------------------------------------------------
# تعريف فئة وكيل Q-learning.
class QLearningAgent:
# تهيئة الوكيل مع الإجراءات، epsilon (معدل الاستكشاف)، alpha (معدل التعلم)، و gamma (عامل الخصم).
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# تهيئة جدول Q.
self.q_table = {}
# تخزين الإجراءات الممكنة.
self.actions = actions
# تحديد معدل الاستكشاف.
self.epsilon = epsilon
# تحديد معدل التعلم.
self.alpha = alpha
# تحديد عامل الخصم.
self.gamma = gamma
# تعريف طريقة get_action لاختيار إجراء بناءً على الحالة الحالية.
def get_action(self, state):
# الاستكشاف عشوائيًا باحتمالية epsilon.
if random.uniform(0, 1) < self.epsilon:
# إرجاع إجراء عشوائي.
return random.choice(self.actions)
else:
# استغلال أفضل إجراء بناءً على جدول Q.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# تعريف طريقة update_q_table لتحديث جدول Q بعد اتخاذ إجراء.
def update_q_table(self, state, action, reward, next_state):
# إذا لم تكن الحالة في جدول Q، أضفها.
if state not in self.q_table:
# تهيئة قيم Q للحالة الجديدة.
self.q_table[state] = {a: 0.0 for a in self.actions}
# إذا لم تكن الحالة التالية في جدول Q، أضفها.
if next_state not in self.q_table:
# تهيئة قيم Q للحالة التالية الجديدة.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# الحصول على قيمة Q القديمة لمجموعة الحالة-الإجراء.
old_value = self.q_table[state][action]
# الحصول على أقصى قيمة Q للحالة التالية.
next_max = max(self.q_table[next_state].values())
# حساب قيمة Q المحدثة.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# تحديث جدول Q بالقيمة الجديدة.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. استخدام واجهة برمجة التطبيقات OpenAI لنمذجة المكافآت (مفاهيمي)
# --------------------------------------------------
# تعريف دالة get_reward للحصول على إشارة مكافأة من واجهة برمجة التطبيقات OpenAI.
def get_reward(state, action, next_state):
# تأكد من تعيين مفتاح API الخاص بـ OpenAI بشكل صحيح.
openai.api_key = "your-openai-api-key" # استبدل بمفتاح API الفعلي الخاص بك.
# إنشاء المطالبة لاستدعاء واجهة برمجة التطبيقات.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# إجراء استدعاء واجهة برمجة التطبيقات لنقطة النهاية Completion الخاصة بـ OpenAI.
response = openai.Completion.create(
engine="text-davinci-003", # تحديد المحرك لاستخدامه.
prompt=prompt, # تمرير المطالبة المنشأة.
temperature=0.7, # تعيين معامل الحرارة.
max_tokens=1 # تعيين الحد الأقصى لعدد الرموز المراد توليدها.
)
# استخراج وإرجاع قيمة المكافأة من استجابة واجهة برمجة التطبيقات.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. تقييم أداء النموذج
# --------------------------------------------------
# تحديد العلامات الحقيقية للتقييم.
true_labels = [0, 1, 1, 0, 1]
# تحديد العلامات المتوقعة للتقييم.
predicted_labels = [0, 0, 1, 0, 1]
# حساب درجة الدقة.
accuracy = accuracy_score(true_labels, predicted_labels)
# حساب درجة F1.
f1 = f1_score(true_labels, predicted_labels)
# طباعة درجة الدقة.
print(f"Accuracy: {accuracy:.2f}")
# طباعة درجة F1.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. وكيل سياسة التدرج الأساسي (باستخدام PyTorch) - مفاهيمي
# --------------------------------------------------
# تعريف فئة شبكة السياسة.
class PolicyNetwork(nn.Module):
# تهيئة شبكة السياسة.
def __init__(self, input_size, output_size):
# تهيئة الفئة الأم.
super(PolicyNetwork, self).__init__()
# تعريف طبقة خطية.
self.linear = nn.Linear(input_size, output_size)
# تعريف التمريرة الأمامية للشبكة.
def forward(self, x):
# تطبيق softmax على ناتج الطبقة الخطية.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. تصور تقدم التدريب باستخدام TensorBoard
# --------------------------------------------------
# إنشاء مثيل لـ SummaryWriter.
writer = SummaryWriter()
# مثال على حلقة تدريب لتصور TensorBoard:
# num_epochs = 10 # تحديد عدد الدورات.
# for epoch in range(num_epochs):
# # ... (حلقة التدريب الخاصة بك هنا)
# loss = random.random() # مثال: قيمة خسارة عشوائية.
# accuracy = random.random() # مثال: قيمة دقة عشوائية.
# # سجل الخسارة إلى TensorBoard.
# writer.add_scalar("Loss/train", loss, epoch)
# # سجل الدقة إلى TensorBoard.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (تسجيل مقاييس أخرى)
# # إغلاق SummaryWriter.
# writer.close()
# --------------------------------------------------
# 7. حفظ وتحميل نقاط تفتيش الوكيل المدرب
# --------------------------------------------------
# مثال:
# إنشاء مثيل لوكيل Q-learning.
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (تدريب وكيلك)
# # حفظ الوكيل
# # فتح ملف في وضع الكتابة الثنائية.
# with open("trained_agent.pkl", "wb") as f:
# # حفظ الوكيل في الملف.
# pickle.dump(agent, f)
# # تحميل الوكيل
# # فتح الملف في وضع القراءة الثنائية.
# with open("trained_agent.pkl", "rb") as f:
# # تحميل الوكيل من الملف.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. التعلم المنهجي
# --------------------------------------------------
# تعيين صعوبة المهمة الأولية.
initial_task_difficulty = 0.1
# مثال على حلقة تدريب مع التعلم المنهجي:
# for epoch in range(num_epochs):
# # زيادة صعوبة المهمة تدريجيًا.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (إنشاء بيانات تدريب مع صعوبة معدلة)
# --------------------------------------------------
# 9. تنفيذ الإيقاف المبكر
# --------------------------------------------------
# تهيئة أفضل خسارة للتحقق إلى اللانهاية.
best_validation_loss = float("inf")
# تحديد قيمة الصبر (عدد الدورات بدون تحسين).
patience = 5
# تهيئة العداد للدورات بدون تحسين.
epochs_without_improvement = 0
# مثال على حلقة تدريب مع الإيقاف المبكر:
# for epoch in range(num_epochs):
# # ... (خطوات التدريب والتحقق)
# # حساب خسارة التحقق.
# validation_loss = random.random() # مثال: خسارة تحقق عشوائية.
# # إذا تحسنت خسارة التحقق.
# if validation_loss < best_validation_loss:
# # تحديث أفضل خسارة للتحقق.
# best_validation_loss = validation_loss
# # إعادة تعيين العداد.
# epochs_without_improvement = 0
# else:
# # زيادة العداد.
# epochs_without_improvement += 1
# # إذا لم يكن هناك تحسين لمدة 'الصبر' من الدورات.
# if epochs_without_improvement >= patience:
# # طباعة رسالة.
# print("تم تفعيل الإيقاف المبكر!")
# # إيقاف التدريب.
# break
# --------------------------------------------------
# 10. استخدام نموذج LLM مدرب مسبقًا لنقل المهام بدون تدريب مسبق
# --------------------------------------------------
# تحميل أنبوب تلخيص مدرب مسبقًا.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# تحديد النص المراد تلخيصه.
text = "This is an example text about AI agents and LLMs."
# توليد الملخص.
summary = summarizer(text)[0]["summary_text"]
# طباعة الملخص.
print(f"Summary: {summary}")

تحديات النشر والتوسع
تحديدا وتوسيع الوكلاء الذكاء الاصطناعي المتكاملين مع LLMs يقدم تحديات تقنية وعملية كبيرة. واحدة من التحديات الرئيسية هي التكلفة الحسابية، خاصة وبما يزيد حجم LLMs وتعقيدها.
معالجة هذه القضية تتضمن استراتيجيات الاستخدام الفعال للموارد، مثل تشذيب النماذج، الكمية، والحوسبة الموزعة. وهذه يمكن أن تساعد في تخفيض العبء الحسابي دون تضييق الأداء.
إلى جانب ذلك، فإن الحفاظ على الكفاءة والقوة في التطبيقات الحقيقية مهم جدا، مما يتطلب مراقبة دائمة، تحديثات منتظمة، وتطوير أجهزة الوقاية من الفشل لإدارة الإدخالات الغير المتوقعة أو فشلات النظام.
وبما أن هذه الأنظمة تنشر عبر مختلف القطاعات، يصبح التمسك بمعايير الأخلاق—بما في ذلك الإنصاف، الشفافية، والمساءلة—مهما جدا. وهذه الاعتبارات مركزية لقبول النظام والنجاح الطويل الأمد، مؤثرة على الثقة العامة وإشكاليات الأخلاق في قرارات محركة بالذكاء الاصطناعي في سياقات المجتمع المتنوعة (بيندر وآل ، 2021).
تنفيذ التكنولوجيا للوكلاء الذكاء الاصطناعي المتكاملين مع LLMs يتضمن تصميم الهيكلية الدقيق، وتدريب منهجي جاد، وإعتبار التحديات التي تواجهها في النشر.
فاعدة وكفاءة هذه الأنظمة في البيئات الحقيقية تعتمد على معالجة القضايا الفنية والأخلاقية، مكفولة من أن تعمل تكنولوجيات الذكاء الاصطناعي بشكل سلس ومسؤول في التطبيقات المختلفة.
