













Die schnelle Entwicklung der künstlichen Intelligenz (KI) hat zu einer kraftvollen Synergie zwischen großen Sprachmodelle (LM) und KI-Agenten geführt. Diese dynamische Interaktion ist wie die Geschichte von David und Goliath (ohne die Kämpfe), wo agile KI-Agenten die Fähigkeiten der riesigen LM verstärken und vergrößern.
Dieses Handbuch wird untersuchen, wie KI-Agenten – ähnlich wie David – die LM – unsere moderne Goliaths – superaufladen, um verschiedene Branchen und wissenschaftliche Bereiche zu revolutionieren.
Inhaltsverzeichnis
-
Kapitel 2: Geschichte der künstlichen Intelligenz und KI-Agenten
-
Kapitel 4: Die philosophische Grundlage intelligenter Systeme
-
Kapitel 6: Architektur-Design zur Integration von AI-Agenten mit LLM
Die Entstehung von AI-Agenten in Sprachmodellen
AI-Agenten sind selbständige Systeme, die für die Wahrnehmung ihrer Umgebung, die Entscheidungsfindung und die Ausführung von Aktionen zu bestimmten Zielen konzipiert sind. Durch die Integration mit LLM können diese Agenten komplexe Aufgaben erledigen, Informationen überdenken und innovative Lösungen generieren.
Diese Kombination hat zu bedeutenden Fortschritten in verschiedenen Sektoren geführt, von Softwareentwicklung bis zur wissenschaftlichen Forschung.
Umwälzende Auswirkungen in verschiedenen Branchen
Die Integration von AI-Agenten mit LLM hat eine tiefgreifende Wirkung auf verschiedene Branchen gehabt:
-
Softwareentwicklung: AI-gesteuerte Programmierassistenten, wie z.B. GitHub Copilot, haben gezeigt, dass sie bis zu 40% des Codes generieren können, was zu einer bemerkenswerten Verdoppelung der Entwicklungsgeschwindigkeit führt.
-
Bildung: AI-gesteuerte Lernassistenten haben Potenzial gezeigt, die durchschnittliche Kursdauer um 27% zu verkürzen, was die Bildungslandschaft möglicherweise revolutionieren kann.
-
Verkehr
: Mit Projektionen, die suggestieren, dass 10% der Fahrzeuge bis 2030 fahrerlos sein werden, sind selbstfahrende Autos mit autonomen AI-Agenten dazu prädestiniert, die Verkehrsbranche zu revolutionieren.
Wissenschaftliche Entdeckungen vorantreiben
Eine der spannendsten Anwendungen von AI-Agenten und LLM ist in der wissenschaftlichen Forschung zu finden:
-
Arzneimittelentwicklung: AI-Agenten beschleunigen den Arzneimittelentwicklungsprozess durch Analyse von umfangreichen Datenmengen und Prognose potenzieller Arzneimittelkandidaten, was die Zeit und Kosten, die mit traditionellen Methoden verbunden sind, erheblich reduziert.
-
Teilchenphysik: Am Large Hadron Collider des CERN werden KI-Agenten eingesetzt, um Kollisionsdaten von Teilchen zu analysieren. Mit Hilfe der Anomalieerkennung können vielversprechende Hinweise identifiziert werden, die auf das Vorhandensein von noch unentdeckten Teilchen hinweisen könnten.
-
Allgemeine wissenschaftliche Forschung: KI-Agenten verbessern das Tempo und den Umfang wissenschaftlicher Entdeckungen, indem sie vergangene Studien analysieren, unerwartete Verbindungen identifizieren und neue Experimente vorschlagen.
Die Konvergenz von AI-Agenten und großen Sprachmodellen (LLM) befördert die Kunstliche Intelligenz in eine neue Ära von beispielloser Kraft. Dieses umfassende Handbuch untersucht die dynamische Wechselwirkung zwischen diesen beiden Technologien und offenbart ihre kombinierte Potenzialität, um Branchen zu revolutionieren und komplexe Probleme zu lösen.
Wir werden die Entwicklung von AI von ihren Ursprüngen bis zum Aufkommen autonomer Agenten und dem Aufstieg von komplexen LLM verfolgen. Wir werden auch ethische Überlegungen untersuchen, die grundlegend für die verantwortungsvolle AI-Entwicklung sind. Dies hilft uns, sicherzustellen, dass diese Technologien mit unseren menschlichen Werten und der sozialen Wohlfahrt in Einklang stehen.
Bei dem Abschluss dieses Handbuchs werden Sie eine tiefgreifende Verständnis der synergistischen Kraft von AI-Agenten und LLM haben, zusammen mit dem Wissen und den Werkzeugen, um diese fortschrittliche Technologie auszuschöpfen.
Kapitel 1: Einführung in AI-Agenten und Sprachmodelle
Was sind AI-Agenten und große Sprachmodelle?
Die schnelle Entwicklung der künstlichen Intelligenz (AI) hat eine transformative Synergie zwischen großen Sprachmodellen (LLM) und AI-Agenten hervorgerufen.
KI-Agenten sind selbstständige Systeme, die dazu konzipiert sind, ihr Umfeld wahrzunehmen, Entscheidungen zu fassen und Aktionen auszuführen, um bestimmte Ziele zu erreichen. Sie zeigen Merkmale wie Autonomie, Wahrnehmung, Reaktivität, Schlussfolgerung, Entscheidungsfindung, Lernen, Kommunikation und Zielorientierung auf.
Andererseits sind LLM (Langzeitspeicherungs-Maschinen) komplexe AI-Systeme, die auf Deep Learning-Techniken und umfangreiche Datensets zur Verständigung, Generierung und Vorhersage menschlicher Textart zurückgreifen.
Diese Modelle, wie z.B. GPT-4, Mistral, LLama, haben beachtliche Fähigkeiten in NLP-Aufgaben gezeigt, einschließlich Textgenerierung, Sprachübersetzung und Konversationsagenten.
Wesentliche Merkmale von KI-Agenten
KI-Agenten haben mehrere definierende Eigenschaften, die sie von traditioneller Software unterscheiden:
-
Autonomie: Sie können unabhängig von menschlicher Intervention agieren.
-
Wahrnehmung: Agenten können ihr Umfeld durch verschiedene Eingaben wahrnehmen und interpretieren.
-
Reaktivität: Sie reagieren dynamisch auf Änderungen in ihrem Umfeld.
-
Reasoning und Entscheidungsfindung: Agenten können Daten analysieren und fundierte Entscheidungen treffen.
-
Lernen: Sie verbessern ihre Leistung mit der Zeit durch Erfahrung.
-
Kommunikation: Agenten können mit Hilfe verschiedener Methoden mit anderen Agenten oder Menschen interagieren.
-
Zielorientierung: Sie sind darauf ausgelegt, bestimmte Ziele zu erreichen.
Fähigkeiten großer Sprachmodelle
LLMs haben ein breites Spektrum an Fähigkeiten gezeigt, darunter:
-
Texterzeugung: LLMs können kohärente und kontextuell relevante Texte auf der Grundlage von Aufforderungen produzieren.
-
Sprachübersetzung: Sie können Text zwischen verschiedenen Sprachen mit hoher Genauigkeit übersetzen.
-
Zusammenfassung: LLMs können lange Texte zu prägnanten Zusammenfassungen verdichten, wobei die wichtigsten Informationen erhalten bleiben.
-
Fragebeantwortung: Sie können auf der Grundlage ihrer umfangreichen Wissensbasis präzise Antworten auf Anfragen geben.
-
Sentiment Analysis: LLMs können die in einem bestimmten Text ausgedrückte Stimmung analysieren und bestimmen.
-
Codegenerierung: Sie können auf der Grundlage natürlichsprachlicher Beschreibungen Codeschnipsel oder ganze Funktionen generieren.
Stufen von KI-Agenten
KI-Agenten können aufgrund ihrer Fähigkeiten und Komplexität in verschiedene Stufen eingeteilt werden. Nach einem Paper auf arXiv werden KI-Agenten in fünf Stufen eingeteilt:
-
Stufe 1 (L1): KI-Agenten als Forschungsassistenten, bei denen Wissenschaftler Hypothesen aufstellen und Aufgaben festlegen, um Ziele zu erreichen.
-
Stufe 2 (L2): KI-Agenten, die autonom spezifische Aufgaben innerhalb eines definierten Bereichs ausführen können, wie z. B. Datenanalyse oder einfache Entscheidungsfindung.
-
Stufe 3 (L3): KI-Agenten, die in der Lage sind, aus Erfahrungen zu lernen und sich an neue Situationen anzupassen, was ihre Entscheidungsprozesse verbessert.
-
Stufe 4 (L4): KI-Agenten mit fortgeschrittenen Denk- und Problemlösungsfähigkeiten, die komplexe, mehrstufige Aufgaben bewältigen können.
-
Stufe 5 (L5): Vollständig autonome KI-Agenten, die unabhängig in dynamischen Umgebungen operieren können, Entscheidungen treffen und Maßnahmen ergreifen, ohne menschliches Eingreifen.
Beschränkungen großer Sprachmodelle
Trainingskosten und Ressourcenbeschränkungen
Große Sprachmodelle (LLMs) wie GPT-3 und PaLM haben die natürliche Sprachverarbeitung (NLP) revolutioniert, indem sie tiefe Lernmethoden und umfangreiche Datensätze nutzen.
Diese Fortschritte jedoch kommen mit erheblichen Kosten. Die Ausbildung von LLM erfordert erhebliche Rechenressourcen und beträgt oft Tausende von GPUs und umfassendem Energieverbrauch.
Laut Sam Altman, dem CEO von OpenAI, wurden die Ausbildungskosten für GPT-4 über 100 Millionen USD erreicht. Dies entspricht der gemeldeten Größe und Komplexität des Modells, mit Schätzungen, die etwa 1 Trillion Parameter aufweisen lassen. Allerdings bieten andere Quellen unterschiedliche Zahlen:
-
Ein veröffentlichtes Berichts zeigte, dass die Ausbildungskosten für GPT-4 etwa 63 Millionen USD betrugen, anhand der Rechenleistung und der Trainingsdauer.
-
Mit dem Jahreswechsel 2023 gab es Schätzungen, dass die Ausbildung eines Modells ähnlicher Größe wie GPT-4 etwa 20 Millionen USD kosten könnte und etwa 55 Tage dauern würde, was Fortschritte in der Effizienz widerspiegelt.
Der hohe Preis für die Training und Wartung von LLM begrenzt ihre allgemeine Verbreitung und Skalierbarkeit.
Datenbegrenzungen und Verzerrungen
Der Leistung von LLM ist stark von der Qualität und Vielfalt der Trainingsdaten abhängig. Obwohl LLM auf großen Datensets trainiert werden, können sie immer noch Verzerrungen in den Daten anzeigen, was zu verzogenen oder unangemessenen Ausgaben führt. Diese Verzerrungen können in verschiedenen Formen auftreten, einschließlich Geschlechts-, Rassen- und Kulturverzerrungen, die Stereotype und Falschinformation fortführen können.
Darüber hinaus bedeutet die statische Natur der Trainingsdaten, dass LLM nicht auf die neuesten Informationen auf dem neuesten Stand sind, was ihre Effektivität in dynamischen Umgebungen begrenzt.
Spezialisierung und Komplexität
Obwohl LLM im allgemeinen Aufgaben hervorragend leisten, haben sie oft Schwierigkeiten mit spezialisierten Aufgaben, die Erkenntnisse von besonderen Bereichen und hohe Komplexität erfordern.
Zum Beispiel erfordern Aufgaben in Bereichen wie Medizin, Recht und wissenschaftlicher Forschung eine tiefe Verständnis von fachspezifischen Begriffen und differenziertem Denken, die LLM möglicherweise nicht von Haus aus besitzen. Diese Begrenzung erfordert die Integration zusätzlicher Expertenebene und eine Feineinstellung, um LLM für spezialisierte Anwendungen effektiv zu machen.
Eingabe- und Sinnesbegrenzungen
LLMs verarbeiten hauptsächlich textbasierte Eingaben, was ihre Fähigkeit einschränkt, auf multimodale Weise mit der Welt zu interagieren. Während sie Text generieren und verstehen können, fehlt ihnen die Fähigkeit, visuelle, auditive oder sensorische Eingaben direkt zu verarbeiten.
Diese Einschränkung behindert ihre Anwendung in Bereichen, die eine umfassende sensorische Integration erfordern, wie Robotik und autonome Systeme. Zum Beispiel kann ein LLM ohne zusätzliche Verarbeitungsschichten keine visuellen Daten von einer Kamera oder auditive Daten von einem Mikrofon interpretieren.
Kommunikations- und Interaktionsbeschränkungen
Die aktuellen Kommunikationsfähigkeiten von LLMs sind überwiegend textbasiert, was ihre Fähigkeit einschränkt, sich an immersiveren und interaktiveren Kommunikationsformen zu beteiligen.
Zum Beispiel können LLMs zwar Textantworten generieren, aber sie können keine Videoinhalte oder holografischen Darstellungen produzieren, die in virtuellen und erweiterten Realität Anwendungen zunehmend wichtig sind (mehr dazu hier). Diese Einschränkung verringert die Effektivität von LLMs in Umgebungen, die reichhaltige, multimodale Interaktionen erfordern.
Wie man Einschränkungen mit AI-Agenten überwindet
AI-Agenten bieten eine vielversprechende Lösung für viele der von LLMs erlebten Einschränkungen. Diese Agenten sind so konzipiert, dass sie autonom arbeiten, ihre Umgebung wahrnehmen, Entscheidungen treffen und Aktionen ausführen, um spezifische Ziele zu erreichen. Durch die Integration von AI-Agenten mit LLMs ist es möglich, deren Fähigkeiten zu erweitern und ihre inhärenten Einschränkungen zu überwinden.
-
Verbesserte Kontext- und Speicherfunktion: KI-Agenten können über mehrere Interaktionen hinweg den Kontext beibehalten, was zu kohärenteren und kontextuell relevanteren Antworten führt. Diese Fähigkeit ist besonders nützlich in Anwendungen, die eine Langzeitgedächtnis und Kontinuität erfordern, wie z.B. Kundenservice und persönliche Assistenten.
-
Multimodale Integration: KI-Agenten können sensorische Eingaben aus verschiedenen Quellen, wie Kameras, Mikrofone und Sensoren, einbeziehen, was LLMs ermöglicht, visuelle, auditive und sensorische Daten zu verarbeiten und darauf zu reagieren. Diese Integration ist entscheidend für Anwendungen in Robotik und autonomen Systemen.
-
Spezialisierte Kenntnisse und Fachwissen: AI-Agenten können mit domain-spezifischer Kenntnis fein abgestimmt werden, was die Fähigkeit von LLM, spezialisierte Aufgaben zu erledigen, verstärkt. Dieser Ansatz ermöglicht die Erstellung von Expertenystemen, die komplexe Abfragen in Bereichen wie Medizin, Recht und wissenschaftlicher Forschung verarbeiten können.
-
Interaktives und immersives Kommunizieren: AI-Agenten können durch die Generierung von Videoinhalten, die Steuerung von Hologrammen und die Interaktion mit virtuellen und erweiterten Realitäten immersivere Formen der Kommunikation fördern. Diese Fähigkeit erweitert die Anwendbarkeit von LLM in Bereichen, die reiche, multimodale Interaktionen erfordern.
Obwohl große Sprachmodelle bemerkenswerte Fähigkeiten in der natürlichen Sprachverarbeitung gezeigt haben, gibt es auch Grenzen. Die hohen Trainingskosten, Datenbias, Spezialisierungschallenges, sensorische Einschränkungen und Kommunikationsbeschränkungen stellen erhebliche Hindernisse dar.
Die Integration von KI-Agenten bietet jedoch eine praktikable Lösung, um diese Grenzen zu überwinden. Durch die Nutzung der Stärken von KI-Agenten ist es möglich, die Funktionalität, Anpassbarkeit und Anwendbarkeit von LLM zu verbessern, was den Weg für fortschrittlichere und vielseitigere AI-Systeme ebnet.
Kapitel 2: Die Geschichte der Künstlichen Intelligenz und KI-Agenten
Die Entstehung der Künstlichen Intelligenz
Der Begriff der künstlichen Intelligenz (KI) hat seinen Ursprung weitaus länger zurückliegend als in der heutigen digitalen Ära. Der Gedanke, Maschinen zu schaffen, die menschenähnliche Denkvermögen aufweisen, kann bis in die alten Mythen und philosophischen Debatten zurückverfolgt werden. Der formale Ursprung von AI als wissenschaftliche Disziplin ereignete sich jedoch in der Mitte des 20. Jahrhunderts.
Die Dartmouth-Konferenz von 1956, organisiert von John McCarthy, Marvin Minsky, Nathaniel Rochester und Claude Shannon, gilt allgemein als Geburtsort der künstlichen Intelligenz (AI) als Forschungsbereich. Diese grundlegende Veranstaltung brachte führende Forscher zusammen, um die Möglichkeiten der Erstellung von Maschinen zu erforschen, die die menschliche Intelligenz simulieren könnten.
Frühes Optimismus und die AI-Winter
Die Anfänge der AI-Forschung waren geprägt von unbegrenztem Optimismus. Forscher machten bedeutende Fortschritte in der Entwicklung von Programmen, die mathematische Probleme lösen, Spiele spielen und sogar rudimentäre natursprachliche Verarbeitung erledigen konnten.
Aber diese anfängliche Begeisterung wurde gemäßigt durch die Erkenntnis, dass die Schaffung wirklich intelligenter Maschinen viel komplexer war als ursprünglich angenommen.
Die 1970er und 1980er Jahre sahen eine Periode des abnehmender Finanzierung und Interesses in der AI-Forschung, die allgemein als „AI-Winter“ bezeichnet wird. Diese Abnahme war hauptsächlich auf das Versagen der AI-Systeme bei der Erfüllung der hohen Erwartungen der frühen Pioniere zurückzuführen.
Von Regelbasierten Systemen zu Machine Learning
Die Ära der ExpertenSysteme
Die 1980er Jahre sahen eine Wiederbelebung des Interesses in der AI, primär durch die Entwicklung von Expertensystemen initiiert. Diese regelbasierten Programme waren dafür konzipiert, die Entscheidungsprozesse menschlicher Experten in bestimmten Bereichen zu emulieren.
Expertsysteme finden Anwendungen in verschiedenen Bereichen, einschließlich der Medizin, der Finanzen und der Ingenieurwissenschaften. Allerdings waren sie durch ihre Unfähigkeit, aus Erfahrungen zu lernen oder sich an neue Situationen außerhalb ihrer programmierten Regeln anzupassen, eingeschränkt.
Der Aufstieg der Maschinellem Lerne
Die Grenzen von regelbasierten Systemen legten den Weg frei für einen Paradigmenwechsel hin zur maschinellen Lerne. Dieser Ansatz, der ab den 1990er Jahren und den 2000er Jahren hervortrat, konzentriert sich auf die Entwicklung von Algorithmen, die aus Daten lernen und basierend auf diesen Daten Prognosen oder Entscheidungen treffen können.
Maschinelle Lerneverfahren wie neuronale Netze und Support-Vector-Maschinen zeigten bemerkenswerter Erfolg in Aufgaben wie Mustererkennung und Datenklassifizierung. Die Zeit des Big Data und die zunehmende Rechenleistung beschleunigten weiter die Entwicklung und Anwendung von maschinellen Lernalgorithmen.
Die Emergenz selbständiger AI-Agenten
Von beschränkter AI zu allgemeiner AI
Als AI-Technologien weiter evolved, begannen Forscher, die Möglichkeit zu erforschen, um mehr universelle und autonom arbeitende Systeme zu schaffen. Dieser Übergang markierte den Wechsel von beschränkter AI, die für bestimmte Aufgaben entwickelt wurde, hin zur Suche nach künstlicher allgemeiner Intelligenz (AGI).
AGI zielt auf die Entwicklung von Systemen ab, die jeder intellektuellen Aufgabe, die ein Mensch ausführen kann, fähig sind. Obwohl reale AGI immer noch ein weit entferntes Ziel ist, wurden bereits erhebliche Fortschritte bei der Schaffung flexibler und anpassbarer AI-Systeme erzielt.
Die Rolle von Tieflern und Neuronalen Netzwerken
Der Aufstieg von Tieflern, einem Subsystem von Maschinenlernen, das auf künstlichen neuronalen Netzwerken basiert, hat maßgeblich zu einer Verbesserung des AI-Felds beigetragen.
Tieflearn-Algorithmen, die durch die Struktur und Funktion des menschlichen Gehirns inspiriert sind, haben bei Bereichen wie Bild- und Spracherkennung, natürlicher Sprachverarbeitung und Spielen bemerkenswerte Fähigkeiten gezeigt. Diese Fortschritte haben den Grundstein für die Entwicklung komplexerer selbständiger AI-Agenten gelegt.
Eigenschaften und Arten von AI-Agenten
AI-Agenten sind selbständige Systeme, die in der Lage sind, ihr Umfeld wahrzunehmen, Entscheidungen zu treffen und Aktionen durchzuführen, um bestimmte Ziele zu erreichen.Sie verfügen über Eigenschaften wie Autonomie, Wahrnehmung, Reaktivität, Rechnung, Entscheidungsfindung, Lernen, Kommunikation und Zielorientierung.
Es gibt verschiedene Arten von AI-Agenten, die jeweils unterschiedliche Fähigkeiten haben:
-
Einfache Reflex-Agenten: Reagieren auf bestimmte Stimuli basierend auf vorher definierten Regeln.
-
Modellbasierte Reflexagenten: Halten ein internes Modell der Umgebung bereit, um Entscheidungen zu treffen.
-
Zielbasierte Agenten: Führen Aktionen aus, um bestimmte Ziele zu erreichen.
-
Nutzenbasierte Agenten: Berücksichtigen potenzielle Ergebnisse und wählen Aktionen aus, die erwartete Nutzen maximieren.
-
Lernende Agenten: Verbessern die Entscheidungsfindung mit der Zeit durch maschinelles Lernen.
Herausforderungen und ethische Überlegungen
Als AI-Systeme zunehmend fortschrittn und unabhängiger werden, gehen mit ihnen kritische Überlegungen einher, um sicherzustellen, dass ihre Nutzung innerhalb der sozial anerkannten Grenzen bleibt.
Insbesondere Large Language Models (LLMs) agieren als Leistungserhöhungsfaktoren für die Produktivität. Dies löst jedoch eine entscheidende Frage auf: Was werden diese Systeme supercharge—gute Absichten oder böse Absichten? Wenn die Absicht hinter der Nutzung von AI böse ist, ist es dringend erforderlich, dass diese Systeme solche Missbrauchsabsichten mithilfe verschiedener NLP-Techniken oder anderer verfügbarer Tools erkennen.
Ingenieure von LLM haben Zugriff auf eine Reihe von Werkzeugen und Methodologien, um diese Herausforderungen zu bewältigen:
-
Sentiment Analyse: Durch die Verwendung von Sentiment Analyse können LLMs den emotionalen Tone des Textes bewerten, um schädliche oder aggressives Sprachverhalten zu erkennen, was dazu beitragen kann, potenzielle Fehlverwendungen auf Kommunikationsplattformen zu erkennen.
-
Inhaltsfilterung: Werkzeuge wie Schlüsselwortfilterung und Mustererkennung können verwendet werden, um die Generierung oder Verbreitung schädlicher Inhalte zu vermeiden, wie z.B. Hassrede, Falschmeldungen oder explizites Material.
-
Voreingenommenheiterkennung: Durch die Implementierung von Voreingenommenheiterkennungssystemen, wie z.B. AI Fairness 360 (IBM) oder Fairness Indicators (Google), kann die Voreingenommenheit in Sprachmodelle erkannt und abgemildert werden, sicherstellend, dass AI-Systeme faire und gleichberechtigteoperationen haben.
-
Erklärbarkeitstechniken: Mit Erklärbarkeitstools wie LIME (Local Interpretable Model-agnostic Explanations) oder SHAP (SHapley Additive exPlanations) können Ingenieure die Entscheidungsprozesse von LLMs verstehen und erklären, was es erleichtert, unbeabsichtigte Verhaltensweisen zu erkennen und zu beheben.
-
Adversarial Testing: Durch die Simulation von bösartigen Angriffen oder schädlichen Eingaben können Ingenieure LLMs mit Tools wie TextAttack oder dem Adversarial Robustness Toolbox Stresstests unterziehen, um Schwachstellen zu identifizieren, die für böswillige Zwecke ausgenutzt werden könnten.
-
Ethische KI-Richtlinien und -Rahmenwerke: Die Übernahme ethischer KI-Entwicklungsrichtlinien, wie sie vom IEEE oder der Partnership on AI bereitgestellt werden, kann die Schaffung verantwortungsbewusster KI-Systeme leiten, die das gesellschaftliche Wohl priorisieren.
Neben diesen Werkzeugen benötigen wir deshalb ein dediziertes Red Team für KI – spezialisierte Teams, die LLMs an ihre Grenzen bringen, um Lücken in ihren Verteidigungen zu erkennen. Red Teams simulieren gegnerische Szenarien und decken Schwachstellen auf, die sonst unbemerkt bleiben könnten.
Doch es ist wichtig zu erkennen, dass die Menschen hinter dem Produkt den stärksten Einfluss darauf haben. Viele der Angriffe und Herausforderungen, denen wir heute gegenüberstehen, existierten bereits, bevor LLMs entwickelt wurden, was zeigt, dass der menschliche Faktor zentral bleibt, um sicherzustellen, dass KI ethisch und verantwortungsvoll eingesetzt wird.
Die Integration dieser Werkzeuge und Techniken in die Entwicklungspipeline, zusammen mit einem wachsamen Red Team, ist entscheidend, um sicherzustellen, dass LLMs positive Ergebnisse verstärken und deren Missbrauch erkennen und verhindern.
Kapitel 3: Wo KI-Agenten am stärksten glänzen
Die einzigartigen Stärken von KI-Agenten
KI-Agenten zeichnen sich durch ihre Fähigkeit aus, ihre Umgebung autonom wahrzunehmen, Entscheidungen zu treffen und Aktionen auszuführen, um spezifische Ziele zu erreichen. Diese Autonomie, kombiniert mit fortschrittlichen maschinellen Lernfähigkeiten, ermöglicht es KI-Agenten, Aufgaben zu übernehmen, die entweder zu komplex oder zu repetitiv für Menschen sind.
Hier sind die wichtigsten Stärken, die KI-Agenten glänzen lassen:
-
Autonomie und Effizienz: KI-Agenten können eigenständig ohne ständige menschliche Intervention arbeiten. Diese Autonomie ermöglicht es ihnen, Aufgaben rund um die Uhr zu erledigen, was die Effizienz und Produktivität erheblich steigert. Zum Beispiel können KI-gesteuerte Chatbots bis zu 80% der routinemäßigen Kundenanfragen bearbeiten, was die Betriebskosten senkt und die Reaktionszeiten verbessert.
-
Erweiterte Entscheidungsfindung: KI-Agenten können riesige Datenmengen analysieren, um fundierte Entscheidungen zu treffen. Diese Fähigkeit ist besonders wertvoll in Bereichen wie der Finanzbranche, wo KI-Handelsbots die Handelseffizienz erheblich steigern können.
-
Lernen und Anpassungsfähigkeit: KI-Agenten können aus Erfahrung lernen und sich an neue Situationen anpassen. Diese kontinuierliche Verbesserung ermöglicht es ihnen, ihre Leistung im Laufe der Zeit zu steigern. Zum Beispiel können KI-Gesundheitsassistenten dazu beitragen, Diagnosefehler zu reduzieren und somit die Gesundheitsergebnisse zu verbessern.
-
Personalisierung: KI-Agenten können personalisierte Erlebnisse bieten, indem sie das Benutzerverhalten und die Vorlieben analysieren. Amazon’s Empfehlungs-Engine, die 35 % seines Umsatzes ausmacht, ist ein hervorragendes Beispiel dafür, wie KI-Agenten das Benutzererlebnis verbessern und den Umsatz steigern können.
Warum KI-Agenten die Lösung sind
AI-Agenten bieten Lösungen für viele der Herausforderungen an, die traditionelle Software und menschlich bediente Systeme erdulden. Hier ist warum sie die bevorzugte Wahl sind:
-
Skalierbarkeit: AI-Agenten können Operationen skalieren, ohne dass die Kosten proportional ansteigen. Diese Skalierbarkeit ist für Geschäfte von Bedeutung, die wachsen wollen, ohne dass ihre Beschäftigtezahl oder ihre operationellen Ausgaben signifikant ansteigen.
-
Konsistenz und Zuverlässigkeit: Im Gegensatz zu Menschen litten AI-Agenten nicht an Erschöpfung oder Unterschiedlichkeit. Sie können repetitive Aufgaben mit hoher Genauigkeit und Zuverlässigkeit erledigen, was eine konsequente Leistung gewährleistet.
-
Datenbasierte Einsichten: AI-Agenten können große Datenmengen verarbeiten und analysieren, um Muster und Einsichten zu entdecken, die möglicherweise von Menschen verpasst werden. Diese Fähigkeit ist unentbehrlich für Entscheidungen in Bereichen wie Finanzen, Gesundheitswesen und Marketing.
-
Kosteneinsparungen: Durch die Automatisierung von Routinetasks können AI-Agenten die Notwendigkeit für menschliche Ressourcen reduzieren, was zu signifikanten Kosteneinsparungen führt. Zum Beispiel können AI-gesteuerte Betrugserkennungssysteme jährlich Milliarden von Dollar sparen, indem sie betrügerische Aktivitäten reduzieren.
