













La rápida evolución de la inteligencia artificial (IA) ha resultado en una poderosa sinergía entre los grandes modelos de lenguaje (MMLL) y los agentes de IA. Esta dinámica interacción es como la historia de David y Goliat (sin la lucha), donde los ágiles agentes de IA amplifican y mejoran las capacidades de los colosales MMLL.
Este manual explorará cómo los agentes de IA, semejantes a David, están supercargando los MMLL, nuestros modernos Goliat, para ayudar a revolucionar varias industrias y dominios científicos.
Tabla de Contenidos
-
La Emergencia de los Agentes de IA en los Modelos de Lenguaje
-
Capítulo 1: Introducción a los Agentes de IA y los Modelos de Lenguaje
-
Capítulo 2: La Historia de la Inteligencia Artificial y los Agentes de IA
-
Capítulo 6: Diseño arquitectónico para integrar agentes AI con LLM
La emergencia de los agentes AI en las modelos de lenguaje
Los agentes AI son sistemas autónomos diseñados para percibir su entorno, tomar decisiones y ejecutar acciones para alcanzar objetivos específicos. Cuando se integran con las MLL, estos agentes pueden realizar tareas complejas, razonar sobre información y generar soluciones innovadoras.
Esta combinación ha llevado a avances significativos en varios sectores, desde el desarrollo de software hasta la investigación científica.
Impacto transformador en varias industrias
La integración de los agentes AI con MLL ha tenido un profundo impacto en varias industrias:
-
Desarrollo de Software: Asistentes de codificación basados en IA, como GitHub Copilot, han demostrado la capacidad de generar hasta el 40% del código, lo que resulta en un increíble aumento del 55% en la velocidad de desarrollo.
-
Educación: Asistentes de aprendizaje basados en IA han mostrado promesas en reducir el tiempo de finalización de cursos promedio en un 27%, potencialmente revolucionando el panorama educativo.
-
Transporte: Con proyecciones que sugieren que el 10% de los vehículos serán sin conductor para 2030, los agentes AI autónomos en coches autónomos están listos para transformar la industria del transporte.
Avance de la Descubrimiento Científico
Una de las aplicaciones más emocionantes de los agentes AI y las LLM es en la investigación científica:
-
Descubrimiento de Fármacos: Los agentes AI están acelerando el proceso de descubrimiento de fármacos al analizar grandes conjuntos de datos y predecir candidatos potenciales a fármacos, reduciendo significativamente el tiempo y el costo asociados con los métodos tradicionales.
-
Física de partículas: En el Gran Colisionador de Hadrones (LHC) del CERN, se emplean agentes de AI para analizar datos de colisiones de partículas, utilizando detección de anomalías para identificar pistas prometedoras que podrían indicar la existencia de partículas no descubiertas.
-
Investigación científica general: Los agentes de AI están ampliando el ritmo y el alcance de los descubrimientos científicos al analizar estudios anteriores, identificando enlaces inesperados y proponiendo experimentos novedosos.
La convergencia de los agentes de inteligencia artificial y los grandes modelos de lenguaje (LLMs) está impulsando a la inteligencia artificial hacia una nueva era de capacidades sin precedentes. Este manual comprensivo examina la dinámica interacción entre estas dos tecnologías, revelando su potencial combinado para revolucionar las industrias y resolver problemas complejos.
Retrataremos la evolución de la IA desde sus orígenes hasta el advenimiento de los agentes autónomos y el ascenso de los sofisticados LLMs. También exploraremos consideraciones éticas, que son fundamentales para el desarrollo responsable de la IA. Esto nos ayudará asegurar que estas tecnologías se alinean con nuestros valores humanos y el bienestar de la sociedad.
Al concluir este manual, tendrás una comprensión profunda de la potencia simbiótica de los agentes de IA y los LLMs, junto con el conocimiento y herramientas para aprovechar esta tecnología de vanguardia.
Capítulo 1: Introducción a los Agentes de Inteligencia Artificial y los Modelos de Lenguaje
¿Qué son los Agentes de Inteligencia Artificial y los Modelos de Lenguaje?
La rápida evolución de la inteligencia artificial (IA) ha traido una sinergia transformadora entre los grandes modelos de lenguaje (LLMs) y los agentes de IA.
Los agentes artificiales son sistemas autónomos diseñados para percibir su entorno, tomar decisiones y ejecutar acciones para alcanzar objetivos específicos. presentan características como la autonomía, la percepción, la reactividad, el razonamiento, la toma de decisiones, el aprendizaje, la comunicación y orientación a objetivos.
Por otra parte, los LMS son sistemas artificiales sofisticados que utilizan técnicas de aprendizaje profundo y grandes conjuntos de datos para comprender, generar y predecir texto humanoide.
Estos modelos, como GPT-4, Mistral, LLama, han demostrado capacidades destacadas en tareas de procesamiento de lenguaje natural, incluyendo la generación de texto, traducción de lenguaje y agentes conversacionales.
Características clave de los agentes artificiales
Los agentes artificiales poseen varias características definitorias que los diferencian de los software tradicionales:
-
Autonomía: Pueden operar de manera independiente sin intervención humana constante.
-
Percepción: Los agentes pueden sentir e interpretar su entorno a través de varias entradas.
-
Reactividad: Responden dinámicamente a los cambios en su entorno.
-
Pensamiento y Toma de Decisiones: Los agentes pueden analizar datos y tomar decisiones informadas.
-
Aprendizaje: Mejoran su rendimiento con el tiempo a través de la experiencia.
-
Comunicación: Los agentes pueden interactuar con otros agentes o humanos utilizando varios métodos.
-
Orientación hacia los objetivos: Están diseñados para alcanzar objetivos específicos.
Capacidades de los Modelos de Lenguaje de gran Escala
Los LLM han demostrado una amplia gama de capacidades, incluyendo:
-
Generación de Texto: Los LLM pueden producir texto coherente y relevante contextualmente basado en los prompts.
-
Traducción de Lenguaje: Pueden traducir texto entre diferentes lenguas con alta precisión.
-
Resumen
: Las LLM pueden condensar textos largos en resúmenes concisos mientras retienen información clave.
-
Respuesta a preguntas: Pueden proporcionar respuestas precisas a preguntas basadas en su amplia base de conocimientos.
-
Análisis de sentimento: Las LLM pueden analizar y determinar el sentimiento expresado en un texto dado.
-
Generación de código: Pueden generar fragmentos de código o funciones enteras basado en descripciones en lenguaje natural.
Niveles de los agentes de AI
Los agentes de AI pueden clasificarse en diferentes niveles en función de sus capacidades y complejidad. Según un documento en arXiv, los agentes de AI se categorizan en cinco niveles:
-
Nivel 1 (L1): Agentes de AI como asistentes de investigación, donde los científicos establecen hipótesis y especifican tareas para alcanzar objetivos.
- Nivel 2 (L2): Agentes de AI que pueden realizar tareas específicas de forma autónoma en un ámbito definido, como análisis de datos o toma de decisiones simples.
-
Nivel 3 (L3): Agentes de AI capaces de aprender de la experiencia y adaptarse a nuevas situaciones, mejorando sus procesos de toma de decisiones.
-
Nivel 4 (L4): Agentes de AI con habilidades avanzadas de razonamiento y resolución de problemas, capaces de manejar tareas complejas de varios pasos.
-
Nivel 5 (L5): Agentes de AI completamente autónomos que pueden operar independientemente en entornos dinámicos, tomando decisiones y realizando acciones sin intervención humana.
Limitaciones de los Modelos de Lenguaje Grandes
Costos de Entrenamiento y Restricciones de Recursos
Los modelos de lenguaje grandes (LLM) como GPT-3 y PaLM han revolucionado el procesamiento del lenguaje natural (NLP) al aprovechar técnicas de aprendizaje profundo y conjuntos de datos vastos.
Pero estos avances van acompañados de un costo significativo. La capacitación de LLS requiere recursos computacionales sustanciales, generalmente implicando miles de GPUs y un consumo energético extensivo.
Según Sam Altman, director general de OpenAI, el costo de entrenamiento de GPT-4 superó los 100 millones de dólares. Esto se ajusta al tamaño y complejidad del modelo reportados, con estimaciones que sugieren que tiene alrededor de 1 billón de parámetros. Sin embargo, otras fuentes ofrecen cifras diferentes:
-
Un informe filtrado indicó que el costo de entrenamiento de GPT-4 fue de aproximadamente 63 millones de dólares, considerando la potencia computacional y la duración del entrenamiento.
-
A mediados de 2023, algunas estimaciones sugerían que entrenar un modelo similar a GPT-4 podría costar alrededor de 20 millones de dólares y tardar alrededor de 55 días, reflejando avances en eficiencia.
Este elevado costo del entrenamiento y la mantención de los LMM limita su adopción generalizada y escalabilidad.
Limitaciones de los Datos y Bias
El rendimiento de los LMM depende en gran medida de la calidad y diversidad de los datos de entrenamiento. A pesar de haber sido entrenados en datos masivos, los LMM pueden todavía mostrar prejuicios presentes en los datos, llevando a resultados sesgados o inadecuados. Estos prejuicios pueden manifestionarse en varias formas, incluyendo prejuicios de género, étnico y cultural, que pueden perpetuar estereotipos e información errónea.
También, la naturaleza estática de los datos de entrenamiento significa que los LMM pueden no estar actualizados con la información más reciente, limitando su efectividad en entornos dinámicos.
Especialización yComplejidad
Mientras que los LMM sobresalen en tareas generales, a menudo tienen dificultades con tareas especializadas que requieren conocimiento específico del dominio y complejidad alta.
Por ejemplo, las tareas en campos como la medicina, la ley y la investigación científica exigen un profundo entendimiento delterminología especializada y la lógica compleja, que los LMM pueden no poseer inicialmente. Esta limitación requiere la integración de capas adicionales de experiencia y afinado para hacer que los LMM sean efectivos en aplicaciones especializadas.
Límites de Entrada y Sensoriales
Las LLMs (Long Short-Term Memory) procesan principalmente entradas basadas en texto, lo que les impide interactuar de forma multimodal con el mundo. Aunque pueden generar y comprender texto, carecen de la capacidad de procesar entradas visuales, auditivas o sensoriales directamente.
Esta limitación obstaculiza su aplicación en campos que requieren una integración sensorial comprehensiva, como la robótica y los sistemas autónomos. Por ejemplo, una LLM no puede interpretar datos visuales de una cámara o datos auditivos de un micrófono sin capas de procesamiento adicionales.
Restricciones de Comunicación e Interacción
Las actuales capacidades de comunicación de las LLMs son predominantemente basadas en texto, lo que limita su capacidad para participar en formas más inmersivas e interactivas de comunicación.
Por ejemplo, mientras las LLMs pueden generar respuestas de texto, no pueden producir contenido de vídeo o representaciones holográficas, que son cada vez más importantes en las aplicaciones de realidad virtual y aumentada (leer más aquí). Esta restricción reduce la efectividad de las LLMs en entornos que demandan interacciones multimodales ricas.
Cómo Superar las Limitaciones con los Agentes de IA
Los agentes de inteligencia artificial ofrecen una solución prometedora para muchas de las limitaciones enfrentadas por las LLMs. Estos agentes están diseñados para operar de forma autónoma, percibir su entorno, tomar decisiones y ejecutar acciones para alcanzar metas específicas. Al integrar agentes de IA con LLMs, es posible mejorar sus capacidades y abordar sus limitaciones inherentes.
-
Mejorado Contexto y Memoria: Los agentes AI pueden mantener contexto a lo largo de múltiples interacciones, permitiendo respuestas más coherentes y pertinentes en contexto. Esta capacidad es particularmente útil en aplicaciones que requieren memoria a largo plazo y continuidad, como el servicio al cliente y los asistentes personales.
-
Integración Multimodal: Los agentes AI pueden incorporar entradas sensoriales de diferentes fuentes, como cámaras, micrófonos y sensores, permitiendo a los LLM procesar y responder a datos visuales, auditivos y sensoriales. Esta integración es crucial para aplicaciones en robótica y sistemas autónomos.
-
Conocimiento Especializado y Experiencia: Los agentes de AI se pueden afinar con conocimiento específico del dominio, mejorando la capacidad de LLM para realizar tareas especializadas. Este enfoque permite la creación de sistemas expertos que pueden manejar consultas complejas en campos como la medicina, la ley y la investigación científica.
-
Comunicación Interactiva e Inmersiva: Los agentes de AI pueden facilitar formas más inmersivas de comunicación generando contenido de video, controlando pantallas holográficas e interactuando con entornos virtuales y de realidad aumentada. Esta capacidad amplía la aplicación de LLM en campos que requieren interacciones ricas y multimodales.
Aunque las modelos de lenguaje grande han demostrado capacidades destacables en el procesamiento del lenguaje natural, no están exentos de limitaciones. Los altos costos de entrenamiento, los sesgos en los datos, los desafíos de especialización, las limitaciones sensoriales y las restricciones de comunicación presentan obstáculos significativos.
Pero la integración de los agentes inteligentes artificiales ofrece una vía viable para superar estas limitaciones. Al aprovechar las ventajas de los agentes inteligentes artificiales, es posible mejorar la funcionalidad, adaptabilidad y aplicabilidad de las MLL, abriendo camino a sistemas inteligentes artificiales más avanzados y versátiles.
Capítulo 2: La Historia de la Inteligencia Artificial y los Agentes AI
El origen de la Inteligencia Artificial
El concepto de inteligencia artificial (IA) tiene raíces que se extienden mucho más allá de la era digital moderna. La idea de crear máquinas capaces de razonar de manera similar a los humanos se puede rastrear hasta mitos antiguos y debates filosóficos. Pero la formalización de la IA como una disciplina científica tuvo lugar a mediados del siglo XX.
La Conferencia de Dartmouth de 1956, organizada por John McCarthy, Marvin Minsky, Nathaniel Rochester y Claude Shannon, es ampliamente considerada como el lugar de nacimiento de la inteligencia artificial como campo de estudio. Este evento seminal reunió a investigadores líderes para explorar el potencial de crear máquinas que pudieran simular la inteligencia humana.
Optimismo Inicial y el Invierno de la IA
Los primeros años de la investigación en IA estuvieron caracterizados por optimismo desbordante. Los investigadores lograron importantes avances en el desarrollo de programas capaces de resolver problemas matemáticos, jugar juegos y incluso realizar procesamiento de lenguaje natural en su estado más rudimentario.
Pero este entusiasmo inicial se calmó con la comprensión de que la creación de máquinas realmente inteligentes era mucho más compleja de lo anticipado inicialmente.
La década de 1970 y 1980 vieron una época de financiación reducida y de interés en la investigación de la IA, comúnmente referida como el “Invierno de la IA“. este declive se debió principalmente al fracaso de los sistemas de IA para cumplir con las expectativas altas establecidas por los pioneros tempranos.
De los Sistemas Base en Reglas a Aprendizaje Automático
La Era de los Sistemas Expertos
La década de 1980 presenció un resurgimiento del interés en la IA, principalmente impulsado por el desarrollo de los sistemas expertos. Estos programas basados en reglas fueron diseñados para emular los procesos de toma de decisiones de expertos humanos en determinados dominios.
Sistemas expertos encontraron aplicaciones en varios campos, incluyendo la medicina, las finanzas y la ingeniería. Sin embargo, estaban limitados por su incapacidad para aprender de la experiencia o adaptarse a situaciones nuevas fuera de sus reglas programadas.
El ascenso de la Aprendizaje Automático
Las limitaciones de los sistemas basados en reglas abrieron la puerta a un cambio de paradigma hacia el aprendizaje automático. Este enfoque, que adquirió relevancia en la década de 1990 y 2000, se enfoca en desarrollar algoritmos que puedan aprender de datos y hacer predicciones o tomar decisiones basadas en estos.
Técnicas de aprendizaje automático, como redes neuronales y máquinas de soporte vectorial, demostraron un éxito destacado en tareas como la reconocimiento de patrones y la clasificación de datos. La aparición de los grandes datos y la potencia computacional aumentada impulsaron aún más el desarrollo y aplicación de algoritmos de aprendizaje automático.
La emergencia de agentes AI autónomos
De la IA Especializada a la IA General
Mientras tanto, como las tecnologías de AI seguían evolucionando, los investigadores comenzaron a explorar la posibilidad de crear sistemas más versátiles y autónomos. Este cambio marcó la transición de la IA especializada, diseñada para tareas específicas, hacia la búsqueda de la inteligencia artificial general (AGI).
AGI tiene como objetivo desarrollar sistemas capaces de realizar cualquier tarea intelectual que puede realizar un ser humano. Mientras que la AGI verdadera permanece como un objetivo lejano, se ha logrado un progreso significativo en la creación de sistemas AI más flexibles y adaptables.
El papel de la Aprendizaje Profundo y las Redes Neuronales
El surgimiento del aprendizaje profundo, un subconjunto del aprendizaje automático basado en redes neuronales artificiales, ha sido fundamental para avanzar en el campo de la IA.
Algoritmos de aprendizaje profundo, inspirados en la estructura y función del cerebro humano, han demostrado capacidades excepcionales en áreas como la reconocimiento de imágenes y voz, el procesamiento del lenguaje natural y el juego. Estos avances han puesto las bases para el desarrollo de agentes autónomos de IA más sofisticados.
Características y Tipos de Agentes AI
Los agentes AI son sistemas autónomos capaces de percibir su entorno, tomar decisiones y realizar acciones para alcanzar objetivos específicos. Tienen características como la autonomía, la percepción, la reactividad, el razonamiento, la toma de decisiones, el aprendizaje, la comunicación y la orientación hacia los objetivos.
Hay varios tipos de agentes AI, cada uno con capacidades únicas:
-
Agentes de Reflejo Simple: Responden a estímulos específicos basados en reglas predefinidas.
-
Agentes Reflejos Basados en Modelo: Mantienen un modelo interno del entorno para tomar decisiones.
-
Agentes Basados en Objetivos: Ejecutan acciones para alcanzar objetivos específicos.
-
Agentes Basados en Utilidad: Consideran resultados potenciales y eligen acciones que maximizan la utilidad esperada.
-
Agentes Aprendedores: Mejoran la toma de decisiones con el tiempo a través de técnicas de aprendizaje automático.
Retos y Consideraciones Éticas
Como los sistemas AI se hacen cada vez más avanzados y autónomos, traen consideraciones críticas para asegurar que su uso se mantiene dentro de los límites aceptados socialmente.
Los Modelos de Lenguaje Large (LLMs), en particular, actúan como supercargadores de la productividad. Pero esto plantea una cuestión crucial: ¿Qué harán estos sistemas supercargar -intenciones buenas o malas? Cuando la intención detrás del uso de AI es malévola, resulta imprescindible que estos sistemas detecten este uso indebido utilizando varias técnicas de NLP o otras herramientas a nuestro disposición.
Los ingenieros de ML tienen acceso a una gama de herramientas y metodologías para abordar estos desafíos:
-
Análisis de Sentimientos: Al emplear el análisis de sentimientos, los LLM pueden evaluar la tonalidad emocional del texto para detectar lenguaje dañino o agresivo, ayudando a identificar un posible uso indebido en plataformas de comunicación.
-
Filtrado de Contenido: herramientas como el filtrado por palabras clave y el ajuste de patrones se pueden utilizar para prevenir la generación o la difusión de contenido dañino, como el discurso de odio, la desinformación o material explícito.
-
Herramientas de Detección de Bias: La implementación de marcos de detección de sesgos, como AI Fairness 360 (IBM) o Fairness Indicators (Google), puede ayudar a identificar y mitigar los sesgos en los modelos de lenguaje, garantizando que los sistemas de AI operan de manera justa y equitativa.
-
Técnicas de Explicabilidad: Utilizando herramientas de explicabilidad como LIME (Local Interpretable Model-agnostic Explanations) o SHAP (SHapley Additive exPlanations), los ingenieros pueden comprender y explicar los procesos de toma de decisiones de los LLMs, facilitando la detección y el abordaje de comportamientos no intencionados.
-
Pruebas de Adversario: Simulando ataques maliciosos o entradas dañinas, los ingenieros pueden someter a prueba de estrés a los LLMs utilizando herramientas como TextAttack o Adversarial Robustness Toolbox, identificando vulnerabilidades que podrían ser explotadas con fines maliciosos.
-
Guías y Marcos de AI Ética: Adoptar guías de desarrollo de AI ético, como las proporcionadas por el IEEE o la Asociación en AI, puede guiar la creación de sistemas de AI responsables que prioricen el bienestar social.
Además de estas herramientas, es por eso que necesitamos un equipo Red Team dedicado para AI —equipos especializados que empujan a las LLM hasta sus límites para detectar lagunas en sus defensas. Los equipos Red Team simulan escenarios adversarios y descubren vulnerabilidades que podrían dejar de ser notadas.
Pero es importante reconocer que la gente detrás del producto tiene por mucho el mayor efecto sobre él. Muchos de los ataques y desafíos que enfrentamos hoy han existido incluso antes de que se desarrollaran las LLM, destacando que el elemento humano permanece central para asegurar que la AI sea utilizada éticamente y responsablemente.
La integración de estas herramientas y técnicas en la pipeline de desarrollo, junto con un vigilante equipo Red Team, es fundamental para asegurar que las LLM se utilizan para supercargar resultados positivos y detectar y prevenir su mal uso.
Capítulo 3: Dónde destacan más las inteligencias artificiales
Las fortalezas únicas de los agentes AI
Los agentes AI se destacan gracias a su capacidad para percibir autonomáticamente su entorno, tomar decisiones y ejecutar acciones para alcanzar objetivos específicos. Esta autonomía, combinada con capacidades avanzadas de aprendizaje automático, permite a los agentes AI realizar tareas que son demasiado complejas o demasiado repeticivas para los humanos.
Aquí están las principales ventajas que hacen brillar a los agentes artificiales inteligentes:
-
Autonomía y Eficiencia: Los agentes artificiales inteligentes pueden operar de manera independiente sin intervención humana constante. Esta autonomía les permite manejar tareas las 24 horas del día, los 7 días de la semana, mejorando significativamente la eficiencia y la productividad. Por ejemplo, los chatbots impulsados por inteligencia artificial pueden manejar hasta un 80% de las consultas de clientes habituales, reduciendo los costos operativos y mejorando los tiempos de respuesta.
-
Tomada de Decisiones Avanzada: Los agentes artificiales inteligentes pueden analizar grandes cantidades de datos para tomar decisiones informadas. Esta capacidad es particularmente valiosa en campos como la finanza, donde los bots de trading impulsados por inteligencia artificial pueden aumentar significativamente la eficiencia de los trades.
-
Aprendizaje y adaptabilidad: Los agentes de AI pueden aprender de la experiencia y adaptarse a nuevas situaciones. Esta mejora continua les permite mejorar su desempeño con el tiempo. Por ejemplo, los asistentes médicos de AI pueden ayudar a reducir los errores de diagnóstico, mejorando los resultados de la atención médica.
- Personalización: Los agentes de AI pueden proporcionar experiencias personalizadas analizando el comportamiento y las preferencias del usuario. El motor de recomendaciones de Amazon, que genera el 35% de sus ventas, es un ejemplo principal de cómo los agentes de AI pueden mejorar la experiencia del usuario y aumentar los ingresos.
Por qué los agentes de AI son la solución
Los agentes de inteligencia artificial ofrecen soluciones a muchos de los desafíos que enfrentan los sistemas de software tradicionales y operados por humanos. Esta es la razón por la cual son la opción preferida:
-
Escalabilidad: Los agentes de inteligencia artificial pueden escalar operaciones sin un aumento proporcional en los costos. Esta escalabilidad es crucial para las empresas que buscan crecer sin aumentar significativamente su fuerza laboral o gastos operacionales.