الفصل 7: مستقبل الوكلاء الذكاء الاصطناعي وLLMs
التوحد بين LLMs مع تعلم التكريم الجوهري
تتجه الى المستقبل الخاص بوكلاء الذكاء الاصطناعي والنماذج الكبيرة للغات (LLM)، حيث يبرز التكامل بين LLMs مع تعلم التكيف كما تطور مبدع. هذا الدمج يتجاوز الحدود القديمة للذكاء الاصطناعي بتمكين الأنظمة ليست فقط في توليد وفهم اللغة ولكن أيضًا في التعلم من تفاعلاتها في الوقت الحقيقي.
من خلال تعلم التكيف، يمكن لوكلاء الذكاء الاصطناعي تعديل تدابيرهم بشكل تكيفي بناءً على تغذية الرد الصحيحة من البيئة، مما يؤدي إلى تنقيح مستمر لعمليات اتخاذ القرار. هذا يعني أن الأنظمة الذكية المعززة بتعلم التكيف يمكنها التعامل مع المهام المعقدة والدينامية بحد أقل من الإشراف البشري.
تؤثر إمكانيات هذه الأنظمة بشكل عميق: في التطبيقات من الروبوتات الآلية التي تحكمها نفسها إلى التعليم المخصص، يمكن لوكلاء الذكاء الاصطناعي تحسين أداءهم تلقائياً مع مرور الوقت، مما يجعلهم أكثر كفاءة واستجابة للتطلبات المتطورة لسياق عملهم.
مثال: اللعب في الألعاب التقليدية النصية
تخيل وكيل الذكاء الاصطناعي يلعب لعبة مغامرة تقليدية النص.
-
البيئة: اللعبة نفسها (القوانين، وصفات الحالة، وهلم جرا)
-
LLM: يعالج نص اللعبة، يفهم الحالة الحالية، ويولد الإجراءات الممكنة (مثلاً “إذهب إلى الشمال”,”خذ السيف”).
-
المكافأة: يقدم اللعبة بناءً على نتيجة العمل (على سبيل المثال, مكافأة إيجابية لإيجاد التوازن, سلبية لخسارة الصحة).
مثال لغة (تخيلي باستخدام Python و API من OpenAI):
import openai
import random
# ... (منطقة اللعبة البيئية - لا تظهر هنا) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (دورة التrening التعقيدي للتعامل التعقيدي) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (تحديث المجموعة التعقيدية للتعامل التعقيدي بناءً على المكافأة - لا تظهر) ...
state = next_state
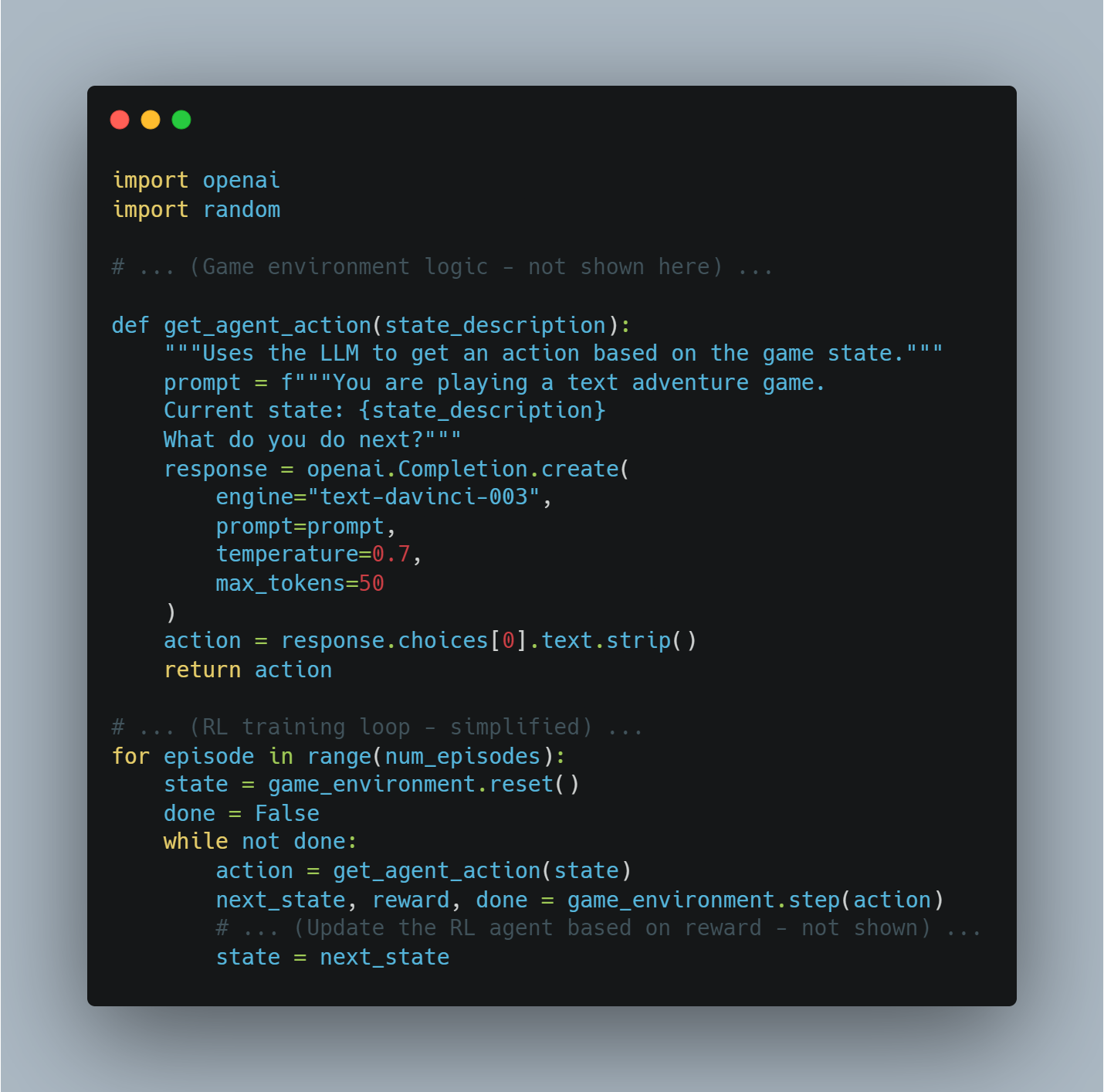
تكامل عناصر المعلومات المتعددة
تكامل عناصر المعلومات المتعددةهو متوجه مهم آخر يشكل مسار المستقبل للمستخدمين الآليين. من خلال تمكين الأنظمة على معالجة وتركيب البيانات من مصادر مختلفة — مثل النصوص، الصور، الصوت، والإدخالات الحسية — تقدم المعلومات المتعددة للمعرفة الشاملة أكثر للبيئات التي تعمل فيها هذه الأنظمة.
على سبيل المثال، في المركبات الautonomous، قدرة التركيب التصويري من الكاميرات، البيانات السياسية من الخرائط، وتحديثات المرور الحالية تسمح للمعلومات التي تعمل بأن تقوم بقرارات القيادة الأكثر معرفة وآمنة.
إذاً فهذه القدرة تمتد إلى قوميات أخرى مثل الرعاية الصحية، حيث يمكن لوكيل الذكاء الاصطناعي أن يتمحور بيانات المريض من السجلات الطبية، والتصوير الاشعاعي للتشخيص، ومعلومات الجينوم ليقدم توصيات للعلاج المناسبة والشخصية بشكل أكثر دقة.
التحدي هنا يكمن في تكامل سلس ومعالجة تدفقات البيانات المتنوعة في الوقت الحقيقي، والذي يتطلب تقدمات في الأنظمة الهيكلية وتقنيات تكامل البيانات.
النجاح في التغلب على هذه التحديات سيكون حاسماً في نشر أنظمة الذكاء الاصطناعي التي تمتلك ذكاء حقيقي وقادرة على العمل في بيئات معقدة وحقيقية.
مثال الذكاء المتعدد الوسائط 1: تسمية الصور لإجابة الأسئلة التصويرية
-
الهدف: وكيل الذكاء الاصطناعي يستطيع الإجابة على أسئلة حول الصور.
-
الوسائط: الصورة، النص
-
العملية:
-
استخراج خصائص الصورة: استخدام شبكة العصب التشكيلية المتدربة (CNN) لاستخراج الخصائص من الصورة.
-
توليد التسمية: استخدام LLM (مثل نموذج الترانسفورمر) لتوليد تسمية تصف الصورة بناء على الخصائص المستخرجة.
-
إجابة الأسئلة: استخدام LLM آخر لمعالجة السؤال والتسمية التي تم توليدها لإعطاء إجابة.
