













הערת עורך: המאמר הבא נכתב ופורסם בדוורט די זון של 2024, התפתחות וביצוע: על שולי בניית מערכות תוכנה עם ביצועים גבוהים.
"איכות אינה פעולה, זו הרגל," אמר אריסטו, עקרון שמתקיים בעולם התוכנה גם. במיוחד למפתחים, זה אומר שמסירת שביעות רצון למשתמשים היא לא מאמץ חד פעמי אלא התחייבות מתמדת. כדי להשיג את ההתחייבות הזו, צוותי פיתוח צריכים להגדיר מטרות אמינות שמגדירות באופן ברור את הביצועים הבסיסיים שמשתמשים יכולים לצפות מהם. בדיוק כאן נכנסות לתמונה מטרות רמת השירות (SLOs).
פשוט מדברים, SLOs הם מטרות אמינות שמוצאים למוצרים להשיג כדי לשמור על שביעות רצון של המשתמשים. הם משמשים כגשר מדידה בין מטרות איכות המופשטות וההחלטות התפעוליות היומיומיות שקבוצות DevOps חייבות לקבל. בגלל חשיבות זו במיוחד, חשוב להגדיר אותם ביעילות עבור השירות שלך. במאמר זה, נעבור דרך שלב אחר שלב להגדיר SLOs עם דוגמה, ולאחר מכן נעבור על כמה אתגרים עם SLOs.
שלבים להגדרת מטרות רמת השירות
כמו כל תהליך אחר, הגדרת ה-SLOs עשויה להראות מרהיבה בהתחלה, אך על ידי עקיפת כמה שלבים פשוטים, תוכל ליצור מטרות יעילות. חשוב לזכור כי ה-SLOs לא מטריקות שמוצבות ושכחה. במקום זאת, הן חלק מתהליך איטרטיבי שמתפתח ככל שצריך יותר תובנות במערכת שלך. אז אפילו אם ה-SLOs הראשוניים שלך אינם מושלמים, זה בסדר — יש אפשרות וצורך לשפר אותם במהלך הזמן.
איור 1. שלבים להגדרת ה-SLOs
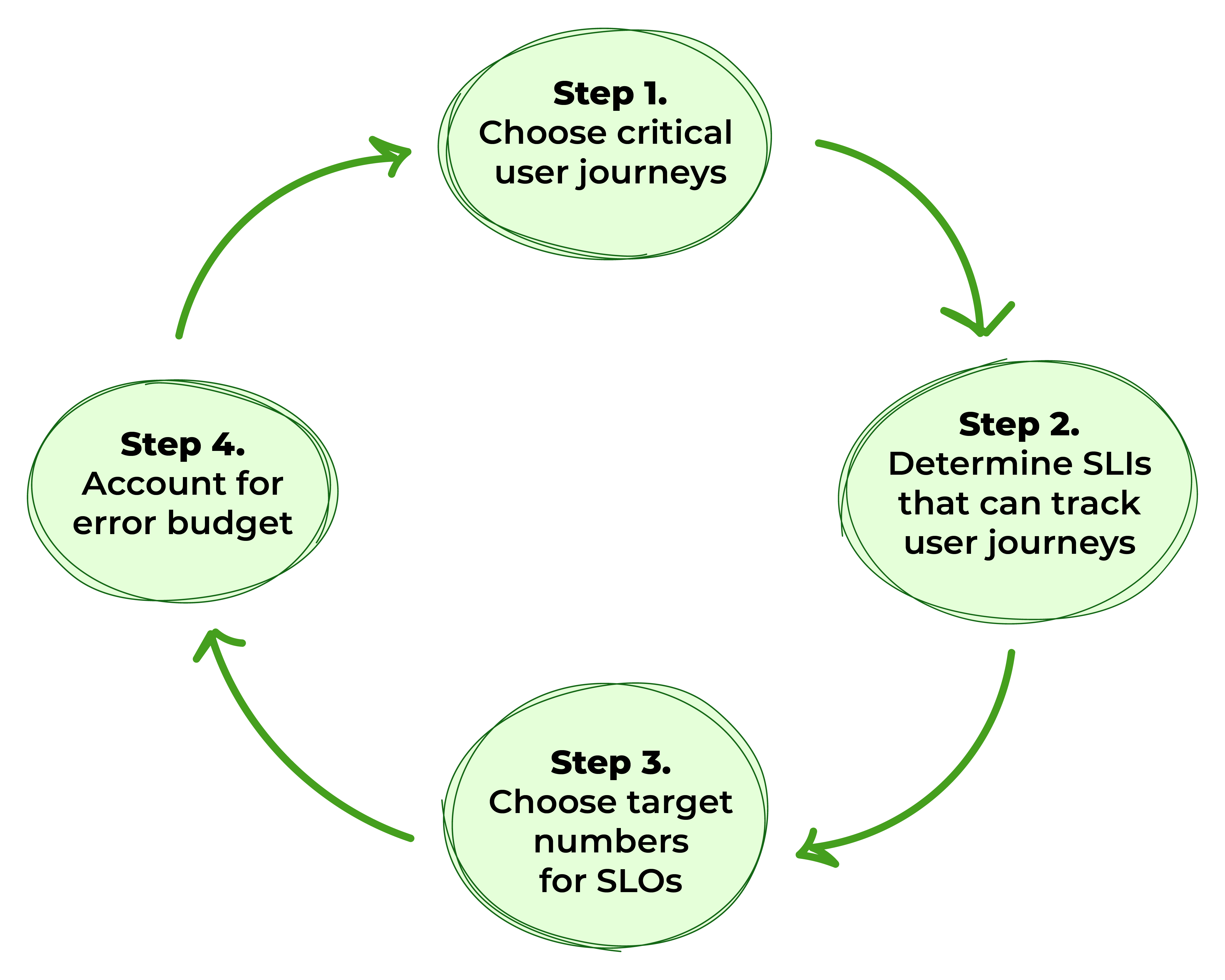
שלב 1: בחירת מסלולי משתמש קריטיים