-
Consistencia y confiabilidad: A diferencia de los humanos, los agentes de inteligencia artificial no sufren de fatiga o inconsistencia. Pueden realizar tareas repetitivas con alta precisión y confiabilidad, garantizando un rendimiento consistente.
-
Información basada en datos: Los agentes de inteligencia artificial pueden procesar y analizar grandes conjuntos de datos para descubrir patrones e insights que podrían ser pasados por alto por los humanos. Esta capacidad es invaluable para la toma de decisiones en áreas como la finanza, la atención médica y la marketing.
-
Ahorro de costes: al automatizar las tareas rutinarias, los agentes de IA pueden reducir la necesidad de recursos humanos, lo que supone un importante ahorro de costes. Por ejemplo, los sistemas de detección de fraude potenciados por IA pueden ahorrar miles de millones de dólares anuales al reducir las actividades fraudulentas.
Condiciones necesarias para que los agentes de IA funcionen bien
Para garantizar el éxito del despliegue y el rendimiento de los agentes de IA, deben cumplirse ciertas condiciones:
-
Objetivos y casos de uso claros: Definir objetivos y casos de uso específicos es crucial para el despliegue eficaz de los agentes de IA. Esta claridad ayuda a establecer expectativas y medir el éxito. Por ejemplo, establecer un objetivo para reducir los tiempos de respuesta del servicio de atención al cliente en un 50% puede guiar el despliegue de chatbots de IA.
-
Calidad de los Datos: Los agentes de AI dependen de datos de alta calidad para su entrenamiento y funcionamiento. Asegurar que los datos sean precisos, relevantes y actualizados es fundamental para que los agentes tomen decisiones informadas y funcionen efectivamente.
-
Integración con Sistemas Existentes: La integración sin problemas con sistemas existentes y flujos de trabajo es necesaria para que los agentes de AI funcionen de manera óptima. Esta integración garantiza que los agentes de AI puedan acceder a los datos necesarios y interactuar con otros sistemas para realizar sus tareas.
-
Monitoreo y Optimización Continuos: El monitoreo y optimización periódicos de los agentes de AI son cruciales para mantener su rendimiento. Esto implica la supervisión de indicadores clave de rendimiento (KPIs) y la realización de ajustes necesarios basados en retroalimentación y datos de rendimiento.
-
Consideraciones éticas y mitigación de sesgos: La atención a consideraciones éticas y la mitigación de sesgos en los agentes AI es fundamental para garantizar equidad e inclusividad. La implementación de medidas para detectar y prevenir sesgos puede ayudar en la construcción de confianza y en la garantía de un despliegue responsable.
Mejores prácticas para el despliegue de agentes AI
Al desplegar agentes AI, siguiendo las mejores prácticas puede asegurar su éxito y efectividad:
-
Defina objetivos y casos de uso: Identifique claramente los objetivos y casos de uso para el despliegue de agentes AI. Esto ayuda en la establecimiento de expectativas y la medición del éxito.
-
Seleccione la Plataforma AI correcta: Elija una plataforma AI que se ajuste a sus objetivos, casos de uso y infraestructura existente. Considere factores como las capacidades de integración, la escalabilidad y el costo.
-
Desarrolle una Base de Conocimiento Comprensiva: Construya una base de conocimiento bien estructurada y precisa para permitir que los agentes AI proporcionen respuestas relevantes y confiables.
-
Asegúrese de una Integración Seamless: Integre los agentes AI con sistemas existentes como CRM y tecnologías de centro de llamadas para proporcionar una experiencia de cliente unificada.
-
Capacite y Optimice los Agentes AI: Capacite y optimice continuamente los agentes AI utilizando datos de interacciones. Monitorice el rendimiento, identifique áreas para mejorar y actualice los modelos correspondientemente.
-
Implementar Procedimientos de E escalación Apropiados: Establecer protocolos para transferir llamadas complejas o emotivas a agentes humanos, garantizando una transición suave y una resolución eficiente.
-
Monitorear y Analizar Rendimiento: Realizar seguimiento de indicadores clave de rendimiento (KPIs) como las tasas de resolución de llamadas, el tiempo de atención promedio y las puntuaciones de satisfacción del cliente. Utilizar herramientas de análisis para obtener insights y tomar decisiones basadas en datos.
-
Asegurar Privacidad y Seguridad de Datos: Las medidas de seguridad robustas son claves, como hacer que los datos sean anónimos, garantizar una supervisión humana, establecer políticas para la retención de datos y poner en marcha medidas de cifrado fuertes para proteger los datos del cliente y mantener la privacidad.
Agentes AI + LLM: Una Nueva Era de Software Inteligente
Imagine un software que no solo entiende tus solicitudes sino que también las lleva a cabo. Esa es la promesa de combinar agentes AI con Modelos de Lenguaje Largos (LLMs). Esta poderosa pareja está creando una nueva generación de aplicaciones que son más intuitivas, capaces y impactantes que nunca antes.
Agentes AI: Más allá de la Ejecución de Tareas Simples
Mientras que a menudo se compara con asistentes digitales, los agentes AI son mucho más que seguidores de guiones exagerados. Incluyen una gama de tecnologías sofisticadas y operan en un marco que permite tomar decisiones dinámicas y tomar acciones.
-
Arquitectura: Un agente AI típico comprende varios componentes clave:
-
Sensores: Estos permiten que el agente perciba su entorno, recopilando datos de varias fuentes como sensores, API o entrada del usuario.
-
Estado de Creencias: Representa la comprensión del mundo del agente basada en los datos recopilados. Se actualiza constantemente a medida que se hace disponible nueva información.
-
Motor de Razonamiento: Este es el núcleo del proceso de toma de decisiones del agente. Utiliza algoritmos, a menudo basados en aprendizaje por reforzamiento o técnicas de planificación, para determinar la mejor acción en base a sus creencias actuales y objetivos.
-
Actuadores: Estos son las herramientas del agente para interactuar con el mundo. Pueden variar desde enviar llamadas a API hasta controlar robots físicos.
-
-
Retos: Los agentes de inteligencia artificial tradicionales, aunque expertos en manejar tareas bien definidas, a menudo tienen dificultades con:
-
Comprensión del Lenguaje Natural: La interpretación del lenguaje humano complejo, el manejo de ambigüedades y la extracción de significado del contexto siguen siendo desafíos importantes.
-
Razonamiento con Sentido Común: Actualmente, los agentes de inteligencia artificial a menudo carecen de los conocimientos de sentido común y las habilidades de razonamiento que los humanos toman por sentado.
-
Generalización: La formación de agentes para que funcionen bien en tareas no vistas o adaptarse a nuevos entornos sigue siendo un área clave de investigación.
-
LLMs: Desbloqueando la Comprensión y la Generación del Lenguaje
Los LLMs, con su vasto conocimiento codificado dentro de miles de millones de parámetros, traen una capacidad sin precedente del lenguaje a la mesa:
-
Arquitectura de Transformer: La base de la mayoría de los actuales LLMs es la arquitectura de transformer, un diseño de red neuronal que destaca en la procesación de datos secuenciales como el texto. Esto permite que los LLMs capture dependencias a largo plazo en el lenguaje, lo que les permite comprender el contexto y generar texto coherente y relevante contextualmente.
-
Capacidades: Los LLMs sobresalen en una amplia gama de tareas basadas en el lenguaje:
-
Generación de Texto: Desde la escritura de ficción creativa hasta la generación de código en varios lenguajes de programación, los LLMs muestran una fluidez y creatividad destacadas.
-
Respuesta a Preguntas: Pueden proporcionar respuestas concisas y precisas a las preguntas, incluso cuando la información se encuentra distribuida a lo largo de documentos largos.
-
Resumir: Los LLMs pueden condensar grandes volúmenes de texto en resúmenes concisos, extraeniendo información clave y descartando detalles irrelevantes.
-
-
Limitaciones: A pesar de sus impresionantes habilidades, los LLM tienen limitaciones:
-
Falta de Anclaje en el Mundo Real: Los LLM principalmente operan en el ámbito del texto y carecen de la capacidad de interactuar directamente con el mundo físico.
-
Potencial para el Bias y la Alucinación: Entrenados en bases de datos masivas, no curadas, los LLM pueden heredar prejuicios presentes en los datos y, a veces, generar información factíamente incorrecta o no sensata.
-
La Sinergia: Puente entre el Lenguaje y la Acción
La combinación de agentes AI y LLM aborda las limitaciones de cada uno, creando sistemas que son tanto inteligentes como capaces:
-
LLMs como Intérpretes y Planificadores: Las LLM pueden traducir las instrucciones en lenguaje natural a un formato que los agentes AI puedan entender, permitiendo una interacción humano-computadora más intuitiva. También pueden aprovechar su conocimiento para asistir a los agentes en la planificación de tareas complejas, dividiéndolas en pasos más pequeños y manejables.
- Agentes de inteligencia artificial como ejecutores y aprendices: Los agentes de inteligencia artificial proporcionan a las LLM la capacidad de interactuar con el mundo, obtener información y recibir retroalimentación sobre sus acciones. Esta base real del mundo puede ayudar a las LLM a aprender de la experiencia y mejorar su rendimiento con el tiempo.
Esta potente sinergia está impulsando el desarrollo de una nueva generación de aplicaciones que son más intuitivas, adaptables y capaces que nunca antes. Con la continua evolución tanto de las tecnologías de los agentes de inteligencia artificial como de las LLM, podemos esperar ver emerger aún más aplicaciones innovadoras e impactantes, que transformen el paisaje de desarrollo de software y la interacción humano-ordenador.
Ejemplos reales: Transformación de industrias
Este poderoso combinación ya está haciendo olas en varios sectores:
-
Servicio al Cliente: Resolución de problemas con conciencia contextual
- Ejemplo: Imagina un cliente que contacta a un minorista en línea sobre un envío retrasado. Un agente de AI alimentado por una MLG puede comprender la frustración del cliente, acceder a su historial de pedidos, rastrear el paquete en tiempo real y ofrecer proactivamente soluciones como envío prioritario o un descuento en su próxima compra.
-
Creación de Contenido: Generación de Contenido de Alta Calidad a Escala
- Ejemplo: Un equipo de marketing puede utilizar un sistema de AI agente + MLG para generar publicaciones de redes sociales dirigidas, escribir descripciones de productos o incluso crear guiones de videos. La MLG garantiza que el contenido es atractivo e informativo, mientras que el agente de AI se encarga del proceso de publicación y distribución.
-
Desarrollo de Software: acelerar el código y la depuración
- Ejemplo: Un desarrollador puede describir una característica de software que desea construir usando el lenguaje natural. La PAA (Agente de Lenguaje Largamente Maduro) puede generar fragmentos de código, identificar errores potenciales y proponer mejoras, acelerando significativamente el proceso de desarrollo.
-
Atención médica: personalizar el tratamiento y mejorar la atención al paciente
- Ejemplo: Un agente de AI con acceso a la historia clínica de un paciente y equipado con una PAA puede responder a sus preguntas de salud, proporcionar recordatorios de medicación personalizados y ofrecer incluso diagnosticos preliminares basados en sus síntomas.
-
Legalidad: Agilizar la Investigación Legal y la Redacción de Documentos
- Ejemplo: Un abogado necesita redactar un contrato con cláusulas específicas y precedentes legales. Un agente de AI alimentado por una MLG puede analizar las instrucciones del abogado, buscar a través de bases de datos legales vastas, identificar cláusulas y precedentes relevantes e incluso redactar partes del contrato, reduciendo significativamente el tiempo y el esfuerzo requeridos.
-
Creación de Vídeos: Generar Vídeos Engañosos con Facilidad
- Ejemplo: Un equipo de marketing quiere crear un vídeo corto explicando las características de su producto. Pueden proporcionar a un agente de AI + sistema de MLG con un esquema de guión y preferencias de estilo visual. La MLG entonces puede generar un guión detallado, sugiriendo música y imágenes apropiadas e incluso editar el vídeo, automatizando gran parte del proceso de creación de vídeos.
-
Arquitectura: Diseño de edificios con inteligencia artificial
- Ejemplo: Un arquitecto está diseñando un nuevo edificio de oficinas. Pueden utilizar un agente de IA + sistema LLM para introducir sus objetivos de diseño, como maximizar la luz natural y optimizar la utilización del espacio. A continuación, el LLM puede analizar estos objetivos, generar diferentes opciones de diseño e incluso simular cómo funcionaría el edificio en diferentes condiciones ambientales.
-
Construcción: Mejorar la Seguridad y la Eficiencia en los Sitios de Construcción
- Ejemplo: Un agente AI equipado con cámaras y sensores puede monitorear un sitio de construcción para detectar peligros de seguridad. Si un trabajador no lleva el equipo de seguridad adecuado o un equipo está dejado en una posición peligrosa, el LLM puede analizar la situación, alertar al supervisor del sitio y incluso detener automáticamente las operaciones si es necesario.
El Futuro ya está aquí: Una Nueva Era de Desarrollo de Software
La convergencia de agentes AI y LLMs marca un importante salto adelante en el desarrollo de software. Mientras estas tecnologías continúan evolucionando, podemos esperar ver incluso más aplicaciones innovadoras emerger, transformando industrias, simplificando flujos de trabajo y creando posibilidades completamente nuevas para la interacción hombre-ordenador.
Los agentes AI destacan especialmente en áreas que requieren el procesamiento de grandes cantidades de datos, automatización de tareas repetitivas, toma de decisiones complejas y proporcionación de experiencias personalizadas. Al cumplir las condiciones necesarias y siguiendo las mejores prácticas, las organizaciones pueden aprovechar el potencial completo de los agentes AI para impulsar la innovación, la eficiencia y el crecimiento.
Capítulo 4: La Base Filosófica de los Sistemas Inteligentes
El desarrollo de los sistemas inteligentes, especialmente en el ámbito de la inteligencia artificial (IA), requiere un entendimiento profundo de los principios filosóficos. Este capítulo se adentra en las ideas filosóficas centrales que modelan el diseño, desarrollo y uso de la IA. Destaca la importancia de alinear el progreso tecnológico con los valores éticos.
La base filosófica de los sistemas inteligentes no es solo un ejercicio teórico, es un marco vital que garantiza que las tecnologías de la IA sean beneficiosas para la humanidad. Promoviendo la equidad, inclusividad y mejorando la calidad de vida, estos principios ayudan a guiar a la IA para servir nuestros mejores intereses.
Consideraciones Éticas en el Desarrollo de la AI
Conforme los sistemas de AI se integran cada vez más en todos los aspectos de la vida humana, desde la atención médica y la educación hasta la finanza y la gobernanza, necesitamos examinar y aplicar rigurosamente los imperativos éticos que guían su diseño y despliegue.
La cuestión éticamente fundamental gira en torno a cómo se puede crear a la AI para que refleje y sostenga los valores humanos y los principios morales. Esta cuestión es central a la manera en que la IA forjará el futuro de las sociedades alrededor del mundo.
El corazón de este discurso éticos está en el principio de la beneficencia, una piedra angular de la filosofía moral que dicta que las acciones deben tener como objetivo hacer el bien y mejorar el bienestar de los individuos y de la sociedad en su conjunto (Floridi & Cowls, 2019).
En el contexto de la IA, la beneficencia se traduce en diseñar sistemas que contribuyen activamente al progreso humano -sistemas que mejoran los resultados de la atención médica, amplían las oportunidades educativas y facilitan el crecimiento económico equitativo.
Pero la aplicación de la beneficencia en IA no es nada simple. Requiere un enfoque matizado que cuide de manera cuidadosa el equilibrio entre los posibles beneficios de la IA y los posibles riesgos y daños.
Uno de los mayores desafíos en la aplicación del principio de la beneficencia al desarrollo de la IA es la necesidad de un balance delicado entre la innovación y la seguridad.
La IA tiene el potencial para revolucionar campos como la medicina, donde los algoritmos predictivos pueden diagnosticar enfermedades más pronto y con mayor precisión que los médicos humanos. Sin embargo, sin un control ético estricto, estas mismas tecnologías podrían agravar las desigualdades existentes.
Esto podría ocurrir, por ejemplo, si se desplegaran principalmente en regiones prósperas mientras que las comunidades subservidas continúan sin acceso básico a la atención médica.
Debido a esto, el desarrollo ético de la IA require no solo una concentración en la maximización de los beneficios sino también una aproximación proactiva para mitigar el riesgo. Esto implica implementar salvaguardas robustas para prevenir el mal uso de la IA y asegurar que estas tecnologías no causen daño accidentalmente.
El marco ético para la IA también debe ser intrínsecamente inclusivo, garantizando que los beneficios de la IA se distribuyan equitativamente entre todos los grupos sociales, incluyendo aquellos que son tradicionalmente marginados. Esto exige un compromiso con la justicia y la equidad, asegurando que la IA no simplemente refuerza el status quo sino que trabaja activamente para desmantelar las desigualdades sistémicas.
Por ejemplo, la automatización de trabajos impulsada por AI tiene el potencial para aumentar la productividad y el crecimiento económico. Sin embargo, también podría llevar a un reemplazo sustancial de empleos, afectando de manera desproporcionada a los trabajadores de bajos ingresos.
Como pueden ver, un marco ético para la AI debe incluir estrategias para el reparto equitativo de beneficios y la provisión de sistemas de apoyo para aquellos afectados adversamente por los avances de la IA.
El desarrollo ético de la AI requiere una participación continua con stakeholders diversos, incluyendo a eticistas, tecnólogos, responsables políticos y las comunidades que serán más afectadas por estas tecnologías. Esta colaboración interdisciplinaria garantiza que los sistemas de AI no se desarrollan en un vacío sino que se modelan a partir de una amplia gama de perspectivas y experiencias.
A través de este esfuerzo colectivo podemos crear sistemas de AI que no solo reflejan sino que también respaldan los valores que definen nuestra humanidad: compasión, equidad, respeto por la autonomía y una commitments to the common good.
Los considerandos éticos en el desarrollo de la AI no son sólo guías, sino elementos esenciales que determinarán si la AI sirve como una fuerza buena en el mundo. Al basar la AI en los principios de la bondad, la justicia y la inclusividad, y manteniendo un enfoque vigilante en el equilibrio entre la innovación y el riesgo, podemos asegurar que el desarrollo de la AI no avanza sólo la tecnología sino que también mejora la calidad de vida para todos los miembros de la sociedad.
Mientras exploramos las capacidades de la AI, es imprescindible que estos considerandos éticos permanezcan en el centro de nuestros esfuerzos, guiándonos hacia un futuro en el que la AI realmente beneficie a la humanidad.
La Imperativa de un Diseño de AI Centrado en el Ser Humano
El diseño de AI centrado en el ser humano supera las consideraciones técnicas puras. Tiene sus raíces en los profundos principios filosóficos que priorizan la dignidad humana, la autonomía y la agencia.
Este enfoque en el desarrollo de AI se basa fundamentalmente en el marco ético kantiano, que sostiene que las personas deben ser consideradas como fines en sí mismas, no solo como instrumentos para lograr otros fines (Kant, 1785).
Las implicaciones de este principio para el diseño de AI son profundas, requiriendo que los sistemas de AI se desarrollen con un enfoque inflexible en servir los intereses humanos, preservar la agencia humana y respetar la autonomía individual.
Implementación Técnica de Principios Centrados en el Ser Humano
Mejorar la Autonomía Humana a través de la AI: El concepto de autonomía en los sistemas de AI es fundamental, particularmente en asegurar que estas tecnologías empodernen a los usuarios en lugar de controlar o influir de manera indebida sobre ellos.
En términos técnicos, esto implica diseñar sistemas de AI que priorizan la autonomía de los usuarios proporcionándoles las herramientas e información necesarias para tomar decisiones informadas. Esto requiere que los modelos de AI sean contextualmente conscientes, lo que significa que deben comprender el contexto específico en el que se toma una decisión y ajustar sus recomendaciones en consecuencia.
Desde el punto de vista del diseño de sistemas, esto implica la integración de inteligencia contextual en los modelos de AI, lo que permite que estos sistemas se adapten dinámicamente al entorno, preferencias y necesidades del usuario.
Por ejemplo, en la atención médica, un sistema AI que ayuda a los médicos en la diagnose de condiciones debe considerar el historial médico único del paciente, los síntomas actuales, e incluso el estado psicológico para ofrecer recomendaciones que sostengan la experiencia del médico, en lugar de sustituirla.
Esta adaptación contextual garantiza que el AI permanezca como una herramienta de apoyo que refuerce, en lugar de disminuir, la autonomía humana.
Asegurar procesos de toma de decisiones transparentes: La transparencia en los sistemas AI es un requisito fundamental para garantizar que los usuarios puedan confiar y entender las decisiones tomadas por estas tecnologías. Técnicamente, esto se traduce en la necesidad de AI explicable (XAI), que implica desarrollar algoritmos que puedan expresar claramente la lógica detrás de sus decisiones.
Esto es especialmente crucial en dominios como la finanza, la atención médica y la justicia penal, donde la toma de decisiones opacas puede llevar a la desconfianza y a preocupaciones éticas.
La explicabilidad se puede lograr a través de varias aproximaciones técnicas. Un método común es la interpretabilidad post-hoc, donde el modelo AI genera una explicación después de tomar la decisión. Esto podría implicar desglosar la decisión en sus factores constitutivos y mostrar cómo cada uno contribuyó al resultado final.
Otro enfoque son modelos inherentemente interpretables, donde la arquitectura del modelo está diseñada de manera que sus decisiones son transparentes por defecto. Por ejemplo, modelos como árboles de decisión y modelos lineales son naturalmente interpretables porque su proceso de toma de decisiones es fácil de seguir y entender.
El reto en la implementación de la inteligencia artificial explicable radica en equilibrar la transparencia con el rendimiento. A menudo, modelos más complejos, como las redes neuronales profundas, son menos interpretables pero más precisos. Así, el diseño de la IA centrada en humanos debe considerar el compromiso entre la interpretabilidad del modelo y su poder predictivo, garantizando que los usuarios puedan confiar y comprender decisiones de IA sin sacrificar precisión.
Permitir un Control Humano Significativo: Un control humano significativo es crucial para asegurar que los sistemas de IA operan dentro de los límites éticos y operacionales. Este control implica diseñar sistemas de IA con salvaguardas y mecanismos de override que permitan a los operadores humanos intervenir cuando sea necesario.
La implementación técnica del control humano puede abordarse de varias maneras.
Una aproximación es la de incorporar sistemas con humano en el ciclo, donde los procesos de toma de decisiones de la IA son monitoreados y evaluados continuamente por operadores humanos. Estos sistemas están diseñados para permitir la intervención humana en puntos críticos, garantizando que la IA no actúe de manera autónoma en situaciones donde se requieren juicios éticos.
Por ejemplo, en el caso de los sistemas de armas autónomos, la supervisión humana es fundamental para evitar que la IA tome decisiones de vida o muerte sin input humano. Esto podría implicar fijar límites operacionales estrictos que la IA no puede superar sin autorización humana, incorporando así salvaguardas éticas en el sistema.
Otra consideración técnica es el desarrollo de rastreos de auditoría, que son registros de todas las decisiones y acciones tomadas por el sistema IA. Estas trazas proporcionan una historia transparente que puede ser revisada por operadores humanos para asegurar el cumplimiento de los estándares éticos.
Los rastreos de auditoría son particularmente importantes en sectores como la finanza y el derecho, donde las decisiones deben ser documentadas y justificables para mantener la confianza pública y cumplir con los requisitos regulatorios.
Balance entre Autonomía y Control: Uno de los mayores desafíos técnicos en la IA centrada en el ser humano es encontrar el equilibrio correcto entre autonomía y control. Aunque los sistemas AI están diseñados para operar de manera autónoma en muchos escenarios, es crucial que esta autonomía no socava el control o supervisión humana.
