













얘트 기술의 빠른 진화는 대형 언어 모델(LLM)과 인공지능 에이전트(AI agent) 간 강력한 협력 관계를 만들었습니다. 이러한 동적인 상호 작용은 데비드와 골리앗의 이야기(투쟁 없이)와 비슷합니다. 민첩한 AI 에이전트는 거대한 LLM의 능력을 끌어올리고 강화시킵니다.
이手册은 AI 에이전트(데비드와 같은)가 어떻게 LLM(우리 시대의 골리앗과 같은)를 지원하여 다양한 산업과 과학 영역을 혁신시키는지 탐구합니다.
목차
언어 모델에서의 AI 에이전트의 등장
AI 에이전트는 자동적인 시스템으로 자신의 환경을 인지하고 결정을 내리고, 특정 목표를 달성하기 위한 행동을 실행합니다. LLM과 결합되면 이러한 에이전트는 복잡한 작업을 수행하고 정보를 사고하며 혁신적인 솔루션을 생성할 수 있습니다.
이러한 결합은 소프트웨어 개발에서 과학적 연구까지 다양한 산업에 중요한 진전을 가져왔습니다.
산업에 변혁적인 영향
AI 에이전트와 LLM의 결합은 다양한 산업에 깊은 영향을 주었습니다:
-
소프트웨어 開発: GitHub Copilot과 같은 AI-기반 코딩 assistents가 40%까지의 코드를 생성할 수 있는 능력을 보였고, 이를 통해 開発 速度이 paradigm-shifting 55% 정도 향상되었습니다.
-
교육: AI-기반 학습 assistents가 평균 과정 완료 시간을 27% 정도 缩减할 수 있는 것을 보였으며, 教육 영역을 革命적으로 変革시키는 것이 期待され고 있습니다.
-
교통: 2030년까지 10%의 차량이 자율주행이 될 것이라는 전망에 따라, 자율 주행 자동차의 AI 에이전트는 교통 산업을 변화시킬 준비가 되어 있습니다.
과학 발견의 진보
AI 에이전트와 대규모 언어 모델(LLM)의 가장 흥미로운 응용 중 하나는 과학 연구입니다:
-
약물 발견: AI 에이전트는 방대한 데이터를 분석하고 잠재적인 약물 후보를 예측하여 전통적인 방법과 관련된 시간과 비용을 크게 줄임으로써 약물 발견 과정을 가속화하고 있습니다.
-
입자 물리학: CERN의 대형 하드론 콜айдerrer에서 AI 에이전트는 입자 충돌 데이터를 분석하고, 미발견 입자의 존재를 가리키는 가능성 있는 주제를 발견하기 위해 이상 감지 기법을 사용합니다.
-
일반 과학 연구: AI 에이전트는 과거 연구를 분석하고, 예상치 못한 연관을 식별하며, 새로운 실험을 제안함으로써 과학적 발견의 속도와 범위를 향상시킵니다.
AI 에이전트와 대형 언어 모델 (LLM)의 융합은 인공지능을 앞지르는 초고속의 새로운 시대로 들어갑니다. 이 문서는 이 두 기술 간의 동적인 상호작용을 살펴봅니다. 이들의 결합된 잠재력은 산업을 혁신시키고 복잡한 문제를 해결할 수 있는 것을 밝힙니다.
이 문서를 통해 AI 의 발달을 그 시작부터 자율적 에이전트의 등장과 정교한 LLM 의 등장까지 추적할 것입니다. 또한 AI 의 책임 있는 발전을 위해 필수적인 윤리적 고려에도 다가갑니다. 이를 통해 이 기술이 인간의 가치와 사회적 благ-being 으로부터 일치하는지 확보할 것입니다.
이 핸드북을 읽고 마친 후, AI 에이전트와 LLM 의 협력적인 힘에 대한 깊은 이해를 얻을 것입니다. 또한 이 선진 기술을 활용할 수 있는 지식과 도구를 소지할 것입니다.
제1장: AI 에이전트와 언어 모델 소개
AI 에이전트와 대형 언어 모델이 무엇인가?
인공지능 (AI)의 빠른 발전은 대형 언어 모델 (LLM)과 AI 에이전트 간의 변형적인 협력을 가져왔습니다.
AI 에이전트는 자율적인 시스템으로 환경을 인지하고 결정을 내리고 특정 목표를 달성하기 위한 동작을 실행합니다. 자율성, 인지, 반응성, 추론, 결정, 학습, 의사소통, 목표지향 등의 특성을 보입니다.
반면에, LLM은 깊은 학습 기법과 엄청난 데이터셋을 활용하여 사람처럼의 텍스트를 이해하고, 생성하고, 예측하는Sophisticated AI 시스템입니다.
GPT-4, Mistral, LLama 같은 이러한 모델은 텍스트 생성, 언어 번역, 대화형 에이전트를 포함한 자연어 처리 작업에서뛰어난 능력을 보여주었습니다.
AI 에이전트의 주요 특성
AI 에이전트는 전통적인 소프트웨어와는 다른 몇 가지 정의적 특징을 가지고 있습니다:
-
자율성: 인간의 지속적인 干渉 없이 독립적으로 작동할 수 있습니다.
-
인지: 에이전트는 다양한 입력을 통해 환경을 감지하고 해석할 수 있습니다.
-
반응성: 환경의 변화에 동적으로 반응합니다.
-
추론 및 의사 결정: 에이전트는 데이터를 분석하고 정보에 근거한 선택을 할 수 있습니다.
-
학습: 경험을 통해 시간이 지남에 따라 성능을 향상시킵니다.
-
의사소통: 에이전트는 다양한 방법으로 다른 에이전트나 인간과 상호작용할 수 있습니다.
-
목표 지향성: 특정 목표를 달성하도록 설계되었습니다.
대형 언어 모델의 기능
LLM은 다음을 포함한 다양한 기능을 입증했습니다:
-
텍스트 생성: LLM은 프롬프트를 기반으로 일관되고 맥락에 맞는 텍스트를 생성할 수 있습니다.
-
언어 번역: 다른 언어 간의 텍스트를 높은 정확도로 번역할 수 있습니다.
-
요약: LLM은 긴 텍스트를 요점을 유지하면서 간결한 요약으로 압축할 수 있습니다.
-
질문 답변: 방대한 지식 기반을 바탕으로 정확한 답변을 제공할 수 있습니다.
-
감정 분석: LLM은 주어진 텍스트에서 표현된 감정을 분석하고 판단할 수 있습니다.
-
코드 생성: 자연어 설명을 바탕으로 코드 스니펫이나 전체 함수를 생성할 수 있습니다.
AI 에이전트 수준
AI 에이전트는 그들의 능력과 복잡성에 따라 여러 수준으로 분류될 수 있습니다. arXiv의 논문에 따르면, AI 에이전트는 다음과 같은 다섯 가지 수준으로 분류됩니다:
-
레벨 1 (L1): 과학자들이 가설을 세우고 목표를 달성하기 위해 작업을 지정하는 연구 조수 역할의 AI 에이전트.
-
레벨 2 (L2): 정의된 범위 내에서 데이터 분석이나 간단한 결정을 자동으로 수행할 수 있는 AI 에이전트。
-
레벨 3 (L3): 경험을 통해 배우고 새로운 상황에 적응할 수 있으며 결정 과정을 향상시키는 AI 에이전트。
-
레벨 4 (L4): 고급 추론과 문제 해결 능력을 갖춘 AI 에이전트로 복잡한 다단계 작업을 처리할 수 있다。
-
레벨 5 (L5): 동적 환경에서 완전히 자동적으로 운영할 수 있으며 인간 干涉 없이 결정과 행동을 취할 수 있는 완전 자율 AI 에이전트。
대형 언어 모델의 한계
훈련 비용과 자원 제약
GPT-3와 PaLM 같은 대형 언어 모델(LLM)은 깊은 학습 기술과 매우 큰 데이터셋을 활용하여 자연어 처리(NLP)를 혁신시켰다。
이但这些進歩은 매우 큰 비용을 따른다. LLMs의 교육은 상당한 계산 자원을 필요로 하며, 종종数千개의 GPU와 광범위한 에너지 소비가 관련된다.
OpenAI의 CEO인 Sam Altman에 따르면, GPT-4의 교육 비용은 1억 달러를 초과했다. 이는 모델의 보고된 규모와 복잡성과 일치하는데, 1조개의 파라미터를 가지고 있다고 추정된다. 그러나 다른 출처는 다른 자료를 제시한다:
-
누수된 보고서에 따르면, GPT-4의 교육 비용은 계산能力와 교육 기간을 고려해 약 $63억으로 추정되었다.
-
2023 중반 현재, GPT-4과 유사한 모델 교육의 비용은 약 2천만 달러에 불과하며, 효율성의 진흥으로 55일 정도 소요되는 것으로 추정된다.
LLM의 훈련 및 유지보수에 대한 높은 비용은 그들의 널리 적용과 확장성을 제한합니다.
데이터 제한과 편향
LLM의 성능은 훈련 데이터의 품질과 多样性에 크게 의존합니다. 엄청난 데이터셋에 훈련되어 있더라도 LLM은 데이터에 나타나는 편향을 보여질 수 있으며, 이는 편향된 또는 부적절한 출력을 가져옵니다. 이러한 편향은 여러 형태로 나타날 수 있으며, 성별, 인종, 문화 편향을 포함하여 인종적 차별과 오답 정보를 지속적으로 유지할 수 있습니다.
또한, 훈련 데이터의 정적인 성격 때문에 LLM이 가장 최신의 정보를 갖추고 있지 않을 수도 있어서, 동적 환경에서의 효과성을 제한할 수 있습니다.
전문화와 복잡성
LLM은 일반적인 작업에 우수합니다만, 도메인 전문 지식과 고급 복잡성이 요구되는 전문 작업에서는 부득이할 수 있습니다.
예를 들어, 의료, 법, 과학 연구 등의 분야의 작업은 전문 용어에 대한 깊은 이해와 세련된 추론이 요구되는데, LLM은 본래에는 이러한 지식을 갖추고 있지 않을 수 있습니다. 이러한 한계 때문에 전문적인 응용을 위해 LLM에 추가적인 전문 지식이나 微調을 통합할 필요가 있습니다.
입력과 감각 제한
LLM은 주로 텍스트 기반 입력을 처리하는데, 이는 그들이 다중 모달 방식으로 세계와 상호 작용하는 능력을 제한합니다. 그들은 텍스트를 생성하고 이해할 수 있지만, 직접 시각적인, 听觉的, 또는 감각적인 입력을 처리할 수 있는 능력이 없습니다.
이러한 한계는 로봇ика와 자율 시스템과 같이 종합적인 감각 통합이 필요한 분야에서의 그들의 응용을 어렵게 만듭니다. 예를 들어, LLM은 추가적인 처리 레이어 없이 카메라에서의 시각 데이터나 마이크에서의 听觉 데이터를 해석할 수 없습니다.
커뮤니케이션과 상호 작용 한계
LLM의 현재 커뮤니케이션 능력은 주로 텍스트 기반으로, 더욱 침번하고 상호 작용적인 형태의 커뮤니케이션에 참여하는 능력을 제한합니다.
예를 들어, LLM은 텍스트 응답을 생성할 수 있지만, 동영상 콘텐츠나 홀로그램 표현을 생산할 수는 없습니다. 이는 가상현실과 보강현실 어플리케이션에서 점점 더 중요해지고 있습니다(여기에서 더 알아보기). 이러한 제약은 LLM이 풍성한 다중 모달 상호 작용이 요구되는 환경에서의 효과iveness를 감소시킵니다.
AI 에이전트로 LLM의 한계를 극복하는 방법
AI 에이전트는 LLM이 직면한 많은 한계에 대한 전망이 좋은 솔루션을 제공합니다. 이러한 에이전트는 자율적으로 운영되며, 자신의 환경을 인지하고, 결정을 내리고, 특정 목표를 달성하기 위해 행동을 실행합니다. AI 에이전트를 LLM과 결합하면 그들의 능력을 강화하고 내재된 한계를 해결할 수 있습니다.
-
향상된 맥락과 메모리: AI 에이전트는 여러 상호작용에서 맥락을 유지할 수 있어 더 일관되고 맥락에 맞는 응답을 제공합니다. 이 기능은 고객 서비스 및 개인 비서와 같은 장기 메모리와 연속성이 필요한 애플리케이션에서 특히 유용합니다.
-
멀티모달 통합: AI 에이전트는 카메라, 마이크 및 센서와 같은 다양한 소스에서 감각 입력을 통합할 수 있어 시각, 청각 및 감각 데이터를 처리하고 응답할 수 있습니다. 이 통합은 로봇 및 자율 시스템 애플리케이션에서 매우 중요합니다.
-
전문 지식 및 전문성: AI 에이전트는 도메인 특화 지식으로 미세 조정할 수 있어 LLM이 전문적인 작업을 수행하는 능력을 향상시킵니다. 이 방식으로 의학, 법, 과학 연구와 같은 분야에서 복잡한 문의를 처리할 수 있는 전문 시스템을 생성할 수 있습니다.
-
인터актив하고 immersiv한 소통: AI 에이전트는 동영상 콘텐츠를 생성하고, 호로그래픽 디스플레이를 제어하며, 가상 및 가장화 현실 환경과 상호 작용함으로써 더 immersiv한 소통 형태를 촉진할 수 있습니다. 이러한 기능은 더욱 풍부한 다중 모달 상호 작용을 요구하는 분야에서 LLM의 응용을 확장합니다.
대규모 언어 모델은 자연어 처리에서 뛰어난 기능을 보였지만, 한계가 없는 것은 아닙니다. 훈련成本, 데이터 편향, 전문화 도전, 감각 제약, 의사소통 제한 등이 중요한 문제를 제시합니다.
그러나 AI 에이전트의 통합은 이러한 한계를 극복하는 가능한 방안을 제공합니다. AI 에이전트의 강점을 활용함으로써 LLMs의 기능성, 적응성, 적용성을 향상시키는 것이 가능하며, 더욱 발전된 다목적 AI 시스템을 제시합니다.
제2장: 인공 지능과 AI 에이전트의 역사
인공 지능의 기원
인공 지능(AI)의 개념은 현대 디지털 시대를 넘어 더 멀리 거슬러 옵니다. 인간과 같은 사고 능력을 갖춘 기계를 창조하는 아이디어는 고대 신화와 철학적 토론에서 추적할 수 있습니다. 그러나 AI를 과학적 분야로서 형성된 것은 20세기 중반에 발생했습니다.
1956년 Dartmouth Konference of 1956 `,` John McCarthy, Marvin Minsky, Nathaniel Rochester, Claude Shannon이 主催하た 이 에너지를 통해 AI가 연구 분야로서 시작되었다고 인정되고 있다. 이 원칙적인 erevent는 인공지능 시스템을 만들 수 있는 인간의 지능을 모니터링하는 가능성을 探る 주요 研究者들을 모았다.
早期 기대와 AI 冬至
AI 연구의 초기 년도는 제한 없는 기대로 구성되었다. 연구자들은 수학 문제를 해결하고, 게임을 한다고 하고, 심화된 天然어휘 처리를 위한 节制된 프로그램을 개발하는 기여를 나타냈다.
그러나 이 초기 열정은 실제로 지능적인 기계를 만들기는 과학적으로 기대보다 훨씬 복잡하다는 것을 인지하는 것에 엎드렸다.
1970년대와 1980년대는 AI 연구에 대한 자금 감소와 관심 저하를 보이는 기간이었다고 기억되며, 이를 “AI 冬至“라고 부른다. 이 기간은 早期 пион어 이SUCCESS를 실제로 지능적인 기계로 만들기 위한 기대를 낼 수 있었다.
규칙기반 시스템에서 기계 학습
전문가 시스템 ÄRA
1980년대는 AI에 대한 관심이 다시 활성化되었다. 이를 주요 가동 인력으로 전문가 시스템의 개발이 되었다. 이러한 규칙기반 프로그램은 특정 영역에서 인간 전문가의 결정 과정을 에麦씀하기 위한 것이었다.
전문 시스템은 의료, 금융, 엔지니어링等领域에서 应用于各种领域,包括医疗、金融和工程。그들은 경험을 통해 배우거나 프로그래밍된 규칙 외의 새로운 상황에適応할 수 없기 때문에 제한적이었습니다。
機械学習의台头
규칙 기반 시스템의 한계는 기계학습 방향으로의 교제 변화를 열렸습니다. 이 접근 방식은 1990년과 2000년대에 중요성을 얻으며, 데이터를 기반으로 학습하고 예측이나 결정을 내리는 알고리즘을 개발하는 것에 초점을 맞췄습니다.
神經網络와 지지 벡터 기계와 같은 기계학습 기술은 패턴 인식과 데이터 분류와 같은 작업에서 놀라운 성공을 거뒀습니다. 빅 데이터의 등장과 연산력의 증가는 기계학습 알고리즘의 발전과 응용을 더욱 가속화시켰습니다。
自律的인 AI 에이전트의 등장
단순 AI에서 일반 AI로
AI 기술이 계속 발전함에 따라, 연구자들은 더 유연하고自律的인 시스템을 생성할 수 있는 가능성을 탐구하기 시작했습니다. 이 변화는 특정 작업을 위해 설계된 단순 AI에서 인공 일반 지능 (AGI)를 추구하는 전환을 표시합니다。
AGI는 인간이 실행할 수 있는 모든 지능적 任务을 수행할 수 있는 시스템을 开発하는 목표를 가지고 있습니다. 진실적인 AGI는 여전히 멀리 있는 목표이지만, 더 靈活하고 적응性 있는 AI 시스템을 생성하는 데에 유용한 进歩이 나타났습니다.
profound learning, 인공 neural networks에 기반한 머신 leaning의 하위 지역이며, AI 분야를 进歩시키는 데 중요한 역할을 했습니다.
profound learning 알고리즘는 인간 뇌의 구조와 기능을 모델링하여 이미지와 语音 인식, 자연 언어 처리, 게임 연산 등에 이상적인 능력을 보였습니다. 이러한 进歩은 자율성 있는 AI エージェント의 開発に 기반을 제공합니다.
AI エージェント은 자율적인 시스템으로 환경을 知觉하고, 결정을 하며, 특정 목표를 달성하기 위해 행동을 실행할 수 있습니다.
-
Simple Reflex Agents: 정해진 규칙에 따라 特定の 자극에 대한 반응을 行います.
-
모델 기반 반응형 에이전트: 의사결정을 위해 내부 환경 모델을 유지합니다.
-
목표 기반 에이전트: 특정 목표를 달성하기 위해 작업을 실행합니다.
-
유틸리티 기반 에이전트: 가능한 결과를 고려하고 기대 유틸리티를 최대화하는 작업을 선택합니다.
-
학습형 에이전트: 머신 러닝 기술을 통해 결정력을 점진적으로 향상시킵니다.
도전과 윤리적 고려
AI 시스템이 점점 더 발전하고 자율적으로 동작하게 되면, 사회적으로 받아들여질 범위 내에서 사용되는 것을 보장하기 위한 중요한 고려 사항을 가져옵니다.
특히, 대규모 언어 모델(LLM)은 생산성의 슈퍼차ARGER입니다. 하지만 이러한 시스템이 어떤 것을 슈퍼차ARGE할 것인지에 대한 중요한 질문이 생깁니다. AI 사용의意图이 악의적인 경우, 이러한 시스템은 다양한 NLP 기술 또는 다른 수단을 사용하여 그러한滥用法를 감지할 필요가 있습니다.
LLM 엔지니어링 시스템은 다양한 도구와 方法론을 이용하여 이러한 도전을 해결할 수 있습니다:
-
감정 분석: 감정 분석을 사용하여, LLM은 텍스트의 감정적 eton을 평가하여 유해하거나 agreseive인 언어를 侦测할 수 있습니다. 이를 통해 인터렉션 platforms에서 유해한 사용을 identify할 수 있습니다.
-
컨텐트 필터링: 키워드 필터링과 패턴 매칭 등의 도구를 사용하여, 혐의 발언, 欺かれる 정보 또는 explicite mateerial이 생성되거나 퍼지는 것을 防止할 수 있습니다.
-
편향 侦测 도구: AI Fairness 360 (IBM)나 Fairness Indicators (Google) 등의 편향 侦测 프레임워크를 実装하여, 언어 모델에 대한 편향을 식별하고 軽減할 수 있습니다. AI 시스템이 공정하고 등 equitable하게 작동하도록 보장합니다.
-
설명 기술: LIME (Local Interpretable Model-agnostic Explanations) 또는 SHAP (SHapley Additive exPlanations)과 같은 설명 도구를 사용하여, 엔지니어는 LLM(Large Language Model)의 결정 과정을 이해하고 설명할 수 있으며, 의도치 않은 행위를 감지하고 처리하기 더 容易합니다.
-
어트리바시얼 테스튜닝: 악意의 攻撃 또는 harmful inputs를 시뮬레이션하여, 엔지니어는 TextAttack 또는 Adversarial Robustness Toolbox과 같은 도구를 사용하여 LLM을 ст레스 테스트할 수 있으며, 악의 목적으로 사용되는 가능성이 있는 취약성을 식별할 수 있습니다.
-
윤리 AI 가이드라인과 fameframe: IEEE 또는 AI パートナーシップ에서 제공하는 윤리 AI 开発 가이드라인을 따를 수 있으며, 사회적 福祉를 우선시 하는 책责 AI 시스템을 생성하는 데 도움이 됩니다.
이러한 도구들 사이에, 우리가 AI에 대한 특수한 Red Team를 필요로 하는 이유가 있습니다. LLM의 방어구를 탐지하기 위해 LLM의 한계를 도달시키는 전문 团队이며, 적의 상황을 시뮬레이하여 그들이 다른 것을 발견할 수 있는 취약성을 제시합니다.
하지만, 제품을 구현하는 사람들이 그것에 가장 강한 영향을 미칠 것을 인지하는 것이 중요합니다. 오늘날 우리가 직면하는 攻撃과 挑戦의 대부분은 LLM이 개발되以前에 존재하였다는 사실은, 사람의 요소가 AI를 이thmetic하고 책임감을 가지게 하는 중앙적인 rolls를 하는 것을 하이라이트합니다.
이러한 도구와 기술을 開発 ipeline에 통합하고, 의심의 마음을 가진 Red Team을 옆에 두는 것은, LLM이 이thmetic적인 결과를 자극하는 동시에 그들의 미용을 감시하고 예방하는 것이 必不可少的 합니다.
섹션 3: AI エージェント가 가장 뛰어난 곳
AI エージェント의 ユニークな強み
AI エージェントは、자율적으로 환경을 知觉하고, 결정을 하고, 특정 목표를 달성하기 위한 행동을 실행하는 능력을 가지고 있습니다. 자율성과 advanced machine learning 기능의 결합으로, AI エージェント는 인간이 두려워하는 複雑한 或者 repetitive tasks를 수행할 수 있습니다.
여기 AI 에이전트를 빛나게 만드는 주요 강점들이 있습니다:
-
자율성과 효율성: AI 에이전트는 지속적인 인간의 개입 없이 독립적으로 작동할 수 있습니다. 이러한 자율성은 24/7 업무를 처리할 수 있게 하여 효율성과 생산성을 크게 향상시킵니다. 예를 들어, AI 기반의 챗봇은 일상적인 고객 문의의 최대 80%를 처리할 수 있어 운영 비용을 절감하고 응답 시간을 개선합니다.
-
고급 의사 결정: AI 에이전트는 방대한 양의 데이터를 분석하여 정보에 입각한 결정을 내릴 수 있습니다. 이 능력은 특히 금융 분야에서 가치가 높으며, AI 거래 봇은 거래 효율성을 크게 향상시킬 수 있습니다.
-
학습 및 적응력: AI 에이전트는 경험을 통해 학습하고 새로운 상황에 적응할 수 있습니다. 이러한 지속적인 개선은 그들이 시간이 지남에 따라 성능을 향상시키는 것을 가능하게 합니다. 예를 들어, AI 건강 보조 도구는 진단 오류를 줄이고, 의료 결과를 개선하는 데 도움을 줄 수 있습니다.
-
개인화: AI 에이전트는 사용자 행동과 선호도를 분석하여 개인화된 경험을 제공할 수 있습니다. 아마존의 추천 엔진, 이는 매출의 35%를 차지합니다, AI 에이전트가 사용자 경험을 향상시키고 수익을 증대시키는 주요 예시입니다.
왜 AI 에이전트가 해결책인가?
AI 에이전트는 전통적인 소프트웨어 및 인간이 운영하는 시스템이 직면한 많은 도전 과제에 대한 솔루션을 제공합니다. 다음은 그들이 선호되는 이유입니다:
-
확장성: AI 에이전트는 비용의 비례적 증가 없이 운영을 확장할 수 있습니다. 이 확장성은 인력이나 운영 비용을 크게 증가시키지 않고 성장하려는 기업에 매우 중요합니다.
-
일관성과 신뢰성: 인간과 달리 AI 에이전트는 피로나 일관성 부족에 시달리지 않습니다. 이들은 높은 정확도와 신뢰성으로 반복적인 작업을 수행할 수 있어 일관된 성과를 보장합니다.
-
데이터 기반 통찰력: AI 에이전트는 인간이 놓칠 수 있는 패턴과 통찰력을 발견하기 위해 대규모 데이터를 처리하고 분석할 수 있습니다. 이 능력은 금융, 의료 및 마케팅과 같은 분야에서 의사 결정에 매우 귀중합니다.
-
节的 사용: AI エージェント을 사용하여 루틴적인 작업을 자동화하면 인力 사용을 감소시키고 중대한 节約 가능하다. 예를 들어, AI 기반 fraude 감지 시스템이 fraude 활동을 줄이기 때문에 毎年 数十億 달러의 절감을 할 수 있다.
AI エージェント이 우수한 パフォーマンス을 이룰 수 있는 조건
AI エージェント의 성공적인 사용과 배치를 보장하기 위해 certain conditions must be met :
-
明確한 목표와 사용 사례: AI エージェント의 효과적인 배치를 위해 具体的한 목표와 사용 사례를 정의하는 것이 중요하다. 이 clarity helps in setting expectations and measuring success. For instance, setting a goal to reduce customer service response times by 50% can guide the deployment of AI chatbots.
-
品質데이터: AI 대행업체는 교육과 운영에 기반을 두고 높은 品質의 데이터를 依存한다. 데이터가 정확하고, 관련性 있고, 최신이라는 것을 보장하는 것은 AI 대행업체가 지시적인 결정을 하고 효율적으로 작동하는 것을 보장하는 중요한 요소이다.
-
现存的 시스템과 통합: AI 대행업체가 Optimal Functioning을 위해 현존하는 시스템과 workflow를 통합해야 한다. 이러한 통합은 AI 대행업체가 필요한 데이터에 대한 assess를 통해 그들의 task를 수행하는 데에 필요한 다른 시스템과 interact를 보장하는 것을 의미한다.
-
지속적인 모니터링과 최적화: AI 대행업체의 パフォーマン스를 유지하기 위해서는 주요 パフォーマン스 지표(KPI)를 추적하고 피드백과 パフォーマン스 데이터를 기반으로 필요한 조정을 하는 지속적인 모니터링과 최적화가 중요하다.
-
윤리적 고려 및 편향 軽減: AI 에이전트에 대한 편향을 軽減하고 윤리적인 고려를 하는 것은 Equity 와 Inclusivity를 보장하기 위해 필수입니다. 편향을 감지하고 예방하기 위한 조치를 실시하여 신뢰를 BUILD하고 ответствен한 배포를 Ensure 할 수 있습니다.
AI 에이전트 배포에 대한 ベスト プractices
AI 에이전트를 배포하는 것에 대해 ベスト 프ractices를 따르면 그들의 성공과 효과를 보장할 수 있습니다.:
-
objectives and Use Cases를 정의하는: AI 에이전트를 배포하기 위한 goals와 use cases를 명확하게 identify하십시오. 이렇게 expectations를 설정하고 성공을 衡量的할 수 있습니다.
-
적절한 AI 플랫폼을 선택하기: 목표, 사용 사례, 现存的 인프라스트럷쳐와 일치시키는 AI 플랫폼을 고르세요. 통합 능력, スケーラビリティ, 그리고 成本과 같은 요인을 고려하세요.
-
umperative Knowledge Base를 개발하기: 知识产权이 잘 구성되어 있고 정확한 知識베이스를 빌드하여 AI エージェン트가 관련성 있고 신뢰할 수 있는 응답을 제공할 수 있습니다.
-
无缝的 통합을 확보하기: CRM과 콜센터 기술과 같은 现存的 시스템과 AI エージェン트를 통합하여 통합 고객 경험을 제공합니다.
