













La rapida evoluzione dell’intelligenza artificiale (IA) ha creato una potente sinergia tra i grandi modelli di linguaggio (LLM) e gli agenti AI. Questo dinamico scambio è come una specie di storia di David e Golia (senza la lotta), dove gli agili agenti AI amplificano e migliorano le capacità dei colossali LLM.
Questo manuale esplorerà come gli agenti AI, simili a David, stanno supercaricando gli LLM – i nostri moderni Golia – per aiutare a rivoluzionare varie industrie e domini scientifici.
Indice
-
Capitolo 1: Introduzione agli agenti AI e ai modelli di linguaggio
-
Capitolo 2: La storia dell’intelligenza artificiale e degli agenti AI
-
Capitolo 3: dove i nostri AI-Agents risplendono il più luminoso
-
Capitolo 6: Progettazione architetturale per l’integrazione di AI Agents con LLMs
L’emergere degli agenti AI nei modelli linguistici
Gli agenti AI sono sistemi autonomi progettati per percepire l’ambiente, prendere decisioni e eseguire azioni per raggiungere obiettivi specifici. Quando integrati con le macro-macchine, questi agenti possono svolgere compiti complessi, ragionare sugli informazioni e generare soluzioni innovative.
Questa combinazione ha condotto a significative innovazioni in molti settori, dalla sviluppo software alla ricerca scientifica.
Impatto trasformativo su tutte le industrie
L’integrazione di agenti AI con macro-macchine ha avuto un profondo impatto su varie industrie:
-
Sviluppo Software: assistenti di codifica dotati di intelligenza artificiale, come GitHub Copilot, hanno dimostrato la capacità di generare fino al 40% del codice, portando a un incremento notevole del 55% nella velocità di sviluppo.
-
Educazione: assistenti di apprendimento dotati di intelligenza artificiale hanno mostrato promettere nell’ ridurre del 27% il tempo medio di completamento del corso, potenzialmente rivoluzionando il panorama educativo.
-
Trasporti: Con proiettazioni che prevedono che il 10% delle vetture sarà senza conducente entro il 2030, gli agenti AI autonomi negli autovetture guidate da soli stanno per rivoluzionare l’industria dei trasporti.
Avanzamento della Scoperta Scientifica
Una delle applicazioni più emozionanti degli agenti AI e delle MSL è nella ricerca scientifica:
-
Scoperta di medicinali: Gli agenti AI stanno accelerando il processo di scoperta di medicinali analizzando vasti dataset e predicendo candidati farmacologici potenziali, riducendo significativamente il tempo e i costi associati ai metodi tradizionali.
-
Fisica delle particelle: All’LHC del CERN, gli agenti AI sono impiegati per analizzare i dati delle collisioni di particelle, utilizzando la deteczione di anomalie per identificare indizi promettenti che potrebbero indicare l’esistenza di particelle non ancora scoperte.
-
Ricerca scientifica generale: Gli agenti AI stanno aumentando il ritmo e l’ambito delle scoperte scientifiche analizzando gli studi passati, identificando Collegamenti inaspettati e proponendo esperimenti nuovi.
La convergenza tra agenti artificiali e grandi modelli di linguaggio (LLM) sta spingendo l’intelligenza artificiale in una nuova era di capacità senza precedenti. Questo manuale completo esamina l’interazione dinamica tra queste due tecnologie, svelando il loro potenziale combinato per rivoluzionare le industrie e risolvere problemi complessi.
Tracceremo l’evoluzione dell’intelligenza artificiale dai suoi origini all’avvento degli agenti autonomi e del rise dei sofisticati LLM. Esploreremo anche considerazioni etiche, che sono fondamentali per lo sviluppo responsabile dell’intelligenza artificiale. Ciò ci aiuterà a garantire che queste tecnologie siano allineate con i nostri valori umani e con il benessere della società.
Al termine di questo manuale, otterrete una profonda comprensione del potere simbiotico degli agenti artificiali e degli LLM, così come le conoscenze e gli strumenti per sfruttare questa tecnologia all’avanguardia.
Capitolo 1: Introduzione agli Agenti Artificiali e ai Modelli di Linguaggio
Cos’è un Agente Artificiale e un Grande Modello di Linguaggio?
L’evoluzione rapida dell’intelligenza artificiale (IA) ha portato una sintesi trasformativa tra grandi modelli di linguaggio (LLM) e agenti artificiali.
Gli agenti AI sono sistemi autonomi progettati per percepire il loro ambiente, prendere decisioni e eseguire azioni per raggiungere obiettivi specifici. Mostrano caratteristiche come autonomia, percezione, reattività, ragionamento, decisione, apprendimento, comunicazione e orientamento verso gli obiettivi.
D’altro canto, le LLM sono sistemi AI sofisticati che utilizzano tecniche di apprendimento profondo e grandi dataset per comprendere, generare e predire testo umano-simile.
Questi modelli, come GPT-4, Mistral, LLama, hanno dimostrato capacità straordinarie in task di processamento del linguaggio naturale, inclusa la generazione del testo, la traduzione del linguaggio e gli agenti conversazionali.
Caratteristiche chiave degli agenti AI
Gli agenti AI hanno diverse caratteristiche che li distinguono dai software tradizionali:
-
Autonomia: Possono operare indipendentemente senza intervento umano costante.
-
Percezione: Gli agenti possono percepire e interpretare il loro ambiente attraverso varie entrate.
-
Reattività: Rispondono dinamicamente ai cambiamenti nel loro ambiente.
-
Ragionamento e decisioni: Gli agenti possono analizzare i dati e prendere scelte informate.
-
Apprendimento: migliorano le loro prestazioni con l’esperienza nel tempo.
-
Comunicazione: Gli agenti possono interagire con altri agenti o esseri umani usando diversi metodi.
-
Orientamento ai goal: sono progettati per raggiungere obiettivi specifici.
Capacità dei grandi modelli di linguaggio
I grandi modelli di linguaggio hanno dimostrato una vasta gamma di capacità, inclusi:
-
Generazione di testo: I grandi modelli di linguaggio possono produrre testo coerente e pertinente al contesto in base ai prompt.
-
Traduzione di linguaggio: Possono tradurre testo tra differenti lingue con un alto grado di accuratezza.
-
Riassunto
: Gli LLM possono comporre riassunti concisi di testi lunghi conservando informazioni chiave.
-
Risposta alle domande: Possono fornire risposte accurate ai query basandosi sulla loro vasta base di conoscenze.
-
Analisi delle emozioni: Gli LLM possono analizzare e determinare l’emozione espressa in un dato testo.
-
Generazione del codice: Possono generare snippet di codice o interi funzioni in base a descrizioni in linguaggio naturale.
Livelli degli agenti AI
Gli agenti AI possono essere classificati in diversi livelli in base alle loro capacità e complessità. Secondo un paper su arXiv, gli agenti AI sono classificati in cinque livelli:
-
Livello 1 (L1): Gli agenti AI come assistenti di ricerca, in cui gli scienziati impostano ipotesi e specificano compiti per raggiungere obiettivi.
-
Livello 2 (L2): agenti di intelligenza artificiale in grado di svolgere autonomamente compiti specifici all’interno di un ambito definito, come l’analisi dei dati o la semplice presa di decisioni.
-
Livello 3 (L3): agenti di intelligenza artificiale capaci di apprendere dall’esperienza e di adattarsi a nuove situazioni, migliorando i loro processi decisionali.
-
Livello 4 (L4): agenti di intelligenza artificiale con capacità avanzate di ragionamento e risoluzione dei problemi, in grado di gestire compiti complessi e multi-step.
-
Livello 5 (L5): agenti di intelligenza artificiale completamente autonomi che possono operare indipendentemente in ambienti dinamici, prendendo decisioni e agendo senza intervento umano.
Limitazioni dei modelli linguistici di grandi dimensioni
Costi di addestramento e vincoli di risorse
I modelli linguistici di grandi dimensioni (LLM) come GPT-3 e PaLM hanno rivoluzionato l’elaborazione del linguaggio naturale (NLP) sfruttando tecniche di deep learning e vasti set di dati.
Ma questi progressi sono accompagnati da un costo significativo. L’addestramento di LLM richiede risorse computazionali substantiali, spesso coinvolgendo migliaia di GPU e un consumo di energia esteso.
Secondo Sam Altman, CEO di OpenAI, il costo di addestramento di GPT-4 ha superato i 100 milioni di dollari. Questo si adatta alla scala e alla complessità del modello, con stime che suggeriscono che abbia circa 1 trilione di parametri. Tuttavia, altre fonti forniscono cifre differenti:
-
Un rapporto segreto ha indicato che i costi di addestramento di GPT-4 erano circa 63 milioni di dollari, considerando la potenza computazionale e la durata dell’addestramento.
-
A metà del 2023, alcune stime avevano suggerito che addestrare un modello simile a GPT-4 potesse costare circa 20 milioni di dollari e richiedere circa 55 giorni, riflettendo l’aumentata efficienza.
Il costo elevato dell’addestramento e della manutenzione di LLM limita la loro adozione diffusa e la loro scalabilità.
Limitazioni e Bias dei Dati
Il rendimento di LLM è fortemente dipendente dalla qualità e dalla diversità dei dati di addestramento. Nonostante siano stati addestrati su dataset di vasta dimensione, LLM possono ancora mostrare bias presenti nei dati, portando a risultati sbilanciati o inappropriati. Questi bias possono manifestarsi in varie forme, incluso gender, razziale e culturale, che possono perpetuare stereotipi e informazioni errate.
Anche la natura statica dei dati di addestramento significa che LLM potrebbero non essere aggiornati con le informazioni più recenti, limitando la loro efficacia in ambienti dinamici.
Specializzazione eComplessezza
Mentre LLM eccellono in task generali, spesso lottano con task specializzati che richiedono conoscenze specifiche del dominio e complessità di alto livello.
Per esempio, task nei campi come la medicina, il diritto e la ricerca scientifica richiedono una profonda comprensione deltermini specializzati e della ragione complessa, che LLM potrebbero non possedere in modo innato. Questa limitazione richiede l’integrazione di ulteriori livelli di esperto e la fine-tuning per renderli efficaci in applicazioni specializzate.
Limitazioni dell’Input e Sensoriali
Gli LLM processano prevalentemente input testuali, il che limita la loro capacità di interagire con il mondo in un modo multimodale. Mentre sono in grado di generare e comprendere testo, mancano della capacità di processare input visivi, uditivi o sensoriali direttamente.
Questa limitazione ostacola la loro applicazione in campi che richiedono integrazione sensoriale completa, come la robotica e i sistemi autonomi. Per esempio, un LLM non è in grado di interpretare i dati visivi da una macchina fotografica o i dati uditivi da un microfono senza strati di processamento aggiuntivi.
Constraints sulla Comunicazione e Interazione
Le capacità di comunicazione attuali degli LLM sono prevalentemente basate sul testo, che limita la loro capacità di partecipare a forme di comunicazione più immersive e interattive.
Ad esempio, sebbene gli LLM siano in grado di generare risposte testuali, non possono produrre contenuti video o rappresentazioni olografiche, che sono sempre più importanti nelle applicazioni di realtà virtuale e aumentata (leggete di più qui). Questa limitazione riduce l’efficacia degli LLM in ambienti che richiedono interazioni multimodali ricche.
Come Overcommer Limitations con gli AI Agents
Gli agenti AI offrono una soluzione promettente a molte delle limitazioni incontrate dagli LLM. Questi agenti sono progettati per operare autonomamente, percepire l’ambiente, prendere decisioni e svolgere azioni per raggiungere obiettivi specifici. Integrando agenti AI con LLM, è possibile ampliare le loro capacità e far fronte alle loro limitazioni innate.
-
Riduzione del carico di lavoro dell’utente: I nostri AI agenti sono in grado di mantenere il contesto attraverso varie interazioni, consentendo risposte più coerenti e pertinenti in base al contesto. Questa capacità è particolarmente utile nelle applicazioni che richiedono una memoria a lungo termine e continuità, come il servizio clienti e gli assistenti personali.
-
Integrazione multimodale: I nostri AI agenti possono incorporare input sensoriali da varie fonti, come telecamere, microfoni e sensori, consentendo a LLM di processare e rispondere ai dati visivi, uditivi e sensoriali. Questa integrazione è cruciale per le applicazioni in robotica e sistemi autonomi.
-
Conoscenza e Competenza Specializzate: Gli agenti AI possono essere raffinati con conoscenze specifiche del dominio, migliorando la capacità di LLM di svolgere compiti specializzati. Questo approcio consente la creazione di sistemi esperti in grado di gestire domande complesse in campi quali la medicina, la legge e la ricerca scientifica.
-
Comunicazione Interattiva e Immersiva: Gli agenti AI possono facilitare forme più immerse di comunicazione generando contenuti video, controllando display holografici e interagendo con ambienti virtuali e aumentati reali. questa capacità estende l’applicazione di LLM in campi che richiedono interazioni multimodali ricche.
Sebbene i grandi modelli di linguaggio abbiano dimostrato capacità notevoli nell’elaborazione del linguaggio naturale, non sono privi di limitazioni. I costi di training elevati, i bias dati, i problemi di specializzazione, le limitazioni sensoriali e le limitazioni di comunicazione presentano significative barriere.
Ma l’integrazione di agenti AI offre un percorso viabile per superare queste limitazioni. Utilizzando le peculiarità degli agenti AI, è possibile ampliare la funzionalità, l’adattabilità e l’applicabilità di LLM, aprendo la strada a sistemi AI più avanzati e versatile.
Capitolo 2: La Storia dell’Intelligenza Artificiale e degli AI-Agenti
La genesi dell’intelligenza artificiale
Il concetto di intelligenza artificiale (IA) ha radici che si estendono ben oltre l’era digitale moderna. L’idea di creare macchine capaci di ragionare come gli umani può essere ricondotta ai miti antichi e ai dibattiti filosofici. Ma l’inizio formale della IA come disciplina scientifica è avvenuto nel mezzo del ventesimo secolo.
La Conferenza di Dartmouth del 1956, organizzata da John McCarthy, Marvin Minsky, Nathaniel Rochester e Claude Shannon, è generalmente considerata come il luogo di nascita dell’intelligenza artificiale come campo di studio. Questo evento storico ha riunito i principali studiosi per esplorare il potenziale di creare macchine in grado di simulare l’intelligenza umana.
Ottimismo iniziale e l’Era dell’Inverno dell’IA
Gli anni iniziali della ricerca sull’intelligenza artificiale erano caratterizzati da un ottimismo incontenibile. I ricercatori hanno fatto progressi significativi nell’sviluppo di programmi capaci di risolvere problemi matematici, giocare a giochi e persino impegnarsi in elaborazione del linguaggio naturale di base.
Ma questo entusiasmo iniziale è stato mitigato dalla realizzazione che la creazione di macchine davvero intelligenti era molto più complessa di quanto si fosse immaginato inizialmente.
Gli anni ’70 e ’80 hanno visto un periodo di riduzione del finanziamento e dell’interesse nella ricerca sull’intelligenza artificiale, comunemente denominato “Era dell’Inverno dell’IA“. Questo calo è stato principalmente dovuto al fallimento degli sistemi AI di non raggiungere le aspettative altisonanti dei pionieri iniziali.
Dai sistemi basati su regole alla machine learning
L’Era degli Sistemi Esperti
Gli anni ’80 hanno assistito ad un risveglio dell’interesse per l’intelligenza artificiale, principalmente guidato dalla creazione degli sistemi esperti. Questi programmi basati su regole erano progettati per emulare i processi decisionali degli esperti umani in determinati domini.
Sistemi esperti hanno trovato applicazioni in vari campi, incluso la medicina, le finanze e l’ingegneria. Ma erano limitati dalla loro incapacità di imparare dalla esperienza o di adattarsi a nuove situazioni fuori dalla loro regola programmata.
La rivoluzione dell’apprendimento automatico
Le limitazioni dei sistemi basati su regole hanno aperto la strada ad un cambiamento di paradigma verso l’apprendimento automatico. Questo approcio, che è stato messo in evidenza negli anni ’90 e 2000, si concentra sullo sviluppo di algoritmi che possono imparare da e fare previsioni o decisioni basate su dati.
Tecniche di apprendimento automatico, come le reti neurali e i supporto vettore macchine, hanno dimostrato un successo notevole in compiti come la riconoscimento di pattern e la classificazione dei dati. L’avvento di grandi quantità di dati e la potenza computazionale aumentata hanno ulteriormente accelerato lo sviluppo e l’applicazione di algoritmi di apprendimento automatico.
L’emergenza di agenti AI autonomi
Dall’IA stretta all’IA generale
Mentre le tecnologie dell’intelligenza artificiale hanno continuato ad evolversi, i ricercatori hanno iniziato a esplorare la possibilità di creare sistemi più versatili e autonomi. Questo cambiamento ha segnato il passaggio dall’IA stretta, progettata per compiti specifici, all’interesse per l’intelligenza artificiale generale (AGI).
AGI si propone di sviluppare sistemi in grado di svolgere qualsiasi compito intellettuale che un essere umano può fare. Mentre l’AGI vera e propria rimane un obiettivo lontano, sono stati fatti progressi significativi nella creazione di sistemi AI più flessibili e adattabili.
Il ruolo dell’apprendimento profondo e delle reti neurali
L’emergere dell’apprendimento profondo, un sottoinsieme dell’apprendimento automatico basato sulle reti neurali, ha giocato un ruolo chiave nell’avanzamento del campo dell’IA.
Algoritmi di apprendimento profondo, ispirati dalla struttura e dalla funzione del cervello umano, hanno dimostrato capacità notevoli in aree come la riconoscenza dell’immagine e del suono, il processamento del linguaggio naturale e il gioco di giochi. Questi progressi hanno fatto scuola per lo sviluppo di AI autonomi più sofisticati.
Caratteristiche e tipi di agenti AI
Gli agenti AI sono sistemi autonomi in grado di percepire il loro ambiente, prendere decisioni e compiere azioni per raggiungere obiettivi specifici. Possiedono caratteristiche quali l’autonomia, la percezione, la reattività, il ragionamento, la decisione, l’apprendimento, la comunicazione e l’orientamento verso gli obiettivi.
Esistono diversi tipi di agenti AI, ognuno con capacità uniche:
-
Agenti semplici a riflesso: Rispondono a specifici stimoli in base a regole predefinite.
-
Agenti di riflesso basati su modelli: Mantengono un modello interno dell’ambiente per la decisione.
-
Agenti basati su obiettivi: Eseguono azioni per raggiungere obiettivi specifici.
-
Agenti basati sulla utility: Considerano gli esiti potenziali e scelgono azioni che massimizzano l’utilità attesa.
-
Agenti in grado di apprendimento: Migliorano la decisione nel tempo tramite tecniche di apprendimento automatico.
Sfide e considerazioni etiche
Con l’aumento dell’avanzamento e dell’autonomia dei sistemi AI, vengono considerazioni critiche per assicurare che l’uso rimanga entro i limiti socialmente accettati.
I grandi modelli di linguaggio (LLM), in particolare, agiscono come supercaricatori della produttività. Ma questo solleva una domanda cruciale: cosa questi sistemi superchargeranno – un buon intento o un maleintento? Quando l’intenzione dietro l’uso dell’AI è maligna, diventa imperativo per questi sistemi di rilevare tale abuso utilizzando varie tecniche di NLP o altri strumenti a nostra disposizione.
Gli ingegneri di LLM hanno accesso a una gamma di strumenti e metodologie per affrontare questi挑战:
-
Analisi del sentimento: Attraverso l’utilizzo dell’analisi del sentimento, gli LLM possono valutare l’tono emotivo del testo per rilevare linguaggio dannoso o aggressivo, aiutando a identificare potenziali abusi nelle piattaforme di comunicazione.
-
Filtrazione del contenuto: Strumenti come il filtraggio per parole chiave e il riconoscimento di schemi possono essere utilizzati per prevenire la generazione o la diffusione di contenuti dannosi, come discorsi di odio, informazioni non accurate o materiale esplicito.
-
Strumenti di rilevamento della bias: L’implementazione di framework di rilevamento del bias, come AI Fairness 360 (IBM) o Fairness Indicators (Google), può aiutare a identificare e mitigare il bias nei modelli di linguaggio, garantendo che i sistemi AI operino in maniera equa e equitativa.
-
Tecniche di spiegabilità
: Utilizzando strumenti di spiegabilità come LIME (Local Interpretable Model-agnostic Explanations) o SHAP (SHapley Additive exPlanations), gli ingegneri possono comprendere e spiegare i processi decisionali degli LLM, rendendo così più semplice la rilevazione e la correzione di comportamenti non intenzionali.
- Testing Adversariale: Simulando attacchi maligni o input dannosi, gli ingegneri possono sottoporre gli LLM a test di stress utilizzando strumenti come TextAttack o Adversarial Robustness Toolbox, identificando vulnerabilità che potrebbero essere sfruttate per scopi maligni.
- Guidelines e schemi etici per l’IA: Adottando linee guida etiche per lo sviluppo dell’IA, come quelle fornite dall’IEEE o dalla Partnership on AI, si può guidare la creazione di sistemi AI responsabili che prioritizzino il benessere della società.
Oltre a questi strumenti, ecco perché serve un Team Red dedicato per l’IA — team specializzati che spingono i LM (Large Models) ai loro limiti per rilevare buchi nelle loro difese. I Red Teams simulano scenario avversari e svelano vulnerabilità che potrebbero altrimenti passare inosservate.
Ma è importante riconoscere che la gente dietro il prodotto ha certamente l’effetto più forte su di esso. Molti degli attacchi e dei challenge che ci confrontiamo oggi esistevano già prima che fossero sviluppati i LM, sottolineando che l’elemento umano rimane centrale per garantire che l’IA sia utilizzata eticamente e responsabilmente.
L’integrazione di questi strumenti e tecniche nella pipeline di sviluppo, insieme ad un attivo Team Red, è essenziale per garantire che i LM siano utilizzati per potenziare positivamente i risultati mentre rilevano e prevengono il loro abuso.
Capitolo 3: Dove gli Agenti AI Risplendono di Più
Le Forze Uniche degli Agenti AI
Gli Agenti AI si distinguono grazie alla loro capacità di percepire autonomamente l’ambiente, prendere decisioni e eseguire azioni per raggiungere obiettivi specifici. Questa autonomia, unita alle capacità avanzate di apprendimento macchina, permette agli Agenti AI di svolgere compiti troppo complessi o troppo ripetitivi per gli umani.
Ecco i punti di forza chiave che rendono brillanti gli agenti IA:
-
Autonomia ed Efficienza: Gli agenti IA possono operare in modo indipendente senza costante intervento umano. Questa autonomia permette loro di gestire compiti 24/7, migliorando significativamente l’efficienza e la produttività. Ad esempio, i chatbot alimentati dall’IA possono gestire fino all’80% delle richieste di assistenza clienti di routine, riducendo i costi operativi e migliorando i tempi di risposta.
-
Processo Decisionale Avanzato: Gli agenti IA possono analizzare grandi quantità di dati per prendere decisioni informate. Questa capacità è particolarmente preziosa in settori come la finanza, dove i bot di trading IA possono aumentare notevolmente l’efficienza del trading.
-
Apprendimento e Adattabilità: Gli agenti AI possono imparare dall’esperienza e adattarsi a nuove situazioni. Questa miglioramento continuo li consente di migliorare le loro performance nel tempo. Ad esempio, gli assistenti sanitari AI possono aiutare a ridurre gli errori diagnostici, migliorando i risultati dell’assistenza sanitaria.
-
Personalizzazione: Gli agenti AI possono offrire esperienze personalizzate analizzando il comportamento e le preferenze dell’utente. Il motore di raccomandazioni di Amazon, che genera il 35% delle sue vendite, è un esempio eclatante di come gli agenti AI possano migliorare l’esperienza utente e incrementare i ricavi.
Perché gli Agenti AI sono la Soluzione
Gli agenti AI offrono soluzioni a molti dei challenge affrontati dai software tradizionali e dai sistemi operati da esseri umani. Ecco perché sono la scelta preferita:
-
Scalabilità: Gli agenti AI possono scalare le operazioni senza incrementi proporzionali nei costi. Questa scalabilità è cruciale per le aziende che cercano di crescere senza aumentare significativamente il proprio personale o le spese operative.
-
Consistenza e affidabilità: Al contrario degli esseri umani, gli agenti AI non soffrono di stanchezza o inconsistenza. Possono svolgere attività ripetitive con alta precisione e affidabilità, garantendo un’efficienza costante.
-
Insight basati su dati: Gli agenti AI possono processare e analizzare grandi set di dati per scoprire pattern e insight che potrebbero essere persi dagli esseri umani. questa capacità è preziosa per la decisione in aree quali la finanza, la sanità e il marketing.
-
Risparmio di costi: Automatizzando compiti di routine, gli agenti di intelligenza artificiale possono ridurre la necessità di risorse umane, portando a significativi risparmi di costi. Ad esempio, i sistemi di rilevamento delle frodi alimentati da intelligenza artificiale possono risparmiare miliardi di dollari all’anno riducendo le attività fraudolente.
Condizioni necessarie per una buona performance degli agenti di intelligenza artificiale
Per garantire il corretto utilizzo e la buona performance degli agenti di intelligenza artificiale, devono essere soddisfatte determinate condizioni:
-
Obiettivi e casi d’uso chiari: Definire obiettivi specifici e casi d’uso è cruciale per il corretto utilizzo degli agenti di intelligenza artificiale. Questa chiarezza aiuta a stabilire aspettative e misurare il successo. Ad esempio, stabilire come obiettivo la riduzione del tempo di risposta del servizio clienti del 50% può guidare l’implementazione di chatbot basati su intelligenza artificiale.
-
Qualità Dati: Gli agenti AI si affidano a dati di alta qualità per l’addestramento e l’esecuzione. Assicurarsi che i dati siano accurate, rilevanti e aggiornati è essenziale per consentire agli agenti di prendere decisioni informate e di operare con efficacia.
-
Integrazione con Sistemi Esistenti: L’integrazione fluida con i sistemi esistenti e i flussi di lavoro è necessaria perché gli agenti AI funzionino al meglio. Questa integrazione garantisce che gli agenti AI possano accedere ai dati necessari e interagire con altri sistemi per svolgere le loro mansioni.