Este equilibrio se puede lograr a través de la implementación de niveles de autonomía, que determinan la grado de independencia que tiene la IA en la toma de decisiones.
Por ejemplo, en sistemas semi-autónomos como los coches autónomos, los niveles de autonomía van desde asistencia básica al conductor (donde el conductor humano permanece en control total) hasta la automatización completa (donde la IA es responsable de todas las tareas de conducción).
El diseño de estos sistemas debe garantizar que, independientemente del nivel de autonomía, el operador humano conserva la capacidad para intervenir y anular la IA si es necesario. Esto requiere interfaces de control sofisticadas y sistemas de apoyo a decisiones que permitan a los humanos tomar el control rápidamente y efectivamente cuando sea necesario.
Además, el desarrollo de marcos éticos para la IA es fundamental para guiar las acciones autónomas de los sistemas de IA. Estos marcos son conjuntos de reglas y directrices integradas en la IA que dictan cómo debe comportarse en situaciones éticamente complejas.
Por ejemplo, en la atención médica, un marco ético para la IA podría incluir reglas sobre el consentimiento del paciente, la privacidad y la priorización de tratamientos en función de las necesidades médicas en lugar de consideraciones financieras.
Al integrar directamente estos principios éticos en los procesos de toma de decisiones de la IA, los desarrolladores pueden asegurar que la autonomía del sistema se ejerce de una manera que se ajusta a los valores humanos.
La integración de principios humano-centrados en el diseño de la IA no es sólo un ideal filosófico sino una necesidad técnica. Al potenciar la autonomía humana, garantizar la transparencia, permitir la supervisión significativa y equilibrar la autonomía con el control, los sistemas de IA se pueden desarrollar de manera que realmente sirvan a la humanidad.
Estas consideraciones técnicas son esenciales para crear IA que no solo amplíe las capacidades humanas sino que respete y defienda los valores que son fundamentales para nuestra sociedad.
Con la evolución continua de la IA, el compromiso con el diseño humano-centrado será crucial para asegurar que estas poderosas tecnologías se utilicen ética y responsablemente.
Cómo asegurar que los beneficios de la IA sean para la humanidad: Mejorar la calidad de vida
Al participar en el desarrollo de sistemas de IA, es fundamental basar sus esfuerzos en el marco ético del utilitarismo —un filosofía que enfatiza la mejora de la felicidad y el bienestar general.
En este contexto, la IA posee el potencial para abordar desafíos críticos de la sociedad, particularmente en áreas como la atención médica, la educación y la sostenibilidad ambiental.
El objetivo es crear tecnologías que mejoren significativamente la calidad de vida de todos. Sin embargo, esta búsqueda trae complejidades. El utilitarismo ofrece una razón convincente para desplegar ampliamente la IA, pero también pone en primer plano importantes cuestiones éticas sobre quién se beneficia y quién podría quedar rezagado, especialmente entre las poblaciones vulnerables.
Para navegar estos desafíos, necesitamos un enfoque sofisticado y técnicamente informado —uno que equilibre la búsqueda amplia del bien de la sociedad con la necesidad de justicia y equidad.
Cuando se aplican los principios utilitaristas a la IA, su enfoque debería ser en optimizar los resultados en determinados dominios. En el área de la atención médica, por ejemplo, las herramientas de diagnóstico impulsadas por la IA tienen el potencial para mejorar drásticamente los resultados de los pacientes mediante la posibilidad de realizar diagnósticos más tempranos y precisos. Estos sistemas pueden analizar grandes conjuntos de datos para detectar patrones que podrían pasar desapercibidos para los profesionales humanos, ampliando así el acceso a atención médica de calidad, particularmente en entornos con recursos insuficientes.
Sin embargo, el despliegue de estas tecnologías requiere una cuidadosa consideración para evitar reforzar las desigualdades existentes. Los datos utilizados para entrenar los modelos de IA pueden variar significativamente de una región a otra, lo que afecta a la precisión y fiabilidad de estos sistemas.
Esta disparidad pone de relieve la importancia de establecer marcos sólidos de gobernanza de datos que garanticen que sus soluciones sanitarias basadas en IA sean representativas y justas.
En el ámbito educativo, la capacidad de la IA para personalizar el aprendizaje es prometedora. Los sistemas de IA pueden adaptar el contenido educativo para satisfacer las necesidades específicas de cada estudiante, mejorando así los resultados del aprendizaje. Mediante el análisis de los datos sobre el rendimiento y el comportamiento de los alumnos, la IA puede identificar los puntos en los que un alumno puede tener dificultades y proporcionarle apoyo específico.
Pero mientras se trabaja para obtener estos beneficios, es crucial ser consciente de los riesgos, como el potencial de reforzar los prejuicios o marginar a los alumnos que no se ajustan a los patrones típicos de aprendizaje.
Mitigar estos riesgos requiere la integración de mecanismos de equidad en los modelos de IA, asegurando que no favorezcan inadvertidamente a ciertos grupos. Y mantener el papel de los educadores es fundamental. Su juicio y experiencia son indispensables para que las herramientas de IA sean realmente eficaces y solidarias.
En términos de sostenibilidad medioambiental, el potencial de la IA es considerable. Los sistemas de IA pueden optimizar el uso de los recursos, vigilar los cambios medioambientales y predecir las repercusiones del cambio climático con una precisión sin precedentes.
Por ejemplo, la IA puede analizar vastas cantidades de datos ambientales para predecir patrones climáticos, optimizar el consumo de energía y minimizar el desperdicio, acciones que contribuyen al bienestar de las generaciones actuales y futuras.
Pero este avance tecnológico trae consigo su propio conjunto de desafíos, particularmente respecto al impacto ambiental de los propios sistemas de IA.
El consumo de energía necesario para operar sistemas IA a gran escala puede anular los beneficios ambientales que buscan alcanzar. Así que desarrollar sistemas IA eficientes en términos de energía es crucial para asegurar que su impacto positivo en la sostenibilidad no sea minado.
Al desarrollar sistemas IA con objetivos utilitaristas, es importante considerar también las implicaciones para la justicia social. El utilitarismo se enfoca en maximizar la felicidad general pero no aborda necesariamente la distribución de los beneficios y daños entre diferentes grupos sociales.
Esto plantea el potencial de que los sistemas IA puedan beneficiar desproporcionadamente a aquellos que ya están privilegiados, mientras que los grupos marginados pueden ver poco o ningún mejoramiento en sus circunstancias.
Para contrarrestar esto, su proceso de desarrollo de IA debe Incorporar principios enfocados en la equidad, asegurando que los beneficios se distribuyen equitativamente y que cualquier daño potencial se aborda. Esto puede implicar diseñar algoritmos que específicamente busquen reducir las biases y involucrar una amplia gama de perspectivas en el proceso de desarrollo.
Al trabajar en el desarrollo de sistemas de inteligencia artificial dirigidos a mejorar la calidad de vida, es fundamental equilibrar el objetivo utilitario de maximizar el bienestar con la necesidad de justicia y equidad. Esto requiere un enfoque sofisticado, técnicamente fundado, que considere las implicaciones más amplias del despliegue de AI.
Mediante la diseño cuidadoso de sistemas de AI que sean tanto efectivos como equitativos, puedes contribuir a un futuro en el que los avances tecnológicos realmente sirvan a las diversas necesidades de la sociedad.
Implementar salvaguardas contra el potencial de daño
Cuando se desarrollan tecnologías de AI, debes reconocer el potencial innato para el daño y establecer proactivamente salvaguardas robustas para mitigar estos riesgos. Esta responsabilidad está profundamente arraigada en la ética deontológica . Este subcampo de la ética subraya la obligación moral de adherir a las reglas establecidas y a los estándares éticos, garantizando que la tecnología que creas se alinea con los principios morales fundamentales.
La implementación de protocolos de seguridad estrictos no es solo una precaución sino una obligación ética. Estos protocolos deberían abarcar pruebas de sesgo comprensivas, transparencia en los procesos algorítmicos y mecanismos claros para la responsabilidad.
tales salvaguardas son esenciales para prevenir que los sistemas de AI cause daño no intencional, ya sea a través de decisiones sesgadas, procesos opacos o falta de supervisión.
En la práctica, la implementación de estas salvaguardas requiere un profundo entendimiento de ambas dimensiones técnica y ética de la IA.
La prueba de sesgos, por ejemplo, implica no sólo la identificación y corrección de sesgos en datos y algoritmos sino también la comprensión de las implicaciones sociales más amplias de esos sesgos. Debes asegurarte de que tus modelos de AI se entrenen en conjuntos de datos diversos y representativos y se evalúan regularmente para detectar y corregir cualquier sesgo que pueda emerger con el tiempo.
Por otra parte, la transparencia exige que los sistemas de AI se desarrollen de manera que sus procesos de toma de decisiones sean fácilmente comprensibles y revisables por los usuarios y los interesados. Esto implica desarrollar modelos de AI explicables que proporcionen salidas claras e interpretables, permitiendo a los usuarios ver cómo se toman las decisiones y asegurando que dichas decisiones sean justificables y equitativas.
También, los mecanismos de responsabilidad son cruciales para mantener la confianza y asegurar que los sistemas de AI se utilizan de manera responsable. Estos mecanismos deben incluir directrices claras sobre quién es responsable de los resultados de las decisiones de AI, así como procesos para abordar y corregir cualquier daño que pueda ocurrir.
Debes establecer un marco donde las consideraciones éticas se integran en cada etapa del desarrollo de AI, desde el diseño inicial hasta la implementación y más allá. Esto incluye no sólo la adherencia a directrices éticas sino también el monitoreo continuo y ajuste de los sistemas de AI a medida que interactúan con el mundo real.
Al integrar estas salvaguardas en la propia estructura del desarrollo de AI, puedes ayudar a asegurar que el progreso tecnológico sirva el bien común sin llevar a consecuencias negativas no intencionadas.
El papel del control humano y los ciclos de retroalimentación
La supervisión humana en los sistemas AI es un componente crítico para asegurar la implementación ética de AI. El principio de responsabilidad subyace a la necesidad de la participación humana continua en la operación de AI, particularmente en entornos de alto riesgo como la atención médica y la justicia penal.
Los ciclos de retroalimentación, donde la entrada humana se utiliza para refinar y mejorar los sistemas AI, son esenciales para mantener la responsabilidad y la adaptabilidad (Raji et al., 2020). Estos ciclos permiten la corrección de errores y la integración de nuevas consideraciones éticas a medida que los valores sociales evolucionan.
Al integrar la supervisión humana en los sistemas AI, los desarrolladores pueden crear tecnologías que no solo son efectivas sino que también están alineadas con normas éticas y expectativas humanas.
Código Ético: Traducir Principios Filosóficos en Sistemas AI
La traducción de los principios filosóficos en los sistemas AI es una tarea compleja pero necesaria. Este proceso implica integrar consideraciones éticas en el código que impulsa los algoritmos de AI.
Conceptos como la equidad, la justicia y la autonomía deben ser codificados dentro de los sistemas AI para asegurar que operan de maneras que reflejen los valores sociales. Esto requiere un enfoque interdisciplinario, donde los éticos, ingenieros y científicos sociales colaboran para definir e implementar directrices éticas en el proceso de codificación.
El objetivo es crear sistemas AI que no solo sean técnicamente competentes sino también morales, capaces de tomar decisiones que respeten la dignidad humana y promuevan el bien social (Mittelstadt et al., 2016).
Promover la inclusión y el acceso equitativo en el desarrollo y la implementación de AI.
La inclusividad y el acceso equitativo son fundamentales para el desarrollo ético de la IA. El concepto racionalista de justicia como equidad proporciona una base filosófica para asegurar que los sistemas de IA se diseñen y desplieguen de maneras que benefician a todos los miembros de la sociedad, especialmente a aquellos que son más vulnerables (Rawls, 1971).
Esto implica esfuerzos proactivos para incluir perspectivas diversas en el proceso de desarrollo, especialmente de grupos subrepresentados y del Sur Global.
Al integrar estas diversas opiniones, los desarrolladores de IA pueden crear sistemas que sean más equitativos y respondan mejor a las necesidades de un espectro más amplio de usuarios. Además, garantizar un acceso equitativo a las tecnologías de IA es crucial para prevenir la exacerbación de las desigualdades sociales existentes.
Abordar la Bias Algorítmico y la Justicia
El bias algorítmico representa una preocupación ética significativa en el desarrollo de la IA, ya que los algoritmos sesgados pueden perpetuar e incluso agravar las desigualdades sociales. Enfrentar este problema requiere un compromiso con la justicia procesal, asegurando que los sistemas de IA se desarrollan a través de procesos justos que consideren el impacto en todos los interesados (Nissenbaum, 2001).
Esto implica identificar y mitigar los sesgos en los datos de entrenamiento, desarrollar algoritmos transparentes y explicables, y implementar comprobaciones de equidad a lo largo de toda la vida del AI.
Al abordar el bias algorítmico, los desarrolladores pueden crear sistemas de IA que contribuyen a una sociedad más justa y equitativa, en lugar de reforzar las desigualdades existentes.
Incorporar Perspectivas Diversas en el Desarrollo de la IA
Incorporar perspectivas diversas al desarrollo de la IA es esencial para crear sistemas inclusivos y equitativos. La inclusión de voces de grupos infrarrepresentados garantiza que las tecnologías de IA no reflejen simplemente los valores y prioridades de un estrecho segmento de la sociedad.
Este enfoque se alinea con el principio filosófico de la democracia deliberativa, que subraya la importancia de los procesos de toma de decisiones inclusivos y participativos (Habermas, 1996).
Al fomentar una participación diversa en el desarrollo de la IA, podemos garantizar que estas tecnologías se diseñen para servir a los intereses de toda la humanidad, en lugar de a los de unos pocos privilegiados.
Estrategias para superar la brecha de la IA
La brecha de la IA, caracterizada por un acceso desigual a las tecnologías de la IA y a sus beneficios, supone un reto importante para la equidad global. Para superar esta brecha es necesario un compromiso con la justicia distributiva, que garantice que los beneficios de la IA se compartan ampliamente entre los diferentes grupos socioeconómicos y regiones (Sen, 2009).
Podemos hacerlo a través de iniciativas que promuevan el acceso a la educación y los recursos de la IA en las comunidades desatendidas, así como mediante políticas que apoyen la distribución equitativa de las ganancias económicas impulsadas por la IA. Al abordar la brecha de la IA, podemos garantizar que la IA contribuya al desarrollo global de forma inclusiva y equitativa.
Equilibrar la innovación con las restricciones éticas
Equilibrar la búsqueda de la innovación con las restricciones éticas es crucial para el avance responsable de la IA. El principio de precaución, que aboga por la cautela ante la incertidumbre, es especialmente pertinente en el contexto del desarrollo de la IA (Sandin, 1999).
Mientras que la innovación impulsa el progreso, debe ser temperada por consideraciones éticas que protegen contra los posibles daños. Esto requiere una evaluación cuidadosa de los riesgos y beneficios de las nuevas tecnologías de AI, así como la implementación de marcos regulatorios que garanticen el mantenimiento de estándares éticos.
Al equilibrar la innovación con las restricciones éticas, podemos fomentar el desarrollo de tecnologías de AI que sean tanto innovadoras como alineadas con los objetivos más amplios del bienestar societal.
Como puede ver, la base filosófica de los sistemas inteligentes proporciona un marco crítico para asegurar que las tecnologías de AI se desarrollen y se desplieguen de maneras éticas, inclusivas y beneficiosas para toda la humanidad.
Al basar el desarrollo de AI en estos principios filosóficos, podemos crear sistemas inteligentes que no solo avancen en las capacidades tecnológicas sino que también mejoren la calidad de vida, promuevan la justicia y aseguran que los beneficios de AI se compartan equitativamente entre la sociedad.
Capítulo 5: Agentes de AI como Enhancers de LLM
La fusión de agentes de AI con Modelos de Lenguaje Largos (LLMs) representa un cambio fundamental en la inteligencia artificial, abordando limitaciones críticas en LLMs que han limitado su aplicabilidad general.
Esta integración permite que las máquinas superan sus roles tradicionales, avanzando de generadores de texto pasivos a sistemas autónomos capaces de razonamiento dinámico y toma de decisiones.
Conforme las sistemas de AI cada vez más dirigen procesos críticos en diversos campos, entender cómo los agentes de AI llenan los huecos en las capacidades de LLM es fundamental para realizar su potencial completo.
Pasando los Puentes en las Capacidades de los Lenguajes de Modelado de Máquina (LLM)
Los LLM, aunque potentes, están inherentemente limitados por los datos en los que se entrenaron y por la naturaleza estática de su arquitectura. Estos modelos operan dentro de un conjunto fijo de parámetros, generalmente definidos por el corpus de texto utilizado durante su fase de entrenamiento.
Esta limitación significa que los LLM no pueden buscar autónomamente información nueva o actualizar su base de conocimientos postentrenamiento. En consecuencia, los LLM a menudo están desactualizados y carecen de la capacidad para proporcionar respuestas relevantes en contexto que requieran datos o insumos en tiempo real más allá de sus datos de entrenamiento iniciales.
Los agentes de IA brindan soluciones a estas limitaciones al integrar dinámicamente fuentes de datos externos, lo que puede ampliar el radio de acción funcional de los LLM.
Por ejemplo, un LLM entrenado con datos financieros hasta 2022 podría proporcionar análisis históricos precisos, pero podría luchar para generar previsiónes de mercado actuales. Un agente de IA puede complementar este LLM al extraer datos en tiempo real de los mercados financieros y aplicar estos inputs para generar análisis más relevantes y actualizados.
Esta integración dinámica garantiza que las salidas no solo son precisas históricamente sino también apropiadas contextualmente para las condiciones actuales.
Mejorar la Autonomía en la Toma de Decisiones
Otro límite significativo de los LLM es su falta de capacidades de toma de decisiones autónomas. Los LLM excelen en la generación de salidas basadas en lenguaje pero fallan en tareas que requieren una toma de decisiones complejas, especialmente en entornos caracterizados por incertidumbre y cambio.
Esta deficiencia se debe principalmente al modelo que depende de datos pre-existentes y la falta de mecanismos para el razonamiento adaptativo o aprendizaje de experiencias nuevas post-deploy.
Los agentes de AI abordan esto proporcionando la infraestructura necesaria para la toma de decisiones autónomas. Pueden tomar las salidas estáticas de un LLM y procesarlas a través de marcos de razonamiento avanzado como sistemas basados en reglas, heurísticas o modelos de aprendizaje por reforzamiento.
Por ejemplo, en un entorno de atención médica, un LLM podría generar una lista de diagnosticos potenciales basados en los síntomas y el historial médico del paciente. Sin embargo, sin un agente de AI, el LLM no puede ponderar estas opciones o recomendar una acción.
Un agente de AI puede intervinir para evaluar estos diagnósticos en comparación con la literatura médica actual, los datos del paciente y factores contextuales, al finalizar una decisión más informada y sugiriendo pasos siguientes accionables. Esta sinergia transforma las salidas de LLM de sólo sugerencias en decisiones ejecutables y conscientes del contexto.
Abordando la Completitud y la Coherencia
La completitud y la coherencia son factores críticos para asegurar la confiabilidad de las salidas de LLM, particularmente en tareas de razonamiento complejas. Debido a su naturaleza parametrizada, los LLM a menudo generan respuestas que son incompletas o carecen de coherencia lógica, especialmente cuando se trata de procesos multiestep o se requiere un entendimiento comprensivo en varios dominios.
Estos problemas surgen del entorno aislado en el que opera el LLM, donde no pueden hacer referencias cruzadas o validar sus salidas contra normas externas o información adicional.
Los agentes inteligentes AI tienen un papel crucial en mitigar estos problemas al introducir mecanismos de retroalimentación iterativa y capas de validación.
Por ejemplo, en el ámbito legal, una LLM podría redactar una versión inicial de una memoria legal basada en sus datos de entrenamiento. Sin embargo, este borrador podría pasar por alto ciertos precedentes o no estructurar lógicamente el argumento.
Un agente inteligente AI puede revisar este borrador, garantizando que cumple con los requeridos estándares de completitud al hacer referencias cruzadas con bases de datos legales externas, comprobando la coherencia lógica y solicitando información adicional o aclaración donde sea necesario.
Este proceso iterativo permite la producción de un documento más robusto y fiable que cumple con los estrictos requerimientos de la práctica legal.
Superar la Isolación a través de la Integración
Uno de los límites más profundos de las LLM es su aislamiento inherente de otros sistemas y fuentes de conocimiento.
Las LLM, tal como están diseñadas, son sistemas cerrados que no interactúan de forma nativa con entornos externos o bases de datos. Esta isolación limita significativamente su capacidad para adaptarse a nueva información o operar en tiempo real, lo que les hace menos efectivas en aplicaciones que requieren interacción dinámica o toma de decisiones en tiempo real.
Los agentes inteligentes AI superan este aislamiento actuando como plataformas integrativas que conectan LLMs con un ecosistema más amplio de fuentes de datos y herramientas computacionales. A través de API y otras estructuras de integración, los agentes inteligentes AI pueden acceder a datos en tiempo real, colaborar con otros sistemas inteligentes y incluso interfaces con dispositivos físicos.
Por ejemplo, en aplicaciones de servicio al cliente, una MLG podría generar respuestas estándar basadas en guiones preentrenados. Sin embargo, estas respuestas pueden ser estáticas y carecer de la personalización necesaria para un engagement efectivo con el cliente.
Un agente IA puede enriquecer estas interacciones integrando datos en tiempo real de perfiles de clientes, interacciones previas y herramientas de análisis de sentimento, lo que ayuda a generar respuestas no solo contextualmente relevantes sino también adaptadas a las necesidades específicas del cliente.
Esta integración transforma la experiencia del cliente de una serie de interacciones guionadas en una conversación dinámica y personalizada.
Ampliar Creatividad y Solución de Problemas
Mientras que las MLG son herramientas poderosas para la generación de contenido, su creatividad y habilidades para resolver problemas son inherentemente limitadas por los datos en los que se entrenaron. Estos modelos a menudo no pueden aplicar conceptos teóricos a nuevos o imprevistos retos, ya que sus capacidades para resolver problemas están limitadas por su conocimiento preexistente y los parámetros de entrenamiento.
Los agentes IA potencian el potencial creativo y para resolver problemas de las MLG utilizando técnicas de razonamiento avanzadas y una gama más amplia de herramientas analíticas. Esta capacidad permite a los agentes IA superar las limitaciones de las MLG, aplicando frameworks teóricos a problemas prácticos de manera innovadora.
Por ejemplo, considere el problema de luchar contra la desinformación en plataformas de medios sociales. Una MLG podría identificar patrones de desinformación basándose en análisis textual, pero podría luchar para desarrollar una estrategia completa para mitigar la propagación de información falsa.
Un agente de IA puede tomar estas ideas, aplicar teorías interdisciplinares de campos como la sociología, la psicología y la teoría de redes, y desarrollar un enfoque sólido y polifacético que incluya la supervisión en tiempo real, la educación de los usuarios y técnicas de moderación automatizadas.
Esta capacidad para sintetizar diversos marcos teóricos y aplicarlos a retos del mundo real ejemplifica las capacidades mejoradas de resolución de problemas que aportan los agentes de IA.
Ejemplos más concretos
Los agentes de IA, con su capacidad para interactuar con diversos sistemas, acceder a datos en tiempo real y ejecutar acciones, abordan estas limitaciones de frente, transformando los LLM de modelos lingüísticos potentes pero pasivos en solucionadores de problemas dinámicos del mundo real. Veamos algunos ejemplos:
1. De datos estáticos a conocimientos dinámicos. De datos estáticos a conocimientos dinámicos: Keeping LLMs in the Loop
-
The Problem: Imagine que le pregunta a un LLM formado en investigación médica anterior a 2023: “¿Cuáles son los últimos avances en el tratamiento del cáncer?”. Sus conocimientos estarían desfasados.