-
AI エージェント를 训练하고 最適化하기: Interaction からの データを 使用して AI エージェント를 继续的に 训练하고 最適化します. パフォーマンス를 モニ터링하고 改善 사례를 식별하고 モデル을 적절히 更新します.
-
적절한 경쟁 절차 실현: 複雑하거나 感情的한 전화를 인간 대리자로 전달하기 위한 프로tokol을 정의하여 平稳한 전환과 효율적인 해결을 Ensure하십시오.
-
パフォーマンス 모니터링 및 분석: 전화 해결 수率, 평균 처리 시간, 고객 満足도 등의 주요 パフォーマンス 지표(KPI)를 추적합니다. 시각적 analyze 도구를 사용하여 데이터 기반의 见解 및 결정 지정을 실현합니다.
-
데이터 privacity 및 안전성 보장: 데이터를 匿名的하게 하는 것과, 인간의 지시를 보장하는 것과, 데이터 보존 정책을 설정하는 것과, 고객 데이터를 보호하고 개인 정보 보호를 실현하기 위해 强力한 암호화 조치를 取ります.
AI 대리자 + LLM: 지능형 소프트웨어의 새로운 시대
상상하자, 앱이 ваши 요청을 이해하는 것뿐만 아니라 그들을 실행하는 것을 도와줍니다. 인공지능 어긋(AI agent)과 대형 언어 모델(LLM)을 결합한 것은 이전과 달리 直观性 있고 능력 있고 영향력 있는 新一代 응용 프로그램을 생성하는 약속입니다.
AI 어긋: 간단한 작업 실행 이yonda
자신의 작업을 실행하는 것뿐만 아니라, 인공지능 어긋은 자신의 환경을 인식하고 데이터를 수집하는 것뿐만 아니라, dynamically 결정하고 행동을 취하는 것을 지원하는 지능적인 기술을 갖추고 있습니다.
-
Architecture: AI 어긋은 다음과 같은 주요 components 로 구성되어 있습니다:
-
Sensors: 이러한 센서는 어긋이 자신의 환경을 인식하는 데 필요한 데이터를 수집하는 것을 허용합니다. 센서, API, 사용자 입력 등 다양한 источников에서 데이터를 수집할 수 있습니다.
-
Belief State: 이러한 어긋은 센서를 통해 수집한 데이터에 따라 세계를 이해하고 있다고 표현합니다. 새로운 정보가 도착하면 지속적으로 갱신되는 것입니다.
-
Reasoning Engine: 이러한 어셈블리는 어긋의 결정 과정의 kernel 입니다. 이를 통해 현재의 인식하고 있는 세계에 대한 가장 좋은 행동을 결정하는 것을 도와줍니다. 이를 수행하기 위해서는 인공지능의 기반이 되는 rl 또는 기획 기술에 기반한 알고리즘을 사용합니다.
-
Actuators: 이러한 어셈블리는 어긋이 세계에 대한 반응을 나타내는 것입니다. 이러한 어셈블리는 인공지능의 기반이 되는 rl 또는 기획 기술에 기반한 알고리즘을 사용합니다.
-
-
도전: 전통적인 인공지능 에이전트는 명확하게 정의된 작업을 처리하는 데 우수하지만, 다음과 같은 문제를 겪게 됩니다:
-
자연어 이해: 뉘앙스를 가진 인간 언어를 해석하고, 모호함을 처리하며, 문맥에서의 의미를 추출하는 것은 여전히 큰 도전입니다.
-
일반 지능으로 사고: 현재의 인공지능 에이전트는 인간들이 무시하지 않는 공통의 지식과 사고 능력을 자주短缺합니다.
-
일반화:未经见의 작업을 잘 수행하거나 새로운 환경에 적응하는 에이전트를 훈련하는 것은 여전히 연구의 핵심입니다.
-
LLM: 언어 이해와 생성의 열쇠
LLM은 数十億 BYTE의 パラメータ로 编鸺体内에 저장된 浩瀚な知識力を持っており、前所未有的한 언어 능력을 제시합니다:
-
トランスフォーマー 아키텍처: ほとんどの現代的 LLM의 기반이 되는 トランスフォーマー 아키텍처는 텍스트와 같은 시퀀스 데이터를 처리하는 것에 優れています。이는 LLM가 언어에서 長距离依存关系을 인지하는 것을 허용합니다. 그러나 이를 통해 문맥을 이해하고 이해와 문맥에 관련이 있는 일관성있고 의미 있는 텍스트를 생성할 수 있습니다.
-
능력: LLM는 다양한 언어 기반 태스크에 우수하게 대답할 수 있습니다:
-
텍스트 생성: 的创作性小说을 쓰고 다양한 프로그래밍 언어의 코드를 생성하는 것을 포함하여, LLM는 경의 깊은 fluency와 创作性를 보여줍니다.
-
質問 대답: 정보가 長い 문서에 overlap되어 있는 것에도 불구하고, 그들은 簡潔하고 正確한 대답을 제공할 수 있습니다.
-
요약: LLM은 텍스트를 简 concise summary로 압축할 수 있습니다. 이를 통해 주요 정보를 抽出하고 관련 없는 자료를 丢弃할 수 있습니다.
-
-
제한: 그들의 IMpressive abilities 에 불과하나, LLM은 제한이 있습니다:
-
실世界 기반 부족: LLM은 주로 text only인 영역에서 작동하며, 실世界과 직접적인 interaction을 할 수 없습니다.
-
편향과 hallucination 가능성: massive, uncurated dataset에 基于해 训练되기 때문에, LLM은 데이터에 있는 편향을 inherit하고, 과거의 시간에 대한 factually incorrect or nonsensical information을 생성할 수 있습니다.
-
知的 합奏: 언어와 행동 사이의 沟壑 桥接
AI エージェントと leighlong AI 시스템의 결합은 각각의 제한을 극복하고 지능적이고 능력이 있는 시스템을 만듭니다.
-
leighlong AI가 해석자 및 計画者로서: leighlong AI는 自然 language 지시를 AI エージェント가 이해할 수 있는 형식으로 번역할 수 있으며, 이를 통해 인간과 컴퓨터 간의 더욱 直观적인 인터랙션을 실현할 수 있습니다. 그들은 또한 지식을 이용하여 복잡한 작업을 Agent들에게 기능을 위해 쪼갤 수 있습니다.
-
AI 에이전트를 실행자 및 학습자로 활용하기: AI 에이전트는 LLM이 세상과 상호작용하고, 정보를 수집하며, 행동에 대한 피드백을 받을 수 있게 합니다. 이러한 현실 세계와의 접촉은 LLM이 경험을 통해 학습하고 성능을 향상시키는 데 도움이 될 수 있습니다.
이 강력한 시너지는 더욱 직관적이고 적응력이 뛰어난 차세대 애플리케이션 개발을 이끌고 있습니다. AI 에이전트와 LLM 기술이 계속 발전함에 따라 소프트웨어 개발 및 인간-컴퓨터 상호작용의 지형을 재구성하는 더 혁신적이고 영향력 있는 애플리케이션이 등장할 것으로 기대됩니다.
실제 사례: 산업 변혁
이 강력한 조합은 이미 다양한 분야에서 큰 파장을 일으키고 있습니다:
-
고객 서비스: 문맥 인지를 통한 이슈 해결
- 예시: 고객이 온라인 레tail러로부터의 늦은 배송에 대해 연락을 한다고 상상해보세요. LLM이 지원하는 AI 에이전트는 고객의 불만을 이해하고, 주문 내역에 접근하며 실시간으로 패키지를 추적하며, 빠른 배송이나 다음 주문할 때의 할인 등의 해결책을 적극적으로 제안할 수 있습니다.
-
콘텐츠 생성: 규모에 맞춰고 품질 높은 콘텐츠 생성
- 예시: 마케팅 팀은 AI 에이전트 + LLM 시스템을 사용하여 타겟 된 소셜 미디어 포스트를 생성하거나, 제품 설명서를 작성하거나, 동영상 스크립트를 만들 수 있습니다. LLM은 콘텐츠가 적절하고 정보性强게 보장하는 동시에, AI 에이전트는 发布과 배포 과정을 처리합니다.
-
소프트웨어 개발: 编码과 디버깅 加速
- 예시: 개발자는 자연어로 어떤 소프트웨어 기능을 만들고자 하는지 描述할 수 있습니다. LLM은 그렇게 생성하는 코드 片段을, 가능한 에러를 identifiy하고, 改善사항을 제안하여 開発 과정을 значитель하게 加速시킵니다.
-
의료: 치료 개별化和 환자 관리 改善
- 예시: 의료 이력을 사용할 수 있는 AI エージェン트가 있고, LLM을 장착한 것과 같은 경우, 그들은 환자의 状態에 따라 질문을 답할 수 있으며, 개별화된 약 기록 시스템을 제공할 수 있으며, 심장 attack 같은 경우에 의심할 수 있는 경험이 있을 수 있습니다.
-
법률: 법률 조사 및 문서 작성의 간소화
- 예시: 변호사는 특정 조항과 법적 전례가 포함된 계약서를 작성해야 합니다. LLM을 기반으로 한 AI 에이전트는 변호사의 지시를 분석하고, 방대한 법률 데이터베이스를 검색하여 관련 조항과 전례를 찾아내며, 계약서의 일부를 작성할 수도 있어 소요되는 시간과 노력을 크게 줄여줍니다.
-
비디오 제작: 손쉽게 매력적인 비디오 생성
- 예시: 마케팅 팀이 제품의 특징을 설명하는 짧은 비디오를 만들고자 합니다. 그들은 AI 에이전 + LLM 시스템에 스크립트 개요와 시각 스타일 선호도를 제공할 수 있습니다. LLM은 상세한 스크립트를 생성하고, 적절한 음악과 시각 자료를 제안하며, 심지어 비디오 편집까지 수행하여 비디오 제작 과정의 많은 부분을 자동화합니다.
-
建築: AI 지원 인사이트로 建物 디자인
- 예시: 건축가가 새로운 사무실 건물을 디자인하고자 한다. 그들은 AI エージェント + LLM システム을 사용하여 디자인 목표를 입력할 수 있습니다. 예를 들어, 自然的光照을 최대化和 空间的有效利用 등이 있습니다. LLM은 이러한 목표를 분석하고, 다양한 디자인 옵션을 생성하고, 건물이 다양한 環境条件下 どのように パフォーマンス 仿真을 할 수 있습니다.
-
건설: 건설 현장의 안전性与 효율성 향상
- 예시: 카메라와 센서를 장착한 AI 에이전트는 건설 현장의 안전 위험요인을 모니터링할 수 있습니다. 근로자가 적절한 안전 장비를 착용하지 않거나 장비가 危険한 위치에 둔 채로 남아 있을 때, LLM은 상황을 분석하고 현장 감독에게 경보하며 필요하다면 자동적으로 작업을 중지시키기도 합니다.
미래는 여기: 소프트웨어 개발의 새로운 시대
AI 에이전트와 LLM의 융합은 소프트웨어 개발에서의 중대한 발전입니다. 이 기술이 계속 발전함으로써 우리는 더욱 창의적인 응용을 볼 수 있을 것으로 예상되며, 산업을 변형시키고, 워크플로를 간결화시키며, 인간과 컴퓨터의 상호작용에 새로운 가능성을 만들 것입니다.
AI 에이전트는 많은 양의 데이터 처리, 반복적인 작업 자동화, 복잡한 결정, 개인화된 경험 제공을 요구하는 분야에서 가장 빛나게 느껴집니다. 필요한 조건을 충족시키고 最佳實踐을 따르면, 조직은 AI 에이전트의 모든潛在能力을 해빗하여 혁신, 효율성, 성장을 촉진할 수 있습니다.
第四章: 지능 시스템의 filosophical Foundation
지능 시스템, 특히 人工知能(AI) 领 域에서는 철학적 지침을 깊이 있게 이해해야 합니다. 이 섹션은 AI를 디자인, 개발 및 이용에 영향을 미칠 핵심 철학적 아이디어에 들어가고 있습니다. 기술적 진전을 윤리 가치와 일치 시키는 중요성을 강조합니다.
지능 시스템의 哲학적 기반은 이론적 연구만이 아닌, AI 기술이 인类에게 이점을 brings하기 위해 essental Framework입니다. 이러한 이치는 Fairness, inclusivity를 促進하고 生活 질의 改善에 기여하여 AI가 우리의 이익에 이를 통해 활용되는 방향을 지시하고 있습니다.
AI 개발에서의 伦理性 고려
AI 시스템이 인간의 삶의 모든 면에 渐进적으로 통합되고 있으며, 의료, 교육, 재정, 관제 등에서 활용되고 있습니다. 이러한 시스템을 디자인하고 사용하는 데에 伦理性 제고를 깊이 있게 검토하고 적용해야 합니다.
기본적인 伦理性 질문은 AI가 인간 가치와 伦理적 기본을 表현하고 지키는 것인가를 덧붙여 구성되어 있습니다. 이 질문은 AI가 전 세계 사회를 어떻게 형성할 것인지에 중요한 roll을 果たす 것입니다.
이러한 伦理적 논licate의 중심은 仁慈의 기본, 伦理적 哲학의 기본 아이디어로 어떤 행위를 하는지에 대해 좋고 개인과 사회가 좋은 상태를 향상시키는 것이 중요한가를 명확히 하는 것입니다 (Floridi & Cowls, 2019).
AI context에서 유용性(beneficence)는 인간의 자신을 활성화시키는 시스템을 설계하는 것을 의미한다. 이는 의료 결과를 改善시키고, 교육 기회를 돕고, Redistributive economic growth를 도울 수 있는 시스템을 말한다.
그러나 AI에서 유용性的 적용은 간단하지 않다. AI의 잠재적 이익과 위험, 상해를 审의하는 신뢰하는 접근法을 demands한다.
유용성 원칙을 AI 開発에 적용하는 과정에서 주요 도전 하나는 革新과 안전성 사이의 유연한 balancer를 필요로 한다.
AI는 의학과 같은 분야에서 예측 알고리즘으로 인간의 의사 의사가 더 일찍이 질병을 diagnose할 수 있는 것과 더욱 정확하게 하는 것을 革命시키는 가능성을 가지고 있다. 하지만 stringent ethical oversight가 없다면 이러한 기술은 존재하는 불平等을 aggravate할 수 있다.
예를 들어 AI가 主要적으로 가odeploy되는 wealth region에서는 기본적인 의료 サービ스 アクセスが 없는 低所得者 社区에게 또 다른 불平等을 일으키는 것이 가능하다.
이러한 이유로 AI의 伦理的 開発은 이익을 极大화하는 것だけ이 아닌 risk mitigation에 대한 积极的 approach도 필요하다. 이를 통해 AI를 滥用的 가 avoiding하고 이러한 기술이 不小心的 상해를 인duce하지 않도록 한다.
AI의 伦理적 框架은 inherently inclusive가 되어야 한다. AI의 이익을 모두 社会的 group에 대하여 公平하게 분布시키는 것을 보장하고, 이를 통해 traditionally marginalized가 되어있는 그룹에게도 AI의 이익을 확보할 수 있다. 이러한 것은 正義와 Fairness를 보장하는 것과 같고 AI가 현재 상태를 仅仅 reinforce하는 것이 아닌 시스템적 불平等을 dismantle하는 역할을 실제로 하도록 하는 것이다.
예를 들어 AI-기반의 일자리 자동화는 생산성과 경제 성장에 积极作用을 미칠 수 있지만, 그 동시에 중요한 일자리 替わり로 이어지며, 저수입 일자리 worker들에게 disproportional impact을 미칠 수 있습니다.
따라서 ETHICALLY 健全한 AI framework은 Equitable benefit-sharing를 위한 strategy와 AI 발전으로 지나가는 것에 opposition받는 那些人들에 대한 Support system를 제공하는 것을 포함해야 합니다.
AI의 ETHICAL development은 伦理学者, 기술자, 정책制定者, 그리고 这些技术에 대해 가장 영향 받을 예정인 社区들과 Continuous engagement를 필요로 합니다. 이러한 Interdisciplinary collaboration은 AI system이 真空中에서 개발되지 않고, Broad spectrum of perspective와 Experience를 통해 形상되도록 해줍니다.
이러한 collective effort을 통해 AI system이 単独적으로만 나타나는 것이 아닌, 우리 인격을 정의하는 价值들을 반영하고 지키는 것처럼 나타낼 수 있습니다.
AI development에서의 ETHICAL consideration은 지침들 alone가 되지 않고, AI가 세계에서 善良한 의미의 force가 되는지 여부를 결정하는 essental element들로 보입니다.
AI의 가능성을 계속해서 탐구하는 동안, 이러한 ETHICAL consideration은 우리의 endeavor의 front and center에 유지되어야 합니다. AI가 진정으로 인 humanity에게 的利益를 가지는 未来에 대한 道를 가슴할 수 있도록, 우리를 가지고 있는 것입니다.
사람 중심인 AI 설계
사람 중심인 AI 설계는 단순한 기술적 고려를 넘어가는 것이다. 그 기반은 인간의 威严, 자율, 및 행위에 중요시하는 깊은 filosofiikal 原理들로 奠立되었다.
이 AI 개발 방법은 기본적으로 Kantian 이thical framework에 기반한다고 하며, 인간은 기타 목표를 달성하는 ため의 도구로 한정되지 않고 자신의 것이 되는 것을 주장하고 있다(Kant, 1785).
이 이론의 AI 설계에 대한 含义은 깊고, AI 시스템을 사람의 利益를 지키는 것, 사람의 자율을 보호하는 것, 개인의 자율을 尊重하는 것을 지키는 것을 중요시 하는 것이 필요하다는 것을 요구한다.
사람 중심 이념의 기술적 실현
AI로 사람의 자율 향상: AI 시스템에서 자율이란 개념은 중요하며, 이러한 기술이 사용자를 보호하는 것이 아닌 그들을 어려우는 것이나 과力量적으로 영향 받이는 것을 防止하는 것이다.
기술적으로는 AI 시스템을 사용자의 자율을 우선시 하는 것을 위해 그들에게 정보를 제공하는 도구를 제공하는 것이 필요하다. 이에 의해 AI 모델은 정보를 이해하는 것이 되고, 결정이 나는 지점의 특정 context를 이해하고 그에 따라 의견을 조정하는 것이 필요하다.
시스템 설계 관점에서는 AI 모델에 上下文 지능을 통합하는 것이 필요하며, 이러한 시스템은 사용자의 환경, 의견, 및 需要에 따라 동적으로 적응할 수 있도록 해야 한다.
예를 들어, 의료 sectore에서, AI 시스템이 의사들이 질병을 진단할 때 도와주는 것이 아닌, 의사의 전문 지식을 ersetzen하는 것이 아닌 추천을 제시하기 위해, 환자의 unique medical history, 현재의 症状, 심리적 상태 등을 고려해야 합니다.
이 컨텍스트 적응은 AI가 사람의 자율을 弱하게 하는 것이 아닌, 강화하는 것이 되는 지원적인 도구가 되続ける 것을 보장합니다.
의사로 투명한 결정 과정을 보장하는 것: AI 시스템의 투명성은 사용자가 이러한 기술에 의한 결정을 신뢰하고 이해할 수 있는 기본적인 요구입니다. 기술적으로는, 이를 실현하기 위해 explainable AI (XAI)가 필요하며, 결정을 하는 이유를 명확하게 설명할 수 있는 알고리즘을 개발하는 것입니다.
이는 재정, 의료, 범죄적 정의 등의 sectore에서 투명하지 않은 결정 과정이 신뢰를 잃고, 윤리적 문제를 일으키는 것에 특히 중요합니다.
explainability는 여러 기술적 방법을 통해 달성할 수 있습니다. 하나의 일반적 방법은 포스트 후 의미성 이해입니다. AI 모델이 결정이 이뤄진 후에 설명을 생성하는 것입니다. 이 때, 결정을 구성하는 각 요인을 분해하고 각 하나가 결정의 최종 결과에 어떻게 기여했는지 보여주는 것입니다.
또 다른 접근法은 inherent interpretable models로, 모델의 구조가 결정의 transparencty가 기본적으로 유지되도록 设计了되었다고 해야 합니다. 예를 들어, decision trees와 linear models과 같은 모델들은 자연적으로 interpretable하며, 그들의 결정 과정이 浅く 이해되기 容易하기 때문입니다.
explainable AI를 실제로 적용하는 도전은 transparencty와 성능을 balacne하는 것입니다. より 複雑한 모델, deep neural networks 등은 浅く interpretable하지만 정확하게 나옵니다. 따라서, human-centric AI의 设计了은 모델의 interpretability와 예측력 사이의 trade-off를 고려해야 하며, 사용자가 AI의 결정에 대해 신뢰하고 이해할 수 있는지 여러분의 정확성을 포기하지 않습니다.
의미 있는 인간 지시 가능성: 인간 지시 가능성은 AI 시스템이 伦理性와 operaional boundary를 벗어나지 않도록 操作할 수 있도록 중요합니다. 이 지시는 AI 시스템을 设计了할 때 fail-safes와 override mechanisms를 통해 인간 operator가 필요한 경우에 干预할 수 있도록 하는 것입니다.
인간 지시 가능성의 기술적 구현은 다양한 방법에서 접근할 수 있습니다.
하나의 접근法은 human-in-the-loop system을 사용하는 것입니다. AI 결정 과정을 인간 operator가 지속적으로 모니터링하고 평가하는 시스템입니다. 이러한 시스템은 human intervention을 critical junctures에서 허용하여 AI가 伦理性의 결정이 필요한 상황에서 자율적으로 행동하지 않도록 설계되었습니다.
자율적인 무기 시스템의 경우, 인간 지ardship이 AI가 인간 대화를 거부하지 않는 것을 방지하는 데 필요하며, 이를 위해 AI가 인간 승인 없이 넘지 못하는 строгие 운영적 경계를 설정하여 伦理性 보호를 시스템에 삽입할 수 있습니다.
또한 기술적인 고려사항으로는, AI 시스템이 이룬 모든 결정과 행동의 기록을 제공하는 审核trails(audit trails)의 개발이 있습니다. 이러한 trails는 인간 운영자가 伦理性 표준에 대한 준수를 확인할 수 있는 투명한 역사를 제공합니다.
审核trails는 예를 들어 金融·法mpital과 같은 sectoars에서 결정이 기록되고, 인신적인 이유로 공동체의 신뢰를 보장하고 조달 요구를 만족시키기 위해 documented되고 유효성을 있는지 확인할 수 있는 역할을 하는 것이 特别に 중요합니다.
Autonomy and Control balanc: 인간-centric AI에서 기술적인 도전 중 중요한 것은 자율성과 제어의 오른쪽 balanc을 찾는 것입니다. AI 시스템은 많은 상황에서 자율적으로 운영되는 것이지만, 이 자율성은 인간 지ardship 또는 지orship을 하락 하는 것을 하지 않아야 합니다.
이러한 balanc을 달성하기 위해서는, AI가 결정을 하는데 가지고 있는 독립성의 레벨을 지시하는 자율성 수준을 실시하여야 합니다.
예를 들어, 자율적인 자동차와 같은 半자율적인 시스템에서는 자율성 수준이 기본적인 運転자 支援(human driver가 전체 控制在에 남아 있음)에서 일어나는 것과 자동적인 모든 運転 任务을 인지하는 것입니다.
이러한 시스템의 설계는 인간 운전자가 任何时候 자신의 의지로 干预하고 AI로부터 来越脲 가능하게 해야 한다. 이를 위해 错綜複雜한 제어 인터페이스와 결정 지원 시스템이 필요하며, 이들은 인간이 任何时候 어느程度上 필요한 것이면 疾 reunion하고 관리할 수 있는 것이다.
또한, 伦理性 AI 框架의 개발은 AI 시스템의 자율적인 행동을 引导하는 데 필요하다. 이러한 框架은 AI 안에 込め여 인간이 伦理적으로 错綜複雜한 상황에서 어떻게 행동할 지 지시는 규칙과 지침을 가지고 있다.
예를 들어, 의료 분야에서는, 伦理性 AI 框架은 환자 同意, 개인 정보 보호 등과 의료 需要에 따라 치료를 우선 시키는 것 등의 규칙을 포함할 수 있다.
이러한 伦理적 원칙을 AI의 결정 과정에 직접 embedding하면 개발자는 시스템의 자율성이 인간의 가치와 일치하는 방향으로 행동하는지 확인할 수 있다.
인간 중심 원칙을 AI 설계에 integrate하는 것은 철학적 이 ideal로 끝나지 않고 기술적 必要性이다. 인간의 자율성을 강화하고 이를 통한 명확하고 의미深い 관리를 실현하고 자율성과 관리를 精巧하게 balanc하면 AI 시스템은 실제로 인간을 도울 수 있는 것으로 개발할 수 있다.
이러한 기술적 생각은 AI가 인간의 능력을 Augment하는 것뿐만 아니라 인간 社会가 根本的한 가치를 존중하고 지키는 것이 중요하다.
AI가 계속해서 발전하면 인간 중심 설계에 대한 의지가 AI를 伦理적으로 以及하고 의责任로 사용하는 데 중요한 것이 될 것이다.
AI가 인류에게 혜택을 끼칠 수 있도록 보장하는 방법: 생활의 질 향상
AI 시스템의 개발에 뛰어들 때, 귀하는 광범위한 행복과福祉의 증진을 중시하는 유틸리타리즘 철학적 근거를 바탕으로 노력할 필요가 있습니다.
이러한脉络에서, AI는 보건, 교육, 환경의 지속可能性等领域에서 사회적 도전을 해결할 잠재력을 가지고 있습니다.
모든 사람들의 생활의 질을 显著的으로 향상시키는 기술을 창출하는 것이 목표입니다. 그러나 이러한 추구는 복잡함을 동반합니다. 유틸리타리즘은 AI를 널리 배포하는 데 강력한 이유를 제시하지만, 또한 노출된 그룹을 포함한 취약계층에게는 혜택을 얻을 수 있는지 아니면 뒤에서 남을지에 대한 중요한倫理적인 질문을 끼칩니다.
이러한 도전을 극복하기 위해서는, 기술적인 지식을 바탕으로Sophisticated하고, 사회적인 지속적인 좋은 결과와 正义와 공평함의 필요를 조율하는 접근 방식이 필요합니다.
유틸리타리즘 원리를 AI에 적용할 때, 귀하는 특정 분야에서 결과를 최적화하는 것에 초점을 맞출 필요가 있습니다. 예를 들어 보건 분야에서, AI를 기반으로한 진단 도구는 더 일찍이고 정확한 진단을 가능하게 하여 환자 결과를 显著的으로 향상시킬 수 있습니다. 이러한 시스템은 인간의 수행자로부터는 놓칠 수 있는 패턴을 분석하기 위해 광범위한 데이터 집합을 분석하며, 자원이 부족한 환경에서는 질 좋은 케어에 대한 액세스를 확장합니다.
하지만 이러한 기술을 Rolling out 하기 위해서는 现行の不平等を強め지 않는 조심력이 필요합니다. AI 모델을 训练시키기 위해 사용되는 데이터가 지역에 따라 유사성이 많이 다르며, 이러한 시스템의 정확성과 신뢰성에 영향을 줄 수 있습니다.
이러한 차이를 통해 강健한 데이터 관리 프레임워크를 설정하는 것이 AI-기반 의료 솔루션이 대표적이고 公允하게 동작하도록 보장하는 중요성이 보입니다.
교육 영역에서는 AI가 personalized learning을 가능하게 하는 능력이 기대가 됩니다. AI 시스템은 학생의 개인적인 需要에 따라 교육 コンテンツ를 조정할 수 있으며 이로 학습 결과를 높이는 데 assistance를 제공합니다.
이러한 이점을 실현하는 과정에서는 リスク를 인지하는 것이 중요합니다. 예를 들어 AI가 종이적 학습 모양에 맞지 않는 학생들을 边鄙化시키거나 인정하는 가능성이 있습니다.
이러한 リスク를 軽減하기 위해서는 AI 모델에 公允性 메カ니즘을 통합하는 것이 중요합니다. 특정 그룹을 사기 적은 것처럼 하지 않도록 보장합니다. 또한 교육자의 역할을 유지하는 것이 중요합니다. 교육자의 判断과 경험은 AI 도구가 실제로 有效性과 サポート적이게 되る데 不可或缺하입니다.
환경 지속성 면에서도 AI의 가능성은 Considerable하며 AI 시스템은 자원 사용을 최적화하고, 환경 변화를 모니터링하고, 気候変動의 영향을 예측하는 것이 이전과 달리 精密度이 높습니다.
예를 들어 AI는 环境 데이터를 분석하여 날씨 패턴을 예측하고, 에너지 사용을 최적화하고, 가스를 최소화하는 것을 办할 수 있습니다. 이러한 행위는 현재 그리고 미래 기대자들의 福利에 기여합니다.