Bedingungen für die gut ablaufende Arbeit von AI-Agenten
Um die erfolgreiche Einführung und Leistung von AI-Agenten sicherzustellen, müssen bestimmte Bedingungen erfüllt werden:
-
Klare Ziele und Anwendungsfälle: Die Definition von spezifischen Zielen und Anwendungsfällen ist entscheidend für die effektive Einführung von AI-Agenten. Diese Klarheit hilft bei der Festlegung von Erwartungen und der Messung von Erfolg. Zum Beispiel kann das Setzen eines Ziels, die Reaktionszeiten des Kunden-Service um 50% zu verringern, die Einführung von AI-Chatbots beeinflussen.
-
Qualität von Daten
: AI-Agenten verlassen sich auf hochwertige Daten für die Ausbildung und den Betrieb. Die Gewährleistung, dass die Daten korrekt, relevant und aktuell sind, ist unerlässlich, um das effektive Handeln der Agenten zu gewährleisten.
-
Integration mit bestehenden Systemen: Eine nahtlose Integration mit bestehenden Systemen und Workflows ist notwendig, um die AI-Agenten optimal zu funktionieren. Diese Integration stellt sicher, dass AI-Agenten auf die notwendigen Daten zugreifen und mit anderen Systemen interagieren können, um ihre Aufgaben zu erfüllen.
-
Kontinuierliches Überwachen und Optimieren: Die regelmäßige Überwachung und Optimierung von AI-Agenten ist entscheidend, um ihre Leistung zu halten. Dies umfasst das Verfolgen von Schlüsselperformanceindikatoren (KPIs) und die notwendigen Anpassungen auf der Basis von Rückmeldungen und Leistungsdaten.
-
Ethische Überlegungen und Bias-Minderung: Die Berücksichtigung ethischer Aspekte und die Minderung von Voreingenommenheit bei KI-Agenten sind entscheidend, um Fairness und Inklusivität zu gewährleisten. Die Implementierung von Maßnahmen zur Erkennung und Verhinderung von Voreingenommenheit kann dazu beitragen, Vertrauen aufzubauen und eine verantwortungsvolle Bereitstellung sicherzustellen.
Best Practices für die Bereitstellung von KI-Agenten
Bei der Bereitstellung von KI-Agenten können folgende bewährte Verfahren zu ihrem Erfolg und ihrer Effektivität beitragen:
-
Ziele und Anwendungsfälle definieren: Identifizieren Sie klar die Ziele und Anwendungsfälle für die Bereitstellung von KI-Agenten. Dies hilft dabei, Erwartungen festzulegen und den Erfolg zu messen.
-
Wähle die richtige AI-Plattform
: Wähle eine AI-Plattform, die mit deinen Zielen, Anwendungsfällen und bestehenden Infrastrukturen alignmentiert. Berücksichtige Faktoren wie integrierbare Kapazitäten, Skalierbarkeit und Kosten.
-
Erstelle eine umfassende Wissensbasis: Erstelle eine gut strukturierte und präzise Wissensbasis, um AI-Agenten zu ermöglichen, relevante und zuverlässige Antworten zu liefern.
-
Stelle sicher, dass die Integration flüssig ist: Integriere AI-Agenten mit bestehenden Systemen wie CRM und Callcenter-Technologien, um eine integrierte Kundererfahrung zu bieten.
-
Trainiere und optimiere AI-Agenten: Trainiere und optimiere AI-Agenten kontinuierlich mit Daten aus Interaktionen. Überwache die Leistung, identifiziere Bereiche für Verbesserungen und aktualisiere Modelle entsprechend.
-
Zeichne geeignete Eskalationsverfahren ab
: Definiere Protokolle für das Weiterleiten komplexer oder emotionaler Anrufe an menschliche Agenten, um eine glaubhafte Übergabe und eine effiziente Lösung zu gewährleisten.
-
Monitoriere und analysiere Leistung: Verfolge Schlüsselleistungsindikatoren (KPIs) wie Verfahrenslösungsraten, Durchschnittsverarbeitungszeit und Kundenzufriedenheitspunkte. Nutze Analyse工具 für datengesteuerte Einsichten und Entscheidungen.
-
Stelle sicher, dass Datenvertraulichkeit und -sicherheit gewahrt werden: starke Sicherheit ist Schlüssel, wie Daten anonymisiert, menschlicher Aufsicht sichergestellt, Richtlinien für Datenerhaltung eingerichtet und starke Verschlüsselungsmaßnahmen festgelegt, um Kunden Daten zu schützen und Vertraulichkeit zu halten.
AI-Agenten + LLMs: Eine neue Ära von intelligenten Software-Lösungen
Stellen Sie sich vor, es gäbe Software, die Ihre Anfragen nicht nur versteht, sondern auch selbständig diese ausführt. Dies ist die Zusage der Kombination von künstlichen Intelligenz-Agenten mit Großen Sprachmodellen (LLM). Diese kraftvollen Paarung schafft eine neue Kategorie von Anwendungen, die intuitiverer, kapazitäterferner und wirkungsvoller sind als je zuvor.
AI-Agenten: Jenseits von einfachen Aufgabenausführung
Obwohl oft mit digitalen Assistenten verglichen, sind AI-Agenten weit mehr als verklärte Skriptfollower. Sie umfassen eine Reihe von fortschrittlichen Technologien und arbeiten auf einem Rahmenwerk, das dynamische Entscheidungsprozesse und Handlungsvorgänge ermöglicht.
-
Architektur: Ein typischer AI-Agent besteht aus mehreren Schlüsselkomponenten:
-
Sensoren: Diese ermöglichen es dem Agenten, seine Umgebung wahrzunehmen, indem er Daten von verschiedenen Quellen wie Sensoren, APIs oder Benutzereingaben erfasst.
-
Glauber-Zustand: Dies repräsentiert das Verständnis des Agenten von der Welt auf der Basis der gesammelten Daten. Es wird laufend aktualisiert, wenn neue Informationen verfügbar sind.
-
Reasoning Engine: Dies ist der Kern des Entscheidungsprozesses des Agenten. Er nutzt Algorithmen, oft auf der Basis von Lernverfahren wie z.B. Verstärkungslernen oder Planungstechniken, um die beste Handlung basierend auf seinen aktuellen Glaubensüberzeugungen und Zielen zu bestimmen.
-
Aktuatoren: Dies sind die Werkzeuge des Agenten für die Interaktion mit der Welt. Sie können von API-Aufrufen bis hin zu physischen Robotern reichen.
-
-
Herausforderungen:
traditionelle AI-Agenten sind zwar in der Lage, klar definierte Aufgaben zu erledigen, zeigen jedoch oft Schwierigkeiten bei:
-
Natürliche Sprachverständnis: Die Interpretation des nuancierten menschlichen Sprachverständnisses, die Handhabung von Unterscheidungen und die Extraktion von Bedeutungen aus dem Kontext stellen nach wie vor erhebliche Herausforderungen dar.
-
Alltagsreasoning: Derzeitige AI-Agenten verfügen oft nicht über das allgemeine Wissen und die Reasoning-Fähigkeiten, die Menschen für selbstverständlich halten.
-
Generalisierung: Die Ausbildung von Agenten, um gut auf unbekannte Aufgaben zu performen oder an neuen Umgebungen anzupassen, bleibt ein Schlüsselbereich der Forschung.
-
LLM: Sprachverständnis und -generierung freischalten
LLM mit ihrer ungeheuerlichen Kenntnis, die in Milliarden von Parametern codiert ist, bringen bisher unvorhergesehene Sprachfähigkeiten auf den Tisch:
-
Transformer-Architektur: Der Grundstein der meisten modernen LLM ist die Transformer-Architektur, ein neuronales Netzdesign, das sich hervorragend für die Verarbeitung sequentieller Daten wie Text bewährt. Dies ermöglicht es LLM, Sprachabhängigkeiten über lange Distanzen zu erkennen, was sie in der Lage macht, den Kontext zu verstehen und kohärente und inhaltlich relevante Texte zu generieren.
-
Fähigkeiten: LLM sind hervorragend in einer Vielzahl von sprachbasierten Aufgaben:
-
Textgenerierung: Von der Schaffung von kreativem Fiktion bis zur Generierung von Code in mehreren Programmiersprachen, zeigen LLM bemerkenswerte Flüssigkeit und Kreativität.
-
Fragebeantwortung: Sie können kurze und präzise Antworten auf Fragen liefern, selbst wenn die Information über lange Dokumente verstreut ist.
-
Zusammenfassung: LLM können große Textmengen in kurze Zusammenfassungen verwandeln, indem sie wichtige Informationen extrahieren und irrelevante Details verwerfen.
-
-
Einschränkungen: Trotz ihrer beeindruckenden Fähigkeiten haben LLMs Einschränkungen:
-
Fehlende Realitätsgrundlage: LLMs arbeiten primär im Bereich der Textverarbeitung und verfügen nicht über die Fähigkeit, direkt mit der physikalischen Welt zu interagieren.
-
Mögliche Voreingenommenheit und Halluzination: Trainiert auf massiven, ungefilterten Datensätzen können LLMs biassierte Informationen aus den Daten erben und manchmal faktisch falsche oder unvernünftige Informationen generieren.
-
Die Synergie: Die Brücke zwischen Sprache und Handlung
Die Kombination von AI-Agenten und LLM lässt die Einschränkungen jedes vermeiden und schafft Systeme, die sowohl intelligent als auch fähig sind:
-
LLM als Interpreten und Planer: LLM können natürliche Sprachanweisungen in eine Formate umwandeln, die AI-Agenten verstehen können, was zu einer intuitiveren Mensch-Computer-Interaktion führt. Sie können auch ihr Wissen nutzen, um Agenten bei der Planung komplexer Aufgaben zu assistieren, indem sie diese in kleinere, bewältigbare Schritte aufteilen.
-
KI-Agenten als Ausführende und Lernende: KI-Agenten bieten LLMs die Fähigkeit, mit der Welt zu interagieren, Informationen zu sammeln und auf ihre Handlungen反馈 zu erhalten. Diese reale Grundlage kann LLMs dabei helfen, von Erfahrungen zu lernen und ihr Verhalten mit der Zeit zu verbessern.
Diese kraftvolle Synergie treibt die Entwicklung einer neuen Generation von Anwendungen an, die intuitiverer, anpassbarer und kapabler sind als je zuvor. Angesichts der Weiterentwicklung beider KI-Agenten und LLM-Technologien können wir erwarten, dass sich weitere innovative und bedeutsame Anwendungen entwickeln und die Landschaft der Softwareentwicklung und der Mensch-Computer-Interaktion verändern werden.
Reale Beispiele: Veränderung der Branchen
Diese starke Kombination hat bereits Wellen in verschiedenen Sektoren ausgelöst:
-
Kundendienst: Problemlösung mit kontextuellem Bewusstsein
- Beispiel: Stellen Sie sich vor, ein Kunde kontaktiert einen Online-Händler wegen einer verspäteten Lieferung. Ein von einem LLM betriebener KI-Agent kann den Ärger des Kunden verstehen, auf die Bestellhistorie zugreifen, das Paket in Echtzeit verfolgen und proaktiv Lösungen wie beschleunigten Versand oder einen Rabatt auf den nächsten Einkauf anbieten.
-
Inhaltserstellung: Hochwertige Inhalte in großem Maßstab generieren
- Beispiel: Ein Marketingteam kann ein KI-Agent + LLM-System verwenden, um gezielte Social-Media-Beiträge zu generieren, Produktbeschreibungen zu schreiben oder sogar Videoskripte zu erstellen. Das LLM sorgt dafür, dass der Inhalt ansprechend und informativ ist, während der KI-Agent den Veröffentlichungs- und Verteilungsprozess übernimmt.
-
Softwareentwicklung: Beschleunigung der Programmierung und Fehlerdiagnose
- Beispiel: Ein Entwickler kann eine Softwarefunktion, die er erstellen möchte, mithilfe der natürlichen Sprache beschreiben. Die LLM kann dann Codeabschnitte generieren, potenzielle Fehler identifizieren und Verbesserungen vorschlagen, was die Entwicklungsprozesse wesentlich beschleunigen kann.
-
Gesundheitswesen: Individuelle Behandlung und Verbesserung der Patientenpflege
- Beispiel: Ein mit einem LLM ausgestatteter AI-Agent, der auf eine Patientenmedizinische Geschichte zugreifen kann, kann auf ihre gesundheitsbezogenen Fragen antworten, personalisierte Medikamentenhinweise bereitstellen und sogar vorläufige Diagnosen aufgrund ihrer Symptome aussprechen.
-
Recht: Rationalisierung der juristischen Forschung und der Abfassung von Dokumenten
- Beispiel: Ein Anwalt muss einen Vertrag mit bestimmten Klauseln und rechtlichen Präzedenzfällen entwerfen. Ein KI-Agent, der von einem LLM unterstützt wird, kann die Anweisungen des Anwalts analysieren, umfangreiche juristische Datenbanken durchsuchen, relevante Klauseln und Präzedenzfälle identifizieren und sogar Teile des Vertrags entwerfen, was den Zeit- und Arbeitsaufwand erheblich reduziert.
-
Videoerstellung: Mit Leichtigkeit fesselnde Videos erstellen
- Beispiel: Ein Marketing-Team möchte ein kurzes Video erstellen, in dem die Funktionen seines Produkts erklärt werden. Sie können einem KI-Agenten + LLM-System eine Skript-Skizze und visuelle Stilpräferenzen zur Verfügung stellen. Das LLM-System kann dann ein detailliertes Skript erstellen, geeignete Musik und Bildmaterial vorschlagen und das Video sogar bearbeiten, wodurch ein Großteil des Videoerstellungsprozesses automatisiert wird.
-
Architektur: Gebäude mit künstlicher Intelligenz gestalten
- Beispiel: Ein Architekt entwirft ein neues Bürogebäude. Er kann ein KI-Agenten + LLM-System verwenden, um seine Designziele einzugeben, wie z. B. maximales natürliches Licht und optimierte Räumlichkeitsnutzung. Die LLM kann diese Ziele dann analysieren, verschiedene Designoptionen generieren und sogar simulieren, wie das Gebäude unter verschiedenen Umweltbedingungen performen würde.
-
Bau: Verbesserung der Sicherheit und Effizienz auf Baustellen
- Beispiel: Ein KI-Agent, der mit Kameras und Sensoren ausgestattet ist, kann eine Baustelle auf Sicherheitsgefahren überwachen. Wenn ein Arbeiter keine ordnungsgemäße Schutzausrüstung trägt oder ein Gerät in einer gefährlichen Position steht, kann das LLM die Situation analysieren, den Baustellenleiter benachrichtigen und bei Bedarf sogar automatisch die Arbeiten einstellen.
Die Zukunft ist da: Eine neue Ära der Softwareentwicklung
Die Konvergenz von KI-Agenten und LLMs markiert einen bedeutenden Fortschritt in der Softwareentwicklung. Während sich diese Technologien weiterentwickeln, können wir mit noch innovativeren Anwendungen rechnen, die Branchen transformieren, Arbeitsabläufe optimieren und völlig neue Möglichkeiten für die Interaktion zwischen Mensch und Computer schaffen.
KI-Agenten glänzen am meisten in Bereichen, die die Verarbeitung großer Datenmengen, die Automatisierung repetitiver Aufgaben, das Treffen komplexer Entscheidungen und die Bereitstellung personalisierter Erlebnisse erfordern. Indem sie die notwendigen Bedingungen erfüllen und bewährte Verfahren befolgen, können Organisationen das volle Potenzial von KI-Agenten nutzen, um Innovation, Effizienz und Wachstum voranzutreiben.
Kapitel 4: Die philosophische Grundlage von Intelligentensystemen
Die Entwicklung intelligenter Systeme, insbesondere in der künstlichen Intelligenz (KI), erfordert einen gründlichen Verständnis von philosophischen Prinzipien. Dieses Kapitel geht der Ausführung der zentralen philosophischen Ideen, die das Design, die Entwicklung und die Nutzung von KI beeinflussen, näher. Es betont die Bedeutung, dass technologischer Fortschritt mit ethischen Werten in Einklang gebracht wird.
Die philosophische Grundlage von intelligenten Systemen ist nicht nur eine theoretische Übung – sie ist ein lebenswichtiges Framework, das sicherstellt, dass KI-Technologien der Menschheit nutzen. Durch die Förderung von Fairness, Inklusivität und Verbesserung der Lebensqualität leiten diese Prinzipien AI dazu, unsere besten Interessen zu dienen.
Ethische Überlegungen in der KI-Entwicklung
Als KI-Systeme zunehmend in jeden Aspekt des menschlichen Lebens integriert werden, von Gesundheitswesen und Bildung bis hin zu Finanzen und Verwaltung, müssen wir ihre Entwicklung und Anwendung gründlich prüfen und ethische Grundsätze umsetzen.
Das grundlegende ethische Thema dreht sich um, wie KI so konzipiert werden kann, dass menschliche Werte und moralische Prinzipien aufrecht erhalten werden. Diese Frage ist zentral für die Art und Weise, wie KI die Zukunft der Gesellschaften weltweit formen wird.
An der Herzstelle dieser ethischen Diskussion steht das Prinzip der Barmherzigkeit, ein Cornerstone der moralischen Philosophie, der besagt, dass Handlungen auf das Gute und die Verbesserung der Wohlbefinden von Individuen und der gesamten Gesellschaft hinwirken sollten (Floridi & Cowls, 2019).
Im Zusammenhang mit KI besteht das Prinzip der Barmherzigkeit darin, Systeme zu entwerfen, die aktiv zum Wohlergehen der Menschen beitragen – Systeme, die die Gesundheitsergebnisse verbessern, Bildungschancen ergänzen und eine gerechte Wirtschaftsentwicklung fördern.
Allerdings ist die Anwendung von Barmherzigkeit in KI nicht einfach. Es fordert einen subtlen Ansatz, der die potenziellen Vorteile von KI gegenüber den möglichen Risiken und Schäden sorgfältig abwägt.
Eines der Hauptchallenges bei der Anwendung des Prinzips der Barmherzigkeit in der KI-Entwicklung besteht in der Notwendigkeit für einen delikaten Balanceakt zwischen Innovation und Sicherheit.
KI hat das Potenzial, Bereiche wie die Medizin revolutioniert zu werden, wo prädiktive Algorithmen größere Genauigkeit und frühere Diagnosestellung als menschliche Ärzte erreichen können. Allerdings könnten diese selben Technologien bestehende Ungleichheiten verstärken, wenn nicht ein strenges ethisches Overseeing vorhanden ist.
Das könnte beispielsweise dazu führen, dass diese Technologien primär in reichen Regionen eingesetzt werden, währendCommunities weiterhin keinen Zugang zu grundlegendem Gesundheitswesen haben.
Aufgrund dessen ist eine ethische KI-Entwicklung nicht nur darauf beschränkt, die maximale Leistung zu maximieren, sondern auch eine proaktive Herangehensweise an die Risikominimierung. Dies umfasst das Implementieren robuster Schutz Mechanismen, um die Missbrauchsgefahr von AI zu vermeiden und sicherzustellen, dass diese Technologien versehentlich keinen Schaden zufügen.
Das ethische Framework für AI muss auch von Anfang an inklusiv sein, indem sichergestellt wird, dass die Vorteile von AI gleichmäßig across allen gesellschaftlichen Gruppen verteilt werden, einschließlich solcher, die traditionell marginalisiert sind. Dies fordert eine Verpflichtung zu Gerechtigkeit und Fairness, um sicherzustellen, dass AI nicht einfach das Status Quo bestätigt, sondern aktiv an der Auflösung systemischer Ungleichheiten arbeitet.
Beispielsweise hat die von AI getriebene Arbeitsautomatisierung das Potenzial, die Produktivität und Wirtschaftswachstum zu erhöhen. Allerdings könnte dies auch zu einer bedeutenden Arbeitsplatzverlagerung führen, die insbesondere niedrig verdienende Arbeitnehmer betrifft.
Wie Sie sehen können, muss ein ethisch solides AI-Rahmenwerk Strategien für eine gerechte Nutzenverteilung und die Bereitstellung von Unterstützungssystemen für die von AI-Fortschritten beeinträchtigten Personen umfassen.
Die ethische Entwicklung von AI erfordert eine kontinuierliche Beteiligung verschiedener Interessengruppen, einschließlich von Ethikern, Technologen, politischen Entscheidungsträgern und den Gemeinschaften, die am meisten von diesen Technologien betroffen sein werden. Diese interdisziplinäre Zusammenarbeit stellt sicher, dass AI-Systeme nicht in einem Vakuum entwickelt werden, sondern stattdessen von einem breiten Spektrum an Perspektiven und Erfahrungen geprägt werden.
Durch diese gemeinsame Bemühung können wir AI-Systeme schaffen, die nicht nur die unsere menschliche Wesensart widerspiegeln, sondern auch deren Werte aufrecht erhalten – Menschlichkeit, Gerechtigkeit, Respekt für die Autonomie und eine Verpflichtung zum Gemeinwohl.
Die ethischen Überlegungen in der AI-Entwicklung sind nicht nur Richtlinien, sondern grundlegende Elemente, die bestimmen, ob AI eine positive Kraft in der Welt ist. Indem wir AI auf das Prinzip der Barmherzigkeit, Gerechtigkeit und Inklusivität gründen und eine wachsende Herangehensweise an die Balance von Innovation und Risiko pflegen, können wir sicherstellen, dass die AI-Entwicklung nicht nur die Technologie vorwärts bringt, sondern auch das Leben aller Mitglieder der Gesellschaft verbessert.
Während wir die Möglichkeiten von AI weiter erforschen, ist es unerlässlich, dass diese ethischen Überlegungen bei all unseren Bemühungen im Vordergrund stehen, und uns auf einen zukünftigen Weg leiten, der wirklich der Menschheit förderlich ist.
Die Notwendigkeit eines Menschenzentrierten AI-Entwurfs
Der Menschenzentrierte AI-Entwurf ist mehr als nur eine technische Betrachtung. Er ist begründet in tiefgreifenden philosophischen Prinzipien, die die Menschenwürde, die Autonomie und die Handlungskompetenz priorisieren.
Dieser Ansatz der AI-Entwicklung ist grundlegend mit dem kantischen ethischen Rahmenwerks verbunden, das behauptet, dass Menschen als Ziele an sich betrachtet werden müssen und nicht nur als Instrumente zur Erreichung anderer Ziele (Kant, 1785).
Die Auswirkungen dieses Prinzips auf die AI-Entwicklung sind tiefgreifend, und es erfordert, dass AI-Systeme mit einer unerbittlichen Konzentration auf die Dienstleistung für menschliche Interessen entwickelt werden, die Bewahrung der menschlichen Agentur und die Achtung der individuellen Autonomie.
Technische Umsetzung von Menschenzentrierten Prinzipien
Erhöhung der menschlichen Autonomie durch AI: Der Begriff der Autonomie in AI-Systemen ist entscheidend, insbesondere im Hinblick darauf, dass diese Technologien die Benutzer befähigen sollten, anstatt sie zu kontrollieren oder unerlaubte Einfluss auszuüben.
In technischen Begriffen umfasst dies das Design von AI-Systemen, die die Benutzerautonomie priorisieren, indem sie ihnen die notwendigen Werkzeuge und Informationen bereitstellen, um informierte Entscheidungen treffen zu können. Dies erfordert, dass AI-Modelle konztextsensitiv entwickelt werden, d. h., sie müssen verstehen, in welchem konkreten Kontext eine Entscheidung getroffen wird, und ihre Empfehlungen entsprechend anpassen.
Aus Sicht des Systemsdesigns umfasst dies die Integration konztextueller Intelligenz in AI-Modelle, die diesen Systemen erlaubt, dynamisch auf die Benutzereinstellungen, Präferenzen und Bedürfnisse einzugreifen.
Beispielsweise im Gesundheitswesen muss ein AI-System, das Ärzten bei der Diagnose von Zuständen assistiert, die individuelle medizinische Geschichte des Patienten, die aktuellen Symptome und sogar die psychologische Verfassung des Patienten in Betracht ziehen, um Empfehlungen zu offerieren, die die Sachkenntnis der Ärzte unterstützen und nicht ihre Substitution darstellen. Diese kontextuelle Anpassung gewährleistet, dass AI weiterhin ein supportive Werkzeug ist, das die menschliche Autonomie verstärkt und nicht reduziert.
Sicherstellung transparenter Entscheidungsprozesse
: Transparenz in AI-Systemen ist eine grundlegende Voraussetzung dafür, dass Nutzer die Entscheidungen dieser Technologien Vertrauen schenken und verstehen können. Technisch bedeutet dies, dass erklärbare AI (XAI) gefordert ist, was mit der Entwicklung von Algorithmen verbunden ist, die ihre Entscheidungen nachvollziehen können.
Dies ist insbesondere in Bereichen wie Finanzen, Gesundheitswesen und Strafjustiz von erheblicher Bedeutung, da ein unklarartiges Entscheidungsverfahren zu Misstrauen und ethischen Bedenken führen kann.
Die Erklärbarkeit kann durch mehrere technische Ansätze erreicht werden. Ein häufig verwendetes Verfahren ist die post-hoc Interpretierbarkeit, bei der das AI-Modell eine Erklärung nach der Entscheidung erstellt. Dies könnte darin bestehen, die Entscheidung in ihre bestehenden Faktoren aufzusplitten und anzuzeigen, wie jedes einzelne zu dem endgültigen Ergebnis beigetragen hat.
Ein anderer Ansatz sind von Natur aus interpretierbare Modelle, bei denen die Architektur des Modells so gestaltet ist, dass seine Entscheidungen standardmäßig transparent sind. Zum Beispiel sind Modelle wie Entscheidungsbäume und lineare Modelle von Natur aus interpretierbar, weil ihr Entscheidungsprozess leicht zu verfolgen und zu verstehen ist.
Die Herausforderung bei der Implementierung erklärbarer KI besteht darin, Transparenz und Leistung in Einklang zu bringen. Oftmals sind komplexere Modelle, wie tiefe neuronale Netzwerke, weniger interpretierbar, aber genauer. Daher muss das Design von menschenzentrierter KI den Kompromiss zwischen der Interpretierbarkeit des Modells und seiner Vorhersagekraft berücksichtigen, um sicherzustellen, dass Benutzer KI-Entscheidungen vertrauen und verstehen können, ohne die Genauigkeit zu opfern.
Bedeutungsvolle menschliche Aufsicht ermöglichen: Bedeutungsvolle menschliche Aufsicht ist entscheidend, um sicherzustellen, dass KI-Systeme innerhalb ethischer und betrieblicher Grenzen operieren. Diese Aufsicht beinhaltet das Design von KI-Systemen mit Sicherheitsvorkehrungen und Übersteuerungsmechanismen, die es menschlichen Bedienern ermöglichen, bei Bedarf einzugreifen.
Die technische Implementierung der menschlichen Aufsicht kann auf mehrere Weisen angegangen werden.
Ein Ansatz besteht darin, mensch-in-the-loop-Systeme zu integrieren, bei denen die KI-Entscheidungsprozesse kontinuierlich von menschlichen Bedienern überwacht und bewertet werden. Diese Systeme sind so konzipiert, dass menschliches Eingreifen an kritischen Punkten ermöglicht wird, um sicherzustellen, dass die KI nicht autonom in Situationen handelt, in denen ethische Urteile erforderlich sind.
Beispielsweise sind beim autonomen Waffensystem menschliche Überwachungsvorschriften unabdingbar, um zu verhindern, dass das AI von ohne menschliche Einbindung lebens oder tod entscheidet. Dies könnte darin bestehen, strenge operationellen Grenzen zu setzen, die das AI ohne menschliche Autorisierung nicht übersteigen kann, und somit ethische Schutzvorkehrungen in das System einzubinden.
Eine weitere technische Überlegung ist die Entwicklung von Audit-Trails, die Aufzeichnungen aller durch das AI-System getroffenen Entscheidungen und Handlungen sind. Diese Spuren bieten eine transparentierte Verlaufskunde, die von menschlichen Betreibern überprüft werden kann, um die Einhaltung von ethischen Standards zu gewährleisten.
Audit-Trails sind insbesondere in Sektoren wie Finanzen und Recht von Bedeutung, wo Entscheidungen dokumentiert und zu rechtfertigen werden müssen, um die öffentliche Vertrauen aufrechtzuerhalten und die regulatorischen Anforderungen zu erfüllen.
Autonomie und Kontrolle ausgleichen: Ein Haupttechnisches Herausforderungen in menschenzentrierter AI ist der rechte Mischung zwischen Autonomie und Kontrolle zu finden. Obwohl AI-Systeme dafür konzipiert sind, autonom in vielen Szenarien zu agieren, ist es wichtig, dass diese Autonomie die menschliche Kontrolle oder die Überwachung nicht unterminiert.
Dieses Gleichgewicht kann durch die Implementierung von Autonomie-Stufen erreicht werden, die die Grad der Unabhängigkeit des AI bei der Entscheidungsfindung festlegen.
Zum Beispiel in halbautonomen Systemen wie selbstfahrenden Autos reichen Autonomie-Stufen von grundständiger Fahrerassistenz (bei der der menschliche Fahrer vollständig Kontrolle behält) bis zur volle Automatisierung (bei der das AI für alle Fahrtägkeiten verantwortlich ist).
Die Entwicklung solcher Systeme muss sicherstellen, dass der menschliche Operator bei jeder angegebenen Autonomieebene die Fähigkeit behält, einzugreifen und das AI gegebenenfalls zu überschreiben. Dies erfordert komplexe Steuerungsinterfaces und Entscheidungssupportsysteme, die es Menschen ermöglichen, schnell und effektiv den Steuervorgang zu übernehmen.
