













Note de l’éditeur : Ce qui suit est un article écrit pour et publié dans le Rapport sur les Tendances 2024 de DZone, Observabilité et Performance : Le Précipice de la Construction de Systèmes Logiciels Hautement Performants.
« La qualité n’est pas un acte, c’est une habitude », a dit Aristote, un principe qui résonne également dans le monde du logiciel. Plus spécifiquement pour les développeurs, cela signifie que la satisfaction de l’utilisateur n’est pas un effort ponctuel, mais un engagement continu. Pour honorer cet engagement, les équipes d’ingénierie doivent avoir des objectifs de fiabilité qui définissent clairement la performance de base que les utilisateurs peuvent attendre. C’est précisément à ce moment que les objectifs de niveau de service (SLO) entrent en jeu.
En termes simples, les SLO sont des objectifs de fiabilité que les produits doivent atteindre pour satisfaire les utilisateurs. Ils servent de pont quantifiable entre les objectifs de qualité abstraits et les décisions opérationnelles quotidiennes que les équipes DevOps doivent prendre. En raison de cette importance cruciale, il est essentiel de les définir efficacement pour votre service. Dans cet article, nous allons passer en revue une approche étape par étape pour définir les SLO avec un exemple, suivi de certains défis liés aux SLO.
Étapes pour Définir les Objectifs de Niveau de Service
Comme tout autre processus, définir des SLO peut sembler accablant au début, mais en suivant quelques étapes simples, vous pouvez créer des objectifs efficaces. Il est important de se rappeler que les SLO ne sont pas des métriques définies une fois pour toutes. Au lieu de cela, ils font partie d’un processus itératif qui évolue à mesure que vous obtenez un meilleur aperçu de votre système. Ainsi, même si vos SLO initiaux ne sont pas parfaits, c’est normal — ils peuvent et devraient être affinés au fil du temps.
Figure 1. Étapes pour définir des SLO
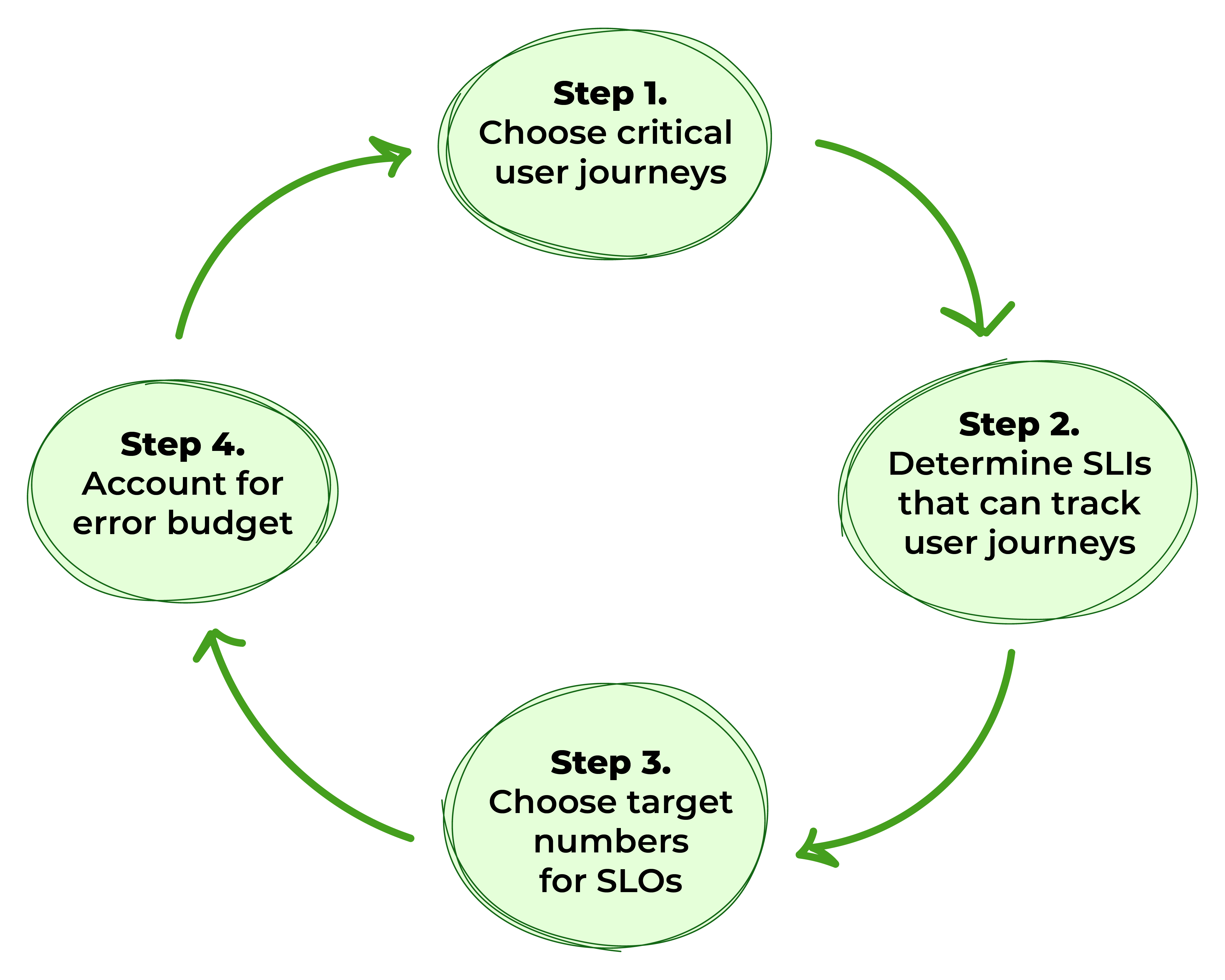
Étape 1 : Choisir les parcours utilisateur critiques