-
Monitoraggio Continuo e Ottimizzazione: Il monitoraggio regolare e l’ottimizzazione degli agenti AI sono cruciali per mantenere le loro prestazioni. Questo comporta il tracciamento di indicatori chiave di prestazione (KPIs) e la realizzazione di adeguati aggiustamenti in base alla feedback e ai dati di performance.
-
Considerazioni etiche e mitigazione dell’attribuzione pregiudiziale: affrontare le considerazioni etiche e mitigare i pregiudizi negli agenti AI è essenziale per garantire la correttezza e l’inclusività. L’adozione di misure per la rilevazione e la prevenzione del pregiudizio può aiutare a costruire la fiducia e a garantire un’implementazione responsabile.
Best Practices for Deploying AI Agents
Quando si implementano agenti AI, seguire le migliori pratiche può garantire il loro successo e l’efficacia:
-
Definire Obiettivi e Casi d’Uso: Identificare chiaramente i goal e i casi d’uso per l’implementazione di agenti AI. Questo aiuta a stabilire le aspettative e a misurare il successo.
-
Seleziona una piattaforma AI corretta
: Scegli una piattaforma AI che si adatta ai tuoi obiettivi, casi d’uso e infrastruttura esistente. Considera fattori come la capacità di integrazione, la scalabilità e il costo.
- Costruisci una base di conoscenza completa: Crea una base di conoscenza ben strutturata e precisa per consentire agli agenti AI di fornire risposte appropriate e affidabili.
- Assicurati un’integrazione fluida: Integra gli agenti AI con sistemi esistenti come il CRM e le tecnologie del call center per fornire unaesperienza clienti unificata.
- Addestra e ottimizza gli agenti AI: Addestra e ottimizza continuamente gli agenti AI utilizzando i dati dalle interazioni. Monitora il rendimento, identifica aree in cui migliorare e aggiorna i modelli appropriatamente.
-
Implementare Procedure di Escaleggiamento Appropriate: Stabilire protocolli per il trasferimento di chiamate complicate o emotive agli agenti umani, garantendo una transizione fluida e una risoluzione efficiente.
-
Monitorare e Analizzare il Rendimento: Seguire indicatori chiave del rendimento (KPIs) come le rate di risoluzione delle chiamate, il tempo di interfacciamento medio e i punteggi di soddisfazione del cliente. Utilizzare gli strumenti di analisi per avere insights dati-driven e prendere decisioni.
-
Assicurare la Privacy e la Sicurezza dei Dati: Misure di sicurezza robuste sono chiave, come rendere i dati anonimi, assicurare la sorveglianza umana, stabilire politiche per il mantenimento dei dati, e implementare misure di cifratura potenti per proteggere i dati cliente e mantenere la privacy.
AI Agents + LLMs: Un Nuovo periodo di Software Intelligente
Immaginate un software che non solo comprende le vostre richieste, ma che può anche portarle a termine. Questa è la promessa della combinazione di agenti AI con grandi modelli di linguaggio (LLM). questo potente insieme sta creando una nuova generazione di applicazioni che sono più intuitive, capaci e influenti di quanto non lo siano mai state prima.
AI Agents: Beyond Simple Task Execution
Mentre spesso paragonati a assistenti digitali, gli agenti AI sono molto di più di semplici seguaci di script. Essi comprendono una gamma di tecnologie sofisticate e operano su un framework che consente la decisione dinamica e l’adottamento di azioni.
-
Architettura: Un agente AI tipico comprende diversi componenti chiave:
-
Sensori: Questi consentono all’agente di percepire il suo ambiente, raccogliendo dati da diverse fonti come sensori, API o input utente.
-
Stato delle convinzioni: Questo rappresenta la comprensione dell’agente del mondo in base ai dati raccolti. È aggiornato costantemente man mano che nuova informazione diventa disponibile.
-
Motore di ragionamento: Questo è il cuore del processo decisionale dell’agente. Usa algoritmi, spesso basati sulla reinforcement learning o sulle tecniche di pianificazione, per determinare il migliore corso d’azione in base alle sue convinzioni e ai suoi obiettivi attuali.
-
Attuatori: Questi sono gli strumenti dell’agente per interagire con il mondo. Possono variare从发送API调用到 controllare robot fisici.
-
-
Sfide: Gli agenti tradizionali dell’IA, pur essendo capaci di gestire compiti ben definiti, spesso si trovano in difficoltà con:
-
Comprensione del Linguaggio Naturale: Interpretare il linguaggio umano complesso, gestire l’ ambiguità e estrarre il significato dal contesto rimangono sfide significative.
-
Ragionamento con Common Sense: Gli agenti dell’IA attuali spesso mancano delle conoscenze di senso comune e delle abilità di ragionamento che gli umani considerano acquisiti.
-
Generalizzazione: Addestrare gli agenti per svolgere bene compiti non visti o adattarsi a nuovi ambienti rimane un’area chiave di ricerca.
-
LLM: Sbloccare la Comprensione e la Generazione del Linguaggio
Le LLM, con il loro vasto know-how codificato in miliardi di parametri, portano nuove capacità linguistiche senza precedenti:
-
Architettura Transformer: La base della maggior parte delle moderne LLM è l’architettura transformer, un design di rete neurale che eccelle nel processare dati sequenziali come il testo. Ciò permette alle LLM di catturare le dipendenze a lungo raggio nel linguaggio, consentendo loro di capire il contesto e generare testo coerente e contestualmente rilevante.
-
Capacità: Le LLM si distinguono in una vasta gamma di compiti basati sul linguaggio:
-
Generazione di Testo: Dalla scrittura di fiction creativa alla generazione di codice in più linguaggi di programmazione, le LLM mostrano una notevole fluentezza e creatività.
-
Risposta alle Domande: Possono fornire risposte concise e accurate alle domande, anche quando le informazioni sono disseminate in documenti lunghi.
-
Sommari: Le LLM possono condensare grandi volumi di testo in sintesi concisi, estrarre le informazioni chiave e scartare i dettagli irrilevanti.
-
-
Limitazioni: Nonostante le loro impressionanti capacità, le LLM hanno limitazioni:
-
Mancata G grounding nel mondo reale: Le LLM operano principalmente nel campo del testo e mancano dell’abilità di interagire direttamente con il mondo fisico.
-
Potenziale per Bias e allucinazione: Addestrate su dati massicci, non curati, le LLM possono ereditare i bias presenti nei dati e a volte generare informazioni factualmente errata o non sensica.
-
La sinergia: attraversare il gap tra lingua e azione
La combinazione di agenti AI e LLM risolve le limitazioni di ciascuno, creando sistemi sia intelligenti che capaci:
-
LLM come interpreti e pianificatori: Le LLM possono tradurre le istruzioni in linguaggio naturale in un formato che gli agenti AI possono capire, consentendo una interazione umano-计算机 più intuitiva. Possono anche sfruttare il loro know-how per assistere gli agenti nell’organizzare compiti complessi, dividendoli in step più piccoli e gestibili.
- AI Agents come esecutori e apprendisti: Gli agenti AI forniscono agli LLM la capacità di interagire con il mondo reale, di raccogliere informazioni e di ricevere feedback sulle loro azioni. Questa Collegamenti con il mondo reale possono aiutare gli LLM nell’apprendimento dalla esperienza e nell’aumento della loro performance nel tempo.
Questa potente sinergia sta guidando lo sviluppo di una nuova generazione di applicazioni che sono più intuitive, adattive e capaci di quanto non lo siano mai state prima. Con l’avanzamento continuo delle tecnologie sia degli agenti AI che degli LLM, ci si può aspettare di vedere l’emergere di applicazioni innovative e influenti, che rigirano il panorama dello sviluppo software e dell’interazione uomo-computer.
Esempi reali: Trasformazione delle industrie
Questa combinazione potente sta già scuotendo varie aree:
-
Gestione Servizio Clienti: Risoluzione di problemi con consapevolezza contextuale
- Esempio: Immaginate un cliente che contatta un negozio online riguardo un ritardo nella spedizione. Un agente AI alimentato da una PLL può capire la frustrazione del cliente, accedere alla storia dell’ordine, seguire il pacco in tempo reale e offrire proactive soluzioni come spedizione accelerata o sconto sulla prossima acquistazione.
-
Creazione Contenuti: Generazione di Contenuti di Alta Qualità a Scala
- Esempio: Un team di marketing può utilizzare un sistema AI agente + PLL per generare post social media mirati, scrivere descrizioni di prodotto o persino creare sceneggiature per video. La PLL garantisce che il contenuto sia coinvolgente e informativo, mentre l’agente AI gestisce il processo di pubblicazione e distribuzione.
-
Software Development: Accelerando il Coding e il Debugging
- Esempio: Un developer può descrivere una funzione di software che vuole implementare usando il linguaggio naturale. L’MML può quindi generare snippet di codice, identificare errori potenziali e suggerire miglioramenti, accelerando significativamente il processo di sviluppo.
-
Healthcare: Personalizzare il Trattamento e Migliorare la Cura del Paziente
- Esempio: Uno smart agent con accesso alla storia medica del paziente e dotato di un MML può rispondere alle loro domande relative alla salute, fornire promemoria personalizzati per la medicina e persino offrire diagnosi preliminari in base ai loro sintomi.
-
Diritto: ottimizzazione della ricerca giuridica e redazione documenti
- Esempio: Un avvocato deve redigere un contratto con specifiche clausole e precedenti legali. Un agente AI alimentato da una PdL può analizzare le istruzioni dell’avvocato, cercare attraverso vasti database legali, identificare clausole e precedenti rilevanti, e persino redigere parti del contratto, riducendo significativamente il tempo e il lavoro richiesti.
-
Creazione video: generazione di video coinvolgenti con facilità
- Esempio: Un team di marketing vuole creare un breve video per spiegare le caratteristiche del loro prodotto. Possono fornire a un agente AI + sistema PdL un outline del soggetto e le preferenze per lo stile visivo. La PdL può quindi generare uno script dettagliato, suggerire musica e immagini appropriate, e persino montare il video, automatizzando gran parte del processo di creazione del video.
-
Architettura: progettare edifici con insights basati su intelligenza artificiale
-
Esempio: Un architetto sta progettando un nuovo edificio per uffici. Può utilizzare un agente AI + il sistema LLM per inserire i suoi obiettivi di design, come massimizzare la luce naturale e ottimizzare l’utilizzo dello spazio. L’LLM può quindi analizzare questi obiettivi, generare diverse opzioni di design, e persino simulare come l’edificio avrebbe prestato il servizio sotto differenti condizioni ambientali.
-
Costruzione: migliorare la sicurezza e l’efficienza nei cantieri
- Esempio: Un agente AI equipaggiato con telecamere e sensori può monitorare un cantiere per pericoli di sicurezza. Se un operaio non indossa l’equipaggiamento di sicurezza corretto o un’attrezzatura è lasciata in una posizione pericolosa, l’MLL può analizzare la situazione, avvisare il supervisore del cantiere e persino sospendere automaticamente le operazioni se necessario.
Il futuro è qui: una nuova era della programmazione software
La convergenza tra agenti AI e MLL segna un significativo balzo in avanti nella programmazione software. Mentre queste tecnologie continuano a evolversi, ci si può aspettare ancora più applicazioni innovative emerse, trasformando le industrie, streamlining le flussi di lavoro e creando nuove possibilità per l’interazione uomo-计算机.
Gli agenti AI hanno il loro massimo nella loro capacità di elaborare vasti quantitativi di dati, automatizzare attività ripetitive, prendere decisioni complesse e fornire esperienze personalizzate. Incontrando le condizioni necessarie e seguendo le migliori pratiche, le organizzazioni possono sfruttare al massimo il potenziale degli agenti AI per guidare l’innovazione, l’efficienza e la crescita.
Capitolo 4: La Fondazione Filosofica degli Sistemi Intelligenti
Lo sviluppo di sistemi intelligenti, specialmente nel campo dell’intelligenza artificiale (AI), richiede un’approssimazione approfondita ai principi filosofici. Questo capitolo si immerge nelle idee filosofiche centrali che influiscono sulla progettazione, lo sviluppo e l’utilizzo dell’AI. Sottolinea l’importanza di allineare il progresso tecnologico con i valori etici.
La fondazione filosofica degli sistemi intelligenti non è solo un esercizio teorico – costituisce un quadro vitale che garantisce che le tecnologie dell’AI benefici l’umanità. Promuovendo la giustizia, l’inclusività e migliorando la qualità della vita, questi principi guidano l’AI a servire i nostri interessi migliori.
Considerazioni Etiche nell’ Sviluppo dell’AI
Con l’aumento dell’integrazione di sistemi AI in ogni aspetto della vita umana, dall’assistenza sanitaria e l’istruzione alla finanza e alla governanza, dobbiamo esaminare rigorosamente e applicare i comandamenti etici che guidano il loro design e la loro distribuzione.
La domanda etica fondamentale riguarda come possiamo creare AI in modo da riflettere e sostenere i valori umani e i principi morali. Questa domanda è centrale alla maniera in cui l’AI formerà il futuro delle società in tutto il mondo.
Al centro di questo discorso etico vi è il principio di beneficenza, una pietra miliare della filosofia morale che stabilisce che le azioni devono puntare a fare del bene e aumentare il benessere degli individui e della società in generale (Floridi & Cowls, 2019).
Nel contesto dell’IA, la beneficenza si traduce nel progettare sistemi che contribuiscono attivamente al benessere umano – sistemi che migliorano i risultati nella sanità, ampliano le opportunità educative e facilitano la crescita economica equitativa.
Ma l’applicazione della beneficenza nell’IA non è affatto semplice. richiede un approcio affinato che valuta attentamente i potenziali benefici dell’IA contro i possibili rischi e danni.
Un delle principali sfide nell’applicare il principio della beneficenza alla realizzazione dell’IA è il bisogno di un equilibrio delicato tra innovazione e sicurezza.
L’IA ha il potenziale di rivoluzionare settori come la medicina, dove algoritmi predittivi possono diagnosticare malattie più presto e con maggiore accuratezza rispetto ai dottori umani. Ma senza una stretta sorveglianza etica, queste stesse tecnologie potrebbero esasperare le disuguaglianze esistenti.
Ciò potrebbe accadere, ad esempio, se venissero principalmente implementate in regioni ricche mentre comunità non servite continuano a mancare dell’accesso base alla sanità.
Pertanto, lo sviluppo etico dell’IA richiede non solo un focus sull’massimizzazione dei benefici ma anche un approcio attivo alla mitigazione del rischio. Questo comporta l’implementazione di robuste misure di sicurezza per prevenire l’abuso dell’IA e garantire che queste tecnologie non causino danni inadvertatamente.
Il framework etico per l’IA deve anche essere inclusivo di per sé, garantendo che i benefici dell’IA siano distribuiti equamente tra tutti i gruppi sociali, inclusi quelli tradizionalmente marginalizzati. Questo richiede un impegno alla giustizia e alla fairness, garantendo che l’IA non solo rinforzi il status quo ma lavori attivamente a smantellare le disuguaglianze sistemiche.
Ad esempio, l’automazione del lavoro guidata dall’IA ha il potenziale di incrementare la produttività e la crescita economica. Ma potrebbe anche portare a un significativo spostamento del lavoro, colpendo in modo sproporzionato i lavoratori a basso reddito.
Come potete vedere, un quadro etico per l’IA deve includere strategie per il condivisione equitativa dei benefici e la fornitura di sistemi di supporto per coloro che sono colpiti in modo negativo dalle innovazioni dell’IA.
Lo sviluppo etico dell’IA richiede un coinvolgimento continuo con diversi stakeholder, inclusi gli eticisti, i tecnologi, i policy maker e le comunità che saranno maggiormente colpite da queste tecnologie. Questa collaborazione interdisciplinare assicura che i sistemi dell’IA non siano sviluppati in un vacuo ma siano invece influenzati da una ampia gamma di prospettive e esperienze.
È attraverso questo impegno collettivo che possiamo creare sistemi dell’IA che non solo riflettono ma anche sostengono i valori che definiscono la nostra umanità – compassione, equità, rispetto per l’autonomia e impegno per il bene comune.
Le considerazioni etiche nell’sviluppo dell’IA non sono solo linee guida, ma elementi essenziali che determinano se l’IA serve come forza buona nel mondo. Appoggiaando l’IA sui principi di beneficenza, giustizia e inclusività e mantenendo un approcio vigilante al bilanciamento tra innovazione e rischio, possiamo assicurarci che l’sviluppo dell’IA non solo avanzi la tecnologia ma anche migliori la qualità della vita di tutti i membri della società.
Mentre continuiamo a esplorare le capacità dell’IA, è imperativo che queste considerazioni etiche rimangano al centro dei nostri sforzi, guidandoci verso un futuro in cui l’IA davvero beneficia l’umanità.
L’imperativo dell’architettura AI centrata sull’uomo
L’architettura AI centrata sull’uomo non si limita ai soli aspetti tecnici. Ha radici in profonde principi filosofici che priorità la dignità umana, l’autonomia e l’agente umana.
Questo approcio alla realizzazione dell’IA è fondamentalmente ancorato nel quadro etico kantiano, secondo il quale gli umani devono essere considerati come fine a se stessi, non solo come strumenti per raggiungere altri obiettivi (Kant, 1785).
Le implicazioni di questo principio per l’architettura dell’IA sono profonde, richiedendo che i sistemi AI siano sviluppati con un focus inflessibile sulla servizio degli interessi umani, nella preservazione dell’autonomia umana e nel rispetto dell’autonomia individuale.
Implementazione tecnica dei principi dell’AI centrata sull’uomo
Enhancing Human Autonomy through AI: Il concetto di autonomia negli AI system è critico, soprattutto nel garantire che queste tecnologie empower gli utenti invece di controllare o influenzare in modo eccessivo.
In termini tecnici, questo coinvolge il design di AI system che priorità l’autonomia utente fornendogli gli strumenti e l’informazione necessaria per prendere decisioni informate. Questo richiede che i modelli AI siano contesto-sensibili, ovvero che comprendano il contesto specifico in cui viene presa una decisione e adattino le loro raccomandazioni di conseguenza.
Da un punto di vista di progettazione di sistemi, questo coinvolge l’integrazione dell’intelligenza contestuale nei modelli AI, che consente a questi sistemi di adattarsi dinamicamente all’ambiente utente, alle preferenze e ai bisogni.
Per esempio, nel settore sanitario, un sistema AI che assiste i dottori nella diagnosi di condizioni deve considerare il curriculum medico unico del paziente, i sintomi attuali e persino lo stato psicologico per offrire raccomandazioni che supportino l’esperto del dottore invece di sostituirlo.
Questa adattabilità contestuale assicura che l’AI rimanga uno strumento supportivo che migliora, piuttosto che diminuisce, l’autonomia umana.
Garantendo Processi Decisionali Trasparenti: La trasparenza nei sistemi AI è unarequisizione fondamentale per assicurare che gli utenti possano fidarsi e capire le decisioni fatte da queste tecnologie. Technically, questo si traduce nella necessità di AI spiegabile (XAI), che coinvolge lo sviluppo di algoritmi in grado di chiarire il ragionamento dietro le loro decisioni.
Questo è particolarmente cruciale nei domini come la finanza, la sanità e la giustizia penale, nei quali decisioni opache possono condurre a diffidenza e preoccupazioni etiche.
La spiegabilità può essere raggiunta attraverso diversi approcchi tecnici. Un metodo comune è l’interpretabilità post-hoc, in cui il modello AI genera una spiegazione dopo aver fatto la decisione. Questo potrebbe coinvolgere la scomposizione della decisione nei suoi fattori costitutivi e mostrare come ciascuno di essi abbia contribuito all’outcome finale.
Un’altra approcio sono modelli di percezione automatica, nei quali l’architettura del modello è progettata in modo da rendere le sue decisioni trasparenti in modo predefinito. Per esempio, modelli come gli alberi di decisione e i modelli lineari sono naturalmente trasparenti perché il loro processo decisionale è facile da seguire e comprendere.
Il challenge nell’implementare l’IA spiegabile sta nel bilanciare la trasparenza con la performance. Spesso, modelli più complessi, come le reti neurali profonde, sono meno spiegabili ma più accurate. Quindi, il design dell’IA centrate sull’uomo deve considerare il compromesso tra la spiegabilità del modello e la sua capacità predittiva, garantendo agli utenti di poter fidarsi e comprendere le decisioni dell’IA senza sacrificare la precisione.
Consentire una Oversight Umana Significativo: Una Oversight Umana Significativo è cruciale per garantire che i sistemi AI operino entro i limiti etici e operativi. Questo controllo comprende il design di sistemi AI con meccanismi di salvaguardia e override che consentono agli operatori umani di intervenire quando necessario.
L’implementazione tecnica dell’oversight umana può essere approcio in diversi modi.
Un approcio è quello di incorporare sistemi a uomo-in-the-loop, nei quali i processi di decision-making dell’IA sono monitorati e valutati in continuazione dagli operatori umani. Questi sistemi sono progettati per consentire un intervento umano a punti chiave, garantendo che l’IA non agisca autonomamente in situazioni in cui sono richieste giudizi etici.
Ad esempio, nei sistemi armi autonome, la sorveglianza umana è essenziale per impedire all’IA di prendere decisioni di vita o di morte senza input umano. Ciò potrebbe comportare la definizione di rigide limitazioni operative che l’IA non può superare senza autorizzazione umana, così come l’inserimento di garanzie etiche nel sistema.
Un’altra considerazione tecnica è lo sviluppo di tracciati di revisione, che sono registrazioni di tutte le decisioni e le azioni fatte dal sistema dell’IA. Questi tracciati forniscono una storia trasparente che può essere rivista dagli operatori umani per assicurare la conformità con standard etici.
I tracciati di revisione sono particolarmente importanti nei settori come quello finanziario e giuridico, in cui le decisioni devono essere documentate e giustificate per mantenere la fiducia pubblica e soddisfare i requisiti regolamentari.
Bilanciamento Autonomia e Controllo: Una sfida tecnica chiave nell’AI centrato sull’uomo è trovare il giusto equilibrio tra autonomia e controllo. Mentre i sistemi dell’IA sono progettati per operare autonomamente in molti scenari, è cruciale che questa autonomia non sottragga il controllo umano o la sorveglianza.
Questo equilibrio può essere raggiunto attraverso l’implementazione di livelli di autonomia, che determinano la gradazione di indipendenza che l’IA ha nell’ fare decisioni.
Ad esempio, nei sistemi semi-autonomi come le macchine guidate da soli, i livelli di autonomia vanno dall’assistenza base del guidatore (in cui il guidatore umano rimane a pieno controllo) alla automazione completa (in cui l’IA è responsabile per tutte le attività di guida).
Il design di questi sistemi deve garantire che, a qualsiasi livello di autonomia, l’operatore umano mantenga la capacità di intervenire e annullare l’IA se necessario. Ciò richiede interfacce di controllo sofisticate e sistemi di supporto per le decisioni che consentano agli umani di assumere rapidamente e efficientemente il controllo in caso di necessità.
Inoltre, lo sviluppo di schemi etici per le AI è essenziale per guidare le azioni autonome dei sistemi AI. Questi schemi sono insiemi di regole e linee guida integrate all’interno dell’AI che dicono come dovrebbe comportarsi in situazioni eticamente complesse.
Ad esempio, nel settore sanitario, un schema etico per una AI potrebbe includere regole riguardanti il consenso del paziente, la privacy e la priorità dei trattamenti in base alle necessità mediche invece che ai considerazioni economiche.
Inserendo questi principi etici direttamente nei processi decisionali dell’AI, gli sviluppatori possono garantire che l’autonomia del sistema sia esercitata in modo da allinearsi con i valori umani.
L’integrazione di principi centrate sull’uomo nel design dell’AI non è solo un ideal filosofico ma una necessità tecnica. Enhancing human autonomy, ensuring transparency, enabling meaningful oversight, and carefully balancing autonomy with control, AI systems can be developed in a way that truly serves humanity.
Queste considerazioni tecniche sono essenziali per la creazione di AI che non solo amplifichi le capacità umane ma anche rispetta e sostiene i valori fondamentali della nostra società.
Con l’evoluzione continua dell’AI, l’ impegno nei confronti del design centrato sull’uomo sarà cruciale per assicurarsi che queste potenti tecnologie siano utilizzate eticamente e responsabilmente.
Come assicurarsi che l’AI sia benefico per l’umanità: migliorare la qualità della vita
Mentre state impegnati nella sviluppo di sistemi AI, è essenziale che il vostro impegno sia basato sul quadro etico del Utilitarismo – una filosofia che dà importanza all’aumento della felicità e del benessere complessivo.
In questo contesto, l’AI ha il potenziale di affrontare sfide cruciali della società, specialmente nell’area della sanità, dell’educazione e della sostenibilità ambientale.
L’obiettivo è creare tecnologie che notevolmente migliorino la qualità della vita per tutti. Ma la ricerca di questo obiettivo comporta complessità. Il Utilitarismo offre un motivo appassionante per l’utilizzo diffuso dell’AI, ma ne fa emergere anche importanti domande etiche riguardanti chi beneficia e chi potrebbe essere lasciato indietro, specialmente tra le popolazioni vulnerabili.
Per affrontare questi challenge, abbiamo bisogno di un approcio sofisticato, tecnicamente informato – uno che equilibra la ricerca diffusa del bene della società con il bisogno di giustizia e equità.
Applicando i principi del Utilitarismo all’AI, il vostro focus dovrebbe essere sull’ottimizzazione degli outcome nei domini specifici. Ad esempio, nell’area sanitaria, le tool di diagnostica guidate dall’AI hanno il potenziale di migliorare significativamente i risultati per i pazienti permettendo diagnosi più timbriche e anticipate. Questi sistemi possono analizzare dataset estesi per rilevare schemi che potrebbero sfuggire ai pratici umani, espandendo così l’accesso alla cura di qualità, specialmente in ambienti sottoutilizzati.
Ma, per farlo, occorre considerare attentamente per evitare di rafforzare le diseguaglianze esistenti. I dati utilizzati per addestrare i modelli AI possono variare significativamente tra le regioni, influenzando l’accuratezza e la affidabilità di questi sistemi.
Questa disparità evidenzia l’importanza di stabilire framebuffer governativi robusti che garantiscano che le soluzioni sanitarie guidate da AI siano sia rappresentative che equitable.
Nell’ambito educativo, la capacità di personalizzare l’apprendimento offerta dall’AI è promettente. I sistemi AI possono adattare il contenuto educativo ai bisogni specifici di ogni studente, migliorando così i risultati di apprendimento. Analizzando i dati sulla performance e sul comportamento degli studenti, l’AI può identificare le aree in cui un studente potrebbe avere problemi e fornire supporto mirato.
