













Nota dell’editore: Il seguente è un articolo scritto per e pubblicato nel Rapporto sulle Tendenze 2024 di DZone, Osservabilità e Prestazioni: La Precipizio della Costruzione di Sistemi Software ad Alta Prestazione.
“”La qualità non è un atto, è un’abitudine”, disse Aristotele, un principio che risuona vero anche nel mondo del software. In particolare per gli sviluppatori, questo significa che soddisfare l’utente non è uno sforzo una tantum, ma un impegno continuo. Per mantenere questo impegno, i team di ingegneria devono avere obiettivi di affidabilità che definiscano chiaramente le prestazioni di base che gli utenti possono aspettarsi. È precisamente qui che entrano in gioco gli obiettivi di livello di servizio (SLO).
In parole povere, gli SLO sono obiettivi di affidabilità che i prodotti devono raggiungere per mantenere felici gli utenti. Servono come ponte quantificabile tra obiettivi di qualità astratti e le decisioni operative quotidiane che i team DevOps devono prendere. A causa di questa importanza cruciale, è fondamentale definirli efficacemente per il proprio servizio. In questo articolo, esploreremo un approccio passo-passo per definire gli SLO con un esempio, seguito da alcune sfide legate agli SLO.
Passaggi per Definire gli Obiettivi di Livello di Servizio
Come qualsiasi altro processo, definire gli SLO può sembrare travolgente all’inizio, ma seguendo alcuni semplici passaggi, puoi creare obiettivi efficaci. È importante ricordare che gli SLO non sono metriche impostate-e-dimenticate. Invece, fanno parte di un processo iterativo che evolve man mano che ottieni maggiore insight sul tuo sistema. Quindi, anche se i tuoi SLO iniziali non sono perfetti, va bene — possono e dovrebbero essere affinati nel tempo.
Figura 1. Passaggi per definire gli SLO
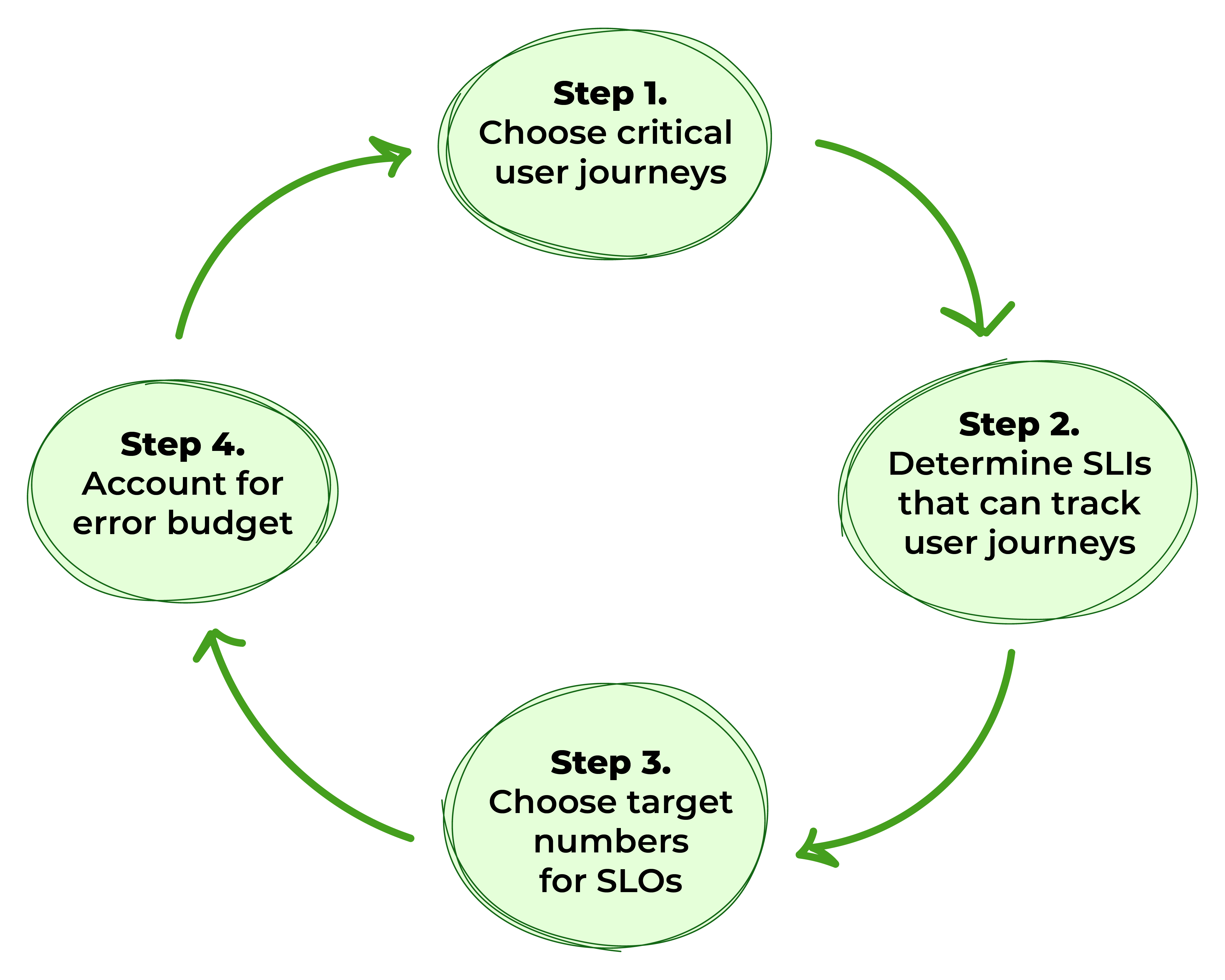
Passaggio 1: Scegliere le Critiche User Journey