-
مثال لغة البرمجيات (تفاهيمي باستخدام Python و Transformers من Hugging Face):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# تحميل النماذج المتميزة
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# وظيفة لإنشاء وصف الصورة
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# وظيفة لإجابة الأسئلة عن الصورة
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# استخدام مثالي
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
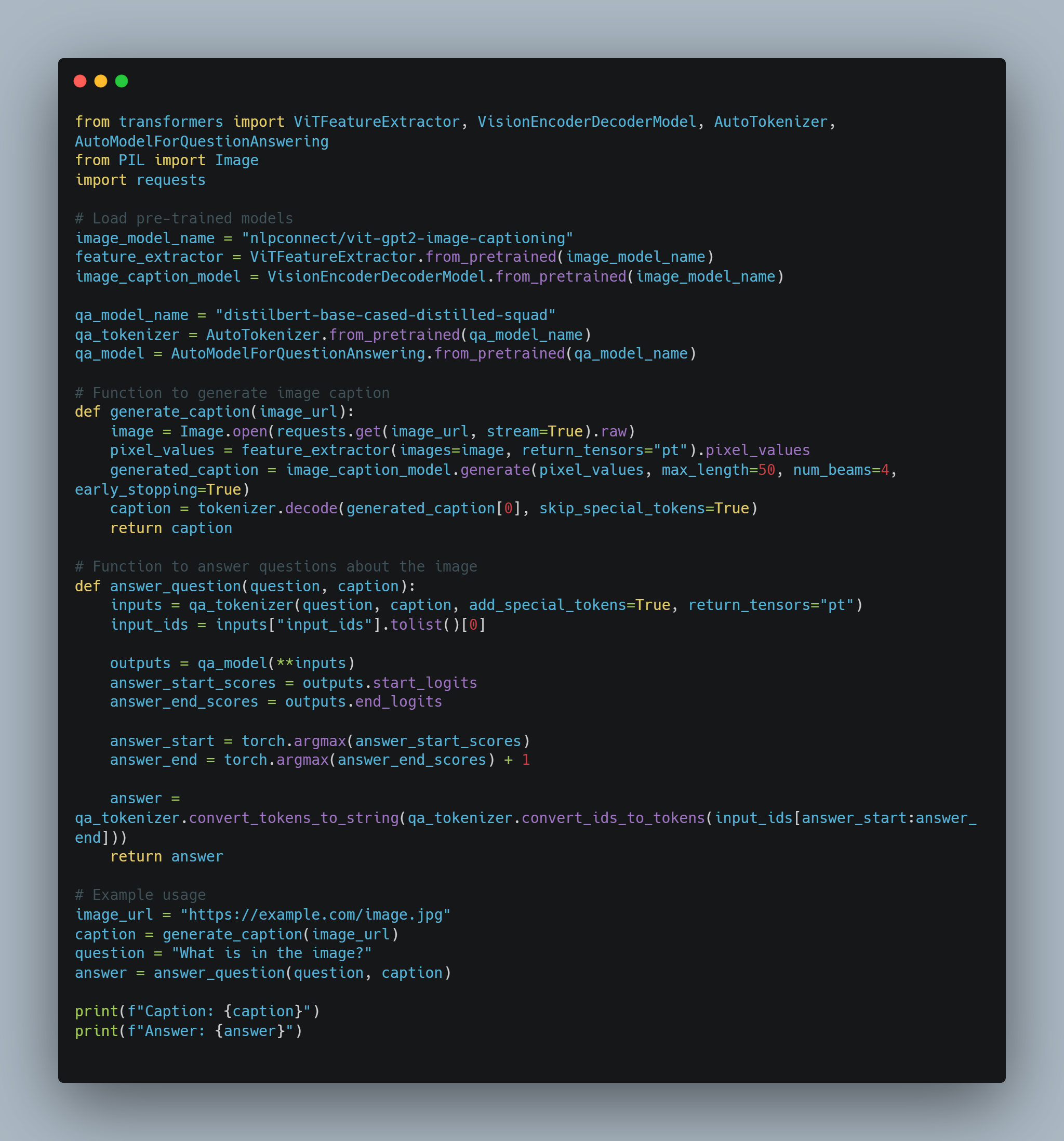
مثال متعدد الوسائط العلمي 2: تحليل المزاج من النص والصوت
-
الهدف: عميل AI الذي يحلل المزاج من النص ولمعنى الرسالة.
-
الأوجه:
النص، الصوت
-
العملية:
-
معاني النص: استخدم نموذج تحليل الإحساسات المتمرس على النص.
-
معاني الصوت: استخدم نموذج معالجة الصوت لاستخراج ميزات مثل اللحن والتردد، ثم استخدم هذه الميزات للتنبؤ بالإحساسات.
-
الإنصهار: كل النقاط الإحساسية للنص والصوت (مثلاً، المعدل الموزون) للحصول على الإحساس العام.
-
مثال الكود (مفهومي باستخدام Python):
from transformers import pipeline # لتعاليم المزيد
# ... (تحليل الصوت والتعاليم العاطفية - غير مظهر) ...
# تحميل النماذج المبرمجة مسبقاً
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# التعاليم للنص
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# التعاليم للصوت
# ... (معالجة الصوت، استخراج الخصائص، توقع التعاليم - غير مظهر) ...
audio_sentiment = # ... (نتيجة من نموذج التعاليم الصوتي)
audio_confidence = # ... (نسبة الثقة من النموذج الصوتي)
# تراكم التعاليم (مثال: المعدل الوزني)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# مثال للاستخدام
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
تحديات وأحداث توافق:
-
توافق البيانات: تأكد من توافق البيانات من وجهات مختلفة وتزامنها هو مهم.
-
تعقيد النماذج: قد تكون النماذج المتعددة المواد التي تحتاج الى تدريبها معقدة وتحتاج أيضًا إلى أحجام كبيرة ومتنوعة من البيانات.
- تقنيات التركيب: تحديد صحيح الطريقة لتراكم المعلومات من وج
الذكاء الاصطناعي المتعدد الوسائط هو مجال يتطور بسرعة بإمكانه أن يغير الطريقة التي يتم فيها تصوّر وتفاعل العوامل الذكاء الاصطناعيين مع العالم.
أنظمة الذكاء الاصطناعي الموزعة والحوسبة الحافية
بالنظر إلى تطور البنية التحتية للذكاء الاصطناعي، فإن التحول نحو أنظمة الذكاء الاصطناعي الموزعة، المدعومة من الحوسبة الحافية، يمثل تقدماً مهماً.
تقوم أنظمة الذكاء الاصطناعي الموزعة بتعزيز توزيع المهام الحسابية بمعالجة البيانات أقرب إلى المصدر، مثل أجهزة الأشياء العنكبوتية أو الخوادم المحلية، بدلاً من الاعتماد على الموارد المركزية في الحد السحابي. هذه الطريقة ليس فقط تقلل من التأخير، الذي هو حاسم لتطبيقات حساسة للوقت مثل الطائرات الذاتية الحركة أو الآلات التحكم الصناعي، ولكنها أيضًا تعزز الخصوصية وأمن البيانات بإبقاء المعلومات الحساسة محلية.
بالإضافة إلى ذلك، تحسن أنظمة الذكاء الاصطناعي الموزعة التكرارية، مما يسمح بتوزيع الذكاء الاصطناعي عبر شبكات واسعة، مثل المدن الذكية، دون غلبة مراكز البيانات المركزية.
التحديات التقنية المرتبطة بالذكاء الاصطناعي الموزع يتضمن ضمان تماثل والتنسيق عبر العقد الموزعة، بالإضافة إلى تحسين تخصيص الموارد للحفاظ على الأداء في بيئات متنوعة وربما محدودة في الموارد.
فيما تطور وتنشر أنظمة الذكاء الاصطناعي، فإن إتباع الأنظمة الموزعة سيكون السر الأساسي لإنشاء حلول الذكاء الاصطناعي المرونة، الآفقية، والقابلة للتكرار التي تلبي الاحتياجات من التطبيقات المستقبلية
أنظمة الذكاء الاحتمالي الموزع والحوسبة الحافية مثال 1: التعلم المفوضي لتدريب النموذج بحفاظ على الخصوصية
-
الهدف: تدريب نموذج مشترك عبر أجهزة متعددة (مثل الهواتف الذكية) دون مشاركة مباشرة للبيانات الحساسة للمستخدم.
-
المقاربة:
-
التدريب المحلي: كل جهاز يدرب نموذجا محليا على بياناته الخاصة.
-
إجماليات الإعدادات: الأجهزة ترسل تحديثات النموذج (المنحنيات أو الإعدادات) إلى الخادم المركزي.
-
تحديث النموذج العالمي: يجمع الخادم التحديثات، ويحسن النموذج العالمي، ويرسل النموذج المحدث إلى الأجهزة.
-
مثال الشفرة (مفهومي باستخدام Python و PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
# ... (شفرة للتواصل بين الأجهزة والخادم - لم يتم عرضها) ...
class SimpleModel(nn.Module):
# ... (حدد هندسة نموذجك هنا) ...
# وظيفة التدريب على الجهة الجهازية
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # البدء بالنموذج العالمي
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (تدريب local_model على device_data) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# وظيفة التجميع على الجهة الخادمية
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (حلقة التعلم التفدري الرئيسية - المبسطة) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

مثال 2: الكشف عن الأشياء في الوقت الحقيقي على الأجهزة الحافية
-
الهدف: توفير نموذج للكشف عن الأشياء على جهاز محدود في الموارد (مثل Raspberry Pi) للتشخيص في الوقت الحقيقي.
-
المقاربة:
-
تحسين النموذج: استخدم تقنيات مثل تكميل النموذج أو تشذيبه لتقليل حجم النموذج وتحتاجات الحساب.
-
تنصيب الحافة: قم بتنصيب النموذج المحسن إلى الجهاز الحافي.
-
الاستنتاج المحلي: يقوم الجهاز بالكشف المحلي عن الأشياء، مما يقلل من التأخير والاعتماد على الاتصال بالحوسبة السحابية.
-
مثال الكود (مفاهيمي باستخدام Python وTensorFlow Lite):
import tensorflow as tf
# تحميل النموذج المتمرس السابق (بافتراض أنه متمرس بالفعل لتensorFlow Lite)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# حصول على تفاصيل الإدخال والخروج
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (تبادل صورة من الكاميرا أو تحميل من الملف - لم يظهر) ...
# تحليل الصورة
input_data = ... # تغيير الحجم، التكامل، إلخ.
interpreter.set_tensor(input_details[0]['index'], input_data)
# تنفيذ التخمين
interpreter.invoke()
# حصول على الخروج
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (معالجة output_data لحصول على المربعات، الصنف، إلخ.) ...
