













编者按:以下文章专为DZone的2024趋势报告撰写并发表,可观测性与性能:构建高性能软件系统的边缘。
“质量不是一种行为,而是一种习惯,”亚里士多德如是说,这一原则在软件世界也同样适用。对于开发者而言,这意味着提供用户满意度不是一次性的努力,而是一项持续的责任。为了实现这一承诺,工程团队需要设定可靠性目标,明确用户可以期待的基准性能。这正是服务水平目标(SLOs)发挥作用的地方。
简单来说,SLOs是产品为了保持用户满意而需要达到的可靠性目标。它们充当抽象质量目标与DevOps团队必须做出的日常运营决策之间的可量化桥梁。正因为这一重要性,为您的服务有效定义SLOs至关重要。在本文中,我们将通过一个示例逐步介绍如何定义SLOs,并探讨SLOs面临的一些挑战。
定义服务水平目标的步骤
像任何其他流程一样,定义服务水平目标(SLOs)起初可能会让人感到不知所措,但通过遵循一些简单的步骤,您可以创建有效的目标。重要的是要记住,SLOs不是设定后就可以忘记的指标。相反,它们是一个迭代过程的一部分,随着您对系统有更深入的了解而不断发展。因此,即使您最初的SLOs并不完美,也没关系——它们可以并且应该随着时间的推移而不断完善。
图1。 定义SLOs的步骤
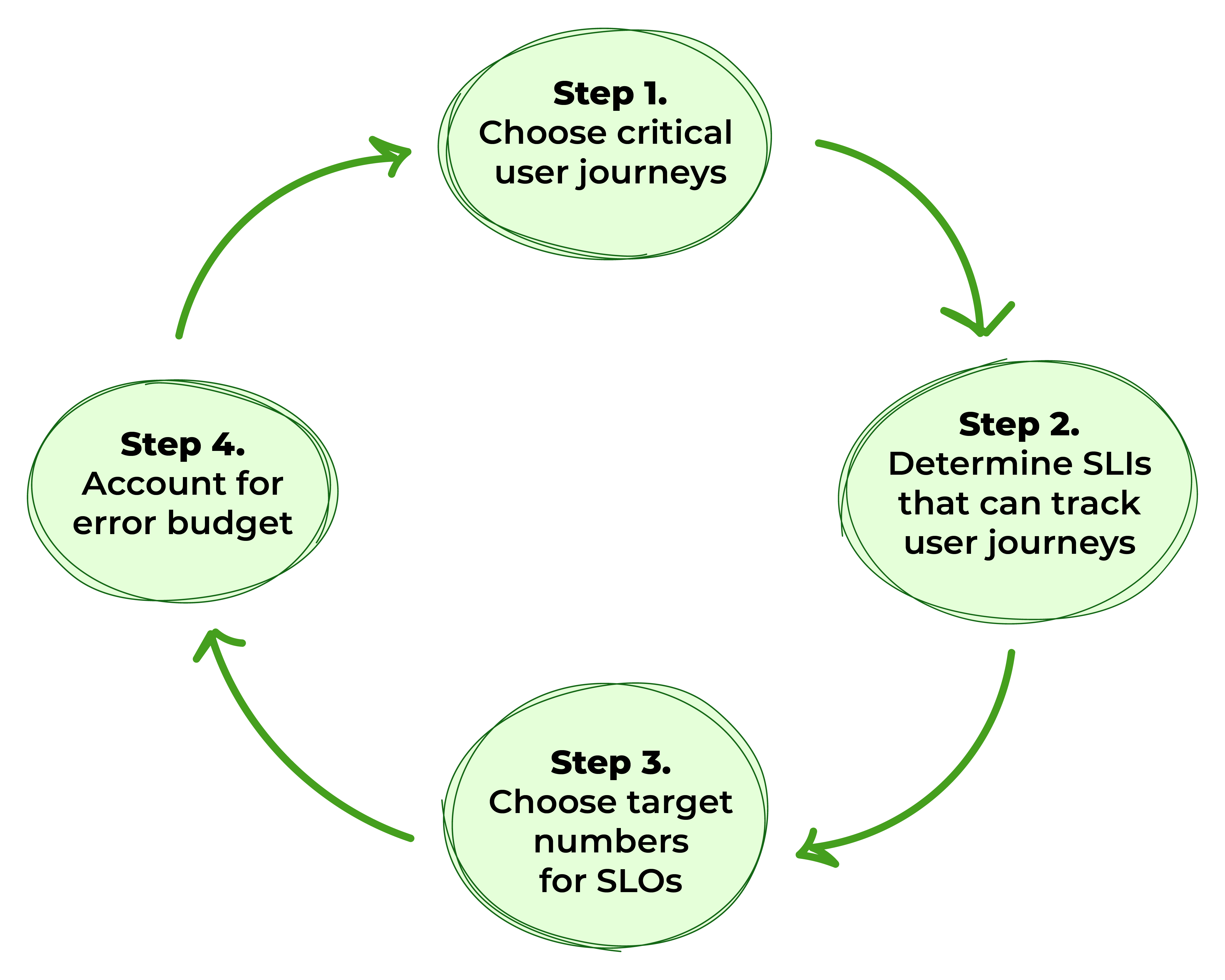
步骤1:选择关键用户旅程
关键用户旅程指的是用户在系统或服务中为达成特定目标而进行的一系列互动。确保这些旅程的可靠性很重要,因为它直接影响客户体验。识别关键用户旅程的一些方法可以通过评估某个工作流失败时的收入/业务影响,并通过用户分析识别频繁的流程。