Una critica user journey si riferisce alla sequenza di interazioni che un utente compie per raggiungere un obiettivo specifico all’interno di un sistema o di un servizio. Garantire la affidabilità di queste journey è importante perché ha un impatto diretto sull’esperienza del cliente. Alcuni modi per identificare le critiche user journey possono essere attraverso la valutazione dell’impatto sul fatturato/negozio quando un certo flusso di lavoro fallisce e identificare flussi frequenti attraverso l’analisi degli utenti.
Ad esempio, considera un servizio che crea macchine virtuali (VM). Alcune delle azioni che gli utenti possono eseguire su questo servizio sono navigare tra le forme di VM disponibili, scegliere una regione in cui creare la VM e avviare la VM. Se il team di sviluppo dovesse ordinarle per impatto aziendale, il ranking sarebbe:
- Avviare la VMperché questo ha un impatto diretto sul fatturato. Se gli utenti non possono avviare una VM, allora la funzionalità principale del servizio è fallita, influenzando direttamente la soddisfazione del cliente e il fatturato.
- Scegliere una regione per creare la VM. Anche se gli utenti possono ancora creare una VM in una regione diversa, ciò potrebbe portare a un’esperienza degradata se hanno una preferenza regionale. Questa scelta può influenzare le prestazioni e la conformità.
- Sfogliare il catalogo delle VM. Anche se questo è importante per la decisione, ha un impatto diretto inferiore sul business perché gli utenti possono cambiare la forma della VM in seguito.
Passo 2: Determinare gli Indicatori di Livello di Servizio che Possono Tracciare i Percorsi Utente
Ora che i percorsi utente sono definiti, il prossimo passo è misurarli efficacemente. Gli indicatori di livello di servizio (SLI) sono le metriche che gli sviluppatori utilizzano per quantificare le prestazioni e la affidabilità del sistema. Per i team di ingegneria, gli SLI servono a un duplice scopo: forniscono dati azionabili per rilevare il degrado, guidare le decisioni architetturali e convalidare le modifiche all’infrastruttura. Inoltre, costituiscono la base per SLO significativi fornendo le misurazioni quantitative necessarie per stabilire e monitorare gli obiettivi di affidabilità.