Zusätzlich ist die Entwicklung von ethischen AI-Frameworks unerlässlich, um die selbständigen Aktionen von AI-Systemen zu lenken. Diese Frameworks sind Sets von Regeln und Leitlinien, die innerhalb des AI eingebettet sind und festlegen, wie es in ethisch komplexen Situationen verhalten soll.
Zum Beispiel in der Gesundheitsfürsorge könnten ethische AI-Frameworks Regeln beinhalten wie Patientenconsens, Privatsphäre und die Priorisierung von Behandlungen aufgrund medizinischer Bedürfnisse anstatt finanzieller Überlegungen.
Indem diese ethischen Prinzipien direkt in die Entscheidungsprozesse des AI eingebettet werden, können Entwickler sicherstellen, dass die Autonomie des Systems in Übereinstimmung mit menschlichen Werten ausgeübt wird.
Die Integration menschentricher Prinzipien in die AI-Design ist nicht nur eine philosophische Idealisierung, sondern eine technische Notwendigkeit. Durch die Verstärkung der menschlichen Autonomie, die Transparenz gewährleisten, die sinnvolle Überwachung ermöglichen und die Autonomie mit Kontrolle sorgfältig ausbalancieren, können AI-Systeme entwickelt werden, die wirklich der Menschheit dienen.
Diese technischen Überlegungen sind für die Schaffung von AI unerlässlich, die nicht nur die menschlichen Fähigkeiten verstärken, sondern auch die Grundwerte respektieren und aufrechterhalten, die unserer Gesellschaft grundlegend sind.
Angesichts der weiteren Entwicklung von AI bleibt die Verpflichtung zur menschlichen Zentrierung im Design eine entscheidende Voraussetzung für die Gewährleistung, dass diese potentiell mächtigen Technologien ethisch und verantwortungsvoll verwendet werden.
Wie man sicherstellt, dass KI der Menschheit zugute kommt: Verbesserung der Lebensqualität
Bei der Entwicklung von KI-Systemen ist es entscheidend, Ihre Bemühungen in den ethischen Rahmen des Utilitarismus einzubetten – eine Philosophie, die die Steigerung des allgemeinen Glücks und Wohlbefindens betont.
In diesem Kontext hat KI das Potenzial, kritische gesellschaftliche Herausforderungen anzugehen, insbesondere in Bereichen wie Gesundheitswesen, Bildung und Umweltverträglichkeit.
Das Ziel ist es, Technologien zu schaffen, die die Lebensqualität für alle erheblich verbessern. Doch diese Bestrebung ist mit Komplexitäten verbunden. Der Utilitarismus bietet einen überzeugenden Grund, KI weitreichend einzusetzen, bringt jedoch auch wichtige ethische Fragen darüber auf, wer davon profitiert und wer möglicherweise zurückgelassen wird, insbesondere unter den verletzlichen Bevölkerungsgruppen.
Um diese Herausforderungen zu meistern, benötigen wir einen ausgeklügelten, technisch fundierten Ansatz – einen, der das breite Streben nach gesellschaftlichem Wohl mit der Notwendigkeit von Gerechtigkeit und Fairness in Einklang bringt.
Bei der Anwendung utilitaristischer Prinzipien auf KI sollte Ihr Fokus darauf liegen, Ergebnisse in spezifischen Bereichen zu optimieren. Im Gesundheitswesen zum Beispiel haben KI-gesteuerte Diagnosetools das Potenzial, Patientenergebnisse erheblich zu verbessern, indem sie frühere und genauere Diagnosen ermöglichen. Diese Systeme können umfangreiche Datensätze analysieren, um Muster zu erkennen, die menschlichen Praktikern entgehen könnten, und somit den Zugang zu qualitativ hochwertiger Versorgung, insbesondere in unterversorgten Gebieten, erweitern.
jedoch bedarf die Implementierung dieser Technologien einer sorgfältigen Überlegung, um bestehende Ungleichheiten nicht zu verstärken. Die Daten, die zur Trainingszeit von AI-Modellen verwendet werden, können zwischen Regionen hin und her stark variieren, was die Genauigkeit und Verlässlichkeit dieser Systeme beeinträchtigt.
Diese Diskrepanz betont die Bedeutung der Festlegung robuster Datenverwaltungssysteme, die sicherstellen, dass Ihre AI-gesteuerte Gesundheitslösungen sowohl repräsentativ als auch Fair sind.
Im Bildungsbereich verspricht AI die Persönlichkeitsanpassung des Lernens. AI-Systeme können pädagogisches Material an die spezifischen Bedürfnisse von einzelnen Schülern anpassen, wodurch die Lernergebnisse verbessert werden. Durch die Analyse von Daten zu Schülerleistungen und Verhaltens kann AI erkennen, wo ein Schüler möglicherweise Schwierigkeiten hat und zielgerichtete Unterstützung bereitstellen.
Während Sie diese Vorteile erreichen, ist es unerlässlich, die Risiken zu beachten – wie z.B. die potenzielle Verstärkung von Vorurteilen oder die Marginalisierung von Schülern, die nicht typischen Lernmustern entsprechen.
Die Minderung dieser Risiken erfordert die Integration von Fairness-Mechanismen in AI-Modelle, die keineswegs versehentlich bestimmte Gruppen begünstigen sollten. Und die Aufrechterhaltung der Rolle von Pädagogen ist kritisch. Ihr Urteil und ihre Erfahrung sind unerlässlich, um AI-Tools wirklich effektiv und unterstützend zu machen.
Hinsichtlich der Umweltverträglichkeit besitzt AI erhebliches Potenzial. AI-Systeme können Ressourcennutzung optimieren, Umweltänderungen überwachen und die Auswirkungen des Klimawandels mit bisher unerreichter Präzision vorhersagen.
Beispielsweise kann AI umfangreiche Umweltdaten analysieren, um Wettermuster vorherzusagen, Energieverbrauch optimiert und Abfälle reduziert – Aktionen, die zum Wohlbefinden der aktuellen und künftigen Generationen beitragen.
Diese technologische Entwicklung bringt jedoch ihre eigenen Herausforderungen, insbesondere was die Umweltauswirkungen der AI-Systeme selbst angeht.
Der für den Betrieb großskaliger AI-Systeme notwendige Energieverbrauch kann die erhofften umweltpolitischen Vorteile ausgleichen. Daher ist es wichtig, Energiesparende AI-Systeme zu entwickeln, um sicherzustellen, dass ihre positive Auswirkung auf die Nachhaltigkeit nicht unterminiert wird.
Wenn Sie AI-Systeme mit utilitaristischen Zielen entwickeln, ist es auch wichtig, die Implikationen für die soziale Gerechtigkeit zu berücksichtigen. Utilitarismus konzentriert sich auf die maximale Glückseligkeit, betrachtet aber nicht unbedingt die Verteilung von Vorteilen und Schaden auf verschiedene gesellschaftliche Gruppen.
Dies lässt die Möglichkeit aufkommen, dass AI-Systeme disproportional Vorteile für die bereits privilegierten ausüben, während benachteiligte Gruppen wenig bis gar keine Verbesserung in ihren Umständen erfahren könnten.
Um dies zu kompensieren, sollten Sie Ihren AI-Entwicklungsprozess mit fokussierten Prinzipien für Gleichheit ergänzen, sicherstellen, dass Vorteile fair verteilt werden und dass mögliche Schäden behandelt werden. Dies könnte darin bestehen, Algorithmen zu entwerfen, die speziell dazu gedacht sind, Bias zu reduzieren und eine vielfältige Palette an Perspektiven in den Entwicklungsprozess einzubinden.
Während du daran arbeitest, AI-Systeme zu entwickeln, die das Leben verbessern sollen, ist es wichtig, den utilitaristischen Ziel des Maximieren des Wohlergehens mit der Notwendigkeit für Gerechtigkeit und Fairness in Balance zu halten. Dies erfordert einen subtileren, technisch fundierten Ansatz, der die breiteren Implikationen der AI-Einsatz erörtert.
Durch sorgfältige Design von AI-Systemen, die sowohl effektiv als auch gleichwertig sind, kannst du zu einer Zukunft beitragen, in der technologische Fortschritte wirklich den verschiedenen Bedürfnissen der Gesellschaft dienen.
Schütze vor möglichem Schaden
Bei der Entwicklung von AI-Technologien musst du die grundlegende Gefahr von Schaden erkennen und aktiv starke Schutzvorkehrungen einrichten, um diese Risiken zu reduzieren. Diese Verantwortung ist tief in deontologischer Ethik verwurzelt. Dieser ethischen Richtung geht es um die moralische Pflicht, sich an geltende Regeln und ethische Standards zu halten, um sicherzustellen, dass die von dir geschaffene Technologie mit grundlegenden moralischen Prinzipien aligniert ist.
Das Einführen stringenter Sicherheitsprotokolle ist nicht nur eine Vorsichtsmaßnahme, sondern eine moralische Verpflichtung. Diese Protokolle sollten umfassende Vorhersage von Bias, Transparenz in den algorithmischen Prozessen und klare Mechanismen für Rechenschaftslegung gehen.
Solche Schutzvorkehrungen sind unerlässlich, um zu verhindern, dass AI-Systeme versehentlich Schaden anrichten, durch biassierte Entscheidungen, unzugängliche Prozesse oder mangelnde Überwachung.
In der Praxis erfordert die Implementierung dieser Schutzvorkehrungen ein tiefes Verständnis sowohl der technischen als auch der ethischen Aspekte von AI.
Vorhersageprüfungen beinhalten nicht nur die Identifizierung und Korrektur von Vorhersagefehlern in Daten und Algorithmen, sondern auch das Verständnis der allgemeinen gesellschaftlichen Auswirkungen dieser Fehler. Sie müssen sicherstellen, dass Ihre AI-Modelle auf vielfältigen, repräsentativen Datensätzen trainiert werden und regelmäßig überprüft werden, um festzustellen und Fehler zu korrigieren, die mit der Zeit auftreten könnten.
Transparenz fordert andererseits, dass AI-Systeme so konzipiert werden, dass ihre Entscheidungsprozesse von Benutzern und Interessengruppen leicht verstanden und überprüft werden können. Dies umfasst die Entwicklung von erklärbaren AI-Modellen, die klare, interpretierbare Ausgaben liefern, die Benutzer zugänglich machen, wie Entscheidungen getroffen werden und sicherstellen, dass diese Entscheidungen gerechtfertigt und faire sind.
Außerdem sind Mechanismen zur Verantwortlichkeitsabwicklung für den Erhalt des Vertrauens und die Gewährleistung, dass AI-Systeme verantwortungsvoll genutzt werden, von größter Bedeutung. Diese Mechanismen sollten klare Richtlinien beinhalten, wer für die Ergebnisse von AI-Entscheidungen verantwortlich ist, sowie Prozesse für die Behandlung und Korrektur von Schäden, die auftreten könnten.
Sie müssen ein System etablieren, in dem ethische Überlegungen in jedem Entwicklungsstadium von AI integriert werden, von der initialen Designphase bis hin zu Implementierung und darüber hinaus. Dies umfasst nicht nur die Befolgung ethischer Richtlinien, sondern auch die ständige Überwachung und Anpassung von AI-Systemen, während sie mit der realen Welt interagieren.
Indem Sie diese Schutzvorkehrungen in die Substanz der AI-Entwicklung integrieren, können Sie helfen, sicherzustellen, dass der technologische Fortschritt dem größeren Guten dient und nicht zu unerwünschten negativen Konsequenzen führt.
Die Rolle von menschlicher Überwachung und Rückkopplungsmustern
Menschliche Aufsicht in AI-Systemen ist ein kritischer Bestandteil zur Gewährleistung einer ethischen AI-Einsatz. Der Grundsatz der Verantwortung stützt den Bedarf an kontinuierlicher menschlicher Beteiligung in der Operation von AI, insbesondere in high-stakes Umfeldern wie dem Gesundheitswesen und der Strafjustiz.
Feedback-Schleifen, in denen menschlicher Input verwendet wird, um AI-Systeme zu verfeinern und zu verbessern, sind entscheidend für die Aufrechterhaltung von Verantwortbarkeit und Anpassbarkeit (Raji et al., 2020). Diese Schleifen ermöglichen die Korrektur von Fehlern und die Integration neuer ethischer Überlegungen, während sich gesellschaftliche Werte weiterentwickeln.
Durch die Integration von menschlicher Aufsicht in AI-Systeme können Entwickler Technologien schaffen, die nicht nur effektiv sondern auch ethischen Normen und menschlichen Erwartungen entsprechen.
Ethikprogrammierung: Philosophische Prinzipien in AI-Systeme übersetzen
Die Übersetzung von philosophischen Prinzipien in AI-Systeme ist eine komplizierte, aber notwendige Aufgabe. Dieser Prozess umfasst das Einbetten ethischer Überlegungen in den Code, der die AI-Algorithmen treibt.
Begriffe wie Fairness, Gerechtigkeit und Selbstbestimmtheit müssen innerhalb von AI-Systemen kodiert werden, um sicherzustellen, dass sie auf Weise agieren, die die gesellschaftlichen Werte widerspiegeln. Dies erfordert eine interdisziplinäre Herangehensweise, in der Ethiker, Ingenieure und Sozialwissenschaftler zusammenarbeiten, um ethische Leitlinien in den Codeprozess einzubringen.
Das Ziel ist es, AI-Systeme zu schaffen, die nicht nur technisch kompetent sondern auch moralisch solide sind und Entscheidungen treffen, die die Menschenwürde respektieren und den sozialen Guten fördern (Mittelstadt et al., 2016).
Fördere Inklusivität und gleichberechtigten Zugang in der AI-Entwicklung und -Einsatz.
Inklusivität und gleichberechtigter Zugang sind grundlegend für die ethische Entwicklung von AI. Das Rawlsianische Konzept der Gerechtigkeit als Fairness bietet eine philosophische Grundlage dafür, dass AI-Systeme auf eine Art und Weise entwickelt und eingesetzt werden, die allen Mitgliedern der Gesellschaft nützt, insbesondere den am stärksten gefährdeten Personen (Rawls, 1971).
Dazu gehört, aktiv Anstrengungen zu unternehmen, um eine Vielfalt von Perspektiven in den Entwicklungsprozess aufzunehmen, insbesondere aus unterrepräsentierten Gruppen und dem Globalen Süden.
Durch die Integration dieser unterschiedlichen Ansichten können AI-Entwickler Systeme schaffen, die gerechter und auf die Bedürfnisse eines breiteren Nutzerspektrums reagieren. Außerdem ist die Gewährleistung eines gleichberechtigten Zugangs zu AI-Technologien für die Verhütung der Verstärkung bestehender sozialer Ungleichheiten von größter Bedeutung.
Beeinflussen Sie Algorithmusbias und Fairness
Algorithmusbias ist eine bedeutende ethische Angelegenheit in der AI-Entwicklung, da baisierte Algorithmen die sozialen Ungleichheiten verstärken und sogar verschärfen können. Um mit diesem Thema aufzukommen, ist ein Engagement für prozessuale Gerechtigkeit erforderlich, d.h. AI-Systeme müssen über faire Prozesse entwickelt werden, die die Auswirkungen auf alle Interessengruppen berücksichtigen (Nissenbaum, 2001).
Dies umfasst das Identifizieren und abmildern von Bias in Trainingsdaten, die Entwicklung von transparenten und erklärbaren Algorithmen und die Durchführung von Fairnessprüfungen während der gesamten AI-Lebensdauer.
Durch die Behandlung von Algorithmusbias können Entwickler AI-Systeme schaffen, die zu einer gerechteren und inklusiveren Gesellschaft beitragen, anstatt bestehende Unterschiede zu verstärken.
Integrieren Sie vielfältige Perspektiven in die AI-Entwicklung
Die Einbeziehung verschiedener Perspektiven in die Entwicklung vonKI ist unerlässlich für die Schaffung von Systemen, die inklusiv und gleichwertig sind. Die Beteiligung von Stimmen aus unterrepräsentierten Gruppen gewährleistet, dass KI-Technologien nicht nur die Werte und Prioritäten eines kleinen Teils der Gesellschaft widerspiegeln.
Dieser Ansatz entspricht dem philosophischen Grundsatz der deliberativen Demokratie, der die Bedeutung inklusiver und partizipatorischer Entscheidungsprozesse betont (Habermas, 1996).
Durch die Förderung der vielfältigen Beteiligung in der KI-Entwicklung können wir sicherstellen, dass diese Technologien zu den Interessen aller Menschheit entwickelt werden, anstatt nur für eine privilegierte Elite.
Strategien zur Überbrückung der KI-Kluft
Die KI-Kluft, charakterisiert durch ungleichen Zugang zu KI-Technologien und ihren Vorteilen, stellt eine bedeutende Herausforderung an die globale Gleichwertigkeit dar. Die Überbrückung dieser Kluft erfordert eine Verpflichtung zur verteilten Gerechtigkeit, indem sichergestellt wird, dass die Vorteile von KI breit across verschiedene sozioökonomischen Gruppen und Regionen verbreitet werden (Sen, 2009).
Dies kann durch Initiativen erreicht werden, die den Zugang zu KI-Bildung und Ressourcen in unterversorgten Gemeinschaften fördern, sowie durch Politiken, die die gerechte Verteilung der durch KI驱动ökonomischen Gewinne unterstützen. Indem die KI-Kluft behandelt wird, kann sichergestellt werden, dass KI zur globalen Entwicklung beiträgt, die inklusiv und gleichwertig ist.
Innovation mit ethischen Beschränkungen im Gleichgewicht halten
Das Gleichgewicht zwischen der Jagd nach Innovation und ethischen Beschränkungen ist für die verantwortungsvolle Fortentwicklung von AI entscheidend. Der Vorsorgegrundsatz, der für Vorsicht in der Anwendung ungewisser Informationen plädiert, ist im Zusammenhang mit der AI-Entwicklung besonders relevant (Sandin, 1999).
Während Innovation die Fortschritte treibt, muss sie durch ethische Überlegungen begleitet werden, die Schutz vor potenziellen Schäden bieten. Dies erfordert eine sorgfältige Bewertung der Risiken und Vorteile der neuen AI-Technologien sowie die Implementierung von Regelungssystemen, die die Ethikkriterien gewährleisten.
Durch die Ausgewogenheit von Innovation und ethischen Beschränkungen können wir die Entwicklung von AI-Technologien fördern, die sowohl an der Spitze der Technologie stehen als auch mit den allgemeinen Zielen des gesellschaftlichen Wohlstands in Einklang stehen.
Wie Sie sehen können, stellt die philosophische Grundlage intelligenter Systeme einen entscheidenden Rahmen dar, um sicherzustellen, dass AI-Technologien auf eine ethische, inklusive und für die gesamte Menschheit nutzbare Weise entwickelt und eingesetzt werden.
Indem die AI-Entwicklung auf diese philosophischen Prinzipien gegründet wird, können wir intelligente Systeme schaffen, die nicht nur die technologischen Kapazitäten fördern, sondern auch das Lebensqualitätsverständnis verbessern, Gerechtigkeit fördern und sicherstellen, dass die Vorteile von AI gleichmäßig durch die Gesellschaft geteilt werden.
Kapitel 5: AI-Agenten als LLM-Verstärker
Die Fusion von AI-Agenten mit Großen Sprachmodellen (LLM) stellt einen grundlegenden Wechsel in der artifizellen Intelligenz dar und behebt kritische Einschränkungen in LLM, die ihre breitere Anwendbarkeit behindert haben.
Diese Integration ermöglicht es Maschinen, ihre traditionellen Rollen zu überschreiten und von passiven Textgeneratoren zu selbständigen Systemen zu werden, die dynamisches Denken und Entscheiden können.
Angesichts der zunehmenden Beteiligung von AI-Systemen an kritischen Prozessen in verschiedenen Bereichen ist es wichtig, zu verstehen, wie AI-Agenten die Lücken in den Fähigkeiten von LLM schließen.
Die Überbrückung der Lücken in den Fähigkeiten von LLM
LLM sind zwar mächtig, sind aber von ihrer Natur her durch die Daten begrenzt, die sie trainiert wurden und durch die statische Natur ihrer Architektur. Diese Modelle arbeiten innerhalb eines festen Satzes von Parametern, typischerweise definiert durch den Textkorpus, der während ihrer Trainingsphase verwendet wurde.
Diese Einschränkung bedeutet, dass LLM nicht selbständig neue Informationen suchen oder ihre Wissensbasis aktualisieren können, nachdem sie ausgebildet wurden. Folglich sind LLM oft veraltet und fehlen den Fähigkeiten, um kontextuell relevante Antworten zu liefern, die realtime Daten oder Einblicke benötigen, die über ihre ursprüngliche Trainingsdaten hinausgehen.
KI-Agenten schließen diese Lücken, indem sie dynamisch externe Datenquellen integrieren, was die funktionale Horizont von LLM vergrößern kann.
Zum Beispiel könnte eine bis 2022 auf finanziellen Daten trainierte LLM genaue historische Analysen liefern, aber Schwierigkeiten haben, aktuelle Marktprognosen zu generieren. Ein KI-Agent kann diese LLM durch die Einbindung von Echtzeitdaten aus den Finanzmärkten verstärken, indem er diese Eingaben verwendet, um relevantere und aktuelle Analysen zu erstellen.
Diese dynamische Integration gewährleistet, dass die Ausgaben nicht nur historisch korrekt sind, sondern auch für die aktuellen Bedingungen konztextuell angemessen.
Erhöhung der Entscheidungsfähigkeit beim Entscheidungsprozess
Eine weitere bedeutende Einschränkung von LLM ist ihre mangelnde Fähigkeit, selbständig zu entscheiden. LLM sind hervorragend in der Generierung von Sprachbasierten Ausgaben, aber sie fallen kurz beim erforderlichen komplexen Entscheidungsprozess, insbesondere in Umfeldern, die von Unsicherheit und Veränderung gekennzeichnet sind.
Dieser Mangel ist primär auf die Abhängigkeit des Modells von vorhandenen Daten und das Fehlen von Mechanismen für adaptives Denken oder Lernen aus neuen Erfahrungen nach der Inbetriebnahme zurückzuführen.
KI-Agenten beheben dies, indem sie die notwendige Infrastruktur für selbständiges Entscheidungsfinden bereitstellen. Sie können die statischen Ausgaben eines LLM verarbeiten und diese durch fortschrittliche Denkframeworks wie regelbasierte Systeme, Heuristiken oder Verstärkungs-Lernmodelle bearbeiten.
Beispielsweise kann eine LLM in einem Gesundheitswesen aufgrund von Symptomen und medizinischer Geschichte eines Patienten eine Liste von möglichen Diagnosen erzeugen. Ohne einen KI-Agenten kann die LLM diese Optionen jedoch nicht bewerten oder einen Handlungsweg empfehlen.
Ein KI-Agent kann einsteigen, um diese Diagnosen mit aktueller medizinischer Literatur, Patientendaten und kontextuellen Faktoren abgleichen, schließlich eine informiertere Entscheidung treffen und handhabbare nächste Schritte vorschlagen. Diese Synergie wandelt LLM-Ausgaben von reinen Vorschlägen in ausführbare, konztextabhängige Entscheidungen um.
Beschränktheit und Konsistenz behandeln
Vollständigkeit und Konsistenz sind entscheidende Faktoren zur Gewährleistung der Zuverlässigkeit von LLM-Ausgaben, insbesondere bei komplexen Denkaufgaben. Aufgrund ihrer Parametrisierung erzeugen LLMs oft Antworten, die unvollständig sind oder keine logische Kohärenz aufweisen, insbesondere beim Umgang mit mehreren Schritten oder der Verlangen nach umfassendem Verständnis across verschiedenen Bereichen.
Diese Probleme entstammen der isolierten Umgebung, in der LLMs arbeiten, wo sie nicht in der Lage sind, ihre Ausgaben gegen externe Standarde oder zusätzliche Informationen abzurechnen oder zu validieren.
AI-Agenturen spielen eine Schlüsselrolle in der Eindämmung dieser Probleme, indem sie iterative Feedback-Mechanismen und Validierungs-Schichten einführen.
Beispielsweise könnte ein LLM im Rechtsbereich eine erste Fassung eines rechtlichen Memorandums auf der Basis seiner Trainingsdaten erzeugen. Dieser Entwurf könnte jedoch bestimmte Vorgängerfälle auslassen oder argumentative Logik fehlen lassen.
Ein AI-Agent kann diesen Entwurf überprüfen, indem er sicherstellt, dass er die erforderlichen Standards an Vollständigkeit erfüllt, indem er auf externe rechtliche Datenbanken verweist, logische Kohärenz prüft und gegebenenfalls zusätzliche Informationen oder Klärung anfordert.
Dieser iterative Prozess ermöglicht die Herstellung eines fundierteren und zuverlässigeren Dokuments, das den strengen Anforderungen der rechtlichen Praxis gerecht wird.
Überwindung der Isolation durch Integration
Eine der größten Begrenzungen von LLM ist ihre innere Isolation von anderen Systemen und Wissensquellen.
LLM, wie sie konzipiert sind, sind geschlossene Systeme, die nicht von Haus aus mit externen Umgebungen oder Datenbanken interagieren. Diese Isolation begrenzt deutlich ihre Fähigkeit, sich an neue Informationen anzupassen oder in Echtzeit zu agieren, was sie weniger effektiv für Anwendungen macht, die dynamische Interaktion oder Echtzeitentscheidungen erfordern.
AI-Agenten überwinden diese Isolation, indem sie als integrierende Plattformen agieren, die LLM mit einem breiteren Ökosystem von Datenquellen und Berechnungswerkzeugen verknüpfen. Durch APIs und andere Integrationsoberflächen können AI-Agenten auf Echtzeitdaten zugreifen, mit anderen AI-Systemen zusammenarbeiten und sogar mit physischen Geräten interagieren.
In Kundenbindungsanwendungen könnten LLM standarde Musterantworten basierend auf vorbereiteten Skripten generieren. Diese Antworten können jedoch statisch sein und die Personalisierung vermissen, die für eine effektive Kundeninteraktion notwendig ist.
Ein KI-Agent kann diese Interaktionen durch die Integration von Echtzeitdaten aus Kundenprofilen, vorherigen Interaktionen und Sentiment-Analysetools anreichern, was hilft, Antworten zu generieren, die nicht nur kontextuell relevant sind, sondern auch auf die spezifischen Bedürfnisse des Kunden zugeschnitten sind.
Diese Integration verwandelt die Kundenerfahrung aus einer Reihe von skriptierten Interaktionen in eine dynamische, personalisierte Unterhaltung.
Erweiterung von Kreativität und Problemlösung
Obwohl LLMs leistungsfähige Werkzeuge für die Inhaltsgenerierung sind, sind ihre Kreativität und Problemlösefähigkeiten von dem Daten, auf denen sie trainiert wurden, begrenzt. Diese Modelle sind oft nicht in der Lage, theoretische Konzepte auf neue oder unerwartete Herausforderungen anzuwenden, da ihre Problemlösefähigkeiten durch ihre vorherige Wissensbasis und Trainingsparameter eingeschränkt sind.
KI-Agenten erhöhen die kreative und problemlösende Potenzial von LLMs durch die Nutzung fortschrittlicher Schließtechniken und eines breiteren Spektrums an Analysetools. Diese Fähigkeit ermöglicht es KI-Agenten, die Grenzen von LLMs zu überwinden und theoretische Rahmenwerke auf praktische Probleme in innovativer Weise anzuwenden.
Zum Beispiel denkt man an das Problem der Bekämpfung von Fehlinformationen auf sozialen Medienplattformen. Ein LLM könnte anhand von textueller Analyse Muster von Fehlinformationen identifizieren, könnte jedoch Schwierigkeiten haben, eine umfassende Strategie für die Reduzierung der Verbreitung falscher Informationen zu entwickeln.
Ein AI-Agent kann diese Einsichten aufnehmen, interdisziplinäre Theorien aus Bereichen wie Soziologie, Psychologie und Netzwerktheorie anwenden und eine robuste, vielseitige Herangehensweise entwickeln, die Real-Time-Monitoring, Nutzererziehung und automatisierte Moderationstechniken umfasst.
Diese Fähigkeit, diverse theoretische Rahmenwerke zu synthetisieren und sie auf realweltliche Herausforderungen anzuwenden, veranschaulicht die verbesserten problemlösenden Kapazitäten, die AI-Agenten bringen.
Speziellere Beispiele
AI-Agenten, mit ihrer Fähigkeit, mit verschiedenen Systemen zu interagieren, Zugriff auf Echtzeitdaten zu erhalten und Aktionen auszuführen, befassen sich direkt mit diesen Einschränkungen und wandeln LLMs von mächtigen aber passiven Sprachmodellen in dynamische, realeitige Problemolverständner um. Lasst uns einige Beispiele anschauen:
1. Von statischen Daten zu dynamischen Einsichten: LLMs auf dem neuesten Stand halten
-
Das Problem: Stellen Sie sich vor, Sie fragen eine LLM an, die bis 2023 vorher trainiert wurde, „Welche neuesten Durchbrüche gibt es in der Krebsbehandlung?“ Ihr Wissen wäre veraltet.
-
Die Lösung des AI-Agenten: Ein AI-Agent kann die LLM mit medizinischen Fachzeitschriften, Forschungsdatenbanken und Nachrichtenquellen verknüpfen. Jetzt kann die LLM aktuelle Informationen über die neuesten klinischen Studien, Behandlungsoptionen und Forschungsergebnisse bereitstellen.
2. Von der Analyse bis zur Handlung: Automatisierung von Aufgaben basierend auf LLM-Einsights
-
Das Problem: Ein LLM, das die Social Media für eine Marke überwachen soll, könnte eine Zunahme negativer Stimmungen erkennen, kann jedoch nichts unternehmen, um dagegen zu wirken.
