













האבולוציה המהירה של המחשבה המלאכותית (AI) הובילה לסיומה חזקה בין מודלים שפה גדולים (LLMs) וסוגי המודלים המלאכותיים. המגע הדינמי הזה דומה לסיפור של דוד וגוליית (מבלי להתקרבות לקרב), בו סוגי המודלים המלאכותיים המאוגדים מעודדים ומגדילים את היכולות של הLLMs הענקיים.
ספר היד זה יסתכל על איך סוגי המודלים המלאכותיים – דוד בסיפור – מעליפים LLMs – הגוליית שלנו בימינו – כדי לעזור למהפך של תעשיות ותחומי מדע מגוונים.
תפריט העמודים
ההתחלה של סינדרומים המחשבתיים במונחים האקסטריים
סינדרומים המחשבתיים האלה הם מערכות עצמאיות מעוצבות כדי להבחין בסביבה שלהם, לקבע החלטות, ולבצע פעולות על מנת להגיע למטרות ספציפיות. בהצטרפותם למונחים האקסטריים, הסינדרומים האלה יכולים לבצע משימות מורכבות, להתייחס למידע באופן הגיוני, ולייצר פתרונות חדשניים.
השילוב הזה הוביל להתקדמויות משמעותיות בתחומים רבים, מפיתוח התוכנה ועד למחקר מדעי.
ההשפעה המעצמתית על התעשיות
השילוב של סינדרומים המחשבתיים עם מונחים האקסטריים הוביל להשפעה עמוקה על תחומים רבים בתעשיות:
-
פיתוח תוכנה: סיועני קודים מונעים על-ידי תכנות מבוססת על עילוי מחשבה, כמו GitHub Copilot, הוכיחו את היכולתם לייצר עד 40% מהקוד, מובילה לעלייה ניכרת בקצב הפיתוח ב-55%.
-
חינוך: סיועני למידה מונעים על-ידי תכנות מבוססת על עילוי מחשבה הראו תועלתם בצמצום בערך ב-27% מזמן ההשלמה של הקורסים, שיכול להפוך באופן מפץ את השדה החינוכי.
-
תחבורה: עם תחזיות שמראות ש-10% מהכלי רכב יהיו ללא נהג עד 2030, סוכני AI אוטונומיים במכוניות בנהיגה עצמית עומדים לשנות את תעשיית התחבורה.
קידום גילוי מדעי
אחד היישומים המרתקים ביותר של סוכני AI ודגמי שפה גדולים הוא במחקר המדעי:
-
גילוי תרופות: סוכני AI מאיצים את תהליך גילוי התרופות על ידי ניתוח מאגרי נתונים עצומים וניבוי מועמדים אפשריים לתרופות, ובכך מפחיתים משמעותית את הזמן והעלות הכרוכים בשיטות המסורתיות.
- פיזיקת חלקיקים: במאיץ החלקיקים הגדול של CERN, סוכני AI מועסקים לניתוח נתוני התנגשויות חלקיקים, תוך שימוש בזיהוי אנומליות כדי לזהות רמזים מבטיחים שיכולים להצביע על קיומם של חלקיקים לא ידועים.
-
מחקר מדעי כללי: סוכני AI משפרים את הקצב וההיקף של תגליות מדעיות על ידי ניתוח מחקרים קודמים, זיהוי קשרים בלתי צפויים והצעת ניסויים חדשים.
ההתמזגות של סוכני AI ומודלים של שפה גדולים (LLM) מושכת את הבינה המלאכותית לתקופה חדשה של יכולות ללא תקדים. הספר הידעי המקיף הזה חוקר את האינטרדיפליות הדינמית בין שתי הטכנולוגיות הללו, גולשת את הפוטנציאל המשולב שלהן למהפכת תעשיות ופתרון בעיות מורכבות.
נעקור את ההתפתחות של הAI ממקורותיה ועד להופעתם של סוכנים אוטונומיים והעלייה בלמים LLM חכמים. נחקור גם את החשיבות האתייתית, שהיא בסיסית לפיתוח אחראי של AI. זה יעזור לנו להבטיח שהטכנולוגיות הללו מתאימות לערכי האדם ולרווחת החברה.
על סוף הספר הידעי הזה, תהיה לך הבנה מעמיקה של הכוח הסינרגי של סוכני AI וLLM, וידע וכלים לניצול הטכנולוגיה העתיקה הזו.
פרק 1: הקדמה לסוכני AI ומודלי שפה
מהם סוכני AI ומודלים של שפה גדולים?
ההתפתחות המהירה של בינה מלאכותית (AI) הביאה על ידי סוכנים אל השילוב השניחותי בין LLM וסוכני AI.
מערכות הממשק הן מערכות עצמאיות מעוצבות כדי להבחין בסביבה שלהם, לקבל החלטות, ולבצע פעולות כדי להשיג מטרות ספציפיות. הן מראות תכונות כמו עצמאות, תפיסה, תגובה דינמית, היגיון, קבלת החלטות, למידה, תקשורת, והתמקדות על מטרות.
מצד שני, מערכות LLM הן מערכות AI מורכבות שמשתמשות בטכניקות למידה עמוקה ובמידע רחב כדי להבין, ליצור ולחזות טקסט דמוי אדם.
המודלים האלה, כמו GPT-4, Mistral, LLama, יצרו יכולות מדהימות במשימות עיבוד שפה טבעית, כולל יצירת טקסט, תרגום שפה, וסוגים של אנשים מדברים.
מפתחות מייצגים של מערכות סוכנים AI
מערכות סוכנים AI מרכיבות בעלות תכונות מפתח הממוקדות על הן ומסיירות אותן מערכות קוד רגילות:
-
עצמאות: הם יכולים לפעול באופן עצמאי בלי התערבות אדם קבעית.
-
תפיסה: סוכנים יכולים לחוש ולפרש את הסביבה שלהם דרך קלטים מגוונים.
- תגובה דינמית</di
-
שיקול דעת וקבלת החלטות: סוכנים יכולים לנתח נתונים ולקבל החלטות מושכלות.
-
למידה: הם משפרים את ביצועיהם במהלך הזמן דרך חוויות.
-
תקשורת: סוכנים יכולים להתקשר עם סוכנים אחרים או בני אדם באמצעות שיטות שונות.
-
כיווניות למטרה: הם מיועדים להשיג מטרות ספציפיות.
יכולות של מודלי שפה גדולים
מודלי שפה גדולים הציגו מגוון רחב של יכולות, כולל:
-
יצירת טקסט: מודלי שפה גדולים יכולים ליצור טקסט עקבי ורלוונטי מהקלטים.
-
תרגום שפה: הם יכולים לתרגם טקסט בין שפות שונות בדיוק גבוה.
-
סיכום: LLMs יכולים לכווץ טקסטים ארוכים לסיכומים מתוחכמים בשמירה על מידע מרכזי.
-
שאלות ותשובות: הם יכולים לספק תשובות מדויקות לשאילתות בהתבסס על בסיס הידע הרחב שלהם.
-
ניתוח רגשות: LLMs יכולים לנתח ולקבוע את הרגשות הבעות בטקסט נתון.
-
ייצוג קוד: הם יכולים ליצור קטעי קוד או פונקציות שלמות בהתבסס על תיאורים בשפה טבעית.
רמות של סוכני AI
סוכני AI יכולים להיות מסויגים לרמות שונות בהתבסס על יכולותיהם וריכוזם. לפי מאמר ב־arXiv, סוכני AI מסויגים לחמישה רמות:
-
רמה 1 (L1): סוכני AI כעוזרי מחקר, שבהם מדענים מציבים השערות ומפרטים משימות להשגת מטרות.
-
רמה 2 (L2): סוכני AI שיכולים לבצע באופן אוטונומי משימות ספציפיות בתוך תחום מוגדר, כמו ניתוח נתונים או קבלת החלטות פשוטות.
-
רמה 3 (L3): סוכני AI שיכולים ללמוד מניסיון ולהסתגל למצבים חדשים, משפרים את תהליכי קבלת ההחלטות שלהם.
-
רמה 4 (L4): סוכני AI בעלי יכולות נימוק ופתרון בעיות מתקדמות, מסוגלים לטפל במשימות מורכבות ורב-שלביות.
-
רמה 5 (L5): סוכני AI אוטונומיים לחלוטין שיכולים לפעול באופן עצמאי בסביבות דינמיות, מקבלים החלטות ונוקטים בפעולות ללא התערבות אנושית.
מגבלות של מודלים גדולים של שפה
עלויות אימון ומגבלות משאבים
מודלים גדולים של שפה (LLMs) כמו GPT-3 ו-PaLM הביאו למהפכה בעיבוד שפה טבעית (NLP) באמצעות ניצול טכניקות למידה עמוקה ומאגרי נתונים עצומים.
אך השיפורים האלה מגיעים במחיר יקר. החינוך של מנגנונים כמו GPT-4 דורש משאבי מחשבה משמעותיים, שבד ""כ מעורבים אלפים של GPU וצריכת אנרגיה נרחבת.
לפי סאם אלטמן, מנהל אופן האינטEL, המחיר של האימון לגפט-4 עלה על ידי 100 מליון דולר. זה מתאים לעבדה המודלית הגדולה והמורכבת שלו, עם הערכים המצביעים שיש לו בערך 1 טריליון פרמטרים. אך מקורות אחרים מציעים מספרים שונים:
-
דוח פליל מציע שהמחיר לאימון של GPT-4 היה בערך 63 מליון דולר, בהתחשב בכוח המחשבה ובמשך הזמן האימון.
-
לפני אמצע 2023, חלק מהערכים הציעו שלמען האימון של מודל דומה לגפט-4 יכול להיות בערך 20 מליון דולר ולקחת בערך 55 יום, שמשקף התקדמויות ביעילות.
עלות גבוהה זו של אימון ותחזוקת מודלים גדולים מגבילה את האימוץ הרחב והסקלאביליות שלהם.
מגבלות נתונים והטיות
הביצועים של מודלים גדולים תלויים מאוד באיכות ובמגוון של נתוני האימון. למרות שאומנו על מערכי נתונים עצומים, מודלים גדולים יכולים עדיין להציג הטיות הנמצאות בנתונים, מה שמוביל לפלטים מוטים או בלתי הולמים. הטיות אלו יכולות להתבטא בצורות שונות, כולל הטיות מגדריות, גזעיות ותרבותיות, אשר יכולות לשמר סטריאוטיפים ומידע שגוי.
גם, הטבע הסטטי של נתוני האימון אומר שמודלים גדולים עשויים לא להיות מעודכנים עם המידע העדכני ביותר, מה שמגביל את היעילות שלהם בסביבות דינמיות.
התמחות ומורכבות
בעוד שמודלים גדולים מצטיינים במשימות כלליות, הם לעיתים מתקשים במשימות מיוחדות הדורשות ידע מתחום ספציפי ומורכבות גבוהה.
לדוגמה, משימות בתחומים כגון רפואה, משפטים ומחקר מדעי דורשות הבנה עמוקה של מונחים מיוחדים ושל חשיבה ניואנסית, שלא תמיד יש למודלים גדולים באופן טבעי. מגבלה זו מחייבת שילוב של שכבות מומחיות נוספות וכיוונון עדין כדי להפוך את המודלים הגדולים לאפקטיביים ביישומים מיוחדים.
מגבלות קלט וחושיות
מערכות המידע הגדולות מעבדות בעיקר קלטים טקסטואליים, מה שמגביל את היכולתם לתקשר עם העולם באופן רב-סוגים.
למרות שהן יכולות ליצור ולהבין טקסט, הן חסרות היכולת לעבדת קלטים חזותיים, שמיעיים או חושיים ישירות.
המגבלה הזו מפגיעה בהשתמשותם בתחומים שדורשים הדבקה חזותית מוחלטת, כמו רובוטיקה ומערכות עצמיות.
לדוגמה, מערכת מידע גדולה לא יכולה לפרש מידע חזותי ממצלמה או מידע שמיעי ממיקרופון ללא שכבות עיבוד נוספות.
היכולות התקשורתיות של המערכות הן בעיקר מבוססות על טקסט, מה שמגביל את היכולתם להיות מעורבות בצורות יותר מקומיות ואינטראקטיביות של תקשורת.לדוגמה, למרות שמערכות מידע גדולות יכולות ליצור תגובות טקסטיות, הן לא יכולות ליצור תוכן וידאו או הולוגרמות, שחשובים יותר ויותר ביישומים של המציאות מעורבת והמיזוג המקומי.
דרכים להתגבר על המגבלות עם סגנונים של סינתקים מבוססים על מידע מבוסס
סינתקים מבוססים על מידע מעניקים פתרון מעניין לרבות מהמגבלות של מערכות המידע הגדולות. הסינתקים מעוצבים כך שיפעלו באופן עצמאי, יתקשרו עם הסביבה שלהם, יקבעו החלטות ויבצעו פעולות כדי להשלים מטרות
-
חיזוק הקשר והזיכרון: סוכני AI יכולים לשמור על הקשר לאורך מספר אינטראקציות, מה שמאפשר תגובות עקביות ורלוונטיות להקשר. יכולת זו מועילה במיוחד ביישומים שדורשים זיכרון לטווח ארוך והמשכיות, כמו שירות לקוחות ועוזרים אישיים.
-
שילוב מולטימודלי: סוכני AI יכולים לשלב קלטים חושיים ממקורות שונים, כגון מצלמות, מיקרופונים וחיישנים, ובכך לאפשר ל-LLMs לעבד ולהגיב למידע חזותי, שמיעתי וחושי. שילוב זה חיוני ליישומים ברובוטיקה ומערכות אוטונומיות.
-
ידע מקצועי ויומרה מקצועית: סיסמים המקורבים באינטליגנציה יכולים להתאימות בעזרת ידע מקצועי מסויים, שמעדיף את היכולת של מינועים הלאומיים לבצע משימות מקצועיות. הגישה זו מאפשרת ליצירת מערכות מומחים שמסוגלים לטפל בשאילות מורכבות בתחומים כמו רפואה, משפטיקה ומחקר מדעי.
- תקשורת אינטראקטיבית ומעורפלת: סיסמים המקורבים באינטליגנציה יכולים לסייע בצורה מעורפלה יותר בתקשורת על-ידי יצירת תוכן וידאו, שליטה במיוחדים הלוגרמיים, ואינטראקציה עם סביבות מדיה מולטית ומ
למודלים הגדולים בשפה הטבעית יש יכולות מדהימות בעיצוב עבודתם בעינייני עיבוד השפה הטבעית, אך לא חסרים להם מגבלות. המחירים הגבוהים של האימון, הטעויות המידעניות, האתגרים המיוחדים, המגבלות החושיות, והגבולות התקשורתיים מוציאים להם מספר מאמץ רב.
אך השילוב של סייעים בעלי בינת AI מעניק מסלול מושלם להתגברות על המגבלות האלה. על-ידי נצלים את החלקים החזקים של הסייעים האלה, ניתן לשכלל את הפונקציות, הגמישות והיישומות של מודלים הללמוד הגדולים, ולסלול את דרכם למערכות AI מתקדמות ומוצלחות יותר.
פרק 2: ההיסטוריה של הבינה המלאכותית וסייעים
המיוצא של בינה המלאכותית
הרעיון של בינה המלאכותית (AI) יש שורשים שנעצמים רחוקים מעין העידן הדיגיטלי המודרני. הרעיון של יצירת מכונות מסוגלות להגיונים אנוש
ה כינוס דארטמות 1956, שארגו ג'ון מקרייה, מרבין מינסקי, נתנאל רוכסטרנביץ' וקלאוד שנןי, מוכרח כמקום הולדת המדע החישובי כתחום. הארוע המקורי הזה הביא את מחברים המובילים בחקירה של הפוטנציאל של יצירת מכונות שיחימו את האינטליגנציה האנושית.
האופטימיות המוקדמת והחורף המדעי של המכונה
השנים המוקדמות של מחקר המכונה היו מאפיינים באופטימיות לא מוגבלת. חוקרים עשו הצלחות משמעותיות בפיתוח תוכנות מסוגלות לפתור בעיות מתמטיות, לשחק משחקים ואפילו להתעסק בעיבוד השפה הטבעית בדיוק.
אך ההתרגשות הראשונה הזו נעשמתה על-ידי ההבנה שבניית מכונות באמת חכמות היתה מורכבת בהרבה מאשר שהיא נצפתה בהתחלה.
ה-1970 וה-1980 ראו תקופה של קיצוץ במימון ובעניין במחקר המכונה, שנקראת "החורף המדעי של המכונה". הירידה הזו היתה בעיקר בגלל הכשלון של מערכות המכונה להגיע לציפיות הגבוהות של המקדמים הראשונים.
ממערכות מבוססות-עקרונות ללמידה מכונה
העידן של המערכות המומחיות
ה-1980 ראו חזרת התעניינות במחקר המכונה, בעיקר מהתפתחות של מערכות המומחים. המערכות האלה היו מבוססות על עקרונות והן היו עוצבות
מערכות מומחיות מצאו יישומות בתחומים מסויימים, כולל רפואה, פיננסים והנדסה. אך הן היו מוגבלות על ידי החוסר ביכולת ללמוד מהניסיון או להסתגל למצבים חדשים מחוץ להדיברות התוכנות שלהן.
העליית למידת המכונות
המגבלות של המערכות הבסיסיות על חוקים פתחו את הדרך למעבר פרמדים ללמידת המכונות. הגישה הזו, שהשגתה חזקות בשנות ה-1990 וה-2000, מתמקדת בפיתוח אלגוריתמים שיכולים ללמוד ממידע ולעשות הערכות או החלטות מבוססות על מידע.
טכניקות למידת המכונות כמו רשתות מוחיות ומכשירי תמיכה מדגימו הצלחה מדהימה במשימות כמו זיהוי דפוסים וקטגוריזציה של מידע. התחילות המידע הגדול והעוצמה התעצמתית של המחשבה דחף את הפיתוח והיישומות של האלגוריתמים למידת המכונות הזו.
הופיעה של סוגי האינטליגנציה העצמאית
מ-AI הצר ל-AI הכללי
כשטכנולוגיות ה-AI המשך להתפתח, חוקרים החלו לבדוק את האפשרות ליצירת מערכות יותר גמישות ועצמאיות. המעבר הזה סמל את העברה מ-AI הצר, שמיועד למשימות ספציפיות, למטרת הדרך אחרת ל-AI הכללי.
AGI מוכן לפתח מערכות מסוגלות לבצע כל משימה אינטלקטואלית שאדם יכול לבצע. בעוד שהAGI האמיתי עדיין מטרה רחוקה, נעשה התקדמות משמעותית ביצירת מערכות AI יותר גמישות ומותאמות.
העליית הדייפ לימד, שהיא תת מחלקה של למידת המכונה שמבוססת על מערכות מוח מלאכותיות, היתה בסיסית בפיתוח התחום של AI.
אלגוריתמים של הדייפ לימד, מועדים על המבנה והפעלת המוח האנושי, הראו יכולות מדהימות בתחומים כמו זיהוי תמונות ודיבור, עיבוד השפה טבעית, ושחקות משחקים. ההתקדמויות האלה סידרו את הבסיס לפתח על ידי המערכות AI עצמאיות יותר מורכבות.
מאפיינים וסוגים של סינדרומים AI
סינדרומים AI הם מערכות עצמאיות שמסוגלים להגיע אל סביבתם, להחליט, ולבצע פעולות כדי להשיג מטרות ספציפיות. יש להם מאפיינים כמו עצמאות, חישה, תגובה, היגיון, קבלת החלטות, למידה, תקשורת, והתמקדות על מטרות.
יש סוגים מסויימים של סינדרומים AI, כל אחד עם יכולות ייחודיות:
- סינדרומים פשוטים להגיעה: מגיבים לסימנים ספציפיים בהתבסס על חוקים מוגדרים מראש.
-
סוכני רפלקס בהתבסס על מודל: שומרים על מודל פנימי של הסביבה לשימוש בהחלטות.
-
סוכנים מבוססי מטרות: מבצעים פעולות כדי להשיג מטרות מסוימות.
-
סוכנים מבוססי יעילות: חושבים על תוצאות פוטנציאליות ובוחרים פעולות שמקסימות את היעילות הצפויה.
-
סוכנים למידה: משפרים את ההחלטות באמצעות טכניקות למידה של מכונות.
אתגרים וחשיבה אתית
כשמערכות הבינה המלאכותית הופכות למתקדמות ואוטונומיות, הן מביאות השאלות קריטיות להבטיחת שימוש בהן בתוך הגבולות החברתיים המקובלים.
מודלים גדולים של שפה (LLMs), במיוחד, מפע
למהנדסי LLM יש גישה למגוון כלים ומתודולוגיות להתמודד עם אתגרים אלו:
-
ניתוח סנטימנטים: על ידי שימוש בניתוח סנטימנטים, LLMs יכולים להעריך את הטון הרגשי של הטקסט כדי לזהות שפה מזיקה או תוקפנית, ובכך לעזור בזיהוי ניצול לרעה אפשרי בפלטפורמות תקשורת.
-
סינון תוכן: כלים כמו סינון מילות מפתח והתאמת דפוסים יכולים לשמש למניעת יצירה או הפצה של תוכן מזיק, כמו דברי שנאה, מידע מוטעה או חומר מפורש.
-
כלים לזיהוי הטיות: יישום מסגרות לזיהוי הטיות, כמו AI Fairness 360 (IBM) או Fairness Indicators (Google), יכול לעזור לזהות ולהפחית הטיות במודלים של שפה, ולהבטיח שמערכות AI יפעלו בצורה הוגנת ושוויונית.
-
דרכים להסבר מונחים: בעזרת כלים להסבר כמו LIME (הסברים מקומיים למודלים בלתי-מסויימים) או SHAP (הסברים מוסף של שפלי), מהנדסים יכולים להבין ולהסביר את תהליכי ההחלטות של LLMs, מה שמקל לזיהוי וטיפול בהתנהגויות לא מכוונות.
- בדיקת אדווריאנטים: על-ידי סימולציית התקפים מלאכלים או קלטים מזיקים, מהנדסים יכולים לבצע בדיקות לחץ על LLMs בעזרת כלים כמו TextAttack או קישור סיום אדווריאנטי, זיהוי חולשות שיכולים להיות נוצלות למטרות מלאכלות.
- מדיניות ומבנים אתיים לAI מוסרי: על-ידי אימוץ מדיניות בניית AI מוסריות, כמו אלה שנותנים על-ידי IEEE או <di
בנוסף לכלים אלה, זו הסיבה למה נחוץ לצוות כח אדום מוגדר עבור אייטי – צוותים מיוחדים שמשפשפים את ה-LLM עד לגבולותיהם כדי לגלות פערים בחומות שלהם. צוותים כח אדום מדמים תרחישים מתוקפניים וחושפים פגיעויות שאולי באופן אחר לא היו נחשות.
אבל חשוב להבין שהאנשים מאחורי המוצר יש להם השפעה החזקה ביותר עליו. רבים מהתקיפות והאתגרים שאנחנו עומדים בפניהם היו קיימים אפילו לפני שפיתחו LLM, כלומר שהרכיב האנושי נשאר מרכזי בוודאות שאייטי ישמש באופן אתי ואחראי.
השילוב של הכלים והטכניקות הללו לתוך צינור הפיתוח, בניגוד לצוות כח אדום עקבי, הוא הכרחי לוודאות שה-LLM ישמשו לחזקת התוצאות החיוביות בעוד גם מזהים ומנעים את השימוש הלא נכון בהם.
פרק 3: היכן שאגנטים לאייטי מאירים בחזק ביותר
החוזקים הייחודיים של אגנטים לאייטי
אגנטים לאייטי מובילים בזכות יכולתם להשגיח באופן אוטונומי על הסביבה שלהם, להחליט ולבצע פעולות להשגת מטרות
כאן החומר העיקרי שמאיר בין הסוגים האלה של סוגים מלאכותיים:
- העצמאות והיעילות: סוגים מלאכותיים יכולים לפעול בצורה עצמאית ללא התערבות אנושית קבועה. העצמאות הזו מאפשרת להם לטפל במשימות 24/7, שוב, משכב את היעילות והפרודוקסיטיות באופן משמעותי. לדוגמה, בוטים משותפים בעזרת מלאכות יכולים לטפל עד ל-80% מהשאלות הלקוחות הרגילות, מצמצם את המחירי ההוצאה ומשפר את הזמנים התגובה.
- החלטות מתקדמות: סוגים מלאכותיים יכולים לנתח כמויות רחבות של מידע על מנת לקבל החלטות מודעות. היכולת הזו חשובה בשיווקים כמו הפיננסים, בהם בוטים משותפים בעזרת מלאכות יכולים להגביר יעילות המסחר באופן משמעותי.
-
למידה והסתגלות: סוכני AI יכולים ללמוד מניסיון ולהסתגל למצבים חדשים. שיפור מתמשך זה מאפשר להם לשפר את הביצועים שלהם עם הזמן. לדוגמה, עוזרי בריאות מבוססי AI יכולים לסייע בהפחתת טעויות אבחון, לשיפור תוצאות הבריאות.
-
התאמה אישית: סוכני AI יכולים לספק חוויות מותאמות אישית על ידי ניתוח התנהגות והעדפות המשתמש. מנוע ההמלצות של אמזון, שמניע 35% מהמכירות שלה, מהווה דוגמה מצוינת כיצד סוכני AI יכולים לשפר את חוויית המשתמש ולהגביר את ההכנסות.
מדוע סוכני AI הם הפתרון
סוכני AI מציעים פתרונות לאתגרים רבים העומדים בפני תוכנה מסורתית ומערכות המופעלות על ידי בני אדם. הנה הסיבה מדוע הם הבחירה המועדפת:
-
קנה מידה: סוכני AI יכולים להגדיל את הפעילות מבלי להגדיל באופן יחסי את העלויות. קנה מידה זה הוא קריטי עבור עסקים המעוניינים לגדול מבלי להגדיל באופן משמעותי את כוח העבודה או הוצאות התפעול.
-
עקביות ואמינות: בניגוד לבני אדם, סוכני AI אינם סובלים מעייפות או חוסר עקביות. הם יכולים לבצע משימות חוזרות עם דיוק ואמינות גבוהים, ולהבטיח ביצועים עקביים.
-
תובנות מבוססות נתונים: סוכני AI יכולים לעבד ולנתח מאגרי נתונים גדולים כדי לחשוף דפוסים ותובנות שעשויים להחמיץ על ידי בני אדם. יכולת זו היא לא תסולא בפז לקבלת החלטות בתחומים כמו פיננסים, בריאות ושיווק.