מסלול משתמש קריטי מתייחס לסדר האינטראקציות שמשתמש מבצע כדי להשיג מטרה ספציפית במערכת או בשירות. לוודא את אמינות מסלולי המשתמש הללו חשוב מאחר וזה משפיע ישירות על חוויית הלקוח. דרכים לזיהוי מסלולי משתמש קריטיים יכולות להיות דרך הערכת השפעת הרווחים/העסקית כאשר זרימת עבודה מסוימת נכשלת וזיהוי זרימות תדירות דרך ניתוחי משתמש.
לדוגמה, נגיד שיש לך שירות שיוצר מכונות וירטואליות (VMs). חלק מהפעולות שמשתמשים יכולים לבצע בשירות זה הן עיון בצורות ה-VMs הזמינות, בחירת אזור ליצירת ה-VM בו, והפעלת ה-VM. אם צוות הפיתוח היה צריך לסדר אותן לפי השפעה עסקית, הדירוג היה:
- הפעלת ה-VMמכיוון שיש לכך השפעה ישירה על הרווחים. אם משתמשים לא יכולים להפעיל VM, אז הפונקציונליות היסודית של השירות נכשלה, משפיעה על שביעות לב של הלקוח ועל הרווחים ישירות.
- בחירת אזור ליצירת ה-VM. בעוד שמשתמשים עדיין יכולים ליצור VM באזור שונה, יתכן שזה יוביל לחווית משתמש מושחתת אם יש להם העדפת אזור. הבחירה הזו עשויה להשפיע על ביצועים ועל תקינות מחמירה.
- עיון בקטלוג ה-VM. אף על פי שזה חשוב לקבלת החלטות, יש לו השפעה ישירה נמוכה יותר על העסק מאחר ומשתמשים יכולים לשנות את צורת ה-VM מאוחר יותר.
שלב 2: לקבוע אינדיקטורים של רמת שירות שיכולים לעקוב אחר מסלולי המשתמש
עכשיו שמסלולי המשתמשים מוגדרים, השלב הבא הוא למדוד אותם בצורה יעילה. אינדיקטורים של רמת שירות (SLIs) הם המדדים שמפתחים משתמשים כדי לשקף ביצועי מערכת ואמינות. לצוותי ההנדסה, SLIs משרתים מטרה כפולה: הם מספקים נתונים פעילים לזיהוי נפילות, מנחים החלטות ארכיטקטוריות, ומאמתים שינויים בתשתיות. הם גם מהווים את היסוד ל-SLOs משמעותיים על ידי הספקת המדידות הכמותיות הנדרשות להגדיר ולעקוב אחר מטרות האמינות.
