













Nota del editor: A continuación se presenta un artículo escrito para y publicado en el Informe de Tendencias 2024 de DZone,Observabilidad y Rendimiento: El Precipicio de Construir Sistemas de Software Altamente Rendibles.
“La calidad no es un acto, es un hábito”, dijo Aristóteles, un principio que también resuena en el mundo del software. Específicamente para los desarrolladores, esto significa que entregar satisfacción al usuario no es un esfuerzo único, sino un compromiso continuo. Para cumplir con este compromiso, los equipos de ingeniería necesitan tener objetivos de fiabilidad que definan claramente el rendimiento básico que los usuarios pueden esperar. Aquí es precisamente donde entran en juego los objetivos de nivel de servicio (SLOs).
En pocas palabras, los SLOs son objetivos de fiabilidad que los productos deben alcanzar para mantener felices a los usuarios. Sirven como el puente cuantificable entre los objetivos de calidad abstractos y las decisiones operativas diarias que los equipos de DevOps deben tomar. Debido a esta importancia, es crucial definirlos de manera efectiva para tu servicio. En este artículo, repasaremos un enfoque paso a paso para definir SLOs con un ejemplo, seguido de algunos desafíos con los SLOs.
Pasos para Definir Objetivos de Nivel de Servicio
Como cualquier otro proceso, definir SLOs puede parecer abrumador al principio, pero siguiendo algunos pasos simples, puedes crear objetivos efectivos. Es importante recordar que los SLOs no son métricas de configurar y olvidar. En cambio, son parte de un proceso iterativo que evoluciona a medida que obtienes más información sobre tu sistema. Así que incluso si tus SLOs iniciales no son perfectos, está bien — pueden y deben ser refinados con el tiempo.
Figura 1. Pasos para definir SLOs
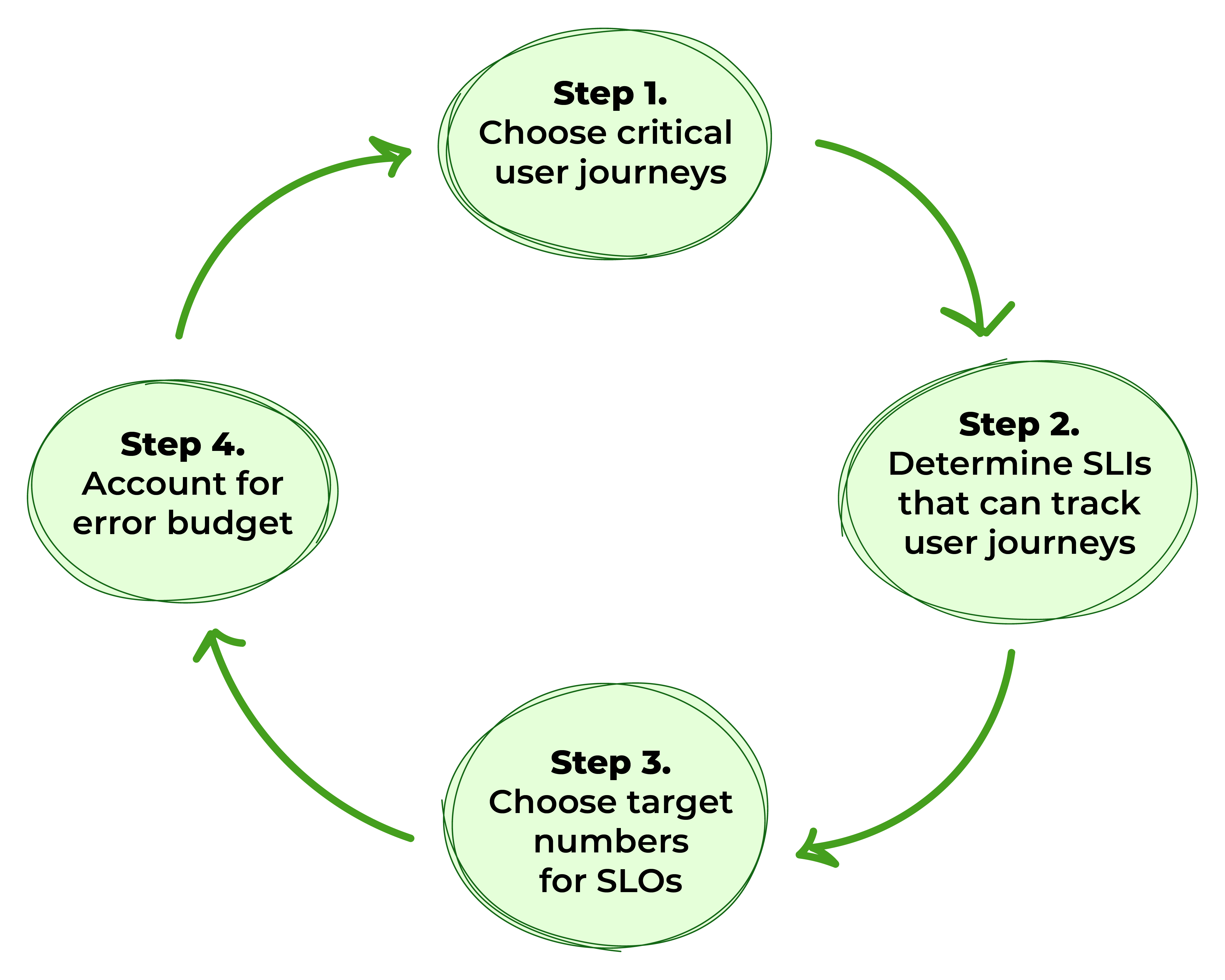
Paso 1: Elegir los Recorridos Críticos del Usuario
