













Примечание редактора: Следующая статья написана для и опубликована в отчете DZone о трендах 2024 года, Наблюдаемость и производительность: Крайостроение высокопроизводительных систем программного обеспечения.
«Качество — это не действие, а привычка», — сказал Аристотель, принцип, который также актуален и в мире программного обеспечения. В частности для разработчиков это означает, что обеспечение удовлетворенности пользователей — это не разовая задача, а постоянное обязательство. Для выполнения этого обязательства инженерные команды должны иметь цели по надежности, которые четко определяют базовый уровень производительности, которого пользователи могут ожидать. Именно здесь на сцену выходят целевые показатели уровня обслуживания (SLO).
Простыми словами, SLO — это цели по надежности, которых продукты должны достигать для того, чтобы пользователи оставались довольными. Они служат количественным мостом между абстрактными целями по качеству и повседневными операционными решениями, которые должны принимать команды DevOps. В силу этой важности критически важно эффективно определить их для вашего сервиса. В этой статье мы рассмотрим пошаговый подход к определению SLO на примере, а также некоторые вызовы, связанные с SLO.
Этапы определения целевых показателей уровня обслуживания
Как и любой другой процесс, определение SLO может показаться сначала подавляющим, но следуя нескольким простым шагам, вы можете создать эффективные цели. Важно помнить, что SLO не являются метриками “установил и забыл”. Вместо этого они являются частью итеративного процесса, который развивается по мере того, как вы получаете больше информации о вашей системе. Поэтому даже если ваши начальные SLO не идеальны, это нормально — их можно и нужно уточнять со временем.
Рисунок 1. Шаги для определения SLO
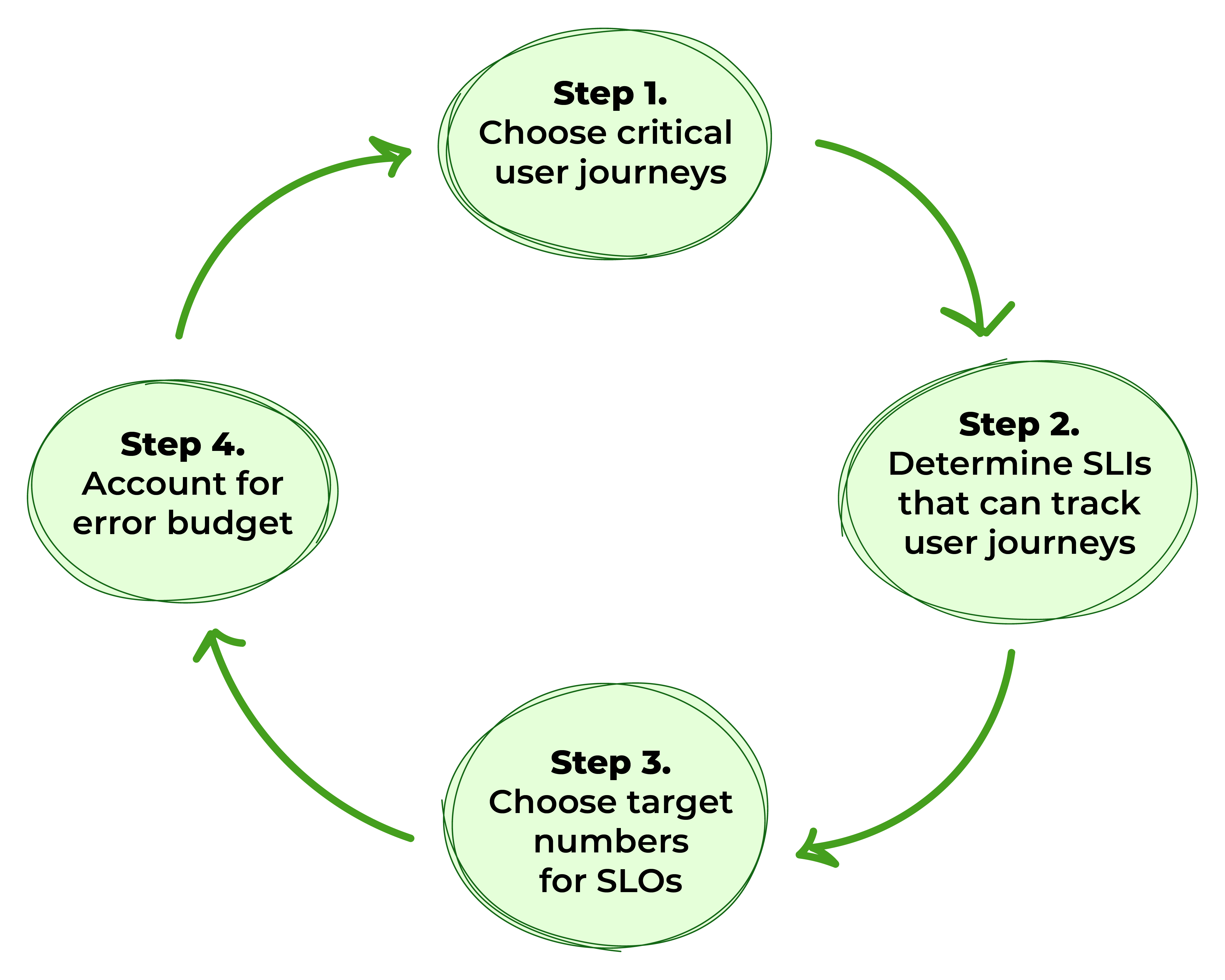
Шаг 1: Выберите критические пользовательские маршруты
