













Nota do Editor: O texto a seguir é um artigo escrito para e publicado no Relatório de Tendências 2024 da DZone,Observabilidade e Desempenho: O Precipício de Construir Sistemas de Software Altamente Performáticos.
“Qualidade não é um ato, é um hábito,” disse Aristóteles, um princípio que também ressoa no mundo do software. Especificamente para desenvolvedores, isso significa que entregar satisfação ao usuário não é um esforço único, mas um compromisso contínuo. Para cumprir esse compromisso, as equipes de engenharia precisam ter metas de confiabilidade que definam claramente o desempenho básico que os usuários podem esperar. É exatamente aí que os objetivos de nível de serviço (SLOs) entram em cena.
Simplificando, SLOs são metas de confiabilidade que os produtos devem alcançar para manter os usuários felizes. Eles servem como a ponte quantificável entre metas de qualidade abstratas e as decisões operacionais diárias que as equipes de DevOps devem tomar. Devido a essa importância, é crucial defini-los de maneira eficaz para o seu serviço. Neste artigo, vamos percorrer uma abordagem passo a passo para definir SLOs com um exemplo, seguido por alguns desafios com SLOs.
Passos para Definir Objetivos de Nível de Serviço
Como qualquer outro processo, definir SLOs pode parecer esmagador no início, mas seguindo alguns passos simples, você pode criar objetivos eficazes. É importante lembrar que SLOs não são métricas de definir-e-esquecer. Em vez disso, eles fazem parte de um processo iterativo que evolui à medida que você ganha mais insights sobre seu sistema. Portanto, mesmo que seus SLOs iniciais não sejam perfeitos, está tudo bem — eles podem e devem ser refinados ao longo do tempo.
Figura 1. Passos para definir SLOs
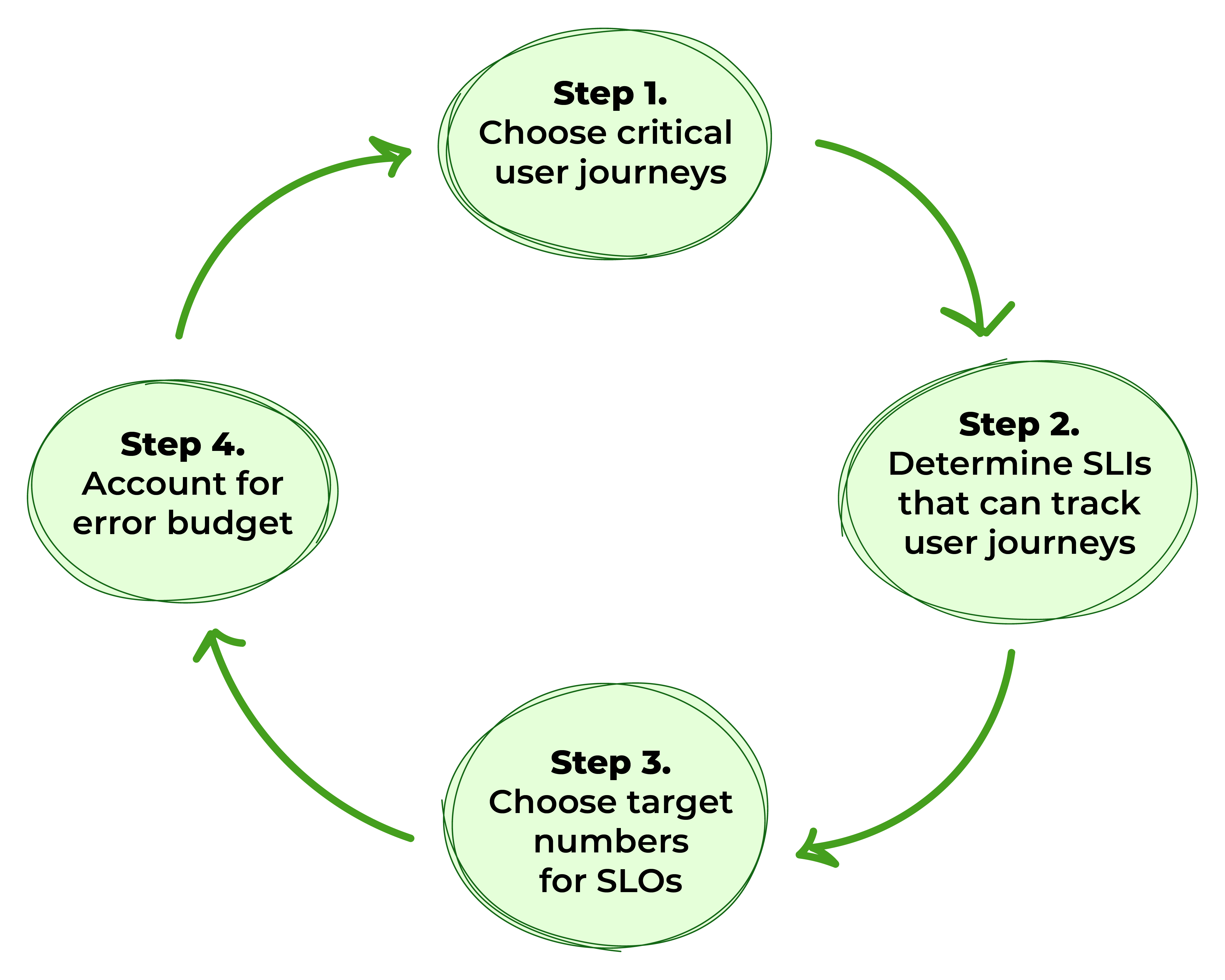
Passo 1: Escolha Jornadas Críticas do Usuário