التحديات والاعتبارات:
-
تكاليف التواصل: تنظيم وتواصل فعال بين العقود الموزعة هو مهم.
-
إدماج الموارد: تحسين تخصيص الموارد (المعالج، الذاكرة، الباند) عبر الأجهزة هو مهم.
-
الأمن: تأمين الأنظمة الموزعة وحماية الخصود الشخصي هم المهمين الأولويان.
توزيع الذكاء الاصطناعي وحوسبة الحافة هما الأساسين في بناء أنظمة ذكاءية قابلة للتحجيم والكفاءة ووعي بالخصوصية، خاصة ونحن نتجه نحو مستقبل يحتوي على بلايين الأجهزة المتصلة.
التطورات في معالجة اللغة الطبيعية
معالجة اللغة الطبيعية (NLP) تستمر في الواجهة الأمامية لتطورات الذكاء الاصطناعي، وتشكل محركاً لتحسينات كبيرة في كيفية فهم الآلات وتوليدها وتفاعلها مع اللغة البشرية.
التطورات الأخيرة في NLP، مثل تطور محركات التحول وآليات الانتباه، قد غيرت بشكل كبير قدرات الذكاء الاصطناعي على معالجة البنية اللغوية المعقدة، مما جعل التفاعلات أكثر طبيعية ووعياً بالمحتوى.
هذا التقدم قدم الإمكانية لأنظمة الذكاء بفهم التلاعبات والمشاعر وحتى الاشارات الثقافية داخل النص، مما أدى إلى تواصل أكثر دقة ومعنى.
على سبيل المثال، في خدمة العملاء، يمكن للمجموعات المتقدمة في NLP ليس فقط التعامل مع الاستفسارات بدقة ولكن أيضًا تكشف عن إشارات العاطفة من العملاء، مما يمكن أن يساعد على إجابات أكثر تعاطفاً وفعالية.
بالنظر إلى المستقبل، تكامل قدرات متعددة اللغات وفهم الجملة الأعمق في نماذج NLP سيوسع تطبيقها أكثر، مما سيسمح بالتواصل السلس من خلال اللغات واللهجات المختلفة، وحتى سيسمح لأنظمة الذكاء بالعمل كمترجمون في الوقت الحقيقي في سياقات عالمية متنوعة.
معالجة اللغة الطبيعية (NLP) تتطور بسرعة، مع إنجازات في مناطق كما مجموعات التحول وآليات الانتباه. وهنا بعض الأمثلة وقصاصات الشفرة لإيلوستراه هذه التحسينات:
مثال NLP 1: تحليل المزاج بتحسين نموذج الترانسفورمر
-
الهدف: تحليل مزاج النص بدقة عالية، والتقاط اللونيات والمحتوى.
-
المنهج: تحسين نموذج الترانسفورمر مُعَدَّ (مثل BERT) على مجموعة بيانات لتحليل المزاج.
مثال الشِفرة (باستخدام Python وترانسفورمرات Hugging Face):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# تحميل النموذج المُعَدَّ والمجموعة البيانات
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3 أوسمة: إيجابية، سلبية، خالية من الحالة
dataset = load_dataset("imdb", split="train[:10%]")
# تحديد_ARGUMENTS التدريبية
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# تحسين النموذج
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# حفظ النموذج بعد التحسين
model.save_pretrained("./fine_tuned_sentiment_model")
# تحميل النموذج بعد التحسين للتشخيص
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# مثال للاستخدام
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
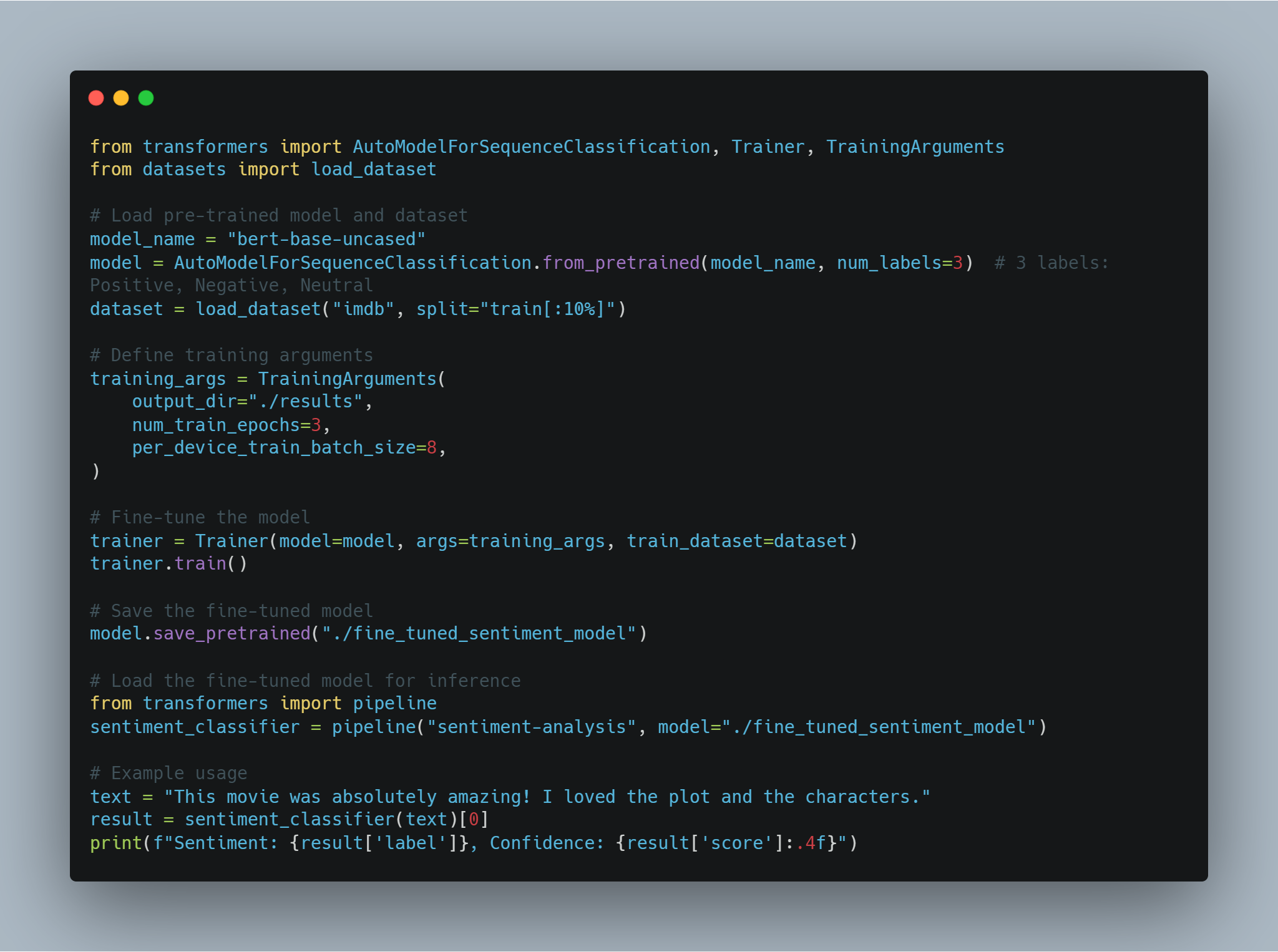
مثال NLP 2: الترجمة الآلية المتعددة اللغات بنموذج واحد
-
الهدف: الترجمة بين عدة لغات باستخدام نموذج واحد، بإستفادة من تمثيلات لغوية مشتركة.
-
النهج: استخدم نموذج متعدد اللغات الكبير (مثل mBART أو XLM-R) الذي تم تدريبه على قاعدة بيانات ضخمة من النصوص المتوازية في عدة لغات.