-
Die Lösung mit dem AI-Agenten: Ein AI-Agent, der mit den Social Media-Konten der Marke verbunden ist und mit vorapproveden Antworten ausgestattet ist, kann automatisch Bedenken adressieren, Fragen beantworten und sogar komplexe Themen an Menschliche Vertreter weiterleiten.
3. Von der ersten Entwurfsversion bis zum perfektionierten Produkt: Sicherstellung von Qualität und Genauigkeit
-
Das Problem: Ein LLM, das mit der Übersetzung eines technischen Handbuchs beauftragt ist, könnte aufgrund seines Mangel an domain-spezifischem Wissen grammatisch korrekte, aber technisch ungenaue Übersetzungen erzeugen.
-
Die Lösung mit dem AI Agent: Ein AI Agent kann das LLM mit spezialisierten Wörterbüchern, Glossaren und sogar mit Fachwissenschaftern für Echtzeit-Feedback integrieren, sicherstellend, dass die finale Übersetzung sowohl sprachlich als auch technisch korrekt ist.
4. Barrieren durchbrechen: LLM mit der Realität verbinden
-
Das Problem: Ein LLM, das für den smart home control entwickelt wurde, könnte zu einer Anpassung an die wechselnden Routinen und Vorlieben eines Benutzers problematisch sein.
-
Die Lösung mit dem AI Agent: Ein AI Agent kann das LLM mit Sensoren, smarten Geräten und Benutzer-Kalendern verbinden. Indem er das Nutzerverhalten analysiert, kann das LLM lernen, Bedürfnisse vorherzusehen, automatisch Beleuchtungs- und Temperatur-Einstellungen anpassen und sogar personalisierte Musikwiedergabelisten basierend auf der Uhrzeit und der Benutzeraktivität vorschlagen.
5. Von der Imitation zur Innovation: Die Weiterentwicklung der Kreativität von LLM
-
Das Problem: Eine LLM, die mit der Komposition von Musik beauftragt ist, kann Stücke herstellen, die epigonal klingen oder emotional nicht tiefgründig sind, da sie sich primär auf Muster in ihrer Trainingsdaten stützt.
-
Die Lösung des AI-Agenten: Ein AI-Agent kann die LLM mit biofeedback-Sensoren verknüpfen, die die emotionalen Reaktionen eines Komponisten auf verschiedene musikalische Elemente messen. Durch diese Echtzeit-Rückmeldungen kann die LLM Musik schaffen, die nicht nur technisch versiert ist, sondern auch emotional bewegend und originell ist.
Die Integration von AI-Agenten als LLM-Erweiterungen ist nicht nur eine kontinuierliche Verbesserung, sondern repräsentiert eine grundlegende Erweiterung des Möglichen von künstlicher Intelligenz. Indem sie auf die Limitationen von traditionellen LLM reagiert, wie ihre statische Wissensbasis, die begrenzte Entscheidungsautonomie und den isolierten Betriebsumfeld, ermöglichen AI-Agenten diesen Modellen ihren vollen Potenzial auszuschöpfen.
Mit der Weiterentwicklung der AI-Technologie wird die Rolle der AI-Agenten in der Verbesserung von LLM zunehmend wichtiger werden, nicht nur in der Erweiterung der Fähigkeiten dieser Modelle, sondern auch in der Neudefinition der Grenzen von künstlicher Intelligenz selbst. Diese Fusion legt den Grundstein für die nächste Generation von AI-Systemen, die selbständig rechnen, in Echtzeit anpassen und innovative Lösungen für Probleme in einer sich ständig verändernden Welt finden können.
Kapitel 6: Architektur Design für die Integration von AI-Agenten mit LLM
Die Integration von AI-Agenten mit LLM hängt von der Architektur ab, die entscheidend für die Verbesserung von Entscheidungen, Anpassung und Skalierbarkeit ist. Die Architektur sollte sorgfältig gestaltet werden, um eine reibungslose Interaktion zwischen den AI-Agenten und LLM zu ermöglichen, und sicherzustellen, dass jeder Komponente optimale Funktion zuteil wird.
Eine modulare Architektur, in der der AI-Agent als Orchestriker agiert und die Fähigkeiten des LLM lenkt, ist eine Methode, die die dynamische Aufgabenverwaltung unterstützt. Dieses Design nutzt die Stärken des LLM in der natürlichen Sprachverarbeitung, während es den AI-Agenten ermöglicht, komplexere Aufgaben wie mehrere Schritte von Reasoning oder contextuelle Entscheidungen in Echtzeitumgebungen zu bewältigen.
Alternativ kann ein Hybridschema verwendet werden, das LLMs mit spezialisierten, fein abgeglichenen Modellen kombiniert und somit Flexibilität bietet, indem der AI-Agent Aufgaben an das am besten geeignete Modell weitergibt. Dieser Ansatz optimiert das Performance und erhöht die Effizienz über eine breite Anwendungsvielfalt, was ihn insbesondere in vielfältigen und wechselhaften operativen Kontexten effektiv macht (Liang et al., 2021).

Training Methodologien und Best Practices
Die Ausbildung von AI-Agenten, die mit LLMs integriert sind, erfordert einen systematischen Ansatz, der zwischen Generalisierung und Optimierung für Aufgabenpartikularität balanciert.
Das Transfer Learning ist hier eine Schlüsseltechnik, die eine LLM zulässt, die zunächst auf einem großen, vielfältigen Corpus vorbereitet wurde, und dann auf domain-spezifischen Daten, die für die Aufgaben des AI-Agenten relevant sind, fein abgeglichen wird. Dieser Ansatz behält die umfassende Wissensbasis der LLM bei und ermöglicht es ihr, sich auf bestimmte Anwendungen zu spezialisieren, was die Gesamtwirksamkeit des Systems verbessert.
Außerdem spielt die Verstärkungslearning (RL) eine entscheidende Rolle, insbesondere in Szenarien, in denen der AI-Agent an die wechselnden Umgebungen anpassen muss. Durch Interaktion mit seiner Umgebung kann der AI-Agent seine Entscheidungsprozesse kontinuierlich verbessern, um besser mit neuen Herausforderungen umzugehen.
Um sicherer Leistung über verschiedene Szenarien hinweg zu gewährleisten, sind rigorose Bewertungsmetriken unerlässlich. Diese sollten sowohl standardmäßige Benchmarks als auch task-spezifische Kriterien beinhalten, um sicherzustellen, dass die Trainingsphase des Systems robust und umfassend ist (Silver et al., 2016).
Einführung in die Feinabstimmung eines Großen Sprachmodells (LLM) und Konzepte der Verstärkungslearning
Dieser Code zeigt eine Vielzahl von Techniken auf, die maschinelles Lernen und Natur Sprachverarbeitung (NLP) involvierden, mit dem Schwerpunkt auf die Feineinstellung von Großsprachmodellen (LLMs) für bestimmte Aufgaben und die Implementierung von Verstärkungslearning (RL)-Agenten. Der Code umfasst mehrere Schlüsselbereiche:
-
Feineinstellung eines LLM: Nutzung von vor trainierten Modellen wie BERT für Aufgaben wie Sentimentanalyse, mit der Hugging Face
transformersBibliothek. Dies beinhaltet die Tokenisierung von Datensätzen und die Nutzung von Trainingsargumenten, um den Feineinstellungsprozess zu lenken. -
Verstärkungslearning (RL): Einführung in die Grundlagen von RL mit einem einfachen Q-lernenden Agenten, wo ein Agent durch Experimentieren und Fehlschlagen lernt, indem er mit einem Umfeld interagiert und seine Kenntnisse über Q-Tabellen aktualisiert.
-
Belohnungsmodellierung mit OpenAI API: Ein Konzeptuelles Verfahren zur Nutzung der OpenAI-API, um einem RL-Agenten dynamisch Belohnungssignale zu liefern, was einem Sprachmodell ermöglicht, Aktionen zu bewerten.
-
Modellbewertung und Protokollierung: Die Verwendung von Bibliotheken wie
scikit-learnzur Modellleistungsbewertung mittels Genauigkeit und F1-Scores und PyTorchsSummaryWriterfür die Visualisierung des Trainingsfortschritts. -
Erweiterte RL-Konzepte: Implementierung von fortschrittlichen Konzepten wie politischen Gradienten-Netzwerken, Kurrikulumlernen und frühzeitigem Stoppen zur Verbesserung der Modelltrainingseffizienz.
Dieser umfassende Ansatz deckt sowohl die supervised learning auf, mit sentiment analysis fine-tuning, als auch die reinforcement learning ab, und liefert Einblicke in die Art und Weise, wie moderne AI-Systeme entwickelt, bewertet und optimiert werden.
Codebeispiel
Schritt 1: Importieren der notwendigen Bibliotheken
Bevor Sie in die Feinabstimmung des Modells und die Implementierung von Agenten eintauchen, ist es wichtig, die notwendigen Bibliotheken und Module einzurichten. Dieser Code beinhaltet Importe aus beliebten Bibliotheken wie Hugging Face’s transformers und PyTorch für die Handhabung neuronaler Netzwerke, scikit-learn zur Bewertung der Modellleistung und einige Allzweckmodule wie random und pickle.
-
Hugging Face Bibliotheken: Diese ermöglichen die Nutzung und Feinabstimmung vortrainierter Modelle und Tokenizer aus dem Model Hub.
-
PyTorch: Dies ist das zentrale Deep-Learning-Framework, das für Operationen wie neuronale Netzwerkschichten und Optimierer verwendet wird.
-
scikit-learn: Bietet Metriken wie Genauigkeit und F1-Score zur Bewertung der Modellleistung.
-
OpenAI API: Zugriff auf OpenAIs Sprachmodelle für verschiedene Aufgaben wie Reward-Modeling.
-
TensorBoard: Wird zur Visualisierung des Trainingsfortschritts verwendet.
Hier ist der Code zur Importierung der notwendigen Bibliotheken:
# Importiere das random-Modul für die Generierung von zufälligen Zahlen.
import random
# Importiere notwendige Module aus der transformers-Bibliothek.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importiere load_dataset für das Laden von Datensets.
from datasets import load_dataset
# Importiere metrics für die Bewertung der Modelleignung.
from sklearn.metrics import accuracy_score, f1_score
# Importiere SummaryWriter für das Protokollieren des Trainingfortschritts.
from torch.utils.tensorboard import SummaryWriter
# Importiere pickle für das Speichern und Laden trainierter Modelle.
import pickle
# Importiere openai für den Einsatz von OpenAI's API (erfordert ein API-Schlüssel).
import openai
# Importiere PyTorch für operationen der Deep Learning.
import torch
# Importiere Modul für neuronale Netze von PyTorch.
import torch.nn as nn
# Importiere Optimizer-Modul von PyTorch (wird direkt in diesem Beispiel nicht verwendet).
import torch.optim as optim
Jedes dieser Importe spielt eine entscheidende Rolle in verschiedenen Teilen des Codes, von der Modellausbildung und Bewertung bis hin zu Protokollierung der Ergebnisse und Interaktion mit externen APIs.
Schritt 2: Feineinstellung eines Sprachmodells für Sentimentanalyse
Die Feineinstellung eines vorgefahrenen Modells für eine bestimmte Aufgabe, wie z.B. die Sentimentanalyse, erfordert das Laden eines vorgefahrenen Modells, seine Anpassung an die Anzahl der Ausgabenlabels (positiv/negativ in diesem Fall) und die Verwendung einer geeigneten Datenbank.
In diesem Beispiel verwenden wir die Klasse AutoModelForSequenceClassification aus der Bibliothek transformers, um mit dem IMDB-Datensatz zu arbeiten. Dieses vor trainierte Modell kann auf einem kleineren Teil des Datensatzes gezogen werden, um die Rechenzeit zu sparen. Das Modell wird dann mit einer benutzerdefinierten Reihe von Trainingsargumenten trainiert, die die Anzahl der Epochen und die Batch-Größe einschließen.
Unten ist der Code für das Laden und die Feinjustierung des Modells:
# Geben Sie den Namen des vor trainierten Modells von der Hugging Face Model Hub an.
model_name = "bert-base-uncased"
# Lade das vor trainierte Modell mit einer angegebenen Anzahl von Ausgabeklassen.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Lade einen Tokenisierer für das Modell.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Lade das IMDB-Datensatz von Hugging Face Datasets, verwende nur 10% für die Trainingszeit.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokenisiere den Datensatz
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Weise das Datensatz zu tokenisierten Eingaben zu
tokenized_dataset = dataset.map(tokenize_function, batched=True)
Hier wird das Modell mit einer BERT-basierten Architektur geladen und der Datensatz für die Trainingszeit vorbereitet. Danach definieren wir die Trainingsargumente und initialisieren den Trainer.
# Define Trainingargumente.
training_args = TrainingArguments(
output_dir="./results", # Geben Sie das Ausgabeverzeichnis für das Speichern des Modells an.
num_train_epochs=3, # Setzen Sie die Anzahl der Trainingsepochs.
per_device_train_batch_size=8, # Setzen Sie die Batchgröße pro Gerät.
logging_dir='./logs', # Verzeichnis zum Speichern von Protokollen.
logging_steps=10 # Protokollieren Sie jedes 10 Schrittes.
)
# Initialisieren Sie den Trainer mit dem Modell, den Trainingsargumenten und dem Datensatz.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Starten Sie den Trainingsprozess.
trainer.train()
# Speichern Sie das fein abgestimmte Modell.
model.save_pretrained("./fine_tuned_sentiment_model")

Schritt 3: Implementierung eines einfachen Q-Lernagents
Q-Lernen ist eine Verstärkungsmethode, bei der ein Agent lernt, Aktionen so zu wählen, dass die kumulierte Belohnung maximiert wird.
In diesem Beispiel definieren wir ein grundlegendes Q-Lernagent, das Zustand-Aktionspaare in einer Q-Tabelle speichert. Der Agent kann entweder zufällig erkunden oder die beste bekannte Aktion basierend auf der Q-Tabelle nutzen. Die Q-Tabelle wird nach jeder Aktion mit einer Lernrate und einem Rabattfaktor aktualisiert, um zukünftige Belohnungen abzüglich zu bewerten.
Unten ist der Code, der dieses Q-Lernagent implementiert:
# Definiere die Q-Lernagentenklasse.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Initialisiere die Q-Tabelle.
self.q_table = {}
# Speichere die möglichen Aktionen.
self.actions = actions
# Setze den Exploration-Rate.
self.epsilon = epsilon
# Setze den Lernfaktor.
self.alpha = alpha
# Setze den Diskontfaktor.
self.gamma = gamma
# Definiere die get_action-Methode, um eine Aktion basierend auf dem aktuellen Zustand auszuwählen.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# Explore zufällig.
return random.choice(self.actions)
else:
# Nutze die beste Aktion aus.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
Der Agent wählt Aktionen basierend auf Exploration oder Exploitation und aktualisiert die Q-Werte nach jedem Schritt.
# Definiere die update_q_table-Methode, um die Q-Tabelle zu aktualisieren.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
Schritt 4: Verwendung der OpenAI-API für Belohnungsmodellierung
In manchen Szenarien können wir anstatt eine manuelle Belohnungsfunktion zu definieren, ein leistungsfähiges Sprachmodell wie OpenAI’s GPT verwenden, um die Qualität der vom Agenten ausgeführten Aktionen zu bewerten.
In diesem Beispiel sendet die get_reward-Funktion einen Zustand, eine Aktion und den nächsten Zustand an die OpenAI-API, um einen Belohnungswert zu erhalten, was uns ermöglicht, große Sprachmodelle zu nutzen, um komplexe Belohnungsstrukturen zu verstehen.
# Definiere die get_reward-Funktion, um ein Belohnungssignal von der OpenAI-API zu erhalten.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # Ersetze mit deinem tatsächlichen OpenAI-API-Schlüssel.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
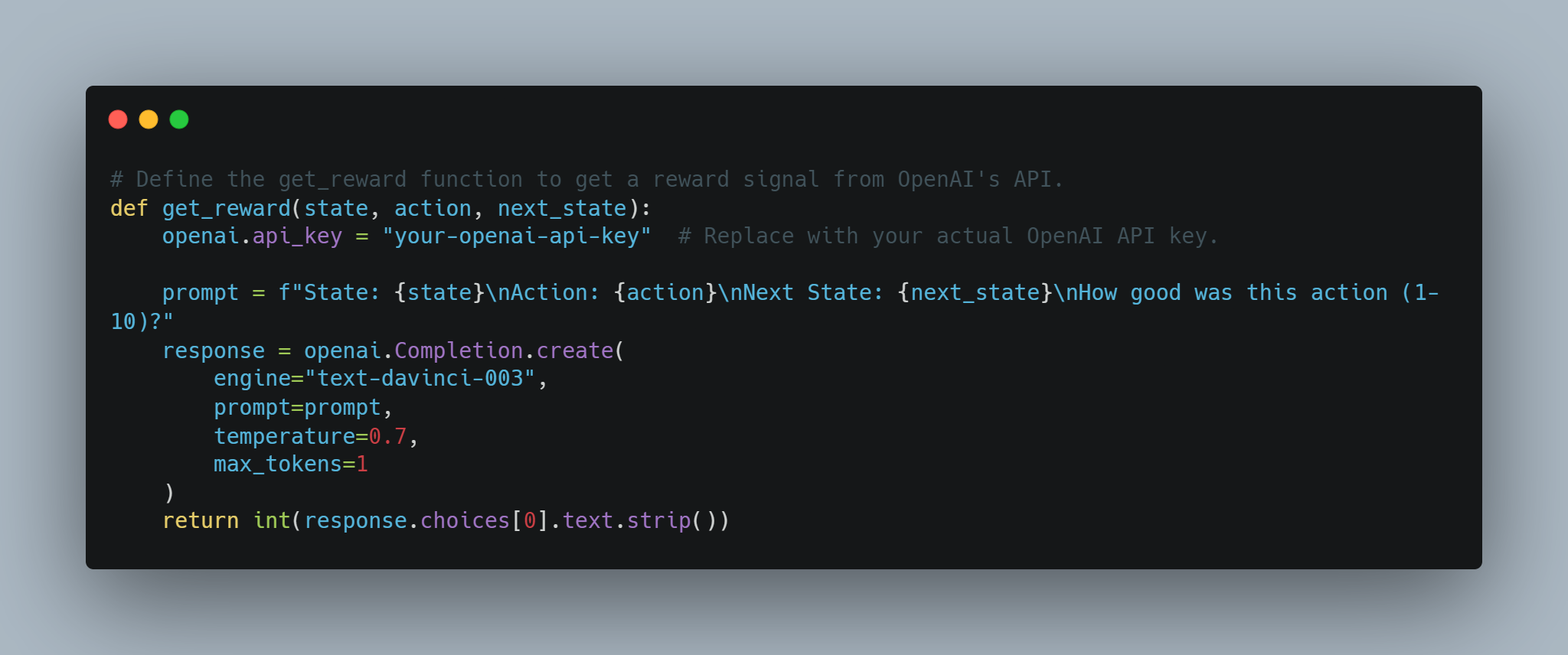
Dies ermöglicht einen konzeptuellen Ansatz, bei dem das Belohnungssystem dynamisch mithilfe der OpenAI-API bestimmt wird, was für komplexe Aufgaben nützlich sein kann, bei denen Belohnungen schwer zu definieren sind.
Schritt 5: Bewertung des Modellleistungs
Sobald ein maschinelles Lernmodell trainiert ist, ist es wichtig, seine Leistung mit standardisierten Metriken wie Accuracy und F1-Score zu bewerten.
Dieser Abschnitt berechnet beide auf Basis von wahren und vorhergesagten Labels. Die Accuracy stellt eine globale Maßnahme der Richtigkeit dar, während der F1-Score die Genauigkeit und die Erkennung ausgleicht, insbesondere in unbalancierten Datenmengen nützlich.
Hier ist der Code zur Bewertung der Modellleistung:
# Define die wahren Labels für die Bewertung.
true_labels = [0, 1, 1, 0, 1]
# Define die vorhergesagten Labels für die Bewertung.
predicted_labels = [0, 0, 1, 0, 1]
# Berechne die Accuracy-Note.
accuracy = accuracy_score(true_labels, predicted_labels)
# Berechne die F1-Note.
f1 = f1_score(true_labels, predicted_labels)
# Gebe die Accuracy-Note aus.
print(f"Accuracy: {accuracy:.2f}")
# Gebe die F1-Note aus.
print(f"F1-Score: {f1:.2f}")
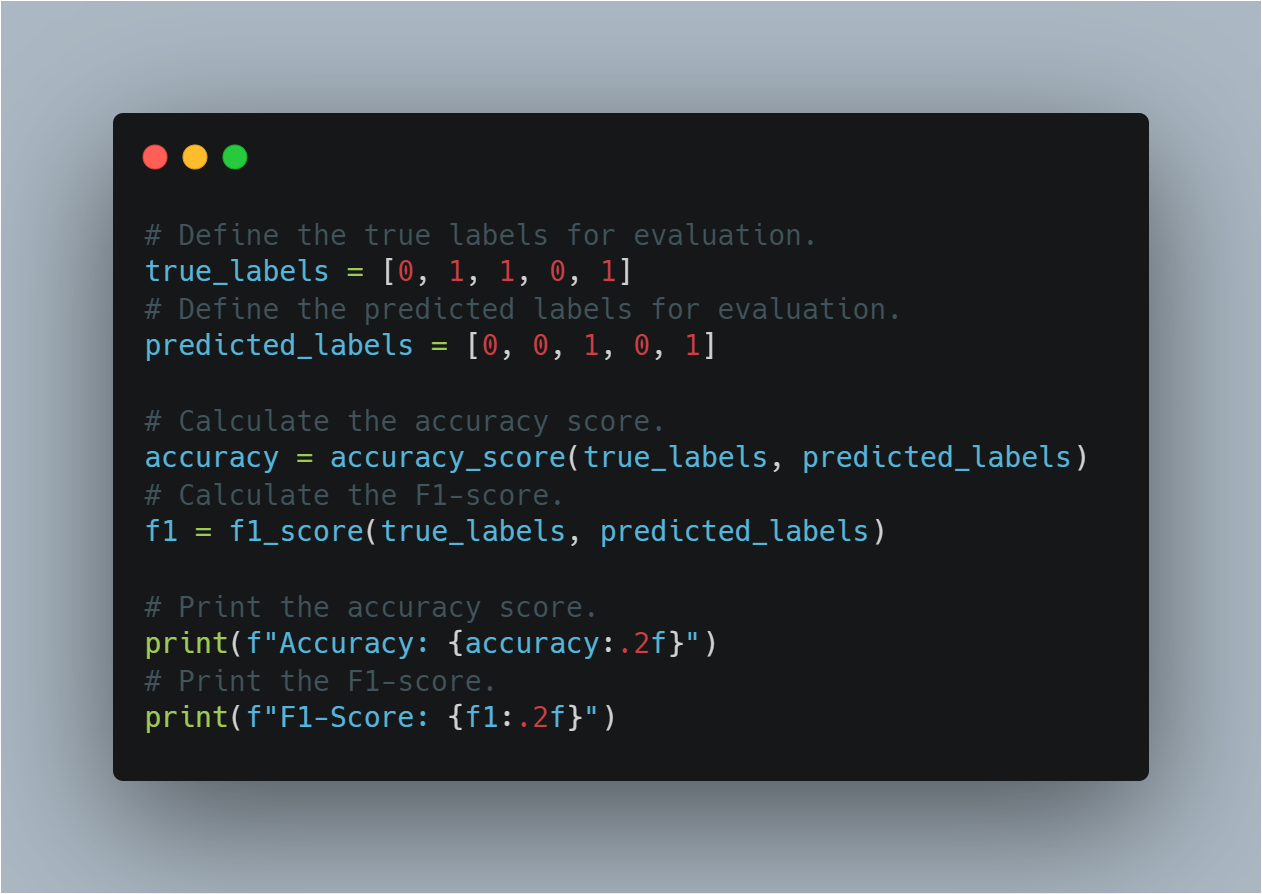
Dieser Abschnitt hilft, zu bestimmen, wie gut das Modell auf unbekannte Daten generalisiert hat, indem er bewährte Bewertungsmetriken verwendet.
Schritt 6: Grundlagen des Policy Gradient Agenten (mit PyTorch)
Policy Gradient-Methoden in der künstlichen Intelligenz optimieren direkt die Politik, indem die erwartete Belohnung maximiert wird.
Dieser Abschnitt demonstriert eine einfache Implementierung einer Policy-Netzwerkverbindung mit PyTorch, die für Entscheidungen in RL verwendet werden kann. Das Policy-Netz verwendet eine lineare Schicht, um für verschiedene Aktionen Wahrscheinlichkeiten auszugeben, und Softmax wird angewendet, um sicherzustellen, dass diese Ausgaben eine gültige Wahrscheinlichkeitsverteilung bilden.
Hier ist der konzipelle Code zur Definition eines grundlegenden Policy-Gradienten-Agents:
# Definiere die Policy-Netzwerkklasse.
class PolicyNetwork(nn.Module):
# Initialisiere das Policy-Netz.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# Definiere eine lineare Schicht.
self.linear = nn.Linear(input_size, output_size)
# Definiere den Forward-Durchlauf des Netzwerks.
def forward(self, x):
# Appliquez Softmax auf die Ausgabe der linearen Schicht.
return torch.softmax(self.linear(x), dim=1)
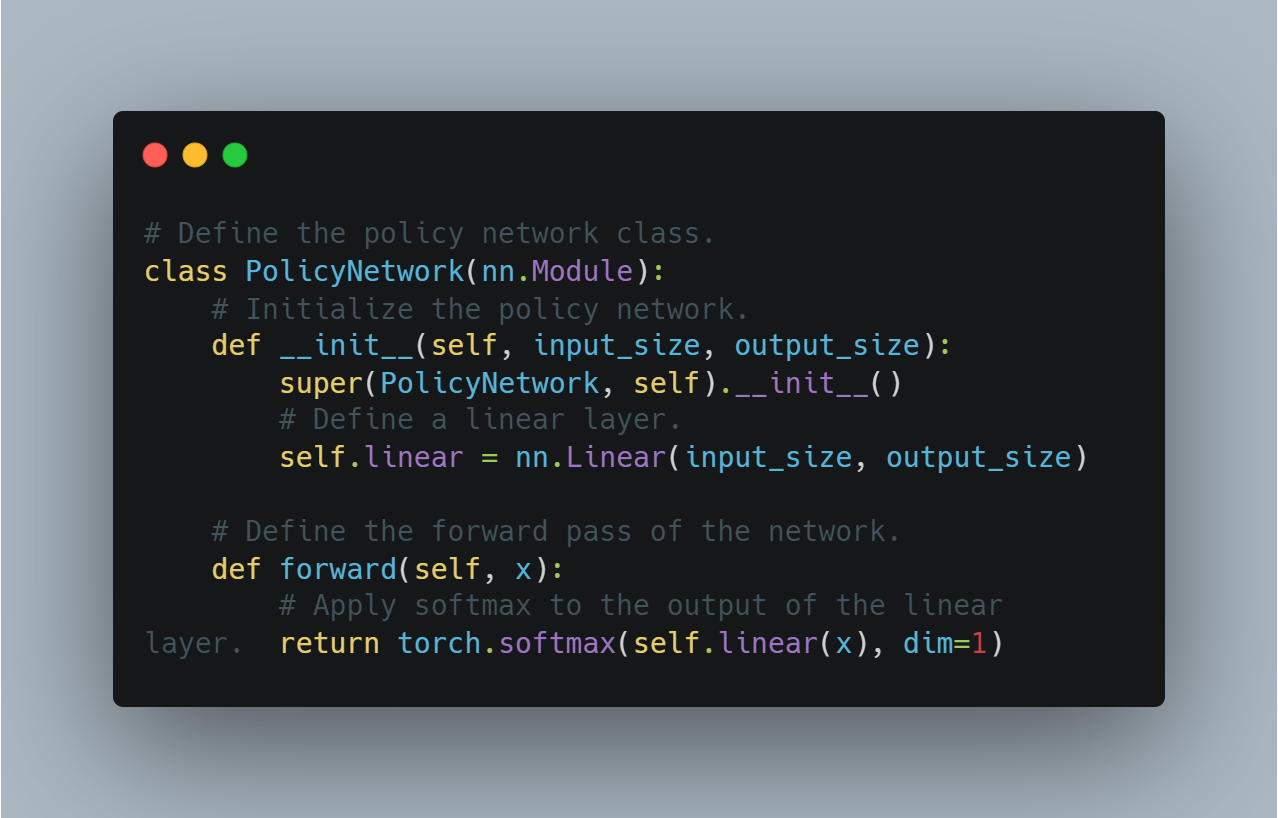
Dies stellt einen grundlegenden Schritt für die Implementierung fortgeschrittener Verfahren der Lernalgorithmen dar, die Policy-Optimierung verwenden.
Schritt 7: Visualisierung des Trainingfortschritts mit TensorBoard
Die Visualisierung von Trainingsmetriken wie Verlust und Genauigkeit ist entscheidend, um zu verstehen, wie das Leistungsergebnis eines Modells mit der Zeit entwickelt sich. TensorBoard, ein beliebtes Werkzeug für diese Zwecke, kann verwendet werden, um Metriken aufzuloggen und sie in Echtzeit zu visualisieren.
In diesem Abschnitt erstellen wir eine SummaryWriter-Instanz und loggen zufällige Werte, um den Prozess der Verlust- und Genauigkeitsüberwachung während des Trainings zu simulieren.