Uma jornada crítica do usuário refere-se à sequência de interações que um usuário realiza para atingir um objetivo específico dentro de um sistema ou serviço. Garantir a confiabilidade dessas jornadas é importante porque impacta diretamente a experiência do cliente. Algumas maneiras de identificar jornadas críticas do usuário podem ser através da avaliação do impacto de receita/negócio quando um determinado fluxo de trabalho falha e identificar fluxos frequentes por meio de análises de usuário.
Por exemplo, considere um serviço que cria máquinas virtuais (VMs). Algumas das ações que os usuários podem realizar neste serviço são navegar pelas formas de VM disponíveis, escolher uma região para criar a VM e lançar a VM. Se a equipe de desenvolvimento fosse ordená-las por impacto no negócio, a classificação seria:
- Lançar a VM porque isso tem um impacto direto na receita. Se os usuários não puderem lançar uma VM, então a funcionalidade principal do serviço falhou, afetando diretamente a satisfação do cliente e a receita.
- Escolhendo uma região para criar a VM. Embora os usuários ainda possam criar uma VM em uma região diferente, isso pode levar a uma experiência prejudicada se tiverem uma preferência regional. Esta escolha pode afetar o desempenho e a conformidade.
- Navegando pelo catálogo de VM. Embora isso seja importante para a tomada de decisão, tem um impacto direto menor no negócio, pois os usuários podem alterar a forma da VM posteriormente.
Passo 2: Determinar Indicadores de Nível de Serviço Que Podem Rastrear Jornadas do Usuário
Agora que as jornadas do usuário estão definidas, o próximo passo é medi-las eficazmente. Indicadores de nível de serviço (SLIs) são as métricas que os desenvolvedores usam para quantificar o desempenho e a confiabilidade do sistema. Para as equipes de engenharia, os SLIs servem a um duplo propósito: eles fornecem dados acionáveis para detectar degradação, orientar decisões arquiteturais e validar mudanças na infraestrutura. Eles também formam a base para SLOs significativos, fornecendo as medições quantitativas necessárias para definir e rastrear metas de confiabilidade.