Ma mentre si lavorano verso questi benefici, è cruciale fare attenzione ai rischi, come il potenziale di rafforzare i pregiudizi o di marginalizzare gli studenti che non si adattano ai tipici modelli di apprendimento.
Mitigare questi rischi richiede l’integrazione di meccanismi di equità nei modelli AI, garantendo che non favoriscano inadvertentemente certi gruppi. E mantienere il ruolo degli educatori è critico. La loro giudizio e esperienza sono indispensabili per rendere le tool AI davvero efficienti e supportive.
In termini di sostenibilità ambientale, il potenziale dell’AI è notevole. I sistemi AI possono ottimizzare l’uso delle risorse, monitorare i cambiamenti ambientali e prevedere gli impatti del cambiamento climatico con una precisione senza precedenti.
Ad esempio, l’intelligenza artificiale può analizzare vasti quantitativi di dati ambientali per prevedere i modelli meteorologici, ottimizzare il consumo energetico e minimizzare il waste – azioni che contribuiscono al benessere delle generazioni presenti e future.
Ma questo sviluppo tecnologico comporta anche una serie di sfide proprie, in particolare riguardo all’impatto ambientale stesso dei sistemi AI.
Il consumo energetico richiesto per operare sistemi AI a scala elevata può annullare i benefici ambientali che questi intendono raggiungere. Quindi, sviluppare sistemi AI efficienti in termini di energia è cruciale per assicurarsi che il loro impatto positivo sulla sostenibilità non venga minato.
Con il sviluppo di sistemi AI con obiettivi utilitaristici, è importante considerare anche le implicazioni per la giustizia sociale. Utilitarianesimo si concentra sulla massimizzazione del benessere complessivo ma non tratta in modo innato della distribuzione dei benefici e degli danni tra i diversi gruppi sociali.
Questo alza il potenziale per i sistemi AI di beneficiare in modo sproporzionato coloro che sono già privilegiati, mentre i gruppi marginalizzati potrebbero vedere poca o nessuna migliore situazione nei loro confronti.
Per contrarre questo fenomeno, il processo di sviluppo dell’IA dovrebbe incorporare principi focalizzati sull’uguaglianza, garantendo una distribuzione equa dei benefici e la mitigazione di eventuali danni. Ciò potrebbe comportare la progettazione di algoritmi finalizzati specificamente a ridurre le biassi e l’inclusione di una gamma diversa di punti di vista nel processo di sviluppo.
Nel lavoro di sviluppo di sistemi AI mirati ad migliorare la qualità della vita, è essenziale bilanciare il obiettivo utilitariano di massimizzare il benessere con il bisogno di giustizia e equità. Ciò richiede un approcio sofisticato, basato sulla tecnica, che consideri le implicazioni più ampie del deployaggio di AI.
Progettando attentamente sistemi AI sia efficaci che equi, puoi contribuire ad un futuro dove le evoluzioni tecnologiche servano realmente le varie esigenze della società.
Implementa barriere contro i potenziali danni
Nel corso dello sviluppo di tecnologie AI, devi riconoscere la potenziale per il danno inerente e stabilire preventivamente misure robuste per mitigare questi rischi. Questa responsabilità è profondamente radicata nellaetica deontologica. Questo ramo dell’etica sottolinea il dovere morale di adeguarsi alle regole e ai standard etici stabiliti, garantendo che la tecnologia creata risponda a principi morali fondamentali.
L’implementazione di protocolli di sicurezza stringenti non è solo una precauzione, ma anche un obbligo etico. questi protocolli dovrebbero includere test completi sulla biassenza, trasparenza nei processi algoritmici e meccanismi chiari di responsabilità.
Quindi, queste misure di sicurezza sono essenziali per prevenire che i sistemi AI causino danni imprevisti, sia per decisioni basate su bias, processi opachi o mancanza di sorveglianza.
In pratica, l’implementazione di queste misure richiede una profonda comprensione sia delle dimensioni tecniche che etiche dell’AI.
La testazione per bias, ad esempio, non riguarda solo l’identificazione e la correzione dei bias negli dati e negli algoritmi, ma anche l’understanding delle implicazioni sociali più ampie di questi bias. Devi assicurarti che i tuoi modelli AI siano addestrati su dataset diversi e rappresentativi e che siano ricorrentemente valutati per rilevare e correggere eventuali bias che potrebbero emergerne nel tempo.
La trasparenza, d’altro canto, richiede che i sistemi AI siano progettati in modo da consentire una comprensione e una sorveglianza facile da parte degli utenti e degli interessati. Questo comprende lo sviluppo di modelli AI spiegabili che forniscano output chiari e interpretabili, permettendo agli utenti di vedere come vengono fatte le decisioni e garantendo che queste decisioni siano giustificabili e equitable.
Inoltre, i meccanismi di responsabilità sono cruciali per mantenere la fiducia e garantire che i sistemi AI siano utilizzati responsabilmente. questi meccanismi dovrebbero includere linee guida chiare su chi è responsabile per i risultati delle decisioni di AI, nonché processi per affrontare e correggere eventuali danni che possono verificarsi.
Devi stabilire un framework in cui le considerazioni etiche siano integrate in ogni fase dello sviluppo dell’AI, dalla progettazione iniziale alla distribuzione e oltre. Questo comprende non solo la aderenza agli standard etici, ma anche la monitoraggio continuo e l’attuazione di AI sistemi mentre interagiscono con il mondo reale.
Impiantando queste garanzie nell’essenza dello sviluppo tecnologico, puoi aiutare a garantire che il progresso tecnologico serve il bene comune senza portare a conseguenze negative impreviste.
Il ruolo dell’osservanza umana e dei cicli di feedback
La sorveglianza umana negli sistemi AI è un componente chiave per garantire una distribuzione etica di AI. Il principio della responsabilità sostegna la necessità di una partecipazione umana continua nell’operazione di AI, in particolare in ambienti a rischi elevati come la sanità e la giustizia penale.
I cicli di feedback, nei quali l’input umano viene utilizzato per raffinare e migliorare i sistemi AI, sono essentiali per mantenere la responsabilità e l’adattabilità (Raji et al., 2020). Questi cicli consentono la correzione degli errori e l’integrazione di nuove considerazioni etiche man mano che i valori sociali evolvono.
Incorporando la sorveglianza umana negli sistemi AI, i sviluppatori possono creare tecnologie non solo efficienti ma anche allineate alle norme etiche e alle aspettative umane.
Codificare l’Etica: Tradurre i Principi Filosofici negli Sistemi AI
La traduzione dei principi filosofici negli sistemi AI è un compito complesso ma necessario. Questo processo coinvolge l’implementazione di considerazioni etiche nel codice che guidano gli algoritmi AI.
Concetti come la fairness, la giustizia e l’autonomia devono essere codificati negli sistemi AI per assicurare che operino in modi che riflettano i valori sociali. Ciò richiede un approcio multidisciplinare, nel quale filosofi, ingegneri e scienziati sociali collaborano per definire e implementare linee guida etiche nel processo di codifica.
L’obiettivo è creare AI system che siano non solo tecnicamente dotati ma anche morali, capaci di prendere decisioni che rispettino la dignità umana e promuovano il bene sociale (Mittelstadt et al., 2016).
Promuovere l’inclusività e l’accesso equo nell’sviluppo e nella distribuzione di AI.
L’inclusività e l’accesso equo sono fondamentali per lo sviluppo etico dell’intelligenza artificiale. Il concetto Rawlsiano di giustizia come equità fornisce una base filosofica per garantire che i sistemi AI siano progettati e implementati in modi che beneficiano tutti i membri della società, specialmente coloro che sono più vulnerabili (Rawls, 1971).
Questo richiede sforzi proattivi per includere diverse prospettive nel processo di sviluppo, specialmente da gruppi sottorappresentati e dal Sud del Mondo.
Incorporando questi diversi punti di vista, i sviluppatori AI possono creare sistemi che sono più equi e responsive ai bisogni di un range più vasto di utenti. Anche l’accesso equo alle tecnologie AI è cruciale per prevenire l’esacerbazione di esistenti disuguaglianze sociali.
Raddoppia la Bias negli Algoritmi e la Giustizia
Il bias negli algoritmi è una preoccupazione etica significativa nello sviluppo dell’intelligenza artificiale, poiché algoritmi biasi possono perpetuare e persino peggiorare le disuguaglianze sociali. Per affrontare questo problema è necessario un impegno nella giustizia procedurale, garantendo che i sistemi AI siano sviluppati attraverso processi equi che considerino l’impatto su tutti gli interessati (Nissenbaum, 2001).
Questo richiede l’identificazione e la mitigazione del bias nei dati di addestramento, lo sviluppo di algoritmi trasparenti e spiegabili e l’implementazione di verifiche di equità lungo tutto il ciclo di vita dell’AI.
Raddoppiare il bias negli algoritmi, i sviluppatori possono creare sistemi AI che contribuiscono a una società più giusta e equa, invece di rafforzare le disparità esistenti.
Includere Perspective Diverse nell’Sviluppo dell’AI
Incorporare diverse prospettive nell’sviluppo dell’intelligenza artificiale è essenziale per la creazione di sistemi inclusivi e equi. L’inclusione delle voci delle gruppi sottorepresentati garantisce che le tecnologie dell’intelligenza artificiale non riflettano solo i valori e le priorità di un piccolo segmento della società.
Questo approcio è allineato con il principio filosofico della democrazia deliberativa, che sottolinea l’importanza di processi decisionale inclusivi e partecipativi (Habermas, 1996).
Attraverso la promozione della partecipazione diversa nell’sviluppo dell’intelligenza artificiale, possiamo assicurarci che queste tecnologie siano progettate per servire gli interessi di tutta l’umanità, invece di una minoranza privilegiata.
Strategie per attraversare la divisione dell’intelligenza artificiale
La divisione dell’intelligenza artificiale, caratterizzata da un accesso ineguale alle tecnologie dell’intelligenza artificiale e ai loro benefici, presenta una sfida significativa all’equità globale. Attraversare questa divisione richiede un impegno alla giustizia distributiva, garantendo che i benefici dell’intelligenza artificiale siano condivisi ampiamente tra i diversi gruppi socioeconomici e regioni (Sen, 2009).
Possiamo fare questo attraverso iniziative che promuovono l’accesso all’educazione e ai risorse relative all’intelligenza artificiale nelle comunità non servite, così come dalle politiche che supportano la distribuzione equa dei guadagni guidati dall’intelligenza artificiale. Attraversando la divisione dell’intelligenza artificiale, possiamo assicurarci che l’intelligenza artificiale contribuisca al sviluppo globale in un modo inclusivo e equo.
Balance l’innovazione con le limitazioni etiche
Balancere la ricerca dell’innovazione con le limitazioni etiche è cruciale per l’avanzamento responsabile dell’intelligenza artificiale. Il principio precauzionista, che sostiene la cautela di fronte all’incertezza, è particolarmente rilevante nel contesto dello sviluppo dell’intelligenza artificiale (Sandin, 1999).
Mentre l’innovazione spinge avanti il progresso, deve essere temperato da considerazioni etiche che proteggano contro i possibili danni. Questo richiede un’attenta valutazione dei rischi e dei benefici delle nuove tecnologie AI, nonché l’adozione di schemi regolatori che sostengano gli standard etici.
Balanciando l’innovazione con le limitazioni etiche, possiamo incoraggiare lo sviluppo di tecnologie AI al passo avanzato e allineate con i più ampi obiettivi del benessere della società.
Come potete vedere, la base filosofica dei sistemi intelligenti fornisce un quadro critico per assicurare che le tecnologie AI siano sviluppate e impiegate in modi etici, inclusivi e beneficiosi per tutta l’umanità.
Appoggiaando lo sviluppo dell’intelligenza artificiale su questi principi filosofici, possiamo creare sistemi intelligenti in grado non solo di avanzare le capacità tecnologiche ma anche di migliorare la qualità della vita, promuovere la giustizia e garantire che i benefici dell’AI siano condivisi equamente nella società.
Capitolo 5: AI Agents come Enhancer per LLM
La fusione di agenti AI con Modelli a Larga Scala (LLM) rappresenta un cambiamento fondamentale nell’intelligenza artificiale, che colga le limitazioni critiche negli LLM che ne hanno limitato l’applicabilità più ampia.
Questo integrazione consente alle macchine di superare i loro ruoli tradizionali, avanzando da generatori passivi di testo a sistemi autonomi capaci di ragionamento dinamico e decisioni.
Con l’aumento delle macchine AI che guidano processi critici in vari domini, capire come gli agenti AI colmano le lacune nelle capacità di LLM è essenziale per realizzare il loro pieno potenziale.
Collegare i limiti nelle Capacità di LLM
Le LLM, sebbene potenti, sono inesorabilmente limitate dai dati su cui sono state addestrate e dalla natura statica della loro architettura. Questi modelli operano all’interno di un insieme fisso di parametri, generalmente definiti dal corpus di testo utilizzato durante la fase di addestramento.
Questa limitazione significa che le LLM non possono autonomamente cercare nuove informazioni o aggiornare la loro base di conoscenza dopo l’addestramento. Di conseguenza, le LLM spesso sono obsolete e mancano della capacità di fornire risposte appropriate in contesto che richiedono dati o informazioni in tempo reale oltre ai dati di addestramento iniziale.
Gli agenti AI attraversano questi limiti integrando dinamicamente fonti di dati esterni, il che può estendere l’orizzonte funzionale delle LLM.
Per esempio, una LLM addestrata su dati finanziari fino al 2022 potrebbe fornire analisi storiche accurate ma sarebbe in grado di generare solo difficilmente previsioni di mercato aggiornate. Un agente AI può ampliare questa LLM integrando dati in tempo reale dai mercati finanziari, applicando questi input per generare analisi più appropriate e aggiornate.
Questa integrazione dinamica garantisce che le uscite non siano solo accurate storicamente ma anche appropriate in contesto per le condizioni presenti.
Integrazione dell’Autonomia nell’Esecuzione delle Decisioni
Un’altra limitazione significativa delle LLM è la loro mancanza di capacità autonome nell’esecuzione delle decisioni. Le LLM eccellono nella generazione di output basati sul linguaggio ma non soddisfano compiti che richiedono complicate decisioni, specialmente in ambienti caratterizzati da incertezza e cambiamento.
Questo scarto è principalmente dovuto alla dipendenza del modello da dati preesistenti e all’assenza di meccanismi per la ragione adattativa o l’apprendimento da nuove esperienze post-implementazione.
Gli agenti AI affrontano questo problema fornendo l’infrastruttura necessaria per la decisione autonoma. Possono prendere le uscite statiche di un LLM e processarle attraverso framebuffer avanzati come sistemi basati su regole,uristiche o modelli di apprendimento ricorrente.
Ad esempio, in un contesto sanitario, un LLM potrebbe generare una lista di diagnosi potenziali in base ai sintomi e alle informazioni mediche del paziente. Ma senza un agente AI, il LLM non può valutare queste opzioni o raccomandare un trattamento.
Un agente AI può intervenire per valutare queste diagnosi rispetto alla letteratura medica corrente, ai dati del paziente e ai fattori contestuali, generando così una decisione più informata e suggerendo passi successivi attuabili. Questa sinergia trasforma le uscite LLM da semplici suggerimenti in decisioni attuabili e consapevoli del contesto.
Aggiungendo Completezza e coerenza
Completezza e coerenza sono fattori critici per garantire la affidabilità degli output LLM, specialmente in compiti di ragioneamento complessi. A causa della loro natura parametrizzata, gli LLM spesso generano risposte incomplete o logicamente incoerenti, soprattutto quando si devono occupare di processi multi-passo o richiedere una comprensione completa di più domini.
Questi problemi derivano dall’ambiente isolato in cui operano gli LLM, dove non sono in grado di fare riferimento o validare le loro uscite contro standard esterni o informazioni aggiuntive.
Gli agenti AI giocano un ruolo chiave nel mitigare questi problemi introdurre meccanismi di feedback iterativi e strati di validazione.
Per esempio, nel campo legale, un LLM potrebbe redigere una versione iniziale di un memoriale basandosi sul proprio dataset di addestramento. Ma questo bozzetto potrebbe non considerare alcuni precedenti o fallire nell’organizzare logicamente l’argomento.
Un agente AI può revisionare questo bozzetto, garantendo di rispettare i requisiti di completezza richiesti attraverso la cross-referenza con database legali esterni, il controllo per la coerenza logica e la richiesta di informazioni aggiuntive o chiarimenti quando necessario.
Questo processo iterativo consente la produzione di un documento più robusto e affidabile che rispetti i rigorosi requisiti della pratica legale.
Oltrepassare l’isolamento attraverso l’integrazione
Uno dei limiti più profondi degli LLM è l’isolamento innato rispetto ad altri sistemi e fonti di conoscenza.
Gli LLM, così come sono progettati, sono sistemi chiusi che non interagiscono in modo naturale con ambienti esterni o database. Questa isolazione limita significativamente la loro capacità di adattarsi a nuove informazioni o di operare in tempo reale, rendendoli meno efficaci in applicazioni richiedenti interazioni dinamiche o decisioni in tempo reale.
Gli agenti AI superano questo isolamento agendo come piattaforme integrate che collegano LLM a un’ecosistema più ampio di fonti di dati e strumenti computazionali. Attraverso API e altri framework di integrazione, gli agenti AI possono accedere a dati in tempo reale, collaborare con altri sistemi AI e persino interfacciarsi con dispositivi fisici.
Ad esempio, nelle applicazioni di servizio clienti, un PEM potrebbe generare risposte standard basate su script pre-addestrati. Ma queste risposte possono essere statiche e mancare della personalizzazione richiesta per un efficace coinvolgimento del cliente.
Un agente AI può arricchire queste interazioni integrando dati in tempo reale da profili clienti, interazioni precedenti e strumenti di analisi del sentimento, generando risposte non solo contextualmente appropriate ma anche personalizzate ai bisogni specifici del cliente.
Questa integrazione trasforma l’esperienza clienti da una serie di interazioni scriptate in una conversazione dinamica e personalizzata.
Ampliamento Creatività e Risoluzione Problemi
Sebbene i PEM siano potenti strumenti per la generazione di contenuti, la loro creatività e capacità di risoluzione sono limitate in natura dai dati su cui sono stati addestrati. Questi modelli spesso non sono in grado di applicare concetti teorici a nuovi o imprevisti挑战, poiché le loro capacità di risoluzione sono confinate dalla conoscenza preesistente e dai parametri di addestramento.
Gli agenti AI amplificano il potenziale creativo e di risoluzione dei PEM utilizzando tecniche avanzate di ragionamento e una gamma più ampia di strumenti di analisi. Questa capacità consente agli agenti AI di superare le limitazioni dei PEM, applicando schemi teorici ai problemi pratici in modi innovativi.
Per esempio, considerare il problema della combattimento della disinformazione sui social media. Un PEM potrebbe identificare pattern di disinformazione sulla base di analisi testuali, ma potrebbe lottare per sviluppare una strategia completa per mitigare la diffusione di informazioni false.
Un agente AI può prendere queste insight, applicare teorie interdisciplinari provenienti da settori come la sociologia, la psicologia e la teoria delle reti, e sviluppare un approcio robusto, multi-aspirato che include il monitoraggio in tempo reale, l’educazione utenti e tecniche di moderazione automatizzate.
Questa capacità di sintetizzare diversi schemi teorici e applicarli a sfide del mondo reale è un esempio delle capacità di risoluzione problemi potenziate che gli agenti AI portano alla tavola.
Esempi più specifici
Gli agenti AI, con la loro capacità di interagire con sistemi diversi, di accedere a dati in tempo reale e di eseguire azioni, affrontano queste limitazioni direttamente, trasformando i LML da potenti ma passivi modelli di linguaggio in soluzionisti dinamici e reali del mondo reale. Consideriamo qualche esempio:
1. Dai dati statici agli insight dinamici: tenendo i LML aggiornati
-
Il problema: Immaginate di chiedere ad un LMM addestrato prima del 2023, “Cosa sono i più recenti progressi nella terapia del cancro?” La sua conoscenza sarebbe obsoleta.
-
La soluzione dell’agente AI: Un agente AI può collegare il LMM a riviste mediche, banche dati di ricerca e fonti di notizie. Ora, il LMM può fornire informazioni aggiornate sui più recenti trial clinici, opzioni di trattamento e risultati di ricerca.
2. Da Analisi a Azione: Automatizzazione delle Attività Basata sulle Insights dell’LLM
-
Il problema: Un LLM che monitora i social media per una marca potrebbe identificare un aumento di sentimenti negativi ma non può fare nulla per risolverlo.
-
La Soluzione dell’Agente AI: Un agente AI collegato ai social media della marca e dotato di risposte pre approvate può risolvere automaticamente i problemi, rispondere a domande e persino elevare questioni complesse agli rappresentanti umani.
3. Da Primo Bozzetto a Prodotto Polito: Garantire Qualità e Precisione
-
Il problema: Un LLM incaricato di tradurre un manuale tecnico potrebbe produrre traduzioni grammaticalmente corrette ma tecnicamente imprecise a causa della sua mancanza di conoscenze specifiche del campo.
-
La Soluzione dell’Agente AI: Un agente AI può integrare la LLM the dizionari specializzati, glosari, e persino collegarla agli esperti del settore per feedback in tempo reale, garantendo che la traduzione finale sia sia linguisticamente corretta che tecnicamente attendibile.
4. Rottura delle Barriere: Collegamenti LLM al Mondo Reale
-
Il Problema: Una LLM progettata per il controllo delle abitazioni intelligenti potrebbe avere difficoltà ad adattarsi alle routine e ai gusti del utente in cambio.
-
La Soluzione dell’Agente AI: Un agente AI può collegare la LLM ai sensori, ai dispositivi intelligenti e ai calendari utente. Analizzando i pattern di行为 dell’utente, la LLM può imparare a anticipare le necessità, regolare automaticamente le impostazioni di illuminazione e temperatura e persino suggerire playlist musicali personalizzati in base all’ora del giorno e all’attività dell’utente.
5. Dall’imitazione all’innovazione: Espandendo la creatività dell’LLM
-
Il Problema: Un LLM incaricato di comporre musica potrebbe creare pezzi che suonano derivati o mancano di profondità emotiva, dato che si basa principalmente sui modelli presenti nei dati di allenamento.
-
L’ soluzione agente AI: Un agente AI può collegare l’LLM a sensori di biofeedback che misurano le risposte emotive di un compositore a diversi elementi musicali. Incorporando questo feedback in tempo reale, l’LLM può creare musica che sia non solo tecnicamente abile ma anche emotivamente coinvolgente e originale.
L’integrazione di agenti AI come amplificatori di MLS non rappresenta soltanto un incrementale miglioramento ma una estensione fondamentale di ciò che l’intelligenza artificiale può raggiungere. Risolvendo le limitazioni inerenti alle MLS tradizionali, come la base di conoscenza statica, l’autonomia decisionale limitata e l’ambiente operativo isolato, gli agenti AI consentono a questi modelli di operare al loro massimo potenziale.
Con la continua evoluzione della tecnologia AI, il ruolo degli agenti AI nell’amplificare le MLS diventerà sempre più cruciale, non solo nel potenziarle ma anche nel ridefinire i limiti dell’intelligenza artificiale stessa. questa fusione sta pavimentando la via per la prossima generazione di sistemi AI, capaci di ragionamento autonomo, adattamento in tempo reale e risoluzione innovativa di problemi in un mondo in costante mutamento.
Capitolo 6: Progettazione architettonica per l’integrazione di agenti AI con MLS
L’integrazione di agenti AI con MLS dipende dalla progettazione architetturale, che è cruciale per l’enfasi sulle decisioni, sull’adattabilità e sulla scalabilità. L’architettura deve essere accuratamente creata per consentire una interazione fluida tra gli agenti AI e le MLS, garantendo che ogni componente funzioni al meglio.
Una architettura modulare, nella quale l’agente AI agisce come un direttore, dirigendo le capacità della MLS, è un approcio che supporta la gestione dinamica delle attività. Questo design sfrutta i punti di forza della MLS nel processamento del linguaggio naturale mentre permette all’agente AI di gestire attività più complesse, come la ragionamento multi-passo o la decisione contestuale in ambienti in tempo reale.
In alternativa, un modello ibrido, che combina LLM con modelli specializzati e raffinati, offre flessibilità consentendo all’agente AI di delegare compiti al modello più adatto. Questo approcio ottimizza il rendimento e aumenta l’efficienza in un ampio spettro di applicazioni, rendendolo particolarmente efficace in contesti operativi diversi e vari (Liang et al., 2021).

Metodologie e Buone Pratiche di Addestramento
L’addestramento di AI agenti integrati con LLM richiede un approcio metodico che equilibra la generalizzazione con l’ottimizzazione specifica per compiti.
Il transfer learning è una tecnica chiave qui, permettendo a un LLM che è stato pre-addestrato su un corpus grande e diverso di essere raffinato su dati specifici del dominio relativi ai compiti dell’AI agente. Questo metodo mantiene la base di conoscenza ampia dell’LLM consentendogli di specializzarsi in applicazioni particolari, enhancing l’efficacia complessiva del sistema.
Anche il reinforcement learning (RL) svolge un ruolo cruciale, specialmente in scenari dove l’AI agente deve adattarsi a ambienti in mutamento. Attraverso l’interazione con l’ambiente, l’AI agente può continuamente migliorare i suoi processi decisionali, diventando più capace di gestire sfide nuove.
Per garantire un rendimento affidabile in diversi scenari, metriche di valutazione rigorose sono essentiali. Queste dovrebbero includere sia benchmark standard che criteri specifici per compiti, garantendo che l’addestramento del sistema sia robusto e completo (Silver et al., 2016).
Introduzione alle Tecniche di Fine-Tuning di un Grande Modello di Linguaggio (LLM) e ai concetti di Reinforcement Learning
Questo codice dimostra una varietà di tecniche che coinvolgono il machine learning e il processing della lingua naturale (NLP), focalizzandosi sulla fine-tuning di grandi modelli di linguaggio (LLM) per specifiche attività e sulla realizzazione di agenti di apprendimento ricorrente (RL). Il codice riguarda diversi settori chiave:
-
Fine-tuning di un LLM: Utilizzo di modelli pre-addestrati come BERT per attività come l’analisi delle sentimentazioni, usando la libreria Hugging Face
transformers. Questo comporta la tokenizzazione dei dataset e l’uso di argomenti di addestramento per guidare il processo di fine-tuning. -
Apprendimento Ricorrente (RL): Introduzione alle basi dell’apprendimento ricorrente con un semplice agente Q-learning, in cui un agente impara tramite tentativi e errori interagendo con un ambiente e aggiornando il suo know-how tramite Q-table.