למשל, בעת השקת VM, חלק מה-SLIs יכולים להיות זמינות וזמן תגובה.
זמינות: מתוך X בקשות להשקת VM, כמה מהן הצליחו? נוסחה פשוטה לחישוב זה היא:
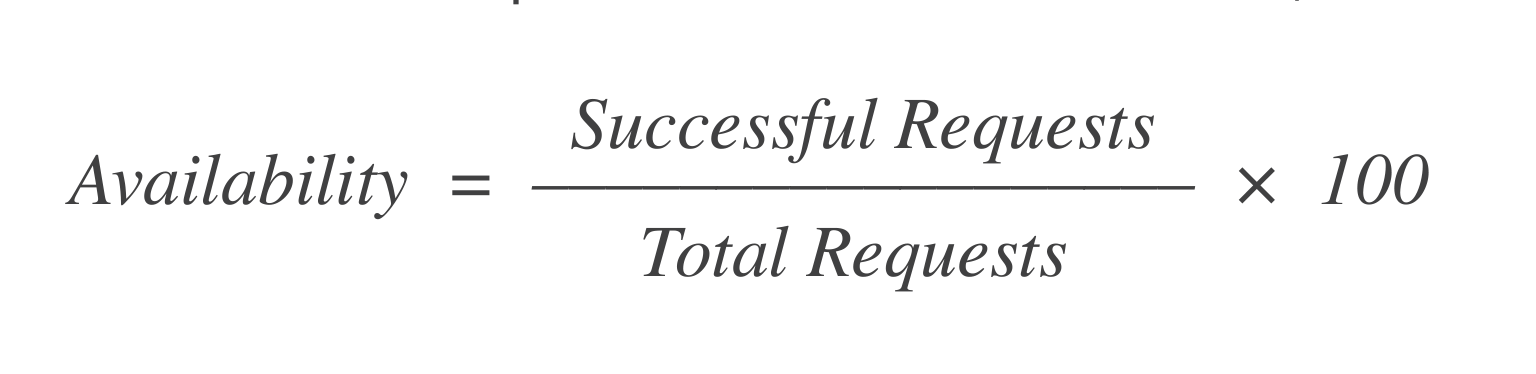
אם היו 1,000 בקשות ו-998 בקשות מהן הצליחו, אז הזמינות היא = 99.8%.
זמן תגובה:מתוך מספר הבקשות הכולל להשקת VM, כמה זמן לקח לבקשה ה-50, ה-95, או ה-99 באחוזים להשקת ה-VM? הפרסנטילים כאן הם רק דוגמאות ויכולים להשתנות לפי המקרה הספציפי או ציפיות רמת השירות.
- בתרחיש עם 1,000 בקשות שבהן 900 בקשות הושלמו ב-5 שניות וה-100 הנותרות לקחו 10 שניות, הלטנסיה בפרסנטיל ה-95 תהיה = 10 שניות.
- בעוד שממוצעים יכולים גם לשמש לחישובי לטנסיות, פרסנטילים נמלצים בדרך כלל מאחר שהם מתייחסים ללטנסיות בזנב, מציעים תמונה מדויקת יותר של חוויית המשתמש.
שלב 3: זהה את המספרים המטרה עבור SLOs
פשוט לומר, SLOs הם המספרים המטרה שבהם אנו רוצים שה- SLIs שלנו יצליחו בחלון זמן ספציפי. לתרחיש של מכונת VM, ה-SLOs יכולים להיות:
- זמינות השירות צריכה להיות גבוהה מ-99% בחלון זמן מתגלגל של 30 יום.
- הלטנסיה בפרסנטיל ה-95 להפעלת ה-VMs לא צריכה לחרוג משמונה שניות.
כאשר מגדירים את היעדים הללו, דברים לשמור עליהם בזכרון הם:
-
שימוש בנתונים היסטוריים. אם צריך לקבוע SLOs בהתבסס על חלון זמן מתגלגל של 30 יום, אסוף נתונים ממספר חלונות 30 ימיים כדי להגדיר את היעדים.
- אם חסרים לך נתונים היסטוריים אלו, התחל עם מטרה ניהלת יותר, כגון להתמקד בזמינות של 99% בכל יום, והתאם אותה במהלך הזמן כשאתה אוסף עוד מידע.