Ad esempio, quando si lancia una VM, alcuni degli SLI possono essere la disponibilità e la latenza.
Disponibilità: Su X richieste per lanciare una VM, quante hanno avuto successo? Una formula semplice per calcolare questo è:
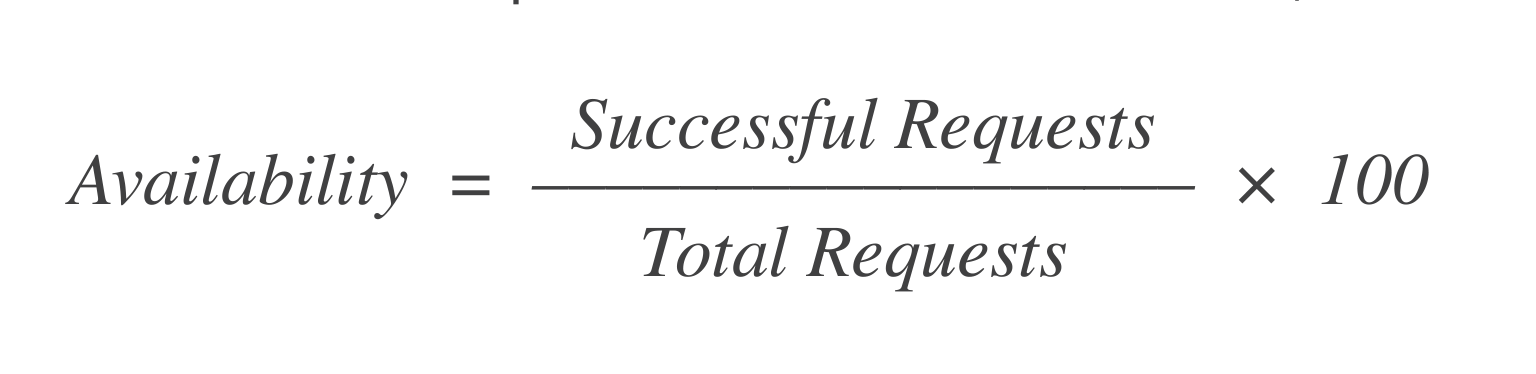
Se ci sono state 1.000 richieste e 998 di esse hanno avuto successo, allora la disponibilità è = 99,8%.
Latenza: Su il numero totale di richieste per lanciare una VM, quanto tempo hanno impiegato il 50°, 95° o 99° percentile delle richieste per lanciare la VM? I percentili qui sono solo esempi e possono variare a seconda del caso d’uso specifico o delle aspettative di livello di servizio.
- In uno scenario con 1.000 richieste dove 900 richieste sono state completate in 5 secondi e le rimanenti 100 hanno impiegato 10 secondi, la latenza del 95esimo percentile sarebbe = 10 secondi.
- Sebbene le medie possano anche essere utilizzate per calcolare le latenze, i percentili sono generalmente consigliati perché tengono conto delle latenze finali, offrendo una rappresentazione più accurata dell’esperienza utente.
Passo 3: Identificare i Numeri Obiettivo per gli SLO
In parole povere, gli SLO sono i numeri obiettivo che vogliamo che i nostri SLI raggiungano in una finestra temporale specifica. Per lo scenario della VM, gli SLO possono essere:
- La disponibilità del servizio dovrebbe essere superiore al 99% su una finestra mobile di 30 giorni.
- Il 95esimo percentile della latenza per il lancio delle VM non dovrebbe superare gli otto secondi.
Quando si stabiliscono questi obiettivi, alcune cose da tenere a mente sono:
-
Utilizzare dati storici. Se è necessario impostare SLO basati su un periodo mobile di 30 giorni, raccogliere dati da più finestre di 30 giorni per definire gli obiettivi.
- Se mancano questi dati storici, iniziare con un obiettivo più gestibile, come mirare al 99% di disponibilità ogni giorno, e adeguarlo nel tempo man mano che si raccolgono più informazioni.
- Ricorda, gli SLO non sono scolpiti nella pietra; dovrebbero evolversi continuamente per riflettere le mutevoli esigenze del tuo servizio e dei clienti.