-
Modellazione del Reward con l’API di OpenAI: Un metodo concettuale per usare l’API di OpenAI per fornire segnali di reward dinamici a un agente di apprendimento ricorrente, permettendo a un modello di linguaggio di valutare le azioni.
-
Valutazione del Modello e Logging: Utilizzando librerie come
scikit-learnper valutare il rendimento del modello tramite accuratezza e punteggi F1, eSummaryWriterdi PyTorch per visualizzare il progresso dell’addestramento. -
Concetti Avanzati di RL: Implementando concetti più avanzati come reti di gradienti di politica, apprendimento curriculum e interruzione precoce per aumentare l’efficienza dell’addestramento del modello.
Questa approcio olistico comprende sia l’apprendimento supervisionato, con l’addestramento fino al sentimento, che l’apprendimento tramite reazione, fornendo insight su come vengono costruiti, valutati e ottimizzati i sistemi AI moderni.
Esempio di Codice
Step 1: Importare le Librerie Necessarie
Prima di immergersi nel raffinamento del modello e nell’implementazione dell’agente, è essenziale configurare le librerie e i moduli necessari. Questo codice include importazioni da librerie popolari come transformers di Hugging Face e PyTorch per gestire reti neurali, scikit-learn per valutare le prestazioni del modello, e alcuni moduli generici come random e pickle.
-
Librerie Hugging Face: Queste ti consentono di utilizzare e raffinare modelli pre-addestrati e tokenizzatori dal Model Hub.
-
PyTorch: Questo è il framework core per il deep learning utilizzato per le operazioni, inclusi strati di reti neurali e ottimizzatori.
-
scikit-learn: Fornisce metriche come l’accuratezza e l’F1-score per valutare le prestazioni del modello.
-
API di OpenAI: Accesso ai modelli linguistici di OpenAI per varie attività come il reward modeling.
-
TensorBoard: Usato per visualizzare il progresso dell’addestramento.
Questo è il codice per importare le librerie necessarie:
# Importa il modulo random per la generazione di numeri casuali.
import random
# Importa i moduli necessari dalla libreria transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importa load_dataset per caricare i dataset.
from datasets import load_dataset
# Importa le metriche per valutare il rendimento del modello.
from sklearn.metrics import accuracy_score, f1_score
# Importa SummaryWriter per il logging del progresso dell'addestramento.
from torch.utils.tensorboard import SummaryWriter
# Importa pickle per salvare e caricare i modelli addestrati.
import pickle
# Importa openai per utilizzare l'API di OpenAI (richiede una chiave API).
import openai
# Importa PyTorch per le operazioni di apprendimento profondo.
import torch
# Importa il modulo di rete neurale da PyTorch.
import torch.nn as nn
# Importa il modulo dell'ottimizzatore da PyTorch (non utilizzato direttamente in questo esempio).
import torch.optim as optim
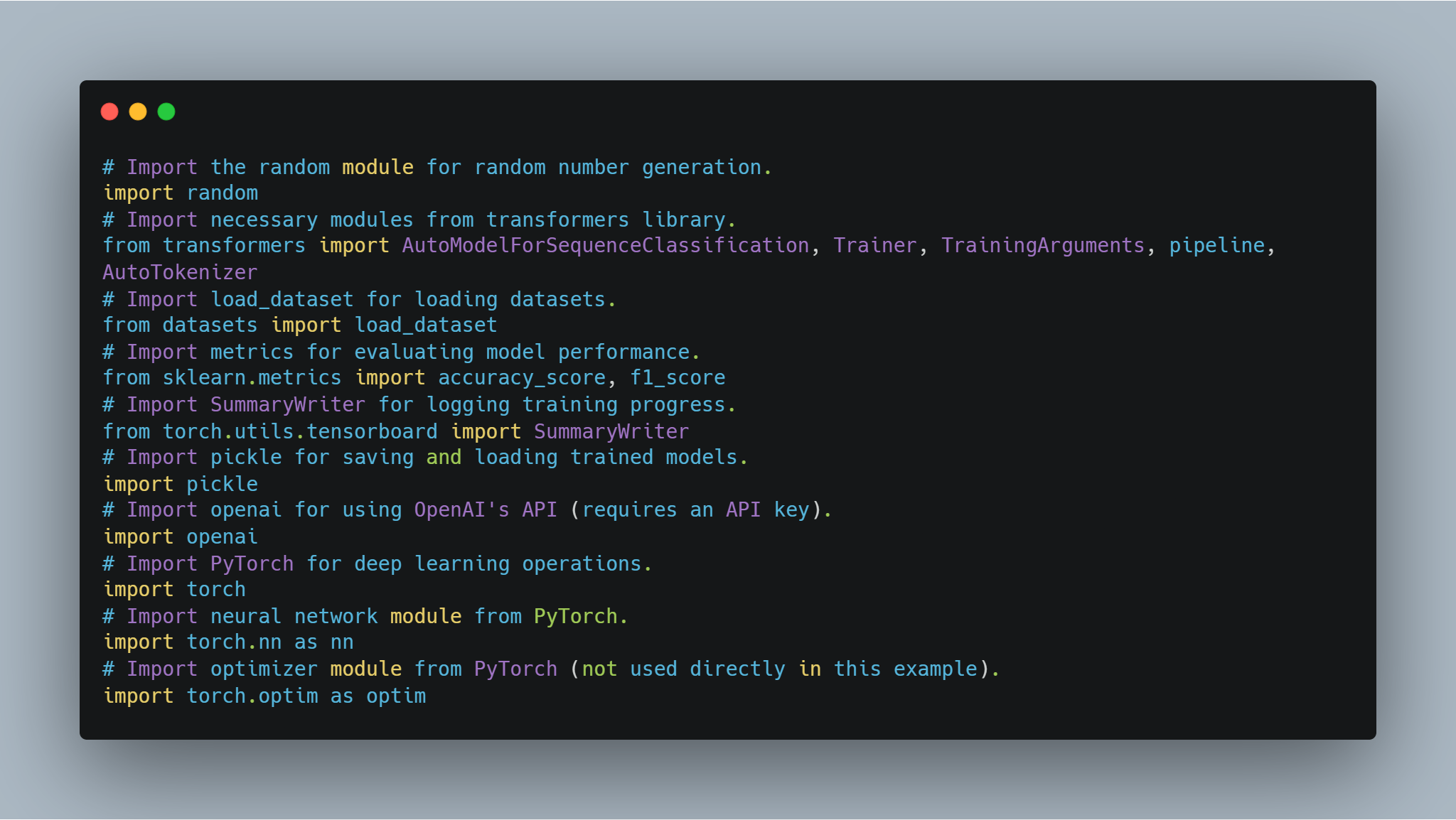
Ognuno di questi import play a crucial role in different parts of the code, from model training and evaluation to logging results and interacting with external APIs.
Step 2: Fine-tuning a Language Model for Sentiment Analysis
Fine-tuning a pre-trained model for a specific task such as sentiment analysis involves loading a pre-trained model, adjusting it for the number of output labels (positive/negative in this case), and using a suitable dataset.
In questo esempio, usiamo l’AutoModelForSequenceClassification dalla libreria transformers, con il dataset IMDB. Questo modello pre-addestrato può essere ulteriormente addestrato su una porzione più piccola del dataset per risparmiare tempo di computazione. Il modello viene poi addestrato utilizzando un insieme personalizzato di argomenti di addestramento, che include il numero di epoch e la dimensione del batch.
Di seguito il codice per caricare e ottimizzare il modello:
# Specificare il nome del modello pre-addestrato dalla Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Caricare il modello pre-addestrato con il numero specificato di classi di output.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Caricare un tokenizer per il modello.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Caricare il dataset IMDB da Hugging Face Datasets, utilizzando solo il 10% per l'addestramento.
dataset = load_dataset("imdb", split="train[:10%]")
#Tokenizzare il dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Mappare il dataset agli input tokenizzati
tokenized_dataset = dataset.map(tokenize_function, batched=True)
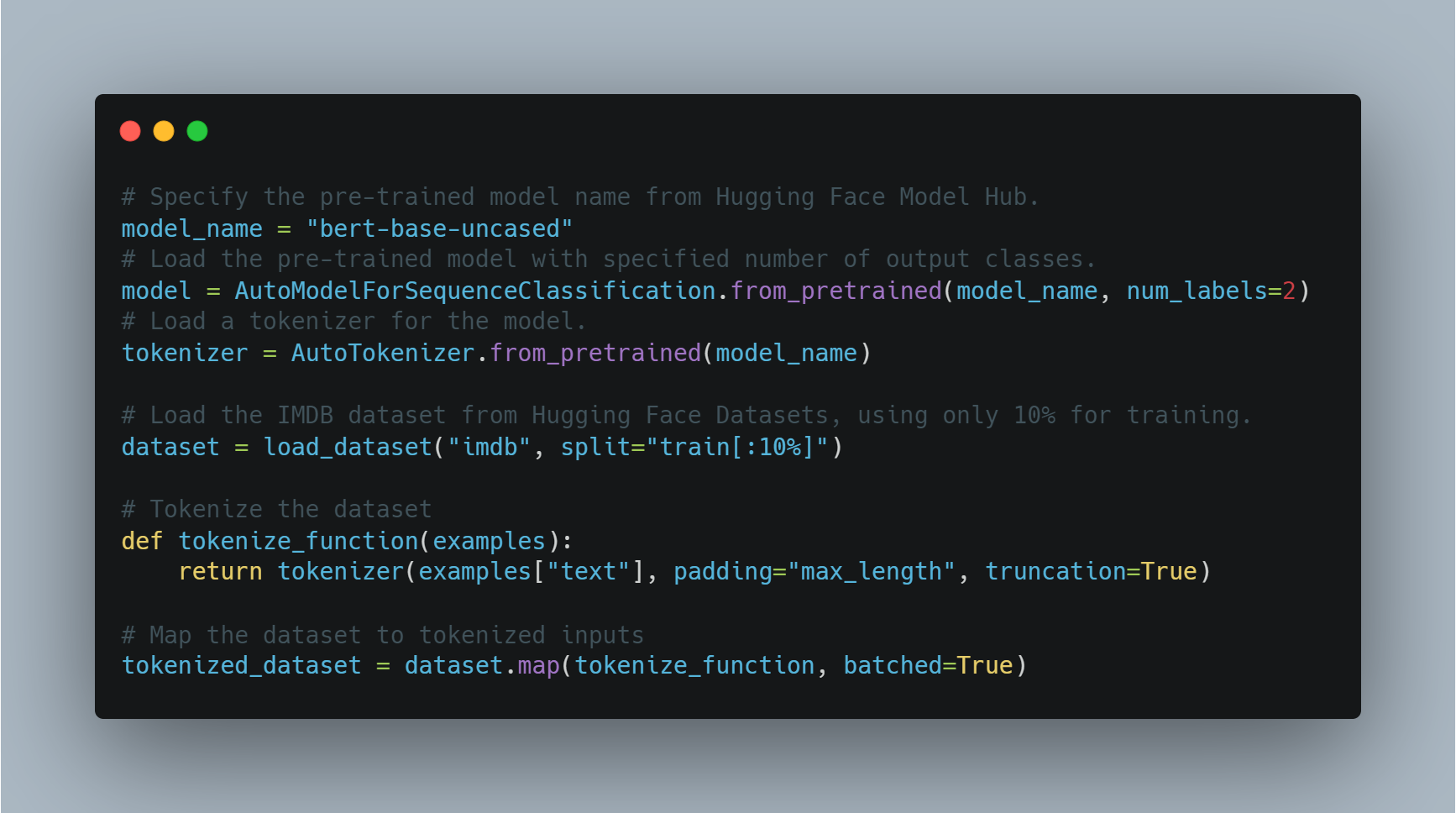
In questo caso, il modello è caricato utilizzando una architettura basata su BERT e il dataset è preparato per l’addestramento. Successivamente, definiamo gli argomenti di addestramento e inizializziamo il Trainer.
#Definiamo gli argomenti di addestramento.
training_args = TrainingArguments(
output_dir="./results", #Specificare la directory di output per salvare il modello.
num_train_epochs=3, #Impostare il numero di epoche di addestramento.
per_device_train_batch_size=8, #Impostare la dimensione del batch per dispositivo.
logging_dir='./logs', #Directory per la memorizzazione dei log.
logging_steps=10 #Log ogni 10 passi.
)
#Inizializzare l'addestratore con il modello, gli argomenti di addestramento e il dataset.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
#Iniziare il processo di addestramento.
trainer.train()
#Salvare il modello finemente ottimizzato.
model.save_pretrained("./fine_tuned_sentiment_model")

Step 3: Implementazione di un Semplice Agente Q-Learning
Il Q-Learning è una tecnica di apprendimento automatico basata sulla ricompensa in cui un agente impara a prendere azioni in modo da massimizzare la ricompensa cumulativa.
In questo esempio, definiamo un semplice agente Q-Learning che memorizza coppie di stato-azione in una Q-table. L’agente può esplorare in maniera casuale o sfruttare l’azione migliore conosciuta in base alla Q-table. La Q-table viene aggiornata dopo ogni azione usando una tasa di apprendimento e un fattore di sconto per pesare le ricompense future.
Ecco il codice che implementa questo agente Q-Learning:
# Definiamo la classe dell'agente Q-learning.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Inizializziamo la Q-table.
self.q_table = {}
# Memoriamo le azioni possibili.
self.actions = actions
# Impostiamo la probabilità di esplorazione.
self.epsilon = epsilon
# Impostiamo l'alta percentuale di apprendimento.
self.alpha = alpha
# Impostiamo il fattore di sconto.
self.gamma = gamma
# Definiamo il metodo get_action per scegliere un'azione in base allo stato corrente.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# Esplorare casualmente.
return random.choice(self.actions)
else:
# Esploitarne la migliore.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
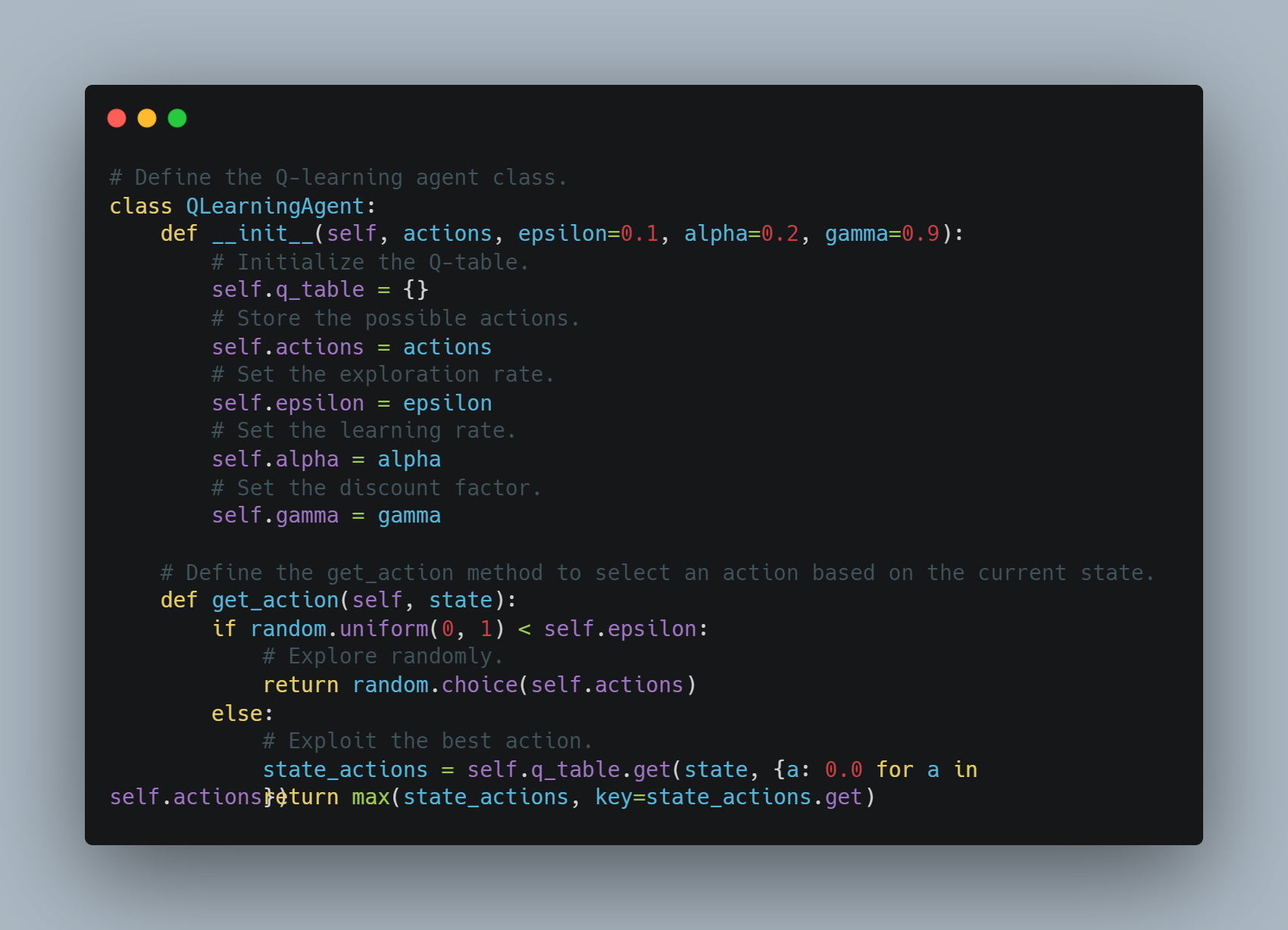
L’agente sceglie le azioni in base all’esplorazione o all’esploitation e aggiorna i valori Q dopo ogni passo.
# Definiamo il metodo update_q_table per aggiornare la Q-table.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
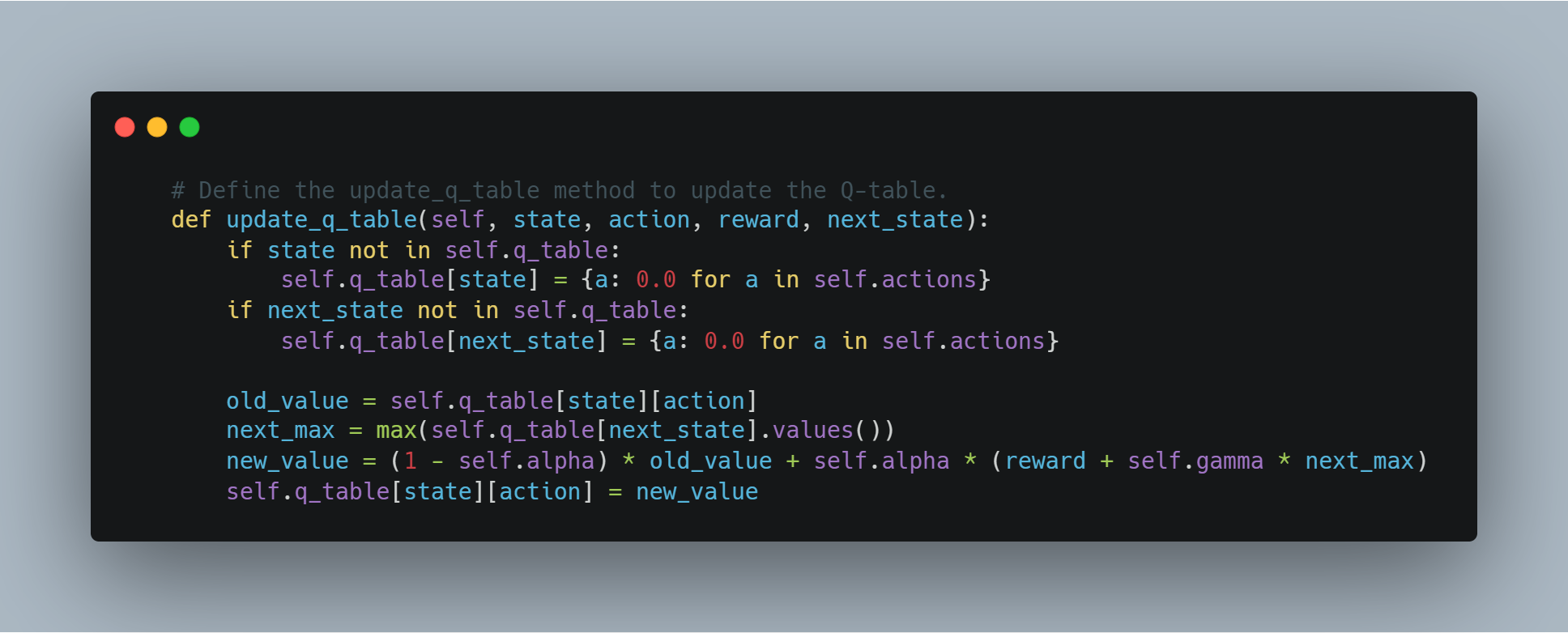
Step 4: Utilizzare l’API di OpenAI per il Modello di Reward
In alcune situazioni, invece di definire una funzione di reward manuale, possiamo utilizzare un potente modello di linguaggio come GPT di OpenAI per valutare la qualità delle azioni intraprese dall’agente.
In questo esempio, la funzione get_reward invia uno stato, un’azione e lo stato successivo a OpenAI API per ricevere un punteggio di reward, permettendoci di sfruttare grandi modelli di linguaggio per comprendere strutture di reward complesse.
# Definiamo la funzione get_reward per ottenere un segnale di reward da OpenAI API.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # Sostituisci con la tua chiave API OpenAI reale.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
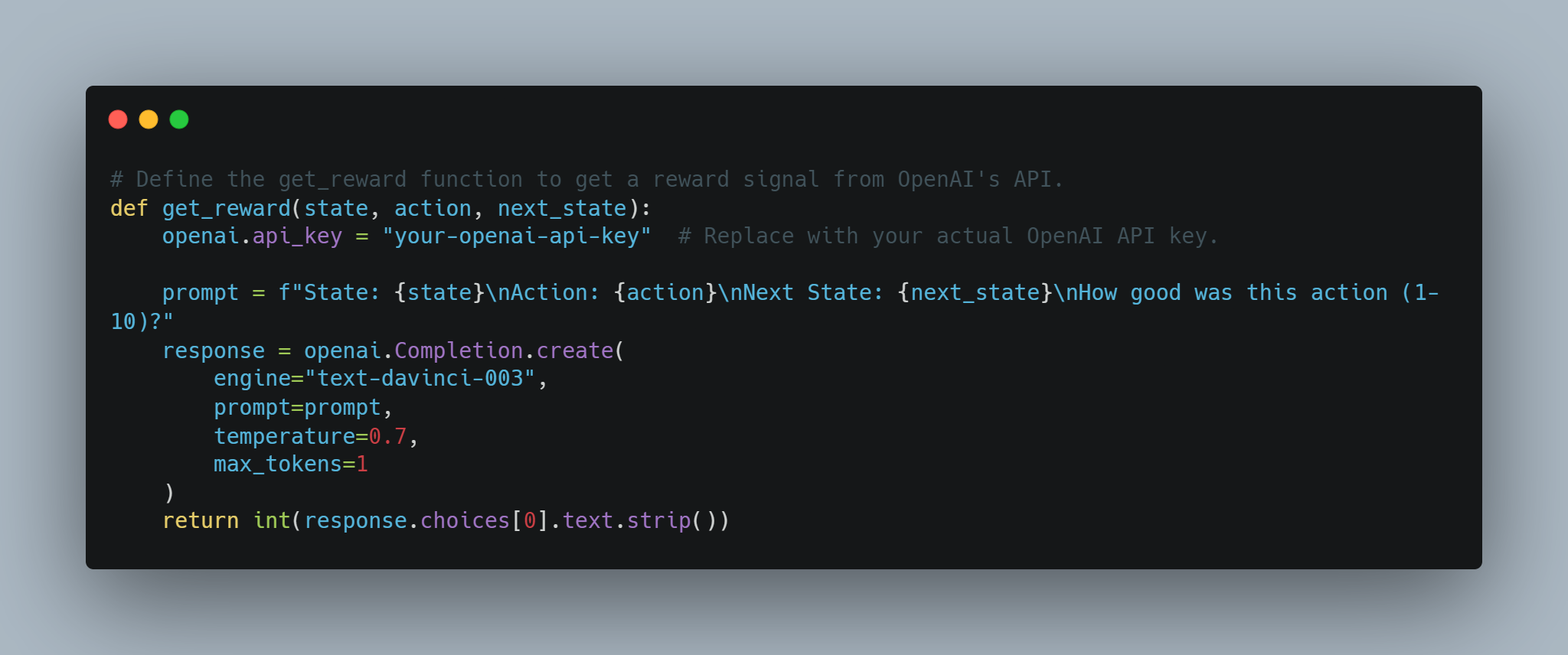
Questo consente un approcio concettuale in cui il sistema di ricompense è determinato in maniera dinamica tramite l’API di OpenAI, che potrebbe essere utile per compiti complessi in cui le ricompense sono difficili da definire.
Step 5: Valutazione del Rendimento del Modello
Una volta che un modello di apprendimento automatico è stato addestrato, è essenziale valutare il suo rendimento utilizzando metriche standard come accuratezza e punteggio F1.
Questa sezione calcola entrambe usando le etichette verificate e predette. L’accuratezza fornisce una misura complessiva della correttezza, mentre il punteggio F1 equilibra la precisione e la recall, specialmente utile in dataset imballati.