Un recorrido crítico del usuario se refiere a la secuencia de interacciones que un usuario realiza para alcanzar un objetivo específico dentro de un sistema o servicio. Asegurar la fiabilidad de estos recorridos es importante porque impacta directamente la experiencia del cliente. Algunas formas de identificar recorridos críticos del usuario pueden ser evaluando el impacto en ingresos/negocio cuando un cierto flujo falla e identificando flujos frecuentes a través de análisis de usuarios.
Por ejemplo, considera un servicio que crea máquinas virtuales (VMs). Algunas de las acciones que los usuarios pueden realizar en este servicio son navegar por las formas de VM disponibles, elegir una región para crear la VM y lanzar la VM. Si el equipo de desarrollo tuviera que ordenarlas por impacto en el negocio, el ranking sería:
- Lanzar la VMporque esto tiene un impacto directo en los ingresos. Si los usuarios no pueden lanzar una VM, entonces la funcionalidad principal del servicio ha fallado, afectando directamente la satisfacción del cliente y los ingresos.
- Elegir una región para crear la VM. Aunque los usuarios aún pueden crear una VM en una región diferente, esto podría llevar a una experiencia degradada si tienen una preferencia regional. Esta elección puede afectar el rendimiento y el cumplimiento.
- Navegar por el catálogo de VM. Aunque esto es importante para la toma de decisiones, tiene un impacto directo menor en el negocio porque los usuarios pueden cambiar la forma de la VM más tarde.
Paso 2: Determinar los Indicadores de Nivel de Servicio que Pueden Rastrear los Recorridos del Usuario
Ahora que los recorridos del usuario están definidos, el siguiente paso es medirlos de manera efectiva. Los indicadores de nivel de servicio (SLIs) son las métricas que los desarrolladores utilizan para cuantificar el rendimiento y la fiabilidad del sistema. Para los equipos de ingeniería, los SLIs tienen un doble propósito: proporcionan datos accionables para detectar degradaciones, guiar decisiones arquitectónicas y validar cambios en la infraestructura. También forman la base para SLOs significativos al proporcionar las mediciones cuantitativas necesarias para establecer y rastrear objetivos de fiabilidad.