Критический пользовательский маршрут относится к последовательности взаимодействий, которые пользователь выполняет для достижения конкретной цели в системе или услуге. Обеспечение надежности этих маршрутов важно, потому что это напрямую влияет на опыт клиента. Некоторые способы идентификации критических пользовательских маршрутов могут включать оценку влияния на доход/бизнес при сбое определенного рабочего процесса и выявление частых маршрутов через аналитику пользователей.
Например, рассмотрим услугу, которая создает виртуальные машины (ВМ). Некоторые действия, которые пользователи могут выполнять в этой услуге, включают просмотр доступных форм ВМ, выбор региона для создания ВМ и запуск ВМ. Если бы разработчики расположили их по степени влияния на бизнес, рейтинг был бы следующим:
- Запуск ВМ,因为这直接影响 доход. Если пользователи не могут запустить ВМ, то основная функциональность услуги fails, что напрямую влияет на удовлетворенность клиентов и доход.
- Выбор региона для создания ВМ. Хотя пользователи все еще могут создать ВМ в другом регионе, это может привести к ухудшению опыта, если у них есть региональные предпочтения. Этот выбор может повлиять на производительность и соответствие требованиям.
- Просмотр каталога ВМ. Хотя это важно для принятия решений, это имеет меньшее прямое влияние на бизнес, потому что пользователи могут изменить конфигурацию ВМ позже.
Шаг 2: Определите показатели уровня обслуживания, которые могут отслеживать пользовательские маршруты
Теперь, когда пользовательские маршруты определены, следующим шагом является их эффективное измерение. Показатели уровня обслуживания (SLI) — это метрики, которые разработчики используют для количественной оценки производительности и надежности системы. Для инженерных команд SLI выполняют двойную функцию: они предоставляютactable данные для обнаружения ухудшений, направляют архитектурные решения и подтверждают изменения инфраструктуры. Они также формируют основу для значимых SLO, предоставляя количественные измерения, необходимые для установки и отслеживания целей надежности.
Например, при запуске ВМ некоторые из SLI могут быть доступность и задержка.
Доступность: Из X запросов на запуск ВМ, сколько из них удалось? Простая формула для расчета этого:
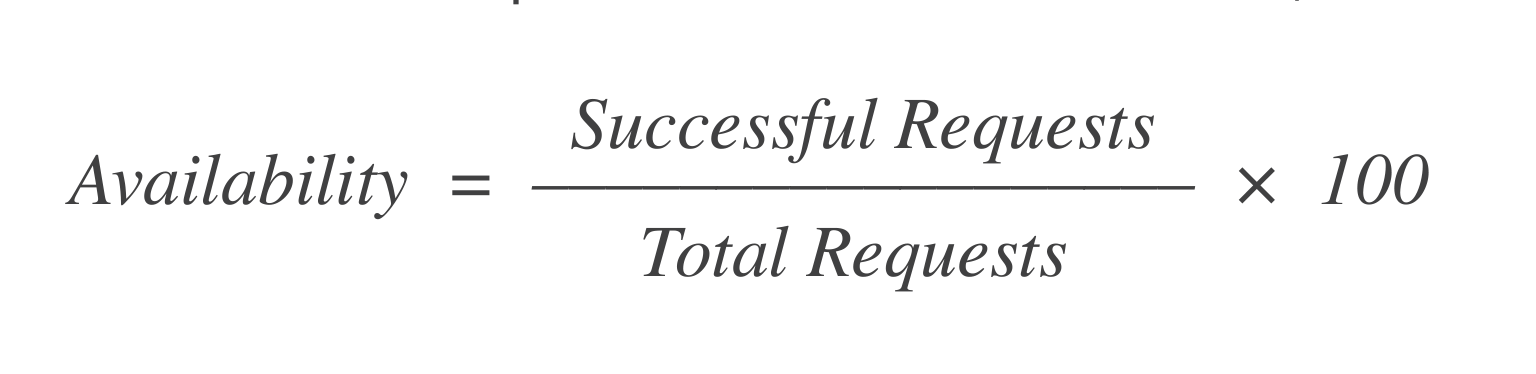
Если было 1 000 запросов и 998 из них удалось, то доступность составляет = 99,8%.