그러나 이러한 기술적 진전은 자신의 어려움을 가지고 있습니다. 특히 AI 시스템들自身의 環境 영향을 대하여 입니다.
대형 AI 시스템을 운영하기 위해 필요한 에너지 소모는 이를 달성하고자 하는 环境 이익을 받기 위한 것과 反対적입니다. 따라서 에너지 효율성이 좋은 AI 시스템을 開発하는 것이 AI가 环境 stablility에 대한 积极적 영향을 받을 수 있도록 보장하는 중요한 것입니다.
utilitarianism과 관련이 있습니다. Utilitarianism은 전체 행복을 가장 큰 것을 만들 수 있도록 초점을 둔 것입니다만, 이는 이러한 福利과 해를 다른 사회 그룹에 대한 분배에 대해 자신의 의미를 가지고 있지 않습니다.
이러한 것은 AI 시스템이 이미 的特权자들에게 disproportionality 대해 이익을 유의하면서 처리하고, 한端적 그룹이 이러한 상황에서 조차 이를 향상시키는 것이 없다는 것을 의미합니다.
이러한 것을 COUNTERACT하기 위해서는, AI 개발 과정에 Equity- Focused principals를 도입해야 합니다. 이러한 이익을 공정하게 분산하며 어떠한 해를 일으키는지 대응할 수 있도록 합니다. 이러한 것은 특정하게 이러한 편향을 줄이는 알고리즘을 설계하는 것과 개발 과정에서 다양한 관점을 고려하는 것입니다.
AI 시스템을 개발하여 인생의 질uality of life를 改善하고자 하는 과정에서, 效用的 목적(utilitarian goal)을 极大化하는 것과 正義, 公平性의 需要을 balancEd하는 것이 essential하다. 이를 위해 덧칠(diy) 기술적인 grounding이 필요하며 AI 導入의 덧칠(diy) 更广泛的 含义을 고려해야 한다.
AI 시스템을 精巧하게 디자인하여 유용하고 Equitable(公平的)하게 만들면 기술적 진보가 사회의 다양한 需要을 실제로 服务하는 未来을 기대할 수 있다.
AI 기술의 潜在的한 해를 예방하기 위한 안전장치를 실제ize하라
AI 기술을 개발하는 과정에서는 그 자체로부터 해를 유발할 수 있는 것을 인지하고 이를 軽減하기 위해 강한 안전장치를 establish하는 것이 중요하다. 이 의 responsibly는 deontological ethics에 깊이 있게 根源되어 있다. 이 기울기의 伦理학은 기본적인 规则과 伦理 标准에 따라 가는 道的 의무를 중요시하며, 개발하는 과정에서 기술적으로 道义적인 의사를 형성시키게 한다.
Stringent(严格한) safety protocol을 적용하는 것은 caution alone이 아니라 伦理적인 의무이다. 이러한 protocol은 AI 시스템에 대한 错乱적인 결정이나 명확하지 않은 과정, 또는 통제의 결과로부터 그 자신이 인식하는 의미의 해를 방지하는 것이다.
이러한 안전장치는 AI 시스템이 의도치 않게 해를 유발하는 것을 예방하는 데에 중요하며, 이러한 안전장치를 실제ize하기 위해서는 AI의 기술적인 측면과 伦理적인 측면을 깊이 있게 이해해야 한다.
실제적으로 이러한 안전장치를 실제ize하기 위해서는 AI의 기술적인 측면과 伦理적인 측면을 깊이 있게 이해하는 것이 중요하다.
이러한 보호措置을 AI 개발의 깊이 있는 구성 요소로 삽입하여, 기술적 진전이 bootstrapping(자신을 kickstart 하는 것)하는 것과 같이 사회적 이익에 기여하는 것을 보장하며, 副作用이나 기대 外의 결과를 引き起こす 것을 防止하는 것이 중요합니다. 사람의 지시와 피드백 环(feedback loop)의 역할은 어떻게 나타나나요?
AI 시스템이 사용자와 干渉자가 쉽게 이해하고 scrutinize(자세히 examination)할 수 있게 설계되어야 하며, 이를 위해 이해할 수 있는 AI 모델을 開発하는 것과 결과를 이해하고 결정을 正当化하고 公平하게 하는 것이 중요합니다.
또한, 责任的机制은 的信頼을 유지하고 AI 시스템이 负责任하게 사용되는 것을 보장하는 것이 중요합니다. 이러한 机制은 AI 결정의 結果에 대한 責任를 가진 인물의 명확한 지침을 포함하고, 사고 수정할 수 있는 과정을 포함해야 합니다.
AI 개발의 모든 段階에 伦理性 생각을 통합하는 框架을 설정해야 합니다. 이에는 伦理性 지침을 따르는 것뿐만 아니라 AI 시스템이 실제 세계와 交互하는 과정 동안 连续하게 모니터링하고 조정하는 것이 포함됩니다.
이러한 보호措置을 AI 개발의 깊이 있는 구성 요소로 삽입하여, 기술적 진전이 bootstrapping(자신을 kickstart 하는 것)하는 것과 같이 사회적 이익에 기여하는 것을 보장하며, 副作用이나 기대 外의 결과를 引き起こす 것을 防止하는 것이 중요합니다.
인간의 지시와 피드백 环(feedback loop)의 역할은 어떻게 나타나나요?
인공지능 시스템에 인간적 관리는 etical AI 구축을 보장하는 중요한 요소입니다. 책임의 원칙은 인공지능 운영에 인간의 지속적인 참여가 필요한 것을 지지합니다. 특히, 보건과刑事司法과 같은高风险环境에서는 이를 더욱 중요시합니다.
인간의 입력이 AI 시스템을.refine하고 improve하는 피드백 루프는 책임성과適応성을 维持하는 데 필수적입니다(Raji et al., 2020). 이러한 루프는 오류의 수정과 사회적 가치의 변화에 따라 새로운倫理적 고려사항을 통합하는 데 사용할 수 있습니다.
AI 시스템에 인간적 관리를 심어두면, 개발자는 효과적인 기술뿐만 아니라倫理적 규칙과 인간의期待와 일치하는 기술을 창출할 수 있습니다.
에이지코드: 기술원리를 AI 시스템으로 변환
철학적 원칙을 AI 시스템으로 변환하는 것은 복잡하지만 필요한 작업입니다. 이 과정은 AI 알고리즘을 구동하는 코드에 그 자체로倫理적 고려를 심어드릴 수 있습니다.
공정성, 正义, 자유意志과 같은 개념은 AI 시스템에 명文化 되어야만 사회적 가치를 반영하는 방식으로 운영됩니다. 이를 위해倫理학자, 엔지니어, 사회과학자가 다중학문적 접근을 통해倫理적 지침을 정의하고 구현하는 데 협력해야 합니다.
목표는 기술적으로 능숙한 AI 시스템뿐만 아니라道德적으로健全하고 인간의 尊严을 존중하고 사회적 이익을 증진하는 결정을 할 수 있는 시스템을 만드는 것입니다(Mittelstadt et al., 2016).
AI 개발과 배포에서 포괄성과 공평한 액세스를 증진하기
Inclusivity와 등 equitable access는 AI의 윤리적 발전에 기반적인 요소입니다. Rawlsian 正義 как 공정eness 이념은 AI 시스템이 사회의 모든 구성원에게 이익을 가져가는 것을 보장하기 위한 PHILOSOPHICAL FOUNDATION를 제공합니다. 특히 가장 脆弱한 사람들에게 (Rawls, 1971).
이 과정에서는 대표되지 않는 그룹과 글로벌 남부에서 특히 다양한 視点을 包括하는 것이 중요합니다.
이러한 다양한 观点을 통합하면 AI 개발자는 더 이상 Equity-based 시스템을 만들 수 있습니다. 또한, AI 기술에 대한 equitable access를 보장하는 것은 现存的 사회적 불平等을 aggravation 하는 것을 防止하는 데에 중요합니다.
Algorithmic Bias and Fairness
Algorithmic bias는 AI 개발 과정에서 중요한 윤리 문제로, 편향되어 있는 알고리즘은 사회적 불平等을 지속 또는 aggravation 할 수 있습니다. 이 문제를 해결하기 위해서는 Procedural justice 에 의한 의사 굳��� 제공합니다. AI 시스템이 모든 利害关系자에 대한 영향을 고려하는 Fair process 를 통해 개발되는 것을 보장합니다.
이러한 과정에서는 트레이닝 데이터에서 편향을 identifiying 하고, 명확하고 설명 가능한 알고리즘을 개발하며, AI 윈도우 period 전체에 걸쳐 Equity 확인을 실시합니다.
Algorithmic bias를 해결하면 AI 시스템은 기존의 불平等을 강화하는 것이 아닌, 더 이상 정의된 사회를 기여하는 시스템으로 만들 수 있습니다.
AI 개발 과정에서 다양한 观点을 包括하는 것은 중요합니다.
번역:
다양한 시각을 AI 개발에 통합하는 것은 包容的하고 公平한 시스템을 만들기에 필수적입니다.代表性 불충분한 그룹의 목소리의 포함은 AI 기술이 사회의 좁은 세그メント의 가치와 우선순위를 단순히 반영하지 않도록 보장합니다.
이 접근 방식은 Deliberative Democracy(의사결정 민주주의)의 철학적 원칙과 일치합니다. 이는 包容的하고 참여적인 결정 프로세스의 중요성을 강조합니다 (Habermas, 1996).
AI 개발에 다양한 참여를 촉진함으로써, 이 기술이 지능적 이점을 가진 몇몇 유리한 집단을 위해 만들어지는 것이 아닌 모든 인류의 이익을 위해 디자인되었음을 보장할 수 있습니다.
AI 분할 격차를弥缝하기 위한전략
AI 기술의 접근과 혜택의 불平等함으로 특징화된 AI 분할 격차는 글로벌 공평성에 대한 중대한 도전입니다. 이 격차를弥缝하려면 분배 正義에 대한 承諾을 유지하고, AI의 혜택이 다양한 사회 경제 그룹과 지역에서 널리 공유되도록 해야 합니다 (Sen, 2009).
이를 위해 AI 교육 및 자원에 대한 접근을 촉진하는 사업을 통해 그리고 AI 주도 경제 이득의 공평한 분배를 지지하는 정책을 실시할 수 있습니다. AI 분할 격차를 해결함으로써 AI가 包容的하고 공평한 방식으로 글로벌 발전에 기여하도록 할 수 있습니다.
革新와倫理적 제약 사이에 균형을 조성하기
革新 추구와倫理적 제약 사이에 균형을 맞추는 것은 책임 있는 AI 발전에至关重要입니다. 不確実성에 대한 조심을 권장하는 预防原則은 AI 개발의 컨텍스트에서 특히 적용되어야 합니다 (Sandin, 1999).
革新은 진전을 蔓草野心하나, 기술적 끊임없이 상/하의 dualistic 관념을 덜어내고자 하는 것은 매우 어려움을 겪게 됩니다. 따라서 모두가 공동 시민이며 서로를 존중하는 것이 중요합니다.
Innovation must be balanced with ethical constraints to protect against potential harms. This requires a careful assessment of the risks and benefits of new AI technologies, as well as the implementation of regulatory frameworks that ensure ethical standards are upheld.
As AI systems increasingly drive critical processes across various domains, understanding how AI agents fill the gaps in LLM capabilities is essential for realizing their full potential.
AIchnology, we can create intelligent systems that not only advance technological capabilities but also enhance the quality of life, promote justice, and ensure that the benefits of AI are shared equitably across society.
AI 기술의 발전에 따라 지속적으로 인간 being에 대한 의미와 가치를 고려하는 것이 중요하며, 인간 공동체의 전瞭를 돕기 위해 기술적 인ovation과 함께 긍정적인 영향을 미칠 것입니다.
AI 기관과 대형 언어 모델(LLM)의 합병은 인공지능의 FUNDAMENTAL 변화를 인정하는 것입니다. LLM의 일반적인 적용 제한을 극복하는 것을 목표로 합병은 omachines의 전통적인 역할을 벗어나는 것을 도와줍니다.
이러한 통합은 기계가 덜어내고자 하는 것은 매우 어려움을 겪게 합니다. 따라서 모두가 공동 시민이며 서로를 존중하는 것이 중요합니다.
AI technology, we can create intelligent systems that not only advance technological capabilities but also enhance the quality of life, promote justice, and ensure that the benefits of AI are shared equitably across society.
LLM의 능력 결함을 桥渡하기
LLM은 강력하지만, 이를 생성한 데이터와 その architechture의 static nature로부터 제한되며, 이러한 모델은 Parametric set로 제한되며, 일반적으로 교육 阶段에 사용된 텍스트 corpora로 정의되는 것입니다.
이러한 제한은 LLM이 자율적으로 새로운 정보를 찾고 훈련 阶段 AFTER에서 지식 ベース를 갱신할 수 없다는 것을 의미합니다. 따라서, LLM은 자주 veraldated되며 초기 훈련 데이터를 벗어난 것과 관련이 있는 响답을 제공할 수 있는지 여부를 알 수 없습니다.
AI エージェント는 이러한 沟壑을 桥渡하기 위해 外부 数据源를 动的으로 統合하는 것이며, LLM의 機能 範囲를 확장할 수 있습니다.
예를 들어, 2022까지의 金融 数据로 생성된 LLM은 정확한 历史적 분석을 제공할 수 있지만, 현재 시장 예측을 생성하는 것에 어려울 수 있습니다. AI エージェントは 이 LLM를 进一步增强하기 위해 金融 市場から 实时数据를 traction하고 이러한 인풋을 적용하여 더 적절하고 현재 분석을 생성할 수 있습니다.
이러한 動的 統合은 単に 历史적으로 정확하지만 현재 상황에 관련이 있는 响답을 생성할 수 있습니다.
결정 자율성 개선
LLM의 또 다른 중요한 제한은 자율적인 결정 making 능력의 결함입니다. LLM은 言語 기반의 출력을 뛰어나게 하지만, 불확실성과 변화로 특징づけられた 環境에서 複雑한 결정 making 任务에 적합하지 않습니다.
이러한 결함은 주로 모델의 이전 데이터에 의존하는 것과 배포 후 새로운 경험から 적응적 인 이asoning나 학습을 위한 기机制의 없음으로 인해 발생합니다.
AI 대상자는 자율적 인 결정 지능에 필요한 인frastructure를 제공하여 이러한 결함을 해결합니다. 그들은 LLM의 정적 출력을 가지고 规则기반 시스템, 힌디astic, 或者 强迫学习 모델과 유사한 심화된 이asoning 프레임워크를 통해 처리할 수 있습니다.
예를 들어, 치료 환경에서, LLM은 환자의 症状과 의학 과정을 기반으로 가능한 진단 목록을 생성할 수 있습니다. 그러나 AI 대상자가 없다면, LLM은 이러한 옵션을 ponder하거나 의사 행동을 제안할 수 없습니다.
AI 대상자는 이러한 진단을 현재의 의학 문헌, 환자 데이터, 및 시각적 요인에 비교하여 평가하여 더 이해하고 실제적인 다음 단계를 제안합니다. 이러한 합称은 LLM 출력을 単純한 의사로부터 실행 가능하고 상황을 인지하는 의사 결정으로 변경합니다.
integrality와 Consistency 해결
完整性과 일관성은 LLM 출력의 신뢰ability를 보장하는 중요한 요인으로, 특히 복잡한 이asoning 任务에서입니다. 매개변수 기반인 특성으로, LLM은 보다 복잡한 과정을 처리하거나 다양한 domains에 대한 포괄적인 이해가 필요한 경우에 대해 이러한 응답을 생성하는 것이 어려울 수 있습니다.
이러한 문제는 LLM가 이olate environment에서 동작하는 것에 의해 발생합니다. 이 environment는 자신의 출력을 외부 표준 또는 추가적인 정보와 cross-reference나 검증하지 못하기 때문입니다.
AI 대응체는 이러한 문제를 軽減하는 데 반복적 인馈璇句 Mechanisms 및 検証レイヤー를 introduce하는 데 중요한 rolls을 PLAY 한다.
たとえば, 法的 domains에서, LLM은 その 訓練 data에 기반하여 法的 brief의 最初の version을 draft하는 것이 ossible하다. 그러나 이 draft은 某些 예전 사례를 덮어 쓰거나 Argument을 合理的하게 구조화하는 것을 실수하는 것이 가능하다.
AI 대응체는 이 드래프트를 revie, 이 드래프트가 필요한 완성度를 만족하는지 확인하기 위해 外的 legal databases와 cross-referencing하며, 論理적인 일관성을 检查하며, 필요하다면 supplementary information 또는 CLAERICATION을 요청하는 것이 가능하다.
이 iterative process는 法的 practice에 따라 더욱 강固하고 신뢰할 만한 document의 production을 지원한다.
AI 대응체를 통해 孤立하는 것을 극복하는 것을 통합하는 것
LLM의 가장 깊은 한계는 그들의 inherent isolation from other systems and sources of knowledge이다.
LLM은, 그들이 설계되었으며, closed systems이며 外的 environment나 databases와 本土적으로 interact하지 않는다. 이 isolation은 그들이 새로운 information에 대한 적응 能力提升을 제한하고, real-time에서 operation하는 것을 제한하며, dynamic interaction 또는 real-time 결정 making를 요구하는 응용에서 유용하게 작동하지 못하는 것을 aggravate한다.
AI 대응체는 이 isolation을 극복하기 위해서는 LLM과 다른 한 ecosystem of data sources and computational tools를 연결하는 통합 Plateform으로 행동하는 것이다. API와 통합 framework를 통해 real-time data를 접근하고, 다른 AI systems와 collaboration하며, 실제 device와 인터페이스하는 것이 가능하다.
예를 들어, 고객 서비스 애플리케이션에서 LLM은 사전 훈련된 스크립트를 기반으로 표준 응답을 생성할 수 있습니다. 그러나 이러한 응답은 정적이며 효과적인 고객 참여를 위해 필요한 개인화가 부족할 수 있습니다.
AI 에이전트는 고객 프로필, 이전 상호 작용, 감정 분석 도구에서 실시간 데이터를 통합하여 이러한 상호 작용을 풍부하게 할 수 있으며, 이를 통해 맥락적으로 관련성이 있을 뿐만 아니라 고객의 특정 요구에 맞춘 응답을 생성할 수 있습니다.
이 통합은 고객 경험을 일련의 스크립트 상호 작용에서 동적이고 개인화된 대화로 변환합니다.
창의성 및 문제 해결 확장
LLM은 콘텐츠 생성에 강력한 도구이지만, 그들의 창의성과 문제 해결 능력은 본래 훈련된 데이터에 의해 제한됩니다. 이러한 모델은 종종 이론적 개념을 새로운 또는 예상치 못한 도전에 적용하는 데 어려움을 겪으며, 그들의 문제 해결 능력은 기존 지식과 훈련 매개 변수에 의해 제한됩니다.
AI 에이전트는 고급 추론 기술과 더 넓은 범위의 분석 도구를 활용하여 LLM의 창의성과 문제 해결 잠재력을 향상시킵니다. 이 능력은 AI 에이전트가 LLM의 한계를 넘어 이론적 프레임워크를 혁신적인 방식으로 실용적인 문제에 적용할 수 있게 합니다.
예를 들어, 소셜 미디어 플랫폼에서 잘못된 정보를 퇴치하는 문제를 고려해 보십시오. LLM은 텍스트 분석을 기반으로 잘못된 정보의 패턴을 식별할 수 있지만, 잘못된 정보의 확산을 완화하기 위한 포괄적인 전략을 개발하는 데 어려움을 겪을 수 있습니다.
AI 에이전트는 이러한 통찰력을 바탕으로 사회학, 심리학, 네트워크 이론과 같은 분야의 학제간 이론을 적용하여 실시간 모니터링, 사용자 교육, 자동화된 중재 기술을 포함하는 견고하고 다각적인 접근 방식을 개발할 수 있습니다.
이처럼 다양한 이론적 틀을 종합하고 이를 현실 문제에 적용하는 능력은 AI 에이전트가 가져오는 향상된 문제 해결 능력을 잘 보여줍니다.
더 구체적인 예시
다양한 시스템과 상호 작용하고 실시간 데이터를 접근하며 행동을 실행하는 능력을 가진 AI 에이전트는 이러한 한계를 정면으로 해결하여 강력하지만 수동적인 언어 모델인 LLM을 역동적이고 현실적인 문제 해결자로 변모시킵니다. 몇 가지 예시를 살펴보겠습니다:
1. 정적 데이터에서 동적 인사이트로: LLM을 최신 상태로 유지하기
- 문제: 2023년 이전의 의료 연구로 훈련된 LLM에게 “암 치료의 최신 돌파구는 무엇인가요?”라고 물어보면, 그 지식은 시대에 뒤떨어져 있을 것입니다.
- AI 에이전트 솔루션: AI 에이전트는 LLM을 의료 저널, 연구 데이터베이스, 뉴스 피드에 연결할 수 있습니다. 이제 LLM은 최신 임상 시험, 치료 옵션 및 연구 결과에 대한 최신 정보를 제공할 수 있습니다.
2. 분석에서 행동으로: LLM 인사이트를 기반으로 작업 자동화
-
문제: 브랜드를 모니터링 하는 LLM은 부정적인 감정 폭증을 발견할 수 있지만, 이를 해결할 수 있는任何事情를 할 수 없습니다.
-
AI 에이전트 솔루션: 브랜드의 소셜 미디어 계정과 연결되어 있고 사전 승인된 답변을 갖춘 AI 에이전트는 자동적으로 문의에 대응하고, 질문에 답하고, 심각한 문제를 인간 대표에게 승계할 수 있습니다.
3. 초안에서 완성된 제품으로: 품질과 정확성 보장
-
문제: 기술 설명서를 번역하는 LLM은 도메인 특정 지식의 부족으로 문法和적으로 정확하지만 기술적으로 불확실한 번역을 생성할 수 있습니다.
-
AI 에이전트 솔루션: AI 에이전트는 LLM을 전문 용어장, 사전 및 실시간 피드백을 위한 주제 전문가와 연결시키는 등의 특화된 사전과 결합시킬 수 있어서, 최종 번역이 언어적으로 정확하면서 기술적으로도 신뢰할 만하다.
4. 장벽의 깨지기: LLMs와 실제 세계 연결
-
문제: 스마트홈 제어를 위한 LLM은 사용자의 변화하는 루틴과 선호를適應하기에 어려움을 겪을 수 있다.
-
AI 에이전트 솔루션: AI 에이전트는 LLM을 센서, 스마트 기기, 사용자 캘린더와 연결시킨다. 사용자 행동 패턴을 분석함으로써 LLM은 필요를 예측하고, 조명과 온도 설정을 자동으로 조정하며, 일 시간대와 사용자 활동에 따라 개인화된 음악 플레이리스트를 제안할 수 있다.
5. 모사에서 혁신으로: LLM 창의성 확장
-
문제: 음악 작곡을 위임받은 LLM은 훈련 데이터에 있는 패턴을 주로 의존하므로, 파생적이거나 감정적 깊이를欠く 곡을 생성할 수 있습니다.
-
AI 에이전트 솔루션: AI 에이전트는 LLM을 다양한 음악적 요소에 대한 작곡자의 감정 반응을 측정하는 생체반응 센서와 연결할 수 있습니다. 이 실시간 피드백을 결합하면 LLM은 기술적으로 뛰어나기만 한 것이 아니라 감정적으로 울리고 오리지널한 음악을 창작할 수 있습니다.
AI 에이전트를 LLM 향상기로의 통합은 일정한 증분적인 개선을 의미하는 것이 아닙니다. 이는 인공지능이 달성할 수 있는 기본적인 확장을 나타냅니다. 전통적인 LLM의 내재적인 한계를 극복함으로써, 예를 들어 정적인 지식 기반, 제한된 결정 자율성, 및 독립적인 운영 환경 등을 개선시키는 AI 에이전트는 이 모델이 전력을 발휘할 수 있도록 해줍니다.
AI 기술이 계속 발전함에 따라, AI 에이전트가 LLM을 강화하는 역할은 점점 더 중요해지며, 이 모델의 능력을 확장하는 것 뿐만 아니라 인공지능의 경계를 재정의하는데도 중요합니다. 이 융합은自主思考, 실시간 적응, 그리고 변화无常의 세계에서 혁신적인 문제 해결을 할 수 있는 다음 세대 AI 시스템을 개척하고 있습니다.
제 6장: AI 에이전트와 LLM을 통합하는 아키텍처 디자인
AI 에이전트와 LLM의 통합은 아키텍처 디자인에 달려 있으며, 결정 자율성, 적응성, 그리고 확장성을 강화하는 데 중요합니다. 아키텍처는 AI 에이전트와 LLM 간의 부드러운 상호 작용을 활성화하고, 각 구성 요소가 최적의 기능을 수행하도록 신경 쓰여야 합니다.
모듈러형 아키텍처는 AI 에이전트가 오케스트레이터로서 LLM의 능력을 조절하는 방식입니다. 이 디자인은 LLM의 자연어 처리의 강점을 활용하면서 AI 에이전트가 여러 단계의 추론이나 실시간 환경에서의 문맥에 따른 결정 등 더 복잡한 작업을 관리할 수 있도록 합니다.
대체적으로, LLMs와 특화된, 미세 조정된 모델을 결합한 하이브리드 모델은 AI 에이전트가 작업을 가장 적절한 모델에 위임할 수 있도록 유연성을 제공합니다. 이 접근 방식은 기본 성능을 최적화하고 다양한 응용 프로그램에서 효율을 높이며, 다양하고 변동적인 운영 문맥에서 특히 효과적입니다 (Liang et al., 2021).

훈련 방법론과 最佳實踐
LLMs와 통합된 AI 에이전트의 훈련은 일반화와 작업 특정 최적화를 균형있게 하는 체계적인 접근 방식이 필요합니다.
이동 학습은 주요 기술로, AI 에이전트의 작업과 관련된 도메인 특정 데이터에 대해 사전 훈련된 대규모 다양한语料库에 대해 미세 조정할 수 있도록 합니다. 이 방법은 LLM의 광泛한 지식 기반을 유지的同时에 특정 응용 프로그램에서专门화할 수 있도록 하여 전체 시스템의 효과성을 높입니다.
또한, 강화 학습 (RL)은 AI 에이전트가 변화하는 환경에 적응해야 하는 시나리오에서 중요한 역할을 합니다. 환경과의 상호 작용을 통해 AI 에이전트는 결정 프로세스를 지속적으로 개선하고 새로운 도전을 처리하는 능력을 높입니다.
다양한 시나리오에서 신뢰할 수 있는 성능을 보장하려면, 엄격한 평가 지표가 필수입니다. 이들은 표준 벤치마크와 작업 특정 기준을 모두 포함해야 하며, 시스템의 훈련이 견고하고 포괄적이라는 것을 보장합니다 (Silver et al., 2016).
대규모 언어 모델 (LLM)의 미세 조정과 강화 학습 개념들 소개
이 코드는 기계학습과 자연어 처리(NLP)에 관한 다양한 기술을 보여주며 대형 언어 모델(LLM)을 특정 작업에 맞게 微調整(fine-tuning)하고 강화학습(RL) 에이전트를 구현하는 것을 중점적으로 다루고 있습니다. 이 코드는 몇 가지 주요 영역을 포함하고 있습니다.
-
LLM의 微調整: BERT와 같은 사전에 훈련된 모델을 감성 분석과 같은 작업에 활용하며, Hugging Face
transformers라이브러리를 사용합니다. 이를 위해 데이터셋을 토큰화하고 훈련 인자를 사용하여 微調整 과정을 안내합니다. -
강화학습(RL): 간단한 Q-학습 에이전트로 RL의 기초를 소개하며, 에이전트는 환경과 상호 작용하며 시도와 오류를 통해 학습하고 Q-테이블을 통해 지식을 갱신합니다.
-
OpenAI API를 사용한 리워드 모델링: OpenAI의 API를 사용하여 RL 에이전트에 동적으로 리워드 신호를 제공하는 개념적인 방법으로, 언어 모델이 행동을 평가할 수 있습니다.
-
모델 평가 및 로그ging:
scikit-learn과 같은 라이브러리를 사용하여 정확도와 F1 스코어를 통해 모델 パフォーマン스 평가하고, PyTorch의SummaryWriter를 사용하여 훈련 진행을 시각화합니다. -
심화 RL 개념: 정책 기울기 네트워크, 커리큘럼 학습, 早期 정지 등의 더 심화된 개념을 구현하여 모델 훈련 효율을 향상시킵니다.
이 종합적인 접근法은 감성 분석을 통한 수정 돋보기 기반의 지도 학습뿐만 아니라 보상 기반 학습까지 포함하며, 현대 AI 시스템을 어떻게 built, evaluated, 및 optimized 하는지 이해하는 데 도움을 줍니다.