Por ejemplo, al lanzar una VM, algunos de los SLIs pueden ser la disponibilidad y la latencia.
Disponibilidad: De las X solicitudes para lanzar una VM, ¿cuántas tuvieron éxito? Una fórmula simple para calcular esto es:
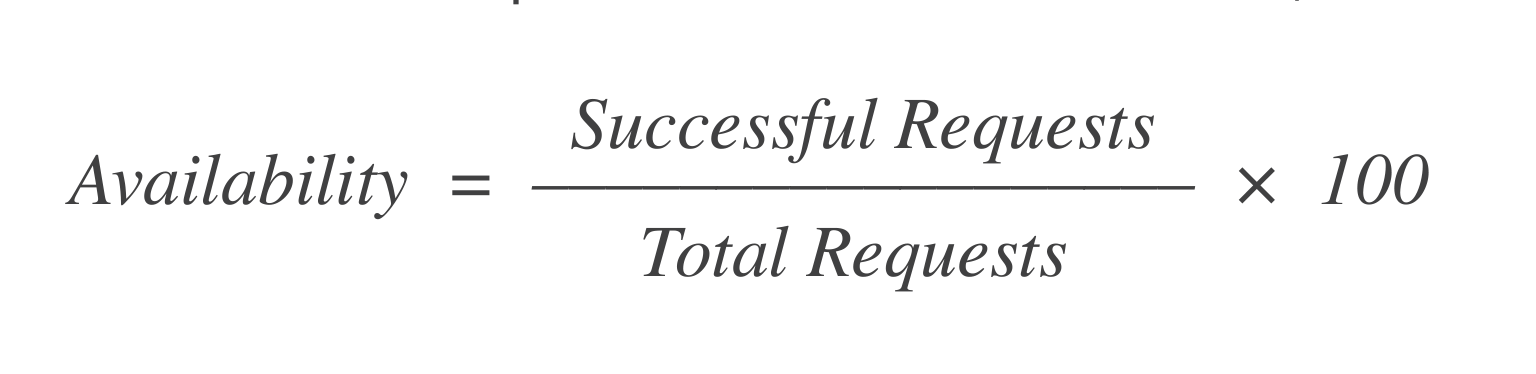
Si hubo 1,000 solicitudes y 998 de ellas tuvieron éxito, entonces la disponibilidad es = 99.8%.
Latencia: De la totalidad de las solicitudes para lanzar una VM, ¿cuánto tiempo tardaron el percentil 50, 95 o 99 de las solicitudes en lanzar la VM? Los percentiles aquí son solo ejemplos y pueden variar según el caso de uso específico o las expectativas de nivel de servicio.
- En un escenario con 1,000 solicitudes donde 900 se completaron en 5 segundos y las 100 restantes tomaron 10 segundos, la latencia del percentil 95 sería = 10 segundos.
- Mientras que los promedios también pueden usarse para calcular latencias, los percentiles suelen ser recomendados porque tienen en cuenta las latencias de cola, ofreciendo una representación más precisa de la experiencia del usuario.
Paso 3: Identificar Números Objetivo para los SLOs
En resumen, los SLOs son los números objetivo que queremos que nuestros SLIs alcancen en un ventana de tiempo específica. Para el escenario de VM, los SLOs pueden ser:
- La disponibilidad del servicio debe ser mayor al 99% en una ventana móvil de 30 días.
- El percentil 95 de la latencia para lanzar las VMs no debe exceder ocho segundos.
Al establecer estos objetivos, algunas cosas a tener en cuenta son:
-
Usar datos históricos.Si necesitas establecer SLOs basados en un período móvil de 30 días, recopila datos de múltiples ventanas de 30 días para definir los objetivos.
- Si careces de estos datos históricos, comienza con un objetivo más manejable, como apuntar a una disponibilidad del 99% cada día, y ajústalo con el tiempo a medida que reúnas más información.
- Recuerda, los SLOs no están escritos en piedra; deben evolucionar continuamente para reflejar las necesidades cambiantes de tu servicio y clientes.