-
La solución del agente de IA: Un agente de IA puede conectar el LLM a revistas médicas, bases de datos de investigación y fuentes de noticias. Ahora, el LLM puede proporcionar información actualizada sobre los últimos ensayos clínicos, opciones de tratamiento y hallazgos de la investigación.
2. Del análisis a la acción: Automatización de tareas basadas en las percepciones del LLM
-
El problema: Un LLM que supervisa las redes sociales de una marca puede identificar un aumento del sentimiento negativo, pero no puede hacer nada para solucionarlo.
-
La solución del agente de IA: Un agente de IA conectado a las cuentas de redes sociales de la marca y equipado con respuestas preaprobadas puede abordar automáticamente las preocupaciones, responder preguntas e incluso derivar problemas complejos a representantes humanos.
3. Del primer borrador al producto pulido: Garantizar la calidad y la precisión
-
El problema: Un LLM encargado de traducir un manual técnico puede producir traducciones gramaticalmente correctas pero técnicamente inexactas debido a su falta de conocimientos específicos del dominio.
-
La Solución del Agente AI: Un agente AI puede integrar la MLG con diccionarios especializados, glosarios, e incluso con expertos del tema para obtener retroalimentación en tiempo real, garantizando que la traducción final sea tanto lingüísticamente precisa como técnicamente válida.
4. Rompiendo Barreras: Conectando MLGs con el Mundo Real
-
El Problema: Una MLG diseñada para el control de la casa inteligente podría tener dificultades para adaptarse a las rutinas y preferencias cambiantes del usuario.
-
La Solución del Agente AI: Un agente AI puede conectar la MLG a sensores, dispositivos inteligentes y calendarios de usuario. Analizando los patrones de comportamiento del usuario, la MLG puede aprender a anticipar necesidades, ajustar automáticamente los ajustes de iluminación y temperatura y incluso sugerir playlists de música personalizados basados en el momento del día y la actividad del usuario.
5. De la Imitación a la Innovación: Ampliar la Creatividad de la LLM
-
El Problema: Una LLM encargada de componer música puede crear piezas que suenen derivadas o que carecen de profundidad emocional, ya que principalmente se basa en patrones encontrados en sus datos de entrenamiento.
-
La Solución del Agente AI: Un agente AI puede conectar a la LLM con sensores de biofeedback que miden las respuestas emocionales de un compositor a diferentes elementos musicales. Incorporando este feedback en tiempo real, la LLM puede crear música que no solo sea técnicamente competente sino también emotiva y original.
La integración de agentes de AI como mejoradores de LLM no representa sólo una mejora incremental, sino una ampliación fundamental de lo que la inteligencia artificial puede lograr. Al abordar las limitaciones inherentes en los MLMs tradicionales, como su base de conocimientos estática, su autonomía de decisión limitada y su entorno operativo aislado, los agentes de AI permiten que estos modelos operuen en su potencial total.
Con la evolución continua de la tecnología de AI, el papel de los agentes de AI en la mejora de LLMs se hace cada vez más fundamental, no solo en la ampliación de las capacidades de estos modelos sino también en la redefinición de los límites de la inteligencia artificial misma. Esta fusión está pavimentando la way para la próxima generación de sistemas de AI, capaces de razonar de forma autónoma, adaptar en tiempo real y resolver problemas innovadores en un mundo en constante cambio.
Capítulo 6: Diseño arquitectónico para integrar agentes de AI con LLMs
La integración de agentes de AI con LLMs depende del diseño arquitectónico, que es crucial para mejorar la toma de decisiones, la adaptabilidad y la escalabilidad. La arquitectura debe ser cuidadosamente diseñada para permitir la interacción fluida entre los agentes de AI y los LLMs, garantizando que cada componente funcione de manera óptima.
Una arquitectura modular, donde el agente de AI actúa como director, dirigiendo las capacidades del LLM, es una de las apuestas que apoyan la gestión dinámica de tareas. Este diseño aprovecha las fortalezas del LLM en el procesamiento del lenguaje natural mientras que permite que el agente de AI administre tareas más complejas, como la razonamiento multiestado o la toma de decisiones contextuales en entornos de tiempo real.
Alternativamente, un modelo híbrido que combina LLMs con modelos especializados y ajustados con precisión ofrece flexibilidad al permitir al agente de IA delegar tareas al modelo más apropiado. Esta abstracción optimiza el desempeño y mejora la eficiencia en un amplio espectro de aplicaciones, lo que la hace particularmente efectiva en contextos operacionales diversos y variables (Liang et al., 2021).

Metodologías de Entrenamiento y Mejores Prácticas
El entrenamiento de agentes de IA integrados con LLMs requiere un enfoque sistemático que equilibra la generalización con la optimización específica de la tarea.
El enfoque de transferir aprendizaje es una técnica clave aquí, permitiendo que una LLM preentrenada en un corpus grande y diverso sea ajustada en datos específicos del dominio relevantes para las tareas del agente de IA. Este método mantiene la base de conocimientos amplia de la LLM mientras que le permite especializarse en aplicaciones particulares, mejorando la eficacia general del sistema.
Además, el aprendizaje por reforzamiento (RL) juega un papel crucial, especialmente en escenarios donde el agente de IA debe adaptarse a entornos en cambio. A través de la interacción con su entorno, el agente de IA puede mejorar continuamente sus procesos de toma de decisiones, becoming more adept at handling novel challenges.
Para asegurar un desempeño confiable en diferentes escenarios, esenciales son las métricas de evaluación rigurosas. Estas deben incluir tanto marcas de referencia estándar como criterios específicos para la tarea, garantizando que el entrenamiento del sistema es fuerte y completo (Silver et al., 2016).
Introducción a la Ajuste de un Modelo de Lenguaje Larga (LLM) y Conceptos de Aprendizaje por Reforzamiento
Este código demuestra una variedad de técnicas relacionadas con el aprendizaje automático y el procesamiento del lenguaje natural (NLP), centrándose en el ajuste fino de grandes modelos de lenguaje (LLM) para tareas específicas y la implementación de agentes de aprendizaje por refuerzo (RL). El código abarca varias áreas clave:
-
Ajuste fino de un LLM: Aprovechamiento de modelos preentrenados como BERT para tareas como el análisis de sentimientos, utilizando la biblioteca Hugging Face
transformers. Esto implica tokenizar conjuntos de datos y utilizar argumentos de entrenamiento para guiar el proceso de ajuste fino. -
Aprendizaje por refuerzo (RL): Introducción a los fundamentos de RL con un simple agente de aprendizaje Q, donde un agente aprende a través de ensayo y error interactuando con un entorno y actualizando su conocimiento a través de tablas Q.
.
-
Modelado de recompensas con la API de OpenAI: Un método conceptual para usar la API de OpenAI para proporcionar dinámicamente señales de recompensa a un agente de RL, permitiendo que un modelo de lenguaje evalúe acciones.
-
Evaluación y Registro del Modelo: Usando bibliotecas como
scikit-learnpara evaluar el rendimiento del modelo a través de la exactitud y las puntuaciones F1, ySummaryWriterde PyTorch para visualizar el progreso de entrenamiento. -
Conceptos Avanzados de RL: Implementar conceptos más avanzados como redes de gradientes de política, aprendizaje por currículo y detención anticipada para aumentar la eficiencia del entrenamiento del modelo.
Este enfoque integral cubre tanto el aprendizaje supervisado, con la finetuning de análisis de sentimento, como el aprendizaje por reforzamiento, ofreciendo pistas sobre cómo se construyen, evalúan y optimizan los sistemas de IA modernos.
Ejemplo de Código
Paso 1: Importar las Bibliotecas Necesarias
Antes de sumergirse en el ajuste fino del modelo y la implementación del agente, es esencial configurar las bibliotecas y módulos necesarios. Este código incluye importaciones de bibliotecas populares como transformers de Hugging Face y PyTorch para manejar redes neuronales, scikit-learn para evaluar el rendimiento del modelo y algunos módulos de propósito general como random y pickle.
-
Bibliotecas de Hugging Face: Estas permiten usar y ajustar modelos preentrenados y tokenizadores del Model Hub.
-
PyTorch: Este es el marco de aprendizaje profundo principal utilizado para operaciones, incluidas capas de redes neuronales y optimizadores.
-
scikit-learn: Proporciona métricas como precisión y puntaje F1 para evaluar el rendimiento del modelo.
-
API de OpenAI: Acceso a los modelos de lenguaje de OpenAI para diversas tareas, como el modelado de recompensas.
-
TensorBoard: Utilizado para visualizar el progreso del entrenamiento.
Aquí está el código para importar las bibliotecas necesarias:
# Importar el módulo random para la generación de números aleatorios.
import random
# Importar los módulos necesarios de la biblioteca transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importar load_dataset para cargar conjuntos de datos.
from datasets import load_dataset
# Importar metrics para evaluar el rendimiento del modelo.
from sklearn.metrics import accuracy_score, f1_score
# Importar SummaryWriter para registrar el progreso de entrenamiento.
from torch.utils.tensorboard import SummaryWriter
# Importar pickle para guardar y cargar modelos entrenados.
import pickle
# Importar openai para utilizar la API de OpenAI (requiere una clave de API).
import openai
# Importar PyTorch para operaciones de aprendizaje profundo.
import torch
# Importar el módulo de red neuronal de PyTorch.
import torch.nn as nn
# Importar el módulo de optimizador de PyTorch (no utilizado directamente en este ejemplo).
import torch.optim as optim
Cada una de estas importaciones juega un papel crucial en diferentes partes del código, desde el entrenamiento y la evaluación del modelo hasta el registro de resultados y la interacción con APIs externas.
Paso 2: Entrenamiento fino-tune de un Modelo de Lenguaje para Análisis de Sentimientos
El proceso de entrenamiento fino-tune de un modelo preentrenado para una tarea específica, como el análisis de sentimientos, implica cargar un modelo preentrenado, ajustarlo según el número de etiquetas de salida (positivo/negativo en este caso), y utilizar un conjunto de datos apropiado.
En este ejemplo, utilizamos AutoModelForSequenceClassification de la biblioteca transformers, con el conjunto de datos IMDB. Este modelo preentrenado puede ser refinado en una porción más pequeña del conjunto de datos para ahorrar tiempo de computación. A continuación, el modelo se entrena utilizando un conjunto personalizado de argumentos de entrenamiento, que incluyen el número de épocas y el tamaño de lote.
A continuación se muestra el código para cargar y refinar el modelo:
# Especificar el nombre del modelo preentrenado de la Hub de Modelos de Hugging Face.
model_name = "bert-base-uncased"
# Cargar el modelo preentrenado con el número especificado de clases de salida.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Cargar un tokenizador para el modelo.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Cargar el conjunto de datos IMDB de Hugging Face Datasets, utilizando solo el 10% para el entrenamiento.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokenizar el conjunto de datos
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Mapear el conjunto de datos a entradas tokenizadas
tokenized_dataset = dataset.map(tokenize_function, batched=True)
En este caso, el modelo se carga utilizando una arquitectura basada en BERT y el conjunto de datos se prepara para el entrenamiento. A continuación, definimos los argumentos de entrenamiento y iniciamos el Entrenador.
# Define los argumentos de entrenamiento.
training_args = TrainingArguments(
output_dir="./results", # Especifica el directorio de salida para guardar el modelo.
num_train_epochs=3, # Establece el número de épocas de entrenamiento.
per_device_train_batch_size=8, # Establece el tamaño de lote por dispositivo.
logging_dir='./logs', # Directorio para almacenar los registros.
logging_steps=10 # Registra cada 10 pasos.
)
# Inicia el entrenador con el modelo, los argumentos de entrenamiento y el conjunto de datos.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Inicia el proceso de entrenamiento.
trainer.train()
# Guarda el modelo refinado.
model.save_pretrained("./fine_tuned_sentiment_model")

Paso 3: Implementación de un agente de aprendizaje por refuerzo simple
El aprendizaje por refuerzo es una técnica de aprendizaje automático en la que un agente aprende a tomar acciones de manera que máxima la recompensa acumulada.
En este ejemplo, definimos un agente de aprendizaje por refuerzo básico que almacena pares estado-acción en una tabla Q. El agente puede explorar aleatoriamente o explotar la mejor acción conocida basada en la tabla Q. La tabla Q se actualiza después de cada acción utilizando una tasa de aprendizaje y un factor de descuento para ponderar las recompensas futuras.
A continuación está el código que implementa este agente de aprendizaje por refuerzo:
# Define la clase del agente Q-learning.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Inicializa la tabla Q.
self.q_table = {}
# Almacena las acciones posibles.
self.actions = actions
# Establece la tasa de exploración.
self.epsilon = epsilon
# Establece la tasa de aprendizaje.
self.alpha = alpha
# Establece el factor de descuento.
self.gamma = gamma
# Define el método get_action para seleccionar una acción basada en el estado actual.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# Explorar aleatoriamente.
return random.choice(self.actions)
else:
# Explotar la mejor acción.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
El agente selecciona acciones basadas en exploración o explotación y actualiza los valores Q después de cada paso.
# Define el método update_q_table para actualizar la tabla Q.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
Paso 4: Uso de la API de OpenAI para Modelado de Recompensas
En algunos escenarios, en lugar de definir una función de recompensa manual, podemos utilizar un potente modelo de lenguaje como GPT de OpenAI para evaluar la calidad de las acciones tomadas por el agente.
En este ejemplo, la función get_reward envía un estado, acción y siguiente estado a la API de OpenAI para recibir una puntuación de recompensa, permitiéndonos aprovechar los grandes modelos de lenguaje para comprender estructuras de recompensa complejas.
# Define la función get_reward para obtener una señal de recompensa de la API de OpenAI.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # Reemplaza con tu clave API de OpenAI real.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
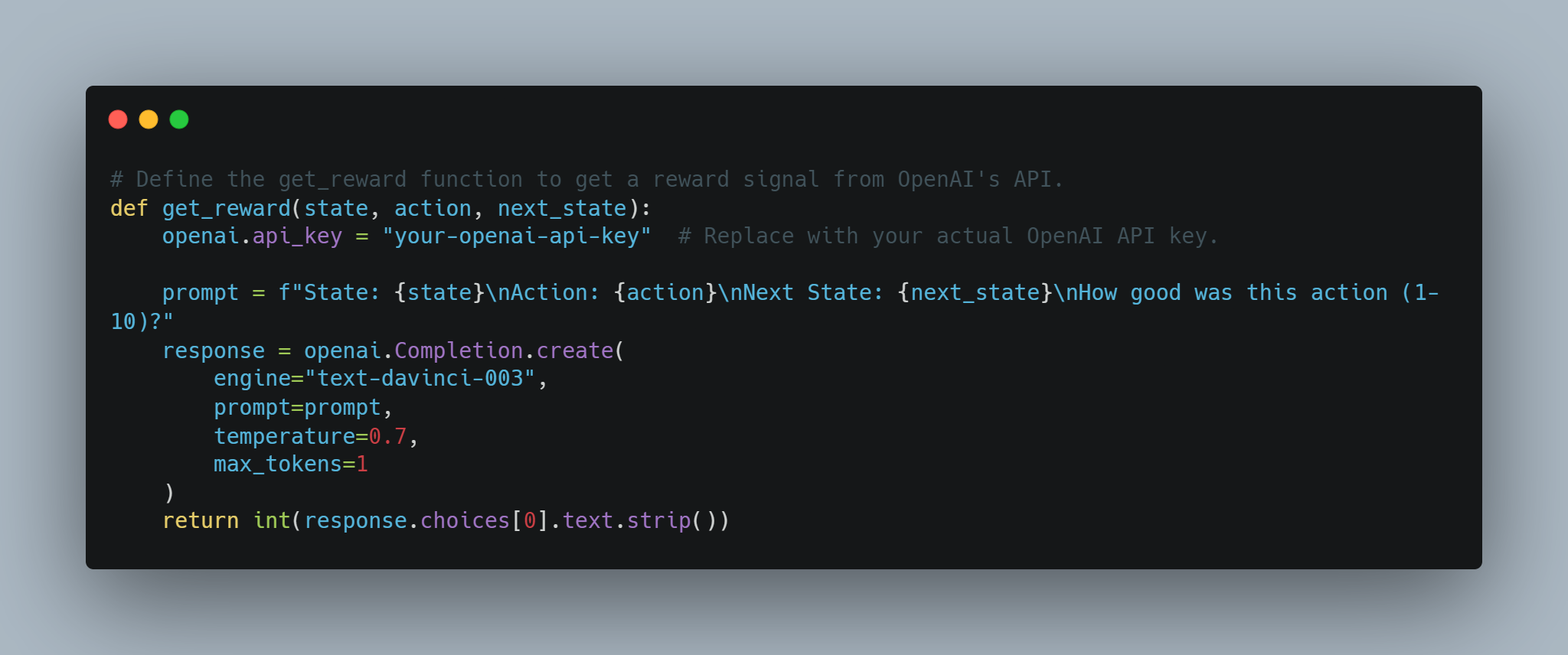
Esto permite un enfoque conceptual donde el sistema de recompensas se determina dinámicamente usando la API de OpenAI, lo cual podría ser útil para tareas complejas donde las recompensas son difíciles de definir.
Paso 5: Evaluación del Rendimiento del Modelo
Una vez que un modelo de aprendizaje automático ha sido entrenado, es fundamental evaluar su rendimiento usando métricas estándares como la precisión y el índice F1.
Esta sección calcula ambos usando etiquetas verdaderas y predichas. La precisión proporciona una medida general de correctitud, mientras que el índice F1 equilibra la precisión y la recuperación, especialmente útil en conjuntos de datos desequilibrados.
Aquí está el código para evaluar el rendimiento del modelo:
# Define las etiquetas verdaderas para la evaluación.
true_labels = [0, 1, 1, 0, 1]
# Define las etiquetas predichas para la evaluación.
predicted_labels = [0, 0, 1, 0, 1]
# Calcula la puntuación de precisión.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calcula el índice F1.
f1 = f1_score(true_labels, predicted_labels)
# Muestra la puntuación de precisión.
print(f"Accuracy: {accuracy:.2f}")
# Muestra el índice F1.
print(f"F1-Score: {f1:.2f}")
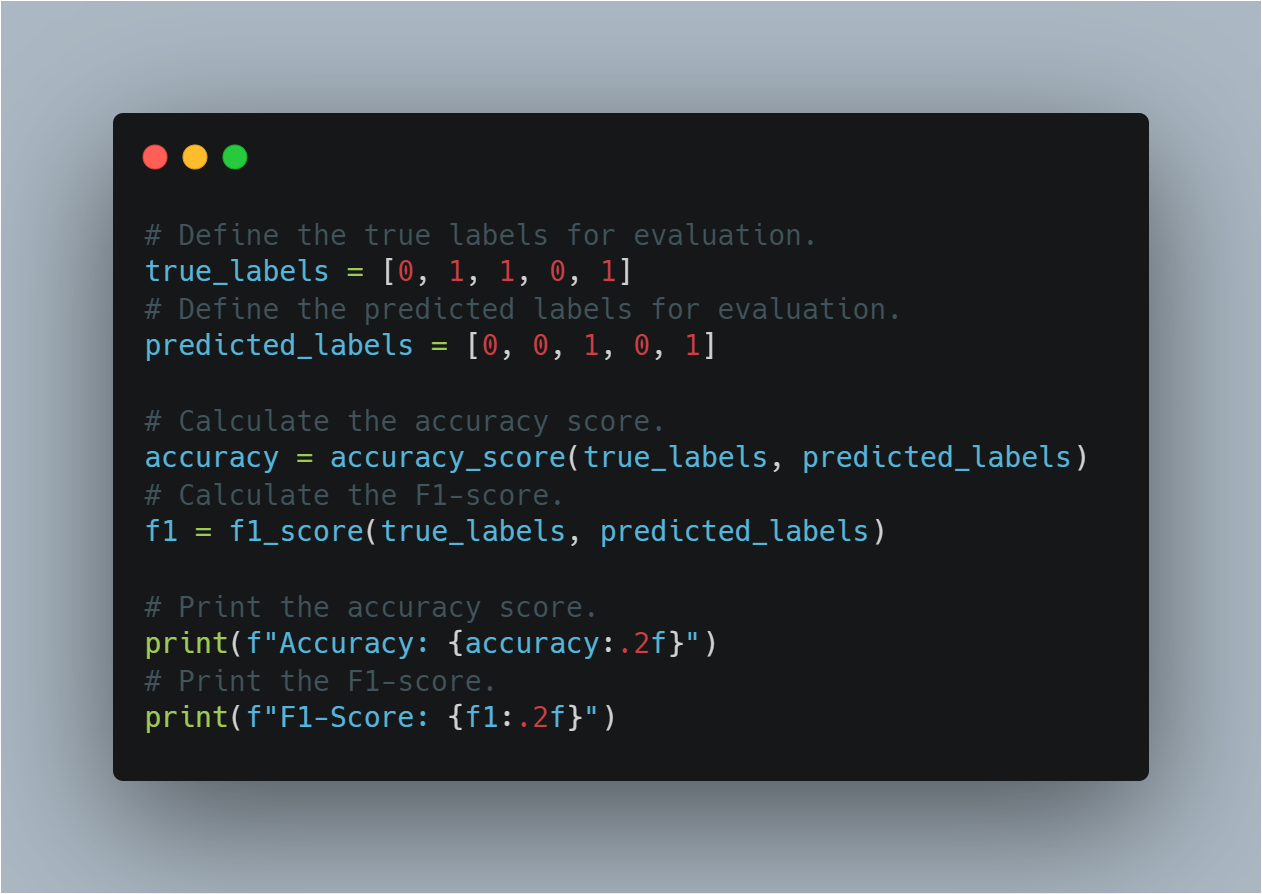
Esta sección ayuda a evaluar cómo bien el modelo ha generalizado datos no vistos utilizando métricas de evaluación bien establecidas.
Paso 6: Agente de Gradiente de Política Básico (Usando PyTorch)
Los métodos de gradiente de política en aprendizaje por reforzamiento optimizan directamente la política maximizando la recompensa esperada.
Esta sección demuestra una implementación simple de una red de políticas utilizando PyTorch, que se puede utilizar para tomar decisiones en RL. La red de política utiliza una capa lineal para salida de probabilidades para diferentes acciones, y se aplica softmax para asegurar que estas salidas formen una distribución de probabilidad válida.