例如,考虑一个创建虚拟机(VMs)的服务。用户可以在该服务上执行的一些操作包括浏览可用的VM形态,选择创建VM的区域,以及启动VM。如果开发团队按业务影响对这些操作进行排序,排名会是:
- 启动VM因为这直接影响到收入。如果用户无法启动VM,那么服务的核心功能就失败了,直接影响客户满意度和收入。
- 选择区域来创建虚拟机。虽然用户仍然可以在不同区域创建虚拟机,但如果他们有区域偏好,可能会导致体验下降。这一选择可能会影响性能和合规性。
- 浏览虚拟机目录。虽然这对决策很重要,但其对业务的直接影响较低,因为用户以后可以更改虚拟机形态。
步骤2:确定可以跟踪用户旅程的服务水平指标
现在用户旅程已经定义,下一步是有效地衡量它们。服务水平指标(SLIs)是开发者用来量化系统性能和可靠性的指标。对于工程团队来说,SLIs具有双重作用:它们提供可操作的数据来检测退化,指导架构决策,并验证基础设施变更。它们还为有意义的服务水平目标(SLOs)奠定基础,提供设定和跟踪可靠性目标所需的定量测量。
例如,在启动虚拟机时,一些SLIs可以是可用性和延迟。
可用性:在X个启动虚拟机的请求中,有多少成功?计算这一指标的简单公式是:
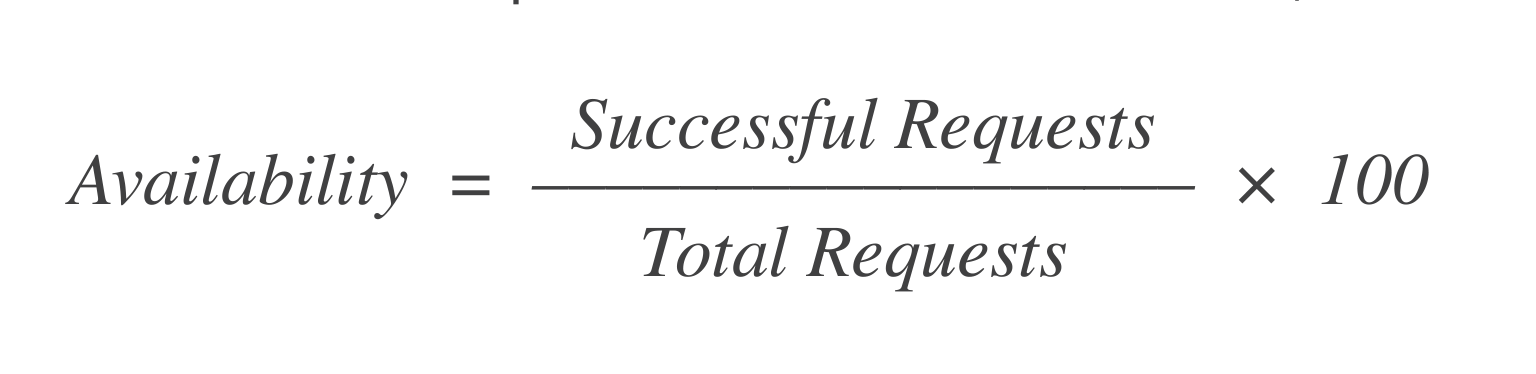
如果有1,000个请求,其中998个请求成功,那么可用性为=99.8%。
延迟:在启动虚拟机的总请求中,第50个、第95个或第99个百分位的请求需要多长时间来启动虚拟机?这里的百分位只是示例,可以根据具体的用例或服务水平期望而变化。
- 在1000个请求的场景中,其中900个请求在5秒内完成,剩余的100个请求耗时10秒,那么95百分位的延迟将是=10秒。