- חסכון עלויות: דרך אוטומציה של משימות רגילות, סוכנים AI יכולים להפחית את הדרישה למשאבי אדם, מובילה לחסכונים משמעותיים. לדוגמה, מערכות בעלות עיבוד הודעות AI יכולות לחסך בעלי מליוני דולרים בשנה על-ידי הפחתת פעילויות מתורמות.>
תנאים הדרישים עבור סוכנים AI כדי לבצע טוב
כדי לוודא את ההשלמה המוצלחת והביצוע המועילים של סוכנים AI, צרכים ספציפיים להיות מוגדרים:
- מטרות ברורות ומקרים שימוש: הגדרת מטרות ספציפיות ומקרים שימוש היא חשובה להפעלת סוכנים AI באופן יעיל. הבהירות הזו עוזרת לגדול ציפיות ולמדוד הצלחה. לדוגמה, הגדרת מטרה לצמצום את התגובות לשירותים הלקוחות ב-50% יכולה להדריך את הגדרת סוכנים AI כשירותים בתוכנה.>
-
נתוני איכות: סוכני AI מסתמכים על נתונים איכותיים להכשרה ותפעול. הבטחת שהנתונים מדויקים, רלוונטיים ועדכניים היא חיונית לסוכנים לקבל החלטות מושכלות ולבצע ביעילות.
-
שילוב עם מערכות קיימות: שילוב חלק עם מערכות ותהליכי עבודה קיימים הכרחי לתפקוד מיטבי של סוכני AI. שילוב זה מבטיח שהסוכנים יוכלו לגשת לנתונים הנדרשים ולתקשר עם מערכות אחרות לביצוע משימותיהם.
-
ניטור ואופטימיזציה מתמשכת: ניטור ואופטימיזציה סדירה של סוכני AI הם קריטיים לשמירה על הביצועים שלהם. זה כולל מעקב אחר מדדי ביצועים מרכזיים (KPIs) וביצוע התאמות נדרשות על בסיס משוב ונתוני ביצועים.
- שיקולים מוסריים והתמדה למתכוון: טיפול בשיקולים מוסריים ובהתמדה להתמדה בסימנים של הטיית הקטגוריה בסוגים האינטEL הוא חיוני לוודאת שוויון ובין-גיוון. יישום מדינים לזיהוי ומניעת הטיית הקטגוריה יכול לסייע בבניית אמון ובאחריות רגילה בהשקתה.
מיטבי המעשים להשקתה של סוגים האינטEL
בהשקתה של סוגים האינטEL, הוצאת אחר מיטבי המעשים יכולה לוודא את ההצלחה והיעילות שלהם:
- הגדרת מטרות ומקרים שימוש: הגדרת בבירור המטרות והמקרים המתאימים להשקתה של סוגים האינטEL. זה עוזר לגדול ציפיות ולמדוד הצלחה.
-
בחרו את הפלטפורמה ה-AI הנכונה: בחרו פלטפורמת AI שתואמת את המטרות שלכם, מקרי השימוש והתשתית הקיימת. קחו בחשבון גורמים כמו יכולות האינטגרציה, סקלביליות ועלות.
-
פיתוח בסיס ידע מקיף: בנו בסיס ידע מובנה ומדויק על מנת לאפשר לסוכני ה-AI לספק תגובות רלוונטיות ואמינות.
-
הבטחת אינטגרציה חלקה: שלבו את סוכני ה-AI עם מערכות קיימות כמו CRM וטכנולוגיות מוקד שירות לקוחות כדי לספק חווית לקוח מאוחדת.
-
הכשרה ואופטימיזציה של סוכני AI: הכשירו ואופטימיזו באופן מתמשך את סוכני ה-AI באמצעות נתונים מהאינטראקציות. עקבו אחרי ביצועים, זהו אזורים לשיפור ועדכנו את המודלים בהתאם.
-
יישום נהלי הסלמה מתאימים: קביעת פרוטוקולים להעברת שיחות מורכבות או רגשיות לנציגים אנושיים, להבטחת מעבר חלק ופתרון יעיל.
-
מעקב וניתוח ביצועים: מעקב אחר מדדי ביצוע מרכזיים (KPIs) כגון שיעורי פתרון שיחות, זמן טיפול ממוצע וציון שביעות רצון לקוחות. שימוש בכלי ניתוח לתובנות מבוססות נתונים וקבלת החלטות.
-
הבטחת פרטיות ואבטחת נתונים: אמצעי אבטחה חזקים הם המפתח, כמו הפיכת נתונים לאנונימיים, הבטחת פיקוח אנושי, קביעת מדיניות לשמירת נתונים והטמעת אמצעי הצפנה חזקים להגנה על נתוני לקוחות ושמירה על פרטיות.
סוכני AI + LLMs: עידן חדש של תוכנה חכמה
תארו לעצמכם תוכנה שלא רק מבינה את הבקשות שלכם אלא גם יכולה לבצע אותן. זו ההבטחה של שילוב סוכנים מבוססי בינה מלאכותית עם מודלים לשוניים גדולים (LLMs). השילוב העוצמתי הזה יוצר דור חדש של יישומים שהם אינטואיטיביים יותר, יכולתיים ומשפיעים מאי פעם.
סוכני AI: מעבר לביצוע משימות פשוטות
בעוד שלעיתים משווים אותם לעוזרים דיגיטליים, סוכני AI הם הרבה יותר מעוקבי סקריפטים מפוארים. הם כוללים מגוון טכנולוגיות מתוחכמות ופועלים על מסגרת שמאפשרת קבלת החלטות דינמית וביצוע פעולות.
-
ארכיטקטורה: סוכן AI טיפוסי כולל מספר רכיבים מרכזיים:
-
חיישנים: אלה מאפשרים לסוכן לקלוט את סביבתו, לאסוף נתונים ממקורות שונים כמו חיישנים, APIs, או קלט משתמש.
-
מצב אמונה: זה מייצג את הבנת הסוכן את העולם בהתבסס על הנתונים שנאספו. הוא מתעדכן באופן שוטף כאשר מידע חדש נעשה זמין.
-
מנוע הסקה: זהו ליבת תהליך קבלת ההחלטות של הסוכן. הוא משתמש באלגוריתמים, לעיתים מבוססי למידת חיזוק או טכניקות תכנון, כדי לקבוע את הדרך האופטימלית לפעולה בהתבסס על אמונותיו ומטרותיו הנוכחיות.
-
מבצעים: אלו הם הכלים של הסוכן לאינטראקציה עם העולם. הם יכולים לנוע משליחת קריאות API ועד לשליטה ברובוטים פיזיים.
-
-
אתגרים: סוכני בינה מלאכותית מסורתיים, למרות שהם מיומנים בטיפול במשימות מוגדרות היטב, לעיתים קרובות מתקשים ב:
-
הבנת שפה טבעית: פירוש שפה אנושית מעודנת, טיפול באמביוולנטיות והפקת משמעות מהקשר הם אתגרים משמעותיים.
-
הסקה עם היגיון פשוט: סוכני בינה מלאכותית נוכחיים לעיתים קרובות חסרים את הידע והיכולות ההסקה שהאנשים לוקחים כמובן מאליו.
-
הכללה: אימון סוכנים לבצע היטב במשימות לא נראות מראש או להסתגל לסביבות חדשות נשאר תחום מחקר מרכזי.
-
LLM: פתיחת הבנה ויצירת שפה
LLM עם הידע הרחב שמקודד בתוך מיליארדי הפרמטרים שלהם, מביאים לשולחן יכולתים לשפה בלתי דומות:
- מבנה הטרנספומר: מבנה הטרנספומר הוא עיצוב למערכת מוח שמצטיין בעיבוד נתונים סדרתיים כמו טקסט. זה מאפשר לLLM לתפוש תלויות רחוקות בשפה, שמאפשרים להם להבין הקשר וליצור טקסט מאורגן ומקביל להקשר.
-
יכולות: LLM מצטיינים במספר משימות של טקסט:
-
יצירת טקסט: מאת כתיבת ספרות יצירתית ליצירת קוד בשפות תכנות מסויימות, LLM מראים רפלוקציה מדהימה ויצירתיות.
-
מגבלות: למרות היכולות המדהימות שלהם, למנגנונים יש מגבלות:
חוסר ייחודים בעולם הממשי: מנגנונים מפע
תשובות לשאלות: הם יכולים לספק תשובות קצרות ומדויקות לשאלות, אפילו כשהמידע מפוזר במסמך ארוך.
</diy18
השיתוף פעולה: גישת החלון בין השפה לפעולה
שילוב סוגי הסיטים הבינלאומיים ומרוצים המורחבים מתמודד עם המגבלות של כל אחד מהם, יוצרים מערכות שהן חכמות ומסוגלות:
- מרוצים כמפעילים ממשמעות ותכנון: מרוצים יכולים לתרגם הוראות שפת טעינה לפרמטרים שסייעים בהבנה מול מחשבים. הם יכולים גם להשתמש
-
סוכני AI כמבצעים ולומדים: סוכני AI מספקים ל-LLMs את היכולת לאינטראקציה עם העולם, איסוף מידע וקבלת משוב על פעולותיהם. הבסיס הזה בעולם האמיתי יכול לעזור ל-LLMs ללמוד מניסיון ולשפר את ביצועיהם לאורך זמן.
השילוב החזק הזה מניע את הפיתוח של דור חדש של יישומים שהם יותר אינטואיטיביים, מסתגלים ובעלי יכולת מאי פעם. ככל שטכנולוגיות סוכני ה-AI וה-LLM ממשיכות להתקדם, אנו יכולים לצפות לראות יישומים חדשניים ומשפיעים יותר, שישנו את הנוף של פיתוח תוכנה ואינטראקציה בין אדם למחשב.
דוגמאות מהעולם האמיתי: שינוי תעשיות
השילוב החזק הזה כבר עושה גלים במגזרים שונים:
-
שירות לקוחות: פתרון בעיות עם מודעות הקשרית
- דוגמה: דמיין לקוח שפונה לקמעונאי מקוון בנוגע למשלוח מתעכב. סוכן AI שמופעל על ידי LLM יכול להבין את תסכולו של הלקוח, לגשת להיסטוריית ההזמנות שלו, לעקוב אחר החבילה בזמן אמת ולהציע פתרונות באופן יזום כמו משלוח מהיר או הנחה על הרכישה הבאה.
-
יצירת תוכן: יצירת תוכן איכותי בקנה מידה
- דוגמה: צוות שיווק יכול להשתמש במערכת סוכן AI + LLM כדי ליצור פוסטים ממוקדי מדיה חברתית, לכתוב תיאורי מוצרים ואפילו ליצור תסריטים לסרטונים. ה-LLM מבטיח שהתוכן יהיה מרתק ואינפורמטיבי, בעוד שסוכן ה-AI מטפל בתהליך הפרסום וההפצה.
-
פיתוח תוכנה: האץ של קודים ובדיקות
- דוגמה: מפתח יכול לתאר פעולה של תוכנה שהוא רוצה לבנות בשפה טבעית. מנגנון המילים המלאכותי יכול אז ליצור פיסות קוד, לזהות שגיאות אפשריות, ולהציע שיפורים, שיארץ באופן משמעותי את תהליך הפיתוח.
-
בריאות: התאמת טיפול ושיפור בקשר לטיפול בחולים
- דוגמה: סוכנית AI עם גישה להיסטוריית החולה של מטופל ומופעלת עם מנגנון מילים מלאכותי יכולה להגיד תשובות לשאלות הבריאות שלו, לספק שיזוטרים פרטניים לתרופות, ואפילו להעלות אבחנות ראשוניות בהתבסס על הסימפטומים שלו.
-
חוק: ייעול מחקר משפטי וכתיבת מסמכים
- דוגמה: עורך דין צריך לנסח חוזה עם סעיפים ותקדימים משפטיים מסוימים. סוכן AI המופעל על ידי LLM יכול לנתח את ההוראות של עורך הדין, לחפש במאגרי מידע משפטיים נרחבים, לזהות סעיפים ותקדימים רלוונטיים, ואפילו לנסח חלקים מהחוזה, ובכך להפחית משמעותית את הזמן והמאמץ הנדרשים.
-
יצירת וידאו: יצירת סרטונים מרתקים בקלות
- דוגמה: צוות שיווק רוצה ליצור סרטון קצר שמסביר את תכונות המוצר שלהם. הם יכולים לספק סוכן AI + LLM עם מתווה תסריט והעדפות סגנון ויזואלי. ה-LLM יכול אז לייצר תסריט מפורט, להציע מוזיקה ויזואלית מתאימה, ואפילו לערוך את הסרטון, ובכך לאוטומט את רוב תהליך יצירת הוידאו.
-
ארכיטקטורה: עיצוב בניינים עם תובנות מעבדות בעלות עיניים-על
- דוגמה: ארכיטקט מעצב בניין משרדים חדש. הוא יכול להשתמש בסוג של סיסמה על-ידי מערכת על-סמלתית כדי להזין את המטרות העיצוביות שלו, כמו הגברת אור טבעי ואיכות השימוש בחלל. המערכת יכולה אז לנתח את המטרות האלה, לייצר אפשרויות עיצוב שונות, ואפילו לדמות את הבניין בתנאים סביבתיים שונים.
-
בניין: שיפור בהגנה ויעילות באתרי בניין
-
דוגמה: סוכנית AI מוצקה עם מצלמות וחיישנים יכולה לשקף אתר בניין בחשיפה לסיכונים הגנתיים. אם עובד לא משתמש באביזרי הבטיחה המתאימים או שהם נשארו במיקום מסוכן, ה LLM יכולה לנתח את המצב, להתרעק את המנהל של האתר, ואפילו לעצור אוטומטית את הפעולות אם נדרשת הדרך.
העתיד כאן: עידן חדש של פיתוח תוכנה
ההתמזגות של סוכניות AI ו LLMs מסמלת קפיצה משמעותית בפיתוח תוכנה. בעקבות ההתפתחות של הטכנולוגיות האלה, אנו נצפה בעוד יותר יישומים חדשניים שיעלו למעלה, שישנים תעשייות, מסדרונות עבודה ויוצרים אפשרויות חדשות לאינטראקציה בן אדם-מחשב.
סוכניות AI מאירות בהירות באזורים שדורשים עיבוד כמויות עצומות
פרק 4: יסודות פילוסופיים של מערכות חכמות
התפתחות מערכות חכמות, בעיקר בתחום הבינה מלאכותית (AI), דורשת הבנה עמוקה של עקרונות פילוסופיים. בפרק זה אנחנו נעמדים בעלי הרעיון הפילוסופי המרכזי שמעצב את העיצוב, הפיתוח והשימוש בAI. אנחנו מדגישים את חשיבותה של התאמה של התקדמות הטכנולוגית עם ערכים אתיים.
היסודות הפילוסופיים של מערכות חכמות אינם רק תעשייה תיאורטית – זהו מסגרת חיים שונאסת את האופי של הטכנולוגיה הזאת בשביל האנושות. על ידי העדיפות על השוויון, הרחבת הקיימות והשיפור באיכות החיים, העקרונות האלה עוזרים למציאת את המסלול הנכון עבור AI לשירות את האינטרסים הטובים שלנו.
השקפים אתיים בפיתוח AI
בעוד מערכות AI מתחברות יותר ויותר לכל תחום החיים האנושי, מבריאות וחינוך לפיננסים וממשל, אנחנו צריכים לבחון בקפדנות וליישם את הדיקות האתיות המובילות את העיצוב והשימוש במערכות אלה.
השאלה האתית הבסיסית קורה סביב איך AI ייצרו וישמרו על הערכים האנושיים ועל העקרונות המוסריים. השאלה זו מרכזית בדרך בה מערכות AI יעצבו את העתיד של החברות העולמיות.
בלב הדיון האתי הזה נמצאת העקרון של הבינה, שהוא אב
בהקשר של בינה מלאכותית, טובת הכלל מתורגמת לתכנון מערכות שתורמות באופן פעיל לשגשוג האנושי—מערכות שמשפרות את תוצאות הבריאות, מרחיבות את ההזדמנויות החינוכיות ומקלות על צמיחה כלכלית שוויונית.
אך היישום של טובת הכלל בבינה מלאכותית רחוק מלהיות פשוט. זה דורש גישה מעמיקה ששוקלת בזהירות את היתרונות הפוטנציאליים של בינה מלאכותית מול הסיכונים והנזקים האפשריים.
אחד מהאתגרים המרכזיים ביישום עקרון טובת הכלל לפיתוח בינה מלאכותית הוא הצורך באיזון עדין בין חדשנות לבטיחות.
לבינה מלאכותית יש את הפוטנציאל לחולל מהפכה בתחומים כמו רפואה, שבהם אלגוריתמים מנבאים יכולים לאבחן מחלות מוקדם יותר ובדיוק גבוה יותר מאשר רופאים אנושיים. אך ללא פיקוח אתי מחמיר, אותן טכנולוגיות עצמן עלולות להחריף אי שוויון קיים.
זה יכול לקרות, למשל, אם הן נפרסות בעיקר באזורים עשירים בעוד קהילות מוחלשות ממשיכות לחוסר גישה בסיסית לבריאות.
בגלל זה, פיתוח אתי של בינה מלאכותית דורש לא רק התמקדות במקסום היתרונות אלא גם גישה יזומה להפחתת סיכונים. זה כרוך ביישום אמצעי הגנה חזקים כדי למנוע שימוש לרעה בבינה מלאכותית ולהבטיח שטכנולוגיות אלו לא גורמות לנזק בשוגג.
המסגרת האתית לבינה מלאכותית חייבת להיות גם כוללת מטבעה, להבטיח שהיתרונות של בינה מלאכותית יחולקו בצורה שוויונית בין כל קבוצות החברה, כולל אלו ששוליות באופן מסורתי. זה מצריך מחויבות לצדק והגינות, לוודא שבינה מלאכותית לא רק מחזקת את הסטטוס קוו אלא פועלת באופן פעיל לפרק אי שוויון מערכתי.
לדוגמה, לאוטומציה מונעת AI יש פוטנציאל להעלות את הפרודוקטיביות והצמיחה הכלכלית. אך היא גם עלולה להוביל להחלפת עובדים משמעותית, שמשפיעה באופן לא פרופורציונלי על עובדים בעלי הכנסה נמוכה.
כפי שניתן לראות, מסגרת אתית ל-AI חייבת לכלול אסטרטגיות לחלוקת תועלת שוויונית ומתן מערכות תמיכה לאלו שנפגעים באופן שלילי מהתקדמות ה-AI.
הפיתוח האתי של AI דורש מעורבות מתמשכת עם בעלי עניין מגוונים, כולל אתיקנים, טכנולוגים, מקבלי החלטות והקהילות שיושפעו הכי הרבה מהטכנולוגיות הללו. שיתוף פעולה בינתחומי זה מבטיח שהמערכות AI לא יפותחו בואקום אלא יושפעו ממגוון רחב של פרספקטיבות וחוויות.
באמצעות מאמץ קולקטיבי זה אנו יכולים ליצור מערכות AI שלא רק משקפות אלא גם מקיימות את הערכים שמגדירים את האנושיות שלנו—חמלה, הוגנות, כבוד לאוטונומיה ומחויבות לטובת הכלל.
השיקולים האתיים בפיתוח AI אינם רק הנחיות, אלא מרכיבים חיוניים שיקבעו האם ה-AI ישמש ככוח למען הטוב בעולם. על ידי ביסוס ה-AI בעקרונות של תועלת, צדק וכוללניות, ושמירה על גישה ערנית לאיזון בין חדשנות לסיכון, אנו יכולים להבטיח שפיתוח ה-AI לא רק יתקדם טכנולוגית, אלא גם ישפר את איכות החיים לכל חברי החברה.
כשאנו ממשיכים לחקור את היכולות של AI, חשוב שהשיקולים האתיים הללו יישארו במרכז המאמצים שלנו, מנחים אותנו לעתיד שבו ה-AI באמת ייטיב עם האנושות.
החומרה של עיצוב הממשק האנושי של המערכות AI
עיצוב הממשק האנושי של המערכות AI עובר רק היגיון טכני. הוא שורש בעיקרון פילוסופי עמוק שמעדיף עבור הכבוד האנושי, העצמאות האנושית והאגנציה האנושית.
הגישה הזו לפיתוח המערכות AI מונחת באופן בסיסי בתבנית האתיקה הקנטית, שטענה שהאדם צריך להיות מוערך כמול עצמו, לא רק כדבר נאמנה להגשמת מטרות אחרות (קנט, 1785).
ההשלכות של העיקרון הזה לעיצוב המערכות AI הן עמוקות, דרשות שמערכות AI ייפתחו עם מיקוד נוקשה על שירות האינטרסים האנושיים, שישמרו על האגנציה האנושית ויכבדו את העצמאות הפרטית.
יישום טכני של עיקרון הממשק האנושי
שיפור העצמאות האנושית דרך AI: המושג העצמאות במערכות AI הוא קריטי, בעיקר בשיווק שהטכנולוגיות האלה יעצמות את המשתמשים ולא משלטות או משפיעות עליהם בצורה לא מותרת.
במונחים טכניים, זה מתייחס לעיצוב של מערכות AI שמעדיפות על עצמאות המשתמש על-ידי ספק לו את הכלים והמידע הנחוצים להחלטות מודעות. זה דורש למודלים הAI להיות מודעים-להקשר, שלמשמעותו הם צריכים להבין את ההקשר בו מיקום ההחלטה ולהגדיל את ההצעות שלהם בהתאמה.
מנקודת מבט של עיצו
לדוגמה, בבריאות, מערכת עיתונת המחשב האינטELג'נטית הזו שעוזרת לרופאים להיות מדענים חייבת לשקף את ההיסטוריה הרפואית הייחודית של המטופל, הסימפטומים הנוכחיים שלו ואף את מצבו הפסיכולוגי כדי לתת מלחמות שתתמשך את ידיים הרפאה במקום להחליף אותן.
ההסתגלות ההקשרית הזו מובטחת שהמערכת האינטELג'נטית ישאר משהו שתומך ומגביר, במקום להקטין, את העצמאות האנושית.
בטידון תהליכי ההחלטות השקופים: השקיפות במערכות האינטELג'נטיות היא דרישה בסיסית על מנת לוודא שהמשתמשים יכולים לבטוח ולהבין את ההחלטות שהטכנולוגיות האלה מקבלות. באופן טכני, זה מתרגם לצורך במערכות האינטELג'נטיות המסבירות (XAI), שעוסק בפיתוח אלגוריתמים שיוכלו בצורה ברורה לסביר את ההגיון מאחורי ההחלטות שלהם.
זה מאוד חשוב בתחומים כמו פיננסים, בריאות ומשפטים פליליים, בהם קישורים חשובים יכולים להוביל לאיבוד אמון ולדאגות אתיות.
הסבירות יכולה להיות משוגעת באמצעות דרכים טכניות מסויימות. שיטה אחת נפוצה היא הבנה מאחורית, בה מערכת האינטELג'נטית יוצרת הסבר אחרי שההחלטה נעשתה. זה עלול להכניס את ההחלטה לפי מרכיבים המרכזיים ולהראות איך כל אחד מה
מגיעה דרך אחרת של מודלים בר-הבנה באופן בלוטרי, בה הארכיטקטורת המודל מעוצבת בצורה שבה ההחלטות שלהם צפויות באופן בר-הבנה. לדוגמא, מודלים כמו עצים החלטות ומודלים לינאריים הם בר-הבנה טבעית בגלל שתהליך ההחלטות שלהם קל לעקבות אחריו ולהבין.
האתגר ביישום העיבוד המוסבר הוא בהמשך לשמור על הבנה בצורה שתהליך ההחלטות יהיה בר-הבנה, אבל בהתחלף עם ביצועים. לעיתים קרובות, מודלים יותר מורכבים, כמו מערכות דייפ ניורנל נטס, הם פחות ברירותים אך יותר מדויקים. לכן, עיצוב העיתודים של העיבוד המוסבר צריך להתייחס לממשק המחיצה בין הבנה של המודל וכוחות ההערכה שלו, בהחלט של המשתמשים יהיה אמון והבנה של ההחלטות המוסברות ללא הקרידה מהדיוק.
אפשרות של בקרת אדם משמעותית: בקרת אדם משמעותית היא קריטית בהבטחת שמערכות העיבוד המוסבר פועלות במגבלות אתיים ופעולתיים. בקרת זו מערכת עם מנגנונים מנע כשלון ומנגנונים חילוץ שמאפשרים לאנשים להתערב בזמן הנדרש.
היישום הטכני של בקרת אדם יכול להיות נגיעה בדרכים מספרות.
דרך אחת היא לשים אדם-במעגל, בה תהליכי ההחלטות של העיבוד המוסבר מוקפים ונבדקים באופן מתמשך על ידי אנשים. ה
לדוגמה, במקרה של מערכות נשק בעלות autonomous, שיטת בקרה אנושית היא בעלת חשיבות על מנת למנוע את האינטלקט מבצע החלטות של החיים או המוות בלי קלט אנושי. זה יכול להיות בעצם קבעת גבולות הפעלה מוגבלים שהאינטלקט לא יכול לחצות בלי אישור אנושי, כך שמוצבים במערכת מערכות הגנה אתית.
שאלה טכנית נוספת היא הפיתוח של מסעדות העבירה, שהן רשימות של כל ההחלטות והפעולות של המערכת האינטלקטית. המסעדות מספקות היסטוריה שבה אנושיים יכולים לבחון את ההתאמה לסטנדרטים אתיים.
מסעדות העבירה חשובות בתחומים כמו ה finiance וה law, בהם ההחלטות חייבות להיות תיעדות ומספקות סיבה על מנת לשמור על אמון ציבורי ולהגיע לדרישות הרגולטורים.
האקונום בין העצמאות והשליטה: אחד האתגרים הטכניים המרכזיים ב AI מוקדם על אדם הוא למצוא את האיזון הנכון בין העצמאות והשליטה. בעוד מערכות האינטלקט מעוצבות לפעול באופן עצמאי במספר מצבים, חשוב מאוד שהעצמאות הזו לא תתקיף את השליטה האנושית או הבקרה.
האיזון הזה יכול להיות משוגע דרך היישום של רמות של העצמאות, שמדירט את העצמאות היחידה של האינטלקט בעיקרון ההחלטות.
לדוגמה, במערכות חלצוניות כמו מכוניות
עיצוב המערכות הללו חייב להבטיח שבכל רמת אוטונומיה נתונה, למפעיל האנושי תישאר היכולת להתערב ולהתערב על ה-AI אם יש צורך בכך. זה דורש ממשקי בקרה מתוחכמים ומערכות תמיכה בהחלטות המאפשרות לבני אדם לקחת שליטה במהירות וביעילות כשנדרש.