Por exemplo, ao lançar uma VM, alguns dos SLIs podem ser disponibilidade e latência.
Disponibilidade: De X solicitações para lançar uma VM, quantas tiveram sucesso? Uma fórmula simples para calcular isso é:
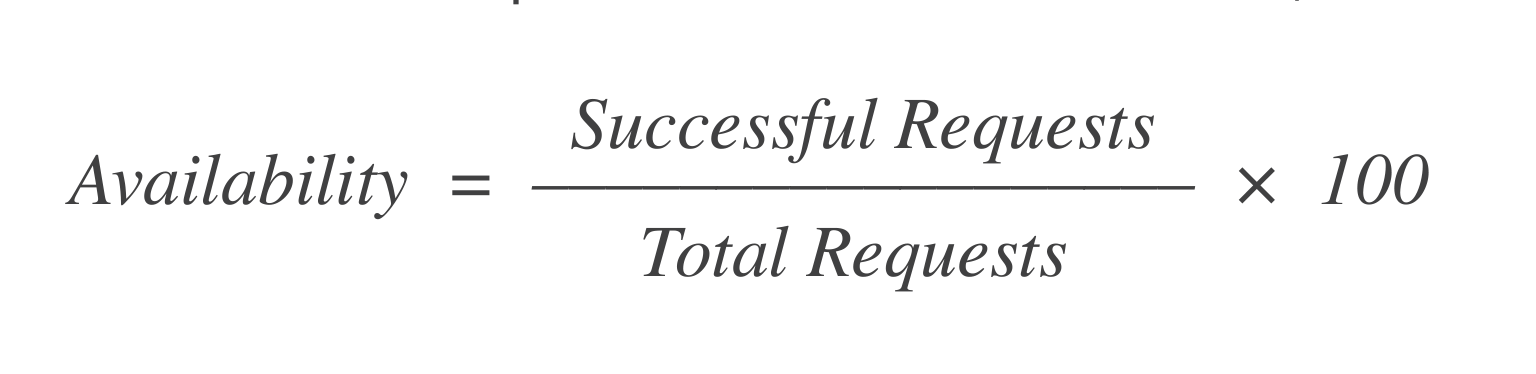
Se houve 1.000 solicitações e 998 delas tiveram sucesso, então a disponibilidade é = 99,8%.
Latência: De todas as solicitações para lançar uma VM, quanto tempo levou para o 50º, 95º ou 99º percentil das solicitações lançar a VM? Os percentis aqui são apenas exemplos e podem variar dependendo do caso de uso específico ou das expectativas de nível de serviço.
- Em um cenário com 1.000 solicitações, onde 900 foram concluídas em 5 segundos e as 100 restantes levaram 10 segundos, a latência do 95º percentil seria = 10 segundos.
- Embora as médias também possam ser usadas para calcular latências, os percentis são geralmente recomendados porque levam em conta as latências de cauda, oferecendo uma representação mais precisa da experiência do usuário.
Etapa 3: Identificar Números-Alvo para SLOs
Simplificando, SLOs são os números-alvo que queremos que nossos SLIs alcancem em uma janela de tempo específica. Para o cenário de VM, os SLOs podem ser:
- A disponibilidade do serviço deve ser maior que 99% em uma janela móvel de 30 dias.
- O 95º percentil de latência para iniciar as VMs não deve exceder oito segundos.
Ao definir esses alvos, algumas coisas a serem lembradas são:
-
Usar dados históricos. Se você precisa definir SLOs com base em um período de 30 dias, colete dados de várias janelas de 30 dias para definir os alvos.
- Se você não tiver esses dados históricos, comece com um objetivo mais gerenciável, como buscar 99% de disponibilidade todos os dias, e ajuste-o ao longo do tempo à medida que coleta mais informações.
- Lembre-se, SLOs não são definitivos; eles devem evoluir continuamente para refletir as necessidades em mudança do seu serviço e clientes.