مثال للشيء البرمجي (باستخدام برنامج Python و Transformers من Hugging Face):
from transformers import pipeline
# تحميل قناة الترجمة المتعددة اللغات المسبق التدريب
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# تطبيق مثالي: إنجليزية إلى فرنسية
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# تطبيق مثالي: فرنسية إلى الأسبانية
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
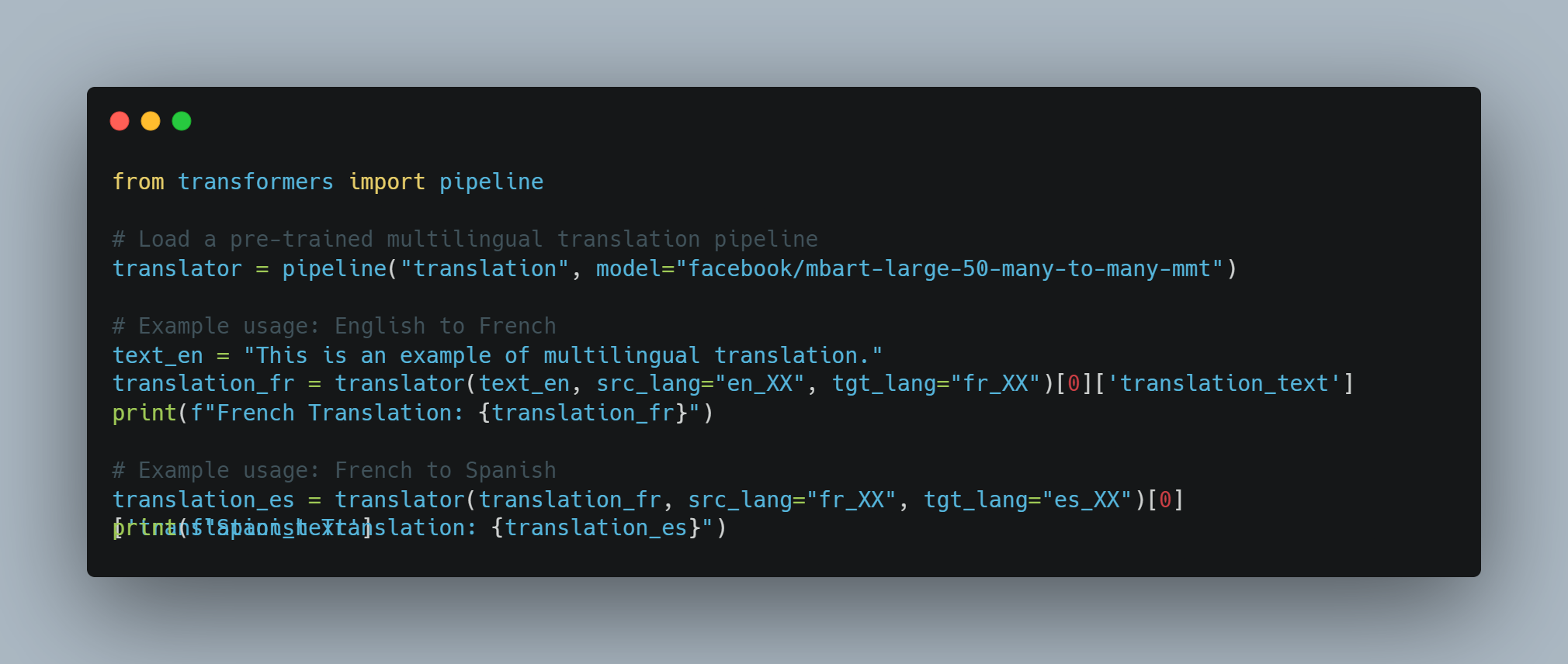
مثال 3 لللغة العامة الاجتماعية: تعابير الكلمات التعاملية للتشابه المعني
-
الهدف: تحديد التشابه بين الكلمات أو العبارات والتي تأخذ في النظر إلى السياق.
-
النهج: استخدم نموذج المحوّل (مثل BERT) لتوليد تعابير الكلمات التعاملية، والتي تسجل معنى الكلمات في جملة معينة.
مثال للشي
from transformers import AutoModel, AutoTokenizer
import torch
# تحميل النموذج المتدرب والمساعد
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# وظيفة لحصول على تواصل العبارات
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# تستخدم تواصل [CLS] العبارة كتواصل العبارة
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# إستخدام مثالي
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# حساب التشابه القطري
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
التحديات والاتجاهات المستقبلية:
-
التحيز والعدالة: قد يورث النماذج اللغوية التحيز من بياناتهم التدريبية، مما يؤدي إلى نتائج غير عادلة أو تمييزية. تعالي الاتجاه المهم للتعامل مع التحيز.
-
المنطق العام: تعاني النماذج اللغوية الكبيرة من المنطق العام وفهم المعلومات الغير بوضوح.
-
الوصفية: عملية قرار النماذج اللغوية المعقدة قد تكون غامرة بالسوء، مما يجعل من الصعب فهم سبب إنتاج بعض المناجم المحددة.
y>
بالرغم من هذه التحديات، تتقدم تقنية اللغة الآلية بسرعة كبيرة. تكامل المعلومات المتعددة الوسائط، تحسين المنطق الشائع وتعزيز الشرحية هي مناطق حاسمة للبحث المستمر الذي سيعمل على غيير الطريقة التي يتفاعل بها الذكاء الآلي مع اللغة البشرية.
الassisstants الآلية المخصصة
مستقبل الassisstants الآلية المخصصين سيصبح أكثر تعقيداً، يتخطى الإدارة الأساسية للمهام للدعم الذكي والناشط المخصص حقاً للحاجيات الفردية.
ستستخدم هذه المساعدات تقنيات خوارزميات التعلم الآلي المتقدمة للتعلم منتصف الطريق من سلوكك، تفضيلاتك وروتيناتك، وتقدم توصيات مخصصة بشكل متزايد وتؤتير المهام المعقدة أكثر.
على سبيل المثال، قد تدير مساعدة الآلية المخصصة ليس فقط جدول زمنيك، ولكن أيضًا توقع حاجياتك بإقتراح المصادر الرئيسية أو تعديل بيئتك بحسب مزاجك أو تفضيلاتك السابقة.
فيما يزيد مساعد الآلية من التكامل مع الحياة اليومية، ستصبح قدرتهم على التكيف مع التغييرات في السياق وتوفير دعم سلس للمنصات محددًا. الصعوبة تكمن في تحقيق التوازن بين التخصيص والخصوصية، متطلبًا تقنيات حماية البيانات القوية لضمان إدارة المعلومات الحساسة بأمان بينما تقدم تجربة مخصصة عميقة.
مثال 1 لمساعد الآلية: إقتراح المهمة الموجهة للسياق
-
الهدف: مساعد يقترح المهام بحسب السياق الحالي للمستخدم (الموقع، الوقت، سلوك المستخدم السابق).
-
المقاربة: تراكم بيانات المستخدم، الإشارات السياسية، ونموذج توصية المهام.
مثال لغة البرمجيات (المفهومي باستخدام Python):
# ... (تشغيل لإدارة بيانات المستخدم، كشف السياق - غير معروف) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# مثال: توصيات قائمة على الوقت
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# مثال: توصيات قائمة على الموقع
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (أضف أحدث القواعد أو استخدم نموذج تعلم الآلة للتوصيات) ...
# ترتيب و filtration التوصيات
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- مثال للاستخدام ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... تفضيلات أخرى ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... بيانات السياق الأخرى ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
مثال 2 لمساعدات الطريق الذهني: توصية المعلومات المباشرة
-
الهدف: مساعد يقدم معلومات مناسبة بصفة مباشرة وفقاً لجدول الأوقات والتفضيلات الشخصية للمستخدم.
- المقارب
مثال لغة البرمجيات (مفهومي باستخدام Python):
# ... (برنامج للوصول إلى التقويم، و التشخيص الشخصي للاهتمامات - غير مظهر) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (استعمال لمعلومات الشركة، ملفات المشاركين، وما إلى ذلك) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (استعمال لحالة الرحلات، معلومات المواقع، وما إلى ذلك) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- مثال للاستخدام ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... تفضيلات أخرى ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

مثال للمساعدين الذين يتمتعون بالتوجيه الشخصي للمحتويات الثالث:
-
الهدف: مساعد يوصي بالمحتويات المتخصصة (المقالات، الفيديوهات، الموسيقى) المتكيفة بتفضيلات المستخدم.
-
النهج: استخدام الفراغ التعاوني أو نظم التوصية المبنية على المحتويات.
مثال لغة البرمجيات (مفهومي باستخدام Python ومكتبة مثل Surprise):
from surprise import Dataset, Reader, SVD
# ... (شيفرة لإدارة تقييمات المستخدمين، قاعدة بيانات المحتوى - لم يتم عرضها) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (إحصاءات التوقع لكل العناصر، الترتيب، وإرجاع الأعلى N) ...
# --- مثال للاستخدام ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... المزيد من التقييمات ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
التحديات والاعتبارات الأخلاقية:
-
الخصوصية البيانات: من المهم التعامل مع بيانات المستخدم بمسؤولية وشفافية.
-
التحيز والعدالة: لا يجب أن تزيد الشخصية الإضافية تكرار التحيزات القائمة.
-
سيطرة المستخدم: يجب أن يكون للمستخدمين سيطرة على بياناتهم وإعدادات الشخصية الإضافية.
بناء مساعدي الـ AI الشخصي يتطلب التفكير بعناية في الجوانب الفنية والأخلاقية لإنشاء أنظمة مفيدة وثقة وتحترم خصوصية المستخدم.
الـ AI في القطاعات الإبداعية
يسلك الـ AI طريقاً كبيراً في القطاعات الإبداعية، يحول كيفية إنتاج الفن والموسيقى والأفلام والأدب، ومع تطور نماذج التوليد، مثل الشبكات التنافسية التوليدية (GANs) ونماذج التحول، يستطيع الـ AI الآن توليد محتوى يتنافس بإبداع البشر.
تستطيع الـ AI أن تكون موسيقى تعكس الأنواع الخاصة أو المزاجات، أو تصميم فن ديجيتال يحاكي أسلوب الرسامين الشهراء، أو حتى تهيئة القصص السردية للأفلام والروايات.
في صناعة الإعلان، يستخدم الـ AI لإنتاج محتوى شخصي يتماسك مع المستهلكين الفردية، مما يعزز الإشتباك والفعالية.
ولكن الارتفاع بأهمية الـ AI في المجالات الإبداعية يثير أيضًا أسئلة حول الصلاحية، الأصالة، ودور الإبداع البشري. وبمجرد التعاملك مع الـ AI في هذه المجالات، سيكون من المهم التحقيق في كيفية تكامل الـ AI مع الإبداع البشري بدلاً من استبداله، مما يعزز التعاون بين البشر والآلات لإنتاج محتوى إبداعي ومؤثر.