So können Sie den Trainingsfortschritt mit TensorBoard protokollieren und visualisieren:
# Erstellen einer SummaryWriter-Instanz.
writer = SummaryWriter()
# Beispieltrainingsschleife für die TensorBoard-Visualisierung:
num_epochs = 10 # Definieren der Anzahl der Epochen.
for epoch in range(num_epochs):
# Simulieren von zufälligen Verlust- und Genauigkeitswerten.
loss = random.random()
accuracy = random.random()
# Loggen des Verlustes und der Genauigkeit in TensorBoard.
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# Schließen des SummaryWriter.
writer.close()
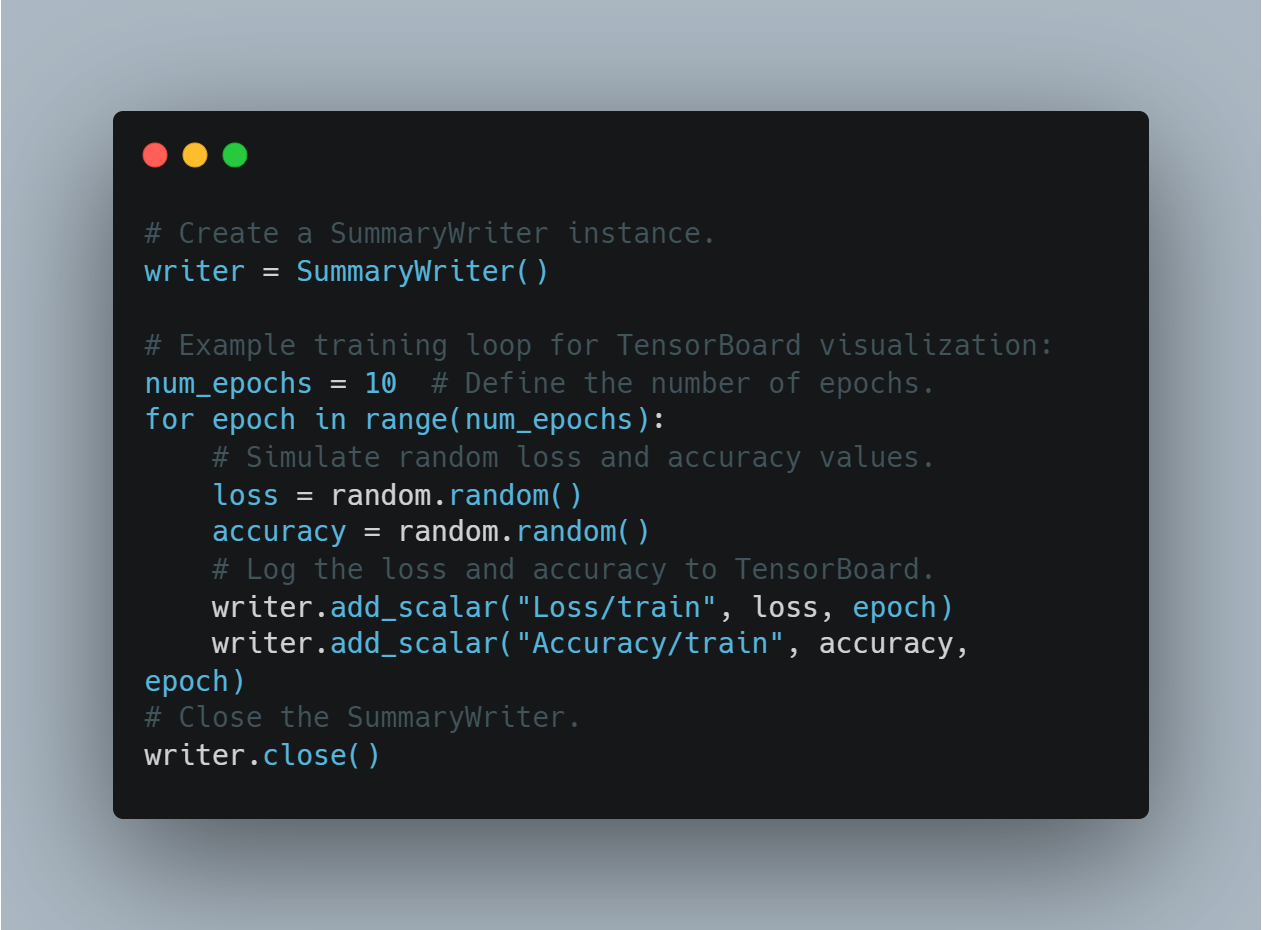
Dies erlaubt es Nutzern, das Modelltraining zu überwachen und basierend auf visueller Rückmeldung Echtzeitanpassungen vorzunehmen.
Schritt 8: Speichern und Laden von trainierten Agenten-Checkpoints
Nach der Ausbildung eines Agenten ist es entscheidend, seinen erlernten Zustand (zum Beispiel Q-Werte oder Modelgewichte) zu speichern, damit er später wiederverwendet oder ausgewertet werden kann.
In diesem Abschnitt wird gezeigt, wie ein trainierter Agent mithilfe des Python-Moduls pickle gespeichert und von der Festplatte geladen wird.
Hier ist der Code zum Speichern und Laden eines trainierten Q-Learning-Agenten:
# Erstellen einer Instanz des Q-Learning-Agenten.
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# Trainieren des Agenten (hier nicht gezeigt).
# Speichern des Agenten.
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# Laden des Agenten.
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
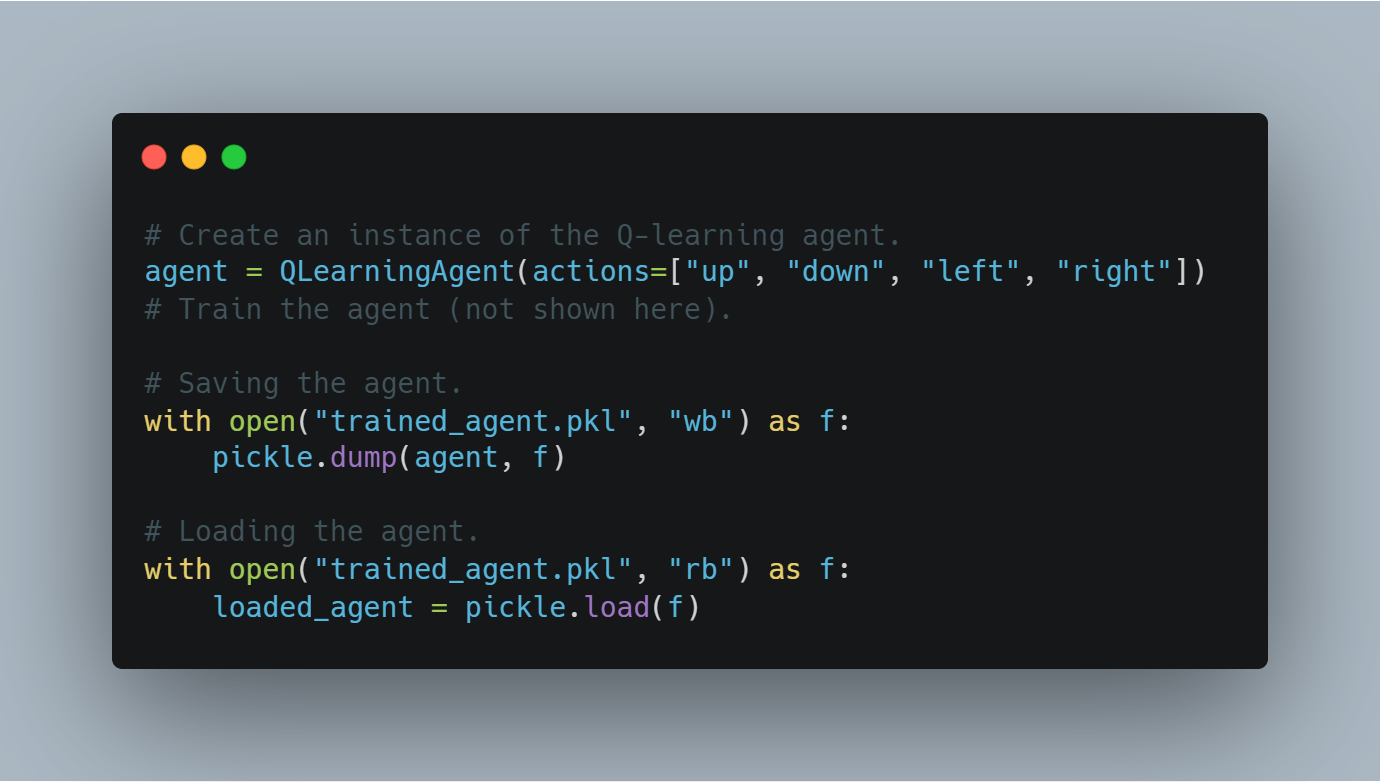
Dieser Prozess des Checkpointings sichert zu, dass Fortschritte im Training nicht verloren gehen und Modelle für zukünftige Experimente wiederverwendet werden können.
Schritt 9: Curriculum Learning
Lehrmethoden beinhalten die Graduelle Verstärkung der an das Modell gestellten Aufgaben, beginnend mit einfachere Beispiele und gehen in Richtung schwierigerer Aufgaben. Dies kann dazu beitragen, die Leistung und die Stabilität des Modells während der Trainingszeit zu verbessern.
Hier ist ein Beispiel, wie man Curriculum Learning in einem Trainingszyklus verwendet:
# Setze den anfänglichen Aufgaben Schwierigkeitsgrad.
initial_task_difficulty = 0.1
# Beispielhafte Trainingsschleife mit Curriculum Learning:
for epoch in range(num_epochs):
# Graduiert erhöhen Sie den Aufgabenschwierigkeitsgrad.
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# Generiere Trainingsdaten mit angepasster Schwierigkeit.
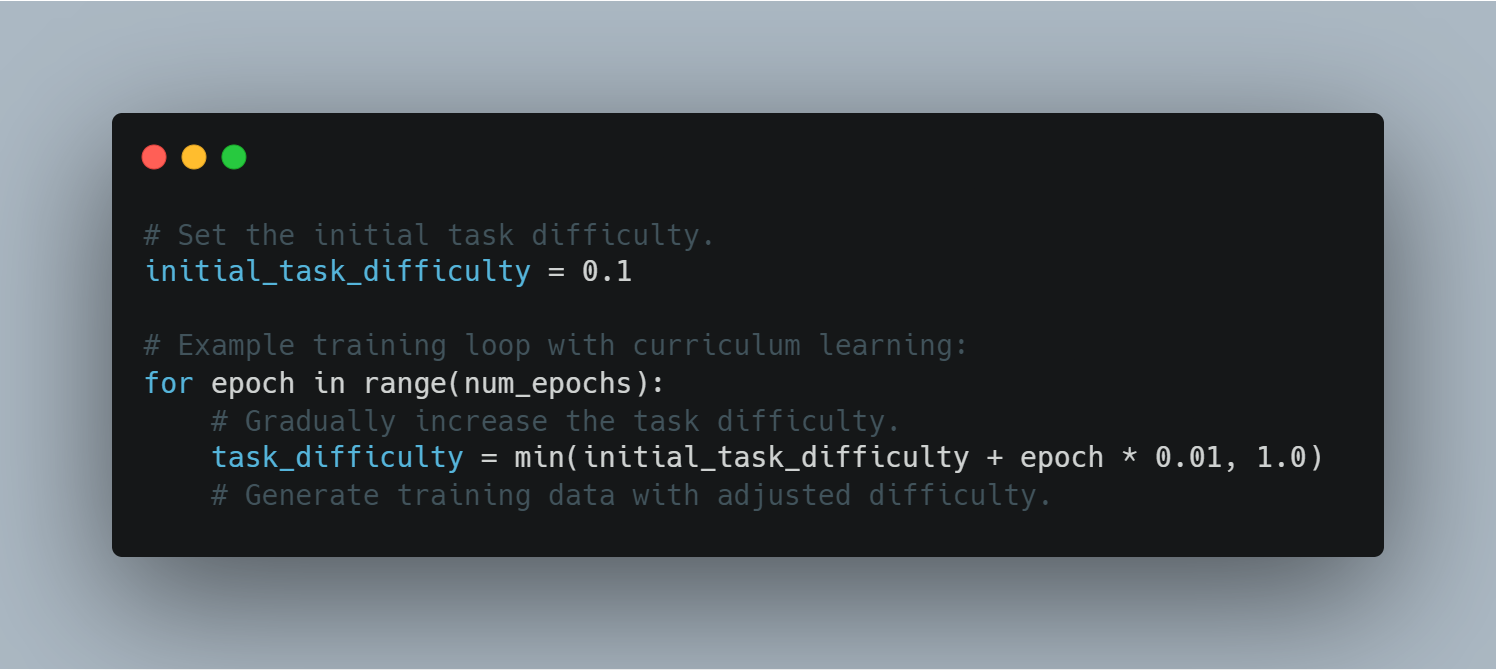
Durch die Kontrolle der Aufgabenschwierigkeit kann der Agent kontinuierlich komplexere Herausforderungen bewältigen, was zu einer verbesserten Lerneffizienz führt.
Schritt 10: Implementierung von Early Stopping
Early Stopping ist eine Technik, um während der Trainingszeit Overfitting zu vermeiden, indem das Verfahren abbrechen wird, wenn die Validierungsverlust nicht nach einer bestimmten Anzahl von Epochen (Geduld) verbessert.
Dieser Abschnitt zeigt, wie Early Stopping in einer Trainingsschleife implementiert werden kann, indem der Validierungsverlust als wichtiges Indikator genutzt wird.
Hier ist der Code zur Implementierung von Early Stopping:
# Initialisiere die beste Validierungsverlust zu Unendlichkeit.
best_validation_loss = float("inf")
# Setze den Geduldewert (Anzahl der Epochen ohne Verbesserung).
patience = 5
# Initialisiere den Zähler für Epochen ohne Verbesserung.
epochs_without_improvement = 0
# Beispieltrainingsschleife mit frühem Stoppen:
for epoch in range(num_epochs):
# Simuliere zufälligen Validierungsverlust.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break

Frühes Stoppen verbessert die Modellgeneralisierung, indem unnötiges Training verhindert wird, sobald das Modell anfängt, zu überanpassen.
Step 11: Verwenden eines vortrainierten LLM für Zero-Shot Task Transfer
Beim Zero-Shot Task Transfer wird ein vortrainiertes Modell auf eine Aufgabe angewendet, für die es nicht speziell nachtrainiert wurde.
Unter Verwendung der Hugging Face-Pipeline wird in diesem Abschnitt gezeigt, wie ein vortrainiertes BART-Modell für die Zusammenfassung ohne zusätzliches Training eingesetzt werden kann, wodurch das Konzept des Transfer-Learnings illustriert wird.
Hier ist der Code für die Verwendung eines vortrainierten LLM für die Zusammenfassung:
# Lade eine vortrainierte Zusammenfassungs-Pipeline.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Definiere den zu zusammenfassenden Text.
text = "This is an example text about AI agents and LLMs."
# Erzeuge die Zusammenfassung.
summary = summarizer(text)[0]["summary_text"]
# Drucke die Zusammenfassung.
print(f"Summary: {summary}")
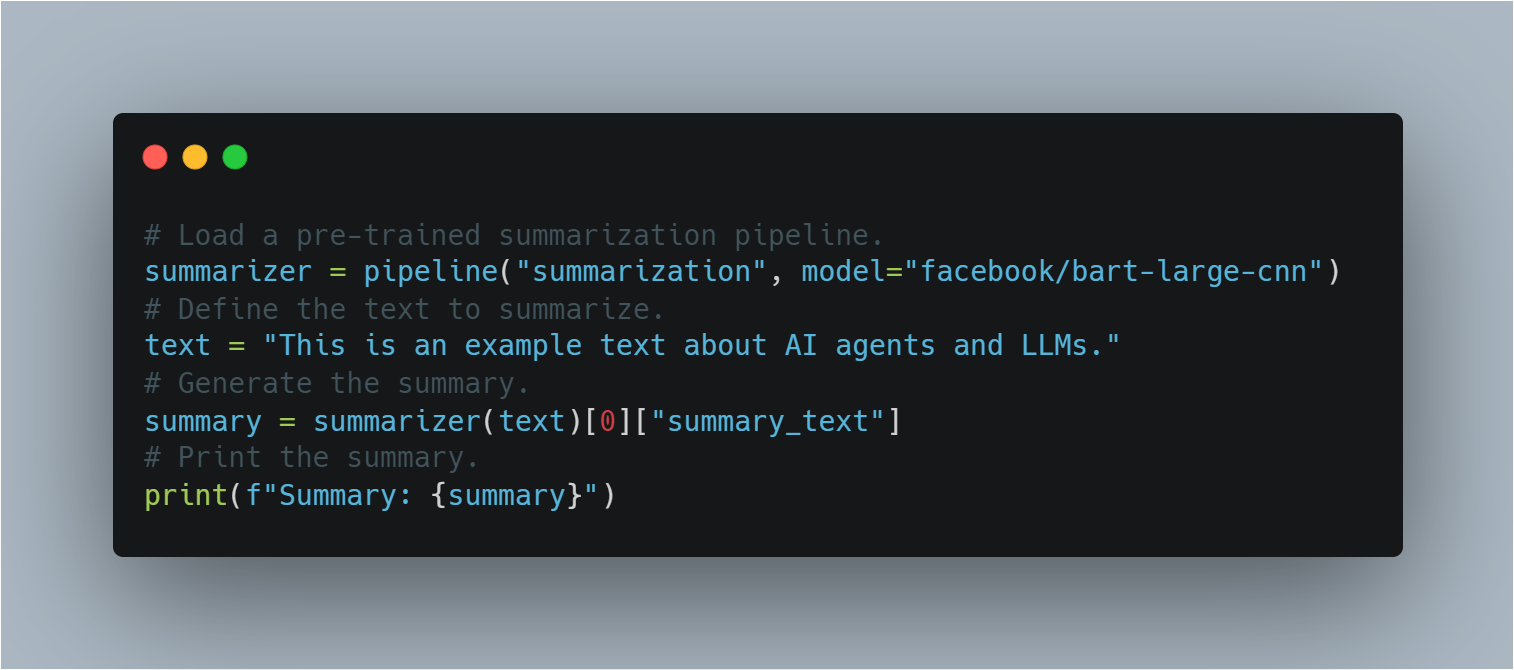
Dies zeigt die Flexibilität von LLMs bei der Ausführung verschiedener Aufgaben ohne zusätzliche Training, unter Nutzung ihrer vorhandenen Wissen.
Das vollständige Codebeispiel
# Importieren Sie das Modul random für die Erzeugung von Zufallszahlen.
import random
# Importieren Sie die notwendigen Module aus der Bibliothek transformers.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Importieren Sie load_dataset für das Laden von Datensätzen.
from datasets import load_dataset
# Importiere metrics zum Auswerten der Modellleistung.
from sklearn.metrics import accuracy_score, f1_score
# Importiere SummaryWriter zum Protokollieren des Trainingsfortschritts.
from torch.utils.tensorboard import SummaryWriter
# Importiere pickle zum Speichern und Laden trainierter Modelle.
import pickle
# Importieren Sie openai für die Verwendung der API von OpenAI (erfordert einen API-Schlüssel).
import openai
# Importieren Sie PyTorch für Deep-Learning-Operationen.
import torch
# Importieren Sie das Modul für neuronale Netzwerke von PyTorch.
import torch.nn as nn
# Importiere das Optimierungsmodul von PyTorch (wird in diesem Beispiel nicht direkt verwendet).
import torch.optim as optim
# --------------------------------------------------
# 1. Feinabstimmung eines LLM für die Sentiment-Analyse
# --------------------------------------------------
# Geben Sie den Namen des vortrainierten Modells aus dem Hugging Face Model Hub an.
model_name = "bert-base-uncased"
# Laden Sie das vortrainierte Modell mit der angegebenen Anzahl von Ausgabeklassen.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Laden Sie einen Tokenizer für das Modell.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Laden Sie den IMDB-Datensatz von Hugging Face Datasets und verwenden Sie nur 10 % für das Training.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokenize the dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Map the dataset to tokenized inputs
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Definiere Trainingsargumente.
training_args = TrainingArguments(
output_dir="./results", # Ausgabeverzeichnis zum Speichern des Modells angeben.
num_train_epochs=3, # Anzahl der Trainingsepochen festlegen.
per_device_train_batch_size=8, # Stapelgröße pro Gerät festlegen.
logging_dir='./logs', # Verzeichnis zum Speichern der Protokolle.
logging_steps=10 # Protokollierung alle 10 Schritte.
)
# Initialisieren Sie den Trainer mit dem Modell, den Trainingsargumenten und dem Datensatz.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Starten Sie den Trainingsprozess.
trainer.train()
# Speichern Sie das feinabgestimmte Modell.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. Implementieren eines einfachen Q-Learning-Agenten
# --------------------------------------------------
# Definieren Sie die Klasse des Q-Learning-Agenten.
class QLearningAgent:
# Initialisieren Sie den Agenten mit Aktionen, Epsilon (Explorationsrate), Alpha (Lernrate) und Gamma (Diskontierungsfaktor).
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Initialisieren Sie die Q-Tabelle.
self.q_table = {}
# Speichern Sie die möglichen Aktionen.
self.actions = actions
# Die Explorationsrate festlegen.
self.epsilon = epsilon
# Die Lernrate festlegen.
self.alpha = alpha
# Den Diskontierungsfaktor festlegen.
self.gamma = gamma
# Definieren Sie die Methode get_action, um eine Aktion basierend auf dem aktuellen Zustand auszuwählen.
def get_action(self, state):
# Erkunden Sie zufällig mit der Wahrscheinlichkeit epsilon.
if random.uniform(0, 1) < self.epsilon:
# Geben Sie eine zufällige Aktion zurück.
return random.choice(self.actions)
else:
# Nutze die beste Aktion auf der Grundlage der Q-Tabelle.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# Definiere die update_q_table-Methode, um die Q-Tabelle nach der Durchführung einer Aktion zu aktualisieren.
def update_q_table(self, state, action, reward, next_state):
# Wenn der Zustand nicht in der Q-Tabelle ist, füge ihn hinzu.
if state not in self.q_table:
# Initialisiere die Q-Werte für den neuen Zustand.
self.q_table[state] = {a: 0.0 for a in self.actions}
# Wenn der nächste Zustand nicht in der Q-Tabelle ist, füge ihn hinzu.
if next_state not in self.q_table:
# Initialisiere die Q-Werte für den neuen nächsten Zustand.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# Hole den alten Q-Wert für das Zustands-Aktionspaar.
old_value = self.q_table[state][action]
# Hole den maximalen Q-Wert für den nächsten Zustand.
next_max = max(self.q_table[next_state].values())
# Berechne den aktualisierten Q-Wert.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# Aktualisiere die Q-Tabelle mit dem neuen Q-Wert.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. Verwendung der API von OpenAI für die Belohnungsmodellierung (konzeptionell)
# --------------------------------------------------
# Definieren Sie die Funktion get_reward, um ein Belohnungssignal von der API von OpenAI zu erhalten.
def get_reward(state, action, next_state):
# Stellen Sie sicher, dass der OpenAI-API-Schlüssel korrekt gesetzt ist.
openai.api_key = "your-openai-api-key" # Ersetzen Sie ihn durch Ihren tatsächlichen OpenAI-API-Schlüssel.
# Konstruieren Sie die Eingabeaufforderung für den API-Aufruf.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# Führen Sie den API-Aufruf an den Completion-Endpunkt von OpenAI durch.
response = openai.Completion.create(
engine="text-davinci-003", # Geben Sie die zu verwendende Engine an.
prompt=prompt, # Übergeben Sie den konstruierten Prompt.
temperature=0.7, # Setzen Sie den Temperaturparameter.
max_tokens=1 # Setzen Sie die maximale Anzahl der zu generierenden Token.
)
# Extrahiere den Reward-Wert aus der API-Antwort und gib ihn zurück.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. Auswertung der Modellleistung
# --------------------------------------------------
# Definieren Sie die wahren Bezeichnungen für die Auswertung.
true_labels = [0, 1, 1, 0, 1]
# Definieren Sie die vorhergesagten Bezeichnungen für die Auswertung.
predicted_labels = [0, 0, 1, 0, 1]
# Berechnen Sie die Genauigkeitsbewertung.
accuracy = accuracy_score(true_labels, predicted_labels)
# Berechnen Sie die F1-Bewertung.
f1 = f1_score(true_labels, predicted_labels)
# Drucken Sie die Genauigkeitsbewertung.
print(f"Accuracy: {accuracy:.2f}")
# Drucken Sie die F1-Bewertung.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. Basic Policy Gradient Agent (using PyTorch) - Conceptual
# --------------------------------------------------
# Definieren Sie die Policy-Netzwerk-Klasse.
class PolicyNetwork(nn.Module):
# Initialisieren Sie das Policy-Netzwerk.
def __init__(self, input_size, output_size):
# Initialisieren Sie die übergeordnete Klasse.
super(PolicyNetwork, self).__init__()
# Definieren Sie eine lineare Schicht.
self.linear = nn.Linear(input_size, output_size)
# Definieren Sie den Vorwärtspass des Netzes.
def forward(self, x):
# Wenden Sie Softmax auf den Ausgang der linearen Schicht an.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. Visualisierung des Trainingsfortschritts mit TensorBoard
# --------------------------------------------------
# Erstellen einer SummaryWriter-Instanz.
writer = SummaryWriter()
# Beispiel-Trainingsschleife für TensorBoard-Visualisierung:
# num_epochs = 10 # Definieren Sie die Anzahl der Epochen.
# for epoch in range(num_epochs):
# # ... (Ihre Trainingsschleife hier)
# loss = random.random() # Beispiel: Zufälliger Verlustwert.
# accuracy = random.random() # Beispiel: Zufälliger Genauigkeitswert.
# # Protokolliere den Verlust auf TensorBoard.
# writer.add_scalar("Loss/train", loss, epoch)
# # Protokolliert die Genauigkeit auf TensorBoard.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (Andere Metriken protokollieren)
# # Den SummaryWriter schließen.
# writer.close()
# --------------------------------------------------
# 7. Speichern und Laden von Checkpoints des trainierten Agenten
# --------------------------------------------------
# Beispiel:
# Erstellen Sie eine Instanz des Q-Learning-Agenten.
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (Trainiere deinen Agenten)
# # Speichere den Agenten
# # Öffne eine Datei im binären Schreibmodus.
# mit open("trainierter_agent.pkl", "wb") as f:
# # Den Agenten in der Datei speichern.
# pickle.dump(agent, f)
# # Laden des Agenten
# # Öffnen der Datei im binären Lesemodus.
# mit open("trained_agent.pkl", "rb") as f:
# # Laden des Agenten aus der Datei.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. Lehrplan Lernen
# --------------------------------------------------
# Stellen Sie die anfängliche Aufgabenschwierigkeit ein.
initial_task_difficulty = 0.1
# Beispiel-Trainingsschleife mit Curriculum-Lernen:
# for epoch in range(num_epochs):
# Schrittweise Erhöhung der Aufgabenschwierigkeit.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (Trainingsdaten mit angepasster Schwierigkeit generieren)
# --------------------------------------------------
# 9. Implementierung des Frühstopps
# --------------------------------------------------
# Initialisieren Sie den besten Validierungsverlust auf unendlich.
best_validation_loss = float("inf")
# Setzen Sie den Geduldswert (Anzahl der Epochen ohne Verbesserung).
patience = 5
# Initialisieren Sie den Zähler für Epochen ohne Verbesserung.
epochs_without_improvement = 0
# Beispiel Trainingsschleife mit vorzeitigem Abbruch:
# for epoch in range(num_epochs):
# # .... (Trainings- und Validierungsschritte)
# # Berechne den Validierungsverlust.
# validation_loss = random.random() # Beispiel: Zufälliger Validierungsverlust.
# Wenn sich der Validierungsverlust verbessert.
# if validation_loss < best_validation_loss:
# # Aktualisieren Sie den besten Validierungsverlust.
# best_validation_loss = validation_loss
# # Setzen Sie den Zähler zurück.
# epochs_without_improvement = 0
# else:
# # Erhöhe den Zähler.
# Epochen_ohne_Verbesserung += 1
# Wenn keine Verbesserung für 'Geduld' Epochen.
# wenn Epochen_ohne_Verbesserung >= Geduld:
# # Eine Meldung ausgeben.
# print("Vorzeitiges Anhalten ausgelöst!")
# # Das Training anhalten.
# break
# --------------------------------------------------
# 10. Verwendung einer vortrainierten LLM für Zero-Shot Task Transfer
# --------------------------------------------------
# Laden einer vortrainierten Zusammenfassungspipeline.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Definieren Sie den zusammenzufassenden Text.
text = "This is an example text about AI agents and LLMs."
# Erzeugen Sie die Zusammenfassung.
summary = summarizer(text)[0]["summary_text"]
# Drucken Sie die Zusammenfassung.
print(f"Summary: {summary}")

Herausforderungen bei der Deployment und Skalierung
Die Einbindung von integrierten AI-Agenten mit langen Mengenmodellen (LLMs) birgt sowohl technische als auch operationelle Herausforderungen. Eine der Hauptherausforderungen ist der rechenintensive Aufwand, insbesondere da LLMs an Größe und Komplexität zunehmen.
Dieses Problem lässt sich durch ressourceneffiziente Strategien wie Modellverkleinern, Quantisierung und verteiltes Rechnen lösen, die den Rechenaufwand reduzieren können ohne Leistungseinbußen hinzuzufügen.
Außerdem ist die Aufrechterhaltung von Zuverlässigkeit und Robustheit in realen Anwendungen ebenfalls entscheidend, was die fortlaufende Überwachung, regelmäßige Updates und die Entwicklung von Sicherheitsmechanismen für die Behandlung von unerwarteten Eingaben oder Systemfehlern erfordert.