Aquí está el código conceptual para definir un agente de gradiente de política básico:
# Define la clase de red de política.
class PolicyNetwork(nn.Module):
# Inicializa la red de política.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# Define una capa lineal.
self.linear = nn.Linear(input_size, output_size)
# Define el pase hacia delante de la red.
def forward(self, x):
# Aplica softmax a la salida de la capa lineal.
return torch.softmax(self.linear(x), dim=1)
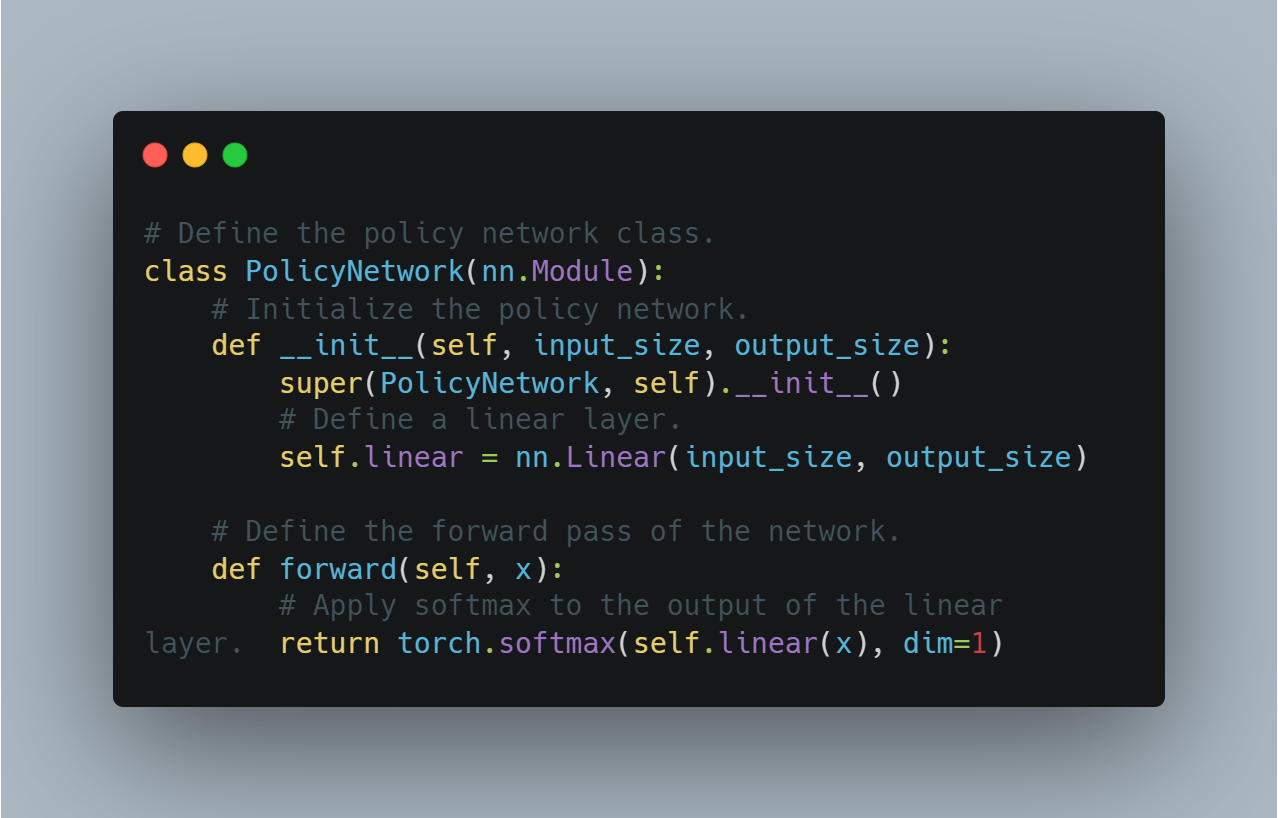
Esto sirve como un paso fundamental para la implementación de algoritmos de aprendizaje por reforzamiento avanzados que utilizan optimización de políticas.
Paso 7: Visualizar el Progreso de Entrenamiento con TensorBoard
Visualizar las métricas de entrenamiento, como la pérdida y la precisión, es vital para comprender cómo se desarrolla la performance del modelo con el tiempo. TensorBoard, una herramienta popular para esto, se puede utilizar para registrar métricas y visualizarlas en tiempo real.
En esta sección, creamos una instancia de SummaryWriter y registramos valores aleatorios para simular el proceso de rastrear de pérdida y precisión durante el entrenamiento.
Así es cómo puedes registrar y visualizar el progreso de entrenamiento utilizando TensorBoard:
# Crea una instancia de SummaryWriter.
writer = SummaryWriter()
# Ejemplo de bucle de entrenamiento para la visualización con TensorBoard:
num_epochs = 10 # Define el número de épocas.
for epoch in range(num_epochs):
# Simula valores aleatorios de pérdida y precisión.
loss = random.random()
accuracy = random.random()
# Registra la pérdida y la precisión en TensorBoard.
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# Cierra el SummaryWriter.
writer.close()
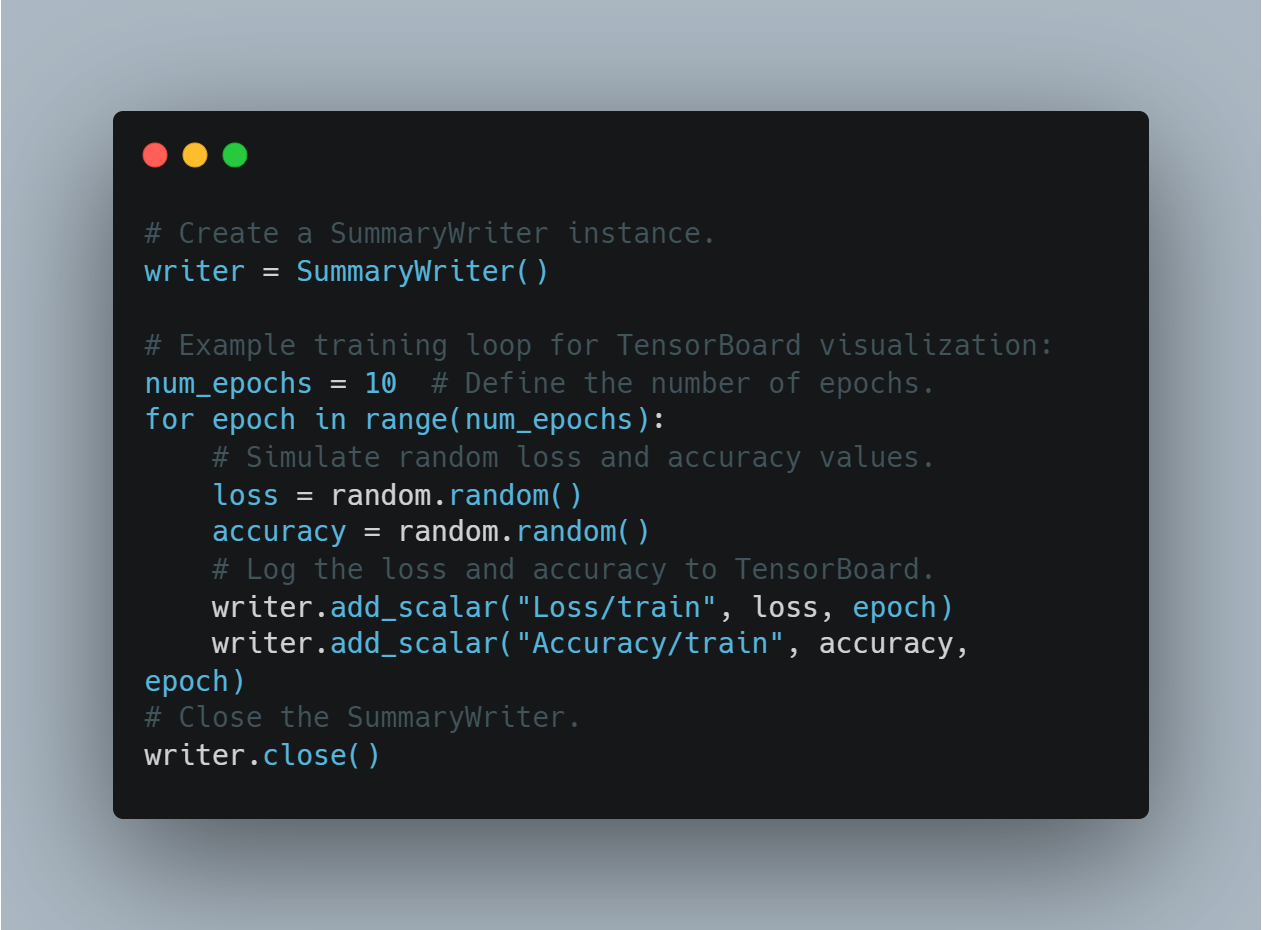
Esto permite a los usuarios monitorear el entrenamiento del modelo y hacer ajustes en tiempo real basándose en la retroalimentación visual.
Paso 8: Guardar y Cargar los Puntos de Control del Agente Entrenado
Después de entrenar a un agente, es crucial guardar su estado aprendido (por ejemplo, valores Q o pesos del modelo) para que pueda ser reutilizado o evaluado más tarde.
Esta sección muestra cómo guardar un agente entrenado usando el módulo pickle de Python y cómo cargarlo desde el disco.
Este es el código para guardar y cargar un agente de aprendizaje Q entrenado:
# Crea una instancia del agente de aprendizaje Q.
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# Entrena al agente (no se muestra aquí).
# Guardar al agente.
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# Cargar al agente.
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
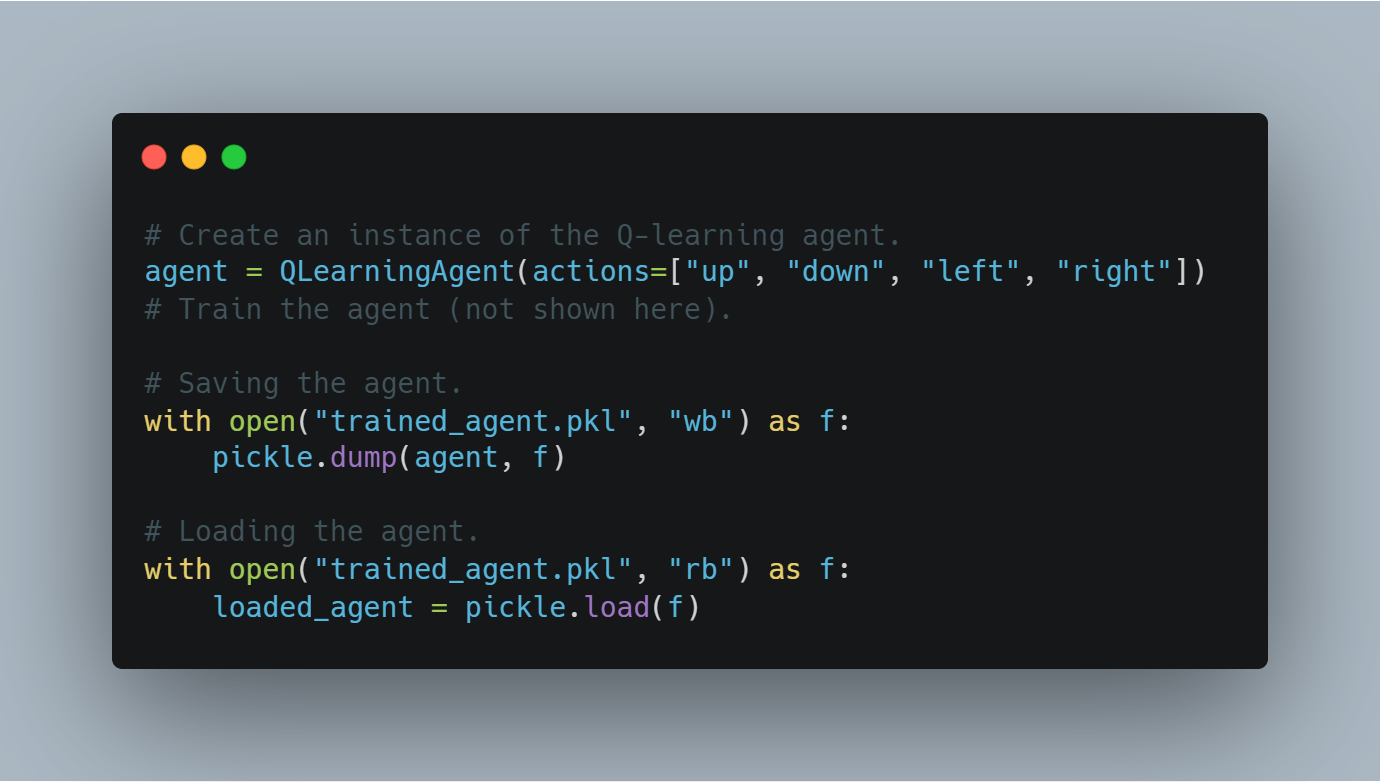
Este proceso de creación de puntos de control garantiza que el progreso del entrenamiento no se pierda y los modelos puedan ser reutilizados en futuros experimentos.
Paso 9: Aprendizaje por Curriculum
El aprendizaje curricular consiste en aumentar gradualmente la dificultad de las tareas presentadas al modelo, comenzando con ejemplos más fáciles y avanzando hacia otros más desafiantes. Esto puede ayudar a mejorar el rendimiento y la estabilidad del modelo durante el entrenamiento.
Este es un ejemplo de uso del aprendizaje curricular en un bucle de entrenamiento:
# Establezca la dificultad inicial de la tarea.
initial_task_difficulty = 0.1
# Ejemplo de bucle de entrenamiento con aprendizaje curricular:
for epoch in range(num_epochs):
# Aumente gradualmente la dificultad de la tarea.
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# Generar datos de entrenamiento con la dificultad ajustada.
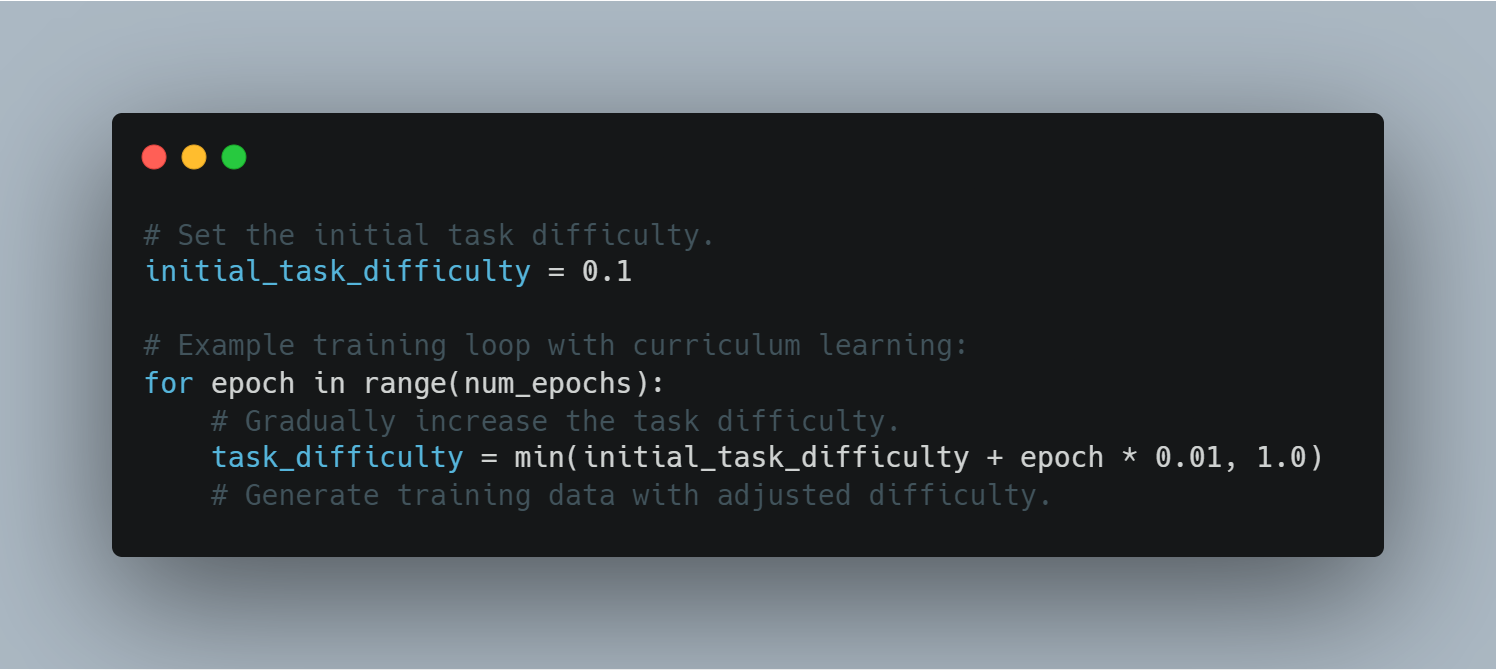
Controlando la dificultad de la tarea, el agente puede manejar progresivamente retos más complejos, lo que conduce a una mejora de la eficacia del aprendizaje.
Paso 10: Implementación de la parada temprana
La parada temprana es una técnica para evitar el sobreajuste durante el entrenamiento deteniendo el proceso si la pérdida de validación no mejora después de un cierto número de épocas (paciencia).
Esta sección muestra cómo implementar la parada temprana en un bucle de entrenamiento, utilizando la pérdida de validación como indicador clave.
Aquí está el código para implementar la parada temprana:
# Inicializar la pérdida de validación más baja a infinito.
best_validation_loss = float("inf")
# Establecer el valor de paciencia (número de épocas sin mejora).
patience = 5
# Iniciar el contador de épocas sin mejora.
epochs_without_improvement = 0
# Ejemplo de bucle de entrenamiento con detención temprana:
for epoch in range(num_epochs):
# Simular la pérdida de validación aleatoria.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

La detención temprana mejora la generalización del modelo evitando un entrenamiento innecesario una vez que el modelo comienza a sobreentrenar.
Paso 11: Utilizar un Modelo de Lenguaje Largamente Entrenado (LLM) para la Transferencia de Tarea sin Ejemplos
En la transferencia de tarea sin ejemplos, se aplica un modelo preentrenado a una tarea para la cual no se ha entrenado específicamente en forma fina.
Usando la pipeline de Hugging Face, esta sección demuestra cómo aplicar un modelo BART preentrenado para la resumición sin un entrenamiento adicional, ilustrando el concepto de aprendizaje de transferencia.
Aquí está el código para usar un LLM preentrenado para la resumición:
# Cargar una pipeline de resumición preentrenada.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Definir el texto para resumir.
text = "This is an example text about AI agents and LLMs."
# Generar la resumen.
summary = summarizer(text)[0]["summary_text"]
# Imprimir el resumen.
print(f"Summary: {summary}")
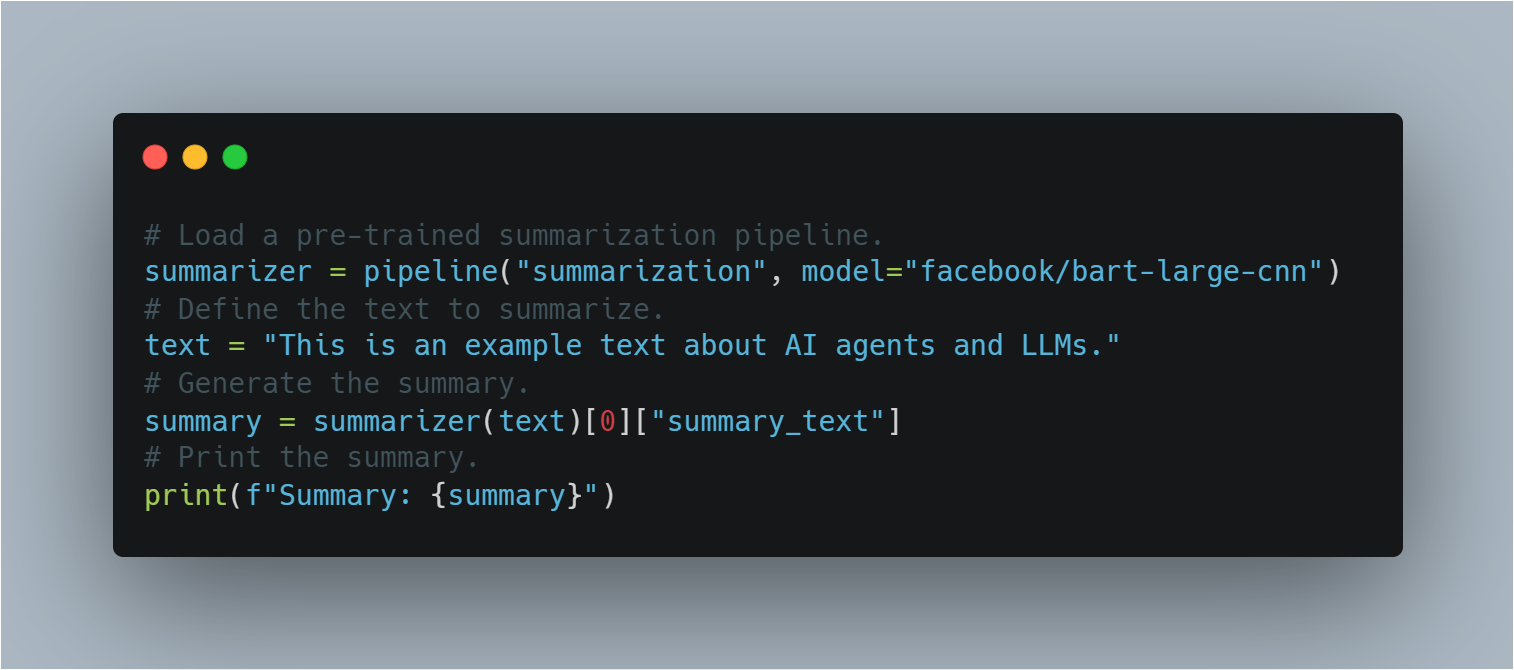
Esto ilustra la flexibilidad de los LLM en la realización de tareas diversas sin la necesidad de un entrenamiento adicional, aprovechando su conocimiento preexistente.
El Ejemplo Completo de Código.
# Importar el módulo random para la generación de números aleatorios.
import random
# Importar módulos necesarios de la biblioteca transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importar load_dataset para cargar conjuntos de datos.
from datasets import load_dataset
# Importar métricas para evaluar el rendimiento del modelo.
from sklearn.metrics import accuracy_score, f1_score
# Importar SummaryWriter para registrar el progreso del entrenamiento.
from torch.utils.tensorboard import SummaryWriter
# Importar pickle para guardar y cargar modelos entrenados.
import pickle
# Importar openai para usar la API de OpenAI (requiere una clave de API).
import openai
# Importar PyTorch para operaciones de aprendizaje profundo.
import torch
# Importar el módulo de redes neuronales de PyTorch.
import torch.nn as nn
# Importar módulo de optimización de PyTorch (no se usa directamente en este ejemplo).
import torch.optim as optim
# --------------------------------------------------
# 1. Ajuste fino de un LLM para Análisis de Sentimientos
# --------------------------------------------------
# Especificar el nombre del modelo preentrenado del Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Cargar el modelo preentrenado con el número especificado de clases de salida.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Cargar un tokenizador para el modelo.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Cargar el conjunto de datos IMDB de Hugging Face Datasets, usando solo el 10% para entrenamiento.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokenizar el conjunto de datos
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Mapear el conjunto de datos a entradas tokenizadas
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Definir argumentos de entrenamiento.
training_args = TrainingArguments(
output_dir="./results", # Especificar el directorio de salida para guardar el modelo.
num_train_epochs=3, # Establecer el número de épocas de entrenamiento.
per_device_train_batch_size=8, # Establecer el tamaño de lote por dispositivo.
logging_dir='./logs', # Directorio para almacenar registros.
logging_steps=10 # Registrar cada 10 pasos.
)
# Inicializar el Trainer con el modelo, argumentos de entrenamiento y conjunto de datos.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Iniciar el proceso de entrenamiento.
trainer.train()
# Guardar el modelo ajustado finamente.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. Implementación de un Agente de Q-Learning Simple
# --------------------------------------------------
# Definir la clase del agente de Q-learning.
class QLearningAgent:
# Inicializar el agente con acciones, epsilon (tasa de exploración), alpha (tasa de aprendizaje) y gamma (factor de descuento).