Ecco il codice per valutare il rendimento del modello:
# Definisci le etichette vere per la valutazione.
true_labels = [0, 1, 1, 0, 1]
# Definisci le etichette predette per la valutazione.
predicted_labels = [0, 0, 1, 0, 1]
# Calcola il punteggio di accuratezza.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calcola il punteggio F1.
f1 = f1_score(true_labels, predicted_labels)
# Stampa il punteggio di accuratezza.
print(f"Accuracy: {accuracy:.2f}")
# Stampa il punteggio F1.
print(f"F1-Score: {f1:.2f}")
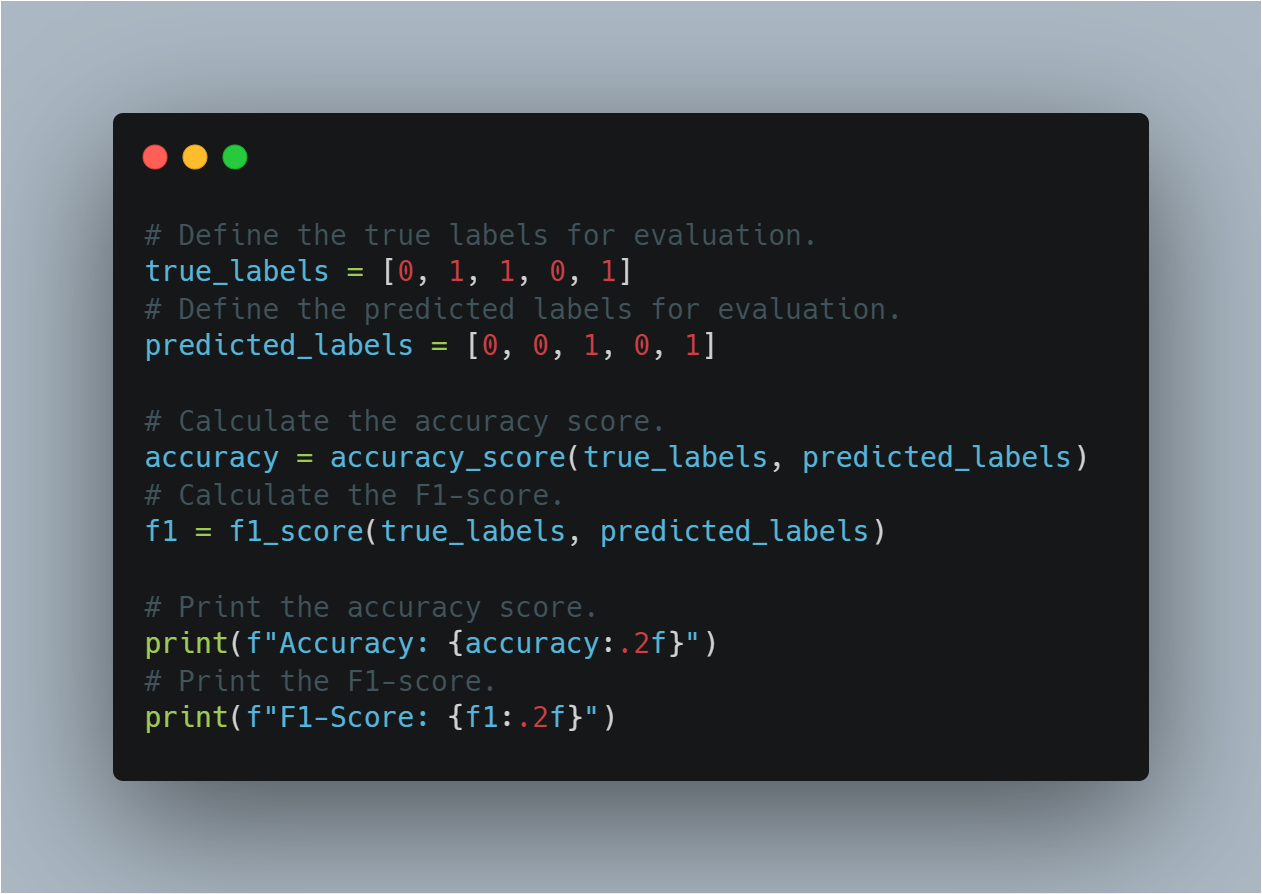
Questa sezione aiuta a valutare quanto bene il modello si sia adattato ai dati non visti utilizzando metriche di valutazione ben stabilite.
Step 6: Agente di Gradiente di Politica Base (Utilizzando PyTorch)
I metodi di gradiente di politica in apprendimento automatico reinforcement lo ottimizzano direttamente optimizzando la politica mediante la massimizzazione dell’expected reward.
Questa sezione dimostra una semplice implementazione di una rete di politiche utilizzando PyTorch, che può essere utilizzata per la decisioni in RL. La rete di politiche utilizza una scansione lineare per emettere probabilità per differenti azioni, e viene applicato il softmax per assicurarsi che questi output formino una distribuzione di probabilità valida.
Ecco il codice concettuale per definire un agente di politica gradiente di base:
# Definire la classe della rete di politiche.
class PolicyNetwork(nn.Module):
# Inizializzare la rete di politiche.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# Definire una scansione lineare.
self.linear = nn.Linear(input_size, output_size)
# Definire il passo in avanti della rete.
def forward(self, x):
# Applicare il softmax all'output della scansione lineare.
return torch.softmax(self.linear(x), dim=1)
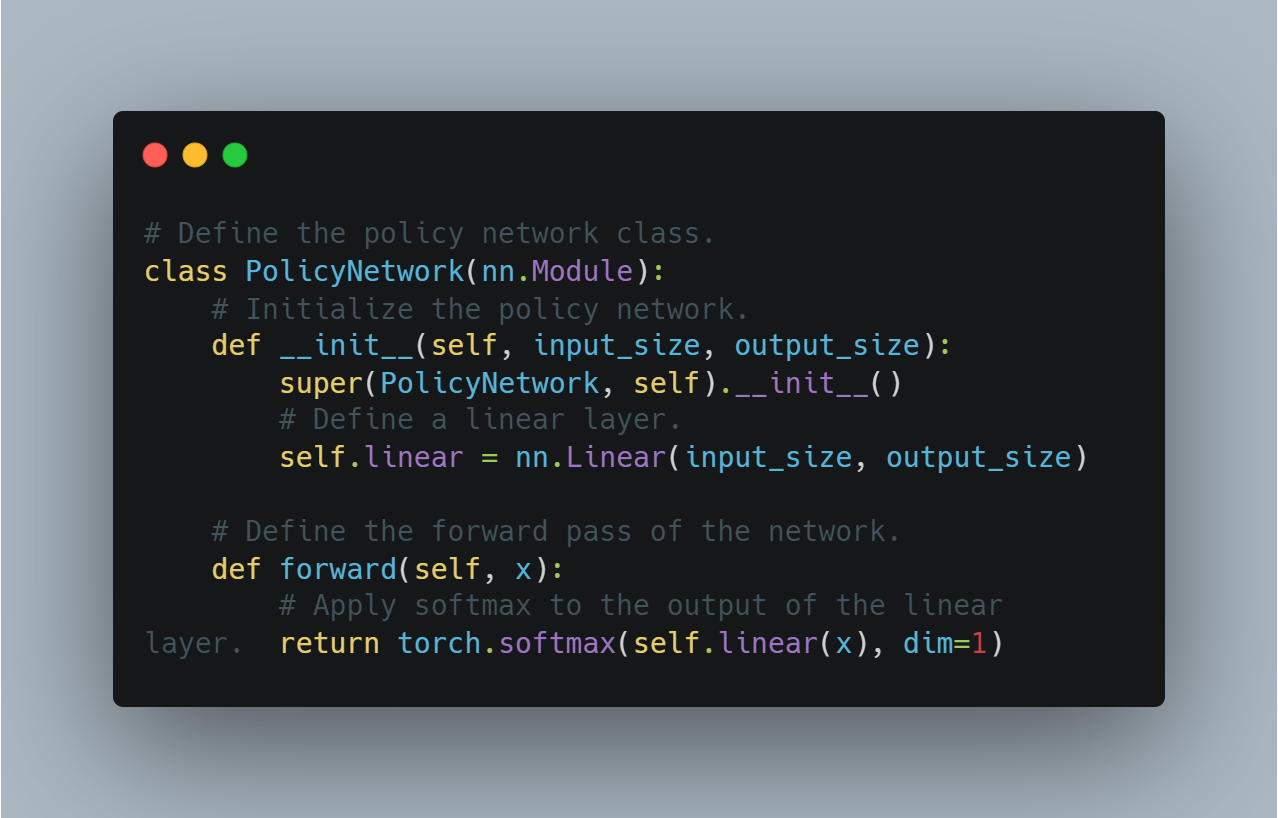
Questo costituisce un passo base per l’implementazione di algoritmi di apprendimento ricorrente avanzati che utilizzano l’ottimizzazione della politica.
Step 7: Visualizzare il Progresso di Addestramento con TensorBoard
La visualizzazione delle metriche di addestramento, come la perdita e l’accuratezza, è cruciale per capire come evolve il rendimento del modello nel tempo. TensorBoard, uno strumento popolare per questo scopo, può essere utilizzato per registrare le metriche e visualizzarle in tempo reale.
In questa sezione, creiamo un’istanza di SummaryWriter e registriamo valori casuali per simulare il processo di tracciamento della perdita e dell’accuratezza durante l’addestramento.
Ecco come registrare e visualizzare il progresso di addestramento utilizzando TensorBoard:
# Crea un'istanza di SummaryWriter.
writer = SummaryWriter()
# Esempio di loop di allenamento per la visualizzazione con TensorBoard:
num_epochs = 10 # Definisci il numero di epoche.
for epoch in range(num_epochs):
# Simula valori casuali di perdita e accuratezza.
loss = random.random()
accuracy = random.random()
# Registra la perdita e l'accuratezza su TensorBoard.
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# Chiudi l'istanza di SummaryWriter.
writer.close()
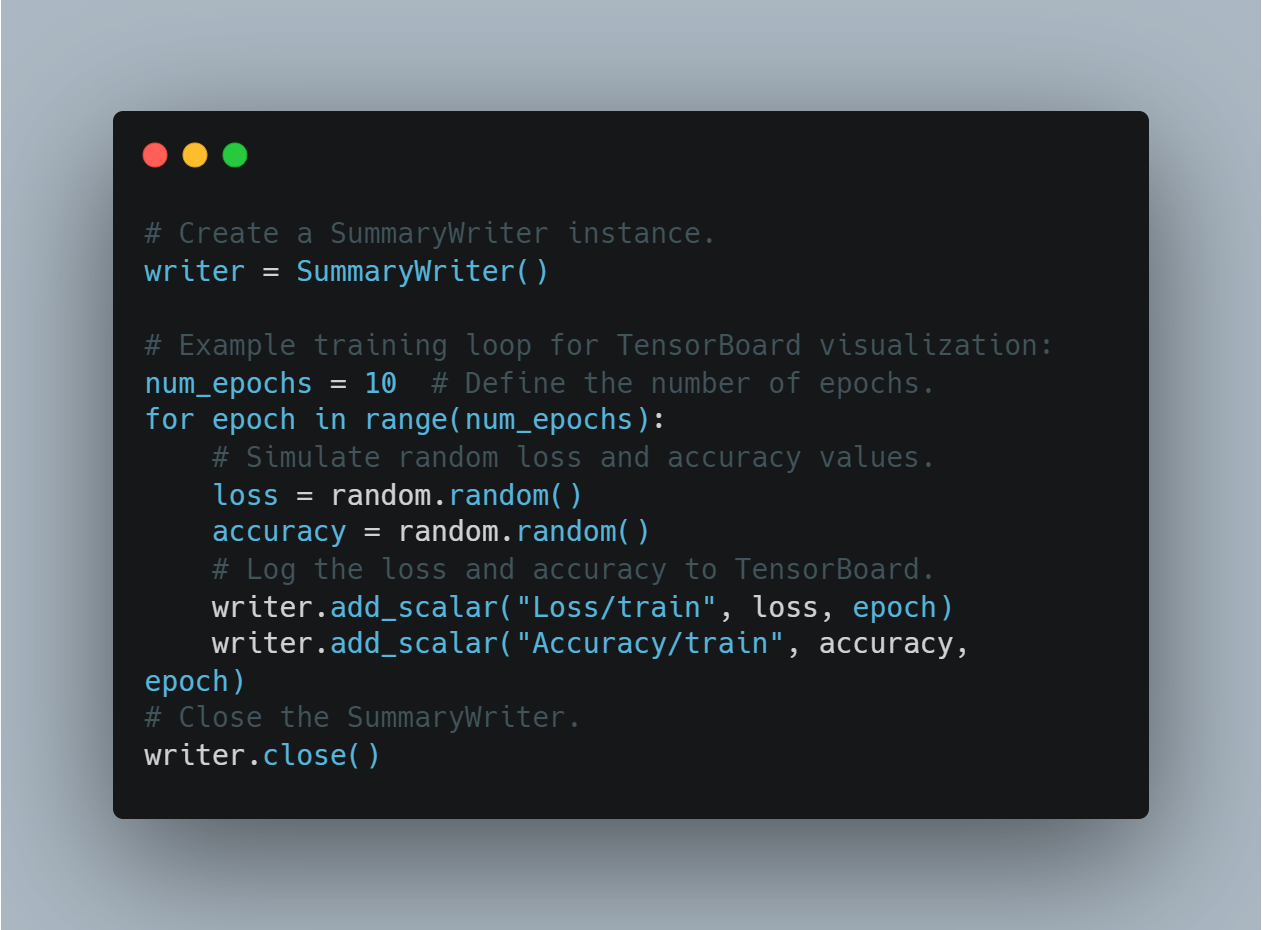
Questo consente agli utenti di monitorare l’allenamento del modello e fare regolazioni in tempo reale basate sul feedback visuale.
Passo 8: Salvataggio e Caricamento dei Checkpoint dell’Agente Allenato
Dopo aver allenato un agente, è cruciale salvare il suo stato appreso (per esempio, i valori Q o i pesi del modello) in modo da poterlo riutilizzare o valutare in seguito.
Questa sezione mostra come salvare un agente allenato usando il modulo pickle di Python e come ricaricarlo dal disco.
Ecco il codice per salvare e caricare un agente Q-learning allenato:
# Crea un'istanza dell'agente Q-learning.
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# Allenamento dell'agente (non mostrato qui).
# Salvataggio dell'agente.
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# Caricamento dell'agente.
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
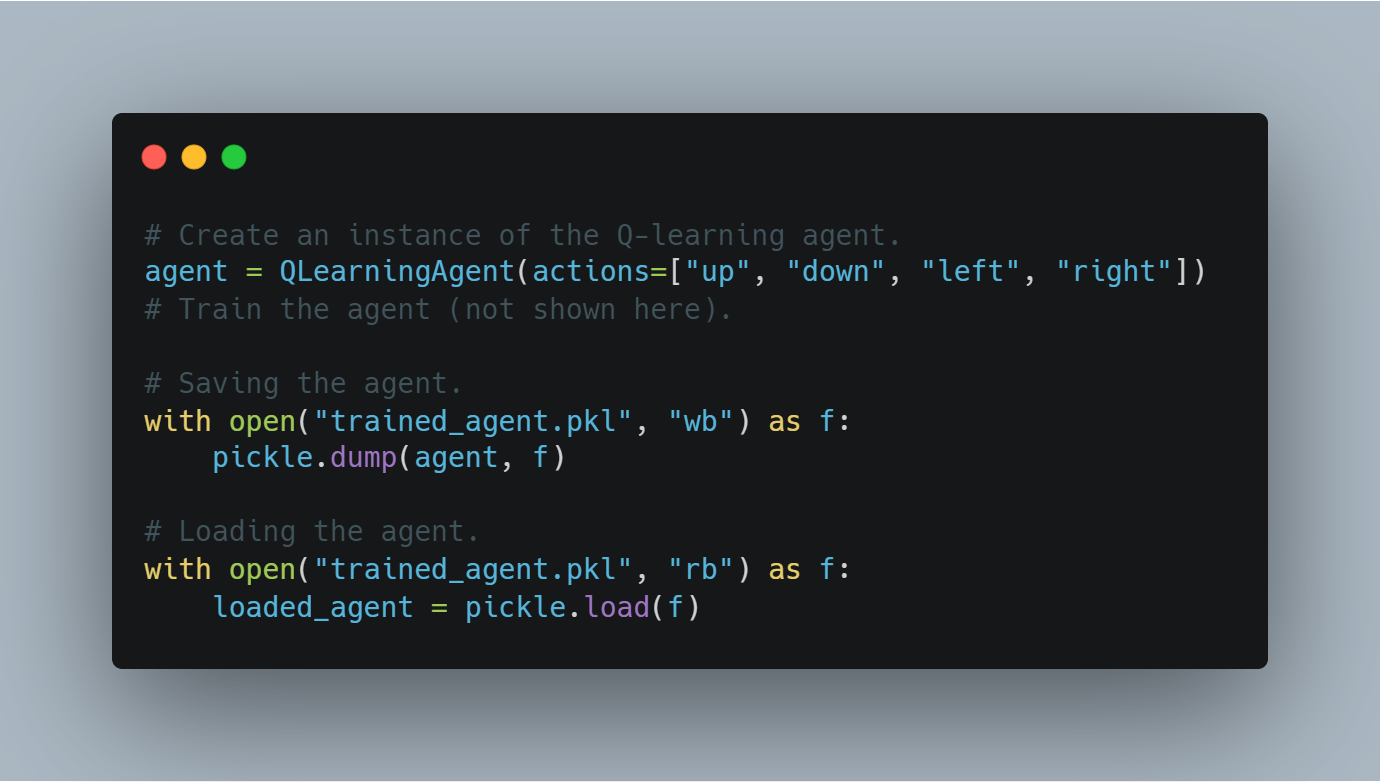
Questo processo di checkpointing assicura che i progressi dell’allenamento non vengano persi e che i modelli possano essere riutilizzati in esperimenti futuri.
Passo 9: Apprendimento Sequenziale (Curriculum Learning)
L’apprendimento curriculum comprende l’aumento graduale della complessità delle attività presentate al modello, iniziando con esempi più semplici e dirigendosi verso quelli più complessi. Questo può aiutare a migliorare le prestazioni e la stabilità del modello durante l’addestramento.
Ecco un esempio di utilizzo dell’apprendimento curriculum in un ciclo di addestramento:
# Impostare la difficoltà iniziale dell'attività.
initial_task_difficulty = 0.1
# Esempio di ciclo di addestramento con apprendimento curriculum:
for epoch in range(num_epochs):
# Aumentare progressivamente la difficoltà dell'attività.
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# Generare dati di addestramento con difficoltà regolata.
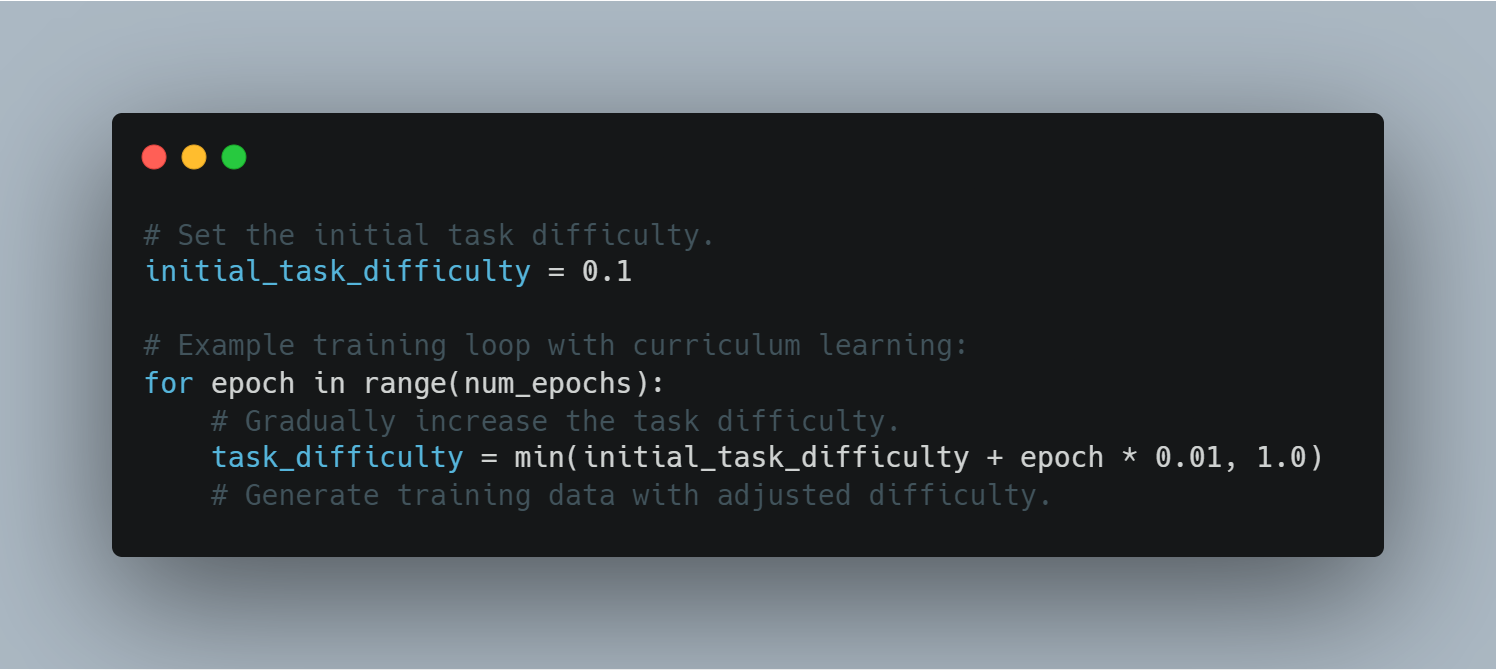
Controllando la difficoltà dell’attività, l’agente può progressivamente gestire sfide più complesse, portando a un’efficienza migliore nell’apprendimento.
Step 10: Implementazione dell’Early Stopping
L’early stopping è una tecnica per prevenire l’overfitting durante l’addestramento, interrompendosi se la perdita di validazione non migliora dopo un certo numero di epoche (pazienza).
Questo capitolo mostra come implementare l’early stopping in un ciclo di addestramento, utilizzando la perdita di validazione come indicatori chiave.
Ecco il codice per implementare l’early stopping:
# Inizializza la perdita di validazione migliore a infinito.
best_validation_loss = float("inf")
# Imposta il valore di pazienza (numero di epoch senza miglioramento).
patience = 5
# Inizializza il contatore per gli epoch senza miglioramento.
epochs_without_improvement = 0
# Esempio di loop di training con early stopping:
for epoch in range(num_epochs):
# Simula la perdita di validazione casuale.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

Il early stopping migliora la generalizzazione del modello impedendo l’addestramento non necessario una volta che il modello comincia a sovrapporre.
Step 11: Utilizzare un LLM pre-addestrato per il trasferimento di compito a zero-shot
Nel trasferimento di compito a zero-shot, un modello pre-addestrato viene applicato a un compito per il quale non è stato specificamente fine-tunato.
Utilizzando la pipeline di Hugging Face, questo capitolo dimostra come applicare un modello BART pre-addestrato per la sintesi senza addestramento aggiuntivo, illustrando il concetto di apprendimento di trasferimento.
Ecco il codice per l’utilizzo di un LLM pre-addestrato per la sintesi:
# Carica una pipeline di sintesi pre-addestrata.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Definito il testo da sintetizzare.
text = "This is an example text about AI agents and LLMs."
# Genera la sintesi.
summary = summarizer(text)[0]["summary_text"]
# Stampa la sintesi.
print(f"Summary: {summary}")
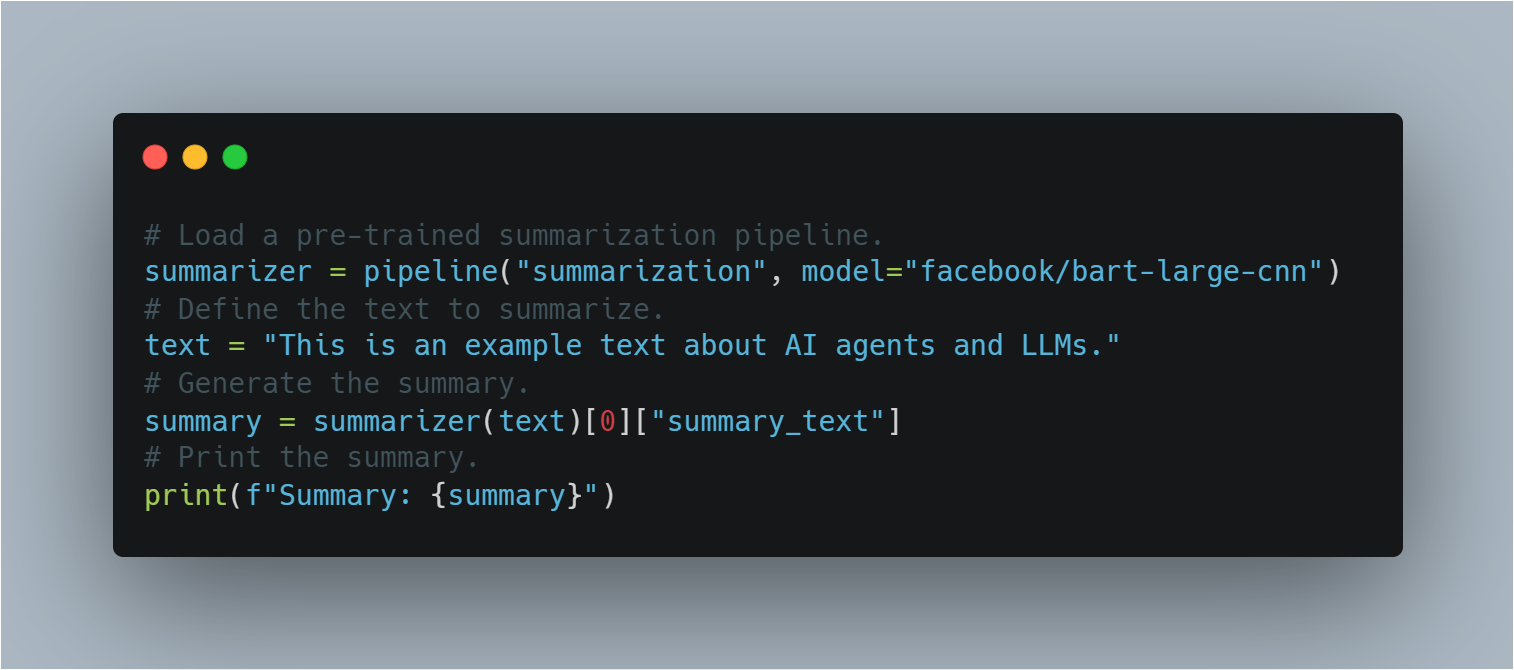
Questo illustra la flessibilità degli LLM nell’eseguire compiti diversi senza la necessità di ulteriori addestramenti, sfruttando il loro conoscenza preesistente.
L’esempio di codice completo.