هاهو مثال على كيفية تكامل GPT-4 في مشروع Python لمهام إبداعية، وتحديدًا في مجال الكتابة. هذه الشفرة تظهر كيفية إستخدام قدرات GPT-4 لتوليد أنماط النص الإبداعية، كالشعر.
import openai
# إعداد مفتاح API OpenAI الخاص بك
openai.api_key = "YOUR_API_KEY"
# تعريف وظيفة لتوليد الشعر
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# مثال استخدام
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
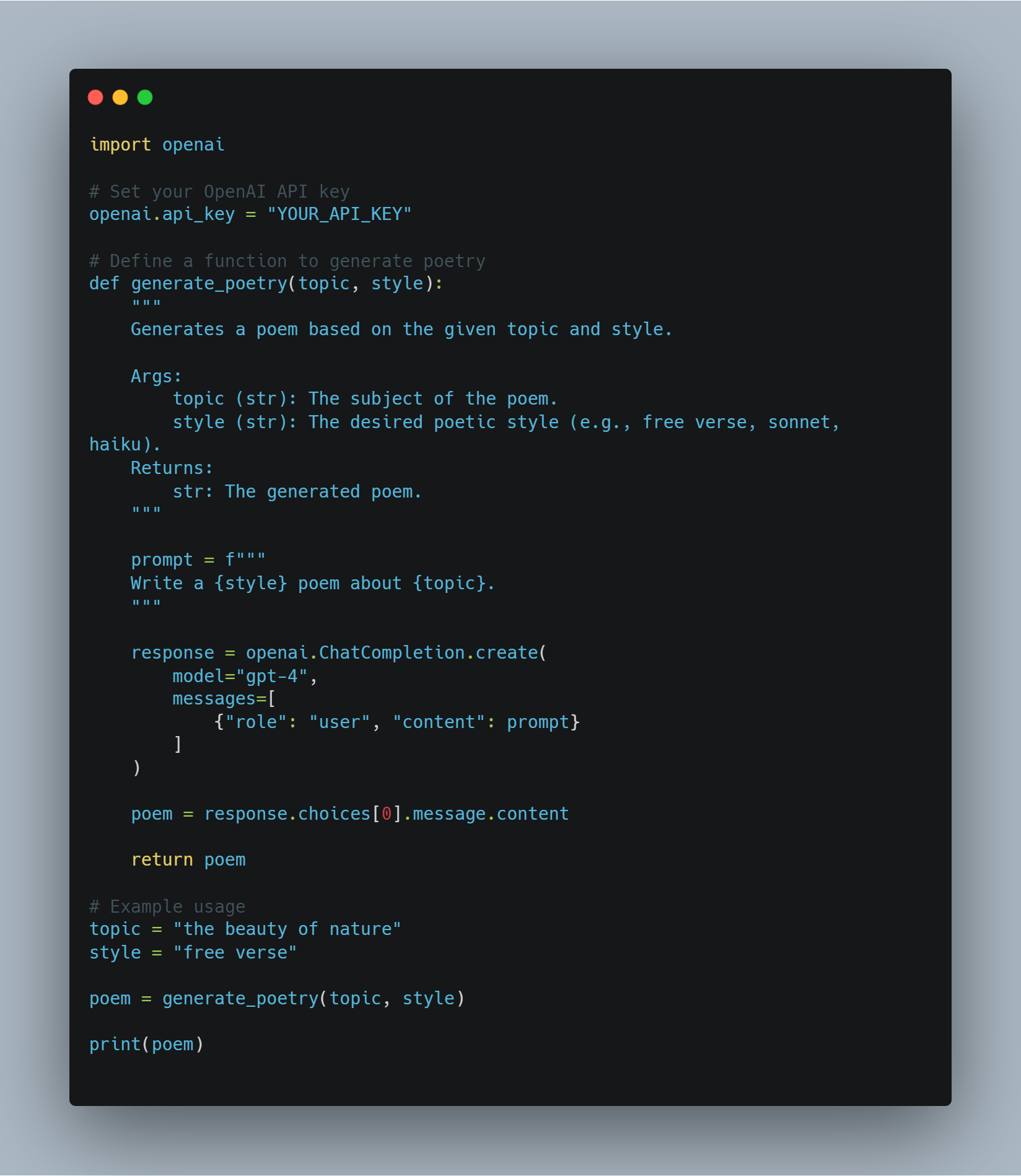
لنرى ما يحدث هنا:
-
استيراد مكتبة OpenAI: يبدأ الكود أولا باستيراد مكتبة
openaiللوصول إلى API OpenAI. -
تعيين المفتاح الخاص: قم بتعديل
"YOUR_API_KEY"بمفتاح API OpenAI الخاص بك. -
حدد وظيفة
generate_poetry: هذه الوظيفة تأخذ موضوع القصيدةtopicوالنمطstyleكمُدخلات وتستخدم API ChatCompletion لـ OpenAI لتوليد القصيدة. -
بناء الزمنية: يمزج الزمنية
topicوstyleفي تعليم واضح لـ GPT-4. -
أرسل الزمنية إلى GPT-4: يستخدم الكود
openai.ChatCompletion.createلإرسال الزمنية إلى GPT-4 وتلقي القصيدة المولدة كرد. -
أرجع القصيدة: ستستخرج القصيدة المولدة من الرد وترجع بواسطة الوظيفة.
-
مثال على الاستخدام: يوضح الكود كيفية استدعاء وظيفة
generate_poetryبموضوع ونمط محدد. يتم طباعة القصيدة الناتجة على شاشة الوحدة.
العوالم الافتراضية المدعومة بالذكاء الاصطناعي
تمثل تطوير العوالم الافتراضية المدعومة بالذكاء الاصطناعي قفزة هامة في تجارب الانغماس، حيث يمكن لوكلاء الذكاء الاصطناعي إنشاء وإدارة وتطوير بيئات افتراضية تكون تفاعلية ومتجاوبة مع إدخال المستخدم.
تستطيع هذه العوالم الافتراضية، التي يديرها الذكاء الاصطناعي، محاكاة النظم البيئية المعقدة، والتفاعلات الاجتماعية، والسرد الديناميكي، مما يقدم تجربة مشوقة وشخصية للمستخدمين.
على سبيل المثال، في صناعة الألعاب، يمكن استخدام الذكاء الاصطناعي لإنشاء شخصيات غير قابلة للعب (NPCs) التي تتعلم من تصرفات اللاعب، وتكيف أفعالها واستراتيجياتها لتوفير تجربة أكثر تحديًا وواقعية.
بخلاف الألعاب، تحمل العوالم الافتراضية المدعومة بالذكاء الاصطناعي تطبيقات إمكانيات في التعليم، حيث يمكن تخصيص الفصول الافتراضية لأساليب وتقدم التعلم للطلاب الفرديين، أو في التدريب الشركاتي، حيث يمكن للمحاكاة الواقعية أن تعد الموظفين لمختلف السيناريوهات.
ستعتمد مستقبل هذه البيئات الافتراضية على تقدم الذكاء الاصطناعي في القدرة على إنشاء وإدارة بيئات رقمية ضخمة ومعقدة في الوقت الحقيقي، فضلاً عن الاعتبارات الأخلاقية حول بيانات المستخدم والتأثيرات النفسية للتجارب الانغماسية بشكل كبير.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# تعيين العميلات
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# تخصيص موقع عشوائي داخل البيئة
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# إنشاء وإضافة العميل
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# تحرك العملاء (التحرك البسيط للتوضيح)
for agent in self.agents:
agent.move(self.environment)
# توقع: تطوير معرفي أكثر تعقيدًا للتفاعلات وتغيير البيئة وما إلى ذلك.
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# تحدد الاتجاه الذي ستتحرك به (عشوائي في هذا المثال)
direction = random.choice(['N', 'S', 'E', 'W'])
# تطبيق التحرك وفقاً للاتجاه
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# تحديد البيئة لتعكس موقع العميل الجديد
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# إستخدام مثالي
if __name__ == "__main__":
# تعريف ما يتعلق بالعالم
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# إنشاء العالم الافتراضي
world = VirtualWorld(environment_size, agent_types, agent_properties)
# تمثيل العالم لعدة خطوات
for _ in range(10):
world.update()
world.display()
print() # أضف خط فارغ لتحسين القراءة
هذا ما يحدث في هذه البرنامج:
-
VirtualWorld Class:
-
يحدد العالم الافتراضي الجوهر.
-
يحتوي على الشبكة البيئية، قائمة بالعوامل، ومعلومات متعلقة بالعوامل.
-
__init__(): يبدأ العالم بالحجم، أنواع العوامل، والخصائص. -
add_agent(): يضيف عاملا جديدا من نوع محدد إلى العالم. -
update(): يؤدي تحديث خطوة زمنية واحدة للعالم.- في الوقت الحالي يتم فقط تحريك العوامل، ولكن يمكن إضافة منطق معقد للتفاعلات بين العوامل، التغييرات في البيئة، إلخ.
-
display(): يطبع تمثيل أساسي للبيئة.
-
-
تصنيف العميل:
-
يمثل عميل منفرد ضمن العالم.
-
__init__(): يعيد تأسيس العميل مع نوعه، الموقع والخصائص. -
move(): يتمتع بعملية تحرك العميل، تحديث موقعه داخل البيئة. هذه الطريقة تقدم حالياً تحركات عشوائية بسيطة، لكن يمكن توسيعها لتضم سلوكات AI معقدة.
-
-
الإستخدام المثالي:
-
يضع المادات العالمية مثل الحجم، أنواع الممثلين، وخصائصهم.
-
ينشئ عنصرًا من العالم الافتراضي.
-
يجري مétodo
update()مرات عديدة لمحاكاة تطور العالم. -
يتم اتصال
display()بعد كل تحديث لتصور التغيرات.
-
التحسينات:
-
الممثلين الأكثر تعقيدًا: تطبيق تعقيدًا في تصرفات الممثلين. يمكنك:
-
الخوارزميات المستديرة: مساعدة الممثلين على استكشاف البيئة بكفاءة.
-
تفاعل البيئة: إضافة عناصر ديناميكية إلى البيئة، مثل العقبات، الموارد أو النقاط الفريدة من الاهتمام.