Задержка: Из общего числа запросов на запуск ВМ, сколько времени заняли 50-й, 95-й или 99-й процентиль запросов для запуска ВМ? Процентили здесь приведены только как примеры и могут варьироваться в зависимости от конкретного случая использования или ожиданий уровня обслуживания.
- В сценарии с 1 000 запросами, где 900 запросов были выполнены за 5 секунд, а оставшиеся 100 заняли 10 секунд, 95-й процентиль латентности будет равен 10 секундам.
- Хотя средние значения также могут использоваться для расчета латентности, обычно рекомендуется использовать процентиля, поскольку они учитывают хвостовые латентности, предоставляя более точное представление о пользовательском опыте.
Шаг 3: Определите целевые показатели для SLO
Простыми словами, SLO — это целевые показатели, которых мы хотим достичь нашими SLI в определенном временном окне. Для сценария с ВМ SLO могут быть такими:
- Доступность сервиса должна быть выше 99% в течение 30-дневного скользящего окна.
- 95-й процентиль латентности для запуска ВМ не должен превышать восьми секунд.
При установке этих целей следует учитывать следующие моменты:
-
Использование исторических данных.Если вам нужно установить SLO на основе 30-дневного скользящего периода, соберите данные из нескольких 30-дневных окон для определения целей.
- Если у вас нет таких исторических данных, начните с более достижимой цели, например, стремитесь к 99% доступности каждый день, и корректируйте ее со временем по мере накопления информации.
- Помните, что SLO не являются незыблемыми; они должны постоянно эволюционировать, отражая изменяющиеся потребности вашего сервиса и клиентов.
-
Учёт SLO зависимостей. Сервисы обычно полагаются на другие сервисы и компоненты инфраструктуры, такие как базы данных и балансировщики нагрузки.
-
Например, если ваш сервис зависит от SQL-базы данных с SLO доступности 99.9%, то SLO вашего сервиса не может превышать 99.9%. Это связано с тем, что максимальная доступность ограничена производительностью его базовых зависимостей, которые не могут обеспечить более высокую надёжность.
-
Вызовы SLO
Установить SLO на уровне 100% может быть заманчиво, но это невозможно. Например, 100% доступность означает, что нет места для важных действий, таких как выпуск функций, патчинг или тестирование, что нереально. Определение SLO требует сотрудничества между несколькими командами, включая инженерную, продуктовую, операционную, QA и руководство. Убедиться, что все заинтересованные стороны согласованы и согласны с целями, необходимо для того, чтобы SLO был успешным и выполнимым.
Шаг 4: Учет бюджета ошибок
Бюджет ошибок — это мера времени простоя, которую система может себе позволить без недовольства клиентов или нарушения контрактных обязательств. Вот один из способов его рассмотрения:
- Если бюджет ошибок почти исчерпан, инженерная команда должна сосредоточиться на улучшении надежности и снижении инцидентов, а не на выпуске новых функций.
- Если бюджет ошибок еще велик, инженерная команда может позволить себе приоритизировать выпуск новых функций, так как система работает в рамках своих показателей надежности.
Существует два общих подхода к измерению бюджета ошибок: основанный на времени и основанный на событиях. Давайте рассмотрим, как заявление “Доступность сервиса должна быть выше 99% в течение 30-дневного скользящего окна” применимо к каждому.