-
Considerando los SLO de dependencias. Los servicios suelen depender de otros servicios y componentes de infraestructura, como bases de datos y balanceadores de carga.
-
Por ejemplo, si tu servicio depende de una base de datos SQL con un SLO de disponibilidad del 99.9%, entonces el SLO de tu servicio no puede superar el 99.9%. Esto se debe a que la máxima disponibilidad está limitada por el rendimiento de sus dependencias subyacentes, que no pueden garantizar una mayor fiabilidad.
-
Desafíos de los SLO
Podría ser intrigante establecer el SLO en 100%, pero esto es imposible. Un 100% de disponibilidad, por ejemplo, significa que no hay espacio para actividades importantes como enviar características, parchear o probar, lo cual no es realista. Definir SLOs requiere colaboración entre múltiples equipos, incluyendo ingeniería, producto, operaciones, QA y liderazgo. Asegurar que todos los interesados estén alineados y acuerden los objetivos es esencial para que el SLO sea exitoso y accionable.
Paso 4: Considerar el Presupuesto de Errores
Un presupuesto de errores es la medida de tiempo de inactividad que un sistema puede permitirse sin molestar a los clientes o incumplir obligaciones contractuales. A continuación, se muestra una forma de verlo:
- Si el presupuesto de errores está casi agotado, el equipo de ingeniería debe centrarse en mejorar la fiabilidad y reducir los incidentes en lugar de lanzar nuevas características.
- Si hay mucho presupuesto de errores restante, el equipo de ingeniería puede permitirse priorizar el envío de nuevas características, ya que el sistema está funcionando bien dentro de sus objetivos de fiabilidad.
Hay dos enfoques comunes para medir el presupuesto de errores: basado en tiempo y basado en eventos. Veamos cómo se aplica la afirmación “La disponibilidad del servicio debe ser mayor al 99% en una ventana móvil de 30 días” a cada uno.
Medición Basada en Tiempo
En un presupuesto de errores basado en tiempo, la afirmación anterior se traduce en que el servicio puede estar inactivo durante 43 minutos y 50 segundos en un mes, o 7 horas y 14 minutos en un año. Así es como se calcula:
-
Determine el número de puntos de datos. Comience determinando el número de unidades de tiempo (puntos de datos) dentro de la ventana de tiempo SLO. Por ejemplo, si la unidad de tiempo base es 1 minuto y la ventana SLO es de 30 días:
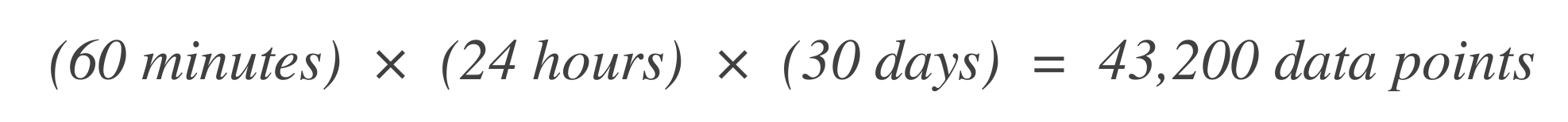
-
Calcule el presupuesto de errores. A continuación, calcule cuántos puntos de datos pueden “fallar” (es decir, tiempo de inactividad). El presupuesto de errores es el porcentaje de fallo permitido.