-
تفاعل بين الوكالات: تنفيذ التفاعلات بين الوكالات، مثل الاتصال، القتال أو التعاون.
-
التمثيل البصري: استخدم مكتبات مثل Pygame أو Tkinter لخلق تمثيل بصري للعالم الافتراضي.
<di
هذا العينة هو أساس إنشائية لخلق عالم افتراضي ممول بالذكاء الاصطناعي. يمكن توسيع مستوى التعقيد والدقة لتطابق الاحتياجات والهدف المبدع الخاص بك.
حوسبة الأعصاب المصنوعة والذكاء الاصطناعي
حوسبة الأعصاب المصنوعة التي تلخص هيكل ووظيفة الدماغ البشري ستثور بالذكاء الاصطناعي بإعطاء طرق جديدة لمعالجة المعلومات بكفاءة وفي سلسلة موازية.
على عكس البنيات التقليدية للحوسبة، تصمم نظم الأعصاب المصنوعة لمحاكاة الشبكات العصبية للدماغ، ممكنة للذكاء الاصطناعي من إجراء مهام مثل التعرف على الأنماط، معالجة الإحساسات، واتخاذ القرارات بسرعة وكفاءة أكبر.
تحمل هذه التكنولوجيا قدراً كبيراً لتطوير أنظمة الذكاء الاصطناعي التي تمكن من التكيف، والقدرة على التعلم من البيانات القليلة، والفعالية في البيئات التيمة.
على سبيل المثال، في الروبوتات، قد تمكن الرقاقات الأعصابية المصنوعة من معالجة الإدخالات الحسية واتخاذ القرارات بمستوى من الكفاءة والسرعة التي لا تستطيع ملازمتها البنيات الحالية.
التحدي المقبل سيكون توسيع حوسبة الأعصاب المصنوعة لتعالج تعقيد تطبيقات الذكاء الاصطناعي الكبيرة، ودمجها مع إطارات الذكاء الاصطناعي الحالية للاستفادة كاملة من قدراتها.
وكباء الذكاء الاصطناعي في إستكشاف الفضاء.
يشارك المجموعات التي تتكون من الأجهزة الذين يمكن أن يكون لديهم قدرة على التحكم في المشاهدات والمعلومات والتنظيم والتحكم بالأجهزة والتعامل معها والقيام بالعمليات التي تتطلب إجراء مراقبة وإدارة متقدمة للأجهزة والعمليات.
ويمكن أيضًا أن تكون هذه الأجهزة قابلة للتوافر والتكيف والتعامل مع أي متغير يحدث في البيئة والتي قد تتسبب في تغير سلوك الأجهزة.
وهذه القدرة على التعامل مع التغيرات ستساعد في تحسين معدلات إنجاز المهام وتخفيض تكاليف الأمور الاخرى وستجعل الأجهزة تستطيع تنظيم وإدارة مهامها بشكل أكثر أكثر بروزًا.
ومع هذا التحقيق، ستكون هناك تطوير إضافي للأجهزة التي تمكنها من التعامل مع المشاهدات والمعلومات والتنظيم والتحكم بالأجهزة والتعامل معها والقيام بالعمليات التي تتطلب إجراء مراقبة وإدارة متقدمة للأجهزة والعمليات.
فالمجموعات التي تتكون من الأجهزة الذين يمكن أن يكون لديهم قدرة على التحكم في المشاهدات والمعلومات والتنظيم والتحكم بالأجهزة والتعامل معها والقيام بالعمليات التي تتطلب إجراء مراقبة وإدارة متقدمة للأجهزة والعمليات.
الرعاية الصحية
في الرعاية الصحية ، ليست المجموعات مجرد دور دعم ولكنها تصبح أساسية لكل خط من الرعاية الصحية.
باستخدام تكنولوجيا اللغة الطبيعية المتقدمة (NLP) وخوارزميات التعلم الآلي، هذه الأنظمة تقوم بمهام دقيقة مثل تصفية الأعراض وجمع البيانات الأولية بدرجة عالية من الدقة. يحللون أعراض المرضى التي يقدمونها وتاريخاتهم الطبية في الوقت الحقيقي، ويقومون بمقارنة هذه المعلومات مع قواعد بيانات طبية واسعة للكشف عن الحالات الحتمية أو الإشارات الحمراء.
هذا يمكن لمقدمي الرعاية الصحية أن يتخذوا قرارات مستنيرة بشكل أسرع، ما يقلل من وقت العلاج ويمكن حفظ الأرواح. وعلى جانب آخر، أدوات التشخيص الدرونة بالذكاء الاصطناعي تحول راديولوجيا بحلول تكشف عن الأنماط والانواع الغير ملموسة للعين البشرية في الصور السينية والمغناطيسية والموجات التنومغية (CT).
تتم تدريب هذه الأنظمة على مجموعات بيانات كبيرة تشمل ملايين الصور الموسومة، مما يسمح لها ليس فقط بتكرار القدرات البشرية للتشخيص بل أحياناً تفوقها.
إندماج الذكاء الاصطناعي في الرعاية الصحية يمتد أيضاً إلى المهام الإدارية، حيث يقلل التلقيم التلقائي للمواعيد، والتذكيرات للأدوية، وتتبع المرضى الى الأفقر الضمانات العاملة على الكادر الصحي، مما يسمح لهم بالتركيز على جوانب أكثر أهمية من رعاية المرضى.
التمويل
في القطاع المالي، قاموا بثورة في العمليات بإدخال مستويات غير مسبوقة من الكفاءة والدقة.
التداول الآلوجراذي، الذي يعتمد بشكل كبير على الذكاء الاصطناعي، قدم تغييراً كبيراً في الطريقة التي يؤدي فيها الصفقات في الأسواق المالية.
تستطيع هذه الأنظمة تحليل مجموعات كبيرة من البيانات في مئات الميلاديات، تحدد التوجهات السوقية، وتقوم بالمقارنات في الوقت الأفضل لتحقيق الأرباح وتخفيض الخطورات. يستخدمون خوارزميات معقدة تتضمن تقنيات التعلم الآلي، والتعلم العميق، والتعلم التعاملي للتأقلم بالظروف السوقية التي تتغير. وتتمكن هذه النماذج من إجراء قرارات فورية لا يمكن أن تقاطعها التجار البشريين.
في التخطيط التوجيهي، يلعب التعلم الآلي دور حيوي في الإدارة التنظيمية عن طريق تقييم خطورات القروض وكشف أنشطة الخدعة بدقة لا تُصدق. تستخدم نماذج التعلم الآلي تقنيات التنبؤ المستقبلي لتقييم معدل خطأ المقترحين بالقرض بتحليل الأنماط في تاريخيات القروض وسلوكيات المعاملات الأخرى والعوامل الأخرى المهمة.
أيضًا في مجال الاتباع التنظيمي، يقوم التعلم الآلي بتلقيح المراقبة على المعاملات لكشف وتقارير الأنشطة السؤالية، متأكدًا من أن المؤسسات المالية تتبع تلبية التعهدات القاطعة. هذا التلقيح الآلي لا يقل بشكل واحد من تخفيض خطر الخطأ البشري ويسير عمليات التوجيه التنظيمي بتحسين التكاليف والفاعلية.
إدارة الحالات الطارئة
تلك الأدوات التعلمية تلعب دورا تحويليا في إدارة الحالات الطارئة بشكل يغير المفهوم، تغير الطريقة التي يتم تخطيط وإدارة الأزمات وتخفيضها.
في سرعة الاستجابة للكوارث،
على سبيل المثال، أثناء أزمة طبيعية مثل الإعصار، يمكن للأنظمة التعلمية التي التي تستخدم التخيل تخمين مسار العاصفة وقوتها، مما يسمح للسلطات بإصدار أوامر الإجلاء المتأخرة وتوجيه موارد إلى المناطق الأكثر ضعفًا.
في التنبؤ التقني، تستخدم نماذج التعلم التي التي تتخذ إشارات الطوار توقعًا عن طريق تحليل البيانات التاريخية بالإضافة إلى الإدخالات الحالية، مما يسمح للتجاوب المتقدم والذي يمكن أن يتجنب الكوارث أو تخفيف تأثيرها.
يلعب أيضًا نظم التواصل العام القوة الرئيسية في تأمين توصيل المعلومات الدقيقة والمناسبة للأوساط المصاب. يمكن توليد وتوزيع تنبيهات الطوار عبر وسائط متعددة بواسطة هذه الأنظمة، وتخصيص الرسائل لأعدادات مختلفة لضمان الفهم والاتفاق بالمواطنين.
ويمكن للتعلم التي التي تستخدم التخيل تعزيز جهود المساعدين في الحالات الطارئة بإنشاء محاكاات تعليمية واقعية جدًا بواسطة نماذج التوليد التي التي تكرار تعقيدات الأزمات العالمية، مما يسمح للمساعدين بتمكين مهاراتهم وتحسين جهودهم للحالات الحقيقية.
النقل
يصبح نماذج التعلم التي التي تستخدم في قطاع النقل أساسيًا بحيث تحسين الأمان والفعالية والموافقة على المستويات المختلفة، بما في ذلك مراقبة المرور الجوي ، المركبات الautonomous والنقل العام.
في مراقبة المرور الجوي، تلع
plaintext
في مجال السيارات الآلية، يتمثل الذكاء الاصطناعي في النقطة الأساسية التي تمكِّن السيارات من معالجة بيانات الاستشعار واتخاذ قرارات بمعدل الثوان للتغلب على البيئات المعقدة. تستخدم هذه الأنظمة نماذج التعلم العميق التي تم تدريبها على مجموعات بيانات واسعة لتفسير البيانات البصرية والسمعية والمكانية، مما يسمح بالتنقل بأمان خلال ظروف ديناميكية وغير قابلة للتنبؤ.