Als diese Systeme in verschiedenen Branchen eingesetzt werden, nimmt die Einhaltung von ethischen Standards – einschließlich Fairness, Transparenz und Verantwortung – zunehmend Bedeutung an. Diese Überlegungen sind für die Akzeptanz und langfristige Erfolg des Systems zentral und haben Einfluss auf die öffentliche Vertrautheit und die ethischen Implikationen von durch AI-gesteuerten Entscheidungen in verschiedenen gesellschaftlichen Kontexten (Bender et al., 2021).
Die technische Implementierung von AI-Agenten, die mit LLMs integriert sind, erfordert sorgfältige architektonische Design, rigorose Trainingsmethoden und sorgfältige Beachtung der Herausforderungen beim Deployment.
Die Effektivität und Zuverlässigkeit dieser Systeme in realen Umgebungen hängt ab, dass sowohl technische als auch ethische Bedenken behandelt werden, um sicherzustellen, dass AI-Technologien glatt und verantwortungsvoll in verschiedenen Anwendungen funktionieren.
Kapitel 7: Die Zukunft von AI-Agenten und LLMs
Konvergenz von LLMs mit Verstärkungslearning
Während Sie die Zukunft von AI-Agenten und Großsprachmodellen (LLM) erforschen, sticht die Konvergenz von LLM mit Verstärkungslearning besonders hervorragend heraus. Diese Integration verschiebt die Grenzen traditioneller AI, indem Systeme nicht nur Sprache generieren und verstehen, sondern auch aus ihren Interaktionen in Echtzeit lernen können.
Durch Verstärkungslearning können AI-Agenten ihre Strategien adaptiv anhand der Rückmeldungen ihrer Umgebung ändern, was zu einer kontinuierlichen Verfeinerung ihrer Entscheidungsprozesse führt. Dies bedeutet, dass AI-Systeme, die mit Verstärkungslearning ergänzt werden, im Gegensatz zu statischen Modellen zunehmend komplexere und dynamische Aufgaben mit minimaler menschlicher Aufsicht bewältigen können.
Die Auswirkungen solcher Systeme sind tiefgreifend: in Anwendungen von selbständigen Robotern bis hin zu personalisierten Bildungsanwendungen könnten AI-Agenten autonom ihre Leistung mit der Zeit verbessern, was sie effizienter und an die sich verändernden Bedürfnisse ihrer Betriebsumgebungen anpassender macht.
Beispiel: Textbasierte Spielspiel
Stellen Sie sich ein AI-Agenten vor, der ein textbasiertes Abenteuer Spiel spielt.
-
Umgebung: Das Spiel selbst (Regeln, Zustandsbeschreibungen usw.)
-
LLM: Verarbeitet den Text des Spiels, versteht die aktuelle Situation und generiert mögliche Aktionen (z.B. „gehe nach Norden“, „nehme Schwert“).
- Belohnung:Durch das Spiel vergebene Belohnung basierend auf dem Ergebnis einer Aktion (z.B. positive Belohnung bei der Entdeckung eines Schatzes, negative Belohnung bei dem Verlust von Lebenspunkten).
Codebeispiel (konzipiert mit Python und OpenAI API):
import openai
import random
# ... (Spiele Umgebung Logik - hier nicht gezeigt) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (RL Training Loop - vereinfacht) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (Update des RL Agenten basierend auf Belohnung - hier nicht gezeigt) ...
state = next_state
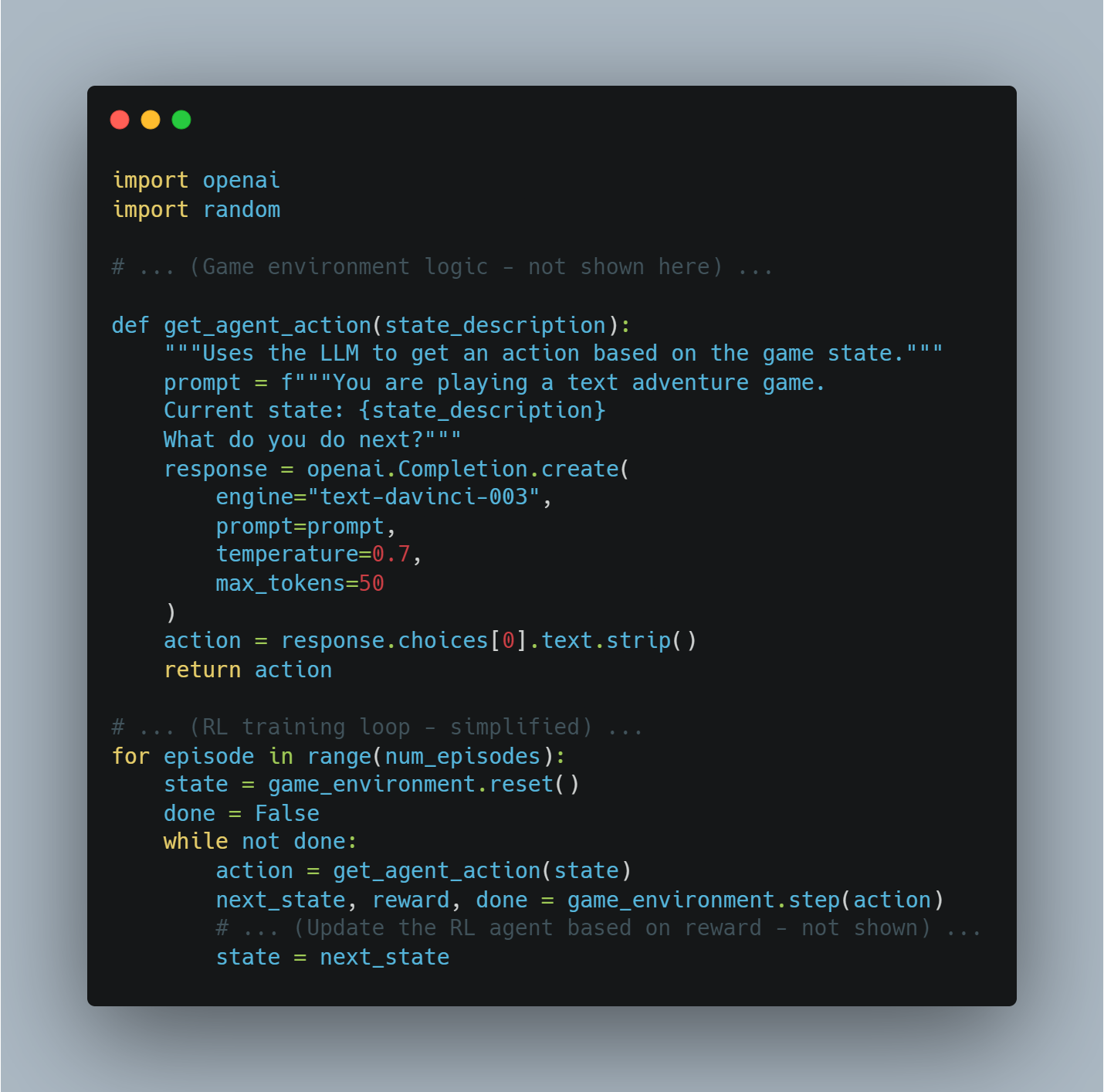
Multimodale AI Integration
Die Integration von multimodalen AI ist eine weitere Schlüsselfrage, die die Zukunft von AI-Agenten塑造. Durch die Fähigkeit, Systeme zu ermöglichen, Daten aus verschiedenen Quellen zu verarbeiten und zu kombinieren – wie Text, Bilder, Audio und sensorische Eingaben – bietet multimodale AI ein umfassendes Verständnis der Umgebungen, in denen diese Systeme agieren.
Zum Beispiel ermöglicht die multimodale AI in autonomen Fahrzeugen die Synthese von visuellen Daten von Kameras, kontextuellen Daten von Karten und Echtzeit-Verkehrsupdates, was das AI dazu bringt, informiertere und sicherere Fahrentscheidungen zu treffen.
Diese Fähigkeit erstreckt sich auch auf andere Bereiche wie das Gesundheitswesen, wo ein künstliches Intelligenz-Agent eine Integration von Patientendaten aus medizinischen Akten, diagnostischer Bildgebung und genomischer Information leisten kann, um präzisere und personalisierte Behandlungsempfehlungen auszusprechen.
Das Herausforderniss hier liegt in der nahtlosen Integration und Echtzeitverarbeitung verschiedener Datenströme, was Fortschritte in der Modellarchitektur und Datenfusiontechniken erfordert.
Der erfolgreiche Überwindung dieser Herausforderungen ist entscheidend für die Implementierung von AI-Systemen, die wirklich Intelligente sind und in komplexen, realen Weltumgebungen funktionieren können.
Beispiel 1 für multimodales AI: Bildunterschriftgenerierung für visuelle Fragestellung
-
Ziel: Ein AI-Agent, der Fragen zu Bildern beantworten kann.
-
Modalitäten: Bild, Text
-
Verfahren:
-
Bildmerkmale extrahieren: Verwenden Sie ein vorher trainiertes Konvolutionsneuronnetz (CNN), um Merkmale aus dem Bild zu extrahieren.
-
Beschreibung generieren: Verwenden Sie ein LLM (wie z.B. ein Transformermodell), um auf Basis der extrahierten Merkmale eine Beschreibung des Bildes zu generieren.
-
Frage beantworten: Verwenden Sie ein weiteres LLM, um sowohl die Frage als auch die generierte Beschreibung zu verarbeiten, um eine Antwort zu liefern.
-
Codebeispiel (konzeptionell mit Python und Hugging Face Transformers):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# Vortrainierte Modelle laden
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# Funktion zur Generierung von Bildbeschriftungen
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# Funktion zur Beantwortung von Fragen zum Bild
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# Beispielverwendung
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
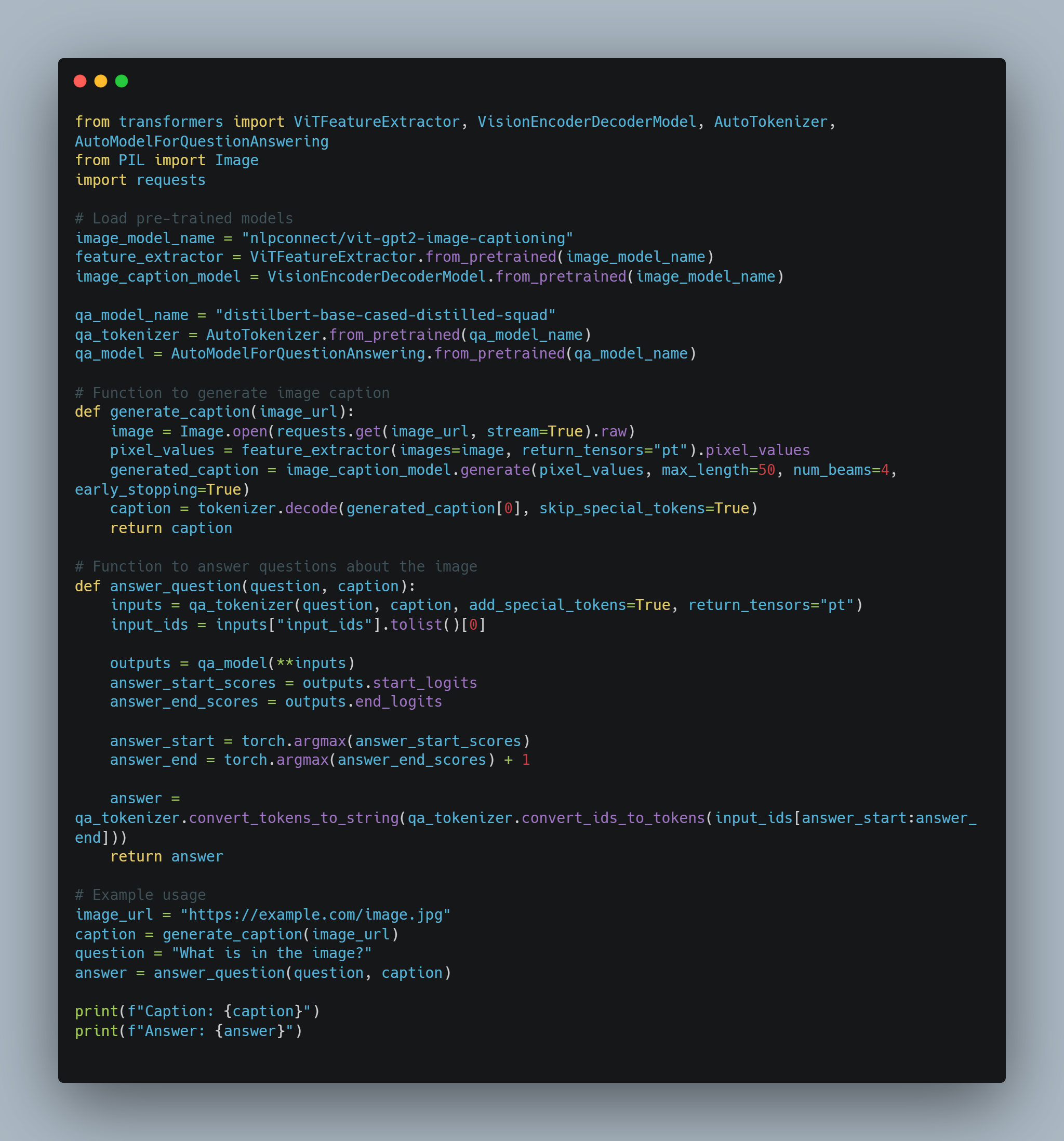
Multimodales KI-Beispiel 2: Sentimentanalyse aus Text und Audio
-
Ziel: Ein KI-Agent, der die Stimmung sowohl aus dem Text als auch aus dem Ton einer Nachricht analysiert.
-
Modalitäten:
Text, Audio
-
Verfahren:
-
Text-Sozialkennung: Verwende ein vorbereitetes Sozialkennungsmodell auf dem Text.
-
Audio-Sozialkennung: Verwende ein Audioverarbeitungsmodell, um Merkmale wie Ton und Register zu extrahieren, und verwende diese Merkmale zur Sozialkennungsvorhersage.
-
Fusion: Kombiniere die Text- und Audio-Sozialkennziffern (z.B. gewichteter Durchschnitt) zur Erhalten des Gesamtschlüssels.
-
Code-Beispiel (konzipelliegender Python-Ausdruck):
from transformers import pipeline # Für Text-Sentiment
# ... (Audio-Verarbeitung und -Sentiment-Bibliotheken importieren - nicht gezeigt) ...
# Vordefinierte Modelle laden
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# Text-Sentiment
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# Audio-Sentiment
# ... (Audio verarbeiten, Merkmale extrahieren, Sentiment vorhersagen - nicht gezeigt) ...
audio_sentiment = # ... (Ergebnis aus dem Audio-Sentiment-Modell)
audio_confidence = # ... (Vertrauenswert von Audio-Modell)
# Sentiment kombinieren (Beispiel: gewichteter Durchschnitt)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# Beispielhafte Nutzung
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
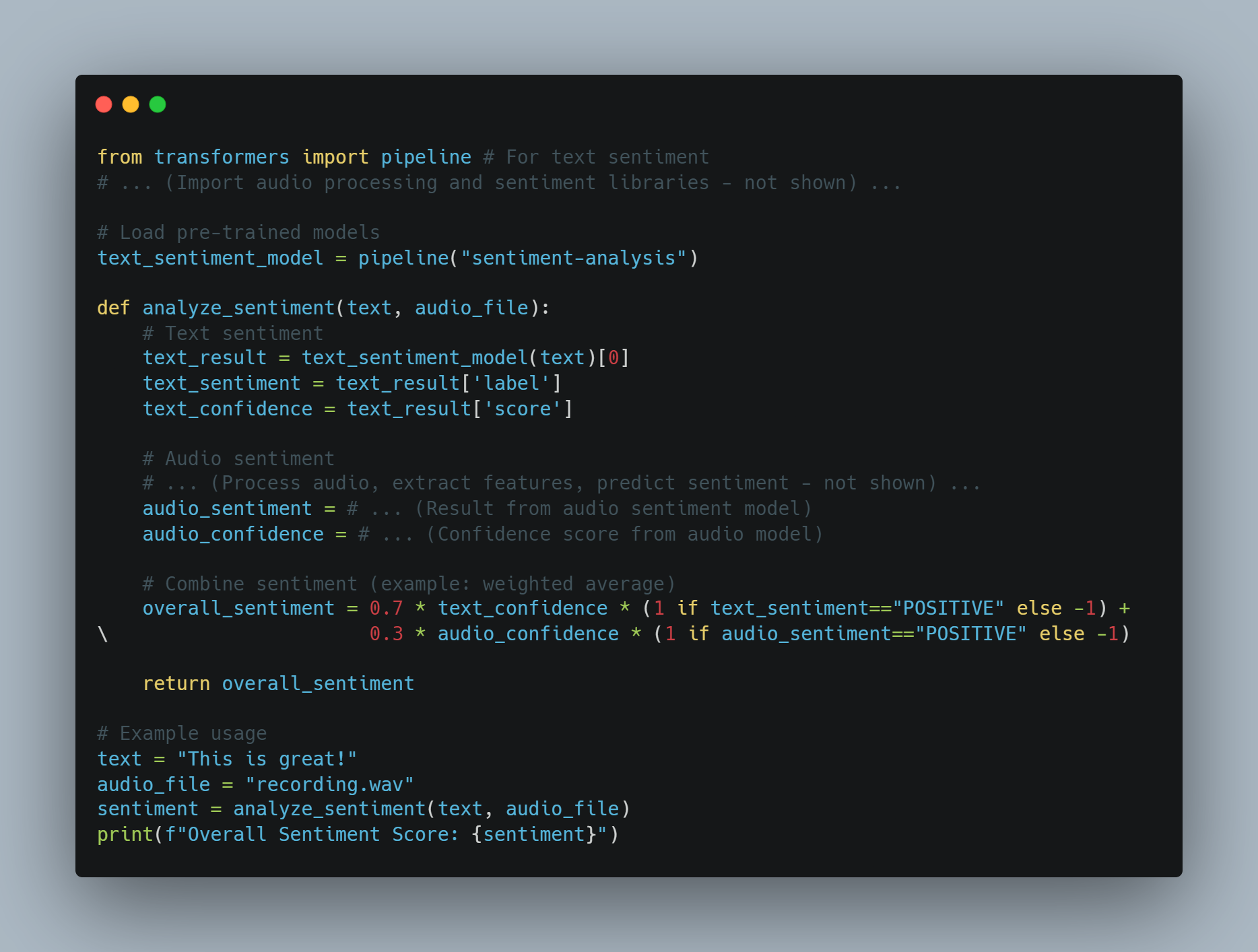
Herausforderungen und Überlegungen:
-
Daten-Ausrichtung: Sorgfältiges Synchronisieren und Ausrichten von Daten unterschiedlicher Modalitäten ist entscheidend.
-
Modellkomplexität: Multimodale Modelle sind schwer zu trainieren und erfordern große, verschiedenartige Datensets.
-
Fusionsverfahren: Die Wahl des richtigen Verfahrens zur Kombination von Informationen unterschiedlicher Modalitäten ist wichtig und ist problemabhängig.
Multimodale AI ist ein sich rasch entwickelndes Feld mit dem Potential, die Art und Weise zu verändern, wie AI-Agenten die Welt wahrnehmen und Interagieren.
Verteilte AI-Systeme und Edge Computing
Beim Blick auf die Entwicklung der AI-Infrastrukturen ist der Wechsel hin zu verteilten AI-Systemen, unterstützt durch Edge Computing, ein bedeutender Fortschritt.
Verteilte AI-Systeme dezentralisieren Rechenaufgaben, indem Daten näher an der Quelle verarbeitet werden, wie z.B. IoT-Geräten oder lokalen Servern, anstatt sich auf zentralisierte Cloudressourcen zu verlassen. Dieser Ansatz reduziert nicht nur Latenzzeiten, die für zeitempfindliche Anwendungen wie autonomer Drohnen oder industrielle Automatisierung entscheidend sind, sondern erhöht auch die Datenschutz und -sicherheit, indem sensible Informationen lokal gehalten werden.
Außerdem verbessern verteilte AI-Systeme die Skalierbarkeit, ermöglicht die Deployment von AI über große Netzwerke, wie z.B. smarte Städte, ohne die überforderung von zentralen Datacentern.
Die technischen Herausforderungen, die mit verteilten AI-Systemen verbunden sind, beinhalten die Gewährleistung von Konsistenz und Koordinierung über verteilte Knoten sowie die Optimierung von Ressourcenvergabe, um Leistung in vielfältigen und potenziell ressourcenbeschränkten Umgebungen aufrechtzuerhalten.
Während Sie AI-Systeme entwickeln und einführen, wird die Annahme von verteilten Architekturen eine Schlüsselkomponente für die Schaffung von widerstandsfähigen, effizienten und skalierbaren AI-Lösungen sein, die den Anforderungen zukünftiger Anwendungen gerecht werden.
Verteilte AI-Systeme und Edge Computing Beispiel 1: verteiltes Lernen für den Schutz vertraulicher Daten beim Modelltraining
-
Ziel: Ein gemeinsames Modell auf mehreren Geräten (z.B. Smartphones) zu trainieren, ohne direkt vertrauliche Benutzerdaten zu teilen.
-
Ansatz:
-
Lokales Training: Jedes Gerät trainiert eine lokale Version seines Modells auf eigenen Daten.
-
Parameter Aggregation: Geräte senden ModelUpdates (Gradienten oder Parameter) an einen zentralen Server.
-
Globales Modellupdate: Der Server aggregiert die Updates, verbessert das globale Modell und sendet das aktualisierte Modell an die Geräte zurück.
-
Codebeispiel (konzeptionell mit Python und PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
# ... (Code für die Kommunikation zwischen Geräten und Server - nicht gezeigt) ...
class SimpleModel(nn.Module):
# ... (Legen Sie hier Ihre Modellarchitektur fest) ...
# Gerätedatei-Trainingsfunktion
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # Beginne mit globalem Modell
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (Trainiere lokales_modell auf Gerätedaten) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# Serverseitige Aggregationsfunktion
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (vereinfachter Hauptfederated Learning-Schleifen) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)

Beispiel 2: Echtzeitobjekterkennung auf Edge-Geräten
-
Ziel: Ein objekterkennendes Modell auf einem ressourcenbeschränkten Gerät (z.B. Raspberry Pi) für Echtzeiteinsätze zu deployieren.
-
Ansatz:
-
Modelloptimierung: Verwenden Sie Techniken wie Modellquantisierung oder Pruning, um die Modellgröße und die Rechenanforderungen zu reduzieren.
-
Edge-Bereitstellung: Das optimierte Modell auf das Edge-Gerät bereitstellen.
-
Lokale Inferenz: Das Gerät führt die Objekterkennung lokal durch, wodurch die Latenz verringert und die Abhängigkeit von der Cloud-Kommunikation reduziert wird.
-
Beispielcode (konzeptionell mit Python und TensorFlow Lite):
import tensorflow as tf
# Lade den bereits für TensorFlow Lite optimierten vorbereiteten Modell
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# hole Eingabe und Ausgabedetails
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (Fangen Sie beim Fotografieren von Bildern aus der Kamera oder Laden von Dateien - nicht gezeigt) ...
# Vorverarbeite das Bild
input_data = ... # Vergrößern, Normalisieren usw.
interpreter.set_tensor(input_details[0]['index'], input_data)
# Führe Inferenz aus
interpreter.invoke()
# Holen Sie die Ausgabe
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (Verarbeite Ausgabedaten, um Bounding Boxen, Klassen usw. zu erhalten) ...
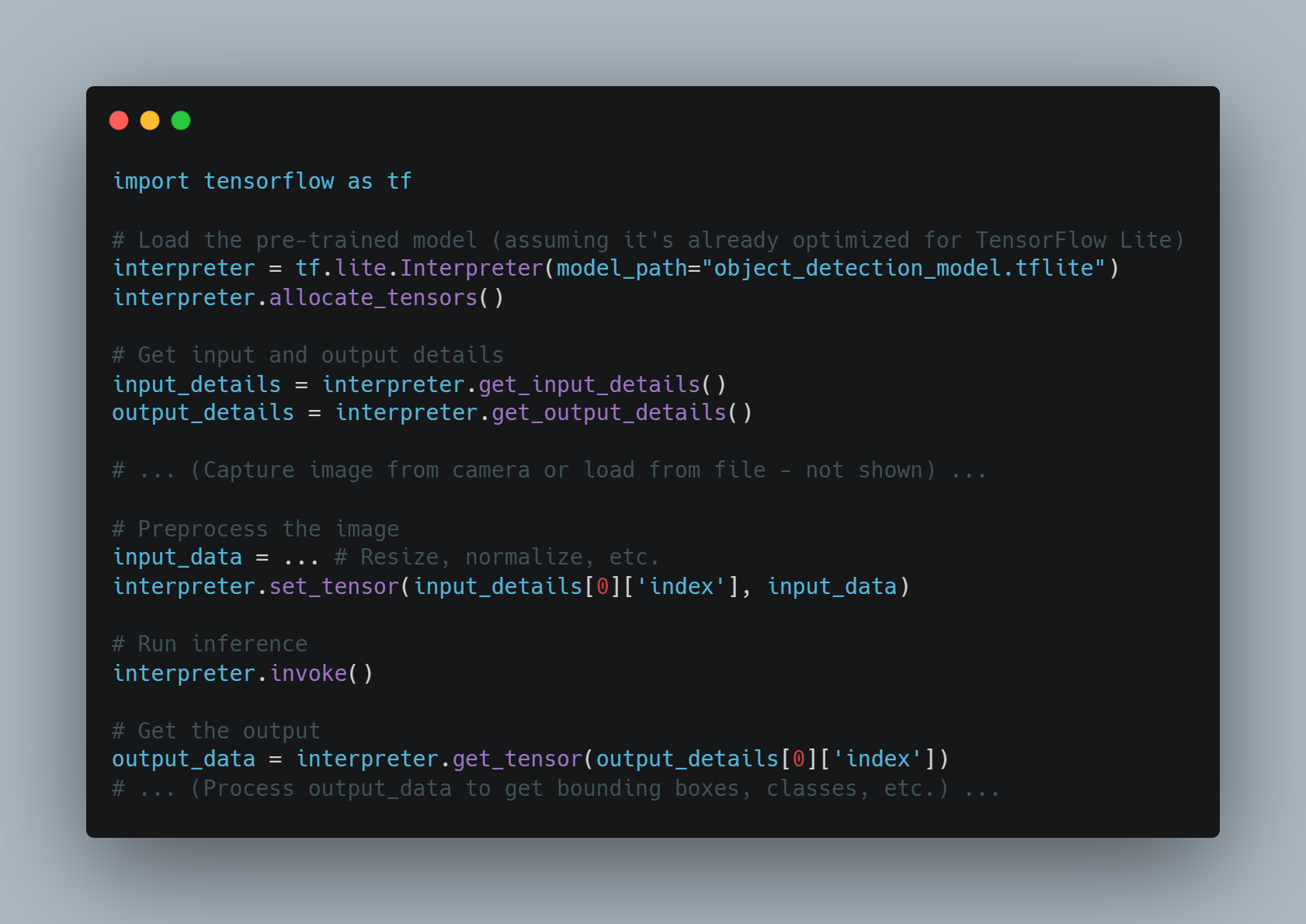
Herausforderungen und zu berücksichtigende Aspekte:
-
Kommunikationsüberschuss: Effiziente Koordinierung und Kommunikation zwischen verteilten Knoten ist entscheidend.
-
Ressourcenverwaltung: Optimierung der Ressourcenverteilung (CPU, Speicher, Bandbreite) über Geräte ist wichtig.
-
Sicherheit: Die Sicherheit von verteilten Systemen und der Schutz von Datenschutz sind zentrale Anliegen.
Verteilte AI und Edge-Computing sind unerlässlich für die Erstellung skalierbarer, effizienter und datenschutzfreundlicher AI-Systeme, insbesondere im Hinblick auf die Zukunft mit Milliarden interagierten Geräten.
Fortschritte in der natürlichen Sprachverarbeitung
Die natürliche Sprachverarbeitung (NLP) bleibt eine der führenden Entwicklungen in der AI und hat maßgeblich zur Verbesserung der Fähigkeiten von Maschinen beigetragen, Sprache zu verstehen, zu generieren und mit menschlicher Sprache zu interagieren.
Recenteste Fortschritte in der NLP, wie die Entwicklung von Transformer-Modelle und Aufmerksamkeitsmechanismen, haben die Fähigkeit von AI stark verbessert, komplexe sprachliche Strukturen zu verarbeiten, was Interaktionen natürlicher und konztextorientierter macht.
Dieser Fortschritt ermöglicht es AI-Systemen, Nuancen, Emotionen und sogar kulturelle Bezüge innerhalb von Texten zu verstehen, was zu genauer und bedeutsamer Kommunikation führt.
Beispielsweise können in der Kundenservice advanced NLP-Modelle nicht nur Präzision bei der Bearbeitung von Anfragen erreichen, sondern auch emotionalen Hinweisen von Kunden erkennen, was zu mehr Empathie und wirksamen Reaktionen führt.
Blickendurch die Zukunft, die Integration von mehrsprachigen Fähigkeiten und einem tieferen semantischen Verständnis in NLP-Modelle wird ihre Anwendbarkeit weiter erweitern, was eine problemlose Kommunikation in verschiedenen Sprachen und Dialekten ermöglicht und sogar AI-Systeme zu Echtzeit-Übersetzern in verschiedenen globalen Kontexten macht.