Un parcours utilisateur critique fait référence à la séquence d’interactions qu’un utilisateur entreprend pour atteindre un objectif spécifique au sein d’un système ou d’un service. Assurer la fiabilité de ces parcours est important car cela impacte directement l’expérience client. Certaines façons d’identifier les parcours utilisateur critiques peuvent être d’évaluer l’impact sur les revenus/activité lorsque un certain flux de travail échoue et d’identifier les flux fréquents grâce à l’analyse des utilisateurs.
Par exemple, considérez un service qui crée des machines virtuelles (VM). Certaines des actions que les utilisateurs peuvent effectuer sur ce service sont parcourir les formes de VM disponibles, choisir une région pour créer la VM, et lancer la VM. Si l’équipe de développement devait les classer par impact commercial, le classement serait :
- Lancer la VM car cela a un impact direct sur les revenus. Si les utilisateurs ne peuvent pas lancer une VM, alors la fonctionnalité principale du service a échoué, affectant directement la satisfaction des clients et les revenus.
- Choisir une région pour créer la VM. Bien que les utilisateurs puissent toujours créer une VM dans une région différente, cela peut entraîner une expérience dégradée s’ils ont une préférence régionale. Ce choix peut affecter les performances et la conformité.
- Naviguer dans le catalogue de VM. Bien que cela soit important pour la prise de décision, cela a un impact direct moindre sur l’entreprise car les utilisateurs peuvent modifier la forme de la VM ultérieurement.
Étape 2 : Déterminer les indicateurs de niveau de service qui peuvent suivre les parcours utilisateur
Maintenant que les parcours utilisateur sont définis, l’étape suivante est de les mesurer efficacement. Les indicateurs de niveau de service (SLIs) sont les métriques que les développeurs utilisent pour quantifier les performances et la fiabilité du système. Pour les équipes d’ingénierie, les SLIs servent un double objectif : ils fournissent des données exploitables pour détecter la dégradation, guider les décisions architecturales et valider les changements d’infrastructure. Ils constituent également la base pour des SLO significatifs en fournissant les mesures quantitatives nécessaires pour fixer et suivre les objectifs de fiabilité.
Par exemple, lors du lancement d’une VM, certains des SLIs peuvent être la disponibilité et la latence.