-
Considerare gli SLO delle dipendenze. I servizi tipicamente dipendono da altri servizi e componenti infrastrutturali, come database e bilanciatori di carico.
-
Ad esempio, se il tuo servizio dipende da un database SQL con un SLO di disponibilità del 99,9%, allora l’SLO del tuo servizio non può superare il 99,9%. Questo perché la massima disponibilità è limitata dalle prestazioni delle sue dipendenze sottostanti, che non possono garantire una maggiore affidabilità.
-
Sfide degli SLO
Potrebbe essere interessante impostare l’SLO al 100%, ma questo è impossibile. Un’ disponibilità del 100%, per esempio, significa che non c’è spazio per attività importanti come il rilascio di funzionalità, il patching o il testing, il che non è realistico. Definire gli SLO richiede collaborazione tra più team, inclusi ingegneria, prodotto, operazioni, QA e leadership. Assicurarsi che tutti gli stakeholder siano allineati e concordino sugli obiettivi è essenziale affinché l’SLO sia efficace e attuabile.
Passo 4: Considerare il Budget di Errore
Un budget di errore è la misura del tempo di inattività che un sistema può permettersi senza scontentare i clienti o violare obblighi contrattuali. Di seguito è riportato un modo per vederlo:
- Se il budget di errore è quasi esaurito, il team di ingegneria dovrebbe concentrarsi sull’aumento della affidabilità e sulla riduzione degli incidenti piuttosto che rilasciare nuove funzionalità.
- Se c’è abbondanza di budget di errore, il team di ingegneria può permettersi di dare priorità al rilascio di nuove funzionalità poiché il sistema sta performando bene all’interno dei suoi obiettivi di affidabilità.
Ci sono due approcci comuni per misurare il budget di errore: basato sul tempo e basato sugli eventi. Esploriamo come l’affermazione “La disponibilità del servizio dovrebbe essere superiore al 99% su una finestra mobile di 30 giorni” si applica a ciascuno.
Misurazione Basata sul Tempo
In un budget di errore basato sul tempo, l’affermazione sopra si traduce nel servizio essere permesso di essere down per 43 minuti e 50 secondi in un mese, o 7 ore e 14 minuti in un anno. Ecco come calcolarlo:
-
Determina il numero di punti dati. Inizia determinando il numero di unità di tempo (punti dati) all’interno della finestra temporale SLO. Ad esempio, se l’unità di tempo base è 1 minuto e la finestra SLO è di 30 giorni:
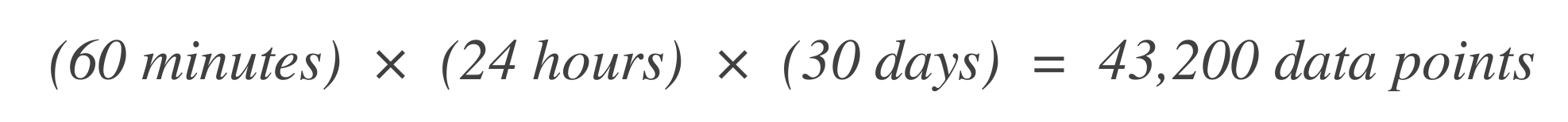
-
Calcola il budget di errore. Successivamente, calcola quanti punti dati possono “fallire” (ossia, tempo di inattività). Il budget di errore è la percentuale di fallimento consentita.