- זכור, SLOs אינם קבועים; הם צריכים להתפתח באופן רציף כדי לשקף את הצרכים המשתנים של השירות והלקוחות שלך.
-
שקילת SLOs תלויים. שירותים בדרך כלל תלויים בשירותים אחרים ובמרכיבי תשתית, כמו מסדי נתונים ומאזני עומס.
-
למשל, אם השירות שלך תלוי במסד נתונים SQL עם SLO זמינות של 99.9%, אז ה-SLO של השירות שלך לא יכול לעלות על 99.9%. זאת מכיוון שהזמינות המרבית מוגבלת על ידי הביצועים של התלויות הבסיסיות שלו, שאינן יכולות להבטיח אמינות גבוהה יותר.
-
אתגרים של SLOs
יתכן שיהיה מרתק להגדיר את ה-SLO כ-100%, אך זה בלתי אפשרי. זמינות של 100%, לדוגמה, אומרת כי אין מקום לפעילויות חשובות כמו משלוח תכונות, תיקון, או בדיקה, דבר שאינו ריאלי. הגדרת SLOs דורשת שיתוף פעולה בין צוותים מרובים, כולל הנדסה, מוצר, תפעול, בקרת איכות, ומנהיגות. הבטחת שכל הצדדים מתאימים ומסכימים על היעדים היא אסורה לכך שה-SLO יהיה מוצלח וניתן להפעלה.
שלב 4: חשבון למסגרת שגיאה
מסגרת השגיאה היא המדידה של הזמן שיכולת המערכת להרשות לעצמה להיות מנותקת מבלי לעצב את לקוחות או להפר את התחייבויות החוזים. הנה אחת הדרכים לראות את זה:
- אם מסגרת השגיאה כמעט נגמרת, צוות ההנדסה צריך להתמקד בשיפור האמינות והפחתת האירועים במקום לשחרר תכונות חדשות.
- אם יש מספיק מסגרת שגיאה שנשארת, צוות ההנדסה יכול להרשות לעצמו לתת עדיפות למשלוח תכונות חדשות מאשר שהמערכת מבצעת טוב בתוך היעדי האמינות שלה.
ישנם שני גישות נפוצות למדידת מסגרת השגיאה: מבוסס זמן ו- מבוסס אירועים. בואו לחקור איך הצהרת "זמינות השירות צריכה להיות גבוהה מ-99% בחלון גלילי של 30 ימים," מתייחסת לכל אחת מהן.
מדידה מבוססת זמן
במסגרת שגיאה מבוססת זמן, ההצהרה לעיל מתרגמת לעובדה שהשירות מורשה להיות כבוי 43 דקות ו-50 שניות בחודש, או 7 שעות ו-14 דקות בשנה. הנה כיצד לחשב את זה:
-
קבע את מספר נקודות המידע. התחל בלקביעת מספר היחידות הזמן (נקודות נתונים) בחלון הזמן של SLO. לדוגמה, אם היחידה הזמן הבסיסית היא דקה אחת וחלון ה-SLO הוא 30 ימים:
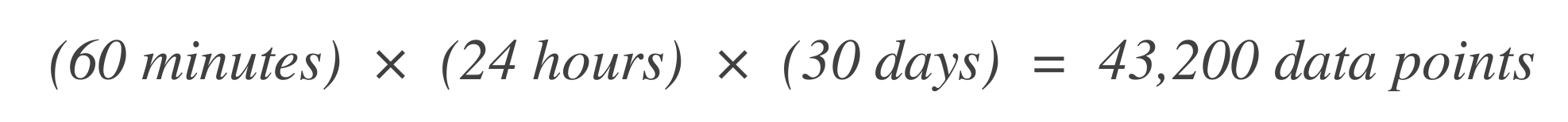
-
חשב את התקציב לשגיאות. לאחר מכן, חשב כמה נקודות נתונים יכולות "לנפול" (כלומר, זמן עצירה). התקציב לשגיאות הוא האחוז המותר של כשלון.