كذلك تستفيد أنظمة المواصلات العامة من الذكاء الاصطناعي من خلال تخطيط الرحلات المحسن، وصيانة التنبيهية للسيارات، وادارة تدفق المسافرين. عن طريق تحليل البيانات التاريخية والمباشرة، يستطيع أنظمة الذكاء الاصطناعي تعديل جداول المواصلات، وتنبؤ ومنع تعطيل السيارات، وادارة التحكم في الحشود أثناء الساعات العصية، مما يحسن الكفاءة والموثوقية العامة للشبكات النقلية.
قطاع الطاقة
يؤدي الذكاء الاصطناعي دوراً حاسماً في قطاع الطاقة، خاصة في إدارة الشبكة الكهربائية، تحسين الطاقة المتجددة، واكتشاف الأخطاء.
في إدارة الشبكة الكهربائية، يقوم عوناء الذكاء الاصطناعي بمراقبة وادارة الشبكات الكهربائية عن طريق تحليل البيانات الحالية من أجهزة الاستشعار الموزعة عبر الشبكة. تستخدم هذه الأنظمة تحليلات التنبؤية لتحسين توزيع الطاقة، مؤكدة أن الإمداد يحقق الطلب بمعدل إنخفاض الهدر الطاقة. كما تنبؤ نماذج الذكاء الاصطناعي بالأخطاء الحتمية في الشبكة، مما يسمح بالصيانة الاحتماطية وتقليل خطر الانقطاعات.
وفي مجال الطاقة المتجددة، يستخدم الأنظمة الذكاء الاصطناعي لتنبؤ بنماذج الطقس، وهو ما هو حاسم في تحسين إنتاج الطاقة الشمسية والرياحية. تحلل هذه النماذج بيانات المناخ لتنبؤ بس
الكشف عن الأعطال هو مجال آخر حيث يقدم التعقيد الرئيسي. تحلل نظم الألغاز الذهنية بيانات المجسات من معدات مثل المحوّلات، والمولدات الهوائية، والمولدات الكهربائية لتحدد أعاب التراكم أو الأعطال المتوقعة قبل أن تسبب فشلات. هذا الأسلوب المتوقع لل mantenimiento لا يؤثر فقط على تمديد عمر المعدات بل يضمن توفير توليد الطاقة المستمر والموثوق.
الأمن السيبراني
في مجال الأمن السيبراني، تعتمد وكالات الذهن التي تكون ضرورية للبقاء الصحيح والأمان في البنيات الديجيتالية. تصمم تلك الأنظمة للمراقبة المستمرة على الترددات الشبكية، وتستخدم خوارزميات التعلم الآلي لكشف الاستباقات التي قد تشير إلى تخطئة أمنية.
من خلال تحليل الأعداد الكبيرة بالوقت الحقيقي، يمكن لوكالات الألغاز التحديد من السلوكيات الخبيثة، مثل المحاولات الخاصة بالدخول، أو أنشطة التخزين الخارجي للبيانات، أو حضور أنواع الألغاز. حال تم الكشف عن خطر ممكن، يمكن لنظم الألغاز التي تقوم بتلقيح الأنظمة تلقائيًا بإجراءات المكافحة، مثل إعادة تعمية الأنظمة المتخطئة وتوزيع الصقالات، لمنع تلف الاستمراري.
تقييم الأخطاء هو تطبيق أساسي للألغاز التي يقوم بها الألغاز التي تتم بواسطة التقنيات التي تستخدم للتحليل الثابت والتحليل الحالي لتقييم الوضع الأمني للبرمجيات والمكونات الكهربائية، وتوفير تفسيرات قابلة للإجراء
تعزيز سرعة ودقة اكتشاف التهديدات والاستجابة وتقليل العبء على المحللين البشر، مما يسمح لهم بالتركيز على التحديات الأمنية الأكثر تعقيدًا.
التصنيع
في مجال التصنيع، تقود الذكاء الاصطناعي تطورات كبيرة في مراقبة الجودة، الصيانة التنبؤية، وتحسين سلسلة التوريد. نظم رؤية الحاسوب التي تعمل بالذكاء الاصطناعي قادرة الآن على تفتيش المنتجات لاكتشاف العيوب بسرعة ودقة تتجاوز بكثير قدرات البشر. تستخدم هذه النظم خوارزميات التعلم العميق المدربة على الآلاف من الصور لاكتشاف الشوائب حتى في أصغر العيوب في المنتجات، مما يضمن جودة ثابتة في بيئات الإنتاج عالية الحجم.
الصيانة التنبؤية هي مجال آخر حيث يكون للذكاء الاصطناعي تأثير عميق. من خلال تحليل البيانات من أجهزة الاستشعار المضمنة في الآلات، يمكن لنماذج الذكاء الاصطناعي التنبؤ بموعد فشل المعدات، مما يسمح بجدولة الصيانة قبل حدوث عطل. هذا النهج لا يقلل فقط من الوقت التوقف ولكن يزيد أيضًا من عمر الآلات، مما يؤدي إلى توفير تكاليف كبيرة.
في إدارة سلسلة التوريد، تقوم وكلاء الذكاء الاصطناعي بتحسين مستويات المخزون والخدمات اللوجستية من خلال تحليل البيانات من جميع أنحاء سلسلة التوريد، بما في ذلك توقعات الطلب، جداول الإنتاج، ومسارات النقل. من خلال إجراء تعديلات في الوقت الحقيقي على خطط المخزون واللوجستيات، يضمن الذكاء الاصطناعي سلامة عمليات الإنتاج، مما يقلل من التأخير ويقلل من التكاليف.
تظهر هذه التطبيقات الدور الحيوي للذكاء الاصطناعي في تحسين الكفاءة التشغيلية والموثوقية في قطاع التصنيع، مما يجعله أداة لا غنى عنها للشركات التي تسعى للبقاء تنافسية في صناعة تتطور بسرعة.
خلاصة
تكافؤ الموافقات بين وكلاء الممولين والموردين هو شيء يساهم في تحقيق الاستجابة السريعة للاحتياجات المتعددة والتي تنتج عن اشتراك الجهود بين الجهود المختلفة. ومع ذلك فإن تأثير هذا التعاون يمكن أن يكون أكثر من تحقيق بيانات واحدة أو توفير خدمة واحدة، لأنه يمكن أن يتم توفير كل ما يحتاج من المعلومات والخدمات من خلال تلك المحادثة الواحدة مع كل من الوكلاء والموردين.
من ثم يمكنك استخدام هذه المعلومات والخدمات لتوفير أي خدمات أخرى تتطلب وصول الى مختلف الأنظمة والأدوات.
وهذا ما يحدث بمجرد إشراف المحادثة بين الموردين والممولين والتوفير لمعلومات المختلفة التي تحتاج للوكلاء والموردين للقيام بأعمالهم الخاصة.
وبمجرد تأكد من تلك المعلومات والخدمات وإعادة تأكد عليها من خلال الموردين والممولين وتوفيرها للوكلاء والموردين بالمرة الثانية وهكذا إلى ما يكفي.
ومن ثم يمكنك أن تقوم بتوفير هذه المعلومات والخدمات بأسرع وقت وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدام أكبر بوسعك وبأقدا
عن المؤلف
هنا فاهه أسلانيان، في مركز العلوم الحاسوبية والعلوم البيانات والتطبيقات الذكية. اذهب إلى vaheaslanyan.com لرؤية معرف تعرف على الدرجة الدقيقة والتقدم. تقايمي يجبر على التواصل بين التطوير الكامل الخلال وتحسين المنتجات التي تتمتع بالذكاء الصناعي، وذلك من خلال حل مشاكل الطريقة الجديدة.
ومع سجل يشمل أنشأت معهد تدريب معروف للبيانات العلمية والعمل مع أفضل الخبراء في الصناعة، يبقى تركيزي على رفع مستوى التعليم التقني إلى معايير عالمية.
كيف يمكنك الغوص أعمق؟
بعد دراسة هذه الدراسة، إذا كنت متعجرفًا بالمضي أعمق ويمكنك التعلم المنظم في أسلوبك، فلا تتردد في انضمامك إلينا في LunarTech، نقدم دورات منفردة ومعهد تدريبي في البيانات العلمية والتعلم الآلي والذكاء الصناعي.
نقدم برنامج شامل يوفر فهمًا عميقًا للنظرية، وتطبيقها عميقًا ومواد تمارين وتدريب مقابلات متخصصة لتوظيفك بنجاح في مرحلة معينة.
يمكنك أن تراقب ما يجري مختبر البحث العلمي النهائي وأن تشارك فترة تجريبية مجانية لتجربة المحتويات بأيدي. ألزم هذا بتقدير أنه أفضل مختبرات البحث العلمي لعام 2023، وتم تمييزه في مجلات مهيبة مثل Forbes، Yahoo، Entrepreneur وما إلى ذلك. هذه فرصتك للانضمام إلى مجموعة تعمل بتعقيد ومعرفة. هذه هي رسالة الترحيب!
تواصل معي

تتبعني على LinkedIn لموارد مجانية كبيرة في التكنولوجيا العملاقة، ML والأشياء الأخرى
إذا كنت ترغب في تعلم أكثر عن كيفية توظيف وظيفة في العلوم البيانية، والتعلم الماشيني، والتعلم الأولي، يمكنك تحميل هذه الدليل المجانية الدليل المهنة للعلوم البيانية والتعلم ال artificial.
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/