Disponibilité : Sur les X demandes de lancement d’une VM, combien ont réussi ? Une formule simple pour calculer cela est :
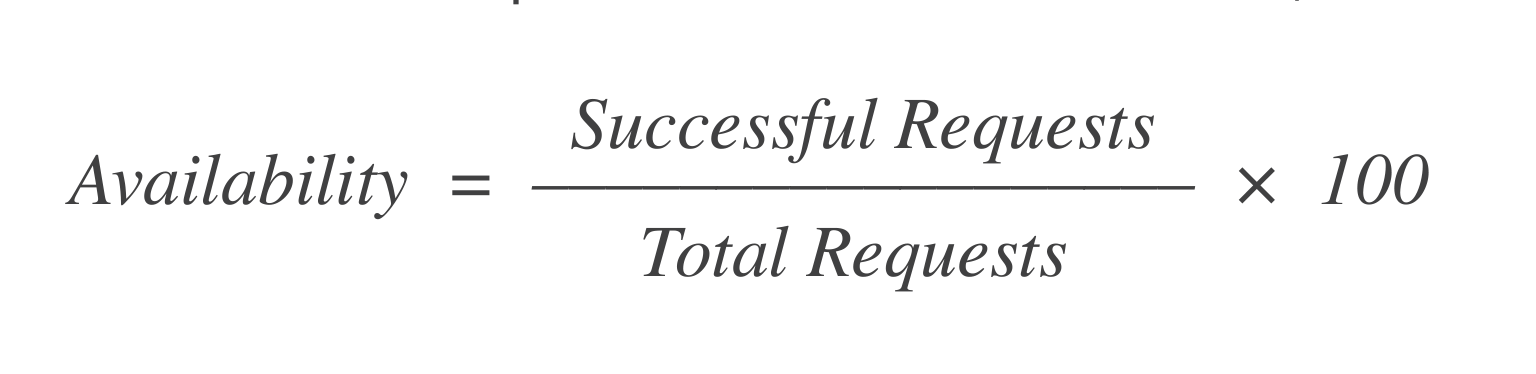
Si il y a eu 1 000 demandes et que 998 d’entre elles ont réussi, alors la disponibilité est = 99,8%.
Latence : Sur le nombre total de demandes de lancement d’une VM, quel temps ont pris les 50e, 95e ou 99e percentile des demandes pour lancer la VM ? Les percentiles ici sont juste des exemples et peuvent varier en fonction du cas d’utilisation spécifique ou des attentes de niveau de service.
- Dans un scénario avec 1 000 requêtes où 900 requêtes ont été complétées en 5 secondes et les 100 restantes ont pris 10 secondes, la latence au 95e percentile serait = 10 secondes.
- Alors que les moyennes peuvent également être utilisées pour calculer les latences, les percentiles sont généralement recommandés car ils prennent en compte les latences de queue, offrant une représentation plus précise de l’expérience utilisateur.
Étape 3 : Identifier les nombres cibles pour les SLO
En termes simples, les SLO sont les nombres cibles que nous voulons que nos SLI atteignent dans une fenêtre de temps spécifique. Pour le scénario de la VM, les SLO peuvent être :
- La disponibilité du service doit être supérieure à 99 % sur une fenêtre glissante de 30 jours.
- La latence au 95e percentile pour le lancement des VM ne doit pas dépasser huit secondes.
Lors de la fixation de ces cibles, voici quelques éléments à garder à l’esprit :
-
Utiliser les données historiques. Si vous devez définir des SLO sur la base d’une période glissante de 30 jours, rassemblez des données de plusieurs fenêtres de 30 jours pour définir les cibles.
- Si vous manquez de ces données historiques, commencez avec un objectif plus gérable, comme viser une disponibilité de 99 % chaque jour, et ajustez-le au fil du temps à mesure que vous collectez plus d’informations.
- Rappelez-vous, les SLO ne sont pas gravés dans le marbre ; ils devraient continuellement évoluer pour refléter les besoins changeants de votre service et de vos clients.