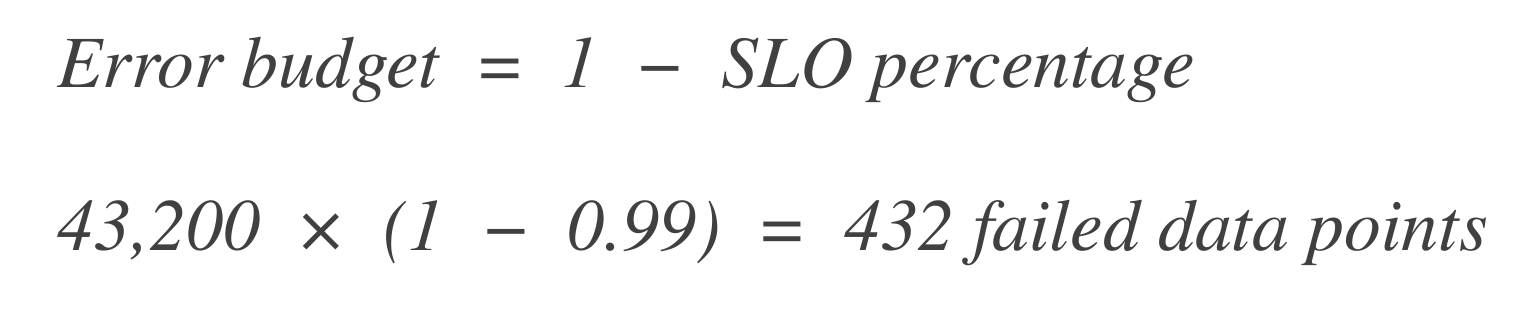
המר את זה לזמן:
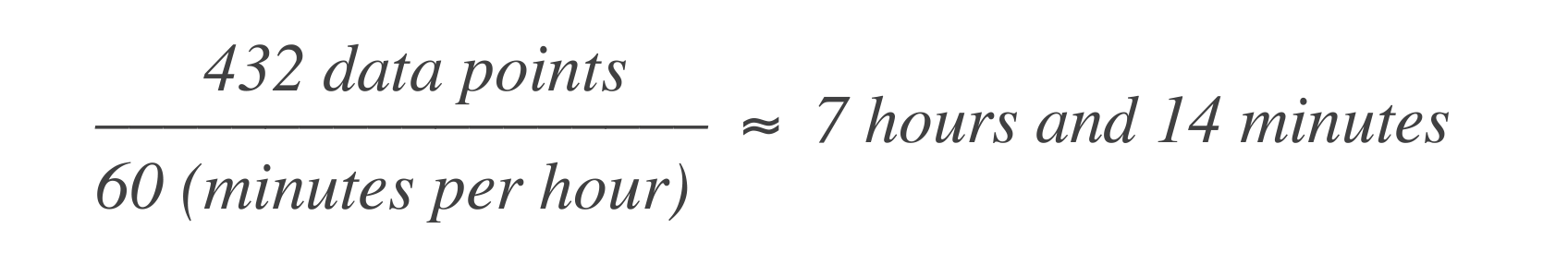
זה אומר שהמערכת יכולה לחוות 7 שעות ו-14 דקות של זמן עצירה בחלון של 30 ימים.
לאחרונה, התקציב לשגיאות הנותר הוא ההבדל בין כמות הזמן העצירה האפשרית לבין הזמן העצירה שכבר נעשה שימוש בו.
מדידה מבוססת אירועים
במדידה מבוססת אירועים, תקציב השגיאות מודד באחוזים. הצהרת המעלה נזכרת כדי בתקציב שגיאה של 1% בחלון מתגלגל של 30 ימים.