Измерение на основе времени
В рамках временного бюджета ошибок, вышеуказанное заявление переводится в то, что сервису разрешено быть недоступным в течение 43 минут и 50 секунд в месяц или 7 часов и 14 минут в год. Вот как это рассчитать:
-
Определите количество точек данных. Начните с определения количества временных единиц (точек данных) в окне SLO. Например, если базовая временная единица составляет 1 минуту, а окно SLO — 30 дней:
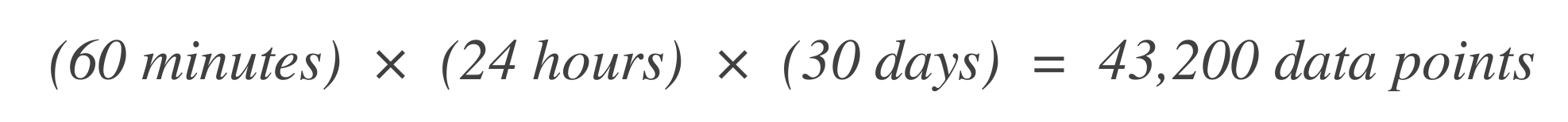
-
Рассчитайте бюджет ошибок. Далее рассчитайте, сколько точек данных могут “провалиться” (то есть время простоя). Бюджет ошибок — это процент допустимых сбоев.
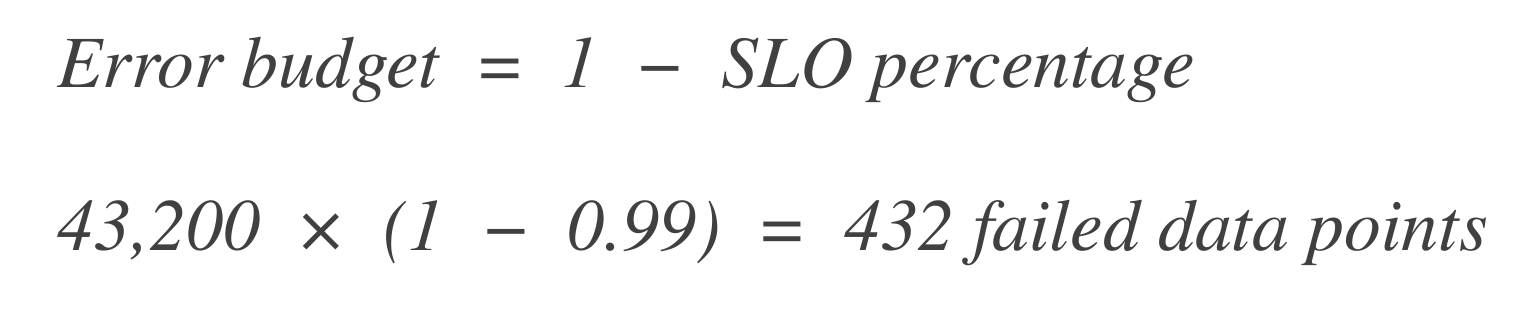
Переведите это в время:
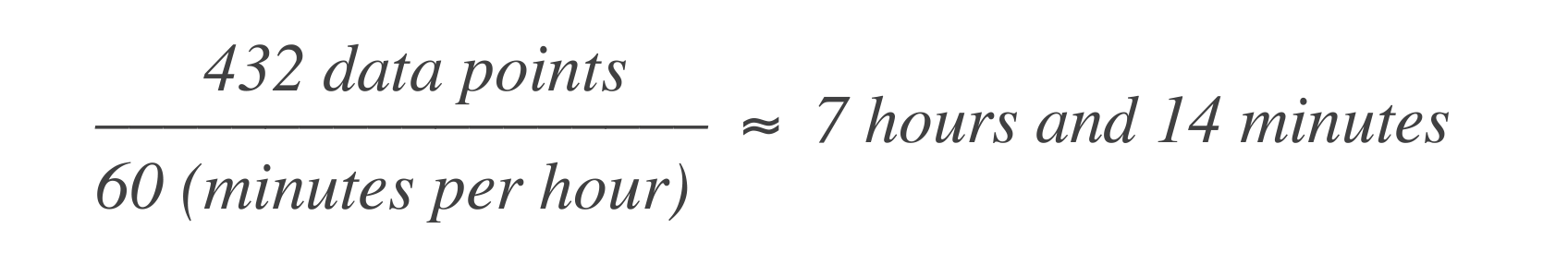
Это означает, что система может испытывать 7 часов и 14 минут простоя в 30-дневном окне.
И наконец, оставшийся бюджет ошибок — это разница между общим возможным временем простоя и уже использованным временем простоя.
Измерение на основе событий
Для измерения на основе событий бюджет ошибок измеряется в процентах. Упомянутое выше утверждение переводится в 1% бюджета ошибок в 30-дневном скользящем окне.