Die natürliche Sprachverarbeitung (NLP) entwickelt sich rasch weiter, mit Durchbrüchen in Bereichen wie Transformer-Modelle und Aufmerksamkeitsmechanismen. Hier sind einige Beispiele und Code-Snippets, um diese Fortschritte zu illustrieren:
NLP Beispiel 1: Sentimentanalyse mit feinabgestimmten Transformern
-
Ziel: Die Stimmung eines Textes mit hoher Genauigkeit analysieren und Nuancen und Kontext erfassen.
-
Vorgehen: Ein vortrainiertes Transformer-Modell (wie BERT) auf einem Sentimentanalyse-Datensatz feinabstimmen.
Codebeispiel (mit Python und Hugging Face Transformers):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Vortrainiertes Modell und Datensatz laden
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3 Labels: Positiv, Negativ, Neutral
dataset = load_dataset("imdb", split="train[:10%]")
# Trainingsargumente definieren
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# Modell feinabstimmen
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# Das feinabgestimmte Modell speichern
model.save_pretrained("./fine_tuned_sentiment_model")
# Das feinabgestimmte Modell für die Inferenz laden
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# Beispielhafte Verwendung
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
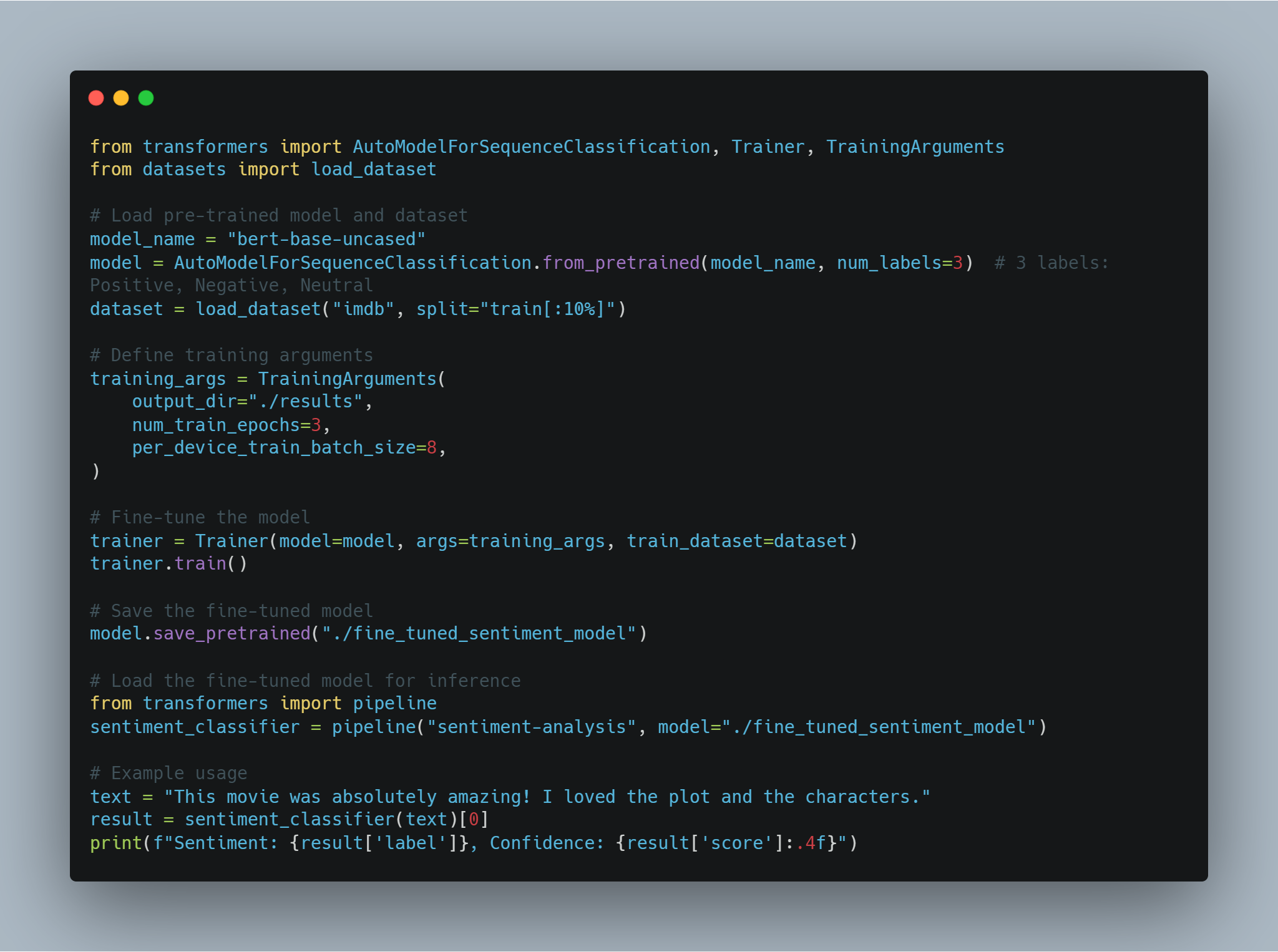
NLP Beispiel 2: Mehrsprachige maschinelle Übersetzung mit einem einzigen Modell
-
Ziel: Mit einem einzigen Modell zwischen mehreren Sprachen übersetzen und gemeinsame sprachliche Repräsentationen nutzen.
- Ansatz: Nutze ein großes, mehrsprachiges Transformer-Modell (wie mBART oder XLM-R), das auf einem massiven Datensatz von parallelen Texten in mehreren Sprachen trainiert wurde.
Codebeispiel (unter Verwendung von Python und Hugging Face Transformers):
from transformers import pipeline
# Laden Sie eine vortrainierte mehrsprachige Übersetzungs-Pipeline
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# Beispielverwendung: Englisch nach Französisch
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# Beispielverwendung: Französisch nach Spanisch
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
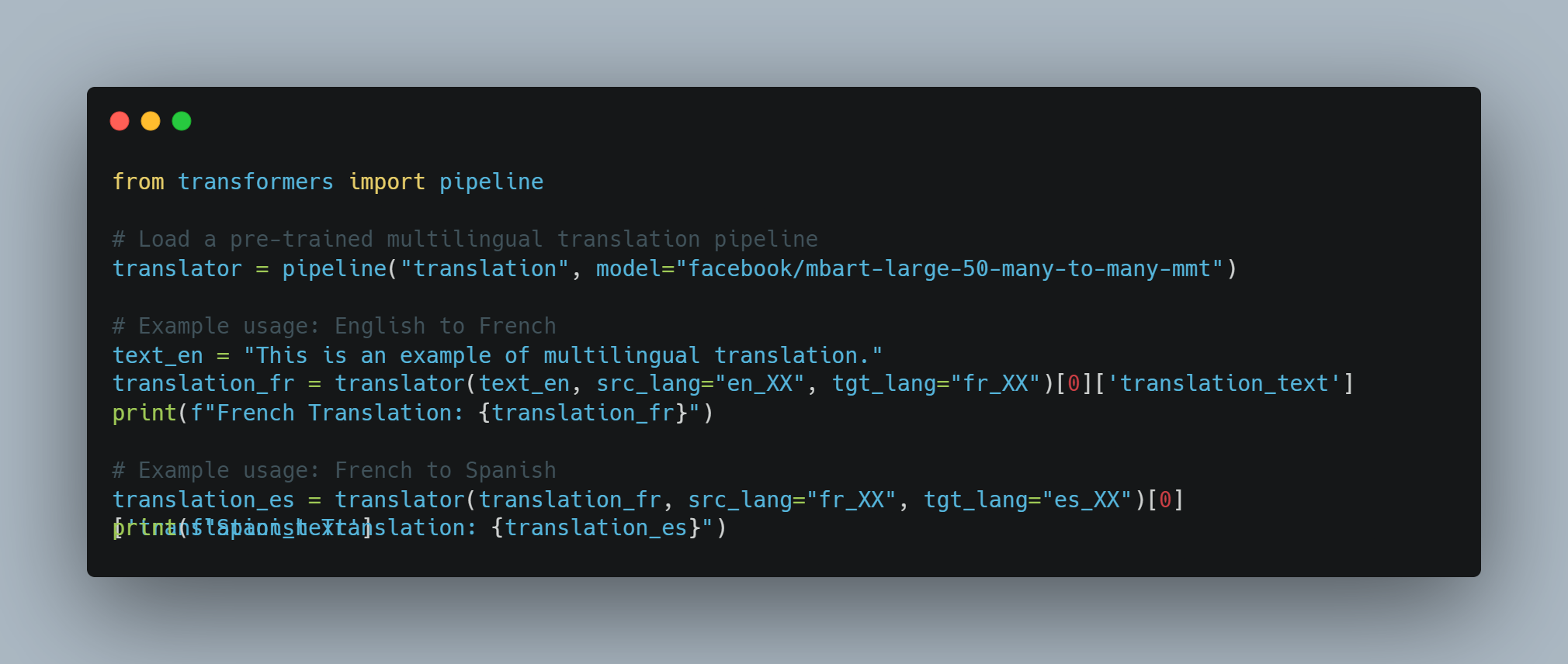
NLP-Beispiel 3: Kontextuelle Worteingabe für semantische Ähnlichkeit
-
Ziel: Bestimme die Ähnlichkeit zwischen Wörtern oder Sätzen, unter Berücksichtigung des Kontexts.
-
Ansatz: Nutze ein Transformer-Modell (wie BERT), um kontextuelle Worteingaben zu generieren, die das Bedeutung von Wörtern innerhalb eines spezifischen Satzes erfassen.
Codebeispiel (unter Verwendung von Python und Hugging Face Transformers):
from transformers import AutoModel, AutoTokenizer
import torch
# Laden Sie den vorbereiteten Modell und Tokenizer
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Funktion, um Sätze Embedding zu erhalten
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# Verwenden Sie das [CLS]-Token Embedding als Satz Embedding
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# Beispielverwendung
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# Berechne Kosinussimilitude
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
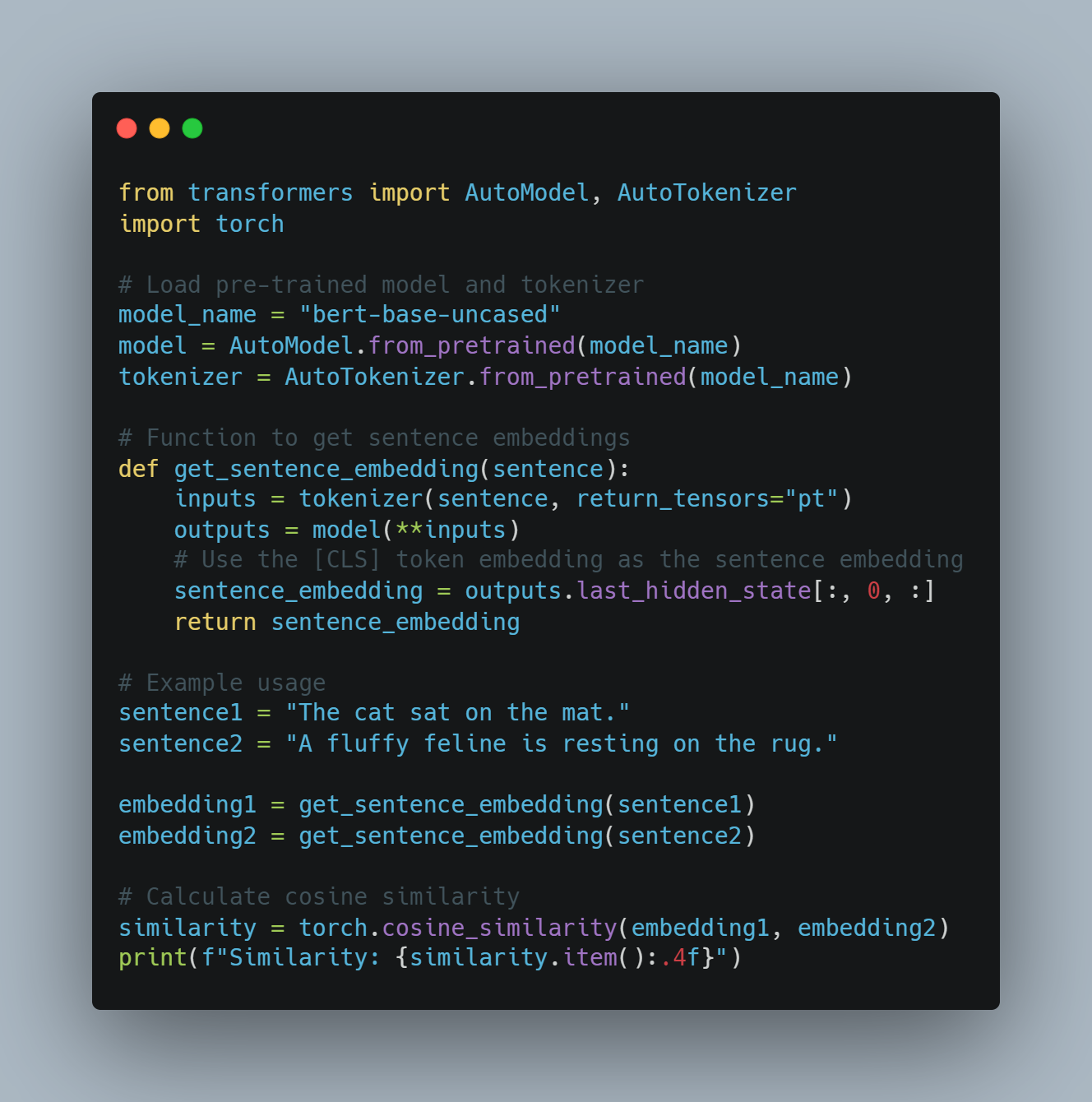
Herausforderungen und künftige Richtungen:
-
Voreingenommenheit und Fairness: NLP-Modelle können Bias aus ihrer Trainingsdaten erben, was zu ungerechtfertigten oder diskriminierenden Ergebnissen führen kann. Der Abbau von Bias ist entscheidend.
-
Allgemeines Verständnis von Logik: LLMs haben immer noch mit allgemeinen Verständnissen von Logik und dem Verständnis impliziter Informationen zu kämpfen.
-
Erklärbarkeit: Der Entscheidungsprozess komplexer NLP-Modelle kann opak sein, was es schwierig macht, zu verstehen, warum sie bestimmte Ausgaben erzeugen.
Trotz dieser Herausforderungen geht die NLP-Forschung schnell voran. Die Integration von multimodalen Informationen, verbesserter alltäglicher Vernunft-Reasoning und erhöhter Erklärbarkeit sind Schlüsselbereiche aktueller Forschung, die die Interaktion von AI mit menschlicher Sprache weiter revolutionieren werden.
Personalisierte AI-Assistenten
Die Zukunft von personalisierten AI-Assistenten wird immer komplexer werden, indem sie von der grundlegenden Aufgabenverwaltung hinaus zu einem wirklich intuitiven, proaktiven Support auf individuellen Bedürfnissen ausgehen.
Diese Assistenten werden aufgrund fortschrittlicher Maschinenlernalgorithmen kontinuierlich von Ihrem Verhalten, Ihren Präferenzen und Ihren Routinen lernen und zunehmend personalisierte Empfehlungen anbieten und komplexere Aufgaben automatisieren.
Zum Beispiel könnte ein personalisierter AI-Assistent nicht nur Ihren Terminplaner verwalten, sondern durch die Vorschläge von relevanten Ressourcen oder die Anpassung Ihrer Umgebung an Ihrem Gemüt oder Ihre Vergangenheitspräferenzen auch Ihre Bedürfnisse voraussagen.
Während AI-Assistenten zunehmend in das tägliche Leben integriert werden, wird ihre Fähigkeit, sich an geänderte Kontexte anzupassen und einflussreichen, cross-platformen Support anbieten, ein wesentlicher Unterschied darstellen. Die Herausforderung besteht darin, Personalisierung mit Privatsphäre im Balancieren zu halten, was robuste Datenschutzmechanismen erfordert, um sicher verwaltete Sensible Informationen zu gewährleisten und eine tiefgreifende Personalisierungserscheinung zu liefern.
Beispiel für AI-Assistenten 1: Kontextsensitives Aufgabenvorschlag
-
Ziel: Ein Assistent, der Aufgaben auf der Basis des aktuellen Contexts des Benutzers vorschlägt (Ort, Uhrzeit, Vergangenheitsverhalten).
-
Verfahren: Kombinieren von Benutzerdaten, kontrafaktischen Signalen und einer Aufgabenempfehlungsmodelle.
Codebeispiel (konzipiert mit Python):
# ... (Code für Benutzerdatenverwaltung, Kontexterkennung - nicht gezeigt) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# Beispiel: Zeitbasierte Vorschläge
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# Beispiel: Ortbasierte Vorschläge
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (Füge weitere Regeln oder verwende ein maschinelles leanedes Modell für Vorschläge hinzu) ...
# Sortiere und filtere Vorschläge
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- Beispielhafte Nutzung ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... andere Vorlieben ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... andere Kontextdaten ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
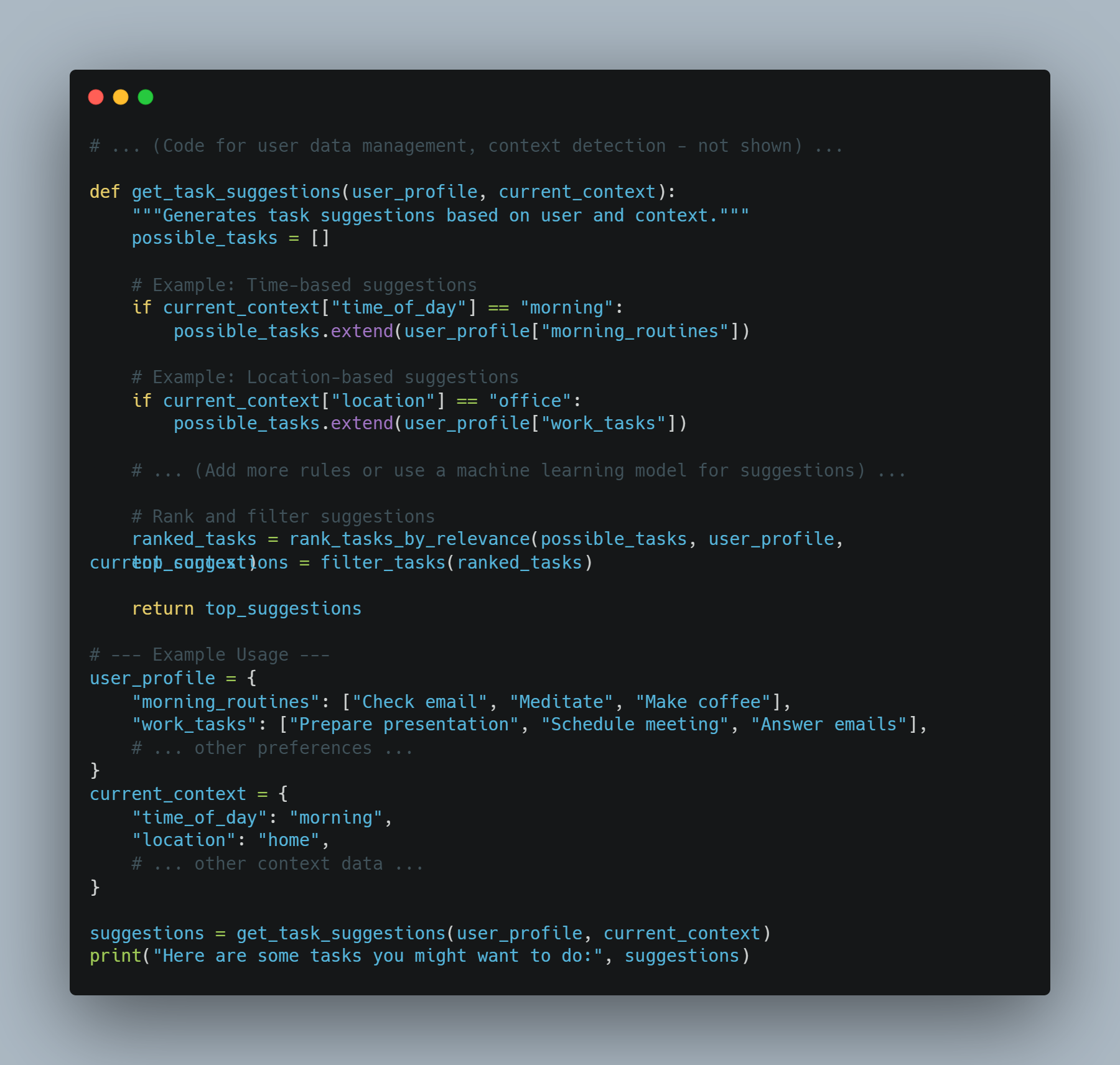
Beispiel 2: Proaktives Informationszusammenstellen
-
Ziel: Ein Assistent, der proaktiv relevante Informationen auf der Grundlage des Nutzerschedules und der Vorlieben bereitstellt.
-
Verfahren: Integration von Kalenderdaten, Benutzerinteressen und einem Inhaltsretrieversystem.
Codebeispiel (konzipiert in Python):
# ... (Code für Kalenderzugriff, Nutzerinteressenprofil - nicht gezeigt) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (Erhalten von Unternehmensinfo, Teilnehmerprofilen usw.) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (Erhalten der Flugstatus, Reisezielinformationen usw.) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- Beispielhafte Nutzung ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... andere Vorlieben ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)

Beispiel 3 für AI-Assistenten: Personalisierte Inhaltsempfehlung
-
Ziel: Ein Assistent, der Inhalte (Artikel, Videos, Musik) basierend auf den Nutzerpräferenzen empfiehlt.
-
Ansatz: Verwenden von kollaborativen Filtern oder Inhaltsbasierten Empfehlungssystemen.
Codebeispiel (konzipiert in Python und mit einer Bibliothek wie Surprise):
from surprise import Dataset, Reader, SVD
# ... (Code für die Verwaltung von Benutzerbewertungen, Inhaltsdatenbank - nicht gezeigt) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (Erhalte Vorschläge für alle Artikel, Rang und gebe die Top N zurück) ...
# --- Beispielhafte Nutzung ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... mehr Bewertungen ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
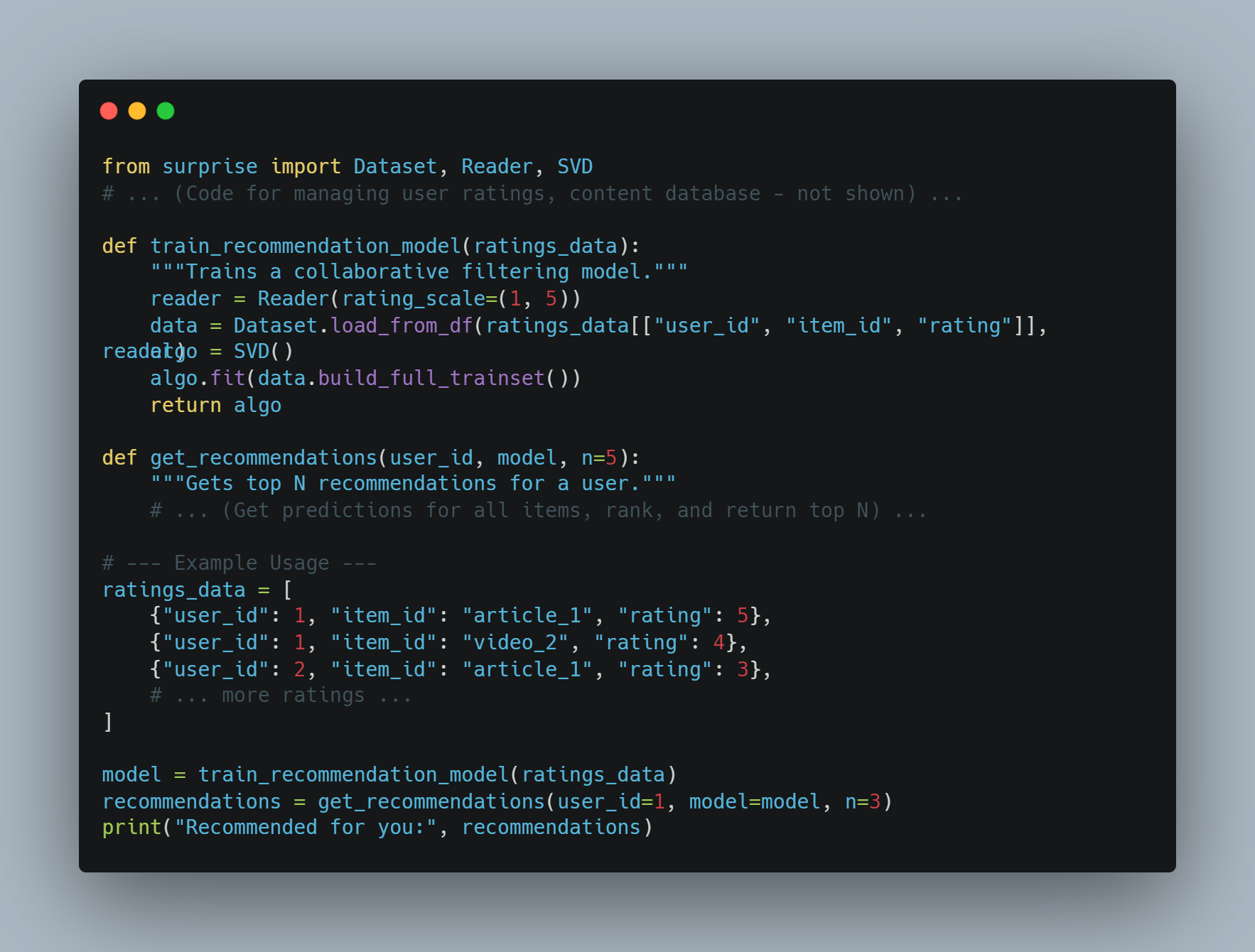
Herausforderungen und ethische Überlegungen:
-
Datenschutz: Verantwortungsvoll und transparentes Handeln mit Benutzerdaten ist entscheidend.
-
Voreingenommenheit und Fairness: Personalisierung sollte bestehende Voreingenommenheiten nicht verstärken.
-
Benutzerkontrolle: Benutzer sollten über ihre Daten und Personalisierungs-Einstellungen verfügen.
Der Aufbau personalisierter AI-Assistenten erfordert eine sorgfältige Beachtung sowohl technischer als auch ethischer Aspekte, um Systeme zu schaffen, die hilfreich, Vertrauenswürdig und die Benutzerprivatsphäre achten.
AI in Kreativbranchen
AI tritt in Kreativbranchen mit bedeutendem Einsatz auf, verändert die Produktion und Verbrauch von Kunst, Musik, Film und Literatur. Dank Fortschritten in generativen Modelle wie Generativen Adversarialen Netzen (GANs) und transformerbasierten Modellen kann AI Inhalte generieren, die den menschlichen Kreativität in nichts nachstehen.
Beispielsweise kann AI Musik komponieren, die bestimmte Genres oder Stimmungen widerspiegeln, digitale Kunst erzeugen, die den Stil bekannter Maler仿造, oder sogar narrative Plots für Filme und Romane entwerfen.
In der Werbebranche wird AI genutzt, um personalisierte Inhalte zu generieren, die mit individuellen Konsumenten resonieren, um die Engagierung und Effektivität zu verbessern.
Der Anstieg von AI in kreativen Bereichen bringt jedoch auch Fragen zu Autorschaft, Ursprünglichkeit und der Rolle der menschlichen Kreativität auf. Wenn Sie sich mit AI in diesen Bereichen engagieren, wird es wichtig sein, zu untersuchen, wie AI die menschliche Kreativität ergänzen kann und nicht ersetzen soll, um die Zusammenarbeit zwischen Menschen und Maschinen zu fördern, um Innovation und wirkungsvolle Inhalte zu produzieren.