-
Prendre en compte les SLO des dépendances. Les services reposent généralement sur d’autres services et composants d’infrastructure, tels que des bases de données et des équilibreurs de charge.
-
Par exemple, si votre service dépend d’une base de données SQL avec un SLO de disponibilité de 99,9%, alors le SLO de votre service ne peut pas dépasser 99,9%. Cela est dû au fait que la disponibilité maximale est limitée par les performances de ses dépendances sous-jacentes, qui ne peuvent garantir une fiabilité plus élevée.
-
Les défis des SLO
Il pourrait être tentant de fixer l’objectif de niveau de service (SLO) à 100%, mais cela est impossible. Une disponibilité de 100%, par exemple, signifie qu’il n’y a pas de place pour des activités importantes comme la livraison de fonctionnalités, les correctifs ou les tests, ce qui n’est pas réaliste. La définition des SLO nécessite une collaboration entre plusieurs équipes, incluant l’ingénierie, le produit, les opérations, la QA et la direction. S’assurer que tous les parties prenantes sont alignées et s’accordent sur les objectifs est essentiel pour que le SLO soit réussi et actionnable.
Étape 4 : Prendre en compte le budget d’erreur
Un budget d’erreur est la mesure du temps d’indisponibilité qu’un système peut se permettre sans mécontenter les clients ou violer des obligations contractuelles. Voici un moyen de le voir :
- Si le budget d’erreur est presque épuisé, l’équipe d’ingénierie devrait se concentrer sur l’amélioration de la fiabilité et la réduction des incidents plutôt que sur la sortie de nouvelles fonctionnalités.
- Si’il y a beaucoup de budget d’erreur restant, l’équipe d’ingénierie peut se permettre de prioriser la livraison de nouvelles fonctionnalités car le système fonctionne bien dans ses objectifs de fiabilité.
Il existe deux approches courantes pour mesurer le budget d’erreur : basée sur le temps et basée sur les événements. Explorons comment l’énoncé « La disponibilité du service doit être supérieure à 99% sur une fenêtre glissante de 30 jours » s’applique à chacune.
Mesure basée sur le temps
Dans un budget d’erreur basé sur le temps, l’énoncé ci-dessus se traduit par le service étant autorisé à être down pendant 43 minutes et 50 secondes dans un mois, ou 7 heures et 14 minutes dans une année. Voici comment le calculer :
-
Déterminez le nombre de points de données. Commencez par déterminer le nombre d’unités de temps (points de données) dans la fenêtre de temps SLO. Par exemple, si l’unité de temps de base est de 1 minute et la fenêtre SLO est de 30 jours:
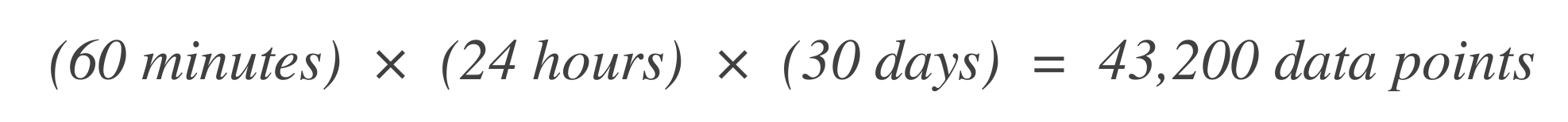
-
Calculez le budget d’erreur. Ensuite, calculez combien de points de données peuvent « échouer » (c’est-à-dire, temps d’arrêt). Le budget d’erreur est le pourcentage de défaillance autorisé.