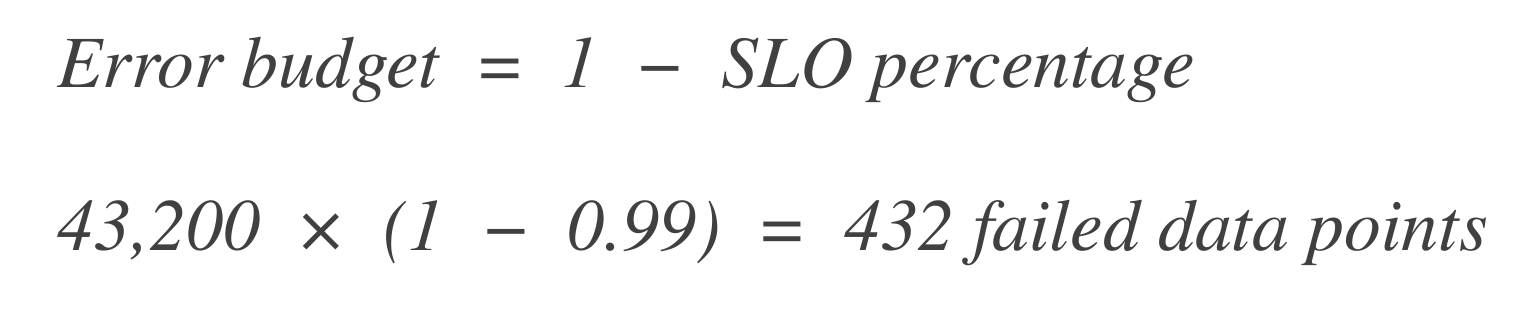
Convierta esto a tiempo:
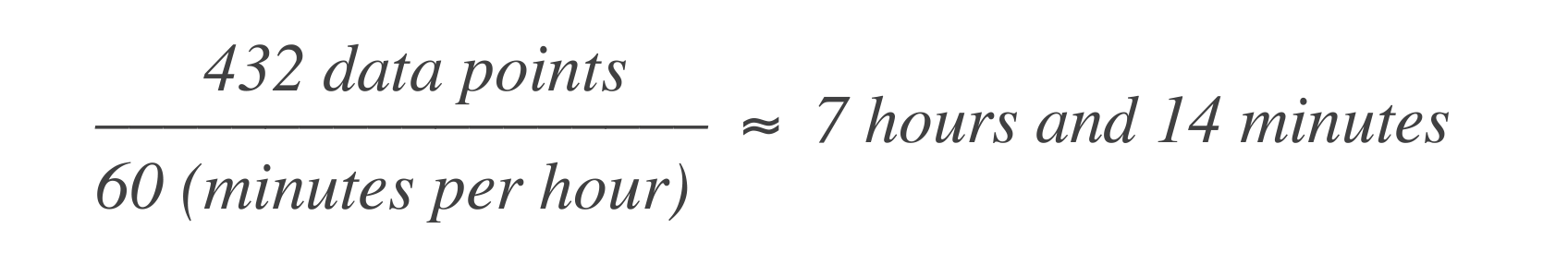
Esto significa que el sistema puede experimentar 7 horas y 14 minutos de tiempo de inactividad en una ventana de 30 días.
Por último, el presupuesto de errores restante es la diferencia entre el tiempo de inactividad total posible y el tiempo de inactividad ya utilizado.
Medición Basada en Eventos
Para la medición basada en eventos, el presupuesto de errores se mide en términos de porcentajes. La declaración anterior se traduce en un presupuesto de errores del 1% en una ventana móvil de 30 días.