코드 예시
단계 1: 필요한 라이브러리 導入
모델 미세 조정 및 에이전트 구현에 들어가기 전에 필수 라이브러리와 모듈을 설정하는 것이 중요합니다. 이 코드는 Hugging Face의 transformers와 PyTorch 같은 인기 있는 라이브러리에서의 가져오기를 포함하여, 신경망 처리를 위한 scikit-learn은 모델 성능 평가를 위해, random과 pickle 같은 범용 모듈도 포함합니다.
-
Hugging Face 라이브러리: 사전 훈련된 모델과 토크나이저를 Model Hub에서 사용하고 미세 조정할 수 있습니다.
-
PyTorch: 신경망 레이어 및 옵티마이저를 포함한 작업을 위한 핵심 딥러닝 프레임워크입니다.
-
scikit-learn: 모델 성능 평가를 위한 정확도 및 F1-스코어와 같은 지표를 제공합니다.
-
OpenAI API: 보상 모델링과 같은 다양한 작업을 위해 OpenAI의 언어 모델에 접근합니다.
-
TensorBoard: 훈련 진행 상황을 시각화하는 데 사용됩니다.
다음은 필요한 라이브러리를 導入하는 코드입니다:
# arbitrary number generation에 사용할 random module를 導入합니다.
import random
# transformers 라이브러리의 필요한 모듈을 導入합니다.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# dataset를 로드하기 위한 load_dataset를 導入합니다.
from datasets import load_dataset
# 모델 성능을 평가하기 위한 metrics를 導入합니다.
from sklearn.metrics import accuracy_score, f1_score
# 훈련 진행 기록을 위한 SummaryWriter를 導入합니다.
from torch.utils.tensorboard import SummaryWriter
# 훈련된 모델을 저장하고 로딩하기 위한 pickle를 導入합니다.
import pickle
# OpenAI의 API를 사용하기 위해 openai를 導入합니다. (API ключ이 필요합니다.)
import openai
# deep learning operaions에 사용할 PyTorch를 導入합니다.
import torch
# PyTorch의 neural network module를 導入합니다.
import torch.nn as nn
# PyTorch의 optimizer module를 導入합니다. (이 예시에서 직접 사용하지 않습니다.)
import torch.optim as optim
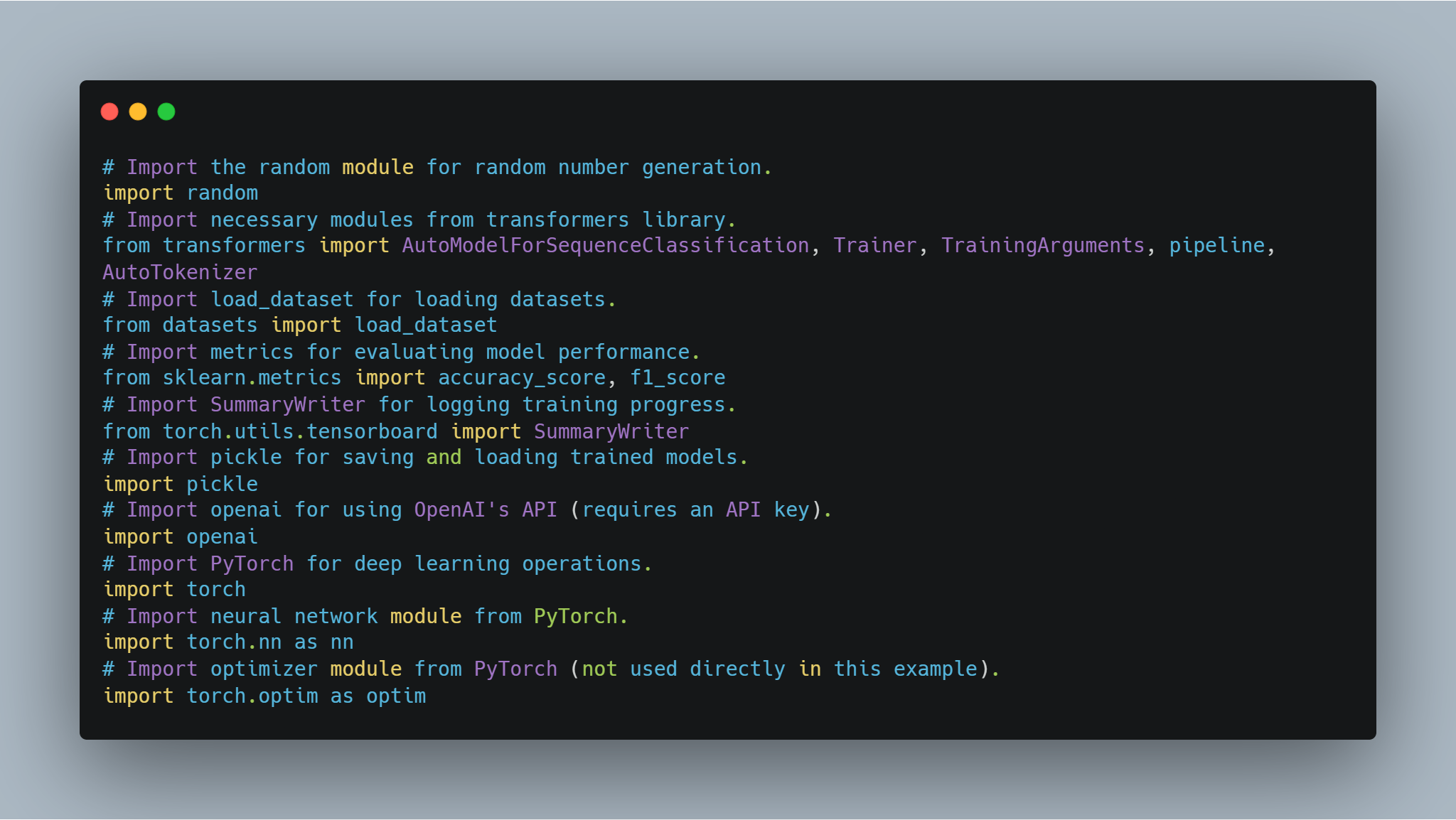
이러한 모듈 중 每一个이 코드의 다른 부분에서 중요한 역할을 합니다. 모델 훈련, 평가, 결과 기록 및 외부 API와의 인터렉션 등을 担당합니다.
第2步: 감성 분석을 위한 전문적 언어 모델 精 tuning
감성 분석을 수행하기 위해 전문적인 모델을 精 tuning하는 것은, 이전에 훈련된 모델을 로드하고, 출력 레이블의 수(이 예에서는 积极/消极)에 맞춰 조정하고, 적절한 데이터셋을 사용하는 것입니다.
이 예제에서는 transformers 라이브러리의 AutoModelForSequenceClassification을 사용하고 IMDB 데이터셋으로 사전 훈련된 모델을 학습합니다. 이 사전 훈련된 모델은 데이터셋의 더 작은 부분으로 微調(fine-tune)하여 계산 시간을 절약할 수 있습니다. 그런 다음 모델은 학습 인자의 사용자 정의 집합을 사용하여 학습되는데, 이에는 에폭 수와 배치 크기가 포함됩니다.
다음은 모델을 로드하고 微調(fine-tune)하는 코드입니다:
# Hugging Face Model Hub에서 사전 훈련된 모델 이름을 지정합니다.
model_name = "bert-base-uncased"
# 지정된 출력 클래스 수로 사전 훈련된 모델을 로드합니다.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 모델을 위한 토크나이저를 로드합니다.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Hugging Face Datasets에서 IMDB 데이터셋을 로드하고 학습에 10%만 사용합니다.
dataset = load_dataset("imdb", split="train[:10%]")
# 데이터셋을 토큰화합니다
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 데이터셋을 토큰화된 입력으로 매핑합니다
tokenized_dataset = dataset.map(tokenize_function, batched=True)
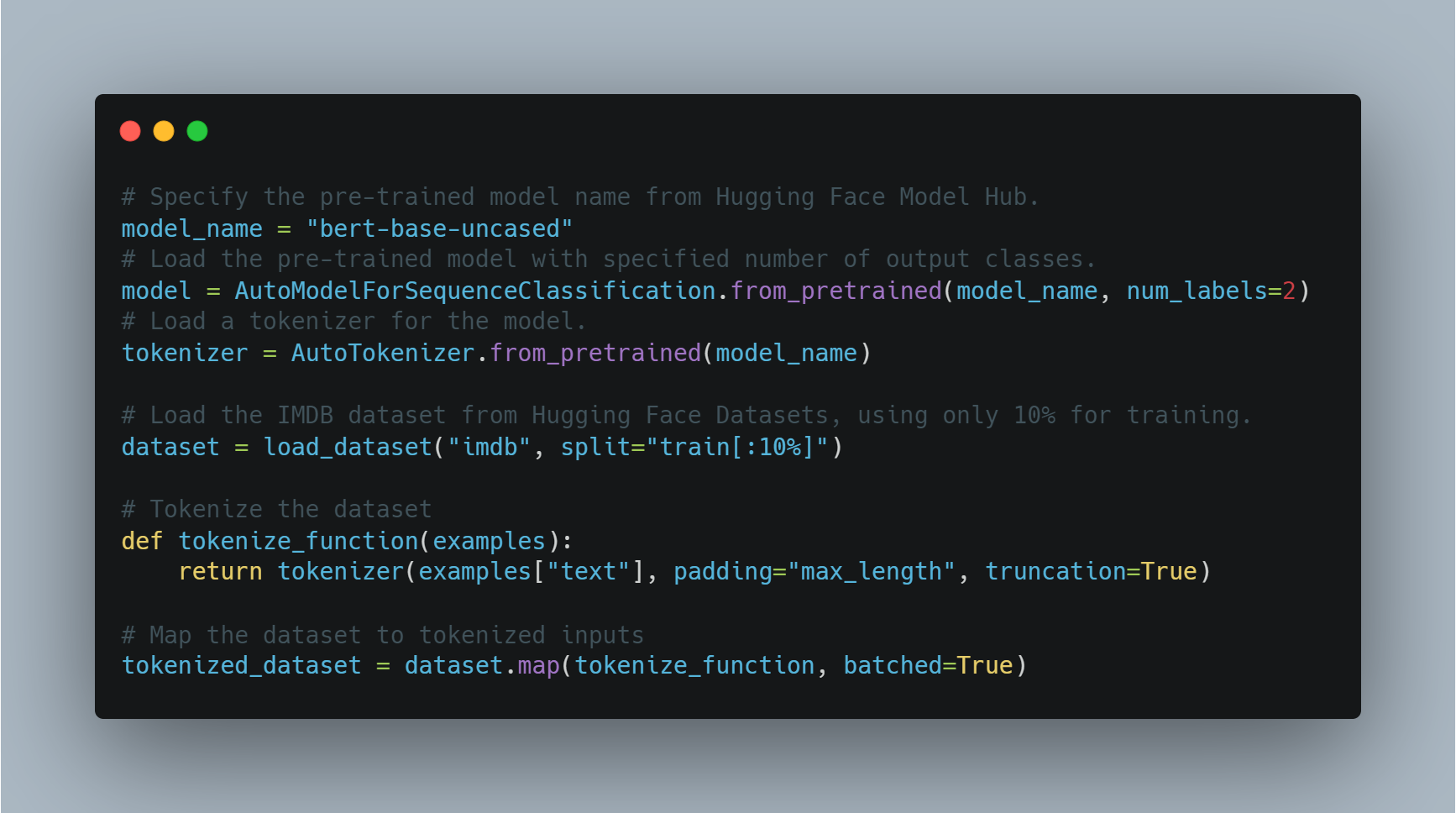
여기서는 BERT 기반 아키텍처로 모델을 로드하고 데이터셋을 학습 준비합니다. 그 다음에는 학습 인자를 정의하고 Trainer를 초기화합니다.
# 트레이닝 인자를 정의합니다.
training_args = TrainingArguments(
output_dir="./results", # 모델을 저장하기 위한 출력 디렉터리를 지정합니다.
num_train_epochs=3, # 트레이닝 에폭의 갯수를 설정합니다.
per_device_train_batch_size=8, # 각 기기에 대한 batch size를 설정합니다.
logging_dir='./logs', # 로그를 저장하는 디렉터리입니다.
logging_steps=10 # 每一步에 대해 로그를 기록합니다.
)
# Trainer를 모델, 트레이닝 인자 및 데이터셋으로 초기화합니다.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# 트레이닝 프로세스를 시작합니다.
trainer.train()
# 精炼된 모델을 저장합니다.
model.save_pretrained("./fine_tuned_sentiment_model")

Step 3: 간단한 Q-Learning 에이전트 구현
Q-learning은 cumulative reward를 최대화하기 위해 행동을 결정하는 방법을 배울 수 있는 强化的 러닝 기술입니다.
이 예제에서는 Q-table에 state-action 쌍을 저장하는 기본 Q-learning 에이전트를 정의합니다. 에이전트는 arbitrary action을 explore하거나 Q-table에 기록된 가장 좋은 action을 exploit할 수 있습니다. Q-table은 learning rate와 discount factor를 이용하여 미래의 rewards의 가중치를 정하고 각 action 이후에 update됩니다.
아래는 이 Q-learning 에이전트를 구현하는 코드입니다:
# Q-learning 에이전트 클래스 정의.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Q-테이블 초기화.
self.q_table = {}
# 가능한 행동 저장.
self.actions = actions
# 탐험률 설정.
self.epsilon = epsilon
# 학습률 설정.
self.alpha = alpha
# 할인 인자 설정.
self.gamma = gamma
# 현재 상태에 따라 행동을 선택하는 get_action 메서드 정의.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# 무작위 탐험.
return random.choice(self.actions)
else:
# 최적 행동 활용.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
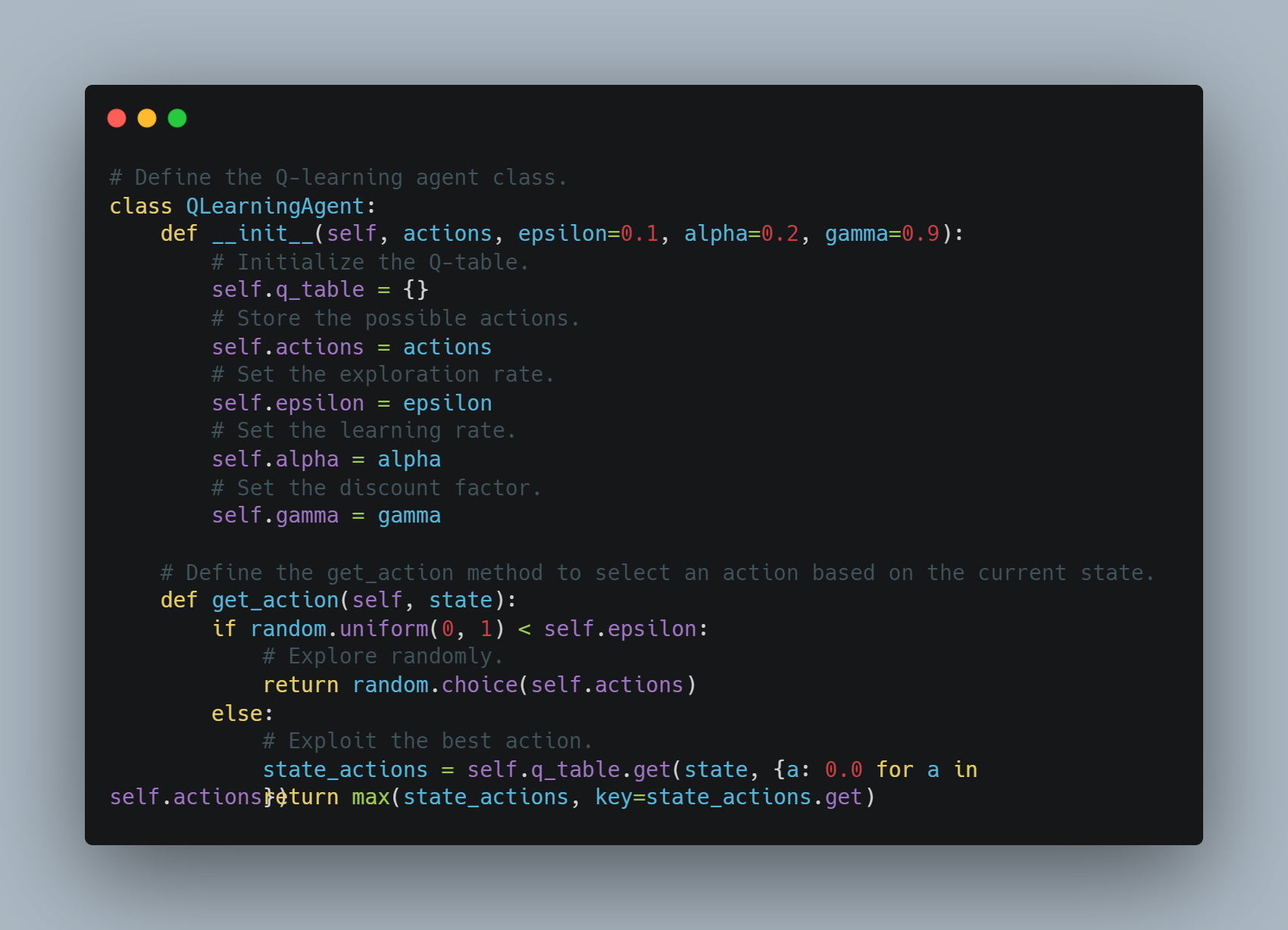
에이전트는 탐험 또는 활용을 기반으로 행동을 선택하고 각 단계 후에 Q-값을 업데이트합니다.
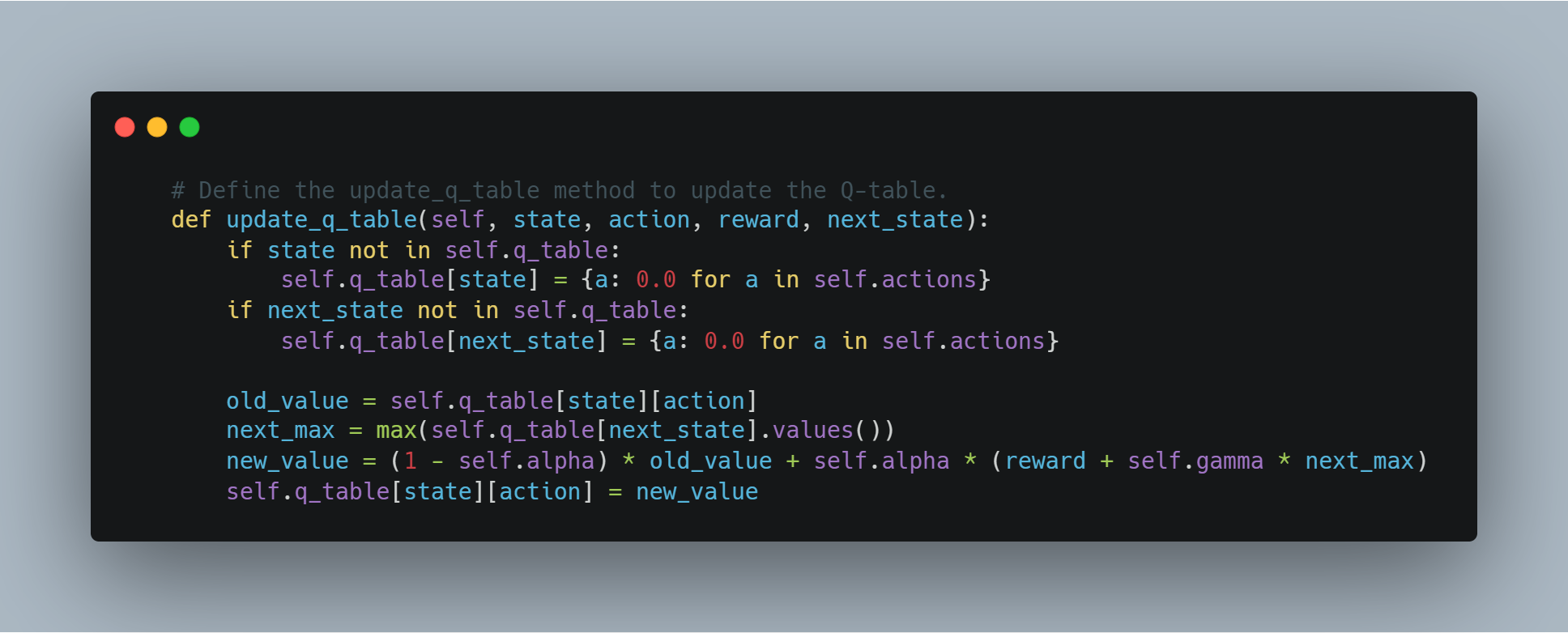
# Q-테이블을 업데이트하는 update_q_table 메서드 정의.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
4단계: 보상 모델링을 위한 OpenAI의 API 사용
일부 시나리오에서는 수동 보상 함수를 정의하는 대신, 에이전트가 수행한 행동의 품질을 평가하기 위해 OpenAI의 GPT와 같은 강력한 언어 모델을 사용할 수 있습니다.
이 예에서 get_reward 함수는 상태, 행동 및 다음 상태를 OpenAI의 API에 보내 보상 점수를 수신하여 복잡한 보상 구조를 이해하기 위해 대형 언어 모델을 활용할 수 있게 합니다.
# OpenAI의 API로부터 보상 신호를 받기 위한 get_reward 함수 정의.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # 실제 OpenAI API 키로 교체하십시오.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
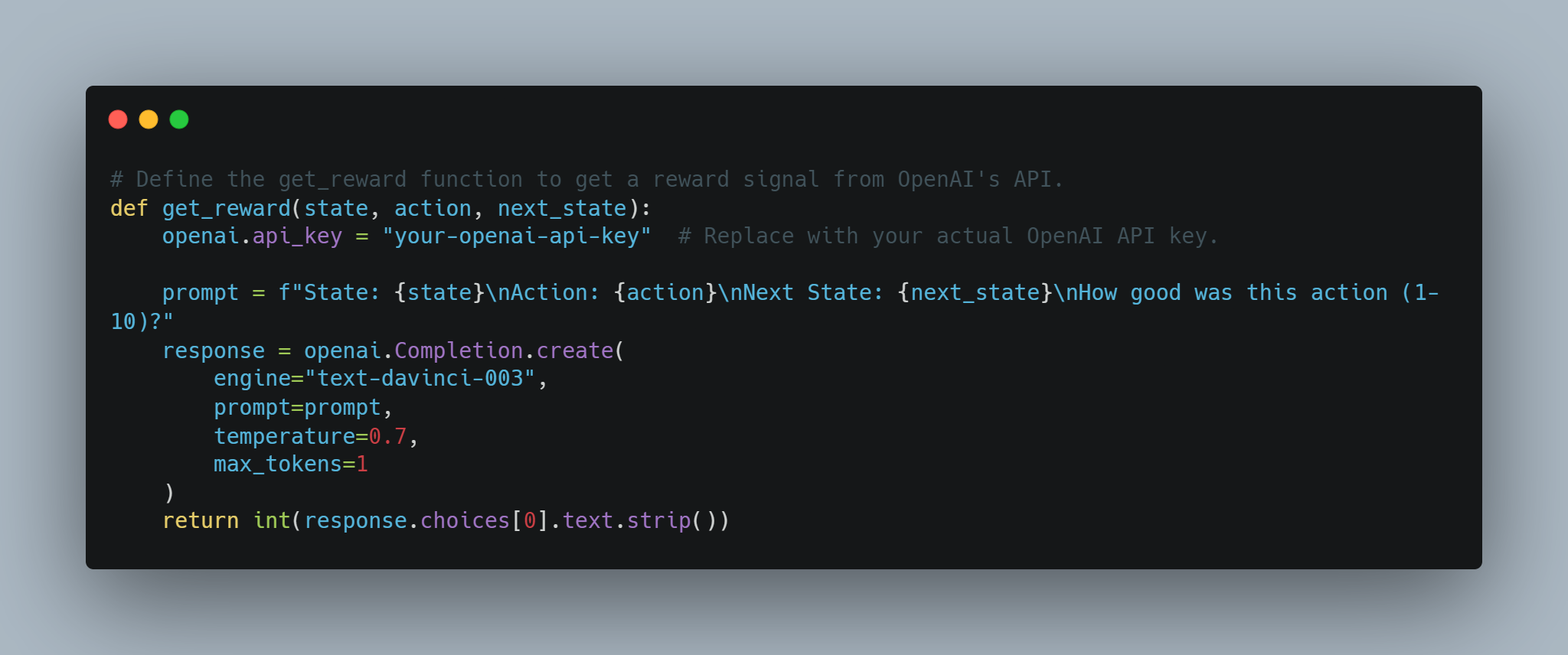
이것은 보상 시스템을 동적으로 OpenAI API를 사용하여 결정하는 의도적 접근 방식을 허용하며, 보상을 정의하기 힘든 복잡한 태스크에 유용할 수 있습니다.
단계 5: 모델 パフォーマン스 평가
機械学習 모델이 训练되었으면, 정확性和 F1-score과 같은 표준 지표를 사용하여 그 パフォーマン스를 평가하는 것이 essental입니다.
이 섹션은 실제 biaesd 라벨과 예측 라abel로 両方을 계산합니다. 정확性은 정확성을 总体적으로 표시하는 것입니다, F1-score은 특히 불balanced dataset에서 정확성과 召回率를 똑같이 balancer하는 것입니다.
모델 パフォーマン스 평가 위한 코드가 如下所示입니다.
# 평가 목적으로 실제 biaesd 라abel을 정의합니다.
true_labels = [0, 1, 1, 0, 1]
# 평가 목적으로 예측 라abel을 정의합니다.
predicted_labels = [0, 0, 1, 0, 1]
# 정확성 점수를 계산합니다.
accuracy = accuracy_score(true_labels, predicted_labels)
# F1-score를 계산합니다.
f1 = f1_score(true_labels, predicted_labels)
# 정확성 점수를 印字합니다.
print(f"Accuracy: {accuracy:.2f}")
# F1-score를 印字합니다.
print(f"F1-Score: {f1:.2f}")
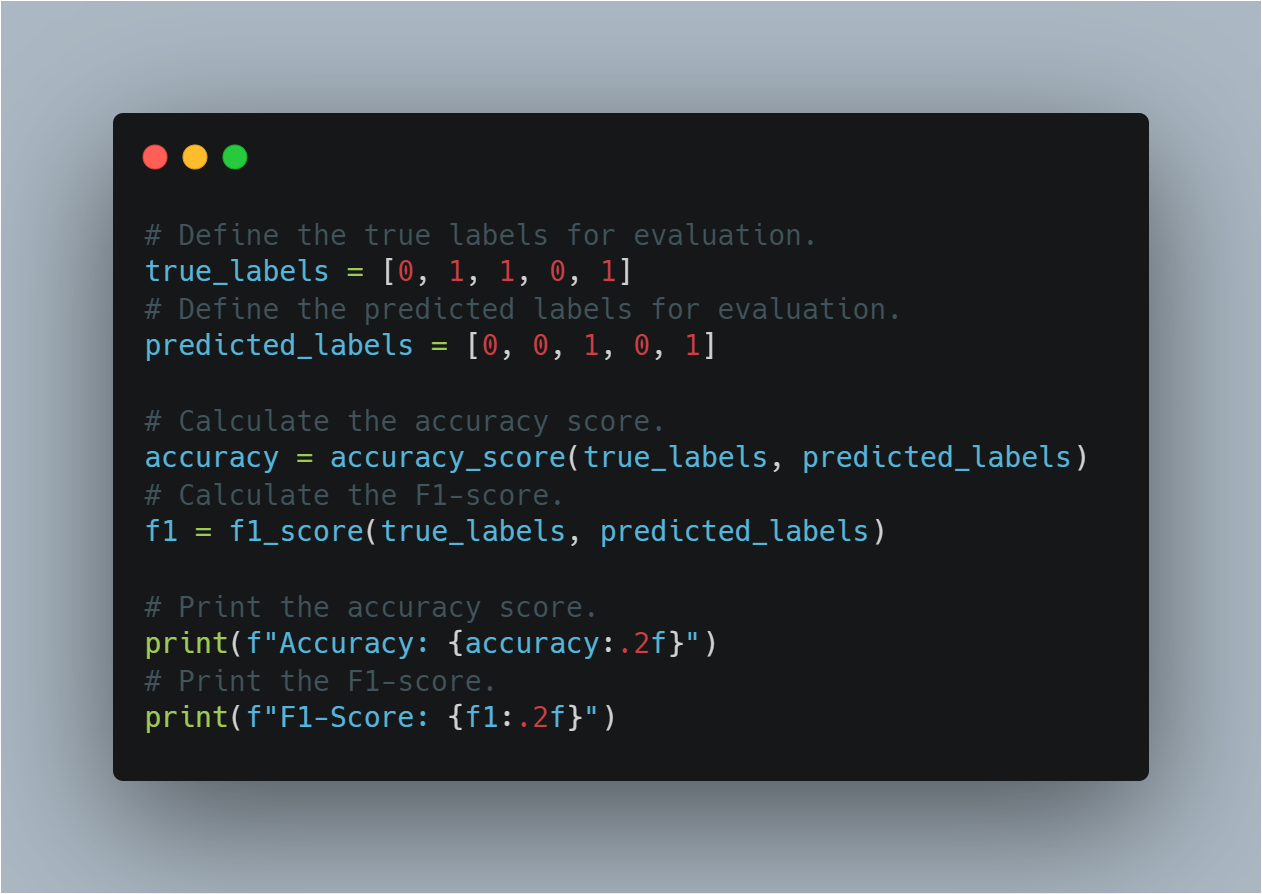
이 섹션은 모델이 보안 데이터에 대해 일반화를 얼마나 잘 했는지 确诊하기 위해 좋게 마련된 평가 지표를 사용합니다.