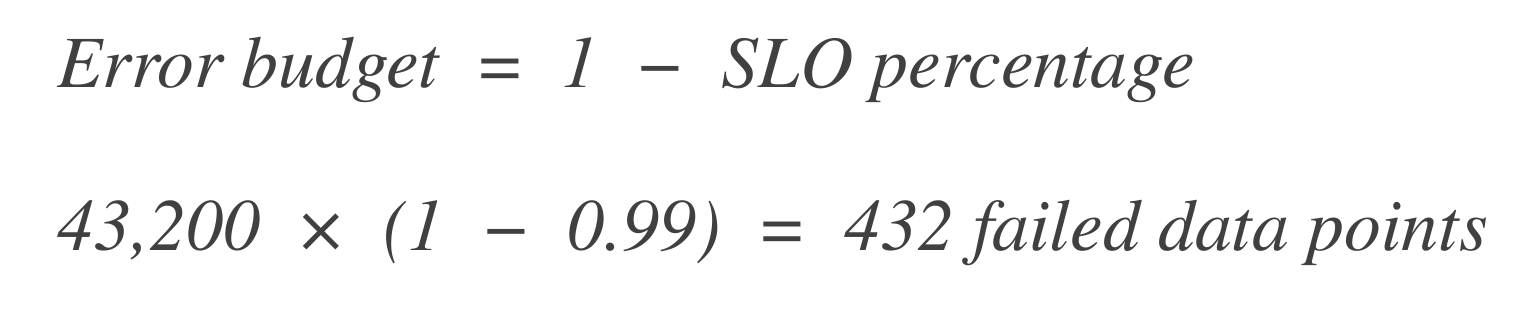
Convertissez ceci en temps:
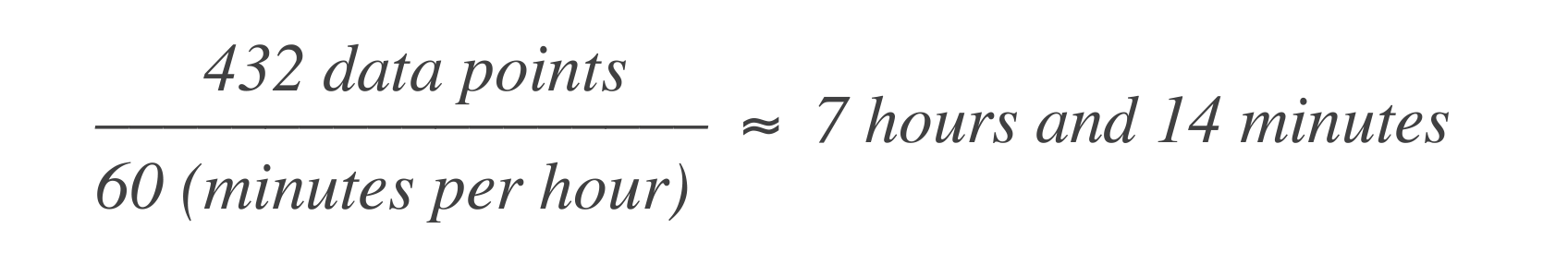
Cela signifie que le système peut subir 7 heures et 14 minutes de temps d’arrêt dans une fenêtre de 30 jours.
Enfin, le budget d’erreur restant est la différence entre le temps d’arrêt total possible et le temps d’arrêt déjà utilisé.
Mesure basée sur les événements
Pour une mesure basée sur les événements, le budget d’erreur est mesuré en termes de pourcentages. L’énoncé précédent se traduit par un budget d’erreur de 1% dans une fenêtre glissante de 30 jours.