Digamos que hay 43,200 puntos de datos en esa ventana de 30 días, y 100 de ellos son malos. Puede calcular cuánto del presupuesto de errores se ha consumido utilizando esta fórmula:
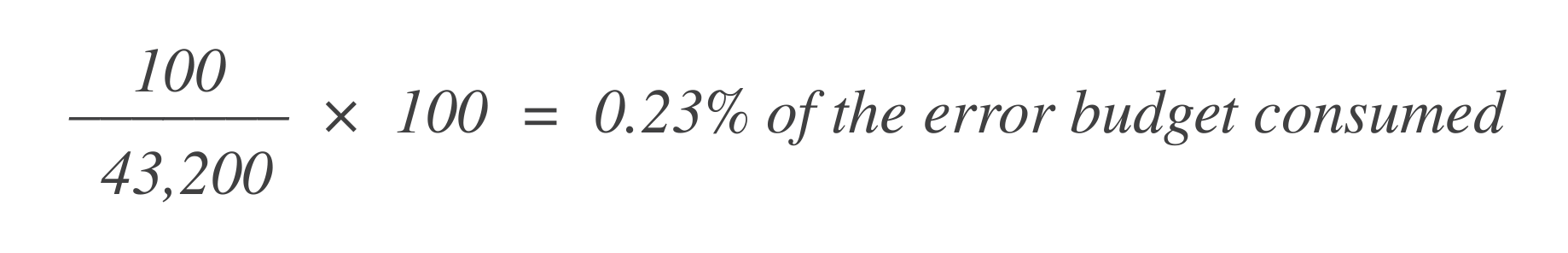
Ahora, para averiguar cuánto presupuesto de errores queda, reste esto del presupuesto de errores total permitido (1%):
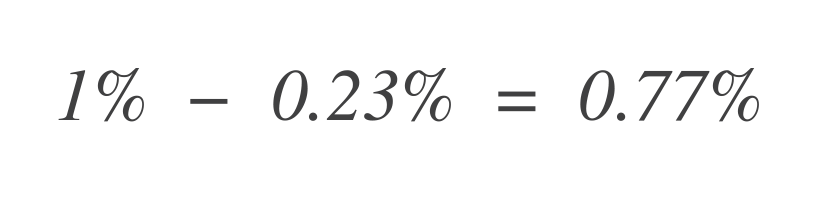
Por lo tanto, el servicio aún puede tolerar 0.77% más puntos de datos deficientes.
Ventajas del Presupuesto de Errores
Los presupuestos de errores pueden utilizarse para configurar monitores y alertas automatizados que notifiquen a los equipos de desarrollo cuando el presupuesto esté en riesgo de agotarse. Estas alertas les permiten reconocer cuándo se requiere mayor precaución al implementar cambios en producción. Los equipos a menudo enfrentan ambigüedad a la hora de priorizar características frente a operaciones. El presupuesto de errores puede ser una forma de abordar este desafío. Al proporcionar métricas claras y basadas en datos, los equipos de ingeniería pueden priorizar las tareas de confiabilidad sobre las nuevas características cuando sea necesario. El presupuesto de errores se encuentra entre las estrategias bien establecidas para mejorar la responsabilidad y la madurez dentro de los equipos de ingeniería.
Precauciones a Tomar con los Presupuestos de Errores
Cuando haya un presupuesto adicional disponible, los desarrolladores deben buscar activamente utilizarlo. Esta es una oportunidad óptima para profundizar el entendimiento del servicio mediante la experimentación con técnicas como la ingeniería del caos. Los equipos de ingeniería pueden observar cómo responde el servicio y descubrir dependencias ocultas que pueden no ser evidentes durante las operaciones normales. Por último, pero no menos importante, los desarrolladores deben monitorear de cerca el agotamiento del presupuesto de errores, ya que incidentes inesperados pueden agotarlo rápidamente.
Conclusión
Los objetivos de nivel de servicio representan un viaje más que un destino en la ingeniería de la fiabilidad. Si bien proporcionan métricas importantes para medir la fiabilidad del servicio, su verdadero valor reside en crear una cultura de fiabilidad dentro de las organizaciones. En lugar de buscar la perfección, los equipos deberían adoptar los SLO como herramientas que evolucionan junto con sus servicios. Mirando hacia el futuro, la integración de la IA y el aprendizaje automático promete transformar los SLO de mediciones reactivas en instrumentos predictivos, permitiendo a las organizaciones anticipar y prevenir fallos antes de que afecten a los usuarios.
Recursos adicionales:
-
Implementación de Objetivos de Nivel de Servicio, Alex Hidalgo, 2020
-
“Objetos de Nivel de Servicio,” Chris Jones et al., 2017
-
“Implementación de SLO,” Steven Thurgood et al., 2018
Este es un extracto del Informe de Tendencias 2024 de DZone, Observabilidad y Rendimiento: El Abismo de la Construcción de Sistemas de Software Altamente Rendimiento.
Source:
https://dzone.com/articles/framework-for-service-level-objectives