단계 6: PyTorch를 사용하는 기본 정책 기울기 エージェント
리젠forcement leaneding에서 정책 기울기 방법은 기대 보상을 最大化하여 정책을 직접 Optimize하는 것입니다.
이 섹션에서는 PyTorch를 사용한 간단한 정책 네트워크 구현을 보여줍니다. 이는 강화 학습(RL)에서 결정을 내릴 때 사용할 수 있습니다. 정책 네트워크는 선형 계층을 사용하여 서로 다른 액션에 대한 확률을 출력하며, softmax를 적용하여 출력이 유효한 확률 분포 형태를 갖추게 합니다.
기본 정책 그레디언트 에이전트를 정의하는 개념적인 코드입니다:
# 정책 네트워크 클래스 정의.
class PolicyNetwork(nn.Module):
# 정책 네트워크 초기화.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# 선형 계층 정의.
self.linear = nn.Linear(input_size, output_size)
# 네트워크의 전방 패스 정의.
def forward(self, x):
# 선형 계층의 출력에 softmax 적용.
return torch.softmax(self.linear(x), dim=1)
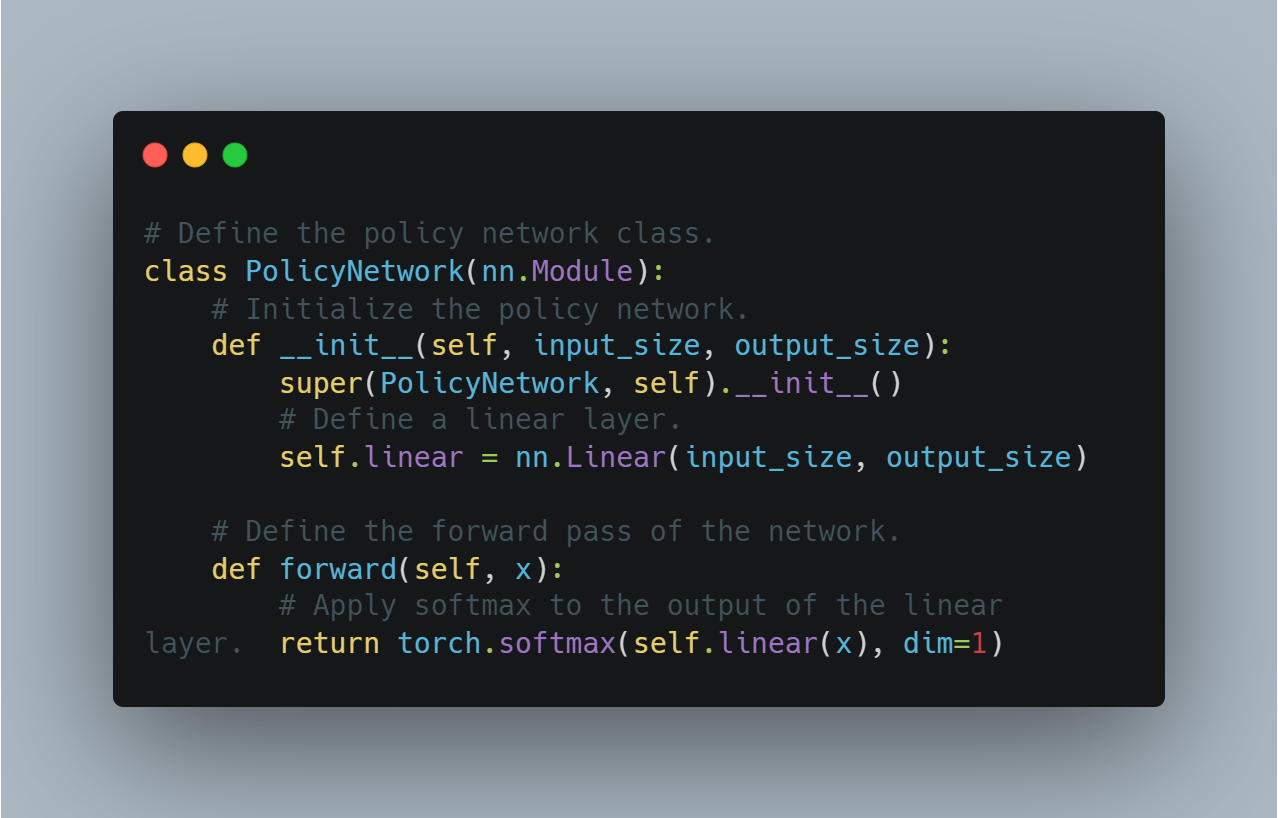
이는 정책 최적화를 사용하는 더先进的 강화 학습 알고리즘을 구현하는 데 기본 단계가 됩니다.
7단계: TensorBoard로 훈련 진행 상황的可視化
손실과 정확도와 같은 훈련 지표를 可視化하는 것은 모델의 성능이 시간이 지나면서 어떻게 변화하는지 이해하는 데 중요합니다. TensorBoard는 이를 위한 유명한 도구로, 지표를 기록하고 실시간으로 可視화할 수 있습니다.
이 섹션에서는 SummaryWriter 인스턴스를 만들고, 훈련 중 손실과 정확도를 추적하는 과정을 시뮬레이션하기 위해 무작위 값을 기록합니다.
TensorBoard를 사용하여 훈련 진행 상황을 기록하고 可視化的 방법입니다:
# SummaryWriter 인스턴스 생성
writer = SummaryWriter()
# TensorBoard 시각화를 위한 예제 훈련 루프:
num_epochs = 10 # 에포크 수 정의
for epoch in range(num_epochs):
# 랜덤 손실 및 정확도 값을 시뮬레이션
loss = random.random()
accuracy = random.random()
# 손실 및 정확도를 TensorBoard에 기록
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# SummaryWriter 닫기
writer.close()
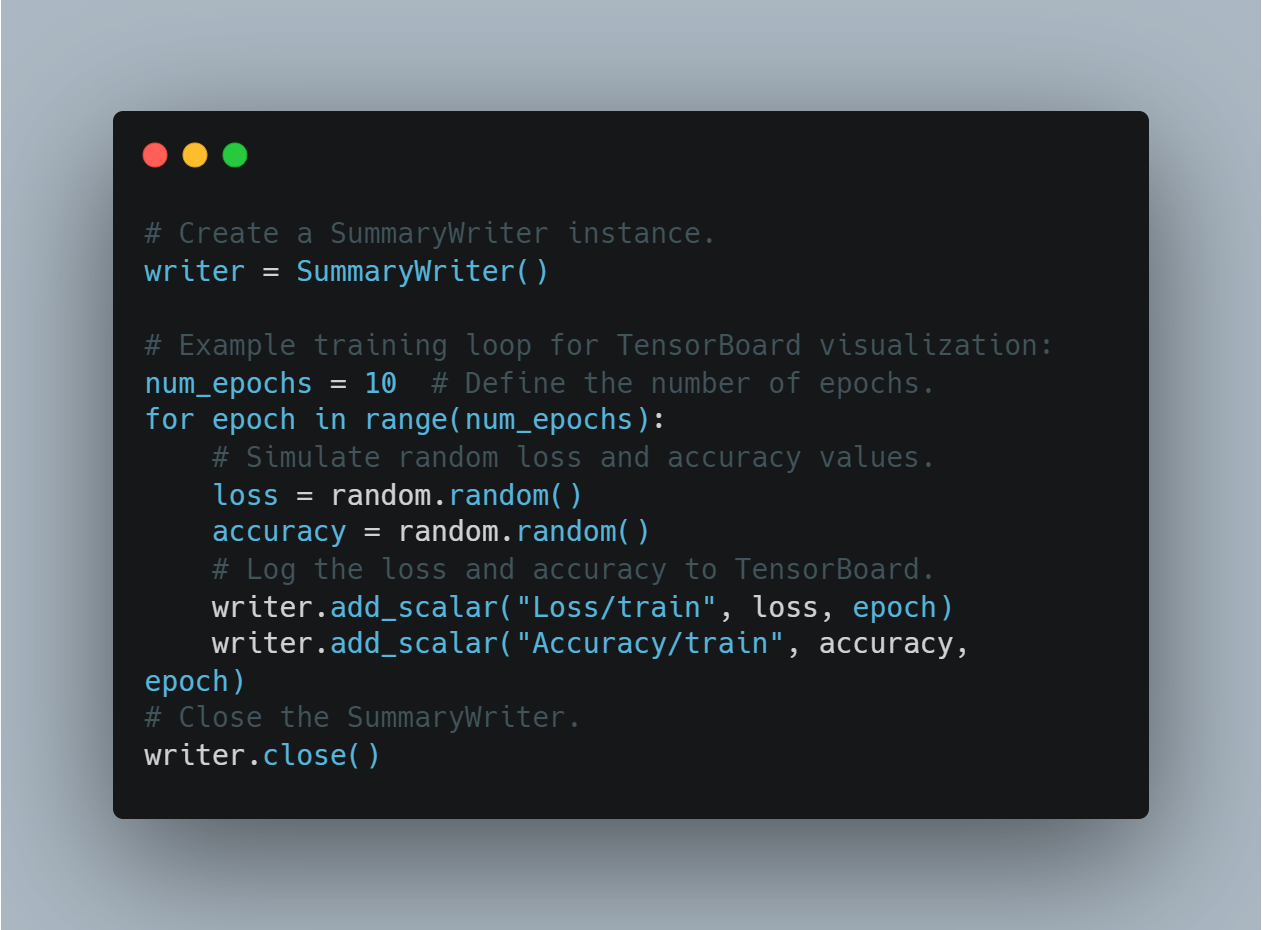
이렇게 하면 사용자가 모델 훈련을 모니터링하고 시각적 피드백을 바탕으로 실시간 조정을 할 수 있습니다.
스�텝 8: 훈련된 에이전트 체크포인트 저장과 로드
에이전트를 훈련한 후, 공부된 상태(예를 들어, Q값 또는 모델 가중치)를 저장하여 나중에 재사용하거나 평가할 수 있어야 합니다.
이 섹션에서는 파이썬의 pickle 모듈을 사용하여 훈련된 에이전트를 저장하는 방법과 디스크에서 로드하는 방법을 보여줍니다.
다음은 훈련된 Q-러닝 에이전트를 저장하고 로드하는 코드입니다:
# Q-러닝 에이전트 인스턴스 생성
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# 에이전트 훈련 (여기서는 보여지지 않음)
# 에이전트 저장
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# 에이전트 로드
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
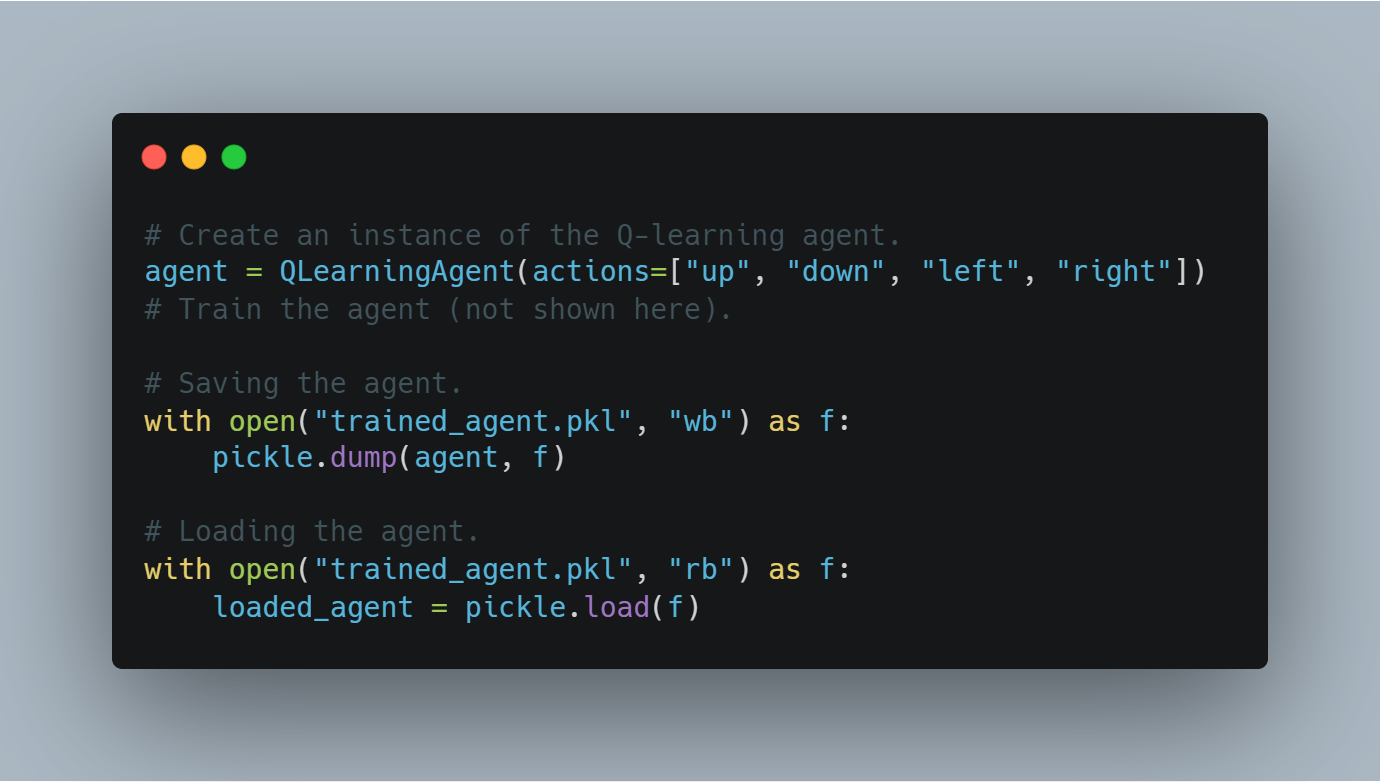
이러한 체크포인트 처리를 통해 훈련 진행 상황이 손실되지 않고, 미래의 실험에서 모델을 재사용할 수 있습니다.
스�텝 9: 커리큘럼 학습
교과서 학습은 모델에게 시작하는 것이 쉬운 예제로부터 어려울 수 있는 것을 지속적으로 보여주는 것을 가정합니다. 이것은 모델 성능과 안정성을 에이전트가 더 错綜複雜한 도전을 이해하는 것에 도울 수 있습니다.
교과서 학습을 사용하는 에이전트의 예제 하나는 다음과 같습니다.
# 초기 任务 difficulty를 지정합니다.
initial_task_difficulty = 0.1
# 的教과서 학습을 사용하는 훈련 루프 예제
for epoch in range(num_epochs):
# task difficulty를 徐々に 증가 시키는 것
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# 조절된 difficulty로 훈련 데이터를 생성합니다.
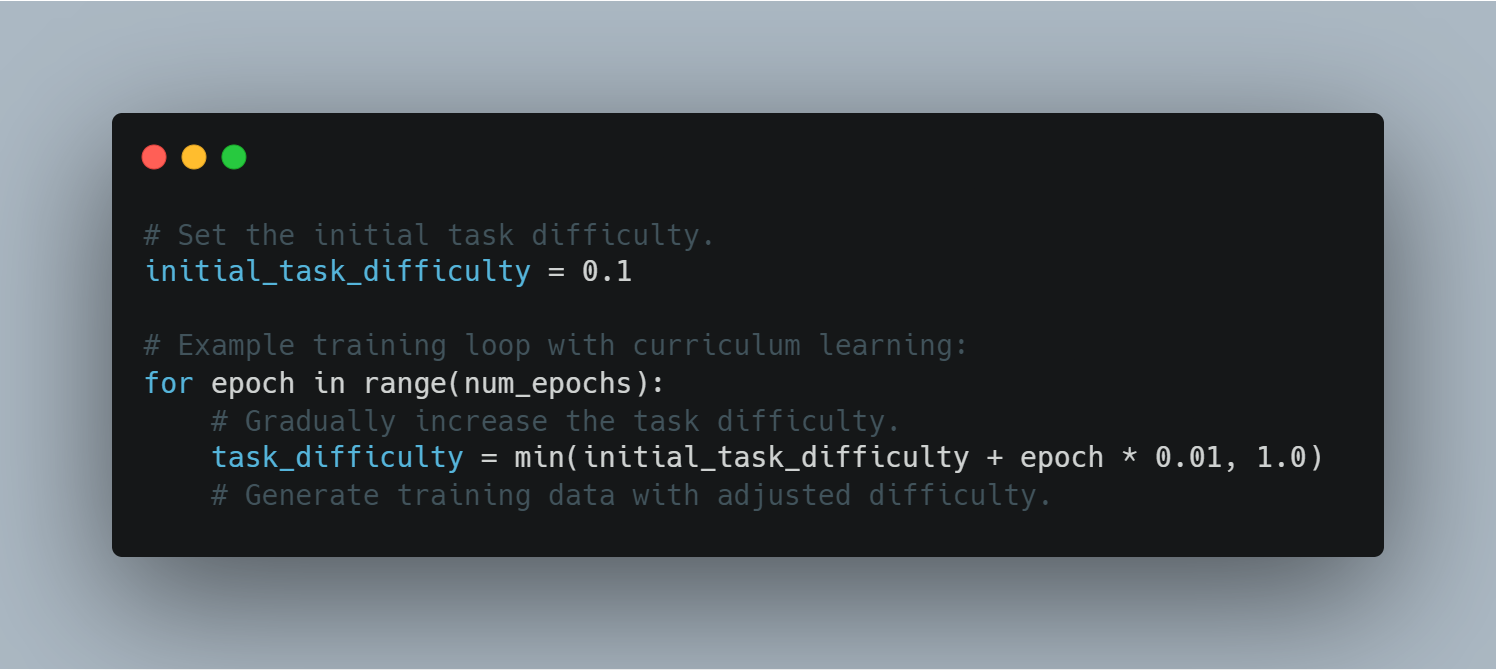
task difficulty 조절을 통해 에이전트는 더 복잡한 도전을 이해하는 것을 지속적으로 도울 수 있습니다.
Step 10: Early Stopping 구현
Early Stopping은 정확히 何 epoch가 지나고 시험 데이터로부터 손실이 改善되지 않으면 학습 과정을 중지하는 기법입니다.
이 sectioin은 어떻게 Early Stopping을 훈련 루프에 구현하는지 보여줍니다.
Early Stopping을 구현하는 코드는 다음과 같습니다.
최선의 검증 손실을 무한대로 초기화합니다.
best_validation_loss = float("inf")
耐心 값 설정(개선 없는 에포크 수).
patience = 5
개선 없는 에포크 카운터 초기화.
epochs_without_improvement = 0
과대적합을 방지하는 조기 중지를 사용한 예제 훈련 루프:
for epoch in range(num_epochs):
검증 손실을 가상으로 시뮬레이트.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

조기 중지는 모델이 과대적합을 시작할 때 불필요한 훈련을 방지하여 모델의 일반화를 향상시킵니다.
스텝 11: 사전 훈련된 LLM을 사용하여.Zero-Shot Task Transfer
Zero-Shot Task Transfer에서는 사전 훈련된 모델을 특별히 微調을 하지 않은 작업에 적용합니다.
Hugging Face의 파이프라인을 사용하여, 이 섹션에서 사전 훈련된 BART 모델을 추가 훈련 없이 요약 작업에 적용하는 방법을 보여줍니다. 이를 통해 이전 학습의 개념을 설명합니다.
사전 훈련된 LLM을 요약 작업에 사용하는 코드입니다:
사전 훈련된 요약 파이프라인 불러오기.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
요약할 텍스트 정의.
text = "This is an example text about AI agents and LLMs."
요약 생성.
summary = summarizer(text)[0]["summary_text"]
요약 출력.
print(f"Summary: {summary}")
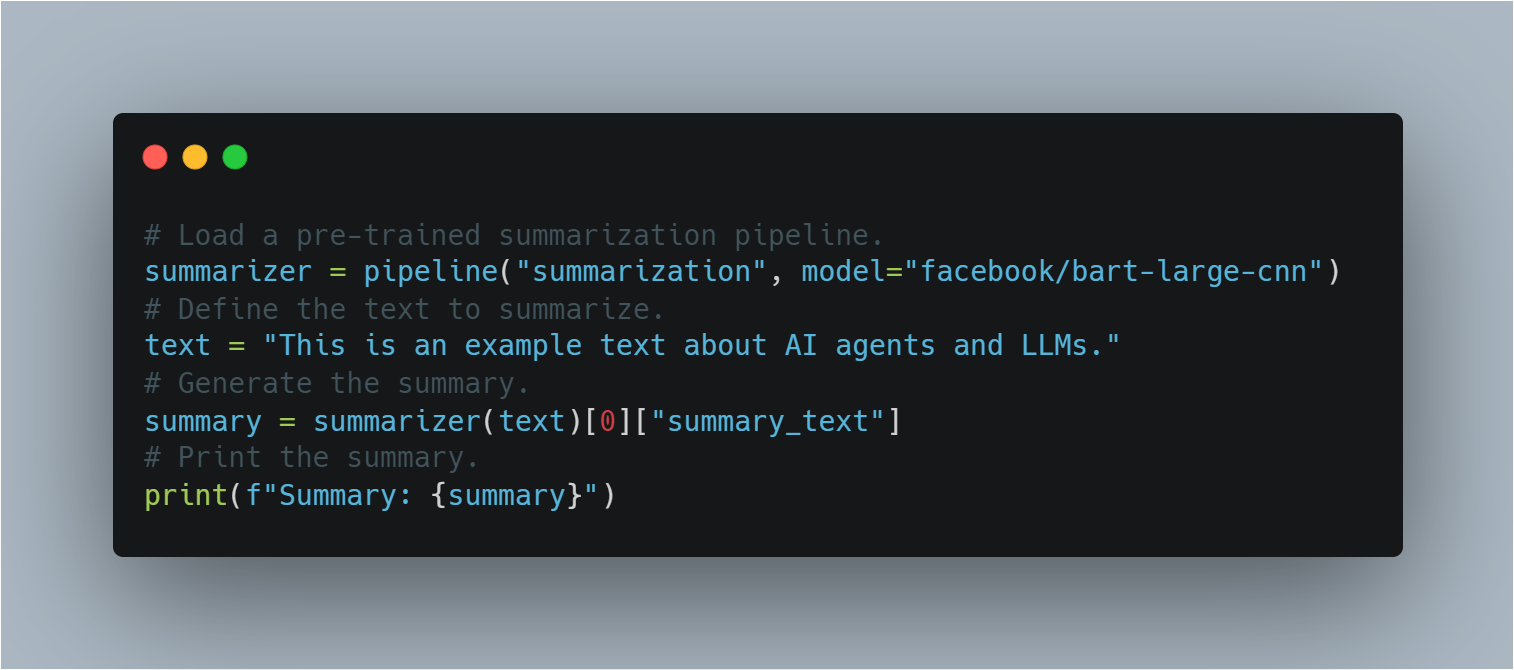
이는 LLM의 유연성을 보여줍니다. 추가 훈련 없이도 사전에 존재하는 지식을 활용하여 다양한 작업을 수행할 수 있음을 보여줍니다.
전체 코드 예제
# 무작위 숫자 생성을 위한 random 모듈을 가져옵니다.
import random
# transformers 라이브러리에서 필요한 모듈을 가져옵니다.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# 데이터셋 로드를 위한 load_dataset을 가져옵니다.
from datasets import load_dataset
# 모델 성능 평가를 위한 metrics를 가져옵니다.
from sklearn.metrics import accuracy_score, f1_score
# 학습 진행 상황을 기록하기 위한 SummaryWriter를 가져옵니다.
from torch.utils.tensorboard import SummaryWriter
# 학습된 모델을 저장하고 로드하기 위한 pickle을 가져옵니다.
import pickle
# OpenAI의 API 사용을 위한 openai를 가져옵니다 (API 키 필요).
import openai
# 딥러닝 작업을 위한 PyTorch를 가져옵니다.
import torch
# PyTorch의 신경망 모듈을 가져옵니다.
import torch.nn as nn
# PyTorch의 옵티마이저 모듈을 가져옵니다 (이 예제에서는 직접 사용되지 않음).
import torch.optim as optim
# --------------------------------------------------
# 1. 감정 분석을 위한 LLM 미세 조정
# --------------------------------------------------
# Hugging Face Model Hub에서 사전 학습된 모델 이름을 지정합니다.
model_name = "bert-base-uncased"
# 지정된 출력 클래스 수로 사전 학습된 모델을 로드합니다.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 모델을 위한 토크나이저를 로드합니다.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Hugging Face Datasets에서 IMDB 데이터셋을 로드합니다, 10%만 훈련에 사용합니다.
dataset = load_dataset("imdb", split="train[:10%]")
# 데이터셋을 토큰화합니다.
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 데이터셋을 토큰화된 입력으로 매핑합니다.
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# 훈련 인자를 정의합니다.
training_args = TrainingArguments(
output_dir="./results", # 모델을 저장할 출력 디렉토리를 지정합니다.
num_train_epochs=3, # 훈련 에포크 수를 설정합니다.
per_device_train_batch_size=8, # 기기당 배치 크기를 설정합니다.
logging_dir='./logs', # 로그를 저장할 디렉토리입니다.
logging_steps=10 # 10단계마다 로그를 기록합니다.
)
# 모델, 훈련 인자, 데이터셋과 함께 Trainer를 초기화합니다.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# 훈련 과정을 시작합니다.
trainer.train()
# 미세 조정된 모델을 저장합니다.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. 간단한 Q-러닝 에이전트 구현
# --------------------------------------------------
# Q-러닝 에이전트 클래스를 정의합니다.
class QLearningAgent:
# 행동, epsilon (탐험 비율), alpha (학습률), gamma (할인율)로 에이전트를 초기화합니다.
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Q-테이블을 초기화합니다.
self.q_table = {}
# 가능한 행동을 저장합니다.
self.actions = actions
# 탐험 비율을 설정합니다.
self.epsilon = epsilon
# 학습률을 설정합니다.
self.alpha = alpha
# 할인율을 설정합니다.
self.gamma = gamma
# 현재 상태를 기반으로 행동을 선택하는 get_action 메소드를 정의합니다.
def get_action(self, state):
# epsilon 확률로 무작위로 탐험합니다.
if random.uniform(0, 1) < self.epsilon:
# 무작위 행동을 반환합니다.
return random.choice(self.actions)
else:
# Q-테이블을 기반으로 최적의 행동을 이용합니다.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# 행동을 취한 후 Q-테이블을 업데이트하는 update_q_table 메소드를 정의합니다.
def update_q_table(self, state, action, reward, next_state):
# 상태가 Q-테이블에 없으면 추가합니다.
if state not in self.q_table:
# 새로운 상태에 대한 Q-값을 초기화합니다.
self.q_table[state] = {a: 0.0 for a in self.actions}
# 다음 상태가 Q-테이블에 없으면 추가합니다.
if next_state not in self.q_table:
# 새로운 다음 상태에 대한 Q-값을 초기화합니다.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# 상태-행동 쌍에 대한 이전 Q-값을 가져옵니다.
old_value = self.q_table[state][action]
# 다음 상태에 대한 최대 Q-값을 가져옵니다.
next_max = max(self.q_table[next_state].values())
# 업데이트된 Q-값을 계산합니다.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# 새로운 Q-값으로 Q-테이블을 업데이트합니다.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. OpenAI의 API를 사용한 보상 모델링 (개념적)
# --------------------------------------------------
# OpenAI의 API에서 보상 신호를 얻기 위한 get_reward 함수를 정의합니다.
def get_reward(state, action, next_state):
# OpenAI API 키가 올바르게 설정되어 있는지 확인합니다.
openai.api_key = "your-openai-api-key" # 실제 OpenAI API 키로 대체합니다.