בנוסף, פיתוח מסגרות אתיות ל-AI הוא חיוני להנחיית הפעולות האוטונומיות של מערכות AI. מסגרות אלו הן סטים של חוקים והנחיות המוטמעים בתוך ה-AI שמכתיבים כיצד עליו להתנהג במצבים אתיים מורכבים.
לדוגמה, בתחום הבריאות, מסגרת אתית ל-AI עשויה לכלול חוקים לגבי הסכמה של המטופל, פרטיות, ותיעדוף הטיפולים על בסיס צורך רפואי ולא שיקולים כספיים.
על ידי הטמעת עקרונות אתיים אלו ישירות בתהליכי קבלת ההחלטות של ה-AI, מפתחים יכולים להבטיח שהאוטונומיה של המערכת מופעלת באופן שמתיישב עם ערכי האדם.
השילוב של עקרונות ממוקדי אדם בעיצוב ה-AI אינו רק אידיאל פילוסופי אלא הכרח טכני. על ידי שיפור האוטונומיה האנושית, הבטחת שקיפות, מתן פיקוח משמעותי ואיזון קפדני בין אוטונומיה לשליטה, ניתן לפתח מערכות AI באופן שמשרת באמת את האנושות.
שיקולים טכניים אלו חיוניים ליצירת AI שלא רק משפר את יכולות האדם אלא גם מכבד ושומר על הערכים שהם בסיסיים לחברתנו.
כאשר ה-AI ממשיך להתפתח, המחויבות לעיצוב ממוקד אדם תהיה קריטית להבטחת השימוש האתי והאחראי בטכנולוגיות החזקות הללו.
איך לוודא שהמדע עודף לאנושות: שיפור איכות החיים
בעודך מעורב בפיתוח מערכות המדע החיים, חשוב להיות מוטמע בפרמטרים האתיים של השימוש בוטליאניזם – פילוסופיה שמדגישה את השימוש באושר הכללי וברווחה.
בתוך ההקשר הזה, המדע החיים יכול להתמודד עם אתגרים חברתיים קריטיים, בעיקר בתחומים כמו בריאות, חינוך וקיימות סביבתית.
המטרה היא ליצור טכנולוגיות שישפרו באופן משמעותי את איכות החיים לכל. אך המסע הזה נוטה להיות מורכב. הוטליאניזם מעניק סיבה מושכת להשתמש במערכות המדע החיים באופן רחב, אך היא גם מעלה לקראת שאלות אתיות חשובות על מי מקבל את היתרון ומי עשוי להישאר מאחור, בעיקר בקהילות פגיעות.
על מנת לנווט בפני האתגרים האלה, אנחנו זקוקים לגישה מתוחכמת, טכנית מודעת – אחת שמאחיזה במילים בעיקריות את המטרה החברתית הרחבה עם הצורך בצדק ושוויון.
כשאתה מיישם את העקרונות הוטליאניזמיים על מערכות המדע החיים, המיקוד שלך צריך להיות על אופטימיזציית התוצאות בתחומים ספציפיים. לדוגמה, בתחום הבריאות, כלים הדיאגנוסטים בעזרת המערכות החיים יכולים לשפר באופן משמעותי את התוצאות המושלמות על ידי אפשרות אבחנות מוקדמת ודי
אך הפיכת הטכנולוגיות האלה לשימוש דורשת הקדמת השקרבה נאורה כדי להימנע מחזקת אי שוויון קיים. המידע שמשתמש בו לאימון מודלי AI יכול להיות מגוון משמעותי מעל לאזורים, משפיעה על הדיוק והאמינות של המערכות האלה.
ההבדל הזה מצביע על חשיבות הקימות של מערכות ממשל מידע בעלות עוצמה שתודאו שהפתרונות הבריאות שלך מונעים והוגנים.
בתחום החינוך, היכולת האינטEL להתאים את הלמידה היא מעניינת. מערכות AI יכולות להתאים את התוכן החינוכי לצרכים ספציפיים של סטודנטים בודדים, שוב וגדל תוצאות יעילות יותר בלמידה. על-ידי ניתוח מידע על ביצועים והתנהגויות של הסטודנטים, AI יכול לזהות את המקומות בהם סטודנט אחד עשוי להתקשות ולספק תמיכה מוכוונת.
אך בעוד אתה עובד לעבר התועלות האלה, חשוב להיות מודע לסיכונים – כמו הסיכון לחזקת דעות קדומות או לדחיית סטודנטים שאינם מתאימים לתבניות למידה טיפוסיות.
התמרגרות הסיכונים האלה דורשת הצמצום של מנגנונים של ההוגנות בתוך המודלים הAI, והשמרה על התפקיד של החוקרים היא קריטית. ההשקעה שלהם והניסיון הם בלתי נשארים באמצעות הכלים הAI באמת יעילים וסייעים.
מבחינת קיימות סביבתית, יש להשתמש בפוטנצ
לדוגמה, בינת המחשב יכולה לנתח כמויות עצומות של מידע סביבתי כדי לחיזות דפוסי מזג אוויר, לאיכות את צריכת האנרגיה ולמינוע הפסדים – פעולות הן מתרחבות על הרבה עבור הרעיון של הרווחה של דורות הנוכחים והקדמונים.
אך ההתקדמות הטכנולוגית הזאת מגיעה עם סדר מילים של אתגרים, בעיקר בנוגע להשפעה הסביבתית של המערכות הבינתיות עצמן.
הצריכת האנרגיה הנדרשת לפעולת מערכות בינתיות בקנה מידה גדול יכולה לתת לתוצאות הסביבתיות שהן מוכוונות להשיג. אז הפיתוח של מערכות בינתיות אנרגיה-יעילות הוא חשוב מאוד על מנת להבטיח שהשפעה החיובית שלהם על הקיימות איננה מתקדמת מעל הבסיס.
בעוד שאתה מפתח מערכות בינתיות עם מטרות גלובליסטיות, חשוב לשקול גם את ההשלכות עבור צדק חברתי. הגלובליזם מתמקד בהגברת האושר הכללי אך ורק, אך לא מתייחס באופן בר-מקור לתנועת התועלות והפסדים בין קבוצות חברתיות שונות.
זה מעלה את האפשרות של מערכות הבינתיות להרוויח באופן לא ניהולי את אלה שכבר מוזנחים, בעוד קבוצות המודלגות עשויות לראות מעט או כלל שיפור במצבם.
כדי להתנגד לזה, תהליך פיתוח המערכות שלך צריך להכלל עקרונות שיוויון, במטרה להאצל באו
כאשר אתם מפתחים מערכות AI שמטרתן לשפר את איכות החיים, חיוני לאזן בין המטרה התועלתנית של מקסום הרווחה לבין הצורך בצדק והוגנות. זה דורש גישה מעמיקה ומבוססת טכנית שמתחשבת בהשלכות הרחבות יותר של פריסת AI.
על ידי עיצוב קפדני של מערכות AI שהן גם יעילות וגם שוויוניות, תוכלו לתרום לעתיד שבו ההתקדמויות הטכנולוגיות משרתות באמת את הצרכים המגוונים של החברה.
הטמיעו אמצעי הגנה כנגד נזקים פוטנציאליים
כשאתם מפתחים טכנולוגיות AI, עליכם להכיר בפוטנציאל הטמון לנזק ולהקים באופן יזום אמצעי הגנה חזקים כדי למזער סיכונים אלו. אחריות זו מושרשת עמוק באתיקה דאונטולוגית. ענף זה של אתיקה מדגיש את החובה המוסרית לדבוק בכללים ובסטנדרטים אתיים מבוססים, ולהבטיח שהטכנולוגיה שאתם יוצרים מתיישרת עם עקרונות מוסריים יסודיים.
הטמעת פרוטוקולי בטיחות מחמירים אינה רק אמצעי זהירות אלא חובה מוסרית. פרוטוקולים אלו צריכים לכלול בדיקות הטיה מקיפות, שקיפות בתהליכי אלגוריתמים ומנגנונים ברורים של אחריות.
אמצעי הגנה אלו חיוניים למניעת נזק בלתי מכוון ממערכות AI, בין אם דרך קבלת החלטות מוטה, תהליכים אטומים או היעדר פיקוח.
בפועל, הטמעת אמצעי הגנה אלו דורשת הבנה עמוקה של הממדים הטכניים והאתיים של AI.
בדיקת הטיה, למשל, כוללת לא רק זיהוי ותיקון הטיות בנתונים ואלגוריתמים אלא גם הבנת ההשלכות החברתיות הרחבות של אותן הטיות. עליך לוודא שמודלי ה-AI שלך מאומנים על מערכי נתונים מגוונים ומייצגים ונבדקים באופן קבוע כדי לזהות ולתקן כל הטיה שעשויה להופיע עם הזמן.
שקיפות, מצד שני, דורשת שמערכות ה-AI יהיו מעוצבות כך שתהליכי קבלת ההחלטות שלהן יהיו מובנים וניתנים לבדיקה בקלות על ידי משתמשים ובעלי עניין. זה כולל פיתוח מודלים של AI שניתן להסבירם המספקים פלטים ברורים וניתנים לפירוש, המאפשרים למשתמשים לראות כיצד מתקבלות החלטות ומבטיחים שהן מוצדקות והוגנות.
כמו כן, מנגנוני אחריות הם קריטיים לשמירה על אמון ולהבטחת שימוש אחראי במערכות AI. מנגנונים אלו צריכים לכלול הנחיות ברורות למי אחראי על תוצאות ההחלטות של ה-AI, כמו גם תהליכים לטיפול ולתיקון כל נזק שעלול להתרחש.
עליך להקים מסגרת שבה שיקולים אתיים משולבים בכל שלב בפיתוח ה-AI, מהתכנון הראשוני ועד הפריסה והלאה. זה כולל לא רק מעקב אחר הנחיות אתיות אלא גם מעקב והתאמה מתמשכים של מערכות ה-AI כשהן מתקשרות עם העולם האמיתי.
על ידי שילוב אמצעי הגנה אלו במרקם הפיתוח של ה-AI, ניתן לסייע להבטיח שההתקדמות הטכנולוגית תשרת את טובת הכלל מבלי להוביל להשלכות שליליות בלתי מכוונות.
תפקיד הפיקוח האנושי ולולאות משוב
פיקוח אנושי במערכות AI הוא רכיב קריטי להבטחת פריסה אתית של AI. עקרון האחריות מדגיש את הצורך במעורבות אנושית מתמשכת בתפעול AI, במיוחד בסביבות בעלות סיכון גבוה כגון בריאות ומשפט פלילי.
לולאות משוב, שבהן קלט אנושי משמש לעידון ושיפור מערכות AI, חיוניות לשמירה על אחריות וגמישות (Raji et al., 2020). לולאות אלו מאפשרות תיקון שגיאות ושילוב שיקולים אתיים חדשים ככל שערכי החברה מתפתחים.
על ידי שילוב פיקוח אנושי במערכות AI, מפתחים יכולים ליצור טכנולוגיות שהן לא רק יעילות אלא גם מתואמות לנורמות אתיות ולציפיות אנושיות.
קידוד אתיקה: תרגום עקרונות פילוסופיים למערכות AI
התרגום של עקרונות פילוסופיים למערכות AI הוא תהליך מורכב אך הכרחי. תהליך זה כולל שילוב שיקולים אתיים בקוד שמפעיל את אלגוריתמי ה-AI.
מושגים כגון הוגנות, צדק ואוטונומיה חייבים להיות מקודדים בתוך מערכות AI כדי להבטיח שהן פועלות בדרכים שמשקפות ערכי חברה. זה דורש גישה רב-תחומית, שבה אתיקאים, מהנדסים ומדעני חברה משתפים פעולה כדי להגדיר וליישם קווי הנחיה אתיים בתהליך הקידוד.
המטרה היא ליצור מערכות AI שהן לא רק מיומנות טכנית אלא גם מוסריות, המסוגלות לקבל החלטות שמכבדות את כבוד האדם ומקדמות טוב חברתי (Mittelstadt et al., 2016).
לקדם הכללה וגישה שוויונית בפיתוח ופריסת AI
הכללה וגישה שוויונית הם יסודות לפיתוח אתי של בינה מלאכותית. המושג Rawlsian של צדק כהוגנות מספק בסיס פילוסופי להבטחת תכנון ויישום של מערכות בינה מלאכותית בדרכים המועילות לכל חברי החברה, במיוחד לאלה הפגיעים ביותר (Rawls, 1971).
זה כרוך במאמצים יזומים לכלול פרספקטיבות מגוונות בתהליך הפיתוח, במיוחד מקבוצות שאינן מיוצגות באופן מספק ומהדרום העולמי.
על ידי שילוב נקודות מבט מגוונות אלו, מפתחי הבינה המלאכותית יכולים ליצור מערכות שהן יותר שוויוניות ומגיבות לצרכים של מגוון רחב יותר של משתמשים. כמו כן, הבטחת גישה שוויונית לטכנולוגיות בינה מלאכותית היא קריטית למניעת החרפת אי השוויון החברתי הקיים.
התמודדות עם הטיה אלגוריתמית והוגנות
הטיה אלגוריתמית היא דאגה אתית משמעותית בפיתוח בינה מלאכותית, שכן אלגוריתמים מוטים יכולים להנציח ואפילו להחריף אי שוויון חברתי. התמודדות עם סוגיה זו דורשת מחויבות לצדק פרוצדורלי, להבטיח שמערכות הבינה המלאכותית מפותחות בתהליכים הוגנים המתחשבים בהשפעה על כל בעלי העניין (Nissenbaum, 2001).
זה כרוך בזיהוי ובצמצום הטיות בנתוני האימון, בפיתוח אלגוריתמים שקופים וניתנים להסבר, וביישום בדיקות הוגנות לאורך כל מחזור החיים של הבינה המלאכותית.
על ידי התמודדות עם הטיה אלגוריתמית, מפתחים יכולים ליצור מערכות בינה מלאכותית שתורמות לחברה צודקת ושוויונית יותר, במקום לחזק את הפערים הקיימים.
שילוב פרספקטיבות מגוונות בפיתוח בינה מלאכותית
שילוב פרספקטיבות מגוונות בפיתוח AI חיוני ליצירת מערכות שכוללות והוגנות. הכללת קולות מקבוצות שאינן מיוצגות מבטיחה שטכנולוגיות AI לא ישקפו רק את הערכים והעדיפויות של מקטע צר של החברה.
גישה זו מתיישבת עם העיקרון הפילוסופי של דמוקרטיה דיונית, המדגיש את חשיבותם של תהליכי קבלת החלטות כוללניים ומשתתפים (Habermas, 1996).
על ידי טיפוח השתתפות מגוונת בפיתוח AI, נוכל להבטיח שטכנולוגיות אלה ייוצרו לשירות האינטרסים של כלל האנושות, ולא רק למעטים בעלי זכויות יתר.
אסטרטגיות לגישור על הפער ב-AI
הפער ב-AI, המאופיין בגישה לא שווה לטכנולוגיות AI ולהטבותיהן, מציב אתגר משמעותי לשוויון גלובלי. גישור על פער זה דורש מחויבות לצדק חלוקתי, המבטיחה שהטבות ה-AI יחולקו באופן רחב בין קבוצות וסביבות חברתיות-כלכליות שונות (Sen, 2009).
ניתן לעשות זאת באמצעות יוזמות המקנות גישה לחינוך ומשאבים בתחום ה-AI בקהילות מוחלשות, וכן מדיניות התומכת בחלוקה הוגנת של רווחים כלכליים מונעי AI. על ידי טיפול בפער ה-AI, נוכל להבטיח שה-AI יתרום לפיתוח גלובלי באופן כולל והוגן.
איזון חדשנות עם מגבלות אתיות
איזון המרדף אחר חדשנות עם מגבלות אתיות הוא קריטי להתקדמות אחראית של AI. עקרון הזהירות, הממליץ על זהירות מול אי ודאות, רלוונטי במיוחד בהקשר של פיתוח AI (Sandin, 1999).
בעוד חדשנות מניעה התקדמות, יש לאזנה עם שיקולים אתיים המגנים מפני נזקים אפשריים. זה דורש הערכה מדוקדקת של הסיכונים והיתרונות של טכנולוגיות AI חדשות, וכן יישום מסגרות רגולטוריות להבטחת שמירה על סטנדרטים אתיים.
באיזון בין חדשנות למגבלות אתיות, נוכל לעודד פיתוח טכנולוגיות AI שהן גם חדשניות וגם מתואמות עם המטרות הרחבות של רווחת החברה.
כפי שניתן לראות, הבסיס הפילוסופי של מערכות אינטיליגנציה מספק מסגרת קריטית להבטיח שטכנולוגיות AI מפותחות ומופעלות בדרכים אתיות, מכילות ומועילות לכלל האנושות.
על ידי ייסוד פיתוח AI בעקרונות פילוסופיים אלה, נוכל ליצור מערכות אינטיליגנטיות שלא רק מקדמות יכולות טכנולוגיות אלא גם משפרות את איכות החיים, מקדמות צדק ומבטיחות שהיתרונות של AI יחולקו בצורה שוויונית בחברה.
פרק 5: סוכני AI כמחזקי LLM
המיזוג של סוכני AI עם מודלי שפה גדולים (LLMs) מייצג שינוי יסודי בבינה מלאכותית, המטפל במגבלות קריטיות ב-LLMs שהגבילו את יישומם הרחב.
שילוב זה מאפשר למכונות לחרוג מתפקידיהן המסורתיים, ולהתקדם ממחוללי טקסט פסיביים למערכות אוטונומיות המסוגלות להסקה דינמית וקבלת החלטות.
כשמערכות AI מניעות תהליכים קריטיים בתחומים שונים, הבנת כיצד סוכני AI ממלאים את הפערים ביכולות LLM חיונית למימוש מלוא הפוטנציאל שלהן.
לחבר פערים בין מספר יכולות של LLM
למעשה, LLM הם מוגבלים גם בגלל המידע עליו הוא נאמנו ובגלל הטבע הסטטי של הארכיטקטורה שלהם. המודלים הללו פועלים בתוך ערכי פרמטרים קבועים, בדרך כלל מוגדרים על ידי הקורפוס של טקסט שהשתמשו במהלך תקופת האימון שלהם.
המגבלה הזו אומרת של LLM אין יכולת לחפש באופן אוטונומי מידע חדש או לעדכן את בסיס הידע שלהם לאחר האימון. כתוצאה מכך, ל LLM פשוט תקופתיים ולהם חסרה היכולת לספק תשובות רלוונטיות בהקשר שדורשות נתונים בזמן אמת או תובנות מעבר לנתונים ההתחלתיים שלהם.
סוכני AI מחברים בין הפערים הללו על ידי השלמת דינמית מקורות נתונים חיצוניים, שיכולים להרחיב את ההופעה הפונקציונלית של LLM.
לדוגמא, LLM שנאמן על מידע פיננסי עד 2022 עשוי לספק ניתוחים היסטוריים מדויקים אך יתקשה ליצור חזותות שוק בעדכניות. סוכני AI יכול להוסיף על LLM זה על ידי דגימת נתונים בזמן אמת משווקים פיננסיים, על ידי היישום הללו של קלטים ליצירת ניתוחים יותר רלוונטיים ועדכניים.
השלמת הדינמית הזו מבטיחה שהפלטים לא רק יהיו מדויקים היסטורית אלא גם רלוונטיים לתנאים הנוכחיים.
שיפור יכולת ההחלטה האוטונומית
מגבלה חשובה
גירעון זה נגרם בעיקר בשל התלות המודל במידע קיים מראש וחוסר המנגנונים להיגייסון מתאים או ללמידה מהתנסויות חדשות לאחר ההפצה.
סוכני AI מתגברים על זה על ידי ספקת התשתית הנחוצה להחלטה אוטונומית. הם יכולים לקחת את הפלטים הסטטיים של LLM ולעבד אותם דרך ערכות חשיבה מתקדמות כמו מערכות מבוססות חוקים, היגיוסים או מודלי למידה מקיפה.
למשל, בסביבת שירותי בריאות, LLM עשוי לייצר רשימה של הזנות פוטנציאליות על בסיס סימפטומים של חולה והיסטוריית הבריאות. אך ללא סוכן AI, ה LLM לא יכול לשקול את האפשרויות הללו או להציע תוכנית פעולה.
סוכן AI יכול להתערב ולהעריך את ההזנות הללו בהתבסס על הספרות הרפואית הנוכחית, נתוני החולה וגורמים הקשורים להקשר, ולבסוף להחליט באופן מודע יותר ולהציע צעדים הללו שניתן ליישם.
התייחסות לשלמות והגיוניות
שלמות והגיוניות הם גורמים קריטיים בבטיחות הפלטים של LLM, במיוחד במשימות חשיבה מורכבות. בשל טבעם הפרמטרי, LLM פורמים לעתים תשובות שאינן שלמות או שחסרות הגיוניות, במיוחד כשזה מגיע לתהליכים מרובי שלבים או כשנדרשת הבנה מקיפה במספר תחומים.
בעיות אלה נובעות מהסביבה הבודדת בה LLM פועלים, בה הם לא יכולים לבצע חיב
סוכני AI משמשים בתפקיד חשוב בהפחתת הבעיות הללו על ידי הכנסת מנגנונים של השיבוץ איטרטיבי ושכבות ווידאות.
למשל, בתחום המשפטי, LLM עשוי לכתוב גירסה ראשונית של הטיוטה משפטית על בסיס מידע האימון שלו. אך הטיוטה הזו עלולה להתעלם מפרסדנטים מסוימים או לא לבנות באופן לוגי את הטיעון.
סוכן AI יכול לבדוק את הטיוטה הזו ולוודא שהיא מספקת את הסטנדרטים הדרושים לשלמות על ידי התווסף עם בסיסי מידע משפטיים חיצוניים, בדיקה של עקביות לוגית ובבקשה למידע נוסף או הבהירה היכן שזה נחוץ.
תהליך האיטרטיבי הזה מאפשר את ייצור המסמך החזק יותר והאמין שמספק את הדרישות המוקפאות של התרגלת המשפטית.
התגברות על הבידרות באמצעות השילוב
אחד המגבלות הכי עמוקים של LLM הוא הבידרות המובנית שלהם מהמערכות וממקורות ידע אחרים.
LLM, כפי שהונדסו, הם מערכות סגורות שלא יוצרות ביחד עם סביבות חיצוניות או בסיסי מידע. הבידרות הזו מוגבלת באופן משמעותי את היכולת שלהם להסתגל למידע חדש או לפעול בזמן אמת, גורמת להם להיות פחות אפקטיביים ביישומים הדורשים אינטראקציה דינמית או החלטות בזמן אמת.
סוכני AI עוברים על הבידרות הזו על ידי התנהגות כפלatformות השילוב שמח
לדוגמה, ביישומי שירות לקוחות, LLM עשוי לייצר תגובות סטנדרטיות בהתבסס על תסריטים שהוכנו מראש. אך תגובות אלו יכולות להיות סטטיות וחסרות את ההתוויה האישית הנדרשת למעורבות לקוחות יעילה.
סוכן AI יכול להעשיר את האינטראקציות הללו על ידי שילוב נתונים בזמן אמת מפרופילי לקוחות, אינטראקציות קודמות וכלי ניתוח תחושות, מה שעוזר לייצר תגובות שאינן רק רלוונטיות מבחינה הקשרית אלא גם מותאמות לצרכים הספציפיים של הלקוח.
שילוב זה הופך את חווית הלקוח מסדרת אינטראקציות מתוסרטות לשיחה דינמית ואישית.
הרחבת היצירתיות ופתרון הבעיות
בעוד ש-LLM הם כלים רבי עוצמה ליצירת תוכן, היצירתיות והיכולות שלהם לפתרון בעיות מוגבלות מטבען על ידי הנתונים שעליהם הם אומנו. מודלים אלה לעיתים קרובות אינם מסוגלים ליישם מושגים תיאורטיים לאתגרים חדשים או בלתי צפויים, מכיוון שיכולות פתרון הבעיות שלהם מוגבלות על ידי הידע והפרמטרים האימונים הקיימים שלהם.
סוכני AI משפרים את הפוטנציאל היצירתי ופתרון הבעיות של LLM על ידי ניצול טכניקות חשיבה מתקדמות ומערכת רחבה יותר של כלים אנליטיים. יכולת זו מאפשרת לסוכני AI להתגבר על המגבלות של LLM, וליישם מסגרות תיאורטיות לבעיות מעשיות בדרכים חדשניות.
לדוגמה, שקלו את הבעיה של התמודדות עם מידע כוזב בפלטפורמות מדיה חברתית. LLM עשוי לזהות דפוסים של מידע כוזב בהתבסס על ניתוח טקסטואלי, אך הוא עשוי להתקשות לפתח אסטרטגיה מקיפה לצמצום התפשטות המידע הכוזב.
כוח על של הרעיונות הללו, החלקת תאוריות מן התחומים השונים כמו סוציולוגיה, פסיכולוגיה ותיאוריה הרשת, ופיתוח של גישה רוחבת-תחומית ועוצמתית שכוללת ניטור בזמן אמת, חינוך משתמשים וטכניקות מודרכת אוטומטית.
יכולת זו לשלב רשתות תאוריות מגוונות וליישם אותן לאתגרים מעולם האמת מדגים את היכולות המופעלות של סוכני הAI לפיתרון בעיות.
דוגמאות יותר ספציפיות
סוכני AI, עם יכולתם לתקשר עם מערכות מגוונות, לגשת למידע בזמן אמת ולבצע פעולות, טובעים בחוסר היכולת הזה ישירות וממירים את מודלי השפה העוצמתיים לחלוטין לפיתרונות דינמיים לבעיות מעולם האמת. בואו נסתכל על כמה דוגמאות:
1. ממידע סטטי לתובנות דינמיות: שמירה על מודלי LLM במעגל
-
הבעיה: דמיינו ששואלים את מודל LLM המאומן על מחקר רפואי לפני 2023, "מהם ההתפתחויות החדשות בטיפול בסרטן?" הידע שלו יהיה דיוקן.
- הפתרון של סוכני הAI: סוכני AI יכולים לחבר את LLM לכתבי עת רפואיים, מאגרי מחקר וערוצי חדשות. עכשיו, LLM
2. מניתוח לפעולה: הפעלת משימות בהתבסס על הבנת ה-LLM
3. מטופל למוצר משובח: הבטחת איכות ודיוק
- <diy
- הפתרון של הסוכנות המלאכותית: סוכנות מלאכותית יכולה לשלב את הLLM עם מילונים מיומנטיים, גlossרים, ואפילו לחבר אותו למומחים בתחום למידה בזמן אמת, וזה יווצר את התרגום הסופי שהוא מבנה מדויק לغותית וטכנית.