-
Considerando os SLOs de dependências. Serviços geralmente dependem de outros serviços e componentes de infraestrutura, como bancos de dados e balanceadores de carga.
-
Por exemplo, se o seu serviço depende de um banco de dados SQL com um SLO de disponibilidade de 99,9%, então o SLO do seu serviço não pode exceder 99,9%. Isso ocorre porque a disponibilidade máxima é limitada pelo desempenho de suas dependências subjacentes, que não podem garantir maior confiabilidade.
-
Desafios dos SLOs
Pode ser interessante definir o SLO como 100%, mas isso é impossível. Uma disponibilidade de 100%, por exemplo, significa que não há espaço para atividades importantes como lançamento de funcionalidades, correções de patches ou testes, o que não é realista. Definir SLOs requer colaboração entre várias equipes, incluindo engenharia, produto, operações, QA e liderança. Garantir que todos os stakeholders estejam alinhados e concordem com os objetivos é essencial para que o SLO seja bem-sucedido e ação.
Etapa 4: Contabilizar o Orçamento de Erros
Um orçamento de erros é a medida de tempo de inatividade que um sistema pode suportar sem desagradar os clientes ou violar obrigações contratuais. Abaixo está uma maneira de visualizar isso:
- Se o orçamento de erros estiver quase esgotado, a equipe de engenharia deve focar em melhorar a confiabilidade e reduzir incidentes em vez de lançar novas funcionalidades.
- Se houver bastante orçamento de erros restante, a equipe de engenharia pode priorizar o lançamento de novas funcionalidades, pois o sistema está performando bem dentro dos objetivos de confiabilidade.
Existem duas abordagens comuns para medir o orçamento de erros: baseada em tempo e baseada em eventos. Vamos explorar como a afirmação “A disponibilidade do serviço deve ser maior que 99% em uma janela móvel de 30 dias” se aplica a cada uma.
Medição Baseada em Tempo
Em um orçamento de erros baseado em tempo, a afirmação acima se traduz em o serviço poder estar inativo por 43 minutos e 50 segundos em um mês, ou 7 horas e 14 minutos em um ano. Aqui está como calcular:
-
Determine o número de pontos de dados. Comece determinando o número de unidades de tempo (pontos de dados) dentro da janela de tempo do SLO. Por exemplo, se a unidade de tempo base é 1 minuto e a janela do SLO é de 30 dias:
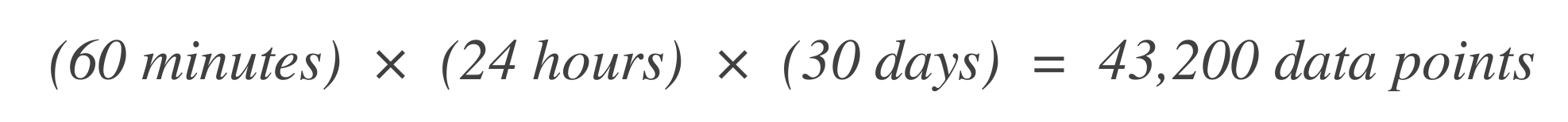
-
Calcule o orçamento de erro. Em seguida, calcule quantos pontos de dados podem “falhar” (ou seja, tempo de inatividade). O orçamento de erro é a porcentagem de falha permitida.