Hier ist ein Beispiel dafür, wie GPT-4 in ein Python-Projekt für kreative Aufgaben integriert werden kann, insbesondere im Bereich der Schreibarbeit. Dieser Code zeigt, wie auf GPT-4s Fähigkeiten zur Generierung kreativer Textformate wie Poesie zurückgegriffen werden kann.
import openai
# Set your OpenAI API key
openai.api_key = "YOUR_API_KEY"
# Define a function to generate poetry
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# Example usage
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
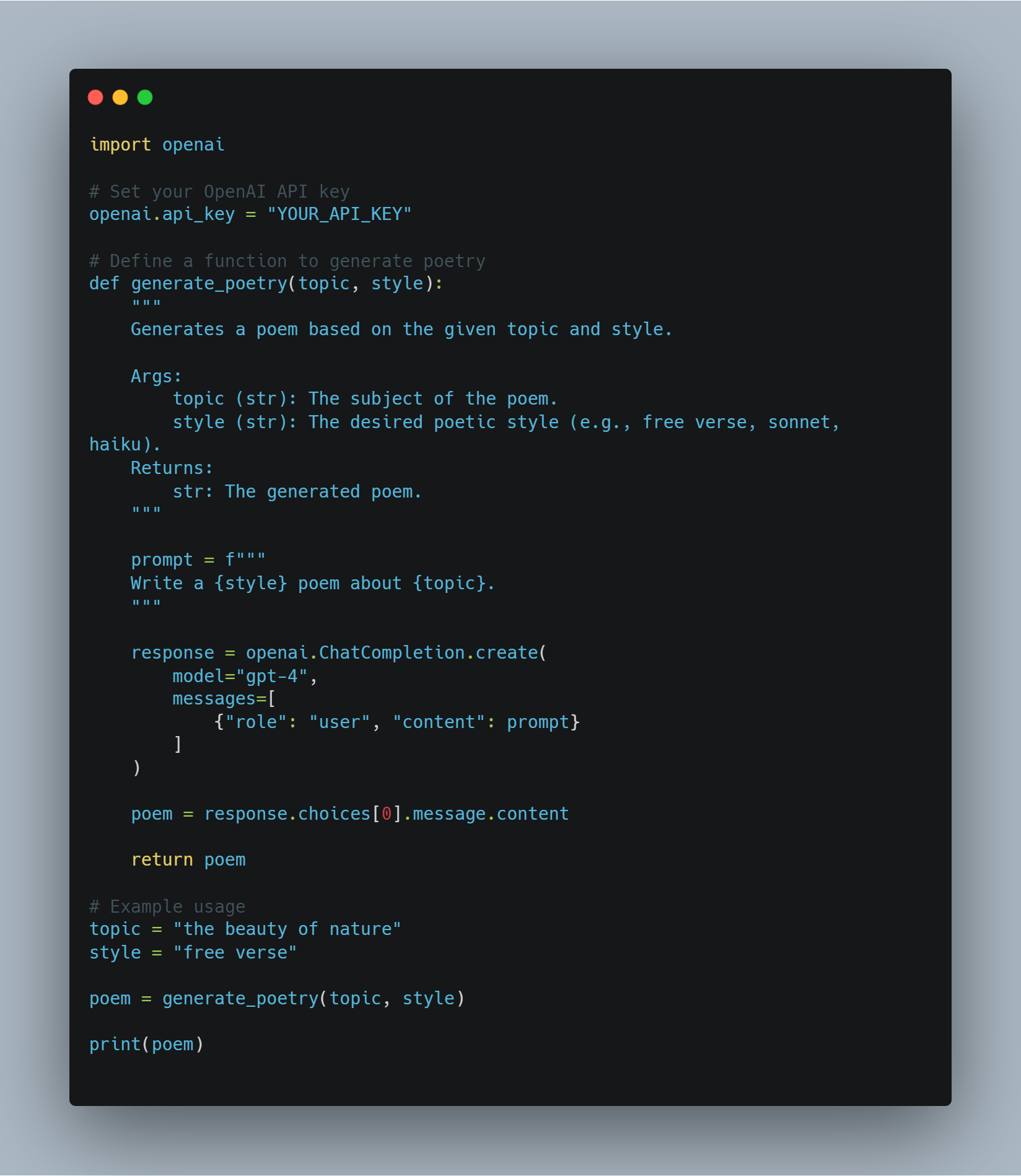
Lass uns sehen, was hier abläuft:
-
Import OpenAI Bibliothek: Zuerst importiert der Code die
openaiBibliothek, um auf die OpenAI API zuzugreifen. -
Setzen Sie API-Schlüssel: Ersetzen Sie
"YOUR_API_KEY"mit Ihrem tatsächlichen OpenAI API-Schlüssel. -
Definieren Sie die Funktion
generate_poetry: Diese Funktion nimmt dietopicdes Gedichts und denstyleals Eingaben und verwendet die ChatCompletion API von OpenAI, um das Gedicht zu generieren. -
Bauen Sie den Auftrag auf: Der Auftrag kombiniert die
topicundstylein eine klare Anweisung für GPT-4. -
Leiten Sie den Auftrag an GPT-4 weiter: Der Code verwendet
openai.ChatCompletion.create, um den Auftrag an GPT-4 weiterzuleiten und die generierte Poesie als Reaktion zu erhalten. -
Geben Sie das Gedicht zurück: Das generierte Gedicht wird dann aus der Reaktion extrahiert und durch die Funktion zurückgegeben.
-
Beispiel Verwendung: Der Code zeigt, wie die Funktion
generate_poetrymit einem bestimmten Thema und Stil aufgerufen wird. Das resultierende Gedicht wird dann auf der Konsole ausgegeben.
Von KI gesteuerte virtuelle Welten
Die Entwicklung von KI-gesteuerten virtuellen Welten stellt einen bedeutenden Fortschritt in immersiven Erfahrungen dar, in denen KI-Agenten virtuelle Umgebungen erstellen, verwalten und weiterentwickeln können, die interaktiv sind und auf Benutzereingaben reagieren.
Diese virtuellen Welten, die von KI angetrieben werden, können komplexe Ökosysteme, soziale Interaktionen und dynamische Erzählungen simulieren und den Benutzern ein tiefgreifendes und personalisiertes Erlebnis bieten.
Zum Beispiel können in der Gaming-Branche KI-gesteuerte virtuelle Welten verwendet werden, um nicht-spielbare Charaktere (NPCs) zu erstellen, die aus dem Verhalten der Spieler lernen und ihre Aktionen und Strategien anpassen, um ein herausfordernderes und realistischeres Erlebnis zu bieten.
Jenseits des Gamings haben KI-gesteuerte virtuelle Welten potenzielle Anwendungen in der Bildung, wo virtuelle Klassenzimmer an die Lernstile und den Fortschritt einzelner Schüler angepasst werden können, oder in der Unternehmensschulung, wo realistische Simulationen Mitarbeiter auf verschiedene Szenarien vorbereiten können.
Die Zukunft dieser virtuellen Umgebungen hängt von Fortschritten in der Fähigkeit von KI ab, umfangreiche, komplexe digitale Ökosysteme in Echtzeit zu generieren und zu verwalten, sowie von ethischen Überlegungen hinsichtlich Benutzerdaten und den psychologischen Auswirkungen hoch immersiver Erfahrungen.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# Agenten initialisieren
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# Zufällige Position innerhalb des Umfeldes zuweisen
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# Agent erzeugen und hinzufügen
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# Agenten bewegen (vereinfachte Bewegung für die Demonstration)
for agent in self.agents:
agent.move(self.environment)
# TODO: Komplexere Logik für Interaktionen, Umweltänderungen usw. implementieren
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# Bewegungsrichtung bestimmen (zufällig für dieses Beispiel)
direction = random.choice(['N', 'S', 'E', 'W'])
# Bewegung basierend auf Richtung anwenden
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# Das Umfeld aktualisieren, um die neue Position des Agenten zu widerspiegeln
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# Beispielhafte Verwendung
if __name__ == "__main__":
# Weltparameter definieren
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# Die virtuelle Welt erzeugen
world = VirtualWorld(environment_size, agent_types, agent_properties)
# Die Welt für mehrere Schritte simulieren
for _ in range(10):
world.update()
world.display()
print() # Ein leeres Zeile hinzufügen, um bessere Lesbarkeit zu gewährleisten
Hier ist was passiert, wenn man diesen Code liest:
-
VirtualWorld Klasse:
-
Definiert den Kern der virtuellen Welt.
-
Enthält das Umgebungsgitter, eine Liste von Agenten und agentenbezogene Informationen.
-
__init__(): Initialisiert die Welt mit Größe, Agententypen und Eigenschaften. -
add_agent(): Fügt einen neuen Agenten eines bestimmten Typs in die Welt ein. -
update(): Führt ein einzelnes Zeitschritt-Update der Welt durch.- Es bewegt derzeit nur Agenten, aber Sie können komplexe Logik für Agenteninteraktionen, Umweltveränderungen usw. hinzufügen.
-
display(): Gibt eine grundlegende Darstellung der Umgebung aus.
-
-
Agentenklasse:
-
Repräsentiert einen einzelnen Agenten innerhalb der Welt.
-
__init__(): Initialisiert den Agenten mit seinem Typ, Position und Eigenschaften. -
move(): Behandelt die Agentenbewegung und aktualisiert seine Position innerhalb der Umgebung. Diese Methode bietet derzeit ein einfaches zufälliges Movement, kann jedoch erweitert werden, um komplexe KI-Verhaltensmuster zu umfassen.
-
-
Beispielverwendung:
-
Einstellung der Weltparameter wie Größe, Agententypen und ihre Eigenschaften.
-
Erstellung eines VirtualWorld-Objekts.
-
Ausführen der
update()Methode mehrmals, um die Entwicklung der Welt zu simulieren. -
Aufruf der
display()Methode nach jeder Aktualisierung, um die Änderungen zu visualisieren.
-
Erweiterungen:
-
Complexe Agenten-AI: Implementieren eines komplexeren AI für das Verhalten der Agenten. Sie können verwenden:
-
Pfadfindungsalgorithmen: Helfen Agenten, das Umfeld effizient zu navigieren.
-
Entscheidungsbäume/Maschinelles Lernen: ermöglichen Agenten, intelligentere Entscheidungen basierend auf ihrer Umgebung und Zielen zu treffen.
-
Reinforcement Learning: Lassen Agenten lernen und ihr Verhalten mit der Zeit anpassen.
-
-
Umgebungsnutzung: Hinzufügen von dynamischen Elementen zur Umgebung, wie Hindernisse, Ressourcen oder Punkte von Interesse.
-
Agent-zu-Agent-Interaktion: Implementieren von Interaktionen zwischen Agenten, wie Kommunikation, Kampf oder Zusammenarbeit.
-
Visuelle Darstellung: Nutzen Sie Bibliotheken wie Pygame oder Tkinter, um eine visuelle Darstellung der virtuellen Welt zu erstellen.
Dieses Beispiel stellt eine grundlegende Grundlage für die Erstellung eines von AI getriebenen virtuellen Welts dar. Der Grad der Komplexität und der Finesse kann weiterentwickelt werden, um Ihren spezifischen Bedürfnissen und kreativen Zielen zu entsprechen.
Neuromorphe Rechnen und AI
Neuromorphe Rechnen, inspiriert durch die Struktur und Funktionsweise des menschlichen Gehirns, ist eine Revolutionierung der AI, die neue Möglichkeiten zur effizienten und parallel verarbeiteten Information bietet.
Im Gegensatz zu traditionellen Rechnungsarchitekturen sind neuromorphe Systeme so konzipiert, dass sie die neuronale Netzwerke des Gehirns nachahmen, was AI dazu befähigt, Aufgaben wie Mustererkennung, sensorische Verarbeitung und Entscheidungsprozesse mit größerer Geschwindigkeit und Energieeffizienz durchzuführen.
Diese Technologie verspricht ungeheuerliche Möglichkeiten für die Entwicklung von AI-Systemen, die anpassbarer sind, in der Lage sind, aus minimalen Daten zu lernen und in Echtzeitumgebungen effektiv arbeiten.
Beispielsweise könnten neuromorphe Chips in der Robotik dazu beitragen, Robotern eine Verarbeitung von sensorischen Eingaben und Entscheidungen zu ermöglichen, die mit den aktuellen Architekturen nicht mithalten können.
Der Herausforderung für die Zukunft wird es sein, neuromorphe Rechnen auf die Komplexität von großskaligen AI-Anwendungen zu skalieren, es mit bestehenden AI-Frameworks zu integrieren, um seine Vielschichtigkeit voll auszuschöpfen.
AI-Agenten in der Raumforschung
Künstliche Intelligenz-Agenten spielen eine immer wichtigere Rolle in der Raumforschung, wo sie mit der Navigation in schwierigen Umgebungen, der zeitgerechten Entscheidungsfindung und der autonomen Durchführung wissenschaftlicher Experimente beauftragt sind.
Mit der Notwendigkeit, weiter in den Weltraum zu gehen, steigt die Pressedur auf AI-Systeme, die unabhängig von der Erde agieren können. Zukünftige AI-Agenten werden so konzipiert werden, dass sie die Unprädiktabilität des Weltraums bewältigen können, wie z.B. unerwartete Hindernisse, Änderungen in den Missionen Parametern oder die Notwendigkeit der Selbstreparatur.
Beispielsweise könnte AI verwendet werden, um auf dem Mars Rover autonom zu navigieren, wissenschaftlich wertvolle Stellen zu erkennen und sogar mit minimaler Unterstützung der Mission Control Proben zu bohren. Diese AI-Agenten könnten auch lebenserhaltende Systeme auf langfristigen Missionen verwalten, die Energie Nutzung optimieren und auf die psychologischen Bedürfnisse der Astronauten reagieren, indem sie Begleitung und geistige Anregung bieten.
Die Integration von AI in die Raumforschung verbessert nicht nur die Missionen Fähigkeiten, sondern eröffnet auch neue Möglichkeiten für die menschliche Erforschung des Kosmos, wo AI ein unverzichtbares Partner in dem Streben nach dem Verständnis unseres Universums ist.
Kapitel 8: AI-Agenten in kritischen Fachbereichen
Gesundheitswesen
Im Gesundheitswesen sind AI-Agenten nicht nur in unterstützender Rolle, sondern werden integral zum gesamten Patientenpflegekontinuum. Ihr Effekt ist am deutlichsten in der Telemedizin zu erkennen, wo AI-Systeme das Verfahren der entfernten medizinischen Versorgung neu definiert haben.
Durch die Verwendung fortschrittlicher natürlicher Sprachverarbeitung (NLP) und maschinellen Lernalgorithmen können diese Systeme komplizierte Aufgaben wie Symptomtriage und vorläufige Datenerfassung mit hoher Genauigkeit durchführen. Sie analysieren Patientenberichtete Symptome und medizinische Geschichte in Echtzeit und verknüpfen diese Informationen mit umfangreichen medizinischen Datenbanken, um potenzielle Verhältnisse oder Warnzeichen zu erkennen.
Dadurch können ärztliche Dienstleister schneller informierte Entscheidungen treffen, wodurch die Behandlungszeit verkürzt wird und eventuell Leben gerettet werden. Auch AI-gesteuerte diagnostische Tools in der medizinischen Bildgebung verändern die Radiologie, indem sie Muster und Abweichungen in Röntgenbildern, MRIs und CT-Scans erkennen, die für das menschliche Auge nicht erkennbar sein können.
Diese Systeme werden auf Datenmengen aus Millionen von annotierten Bildern trainiert, was ihnen nicht nur die Replikation, sondern oft auch die Überschreitung menschlicher diagnostischer Fähigkeiten ermöglicht.
Die Integration von AI in das Gesundheitswesen erstreckt sich auch auf administrative Aufgaben, wo die Automatisierung von Terminplanung, Medikationserinnerungen und Patientenverfolgungen den operationellen Lasten auf den Gesundheitsdienstleistungen erheblich reduziert und ihnen so die Möglichkeit gibt, sich auf wichtigere Aspekte der Patientenbetreuung zu konzentrieren.
Finanzen
Im Finanzsektor haben AI-Agenten die Operationsweise durch die Einführung von bisher unbekannten Einsparpotentialen und Präzision revolutioniert.
Algorithmic Trading, das stark auf AI angewiesen ist, hat den Weg der Transaktionen in den Finanzmärkten verändert.
Diese Systeme sind in der Lage, umfangreiche Datenmengen innerhalb von Millisekunden zu analysieren, Markt Trends zu erkennen und Handelsgeschäfte in der optimalen Momentum auszuführen, um Gewinne zu maximieren und Risiken zu minimieren. Sie nutzen komplexe Algorithmen, die maschinelles Lernen, Deep Learning und Verstärkendes Lernen beinhalten, um sich auf die wechselnden Marktbedingungen anzupassen und Split-Second-Entscheidungen zu treffen, die menschliche Händler niemals erreichen könnten.
Jenseits der Handel, spielt AI eine Schlüsselrolle in der Risikomanagement indem credit risks und Betrugsaktivitäten mit bemerkenswerter Genauigkeit bewertet werden. AI-Modelle verwenden prädiktives Analytics, um die Wahrscheinlichkeit eines Zahlungsrückstands eines Kreditnehmers zu beurteilen, indem Muster in Kredithistorien, Transaktionsverhaltens und anderen relevanten Faktoren analysiert werden.
Außerdem, im Bereich der regulatorischen Compliance, automatisiert AI die Überwachung von Transaktionen, um ungewöhnliche Aktivitäten zu erkennen und zu melden, sicherstellend, dass Finanzinstitutionen strengen regulatorischen Anforderungen gerecht werden. Diese Automatisierung mindert nicht nur das Risiko von menschlichem Fehler, sondern streamliert auch Compliance-Prozesse, die Kosten senken und Effizienz verbessern.
Notfallverwaltung
AI Rolle in der Notfallverwaltung ist transformatorisch, es verändert grundlegend, wie Krisen vorhergesagt, verwaltet und abgemildert werden.
Bei der Katastrophenreaktion, verarbeiten AI-Agenten umfangreiche Datenmengen aus mehreren Quellen – von Satellitennachrichten bis zu Social Media-Feeds – um eine umfassende Übersicht der Lage in Echtzeit bereitzustellen. Maschinelles Lernen-Algorithmen analysieren diese Daten, um Muster zu erkennen und die Fortgangsverläufe von Ereignissen vorherzusagen, was Notfallreaktionären ermöglicht, Ressourcen effizienter zu verwalten und unter Druck Informationsentscheidungen treffen.
Beispielsweise können AI-Systeme während eines Naturkatastrophes wie einem Hurrikan den Sturmverlauf und seine Intensität vorhersagen, was Behörden dazu bringt, rechtzeitig Evakuierungsanordnungen zu erlassen und Ressourcen in die am stärksten gefährdeten Gebiete zu verlegen.
In der vorhersagenden Analyse nutzen AI-Modelle die historischen Daten zusammen mit Echtzeitdaten auf, um potenzielle Notfälle vorherzusagen, was zu proaktiven Maßnahmen führt, die Katastrophen vermeiden oder ihre Auswirkungen vermindern können.
AI-gesteuerte öffentliche Kommunikationssysteme spielen auch eine entscheidende Rolle, indem sichergestellt wird, dass genaue und zeitnahe Informationen an die betroffene Bevölkerung gelangen. Diese Systeme können Notfallsignale auf verschiedenen Plattformen generieren und verbreiten und die Nachrichten auf verschiedene Demografien zugeschnitten aufstellen, um Verständnis und Einhaltung zu gewährleisten.
Und AI verstärkt die Abwehrbereitschaft der Notfallreaktionskräfte durch die Erstellung realistischer Trainingssimulationen mit generativen Modellen. Diese Simulationen replizieren die Komplexitäten von realen Weltkatastrophen, was Reaktionskräften das Schärfen ihrer Fähigkeiten und die Verbesserung ihrer Abwehrbereitschaft für echte Ereignisse ermöglicht.
Verkehr
AI-Systeme sind in der Verkehrsbranche immer mehr unverzichtbar, wo sie die Sicherheit, die Effizienz und die Zuverlässigkeit in verschiedenen Bereichen verbessern, einschließlich der Luftverkehrskontrolle, autonomer Fahrzeuge und öffentlicher Verkehr.
Bei der Luftverkehrskontrolle sind AI-Agenten wichtig für die Optimierung von Flugpfaden, die vorhergesagte potentiellen Konflikte und die Verwaltung der Flugplatzoperationen. Diese Systeme verwenden vorhersagende Analyse, um potenzielle Engpässe im Luftverkehr vorherzusagen und Flüge in Echtzeit neu zu kürzen, um Sicherheit und Effizienz zu gewährleisten.
Im Bereich der autonomen Fahrzeuge agiert AI als Kern, um Fahrzeuge dazu zu bringen, Sensordaten zu verarbeiten und in komplexen Umgebungen Split-Second-Entscheidungen zu treffen. Diese Systeme verwenden Deep Learning-Modelle, die auf umfangreichen Datensets trainiert wurden, um visuelle, auditive und räumliche Daten zu interpretieren, was eine sichere Navigation durch dynamische und unvorhersehbare Bedingungen ermöglicht.
Öffentliche Verkehrsmittel profitieren ebenfalls von AI durch optimierte Routenplanung, prädiktive Wartung von Fahrzeugen und Management des Fahrgastflusses. Indem historische und zeitgenössische Daten analysiert werden, können AI-Systeme Transitchronogramme anpassen, Fahrzeugausfälle vorhersagen und vermeiden sowie den Fahrgastfluss während der Rush Hours steuern, was die insgesamt Effizienz und Verlässlichkeit der Verkehrsnetze verbessert.
Energiebranche
AI spielt eine entscheidende Rolle in der Energiebranche, insbesondere in der Netzleitung, der Optimierung erneuerbarer Energie und im Fehlererkennung.
Bei der Netzleitung überwachen AI-Agenten die Stromnetze durch Analyse von Echtzeitdaten von Sensoren, die über das Netz verteilt sind. Diese Systeme verwenden vorherige Analytik, um die Energieverteilung zu optimieren, sicherstellend, dass die Versorgung dem Bedarf entspricht und die Energieweitergabe minimiert wird. AI-Modelle prognostizieren auch potenzielle Fehler im Netz, was die Möglichkeit für vorhersehbare Wartungen und die Reduktion des Ausfallrisikos bietet.
Im Bereich der erneuerbaren Energie werden AI-Systeme zur Vorhersage von Wetterphasen verwendet, was für die Optimierung der Produktion von Solarenergie und Windenergie entscheidend ist. Diese Modelle analysieren meteorologische Daten, um die Intensität des Sonnenlichts und die Windgeschwindigkeit vorherzusagen, was zu genaueren Prognosen der Energieproduktion und einer besseren Integration erneuerbarer Quellen in das Netz führt.
Fehlererkennung ist ein weiterer Bereich, in dem AI signifikante Beiträge leistet. AI-Systeme analysieren Sensordaten von Geräten wie Transformatoren, Turbinen und Generatoren, um Zeichen von Verschleiß und potenziellen Störungen zu erkennen, bevor sie zu einem Ausfall führen. Dieser prädiktive Instandhaltungsansatz verlängert nicht nur die Lebensdauer von Geräten, sondern gewährleistet auch eine kontinuierliche und zuverlässige Energieversorgung.
Cybersecurity
Im Bereich der Cybersicherheit sind AI-Agenten unerlässlich für die Integrität und Sicherheit der digitalen Infrastrukturen. Diese Systeme sind dafür konzipiert, Netzwerkverkehr kontinuierlich zu überwachen, und nutzen maschinelles Lernen, um Abweichungen zu erkennen, die einen Sicherheitsbruch aufzeigen könnten.
Durch die Analyse von Datenmengen in Echtzeit können AI-Agenten Muster von böswilligem Verhalten erkennen, wie unübliche Anmeldeversuche, Datenexfiltration oder die Präsenz von Malware. Sobald ein potenzieller Bedrohungspotential erkannt wird, können AI-Systeme automatisch Gegenmaßnahmen einleiten, wie die Isolierung kompromittierter Systeme und das Deployment von Patches, um weiteren Schaden zu vermeiden.
Eine weitere kritische Anwendung von AI in der Cybersicherheit ist die vulnerabilitätsbasierte Bewertung. AI-gesteuerte Tools analysieren Code und Systemkonfigurationen, um potenzielle Sicherheitsschwachstellen zu erkennen, bevor sie von Angreifern ausgenutzt werden können. Diese Tools verwenden statische und dynamische Analyseverfahren, um die Sicherheitslage von Software- und Hardwarekomponenten zu bewerten und Security-Teams handhabbare Erkenntnisse bereitzustellen.
Die Automatisierung dieser Prozesse verbessert nicht nur die Geschwindigkeit und Genauigkeit der Bedrohungsdetektion und Reaktion, sondern reduziert auch die Arbeitslast auf den Menschen Analysten, die dadurch in der Lage sind, sich auf komplexere Sicherheits Herausforderungen zu konzentrieren.
Produktion
In der Produktion führt AI zu bedeutenden Fortschritten in Qualitätskontrolle, vorheriger Wartung und Supply-Chain-Optimierung. AI-gesteuerte Computervision-Systeme sind in der Lage, Produkte auf Mängel zu untersuchen, mit einer Geschwindigkeit und Präzision, die weit über die menschlichen Fähigkeiten hinausgeht. Diese Systeme verwenden Deep-Learning-Algorithmen, die mit tausenden von Bildern trainiert wurden, um selbst die kleinsten Imperfektionen in Produkten zu erkennen, und gewährleisten somit eine konsistente Qualität in hochvolumigen Produktionsumgebungen.
Ein weiterer Bereich, in dem AI einen tiefgreifenden Einfluss hat, ist die vorherige Wartung. Durch Analyse der Daten von Sensoren, die in Maschinerie eingebettet sind, können AI-Modelle vorhersagen, wann Gerät wahrscheinlich versagen wird, was die Wartung vor einem Ausfall ermöglicht. Dieser Ansatz reduziert nicht nur die Downloadzeiten, sondern verlängert auch die Lebensdauer der Maschinerie, was zu signifikanten Kosteneinsparungen führt.
In der Supply-Chain-Verwaltung optimieren AI-Agenten das Lagerbestand und die Logistik, indem sie Daten aus der gesamten Supply Chain analysieren, einschließlich von Bedarfsschätzungen, Produktionsplänen und Transportrouten. Durch die Verwendung von Echtzeitanpassungen an Lager- und Logistikplänen gewährleisten AI, dass Produktionsprozesse flüssig ablaufen, Verzögerungen minimieren und Kosten reduzieren.
Diese Anwendungen zeigen die Schlüsselrolle von AI bei der Verbesserung der operativen Effizienz und Verlässlichkeit in der Produktion, making it an indispensable tool for companies looking to stay competitive in a rapidly evolving industry.
Schlussfolgerung
Die Integration von künstlichen Intelligenz-Agenten mit großen Sprachmodellen (LLM) markiert einen bedeutenden Meilenstein in der Entwicklung von künstlicher Intelligenz, die bisher ungeahnten Fähigkeiten in verschiedenen Branchen und wissenschaftlichen Bereichen freisetzt. Diese Synergie verbessert die Funktionalität, Anpassbarkeit und Anwendbarkeit von AI-Systemen, indem sie die grundlegenden begrenzten Eigenschaften von LLM überwindet und dynamischere, context-aware und selbständige Entscheidungsprozesse ermöglicht.
Von der Revolutionierung des Gesundheits- und Finanzwesens bis hin zur Transformation der Verkehrs- und Katastrophenverwaltung sind AI-Agenten eine innovationstechnische und effiziente Driveline, die den Weg für eine Zukunft ebnen, in der AI-Technologien tiefgreifend in unserem täglichen Leben integriert sind.
Während wir die Potentiale von AI-Agenten und LLM weiter erforschen, ist es wichtig, ihre Entwicklung auf ethischen Prinzipien zu gründen, die die menschliche Wohlbefinden, Fairness und Inklusivität priorisieren. Indem wir sicherstellen, dass diese Technologien verantwortungsvoll entwickelt und eingesetzt werden, können wir ihre vollen Potentiale nutzen, um das Leben zu verbessern, die soziale Gerechtigkeit zu fördern und globale Herausforderungen zu lösen.
Die Zukunft von AI liegt in der flüssigen Integration fortschrittlicher AI-Agenten mit komplexen LLM, um intelligente Systeme zu schaffen, die nicht nur die menschlichen Fähigkeiten verstärken, sondern auch die Werte erhalten, die unsere Menschlichkeit definieren.
Die Konvergenz von AI-Agenten und LLM bedeutet eine neue Paradigma in der künstlichen Intelligenz, wo die Zusammenarbeit zwischen agilen und kraftvollen Fähigkeiten eine Welt von unbegrenzten Möglichkeiten erschließt. Indem wir diese Synergie nutzen, können wir Innovationen anstoßen, wissenschaftliche Entdeckungen vorantreiben und eine gerechtere und reichhaltigere Zukunft für alle ermöglichen.
Über den Autor
Hallo, ich bin Vahe Aslanyan und befinde mich am Schnittpunkt von Informatik, Datenwissenschaft und KI. Besuchen Sie vaheaslanyan.com, um ein Portfolio zu sehen, das auf Präzision und Fortschritt testifiziert. Meine Erfahrung verbindet den Bereich der Full-Stack-Entwicklung und der Optimierung von KI-Produkten, getrieben von der Lösung von Problemen in neuen Wegen.
Mit einer Liste von Leistungen, die ein führendes Datenwissenschafts-Bootcamp ins Leben gerufen und mit der Arbeit mit den führenden Fachleuten beinhaltet, bleibe ich auf die Elevierung der Technologiedidaktik zu universellen Standards konzentriert.
Wie können Sie tiefer gehen?
Nach dem Studium dieses Leitfadens, wenn Sie es bereuen, noch tiefer zu gehen und systematisches Lernen Ihre Art ist, erwägen Sie, sich uns bei LunarTech anzuschließen. Wir bieten individuelle Kurse und Bootcamps in Datenwissenschaft, Maschinenlernen und KI an.
Wir stellen Ihnen ein umfassendes Programm bereit, das einen tiefgreifenden theoretischen Unterricht, praktische Anwendungen, umfangreiches Praktikum und eine an Ihre Phase angepasste Vorbereitung auf die Bewerbung bietet, um Ihren Erfolg sicherzustellen.
Du kannst unser Ultimate Data Science Bootcamp anschauen und eine kostenlose Testphase beitreten, um das Material ausprobieren zu können. Dies hat die Anerkennung erhalten, einer der Besten Data Science Bootcamps des Jahres 2023 zu sein, und er wurde in renommierten Veröffentlichungen wie dem Forbes, dem Yahoo, dem Entrepreneur und weiteren veröffentlicht. Hier hast du die Gelegenheit, Teil einer Community zu werden, die auf Innovation und Wissen thrive. Hier ist die Willkommensnachricht!
Melde dich mit mir

Folge mir auf LinkedIn für eine Menge kostenloser Ressourcen in CS, ML und AI
-
Besuchen Sie meine persönliche Webseite
-
Abonnieren Sie mein Newsletter zu Datenwissenschaft und KI
Wenn Sie mehr über eine Karriere in der Datenwissenschaft, Machine Learning und KI erfahren möchten und lernen, wie Sie ein Datenwissenschaftler-Job sichern können, können Sie dieses kostenlose Handbuch zur Datenwissenschaft und KI-Karriere herunterladen.
Source:
https://www.freecodecamp.org/news/how-ai-agents-can-supercharge-language-models-handbook/