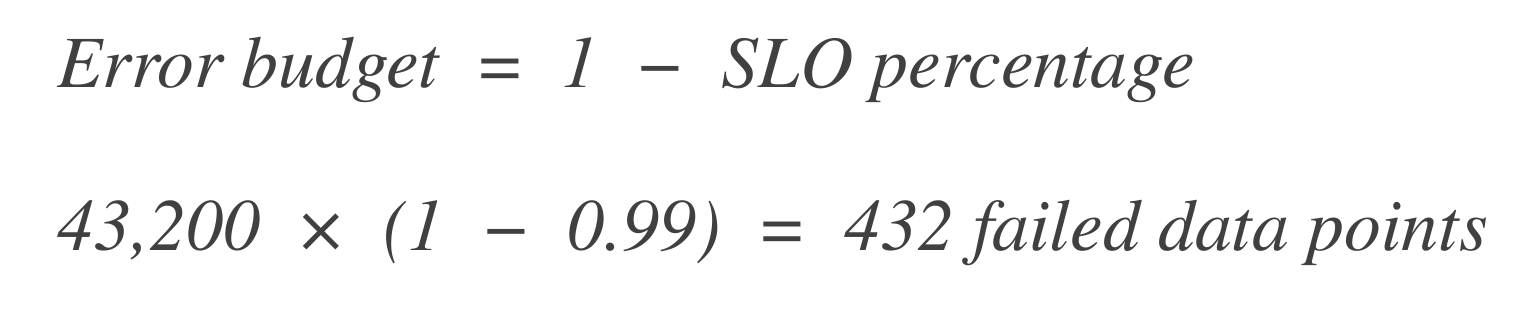
Converti questo in tempo:
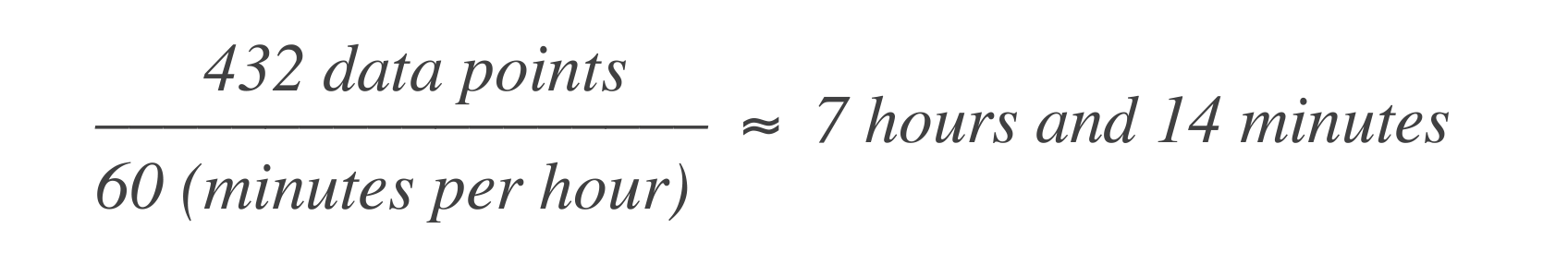
Ciò significa che il sistema può sperimentare 7 ore e 14 minuti di tempo di inattività in una finestra di 30 giorni.
Infine, il budget di errore residuo è la differenza tra il tempo di inattività totale possibile e il tempo di inattività già utilizzato.
Misurazione Basata su Eventi
Per la misurazione basata su eventi, il budget di errore è misurato in termini di percentuali. La dichiarazione sopra menzionata si traduce in un budget di errore dell’1% in una finestra mobile di 30 giorni.