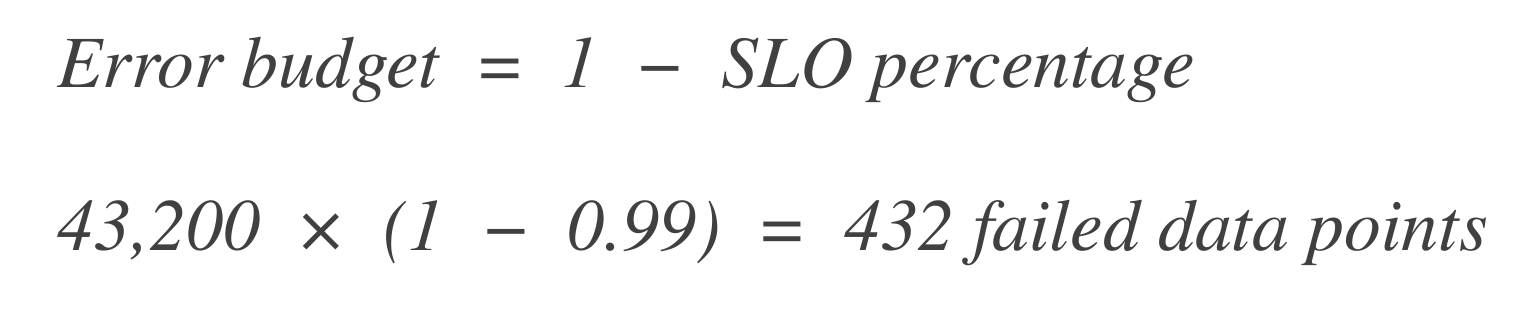
Converta isso em tempo:
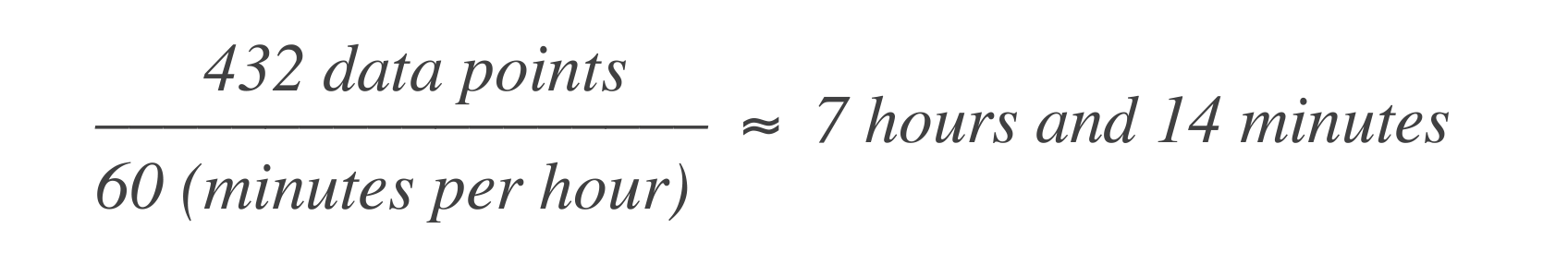
Isso significa que o sistema pode experimentar 7 horas e 14 minutos de tempo de inatividade em uma janela de 30 dias.
Por último, mas não menos importante, o orçamento de erro restante é a diferença entre o tempo de inatividade total possível e o tempo de inatividade já utilizado.
Medição Baseada em Eventos
Para medição baseada em eventos, o orçamento de erro é medido em termos de porcentagens. A afirmação mencionada anteriormente se traduz em um orçamento de erro de 1% em uma janela móvel de 30 dias.