# Importa il modulo random per la generazione di numeri casuali.
import random
# Importa i moduli necessari dalla libreria transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importa load_dataset per caricare i dataset.
from datasets import load_dataset
# Importa metrics per valutare le prestazioni del modello.
from sklearn.metrics import accuracy_score, f1_score
# Importa SummaryWriter per registrare i progressi dell'addestramento.
from torch.utils.tensorboard import SummaryWriter
# Importa pickle per salvare e caricare modelli addestrati.
import pickle
# Importa openai per utilizzare l'API di OpenAI (richiede una chiave API).
import openai
# Importa PyTorch per operazioni di deep learning.
import torch
# Importa il modulo di reti neurali da PyTorch.
import torch.nn as nn
# Importa il modulo optimizer da PyTorch (non utilizzato direttamente in questo esempio).
import torch.optim as optim
# --------------------------------------------------
# 1. Fine-tuning di un LLM per l'Analisi Sentimentale
# --------------------------------------------------
# Specifica il nome del modello pre-addestrato da Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Carica il modello pre-addestrato con il numero specificato di classi di output.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Carica un tokenizer per il modello.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Carica il dataset IMDB da Hugging Face Datasets, utilizzando solo il 10% per l'addestramento.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokenizza il dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Mappa il dataset sugli input tokenizzati
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Definisci gli argomenti di addestramento.
training_args = TrainingArguments(
output_dir="./results", # Specifica la directory di output per salvare il modello.
num_train_epochs=3, # Imposta il numero di epoche di addestramento.
per_device_train_batch_size=8, # Imposta la dimensione del batch per dispositivo.
logging_dir='./logs', # Directory per memorizzare i log.
logging_steps=10 # Registra ogni 10 passi.
)
# Inizializza il Trainer con il modello, gli argomenti di addestramento e il dataset.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Avvia il processo di addestramento.
trainer.train()
# Salva il modello fine-tuned.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. Implementazione di un Agente Q-Learning Semplice
# --------------------------------------------------
# Definisci la classe dell'agente Q-learning.
class QLearningAgent:
# Inizializza l'agente con azioni, epsilon (tasso di esplorazione), alpha (tasso di apprendimento) e gamma (fattore di sconto).
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Inizializza la Q-table.
self.q_table = {}
# Memorizza le azioni possibili.
self.actions = actions
# Imposta il tasso di esplorazione.
self.epsilon = epsilon
# Imposta il tasso di apprendimento.
self.alpha = alpha
# Imposta il fattore di sconto.
self.gamma = gamma
# Definisci il metodo get_action per selezionare un'azione basata sullo stato attuale.
def get_action(self, state):
# Esplora casualmente con probabilità epsilon.
if random.uniform(0, 1) < self.epsilon:
# Restituisci un'azione casuale.
return random.choice(self.actions)
else:
# Sfrutta la migliore azione basata sulla Q-table.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# Definisci il metodo update_q_table per aggiornare la Q-table dopo aver preso un'azione.
def update_q_table(self, state, action, reward, next_state):
# Se lo stato non è nella Q-table, aggiungilo.
if state not in self.q_table:
# Inizializza i Q-valori per il nuovo stato.
self.q_table[state] = {a: 0.0 for a in self.actions}
# Se il prossimo stato non è nella Q-table, aggiungilo.
if next_state not in self.q_table:
# Inizializza i Q-valori per il nuovo stato successivo.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# Ottieni il vecchio Q-valore per la coppia stato-azione.
old_value = self.q_table[state][action]
# Ottieni il massimo Q-valore per il prossimo stato.
next_max = max(self.q_table[next_state].values())
# Calcola il Q-valore aggiornato.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# Aggiorna la Q-table con il nuovo Q-valore.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. Utilizzo dell'API di OpenAI per il Reward Modeling (Concettuale)
# --------------------------------------------------
# Definisci la funzione get_reward per ottenere un segnale di ricompensa dall'API di OpenAI.
def get_reward(state, action, next_state):
# Assicurati che la chiave API di OpenAI sia impostata correttamente.
openai.api_key = "your-openai-api-key" # Sostituisci con la tua chiave API di OpenAI effettiva.
# Costruisci il prompt per la chiamata API.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# Effettua la chiamata API all'endpoint Completion di OpenAI.
response = openai.Completion.create(
engine="text-davinci-003", # Specifica il motore da utilizzare.
prompt=prompt, # Passa il prompt costruito.
temperature=0.7, # Imposta il parametro di temperatura.
max_tokens=1 # Imposta il numero massimo di token da generare.
)
# Estrarre e restituire il valore di ricompensa dalla risposta API.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. Valutazione delle Prestazioni del Modello
# --------------------------------------------------
# Definisci le etichette vere per la valutazione.
true_labels = [0, 1, 1, 0, 1]
# Definisci le etichette previste per la valutazione.
predicted_labels = [0, 0, 1, 0, 1]
# Calcola il punteggio di accuratezza.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calcola il punteggio F1.
f1 = f1_score(true_labels, predicted_labels)
# Stampa il punteggio di accuratezza.
print(f"Accuracy: {accuracy:.2f}")
# Stampa il punteggio F1.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. Agente di Gradiente di Politica di Base (usando PyTorch) - Concettuale
# --------------------------------------------------
# Definisci la classe della rete di policy.
class PolicyNetwork(nn.Module):
# Inizializza la rete di policy.
def __init__(self, input_size, output_size):
# Inizializza la classe padre.
super(PolicyNetwork, self).__init__()
# Definisci un layer lineare.
self.linear = nn.Linear(input_size, output_size)
# Definisci il passaggio forward della rete.
def forward(self, x):
# Applica softmax all'output del layer lineare.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. Visualizzare i Progressi dell'Addestramento con TensorBoard
# --------------------------------------------------
# Crea un'istanza di SummaryWriter.
writer = SummaryWriter()
# Esempio di ciclo di addestramento per la visualizzazione con TensorBoard:
# num_epochs = 10 # Definisci il numero di epoche.
# for epoch in range(num_epochs):
# # ... (Il tuo ciclo di addestramento qui)
# loss = random.random() # Esempio: Valore di perdita casuale.
# accuracy = random.random() # Esempio: Valore di accuratezza casuale.
# # Registra la perdita su TensorBoard.
# writer.add_scalar("Loss/train", loss, epoch)
# # Registra l'accuratezza su TensorBoard.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (Registra altre metriche)
# # Chiudi il SummaryWriter.
# writer.close()
# --------------------------------------------------
# 7. Salvare e Caricare Checkpoint di Agenti Addestrati
# --------------------------------------------------
# Esempio:
# Crea un'istanza dell'agente Q-learning.
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (Addestra il tuo agente)
# # Salvare l'agente
# # Apri un file in modalità scrittura binaria.
# with open("trained_agent.pkl", "wb") as f:
# # Salva l'agente nel file.
# pickle.dump(agent, f)
# # Caricare l'agente
# # Apri il file in modalità lettura binaria.
# with open("trained_agent.pkl", "rb") as f:
# # Carica l'agente dal file.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. Curriculum Learning
# --------------------------------------------------
# Imposta la difficoltà iniziale del compito.
initial_task_difficulty = 0.1
# Esempio di ciclo di addestramento con curriculum learning:
# for epoch in range(num_epochs):
# # Aumenta gradualmente la difficoltà del compito.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (Genera dati di addestramento con difficoltà regolata)
# --------------------------------------------------
# 9. Implementazione dell'Early Stopping
# --------------------------------------------------
# Inizializza la migliore perdita di validazione a infinito.
best_validation_loss = float("inf")
# Imposta il valore di pazienza (numero di epoche senza miglioramenti).
patience = 5
# Inizializza il contatore per le epoche senza miglioramenti.
epochs_without_improvement = 0
# Esempio di ciclo di addestramento con early stopping:
# for epoch in range(num_epochs):
# # ... (Passi di addestramento e validazione)
# # Calcola la perdita di validazione.
# validation_loss = random.random() # Esempio: Perdita di validazione casuale.
# # Se la perdita di validazione migliora.
# if validation_loss < best_validation_loss:
# # Aggiorna la migliore perdita di validazione.
# best_validation_loss = validation_loss
# # Resetta il contatore.
# epochs_without_improvement = 0
# else:
# # Incrementa il contatore.
# epochs_without_improvement += 1
# # Se nessun miglioramento per 'patience' epoche.
# if epochs_without_improvement >= patience:
# # Stampa un messaggio.
# print("Early stopping triggered!")
# # Ferma l'addestramento.
# break
# --------------------------------------------------
# 10. Utilizzo di un LLM Pre-addestrato per il Trasferimento di Compiti Zero-Shot
# --------------------------------------------------
# Carica un pipeline di sintesi pre-addestrato.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Definisci il testo da sintetizzare.
text = "This is an example text about AI agents and LLMs."
# Genera il riassunto.
summary = summarizer(text)[0]["summary_text"]
# Stampa il riassunto.
print(f"Summary: {summary}")

Sfide nell’Implementazione e nella Scaling
L’implementazione e la scalabilità di agenti AI integrati con LM (Long-tail Models) presentano sfide tecniche e operative significative. Uno dei principali problemi è il costo computazionale, specialmente con la crescita delle dimensioni e della complessità delle LM.
Per affrontare questo problema si richiedono strategie efficienti in termini di risorse quali la pulizia del modello, la quantizzazione e il calcolo distribuito. Queste possono aiutare a diminuire il carico computazionale senza sacrificare le prestazioni.
La mantenibilità della affidabilità e della robustezza negli applicativi reali è anche fondamentale, richiedendo monitoraggi continui, aggiornamenti regolari e la creazione di meccanismi di sicurezza per gestire input imprevisti o fallimenti del sistema.
Quando questi sistemi vengono implementati in diversi settori, l’adesione agli standard etici – inclusa la fairness, la trasparenza e l’accountability – diventa sempre più importante. questi considerazioni sono centrali alla accettazione del sistema e al suo successo a lungo termine, influenzando la fiducia pubblica e le implicazioni etiche delle decisioni guidate dall’IA in diversi contesti societali (Bender et al., 2021).
L’implementazione tecnica di agenti AI integrate con LM richiede una progettazione architetturale attenta, metodologie di addestramento rigorose e un’attenta considerazione delle sfide nell’implementazione.
L’efficacia e la affidabilità di questi sistemi nell’ambiente reale dipendono dall’indirizzo sia delle sfide tecniche che degli aspetti etici, garantendo che le tecnologie AI funzionino fluentemente e responsabilmente in diversi applicativi.
Capitolo 7: Il Futuro degli Agenti AI e delle LM
Convergenza delle LM con l’apprendimento tramite ricompense.
Nel futuro dell’intelligenza artificiale e dei grandi modelli di linguaggio (LLM), la convergenza tra LLM e l’apprendimento tramite la reinattivazione emerge come un particolarmente rivoluzionario sviluppo. Questa integrazione spinge i confini dell’intelligenza artificiale tradizionale, permettendo ai sistemi non solo di generare e comprendere il linguaggio, ma anche di imparare in tempo reale dalle loro interazioni.
Attraverso l’apprendimento tramite la reinattivazione, gli agenti artificiali possono adattare in modo dinamico le loro strategie in base alle risposte ricevute dall’ambiente, portando a una continua raffinazione del loro processo decisionale. Questo significa che, contrariamente ai modelli statici, i sistemi dotati di apprendimento tramite la reinattivazione possono affrontare compiti sempre più complessi e dinamici con minimali controlli umani.
Le implicazioni per questi sistemi sono profonde: nelle applicazioni che vanno dalle robotica autonoma alle didattiche personalizzate, gli agenti artificiali potrebbero autonomamente migliorare le loro performance nel tempo, rendendoli più efficienti e reattivi alle richieste in evoluzione del loro contesto operativo.
Esempio: Il gioco di ruolo da testo
Immaginate un agente artificiale che gioca a un gioco di avventura da testo.
-
Ambiente: Il gioco stesso (regole, descrizioni di stato e così via)
-
LLM: Processa il testo del gioco, comprende la situazione attuale e genera azioni possibili (ad esempio, “va a nord”, “prende la spada”).
-
Ricompensa: Consegnata dal gioco in base al risultato dell’azione (ad esempio, una ricompensa positiva per la scoperta del tesoro, una negativa per la perdita di salute).
Esempio di codice (concepito utilizzando Python e l’API di OpenAI):
import openai
import random
# ... (Logica dell'ambiente del gioco - non mostrata qui) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (Ciclo di addestramento RL - semplificato) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (Aggiorna l'agente RL in base alla ricompensa - non mostrato) ...
state = next_state
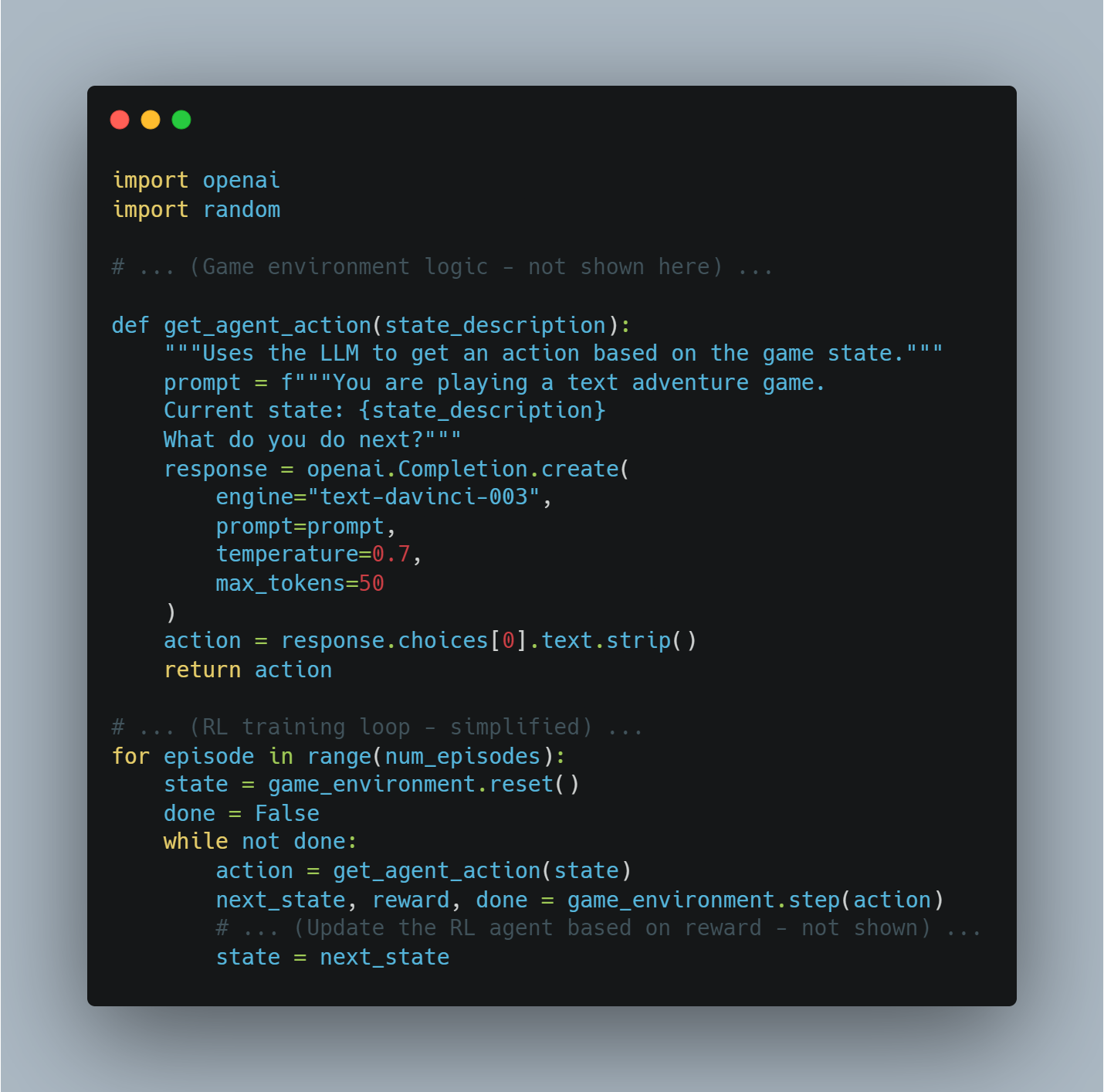
Integrazione dell’IA Multimodale
L’integrazione dell’IA multimodale è un’altra tendenza chiave che sta塑造 il futuro degli agenti artificiali. Permettendo ai sistemi di processare e combinare dati da varie fonti – come testo, immagini, audio e input sensoriali – l’IA multimodale offre una comprensione più completa degli ambienti in cui operano questi sistemi.
Ad esempio, nelle vetture autonome, la capacità di sintetizzare dati video dalle telecamere, dati contestuali dai map e aggiornamenti del traffico in tempo reale permette all’AI di prendere decisioni di guida più informate e sicure.
Questa capacità si estende ad altri domini come la sanità, in cui un agente AI può integrare i dati del paziente da record medici, immagini diagnostiche e informazioni genomiche per fornire consigli di trattamento più accurate e personalizzati.
Il problema qui sta nell’integrazione fluida e nel processamento in tempo reale di flussi di dati diversi, che richiede miglioramenti nell’architettura del modello e nelle tecniche di fusione dati.
Riuscire a superare questi挑战 sarà decisivo per la distribuzione di sistemi AI veramente intelligenti e capaci di operare in ambienti complessi e reali.
Esempio di AI multimodale 1: Il sottotitolo dell’immagine per la risposta alle domande visuali
-
Obiettivo: Un agente AI in grado di rispondere a domande relative alle immagini.
-
Modalità: Immagine, Testo
-
Processo:
-
Estrazione di caratteristiche dell’immagine: Utilizzare una rete neurale convoluzionale (CNN) addestrata precedentemente per estrarre le caratteristiche dall’immagine.
-
Generazione del sottotitolo: Utilizzare un LLM (come un modello Transformer) per generare un sottotitolo descrivente l’immagine in base alle caratteristiche estratte.
-
Risposta alla domanda: Utilizzare un altro LLM per processare sia la domanda che il sottotitolo generato per fornire una risposta.
-
Esempio di codice (concepito in Python e Hugging Face Transformers):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# Carica modelli pre-addestrati
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# Funzione per generare la didascalia dell'immagine
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# Funzione per rispondere alle domande sull'immagine
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# Esempio d'uso
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
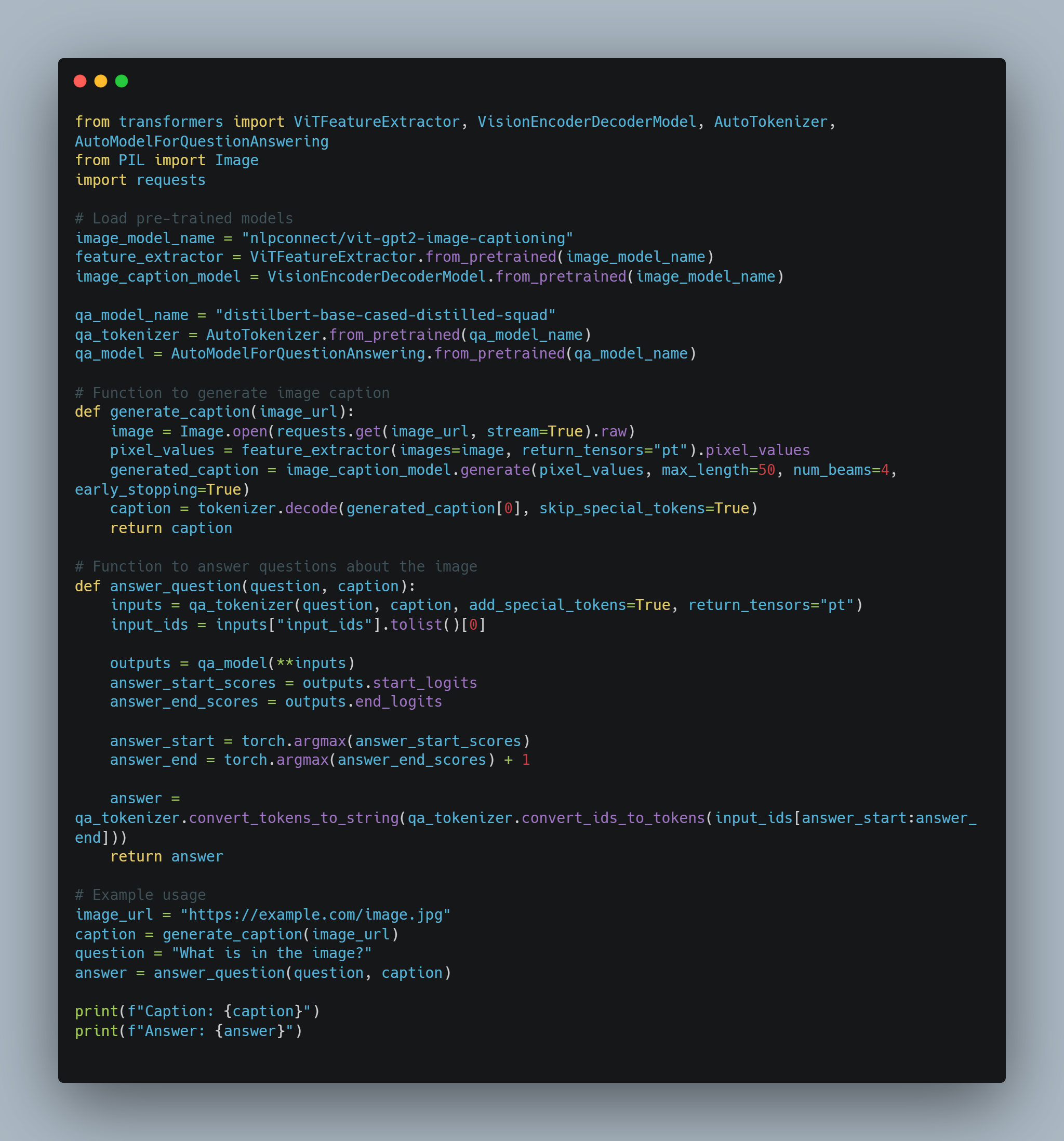
Esempio multimodale dell’intelligenza artificiale 2: Analisi del sentimento da testo e audio
- Obiettivo: Un’agente artificiale che analizza il sentimento sia dal testo che dalla tonalità di un messaggio.
-
Modalità: Testo, Audio
-
Processo:
-
Valutazione del Testo: Utilizzare un modello pre-addestrato per l’analisi del sentiment sul testo.
-
Valutazione dell’Audio: Utilizzare un modello di elaborazione audio per estrarre caratteristiche come il tono e la frequenza, quindi utilizzare queste caratteristiche per prevedere il sentiment.
-
Fusione: Combinare i punteggi di sentiment del testo e dell’audio (per esempio, media ponderata) per ottenere il sentiment complessivo.
-
Esempio di Codice (Concettuale in Python):
from transformers import pipeline # Per sentimento del testo
# ... (Importare librerie di processamento audio e sentimento - non mostrato) ...
# Caricare modelli pre-addestrati
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# Sentimento del testo
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# Sentimento dell'audio
# ... (Processare l'audio, estrarre caratteristiche, predire sentimento - non mostrato) ...
audio_sentiment = # ... (Risultato dal modello di sentimento dell'audio)
audio_confidence = # ... (Punteggio di fiducia dal modello audio)
# Combine sentiment (esempio: media pesata)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# Esempio d'uso
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
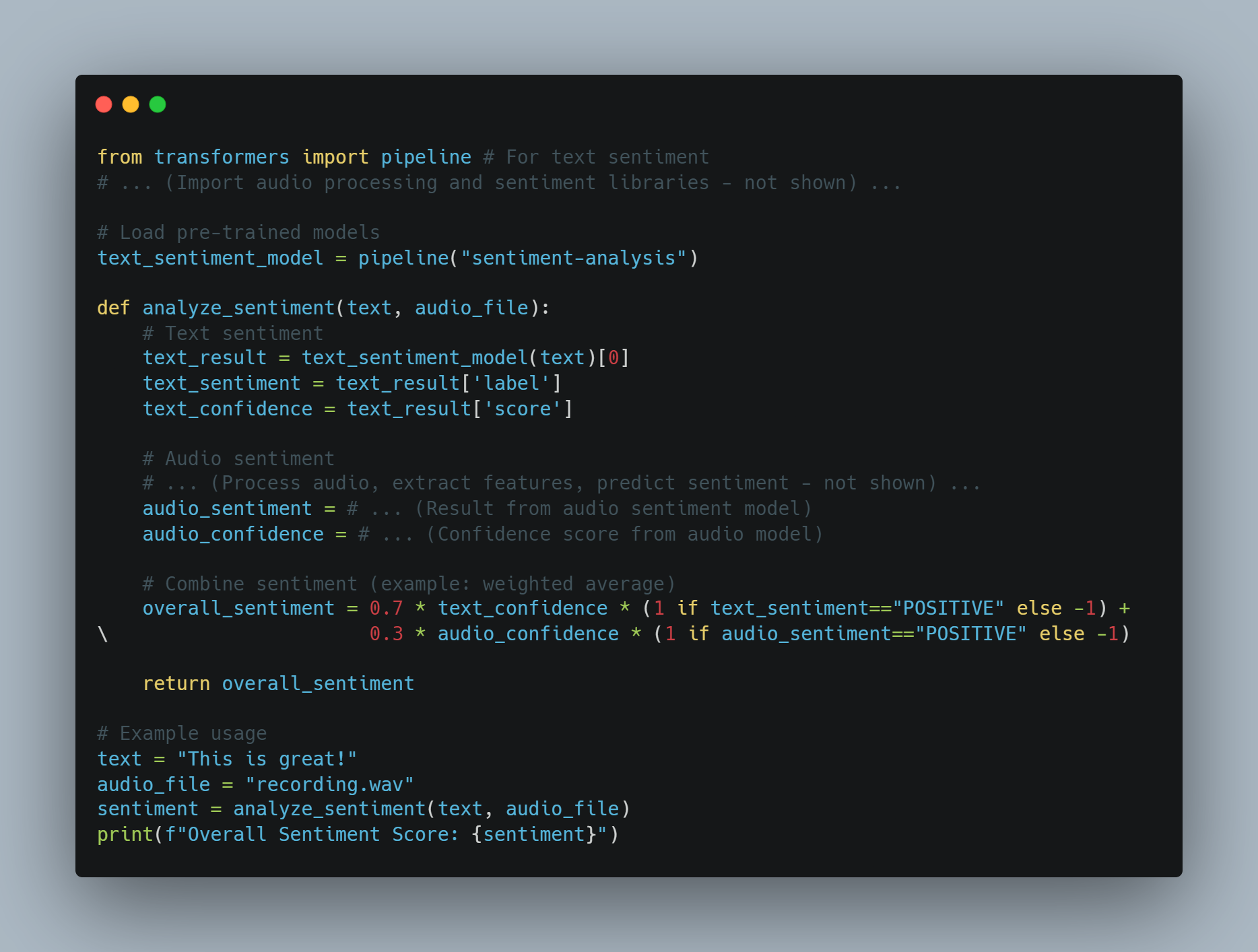
Sfide e considerazioni:
-
Data Alignment: Assicurarsi che i dati di differenti modalità siano sincronizzati e allineati è fondamentale.