Supponiamo che ci siano 43.200 punti dati in quella finestra di 30 giorni, e che 100 di essi siano errati. Puoi calcolare quanto del budget di errore è stato consumato utilizzando questa formula:
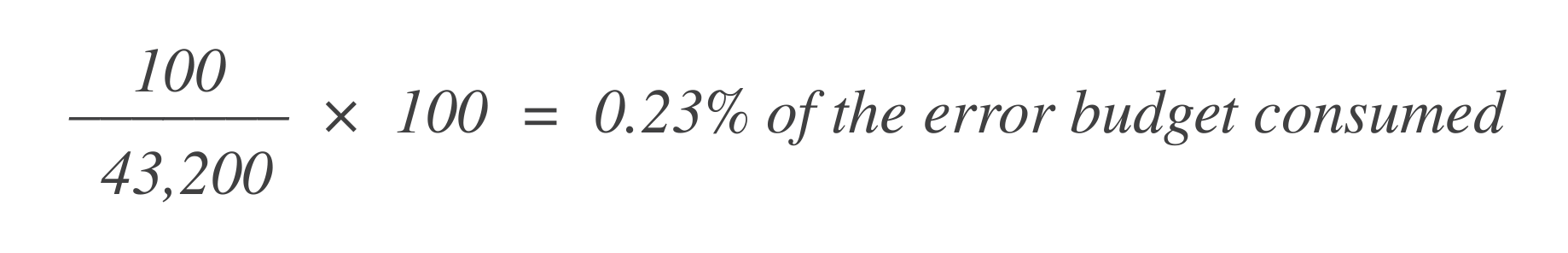
Ora, per scoprire quanto budget di errore rimane, sottrai questo dal budget di errore totale consentito (1%):
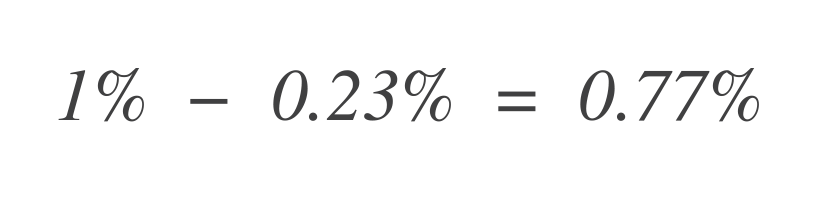
Pertanto, il servizio può ancora tollerare 0,77% di punti di dati errati in più.
Vantaggi del Budget degli Errori
I budget degli errori possono essere utilizzati per configurare monitoraggi automatici e avvisi che notificano i team di sviluppo quando il budget è a rischio di esaurimento. Questi avvisi consentono loro di riconoscere quando è necessaria una maggiore cautela durante il rilascio di modifiche in produzione. I team spesso si trovano di fronte a incertezze quando si tratta di dare priorità alle funzionalità rispetto alle operazioni. Il budget degli errori può essere un modo per affrontare questa sfida. Fornendo metriche chiare e basate sui dati, i team di ingegneria sono in grado di dare priorità alle attività di affidabilità rispetto a nuove funzionalità quando necessario. Il budget degli errori è tra le strategie ben consolidate per migliorare la responsabilità e la maturità all’interno dei team di ingegneria.
Precauzioni da Adottare con i Budget degli Errori
Quando c’è un budget extra disponibile, gli sviluppatori dovrebbero cercare attivamente di utilizzarlo. Questa è un’ottima opportunità per approfondire la comprensione del servizio sperimentando con tecniche come l’ingegneria del caos. I team di ingegneria possono osservare come il servizio risponde e scoprire dipendenze nascoste che potrebbero non essere evidenti durante le operazioni normali. Infine, ma non meno importante, gli sviluppatori devono monitorare attentamente l’esaurimento del budget degli errori, poiché incidenti imprevisti possono rapidamente esaurirlo.
Conclusione
Gli obiettivi di livello di servizio rappresentano un viaggio piuttosto che una destinazione nell’ingegneria della affidabilità. Sebbene forniscano importanti metriche per misurare l’affidabilità del servizio, il loro vero valore risiede nella creazione di una cultura di affidabilità all’interno delle organizzazioni. Piuttosto che perseguire la perfezione, i team dovrebbero abbracciare gli SLO come strumenti che evolvono insieme ai loro servizi. Guardando avanti, l’integrazione di intelligenza artificiale e machine learning promette di trasformare gli SLO da misure reattive a strumenti predittivi, consentendo alle organizzazioni di anticipare e prevenire i guasti prima che impattino gli utenti.
Risorse aggiuntive:
-
Implementing Service Level Objectives, Alex Hidalgo, 2020
-
“Service Level Objects,” Chris Jones et al., 2017
-
“Implementing SLOs,” Steven Thurgood et al., 2018
Questo è un estratto dal Report sulle Tendenze 2024 di DZone, Osservabilità e Prestazioni: La Precipizio per la Costruzione di Sistemi Software ad Alta Prestazione.
Source:
https://dzone.com/articles/framework-for-service-level-objectives