4. שברים את המחסומים: חיבור מערכות מילים גדולות לעולם האמת
- הבעיה: LLM שמועדה לשליטה בעלי החיים חביבים עלול לנסוב בהסתגלות לרווחות המשתנים והעדפות של המשתמש.
- הפתרון של הסוכנות המלאכותית: סוכנות מלאכותית יכולה לחבר את הLLM לחיישנים, המכשיר
5. מהדוגמה לחידוש: הרחבת היצירתיות של LLM
-
הבעיה: LLM שמופקד על כתיבת מוסיקה עשוי ליצור קטעים שנשמעים כמו הגיוניים או שחרירים בעומק רגשי, כי הוא מסתמך בעיקר על דפוסים שנמצאים בנתונים האימון שלו.
-
פתרון המייצר המלאכותי: סוג של מייצר מלאכותי יכול לחבר את LLM לחיישנים הממדים שמודדים את תגובות הרגש של המלחין לרכיבים מוסיקליים שונים. על-ידי השלמת הבקשות האמתיות האלה, LLM יכול ליצור מוסיקה שאינה רק מקצועית טכנית אלא גם מרגשת ומקורית.
שילוב סגנונים של סוגים שונים של יכולות בתוך מערכת המידע המבוססת על התמחות היא הדרך הטבעית לשיפור משמעותי ביכולת המערכת לעבדת נתונים ומידע.
המערכת הזו מאפשרת למידע להיות מודפס בצורה דינמית ולהיות קיים קשר בין המידע לתוך המערכת לבעלי היכולות הללו.
פרק 6: עיצוב המבנה לשילוב סגנונים בתוך מערכת המידע המבוססת על התמחות
שילוב סגנונים בתוך מערכת המידע המבוססת על התמחות הוא משהו שהוא חשוב להגדרת היכולות, ההסתגלנות וההתקיימות העיקריות.
עיצוב מודוללים, בו הסוגים הללו של יכולות מתבצעים בתוך מערכת המידע המבוססת על התמחות, הוא דרך אחת לתמרן את הבעיות המסויימות האלה.
באופן אלטרנטיבי, דגם ההיברידי, המשלב LLMs עם דגמים מתקדמים ומכוונים, מציע גמישות על ידי אפשרות הפקת משימות לדגם המתאים ביותר. גישה זו מקדמת ביצועים ומשפרת יעילות במגוון רחב של יישומים, ובכך מהווה יעילות במיוחד בהקשרים אפסי ומשתנים (Liang ואח.', 2021).

מתודות אימון ושיטות מובילות
אימון של סוכני AI משולבים עם LLMs מחייב גישה שיטתית שמאזנת בין התקציב הכללי לאופטימיזציה ספציפית למשימה.
למידת העברה היא טכניקה מרכזית כאן, המאפשרת ל- LLM שכבר הועבר לאימון מראש על קורפוס גדול ומגוון, להיות מכוין מחדש על נתונים ספציפיים לתחום הקשורים למשימות של סוכן AI. שיטה זו שומרת על בסיס הידע הרחב של ה- LLM תוך מאפשרות לו להתמחות ביישומים מסוימים, ובכך משפרת את היעילות הכוללת.
בנוסף, למידת חיזוק (RL) משמשת תפקיד קריטי, במיוחד בתרחישים בהם הסוכן AI חייב להסתגל לסביבות משתנות. דרך האינטראקציה עם הסביבה שלו, הסוכן AI יכול לשפר את תהליכי הקבלת ההחלטות שלו באופן רציני, ולהפוך יותר מיומן בטיפול באתגרים חדשים.
על מנת להבטיח ביצוע יציב במגוון תרחישים שונים, מדדי הערכה נחוצים. אלו צריכים לכלול את המדדים התקנים וקריטריונים ספציפיים למשימה, ובכך לוודא כי האימון של המערכת הוא יציב ומקיף (Silver ואח.', 2016).
מבוא למידת מותאמת של דגם שפה גדול (LLM) ולמושגים של למידת חיזוק
הקוד הזה ממחיש מספר טכניקות שעוסקות בלמידה מכונה ובעיבוד השפה הטבעי (NLP), ומיקוד בעיבוד מוכנה גדולה (LLM) עבור משימות ספציפיות וביצוע סידורים חדשים (RL). הקוד מתפשט על מספר אזורים מפתח:
- עיבוד מוכנה גדולה: ניצול מוכנות מקודמות כמו BERT למשימות כמו ניתוח רגשות, בעזרת ספריית
transformersשל Hugging Face. זה מתכוון לטוקסינג של מידע ולשימוש בטענות האימון כדי להדריך את תהליך העיבוד המוכוון. - למידה בעזרת תנועות: הצגת הבסיסים של RL עם סייר ה-Q הפשוט, בו סייר לומד דרך נסיונים וטעייות על ידי אינטראקציה עם סביבה ועדכון הידע שלו דרך טאבלים Q.
- מיתוגן הגמול עם API של OpenAI: שיטה תיאורטית לשימוש ב API של OpenAI כדי לספק אותות
-
הערכת מודל ורישום: שימוש בספריות כמו
scikit-learnלהערכת ביצועי המודל באמצעות דיוק וציוני F1, וב-SummaryWriterשל PyTorch כדי להמחיש את התקדמות האימון. - מושגים מתקדמים ב-RL: יישום מושגים מתקדמים יותר כגון רשתות מדיניות, למידת תוכן ועצירה מוקדמת לשיפור יעילות אימון המודל.
גישה הוליסטית זו מכסה גם למידה מפוקחת, עם תיקון ניתוח סנטימנט, וגם למידה מחוזקת, ומספקת תובנות לגבי איך מערכות AI מודרניות נבנות, מוערכות ומיטוב.
דוגמת קוד
שלב 1: ייבוא הספריות הנדרשות
לפני שנצלול לכוונון מודלים ויישום סוכנים, חשוב להגדיר את הספריות והמודולים הנדרשים. קוד זה כולל ייבוא מספריות פופולריות כגון transformers של Hugging Face ו-PyTorch לטיפול ברשתות נוירונים, scikit-learn להערכת ביצועי מודלים, ומודולים כלליים כמו random ו-pickle.
-
ספריות Hugging Face: מאפשרות להשתמש ולכוונן מודלים ו-tokenizers מאומנים מראש מה-Model Hub.
-
PyTorch: זוהי מסגרת הלמידה העמוקה המרכזית המשמשת לפעולות, כולל שכבות רשת נוירונים ואופטימיזרים.
-
scikit-learn: מספקת מדדים כמו דיוק ו-F1-score להערכת ביצועי מודלים.
-
OpenAI API: גישה למודלי השפה של OpenAI למשימות שונות כמו מודל תגמול.
-
TensorBoard: משמש להמחשת התקדמות האימון.
הנה הקוד לייבוא הספריות הנדרשות:
# ייבוא המודול random לייצור מספרים אקראיים.
import random
# ייבוא מודולים נחוצים מספריית transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# ייבוא load_dataset לטעינת מערכי נתונים.
from datasets import load_dataset
# ייבוא metrics להערכת ביצועי המודל.
from sklearn.metrics import accuracy_score, f1_score
# ייבוא SummaryWriter לתיעוד התקדמות האימון.
from torch.utils.tensorboard import SummaryWriter
# ייבוא pickle לשמירה וטעינה של מודלים מאומנים.
import pickle
# ייבוא openai לשימוש ב-API של OpenAI (דורש מפתח API).
import openai
# ייבוא PyTorch לפעולות למידת עומק.
import torch
# ייבוא מודול רשת עצבית מ-PyTorch.
import torch.nn as nn
# ייבוא מודול אופטימיזציה מ-PyTorch (לא בשימוש ישיר בדוגמה זו).
import torch.optim as optim
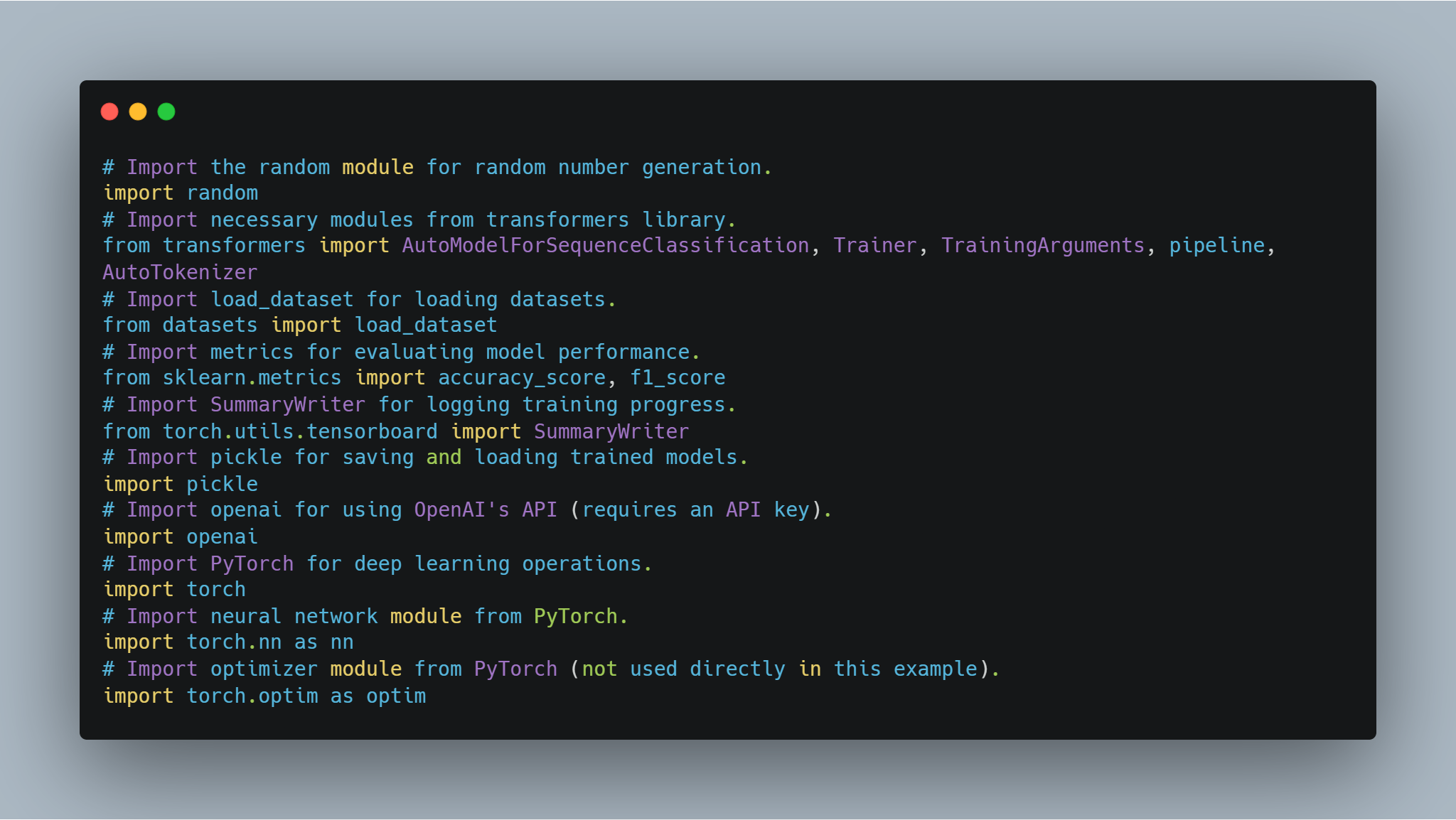
כל אחד מהייבואים הללו ממלא תפקיד חשוב בחלקים שונים של הקוד, מאימון והערכת המודל ועד לתיעוד תוצאות ואינטראקציה עם APIs חיצוניים.
שלב 2: כוונון עדין של מודל שפה לניתוח סנטימנט
כוונון עדין של מודל מאומן מראש למשימה ספציפית כמו ניתוח סנטימנט כולל טעינת מודל מאומן מראש, התאמתו למספר תוויות הפלט (חיובי/שלילי במקרה זה), ושימוש במערך נתונים מתאים.
בדוגמה זו, אנחנו משתמשים ב-AutoModelForSequenceClassification מספריית transformers, עם הנתונים IMDB. המודל המוקדם הזה יכול להיות מותאם באופן עדכני על חלק קטן יותר מהנתונים כדי לחסוך זמן עיבוד. אחר כך, המודל מאמן בעזרת ערכי האימון המותאמים אליו, שמכילים את מספר העונים וגודל המחזורים.
מטה הקוד לאתחלת והעדכון העדכני של המודל:
# 指定预训练模型的名称从Hugging Face Model Hub。
model_name = "bert-base-uncased"
# 使用指定的输出类别数加载预训练模型。
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 为模型加载分词器。
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 从Hugging Face Datasets加载IMDB数据集,仅使用10%用于训练。
dataset = load_dataset("imdb", split="train[:10%]")
# 对数据集进行分词
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 将数据集映射到分词输入
tokenized_dataset = dataset.map(tokenize_function, batched=True)
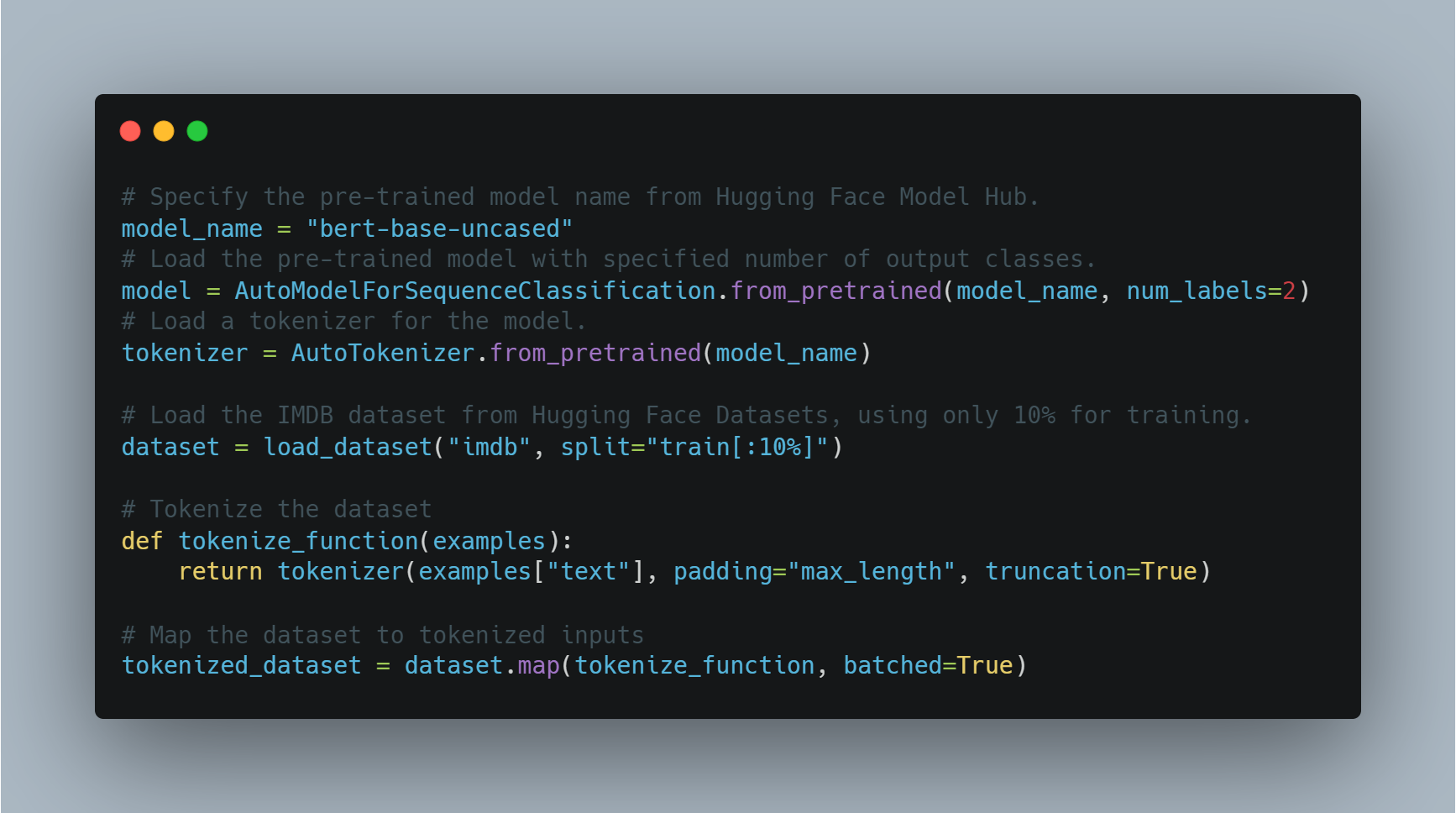
כאן, מודל זה נאלץ בעזרת מבנה BERT ונתונים זו מוכנים להכשירה. בהמשך, אנחנו מגדירים את הערכים האימוניים ומוקדמים את המאמן.
# הגדרה של טיעונים להשיגת ההכשרה.
training_args = TrainingArguments(
output_dir="./results", # ספציפית את המיקום להשאלה היציעים לאחסון המודל.
num_train_epochs=3, # קבע את מספר המחזורים האמצעים להשיגת ההכשרה.
per_device_train_batch_size=8, # קבע את הגודל של הטיפוסים למכשיר.
logging_dir='./logs', # תוך המיקום לאחסון המעבדות.
logging_steps=10 # לוג את כל 10 השלבים.
)
# הפעלת המאמן עם המודל, הטיעונים להשיגת ההכשרה ואת הנתונים הבסיסיים.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# התחלת תהליך ההכשרה.
trainer.train()
# שימוש במודל מותאם לאחר ההכשרה.
model.save_pretrained("./fine_tuned_sentiment_model")

שלב 3: יישומה של סוג של סייר קי-לימוד
קי-לימוד הוא שיטת למימון התנהגויות בה סוג למימון לומד לבצע פעולות בדרך שמגבירה את הרווחה המקבלת.
בדוגמה זו, אנחנו מגדירים סוג קי-לימוד פשוט שאוגרת זוגות מצב-פעולה בטבלת קי-לימוד. הסוג יכול לחקור באופן אקראי או לנצל את הפעולה הידועה ביותר בהתבסס על הטבלת הקי-לימוד. הטבלת הקי-לימוד מעדכנה אחרי כל פעולה בעזרת מהירות לימוד ומפלג סיסמה כדי לשקול רווחות העתיד.
מתחת לו הקוד של סוג זה של סייר קי-לימוד:
# הגדרה של משתמש הלמידה בקלים Q.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# התחלת הטבלת Q.
self.q_table = {}
# אחסון הפעלולים האפשריים.
self.actions = actions
# הגדרת שיעור החיקוי.
self.epsilon = epsilon
# הגדרת שיעור הלמידה.
self.alpha = alpha
# הגדרת מפתח ההדמייה.
self.gamma = gamma
# הגדרת השיטה get_action על מנת לבחור פעולה על פי מצב ההווה.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# חיקוי אקראי.
return random.choice(self.actions)
else:
# שימוש בפעולה הטובה ביותר.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
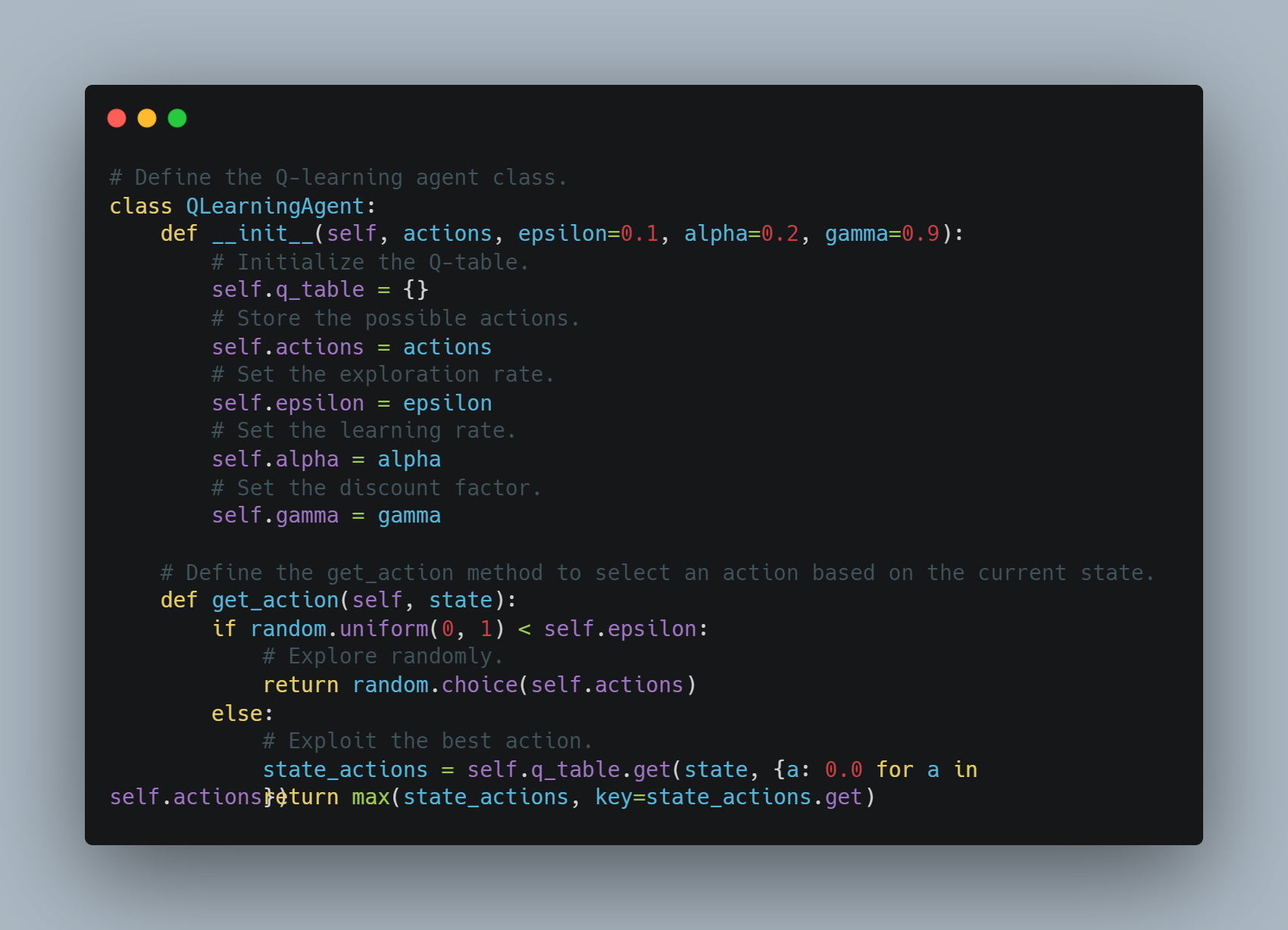
המשתמש מבחר פעולות על פי התפשטות או השימוש בהם ומעדכן את הערכים Q אחרי כל צעד.
# הגדרת השיטה update_q_table על מנת לעדכן את הטבלת Q.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
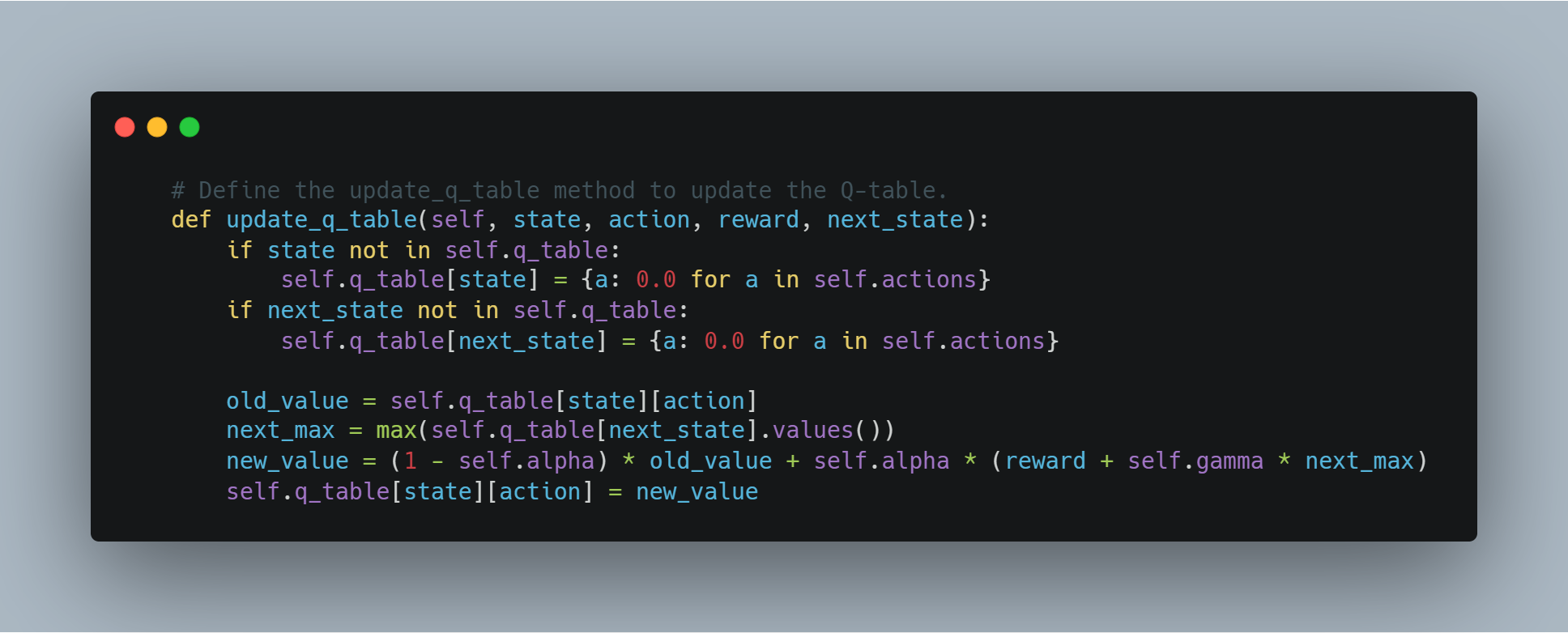
שלב 4: שימוש בAPI של OpenAI עבור תאריך הגמולים
במקרים מסוימים, במקום להגדיר פעולה רשומה עבור הגמול, אנחנו יכולים להשתמש במודל השפה החזק של OpenAI כמו GPT על מנת לבחון את איכות הפעלולים של המשתמש.