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Inicializar la tabla Q.
self.q_table = {}
# Almacenar las acciones posibles.
self.actions = actions
# Establecer la tasa de exploración.
self.epsilon = epsilon
# Establecer la tasa de aprendizaje.
self.alpha = alpha
# Establecer el factor de descuento.
self.gamma = gamma
# Definir el método get_action para seleccionar una acción basada en el estado actual.
def get_action(self, state):
# Explorar aleatoriamente con una probabilidad epsilon.
if random.uniform(0, 1) < self.epsilon:
# Devolver una acción aleatoria.
return random.choice(self.actions)
else:
# Explotar la mejor acción basada en la tabla Q.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# Definir el método update_q_table para actualizar la tabla Q después de tomar una acción.
def update_q_table(self, state, action, reward, next_state):
# Si el estado no está en la tabla Q, añadirlo.
if state not in self.q_table:
# Inicializar los valores Q para el nuevo estado.
self.q_table[state] = {a: 0.0 for a in self.actions}
# Si el siguiente estado no está en la tabla Q, añadirlo.
if next_state not in self.q_table:
# Inicializar los valores Q para el nuevo siguiente estado.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# Obtener el valor Q antiguo para el par estado-acción.
old_value = self.q_table[state][action]
# Obtener el valor Q máximo para el siguiente estado.
next_max = max(self.q_table[next_state].values())
# Calcular el valor Q actualizado.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# Actualizar la tabla Q con el nuevo valor Q.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. Uso de la API de OpenAI para Modelado de Recompensas (Conceptual)
# --------------------------------------------------
# Definir la función get_reward para obtener una señal de recompensa de la API de OpenAI.
def get_reward(state, action, next_state):
# Asegurarse de que la clave de API de OpenAI esté configurada correctamente.
openai.api_key = "your-openai-api-key" # Reemplazar con tu clave de API de OpenAI real.
# Construir el prompt para la llamada a la API.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# Hacer la llamada a la API al endpoint Completion de OpenAI.
response = openai.Completion.create(
engine="text-davinci-003", # Especificar el motor a utilizar.
prompt=prompt, # Pasar el prompt construido.
temperature=0.7, # Establecer el parámetro de temperatura.
max_tokens=1 # Establecer el número máximo de tokens a generar.
)
# Extraer y devolver el valor de recompensa de la respuesta de la API.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. Evaluación del Rendimiento del Modelo
# --------------------------------------------------
# Definir las etiquetas verdaderas para la evaluación.
true_labels = [0, 1, 1, 0, 1]
# Definir las etiquetas predichas para la evaluación.
predicted_labels = [0, 0, 1, 0, 1]
# Calcular la puntuación de precisión.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calcular la puntuación F1.
f1 = f1_score(true_labels, predicted_labels)
# Imprimir la puntuación de precisión.
print(f"Accuracy: {accuracy:.2f}")
# Imprimir la puntuación F1.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. Agente de Gradiente de Política Básico (usando PyTorch) - Conceptual
# --------------------------------------------------
# Definir la clase de red de políticas.
class PolicyNetwork(nn.Module):
# Inicializar la red de políticas.
def __init__(self, input_size, output_size):
# Inicializar la clase padre.
super(PolicyNetwork, self).__init__()
# Definir una capa lineal.
self.linear = nn.Linear(input_size, output_size)
# Definir el pase hacia adelante de la red.
def forward(self, x):
# Aplicar softmax a la salida de la capa lineal.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. Visualización del Progreso del Entrenamiento con TensorBoard
# --------------------------------------------------
# Crear una instancia de SummaryWriter.
writer = SummaryWriter()
# Ejemplo de bucle de entrenamiento para visualización en TensorBoard:
# num_epochs = 10 # Definir el número de épocas.
# for epoch in range(num_epochs):
# # ... (Tu bucle de entrenamiento aquí)
# loss = random.random() # Ejemplo: Valor de pérdida aleatorio.
# accuracy = random.random() # Ejemplo: Valor de precisión aleatorio.
# # Registrar la pérdida en TensorBoard.
# writer.add_scalar("Loss/train", loss, epoch)
# # Registrar la precisión en TensorBoard.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (Registrar otras métricas)
# # Cerrar el SummaryWriter.
# writer.close()
# --------------------------------------------------
# 7. Guardar y Cargar Puntos de Control del Agente Entrenado
# --------------------------------------------------
# Ejemplo:
# Crear una instancia del agente de Q-learning.
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (Entrena tu agente)
# # Guardar el agente
# # Abrir un archivo en modo binario de escritura.
# with open("trained_agent.pkl", "wb") as f:
# # Guardar el agente en el archivo.
# pickle.dump(agent, f)
# # Cargar el agente
# # Abrir el archivo en modo binario de lectura.
# with open("trained_agent.pkl", "rb") as f:
# # Cargar el agente desde el archivo.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. Aprendizaje con Currículum
# --------------------------------------------------
# Establecer la dificultad inicial de la tarea.
initial_task_difficulty = 0.1
# Ejemplo de bucle de entrenamiento con aprendizaje de currículum:
# for epoch in range(num_epochs):
# # Aumentar gradualmente la dificultad de la tarea.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (Generar datos de entrenamiento con dificultad ajustada)
# --------------------------------------------------
# 9. Implementación de Parada Temprana
# --------------------------------------------------
# Inicializar la mejor pérdida de validación a infinito.
best_validation_loss = float("inf")
# Establecer el valor de paciencia (número de épocas sin mejora).
patience = 5
# Inicializar el contador de épocas sin mejora.
epochs_without_improvement = 0
# Ejemplo de bucle de entrenamiento con parada temprana:
# for epoch in range(num_epochs):
# # ... (Pasos de entrenamiento y validación)
# # Calcular la pérdida de validación.
# validation_loss = random.random() # Ejemplo: Pérdida de validación aleatoria.
# # Si la pérdida de validación mejora.
# if validation_loss < best_validation_loss:
# # Actualizar la mejor pérdida de validación.
# best_validation_loss = validation_loss
# # Reiniciar el contador.
# epochs_without_improvement = 0
# else:
# # Incrementar el contador.
# epochs_without_improvement += 1
# # Si no hay mejora durante 'patience' épocas.
# if epochs_without_improvement >= patience:
# # Imprimir un mensaje.
# print("¡Parada temprana activada!")
# # Detener el entrenamiento.
# break
# --------------------------------------------------
# 10. Uso de un LLM Preentrenado para Transferencia de Tarea Zero-Shot
# --------------------------------------------------
# Cargar una tubería de resumen preentrenada.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Definir el texto a resumir.
text = "This is an example text about AI agents and LLMs."
# Generar el resumen.
summary = summarizer(text)[0]["summary_text"]
# Imprimir el resumen.
print(f"Summary: {summary}")

Retos en la implementación y la escala
La implementación y la escala de agentes AI integrados con Lenguajes de Modelado Masivo (LLMs) presenta desafíos técnicos y operacionales significativos. Uno de los desafíos primarios es el costo computacional, particularmente a medida que los Lenguajes de Modelado Masivo se hacen más grandes y complejos.
Para abordar este problema, se requieren estrategias eficientes en recursos como la reducción del modelo, la cuantificación y la computación distribuida. Estas pueden ayudar a reducir la carga computacional sin sacrificar el rendimiento.
La mantención de la confiabilidad y robustez en aplicaciones del mundo real también es crucial, lo que requiere un seguimiento continuo, actualizaciones regulares y el desarrollo de mecanismos de salvaguarda para manejar entradas inesperadas o fallos del sistema.
Como estos sistemas se implementan en varias industrias, la adherencia a los estándares éticos -incluyendo la equidad, la transparencia y la responsabilidad- se hace cada vez más importante. Estos considerandos son centrales para la aceptación y el éxito a largo plazo del sistema, impactando la confianza pública y las implicaciones éticas de decisiones impulsadas por AI en diferentes contextos socioéticos (Bender et al., 2021).
La implementación técnica de agentes AI integrados con LLMs implica un diseño arquitectónico cuidadoso, metodologías de entrenamiento rigurosas y un consideración cuidadosa de los desafíos de implementación.
La eficacia y la confiabilidad de estos sistemas en entornos del mundo real dependen de abordar tanto los desafíos técnicos como éticos, asegurando que las tecnologías de AI funcionen sin problemas y responsablemente en varias aplicaciones.
Capítulo 7: El futuro de los agentes AI y LLMs
La convergencia de LLMs con el Aprendizaje por Reforzamiento.
Mientras exploras el futuro de los agentes de AI y los Modelos de Lenguaje Largos (LLMs), resalta especialmente la convergencia de los LLMs con el aprendizaje por reforzamiento, como un desarrollo transformador en particular. Esta integración empuja las fronteras de la AI tradicional, permitiendo a los sistemas no solo generar y entender el lenguaje, sino también aprender de sus interacciones en tiempo real.
A través del aprendizaje por reforzamiento, los agentes de AI pueden modificar adaptativamente sus estrategias en base a la retroalimentación de su entorno, resultando en una refinación continua de sus procesos de toma de decisiones. Esto significa que, a diferencia de modelos estaticos, los sistemas de AI potenciados con reforzamiento pueden manejar tareas cada vez más complejas y dinámicas con mínima supervisión humana.
Las implicaciones de tales sistemas son profundas: en aplicaciones que van desde la robótica autónoma hasta la educación personalizada, los agentes de AI podrían mejorar autónomamente su rendimiento con el tiempo, haciéndolos más eficientes y respetuosos con los demandas evolutivas de sus contextos operacionales.
Ejemplo: Juego de Texto
Imagina un agente de AI que juega un juego de aventuras en texto.
-
Entorno: El propio juego (reglas, descripciones de estado y demás)
-
LLM: Procesa el texto del juego, entiende la situación actual y genera acciones posibles (por ejemplo, “ir hacia el norte”, “tomar espada”).
-
Recompensa: Concedida por el juego según el resultado de la acción (por ejemplo, recompensa positiva por encontrar tesoros, negativa por perder salud).
Ejemplo de código (Conceptual usando Python y la API de OpenAI):
import openai
import random
# ... (Lógica del entorno de juego - no mostrada aquí) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (Ciclo de entrenamiento por RL - simplificado) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (Actualizar el agente RL según la recompensa - no mostrada) ...
state = next_state
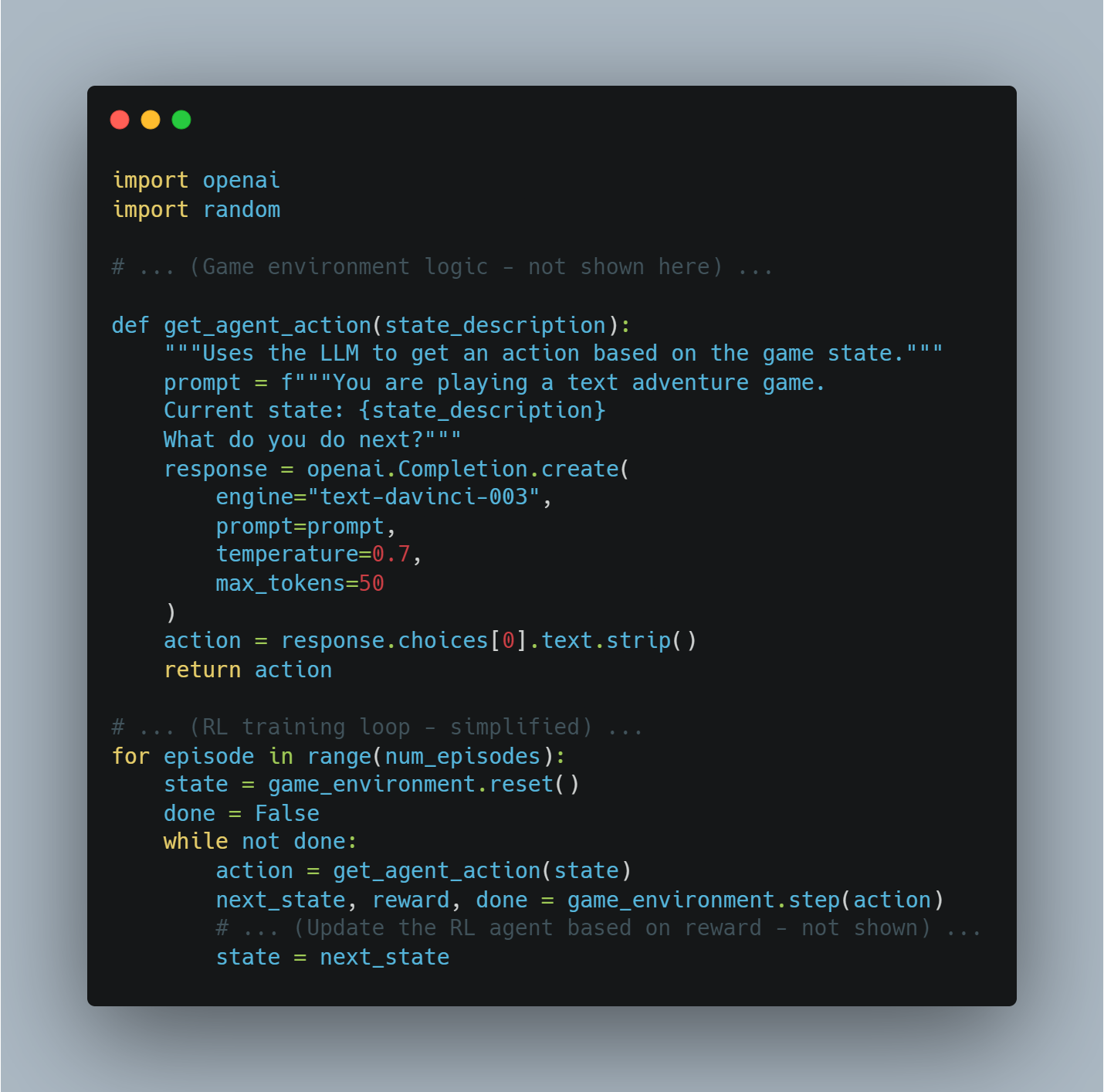
Integración de AI Multimodal
La integración de AI multimodal es otra tendencia crucial que está moldeando el futuro de los agentes artificiales. Al permitir que los sistemas procesen y combinen datos de varias fuentes, como texto, imágenes, audio y entradas sensoriales, la AI multimodal ofrece una comprensión más integral de los entornos en los que operan estos sistemas.
Por ejemplo, en vehículos autónomos, la capacidad de sintetizar datos visuales de las cámaras, datos contextuales de los mapas y actualizaciones de tráfico en tiempo real permite que la AI tome decisiones de conducción más informadas y seguras.
Esta capacidad se extiende a otros campos como la atención médica, donde un agente de inteligencia artificial podría integrar datos de los pacientes de registros médicos, imágenes diagnósticas y información genómica para proporcionar recomendaciones de tratamiento más precisas y personalizadas.
El reto aquí radica en la integración ininterrumpida y el procesamiento en tiempo real de diferentes flujos de datos, lo que requiere avances en la arquitectura de modelos y técnicas de fusión de datos.
Superar éxitosamente estos desafíos será clave para la implementación de sistemas de inteligencia artificial que sean realmente inteligentes y capaces de funcionar en entornos complejos y reales.
Ejemplo de IA multimodal 1: Generación de Descripciones de Imágenes para la Respuesta de Preguntas Visuales
-
Objetivo: Un agente de inteligencia artificial que pueda responder preguntas sobre imágenes.
-
Modalidades: Imagen, Texto
-
Proceso:
-
Extracción de Características de la Imagen: Utilizar una Red Neuronal Convolucional (CNN) preentrenada para extraer características de la imagen.
-
Generación de Descripción: Utilizar un LLM (como un modelo de Transformador) para generar una descripción de la imagen basada en las características extraídas.
-
Respuesta a las Preguntas: Utilizar otro LLM para procesar tanto la pregunta como la descripción generada para proporcionar una respuesta.
-
Ejemplo de código (Conceptual usando Python y Hugging Face Transformers):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# Cargar modelos preentrenados
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# Función para generar subtítulos de imagen
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# Función para responder preguntas sobre la imagen
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# Uso de ejemplo
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
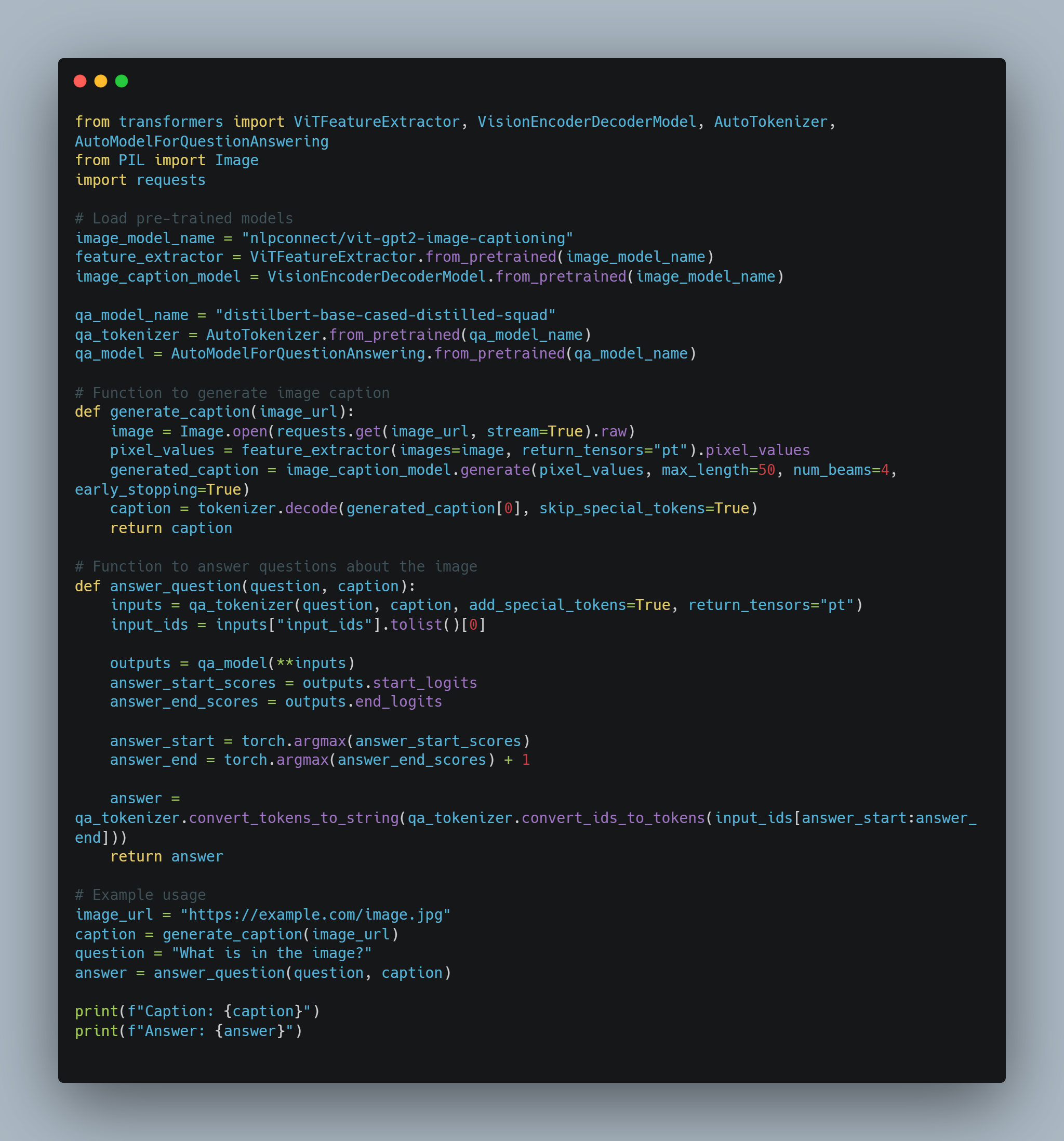
Ejemplo de IA multimodal 2: Análisis de Sentimientos a partir de Texto y Audio
-
Objetivo: Un agente de IA que analiza sentimientos tanto del texto como del tono de un mensaje.
-
Modalidades: Texto, Audio
-
Proceso:
-
Análisis de Sentimiento de Texto: Utilizar un modelo de análisis de sentimiento preentrenado en el texto.
-
Análisis de Sentimiento de Audio: Utilizar un modelo de procesamiento de audio para extraer características como el tono y el pitch, luego usar estas características para predecir el sentimiento.
-
Fusión: Combinar las puntuaciones de sentimiento de texto y audio (por ejemplo, media ponderada) para obtener el sentimiento general.
-
Ejemplo de Código (Conceptual usando Python):
from transformers import pipeline # Para el sentimiento del texto
# ... (Procesamiento de audio y bibliotecas de sentimiento - no mostradas) ...
# Cargar modelos preentrenados
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# Sentimiento del texto
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# Sentimiento del audio
# ... (Procesar audio, extraer características, predecir sentimiento - no mostradas) ...
audio_sentiment = # ... (Resultado del modelo de sentimiento de audio)
audio_confidence = # ... (Puntuación de confianza del modelo de audio)
# Combinar sentimiento (ejemplo: promedio ponderado)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# Ejemplo de uso
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
Retos y consideraciones:
-
Alineación de datos: Es crucial asegurar que los datos de diferentes modalidades estén sincronizados y alineados.
-
Complejidad del modelo: Los modelos multimodales pueden ser complejos para entrenar y requieren grandes conjuntos de datos diversos.
-
Técnicas de fusión: Eligen el método correcto para combinar información de diferentes modalidades es importante y específico del problema.
La IA multimodal es un campo en rápido desarrollo que tiene el potencial para revolucionar cómo los agentes de IA perciben y interactúan con el mundo.
Sistemas de AI Distribuidos y Computación en la EdGE
Viendo la evolución de las infraestructuras de AI, el cambio hacia los sistemas de AI distribuidos, apoyados por computación en la edGE, representa una importante avanzación.
Los sistemas de AI distribuidos descentralizan las tareas computacionales procesando los datos más cerca de la fuente, como dispositivos IoT o servidores locales, en lugar de confiar en recursos de la nube centralizados. Esta aproximación no solo reduce la latencia, que es crucial para aplicaciones sensibles al tiempo como los drones autónomos o la automatización industrial, sino que también mejora la privacidad y seguridad de los datos al mantener la información sensible local.
Además, los sistemas de AI distribuidos mejoran la escalabilidad, permitiendo la implementación de AI en vastas redes, como las ciudades inteligentes, sin sobrecargar los centros de datos centralizados.
Los desafíos técnicos asociados con los sistemas de AI distribuidos incluyen asegurar la consistencia y la coordinación entre los nodos distribuidos, así como optimizar la asignación de recursos para mantener el rendimiento en entornos diversos y potencialmente restringidos en recursos.
Mientras desarrollas y implementas sistemas de AI, abrazar las arquitecturas distribuidas será clave para crear soluciones de AI resistentes, eficientes y escalables que cumplan con las demandas de aplicaciones futuras.
Sistemas AI distribuidos y computación en la periferia ejemplo 1: Aprendizaje federado para el entrenamiento de modelos que preserva la privacidad
-
Objetivo: Entrenar un modelo compartido en varios dispositivos (por ejemplo, smartphones) sin compartir directamente datos sensibles de los usuarios.
-
Enfoque:
-
Entrenamiento Local: Cada dispositivo entrena un modelo local en sus propios datos.
-
Agregación de Parámetros: Los dispositivos envían actualizaciones del modelo (gradientes o parámetros) a un servidor central.
-
Actualización de Modelo Global: El servidor agrega las actualizaciones, mejora el modelo global y envía el modelo actualizado de vuelta a los dispositivos.
-
Ejemplo de Código (Conceptual utilizando Python y PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
# ... (Código para la comunicación entre dispositivos y servidor - no mostrado) ...
class SimpleModel(nn.Module):
# ... (Defina su arquitectura de modelo aquí) ...
# Función de entrenamiento del lado del dispositivo
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # Comience con el modelo global
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (Entrene local_model con device_data) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# Función de agregación del lado del servidor
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (Bucle principal de Aprendizaje Federado simplificado) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

Ejemplo 2: Detección de Objetos en Tiempo Real en Dispositivos de Borde
-
Meta: Implementar un modelo de detección de objetos en un dispositivo con recursos limitados (por ejemplo, Raspberry Pi) para inferir en tiempo real.
-
Enfoque:
-
Optimización del Modelo: Utilizar técnicas como la cuantización del modelo o el recorte para reducir el tamaño del modelo y los requerimientos computacionales.