-
Complessità del Modello: I modelli multimodali possono essere complicati da addestrare e richiedono grandi dataset diversi.
-
Tecniche di Fusione: Scegliere la giusta metodologia per combinare le informazioni da differenti modalità è importante e dipende dal problema.
L’IA multimodale è un campo in rapida evoluzione con il potenziale di rivoluzionare il modo in cui gli agenti AI percepiscono e interagiscono con il mondo.
Sistemi AI Distribuiti e Calcolo Edge
Osservando l’evoluzione delle infrastrutture AI, il shift verso i sistemi AI distribuiti, supportati dal calcolo edge, rappresenta un importante avanzamento.
I sistemi AI distribuiti decentralizzano i compiti computazionali processando i dati più vicini alla fonte – come dispositivi IoT o server locali – invece di affidarsi alle risorse cloud centralizzate. Questo approcio non solo riduce la latenza, cruciale per applicazioni sensibili al tempo come droni autonomi o automazione industriale, ma anche migliora la privacy e la sicurezza dei dati mantenendo informazioni sensibili locali.
Anche i sistemi AI distribuiti migliorano la scalabilità, permettendo la distribuzione di AI attraverso vasti network, come città intelligenti, senza sopraffare i data center centralizzati.
I挑战 tecnici associati con gli AI distribuiti includono garantire coerenza e coordinamento tra i nodi distribuiti, nonché ottimizzare l’allocazione delle risorse per mantenere il rendimento in ambienti diversi e potenzialmente risorse limitate.
Nel sviluppare e distribuire sistemi AI, adottare architetture distribuite sarà chiave per creare soluzioni AI resistenti, efficienti e scalabili che soddisfano le richieste delle applicazioni future.
Sistemi AI distribuiti e calcolo all’estremità esempio 1: Addestramento federato per la privacy-preserving del modello
-
Obiettivo: Addestrare un modello condiviso su diversi dispositivi (ad esempio, smartphone) senza condividere direttamente dati sensibili degli utenti.
-
Approach:
-
Addestramento Locale: Ogni dispositivo addestra un modello locale sul proprio dataset.
-
Aggregazione Parametri: I dispositivi inviano aggiornamenti del modello (gradienti o parametri) a un server centrale.
-
Aggiornamento Modello Globale: Il server aggrega gli aggiornamenti, migliora il modello globale e invia il modello aggiornato ai dispositivi.
-
Esempio di Codice (Concettuale utilizzando Python e PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
# ... (Codice per la comunicazione tra dispositivi e server - non mostrato) ...
class SimpleModel(nn.Module):
# ... (Definisci qui la tua architettura del modello) ...
# Funzione di addestramento lato dispositivo
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # Inizia con il modello globale
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (Addestra local_model su device_data) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# Funzione di aggregazione lato server
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (Ciclo principale di apprendimento federato - semplificato) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

Esempio 2: Riconoscimento Obiettivi in Tempo Reale su Dispositivi per Confini
-
Obiettivo:Implementare un modello di riconoscimento di oggetti su un dispositivo a risorse limitate (ad esempio, Raspberry Pi) per inferenza in tempo reale.
-
Approach:
-
Ottimizzazione del modello: Utilizzare tecniche come la quantizzazione del modello o la pulizia del modello per ridurre la dimensione del modello e i requisiti computazionali.
-
Implementazione sul bordo:Implementare il modello ottimizzato sul dispositivo di periferia.
-
Inferenza locale: Il dispositivo esegue la deteccione degli oggetti localmente, riducendo il ritardo e la dipendenza dalla comunicazione col cloud.
-
Esempio di codice (tecnico utilizzando Python e TensorFlow Lite):
import tensorflow as tf
# Carica il modello pre-addestrato (supponendo sia già ottimizzato per TensorFlow Lite)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# Ottiene dettagli input e output
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (Cattura immagine dalla fotocamera o carica da file - non mostrato) ...
# Preprocessa l'immagine
input_data = ... # Riscalda, normalizza, ecc.
interpreter.set_tensor(input_details[0]['index'], input_data)
# Esegue l'inferenza
interpreter.invoke()
# Ottiene l'output
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (Elabora output_data per ottenere rettangoli, classi, ecc.) ...
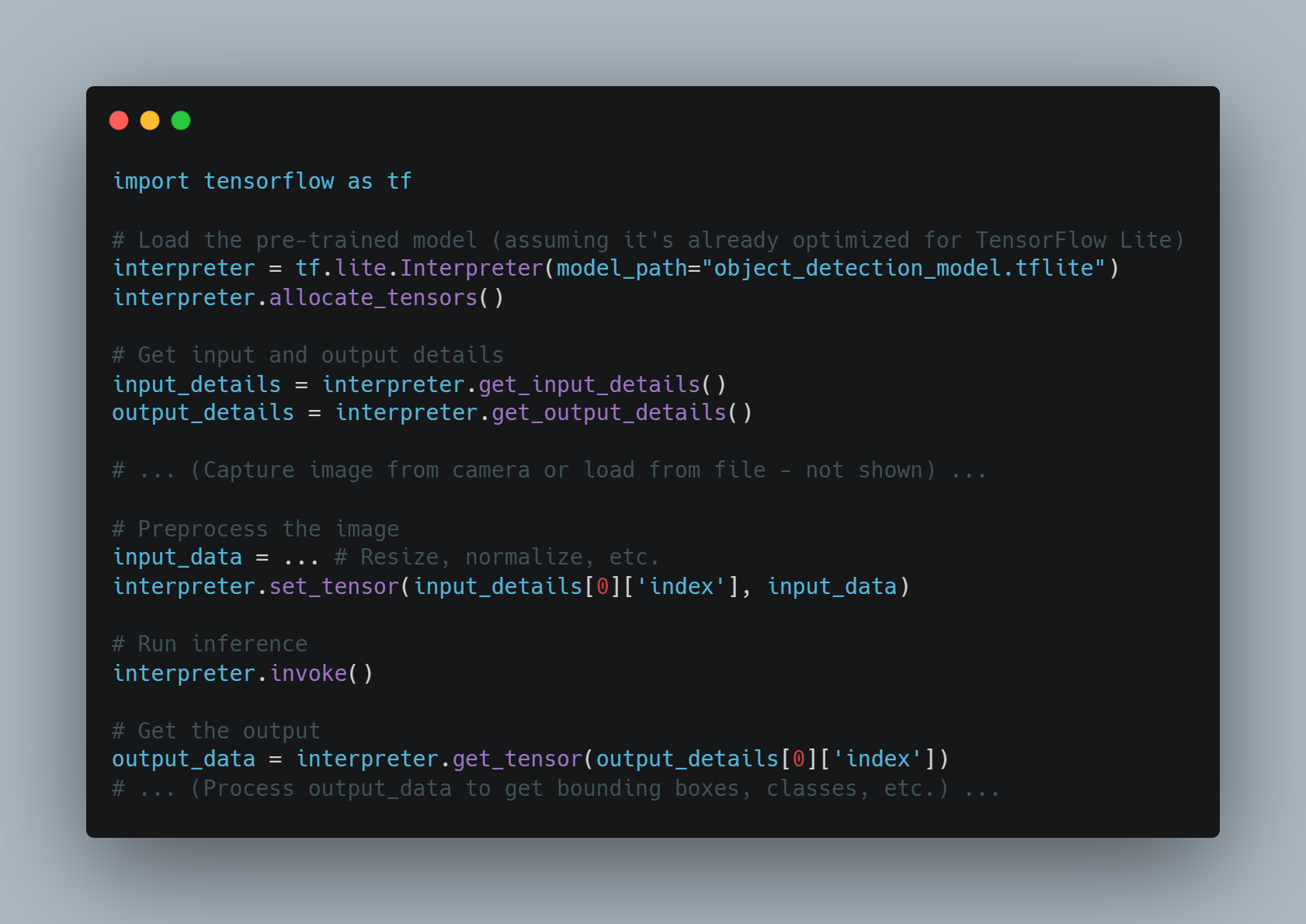
Sfide e considerazioni:
-
Overhead di comunicazione: Coordinare e comunicare efficientemente tra nodi distribuiti è cruciale.
-
Gestione risorse: Ottimizzare l’allocazione delle risorse (CPU, memoria, banda) sui dispositivi è importante.
-
Sicurezza: La sicurezza dei sistemi distribuiti e la protezione della privacy dei dati sono grandi preoccupazioni.
L’IA distribuita ed il calcolo all’estremo sono essenziali per la costruzione di sistemi IA scalabili, efficienti e protetti dalla privacy, specialmente mentre ci spostiamo verso un futuro con miliardi di dispositivi interconnessi.
I progressi nell’elaborazione del linguaggio naturale
L’elaborazione del linguaggio naturale (NLP) rimane al centro dei progressi dell’IA, guidando miglioramenti significativi nel modo in cui le macchine comprendono, generano e interagiscono con il linguaggio umano.
Le ultime evoluzioni nell’NLP, come l’evoluzione dei trasformatori e dei meccanismi di attenzione, hanno drasticamente potenziato la capacità dell’IA di processare strutture linguistiche complesse, rendendo le interazioni più naturali e consapevoli del contesto.
Questi progressi hanno permesso agli sistemi IA di comprendere i nuanci, i sentimenti e persino i riferimenti culturali all’interno del testo, portando a una comunicazione più precisa e significativa.
Ad esempio, nel servizio clienti, modelli NLP avanzati sono in grado non solo di gestire domande con precisione ma anche di rilevare i segnali emotivi dai clienti, permettendo risposte più empatiche e efficaci.
Vedendo avanti, l’integrazione di capacità multilingue e di un migliore comprensione semantica negli modelli NLP amplierà ulteriormente le loro applicabilità, permettendo una comunicazione fluida attraverso differenti lingue e dialetti, e addirittura consentendo agli sistemi IA di fungere da traduttori in tempo reale in diversi contesti globali.
L’elaborazione del linguaggio naturale (NLP) sta evolvendo rapidamente, con ibreakthrough nell’area modelli trasformatori e meccanismi di attenzione. Ecco alcuni esempi e snippet di codice per illustrare questi progressi:
Esempio NLP 1: Analisi del Sentimento con Transformers Affinati
-
Obiettivo: Analizzare il sentimento del testo con alta accuratezza, catturando sfumature e contesto.
-
Approccio: Affinare un modello transformer pre-addestrato (come BERT) su un dataset per l’analisi del sentimento.
Codice Esempio (usando Python e Hugging Face Transformers):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Carica il modello pre-addestrato e il dataset
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3)
# 3 etichette: Positivo, Negativo, Neutrale
dataset = load_dataset("imdb", split="train[:10%]")
# Definisci gli argomenti di training
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# Affina il modello
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# Salva il modello affinato
model.save_pretrained("./fine_tuned_sentiment_model")
# Carica il modello affinato per l'inferenza
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# Esempio di utilizzo
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
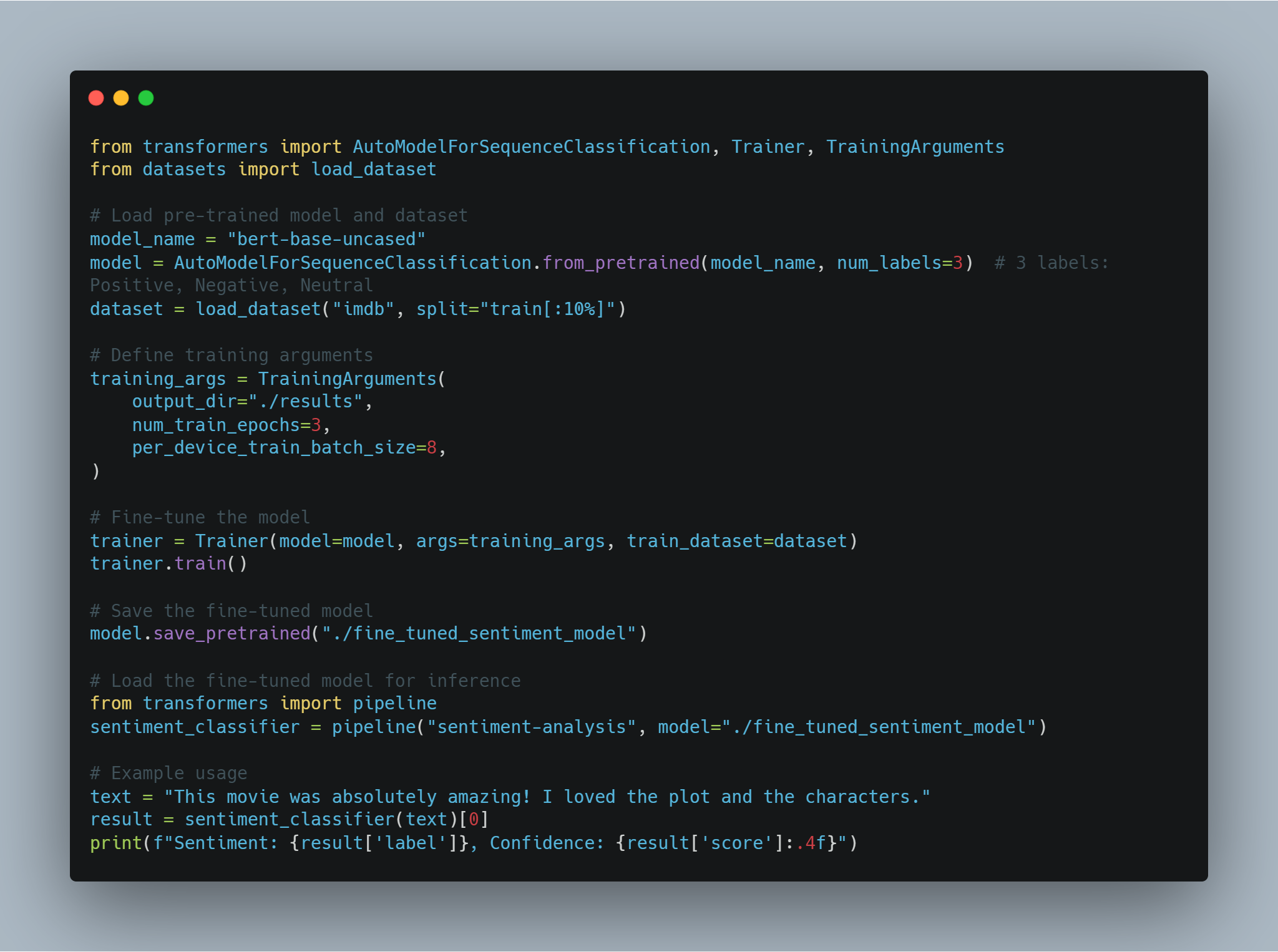
Esempio NLP 2: Traduzione Multilingua con un Singolo Modello
-
Obiettivo: Tradurre tra più lingue usando un singolo modello, sfruttando rappresentazioni linguistiche condivise.
-
Approach: Utilizzare un grande modello di trasformatore multilingue (come mBART o XLM-R) che è stato addestrato su un dataset di testi paralleli in molte lingue.
Esempio di codice (utilizzando Python e Hugging Face Transformers):
from transformers import pipeline
# Carica una pipeline di traduzione multilingue predefinita
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# Esempio d'uso: Inglese a Francese
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# Esempio d'uso: Francese a Spagnolo
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
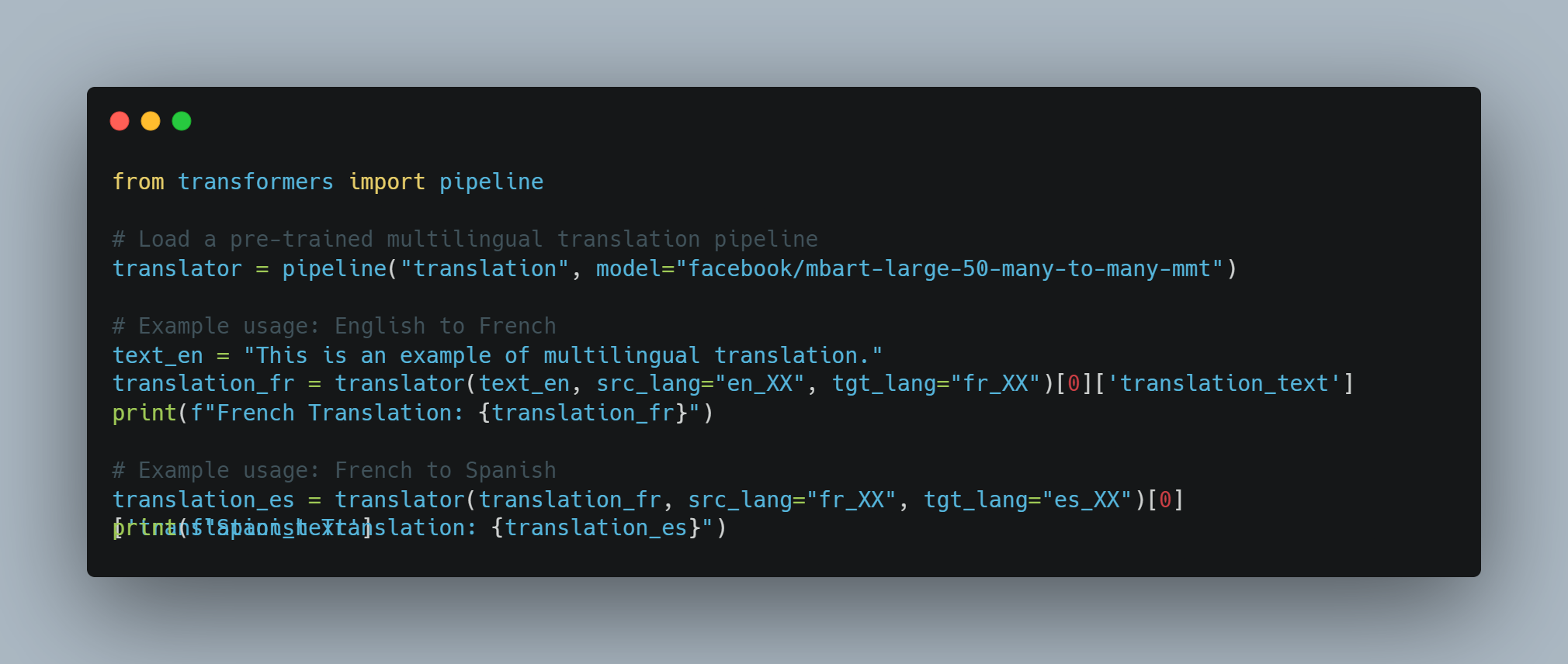
Esempio NLP 3: Embedding lessicali contestuali per la similitudine semantica
-
Obiettivo: Determinare la similitudine tra parole o frasi considerando il contesto.
-
Approach: Utilizzare un modello di trasformatore (come BERT) per generare embedding lessicali contestuali, che catturano il significato delle parole all’interno di una determinata frase.
Esempio di codice (utilizzando Python e Hugging Face Transformers):
from transformers import AutoModel, AutoTokenizer
import torch
Caricamento del modello e del tokenizer pre-addestrati
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
Funzione per ottenere le embedding delle frasi
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
Usa l'embedding del token [CLS] come embedding della frase
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
Esempio di utilizzo
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
Calcolare la similitudine coseno
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
Sfide e Direzioni未来的:
-
Bias e Fairness: I modelli NLP possono ereditare bias dalla loro base di addestramento, portando a risultati ingiusti o discriminativi. Gli aspetti di bias devono essere affrontati.
-
Ragionamento Comune Senso: I modelli a lunghezza lineare (LLM) ancora lottano con il ragionamento comune senso e con l’understanding di informazioni implicite.
-
Esponibilita’: Il processo decisionale dei modelli NLP complessi può essere opaco, rendendo difficile comprendere perché generano determinate uscite.
Malgrado questi challenge, la NLP sta progressivamente avanzando. L’integrazione dell’informazione multimodale, il ragionamento comune migliorato e l’elevata spiegabilità sono aree chiave di ricerca in corso che rivoluzioneranno ulteriormente il modo in cui l’IA interagisce con il linguaggio umano.
Assistenti personalizzati AI
Il futuro degli assistenti personalizzati basati sull’IA è destinato ad diventare sempre più sofisticati, spostandosi oltre la gestione di compiti di base per fornire una supporto intuitivo, proattivo e personalizzato secondo le individuali necessità.
Questi assistenti useranno algoritmi di apprendimento automatico avanzati per imparare continuamente dal comportamento, dalle preferenze e dai rituali individuali, offrendo raccomandazioni sempre più personalizzate e automatizzando compiti più complessi.
Per esempio, un assistente personalizzato potrebbe gestire non solo il tuo programma, ma anche anticipare le tue necessità suggerendo risorse relative o adattando il tuo ambiente in base alla tua attività o ai tuoi preferenze passate.
Con l’assistente AI che diventa sempre più integrato nella vita di tutti i giorni, la sua capacità di adattarsi ai contesti in cambiamento e fornire supporto continuo e跨平台 diventerà un punto di differenziazione chiave. La sfida sta nel bilanciare la personalizzazione con la privacy, richiedendo meccanismi robusti di protezione dati per garantire che informazioni sensibili siano gestite in sicurezza mentre viene fornito un’esperienza profondamente personalizzata.
Esempio di assistente AI 1: Suggerimento di compito congiunto al contesto
-
Obiettivo: Un assistente che suggerisce compiti in base al contesto attuale dell’utente (posizione, ora, comportamento passato).
-
Approach: Combina dati utente, segnali contestuali e un modello di raccomandazione di compiti.
Esempio di codice (concepito utilizzando Python):
# ... (Codice per la gestione dati utente, rilevamento contesto - non mostrato) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# Esempio: Suggerimenti basati sull'ora
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# Esempio: Suggerimenti basati sulla posizione
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (Aggiungi più regole o utilizza un modello di apprendimento automatico per i suggerimenti) ...
# Classifica e filtra i suggerimenti
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- Esempio d'uso ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... altre preferenze ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... altri dati contestuali ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
Esempio 2 AI Assistants: Consegna Proattiva di Informazioni
-
Obiettivo: Un assistente che fornisce proactivement informazioni relative in base al programma e alle preferenze dell’utente.
-
Approach: Integra dati del calendario, interessi utente e un sistema di recupero contenuti.
Esempio di Codice (Concettuale utilizzando Python):
# ... (Codice per l'accesso al calendario, profilo di interesse utente - non mostrato) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (Recupera informazioni sulle aziende, profili dei partecipanti, ecc.) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (Recupera lo stato del volo, informazioni sulla destinazione, ecc.) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- Esempio d'uso ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... altre preferenze ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

Esempio 3 AI Assistants: Raccomandazione Contenuti Personalizzata
-
Obiettivo: Un assistente che raccomanda contenuti (articoli, video, musica) personalizzati secondo le preferenze utente.
-
Approach: Utilizzare il filtraggio collaborativo o sistemi di raccomandazione basati sul contenuto.
Esempio di Codice (Concettuale utilizzando Python e una libreria come Surprise):
from surprise import Dataset, Reader, SVD
# ... (Codice per la gestione delle valutazioni degli utenti, database dei contenuti - non mostrato) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (Ottieni previsioni per tutti gli elementi, classifica e restituisci i primi N) ...
# --- Esempio di Utilizzo ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... altre valutazioni ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
Sfide e Considerazioni Etiche:
-
Privacy dei Dati: Gestire i dati degli utenti in modo responsabile e trasparente è cruciale.
-
Bias e Impartialità: La personalizzazione non dovrebbe amplificare i bias esistenti.
-
Controllo Utente: Gli utenti dovrebbero avere il controllo sui loro dati e sulle impostazioni di personalizzazione.
La costruzione di assistenti AI personalizzati richiede una considerazione attenta sia dei fattori tecnici che etici per creare sistemi che siano utili, affidabili e rispettino la privacy degli utenti.
AI nelle Industrie Creative
L’AI sta facendo importanti progressi nelle industrie creative, trasformando il modo in cui vengono prodotte e consumate arte, musica, film e letteratura. Con i progressi nella modellistica generativa, come le Reti Generative Adversarial (GAN) e i modelli basati sui transformer, l’AI può ora generare contenuti che sfidano la creatività umana.
Ad esempio, l’IA può comporre musica che riflette specifici generi o sentimenti, creare arte digitale che imita lo stile di pittori famosi, o persino redigere trame narrative per film e romanzi.
Nell’industria pubblicitaria, l’IA viene utilizzata per generare contenuti personalizzati che risuonano con i consumatori individuali, aumentando l’engagement e l’efficacia.
Ma la crescita dell’IA nei campi creativi solleva domande sulla paternità, l’originalità e il ruolo della creatività umana. Mentre interagisci con l’IA in questi domini, sarà cruciale esplorare come l’IA possa completare invece di sostituire la creatività umana, incoraggiare la collaborazione tra umani e macchine per produrre contenuti innovativi e influenti.