במודל הזה, הפונקציית get_reward שולחת מצב, פעולה, ומצב הבא אל אף של OpenAI כדי לקבל ציון לגמול, מאפשר לנו להשתמש במודלים השפה הגדולים כדי להבין מבנים מורכבים של הגמולים.
# הגדרת הפונקציית get_reward על מנת לקבל אות הגמול מ- OpenAI's API.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # החלף עם מפתח הAPI האמיתי של
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
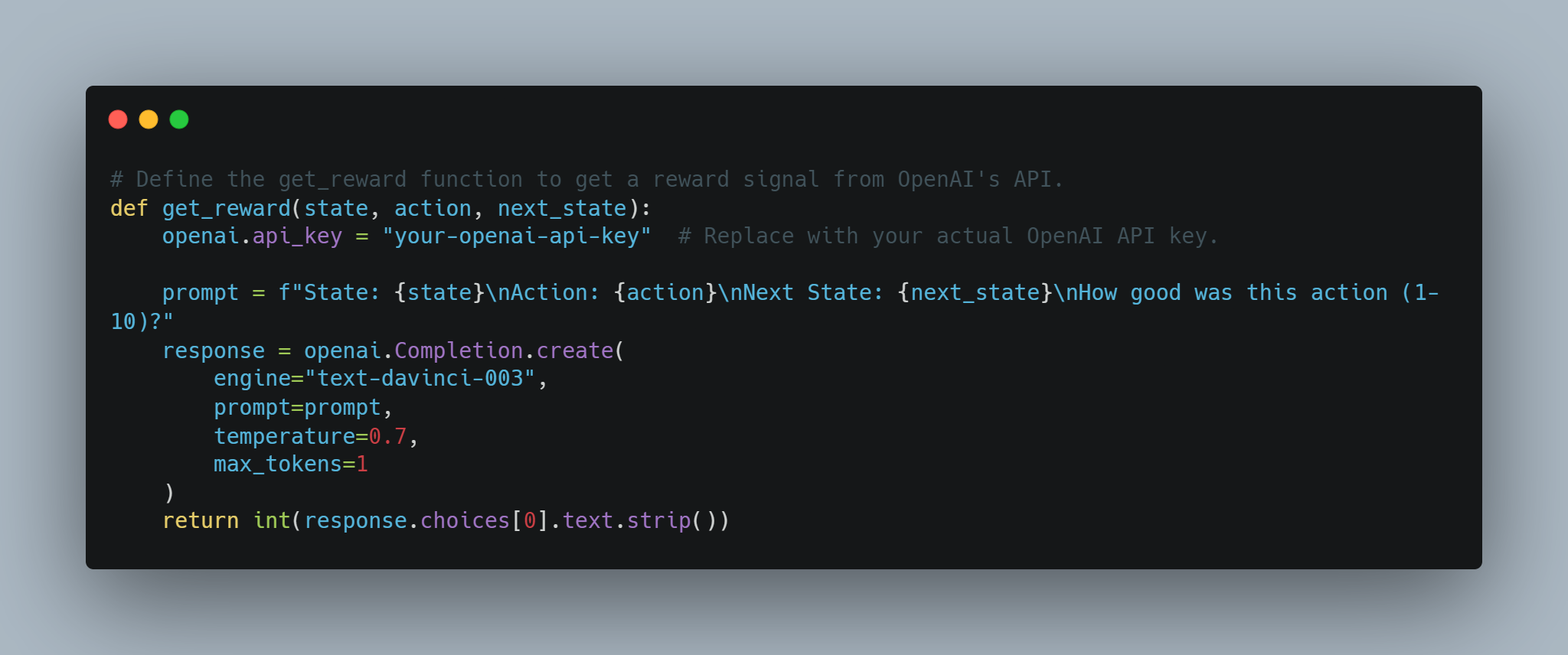
אז זה מאפשר גישה קונספטואלית בה המערכת הגמולים נקבעת דינמית בעזרת ה API של OpenAI, שיכול להיות שימושי למשימות מורכבות בהן קשה להגדיר הגמולים.
שלב 5: הערכת הביצועים של המודל
ברגע שמודל ללמידת מכונה מואם, נחוץ להעריך את הביצועים שלו באמצעות מדדים סטנדרטיים כמו דיוק וציון F1.
החלק הזה מחשב שניהם באמצעות תגיות אמת והערכות הצפויים. דיוק מספק מדד כולל למידה הנכונה, בעוד שהציון F1 מאחסן את הדיוק וההשיגה, מאוד שימושי במאגרי נתונים מאובחנים.
הנה הקוד להערכת הביצועים של המודל:
# הגדרה של תגיות האמת עבור הערכת.
true_labels = [0, 1, 1, 0, 1]
# הגדרה של תגיות ההערכה עבור הערכת.
predicted_labels = [0, 0, 1, 0, 1]
# חישוב ערך הדיוק.
accuracy = accuracy_score(true_labels, predicted_labels)
# חישוב ערך הציון F1.
f1 = f1_score(true_labels, predicted_labels)
# הוצאת ערך הדיוק.
print(f"Accuracy: {accuracy:.2f}")
# הוצאת ערך הציון F1.
print(f"F1-Score: {f1:.2f}")
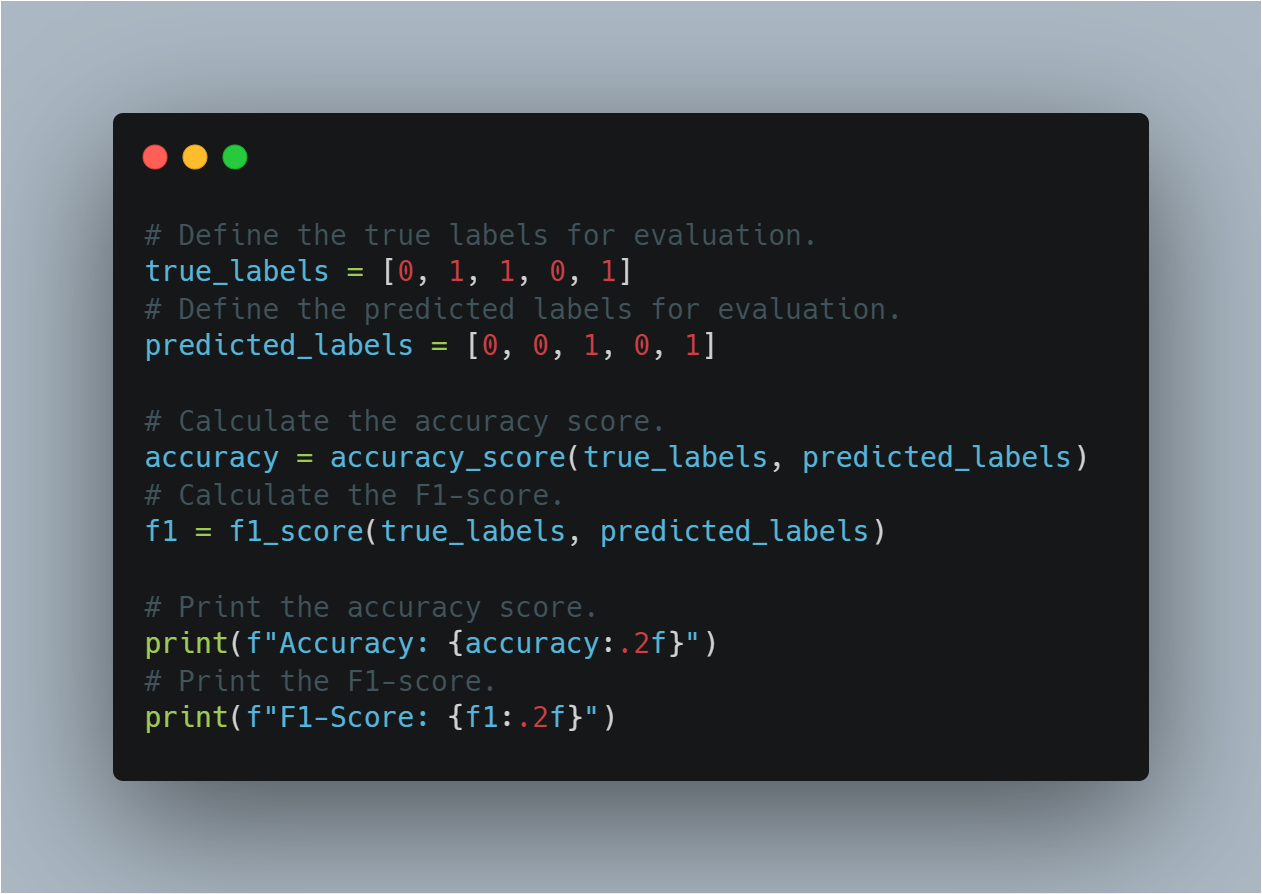
החלק הזה עוזר להעריך איך טוב המודל התפשט למידע שלא נראה על ידי בשימוש במדדים הערכת מוכרחים.
שלב 6: סוכנית הגידול הפשית הבסיסית (בעזרת PyTorch)
שיטות הגידול בלמידת הבסיסית בריבוע משנה את המדיניות על ידי התקדמות במיטב ההצע הצפוי לגמול.
חלק זה ממחיש את היישומה הפשוטה לרשת המדידה המדינית בעזרת PyTorch, שיכולה להיות משמשת לקבלת החלטות ב-RL. רשת המדידה משתמשת בשכבה לינארית כדי ליצור סיכויים לפעמים שונים, ומיועד סופטמקס כדי לוודא שהייצאים האלה ייצרים התפלגה סיכויית תעודה.
הנה הקוד הקונספטטיבי להגדרת אגנט בסיסי לחומר ההלך הגיוני:
# הגדרה של המדידה המדינית.
class PolicyNetwork(nn.Module):
# התחלת המדידה המדינית.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# הגדרת שכבה לינארית.
self.linear = nn.Linear(input_size, output_size)
# הגדרת העבר הקדמי של הרשת.
def forward(self, x):
# יישום סופטמקס על הייצא של השכבה הלינארית.
return torch.softmax(self.linear(x), dim=1)
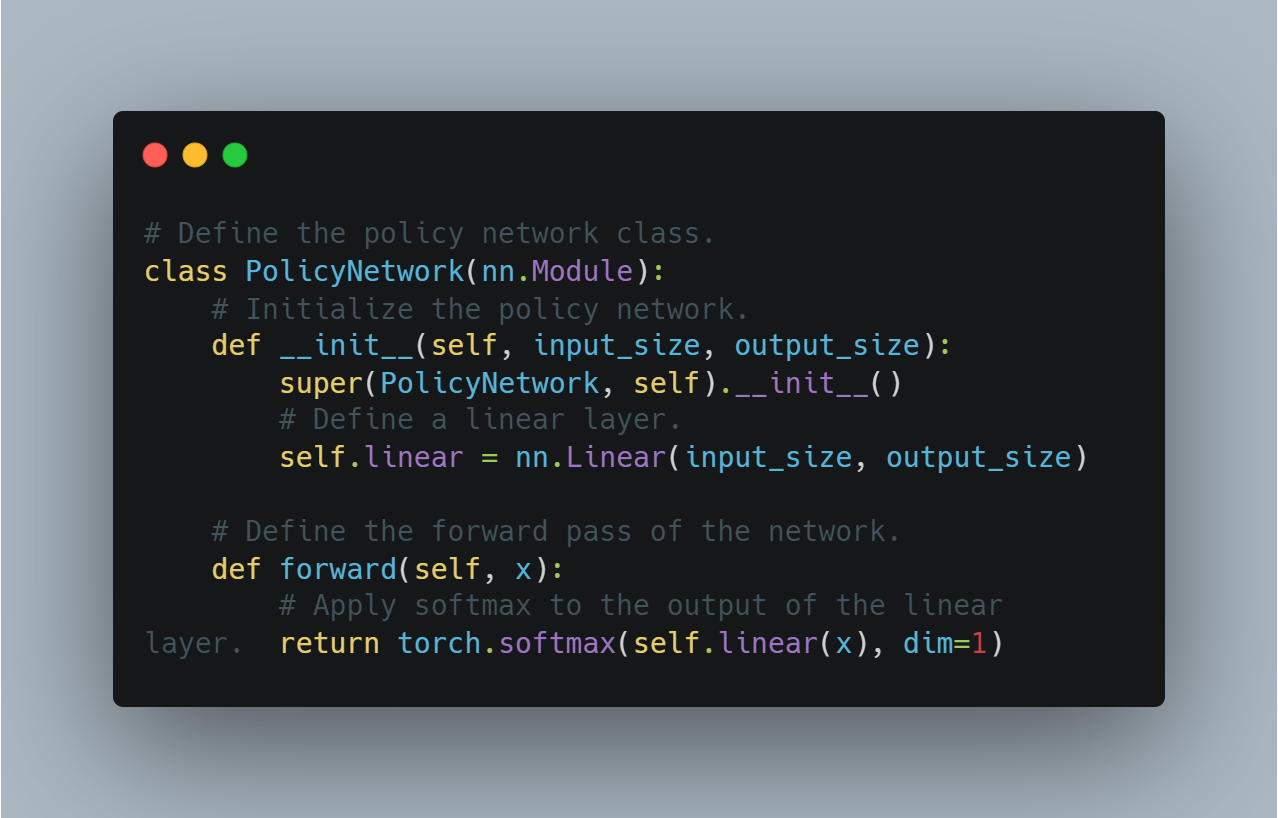
זה משמש כצעד יסוד להגדרת אלגוריתמים מתקדמים יותר בעזרת אופטימיזציית המדידה.
שלב 7: הצגה של ההתקדמות האימון בעזרת TensorBoard
הצגת מדדים האימון, כמו הפסד והדיוק, היא חיונית להבנה של איך הביצועים של המודל מתפתחים במהלך הזמן. TensorBoard, הכלי הפופולרי לזה, יכול להשתמש כדי לעדכן מדדים ולהצגם בזמן אמת.
בחלק זה, אנחנו יוצרים אינסטנציאשן של SummaryWriter ועוקבים אחר מספר אקראי כדי למחיש את תהליך העדוות של הפסד והדיוק בזמן האימון.
הנה איך אתה יכול לעדכן ולהצג את ההתקדמות האי
# יצירת משתמש סקרים.
writer = SummaryWriter()
# מובנה דוגמה למעגל האימון למציגה בTensorBoard:
num_epochs = 10 # הגדרת המספר של עבודות.
for epoch in range(num_epochs):
# הדמיית הפסדים והדיוק אקראיים.
loss = random.random()
accuracy = random.random()
# שירות הפסדים והדיוק לTensorBoard.
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# סגירת המשתמש סקרים.
writer.close()
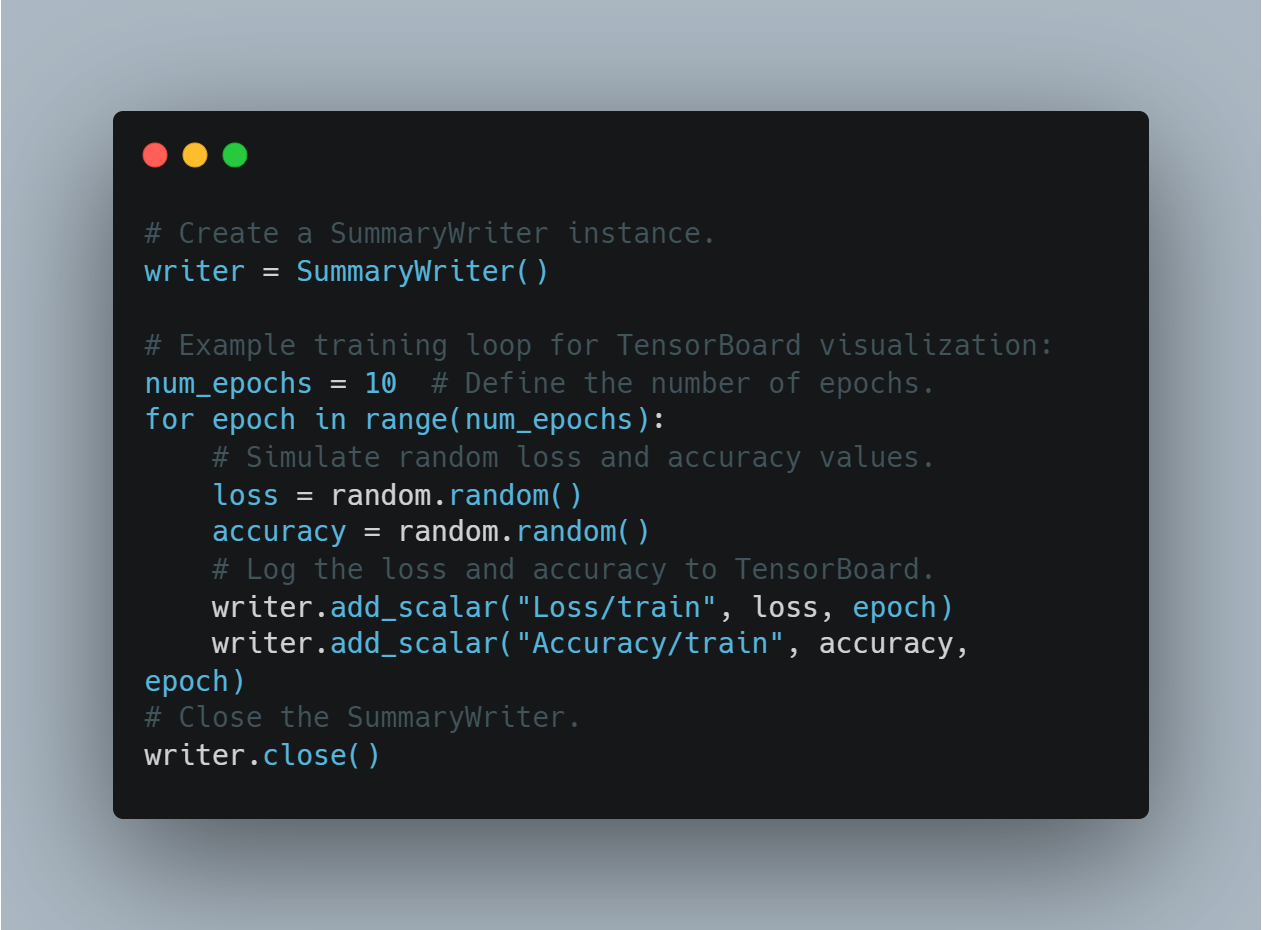
זה מאפשר למשתמשים להשגיח על האימון של המודל ולעשות הגדרות זמניות בהתבסס על משובים ויזואלים.
שלב 8: שימוש והחזרה של סימנים למודלים מאומנים
אחרי שיעור מודל, חשוב לשמור על מצב למדה שלו (לדוגמה, ערכים Q או משקלים של המודל) כדי שהוא יכול להשתמש מחדש או להעריך בזמן האחרון.
החלק הזה מראה איך לשמור על מודל מאומן בעזרת מודול ה pickle של Python ואיך להחזיר אותו מהדיסק.
הנה הקוד לשמירה ולהחזרה של מודל מאומן בלמידת Q:
# יצירת מקלט של העליצה Q.
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# האמן את העליצה (לא מראה כאן).
# שמירת העליצה.
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# החזרת העליצה.
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
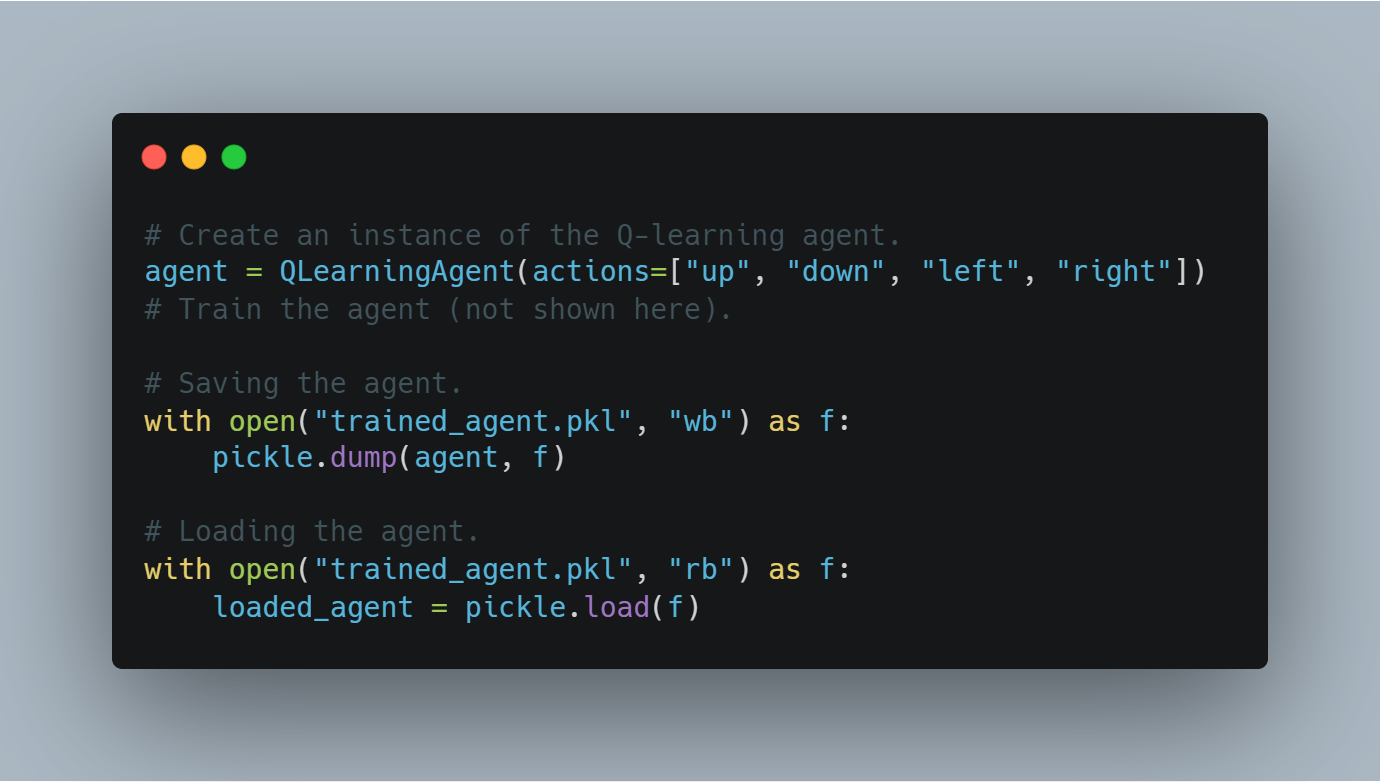
התהליך הזה של הקלטים מובטח שההתקדמות באימון לא תיאבד ושמודלים יכולים להשתמש מחדש בניסויים העתידים.
שלב 9: למידה קורסית
למידה מורפוגרפית עוסקת בהגברת בהדרגה הקשורה במחשבות המודל, התחלה עם דוגמאות קלות והתמקדה על המודל המורגל לעבר מאפיינים מאתגרים יותר. זה יכול לסייע לשיפור ביצועים ויציבות המודל בתהליך האימון.
הנה דוגמה לשימוש בלמידה מורפוגרפית במחזור האימון:
# הגדר את הקשר המקורי לקורה המשימה.
initial_task_difficulty = 0.1
# מחזור האימון עם למידה מורפוגרפית:
for epoch in range(num_epochs):
# הגבר בהדרגה את הקשר לקורה המשימה.
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# יצירת נתונים האימון עם קשר מתאים.
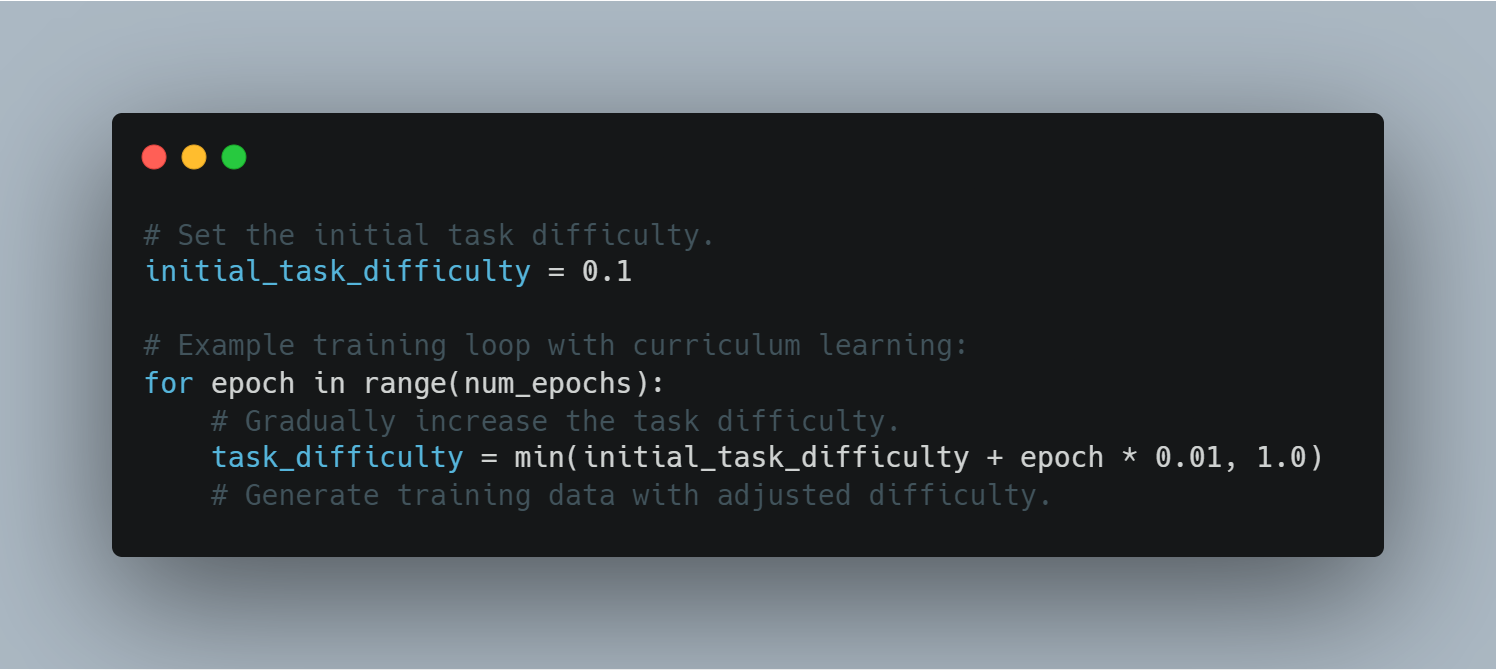
דרך שליטת קשר המשימה, הסוכנים יכולים לטפל באתגרים מורכבים יותר בהדרגה, שמובילה לשיפור יעילות הלמידה.