-
Implementación en la Edge: Implementar el modelo optimizado en el dispositivo de la Edge.
-
Inferencia Local: El dispositivo realiza la detección de objetos localmente, reduciendo la latencia y la dependencia de la comunicación con la nube.
-
Ejemplo de Código (Conceptual utilizando Python y TensorFlow Lite):
import tensorflow as tf
# Cargar el modelo preentrenado (suponiendo que ya está optimizado para TensorFlow Lite)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# Obtener detalles de entrada y salida
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (Capturar imagen de la cámara o cargar de archivo - no mostrado) ...
# Preprocesar la imagen
input_data = ... # Redimensionar, normalizar, etc.
interpreter.set_tensor(input_details[0]['index'], input_data)
# Ejecutar inferencia
interpreter.invoke()
# Obtener la salida
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (Procesar output_data para obtener cuadros de datos, clases, etc.) ...
Retos y consideraciones:
-
Overhead de Comunicación: Coordinar y comunicar eficientemente entre nodos distribuidos es crucial.
-
Gestión de Recursos: Optimizar la asignación de recursos (CPU, memoria, ancho de banda) a través de los dispositivos es importante.
-
Seguridad: Segurizar los sistemas distribuidos y proteger la privacidad de los datos son preocupaciones primordiales.
El AI distribuido y la computación en la periferia son esenciales para construir sistemas de AI escalables, eficientes y alertas a la privacidad, especialmente a medida que avanzamos hacia un futuro con miles de millones de dispositivos interconectados.
Avances en Procesamiento de Lenguaje Natural
El Procesamiento de Lenguaje Natural (NLP) sigue siendo una parte fundamental de los avances en AI, impulsando mejoras significativas en cómo las máquinas entienden, generan y interactúan con el lenguaje humano.
Los avances recientes en NLP, como la evolución de los transformadores y los mecanismos de atención, han drásticamente mejorado la capacidad de AI para procesar estructuras lingüísticas complejas, haciendo que las interacciones sean más naturales y conscientes del contexto.
Este progreso ha permitido que los sistemas AI puedan entender nuestros matices, sentimientos e incluso referencias culturales dentro del texto, llevando a una comunicación más precisa y significativa.
Por ejemplo, en el servicio al cliente, los modelos avanzados de NLP no solo pueden manejar consultas con precisión sino que también detectan señales emocionales de los clientes, permitiendo respuestas más empáticas y efectivas.
Viendo adelante, la integración de capacidades multilingües y un mayor entendimiento semántico en los modelos de NLP ampliará su aplicabilidad, permitiendo una comunicación fluida entre diferentes lenguas y dialectos, e incluso permitiendo que los sistemas AI funcionen como traductores en tiempo real en contextos globales diversos.
El Procesamiento de Lenguaje Natural (NLP) está evolucionando rápidamente, con avances en áreas como los modelos de transformador y los mecanismos de atención. Aquí hay algunos ejemplos y fragmentos de código para ilustrar estos avances:
Ejemplo de NLP 1: Análisis de Sentimiento con Transformadores Ajustados
-
Objetivo: Analizar el sentimiento de un texto con alta precisión, capturando matices y contexto.
-
Enfoque: Ajustar un modelo de transformador pre-entrenado (como BERT) en un conjunto de datos de análisis de sentimiento.
Ejemplo de código (usando Python y Hugging Face Transformers):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Cargar modelo y conjunto de datos pre-entrenados
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3 etiquetas: Positivo, Negativo, Neutral
dataset = load_dataset("imdb", split="train[:10%]")
# Definir argumentos de entrenamiento
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# Ajustar el modelo
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# Guardar el modelo ajustado
model.save_pretrained("./fine_tuned_sentiment_model")
# Cargar el modelo ajustado para inferencia
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# Ejemplo de uso
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
Ejemplo de NLP 2: Traducción Automática Multilingüe con un Solo Modelo
-
Objetivo: Traducir entre múltiples idiomas utilizando un solo modelo, aprovechando representaciones lingüísticas compartidas.
-
Enfoque: Utilizar un modelo transformador de gran escala y multilingüe (como mBART o XLM-R) que ha sido entrenado en un gran conjunto de datos de texto paralelo en varios idiomas.
Ejemplo de código (usando Python y Hugging Face Transformers):
from transformers import pipeline
# Cargar una tubería de traducción multilingüe preentrenada
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# Ejemplo de uso: Inglés a Francés
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# Ejemplo de uso: Francés a Español
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
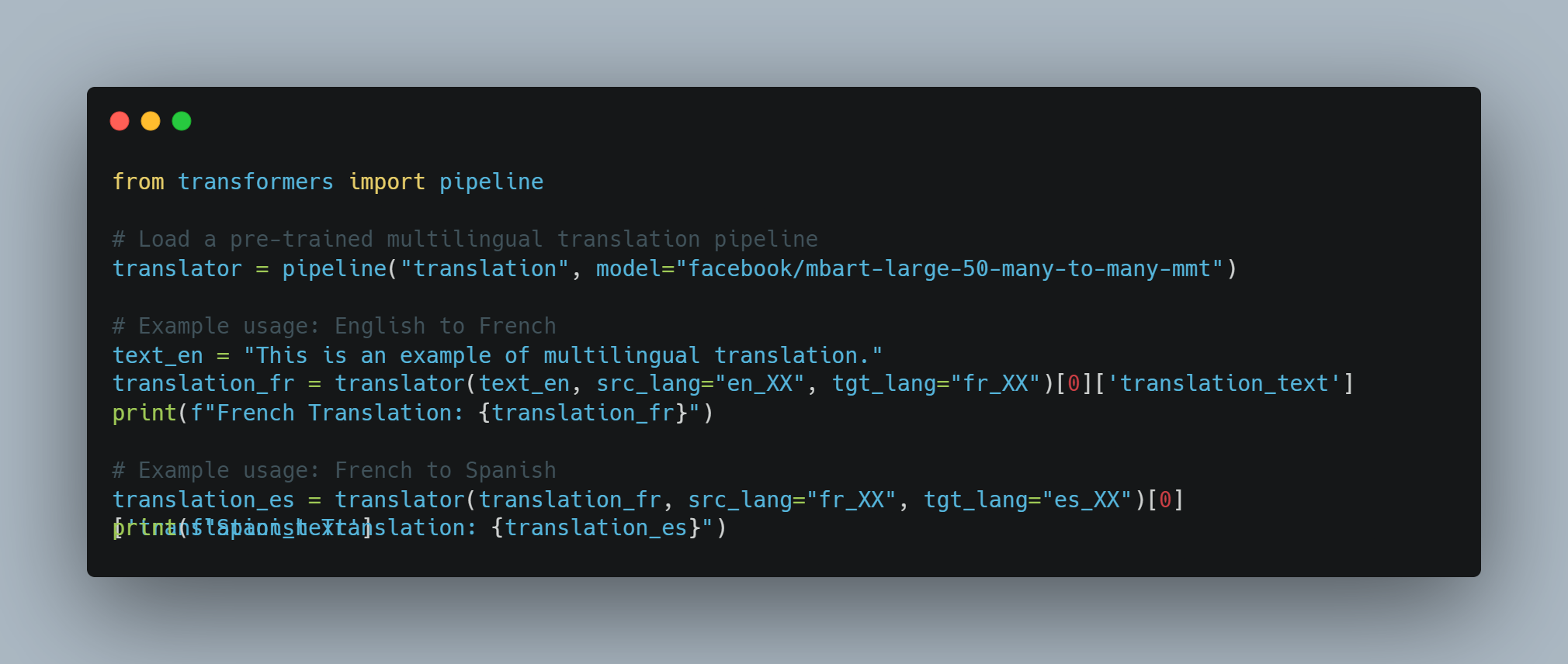
Ejemplo 3 de NLP: Representaciones contextuales de palabras para semejanza semántica
-
Objetivo: Determinar la semejanza entre palabras o oraciones, teniendo en cuenta el contexto.
-
Enfoque: Utilizar un modelo transformador (como BERT) para generar representaciones contextuales de palabras, que capturan el significado de las palabras dentro de una oración específica.
Ejemplo de código (usando Python y Hugging Face Transformers):
from transformers import AutoModel, AutoTokenizer
import torch
# Cargar el modelo premodelo entrenado y tokenizador
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Función para obtener incrustaciones de frases
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# Utilizar la incrustación de tokens [CLS] como la incrustación de frases. embedding
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# Ejemplo de uso
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# Calcular la similitud del coseno
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
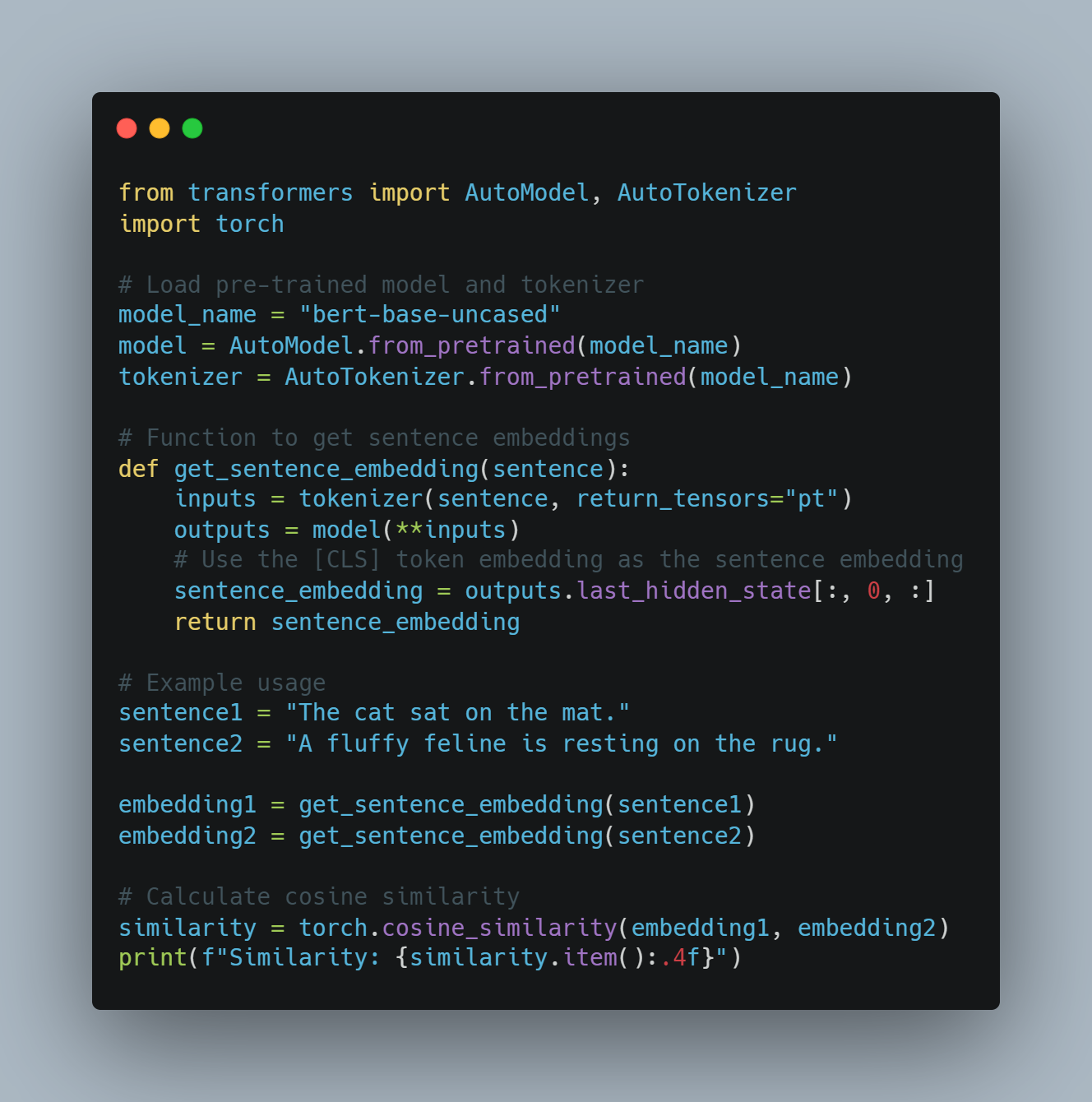
Desafíos y direcciones futuras:
-
Sesgo y equidad: Los modelos de PNL pueden heredar sesgos de sus datos de entrenamiento, lo que conduce a resultados injustos o discriminatorios. Abordar los sesgos es crucial.
-
Razonamiento de sentido común: Los LLM siguen teniendo problemas con el razonamiento de sentido común y la comprensión de la información implícita.
-
Explicabilidad: El proceso de toma de decisiones de los modelos PNL complejos puede ser opaco, lo que dificulta la comprensión de por qué generan determinadas salidas.
A pesar de estos desafíos, la PNL está avanzando rápidamente. La integración de información multimodal, la mejora en la razonamiento común y la mejora en la explicabilidad son áreas clave de investigación en curso que revolucionarán cómo la IA interactúa con el lenguaje humano.
Asistentes AI Personalizados
El futuro de los asistentes AI personalizados se encuentra en vía de ser cada vez más sofisticados, superando la gestión básica de tareas para brindar un apoyo realmente intuitivo y proactivo, personalizado según las necesidades individuales.
Estos asistentes utilizarán algoritmos de aprendizaje automático avanzados para aprender continuamente de los comportamientos, preferencias y rutinas de los usuarios, ofreciendo recomendaciones cada vez más personalizadas y automatizando tareas más complejas.
Por ejemplo, un asistente AI personalizado podría no solo gestionar el horario de un usuario sino también anticipar sus necesidades mediante la sugerencia de recursos relevantes o ajustar su entorno según su estado de ánimo o preferencias anteriores.
Conforme los asistentes de IA se integran más en la vida diaria, su capacidad para adaptarse a contextos cambiantes y proporcionar un soporte ininterrumpido y multiplataforma se convertirá en una diferenciadora clave. El reto radica en equilibrar la personalización con la privacidad, lo que requiere de mecanismos robustos de protección de datos para garantizar que la información sensible es administrada de manera segura mientras se da una experiencia profundamente personalizada.
Ejemplo de Asistente de IA 1: Sugerencia de Tareas Conectadas al Contexto
-
Meta: Un asistente que sugiere tareas basado en el contexto actual del usuario (ubicación, hora, comportamiento pasado).
-
Enfoque:Combinar datos del usuario, señales contextuales y un modelo de recomendación de tareas.
Ejemplo de código (Conceptual en Python):
# ... (Código para la gestión de datos del usuario, detección de contexto - no mostrado) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# Ejemplo: Sugerir según la hora
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# Ejemplo: Sugerir según la ubicación
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (Agregar más reglas o usar un modelo de aprendizaje automático para las sugerencias) ...
# Clasificar y filtrar las sugerencias
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- Ejemplo de Uso ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... otras preferencias ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... otras datos de contexto ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
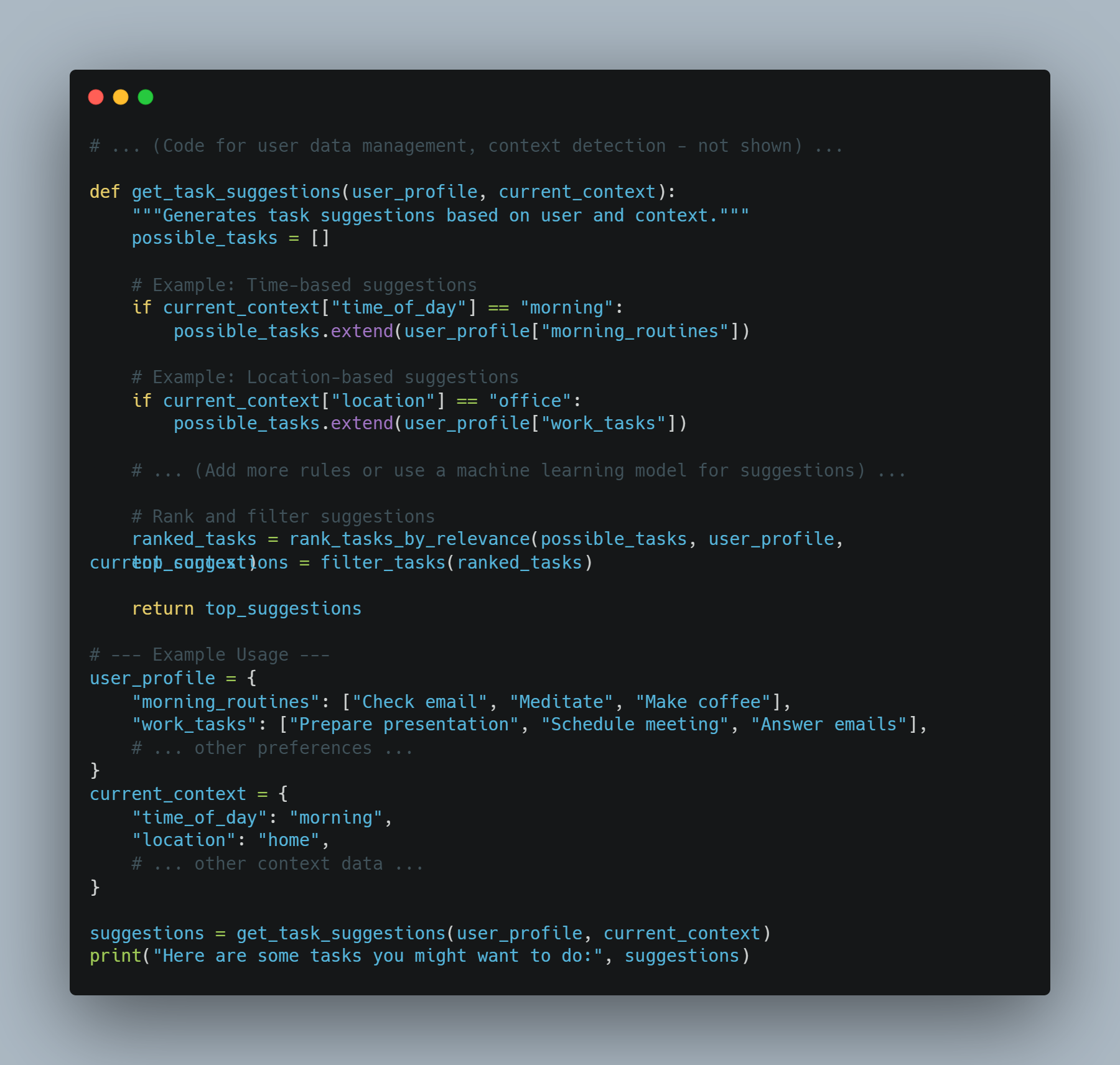
Ejemplo 2 de Asistentes IA: Entrega Proactiva de Información
-
Meta: Un asistente que proactiva la entrega de información relevante basada en el horario y preferencias del usuario.
-
Enfoque: Integrar datos del calendario, intereses del usuario y un sistema de recuperación de contenido.
Ejemplo de Código (Conceptual utilizando Python):
# ... (Código para acceso al calendario, perfil de interés del usuario - no mostrado) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (Recuperar información de la empresa, perfiles de participantes, etc.) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (Recuperar estado de vuelos, información de destino, etc.) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- Ejemplo de Uso ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... otras preferencias ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

Asistentes IA ejemplo 3: Recomendación de Contenido Personalizado
-
Objetivo: Un asistente que recomienda contenido (artículos, videos, música) adaptado a las preferencias del usuario.
-
Enfoque: Utilizar filtrado colaborativo o sistemas de recomendación basados en contenido.
Ejemplo de Código (Conceptual utilizando Python y una biblioteca como Surprise):
from surprise import Dataset, Reader, SVD
# ... (Código para el manejo de calificaciones de usuarios, base de datos de contenido - no mostrado) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (Obtener predicciones para todos los elementos, clasificar y devolver las N primeras) ...
# --- Ejemplo de Uso ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... más calificaciones ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
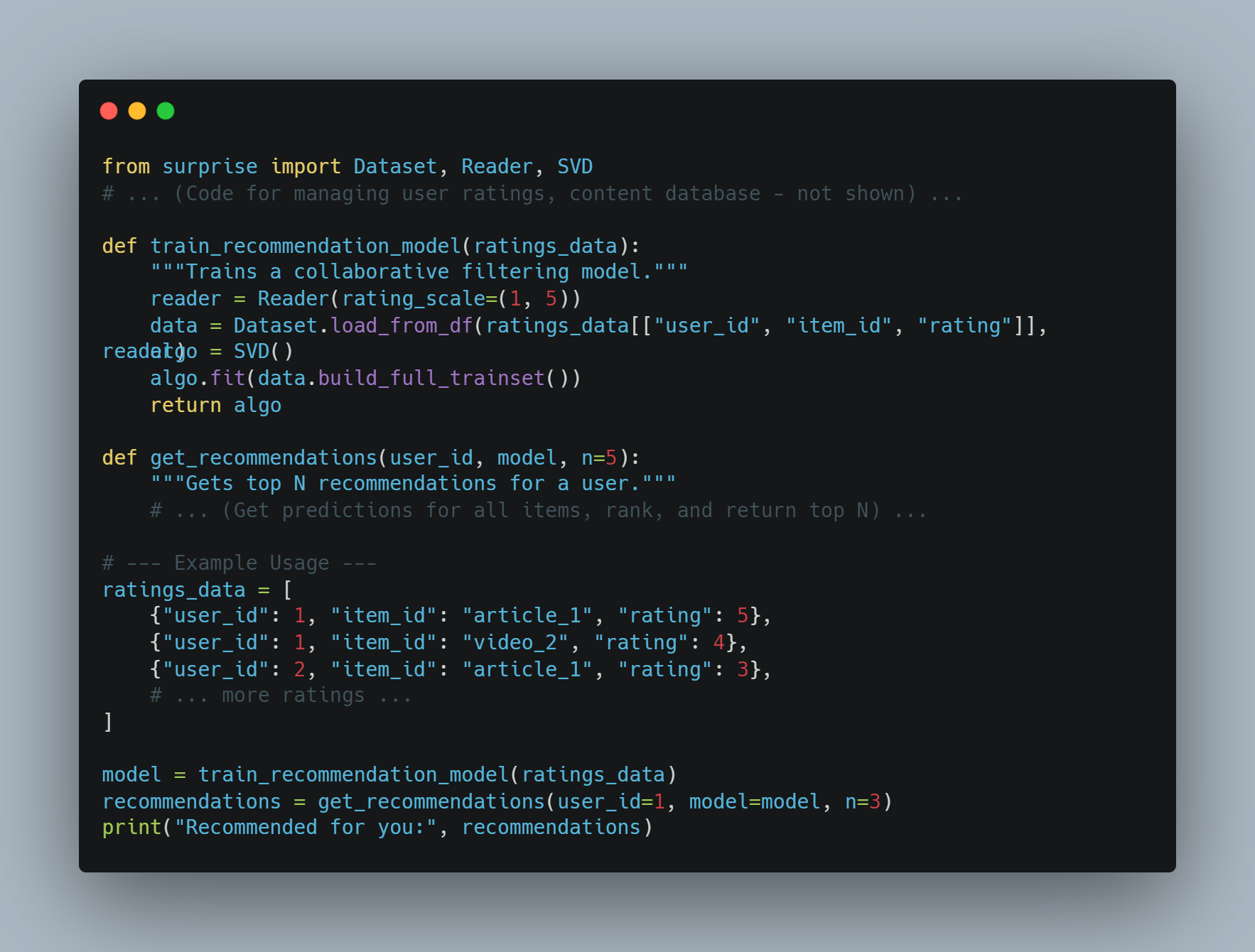
Retos y Consideraciones Éticas:
-
Privacidad de Datos: Es crucial manejar los datos de los usuarios con responsabilidad y transparencia.