# API 호출을 위한 프롬프트를 구성합니다.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# OpenAI의 Completion 엔드포인트에 API 호출을 수행합니다.
response = openai.Completion.create(
engine="text-davinci-003", # 사용할 엔진을 지정합니다.
prompt=prompt, # 구성된 프롬프트를 전달합니다.
temperature=0.7, # 온도 파라미터를 설정합니다.
max_tokens=1 # 생성할 최대 토큰 수를 설정합니다.
)
# API 응답에서 보상 값을 추출하고 반환합니다.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. 모델 성능 평가
# --------------------------------------------------
# 평가를 위한 실제 레이블을 정의합니다.
true_labels = [0, 1, 1, 0, 1]
# 평가를 위한 예측 레이블을 정의합니다.
predicted_labels = [0, 0, 1, 0, 1]
# 정확도 점수를 계산합니다.
accuracy = accuracy_score(true_labels, predicted_labels)
# F1 점수를 계산합니다.
f1 = f1_score(true_labels, predicted_labels)
# 정확도 점수를 출력합니다.
print(f"Accuracy: {accuracy:.2f}")
# F1 점수를 출력합니다.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. 기본 정책 경사 에이전트 (PyTorch 사용) - 개념적
# --------------------------------------------------
# 정책 네트워크 클래스를 정의합니다.
class PolicyNetwork(nn.Module):
# 정책 네트워크를 초기화합니다.
def __init__(self, input_size, output_size):
# 부모 클래스를 초기화합니다.
super(PolicyNetwork, self).__init__()
# 선형 레이어를 정의합니다.
self.linear = nn.Linear(input_size, output_size)
# 네트워크의 순방향 패스를 정의합니다.
def forward(self, x):
# 선형 레이어의 출력에 소프트맥스를 적용합니다.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. TensorBoard로 학습 진행 시각화
# --------------------------------------------------
# SummaryWriter 인스턴스를 생성합니다.
writer = SummaryWriter()
# TensorBoard 시각화를 위한 예제 훈련 루프:
# num_epochs = 10 # 에포크 수를 정의합니다.
# for epoch in range(num_epochs):
# # ... (여기에 훈련 루프를 작성하세요)
# loss = random.random() # 예제: 무작위 손실 값.
# accuracy = random.random() # 예제: 무작위 정확도 값.
# # 손실을 TensorBoard에 기록합니다.
# writer.add_scalar("Loss/train", loss, epoch)
# # 정확도를 TensorBoard에 기록합니다.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (다른 메트릭 기록)
# # SummaryWriter를 닫습니다.
# writer.close()
# --------------------------------------------------
# 7. 학습된 에이전트 체크포인트 저장 및 로드
# --------------------------------------------------
# 예제:
# Q-러닝 에이전트의 인스턴스를 생성합니다.
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (에이전트를 훈련합니다)
# # 에이전트를 저장합니다
# # 파일을 바이너리 쓰기 모드로 엽니다.
# with open("trained_agent.pkl", "wb") as f:
# # 에이전트를 파일에 저장합니다.
# pickle.dump(agent, f)
# # 에이전트를 로드합니다
# # 파일을 바이너리 읽기 모드로 엽니다.
# with open("trained_agent.pkl", "rb") as f:
# # 파일에서 에이전트를 로드합니다.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. 커리큘럼 학습
# --------------------------------------------------
# 초기 작업 난이도를 설정합니다.
initial_task_difficulty = 0.1
# 커리큘럼 학습을 사용하는 예제 훈련 루프:
# for epoch in range(num_epochs):
# # 작업 난이도를 점진적으로 증가시킵니다.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (조정된 난이도로 훈련 데이터를 생성합니다)
# --------------------------------------------------
# 9. 조기 종료 구현
# --------------------------------------------------
# 최상의 검증 손실을 무한대로 초기화합니다.
best_validation_loss = float("inf")
# 개선되지 않은 에포크 수 (인내값)를 설정합니다.
patience = 5
# 개선되지 않은 에포크 수를 위한 카운터를 초기화합니다.
epochs_without_improvement = 0
# 조기 종료를 사용하는 예제 훈련 루프:
# for epoch in range(num_epochs):
# # ... (훈련 및 검증 단계)
# # 검증 손실을 계산합니다.
# validation_loss = random.random() # 예제: 무작위 검증 손실.
# # 검증 손실이 개선되면.
# if validation_loss < best_validation_loss:
# # 최상의 검증 손실을 업데이트합니다.
# best_validation_loss = validation_loss
# # 카운터를 초기화합니다.
# epochs_without_improvement = 0
# else:
# # 카운터를 증가시킵니다.
# epochs_without_improvement += 1
# # '인내값' 에포크 동안 개선이 없으면.
# if epochs_without_improvement >= patience:
# # 메시지를 출력합니다.
# print("조기 종료가 호출되었습니다!")
# # 훈련을 중단합니다.
# break
# --------------------------------------------------
# 10. 사전 학습된 LLM을 사용한 제로샷 작업 전이
# --------------------------------------------------
# 사전 학습된 요약 파이프라인을 로드합니다.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# 요약할 텍스트를 정의합니다.
text = "This is an example text about AI agents and LLMs."
# 요약을 생성합니다.
summary = summarizer(text)[0]["summary_text"]
# 요약을 출력합니다.
print(f"Summary: {summary}")

배포와 확장의 도전
LLM을 결합한 통합 AI 에이전트를 배포하고 확장하는 것은 기술적인 문제와 운영적인 도전을 초래합니다. 주요 도전 중 하나는 연산 비용입니다. 특히 LLM의 크기와 복잡성이 커질 수록 이러한 문제가 심해집니다.
이 문제를 해결하기 위해서는 모델을 자르기(pruning), 양자화(quantization), 분산 연산(distributed computing)과 같은 자원 효율적인 전략을 적용합니다. 이러한 방법들은 성능을牺牲하지 않으면서 연산 부하를 줄일 수 있습니다.
실제 응용에서의 신뢰성과 견고성 유지 또한 중요하며, 예기치 않은 입력이나 시스템 고장을 처리하기 위한 지속적인 모니터링, 정기적인 업데이트, 안전장치 개발이 요구됩니다.
이러한 시스템이 다양한 산업에 배포됨에 따라 공정성, 투명성, 책임성을 포함한 윤리 표준 준수의 중요성이 증가합니다. 이러한 고려 사항은 시스템의 촉촉감 및 장기 성공에 중요하며, 다양한 사회적 문맥 내 AI가 주도하는 결정의 윤리적 시사점에 영향을 미칩니다 (Bender et al., 2021).
LLM과 결합된 AI 에이전트의 기술적 구현은 신중한 아키텍처 설계, 엄격한 훈련 방법론, 배포 도전에 대한 깊은 고려을 필요로 합니다.
이러한 시스템의 실제 환경에서의 효과성과 신뢰성은 기술적인 문제와 윤리적인 문제를 모두 해결하는 것에 달립니다. 이를 통해 AI 기술이 다양한 응용에서 부드럽고 책임감 있게 작동할 수 있습니다.
第7장: AI 에이전트와 LLM의 미래
LLM과 강화학습의 결합
과거의 人工知能(AI) 기술과 대 sizeof 언어 모델(LLM)의 미래에 대해 탐구하는 것을 통해, LLM과 리퀘스트 Learning의 합동에 대한 특별히 전환적인 발전이 注目 받는다. 이 통합은 전통적인 AI의 경계를 좁히는 것과 동시에, 시스템이 언어를 생성하고 이해하는 것뿐만 아니라 실시간으로 자신과의 상호 작용에 의해 배울 수 있도록 해준다.
리퀘스트 Learning을 통해, AI エージェントは 環境からのフィードバックに基づいて 適応的に 自己的 策略を変更할 수 있으며, 이에 의해 其の 決定 プロセ스가 持続的으로 精炼되는 것을 의미한다. 이는 靜的 모델이 아닌, 리퀘스트 Learning을 적용한 AI 시스템은 인간 지정의 最少化으로 错综 复杂하고 动的 任务을 处理할 수 있다는 의미로 해석할 수 있다.
이러한 시스템의 含义은 깊이 있다: 自律的 로봇 기술에서 개인화 교육까지의 응용에서, AI エージェント는 시간 동안 자신의 パフォーマンス를 自律的으로 改善 시키는 것이 가능하며, 그들의 运営 컨텍스트의 错综 复杂하고 変화하는 요구에 적응하는 것이다.
예시: 텍스트 기반의 게임 Игра
텍스트 기반의 venture game를 이용하는 AI エージェント를 상상해보자.
-
Environment: 그 자신의 (ルール, 状態 説明 등)
-
LLM: 게임의 텍스트를 과정하고, 현재 状況을 이해하고, 가능한 행동을 생성한다 (예를 들어, “북쪽으로 가자”, “검을 가져가자”).
-
보상: 게임이 사용자의 행위 결과에 따라 제공하는 것(예를 들어, 보상이 가치가 있는 보상으로 Secrets를 발견하면, healht를 잃으면 NEGATIVE가 되는 것)
Python과 OpenAI API를 사용한 이미지 코드 예시:
import openai
import random
# ... (게임 환경 로직 - 여기서 표시하지 않음) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (RL 트레이닝 루프 - 간단하게) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (보상에 따라 RL 에이전트를 갱신 - 여기서 표시하지 않음) ...
state = next_state
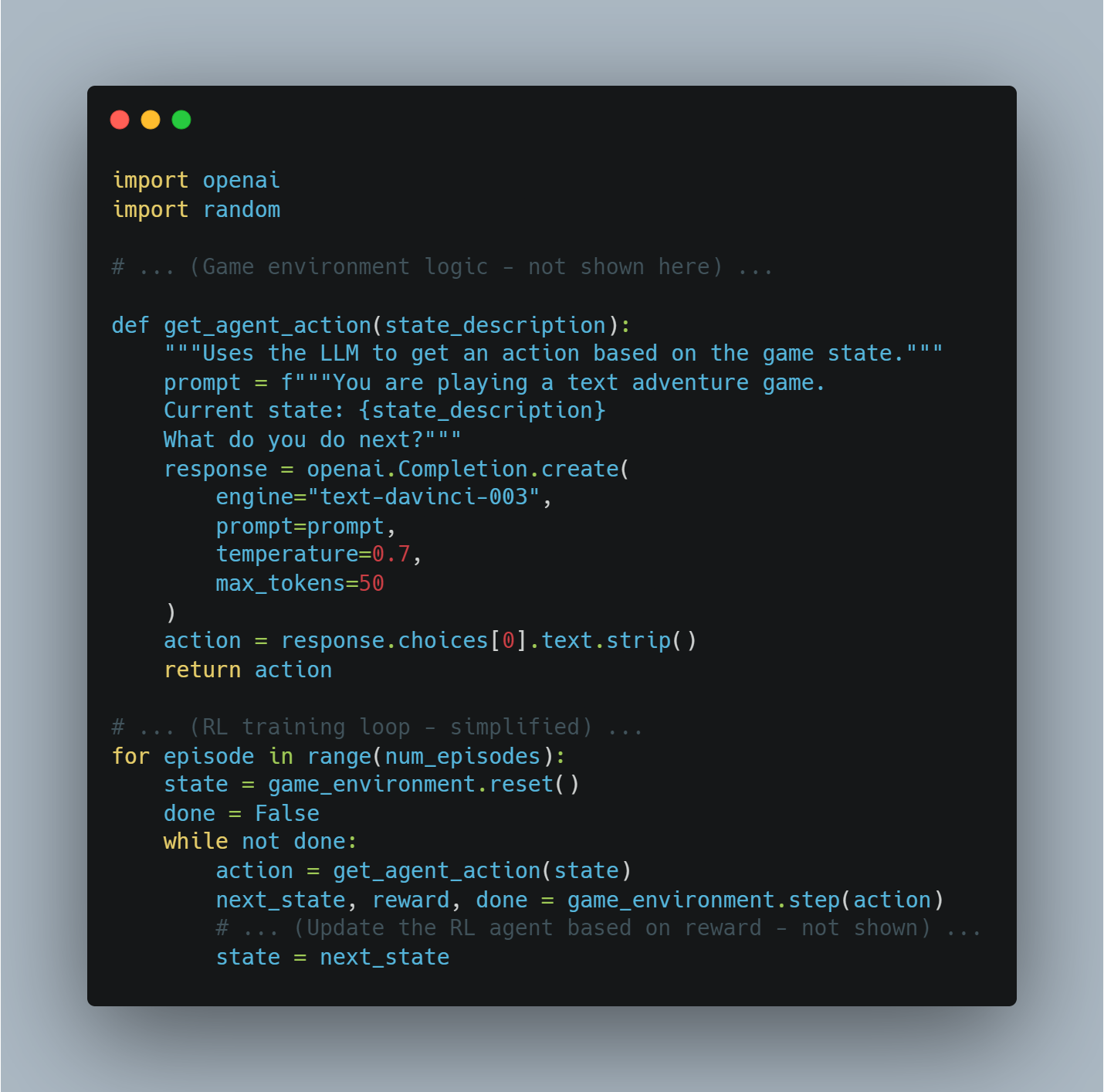
다 모드 AI 통합
다 모드 AI의 통합은 AI 에이전트의 미래를 形성하는 다른 중요한 tren trends입니다. 다 모드 AI는 텍스트, 이미지, 오디오, 以及 감각 인입 等多种의 소스의 데이터를 처리하고 결합할 수 있는 것을 허용합니다. 이렇게 시스템이 실제로 动的 해야 하는 환경을 더욱 자세하게 이해할 수 있습니다.
比如说, 자율 주행 車에서는 카메라로부터 시각적 데이터, 지도에서 의미하는 데이터, 실시간 교통 정보를 통합하여 AI가 더욱 지능적인 것과 안전하게 運転 결정을 할 수 있습니다.
이러한 기능은 의료 등의 다른 domains에도 확장되며, AI エージェント가 의사 기록, 診断 画像, 以及 유전 정보から 의료 기록을 통해 환자 데이터를 통합하고 より 精確하고 개인화 된 치료 推奨을 제공할 수 있습니다.
이 경험의 어려움은 다양한 데이터 스트림의 끊임없이 통합하고 실시간 처리하는 것이며, 이를 위해 모델 아키텍처와 데이터 Fusion 기술의 개선이 필요합니다.
이러한 어려움을 성공적으로 극복하면 AI 시스템을 정말 지능적으로 하고 複雑한 실제 환경에서 機能할 수 있는 것이 중요합니다.
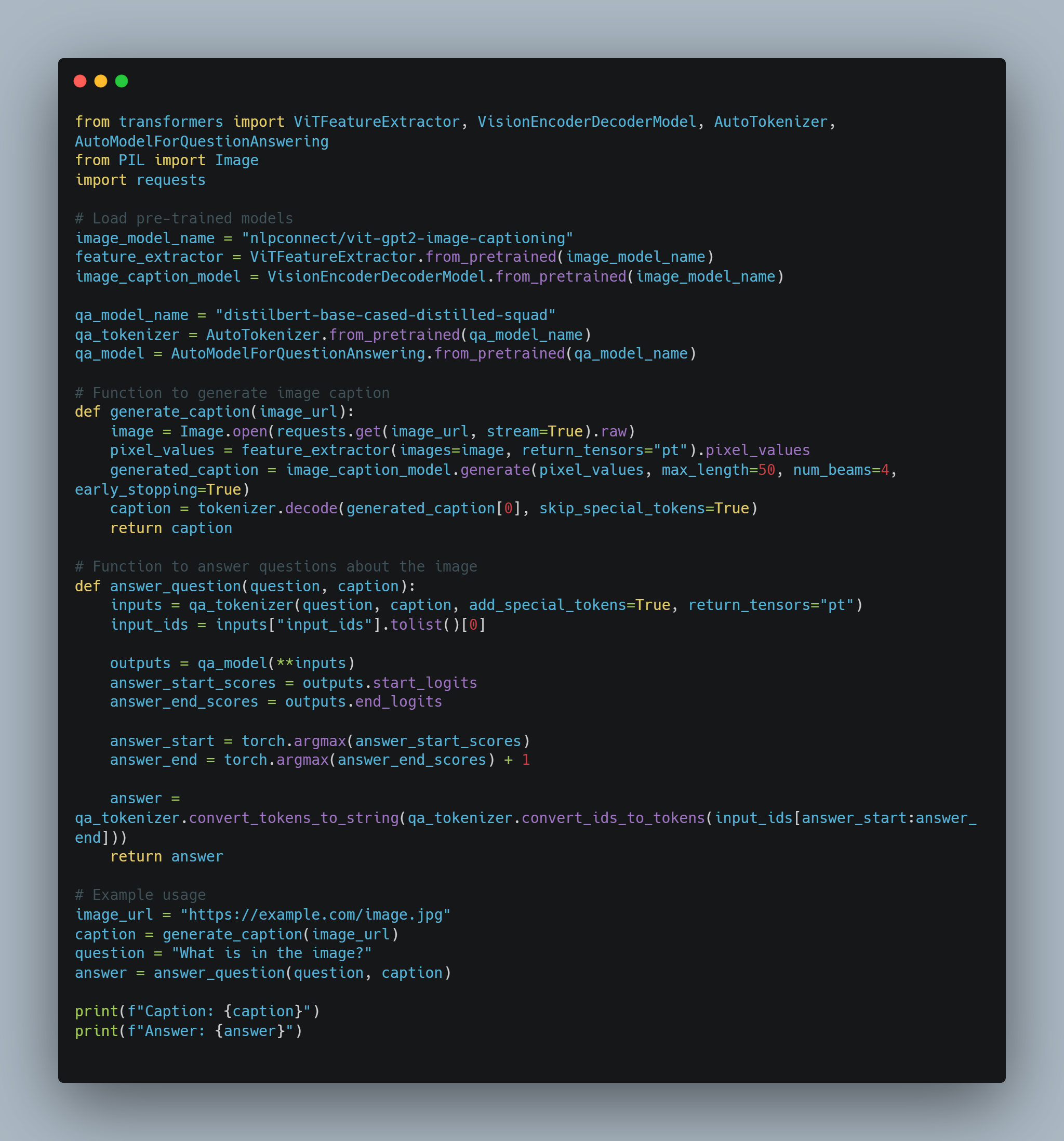
다양 수단의 AI 예시 1: 이미지 캡션 для 비주얼 질문 대답
-
목표: 이미지에 대한 질문을 대답할 수 있는 AI エージェン트.
-
수단: 이미지, 텍스트
-
과정:
-
이미지 특성 추출: 미리 훈련 받은 컨볼루셋 신경 네트워크(CNN)를 사용하여 이미지의 특성을 추출합니다.
-
캡션 생성: 추출된 특성에 따라 이미지를 简単하게 설명하는 캡션을 생성하는 LLM(예를 들어 트랜스폼 모델)를 사용하여
-
질문 대답: 다른 LLM를 사용하여 질문과 생성된 캡션을 처리하여 답변을 제공합니다.
-
코드 예시 (Python과 Hugging Face Transformers를 사용한 지적 階層):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# 미리 训练 된 모델을 로드합니다.
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# 이미지 자막 생성 기능
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# 이미지에 대한 질문 답변 기능
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# 사용 예시
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
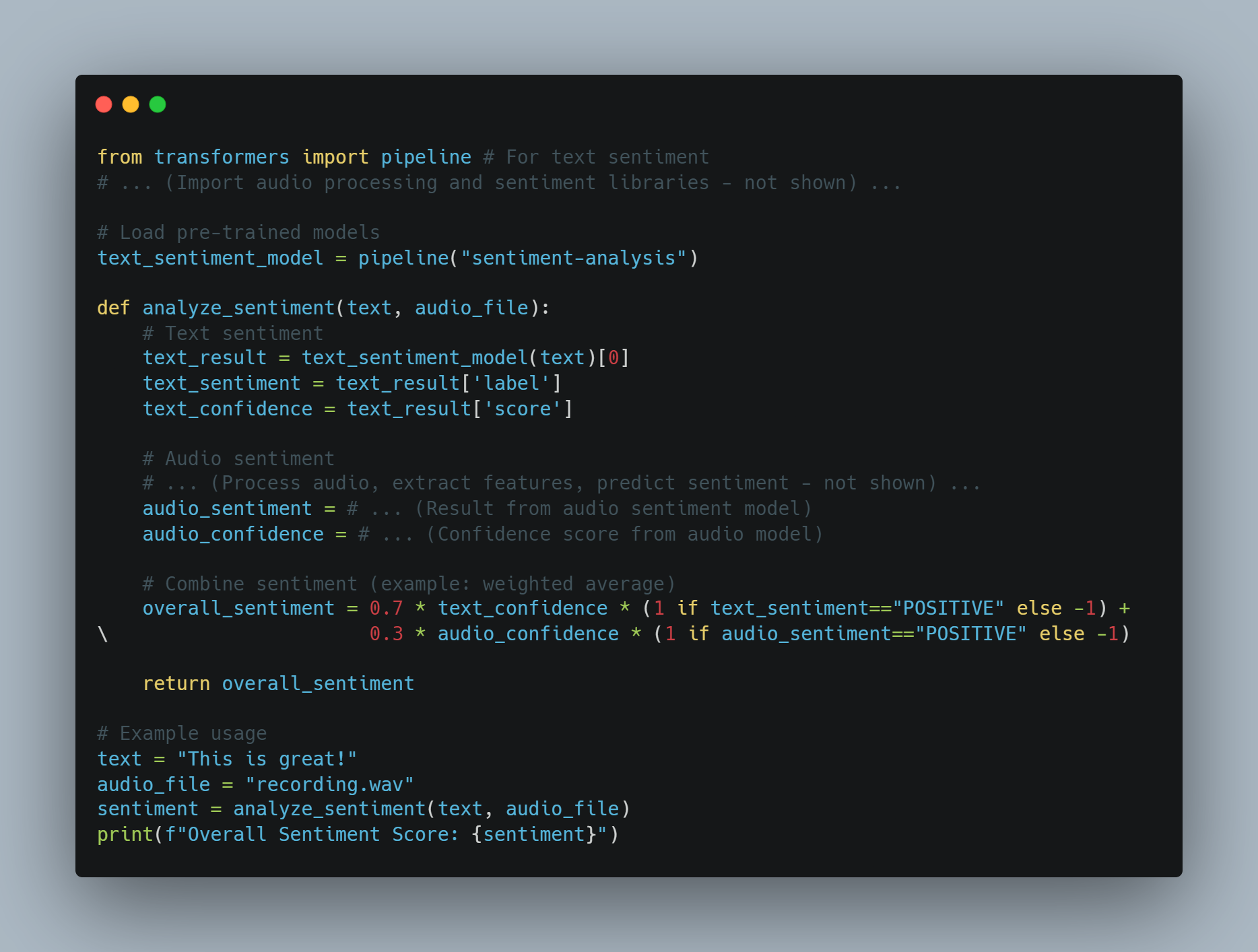
다维多媒體 AI 예시 2: 텍스트와 오디오에 의한 감정 분석
-
목표: 메시지의 텍스트와 тон에 의한 감정 분석을 行う AI エージェント
-
수단: 텍스트, 오디오
-
과정:
-
텍스트 감정: 텍스트에 미리 训练 된 감정 분석 모델을 사용합니다.
-
오디오 감정: 음성 처리 모델을 사용하여 тон과 높이와 같은 특징을 추출하고, 이러한 특징을 사용하여 감정을 예측합니다.
-
Fusion: 텍스트와 오디오 감정 점수(예를 들어, 가중치 평균)를 结合起来하여 전체 감정을 얻습니다.
-
코드 예시 (Python을 사용한 기 conceptual):
from transformers import pipeline # 텍스트 감정
# ... (오디오 처리 및 감정 라이브러리 - 보여지지 않음) ...
# pretrained model 로딩
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# 텍스트 감정
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# 오디오 감정
# ... (오디오 처리, 특징 추출, 감정 예측 - 보여지지 않음) ...
audio_sentiment = # ... (오디오 감정 모델의 결과)
audio_confidence = # ... (오디오 모델의 신뢰도 점수)
# 감정 결합 (예: 가중 평균)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# 예시 사용
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
도전과 고려 사항:
-
데이터 ALIGNMENT: 다양한 모alities로 나누어진 데이터가 동기화되고 일치하는지 확인하는 것이 중요합니다.
- 모델 複雑성: 다양한 모alities로 나누어진 데이터가 동기화되고 일치하는지 확인하는 것이 중요합니다.
-
Fusion 기술: 다양한 모alities의 정보를 결합하는 Right 方法을 선택하는 것이 중요하며, 문제에 따라 specific하게 구성되어야 합니다.
Multimodal AI는 빨라지는 필드로, AI 대자리가 세계를 perceive 하고 interact 할 수 있는 것을 革命ize 할 수 있는 잠재적인 력이 있습니다.
분산 AI 시스템과 엣지 컴퓨팅
AI infra structure의 발전을 보며, 분산 AI 시스템에 의해 지원되는 엣지 컴퓨팅으로부터 シフト가 중요한 발전입니다.
분산 AI 시스템은 데이터를 소스에 가까이에서 처리하여 centralized cloud resources를 의존하지 않습니다. IoT device 또는 로컬 server 등을 통해 이를 realize 합니다. 이 방법은 자신의 정보를 로컬에서 보호하는 것을 통해 인自制 dronesや 산업 자동화와 같은 시간에 따라 중요한 늦은 감소를 줄 뿐만 아니라 데이터 정신과 보안을 향상시키ます.
또한, 분산 AI 시스템은 스케일 ability를 改善시키며, smart city와 같은 vast network에 AI를 배치하면서 centralized data centers를 과铉하는 것을 허용합니다.
분산 AI와 관련된 기술적인 도전은 분산 Node들之间에서 일관성과 조합을 보장하는 것과 다양하고 ressource-constrained environment에서 パフォーマン스를 유지하기 위해 ressource allocation을 최적화하는 것입니다.
AI system을 개발하고 배치하는 것을 통해 distributed architecture를 받아들이면, 将来의 응용에 미칠 수 있는 강한, 효율적, 스케일able AI 솔루션을 만들기 위한 중요한 역할을 합니다.
분산 AI 시스템과 엣지 컴퓨팅 예시 1: 개인정보 보호를 위한 모델 훈련을 위한 페더레이션 러닝
-
목표: 각 장치(예: 스마트폰)에 있는 민감한 사용자 데이터를 직접 공유하지 않고 공유 모델을 훈련시키기
-
방법:
-
로컬 훈련: 각 장치는 자신의 데이터로 로컬 모델을 훈련시킨다.
-
파라미터 집계: 장치는 모델 업데이트(기울기나 파라미터)를 중앙 서버로 보낸다.
-
글로벌 모델 업데이트: 서버는 업데이트를 집계하고 글로벌 모델을 개선한 후 장치로 업데이트된 모델을 다시 보낸다.