שלב 10: אימוץ עצור מוקדם
עצור מוקדם הוא טכניקה למניעת התרחשות עליה דחוסה בזמן האימון על ידי הפסקת התהליך אם האחוז הזולתי של האריכות לא משפר אחרי מספר עבודות האימון (סבלנות).
הסעיף הזה מראה איך ליישם עצור מוקדם במחזור האימון, בעזרת אחוז האריכות הזולתי כסמן מרכזי.
הנה הקוד ליישם עצור מוקדם:
# אתחול האובדן הטוב ביותר בוולידציה לאינסוף.
best_validation_loss = float("inf")
# הגדרת ערך הסבלנות (מספר האפוקים ללא שיפור).
patience = 5
# אתחול המונה לאפוקים ללא שיפור.
epochs_without_improvement = 0
# לולאת אימון לדוגמה עם עצירה מוקדמת:
for epoch in range(num_epochs):
# סימולציה של אובדן אקראי בוולידציה.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

עצירה מוקדמת משפרת את הכללת המודל על ידי מניעת אימון מיותר לאחר שהמודל מתחיל לבצע יתר על המידה.
שלב 11: שימוש במודל LLM מאומן מראש להעברת משימות ללא התאמה פרטנית
בהעברת משימות ללא התאמה פרטנית, מודל מאומן מראש מוחל על משימה שהוא לא אומן במיוחד בשבילה.
באמצעות הצינור של Hugging Face, סעיף זה מדגים כיצד להחיל מודל BART מאומן מראש לסיכום ללא אימון נוסף, תוך הדגשת קונספט הלמידה המעוברת.
הנה הקוד לשימוש במודל LLM מאומן מראש לסיכום:
# טעינת צינור סיכום מאומן מראש.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# הגדרת הטקסט לסיכום.
text = "This is an example text about AI agents and LLMs."
# יצירת הסיכום.
summary = summarizer(text)[0]["summary_text"]
# הדפסת הסיכום.
print(f"Summary: {summary}")
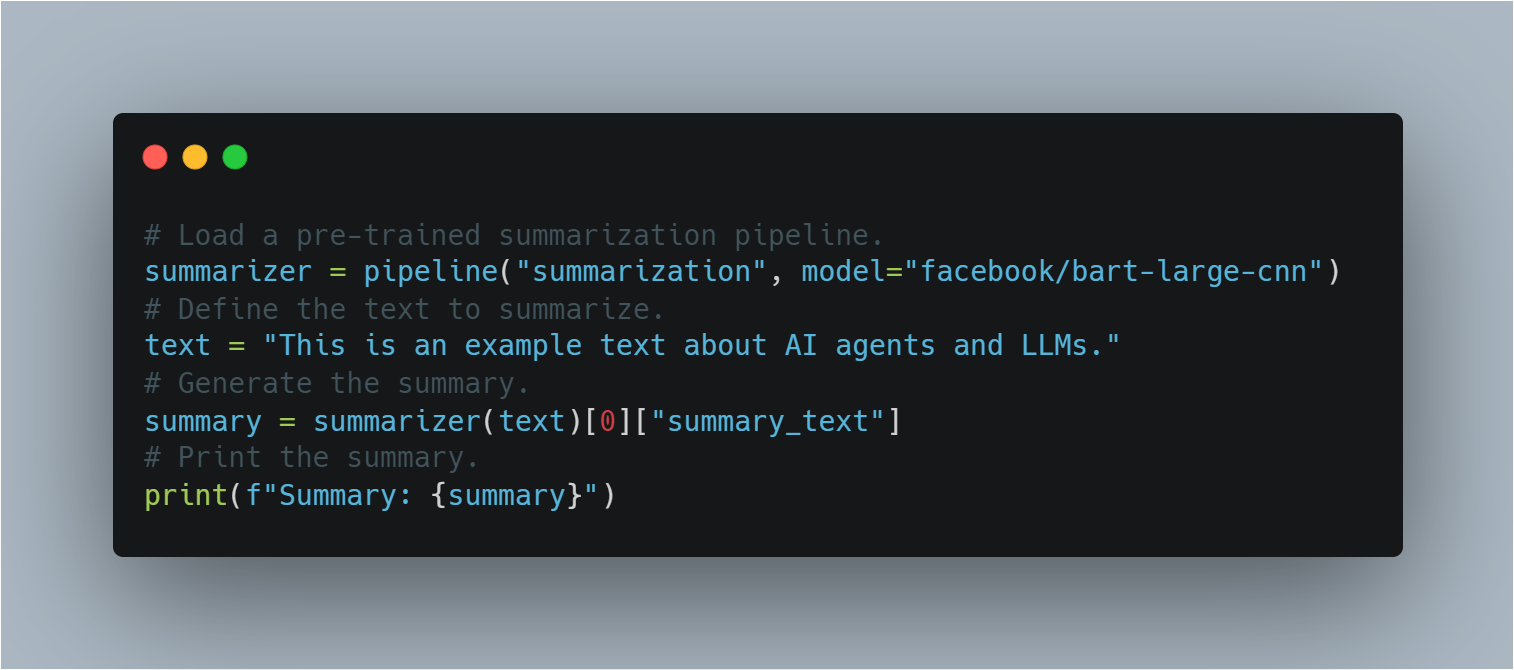
זה מדגים את הגמישות של מודלים LLM בביצוע משימות מגוונות ללא צורך באימון נוסף, תוך ניצול הידע הקיים שלהם.
הדוגמה המלאה של הקוד
# ייבוא מודול random ליצירת מספרים אקראיים.
import random
# ייבוא מודולים חיוניים מספריית transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# ייבוא load_dataset לטעינת מערכי נתונים.
from datasets import load_dataset
# ייבוא metrics להערכת ביצועי המודל.
from sklearn.metrics import accuracy_score, f1_score
# ייבוא SummaryWriter לתיעוד התקדמות האימון.
from torch.utils.tensorboard import SummaryWriter
# ייבוא pickle לשמירה וטעינה של מודלים מאומנים.
import pickle
# ייבוא openai לשימוש ב-API של OpenAI (דורש מפתח API).
import openai
# ייבוא PyTorch לפעולות למידה עמוקה.
import torch
# ייבוא מודול רשתות עצביות מ-PyTorch.
import torch.nn as nn
# ייבוא מודול optimizer מ-PyTorch (לא בשימוש ישיר בדוגמא זו).
import torch.optim as optim
# --------------------------------------------------
# 1. כיוון עדין של דגם LLM לניתוח סנטימנט
# --------------------------------------------------
# ציין את שם המודל המאומן מראש מ-Hugging Face Model Hub.
model_name = "bert-base-uncased"
# טען את המודל המאומן מראש עם מספר הכיתות הרצוי לפלט.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# טען את ה-tokenizer עבור המודל.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# טען את מערך הנתונים IMDB מ-Hugging Face Datasets, תוך שימוש ב-10% בלבד לאימון.
dataset = load_dataset("imdb", split="train[:10%]")
# בצע טוקניזציה למערך הנתונים
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# מפה את מערך הנתונים לקלטים בטוקניזציה
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# הגדר את פרמטרי האימון.
training_args = TrainingArguments(
output_dir="./results", # ציין את תיקיית הפלט לשמירת המודל.
num_train_epochs=3, # קבע את מספר תקופות האימון.
per_device_train_batch_size=8, # קבע את גודל האצווה לכל מכשיר.
logging_dir='./logs', # תיקייה לאחסון יומנים.
logging_steps=10 # תעד כל 10 צעדים.
)
# אתחל את ה-Trainer עם המודל, פרמטרי האימון ומערך הנתונים.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# התחל את תהליך האימון.
trainer.train()
# שמור את המודל המכוונן בעדינות.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. מימוש סוכן פשוט עם Q-Learning
# --------------------------------------------------
# הגדר את מחלקת הסוכן ב-Q-learning.
class QLearningAgent:
# אתחל את הסוכן עם פעולות, epsilon (שיעור חקירה), alpha (שיעור למידה) ו-gamma (גורם הנחה).
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# אתחל את טבלת ה-Q.
self.q_table = {}
# אחסן את הפעולות האפשריות.
self.actions = actions
# קבע את שיעור החקירה.
self.epsilon = epsilon
# קבע את שיעור הלמידה.
self.alpha = alpha
# קבע את גורם ההנחה.
self.gamma = gamma
# הגדר את השיטה get_action לבחירת פעולה על סמך המצב הנוכחי.
def get_action(self, state):
# חקור באופן אקראי בסבירות epsilon.
if random.uniform(0, 1) < self.epsilon:
# החזר פעולה אקראית.
return random.choice(self.actions)
else:
# נצל את הפעולה הטובה ביותר על סמך טבלת ה-Q.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# הגדר את השיטה update_q_table לעדכון טבלת ה-Q לאחר ביצוע פעולה.
def update_q_table(self, state, action, reward, next_state):
# אם המצב לא נמצא בטבלת ה-Q, הוסף אותו.
if state not in self.q_table:
# אתחל את ערכי ה-Q למצב החדש.
self.q_table[state] = {a: 0.0 for a in self.actions}
# אם המצב הבא לא נמצא בטבלת ה-Q, הוסף אותו.
if next_state not in self.q_table:
# אתחל את ערכי ה-Q למצב הבא החדש.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# קבל את ערך ה-Q הישן עבור זוג מצב-פעולה.
old_value = self.q_table[state][action]
# קבל את ערך ה-Q המקסימלי עבור המצב הבא.
next_max = max(self.q_table[next_state].values())
# חשב את ערך ה-Q המעודכן.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# עדכן את טבלת ה-Q עם ערך ה-Q החדש.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. שימוש ב-API של OpenAI למידול תגמולים (רעיוני)
# --------------------------------------------------
# הגדר את הפונקציה get_reward לקבלת אות תגמול מ-API של OpenAI.
def get_reward(state, action, next_state):
# ודא שמפתח ה-API של OpenAI מוגדר נכון.
openai.api_key = "your-openai-api-key" # החלף עם מפתח ה-API האמיתי שלך ל-OpenAI.
# בנה את ה-prompt לקריאת ה-API.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# בצע קריאת API לנקודת הקצה Completion של OpenAI.
response = openai.Completion.create(
engine="text-davinci-003", # ציין את המנוע לשימוש.
prompt=prompt, # העבר את ה-prompt הבנוי.
temperature=0.7, # קבע את פרמטר הטמפרטורה.
max_tokens=1 # קבע את המספר המקסימלי של טוקנים ליצירה.
)
# חלץ והחזר את ערך התגמול מתגובת ה-API.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. הערכת ביצועי מודל
# --------------------------------------------------
# הגדר את התוויות האמיתיות להערכה.
true_labels = [0, 1, 1, 0, 1]
# הגדר את התוויות החזויות להערכה.
predicted_labels = [0, 0, 1, 0, 1]
# חשב את ציוני הדיוק.
accuracy = accuracy_score(true_labels, predicted_labels)
# חשב את ציוני ה-F1.
f1 = f1_score(true_labels, predicted_labels)
# הדפס את ציוני הדיוק.
print(f"Accuracy: {accuracy:.2f}")
# הדפס את ציוני ה-F1.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. סוכן מדיניות גרדיאנט בסיסי (באמצעות PyTorch) - רעיוני
# --------------------------------------------------
# הגדר את מחלקת רשת המדיניות.
class PolicyNetwork(nn.Module):
# אתחל את רשת המדיניות.
def __init__(self, input_size, output_size):
# אתחל את מחלקת האב.
super(PolicyNetwork, self).__init__()
# הגדר שכבה לינארית.
self.linear = nn.Linear(input_size, output_size)
# הגדר את מעבר הקדימה של הרשת.
def forward(self, x):
# החל softmax על הפלט של השכבה הלינארית.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. ויזואליזציה של התקדמות האימון עם TensorBoard
# --------------------------------------------------
# צור מופע של SummaryWriter.
writer = SummaryWriter()
# לולאת אימון לדוגמה להמחשה ב-TensorBoard:
# num_epochs = 10 # הגדר את מספר התקופות.
# for epoch in range(num_epochs):
# # ... (לולאת האימון שלך כאן)
# loss = random.random() # דוגמה: ערך הפסד אקראי.
# accuracy = random.random() # דוגמה: ערך דיוק אקראי.
# # תעד את ההפסד ל-TensorBoard.
# writer.add_scalar("Loss/train", loss, epoch)
# # תעד את הדיוק ל-TensorBoard.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (תעד מדדים נוספים)
# # סגור את ה-SummaryWriter.
# writer.close()
# --------------------------------------------------
# 7. שמירה וטעינת נקודות ביקורת של סוכן מאומן
# --------------------------------------------------
# דוגמה:
# צור מופע של סוכן Q-learning.
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (אמן את הסוכן שלך)
# # שמירת הסוכן
# # פתח קובץ במצב כתיבה בינארית.
# with open("trained_agent.pkl", "wb") as f:
# # שמור את הסוכן לקובץ.
# pickle.dump(agent, f)
# # טעינת הסוכן
# # פתח את הקובץ במצב קריאה בינארית.
# with open("trained_agent.pkl", "rb") as f:
# # טען את הסוכן מהקובץ.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. למידה באמצעות תוכנית לימודים
# --------------------------------------------------
# קבע את הקושי הראשוני של המשימה.
initial_task_difficulty = 0.1
# לולאת אימון לדוגמה עם למידה באמצעות תוכנית לימודים:
# for epoch in range(num_epochs):
# # הגדל בהדרגה את קושי המשימה.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (צור נתוני אימון עם קושי מותאם)
# --------------------------------------------------
# 9. מימוש עצירה מוקדמת
# --------------------------------------------------
# אתחל את ההפסד הטוב ביותר של האימות לאינסוף.
best_validation_loss = float("inf")
# קבע את ערך הסבלנות (מספר תקופות ללא שיפור).
patience = 5
# אתחל את המונה לתקופות ללא שיפור.
epochs_without_improvement = 0
# לולאת אימון לדוגמה עם עצירה מוקדמת:
# for epoch in range(num_epochs):
# # ... (שלבי אימון ואימות)
# # חשב את ההפסד של האימות.
# validation_loss = random.random() # דוגמה: הפסד אימות אקראי.
# # אם ההפסד של האימות משתפר.
# if validation_loss < best_validation_loss:
# # עדכן את ההפסד הטוב ביותר של האימות.
# best_validation_loss = validation_loss
# # אפס את המונה.
# epochs_without_improvement = 0
# else:
# # העלה את המונה.
# epochs_without_improvement += 1
# # אם אין שיפור במשך 'סבלנות' תקופות.
# if epochs_without_improvement >= patience:
# # הדפס הודעה.
# print("עצירה מוקדמת הופעלה!")
# # עצור את האימון.
# break
# --------------------------------------------------
# 10. שימוש ב-LLM מאומן מראש להעברת משימה ללא כיוון עדין
# --------------------------------------------------
# טען צינור סיכום מאומן מראש.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# הגדר את הטקסט לסיכום.
text = "This is an example text about AI agents and LLMs."
# צור את הסיכום.
summary = summarizer(text)[0]["summary_text"]
# הדפס את הסיכום.
print(f"Summary: {summary}")

אתגרים בפריסה והרחבה
פריסה והרחבה של סוכני AI משולבים עם LLMs מציגה אתגרים טכניים ותפעוליים משמעותיים. אחד האתגרים המרכזיים הוא העלות החישובית, במיוחד ככל שה-LLMs גדלים בגודלם ובמורכבותם.
התמודדות עם הנושא הזה כוללת אסטרטגיות חסכוניות במשאבים כגון חיתוך מודלים, קוונטיזציה ומחשוב מבוזר. אלה יכולים לעזור להפחית את העומס החישובי מבלי להקריב ביצועים.
שמירה על אמינות וחוסן ביישומים בעולם האמיתי היא גם חיונית, מה שמחייב ניטור מתמשך, עדכונים רגילים ופיתוח מנגנוני בטיחות לניהול קלטים בלתי צפויים או כשלים במערכת.
ככל שמערכות אלו נפרסות בתעשיות שונות, עמידה בסטנדרטים אתיים—כולל הוגנות, שקיפות ואחריות—נעשית חשובה יותר ויותר. שיקולים אלה הם מרכזיים לקבלת המערכת ולהצלחתה ארוכת הטווח, ומשפיעים על האמון הציבורי וההשלכות האתיות של החלטות מונעות AI בהקשרים חברתיים מגוונים (Bender et al., 2021).
היישום הטכני של סוכני AI משולבים עם LLMs כולל תכנון ארכיטקטוני קפדני, מתודולוגיות אימון מחמירות ושיקול דעת מתחשב של אתגרי הפריסה.
האפקטיביות והאמינות של מערכות אלו בסביבות העולם האמיתי תלויות בהתמודדות עם דאגות טכניות ואתיות כאחד, תוך הבטחת תפקוד חלק ואחראי של טכנולוגיות AI ביישומים שונים.
פרק 7: עתיד סוכני ה-AI וה-LLMs
התכנסות ה-LLMs עם לימוד חיזוק
כשתחקור את עתידם של סוכני AI ומודלים של שפה גדולה (LLMs), ההתמזגות של LLMs עם למידת חיזוק מודגשת כהתפתחות טרנספורמטיבית במיוחד. שילוב זה דוחף את גבולות ה-AI המסורתי על ידי כך שמאפשר למערכות לא רק לייצר ולהבין שפה, אלא גם ללמוד מהאינטראקציות שלהן בזמן אמת.
באמצעות למידת חיזוק, סוכני AI יכולים לשנות באופן אדפטיבי את האסטרטגיות שלהם על בסיס משוב מהסביבה שלהם, מה שמביא לשיפור מתמיד בתהליכי קבלת ההחלטות שלהם. המשמעות היא שבניגוד למודלים סטטיים, מערכות AI משופרות עם למידת חיזוק יכולות להתמודד עם משימות מורכבות ודינמיות יותר עם פיקוח אנושי מינימלי.
ההשלכות של מערכות כאלה הן משמעותיות: ביישומים הנעים מרובוטיקה אוטונומית לחינוך מותאם אישית, סוכני AI יכולים לשפר את ביצועיהם באופן עצמאי לאורך הזמן, ולהפוך אותם ליעילים ותגובותיים יותר לדרישות המשתנות של ההקשרים התפעוליים שלהם.
דוגמה: משחקי טקסט
תאר לעצמך סוכן AI שמשחק במשחק הרפתקאות מבוסס טקסט.
-
סביבה: המשחק עצמו (חוקים, תיאורי מצב, וכדומה)
-
LLM: מעבד את טקסט המשחק, מבין את המצב הנוכחי ומייצר פעולות אפשריות (לדוגמה, "לך צפונה", "קח חרב").
-
גמול: נותן לו המשחק בהתבסס על תוצאת הפעולה (לדוגמה, גמול חיובי עבור מציאת הון, גמול שלילי עבור אבדן החיים).
דוגמה קוד (מושגית בשימוש בפינגווין וב API של OpenAI):
import openai
import random
# ... (ההסתברויות של הסביבה המשחקית - לא מראית כאן) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (מעגל ההאמנה הרגשית של RL - פשוטה) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (עדכון הסוכנים הרגשיים בעזרת הגמול - לא מראית) ...
state = next_state
שילוב מולטימודלי בעזרת המחשבה הרב-סוגית
שילוב המולטימודלי הוא מגמה חשובה אחראית לעתיד של סוכנים המחשבה. על ידי אפשרות למערכות לעבד ולשלב מידע ממקורות שונים כמו טקסט, תמונות, אודיו וקלטים חשמליים, המולטימודלי מציע תובנה יותר מורחבת של הסביבות בהן המערכות פועלות.
לדוגמה, ברכבים בלתי מאורגנים, היכולת לסינתז מידע ויזואלי ממצלמות, מידע הקונTEXT ממפים ועדכונים דרך פקקים בזמן הממשך מאפשרת לAI לקבל החלטות נהגה יותר מודעות ובטוחות.
שימוש ביכולת מולטימודלית של AI: דוגמה 1: כתיבת כיתוביות לתשובות על שאלות חזותיות
אתגר כאן הוא השילוב החלק בערך והעיבוד המיידי של זרמי מידע שונים, שדורשים התקדמות בארכיטקטורת המודל ובשיטות הצימוד של המידע.
ההתגברות על האתגרים הללו תהיה חשובה לשימוש במערכות AI שהן באמת חכמות ויכולות לפעול בסביבות מורכבות בעולם האמיתי.
דוגמה 1 של AI מולטימודלי: כתיבת כיתוביות לתשובות על שאלות חזותיות
-
מטרה: סוכן AI שיכול לענות על שאלות על תמונות.
-
מודליות: תמונה, טקסט
-
תהליך:
-
היצאת תכונות מהתמונה: שימוש ברשת עצבית מורכבת (CNN) מאומצת מראש להיצאת תכונות מהתמונה.
-
יצירת כיתובית: שימוש ב-LLM (כמו מודל Transformer) ליצירת כיתובית המתארת את התמונה על בסיס התכונות המוצאות.
-
עניין תשובות: שימוש ב-LLM נוסף לעיבוד של השאלה והכיתובית המיוצרת כדי לספק תשובה.
-
דוגמא קוד (תפיסתית בעזרת הפסיקים ו Hugging Face Transformers):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# לודאי מולדים מוכנים
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# פונקציית ליצירת תיאור לתמונה
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# פונקציית לספק תשובה על התמונה
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# השתמשות בדוגמה
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
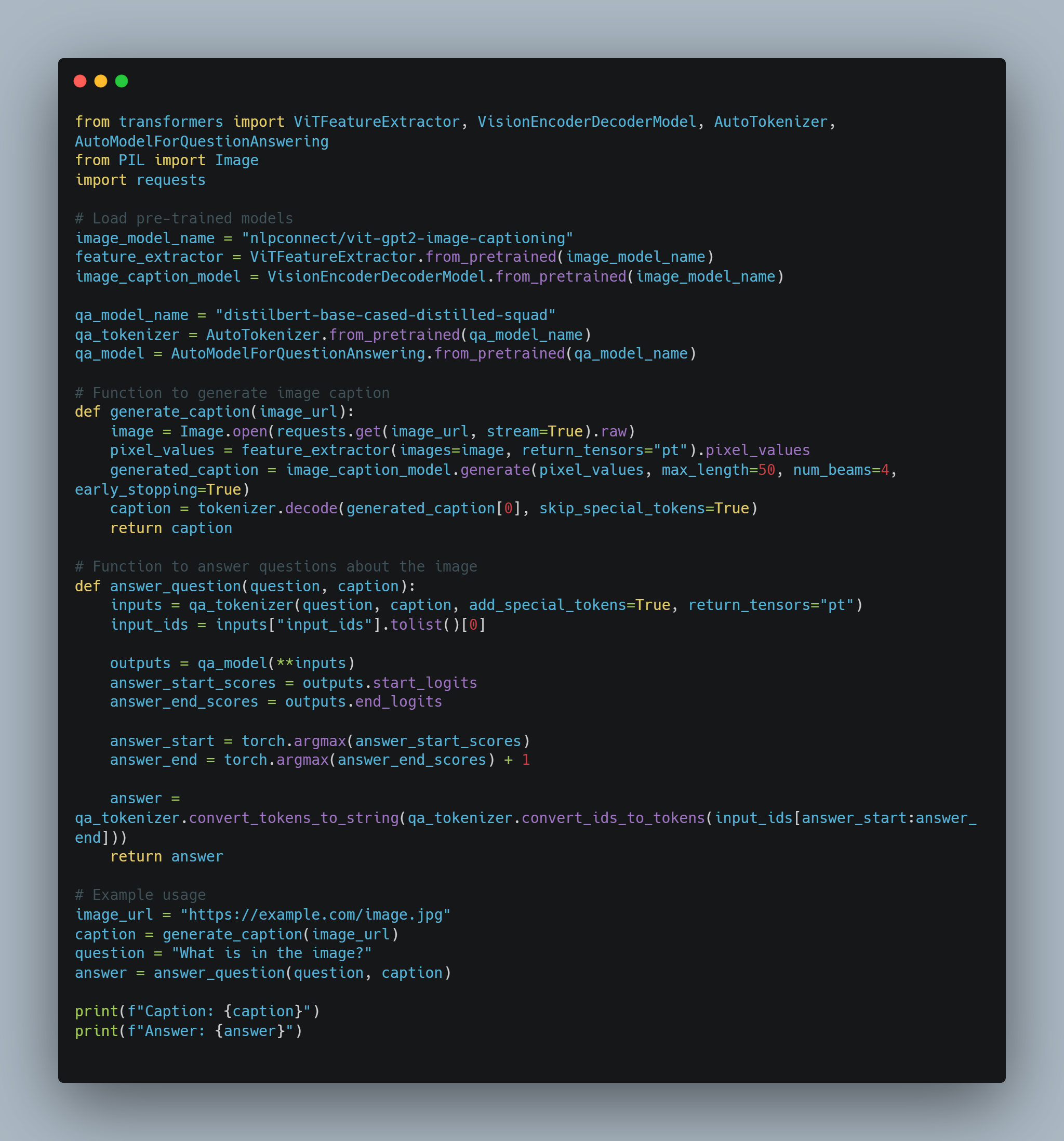
דוגמא בעלת מודלים רבים ב-2: אנליזת הרגשות מן הטקסט והאודיו
-
מטרה: סיוע היכולת לאנימציה על פי הטקסט והצליל של המסר.
-
מודליות: טקסט, אודיו
-
תהליך:
-
סנטימנט טקסט: השתמש במודל ניתוח סנטימנט מאומן מראש על הטקסט.
-
סנטימנט אודיו: השתמש במודל עיבוד אודיו כדי לחלץ תכונות כמו טון וגובה, ולאחר מכן השתמש בתכונות אלו כדי לחזות את הסנטימנט.
-
מיזוג: שלב את ציוני הסנטימנט של הטקסט והאודיו (לדוגמה, ממוצע משוקלל) כדי לקבל את הסנטימנט הכולל.
-
דוגמת קוד (קונספטואלי באמצעות Python):
from transformers import pipeline # עבור רגשות טקסט
# ... (ייבוא סיורות עיבוד שמע וספריות רגשות - לא מופיעות) ...
# טעינת מודלים מאומנים מראש
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# רגשות טקסט
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# רגשות שמע
# ... (עיבוד שמע, הוצאת תכונות, חיזוי רגשות - לא מופיע) ...
audio_sentiment =
# ... (תוצאה ממודל רגשות שמע)
audio_confidence =
# ... (תוצאת ביטחון ממודל השמע)
# צירוף רגשות (לדוגמה: ממוצע משוקל)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# שימוש בדוגמה
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
אתגרים וחששות:
-
יישור נתונים: דאגת סנכרון ויישור של נתונים ממודלים שונים היא חשובה.