- 虽然平均值也可以用来计算延迟,但通常推荐使用百分位数,因为它们考虑了尾部延迟,能更准确地反映用户体验。
步骤3:确定SLO的目标数值
简单来说,SLO是我们希望SLI在特定时间窗口内达到的目标数值。对于虚拟机场景,SLO可以是:
- 服务可用性在30天滚动窗口内应大于99%。
- 启动虚拟机的95百分位延迟不应超过8秒。
在设定这些目标时,需要记住以下几点:
-
使用历史数据。如果你需要基于30天滚动周期设定SLO,收集多个30天窗口的数据来定义目标。
- 如果你缺乏这些历史数据,可以从更易实现的目标开始,例如每天争取达到99%的可用性,并根据收集到的更多信息逐步调整。
- 记住,SLO不是一成不变的;它们应持续演变,以反映服务和客户需求的变化。
-
考虑依赖服务的SLO。服务通常依赖于其他服务和基础设施组件,例如数据库和负载均衡器。
-
例如,如果您的服务依赖于一个可用性SLO为99.9%的SQL数据库,那么您服务的SLO也不能超过99.9%。这是因为最大可用性受其底层依赖性能的限制,这些依赖无法保证更高的可靠性。
-
SLO的挑战
将SLO设置为100%可能很有吸引力,但这是不可能的。例如,100%的系统可用性意味着没有时间进行发布新功能、修补程序或测试等重要活动,这是不现实的。定义SLO需要跨多个团队的合作,包括工程、产品、运营、质量保证和领导层。确保所有利益相关者对目标达成一致并同意这些目标是SLO成功和可执行的关键。
步骤4:考虑错误预算
错误预算是衡量系统在不惹恼客户或不违反合同义务的情况下可以承受的停机时间的指标。以下是一种看待它的方式:
- 如果错误预算即将耗尽,工程团队应专注于提高可靠性和减少事故,而不是发布新功能。
- 如果还有大量错误预算剩余,工程团队可以优先考虑发布新功能,因为系统在其可靠性目标范围内表现良好。
有两种常见的衡量错误预算的方法:基于时间和基于事件。让我们探讨一下“服务的可用性应在30天的滚动窗口期内大于99%”这一声明如何适用于每种方法。
基于时间的测量
在基于时间的错误预算中,上述声明转化为允许服务在一个月内停机43分钟50秒,或在一年内停机7小时14分钟。以下是计算方法:
-
确定数据点的数量。 首先确定SLO时间窗口内的时单元(数据点)数量。例如,如果基本时间单元是1分钟,SLO窗口是30天:
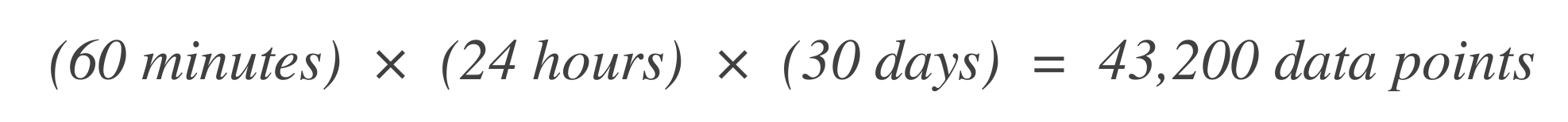
-
计算错误预算。接下来,计算有多少数据点可以“失败”(即停机时间)。错误预算是允许失败的比例。
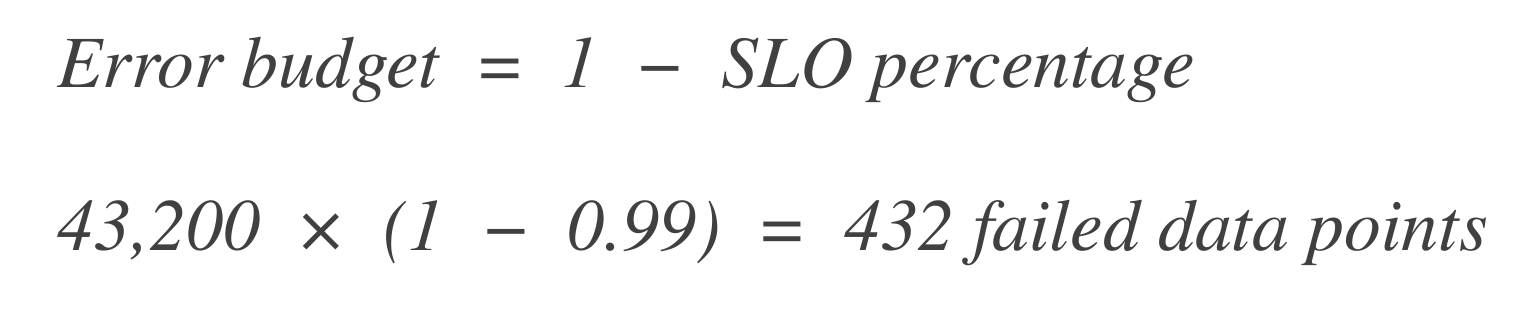
将其转换为时间:
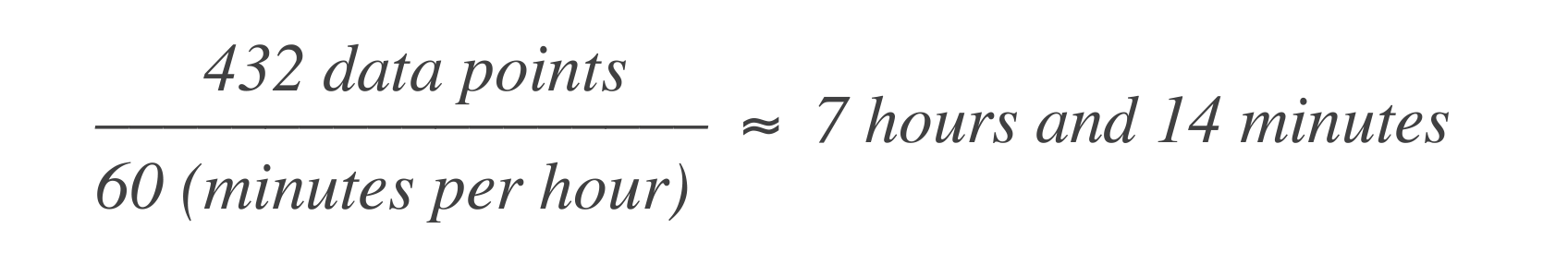
这意味着系统在30天窗口内可以经历7小时14分钟的停机时间。
最后但同样重要的是,剩余的错误预算是总可能停机时间与已用停机时间之间的差值。
基于事件的测量
对于基于事件的测量,错误预算是以百分比来衡量的。上述声明在30天滚动窗口中转化为1%的错误预算。
假设在那个30天窗口内有43,200个数据点,其中100个是坏的。你可以使用这个公式计算已经消耗了多少错误预算:
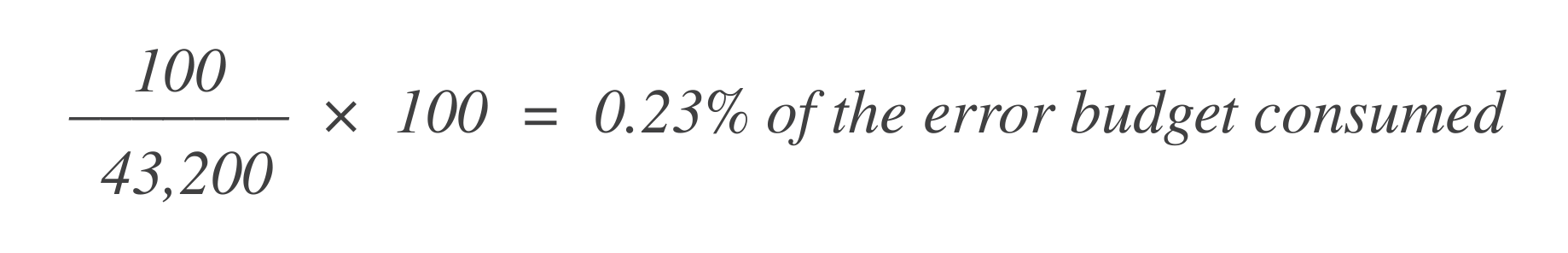