נניח כי יש 43,200 נקודות נתונים באותו חלון של 30 ימים, ו-100 מהן הן רעות. אתה יכול לחשב כמה מתקציב השגיאות כבר נצרפו באמצעות הנוסחה הבאה:
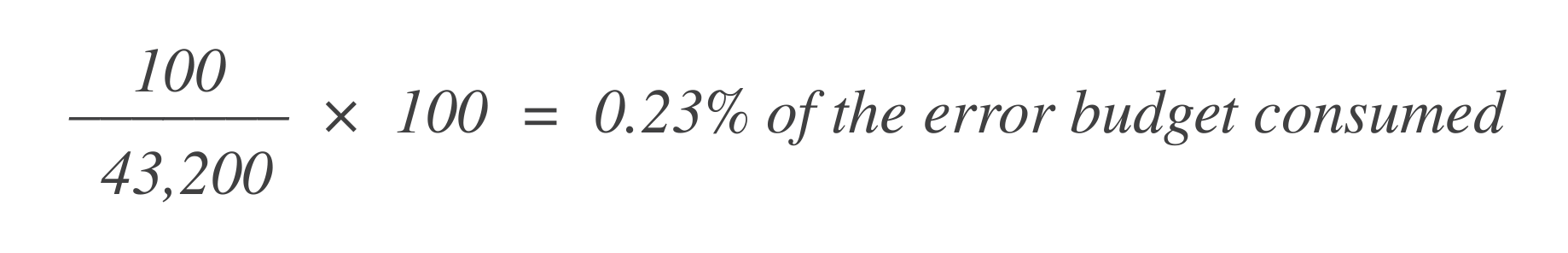
עכשיו, כדי לגלות כמה תקציב שגיאות נשאר, יש להוריד את זה מתקציב השגיאות המותר בסך הכול (1%):
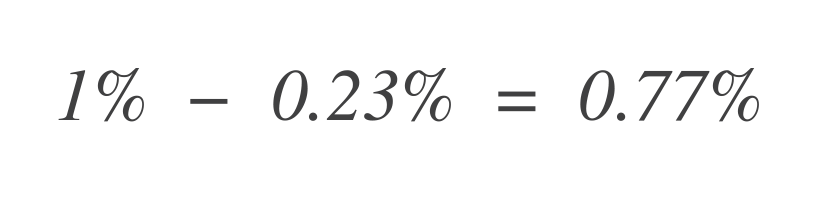
לכן, השירות יכול להתמודד עד 0.77% נקודות נתונים רעים נוספות.
יתרונות של מסגרת שגיאות
מסגרת השגיאות יכולה לשמש להגדרת מעקבים אוטומטיים והתראות שמודיעות לצוותי פיתוח כאשר התקציב בסיכון לגירוד. ההתראות הללו מאפשרות להם לזהות כשצריכה זהירות גדולה יותר בעת הפצת שינויים לייצור. צוותים נתקלים לעתים קרובות באי-צדק ברמת העדיפויות בין תכונות לפעולות. מסגרת שגיאות עשויה להיות דרך אחת לטפל באתגר זה. על ידי מתן מדדים ברורים ומבוססי נתונים, צוותי ההנדסה יכולים להעדיף משימות אמינות מעל תכונות חדשות כאשר נדרש. מסגרת השגיאות היא אחת מהאסטרטגיות המוכחות לשפר אחריות ובשלות במערכות ההנדסה.
אזהרות לקחת עם מסגרת שגיאות
כאשר יש תקציב זמין נוסף, מפתחים צריכים לחקור פעילות לשימוש בו באופן פעיל. זו הזדמנות ראשונית להעמיק את ההבנה בשירות על ידי ניסויים עם טכניקות כמו הנדסת כאוס. צוותי ההנדסה יכולים לראות כיצד השירות מגיב ולחשוף תלותים נסתרות שייתכן שלא יהיו ברורות במהלך הפעולות הרגילות. לבסוף, מפתחים חייבים לעקוב אחר הגירוד בתקציב השגיאות בקרבה מוחלטת מאחר שאירועים בלתי צפויים עלולים לגרום לגירוד מהיר שלו.
מסקנה
מטרות רמת שירות מייצגות מסע ולא יעד בהנדסת אמינות. בעוד שהן מספקות מדדים חשובים למדידת אמינות השירות, הערך האמיתי שלהן טמון ביצירת תרבות אמינות בתוך הארגונים. במקום לרדוף אחר שלמות, הצוותים צריכים לאמץ את מטרות רמת השירות ככלים שמתפתחים יחד עם השירותים שלהם. בהסתכלות קדימה, השילוב של בינה מלאכותית ולמידת מכונה מבטיח להפוך את מטרות רמת השירות ממדידות תגובתיות לכלים חיזוי, מה שמאפשר לארגונים לחזות ולמנוע תקלות לפני שהן משפיעות על המשתמשים.
משאבים נוספים:
-
יישום מטרות רמת שירות, אלכס הידלגו, 2020
-
"אובייקטי רמת שירות," כריס ג'ונס ואחרים, 2017
-
"יישום מטרות רמת שירות," סטיבן ת'ורגוד ואחרים, 2018
זהו קטע מדווח הטרנדים של DZone לשנת 2024, ניתוח וביצוע: הסיף של בניית מערכות תוכנה ביצועיות במיוחד.
Source:
https://dzone.com/articles/framework-for-service-level-objectives