Предположим, что в этом 30-дневном окне есть 43 200 точек данных, и 100 из них являются плохими. Вы можете рассчитать, сколько бюджета ошибок было использовано, используя эту формулу:
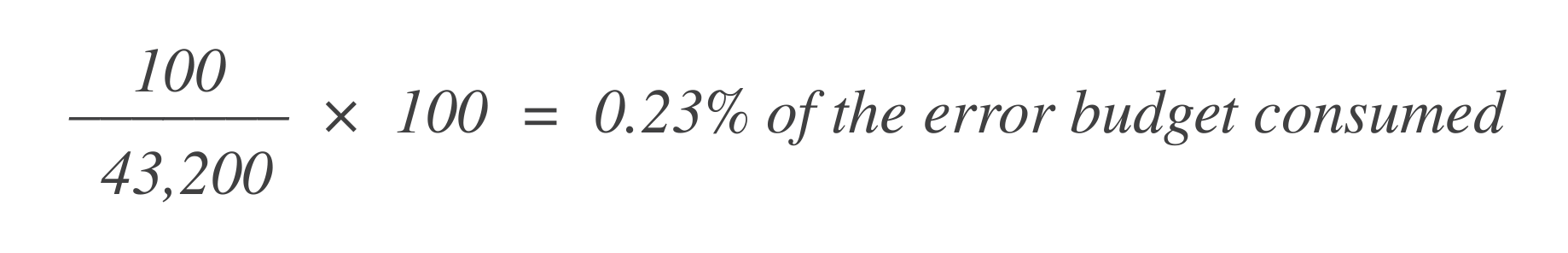
Теперь, чтобы узнать, сколько бюджета ошибок осталось, вычтите это из общего допустимого бюджета ошибок (1%):
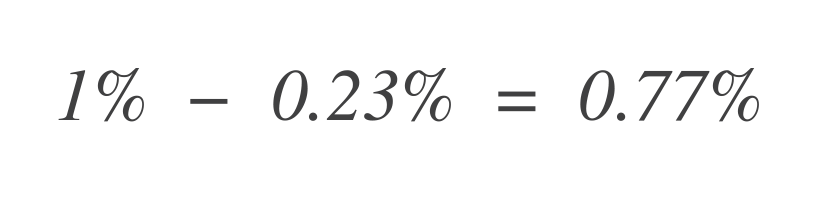
Таким образом, сервис все еще может терпеть 0,77% больше плохих данных.
Преимущества бюджета ошибок
Бюджеты ошибок могут использоваться для настройки автоматических мониторов и оповещений, которые уведомляют команды разработчиков о риске исчерпания бюджета. Эти оповещения позволяют им распознавать, когда требуется большая осторожность при внедрении изменений в производство. Команды часто сталкиваются с неопределенностью при приоритизации функций и операций. Бюджет ошибок может быть одним из способов решения этой проблемы, предоставляя четкие, основанные на данных метрики, позволяющие инженерным командам приоритизировать задачи по обеспечению надежности над новыми функциями. Бюджет ошибок является одной из хорошо зарекомендовавших себя стратегий для повышения ответственности и зрелости инженерных команд.
Предостережения при использовании бюджетов ошибок
Когда у разработчиков есть дополнительный бюджет, они должны активно его использовать. Это отличная возможность углубить понимание сервиса, экспериментируя с техниками, такими как хаос-инжиниринг. Инженерные команды могут наблюдать, как сервис реагирует и выявлять скрытые зависимости, которые могут не быть очевидны в обычных условиях. Важно также внимательно следить за исчерпанием бюджета ошибок, так как неожиданные инциденты могут быстро его истощить.
Заключение
Цели уровня обслуживания представляют собой путь, а не конечную точку в инженерии надежности. Хотя они предоставляют важные метрики для измерения надежности услуг, их истинная ценность заключается в создании культуры надежности в организациях. Вместо стремления к совершенству, команды должны воспринимать SLO как инструменты, которые эволюционируют вместе с их услугами. Взгляд в будущее показывает, что интеграция ИИ и машинного обучения обещает превратить SLO из реактивных измерений в прогностические инструменты, позволяя организациям предвидеть и предотвращать сбои до того, как они повлияют на пользователей.
Дополнительные ресурсы:
-
Внедрение целей уровня обслуживания, Алекс Идальго, 2020
-
“Объекты уровня обслуживания,” Крис Джонс и др., 2017
-
“Внедрение SLO,” Стивен Тургод и др., 2018
Это отрывок из отчета DZone о трендах 2024 года, Наблюдаемость и производительность: Крайостроение высокопроизводительных систем программного обеспечения.
Source:
https://dzone.com/articles/framework-for-service-level-objectives