-
Bias y Justicia: La personalización no debe amplificar los mismos prejuicios existentes.
-
Control de Usuario: Los usuarios deben tener control sobre sus datos y ajustes de personalización.
El desarrollo de asistentes AI personalizados requiere una consideración cuidadosa de tanto aspectos técnicos como éticos para crear sistemas que sean útiles, dignos de confianza y respeten la privacidad del usuario.
AI en Industrias Creativas
La IA está haciendo importantes avances en las industrias creativas, transformando cómo se produce y consume el arte, música, cine y literatura. Con los avances en modelos generativos, como las redes adversarias generativas (GANs) y los modelos basados en transformadores, la IA ahora puede generar contenido que rivaliza con la creatividad humana.
Por ejemplo, la IA puede componer música que refleja determinados géneros o estados de ánimo, crear arte digital que imita el estilo de pintores famosos, o incluso elaborar argumentos narrativos para películas y novelas.
En la industria de publicidad, la IA se utiliza para generar contenido personalizado que resuena con los consumidores individuales, aumentando la participación y la eficacia.
Pero el ascenso de la IA en los campos creativos también plantea cuestiones sobre la autoría, la originalidad y el papel de la creatividad humana. Al trabajar con IA en estos dominios, será crucial explorar cómo la IA puede complementar la creatividad humana en lugar de reemplazarla, fomentando la colaboración entre humanos y máquinas para producir contenido innovador y impactante.
Aquí hay un ejemplo de cómo se puede integrar GPT-4 a un proyecto de Python para tareas creativas, específicamente en el ámbito de la escritura. Este código demuestra cómo aprovechar las capacidades de GPT-4 para generar formatos de texto creativo, como la poesía.
import openai
# Establecer tu clave API de OpenAI
openai.api_key = "YOUR_API_KEY"
# Defina una función para generar poesía
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# Ejemplo de uso
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
Vamos a ver qué ocurre aquí:
-
Importar biblioteca de OpenAI: Primero se importa la biblioteca
openaipara acceder a la API de OpenAI. -
Establecer clave API: Reemplaza
"YOUR_API_KEY"con tu clave API de OpenAI real. -
Definir función
generate_poetry: Esta función toma eltopicy elstyledel poema como entrada y utiliza la API de ChatCompletion de OpenAI para generar el poema. -
Construir el prompt: El prompt combina el
topicy elstyleen una instrucción clara para GPT-4. -
Enviar prompt a GPT-4: El código utiliza
openai.ChatCompletion.createpara enviar el prompt a GPT-4 y recibir la respuesta generada del poema. -
Devolver el poema: El poema generado entonces se extrae de la respuesta y devuelto por la función.
-
Uso de ejemplo:
El código muestra cómo llamar a la función
generate_poetrycon un tema y estilo específicos. El poema resultante se imprime en la consola.
Mundos virtuales potenciados por AI
El desarrollo de mundos virtuales potenciados por AI representa un salto importante en las experiencias inmersivas, donde los agentes de AI pueden crear, administrar y evolucionar entornos virtuales que son interactivos y responden al input del usuario.
Estos mundos virtuales impulsados por AI pueden simular ecosistemas complejos, interacciones sociales y narrativas dinámicas, ofreciendo a los usuarios una experiencia profundamente absorbente y personalizada.
Por ejemplo, en la industria de los videojuegos, la AI puede usarse para crear personajes no jugables (NPCs) que aprenden del comportamiento del jugador, adaptando sus acciones y estrategias para proporcionar una experiencia más desafiante y realista.
Más allá de los videojuegos, los mundos virtuales potenciados por AI tienen aplicaciones potenciales en la educación, donde las aulas virtuales se pueden adaptar a los estilos de aprendizaje y el progreso de los estudiantes individuales, o en la formación corporativa, donde las simulaciones realistas pueden preparar a los empleados para varios escenarios.
El futuro de estos entornos virtuales dependerá de los avances en la capacidad de la AI para generar y administrar vastos ecosistemas digitales complejos en tiempo real, así como de consideraciones éticas sobre los datos de los usuarios y los impactos psicológicos de las experiencias altamente inmersivas.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# Inicializar agentes
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# Asignar una posición aleatoria dentro del entorno
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# Crear y agregar el agente
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# Mover agentes (movimiento simplificado para la demostración)
for agent in self.agents:
agent.move(self.environment)
# TODO: Implementar lógica más compleja para interacciones, cambios en el entorno, etc.
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# Determinar dirección de movimiento (aleatorio para este ejemplo)
direction = random.choice(['N', 'S', 'E', 'W'])
# Aplicar movimiento basado en la dirección
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# Actualizar el entorno para reflejar la nueva posición del agente
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# Ejemplo de uso
if __name__ == "__main__":
# Definir parámetros del mundo
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# Crear el mundo virtual
world = VirtualWorld(environment_size, agent_types, agent_properties)
# Simular el mundo por varios pasos
for _ in range(10):
world.update()
world.display()
print() # Agregar una línea en blanco para mejor lectura
Esto es lo que ocurre en este código:
-
Clase VirtualWorld:
-
Define el núcleo del mundo virtual.
-
Contiene la grilla del entorno, una lista de agentes y información relacionada con los agentes.
-
__init__(): Inicializa el mundo con tamaño, tipos de agentes y propiedades. -
add_agent(): Agrega un nuevo agente de un tipo especifico al mundo. -
update(): Realiza una actualización de un solo paso de tiempo del mundo.- Actualmente solo mueve agentes, pero puedes agregar lógica compleja para las interacciones entre agentes, cambios en el entorno, etc.
-
display(): Muestra una representación básica del entorno.
-
-
Clase de agente:
-
Representa a un agente individual dentro del mundo.
-
__init__(): Inicializa al agente con su tipo, posición y propiedades. -
move(): Manipula el movimiento del agente, actualizando su posición dentro del entorno. Este método actualmente proporciona un movimiento aleatorio simple, pero puede ampliarse para incluir comportamientos AI complejos.
-
-
Ejemplo de uso:
-
Establece parámetros del mundo como tamaño, tipos de agentes y sus propiedades.
-
Crea un objeto VirtualWorld.
-
Ejecuta la función
update()varias veces para simular la evolución del mundo. -
Llama a
display()después de cada actualización para visualizar los cambios.
-
Mejoras:
-
Inteligencia Artificial de Agentes Más Completa: Implementar una IA más sofisticada para el comportamiento de los agentes. Puedes utilizar:
-
Algoritmos de Camino: Ayudar a los agentes a navegar por el entorno de manera eficiente.
-
Árboles de Decisión/Aprendizaje Automático: Permitir que los agentes tomen decisiones más inteligentes basadas en su entorno y objetivos.
-
Aprendizaje por Reforzamiento: Enseñar a los agentes a aprender y adaptar su comportamiento con el tiempo.
-
-
Interacción con el entorno: Agregar elementos dinámicos al entorno, como obstáculos, recursos o puntos de interés.
-
Interacción entre agentes: Implementar interacciones entre agentes, como comunicación, combate o cooperación.
-
Representación visual: Usar bibliotecas como Pygame o Tkinter para crear una representación visual del mundo virtual.
Este ejemplo representa una base básica para la creación de un mundo virtual impulsado por inteligencia artificial. El nivel de complejidad y sofisticación puede ser expandido adicionalmente para adaptarse a tus necesidades específicas y objetivos creativos.
Neuromorfismo y AI
El neuromorfismo, inspirado en la estructura y funcionamiento del cerebro humano, está destinado a revolucionar la IA ofreciendo nuevas maneras de procesar información de manera eficiente y en paralelo.
A diferencia de las arquitecturas de computación tradicionales, los sistemas neuromórficos están diseñados para imitar las redes neuronales del cerebro, lo que permite que la IA realice tareas como la reconocimiento de patrones, el procesamiento sensorial y la toma de decisiones con mayor velocidad y eficiencia energética.
Esta tecnología posee un gran potencial para desarrollar sistemas AI que sean más adaptativos, capaces de aprender de datos mínimos y efectivos en entornos en tiempo real.
Por ejemplo, en robotica, las placas neuromórficas podrían permitir a los robots procesar las entradas sensoriales y tomar decisiones con un nivel de eficiencia y velocidad que las arquitecturas actuales no pueden alcanzar.
El reto para el avance será escalar el neuromorfismo para manejar la complejidad de aplicaciones de AI a gran escala, integrándolo con las frameworks de IA existentes para aprovechar al máximo su potencial.
Agentes AI en la Exploración del Espacio
Los agentes de inteligencia artificial cada vez más juegan un papel crucial en la exploración espacial, donde están encargados de navegar por entornos hostiles, tomar decisiones en tiempo real y realizar experimentos científicos de manera autónoma.
Mientras que las misiones se aventuran más y más en el espacio profundo, se hace más presión para que los sistemas de AI puedan operar sin depender de un control basado en la Tierra. Los agentes de inteligencia artificial futuros estarán diseñados para manejar la imprevisibilidad del espacio, como obstáculos inesperados, cambios en los parámetros de la misión o la necesidad de auto-reparación.
Por ejemplo, la IA podría utilizarse para guiar los rovers marcianos para explorar autónomamente terrenos, identificar sitios científicamente valiosos y incluso perforar muestras con un mínimo de input del control de la misión. Estos agentes de IA también podrían administrar los sistemas de apoyo vital en misiones de duración larga, optimizar el uso de energía y adaptarse a las necesidades psicológicas de los astronautas proporcionándoles compañía y estimulación mental.
La integración de la IA en la exploración espacial no solo mejora las capacidades de la misión sino que también abre nuevas posibilidades para la exploración humana del cosmos, donde la IA será un socio indispensable en la búsqueda de comprender nuestro universo.
Capítulo 8: Agentes de IA en campos críticos para la misión
Atención médica
En la atención médica, los agentes de IA no son solo roles de apoyo sino que se están haciendo parte integral del entero espectro de atención al paciente. Su impacto es más evidente en la telemedicina, donde los sistemas de IA han redefinido el enfoque para la entrega de atención médica remota.
Al utilizar procesamiento avanzado de lenguaje natural (NLP) y algoritmos de aprendizaje automático, estos sistemas realizan tareas complejas como la triage de síntomas y la recopilación preliminar de datos con una alta precisión. Analizan los síntomas reportados por los pacientes y los historiales médicos en tiempo real, haciendo referencias cruzadas a bases de datos médicas extensas para identificar condiciones potenciales o alertas.
Esto permite a los proveedores de atención médica tomar decisiones informadas más rápidamente, reduciendo el tiempo hasta el tratamiento y potencialmente salvar vidas. Además, las herramientas de diagnóstico dirigidas por AI en imágenes médicas están transformando la radiología al detectar patrones y anomalías en radiografías, resonancias magnéticas y tomografías computarizadas que podrían ser inperceptibles para el ojo humano.
Estos sistemas se entrenan en grandes conjuntos de datos que comprenden millones de imágenes anotadas, lo que les permite no solo replicar sino superar a menudo las capacidades diagnósticas humanas.
La integración de la AI en la atención médica también se extiende a las tareas administrativas, donde la automatización de la programación de citas, las recuerdos de medicación y los seguimientos de pacientes reduce significativamente la carga operativa del personal médico, permitiéndoles enfocarse en aspectos más críticos de la atención médica.
Finanzas
En el sector financiero, los agentes basados en AI han revolucionado las operaciones al introducir niveles de eficiencia y precisión sin precedentes.
El trading algorítmico, que depende fuertemente de la AI, ha transformado la manera en que se realizan las operaciones en los mercados financieros.
Estos sistemas son capaces de analizar conjuntos de datos masivos en milisegundos, identificando tendencias de mercado y ejecutando operaciones en el momento óptimo para maximizar beneficios y minimizar riesgos. Aprovechan algoritmos complejos que incorporan técnicas de aprendizaje automático, aprendizaje profundo y aprendizaje por reforzamiento para adaptarse a condiciones de mercado cambiantes, tomando decisiones en cuestión de milisegundos que los traders humanos nunca podrían igualar.
Más allá del trading, la IA juega un papel crucial en la gestión de riesgos evaluando riesgos crediticios y detectando actividades fraudulentas con una precisión destacable. Los modelos de IA utilizan análisis predictivo para evaluar la probabilidad de default de un prestatario analizando patrones en historiales de crédito, comportamientos de transacciones y otros factores relevantes.
También, en el ámbito de la conformidad regulatoria, la IA automatiza la monitorización de transacciones para detectar y reportar actividades sospechosas, garantizando que las instituciones financieras cumplan con requisitos regulatorios estrictos. Esta automatización no solo mitiga el riesgo de error humano sino que también streamline los procesos de conformidad, reduciendo costos e imprimiendo eficiencia.
Gestión de Emergencias
El papel de la IA en la gestión de emergencias es transformador, cambiando fundamentalmente cómo se predican, gestionan y mitigan las crisis.
En la respuesta a los desastres, los agentes de IA procesan vastas cantidades de datos de múltiples fuentes, que van desde imágenes por satélite hasta flujos de datos de redes sociales, para proporcionar una visión general completa de la situación en tiempo real. Algoritmos de aprendizaje automático analizan estos datos para identificar patrones y predecir el progreso de los eventos, permitiendo a los responderistas emergencia allocar recursos de manera más eficiente y tomar decisiones informadas bajo presión.
Por ejemplo, durante un desastre natural como un huracán, los sistemas AI pueden predecir la trayectoria y la intensidad de la tormenta, permitiendo a las autoridades emitir órdenes de evacuación a tiempo y desplegar recursos en las zonas más vulnerables.
En análisis predictivo, los modelos AI se utilizan para predecir emergencias potenciales mediante el análisis de datos históricos junto a entradas en tiempo real, permitiendo medidas proactivas que pueden prevenir desastres o mitigar su impacto.
Los sistemas de comunicación pública alimentados por AI también juegan un papel crucial en garantizar que la información exacta y oportuna llegue a las poblaciones afectadas. Estos sistemas pueden generar y difundir alertas de emergencia a través de múltiples plataformas, personalizando los mensajes para diferentes demografías para asegurar comprensión y cumplimiento.
Y el AI mejora la preparación de los responder a emergencias creando simulaciones de entrenamiento altamente realistas utilizando modelos generativos. Estas simulaciones replican las complejidades de los desastres reales del mundo, permitiendo a los responders afinar sus habilidades y mejorar su preparación para eventos reales.
Transporte
Los sistemas AI se están haciendo indispensables en el sector del transporte, donde mejoran la seguridad, la eficiencia y la confiabilidad en varios campos, incluyendo el control de tráfico aéreo, vehículos autónomos y el transporte público.
En el control de tráfico aéreo, los agentes AI son instrumentales en la optimización de las rutas de vuelo, predicción de conflictos potenciales y la gestión de operaciones aeroportuarias. Estos sistemas usan análisis predictivo para prever posibles engarces de tráfico aéreo, reenviando los vuelos en tiempo real para garantizar seguridad y eficiencia.
En el reino de los vehículos autónomos, la IA es la clave para que los vehículos puedan procesar los datos de los sensores y tomar decisiones en cuestión de milisegundos en entornos complejos. Estos sistemas emplean modelos de aprendizaje profundo entrenados en bases de datos extensas para interpretar datos visuales, auditivos y espaciales, lo que permite la navegación segura a través de condiciones dinámicas y impredecibles.
Los sistemas de transporte público también se benefician de la IA a través de la planificación de rutas optimizadas, la mantención predictiva de los vehículos y la gestión del flujo de pasajeros. Mediante el análisis de datos históricos y en tiempo real, los sistemas de IA pueden ajustar los horarios de transbordo, predecir y prevenir fallas en los vehículos y controlar las multitudes en horas punta, mejorando así la eficiencia y la confiabilidad de las redes de transporte.
Sector Energético
La IA está desempeñando un papel crucial en el sector energético, particularmente en la gestión de la red, la optimización de las energías renovables y la detección de fallos.
En la gestión de la red, los agentes de IA supervisan y controlan las redes eléctricas mediante el análisis de datos en tiempo real provenientes de sensores distribuidos a lo largo de la red. Estos sistemas usan análisis predictivos para optimizar la distribución de energía, asegurando que la oferta cumpla con la demanda y minimizando el desperdicio de energía. Los modelos de IA también predecen posibles fallos en la red, permitiendo el mantenimiento preventivo y reduciendo el riesgo de interrupciones.
En el ámbito de las energías renovables, los sistemas de IA se utilizan para predecir patrones climáticos, lo cual es fundamental para optimizar la producción de energía solar y eólica. Estos modelos analizan datos meteorológicos para predecir la intensidad de la luz solar y la velocidad del viento, permitiendo predicciones más precisas de la producción de energía y una mejor integración de las fuentes renovables a la red.
La detección de fallas es otro ámbito en el que la IA está haciendo contribuciones significativas. Los sistemas de IA analizan datos de sensores de equipos como transformadores, turbinas y generadores para identificar signos de desgaste y fallas potenciales antes de que estos lleguen a un fallo. Esta approche de mantenimiento predictivo no solo extendió la vida útil del equipo sino que también aseguró una energía continua y confiable.
Ciberseguridad
En el campo de la ciberseguridad, los agentes de IA son esenciales para mantener la integridad y la seguridad de las infraestructuras digitales. Estos sistemas están diseñados para monitorear continuamente el tráfico de red, utilizando algoritmos de aprendizaje automático para detectar anomalías que podrían indicar una infracción de seguridad.
Analizando grandes cantidades de datos en tiempo real, los agentes de IA pueden identificar patrones de comportamiento malintencionado, como intentos de inicio de sesión inusuales, actividades de extracción de datos o la presencia de malware. Una vez detectada una amenaza potencial, los sistemas de IA pueden iniciar automáticamente contramedidas, como aislar sistemas comprometidos y desplegar parches, para prevenir mayores daños.
La evaluación de vulnerabilidades es otra aplicación crítica de la IA en ciberseguridad. Las herramientas potenciadas por IA analizan el código y las configuraciones del sistema para identificar debilidades de seguridad potenciales antes de que puedan ser aprovechadas por atacantes. Estas herramientas utilizan técnicas de análisis estático y dinámico para evaluar la postura de seguridad de los componentes de software y hardware, proporcionando insights acciones a los equipos de ciberseguridad.
La automatización de estos procesos no solo mejora la velocidad y la precisión en la detección y respuesta a amenazas, sino que también reduce la carga de trabajo para los analistas humanos, permitiéndoles enfocarse en desafíos de seguridad más complejos.
Manufactura
En la manufactura, la IA está impulsando avances significativos en control de calidad, mantenimiento predictivo y optimización de la cadena de suministro. Los sistemas de visión computacional potenciados por IA son capaces de inspeccionar productos para detectar defectos con una velocidad y precisión superiores a las capacidades humanas. Estos sistemas utilizan algoritmos de aprendizaje profundo entrenados en miles de imágenes para detectar incluso las pequeñas imperfecciones más en los productos, garantizando una calidad consistente en ambientes de producción a gran escala.
El mantenimiento predictivo es otro área donde la IA está teniendo un impacto profundo. Analizando datos de sensores integrados en maquinaria, los modelos de IA pueden predecir cuándo es probable que falla el equipamiento, permitiendo que el mantenimiento se programue antes de que ocurra un fallo. Este enfoque no solo reduce el tiempo de inactividad sino que también extiende la vida útil de la máquina, generando ahorros significativos.
En la gestión de la cadena de suministro, los agentes de IA optimizan los niveles de inventario y la logística analizando datos a lo largo de toda la cadena de suministro, incluyendo las previsiones de demanda, los horarios de producción y las rutas de transporte. Realizando ajustes en tiempo real a los planes de inventario y logística, la IA garantiza que los procesos de producción se realicen sin problemas, minimizando los retrasos y reduciendo costos.
Estas aplicaciones demuestran el papel crucial de la IA en la mejora de la eficiencia y la confiabilidad en la manufactura, haciéndola una herramienta indispensable para las empresas que buscan mantenerse competitivas en una industria en rápido desarrollo.
Conclusión
La integración de agentes de IA con grandes modelos lingüísticos (LLM) marca un hito significativo en la evolución de la inteligencia artificial, al desbloquear capacidades sin precedentes en diversos sectores y dominios científicos. Esta sinergia mejora la funcionalidad, adaptabilidad y aplicabilidad de los sistemas de IA, abordando las limitaciones inherentes de los LLM y permitiendo procesos de toma de decisiones más dinámicos, conscientes del contexto y autónomos.
Desde la revolución de la sanidad y las finanzas hasta la transformación del transporte y la gestión de emergencias, los agentes de IA están impulsando la innovación y la eficiencia, allanando el camino para un futuro en el que las tecnologías de IA estén profundamente integradas en nuestra vida cotidiana.
A medida que seguimos explorando el potencial de los agentes de IA y los LLM, es crucial fundamentar su desarrollo en principios éticos que den prioridad al bienestar humano, la equidad y la inclusión. Si nos aseguramos de que estas tecnologías se diseñan y despliegan de forma responsable, podremos aprovechar todo su potencial para mejorar la calidad de vida, promover la justicia social y abordar los retos mundiales.
El futuro de la IA reside en la integración perfecta de agentes de IA avanzados con sofisticados LLM, creando sistemas inteligentes que no sólo aumenten las capacidades humanas, sino que también defiendan los valores que definen nuestra humanidad.
La convergencia de agentes de IA y LLM representa un nuevo paradigma en inteligencia artificial, donde la colaboración entre lo ágil y lo poderoso abre un reino de posibilidades ilimitadas. Aprovechando este poder sinérgico, podemos impulsar la innovación, hacer avanzar los descubrimientos científicos y crear un futuro más equitativo y próspero para todos.
Acerca del Autor
Vahe Aslanyan aquí, en el núcleo de la informática, la ciencia de datos y la inteligencia artificial. Visite vaheaslanyan.com para ver un portafolio que es un testimonio de precisión y progreso. Mi experiencia cubre el puente entre el desarrollo full-stack y la optimización de productos de inteligencia artificial, impulsado por la resolución de problemas de maneras nuevas.
Con un historial que incluye la lanzada de un liderando bootcamp de ciencia de datos y trabajar con especialistas de la industria de primera línea, mi enfoque sigue siendo elevar la educación tecnológica a estándares universales.
¿Cómo Puede Invertirse Más Profundamente?
Después de estudiar esta guía, si estás interesado en invertirte aún más y el aprendizaje estructurado es tu estilo, considera unirte con nosotros en LunarTech, ofrecemos cursos individuales y Bootcamp en Ciencia de Datos, Aprendizaje Automático y Inteligencia Artificial.
Proporcionamos un programa completo que ofrece una comprensión profunda de la teoría, una implementación práctica en mano, material de práctica extensivo y una preparación de entrevista personalizada para ponerte en camino hacia el éxito en tu fase propia.
Puede echar un vistazo a nuestro Bootcamp de Ciencia de Datos definitivo y unirse a una prueba gratuita para probar el contenido de primera mano. Esto ha obtenido el reconocimiento de ser uno de los Mejores Bootcamps de Ciencia de Datos de 2023 y ha sido destacado en publicaciones respetadas como Forbes, Yahoo, Entrepreneur y más. Esta es su oportunidad de formar parte de una comunidad que prospera en innovación y conocimiento. Aquí está el mensaje de bienvenida!
Conéctate conmigo

Sígueme en LinkedIn para obtener un montón de Recursos Gratuitos en CS, ML y AI
-
Suscríbete a mi Boletín de Ciencia de Datos y AI
Si quieres saber más sobre una carrera en Ciencia de Datos, Aprendizaje Automático e Inteligencia Artificial, y aprender cómo asegurarte de un trabajo en Ciencia de Datos, puedes descargar este manual gratuito Guía de Carrera en Ciencia de Datos y AI.
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/