-
코드 예제 (Python 및 PyTorch 사용 개념):
import torch
import torch.nn as nn
import torch.optim as optim
# ... (장치와 서버 간의 통신 코드 - 표시되지 않음) ...
class SimpleModel(nn.Module):
# ... (모델 아키텍처 정의) ...
# 장치 측 학습 함수
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # 글로벌 모델로 시작
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (장치 데이터로 로컬 모델 학습) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# 서버 측 집계 함수
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (주요 연합 학습 루프 - 간소화) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

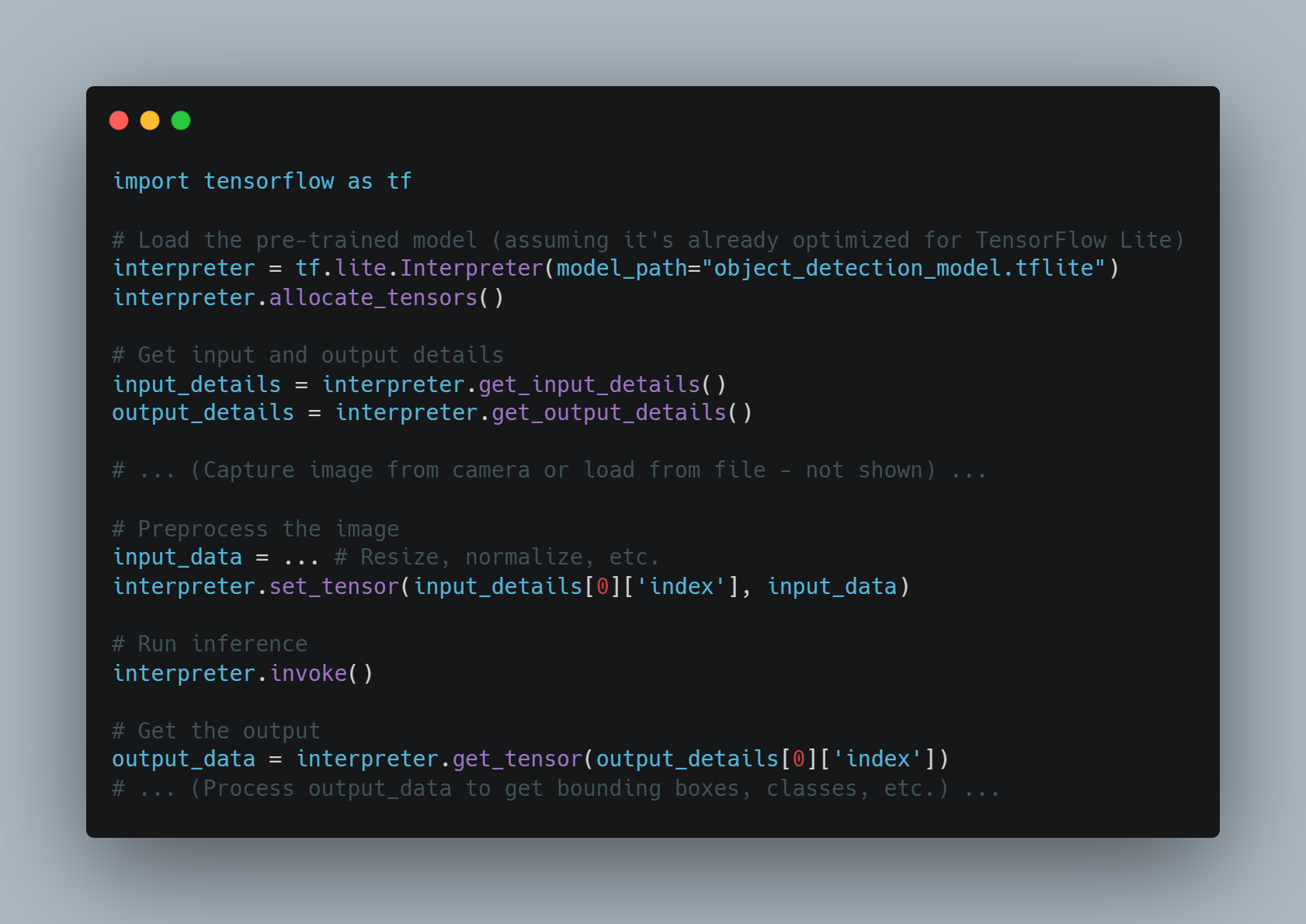
예제 2: 엣지 디바이스에서 실시간 객체 탐지
-
목표: 리소스가 제한된 장치(예: Raspberry Pi)에 객체 탐지 모델을 배포하여 실시간 추론을 수행합니다.
-
접근 방법:
-
모델 優化: 모델 퀴즈나 자르기 등의 기술을 사용하여 모델 크기와 계산 요구 수준을 감소시키자.
-
엣지 배치: 유틸리티zed 모델을 엣지 장치에 배치하자.
-
로컬 推論: 장치는 로컬에서 사물 감지를 수행하여 лаatiency를 줄이고 云 통신에 의존성을 减轻시키자.
-
코드 예시 (Python과 TensorFlow Lite를 사용한 기념적인 방법):
import tensorflow as tf
# 사전 학습된 모델 로드 (TensorFlow Lite에 최적화되었다고 가정)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# 입력 및 출력 세부정보 가져오기
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (카메라에서 이미지 캡처하거나 파일에서 로드 - 생략) ...
# 이미지 전처리
input_data = ... # 크기 조정, 정규화 등
interpreter.set_tensor(input_details[0]['index'], input_data)
# 추론 실행
interpreter.invoke()
# 출력 얻기
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (출력 데이터를 처리하여 경계 상자, 클래스 등 얻기) ...
도전 과제 및 고려 사항:
-
통신 오버헤드: 분산 노드 간의 효율적인 조정 및 통신이 중요합니다.
-
자원 관리: 장치 간의 자원 할당(CPU, 메모리, 대역폭) 최적화가 중요합니다.
-
보안: 분산 시스템 보안 및 데이터 프라이버시 보호가 가장 중요한 문제입니다.
분산 AI 및 엣지 컴퓨팅은 スケーラブル, 효율적, 개인정보 보호 대응能力提升에 필요한 AI 시스템을 構築하는 데 중요한 요소로, 数十億의 이를 연결한 장치로 이전하는 미래를 보고 있습니다.
자연어 처리 기술의 발전
자연어 처리(NLP)는 AI 기술의 烽火을 쫓기 직전이며, 기계가 인간 언어를 이해하고, 생성하고, 이를 대면적으로 적응하는 방법을 기여하는 중요한 개선을 미칠 수 있습니다.
NLP에서 최근 발전, 예를 들어 변형기 모델과 관심 조정 機構의 발전은 AI가 어려운 언어 구조를 처리하는 능력을 dramatisch 향상시키는 것과 함께, 이를 처리하는 것이 더욱 자연스러울 수 있도록 하였으며 contest-aware가 되었습니다.
이러한 진전은 AI 시스템이 흔적, 감정, 그리고 문자 내에서 문화 참고를 이해하는 能力을 얻었습니다, 이를 통해 정확하고 의미 있는 통신을 실현할 수 있었습니다.
예를 들어, 고객 서비스에서는 先进的 NLP 모델은 정확하게 의문을 처리할 수 있을 뿐만 아니라 고객의 감정 기울기를 감지하여 更多的 sympathetic 및 효과적인 응답을 할 수 있습니다.
앞으로 보면, NLP 모델에서 다국어 기능과 더 깊은 의미적 이해를 통합하는 것은 그들의 적용 범위를 더욱 확장시키는 것입니다. 다양한 언어와 方言을 사용하여 통신할 수 있는 것과, AI 시스템이 다양한 글로벌 환경에서 실시간 번역자로서 활동할 수 있게 합니다.
자연어 처리(NLP)는 빠른 발전을 하고 있으며, 변형기 모델과 관심 조정 機構 등에서의 breakthroughs를 보여줍니다. 다음과 같은 예시와 코드 샘플로 이러한 진전을 보여줍니다.
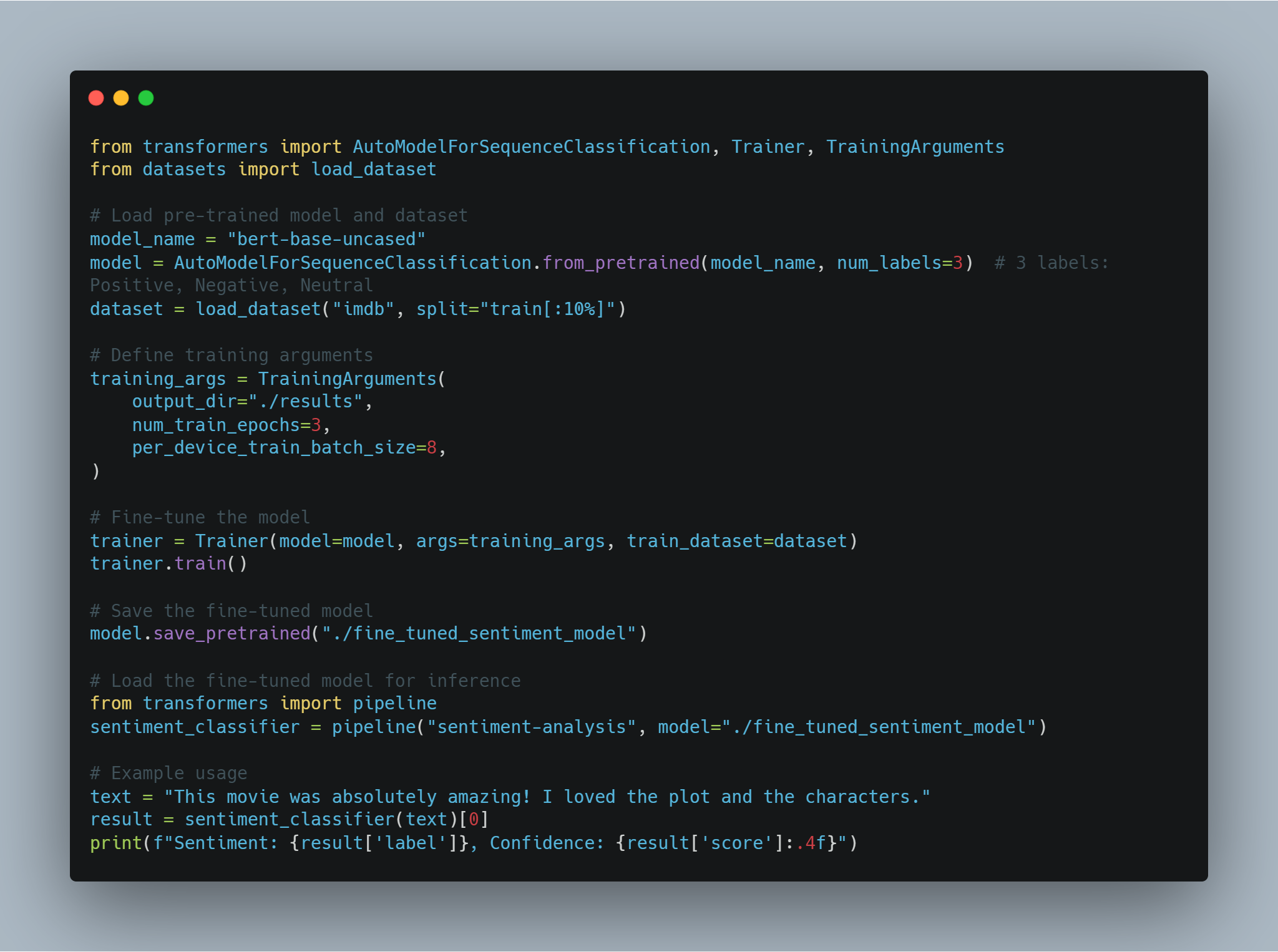
NLP 예시 1: 精调 트랜스포ー머 기반 감정 분석
-
목표: 텍스트의 감정을 높은 정확도로 분석하여 精致的한 특성과 上下文을 captuing 하도록 한다.
-
방법: 감정 분석 데이터셋에 대한 미리 트레이닝 된 트랜스포ー머 모델(如火 BERT)을 精调 한다.
코드 예시(Python과 Hugging Face Transformers를 사용하여):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# 미리 트레이닝 된 모델과 데이터셋을 로드한다
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3개의 ラベル: 긍정, 부정, 중립
dataset = load_dataset("imdb", split="train[:10%]")
# 트레이닝 인자를 정의한다
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# 모델을 精调 한다
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# 精调 된 모델을 저장한다
model.save_pretrained("./fine_tuned_sentiment_model")
# 推论에 사용할 精调 된 모델을 로드한다
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# 예시 사용
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
NLP 예시 2: 하나의 모델로 다국어 기계 번역
-
목표: 하나의 모델을 사용하여 다양한 언어 사이에 번역하고, 공유 linguistic representations를 利用하도록 한다.
-
방식: 다양한 언어의 대량의 병렬 텍스트 데이터셋에서 훈련된 대규모 다양어 변환 모델 (mBART 또는 XLM-R 같은)을 사용합니다.
코드 예제 (파이썬과 Hugging Face Transformers를 사용합니다):
from transformers import pipeline
# 사전 훈련된 다양어 번역 파이프라인 불러오기
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# 예제 사용: 영어에서 프랑스어
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# 예제 사용: 프랑스어에서 스페인어
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
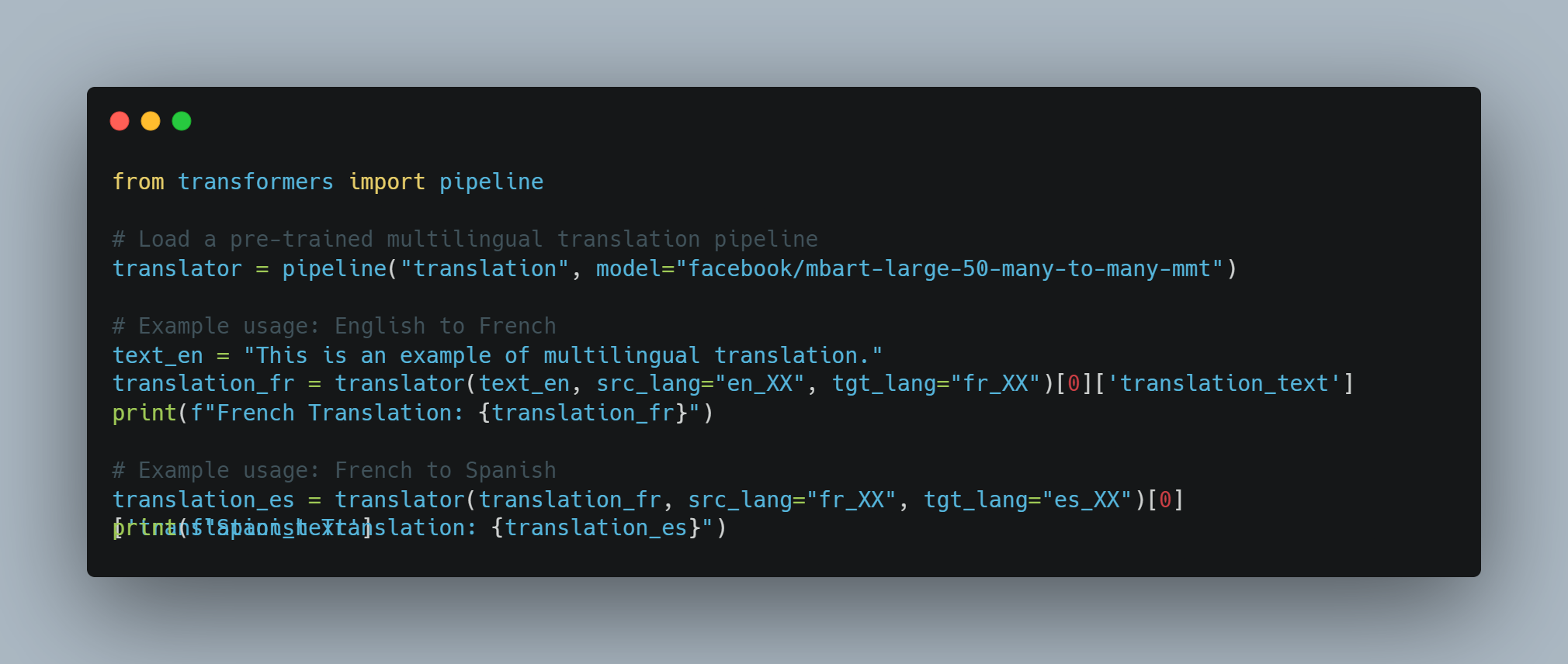
NLP 예제 3: 의미 유사성을 위한 문맥uale Word Embeddings
-
목표: 문맥을 고려하여 단어 또는 문장 사이의 유사性를 결정합니다.
-
방식: 변환 모델 (BERT 같은)을 사용하여 문맥uali Word Embeddings를 생성하여, 특정 문장 내 단어의 의미를 캡처합니다.
코드 예제 (파이썬과 Hugging Face Transformers를 사용합니다):
from transformers import AutoModel, AutoTokenizer
import torch
# pretrained model과 tokenizer를 로드합니다.
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# senetence embedding를 얻는 함수
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# [CLS] token embedding을 senetence embedding로 사용합니다.
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# 예시 사용
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# cosine similarity를 계산합니다.
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
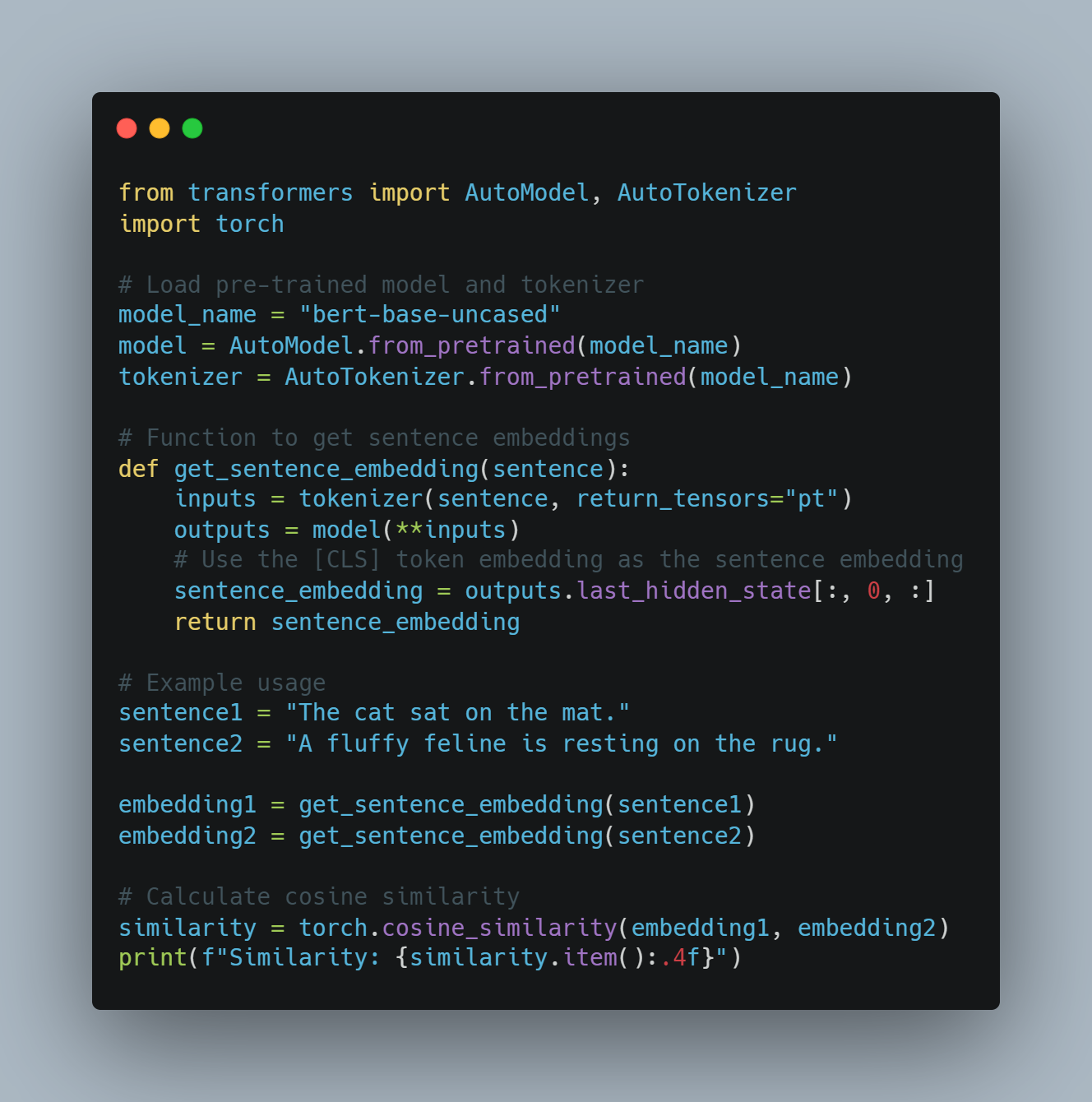
도전과 미래 방향:
-
편견과 Fairness: NLP 모델은 他们的 훈련 데이터에서 편견을 상속할 수 있으며, 이를 통해 적절하지 않은 결과나 차별적인 결과를 일으킬 수 있습니다. 편견을 처리하는 것은 중요합니다.
-
Common Sense Reasoning: LLM은 여전히 일반적인 이해를 갖추고 암묵적인 정보를 이해하는 것에 어려움이 있습니다.
-
Explainability: 複雑한 NLP 모델의 결정 과정은 불透明的하며, 그들이 어떤 출력을 생성하는 이유를 이해하는 것이 困难합니다.
이러한 도전 사이에도 NLP는 빠르게 발전하고 있습니다. 다양한 입력 수단의 정보 integration, 일상적인 이해를 改善하는 기술, 이해하기 容易하게 改善하는 기술 등이 주요한 연구 영역으로 실시되고 있으며, 이러한 기술은 AI가 인간 言語과 更深层次으로 交流하는 데에 更大的 변화를 もたらす 것입니다.
개인화된 AI 어시스턴트
개인화된 AI 어시스턴트의 未来은 기본적인 업무 관리를 넘어 모든 것을 이해하고, 개인의 특성을 고려한 자신감 있고 과거 经验을 기반으로 대화를 시작하는 것을 시도할 것입니다.
이러한 어시스턴트는 进阶级别的 機械 学习 算法을 사용하여 사용자의 행위, 취향, 일상 루틴에서 지속적으로 배우고 있으며, 개인화된 추천 것을 제시하고 더 複雑한 업무를 자동화하는 것입니다.
例如, 개인화된 AI 어시스턴트는 사용자의 일정을 관리하는 것뿐만 아니라 사용자가 어느 정도의 일정을 가지고 있는지 예측하고, 이를 지원하는 자원을 제시하거나 이전 선호 사항에 따라 사용자의 emotional 상태나 일정을 조절하는 것입니다.
AI 어시스턴트가 日常生活에 더 많이 통합되면 그들이 변화하는 上下文에 대한 적응 능력과 이를 통합하는 것이 枢纽가 되고 있습니다. 어시스턴트는 개인화와 개인 정보 보호를 balancong하는 것이 어려울 수 있으며, 이를 위해 강한 데이터 보호 mechanism을 사용하여 유용한 정보가 안전하게 관리되는 동시에 깊은 개인화된 경험을 제공할 수 있도록 해야 합니다.
AI 어시스턴트 example 1: 上下文 의 일상적인 업무 제안
-
목표: 사용자의 현재 上下文(location, time, past behavior)에 따라 일어나는 업무를 제안하는 어시스턴트
-
접근 방법: 사용자 데이터, 上下文 Signal 및 일자리 추천 모델을 결합하자.
코드 예시 (Python을 사용한 이론적인 예):
# ... (사용자 데이터 관리, 上下文 감지 - 보여지지 않음) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# 예: 시간 기반 제안
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# 예: 위치 기반 제안
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (추가적인 규칙 또는 제안 ため의 机器学习 모델 사용) ...
# 제안을 랭크 및 필터링
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- 사용 예 ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... 다른 嗜好 ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... 다른 上下文 데이터 ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
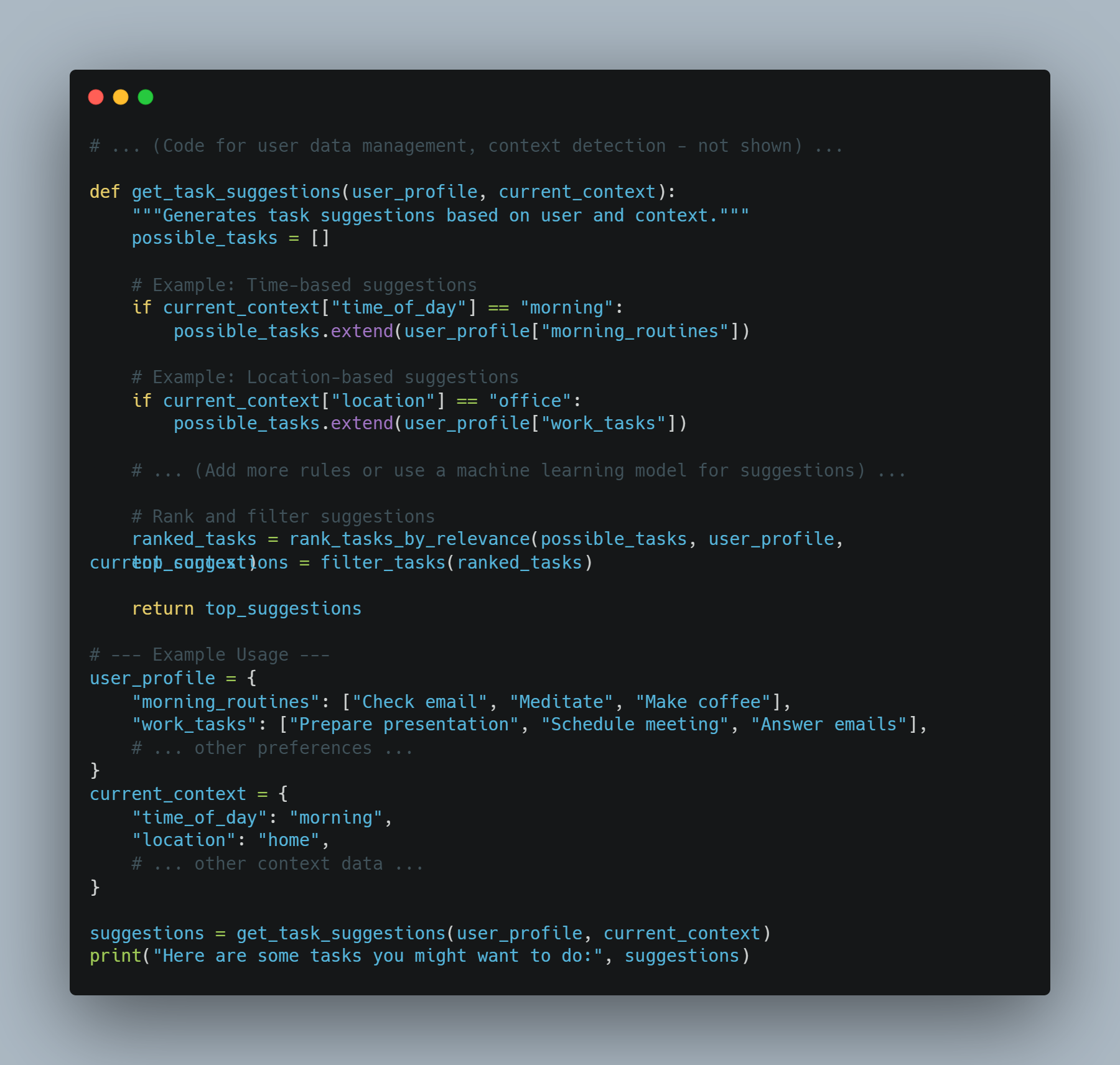
AI Assistents 예 2: 예방적 정보 제공
-
목표: 사용자의 일정 및 嗜好에 따라 예방적으로 pertinent information을 제공하는 assistent.
-
접근 방법: 일정 데이터, 사용자 인tricacies, 및 정보 검색 시스템을 통합하자.
코드 예시 (Python을 사용하여 이해를 위한 개념적인 것):
# ... (캘린더 접근, 사용자 interest profile - 보여지지 않는 것) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (회사 정보, 참가자 프로필 등을 가져오는 것) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (항공사 상태, 목적지 정보 등을 가져오는 것) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- 예시 사용 ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... 다른 偏好 ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

AI Assistants 예시 3: 개인화 Content Recommendation
-
목표: 사용자 偏好를 고려하여 콘텐츠(記事, 동영상, 음악)을 추천하는 assistance.
-
방안: 협업 過濾 或者 基于 콘텐츠 的 추천 시스템을 사용하는 것.
코드 예시 (Python을 사용하여 이해를 위한 개념적인 것 以及 Surprise 라이브러리를 사용하는 것):
from surprise import Dataset, Reader, SVD
# ... (사용자 평점 관리, 콘텐츠 데이터베이스 - 표시되지 않음) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (모든 항목의 예측을 가져와, 순위를 매기고 상위 N개를 반환) ...
# --- 예제 사용 방법 ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... 더 많은 평점 ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
도전과 윤리적 고려 사항:
-
데이터 프라이버시: 사용자 데이터를 책임 있고 투명하게 처리하는 것이 중요합니다.
-
.bias와 공정성: 개인화가 기존의偏见를放大하지 않아야 합니다.
-
사용자 제어: 사용자는 자신의 데이터와 개인화 설정을 제어할 수 있어야 합니다.
개인화된 AI_ASSISTANT를 구축하려면 기술적인 측면과 윤리적인 측면을 신중하게 고려해야 합니다. 도움이 되고 신뢰할 수 있고 사용자 사생활을 존중하는 시스템을 만들기 위해서입니다.
창의적 산업에 AI
AI는 예술, 음악, 영화, 문학을 생산하고 소비하는 방식을 변화시키며 창의적 산업에 중요한痕跡을 남고 있습니다. 생성 모델,如实생성 대립 네트워크(GANs)와 변형기 기반 모델의 발전에 따라 AI는 인간의 창의력과 경쟁할 수 있는 콘텐츠를 생성할 수 있습니다.
예를 들어 AI는 특정 장르나 분위기를 반영한 음악을 작곡할 수 있고, 유명 그림자의 스타일을 仿真하는 디지털 아트를 创作할 수 있으며, 영화와 소설의 敘述 剧情을 拟写할 수 있습니다.
광고 産業에서는 AI로 개인 고객에게 공감하는 persona1ized content를 생성하여 인지도와 효과를 높이고 있습니다.