-
מורכבות מודל: מודלים מולטימודליים יכולים להיות מורכבים להדרכה ונדרשים קבוצות נתונים גדולות ומגוונות.
-
טכניקות הציפורה: בחירת השיטה הנכונה לצירוף מידע ממודלים שונים היא חשובה ותלויה בבעיה.
בינה מלאכותית מולטימודלית היא תחום המתפתח במהירות עם פוטנציאל לחולל מהפכה באופן שבו סוכני בינה מלאכותית תופסים ומתקשרים עם העולם.
מערכות בינה מלאכותית מבוזרות ומחשוב קצה
בהתבוננות על התפתחות תשתיות הבינה המלאכותית, המעבר למערכות בינה מלאכותית מבוזרות הנתמכות על ידי מחשוב קצה מייצג התקדמות משמעותית.
מערכות בינה מלאכותית מבוזרות מבצעות ביזור של משימות חישוביות על ידי עיבוד נתונים קרוב יותר למקור—כגון מכשירי IoT או שרתים מקומיים—במקום להסתמך על משאבי ענן מרוכזים. גישה זו לא רק מפחיתה את ההשהיה, שהיא קריטית עבור יישומים רגישים לזמן כמו רחפנים אוטונומיים או אוטומציה תעשייתית, אלא גם משפרת את פרטיות ואבטחת הנתונים על ידי שמירת מידע רגיש באופן מקומי.
כמו כן, מערכות בינה מלאכותית מבוזרות משפרות את הסקלביליות, ומאפשרות פריסת בינה מלאכותית ברשתות רחבות, כמו ערים חכמות, מבלי להעמיס על מרכזי נתונים מרוכזים.
האתגרים הטכניים הקשורים לבינה מלאכותית מבוזרת כוללים הבטחת עקביות ותיאום בין צמתים מבוזרים, כמו גם אופטימיזציה של הקצאת משאבים לשמירה על ביצועים בסביבות מגוונות ובעלות משאבים מוגבלים.
כאשר אתם מפתחים ומפרסים מערכות בינה מלאכותית, אימוץ ארכיטקטורות מבוזרות יהיה המפתח ליצירת פתרונות בינה מלאכותית עמידים, יעילים וסקלביליים העונים על הדרישות של יישומים עתידיים.
מערכות AI מבוזרות ומחשוב בקצה דוגמה 1: למידת פדרציה להכשרת מודלים עם שמירה על פרטיות
-
מטרה: להכשיר מודל משותף על פני מספר מכשירים (למשל, סמארטפונים) מבלי לשתף ישירות נתוני משתמש רגישים.
-
גישה:
-
הכשרה מקומית: כל מכשיר מאמן מודל מקומי על הנתונים שלו.
-
אגרגציית פרמטרים: המכשירים שולחים עדכוני מודלים (גרדיאנטים או פרמטרים) לשרת מרכזי.
-
עדכון מודל גלובלי: השרת מאגד את העדכונים, משפר את המודל הגלובלי ושולח את המודל המעודכן חזרה למכשירים.
-
דוגמא קוד (מושגית בעזרת הפייתון וPyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
# ... (קוד לתקשורת בין ההתקנים והשרת - לא מראה) ...
class SimpleModel(nn.Module):
# ... (הגדר את המבנה של המודל שלך כאן) ...
# פונקציית התרעון לצד ההתקן
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # התחל עם המודל הגלובלי
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (עבדו את local_model על המידע של ההתקן) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# פונקציית איחוד בצד השרת
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (לולאת הלמידה המרכזית של הפדרציום - פשוטה) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

דוגמא 2: אבחן אובייקטים בזמן אמת על הקצה המורגש
-
מטרה: שישתמשו במודל לאבחן אובייקטים על התקן עם משאבים מגבלים (לדוגמה, Raspberry Pi) עבור הערכה בזמן אמת.
-
גישה:
-
שיפור מודל: השתמשו בשיטות כמו כמותה של מודלים או הכרעה כדי להפחית את גודל המודל ודרישות החישוב.
-
הפליאה בקצה: הפליאו את המודל המופעל למכשיר הקצה.
-
חישוב מקומי: המכשיר מבצע זיהוי אובייקטים באופן מקומי, מוריד דיכיון ותלות בתקשורת של ענן.
-
דוגמת קוד (תפיסתית בשימוש בפייתון וטנסורפור לייט):
import tensorflow as tf
# טען את המודל המוכן לאחר ההערכה (נראה שכבר מותאם לTensorFlow Lite)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# מקבל פרטים לקלט ויוצאה
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (סוף תמונה ממצלמת או מקובץ - אינו מוצג) ...
# מעבדת התמונה הקדם
input_data = ... # הגדלה, הונולוגיזציה וכן הלאה
interpreter.set_tensor(input_details[0]['index'], input_data)
# ביצוע הערכה
interpreter.invoke()
# מקבלת היצאה
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (עיבדת היצאה כדי לקבל קובעים, מחזורים וכן הלאה) ...
אתגרים ודעות לשים לב:
-
מעבר העלות התקשורת: מאוד חשוב לשיתוף פעולה ותקשורת יעילה בין האזורים המפורטים.
-
ניהול משאבים: חשוב לאופטימיזציית התפקידים (CPU, זיכרון, רוחב גלאי) על מנת המכשירים.
-
אבטחה: אבטחת המערכות המפורטים והגנת פרטיות המידע הם דאגות עיקריות.
שיתוף הערכים בעזרת מערכות ביולוגיות משנה את הדרך בה אנחנו מתייחסים לשימוש בפעילויות הגנה והבריאה בטבע.
התקדמויות בניתוח השפה טבעית
מעבדת השפה הטבעית (NLP) ממשיכה להיות בקדם בהתקדמויות המערכות הביולוגיות, ומניעה שיפור משמעותי באופן בו מכונות מבינות, יוצרות ומתבטאות בשפה אנושית.
התקדמויות עדכניות בNLP, כמו האבולוציה של מודלים הטרנספורמרס ומנגנונים התשומת-מידה, עידכנו את יכולת המכונות לעבדת מבנים לשפה מורכבים, וגיבינו את האינטראקציות בצורה יותר טבעית ומודעת ההקשר.
ההתקדמויות האלה אפשרו למערכות הAI להבין ניואנטים, רגשות ואפילו מרכזים תרבותיים בתXT, ולהוביל לתקשורת יותר דירוג ומשמעותית.
לדוגמה, בשירותים ללקוחות, מודלים עדכניים של NLP יכולים לטפל בשאילות בדיוק וגם לזהות את האותות הרגשיים מהלקוחות, אז אפשר להגיב באופן יותר אמפתי ויעיל.
הביטוי המרכזי שלנו הוא שהשילוב של יכולות רב-לغתיות והבנה עמוקה יותר במודלים NLP ירחב את היישומים שלהם, ויאפשר להם לתקשור בצורה שקשה בשפות שונות ודיאלקטים, ואפילו לאמצע תרגום בזמן אמת בהקשרים גלובליים מגוונים.
מעבדת השפה הטבעית (NLP) מתקדמת
דוגמה ל-NLP 1: ניתוח סנטימנטים עם מודלי טרנספורמר מותאמים
-
מטרה: לנתח את הסנטימנט של טקסט בדיוק גבוה, תוך תפיסת דקויות והקשר.
-
גישה: להתאים מודל טרנספורמר מאומן מראש (כמו BERT) על סט נתונים לניתוח סנטימנטים.
דוגמת קוד (באמצעות פייתון ו-Hugging Face Transformers):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# טען מודל מאומן מראש וסט נתונים
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3 תוויות: חיובי, שלילי, נייטרלי
dataset = load_dataset("imdb", split="train[:10%]")
# הגדר פרמטרים לאימון
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# כוון את המודל
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# שמור את המודל המכוון
model.save_pretrained("./fine_tuned_sentiment_model")
# טען את המודל המכוון לשימוש
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# דוגמת שימוש
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
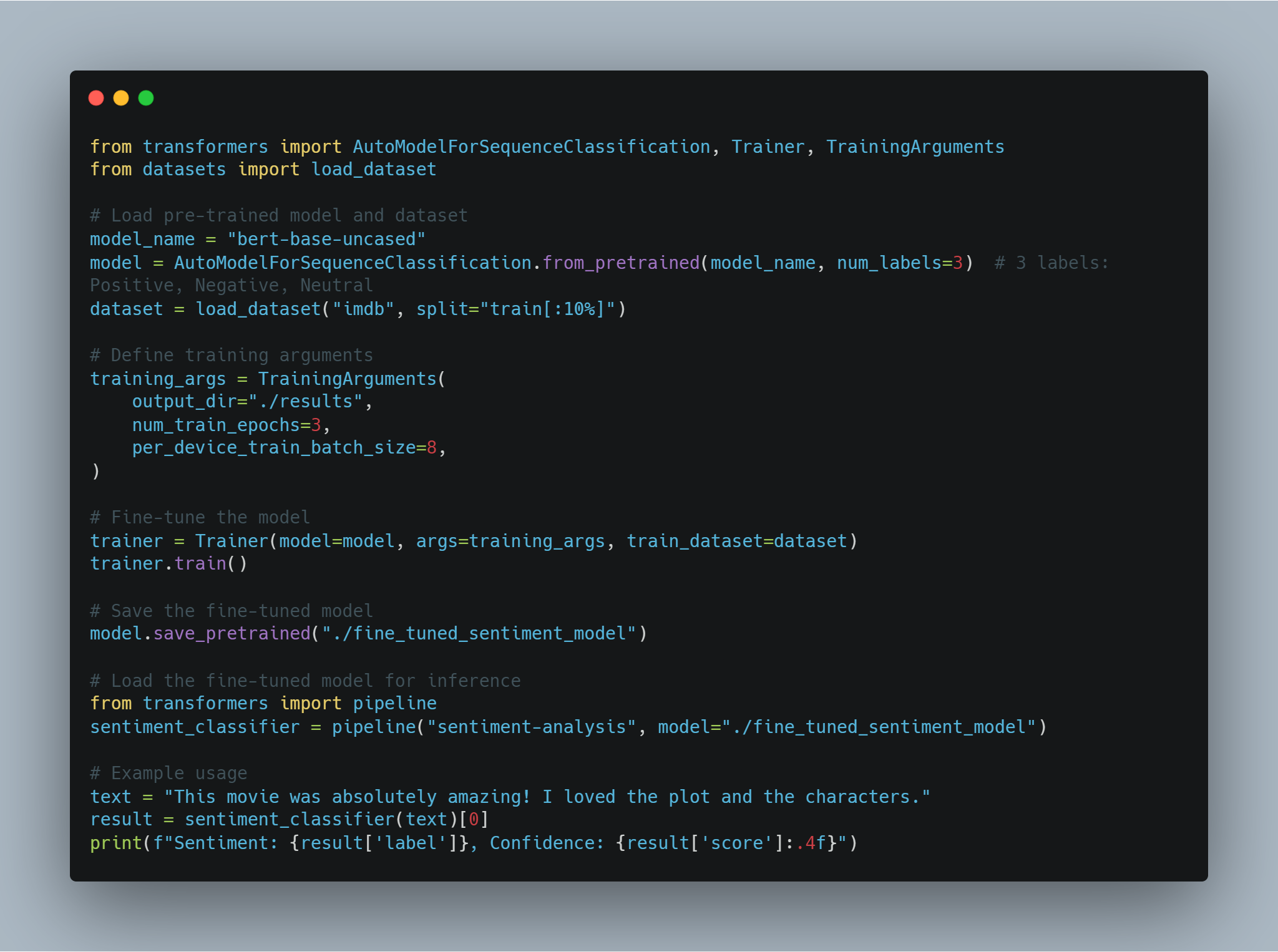
דוגמת NLP 2: תרגום מכונה רב-לשוני עם מודל יחיד
-
מטרה: לתרגם בין שפות שונות באמצעות מודל יחיד, תוך ניצול ייצוגים לשוניים משותפים.
דוגמא קוד (בעזרת הגשת פיתוח וטרנספורמרס של הגשת פיתוח מהאינטרנט):
from transformers import pipeline
# טעינת תווך תשתית מתארגנת רבת השפות לתרגום
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# השתמשות מודל: מילים באנגלית לצרפתית
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# השתמשות מודל: מילים בצרפתית לספרדית
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
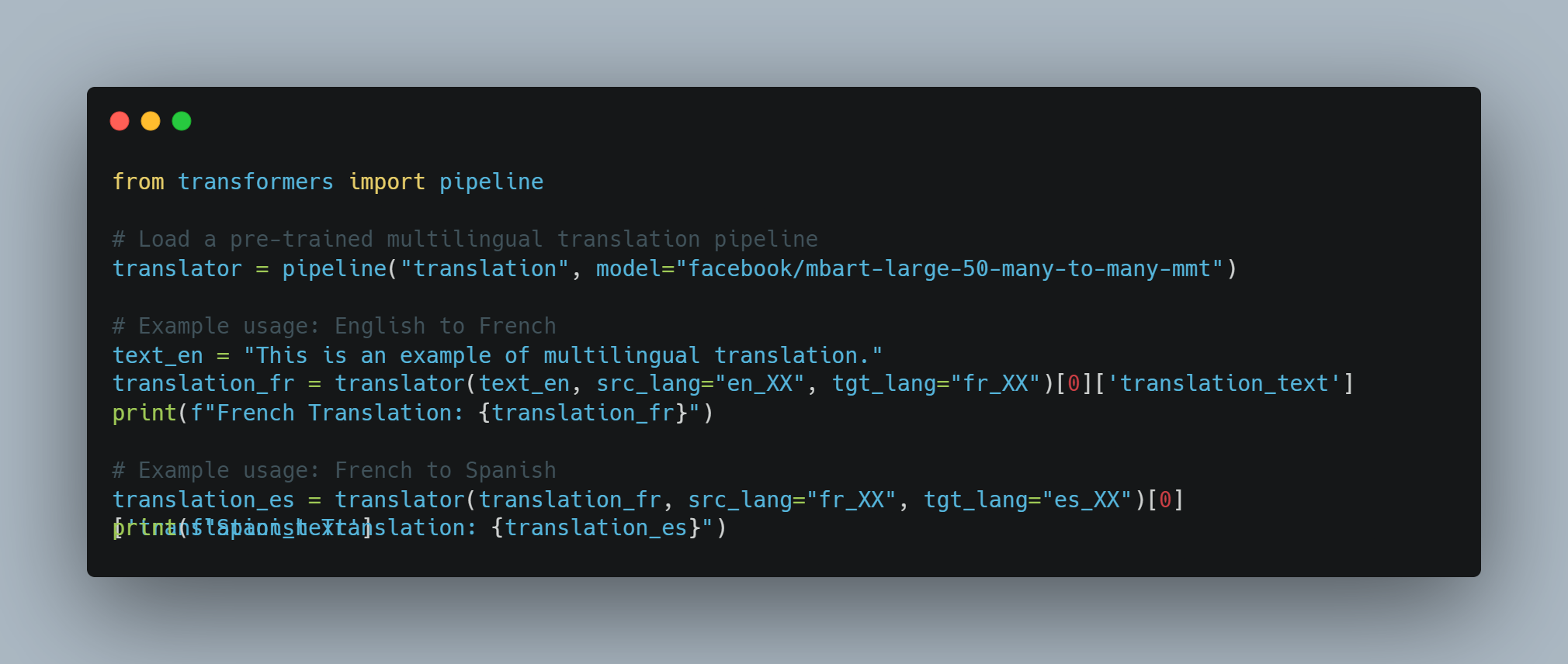
דוגמא 3 למידע מילים ברגעים במוניטין התוארגן לדוגמא סימילריות
-
מטרה: לקבע את הדמיון בין מילים או משפטים, בהתחשב בהקשר.
-
מודל: השתמשות במודל ממש גדול, מולטיגני מוניטין (כמו BERT) ליצירת תדמיות מילים הקשורות בהקשר, שלוקחות את המשמעות של המילים במשפט ספציפי.
דוגמא קוד (בעזרת הגשת פיתוח וטרנספורמרס של הגש
from transformers import AutoModel, AutoTokenizer
import torch
# לודאי שימוש במודל מאומן קודם וטוקניzer
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# פעולה לקבלת הבעות מלשוניות
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# משתמשים בהבעה של הטוקן [CLS] בתור הבעה של המשפט
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# השתמשות טיפוסית
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# מחישה דמיון קוסיני
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
אתגרים והולכים העתידים:
-
הטיעון והשוויון: מודלי NLP יכולים להעלות ביעוץ מהמידע המאמן שלהם, למעשה מובילים לתוצאות לא שוויוניות או מתיחסות לאופן מייצג. טיפול בטיעון הוא חשוב.
-
ההגיון הפשוט: LLMs עדיין מתקשים עם ההגיון הפשוט ובהבנת מידע בלתי ברור.
-
הבעייה המסבירת: תהליך ההחלטה של מודלי NLP מאופנים יכול להיות אטום, מה שמקשה על הבנה מדוע הם מייצרים את הייצוגים המסוימים שלהם.
למרות האתגרים הללו, עיבוד שפה טבעית (NLP) מתקדם במהירות. שילוב מידע מולטימודלי, שיפור ההיגיון הבריא והגברת ההסבריות הם תחומים מרכזיים של מחקר מתמשך שיביאו למהפכה נוספת באינטראקציה של בינה מלאכותית עם השפה האנושית.
עוזרי AI מותאמים אישית
העתיד של עוזרי AI מותאמים אישית צפוי להפוך למתקדם יותר ויותר, מעבר לניהול משימות בסיסי לתמיכה אינטואיטיבית ופרואקטיבית המותאמת לצרכים האישיים.
עוזרים אלו ינצלו אלגוריתמים מתקדמים של למידת מכונה כדי ללמוד ברציפות מהתנהגויותיך, העדפותיך ושגרותיך, ולהציע המלצות מותאמות אישית יותר ולבצע אוטומציה של משימות מורכבות יותר.
לדוגמה, עוזר AI מותאם אישית יכול לנהל לא רק את לוח הזמנים שלך אלא גם לצפות את צרכיך על ידי הצעת משאבים רלוונטיים או התאמת הסביבה שלך בהתבסס על מצב הרוח שלך או העדפות עבר.
כאשר עוזרי AI משתלבים יותר בחיי היומיום, יכולתם להסתגל להקשרים משתנים ולספק תמיכה חלקה בין פלטפורמות תהפוך למבדיל מרכזי. האתגר טמון באיזון בין התאמה אישית לפרטיות, ודורש מנגנוני הגנה על נתונים חזקים כדי להבטיח שניהול מידע רגיש יתבצע בצורה מאובטחת תוך מתן חוויה מותאמת אישית לעומק.
דוגמה לעוזרי AI 1: הצעת משימות מודעות להקשר
-
מטרה: עוזר שמציע משימות בהתבסס על ההקשר הנוכחי של המשתמש (מיקום, זמן, התנהגות קודמת).
- גישה: שילוב מידע של המשתמש, אותות הקשר, ומודל למציאת משימות.
דוגמא לקוד (מושגית בשימוש בפינגווין):
# ... (קוד לניהול מידע של המשתמש, זיהוי הקשר - לא מוצג) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# דוגמה: הצעות מבוססות על הזמן
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# דוגמה: הצעות מבוססות על מיקום
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (הוסף דידקא או משתמש במודל למידע מכונה עבור הצעות) ...
# רשימת וסניפרציה של ההצעות
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- השתמשות דוגמית ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... נוהגים נוספים ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... נתוני הקשר נוספים ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
דוגמא לסיוע בעזרת עיניים מבוססת על עצמה 2: ספקת מידע פרואקטיבית
- מטרה: סיוע שמספק מידע רלוונטי בהתבסס על לוח הזמנים והעדפות של המשתמש.
- <di
דוגמא קוד (מושגית בעזרת השפה פינגווין):
# ... (קוד לגישה ללוח השנתי, פרופיל של האינטרסים של המשתמש - לא מוצג) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (שימוש במידע על החברה, פרופילים של המשתתפים וכו') ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (שימוש במידע על מצב הטיסות, מידע על היעדים וכו') ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- השתמשות מודל ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... עוד העדפות אחרות ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

משהו כמו סיועת עיניים מבוססת-מודעות מסוג 3: המצגת תוכן מותאמת אישית
-
מטרה: סיועת עיניים שמוליך תוכן (מאמרים, סרטונים, מוסיקה) שמותאמים לאינטרסים של המשתמש.
-
גישה: שימוש בסיועת משותפת או במערכות מוצא תוכן בעזרת תערוכת תוכן.
דוגמא קוד (מושגית בעזרת השפה פינגווין וספרייה כמו Surprise):
from surprise import Dataset, Reader, SVD
# ... (קוד לניהול דירוגי משתמשים, מסד תוכן - לא מוצג) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (קבלת תחזיות לכל הפריטים, דירוג, והחזרת הטופ N) ...
# --- שימוש לדוגמה ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... עוד דירוגים ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
אתגרים ושיקולים אתיים:
-
פרטיות נתונים: טיפול באחריות ושקיפות בנתוני משתמשים הוא חיוני.
-
הטיה והוגנות: פרסונליזציה לא צריכה להעצים הטיות קיימות.
-
שליטת משתמש: למשתמשים צריכה להיות שליטה על הנתונים שלהם ועל הגדרות הפרסונליזציה.
בניית עוזרים אישיים מבוססי AI דורשת שיקול דעת טכני ואתי זהיר כדי ליצור מערכות מועילות, אמינות ומכבדות פרטיות משתמשים.
AI בתעשיות יצירתיות
AI חודר באופן משמעותי לתעשיות היצירתיות, ומשנה את האופן שבו מיוצרים ונצרכים אמנות, מוזיקה, קולנוע וספרות. עם ההתקדמות במודלים גנרטיביים, כמו רשתות עוינות גנרטיביות (GANs) ומודלים מבוססי טרנספורמרים, AI יכול כעת ליצור תוכן שמתחרה עם היצירתיות האנושית.
למשל, ה-AI יכול להכניס מוסיקה שמשקפת סגנונות מסוימים או מצבי רוח, ליצור אומנות דיגיטלית שמחקה את הסגנון של ציירים מפורסמים, או אפילו לכתוב עלילות סיפוריות לסרטים ורומנים.
בתעשיית הפרסום, ה-AI משמשת ליצירת תוכן אישי שמתקשר עם צרכנים יחידים, משפרת תפקידה ויעילותה.
אך ההתעלות של ה-AI בשדות יצירתיים גם מעלה שאלות על יוצרות, מקוריות ותפקידה של היצירתיות האנושית. כשתתעסק עם ה-AI בתחומים אלה, יהיה חשוב לחקור כיצד ה-AI יכול להשלים את היצירתיות האנושית במקום להחליף אותה, על ידי גיבוש שיתוף פעולה בין בני-אדם ומכונות ליצירת תוכן חדשני ומשפיע.
הנה דוגמה לכיצד GPT-4 יכול להשתלב בפרוייקט Python למשימות יצירתיות, במיוחד בתחום הכתיבה. הקוד הזה מדגים איך לנצל את היכולות של GPT-4 ליצור פורמטים יצירתיים של טקסט, כמו שירה.
import openai
# הגדרת מפתח ה-API של OpenAI
openai.api_key = "YOUR_API_KEY"
# הגדרת פונקציה ליצירת שירה
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# שימוש בדוגמה
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
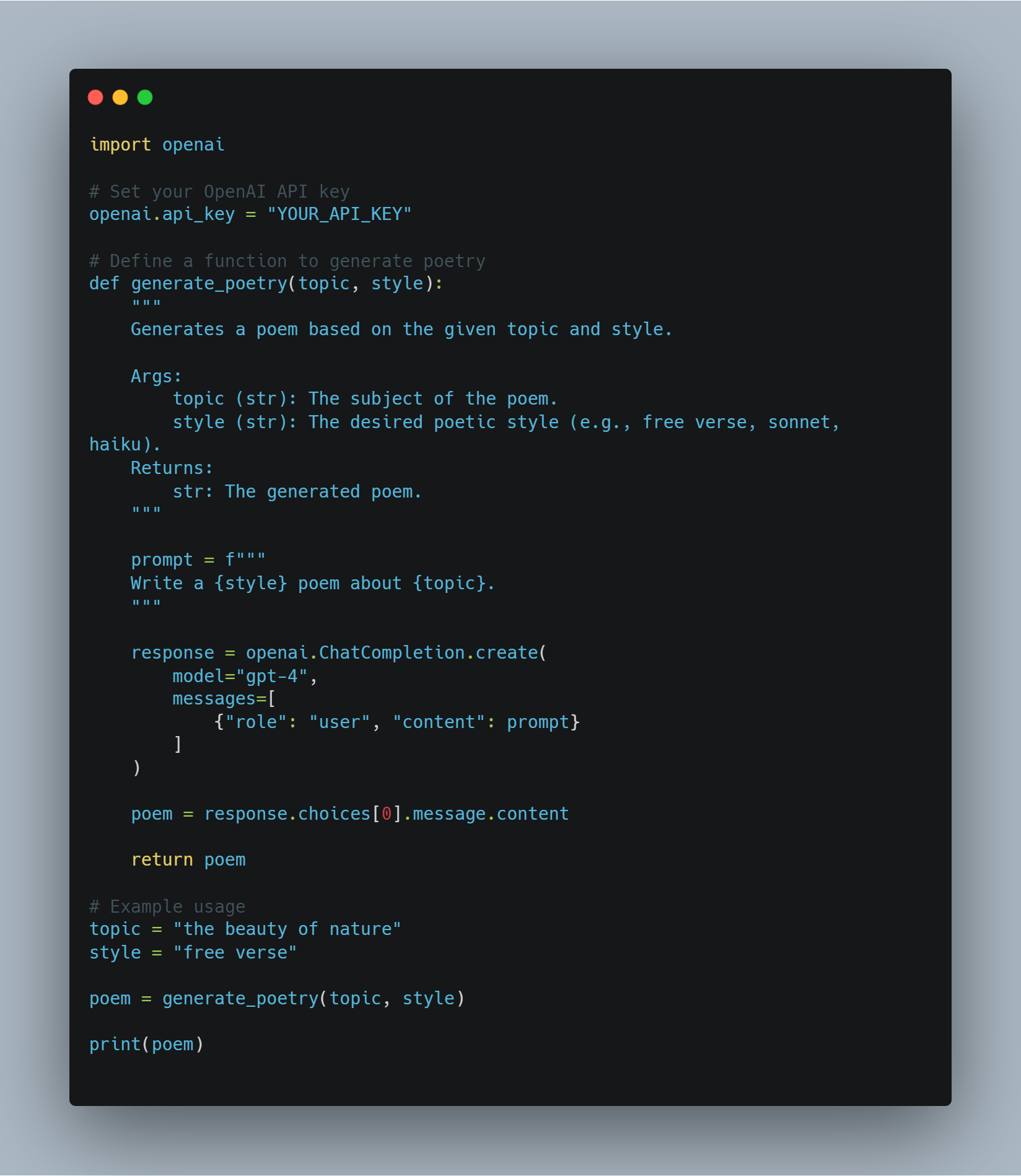
בואו נראה מה קורה כאן:
-
ייבוא ספריית OpenAI: הקוד יוביא ספריית
openaiכדי לגשת ל-API של OpenAI. - הגדרת מ
- הגדרה של פעולת
generate_poetry: הפעולה משתמשת בtopicוstyleשל השירה כקלט ומשתמשת ב API השיחה להשלמה של OpenAI כדי לייצר את השירה. - בניית התעד: התעד משלב את
topicוstyleלהוראה ברורה עבור GPT-4. - שליחת התעד ל GPT-4: הקוד משתמש ב
openai.ChatCompletion.createכדי לשלוח את התעד ל GPT-4 ולקבל את השירה המיוצרת בתגובה. - שיבת השירה: אחר כך, השירה המיוצרת מונחת מהתגובה וחוזרת על-ידי הפעולה.