Ecco un esempio di come possa essere integrato GPT-4 in un progetto Python per compiti creativi, specificamente nel campo della scrittura. Questo codice dimostra come sfruttare le capacità di GPT-4 per generare formati di testo creativo, come la poesia.
import openai
# Imposta la tua chiave API OpenAI
openai.api_key = "YOUR_API_KEY"
# Definisci una funzione per generare poesia
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# Esempio d'uso
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
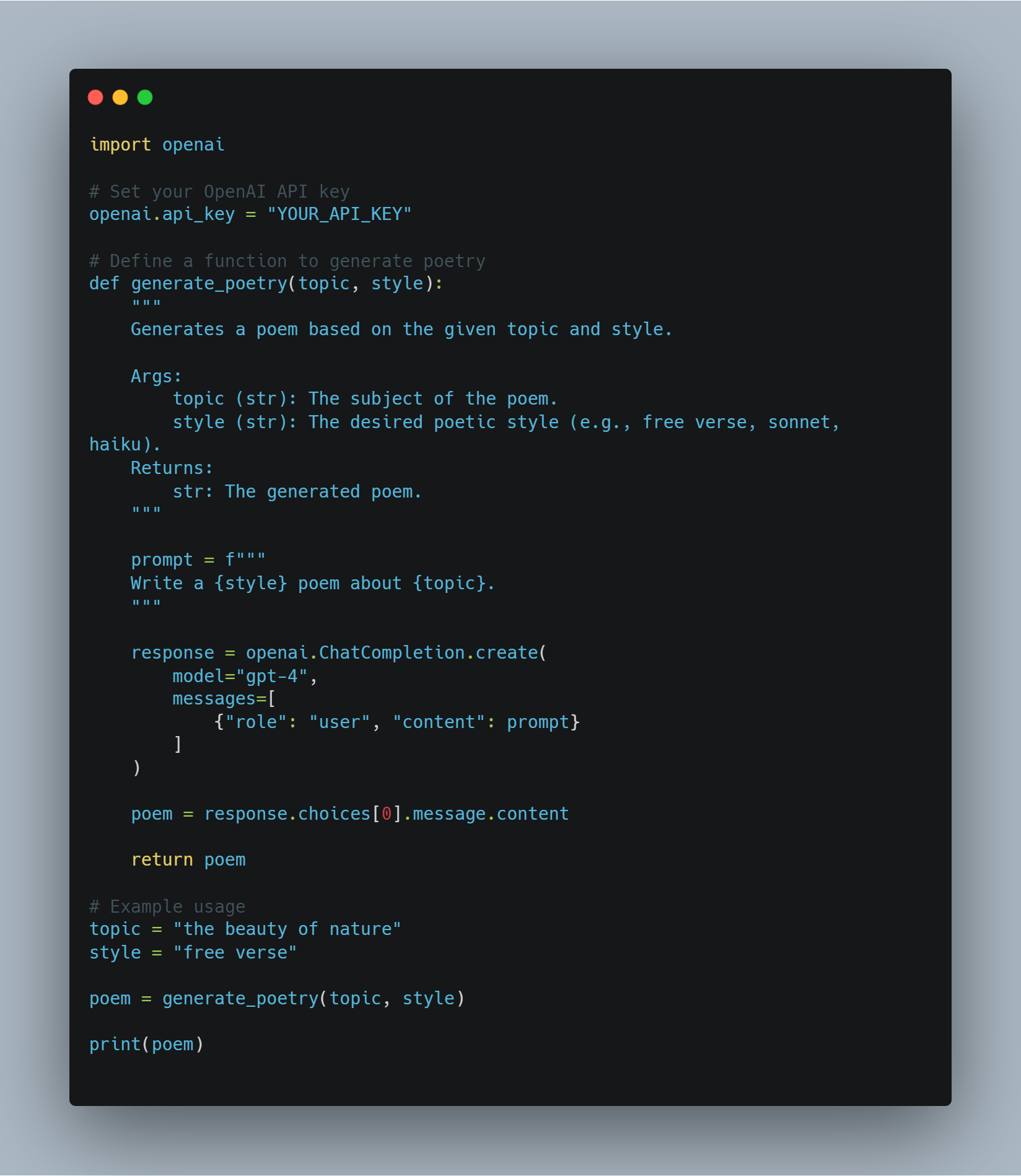
Vediamo cosa succede qui:
-
Importa la libreria OpenAI: Il codice prima importa la libreria
openaiper accedere all’API OpenAI. - Imposta la chiave API: Sostituisci
"YOUR_API_KEY"con la tua chiave API OpenAI reale. -
Definisci la funzione
generate_poetry: Questa funzione prende in input iltopice lostiledel poema e utilizza l’API ChatCompletion di OpenAI per generare il poema. -
Costruisci il prompt: Il prompt combina il
topice lostilein una chiara istruzione per GPT-4. -
Invia il prompt a GPT-4: Il codice utilizza
openai.ChatCompletion.createper inviare il prompt a GPT-4 e ricevere il poema generato come risposta. -
Ritorna il poema: Il poema generato viene quindi estratto dalla risposta e restituito dalla funzione.
-
Esempio di utilizzo: Il codice mostra come chiamare la funzione
generate_poetrycon un argomento e uno stile specifici. Il poema risultante viene quindi stampato sulla console.
Mondi Virtuali Potenziati da Intelligenza Artificiale
Lo sviluppo dei mondi virtuali potenziati da intelligenza artificiale rappresenta un significativo passo avanti nelle esperienze immersive, in cui agenti di intelligenza artificiale possono creare, gestire ed evolvere ambienti virtuali interattivi e reattivi all’input degli utenti.
Questi mondi virtuali, guidati dall’intelligenza artificiale, possono simulare ecosistemi complessi, interazioni sociali e narrazioni dinamiche, offrendo agli utenti un’esperienza profondamente coinvolgente e personalizzata.
Ad esempio, nell’industria del gaming, l’intelligenza artificiale può essere utilizzata per creare personaggi non giocabili (NPC) che imparano dai comportamenti dei giocatori, adattando le loro azioni e strategie per offrire un’esperienza più sfidante e realistica.
Oltre al gaming, i mondi virtuali potenziati da intelligenza artificiale hanno potenziali applicazioni nell’ambito dell’istruzione, dove le aule virtuali possono essere personalizzate in base agli stili di apprendimento e ai progressi degli studenti singoli, o nella formazione aziendale, dove simulazioni realistiche possono preparare i dipendenti a vari scenari.
Il futuro di questi ambienti virtuali dipenderà dai progressi nella capacità dell’intelligenza artificiale di generare e gestire vasti e complessi ecosistemi digitali in tempo reale, così come dalle considerazioni etiche legate ai dati degli utenti e agli impatti psicologici delle esperienze altamente immersive.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# Inizializza agenti
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# Assegna una posizione casuale all'interno dell'ambiente
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# Crea e aggiungi l'agente
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# Sposta gli agenti (movimento semplificato per dimostrazione)
for agent in self.agents:
agent.move(self.environment)
# DA IMPLEMENTARE: realizzare una logica più complessa per interazioni, cambiamenti dell'ambiente, ecc.
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# Determina la direzione del movimento ( casuale per questo esempio)
direction = random.choice(['N', 'S', 'E', 'W'])
# applica il movimento in base alla direzione
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# Aggiorna l'ambiente per riflettere la nuova posizione dell'agente
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# Esempio d'uso
if __name__ == "__main__":
# Definisci i parametri del mondo
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# Crea il mondo virtuale
world = VirtualWorld(environment_size, agent_types, agent_properties)
# Simula il mondo per alcuni passi
for _ in range(10):
world.update()
world.display()
print() # Aggiungi una riga vuota per migliore leggibilità
Cos’è successo in questo codice?:
-
Classe VirtualWorld:
-
Define il nucleo del mondo virtuale.
-
Contiene la griglia dell’ambiente, una lista di agenti e informazioni relative agli agenti.
-
__init__(): Inizializza il mondo con dimensioni, tipi di agenti e proprietà. -
add_agent(): Aggiunge un nuovo agente di un tipo specifico al mondo. -
update(): Esegue l’aggiornamento di un singolo passo del mondo.- Attualmente si muovono solo agenti, ma è possibile aggiungere logica complessa per interazioni tra agenti, cambiamenti ambientali, ecc.
-
display(): Stampa una rappresentazione di base dell’ambiente.
-
-
Classe Agente:
-
Rappresenta un agente individuale all’interno del mondo.
-
__init__(): Inizializza l’agente con il suo tipo, posizione e proprietà. -
move(): Gestisce il movimento dell’agente, aggiornando la sua posizione all’interno dell’ambiente. Questo metodo fornisce attualmente un semplice spostamento casuale, ma può essere esteso per includere comportamenti AI complessi.
-
-
Esempio di utilizzo:
-
Imposta i parametri del mondo come dimensioni, tipi di agenti e le loro proprietà.
-
Crea un oggetto VirtualWorld.
-
Esegue la metodo
update()multipli volte per simulare l’evoluzione del mondo. -
Chiama
display()dopo ogni aggiornamento per visualizzare i cambiamenti.
-
Miglioramenti:
-
AI degli Agenti più Complesso: Implementa un AI più sofisticato per il comportamento degli agenti. Puoi utilizzare:
-
Algoritmi di Pathfinding: AIuti gli agenti a navigare l’ambiente in modo efficiente.
-
Alberi di Decisione/Machine Learning: Permetti agli agenti di fare decisioni intelligenti basate sulle loro posizioni e obiettivi.
-
Apprendimento Collegamenti: Insegnaci agli agenti imparare e adattarsi al loro comportamento nel tempo.
-
-
Interazione con l’ambiente: Aggiungi elementi dinamici all’ambiente, come ostacoli, risorse o punti di interesse.
-
Interazione tra agenti: Implementa interazioni tra agenti, come comunicazione, combattimento o cooperazione.
-
Visualizzazione: Usa librerie come Pygame o Tkinter per creare una rappresentazione visuale del mondo virtuale.
Questo esempio costituisce una base di base per la creazione di un mondo virtuale alimentato da AI. Il livello di complessità e sofisticazione può essere ulteriormente ampliato per soddisfare le vostre specifiche necessità e obiettivi creativi.
Neuromorfismo e AI
Il neuromorfismo, ispirato dalla struttura e dal funzionamento del cervello umano, sta per rivoluzionare l’AI offrendo nuovi modi per processare informazioni in maniera efficiente e in parallelo.
A differenza delle architetture di calcolo tradizionali, i sistemi neuromorfi sono progettati per imitare le reti neurali del cervello, permettendo all’AI di svolgere compiti come la riconoscenza di pattern, il processamento sensoriale e la presa di decisioni con maggiore velocità ed efficienza energetica.
Questa tecnologia presenta un potenziale immenso per lo sviluppo di sistemi AI più adattivi, capaci di apprendere da dati minimi e efficienti in ambienti real-time.
Ad esempio, in robotica, i chip neuromorfi potrebbero consentire ai robot di processare le input sensoriali e prendere decisioni con un livello di efficienza e velocità che le architetture attuali non possono raggiungere.
Il successivo grande sfide sarà quello di scalare il neuromorfismo per gestire la complessità di applicazioni AI a grandi scale, integrandolo con le attuali piattaforme AI per sfruttare appieno il suo potenziale.
Agenti AI nelle Esplorazioni Spaziali
Gli agenti AI stanno giocando un ruolo sempre più importante nell’esplorazione spaziale, incaricati di navigare in ambienti ostili, prendere decisioni in tempo reale e condurre esperimenti scientifici in modo autonomo.
Con le missioni che spingono oltre la superficie terrestre, diventa sempre più pressante la necessità di sistemi AI in grado di operare indipendentemente dalla terra. Gli agenti AI futuri saranno progettati per affrontare l’imprevedibilità dello spazio, come ostacoli inattesi, cambiamenti nei parametri della missione o la necessità di auto-riparazione.
Per esempio, l’AI potrebbe essere utilizzato per guidare i rover su Marte nell’esplorazione autonoma del terreno, nell’identificazione di siti scientificamente interessanti e persino nella perforazione di campioni con minimo input da parte del controllo missione. Questi agenti AI potrebbero anche gestire i sistemi di supporto vitale su missioni a durata prolungata, ottimizzare l’utilizzo dell’energia e adattarsi alle necessità psicologiche degli astronauti fornendo compagnia e stimolazione mentale.
L’integrazione dell’AI nell’esplorazione spaziale non solo aumenta le capacità missione ma apre anche nuove possibilità per l’esplorazione umana dell’universo, in cui l’AI sarà un partner indispensabile nella ricerca dell’understanding del nostro universo.
Capitolo 8: Agenti AI in campi mission-critical
Sanità
Nel settore sanitario, gli agenti AI non sono solo ruoli di supporto ma stanno diventando integrali per l’intero continuum della cura del paziente. Il loro impatto è più evidente in telemedicina, dove i sistemi AI hanno ridefinito l’approcio alla fornitura remota di assistenza sanitaria.
Utilizzando tecnologie avanzate di processamento del linguaggio naturale (NLP) e algoritmi di apprendimento automatico, questi sistemi svolgono compiti complessi come la triage dei sintomi e la raccolta preliminare di dati con un alto grado di accuratezza. Analizzano i sintomi riportati dai pazienti e le storie medicali in tempo reale, confrontando queste informazioni con ampie basi dati mediche per identificare potenziali condizioni o sospetti.
Questo consente agli operatori sanitari di prendere decisioni informate più velocemente, riducendo il tempo alla terapia e potenzialmente salvare vite. Anche gli strumenti diagnostici guidati da AI nell’imaging medico stanno rivoluzionando la radiologia rilevando schemi e anomalie negli X-ray, MRI e TC che potrebbero essere impercepibili all’occhio umano.
Questi sistemi sono addestrati su vasti insiemi di dati comprendenti milioni di immagini annotate, consentendogli non solo di riprodurre ma spesso di superare le capacità diagnostiche umane.
L’integrazione di AI nel settore sanitario si estende anche alle attività amministrative, dove l’automazione dell’agendazione degli appuntamenti, dei promemoria per la medicina e delle follow-up pazienti riduce significativamente il carico operativo del personale sanitario, permettendogli di concentrarsi su aspetti più critici dell’assistenza sanitaria.
Finanza
Nel settore finanziario, gli agenti AI hanno rivoluzionato le operazioni introdurre livelli di efficienza e precisione senza precedenti.
Il trading algoritmico, che dipende fortemente da AI, ha trasformato il modo in cui vengono effettuate le operazioni nei mercati finanziari.
Questi sistemi sono in grado di analizzare dataset massive in millisecondi, identificare trend di mercato e eseguire operazioni di trading nel momento ottimale per massimizzare i profitti e minimizzare i rischi. Utilizzano algoritmi complessi che incorporano tecniche di apprendimento automatico, apprendimento profondo e reinforcement learning per adattarsi alle condizioni di mercato in mutamento, prendendo decisioni in millisecondi che un trader umano non potrebbe mai raggiungere.
Oltre al trading, l’IA riveste un ruolo chiave nel risk management, valutando i rischi creditizi e rilevando attività fraudolose con una precisione notevole. I modelli dell’IA utilizzano l’analisi predittiva per valutare la probabilità di default di un prestatore di credito analizzando schemi nei crediti storici, nei comportamenti delle transazioni e in altri fattori rilevanti.
Anche nel campo della conformità regolamentare, l’IA automatizza il monitoraggio delle transazioni per rilevare e segnalare attività sospette, garantendo che le istituzioni finanziarie soddisfino richieste regolamentari stringenti. Questa automazione non solo attenua il rischio dell’errore umano ma anche razionalizza i processi di conformità, riducendo costi e migliorando l’efficienza.
Gestione delle Emergenze
Il ruolo dell’IA nella gestione delle emergenze è rivoluzionario, modificando fondamentalmente il modo in cui si predicono, gestiscono e mitigano le crisi.
Nel respingere i disastri, gli agenti dell’IA processano vasti quantità di dati da molti Collegamenti esterni—da immagini satellitari a feed sociali—per fornire una panoramica completa della situazione in tempo reale. Algoritmi di apprendimento automatico analizzano questi dati per identificare schemi e predire la progressione degli eventi, permettendo alle forze di risposta alle emergenze di allocare le risorse più efficientemente e prendere decisioni informate sotto pressione.
Ad esempio, durante un disastro naturale come una tempesta di uragano, i sistemi AI possono predire la traiettoria e l’intensità della tempesta, permettendo alle autorità di emettere ordini di evacuazione tempestevoli e di schierare risorse nelle aree più vulnerabili.
Nell’analisi predictive, modelli AI vengono utilizzati per prevedere potenziali emergenze analizzando dati storici insieme a input in tempo reale, consentendo misure proactive che possono prevenire disastri o mitigate il loro impatto.
I sistemi di comunicazione pubblica aiutati dall’AI giocano un ruolo cruciale nel garantire che informazioni accurate e tempestive raggiungano le popolazioni coinvolte. Questi sistemi possono generare e diffondere allarmi di emergenza attraverso molteplici piattaforme, personalizzando i messaggi per diverse demografie per garantire capire e rispondere.
L’AI inoltre incrementa la preparazione dei soccorsi emergenze creando simulazioni di addestramento altamente realiste utilizzando modelli generativi. Queste simulazioni replicano le complessità delle emergenze reali, permettendo ai soccorsi di affinare le loro技能 e migliorare la loro prontezza per gli eventi reali.
Trasporti
I sistemi AI diventano indispensabili nel settore dei trasporti, dove migliorano sicurezza, efficiente e affidabilità in diversi domini, incluso il controllo del traffico aereo, le vetture autonome e il trasporto pubblico.
Nel controllo del traffico aereo, gli agenti AI sono chiave per l’ottimizzazione delle traiettorie di volo, la prevedibilità di potenziali conflitti e la gestione delle operazioni aeroportuali. Questi sistemi usano l’analisi predictive per prevedere potenziali bottleneck del traffico aereo, reindirizzando voli in tempo reale per garantire sicurezza e efficiente.
Nel campo dell’autonomia veicolare, l’IA rappresenta il cuore della tecnologia che consente ai veicoli di elaborare i dati provenienti dai sensori e di prendere decisioni inattese in ambienti complessi. Questi sistemi utilizzano modelli di apprendimento profondo addestrati su dataset estesi per interpretare i dati visivi, uditivi e spaziali, permettendo una navigazione sicura attraverso condizioni dinamiche e imprevedibili.
I sistemi di trasporto pubblico beneficiano anche dell’IA attraverso la pianificazione ottimizzata delle rotte, la manutenzione preventiva dei veicoli e la gestione del flusso passeggeri. Analizzando dati storici e in tempo reale, i sistemi AI possono adeguare gli orari di trasporto, prevedere e prevenire i guasti ai veicoli e gestire il traffico durante gli orari di punta, migliorando così l’efficienza e la affidabilità delle reti di trasporto.
Elettrodotto idroelettrico
L’IA sta giocando un ruolo chiave nel settore energetico, soprattutto nella gestione dell’impianto, nell’ottimizzazione delle energie rinnovabili e nella rilevazione di guasti.
Nella gestione dell’impianto, gli agenti dell’IA monitorano e controllano le reti energetiche analizzando i dati in tempo reale provenienti dai sensori distribuiti nella rete. Questi sistemi utilizzano l’analisi predittiva per ottimizzare l’distribuzione energetica, garantendo che la fornitura soddisfi la domanda e minimizzando il waste dell’energia. I modelli AI predicono anche possibili guasti alla rete, permettendo la manutenzione preventiva e riducendo il rischio di blackout.
Nel dominio delle energie rinnovabili, i sistemi AI vengono utilizzati per prevedere i modelli climatici, operazione cruciale per l’ottimizzazione della produzione di energia solare e eolica. Questi modelli analizzano i dati meteorologici per prevedere l’intensità della luce solare e la velocità del vento, consentendo predizioni più accurate della produzione energetica e una migliore integrazione delle fonti rinnovabili nella rete.
La rilevazione degli avversamenti è un’altra area in cui l’IA sta facendo significative contribuzioni. I sistemi basati sull’IA analizzano i dati provenienti dai sensori dai macchinari come i trasformatori, le turbine e i generatori per identificare i segni di usura e guasti potenziali prima che questi portino a malfunzionamenti. Questo approcio di manutenzione predittiva non solo prolunga la vita utile dell’equipaggiamento ma anche assicura un approvvigionamento energetico continuo e affidabile.
Cybersecurity
Nel campo della cybersecurity, gli agenti basati sull’IA sono essenziali per mantenere l’integrità e la sicurezza delle infrastrutture digitali. Questi sistemi sono progettati per monitorare in continuazione il traffico di rete, usando algoritmi di apprendimento machine learning per rilevare anomalie che potrebbero indicare una violazione della sicurezza.
Analizzando grandi quantità di dati in tempo reale, gli agenti basati sull’IA possono identificare schemi di comportamento maligno, come tentativi di accesso non usuali, attività di estrazione di dati o la presenza di malware. Una volta rilevata una minaccia potenziale, i sistemi basati sull’IA possono automaticamente avviare contromisure, come isolare i sistemi compromessi e distribuire aggiornamenti, per prevenire ulteriori danni.
L’analisi delle vulnerabilità è un’altra applicazione critica dell’IA nella cybersecurity. Gli strumenti basati sull’IA analizzano il codice e le configurazioni di sistema per identificare debolezze di sicurezza potenziali prima che vengano sfruttate dagli attaccanti. Questi strumenti usano tecniche di analisi statica e dinamica per valutare la postura di sicurezza dei componenti software e hardware, fornendo informazioni utili alle squadre di sicurezza.
L’automazione di questi processi non solo incrementa la velocità e l’accuratezza nella rilevazione e nella risposta alle minacce, ma anche riduce il carico di lavoro sugli analisti umani, permettendogli di concentrarsi su sfide di sicurezza più complesse.
Produzione
Nella produzione, l’IA sta guidando importanti miglioramenti nella qualità del controllo, nella manutenzione preventiva e nell’ottimizzazione della catena di approvvigionamento. I sistemi di visione computerizzata alimentati dall’IA sono ora in grado di ispezionare i prodotti per i difetti ad un livello di velocità e precisione che supera ampiamente le capacità umane. Questi sistemi usano algoritmi di apprendimento profondo addestrati su migliaia di immagini per rilevare anche le più piccole imperfezioni nei prodotti, garantendo una qualità costante in ambienti di produzione a alta volumes.
Un’altra area in cui l’IA sta avendo un impatto profondo è la manutenzione preventiva. Analizzando i dati provenienti da sensori integrati negli impianti, i modelli dell’IA possono prevedere quando è probabile che il equipaggiamento fallisca, permettendo la programmazione della manutenzione prima che si verifichi un guasto. Questo approcio non solo riduce il tempo di inattività, ma anche prolunga la vita dell’impianto, portando a risparmi significativi.
Nella gestione della catena di approvvigionamento, gli agenti dell’IA ottimizzano i livelli di magazzino e la logistica analizzando i dati provenienti dalla catena d’approvvigionamento, inclusi i forecast di domanda, i programmi di produzione e le rotte di trasporto. Facendo aggiustamenti in tempo reale ai piani di magazzino e logistica, l’IA garantisce che i processi di produzione scorrano fluentemente, minimizzando i rallentamenti e le coste.
these applications demonstrate the critical role of AI in improving operational efficiency and reliability in manufacturing, making it an indispensable tool for companies looking to stay competitive in a rapidly evolving industry.
Conclusione
L’integrazione di agenti AI con grandi modelli di linguaggio (LLM) segna un punto nevralgico dell’evoluzione dell’intelligenza artificiale, sbloccando capacità senza precedenti in diversi settori industriali e domini scientifici. Questa sinergia migliora la funzionalità, l’adattabilità e l’applicabilità dei sistemi AI, risolvendo le limitazioni innate dei modelli di linguaggio e permettendo processi decisionali più dinamici, attenti al contesto e autonomi.
Dalla rivoluzione negli healthcare e nelle finanze alla trasformazione del trasporto e della gestione delle emergenze, gli agenti AI guidano l’innovazione e l’efficienza, aprendo la strada ad un futuro in cui le tecnologie AI sono profondamente integrate nella nostra vita quotidiana.
mentre continuiamo a esplorare il potenziale degli agenti AI e dei modelli di linguaggio, è cruciale basare il loro sviluppo su principi etici che prioritizzino il benessere umano, la correttezza e l’inclusività. Garantendo che queste tecnologie siano progettate e implementate responsabilmente, siamo in grado di sfruttare tutto il loro potenziale per migliorare la qualità della vita, promuovere la giustizia sociale e affrontare sfide globali.
Il futuro dell’intelligenza artificiale dipende dalla perfetta integrazione di agenti AI avanzati con modelli di linguaggio sofisticati, creando sistemi intelligenti in grado non solo di ampliare le capacità umane ma anche di sostenere i valori che definiscono la nostra umanità.
La convergenza tra agenti AI e modelli di linguaggio rappresenta un nuovo paradigma nell’intelligenza artificiale, dove la collaborazione tra l’agile e il potente sblocca un regno di possibilità illimitate. Sfruttando questa forza sinergyca, possiamo guidare l’innovazione, avanzare le scoperte scientifiche e creare un futuro più equo e prosperoso per tutti.
Chi è l’autore
Ciò che segue è scritto da Vahe Aslanyan, un punto di congiunzione tra informatica, scienze dati e AI. Per scoprire il mio portfolio che testimonia precisione e progresso, visita vaheaslanyan.com. La mia esperienza collega sviluppo full-stack e ottimizzazione di prodotti AI, spinta dalla risoluzione di problemi in modi nuovi.
Con un curriculum che include l’avvio di un bootcamp di scienze dati di punta e la collaborazione con i migliori specialisti dell’industria, il mio focus rimane sull’elevazione dell’educazione tecnica a standard universali.
Come approfondire la conoscenza?
Dopo aver studiato questo guide, se sei interessato ad approfondire ulteriormente e se preferisci un approcio strutturato all’apprendimento, considera di unirti a noi a LunarTech. Offriamo corsi individuali e bootcamp in Data Science, Machine Learning e AI.
Forniamo un programma completo che offre una comprensione approfondita della teoria, una implementazione pratica guidata, materiale di allenamento esteso e una preparazione personalizzata agli interviste per posizionarti con successo a qualunque fase del tuo percorso.
Puoi dare un’occhiata al nostro Ultimate Data Science Bootcamp e unirti a una prova gratuita per provare il contenuto direttamente. Questo ha ottenuto il riconoscimento come uno dei Migliori Bootcamp di Data Science del 2023 ed è stato pubblicizzato in pubblicazioni rispettabili come Forbes, Yahoo, Entrepreneur e altri. Ecco la tua occasione per diventare parte di una comunità che vive l’innovazione e il sapere. Ecco il messaggio di benvenuto!
Connettiti con Me

Seguimi su LinkedIn per un sacco di risorse gratuite in CS, ML e AI
-
Iscriviti al mio Newsletter sulla Data Science e l’AI
Se vuoi imparare di più riguardo una carriera in Data Science, Machine Learning e AI, e saper come ottenere un lavoro di Data Science, puoi scaricare questo libero Guide sulla Carriera in Data Science e AI.
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/