现在,要找出剩余的错误预算,从总允许错误预算(1%)中减去这个值:
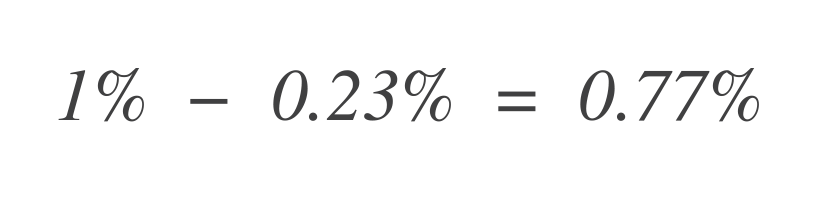
因此,该服务仍然可以容忍0.77%更多的坏数据点。
错误预算的优点
错误预算可用于设置自动化监控和警报,当预算面临耗尽风险时通知开发团队。这些警报使他们能够识别在将更改部署到生产环境时需要更加谨慎的情况。团队在优先考虑功能与运营时常常面临模糊性。错误预算可以是解决这一挑战的一种方式。通过提供清晰、数据驱动的指标,工程团队能够在必要时优先考虑可靠性任务而非新功能。错误预算是提高工程团队责任感和成熟度的成熟策略之一。
使用错误预算时应注意的事项
当有额外预算可用时,开发者应积极考虑使用它。这是通过尝试混沌工程等技术加深对服务理解的绝佳机会。工程团队可以观察服务的响应情况,并发现正常操作中可能不明显的隐藏依赖关系。最后但同样重要的是,开发者必须密切监控错误预算的耗尽情况,因为意外事件可能会迅速耗尽它。
结论
服务水平目标(SLO)在可靠性工程中代表的是一段旅程,而非一个终点。虽然它们为衡量服务可靠性提供了重要指标,但其真正价值在于在组织内部创造一种可靠性文化。团队不应追求完美,而应将SLO视为随服务一起演变的工具。展望未来,人工智能和机器学习的融合有望将SLO从被动测量转变为预测性工具,使组织能够提前预见并预防故障,以免影响用户。
额外资源:
这是DZone 2024趋势报告的摘录,可观测性与性能:构建高性能软件系统的边缘。
Source:
https://dzone.com/articles/framework-for-service-level-objectives