Supposons qu’il y ait 43 200 points de données dans cette fenêtre de 30 jours, et que 100 d’entre eux soient mauvais. Vous pouvez calculer combien du budget d’erreur a été consommé en utilisant cette formule:
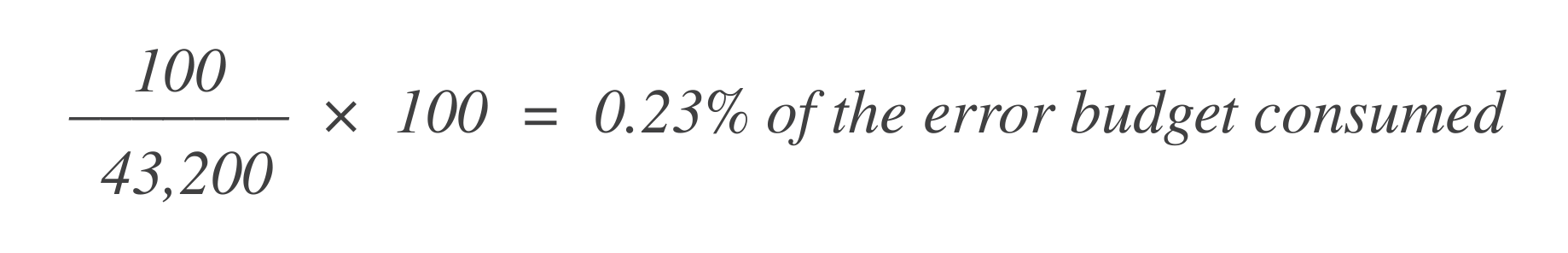
Maintenant, pour savoir combien de budget d’erreur reste, soustrayez ceci du budget d’erreur total autorisé (1%) :
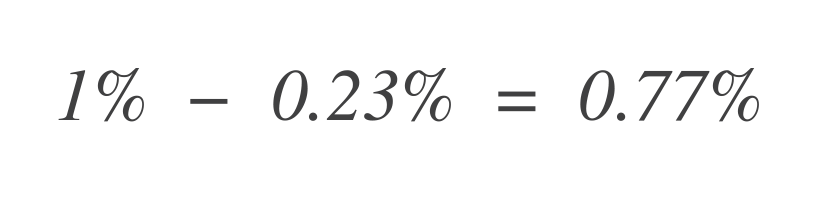
Ainsi, le service peut encore tolérer 0,77% de points de données erronés supplémentaires.
Avantages du Budget d’Erreur
Les budgets d’erreur peuvent être utilisés pour configurer des moniteurs et des alertes automatisés qui informent les équipes de développement lorsque le budget est en danger d’épuisement. Ces alertes leur permettent de reconnaître quand une plus grande prudence est nécessaire lors du déploiement de modifications en production. Les équipes sont souvent confrontées à des ambiguïtés lorsqu’il s’agit de prioriser les fonctionnalités par rapport aux opérations. Le budget d’erreur peut être une façon de relever ce défi. En fournissant des métriques claires et basées sur des données, les équipes d’ingénierie sont en mesure de prioriser les tâches de fiabilité par rapport aux nouvelles fonctionnalités lorsque cela est nécessaire. Le budget d’erreur fait partie des stratégies bien établies pour améliorer la responsabilité et la maturité au sein des équipes d’ingénierie.
Précautions à Prendre Avec les Budgets d’Erreur
Lorsqu’il y a un budget supplémentaire disponible, les développeurs doivent activement chercher à l’utiliser. C’est une excellente opportunité pour approfondir la compréhension du service en expérimentant des techniques comme l’ingénierie du chaos. Les équipes d’ingénierie peuvent observer comment le service réagit et découvrir des dépendances cachées qui peuvent ne pas être apparentes lors des opérations normales. Enfin, les développeurs doivent surveiller de près l’épuisement du budget d’erreur, car des incidents inattendus peuvent rapidement l’épuiser.
Conclusion
Les objectifs de niveau de service représentent un voyage plutôt qu’une destination en ingénierie de la fiabilité. Bien qu’ils fournissent des métriques importantes pour mesurer la fiabilité des services, leur véritable valeur réside dans la création d’une culture de fiabilité au sein des organisations. Plutôt que de rechercher la perfection, les équipes devraient adopter les SLO comme des outils qui évoluent parallèlement à leurs services. En regardant vers l’avenir, l’intégration de l’IA et de l’apprentissage automatique promet de transformer les SLO de mesures réactives en instruments prédictifs, permettant aux organisations d’anticiper et de prévenir les pannes avant qu’elles n’affectent les utilisateurs.
Ressources supplémentaires :
-
Mise en œuvre des objectifs de niveau de service, Alex Hidalgo, 2020
-
« Objets de niveau de service, » Chris Jones et al., 2017
-
« Mise en œuvre des SLO, » Steven Thurgood et al., 2018
Ceci est un extrait du Rapport sur les Tendances 2024 de DZone, Observabilité et Performance : Le Précipice de la Construction de Systèmes Logiciels à Haute Performance.
Source:
https://dzone.com/articles/framework-for-service-level-objectives