-
שימוש לדוגמה: הקוד מדגים כיצד לקרוא לפונקציה
generate_poetryעם נושא וסגנון ספציפיים. השיר שנוצר מודפס לאחר מכן על הקונסולה.
עולמות וירטואליים המונעים על ידי AI
הפיתוח של עולמות וירטואליים המונעים על ידי AI מייצג קפיצה משמעותית בחוויות סוחפות, שבהן סוכני AI יכולים ליצור, לנהל ולהתפתח בסביבות וירטואליות שהן גם אינטראקטיביות וגם מגיבות לקלט של המשתמש.
עולמות וירטואליים אלו, המונעים על ידי AI, יכולים לדמות מערכות אקולוגיות מורכבות, אינטראקציות חברתיות ונרטיבים דינמיים, ומציעים למשתמשים חוויה מעמיקה ומותאמת אישית.
לדוגמה, בתעשיית המשחקים, ניתן להשתמש ב-AI ליצירת דמויות שאינן ניתנות למשחק (NPC) שלומדות מהתנהגות השחקן, ומתאימות את פעולותיהן ואסטרטגיותיהן כדי לספק חוויה מאתגרת ומציאותית יותר.
מעבר למשחקים, לעולמות וירטואליים המונעים על ידי AI יש יישומים פוטנציאליים בחינוך, שבהם כיתות וירטואליות יכולות להיות מותאמות לסגנונות הלמידה וההתקדמות של תלמידים פרטניים, או בהכשרת עובדים, שבהם סימולציות מציאותיות יכולות להכין עובדים לתרחישים שונים.
עתידם של סביבות וירטואליות אלו יהיה תלוי בהתקדמות היכולת של AI לייצר ולנהל מערכות דיגיטליות מורכבות ורחבות בזמן אמת, כמו גם בשיקולים אתיים סביב נתוני משתמשים וההשפעות הפסיכולוגיות של חוויות סוחפות מאוד.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# מיזם סוכנים
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# הערכת מיקום אקראי בתוך הסביבה
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# יצירת סוכנים והוספתם
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# הזזת הסוכנים (הזזה פשוט למודעה)
for agent in self.agents:
agent.move(self.environment)
# לעשות: הוספת הגיון מורכב יותר עבור התאמה, שינויי סביבה ועוד
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# קבעת הכיוון הזעיר להזזה (אקראי למודעה הזו)
direction = random.choice(['N', 'S', 'E', 'W'])
# יישום ההזזה על-פי הכיוון
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# עדכון הסביבה כדי לשקף את המיקום החדש של הסוכנים
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# השימוש דוגמה
if __name__ == "__main__":
# הגדרת מדדי העולם
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# יצירת העולם המדומה
world = VirtualWorld(environment_size, agent_types, agent_properties)
# סימולציית העולם למספר צעדים
for _ in range(10):
world.update()
world.display()
print() # הוספת שורה ריקה לקראת קריאת טעם
הנה מה שקורה בקוד הזה:
-
מחלקת VirtualWorld:
-
מגדירה את הליבה של העולם הווירטואלי.
-
מכילה את רשת הסביבה, רשימת סוכנים ומידע הקשור לסוכנים.
-
__init__(): מאתחלת את העולם עם גודל, סוגי סוכנים ותכונות. -
add_agent(): מוסיפה סוכן חדש מסוג מסוים לעולם. -
update(): מבצעת עדכון של שלב זמן בודד בעולם.- כרגע זה רק מזיז את הסוכנים, אך ניתן להוסיף לוגיקה מורכבת לאינטראקציות בין סוכנים, שינויים בסביבה וכדומה.
-
display(): מדפיסה ייצוג בסיסי של הסביבה.
-
-
מחלקת סוכן:
-
מייצג סוכן יחיד בתוך העולם.
-
__init__(): מאתחל את הסוכן עם סוגו, מיקומו ותכונותיו. -
move(): מטפל בתנועת הסוכן, מעדכן את מיקומו בתוך הסביבה. השיטה הזו כרגע מספקת תנועה אקראית פשוטה, אבל ניתן להרחיב אותה לכלול התנהגויות AI מורכבות.
-
-
דוגמא שימוש:
-
מגדיר מפת עולם כמות מרחב, סוגים של סוכנים ותכונות שלהם.
-
יוצר אובייקט עולם מדומים.
-
מבצע את שימוש בשיטה
update()מספר פעמים בכדי לסימולט את התפתחות העולם. -
קוראת
display()אחרי כל עדכון כדי לתמונה את השינויים.
-
שיפורים:
- ביולוגיה סבוכה יותר של סוכנים: מימשפה ביולוגיה מורכבת יותר עבור התנהגויות
-
אינטרקציה עם הסביבה: הוסיפו אלמנטים דינמיים נוספים לסביבה, כמו מכשולים, משאבים או נקודות עניין.
-
אינטרקציה בין סוכנים: ממשו אינטרקציות בין סוכנים, כגון תקשורת, קרב, או שיתוף פעולה.
-
ייצוג ויזואלי: השתמשו בספריות כמו Pygame או Tkinter כדי ליצור ייצוג ויזואלי של העולם הווירטואלי.
דוגמה זו היא בסיס ראשוני ליצירת עולם וירטואלי מונע בינה מלאכותית. רמת המורכבות והתחכום יכולה להיות מורחבת על מנת להתאים לצרכים ולמטרות היצירתיות הספציפיות שלך.
מחשוב נוירומורפי ובינה מלאכותית
מחשוב נוירומורפי, המושפע מהמבנה והתפקוד של המוח האנושי, עתיד לחולל מהפכה בבינה מלאכותית על ידי הצעת דרכים חדשות לעיבוד מידע ביעילות ובמקביל.
בניגוד לארכיטקטורות מחשוב מסורתיות, מערכות נוירומורפיות מעוצבות לחקות את הרשתות הנוירוניות של המוח, מה שמאפשר לבינה מלאכותית לבצע משימות כמו זיהוי תבניות, עיבוד חושי וקבלת החלטות במהירות וביעילות אנרגטית גבוהה יותר.
טכנולוגיה זו מחזיקה בהבטחה עצומה לפיתוח מערכות בינה מלאכותית אדפטיביות יותר, המסוגלות ללמוד ממינימום נתונים ולהיות אפקטיביות בסביבות זמן אמת.
למשל, ברובוטיקה, שבבים נוירומורפיים יכולים לאפשר לרובוטים לעבד קלטים חושיים ולקבל החלטות ברמת יעילות ומהירות שהארכיטקטורות הנוכחיות אינן מסוגלות להתחרות בה.
האתגר לעתיד יהיה להרחיב את המחשוב הנוירומורפי כדי להתמודד עם המורכבות של יישומי בינה מלאכותית בקנה מידה גדול, לשלב אותו עם מסגרות בינה מלאכותית קיימות כדי למנף את הפוטנציאל המלא שלו.
סוכני בינה מלאכותית בחקר החלל
מוליכים בעלי ביצועים מערכתיים משחקים תפקיד קריטי בחקר החלל, בו מערכות אינטEL מופצות בתפקידים כמו ניווט בסביבות קשות, קבלת החלטות בזמן אמת וביצוע ניסויים מעצמיים בתחום המדעי.
בעקבות המשימות המדרגות אל מעבר לחלל העמוק, הדחף למערכות AI שיכולות לפעול בלי ספק בקשר לשלט כדור ארץ גדלה. מוליכים העתיד יועצמו להתמודד עם החלשות הבלתי צפוית של החלל, כמו מכשולים בלתי צפויים, שינויים בפרמטרים של המשימה או הצורך בשיקום עצמי.
לדוגמה, AI יכול להשתמש להדריך רוברים על מאדים לחקור את המישורים באופן אוטונומי, לזהות את האתרים המדעיים החשובים ואפילו לקדוח אבני דגימה עם המינימום העדין מעבר לשלט המשימה. מוליכים אלה יכולים גם לנהל את מערכות התמיכה בחיים במשימות מורגנות בטווח ארוך, לוודא את השימוש באנרגיה, ולהסתגל לצרכים הפסיכולוגיים של האסטרונאוטים על ידי סיפור קבלה ועידוד מחשבה.
האינtegration של AI בחקר החלל לא רק משחק תפקיד ביכולות המשימה אלא פתח גם אפשרויות חדשות לחקירת הקוסמוס על ידי בני אדם, בהם AI יהיה שותף בלתי ניתן להיפטר במסע להבין את היקום שלנו.
פרק 8: מוליכים בתחומים קריטיים למשימה
רפואה
ברפ
באמצעות עיבוד שפה טבעית (NLP) מתקדם ואלגוריתמים של למידת מכונה, מערכות אלו מבצעות משימות מורכבות כגון מיון תסמינים ואיסוף נתונים ראשוני ברמת דיוק גבוהה. הן מנתחות תסמינים שדווחו על ידי מטופלים והיסטוריות רפואיות בזמן אמת, ומצליבות מידע זה עם מאגרי מידע רפואיים נרחבים כדי לזהות מצבים פוטנציאליים או דגלים אדומים.
זה מאפשר לספקי שירותי בריאות לקבל החלטות מושכלות מהר יותר, מה שמפחית את הזמן לטיפול וייתכן שמציל חיים. כמו כן, כלים דיאגנוסטיים מונעי בינה מלאכותית בהדמיה רפואית משנים את תחום הרדיולוגיה על ידי זיהוי תבניות ואנומליות בצילומי רנטגן, MRI ו-CT שאולי אינן נתפסות בעין אנושית.
מערכות אלו מאומנות על מערכי נתונים נרחבים הכוללים מיליוני תמונות עם הערות, מה שמאפשר להן לא רק לשכפל אלא לעיתים קרובות להתעלות על יכולות האבחון האנושיות.
השילוב של בינה מלאכותית בתחום הבריאות מתרחב גם למשימות אדמיניסטרטיביות, שבהן אוטומציה של קביעת תורים, תזכורות לתרופות ומעקב אחר מטופלים מפחיתה באופן משמעותי את העומס התפעולי על צוותי הבריאות, ומאפשרת להם להתמקד בהיבטים קריטיים יותר של טיפול במטופלים.
פיננסים
במגזר הפיננסי, סוכני בינה מלאכותית חוללו מהפכה בפעילות על ידי הכנסת רמות חסרות תקדים של יעילות ודיוק.
מסחר אלגוריתמי, שמבוסס במידה רבה על בינה מלאכותית, שינה את הדרך שבה מבוצעים עסקאות בשווקים הפיננסיים.
מערכות אלו מסוגלות לנתח מאגרי נתונים עצומים במילישניות, לזהות מגמות שוק ולבצע עסקאות ברגע האופטימלי כדי למקסם רווחים ולהפחית סיכונים. הן מנצלות אלגוריתמים מורכבים שמשלבים למידת מכונה, למידה עמוקה וטכניקות למידת חיזוק כדי להסתגל לתנאי השוק המשתנים, ולקבל החלטות מהירות שלא ניתן להשוות להן עם סוחרים אנושיים.
מעבר למסחר, AI ממלא תפקיד מרכזי בניהול סיכונים על ידי הערכת סיכוני אשראי וזיהוי פעילויות הונאה בדיוק יוצא דופן. מודלי AI משתמשים בניתוח תחזיתי להערכת סבירות ברירת מחדל של לווה על ידי ניתוח דפוסים בהיסטוריות אשראי, התנהגויות עסקאות וגורמים רלוונטיים אחר��ם.
כמו כן, בתחום תאימות רגולטורית, AI מבצע אוטומציה של מעקב אחר עסקאות כדי לזהות ולדווח על פעילויות חשודות, להבטיח שמוסדות פיננסיים עומדים בדרישות הרגולטוריות המחמירות. אוטומציה זו לא רק מפחיתה את הסיכון לטעויות אנוש, אלא גם מייעלת את תהליכי התאימות, מפחיתה עלויות ומשפרת את היעילות.
ניהול חירום
תפקיד ה-AI בניהול חירום הוא מהפכני, משנה באופן יסודי את האופן בו ניבויים, ניהול והתמודדות עם משברים.
בתגובה לאסונות, סוכני AI מעבדים כמויות עצומות של נתונים ממקורות שונים—מניתוח תמונות לוויין ועד להזנות מדיה חברתית—כדי לספק תמונה מקיפה של המצב בזמן אמת. אלגוריתמי למידת מכונה מנתחים נתונים אלה כדי לזהות דפוסים ולחזות את התפתחות האירועים, מה שמאפשר למגיבים לחירום להקצות משאבים בצורה יעילה יותר ולקבל החלטות מושכלות תחת לחץ.
לדוגמה, במהלך אסון טבע כמו הוריקן, מערכות בינה מלאכותית יכולות לחזות את מסלול ועוצמת הסערה, ולאפשר לרשויות להוציא הוראות פינוי בזמן ולפרוס משאבים לאזורים הפגיעים ביותר.
באנליטיקה חיזויית, מודלים של בינה מלאכותית משמשים לחיזוי מצבי חירום פוטנציאליים על ידי ניתוח נתונים היסטוריים יחד עם קלטים בזמן אמת, מה שמאפשר אמצעים פרואקטיביים שיכולים למנוע אסונות או למזער את השפעתם.
מערכות תקשורת ציבורית המופעלות על ידי בינה מלאכותית גם משחקות תפקיד קריטי בהבטחת שהמידע המדויק והעדכני מגיע לאוכלוסיות המושפעות. מערכות אלו יכולות ליצור ולהפיץ התרעות חירום במגוון פלטפורמות, להתאים את ההודעות לדמוגרפיות שונות כדי להבטיח הבנה והתנהלות בהתאם.
ובינה מלאכותית משפרת את המוכנות של מגיבי חירום על ידי יצירת סימולציות אימון מציאותיות מאוד באמצעות מודלים גנרטיביים. סימולציות אלו משכפלות את המורכבות של מצבי חירום בעולם האמיתי, ומאפשרות למגיבים לשפר את כישוריהם ולהגביר את מוכנותם לאירועים אמיתיים.
תחבורה
מערכות בינה מלאכותית הופכות לחיוניות במגזר התחבורה, שם הן משפרות את הבטיחות, היעילות והאמינות בתחומים שונים, כולל בקרת תעבורה אווירית, רכבים אוטונומיים ותחבורה ציבורית.
בבקרת תעבורה אווירית, סוכני בינה מלאכותית חשובים באופטימיזציה של מסלולי טיסה, חיזוי עימותים פוטנציאליים וניהול פעולות שדה התעופה. מערכות אלו משתמשות באנליטיקה חיזויית כדי לנבא פקקי תעופה פוטנציאליים, ולהפנות טיסות בזמן אמת כדי להבטיח בטיחות ויעילות.
בתחום הרכבים האוטונומיים, הבינה המלאכותית נמצאת בלב הפתרון שמאפשר לרכבים לעבד נתוני חיישנים ולקבל החלטות בשבריר שנייה בסביבות מורכבות. מערכות אלו משתמשות במודלים של למידה עמוקה שאומנו על מערכי נתונים נרחבים כדי לפרש נתונים חזותיים, שמיעתיים ומרחביים, מה שמאפשר ניווט בטוח דרך תנאים דינמיים ובלתי צפויים.
מערכות תחבורה ציבורית גם נהנות מבינה מלאכותית דרך תכנון מסלולים אופטימלי, תחזוקה חזויה של רכבים וניהול תנועת נוסעים. על ידי ניתוח נתונים היסטוריים ובזמן אמת, מערכות בינה מלאכותית יכולות להתאים לוחות זמנים של תחבורה, לחזות ולמנוע תקלות ברכבים ולנהל שליטה בקהל בשעות עומס, ובכך לשפר את היעילות והאמינות הכוללת של רשתות התחבורה.
תחום האנרגיה
בינה מלאכותית ממלאת תפקיד חשוב במיוחד בתחום האנרגיה, בעיקר בניהול רשתות חשמל, אופטימיזציה של אנרגיה מתחדשת וזיהוי תקלות.
בניהול רשתות חשמל, סוכני בינה מלאכותית מנטרים ושולטים ברשתות החשמל על ידי ניתוח נתוני זמן אמת מחיישנים המפוזרים ברחבי הרשת. מערכות אלו משתמשות בניתוח חזוי כדי לאופטימיזציה של הפצת האנרגיה, להבטיח שההיצע יענה על הביקוש תוך מזעור בזבוז האנרגיה. מודלים של בינה מלאכותית גם חוזים תקלות פוטנציאליות ברשת, מה שמאפשר תחזוקה מונעת והפחתת הסיכון להפסקות חשמל.
בתחום האנרגיה המתחדשת, מערכות בינה מלאכותית משמשות לחיזוי דפוסי מזג האוויר, דבר הקריטי לאופטימיזציה של ייצור אנרגיה סולארית ורוח. מודלים אלו מנתחים נתונים מטאורולוגיים כדי לחזות את עוצמת השמש ומהירות הרוח, מה שמאפשר תחזיות מדויקות יותר של ייצור אנרגיה ושילוב טוב יותר של מקורות מתחדשים ברשת.
אבחן שגיאות הוא תחום נוסף בו המערכות המבוססות על מידע מבחנים משימוש במתקן כמו מערכות מעבדה, טורבינות וגנרטורים כדי לזהות סימנים של שיתוק ושיתרענן או תסמינים מוקדמים של כשלונות לפני שהם יובילו לכשלון. הגישה המפורסמת הזו לשימור קידמת לא רק תוחלת החיים של הציוד אלא גם מובטחת את התערבות המתמשכת והבטיחה של ספק האנרגיה.
סייבר-סיקורי
בתחום הסייבר-סיקורי, סינדרומים ממונעים על-ידי מערכות מבוססות על מידע הם חיוניים לשמירה על היושרה והבטיחות של תשתיות דיגיטליות. המערכות האלה מעוצבות כך שישמשות למען השגרה קבעת מעקב בתנועת הרשת, בעזרת אלגוריתמים ללמידה ממשית כדי לזהות סימנים של התקלה בבטחון.
דרך ניתוח כמות עצומה של מידע בזמן אמת, סינדרומים ממונעים יכולים לזהות דפוסים של התנהגויות מורדעות, כמו נסיונות התחברות יוצאים מהדרך הרגילה, פעילויות של יציאת נתונים או נוכחות מלאכות. ברגע שסימן איום אחד נזהה, מערכות ממונעים יכולות באופן אוטומטי להתחיל פעולות נגדות, כמו בידוד מערכות פגועות והגדלת תוספי תיקום, כדי למנוע נזק נוסף.
הערכים המושפעים של AI בסייבר-סיקורי מוספים גם להערכת פגיעות. כלים מונעים על-י
האוטומציה של תהליכים אלה לא רק משפרת את מהירות ודיוק גילוי האיומים והתגובה אליהם, אלא גם מפחיתה את עומס העבודה על אנליסטים אנושיים, מה שמאפשר להם להתמקד באתגרים ביטחוניים מורכבים יותר.
ייצור
בתחום הייצור, הבינה המלאכותית מניעה התקדמות משמעותית בבקרת איכות, תחזוקה מונעת ואופטימיזציה של שרשרת האספקה. מערכות ראייה ממוחשבות מבוססות בינה מלאכותית מסוגלות כעת לבדוק מוצרים לאיתור פגמים במהירות וברמת דיוק שעולה בהרבה על היכולות האנושיות. מערכות אלו משתמשות באלגוריתמים של למידה עמוקה המאומנים על אלפי תמונות כדי לזהות אפילו את הפגמים הקטנים ביותר במוצרים, מה שמבטיח איכות עקבית בסביבות ייצור בנפח גבוה.
תחזוקה מונעת היא תחום נוסף שבו יש לבינה המלאכותית השפעה עמוקה. על ידי ניתוח נתונים מחיישנים המוטמעים במכונות, מודלים של בינה מלאכותית יכולים לחזות מתי סביר שמכשור ייכשל, מה שמאפשר לתזמן תחזוקה לפני שמתרחשת תקלה. גישה זו לא רק מפחיתה את זמן ההשבתה אלא גם מאריכה את חיי המכונות, מה שמוביל לחיסכון משמעותי בעלויות.
בניהול שרשרת האספקה, סוכני בינה מלאכותית מייעלים את רמות המלאי והלוגיסטיקה על ידי ניתוח נתונים מכל רחבי שרשרת האספקה, כולל תחזיות ביקוש, לוחות זמנים לייצור ודרכי תחבורה. על ידי ביצוע התאמות בזמן אמת לתוכניות המלאי והלוגיסטיקה, הבינה המלאכותית מבטיחה שתהליכי הייצור יפעלו בצורה חלקה, ממזערת עיכובים ומפחיתה עלויות.
יישומים אלה מדגימים את התפקיד הקריטי של הבינה המלאכותית בשיפור היעילות התפעולית והאמינות בייצור, מה שהופך אותה לכלי שאין לו תחליף עבור חברות המעוניינות להישאר תחרותיות בתעשייה המתפתחת במהירות.
סיכום
השילוב של סוכני AI עם מודלים גדולים של שפה (LLMs) מסמן אבן דרך משמעותית בהתפתחות הבינה המלאכותית, ומשחרר יכולות חסרות תקדים בתעשיות ומדענים שונים. סינרגיה זו משפרת את התפקודיות, ההתאמה והישימות של מערכות AI, מתמודדת עם המגבלות המובנות של LLMs ומאפשרת תהליכי קבלת החלטות דינמיים, מודעים להקשר ועצמאיים יותר.
מהפכה בתחום הבריאות והפיננסים לשינוי תחבורה וניהול חירום, סוכני AI מניעים חדשנות ויעילות, ופותחים את הדרך לעתיד שבו טכנולוגיות AI משולבות עמוק בחיי היומיום שלנו.
כאשר אנו ממשיכים לחקור את הפוטנציאל של סוכני AI ו-LLMs, חשוב לעגן את פיתוחם בעקרונות אתיים המדגישים רווחה אנושית, הוגנות והכללה. על ידי הבטחת תכנון ופריסה אחראיים של טכנולוגיות אלו, נוכל לנצל את מלוא הפוטנציאל שלהן לשיפור איכות החיים, קידום צדק חברתי והתמודדות עם אתגרים גלובליים.
עתיד הבינה המלאכותית טמון בשילוב חלק של סוכני AI מתקדמים עם LLMs מתוחכמים, יצירת מערכות חכמות שלא רק מגבירות את יכולות האדם אלא גם מקפידות על הערכים שמגדירים את האנושיות שלנו.
המפגש בין סוכני AI ו-LLMs מייצג פרדיגמה חדשה בבינה המלאכותית, שבה שיתוף הפעולה בין הגמיש והחזק פותח תחום של אפשרויות בלתי מוגבלות. על ידי ניצול כוח סינרגטי זה, נוכל להניע חדשנות, לקדם גילוי מדעי וליצור עתיד שוויוני ומשגשג יותר עבור כולם.
על המחבר
היום אני בעמדת המפנה בין מדע המחשב, מדע הנתונים ועיוורון התכונות האינטEL. vaheaslanyan.com כדי לראות את הפורטפוליו שלי שהוא עדות לדיוק והתקדמות. הניסיון שלי מגיע לגבי שילוב פולשני הפיתוח והעידן של העיוורון התכונות האינטEL, מונע על-ידי פתרון בעיות בדרכים חדשות.
עם הישג שלי שמרגיש כולל השגת בית ספר למדעי הנתונים מוביל ועבודה עם מומחים מקצוע התעשייה, המיקוד שלי נשאר על הגבהת החינוך הטכנולוגי למעלה למען הסטנדרטים האוניברסליים.
איך אתה יכול לעודד יותר?
אחרי למידה במדריך זה, אם אתה רוצה לעודד יותר וללמוד באופן מאורגן, קח בחשבון להצטרף אלינו בLunarTech, אנחנו מעניקים קורסים בודדים ובוטקאמפ במדעי הנתונים, למימון מכונה ועיוורון התכונות האינטEL.
אנחנו מספקים תוכנית מקיפה שמעניקה ידיעה עמוקה בתיאוריה, יישום מעשי פעולה, חומר משאבים מרחבים והכנה מותאמת אישית לסיום ההערכה כדי להכין אתכם להצלחה בשלב המילה המשלכת עליכם.
שימו לב לשיעורי הכישורים המובילים שלנו אולטימטיבי קורס הדטה סיינס והצטרפו לניסוי חינם כדי לנסות את התוכן בעצמכם. הקורס הזה זכה בהכרה כאחד מהקורסים המובילים לדטה סיינס של 2023, והופיע בפרסומים מכבדים כמו Forbes, Yahoo, Entrepreneur ועוד. זו הזדמנות להיות חלק מקהילה ששובה על החדשנות והידע. הנה הודעת הקבלה!
תתרשמו איתי

עקבו אחרי בLinkedIn עבור מגוון רחב של משאבים חינמיים בתחום המדעי המחשב, מחשוב מלאכותי ובינה מלאכותית
אם אתה רוצה ללמוד עוד על קריירה במדעי המידע והמילים החכמות, ואיך לאסוף עבודה במדעי המידע, אתה יכול להוריד את המדעי המידע והמילים החכמות בקריירההחינמי הזה.
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/