Digamos que haja 43.200 pontos de dados nessa janela de 30 dias, e 100 deles são ruins. Você pode calcular quanto do orçamento de erro foi consumido usando esta fórmula:
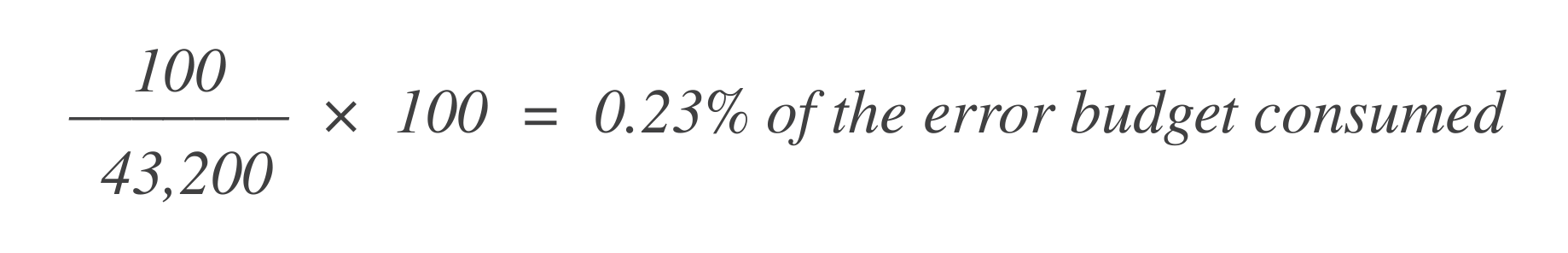
Agora, para descobrir quanto de orçamento de erro resta, subtraia isso do orçamento de erro total permitido (1%):
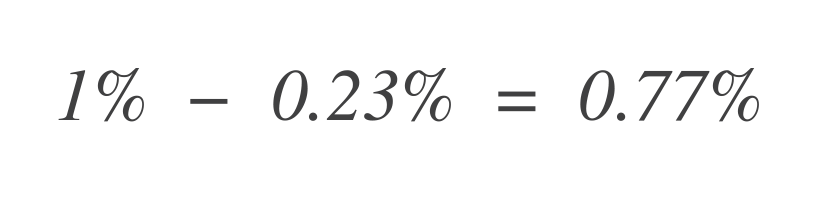
Assim, o serviço ainda pode tolerar 0,77% mais pontos de dados ruins.
Vantagens do Orçamento de Erros
Os orçamentos de erros podem ser utilizados para configurar monitores e alertas automatizados que notificam as equipes de desenvolvimento quando o orçamento está em risco de esgotamento. Esses alertas permitem que eles reconheçam quando é necessária uma maior cautela ao implantar mudanças na produção. As equipes frequentemente enfrentam ambiguidade quando se trata de priorizar recursos versus operações. O orçamento de erros pode ser uma maneira de abordar esse desafio. Ao fornecer métricas claras e baseadas em dados, as equipes de engenharia são capazes de priorizar tarefas de confiabilidade sobre novos recursos quando necessário. O orçamento de erros está entre as estratégias bem estabelecidas para melhorar a responsabilidade e a maturidade dentro das equipes de engenharia.
Cuidados a Tomar com Orçamentos de Erros
Quando há orçamento extra disponível, os desenvolvedores devem procurar ativamente utilizá-lo. Esta é uma excelente oportunidade para aprofundar o entendimento do serviço experimentando com técnicas como engenharia de caos. As equipes de engenharia podem observar como o serviço responde e descobrir dependências ocultas que podem não ser aparentes durante as operações normais. Por último, mas não menos importante, os desenvolvedores devem monitorar de perto o esgotamento do orçamento de erros, pois incidentes inesperados podem esgotá-lo rapidamente.
Conclusão
Objetivos de nível de serviço representam uma jornada, e não um destino, na engenharia de confiabilidade. Embora forneçam métricas importantes para medir a confiabilidade do serviço, seu verdadeiro valor reside em criar uma cultura de confiabilidade dentro das organizações. Em vez de buscar a perfeição, as equipes devem adotar os SLOs como ferramentas que evoluem junto com seus serviços. Olhando para o futuro, a integração de IA e aprendizado de máquina promete transformar os SLOs de medições reativas em instrumentos preditivos, permitindo que as organizações antecipem e previnam falhas antes que elas afetem os usuários.
Recursos adicionais:
-
Implementando Objetivos de Nível de Serviço, Alex Hidalgo, 2020
-
“Objetos de Nível de Serviço,” Chris Jones et al., 2017
-
“Implementando SLOs,” Steven Thurgood et al., 2018
Este é um trecho do Relatório de Tendências 2024 da DZone, Observabilidade e Desempenho: O Abismo da Construção de Sistemas de Software Altamente Desempenhantes.
Source:
https://dzone.com/articles/framework-for-service-level-objectives