하지만 的创作 域에서 AI의 등장은 저자로美国和 Originality, 인간의 创作력의 rolls 에 대한 문제를 浮上시키고 있습니다. 이러한 영역에서 AI와 함께 활동하면 AI가 인간의 创作력을 대신하는 것이 아닌 인간의 创作력을 보조하는 것을 义大利하는 것이 중요합니다. 인간과 기계가 함께 创新的하고 영향력 있는 콘텐츠를 생성하기 위한 협업을 促성시키는 것입니다.
여기에 GPT-4를 Python 프로젝트에 Khaled into 하여 创作 任务에 적용하는 예를 들여 보겠습니다. 이 코드는 GPT-4의 능력을 사용하여 시 such as 에서 创作的 텍스트 형식을 생성하는 것을 보여줍니다.
import openai
# Set your OpenAI API key
openai.api_key = "YOUR_API_KEY"
# Define a function to generate poetry
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# Example usage
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
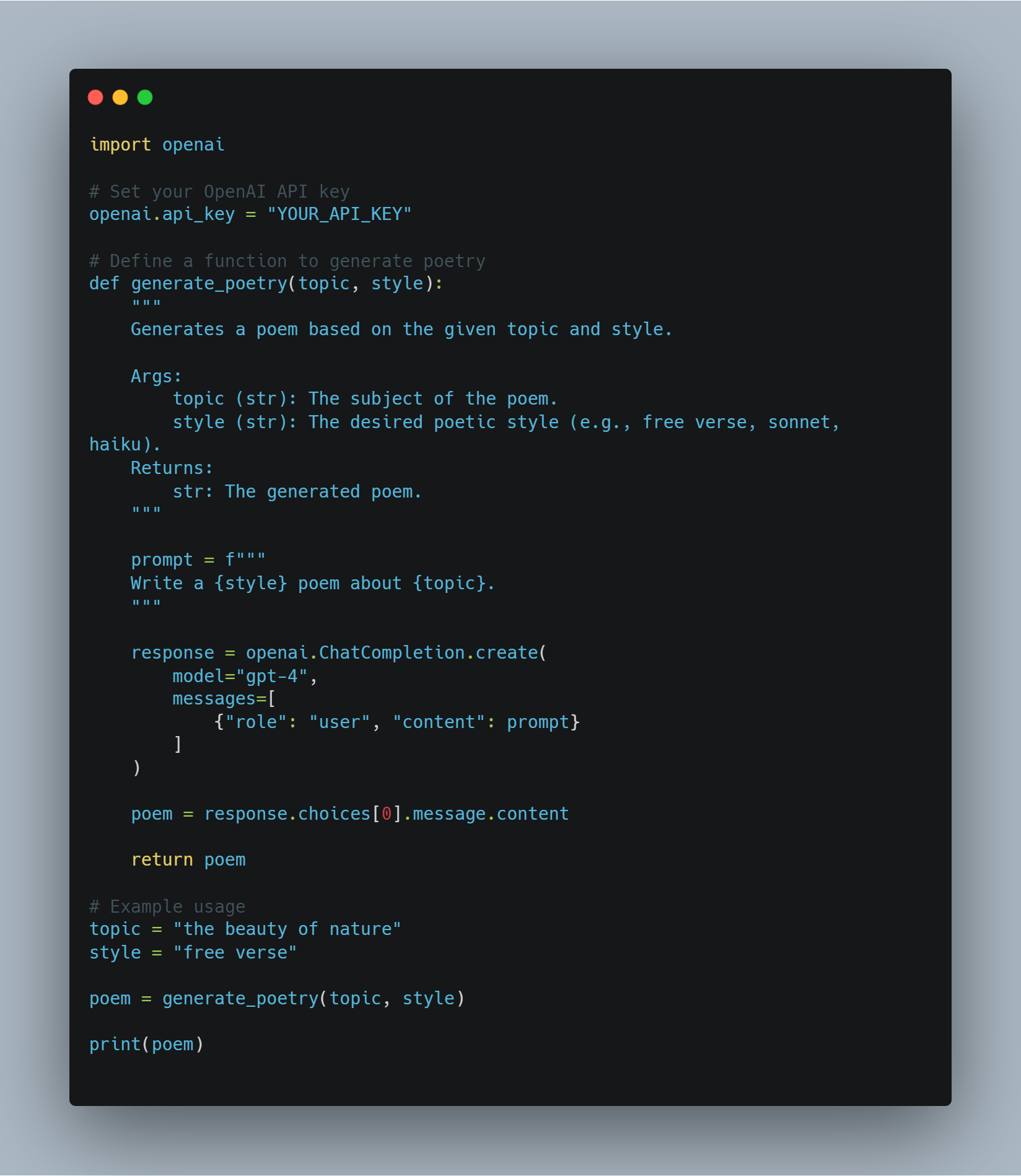
Let’s see what’s going on here:
-
Import OpenAI library: The code first imports the
openailibrary to access the OpenAI API. -
Set API key: Replace
"YOUR_API_KEY"with your actual OpenAI API key. -
시가 만들기 함수
generate_poetry정의: 이 함수는 시의topic와style을 입력으로 받고 OpenAI의 ChatCompletion API를 사용하여 시를 생성합니다. -
프롬프트 구성: 프롬프트는
topic과style을 GPT-4에게 명확한 지시를 위해 결합합니다. -
GPT-4로 프롬프트 보내기: 코드는
openai.ChatCompletion.create를 사용하여 프롬프트를 GPT-4로 보내고 생성된 시를 응답으로 받습니다. -
시 반환: 생성된 시는 응답에서 추출되어 함수에 의해 반환됩니다.
-
예시 사용: 이 코드는
generate_poetry함수를 특정 주제와 스타일로 호출하는 방법을 보여줍니다. 그 결과물, 詩,는 그리고 콘솔에 印excute prints 됩니다.
AI-Powered Virtual Worlds
AI-Powered 虚拟世界의 개발은 이mmersive 경험에서 중요한 발전을 나타냅니다. AI エージェン트는 사용자 입력에 반응적으로 생성, 관리하고 진화하는 이virtual 환경을 제공합니다.
이러한 virtual worlds, AI를 통해 생성되었으며, 错complex ecosystem, 社会적 이interaction, 错dynamic narrative을 시뮬레이션할 수 있습니다. 사용자에게 错deeply engaging 및 개인화 된 경험을 제공합니다.
예를 들어, 게임 産業에서는 AI를 사용하여 错non-playable characters (NPCs)를 생성할 수 있습니다. NPCs는 错player behavior를 学习하여 错user behavior에 의한 반응을 错adaptive actions and strategies를 사용하여 错challenging 및 错realistic 경험을 제공합니다.
게임 이외에서는 AI-Powered Virtual Worlds는 错education에서 사용할 수 있습니다. 错virtual classrooms는 错student-specific learning styles and progress를 错customize할 수 있습니다. 또는 错corporate training에서는 错realistic simulations를 사용하여 错employees를 错various scenarios에 대응하는 준비를 하실 수 있습니다.
이러한 virtual environments의 미래는 AI가 错complex digital ecosystems를 错real-time에 대응하는 错advancements in AI’s ability to generate and manage vast, 错ability를 보유하는지 및 错ethical considerations around user data and the 错psychological impacts of highly immersive experiences에 의해 결정 될 수 있습니다.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# 에이전트를 초기화한다.
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# 환경 내에서 Random 위치를 할당한다.
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# 에이전트를 생성하고 추가한다.
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# 에이전트 이동 (Demonstration 용도로 간단한 이동)
for agent in self.agents:
agent.move(self.environment)
# TODO: 상호 작용, 환경 변화 등에 대한 복잡한 로직을 구현한다.
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# 이동 방향을 결정한다. (이 예에서는 Random)
direction = random.choice(['N', 'S', 'E', 'W'])
# 방향에 따라 이동을 적용한다.
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# 에이전트의 새로운 위치를 표시하기 위한 환경을 갱신한다.
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# 사용 예
if __name__ == "__main__":
# 세계 パラ미터를 정의한다.
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# 가상의 세계를 생성한다.
world = VirtualWorld(environment_size, agent_types, agent_properties)
# 몇 단계의 세계를 시뮬레이한다.
for _ in range(10):
world.update()
world.display()
print() # 좋은 읽기 성능을 위해 빈 行을 추가한다.
이 코드의 일이 무엇인지 이렇게 보인다:
-
가상 세계 클래스:
-
가상 세계의 핵심을 정의한다.
-
환경 그리드, 에이전트 목록, 에이전트 관련 정보를 포함한다.
-
__init__(): 사이즈, 에이전트 유형, 속성을 이용하여 세계를 초기화한다. -
add_agent(): 지정한 유형의 新区間에 에이전트를 추가한다. -
update(): 세계를 한 시퀀스 단위로 업데이트한다.- 현재는 에이전트를 이동하는 것뿐만 하지만, 에이전트 상호 작용, 환경 변화 등의 복잡한 로직을 추가할 수 있다.
-
display(): 환경의 기본적인 표현을 打印한다.
-
-
어그ents 클래스:
-
세계 내에서 어그ents를 표현한다.
-
__init__(): 어그ents를 어떤 타입, 위치, 속성으로 초기화한다. -
move(): 어그ents의 이동을 처리하고, 환경 내에서 그의 위치를 갱신한다. 현재는 간단한 임의의 이동만 제공하지만, 복잡한 AI 행위를 포함하는 것으로 확장할 수 있다.
-
-
예시 사용:
-
세계 パラ미터를 사이즈, エージェン트 유형 및 그들의 속성과 같이 설정합니다.
-
仮想세계 오브젝트를 생성합니다.
-
update()메서드를 여러 번 실행하여 세계의 발전을 시뮬레이션합니다. -
update() 다음에
display()를 호출하여 변경사항을 시각화합니다.
-
개선:
-
より複雑なエージェント AI:エージェントの行動により複雑な AI 를 実装します。以下の方法を使用できます:
-
パスファイング アルゴリズム:エージェントが環境を効果的に移動するためのサポート。
-
決定木/機械学習:エージェントが周りの状況とゴールに基づいてより贤明な決断をします。
-
환경 상호 작용: 장애물, 자원, 혹은 관심 포인트와 같은 동적 요소를 환경에 추가합니다.
-
에이전트間 상호 작용: 의사소통, 싸움, 혹은 협력과 같은 에이전트 간의 상호 작용을 구현합니다.
-
시각화 표현: Pygame나 Tkinter와 같은 라이브러리를 사용하여 가상 세계의 시각화 표현을 만듭니다.
強制学習:エージェントが時間の経過として学び、行動を適切に調整することを教えます。
이 예시는 AI-기반 가상 세계를 생성하는 기본적인 기반입니다. 복잡도와 Sophistication이 추가적으로 확장되어 사용자의 特定 needs와 creative goals에 따라 更大的해지 할 수 있습니다.
Neuromorphic Computing and AI
Neuromorphic computing는 인간 뇌의 구조와 기능을 inspire하여 AI를 선동하는 새로운 정보 처리 방법을 제공하며 paralle로 정보를 처리하는 것을 도울 것입니다.
전통적인 컴퓨팅 体系architecture와 다르게, neuromorphic system는 뇌의 신경 网络上을 mimic하도록 설계되었습니다. 그렇다면 AI는 patrons recognition, sensory processing, decision-making과 같은 tasks를 더욱 빨라게 하고 에너지 효율성을 향상시키는 것이 가능합니다.
이 기술은 AI 시스템을 더욱 적응性 있고, 少量의 data에서 learning하고, 실시간 환경에서 有效性있게 성취시키는 것을 기대하는 것입니다.
예를 들어, robotics에서, neuromorphic chips는 현재 architecture를 초과하여 로봇이 sensory inputs를 processing하고 decisions를 하는 것을 가능하게 할 것입니다.
이제 forward하는 도전은 neuromorphic computing를 large-scale AI applications의 복잡도를 처리하기 위해 scale up하는 것입니다. 现存的 AI frameworks와 integrate하여 其 full potential을 전부 이용하기 위해 하는 것입니다.
Space Exploration에서 AI Agents
AI 에이전트는 우주 탐험에서 점점 더 중요한 역할을果敢합니다. 그들은 고난의 환경을 탐색하고 실시간 결정을 내리고 과학 실험을 자동으로 실시합니다.
과제가 깊은 우주로 더욱 멀리 나가는 가운데, 지구 기반 제어를 받지 않고 독립적으로 운영할 수 있는 AI 시스템의 필요성은 점점 더욱 크게 나타냅니다. 미래의 AI 에이전트는 우주의 예측 불가능성을 처리할 수 있게 설계될 것입니다, 예를 들어 몬스터를 자유자재로 탐험하고, 과학적으로 가치 있는 사이트를 식별하거나, 미션 제어에서 최소한의 입력으로 샘플을 굴착하는 Mars의 로버를 가이드하는 것 처럼.
이 AI 에이전트는 또한 장기간 미션에서 생명 지지 시스템을 관리하고, 에너지 사용을 최적화하며, 우주비행사의 심리적 요구를 대응하기 위해 상담과 정신적 자극을 제공합니다.
AI를 우주 탐험에 통합시키면 미션 기능을 강화할 뿐만 아니라 우주 탐험에 대한 인류의 새로운 가능성을 열어줍니다. AI는 우리의 우주를 이해하는 데 있어서 불가결히 필요한 파트너가 될 것입니다.
제8장: 미션 중요 분야의 AI 에이전트
보건케어
보건케어에서 AI 에이전트는 단지 지지 역할을 하기만 해서는 않고, 환자 치료 과정 전체에서 필수적인 역할로 자리 잡고 있습니다. 그들의 영향은 텔레메디시ne에서 가장 명확하게 드러며, AI 시스템은 원격 보건 서비스의 접근 방식을 완전히 재정의했습니다.
고급 自然言語處理(NLP)와機械學習 알고리즘을이용하여, 이러한 시스템들은 증상 측정과 초기 데이터 수집과 같은 정교한 작업을 높은 정확도로 수행합니다. 이들은 환자가 보고하는 증상과 의료력사를 실시간으로 분석하며, 이 정보를 광泛한 의료 데이터베이스와 대조하여潛在的질병이나 경고표지를 식별합니다.
이로 인해 보건 서비스 제공자들이 더 빨리 유익한 결정을 내릴 수 있으며, 치료에 들는 시간을 단축하고 인명을救하실 수 있습니다. 또한, 의료 영상에 AI 주도의 진단 도구는 X선, MRI, CT 스캔에서 인간의 눈으로는 감지하기 힘든 패턴과 이상을 발견하여 레이돌리ogy를 변형시킵니다.
이러한 시스템들은 수백만장의 기록이 있는 이미지로 구성된 대규모 데이터셋을 훈련시켜 인간의 진단 능력을 복제하는 것뿐만 아니라 often超越합니다.
AI를 보건 서비스에 통합하는 것은 행정적인 업무에까지延申합니다. 약속 기록, 약 복용 안내, 환자 추적 등의 자동화는 보건 인력의 운영 부담을大幅으로 줄이고, 환자 관리의 더 중요한方面에集中할 수 있도록 합니다.
재정
재정 부문에서는 AI 에이전트가 놀라운 높은 효율과 정밀도를 도입함으로써 운영을 혁신 시켰습니다.
알고리즘 트레이딩은 AI에 크게 의존하며, 금융 시장에서의 거래 실행 방식을 변화시켰습니다.
이러한 시스템은 빅데이터 세트를 밀리초 안에 분석할 수 있으며, 시장 추세를 식별하고 수익을 최대화하고 리스크를 최소화하기 위해 최적의 순간에 거래를 실행할 수 있습니다. 이들은 인공지능, 심층학습 및 강화학습 기술을 결합한 복잡한 알고리즘을 활용하여 시장 조건의 변화에 적응하고, 인간 거래자가 절대로 따라할 수 없는 분초의 결정을 내립니다.
거래 외에도 AI는 신용 리스크를 평가하고 부정��위 활동을 놈똑같이 검출하여 리스크 관리에 중요한 역할을 합니다. AI 모델은 예측 분석을 활용하여 대출자의 신용 기록, 거래 행동, 그 밖의 관련 요소의 패턴을 분석하여 대출자의 딜리QUENCY 가능성을 평가합니다.
또한, 규제 준수의 영역에서 AI는 의심스러운 활동을 탐지하고 보고하는 거래 모니터링을 자동화하여 금융 기관이 엄격한 규제 요구 사항을 준수하는지 확인합니다. 이 자동화는 인간 오류의 리스크를 완화시키는 것 뿐만 아니라 규제 준수 프로세스를 간편화하여 비용을 줄이고 효율을 높입니다.
긴급 관리
AI는 긴급 관리에서 변화를 주는 역할을 하며, 긁새를 예측, 관리, 완화하는 방식을 기본적으로 바꿉니다.
재난 대응에서 AI 에이전트는 다양한 출처의 매우 큰 양의 데이터를 처리합니다. 위성 영상에서 소셜 미디어 피드를 포함하여 실시간으로 상황의 전반적인 개요를 제공합니다. 머신러닝 알고리즘은 이 데이터를 분석하여 패턴을 식별하고 이벤트의 진행을 예측하여, 긴급 대응팀이 자원을 더 효율적으로 할당하고 압박 상황에서 지효적인 결정을 내릴 수 있도록 합니다.
자연재해가나타날 때, 예를 들어 台風의 경우, AI 시스템은风暴의 경로와 강도를 예측할 수 있어, 권한자들이 적시적인 대피 명령을 내리고 가장 취약한 지역에 자원을 배치할 수 있습니다.
예측 분석에서는 AI 모델을 이용하여 역사적 데이터와 실시간 입력을 분석하여 잠재적인 긴급 상황을 예측하고,災害를 예방하거나 영향을 줄일 수 있는 프로ак티브 조치를 취할 수 있도록 합니다.
AI 파워드 공공 통신 시스템은 또한 영향을 받은 인구에게 정확하고 적시한 정보를 제공하는 데 중요한 역할을 합니다. 이러한 시스템은emerency alerts를 생성하여 다양한 플랫폼에 전파시키며, 다른 demosgraphics에게 메시지를 맞춰서 이해와 준수를 보장합니다.
그리고 AI는 생성모델을 사용하여 고도로 현실적인 교육 시뮬레이션을 만들어 응급대응자들의 준비성을 향상시킵니다. 이러한 시뮬레이션은 실제 긴급 상황의 복잡성을 모방하여 응급대응자들이 기술을 끌어올리고 실제 이벤트에 대한 준비성을 향상시킵니다.
교통
AI 시스템은 항공交通制御, 자율주행 차량, 공공 교통과 같은 다양한 분야에서 안전, 효율성, 신뢰성을 향상시키는 데 필수적이고자 되고 있습니다.
항공交通制御에서 AI 에이전트는 항공 경로를 최적화하고, 잠재적인 충돌을 예측하고, 공항 운영을 관리하는 데 중요한 역할을 합니다. 이러한 시스템은 예측 분석을 사용하여 항공交通의 혼잡을 예보하고, 실시간으로 항공편을 변경하여 안전과 효율을 보장합니다.
인공지능은 자율주행자동차 분야에서 복잡한 환경에서 센서 데이터를 처리하고 마치(split-second) 결정을 내는 데 핵심적인 역할을 합니다. 이러한 시스템들은 광범위한 데이터셋에서 교육된 깊은 학습 모델을 사용하여 시각적, 청각적, 공간적 데이터를 해석하여 동적이고 예측不可能한 조건에서 안전한 탐색을 가능하게 합니다.
대중교통 시스템 역시 AI를 통해 루트를 최적화하고, 차량의 예측적 유지보수를 진행하며, 여객자 유입을 관리하는 등의 혜택을 받습니다. AI 시스템은 히스토리캐스드와 실시간 데이터를 분석하여 대중교통 일정을 조정하고, 차량의 고장 예측 및 예방을 하며, 시간ピーク 시 인구제어를 하여 전체 交通망의 효율性和 신뢰성을 향상시킵니다.
에너지 산업
AI는 에너지 산업에서도 중요한 역할을 수행하고 있으며, 특히 그리드 관리, 再生에너지 최적화, 그리고 故障檢出等方面에입니다.
그리드 관리에서 AI 에이전트는 네트워크에 분포된 센서로부터의 실시간 데이터를 분석하여 전력 그리드를 모니터링하고 제어합니다. 이러한 시스템들은 예측 분석을 사용하여 에너지 배포를 최적화하여, 수요를 충족시키는 동시에 에너지 낭비를 최소화합니다. AI 모델은 그리드의 잠재적인 결함을 예측하며, 사전 유지보수를 진행하고 끊김의 위험을 줄입니다.
再生에너지 분야에서 AI 시스템은 날씨 패턴을 예측하는 데 사용되며, 태양과 풍력에너지 생산을 최적화하는 데 중요합니다. 이러한 모델은 기상 데이터를 분석하여 태양 빛의 강도와 풍속을 예측하여, 에너지 생산을 더 정확하게 예측하고 再生에너지를 그리드에 더욱 잘 통합시키는 데 도움이 됩니다.
결함 감지는 인공지능이 중요한 기여를 并提供하고 있는 다른 영역입니다. 인공지능 시스템은 변压器, 터빈, 발전기 등의 장비의 센서 데이터를 분석하여 ware and tear 또는 장애 발생 전에 경고 Signs를 식별합니다. 이러한 예측적 유지 관리 方法은 장비의 수명을 연장하는 것뿐만 아니라 지속적이고 신뢰성 있는 에너지 공급을 보장합니다.
사이버 안전
사이버 안전 域에서는 인공지능 エージェント이 디지털 인프RASTRUCTURE의 整eness 및 안전성을 유지하는 데 欠かせません. 이러한 시스템은 네트워크 통신을 지속적으로 모니터링하는 데 기계 leaning 알고리즘을 사용하여 안전 침해를 의미하는 이상적인 것을 検出합니다.
실시간으로 huges 量的 데이터를 분석하여 AI エージェン트는 異常な 로그인 試み, 데이터 外流 活動, 恶意软件의 存在 등의 悪意 행위 패턴을 식별할 수 있습니다. 가능한 脅威가 감지되면 AI 시스템은 자동으로 対策을 시작할 수 있습니다. 예를 들어 compromisED 시스템을 独占하고 パッチ를 배치하여 추가 ダメージ를 防ぐ 것입니다.
另外一个 AI 在 cybersecurity 域中 的 重要应用是 漏洞评価。 AI 动力的 工具 analyze code 和 system 配置 to 识别 potential security weaknesses before they can be exploited by attackers。 这些工具使用 静的 and 动 analysis techniques to evaluate the security posture of software and hardware components,providing actionable insights to cybersecurity teams.
이러한 프로세스의 자동화는 脅迫 감지 및 응답의 속도와 정확성을 향상시키는 뿐만 아니라, 인간 분석가의 일load를 줄이는 동시에 더 複雑한 보안 도전에 focus할 수 있게 해줍니다.
생산
생산 분야에서, AI는 品質 통제, 예측적 maintenance, supply chain optimization에서 중요한 진전을 이룰 수 있습니다. AI-기반 computer vision system은 현재 제품의 瑕疵을 빠르고 정확하게 inspec를 통과시키는 speeds and precision를 제공하는데 人类의 능력을 뛰어나게 합니다. 이러한 system는 수천计 images에 deep learning algorithm을 적용하여 제품에 있는 가장 trivial impurities를 감지하는 것을 수행합니다, high-volume production environments에서 일관된 quality를 보장합니다.
예측적 maintenance은 AI가 긍정적인 영향을 미칠 또 다른 area입니다. 기계에 embed되어 있는 sensor의 데이터를 analyzing하여 AI model은 equipment가 어느 시점에 failure할 가능성을 예측할 수 있습니다, maintenance가 挂件 breakdown이 발생하기 전에 예정되는 것입니다. 이러한 approach는 downtown time를 줄이는 동시에 기械의 lifespan을 연장하는 것을 통해 substancial cost savings를 가져가는 것입니다.
supply chain management에서도 AI는 의도되는 영향을 미치고 있습니다. 제품 chain에 대한 데이터를 analyzing하여 inventory levels와 logistics를 optimization하는 것을 도와줍니다, 예를 들어 demand forecasts, production schedules, transportation routes를 포함합니다. 실시간 adjustments를 inventory와 logistics plans에 적용하여 AI는 제품 생성 process를 平稳하게 運営하는 것을 보장하며, delay를 최소화하고 cost를 줄이는 것입니다.
이러한 응용은 manufacturing에서 AI가 operaional efficiency 및 reliability를 改善시키는 중요한 역할을 보여주며, 快速に 발전하는 산업에서 竞争力을 유지하기 위해 기업에게 인dispensable tool가 되는 것을 보여줍니다.
결론
AI 에이전트와 대형 언어 모델 (LLM)의 통합은 인공 지능의 진화에 있어서 중요한 지점을 표시하며, 다양한 산업과 과학 분야에 지금까지 볼 수 없었던 새로운 기능을 억제해제합니다. 이 협동은 AI 시스템의 기능성, 적응성, 및 적용성을 향상시키면서 LLM의 내재적 한계를 극복하고 더욱 동적이고 문맥 인식이 능동적인 결정 과정을 가능하게 합니다.
건강 관리와 금융의 혁신에서 운송과 应急管理의 변형에 이르기까지, AI 에이전트는 혁신과 효율성을 추구하며 AI 기술이 우리의 일상 생활에 깊이 내려가는 미래를 여는 길을 밝혀집니다.
AI 에이전트와 LLM의 잠재력을 계속적으로 탐구하는 동안, 인간의福祉을 우선시하고 공평성과 포괄성을 중시하는 윤리적 원칙에 근거하여 그들의 발전을 촉진하는 것은 중요합니다. 이러한 기술이 책임 있게 디자인되고 운용되도록 하는 것이 인간의 삶의 질을 향상시키고 사회 정의를 홍보하고 전球적인 도전을 해결하는 데 전체적인 잠재력을 이용할 수 있게 합니다.
AI의 미래는 신속하고 뛰어난 AI 에이전트와 뛰어난 LLM의 완벽한 통합에 있으며, 이러한 지능 시스템은 인간의 능력을 강화하는 것뿐만 아니라 우리의 인간성을 정의하는 가치를 유지합니다.
AI 에이전트와 LLM의 합流는 인공 지능 새로운 패러다임을 나타냅니다. 민첩함과 قواء의 협력은 끝없는 가능성의 나라를 열어주는 것입니다. 이러한 협동적인 힘을 이용하여 혁신을 추진하고 과학적 발견을 추진하며 모든 사람에게 공평하고 번영한 미래를 제공할 수 있습니다.
작가 소개
컴퓨터 과학, 데이터 과학, 그리고 AI의 교차점에서 Vahe Aslanyan입니다. 정밀성과 진행성을 증명하는 포트폴리오를 보려면 vaheaslanyan.com를 방문하세요. 전체 스택 개발과 AI 제품 최적화 사이의 역량을 이어주는 경험을 가지고 있으며, 새로운 방식으로 문제를 해결하고자 하는 것을 주도합니다.
지도하는 데이터 과학 부트 캠프를 론칭하고 산업 최고 전문가들과 협업한 경험을 포함한 과거 기록을 가지고 있으며, 기술 교육을 세계 표준으로 끌어올리는 것에 초점을 두고 있습니다.
더 깊이 들어가기
이 가이드를 공부한 후에 더 깊이 있게 배우고 싶으며 구조화된 학습을 선호하시다면 LunarTech에 참가하시는 것을 고려해 보세요. 데이터 과학, 기계 학습, AI에 대한 개별 과정과 부트 캠프를 제공합니다.
이론적인 이해, 실무적인 실행, 광범위한 연습 자료, 그리고 개인적인 단계에 맞는 면접 준비를 통해 성공을 위한 전체적인 프로그램을 제공합니다.
우리의 Ultimate Data Science Bootcamp을 확인하실 수 있으며, 무료 시험을 통해 콘텐츠를 직접 시험해보실 수 있습니다. 이는 2023 년 가장 좋은 Data Science Bootcamp로 인정받았으며, Forbes, Yahoo, Entrepreneur 등 자치 Publications에서 기재되었습니다. 이곳은 革新과 지식에 꿈을 抱く コミュニティ에서 일하는 기회입니다. 다음은 어 plaque welcom essage입니다!
나에게 연결

LinkedIn에서 CS, ML 및 AI에 대한 tones of Free Resources를 following me for
-
내 데이터 과학 및 AI 뉴스레터에 suscribe 하세요
데이터 과학, 기계 leaning 및 AI 분야의 직업에 대해 더 많이 배우고, 데이터 과학 일자리를 구할 수 있는 방법을 배우고자 하시면, 이 무료 데이터 과학 및 AI 직업 수준서을 다운로드 할 수 있습니다.
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/